TUGAS AKHIR
APLIKASI KOMPRESI SMS MENGGUNAKAN KODE
HUFFMAN
PADA
MOBILE PHONE
BERBASIS JAVA
TMDiajukan untuk memenuhi salah satu persyaratan dalam menyelesaikan
pendidikan sarjana (S-1) pada Departemen Teknik Elektro
Oleh:
ANASTASYA CITRA
050402086
DEPARTEMEN TEKNIK ELEKTRO
FAKULTAS TEKNIK
UNIVERSITAS SUMATERA UTARA
MEDAN
ABSTRAK
Telekomunikasi memiliki peranan penting dalam kehidupan sosial saat ini.
Komunikasi yang tidak dapat dilakukan secara langsung menciptakan sebuah
teknologi yang dapat memudahkan pengguna berkomunikasi jarak jauh.
Perkembangan telekomunikasi pun sangat pesat, seiring dengan kebutuhan
masyarakat yang terus meningkat.
Dalam berkomunikasi, pesan teks merupakan sarana yang sering
digunakan selain layanan suara. Salah satu cara penggunaaan pesan teks adalah
dengan SMS. Fitur ini banyak digunakan karena tersedia pada setiap mobile
phone, penggunaannya yang mudah dan costnya yang murah.
Penggunaan teknologi SMS masih memiliki kekurangan. Keterbatasan
memori misalnya, sehingga dibutuhkan sebuah mekanisme agar besar data yang
ditransmisikan dapat seminimal mungkin. Oleh sebab itu, diperlukan proses
kompresi yang dapat meminimalisasikan ukuran sebuah data yang akan
dikirimkan.
Pada Tugas Akhir ini dibuat sebuah kompresi SMS dengan menggunakan
Kode Huffman yang diharapkan akan menjadikan ukuran SMS tersebut seminimal
mungkin pada saat dikirimkan. Dari pengujian yang telah dilakukan, dapat
dibuktikan bahwa kompresi SMS dengan jumlah karakter ≤ 160, 160 < x ≤ 320, > 320 menggunakan kode Huffman akan menghasilkan persentase kompresi
KATA PENGANTAR
Puji dan syukur penulis panjatkan kehadirat Allah SWT atas rahmat dan
karunia-Nya penulis dapat menyelesaikan Tugas Akhir ini, yang berjudul
“APLIKASI KOMPRESI SMS MENGGUNAKAN KODE HUFFMAN PADA MOBILE PHONE BERBASIS JAVATM”. Tugas Akhir ini dibuat untuk memenuhi syarat kesarjanaan di Departemen Teknik Elektro, Fakultas Teknik,
Universitas Sumatera Utara.
Tugas Akhir ini penulis persembahkan kepada yang teristimewa Nyaksyi
Hj. Nurhayati, S.Ag yang selalu sabar dan setia menemani penulis melalui masa
perkuliahan selama di Medan. Mama tercinta Hj. Cut Isra Eka Putri dan Bapak
Panjang Hartawan Tarigan untuk segala doa, dukungan dan cintanya selama ini.
Papa Aldi Aldanny serta Mami Tia dan Mami Yani. Kesebelas adik penulis yang
selalu memberikan inspirasi, „Irfaan, Balqis, Raja, Nabila, Ghina, Amira, Ratu
serta Zhico, Cachito, Nia dan Mario. Paman, Papa sekaligus sahabat dan
motivator bagi penulis, H. Teuku Bardansyah serta keluarga. Dan seluruh
keluarga besar yang selalu memberikan dukungan dan motivasi bagi penulis. Dan
juga untuk Adriuli atas semua yang telah dilakukan untuk penulis.
Selama penulisan Tugas Akhir ini hingga menyelesaikannya, penulis
banyak mendapat bantuan dan dukungan serta masukan dalam penulisan Tugas
Pada kesempatan ini penulis mengucapkan terima kasih yang
sebesar-besarnya kepada:
1. Bapak Prof. Dr. Ir. Usman Baafai dan Bapak Rahmad Fauzi, ST, MT,
selaku Pelaksana Harian dan Sekretaris Departemen Teknik Elektro,
Fakultas Teknik, Universitas Sumatera Utara.
2. Bapak Ir. M. Zulfin, MT sebagai Dosen Pembimbing penulis yang telah
dengan sabar membimbing penulis dan sangat banyak membantu dalam
penulisan Tugas Akhir ini.
3. Bapak Ir. Arman Sani, MT sebagai Dosen Wali penulis, Tim Judul dan
juga Dosen Penguji, yang selalu memberikan dukungan sebagai wali
penulis serta memotivasi penulis agar menjadi lebih baik.
4. Bapak Rahmad Fauzi, ST. MT dan Bapak Maksum Pinem, ST. MT
sebagai Dosen Pembimbing Seminar yang memberikan koreksi dan saran
sehingga Tugas Akhir ini menjadi lebih baik.
5. Seluruh staf pengajar Departemen Teknik Elektro, khususnya Konsentrasi
Teknik Telekomunikasi yang banyak memberikan inspirasi, pelajaran
moril dan spiritual serta masukan dan dorongan bagi penulis untuk selalu
menjadi lebih baik.
6. Seluruh karyawan di Departemen Teknik Elektro, Fakultas Teknik
Universitas Sumatera Utara.
7. Semua teman seperjuangan, Stambuk 2005. Kira yang sangat membantu
proses Tugas Akhir ini. Gemboeng Betina, Muteng, Once, Yoneng, Chici,
PSUS, D, Icha, Ami, Dewi, Nisa, Christ. Gemboeng Jantan Ebby, V, Fari,
Putra, Andica, Rifqi, Riza serta seluruh anggota ‟05 yang tidak bisa
disebutkan satu per satu.
8. Dan pihak-pihak yang tidak dapat penulis sebutkan satu per satu.
Penulis menyadari bahwa Tugas Akhir ini jauh dari sempurna. Oleh
karena itu, saran dan kritik dengan tujuan menyempurnakan dan mengembangkan
kajian dalam bidang ini sangat penulis harapkan.
Akhir kata penulis berharap agar Tugas Akhir ini dapat bermanfaat bagi
pembaca dan penulis.
Medan, 1 Mei 2010
Penulis,
DAFTAR ISI
Abstrak ... i
Kata Pengantar ... ii
Daftar Isi ... v
Daftar Gambar ... viii
Daftar Tabel ... x
Daftar Lampiran ... xi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang.……..……… ... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan Penulisan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penulisan ... 3
1.6 Sistematika Penulisan ... 3
BAB II TEKNIK PENGKODEAN ... 5
2.1 Pendahuluan ... 5
2.2 Pengkodean Data ... 5
2.2.1 Data digital, sinyal digital ... 8
2.2.2 Data digital, sinyal analog ... 11
2.2.3 Data analog, sinyal digital ... 13
BAB III KOMPRESI DATA ... 19
3.1 Umum ... 19
3.2 Jenis Kompresi ... 21
3.2.1 Algoritma Kompresi Lossy ... 21
3.2.1.1 JPEG ... 22
3.2.1.2 MPEG ... 24
3.2.2 Algoritma Kompresi Lossless ... 26
3.2.2.1 Run-Length ... 27
3.2.2.2 Half Byte ... 29
3.2.2.3 LZW (Lempel-Ziv-Welch) ... 31
3.2.2.4 Huffman ... 35
3.3 Metode Kompresi ... 35
3.3.1 Metode Statis (static method) ... 35
3.3.2 Metode Kamus (dictionary method) ... 36
BAB IV KOMPRESI DATA MENGGUNAKAN KODE HUFFMAN ... 37
4.1 Pendahuluan ... 37
4.2 Variasi Kode Huffman ... 38
4.3 Encoding dan Decoding Menggunakan Kode Huffman ... 42
4.3.1 Encoding ... 42
4.3.2 Decoding ... 47
BAB V APLIKASI KOMPRESI SMS MENGGUNAKAN KODE HUFFMAN PADA MOBILE PHONE BERBASIS JAVATM ... 50
5.1 Pendahuluan ... 50
5.3 Aplikasi Kompresi SMS Menggunakan Kode Huffman pada mobile
phone berbasis JAVATM ... 53
5.3.1 Aplikasi Kompresi SMS dengan karakter ≤ 160 ... 53
5.3.2 Aplikasi Kompresi SMS dengan karakter 160 < x≤ 320 ... 59
5.3.3 Aplikasi Kompresi SMS dengan karakter > 320 ... 66
BAB VI KESIMPULAN DAN SARAN ... 76
6.1 Kesimpulan ... 76
6.2 Saran ... 76
DAFTAR PUSTAKA
DAFTAR GAMBAR
Gambar 2.1 Teknik Pengkodean Data dan Modulasi ... 7
Gambar 2.2 Format Pengkodean Sinyal Digital ... 11
Gambar 2.3 Teknik Dasar Modulasi untuk Mengubah Data Digital menjadi Sinyal Analog ... 13
Gambar 2.4 Teknik PCM ... 15
Gambar 2.5 PCM Block Diagram ... 15
Gambar 2.6 Delta Modulation ... 16
Gambar 2.7 Modulasi Data Analog, Sinyal Analog ... 18
Gambar 3.1 Karakter pada Run-Length ... 27
Gambar 3.2 Contoh kompresi menggunakan algoritma Run-Length ... 28
Gambar 3.3 Format menggunakan algoritma half byte ... 29
Gambar 3.4 Contoh kompresi menggunakan algoritma half byte ... 30
Gambar 3.5 Hasil Proses kompresi LZW ... 33
Gambar 4.1 Proses Encoding Menggunakan Pohon Huffman ... 45
Gambar 4.2 Tampilan proses Encoding Huffmanyang lebih sederhana ... 46
Gambar 4.3 Proses Decoding Menggunakan Pohon Huffman ... 48
Gambar 5.1 Tampilan Pada Layar Komputer pada saat Pengiriman File Aplikasi HuffSMS melalui Bluetooth ... 52
Gambar 5.2 Tampilan Aplikasi pada mobile phone Nokia 5130 XpreesMusic ... 52
Gambar 5.3 Tampilan Proses Pengiriman SMS ≤ 160 Karakter dengan Kode Huffman pada Mobile Phone Nokia 5130 XpressMusic ... 58
Gambar 5.4 Tampilan Proses Penerimaan SMS ≤ 160 Karakter dengan Kode Huffman pada Mobile Phone Nokia 5130 XpressMusic ... 59
Gambar 5.5 Tampilan Proses Pengiriman SMS 160 < x ≤ 320 Karakter dengan Kode Huffman pada Mobile Phone Nokia 5130 XpressMusic ... 65
Gambar 5.6 Tampilan Proses Penerimaan SMS 160 < x ≤ 320 Karakter dengan Kode Huffman pada Mobile Phone Nokia 5130 XpressMusic ... 66
Gambar 5.8 Tampilan Proses Penerimaan SMS > 320 Karakter dengan Kode
DAFTAR TABEL
Tabel 3.1 Tahapan kompresi LZW ... 33
Tabel 4.1 Frekuensi Kemunculan Karakter pada Data ... 44
Tabel 4.2 Hasil Encoding Menggunakan Algoritma Huffman ... 46
Tabel 5.1 Frekuensi Kemunculan pada Kompresi SMS ≤ 160 karakter ... 54
Tabel 5.2 Kode Huffman Hasil Kompresi pada SMS ≤ 160 karakter ... 54
Tabel 5.3 Frekuensi Kemunculan pada Kompresi SMS 160 < x ≤ 320 karakter ... 60
Tabel 5.4 Kode Huffman Hasil Kompresi pada SMS 160 < x ≤ 320 karakter ... 61
Tabel 5.5 Frekuensi Kemunculan pada Kompresi SMS > 320 karakter ... 67
Tabel 5.6 Kode Huffman Hasil Kompresi pada SMS > 320 karakter ... 69
DAFTAR LAMPIRAN
Lampiran 1 Pembentukan Pohon Huffman pada Kompresi SMS ≤ 160 Karakter Lampiran 2 Pembentukan Pohon Huffman pada Kompresi SMS 160 < x ≤ 320
Karakter
Lampiran 3 Pembentukan Pohon Huffman pada Kompresi SMS > 320 Karakter
Lampiran 4 Tabel ASCII
Lampiran 5 Tabel fixed Huffman
Lampiran 6 Pembentukan Pohon Huffman untuk Tabel fixed Huffman
Lampiran 7 Daftar Mobile phone Berbasis JavaTM
Lampiran 8 Flowchart Program Utama, Pengiriman HuffSMS
Lampiran 9 Flowchart Program Utama, Penerimaan HuffSMS
Lampiran 10 Flowchart Kompresi Huffman
Lampiran 11 Flowchart Dekompresi Huffman
Lampiran 12 Flowchart MessageScreen
Lampiran 13 Flowchart SendScreen
ABSTRAK
Telekomunikasi memiliki peranan penting dalam kehidupan sosial saat ini.
Komunikasi yang tidak dapat dilakukan secara langsung menciptakan sebuah
teknologi yang dapat memudahkan pengguna berkomunikasi jarak jauh.
Perkembangan telekomunikasi pun sangat pesat, seiring dengan kebutuhan
masyarakat yang terus meningkat.
Dalam berkomunikasi, pesan teks merupakan sarana yang sering
digunakan selain layanan suara. Salah satu cara penggunaaan pesan teks adalah
dengan SMS. Fitur ini banyak digunakan karena tersedia pada setiap mobile
phone, penggunaannya yang mudah dan costnya yang murah.
Penggunaan teknologi SMS masih memiliki kekurangan. Keterbatasan
memori misalnya, sehingga dibutuhkan sebuah mekanisme agar besar data yang
ditransmisikan dapat seminimal mungkin. Oleh sebab itu, diperlukan proses
kompresi yang dapat meminimalisasikan ukuran sebuah data yang akan
dikirimkan.
Pada Tugas Akhir ini dibuat sebuah kompresi SMS dengan menggunakan
Kode Huffman yang diharapkan akan menjadikan ukuran SMS tersebut seminimal
mungkin pada saat dikirimkan. Dari pengujian yang telah dilakukan, dapat
dibuktikan bahwa kompresi SMS dengan jumlah karakter ≤ 160, 160 < x ≤ 320, > 320 menggunakan kode Huffman akan menghasilkan persentase kompresi
BAB I
PENDAHULUAN
1.1 Latar Belakang
Perkembangan telekomunikasi dewasa ini sangat pesat, seiring dengan
kebutuhan masyarakat akan mobilitas komunikasi yang meningkat. Berbagai
macam fasilitas teknologi telekomunikasi terus dikembangkan agar user dapat
melakukan komunikasi suara, data dan gambar dengan baik.
Perkembangan mobile phone saat ini pun dapat menggambarkan betapa
besar animo masyarakat dalam perkembangan teknologi. Selain komunikasi suara,
fitur SMS yang disediakan dapat digunakan untuk pengiriman pesan singkat yang
penggunaannya mudah dan dengan cost yang murah.
Pengiriman SMS memiliki beberapa kendala, pesan yang dikirim sering
kali berukuran terlalu besar sehingga memakan waktu yang cukup lama dalam
proses pentransmisian data tersebut. Selain itu dalam penyimpanan data, file yang
cukup besar memakan ruang yang besar pula. SMS tersebut memiliki batasan 160
karakter, jika pesan yang dikirim lebih dari 160 karakter, maka mobil phone akan
mengirim dua SMS. Dari segi biaya, tentu saja diperlukan biaya yang lebih besar
dibandingkan jika hanya mengirim satu SMS.
Masalah-masalah tersebut dapat diatasi dengan proses kompresi isi dari
SMS tersebut sehingga waktu dan ruang yang digunakan dapat seminimal
mungkin. Salah satu metode yang digunakan pada metode kompresi data adalah
kode Huffman. Pada aplikasi kompresi SMS, kode Huffman digunakan untuk
Berdasarkan uraian diatas, maka pada Tugas Akhir ini penulis
memaparkan kompresi data SMS dengan menggunakan kode Huffman serta
menampilkan aplikasi kompresi ini menggunakan bahasa pemrograman J2ME
(JAVA 2 Micro Edition) yang hanya dapat digunakan pada mobile phone berbasis
JAVATM. Diharapkan hasil kompresi SMS pada Tugas Akhir ini dapat mengoptimalkan penggunaan saluran transmisi, penggunaan memori dan
penekanan biaya.
1.2 Rumusan Masalah
Dari latar belakang di atas, maka dapat dirumuskan beberapa
permasalahan, yaitu:
1. Apa yang dimaksud dengan kompresi data.
2. Apa saja metode kompresi data yang ada.
3. Bagaimana metode Huffman dalam proses kompresi SMS.
4. Bagaimana cara menghitung compression ratio dan increase percentage.
5. Bagaimana penerapan metode Huffman pada mobile phone berbasis
JAVATM.
1.3 Tujuan Penulisan
Tujuan dari penulisan Tugas Akhir ini adalah untuk memahami metode
kompresi data SMS dengan metode Huffman, serta menghitung compresion ratio
sehingga dapat diketahui persentase kompresi dan juga visualisasi hasil kompresi
1.4 Batasan Masalah
Untuk memudahkan pembahasan dalam tulisan ini, maka dibuat
pembatasan masalah sebagai berikut :
1. Hanya membahas teknik pengkodean secara umum.
2. Hanya membahas kompresi data secara umum.
3. Kompresi yang dilakukan hanya pada data SMS yang memiliki variasi
karakter dan hanya menggunakan metode Huffman.
4. J2ME hanya dipakai dalam penggunaan aplikasi, tidak dibahas secara
khusus dan detail.
1.5 Metodologi Penulisan
Metodologi penulisan yang digunakan oleh penulis dalam penulisan Tugas
Akhir ini adalah: Studi Literatur, yaitu berupa studi kepustakaan dan kajian dari
buku-buku dan jurnal-jurnal pendukung, baik dalam bentuk hardcopy dan
softcopy.
1.6 Sistematika Penulisan
Penulisan Tugas Akhir ini disajikan dengan sistematika penulisan sebagai
berikut :
BAB I : PENDAHULUAN
Bab ini merupakan pendahuluan yang berisikan tentang
latar belakang masalah, tujuan penulisan, batasan masalah,
metode penulisan, dan sistematika penulisan dari Tugas
BAB II : TEKNIK PENGKODEAN
Bab ini membahas mengenai teknik-teknik pengkodean.
BAB III : KOMPRESI DATA
Bab ini membahas tentang proses kompresi suatu data,
kompresi Lossless dan kompresi Lossy.
BAB IV : KOMPRESI DATA MENGGUNAKAN KODE
HUFFMAN
Bab ini membahas tentang kompresi data menggunakan
kode Huffman dengan terperinci.
BAB V : APLIKASI KOMPRESI SMS MENGGUNAKAN KODE
HUFFMAN PADA MOBILE PHONE BERBASIS
JAVATM
Bab ini berisi tentang proses kompresi SMS menggunakan
metode Huffman dan perhitungan Compression ratio dan
Increase percentage serta tampilan aplikasinya pada mobile
phone berbasis JAVATM.
BAB VI : KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan hasil Tugas Akhir ini dan saran
BAB II
TEKNIK PENGKODEAN
2.1 Pendahuluan
Pengkodean karakter, kadang disebut penyandian karakter, terdiri dari
kode yang memasangkan karakter berurutan dari suatu kumpulan dengan sesuatu
yang lain. Seperti urutan bilangan natural, octet atau denyut elektrik. Untuk
memfasilitasi penyimpanan teks pada komputer dan transmisi teks melalui
jaringan telekomunikasi. Contoh umum adalah sandi morse, yang menyandikan
huruf alphabet ke dalam rangkaian tekanan panjang pendek dari kunci telegraf,
serta ASCII, yang menyadikan huruf, numeral dan simbol-simbol lain, sebagai
integrer dan versi biner 7-bit dari integrer tersebut, umumnya ditambah nol-bit
untuk memfasilitasi penyimpanan dalam bita 8-bit (octet).
Dalam sistem komunikasi digital, pesan yang dikeluarkan oleh sumber
umumnya dikompresikan menjadi bentuk lain yang lebih efisien. Proses tersebut
dilakukan dalam source encoder, dimana informasi dari sumber dikonversikan
menjadi deretan digit biner yang efisien dengan jumlah digit biner yang digunakan
dibuat seminimal mungkin.
2.2 Pengkodean Data
Dalam proses telekomunikasi, data tersebut harus dimengerti baik dari sisi
pengirim maupun dari sisi penerima. Untuk mencapai hal tersebut, data harus
Berikut adalah sistem sandi yang biasa digunakan:
1. ASCII (American Standard Code for Information Interchange)
a. Standar ini paling banyak digunakan
b. Merupakan sandi 7 bit
c. Terdapat 128 macam symbol yang dapat diberi sandi ini
d. Untuk transmisi asinkron terdiri dari 10 atau 11 bit, yaitu: 1 bit
awal, 7 bit data, 1 bit paritas, 1 atau 2 bit akhir
2. Sandi Baudot Code (CCITT alphabet No.2 / Telex Code)
a. Terdiri dari 5 bit
b. Terdapat 32 macam symbol
c. Digunakan dua sandi khusus sehingga semua abjad dan angka
dapat diberi sandi yaitu:
1. LETTERS (11111)
2. FIGURES (11011)
d. Tiap karakter terdiri dari: 1 bit awal, 5 bit data dan 1 bit akhir
3. Sandi 4 atau 8
a. Sandi dari IBM dengan kombinasi yang diperbolehkan adalah 4
buah “1” dan 4 buah “0”
b. Terdapat 70 karakter yang dapat diberi sandi ini
c. Transmisi asinkron membutuhkan 10 bit, yaitu: 1 bit awal, 8 bit
data dan 1 bit akhir
4. BCD (Binary Coded Decimal)
a. Terdiri dari 6 bit
c. Transmisi asinkron membutuhkan 9 bit, yaitu: 1 bit awal, 6 bit
data, 1 bit paritas dan 1 bit akhir
5. EBCDIC (Extended Binary Coded Decimal Interchange Code)
a. Sandi 8 bit untuk 256 karakter
b. Transmisi asinkron membutuhkan 11 bit, yaitu: 1 bit awal, 8 bit
data, 1 bit paritas dan 1 bit akhir.
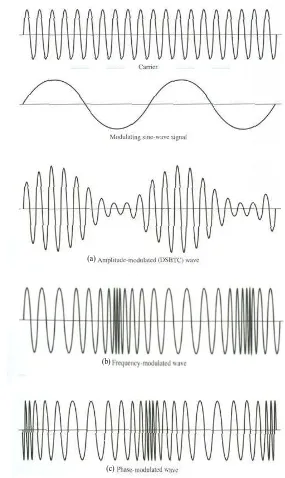
Gambar 2.1 Teknik Pengkodean Data dan Modulasi
Pada Gambar 2.1, bentuk x(t) tergantung pada teknik pengkodean dan
dipilih yang sesuai dengan karakteristik media transmisi. Gambar 2.1(a)
menjelaskan tentang pensinyalan digital, suatu sumber data g(t) dapat berupa
digital atau analog, yang di-encode menjadi suatu sinyal digital x(t) dan Gambar
2.1(b) menjelaskan tentang pensinyalan analog, input sinyal m(t) dapat berupa
dimodulasi menjadi sinyal termodulasi s(t). Dasarnya adalah modulasi sinyal
carrier yang dipilih sesuai dengan media transmisinya.
Ada empat kombinasi hubungan data dan sinyal, yaitu:
1 Data digital, sinyal digital
Perangkat pengkodean data digital menjadi sinyal digital lebih sederhana
daripada perangkat modulasi digital-to-analog.
2 Data analog, sinyal digital
Konversi data analog ke bentuk digital memungkinkan pengguna
perangkat transmisi dan switching digital.
3 Data digital, sinyal analog
Beberapa media transmisi hanya bisa merambatkan sinyal analog,
misalnya unguided media.
4 Data analog, sinyal analog
Data analog dapat dikirimkan dalam bentuk sinyal baseband, misalnya
transmisi suara pada saluran pelanggan PSTN.
2.2.1 Data Digital, Sinyal Digital
Data digital merupakan data yang memiliki deretan data yang memiliki
ciri-ciri tersendiri. Salah satu contoh data digital adalah teks. Permasalahannya
adalah data tersebut tidak dapat langsung ditransmisikan dalam sistem
komunikasi. Data tersebut harus terlebih dahulu diubah dalam bentuk biner.
Elemen sinyal adalah tiap pulsa dari sinyal digital. Data binary atau digital
Faktor kesuksesan penerima dalam mengartikan sinyal yang datang:
a. Ratio Signal to Noise (S/N) : peningkatan S/N akan menurunkan bit error
rate.
b. Kecepatan data (data rate) : peningkatan data rate akan meningkatkan bit
error rate (kecepatan error pada bit)
c. Bandwidth : peningkatan bandwidth data meningkatkan
data rate
Hubungan ketiga faktor tersebut adalah:
1. Kecepatan data bertambah, maka kecepatan error pun bertambah,
sehingga memungkinkan bit yang diterima error.
2. Kenaikan S/N mengakibatkan kecepatan error berkurang.
3. Lebar bandwidth membesar yang diperbolehkan, kecepatan data akan
bertambah.
Faktor-faktor yang mempengaruhi coding:
a. Spektrum sinyal = jumlah komponen frekuensi tinggi yang sedikit berarti
lebih hemat bandwidth transmisi
b. Clocking = menyediakan mekanisme sinkronisasi antara source
dan destination.
c. Deteksi kesalahan = kemampuan errordetection dapat dilakukan secara
sederhana oleh skema line coding.
d. Kekebalan terhadap interferensi sinyal dan derau = dinyatakan dalam BER
e. Biaya dan kompleksitas = semakin tinggi laju pensinyalan atau laju data,
Teknik data digital, sinyal digital terbagi atas:
1. Non-Return to Zero / NRZ
a. NRZ-L (NRZ-Level)
Hal ini dapat dilihat pada Gambar 2.2a.
1. Dua tegangan yang berbeda antara bit 1 dan bit 0
2. Tegangan konstan selama interval bit
3. Tidak ada transisi yaitu tegangan no return to zero
b. NRZ-I (NRZ-Inverted)
Hal ini dapat dilihat pada Gambar 2.2b.
1. Pulsa tegangan konstan untuk durasi bit
2. Transisi = 1
3. Tidak ada transisi = 0
2. Biphase
a. Manchester, dapat dilihat pada Gambar 2.2e.
b. Differensial Manchester, dapat dilihat pada Gambar 2.2f.
3. Multilevel Binary
a. Bipolar AMI
Suatu kode dimana binary „0‟ diwakili dengan tidak adanya line
sinyal dan binary „1‟ diwakili oleh suatu pulsa positif atau
negatif. Hal ini dapat dilihat pada Gambar 2.2c.
b. Pseudoternary
Suatu kode dimana binary '1' diwakili oleh ketiadaan line sinyal
dan binary '0' oleh pergantian pulsa-pulsa positif dan negatif.
DATA
(a)
(b)
(c)
(d)
(e)
(f)
Gambar 2.2 Format Pengkodean Sinyal Digital
2.2.2 Data Digital, Sinyal Analog
Transmisi data digital dengan menggunakan sinyal analog. Contoh umum
yaitu public telephone network. Device yang dipakai yaitu modem (modulator
demodulator) yang mengubah data digital ke sinyal analog (modulator) dan
Tiga teknik dasar encoding atau modulasi untuk mengubah data digital
menjadi sinyal analog:
1. ASK (Amplitude-shift keying)
Modulasi yang menyatakan sinyal digital 1 sebagai suatu nilai
tegangan tertentu (misalnya 1 Volt) dan sinyal digital 0 sebagai sinyal
digital dengan tegangan 0 Volt. Hal ini dapat dilihat pada Gambar 2.3a.
2. FSK (Frequency-shift keying)
Modulasi yang menyatakan sinyal digital 1 sebagai suatu nilai
tegangan dengan frekuensi tertentu, sementara sinyal digital 0 dinyatakan
sebagai suatu nilai tegangan dengan frekuensi tertentu yang berbeda. Hal
ini dapat dilihat pada Gambar 2.3b.
3. PSK (Phase-shift keying)
Modulasi yang menyatakan sinyal digital 1 sebagai suatu nilai
tegangan tertentu dengan beda fasa tertentu pula (misalnya tegangan 1
Volt dengan beda fasa 0 derajat), dan sinyal digital 0 sebagai suatu nilai
tegangan tertentu (yang sama dengan nilai tegangan sinyal PSK bernilai 1,
misalnya 1 Volt) dengan beda fasa yang berbeda (misalnya beda fasa 180
derajat). Hal ini dapat dilihat pada Gambar 2.3c.
Tiga teknik dasar encoding atau modulasi tersebut dapat dilihat pada
Gambar 2.3 Teknik Dasar Modulasi untuk Mengubah Data Digital menjadi
Sinyal Analog
2.2.3 Data Analog, Sinyal Digital
Transformasi data analog ke sinyal digital, proses ini dikenal sebagai
digitalisasi. Tiga hal yang paling umum terjadi setelah proses digitalisasi adalah:
1. Data digital dapat ditransmisikan menggunakan NRZ-L.
2. Data digital dapat di-encode sebagai sinyal digital memakai kode NRZ-L.
Dengan demikian, diperlukan step tambahan
3. Data digital dapat diubah menjadi sinyal analog, menggunakan salah satu
Codec (Coder-decoder) adalah device yang digunakan untuk mengubah
data analog menjadi bentuk digital untuk transmisi, yang kemudian mendapatkan
kembali data analog dari data digital tersebut.
Dua teknik yang digunakan dalam codec adalah:
1. Pulse Code Modulation
Dari teori sampling diketahui bahwa frekuensi sampling
(fS) harus lebih besar atau sama dengan dua kali frekuensi tertinggi
dari sinyal (fH), fS ≥ 2 fH. Sinyal asal dianggap mempunyai
bandwidth B maka kecepatan pengambilan sampel yaitu 2B atau
1/2B detik. Sampel-sampel ini diwakilkan sebagai pulsa-pulsa
pendek yang amplitudo nya proporsional terhadap nilai dari sinyal
asal. Proses ini dikenal sebagai pulse amplitude modulation
(PAM). Kemudian amplitudo tiap pulsa PAM dihampiri dengan
n-bit integer, sehingga dihasilkan data PCM. Sedangkan pada
receiver, prosesnya merupakan kebalikan dari proses diatas untuk
memperoleh data analog. Proses PCM ini dapat dilihat pada
Gambar 2.4 Teknik PCM
Gambar 2.5 merupakan Block Diagram dari proses PCM.
Pada Block Diagram ini dapat dilihat bagaimana proses dari data
analog menjadi sinyal digital.
2. Delta Code Modulation
Proses dimana suatu input analog didekati dengan suatu
fungsi tangga yang bergerak naik atau turun dengan satu level
quantization (δ) pada tiap interval sampling (TS), dan outputnya diwakilkan sebagai suatu bit binary tunggal untuk tiap sampel ('1'
dihasilkan bila fungsi tangganya naik selama interval berikutnya;
'0' dihasilkan untuk keadaan sebaliknya). Hal ini dapat dilihat pada
Gambar 2.6.
2.2.4 Data Analog, Sinyal Analog
Alasan dasar dari proses ini adalah diperlukannya frekuensi tinggi untuk
transmisi yang efektif. Untuk transmisi unguided, hal tersebut tidak mungkin
untuk mentransmisi sinyal-sinyal baseband dan juga antena-antena yang
diperlukan akan menjadi beberapa kilometer diameternya, modulasi mendukung
frequency-division multiplexing.
Teknik Modulasi memakai data analog adalah:
1. Amplitude Modulation (AM)
Modulasi ini menggunakan amplitudo sinyal analog untuk
membedakan kedua keadaan sinyal digital, dimana frekuensi dan phasenya
tetap, amplitudo yang berubah. AM adalah modulasi yang paling mudah,
tetapi mudah juga dipengaruhi oleh keadaan media transmisinya. Hal ini
dapat dilihat Gambar 2.7(a).
2. Frequency Modulation (FM)
Modulasi ini menggunakan sinyal analog untuk membedakan
kedua keadaan sinyal digital, dimana amplitudo dan phasenya tetap,
frekuensi yang berubah. Kecepatan transmisi mencapai 1200 bit per detik.
Untuk transmisi data sistem yang umum dipakai FSK. Hal ini dapat dilihat
Gambar 2.7(b).
3. Phase Modulation (PM)
Modulasi ini menggunakan perbedaan sudut phase sinyal analog
untuk membedakan kedua keadaan sinyal digital, dimana frekuensi dan
amplitudo tetap, phase yang berubah. Cara ini paling baik, tapi paling
yang banyak dan kecepatan yang tinggi. Hal ini dapat dilihat Gambar
2.7(c).
Teknik Modulasi memakai data analog ini dapat dilihat pada
Gambar 2.7.
(a)
[image:31.595.163.448.209.687.2](c) (b)
BAB III
KOMPRESI DATA
3.1 Umum
Kompresi data merupakan cabang dari Teori Informasi. Teori Informasi
sendiri adalah salah satu cabang Matematika yang berkembang sekitar akhir
1940an. Tokoh utama dari Teori Informasi adalah Claude Shannon dari Bell
Laboratory. Teori Informasi memfokuskan pada berbagai metode tentang
informasi termasuk penyimpanan dan pemrosesan pesan. Teori Informasi
mempelajari pula tentang pula tentang redundancy pada pesan. Semakin banyak
redundancy semakin besar pula ukuran pesan, upaya mengurangi redundancy ini
yang akhirnya melahirkan subyek ilmu tentang kompresi data.
Kompresi data adalah sebuah cara untuk memadatkan data sehingga
hanya memerlukan ruangan penyimpanan lebih kecil sehingga lebih efisien dalam
penyimpanannya dan mempersingkat waktu pertukaran data tersebut.
Keuntungan kompresi data adalah penghematan tempat pada media
penyimpanan dan penghematan bandwidth pada pengiriman data. Namun
kompresi data juga memiliki sisi negatif, bila data yang terkompresi ingin dibaca,
perlu dilakukan dekompresi terlebih dahulu. Pada pengiriman data, penerima data
harus mengerti proses encoding dalam data terkompresi yang diterima atau
dengan kata lain, penerima juga harus memiliki perangkat lunak yang sama
Berikut ini adalah beberapa teknik kompresi data yang dikategorikan
menurut jenis data yang akan dikompresi, yaitu:
1. Teknik kompresi untuk citra diam (still image)
Contoh: JPEG, GIF dan run-length.
2. Teknik kompresi untuk citra bergerak (motion picture)
Contoh: MPEG.
3. Teknik kompresi untuk data teks
Contoh: half byte.
4. Teknik kompresi untuk data umum
Contoh: LZW, half byte dan Huffman.
5. Teknik kompresi untuk data sinyal speech
Contoh: PCM, SBC, LPC dan CELP.
Ada empat pendekatan yang digunakan pada kompresi suatu data, yaitu:
1. Pendekatan statistik
Contoh: Huffman coding.
2. Pendekatan ruang
Contoh: Run-Length encoding
3. Pendekatan kuantisasi
Contoh: Kompresi kuantisasi (CS&Q)
4. Pendekatan Fraktal
3.2 Jenis Kompresi
Algoritma Kompresi Data dapat diklasifikasikan menjadi dua jenis, yaitu:
1. Algoritma Kompresi Lossy
2. Algoritma Kompresi Lossless
3.2.1 Algoritma Kompresi Lossy
Kompresi adalah suatu metode untuk mengkompresi data dan
mendekompresikannya, data yang diperoleh mungkin berbeda dari yang aslinya
tetapi cukup dekat perbedaannya. Format kompresi Lossy mengalami generation
loss, yaitu jika melakukan berulang kali kompresi dan dekompresi file akan
menyebabkan kehilangan kualitas secara progresif.
Keuntungan metode Lossy ini adalah rasio kompresi yang cukup tinggi.
Hal ini dikarenakan cara kompresi Lossy yang akan mengeleminasi beberapa data
dari suatu berkas. Namun data yang dieliminasikan biasanya adalah data yang
kurang diperhatikan atau hanya mengurangi sedikit dari nilai data tersebut
sehingga tidak terlalu menimbulkan perbedaan yang besar. Contoh format yang
menggunakan algoritma Lossy adalah JPEG dan MPEG.
Rasio Kompresi atau perbandingan ukuran file sebelum dan setelah
dikompresi pada kompresi dengan menggunakan algoritma Lossy memang tinggi.
Pada video misalnya, dapat terkompres dengan rasio kompresi hingga 100:1,
tanpa terlihat perbedaan kualitas yang signifikan dengan data aslinya. Pada audio
dan gambar dapat terkompresi hingga 10:1, perbedaannya adalah jika pada audio
perbedaan kualitas dari data yang terkompresi dan data aslinya tidak terlalu
Ada dua skema dasar Lossy kompresi, yaitu:
1. Lossytransform codec
2. Lossy predictive codec
3.2.1.1 JPEG
JPEG merupakan sebuah organisasi Joint Photographic Experts Group
yang mengeluarkan format .jfif, namun pada perkembangannya, nama JPEG itu
sendiri lebih dikenal sebagai nama format itu sendiri. JPEG adalah metode
kompresi yang umum digunakan untuk gambar-gambar berupa foto. Pada tahun
1994, standar JPEG disahkan sebagai ISO 10918-1. Standar JPEG memberikan
spesifikasi codec kompresi data ke dalam stream data byte dan didekompresi
kembali ke bentuk gambar serta format data penyimpanannya. Metode kompresi
data yang digunakan umumnya berupa lossy compression, yang membuang detail
visual tertentu, dimana hilangnya data tersebut tidak bisa dikembalikan. File JPEG
memiliki ekstensi .jpg, .jpeg, .jpe, .jfif dan .jif.
Format JPEG banyak digunakan untuk penyimpanan dan transfer data
berupa foto. JPEG mampu mengkompresi data citra yang kaya warna (24 bit) atau
gradasi warna abu-abu (bayangan). Dalam hal ini format JPEG lebih baik dari GIF
yang menggunakan pallete maksimum 256 warna. Sebaliknya algoritma kompresi
Gambar dalam format JPEG umumnya dikompresi dengan menggunakan
JFIF encoding:
1. Representasi warna diubah dari RGB (Red, Green, Blue) ke YCbCr yaitu
satu komponen brightness, luma (Y) dan dua komponen warna, chroma
(CbCr).
2. Resolusi data chroma diturunkan (down sampling), biasanya dengan faktor
pembagian 2. Hal ini dikarenakan mata manusia lebih peka terhadap detail
brightness daripada detail warna.
3. Gambar dibagi kedalam blok-blok 8x8 pixel. Tiap blok akan melalui
proses transformasi Discrete Cosine Transform (DCT). DCT akan
menghasilkan spektrum spatial dari data Y, Cb dan Cr.
4. Amplitudo dari frekuensi komponen-komponen tersebut dikuantisasi.
Mata manusia lebih sensitif terhadap variasi kecil warna atau brightness
dalam lingkup area yang luas daripada variasi brightness pada frekuensi
tinggi. Oleh karena itu, nilai dari komponen yang berfrekuensi tinggi
disimpan dalam akurasi yang lebih rendah daripada komponen yang
berfrekuensi rendah. Dalam kasus encoding dengan settings kualitas yang
sangat rendah, komponen frekuensi tinggi akan dibuang seluruhnya.
5. Hasil dari setiap blok 8x8 tersebut akan dikompresi lebih lanjut dengan
algoritma lossless yaitu dengan menspesifikasikan tabel kode Huffman
3.2.1.2 MPEG
MPEG (Moving Picture Experts Group) adalah nama organisasi
internasional ISO/IEC yang mengembangkan standar pengkodean citra bergerak.
Pertemuan pertama terjadi pada bulan Mei 1998 di Ottawa, Kanada. Beberapa
standar yang dikembangkan adalah MPEG-2 dan MPEG-3. Encoding MPEG-2
digunakan pada video CD, sementara MPEG-3 menjadi populer dengan
tampilannya lapisan audio (audio layer) MPEG-3, atau yang lebih dikenal dengan
MP3.
MPEG berkembang menjadi beberapa kategori, yaitu:
1. MPEG-1
Standar pengompresian suara dan gambar pada video CD
termasuk juga lapisan audio 3 (audio layer 3) MP3 format
kompresi suara (audio).
2. MPEG-2
Standar untuk penyiaran suara dan gambar over-the-air televisi
digital ATSC, DVB dan ISDB, satelit televisi digital Dish
Network, sinyal digital cable television dan juga DVD.
3. MPEG-3
Standar untuk High-definition television HDTV.
4. MPEG-4
Pengembangan dari MPEG-1 untuk mendukung objek suara
5. MPEG-7
Standar suatu sistem formal untuk menggambarkan isi dari
suatu multimedia.
6. MPEG-21
Standar MPEG untuk generasi masa depan (rangka
multimedia).
Berikut ini adalah metode yang biasa digunakan dalam kompresi MPEG:
1. Estimasi pergerakan dilakukan pada setiap macroblock. MPEG mampu
melakukan prediksi terhadap frame sebelumnya, sesudahnya atau
kombinasi keduanya.
2. Setiap macroblock mempunyai dua buah motion vektor, satu untuk
frame sebelumnya dan satu lagi untuk frame sesudahnya. Hal ini
dikarenakan objek dalam frame tidak bergerak secara tetap dari frame
ke frame. Untuk melakukan prediksi terhadap frame selanjutnya, harus
dilakukan buffer terhadap frame ekstra. Estimasi pergerakan juga dapat
dilakukan hingga range yang lebih besar (hingga ±1023) dan dengan
resolusi half-pixel.
3. MPEG malakukan prediksi yang dibentuk dari perbedaan aritmatika
antara macroblock sekarang dengan macroblock dari frame
sebelumnya, frame selanjutnya, rata-rata antara frame sebelumnya
dengan frame selanjutnya atau mengkodekan macroblock sekarang
dari awal. Sebuah DCT 8x8 diaplikasikan kedalam masing-masing
blok pada macroblock sekarang. MPEG menggunakan matriks dan
4. Karena visual efek dari kuantisasi frequency bin berbeda antara blok
perkiraan dengan blok sekarang, MPEG dapat menggunakan dua
matriks (masing-masing satu untuk setiap tipe). Biasanya, matriks
tersebut diset sekali untuk urutan gambar dan skala kuantisasinya
disesuaikan untuk mengontrol rasio kompresi.
5. Tahap terakhir adalah zig-zag scanning, Run-Length encoding dan
entropy coding. MPEG menspesifikasikan tabel kode Huffman untuk
entropy coding.
Pada proses dekompresinya, setiap operasi dilakukan terbalik, kecuali
untuk estimasi pergerakan. Karena vektor pergerakan dimasukkan dalam
bit-stream yang dikompresi, dekompresor MPEG hanya cukup menerapkan vektor
pergerakan untuk memprediksi frame sebelumnya maupun frame selanjutnya jika
diperlukan.
3.2.2 Algoritma Kompresi Lossless
Kompresi Lossless adalah kelas dari algoritma data kompresi yang
memungkinkan data yang asli dapat disusun kembali dari data kompresi.
Kompresi Lossless menghasilkan data yang identik dengan data yang asli, hal ini
dibutuhkan untuk banyak tipe data, contohnya: executablecode, word processing
files, tabulated numbers dan sebagainya. Rasio kompresi (ukuran file sebelum
dikompresi dibanding file yang telah dikompresi) dengan metode ini sangat
rendah.
Kompresi Lossless bekerja dengan cara mencari bentuk-bentuk yang
Karena pengurangan bentuk yang berulang tergantung dari bentuk dari data,
kompresi ini tidak bekerja baik pada data acak. Kompresi ini dapat berjalan
dengan baik apabila dilakukan terhadap data simbolik yang berbasis teks dan
executable program.
Algoritma ini cocok untuk kompresi informasi penting yang tidak boleh
merusak nilai dari data tersebut akibat kompresi, karena ingin mengembalikan
data yang telah dikompresi sesuai dengan aslinya. Algoritma ini biasa digunakan
untuk kompresi text. Contoh format gambar yang menggunakan algoritma
Lossless adalah GIF dan PNG dan contoh kompresi Lossless adalah Run-Length,
Half-Byte, LZW, Huffman dll.
3.2.2.1 Run-Length
Teknik Run-Length bekerja berdasarkan sederetan karakter yang
berurutan. Data masukan akan dibaca dan sederetan karakter yang sesuai dengan
karakter yang sudah ditentukan sebelumnya disubstitusi dengan kode tertentu.
Kode khusus ini biasanya terdiri dari tiga buah karakter. Seperti yang
diperlihatkan pada Gambar 3.1.
Sc Cc X
Gambar 3.1 Karakter pada Run-Length
Keterangan:
Sc = Karakter khusus yang dipakai sebagai tanda kompresi
Cc = Banyaknya karakter yang dekompresi
Sebagai contoh sederhana apabila karakter khusus (Sc) yang digunakan
adalah # dan Cc dalam bilangan desimal, maka jika digunakan untuk kompresi
string “Jarrrrrringan”, maka akan diperoleh hasil “Ja#6ringan”. Gambar 3.2 memperlihatkan contoh kompresi dengan menggunakan Run-Length.
010000001 010000001 010000001 010000001 010000001 010000001 010000001 010000001
11111110 00001000 01000001
Bit Penanda
[image:41.595.180.430.217.335.2]8X
Gambar 3.2 Contoh kompresi menggunakan algoritma Run-Length
Algoritma komperesi dengan menggunakan metode Run-Length adalah
sebagai berikut:
1. Cari deretan karakter yang sama secara berurutan, jika ada lakukan
kompresi.
2. Tulis byte penanda file kompresi, byte penanda berupa 8 deretan bit yang
boleh dipilih sembarang asalkan digunakan secara konsisten pada seluruh
byte penanda kompresi. Byte penanda ini berfungsi untuk menandai bahwa
karakter selanjutnya adalah karakter kompresi sehingga tidak
membingungkan pada saat mengembalikan file yang sudah dikompresi ke
file aslinya.
3. Tulis deretan bit untuk menyatakan jumlah karakter yang sama berurutan.
4. Tulis deretan bit untuk menyatakan karakter yang berulang.
Dan untuk algoritma dekomperesi dengan menggunakan metode
Run-Length adalah sebagai berikut:
1. Lihat karakter pada hasil kompresi satu per satu dari awal hingga akhir,
jika ditemukan byte penanda, lakukan proses pengembalian.
2. Lihat karakter setelah byte penanda, konversikan ke bilangan desimal
untuk menentukan jumlah karakter yang berurutan.
3. Lihat karakter berikutnya, kemudian lakukan penulisan karakter tersebut
sebanyak bilangan yang telah diperoleh pada karakter sebelumnya.
4. Ulangi langkah 1-3 sampai karakter terakhir.
3.2.2.2 Half Byte
Seperti halnya pada Run-Length, dalam teknik half byte juga memerlukan
karakter khusus sebagai tanda dari sederetan data yang sudah dikompresi. Hal ini
diperlihatkan pada Gambar 3.3.
Sc N1 N2
N3 N4
N5
Sc ...
... NX
[image:42.595.192.392.502.562.2]NX
Gambar 3.3 Format menggunakan Algoritma half byte
Keterangan:
Sc adalah karakter khusus sebagai tanda kompresi.
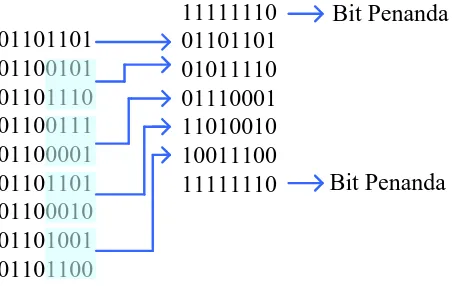
01101101 01100101 01101110 01100111 01100001 01101101 01100010 01101001 01101100
11111110 01101101 01011110 01110001 11010010 10011100 11111110
Bit Penanda
[image:43.595.213.443.98.241.2]Bit Penanda
Gambar 3.4 Contoh Kompresi menggunakan Algoritma half byte
Deretan pada Gambar 3.4, sebelah kiri merupakan deretan data pada file
asli, sedangkan deretan data sebelah kanan merupakan deretan data hasil kompresi
dengan algoritma half byte.
Algoritma komperesi dengan menggunakan metode half byte adalah sebagai
berikut:
1. Cari deretan karakter yang 4 bit pertamanya sama secara berurutan,
lakukan kompresi.
2. Tulis byte penanda pada file kompresi, berupa 8 deretan bit (1 byte) yang
boleh dipilih sembarangan asalkan digunakan secara konsisten pada
seluruh byte penanda kompresi. Byte penanda ini berfungsi untuk
menandai bahwa karakter selanjutnya adalah karakter kompresi, sehingga
tidak membingungkan pada saat mengembalikan file yang sudah
dikompresi ke file aslinya.
3. Tulis karakter pertama dari 4 bit kiri berurutan dari file asli.
4. Gabungkan 4 bit kanan karakter kedua dan ketiga kemudian tulis ke file
5. Tutup dengan menulis byte penanda pada file kompresi.
6. Ulangi langkah 1-5 sampai karakter terakhir.
Dan untuk algoritma dekomperesi dengan menggunakan metode half byte
adalah sebagai berikut:
1. Lihat karakter pada hasil kompresi satu per satu dari awal sampai akhir,
jika ditemukan byte penanda, lakukan proses pengembalian.
2. Lihat karakter setelah byte penanda, tulis karakter tersebut pada file
pengembalian.
3. Lihat karakter berikutnya, ambil 4 bit kiri dan 4 bitkanannya, lalu
masing-masing 4 bit kiri dan 4 bit kanan digabungkan dengan 4 bit kiri karakter
setelah byte penanda. Hasil gabungan tersebut ditulis pada file
pengembalian. Lakukan sampai ditemukan bitpenanda.
4. Ulangi langkah 1-3 sampai karakter terakhir.
3.2.2.3 LZW (Lempel-Ziv-Welch)
Algoritma ini menggunakan metode kamus dalam proses kompresinya.
Dimana string karakter digantikan oleh kode tabel yang dibuat setiap ada string
yang masuk. Tabel dibuat untuk referensi masukan string selanjutnya. Ukuran
tabel kamus pada algoritma LZW asli adalah 4096 sampel atau 12 bit, dimana 256
sampel pertama digunakan untuk tabel karakter single (Extended ASCII), dan
sisanya digunakan untuk pasangan karakter atau string dalam data input.
Algoritma LZW melakukan kompresi dengan menggunakan kode tabel
ini banyak string yang dapat dikodekan dengan mengacu pada string yang telah
muncul sebelumnya dalam teks.
Algoritma komperesi dengan menggunakan metode LZW adalah sebagai
berikut:
1. Kamus diinisialisasikan dengan semua karakter dasar yang ada :
{„A‟…‟Z‟,‟a‟…‟z‟,‟0‟…‟9‟}.
2. W = karakter pertama dalam stream karakter.
3. K = karakter berikutnya dalam stream karakter.
4. Lakukan pengecekan apakah (W+K) terdapat dalam kamus.
a. Jika ya, maka W ← W + K (gabungkan W dan K menjadi string
baru).
b. Jika tidak, maka:
1. Output sebuah kode untuk menggantikan stringW.
2. Tambahkan string (W+K) ke dalam kamus dan diberikan
kode berikutnya yang belum digunakan dalam kamus untuk
string tersebut.
3. W ← K
c. Lakukan pengecekan apakah masih ada karakter berikutnya dalam
stream karakter
1. Jika iya, maka kembali ke langkah 2.
2. Jika tidak, maka output kode yang menggantikan string W,
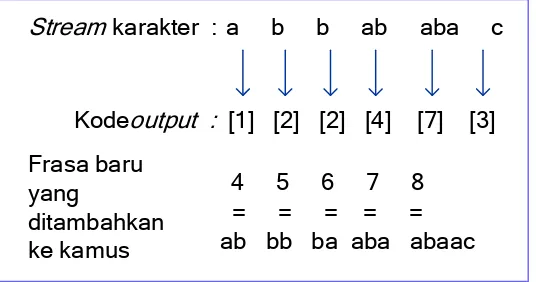
Sebagai contoh, string “ABBABABAC” akan dikompresi dengan LZW.
[image:46.595.180.448.577.718.2]Isi kamus pada awal proses diset dengan tiga karakter dasar yang ada: “A”, “B” dan “C”. Tahapan proses kompresi ditunjukkan pada Tabel 3.1.
Tabel 3.1 Tahapan kompresi LZW
Langkah Posisi Karakter Kamus Output
1 1 A [4] A B [1]
2 2 B [5] B B [2]
3 3 B [6] B A [2]
4 4 A [7] A B A [4]
5 6 A [8] A B A C [7]
6 9 C - [3]
Kolom posisi menyatakan posisi sekarang dari stream karakter
menyatakan karakter yang terdapat pada posisi tersebut. Kolom kamus
menyatakan string baru yang sudah ditambahkan ke dalam kamus dan nomor
indeks untuk string tersebut ditulis dalam kurung siku. Kolom output menyatakan
kode output yang dihasilkan oleh langkah kompresi. Hasil kompresi ditunjukkan
pada Gambar 3.5.
Stream karakter : a b b ab aba c
Kode output : [1] [2] [2] [4] [7] [3]
Frasa baru yang
ditambahkan ke kamus
4 5 6 7 8 = = = = = ab bb ba aba abaac
Proses dekompresi data pada algoritma LZW tidak jauh berbeda dengan
proses kompresinya. Pada dekompresi LZW, juga dibuat tabel kamus dari data
input kompresi, sehingga tidak diperlukan penyertaan tabel kamus ke dalam data
kompresi. Berikut adalah algoritma dekompresi LZW:
1. Kamus diinisialisasikan dengan semua karakter dasar yang ada:
{„A‟…‟Z‟,‟a‟…‟z‟,‟0‟…‟9‟}.
2. CW = kode pertama dari stream kode (menunjuk ke salah satu karakter
dasar).
3. Lihat kamus dan outputs string dari kode tersebut (string.CW) ke stream
karakter.
4. PW←CW; CW← kode berikutnya dari stream kode. 5. Apakah string.CW terdapat dalam kamus?
a. Jika ada, maka:
1. Output string.CW ke stream karakter
2. P ← string.PW
3. C ← karakter pertama dari string.CW
4. Tambahkan string (P+ C) ke dalam kamus
b. Jika tidak, maka:
1. P ← string.PW
2. C ← karakter pertama dari string.PW
3. Output string (P+ C) ke stream karakter dan tambahkan
string tersebut ke dalam kamus (sekarang
c. Apakah terdapat kode lagi di stream kode?
1. Jika ya, maka kembali ke langkah 4.
2. Jika tidak, maka terminasi proses (stop).
3.2.2.4 Huffman
Uraian mengenai kompresi menggunakan kode Huffman akan
dibahas secara rinci pada Bab IV.
3.3 Metode Kompresi
Ada banyak metode yang dapat digunakan dalam proses kompresi.
Namun, secara garis besarnya metode yang digunakan dapat diklasifikasikan ke
dalam dua metode, yaitu :
1. Metode statis (static method)
2. Metode kamus (dictionary method)
3.3.1 Metode Statis (Static Method)
Metode statis (static method) adalah metode kompresi yang bekerja
dengan cara memetakan data terlebih dahulu kedalam kode-kode (encoding)
sebelum proses kompresi dilakukan, sehingga data tersebut akan dipresentasikan
dengan kode-kode pada saat data itu disimpan atau akan dikirimkan sebelum
3.3.2 Metode Kamus (Dictionary Method)
Metode kamus (dictionary method) adalah metode kompresi yang
melakukan penyeleksian string dari data, yang kemudian sebagian dari string
tersebut akan diubah menjadi kode dan kamus akan menyimpan kode string setiap
proses penyeleksian dilakukan. Isi dari kamus tersebut bisa tetap atau
berubah-ubah. Hal ini tergantung pada input data, karena setiap pembacaan data akan
dilakukan proses penyeleksian yang akan mengakibatkan bertambahnya isi dari
BAB IV
KOMPRESI DATA MENGGUNAKAN KODE HUFFMAN
4.1 Pendahuluan
Kode Huffman dikembangkan oleh David A. Huffman pada tahun 1951.
Pada awalnya David A. Huffman menulis paper sebagai salah satu tugas
kuliahnya di MIT. Algoritma ini merupakan pengembangan lebih lanjut dari
algoritma kompresi yang dilakukan oleh Claude Shannon dan R.M. Rano.
Algoritma Huffman disebut juga algoritma prefix, dimana setiap kode
yang dihasilkan tidak akan menghasilkan kode yang sama dari karakter yang
muncul. Algoritma ini berdasarkan frekuensi kemunculan tiap karakter, yang akan
menghasilkan kode-kode baru yang dihasilkan dari pembentukan pohon Huffman.
Pembentukan pohon Huffman dilakukan secara bottom-up, yakni berdasarkan
frekuensi kemunculan karakter yang terkecil ke yang terbesar.
Kode Huffman merupakan algoritma yang cukup popular dan banyak
digunakan untuk melakukan kompresi text maupun data. Kode Huffman ini
memiliki prinsip berdasarkan metode statistik, yakni dengan menghitung
kekerapan karakter yang muncul.
Jika ditijau dari segi teknik pengkodean karakter yang digunakan,
algoritma Huffman ini termasuk dalam algoritma yang menggunakan metode
symbolwise, yaitu suatu metode yang menghitung probabilitas kemunculan suatu
karakter dalam satu waktu, karakter yang sering muncul akan dikodekan dalam
suatu untaian bit yang lebih pendek dan karakter yang jarang muncul akan
mempercepat proses inisialisasi karakter yang lebih sering muncul dalam sebuah
string, yang tentu saja akan berpengaruh saat encoding dan decoding kode
Huffman.
Kelebihan kompresi data menggunakan Kode Huffman adalah:
1. Kompresi menggunakan kode Huffman merupakan kompresi Lossless
sehingga pada saat data yang telah terkompresi didekompresikan, maka
data tersebut akan sama dengan data aslinya. Hal ini baik digunakan pada
kompresi data berupa teks karena tidak akan mengurangi nilai dari data
tersebut.
2. Proses kompresi menggunakan kode Huffman lebih sederhana
dibandingkan dengan kompresi menggunakan metode lain.
3. Persentase kompresi menggunakan Kode Huffman pada kompresi data
berupa teks berkisar hingga 45%.
4.2 Variasi Kode Huffman
Ada beberapa variasi dari kode Huffman, beberapa diantaranya
menggunakan algoritma yang sama dengan algoritma pembentukan kode
Huffman, beberapa yang lain menemukan kode awalan yang lebih optimal.
Berikut adalah beberapa variasi dari kode Huffman:
1. Kode Huffman n-ary
Algoritma Huffman n-ary menggunakan alphabet {0,1, …, n-1} untuk encoding suatu pesan dan membuat pohon n-ary. Pendekatan ini
adalah ide awal David Huffman. Algoritma sama dengan yang
yang paling sedikit kemunculannya diambil secara bersamaan, tidak
diambil 2 yang paling sedikit saja. Untuk n>2, tidak semua himpunan
kata-kata sumber dapat membentuk pohon n-ary untuk kode Huffman
dengan benar. Pada kasus ini, tambahan probabilitas 0 harus
ditambahkan. Hal ini dilakukan karena pohonnya harus membentuk
kontraktor n ke 1. Kode biner memiliki kontraktor 2 ke 1, himpunan
kata berukuran berapa pun dapat membentuk kontraktor ini.
2. Kode Huffman Adaptif
Variasi ini menghitung probabilitas secara dinamis berdasarkan
frekuensi terakhir dari string sumber (adaptif). Ide dasar kode Huffman
adaptif ini adalah meringkas tahapan algoritma Huffman tanpa perlu
menghitung jumlah karakter keseluruhan dalam membangun pohon
biner. Algoritma ini dikembangkan oleh Faller, Gallager dan Knuth
yang kemudian dikembangkan lebih lanjut oleh Vitter, sehingga
tercipta dua buah kode Huffman adaptif, yaitu:
a. Algoritma FGK
b. Algoritma V
3. Algoritma Lain yang Menggunakan Dasar Algoritma Huffman
Sering kali bobot yang digunakan dalam implementasi Kode
Huffman mempresentasikan probabilitas numerik, namun ada juga
beberapa contoh pembentukan Kode Huffman yang hanya memerlukan
Beberapa algoritma lain yang menggunakan dasar dari algoritma
Huffman, bobotnya bisa apa pun (misalnya harga, frekuensi, bobot
sepasang, bobot yang tidak numerik) dan metode kombinasi yang lain
(tidak hanya penjumlahan). Algoritma ini dapat menyelesaikan
masalah minimalisasi yang lain, misalnya meminimalisasi pada design
rangkaian digital.
4. Kode Huffman dengan Panjang Dibatasi
Ini adalah salah satu variasi kode Huffman yang tujuannya sama,
yaitu membangun pohon biner dengan panjang lintasan minimum,
tetapi yang membedakannya adalah panjang kode Huffman harus lebih
kecil dari konstanta tertentu yang telah ditentukan.
5. Kode Huffman dengan Bobot Sumber Tidak Sama
Pada masalah penentuan kode Huffman yang biasa, diasumsikan
setiap karakter pada sumber memiliki bobot yang sama. Kode biner
dengan bobot N akan selalu berbobot N, tidak peduli berapa banyak
digitnya yang 0 dan berapa banyak digitnya yang 1. Dengan asumsi
seperti ini, meminimalisasikan harga total suatu pesan sama dengan
meminimalisasi jumlah digit total.
Kode Huffman dengan bobot sumber tidak sama adalah
generalisasinya, dimana asumsi tersebut tidak berlaku.
Karakter-karakter pada sumber panjangnya bisa berbeda-beda, karena adanya
encoding alphabet pada Kode Morce, dimana sebuah „-„ (garis)
memakan waktu pengiriman yang lebih lama dibandingkan sebuah „.‟
(titik), dengan demikian bobot garis dalam pengiriman lebih besar.
Tujuannya masih sama, yaitu meminimalisasikan panjang kode
rata-rata, tetapi tidak cukup dengan hanya meminimalisasi jumlah simbol
yang digunakan dalam suatu pesan. Belum ada algoritma yang
diketahui dapat menyelesaikan masalah ini dengan tingkat efisiensi
yang sama dengan Kode Huffman yang konvensional.
6. Pohon biner Alfabetis (Kode Hu-Tucker)
Pada masalah penentuan Kode Huffman yang biasa, diasumsikan
bahwa setiap kode dapat mengacu pada simbol apapun pada sumber.
Pada versi alfabetis ini, urutan alfabetis pada sumber dan hasil
encoding harus sama. Kode Hu-Tucker ini sering digunakan sebagai
pohon pencarian biner (BST/Binary Search Tree).
7. Kode Huffman Kanonik
Kode yang didapatkan dari sumber yang diurutkan kembali, yang
disebut Kode Huffman kanonik ini adalah kode yang sering digunakan,
karena kemudahannya dalam encoding dan decoding. Teknik
menentukan kode ini sering disebut Kode Huffman-Shannon-Fano,
karena optimalitasnya seperti Kode Huffman dan probabilitas bobotnya
4.3 Encoding dan Decoding Menggunakan Kode Huffman
Pada setiap model kompresi, dilakukan proses konversi simbol dari
representasi string menjadi representasi kode lain dan sebaliknya. Ada dua alat
konversi dalam hal ini, yaitu encoder dan decoder.Encoder merupakan alat untuk
menjalankan suatu mekanisme untuk melakukan konversi simbol dari representasi
string menjadi suatu representasi kode lainnya yang bersifat unik. Mekanisme
yang dilakukan oleh encoder disebut encoding. Sedangkan decoder merupakan
alat yang menjalankan suatu mekanisme untuk mengembalikan representasi unik
dari suatu string menjadi sebuah representasi string awalnya. Mekanisme yang
dilakukan encoder adalah decoding.
4.3.1 Encoding
Pembentukan pohon Huffman adalah untuk membuat prefix code, yaitu
kode berupa string biner dimana kode yang satu bukan merupakan awalan dari
kode yang lain, sehingga pembentukan kode biner setelah dikompresi tidak
menghasilkan kode yang sama. Secara garis besar proses kompresi dimulai
dengan membuat pohon Huffman, setelah itu mengubah setiap karakter menjadi
kode biner dan menyimpan kembali menjadi karakter yang lain karena ada
pengerutan jumlah bit.
Yang perlu diperhatikan adalah penyimpanan pohon Huffman, jika terjadi
kesalahan maka file kompresi tidak akan terbaca. Berikut adalah Algoritma
Huffman:
1. Baca SMS yang akan diencoding (SMS yang akan dikirimkan)
3. Urutkan dari frekuensi kemunculan yang terkecil hingga yang terbesar.
4. Buat pohon Huffman dengan cara :
a. Setiap karakter dinyatakan sebagai pohon bersimpul tunggal dan
setiap karakter disertai dengan jumlah frekuensi kemunculannya.
b. Gabungkan dua pohon dengan frekuensi terkecil pada sebuah akar.
c. Setelah digabungkan akar tersebut akan mempunyai frekuensi yang
merupakan jumlah frekuensi dari dua pohon penyusun tersebut.
d. Ulangi hingga hanya tersisa satu buah pohon Huffman. Dan
urutkan berdasarkan frekuensi dari yang terkecil ke yang terbesar.
e. Jika frekuensi kedua pohon sama, maka beri simbol 0 untuk
sebelah kiri dan simbol 1 untuk sebelah kanan. Dan jika frekuensi
kedua pohon berbeda, maka beri simbol 0 untuk frekuensi yang
lebih kecil dan 1 untuk frekuensi yang lebih besar.
5. Setelah pohon Huffman selesai. Urutkanlah biner yang terbentuk dari akar
hingga ke karakter tunggal.
6. Urutan biner tersebut adalah kode Huffman yang menggantikan kode
ASCII untuk mempresentasikan karakter tersebut.
Setelah proses encoding dilakukan, maka akan dapat diperoleh persentase
dari kompresi dengan persamaan:
Dan diperoleh rasio kompresi dengan persamaan:
Cr =
...
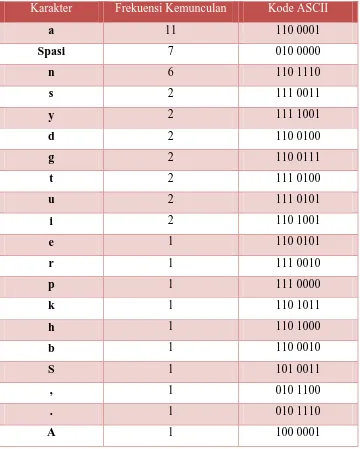
(4.2)Sebagai contoh sederhana sebuah kompresi, dalam kode ASCII string 7
huruf “ABACCDA” membutuhkan representasi 7 x 7 bit = 49 bit, dengan rincian
seperti pada Tabel 4.1.
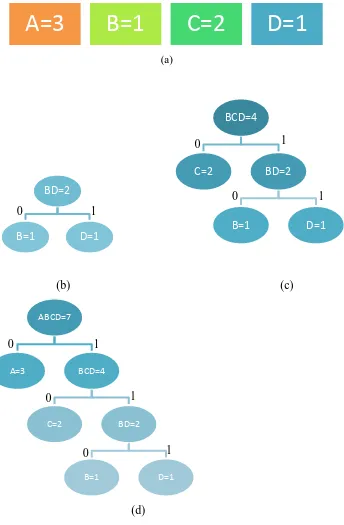
Tabel 4.1 Frekuensi Kemunculan Karakter pada Data
karakter Frekuensi kemunculan Kode ASCII
A 3 1000001
B 1 1000010
C 2 1000011
D 1 1000100
Maka dari Tabel 4.1 pembentukan pohon Huffman untuk proses kompresi
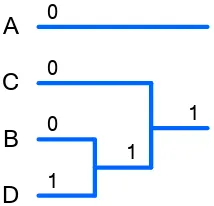
yang dapat terjadi deperlihatkan pada Gambar 4.1. Seluruh karakter beserta
frekuensi kemunculannya dapat dilihat pada gambar 4.1(a), lalu dua buah karakter
dengan frekuensi terkecil yaitu “B” dan “D” digabungkan serta tambahkan kode
“0” untuk node pertama “B” dan kode “1” untuk node kedua “D”. Hal ini dapat dilihat pada Gambar 4.1(b). Kemudian gabungan karakter tersebut digabungkan
dengan karakter dengan frekuensi yang paling mendekati yaitu “C”, karakter gabungan tersebut yang terlihat pada Gambar 4.1(c). Kemudian karakter
gabungan tersebut digabungkan lagi dengan karakter “A” seperti pada Gambar
(a)
(b) (c)
[image:58.595.135.479.83.608.2](d)
Gambar 4.1 Proses Encoding Menggunakan Pohon Huffman
D=1
C=2
B=1
A=3
BD=2
B=1 D=1
BCD=4
BD=2
D=1 B=1
C=2
ABCD=7
BCD=4
BD=2
D=1 B=1
C=2 A=3
0 1
0 1
0
0
0
0
1
1
1
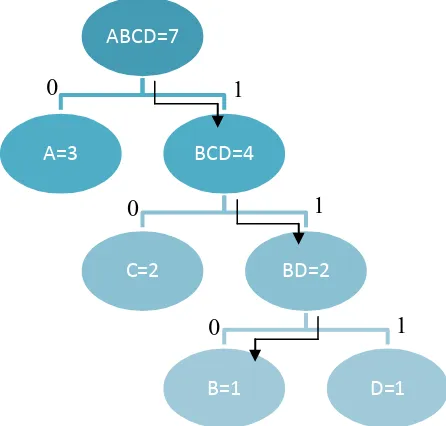
Gambaran yang lebih sederhana diperlihatkan pada Gambar 4.2.
A
C
B
D
0
1
1 0
0
1
Gambar 4.2 Tampilan proses encoding Huffman yang lebih sederhana
[image:59.595.109.462.340.439.2]Dapat diperoleh hasil encoding tersebut, seperti pada Tabel 4.2.
Tabel 4.2 Hasil encoding Menggunakan Algoritma Huffman
Karakter Frekuensi kemunculan Kode Huffman
A 3 0
B 1 110
C 2 10
D 1 111
Dari Tabel 4.2 dapat diketahui bahwa dibutuhkan representasi (3x1) +
(1x3) + (2x2) + (1x3) = 13 bit.
Maka dapat diperoleh persentase kompresi dengan menggunakan
persamaan 4.1 sebesar:
Dan juga dapat diketahui rasio kompresinya dengan menggunakan persamaan 4.2,
yaitu sebesar:
Cr =
Algoritma Huffman mempunyai kompleksitas waktu O(n log n). Karena
dalam melakukan sekali proses itersi pada saat penggabungan dua buah pohon
yang mempunyai frekuensi terkecil pada sebuah akar membutuhkan waktu O(log
n), dan proses itu dilakukan berkali-kali sampai hanya tersisa satu buah pohon
Huffman itu berarti dilakukan sebanyak n kali.
4.3.2 Decoding
Decoding merupakan proses mengembalikan suatu data dari suatu kode
tertentu. Proses Decoding ini merupakan proses kebalikan dari proses encoding.
Terdapat dua cara yang cukup cepat untuk melakukan decoding simbol, yaitu:
1. Membaca dari pohon Huffman
Hal ini dapat dilakukan dengan cara membaca sebuah bit dari kode
binernya dan menelusuri hingga sampai pada simpul daun yang
mengandung simbol tersebut untuk setiap bitnya. Ketika suatu bit sampai
pada daun suatu pohon, suatu simbol yang terkandung dalam daun tersebut
ditulis untuk decoded data tersebut dan mengulanginya kembali dari akar
Gambar 4.3 Proses Decoding Menggunakan Pohon Huffman
2. Menggunakan Tabel Kode Huffman
Decoding cara ini dilakukan dengan menyimpan setiap kode pada suatu
tabel yang terurut berdasarkan panjang kode dan mencari kesamaan dari
setiap bit yang dibaca.
Dengan menggunakan Tabel 4.2 string ”ABACCDA” tersebut akan dipresentasikan menjadi rangkaian bit: 0 110 0 10 10 111 0. Jadi jumlah
bit yang dibutuhkan hanya 13 bit. Dari Tabel 4.2 tampak bahwa kode
untuk sebuah karakter tidak boleh menjadi awalan dari kode simbol yang
lain guna menghindari keraguan dalam proses decoding. Karena tiap kode
Huffman yang dihasilkan unik, maka proses decoding dapat dilakukan
dengan mudah. Contoh: saat membaca kode bit pertama dalam rangkaian
bit ”0110010101110”, yaitu bit ”0” dapat langsung disimpulkan
ABCD=7
BCD=4
BD=2
D=1 B=1
C=2 A=3
0
0
0 1
1
[image:61.595.191.414.92.305.2]merupakan pemetaan dari simbol ”A”. Kemudian baca kode bit selanjutnya ”1”, tidak ada kode Huffman ”1”, sehingga menjadi ”11”, tidak ada juga kode Huffman ”11”, sehingga menjadi ”110”. Rangkaian
BAB V
APLIKASI KOMPRESI SMS MENGGUNAKAN KODE
HUFFMAN PADA
MOBILE PHONE
BERBASIS JAVA
TM5.1 Pendahuluan
SMS (Short Message Service) awalnya merupakan sebuah fitur aplikasi
GSM (Global System For Mobile Communication), yang dikembangkan dan
distandarisasi oleh ETSI (European Telecommunication Standards Institute),
namun kini sudah didapatkan pada jaringan bergerak lainnya termasuk jaringan
UMTS. Meskipun saat ini sudah banyak fitur dari GSM seperti MMS (Multimedia
Message Service) dan GPRS (General Packet Radio Service), akan tetapi
keberadaan jasa dan industri yang menggunakan SMS semakin lama semakin
banyak dijumpai karena biayanya yang relatif murah.
Pada proses pengiriman SMS, SMS tersebut tidak langsung dikirimkan
dari ponsel ke ponsel tujuan, akan tetapi terlebih dahulu dikirim ke SMS center
(SMSC), kemudian dengan system store and forward SMS tersebut dikirimkan ke
ponsel tujuan.
Sebuah pesan SMS maksimal terdiri dari 140 bytes, dengan kata lain
sebuah pesan bisa memuat 140 karakter 8 bit, 160 karakter 7 bit atau 70 karakter
16 bit untuk Bahasa Jepang, Bahasa Arab, Bahasa Mandarin dan Bahasa korea
yang memakai Hanzi (Aksara Kanji/Hanja). Pengiriman SMS memiliki beberapa
kendala. Pesan yang dikirim sering kali berukuran terlalu besar sehingga
memakan waktu yang cukup lama dalam proses pentransmisian data tersebut.
besar pula. Dari segi biaya, apabila kita ingin mengirimkan pesan melebihi jumlah
karakter yang telah ditentukan oleh mobile phone kita, maka kita harus membayar
lebih.
Masalah-masalah tersebut dapat diatasi dengan proses pemadatan atau
kompresi isi dari SMS tersebut sehingga waktu dan ruang yang digunakan dapat
seminimal mungkin. Aplikasi kompresi SMS merupakan aplikasi yang dibuat agar
dapat melakukan proses kompresi dan dekompresi terhadap teks SMS yang
kemudian mengirimkan atau menerima pesan tersebut. Algoritma kompresi yang
digunakan pada aplikasi ini adalah algoritma Huffman.
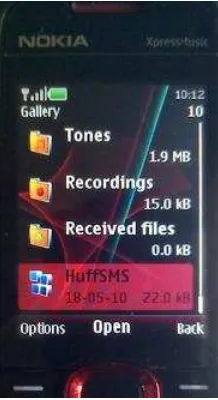
5.2 Pengiriman File Aplikasi HuffSMS melalui Bluetooth
Pada saat file aplikasi HuffSMS akan dikirimkan, pastikan Bluetooth pada
mobile phone telah diaktifkan. Proses pengiriman file aplikasi HuffSMS melalui
Bluetooth dapat dilihat pada Gambar 5.1. Dengan klik kanan pada file aplikasi
HuffSMS tersebut, arahkan kursor pada send to,