1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
Banyak penelitian dilakukan untuk mencari informasi, inovasi baru ataupun lainnya. Salah satunya penelitian di Kalvin Socks Production. Penelitian tersebut dilakukan untuk mencari dan menggali informasi lebih dari para pelanggannya melalui data transaksi penjulan. Dengan adanya data transaksi penjualan Kalvin Socks Production menggunakan teknologi data mining untuk mencari pola pembelian dari pelanggannya dan mencari item mana saja yang sering dipesan secara bersamaan oleh pelanggannya. Penelitian di Kalvin Socks Production dilakukan oleh Deasy Rusmawati dengan judul “Penerapan Data Mining Pada Penjualan Kaos Kaki Di Pabrik Kalvin Socks Production Menggunakan Metode Association” dan hasil dari penelitian tersebut menghasilkan suatu pola pembelian dari pelanggan Kalvin Socks Production, lalu dari pola tersebut didapatlah sebuah informasi mengenai jenis-jenis kaos kaki mana saja yang sering dipesan secara bersamaan oleh pelanggan Kalvin Socks Production, yang mana dari informasi tersebut digunakan oleh pihak perusahaan dalam mempertimbangkan jenis kaos kaki yang akan diproduksi bulan selanjutnya[1].
2
confidence maka semakin lama pula waktu yang dibutuhkan karena akan terdapat banyak kombinasi itemnya.
Association rule adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Terdapat banyak algoritma yang ada pada Association rule seperti algoritma apriori, fg growth, ct-pro, improved apriori dll. Algoritma apriori merupakan algoritma klasik yang sering digunakan. Kekurangan yang ada pada algoritma apriori adalah harus melakukan scanning berulang terhadap keseluruhan database tiap kali iterasi. Semakin banyak data transaksi yang akan diproses maka semakin lama juga waktu yang dibutuhkan. Salah satu cara untuk mengatasi masalah tersebut adalah dengan menggunakan improved apriori algorithm. Improved apriori mempresentasikan database ke dalam bentuk matrix untuk menggambarkan relasi dalam database. Kemudian matrix dihitung untuk mencari nilai support dari candidate frequent itemset yang memenuhi kriteria untuk menghasilkan frequent itemset tanpa melakukan scanning ulang terhadap databasedengan menggunakan operasi ”AND” terhadap baris matrix sesuai dengan item dalam candicate frequent itemset [2].
Dalam penelitian ini diharapkan dapat membangun aplikasi, sehingga dapat mengoptimalisasi waktu pemrosesan data pada saat proses analisis menggunakan improved apriori algorithm. Dengan begitu peneliti tertarik melakukan penelitian dengan judul “Penerapan Improved Apriori Pada Aplikasi Data Mining Di Perusahaan Kalvin Socks Production”.
I.2 Rumusan Masalah
3
I.3 Maksud Dan Tujuan
Maksud dari penelitian ini adalah membangun aplikasi data mining menggunakan algoritma improved apriori.
Sedangkan tujuan dari penelitian ini adalah :
1. Untuk mengetahui apakah algoritma improved apriori dapat meminimalkan masalah yang terjadi pada algoritma apriori.
2. Untuk membantu pihak perusahaan sehingga dapat mengoptimalisasi waktu pemrosesan data.
I.4 Batasan Masalah
Dalam penelitian ini, peneliti membatasi masalaah sebagai berikut :
1. Data yang akan dianalisis merupakan data transaksi penjualan produk kaos kaki di Kalvin Socks Production pada bulan Agusuts 2015. 2. Algoritma yang digunakan menggunakan algoritma improved apriori
untuk mencari jenis-jenis kaos kaki apa saja yang sering dibeli oleh konsumen.
3. Metode pembuatan program yang digunakan menggunakan Object Oriented programming (OOP).
4. Perangkat lunak database yang digunakan adalah MySql. 5. Aplikasi dibangun menggunakan bahasa pemograman C#.
I.5 Metodologi Penelitian
4
1. Metode Pengumpulan Data
Metode yang digunakan dalam mengumpulkan data dalam penelitian ini adalah sebagai berikut :
a. Wawancara
Teknik pengumpulan data dengan cara berinteraksi atau berkomunikasi secara langsung kepada responden dengan cara mengajukan pertanyaan yang sesuai dengan topik yang diambil.
b. Studi Literatur
Teknik pengumpulan data dengan cara mengadakan studi penelaahan terhadap buku-buku, literatur-literatur, catatan-catatan, dan laporan-laporan yang ada hubungannya dengan masalahh yang akan dipecahkan.
2. Metode Pembangunan Perangkat Lunak
Metode yang digunakan dalam proses pembangunan perangkat lunak ini adalah dengan model waterfall. Model ini melakukan pendekatan pada perkembangan perangkat lunak secara sistematik dan sekuensial [4].
Tahap-tahap utama dari model ini memetakan kegiatan-kegiatan pembangunan dasar yaitu:
a. Analisys
Proses pengumpulan kebutuhan dilakukan secara intensif untuk mespesifikasikan kebutuhan perangkat lunak agar dapat dipahami perangkat lunak seperti apa yang dibutuhkan oleh user.
5
1. Business understanding
Dalam proses bisnisnya Kalvin Socks Production memasarkan berbagai jenis kaos kakinya langsung kepada konsumen dan kepada agen retail. Untuk membuat strategi bisnis perusahaan, pihak Kalvin Socks Production harus menganalisa data penjualan. Tujuan dari menganalisa data penjualan yakni untuk mengetahui kecenderungan pemilihan jenis kaos kaki yang sering dibeli dengan cara mengetahui pola pemesanan dari konsumen agar jenis kaos kaki yang diproduksi tepat sasaran.
2. Data understanding
Pada tahap pemahaman data ini terlebih dahulu akan mengumpulkan semua data yang diperlukan dari hasil data-data transaksi pejualan di Kalvin Socks Production periode Agustus 2015.
3. Data preparation
Pada tahapan ini akan dilakukan proses pemilihan dan pengolahan data yang nantinya akan diperlukan dalam tahap pemodelan sehingga pemodelan yang dilakukan dapat memberikan hasil yang maksimal sesuai dengan target yang diinginkan.
4. Modeling
Dalam tahapan pemodelan ini akan menggunakan teknik metode data mining dengan metode association rule dengan cara menemukan aturan asosiatif atau pola kombinasi jenis kaos kaki berdasarkan hasil data transaksi, sehingga dapat diketahui jenis kaos kaki apa saja yang sering dibeli secara bersamaan oleh konsumen.
5. Evaluation
6
6. Deployment
Setiap tahap evaluasi dimana menilai secara detail hasil dari pemodelan, maka akan dilakukan pengimplementasian dari keseluruhan model yang telah dirancang. Selain itu juga dilakukan penyesuaian dari model dengan sistem yang akan dibangun sehingga dapat menghasilkan suatu hasil yang sesuai dengan target pemahaman bisnis.
b. Design
Design perangkat lunak adalah proses multi langkah yang fokus pada design pembuatan program perangkat lunak termasuk struktur data, arsitektur perangkat lunak, repesentasi antarmuka dan prosedur pengodean.
c. Code
Design yang ditranslasikan ke dalam program perangkat lunak. Kasil dari tahap ini adalah program komputer sesuai dengan design yang telah dibuat pada tahap design.
d. Test
Pengujian fokus pada perangkat lunak secara dari segi lojik dan fungsional dan memastikan bahwa semua bagian sudah diuji.
e. Maintenance
7
Berikut merupakan gambaran model waterfall
Gambar I. 1 Model Waterfall [4]
I.6 Sistematika Penulisan
Sistematika penulisan laporan akhir ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang masalah, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian serta sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini membahas tentang profil perusahaan, proses produksi, hasil produksi serta berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan.
Analisys
Design
Maintenance Test
8
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini menganalisis masalah dari data hasil penelitian, kemudian dilakukan pula proses perancangan sistem yang akan dibangun sesuai dengan analisa yang telah dilakukan.
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi tentang implementasi dari tahapan tahapan penting yang telah dilakukan sebelumnya kemudian dilakukan pengujian terhadap sistem sesuai dengan tahapan yang telah dijalani untuk memperlihatkan sejauh mana sistem yang dibangun layak digunakan.
BAB V KESIMPULAN DAN SARAN
9
BAB II
TINJAUAN PUSTAKA
II.1 Tentang Kalvin Socks Production
Kalvin socks production merupakan perusahaan perorangan yamg bergerak dibidang produksi kaos kaki dan pemasaran dengan menggunakan sistem jaringan pemasaran yang menempatkan 14 agen pemasaran di beberapa lokasi pemasaran dengan tujuan untuk memasok pasar-pasar tradisional yang ada di Indonesia.
Pada awalnya H. Sutarna sebagai pemilik perusahaan, membangun usaha ini sekitar tahun 1987 dengan bermodalkan semangat dan jiwa usaha yang tinggi untuk meningkatkan taraf hidup dan kesejahteraan keluarga, ketika itu H. Sutarna masih bekerja sebagai karyawan di salah satu perusahaan textile yang ada di Bandung selatan, seiring dengan meningkatnya kebutuhan hidup dan tuntutan hidup yang semakin banyak, maka H. Sutarna berusaha merintis usaha dengan cara berdagang dari pasar ke pasar di waktu liburnya sebagai karyawan, dan setelah H. Sutarna merasa matang dalam berdagang dan mengetahui akan permintaan kaos kaki saat itu, maka H. Sutarna memutuskan memproduksi kaos kaki dengan menggunakan modal awal senilai Rp 1.250.000,00 dari uang pesangon dan 3 unit mesin kaos kaki manual ( mesin tangan).
Selain untuk meningkatkan taraf hidup keluarga, usaha ini dibangun juga atas dasar peduli pada keluarga, kerabat, dan lingkungan sekitar. Dengan menciptakan lapangan pekerjaan bagi mereka dan membantu program pemerintah dalam mengurangi tingkat pengangguran, mudah-mudahan usaha ini mendatangkan kebaikan dan memberikan nilai positif bagi kami semua.
Nama Perusahaan : KALVIN
Lokasi : Kp. Kebon Kalapa Rt04/Rw03 No. 39 Ds.Batukarut kec. Arjasari Kab. Bandung Pemilik Perusahaan : H. Sutarna
10
III.1.1Struktur organisasi perusahaan
Struktur organisasi perusahaan adalah gambar bagan yang menjelaskan posisi dan hierarki struktur kerja pegawai di dalam perusahaan. Struktur organisasi perusahaan dari Kalvin Sock Production dapat dilihat pada Gambar II.1.
Montir Teknisi Karyawan Harian Karyawan Borongan Karyawan Harian
Ka. Bagian Mesin Ka. Bagian Produksi
Hendra Ka. Bagian Gudang
Pengelola Yeni Meilawati, S.E
Pemimpin H. Sutarna
Gambar II. 1 Struktur Organisasi Kalvin Socks Production
Uraian tugas dan wewenang masing-masing bagian pada struktur organisasi Kalvin Socks Production adalah sebagai berikut :
1. Pengelola
Mengawasi kegiatan produksi, penjualan, keuangan, pembelian, administrasi dan kegiatan lain dalam rangka pencapaian tujuan perusahaan 2. Kepala Bagian Mesin
Mengawasi Seluruh kegiatan produksi yang berhubungan dengan mesin atau alat produksi lainnya.
3. Kepala Bagian Produksi
Megawasi kegiatan produksi dari awal bahan mentah hingga akhir proses menjadi barang siap jual.
4. Kepala Bagian Gudang
11
II.2 Landasan Teori
Landasan teori yang berkaitan dengan materi atau teori yang digunakan sebagai acuan dalam melakukan penelitian. Landasan teori yang diuraikan merupakan hasil dari literatur dan buku-buku.
II.2.1 Pengertian Data Mining
“Data mining adalah proses menemukan pengetahuan yang menarik dari sejumlah data yang besar yang disimpan di dalam database, gudang data, atau repositori informasi lainnya” [6].
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa fuser, antara lain [6]:
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetensi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Dari definisi-definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah :
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar.
12
II.2.2 Cross- Industry Standard Process for Data Mining (CRISP- DM)
Cross- Industry Standard Process for Data Mining (CRISP- DM) yang dikembangkan tahun 1996 oleh analis dari beberapa industry seperti Daimler Chrysler, SPSS, dan NCR. CRISP DM menyediakan standar proses data mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit penelitian. Dalam CRISP- DM, sebuah proyek data mining memiliki siklus hidup yang terbagi dalam enam fase. Keseluruhan fase berurutan yang ada tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada keluaran dari fase sebelumnya. Hubungan penting antarfase digambarkan dengan panah. Sebagai contoh, jika proses berada pada fase modelling. Berdasar pada perilaku dan karakteristik model, proses mungkin harus kembali kepada fase data preparation untuku perbaikan lebih lanjut terhadap data atau berpindah maju kepada fase evaluation [5].
13
Enam fase CRISP- DM [5] :
1. Fase Pemahaman Bisnis (Business Understanding Phase)
a. Penentuan tujuan objek dan kebutuhan secara detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
c. Menyiapkan strategi awal untuk mencapai tujuan 2. Fase Pemahaman Data (Data Understanding Phase)
a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
c. Mengevaluasi kualitas data
d. Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan
3. Fase Pengolahan Data (Data Preparation Phase)
a. Siapkan dari data awal, kumpulan data yang akan digunakan untuk keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai analisis yang akan dilakukan.
c. Lakukan perubahan pada beberapa variabel jika dibutuhkan. d. Siapkan data awal sehingga siap untuk perangkat pemodelan. 4. Fase Pemodelan (Modelling Phase)
a. Pilih dan aplikasikan teknik pemodelan yang sesuai. b. Kalibrasi aturan model untuk mengoptimalkan hasil.
c. Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan pada permasalahan data mining yang sama.
14
5. Fase Evaluasi (Evaluation Phase)
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitas dan efektivitas sebelum disebarkan untuk digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal.
c. Menentukan apakah terdapat permasalahan penting dari bisnis atau penelitian yang tidak tertangani dengan baik.
d. Mengambil keputusan berkaitan dengan penggunaan hasil dari data mining.
6. Fase Penyebaran (Deployment Phase)
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikannya proyek.
b. Contoh sederhana penyebaran : Pembuatan laporan.
c. Contoh kompleks penyebaran : Penerapan proses data mining d. secara paralel pada departemen lain.
II.2.3 Knowledge Discovery in Database
Istilah data mining dan knowledge discovery in database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut [6]:
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-Processing/cleaning
15
lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. Pre-processing data adalah hal yang harus dilakukan dalam proses data mining karena tidak semua data atau atribut data dalam data digunakan dalam proses data mining. Proses ini dilakukan agar data yang akan digunakan sesuai dengan kebutuhan. Adapun langkah-langkah preprocessing adalah sebagai berikut :
a. Pemilihan Atribut (atribut selection)
Pemilihan atribut adalah proses pemilihan mana saja atribut data yang akan digunakan sehingga data tersebut dapat kita olah sesuai dengan kebutuhan proses data mining.
b. Pembersihan data (data cleaning)
Proses menghilangkan noise dan menghilangkan data yang tidak relevan disebut pembersihan data.
3. Transformation
Coding adalah proses pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. 5. Interpretation/evaluation
16
mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
II.2.4 Arsitektur Data Mining
Umumnya sistem data mining terdiri dari komponen-komponen berikut[6]:
a. Database, data warehouse, atau media penyimpanan informasi
Media dalam hal ini bisa jadi berupa database, data warehouse, spreadsheets, atau jenis-jenis penampung informasi lainnya. Data cleaning dan data intregration dapat dilakukan pada data-data tersebut.
b. Database atau data warehouseserver
Database atau data warehouse server bertanggung jawab untuk menyediakan data yang relevan berdasarkan permintaan dari user pengguna data mining.
c. Basis Pengetahuan (knowledge base)
Merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
d. Data mining engine
Yaitu bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
e. Pattern evaluation module
Yaitu bagian dari software yang berfungsi untuk menemukan pattern atau pola-pola yang terdapat di dalam database yang diolah sehingga nantinya proses data mining dapat menemukan knowledge yang sesuai.
f. Graphical user interface
17
dihasilkan, dan menampilkan pattern tersebut dengan tampilan yang berbeda-beda.
II.2.5 Asosiasi (Association)
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisi keranjang belanja. Aturan yang menyatakan asosiasi antara beberapa atribut sering disebut affinity analiysis atau market basket analysis. Analisis asosiasi atau Association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item [6].
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support (nilai penunjang) adalah presentase kombinasi item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-item dalam aturan asosiasi.
Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence(minimum confidence).
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap [5] : 1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut.
x100.. Persamaan (II.1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut.
18
x100….. Persamaan (II.3) 2. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan asosiasi yang cukup kuat tingkat ketergantungan antar item dalam antecedent (pendahulu) dan consequent (pengikut) serta memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan Asosiatif .
Misalkan D adalah himpunan transaksi, dimana setiap transaksi T dalam D merepresentasikan himpunan item yang berada dalam I. I adalah himpunan item yang dijual. Misalkan kita memilih himpunan item A dan himpunan item lain B, kemudian aturan asosiasi akan berbentuk:
Dimana antecedent A dan consequent B merupakan subset dari I, dan A dan B merupakan mutually exclusive dimana aturan :
Tidak berarti
Sebuah itemset adalah himpunan item-item yang ada dalam I, dan k-itemset adalah itemset yang berisi k item. Frekuensi itemset merupakan itemset yang memiliki frekuensi kemunculan lebih dari nilai minimum yang telah ditentukan (ɸ). Misalkan ɸ = 2, maka semua itemset yang frekuensi kemunculannya lebih dari atau sama dengan 2 kali disebut frequent. Himpunan dari frequent k-itemset dilambangkan dengan Fk.
Nilai confidence dari aturan diperoleh dari rumus berikut.
19
II.2. 5.1 Langkah-Langkah Proses Aturan Asosiasi
Proses aturan asosiasi terdiri dari beberapa tahap sebagai berikut [6]: 1. Sistem men-scan database untuk mendapatkan kandidat 1-itemset (himpunan item yang terdiri dari 1 item) dan menghitung nilai supportnya. Kemudian nilai supportnya tersebut dibandingkan dengan minimum support yang telah ditentukan, jika nilainya lebih besar atau sama dengan minimum support maka itemset tersebut dalam largeitemset.
2. Itemset yang tidak termasuk dalam large itemset tidak diikutkan dalam itersi selanjutnya(di prune).
3. Pada iterasi kedua sistem akan menggunakan hasil large itemset pada iterasi pertama(L1) untuk membentuk kandidat itemset kedua(L2). Pada itersi selanjutnya akan menggunakan hasil large itemset pada iterasi sebelumnya(Lk-1) untuk membentuk kandidat itemset berikut(LK). Sistem akan menggabungkan(join) (Lk-1) dengan (Lk-1) untuk mendapatkan (Lk), seperti pada iterasi sebelumnya sistem akan menghapus(prune) kombinasi itemset yang tidak termasuk dalam large itemset.
4. Setelah dilakukan operasi join, maka pasangan itemset baru hasil proses join tersebut dihitung supportnya.
5. Proses pembentuk kandidat yang terdiri dari proses join dan prune akan terus dilakukan hingga himpunan kandidat itemsetnya null, atau sudah tidak ada lagi kandidat yang akan dibentuk.
6. Setekah itu, dari hasil frequent itemset tersebut dibentuk association rule yang memenuhi nilai support dan confidence yang telah ditentukan.
7. Pada pembentukan association rule, nilai yang sama dianggap sebagai satu nilai.
8. Association rule yang berbentuk harus memenuhi nilai minimum yang telah ditentukan.
20
II.2.6 Algoritma ImprovedApriori
Algoritma Improved Apriori berbasis Matrix diusulkan oleh beberapa peneliti, namun dengan teknik yang berbeda saat pencarian frequent itemset. merepresentasikan database ke dalam bentuk matrix untuk menggambarkan relasi dalam database. Kemudian matrix dihitung untuk mencari nilai support dari candidate frequent itemset yang memenuhi kriteria untuk menghasilkan frequent itemset tanpa melakukan scanning ulang terhadap database dengan menggunakan operasi “AND” terhadap baris matrix sesuai dengan item dalam candidate frequent itemset dan menambahkan hasil dari AND, dengan hasilnya adalah Support. [7]
Karena algoritma tidak melakukan scan ulang terhadap database untuk mencari hubungan seperti algoritma sebelumnya, maka waktu komputasi dan pencarian candidate frequent itemset menjadi lebih cepat.
Tahapan algoritma ini berjalan sebagai berikut [2]: 1. Konversidatabase ke dalam bentuk matrix.
a Konversi database yang berisi In item dan transaksi Tm ke dalam bentuk matrix. Baris dari matrix mewakili transaksi dan kolom dari matrix mewakili item. Jika pada suatu transaksi terdapat item maka nilainya adalah 1 dan bernilai 0 jika sebaliknya.
b Jumlah nilai dari kolom adalah nilai support count dan jumlah nilai dari baris adalah banyaknya item dalam suaatu transaksi atau disebut count.
2. Periksa jumlah kolom dan jumlah baris
a Hapus kolom yang jumlah kolomnya kurang dari nilai minimum support
b Hapus baris yang jumlah barisnya kurang dari sama dengan nilai k ( k-frequent itemset )
3. Gabungkan tiap kolomnya untuk menemukan frequent 2-itemset dan gunakan operasi DAN untuk mendapatkan nilainya.
4. Periksa jumlah kolom dan jumlah baris
21
b Hapus baris yang jumlah barisnya kurang dari sama dengan nilai k ( k-frequent itemset ).
5. Demikian pula untuk mencari Kth -frequent itemset. Gabungkan tiap kolomnya dan hapus kolom yang kurang dari minimum support dan hapus baris yang jumlah barisnya kurang dari sama dengan k.
II.2.7 Basis Data (Database)
Basis Data terdiri dari atas dua kata, yaitu Basis dan Data. Basis kurang lebih dapat diartikan sebagai markas atau gudang, tempat bersarang atau berkumpul. Sedangkan Data adalah representasi fakta dunia nyata yang mewakili objek seperti manusia, barang, hewan, peristiwa, konsep, keadaan, dan sebagainya yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi, atau kombinasinya[4].
Database adalah kumplan data yang saling berkaitan, berhubungan yang disimpan secara bersama-sama sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai kebutuhan. Data-data ini harus mengandung semua informasi untuk mendukung semua kebutuhan sistem. Proses dasar yang dimiliki oleh database ada empat, yaitu:
1. Pembuatan data-data baru (create database) 2. Penambahan data (insert)
3. Mengubah data (update) 4. Menghapus data (delete).
22
a. Menyediakan penyimpanan data untuk dapat digunakan oleh organisasi saat sekarang dan masa yang akan datang.
b. Cara pemasukan data sehingga memudahkan tugas operator dan menyangkut pula waktu yang diperlukan oleh pemakai untuk mendapatkan data serta hak-hak yang dimiliki terhadap data yang ditangani.
c. Pengendalian data untuk setiap siklus agar data selalu up-to-date dan dapat mencerminakan perubahan spesifik yang terjadi di setiap sistem.
d. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian dan gangguan-gangguan lain.
Dalam basis data sistem informasi digambarkan dalam model entity relationship (E-R). Bahasa yang digunakan dalam basis data (database) yaitu : a. DDL (Data Definition Language)
Merupakan bahasa definisi data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel dan view.
b. DML (Data Manipulation Language)
Merupakan bahasa manipulasi data yang digunakan untuk memanipulasi data pada objek database seperti tabel.
c. DCL (Data Control Language)
Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data. Penyusunan basis data meliputi proses memasukkan data kedalam media penyimpanan data, dan diatur dengan menggunakan perangkat Sistem Manajemen Basis Data (Database Management System / DBMS).
II.2.8 Database Management System (DBMS)
“Managemen Sistem Basis Data (DatabaseManagement System /DBMS) adalah perangkat lunak yang di desain untuk membantu dalam hal pemeliharaan dan utilitas kumpulan data dalam jumlah besar”[4].
23
dipakai. Sistem manajemen database merupakan suatu perluasan software sebelumnya mengenai software pada generasi komputer yang pertama. Dalam hal ini data dan informasi merupakan kesatuan yang saling berhubungan dan berkerja sama yang terdiri dari: peralatan, tenaga pelaksana dan prosedur data. Sehingga pengolahan data ini membentuk sistem pengolahan data. Peralatan dalam hal ini berupa perangakat keras (hardware) yang digunakan, dan prosedur data yaitu berupa perangakat lunak (software) yang digunakan dan dipakai untuk mengalokasikan dalam pembuatan sistem informasi pengolahan database.
Manipulasi basis data meliputi pembuatan pernyataan (query) untuk mendapatkan informasi tertentu, melakukan pembaharuan atau penggantian (update) data, serta pembuatan report dari data. Tujuan utama DBMS adalah untuk menyediakan tinjauan abstrak dari data bagi user. Jadi sistem menyembunyikan informasi mengenai bagaimana data disimpan dan dirawat, tetapi data tetap dapat diambil dengan efisien.
Pertimbangan efisiensi yang digunakan adalah bagaimana merancang struktur data yang kompleks, tetapi tetap dapat digunakan oleh pengguna yang masih awam, tanpa mengetahui kompleksitas stuktur data. Sistem manajemen database atau database management system (DBMS) adalah merupakan suatu sistem software yang memungkinkan seorang user dapat mendefinisikan, membuat, dan memelihara serta menyediakan akses terkontrol terhadap data. Database sendiri adalah sekumpulan data yang berhubungan dengan secara logika dan memiliki beberapa arti yang saling berpautan. DBMS yang utuh biasanya terdiri dari :
1. Hardware
Hardware merupakan sistem komputer aktual yang digunakan untuk menyimpan dan mengakses database. Dalam sebuah organisasi berskala besar, hardware terdiri : jaringan dengan sebuah server pusat dan beberapa program client yang berjalan di komputer desktop.
24
lain DBMS merupakan mediator antara database dengan user. Sebuah database harus memuat seluruh data yang diperlukan oleh sebuah organisasi. 3. Prosedur
Bagian integral dari setiap sistem adalah sekumpulan prosedur yang mengontrol jalannya sistem, yaitu praktik-praktik nyata yang harus diikuti user untuk mendapatkan, memasukkan, menjaga, dan mengambil data.
4. Data
Data adalah jantung dari DBMS. Ada dua jenis data. Pertama, adalah kumpulan informasi yang diperlukan oleh suatu organisasi. Jenis data kedua adalah metadata, yaitu informasi mengenai database.
5. User (Pengguna)
Ada sejumlah user yang dapat mengakses atau mengambil data sesuai dengan kebutuhan penggunaan aplikasi-aplikasi dan interface yang disediakan oleh DBMS, antara lain adalah :
a. Database administrator adalah orang atau group yang bertanggungjawab mengimplementasikan sistem database di dalam suatu organisasi.
b. Enduser adalah orang yang berada di depan workstation dan berinteraksi secara langsung dengan sistem.
c. Programmer aplikasi, orang yang berinteraksi dengan database melalui cara yang berbeda.
II.2.9 Object Oriented Analysis Design
25
a. Unified Modelling Language
Unified Modeling Language (UML) adalah termasuk ke dalam rumpun jenis pemodelan notasi grafis yang didukung oleh meta-model tunggal, Pemodelan ini berguna untuk membantu dalam menjelaskan dan merancang perangkat lunak yang dibangun dengan object-oriented (OO). UML merupakan standar terbuka yang dikelola oleh Open Management Group (OMG) yang berada dibawah naungan perusahaan-perusahaan konsorsium terbuka[8]. UML merupakan suatu bahasa pemodelan yang terdiri banyak model diantaranya adalah :
1. Use Case Diagram
Use case adalah teknik untuk menggambarkan fungsional sebuah sistem. Use case diagram memperlihatkan hubungan diantara actor dan use case. User mempresentasikan seorang user atau subsistem lain yang akan berinteraksi dengan sistem. Sedangkan use case merupakan urutan kejadian yang menggambarkan interaksi antara user dengan sistem. Fungsionalitas sistem didefinisikan ke dalam use case dari sudut eksternal sistem yang berguna untuk diuji kelayakan sistem[8].
2. Sequence Diagram
26
dilakukan sebagai sebuah respon dari suatu kejadian/even untuk menghasilkan output tertentu[8].
3. Class Diagram
Class diagram mendeskripsikan jenis-jenis objek dalam sistem dan berbagai macam hubungan statis yang terdapat diantara mereka. Diagram kelas atau class diagram menggambarkan struktur sistem dari segi pendifinisian kelas-kelas yang akan dibuat untuk membangun sistem. Kelas memiliki apa yang disebut atribut dan metode atau operasi. Atribut merupakan variable-variabel yang dimiliki oleh suatu kelas, atribut mendeskripsikan properti dengan sebaris teks di dalam kotak kelas tersebut. Operasi atau metode adalah fungsi fungsi yang dimiliki oleh suatu kelas[8].
II.2.10MySQL
SQL (Structured Query Language) adalah bahasa standar yang digunakan untuk mengakses server database. Semenjak tahun 70-an bahasa ini telah dikembangkan oleh IBM, yang kemudian diikuti dengan adanya Oracle, Informix dan Sybase. Dengan menggunakan SQL, proses akses database menjadi lebih user-friendly dibandingkan dengan misalnya dBase ataupun Clipper yang masih menggunakan perintah –perintah pemrograman murni [9].
27
bahasa pemrograman semisal Pascal. MySQL sering digunakansebagai SQL server karena berbagai kelebihannya, antara lain:
1. Source MySQL dapat diperoleh dengan mudah dan gratis. 2. Sintaksnya lebih mudah dipahami dan tidak rumit.
3. Pengaksesan database dapat dilakukan dengan mudah.
II.2.11Microsoft Visual Studio .Net Dan C#
Microsoft Visual Studio merupakan sebuah perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun aplikasi Web. Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework).[10]
29
BAB III
ANALISIS DAN PERANCANGAN SISTEM
III.1 Analisis Sistem
Analisis sistem adalah penguraian dari suatu sistem informasi yang utuh kedalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan, kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan. Tahap analisis sistem merupakan tahapan yang sangat kritis dan penting, karena kesalahan di dalam tahap ini akan menyebabkan juga kesalahan di tahap selanjutnya. Tugas utama analisis sistem dalam tahap ini adalah menemukan kelemahan-kelemahan dari sistem yang berjalan sehingga dapat diusulkan perbaikannya. Dalam analisa sistem ini meliputi beberapa bagian, yaitu :
1. Analisis Masalah 2. Analisis Data Mining
3. Analisis Kebutuhan Non-Fungsional 4. Analisis Kebutuhan Fungsional III.2 Analisis Masalah
Adapun analisis masalah di Kalvin Sock Production adalah pemrosesan data membutuhkan waktu yang cukup lama, hal tersebut disebabkan karena banyaknya data transaksi penjualan dan algoritma yang telah diterapkan pada aplikasi sebelumnya yaitu algoritma apriori harus melakukan scan database setiap kali iterasinya dalam menemukan jenis kaos kaki yang sering dipesan oleh para konsumennya.
III.3 Analisis Data Mining
30
III.3.1 Pemahaman Bisnis
Tahapan pemahaman bisnis merupakan tahapan pertama yang dilakukan dalam kerangka kerja CRISP-DM. dalam tahapan bisnis ini terdapat beberapa tahapan lainnya, yaitu :
1. Identifikasi Tujuan Bisnis
Dalam proses bisnisnya Kalvin Socks Production memasarkan berbagai jenis kaos kakinya langsung kepada konsumen dan kepada agen retail. Untuk membuat strategi bisnis perusahaan, pihak Kalvin Socks Production harus menganalisa data penjualan. Tujuan dari menganalisa data penjualan yakni untuk mengetahui kecenderungan pemilihan jenis kaos kaki yang sering dibeli dengan cara mengetahui pola pemesanan dari konsumen agar jenis kaos kaki yang diproduksi tepat sasaran.
2. Penentuan Sasaran Data Mining
Tujuan data mining untuk perusahaan adalah menggali pengetahuan (discovering knowledge) tentang pola (pattern) jenis kaos kaki apa saja yang sering dibeli oleh konsumen sehingga diketahui jenis kaos kaki mana saja yang sering dipesan komsumen.
III.3.2 Pemahaman Data
Tahapan pemahaman data merupakan tahapan kedua yang dilakukan setelah tahapan bisnis dalam kerangka kerja CRISP-DM. dalam tahap pemahaman data ini terdapat beberapa langkah diantaranya:
a. Pengumpulan data awal
31
Data yang digunakan untuk proses perhitungan secara manual dengan mengambil sebanyak 178 transaksi untuk dilakukan pengolahan ke tahap selanjutnya. Adapun detail informasi mengenai data transaksi yang digunakan dapat dilihat dalam table III.1 dibawah ini.
Tabel III. 1 Struktur Data Transaksi Penjualan
DOKUMENT KETERANGAN
Detail Data Transaksi Penjualan
Deskripsi
Data ini berisi mengenai transaksi penjualan pada bulan Agustus 2015 di Kalvin Socks Production
Fungsi
Untuk mengatahui jenis kaos kaki apa saja yang sering dipesan oleh konsumen pada bulan Agustus
Format Microsoft excel (.xlsx)
Atribut Tanggal Waktu transaksi
NoNota Nomor komsumen pada saat transaksi kodeBarang Kode dari jenis kaos kaki
NamaBarang Kode dari nama kaos kaki Jumlah Jumlah pemesanan kaos kaki
Berikut adalah contoh data transaksi penjualan pada bulan Agustus yang ada di Kalvin Socks Production yang akan digunakan untuk proses perhitungan manual dengan metode association rule dan menggunakan algoritma Improved Apriori, dimana atribut-atribut yang terdapat dalam data penjualan tersebut antara lain Tanggal, NoNota, kodeBarang, NamaBarang, Jumlah. Untuk lebih jelasnya, dapat dilihat pada lampiran tabel D-1 di lembar lampiran.
III.3.3 Preprocessing Data
Preprocessing data adalah hal yang harus dilakukan dalam proses data mining, karena tidak semua data atau atribut data dalamdata digunakan pada data mining. Proses ini dilakukan agar data yang akan digunakan sesuai dengan kebutuhan. Adapun tahapan-tahapan preprocessing data dalam penelitian ini adalah sebagai berikut:
1. Ekstraksi data
32
Dalam penelitian ini, data yang berasal dari flat file berupa microsoft excel (.xlsx) diekstrak, kemudian disimpan ke dalam sebuah database agar memudahkan dalam proses pengolahan data.
2. Pemilihan atribut (artibut selection)
Pemilihan atribut adalah proses pemilihan atribut data yang akan digunakan, sehingga data tersebut dapat diproses sesuai dengan kebutuhan data mining. Dalam penelitian ini, atribut yang akan digunakan yakni NoNota dan kodeBarang. Pada NoNota berguna untuk membedakan antar konsumen sedangkan kodebarang berguna untuk mengetahui jenis kaos kaki apa saja yang dibeli oleh konsumen dalam satu transaksi. Tahapan pemilihan atribut ini sama seperti penelitian sebelumnya[1]. Data pemilihan atribut dapat dilihat pada tabel D-2 dalam lampiran D.
3. Pembersihan data (data cleaning)
Pada tahap pembersihan data, hasil pemilihan atribut pada tabel D-2 akan dibersihkan dari NoNota yang hanya memiliki Kodebarang tunggal. Artinya pada satu transaksi konsumen hanya membeli satu jenis kaos kaki saja. Data transaksi yang memiliki kodeBarang tunggal ini tidak memiliki hubungan asosiasi dengan kodeBarang lain yang sudah dibeli. Tahapan pemilihan atribut ini sama seperti penelitian sebelumnya[1]. Hasil pembersihan data dapat dilihat pada tabel D-3 dalam lampiran D.
III.3.4 Pemodelan
Pemodelan merupakan tahap pembuatan model yang akan digunakan dalam proses data mining. Tahap ini dilakukan dengan menggunakan metode association rule yang akan dibagi ke dalam dua tahap yaitu :
a. Frequent Itemset
33
1. Asumsi nilai minimum support yang akan digunakan adalah 7% dari total transakasi yaitu 10,5 ≈ 10. Nilai tersebut diambil agar mendapatkan 3 kombinasi item.
2. Nilai minimum confidence digunakan untuk menyakinkan kuatnya hubungan antara item yang satu dengan yang lainnya. Asumsi nilai minimum confidence yang akan digunakan dalam perhitungan manual sebesar 60%.
3. Data yang sudah melewati tahap preprocessing kemudian diubah kedalam bentuk matrix, kemudian isi bagian baris dengan NoNota dan isi bagian kolom dengan kodeBarang. Jika pada suatu NoNota terdapat kodeBarang maka masukan value 1 pada kolom kodeBarang di NoNota tersebut, sedangkan jika tidak terdapat kodeBarang pada suatu NoNota maka masukan value 0 pada kolom kodeBarang di NoNota tersebut. Hasil transformasi ke dalam bentuk matrix dapat dilihat pada tabel D-4 dalam lampiran D.
4. Data yang sudah dalam bentuk matrix kemudian dihitung untuk mencari frequent item-nya, Caranya yaitu jumlahkan tiap kodeBarang pada bagian kolom untuk mencari nilai support count dari setiap kodeBarangnya. Hasilnya dapat dilihat pada tabel D-5 dalam lampiran D.
5. Dari data tabel D-5 dalam lampiran D dapat diketahui kandidat frequent 1-hapus NoNota yang jumlah nilai Count-nya 1. Hasilnya dapat dilihat pada tabel D-7 dalam lampiran D.
34
support-nya lalu jumlahkan tiap baris dan kolomnya. Hasilnya dapat dilihat pada tabel D-8
8. Dari tabel D-8 kemudian cari frequent 2-itemset-nya. Hapus kodeBarang yang jumlah nilai Support Count-nya kurang dari minimum support dan hapus NoNota yang jumlah nilai Count-nya 2. Hasilnya dapat dilihat pada tabel D-9 dalam lampiran D.
9. Setelah frequent 2-itemset didapatkan maka lakukan cross product lagiuntuk mendapatkan 3 kombinasi item, lalu setelah melakukan crossproduct hitung nilai support-nya menggunakan operan AND. Setelah didapatkan nilai support-nya lalu jumlahkan tiap baris dan kolomnya. Hasilnya dapat dilihat pada tabel D-10
10. Dari tabel D-10 kemudian cari frequent 3-itemset-nya. Hapus kodeBarang yang jumlah nilai Support Count-nya kurang dari minimum support dan hapus NoNota yang jumlah nilai Count-nya 3. Hasilnya dapat dilihat pada tabel D-11 dalam lampiran D.
11. Setelah frequent 3-itemset didapatkan maka lakukan cross product lagiuntuk mendapatkan 4 kombinasi item, lalu setelah melakukan crossproduct hitung nilai support-nya menggunakan operan AND. Setelah didapatkan nilai support-nya lalu jumlahkan tiap baris dan kolomnya. Hasilnya dapat dilihat pada tabel D-12
12. Dari tabel D-12 kemudian cari frequent 4-itemset-nya. Hapus kodeBarang yang jumlah nilai Support Count-nya kurang dari minimum support dan hapus NoNota yang jumlah nilai Count-nya 4. Hasilnya dapat dilihat pada tabel D-13 dalam lampiran D.
35
b. Generate Rule
Setelah mencari dan mendaptkan frequent itemset-nya, lalu dibentuk aturan asosiasi untuk mencari rule yang memenuhi nilai minimumconfidence. Berikut adalah tahapannya:
1. Karena hanya mendapatkan frequent itemset-nya sampai 3 maka lakukan pembentukan rule pada {B17,B18,B19}, {B18,B19,B20}, {B14,B18}, {B14,B19}, {B15,B18}, {B16,B18}, {B17,B18}, {B17,B19}, {B17,B20}, {B18,B19}, {B18,B20}, {B18,B29}, {B19,B20}, {B20,B29} kemudian melakukan perhitungan nilai confidence-nya. Hasilnya dapat dilihat pada tabel III.2
Tabel III. 2 Pembentukan Rule
Kombinasi item Confidence % Kombinasi item Confidence %
36
2. Dari tabel III.3 kemudian rule diseleksi. Rule yang nilai confidence-nya kurang dari nilai minimum confidence dihilangkan. Hasilnya dapat dilihat pada tabel III.3.
Tabel III. 3 Rule yang memenuhi nilai minimum confidence
Kombinasi item Confidence %
B17 ˄B → B 91 disesuaikan dengan tabel barang. Sehingga kodebarang yang terdapat pada rule sesuai dengan nama barangnya dan dapat dijadikan informasi. Tabel barang dapat dilihat pada tabel III.4
Tabel III. 4 Tabel barang
kodeBarang namaBarang kodeBarang namaBarang
B1 ankle nylon pj B27 sma pramuka katun B2 ankle nylon tg B28 bayi lurus kids B3 ankle nylon pdk B29 bayi lipat kids B4 arygle nylon pj B30 bayi lipat/lurus anti slip qino
B5 arygle nylon tg B31 children
B6 arygle nylon pdk B32 strawberry
B7 bed nylon pj B33 jempol
B8 bed nylon tg B34 handset
B9 bed nylon pdk B35 jempol telapak (shofa) nylon pj B10 slipper nylon pj B36 jempol telapak (shofa) nylon tg B11 slipper nylon tg B37 jempol telapak (shofa) nylon pdk B12 slipper nylon pdk B38 jempol telapak (muslim) polys pj B13 sd h kaoxin B39 jempol telapak (muslim) polys tg B14 smp h kaoxin B40 jempol telapak (muslim) polys pdk B15 sma h kaoxin B41 long mashika p/h/krem B16 sd hp kaoxin B42 paskibra vinsaya B17 smp hp kaoxin B43 jempol polos nylon m
37
kodeBarang namaBarang kodeBarang namaBarang
B19 sd p kaoxin B45 sport motif / catur polys kaki berdasarkan kodeBarangnya sesuai pada tabel III.4. Hasilnya dapat dilihat pada tabel III.5
Tabel III. 5 Informasi yang dihasilkan dari rule
Kombinasi item Informasi produk
B17 ˄B → B Smp hp kaoxin ˄ Sd p kaoxin → Sma hp kaoxin lebih dibulan selanjutnya oleh pihak KALVIN SOCKS PRODUCTION akan tetapi tidak berikut dengan jumlahnya karena yang akan menentukan jumlah atau banyaknya adalah pihak KALVIN SOCKS PRODUCTION yang menentukannya. Berikut adalah informasi rekomendasi jenis kaos kaki yang akan diproduksi lebih dibulan selanjutnya :
38
III.4 Analisis Kebutuhan Non-Fungsional
Analisis kebutuhan non fungsional dilakukan untuk mengetahui spesifikasi kebutuhan sistem. Spesifikasi kebutuhan melibatkan analisis perangkat keras (hardware), analisis perangkat lunak (software), dan analisis pengguna (user).
III.4.1 Analisis Kebutuhan Perangkat Keras
Perangkat keras pendukung dalam pembangunan perangkat lunak ini adalah sebagai berikut :
1. Analisis spesifikasi kebutuhan perangkat keras pada sistem yang sedang berjalan di Kalvin Socks Production adalah :
a. Processor : Intel Core Duo
2. Analisis spesifikasi minimum kebutuhan perangkat keras pada sistem yang akan dibangun membutuhkan :
a. Processor berkecepatan minimal 2Ghz b. Hardisk 1GB untuk penyimpanan data c. Memory 1 GB
d. Monitor e. Keyboard f. Mouse
3. Evaluasi kebutuhan perangkat keras
39
III.4.2 Analisis Kebutuhan Perangkat Lunak
Kebutuhan perangkat lunak pendukung sangatlah penting bagi pembangunan perangkat lunak yang sedang dirancang. Perangkat lunak pendukung dalam pembangunan perangkat lunak ini adalah sebagai berikut :
1. Analisis kebutuhan perangkat lunak pada sistem yang sedang berjalan di Kalvin Socks Production adalah :
a. Sistem operasi Windows 7 b. Microsoft office
2. Analisis spesifikasi kebutuhan perangkat lunak untuk menjalankan sistem yang akan dibangun adalah :
a. Sistem Operasi Windows 7 b. XAMPP sebagai database server c. Visualstudio 2010
3. Evaluasi kebutuhan perangkat lunak
Berdasarkan analisis spesifikasi perangkat lunak yang ada di Kalvin Socks Production, spesifikasi perangkat lunak yang akan digunakan sudah memadai
III.4.3 Analisis User (Pengguna)
Analisis user dibuat untuk mengetahui siapa saja dan seperti apa saja karakteristik yang dimiliki oleh orang yang dapat menggunakan aplikasi yang akan dibuat. Untuk lebih jelas mengenai karakteristik pengguna, dapat dilihat pada tabel III.6
Tabel III. 6 Karakteristik Pengguna
40
III.5 Analisis Kebutuhan Fungsional
Analisis kebutuhan fungsional bertujuan untuk perancangan terhadap aplikasi yang akan dibangun. Aplikasi yang akan dibangun menggunakan pendekar berorientasi objek dengan menggunakan pemodelan UML. Pemodelan yang akan digunakan untuk memodelkan terdiri dari diagram use case, sequence diagram, activity diagram, dan class diagram.
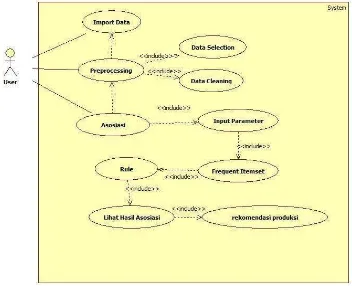
III.5.1 Diagram Use Case
Use case atau diagram use case merupakan pemodelan untuk kelakuan (behavior) sistem yang akan dibuat. Diagram use case yang terdapat pada sistem yang akan dibangun terdiri dari satu user dan sepuuluh use case. Diagram use case dapat dilihat pada gambar III.1 Dan penjelasan user dan use case dapat dilihat pada Tabel III.7 dan Tabel III.8
41
Tabel III. 7 Definisi User
User Deskripsi
User Bertugas untuk melakukan import data, menginputkan nilai minimum support dan minimum confidence.
Tabel III. 8 Deskripsi Use Case
No Use Case Deskripsi
1 Import Data Sistem mengharuskan user yang belum melakukan import data untuk melakukan import data terlebih dahulu lalu menyimpan data data tersebut kedalam database
2 Preprocessing Data yang sudah berada pada database kemudian dilakukan proses data selection dan data cleaning 3 Data Selection Sistem melakukan pemilihan atribut NoNota dan
kodeBarang jika user sudah melakukan import data 4 Data Cleaning Sistem melakukan pembersihan data pada NoNota
yang mengandung kodeBarang tunggal jika user sudah melakukan import data dan data selection 5 Proses Asosiasi Sistem melakukan proses pencarian frequent
itemset, rule, melihat hasil asosiasi dan menampilkan informasi. Sedangkan user menginputkan nilai minimum support dan confidence sebagai parameter.
6 Input parameter User menginputkan nilai minimum support dan minimum confidence sebagai parameter
7 Frequent itemset Sistem melakukan pencarian kombinasi kaos kaki sesuai dengan nilai support yang diinputkan oleh
9 Lihat hasil asosiasi Sistem menampilkan kombinasi jenis kaos kaki yang memenuhi nilai minimum support dan minimum confidence.
42
III.3.2.1 Skenario Use Case
Skenario use case menjelaskan skenario dari setiap proses yang digambarkan pada diagram use case. Berikut ini skenario use case dari gambar III.1.
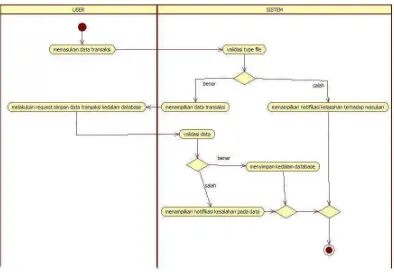
1. Skenario Use Case Import Data
Skenario use case import data menggambarkan langkah – langkah aksi user terhadap sistem untuk melakukan import data transaksi penjualan yang akan disimpan ke dalam database. Skenario use case import data dapat dilihat pada tabel III. 9 Requirement A.1 dan tabel III.10. Skenario Use Case Import Data.
Tabel III. 9 Requirement A.1
Requirement A.1
Sistem menyediakan fasilitas import data untuk melakukan import data terlebih dahulu
sebelum melakukan preprocessing dan proses asosiasi
Tabel III. 10 Skenario Use Case Import Data
Use case Name Import Data
Related Requirements Requirement A.1
Goal In Context Import data transaksi penjualan dan menyimpannya ke dalam database
Precondition User menyiapkan data transaksi Successful End
Condition
Data transaksi berhasil disimpan ke dalam database Failed End Condition Data transaksi tidak berhasil disimpan ke dalam
database
Actors User
Triger User memasukan data transaksi
Included Cases -
Main Flow Step Action
1 User memasukan data transaksi penjualan 2 Sistem melakukan proses validasi format file
terhadap masukan
3 Sistem menampilkan data transaksi
4 User melakukan request kepada sistem untuk menyimpan data transaksi kedalam database 5 Sistem melakukan validasi terdapat data 6 Sistem menyimpan data transaksi kedalam
43
Extension Step Branching Action
3.1 Menampilkan notifikasi kesalahan terhadap masukan
6.1 Menampilkan notifikasi kesalahan pada data
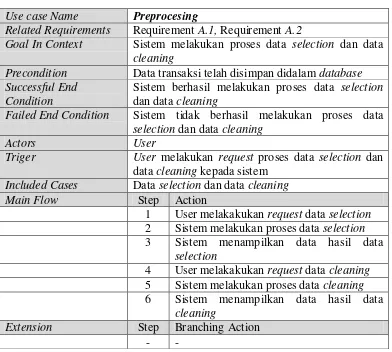
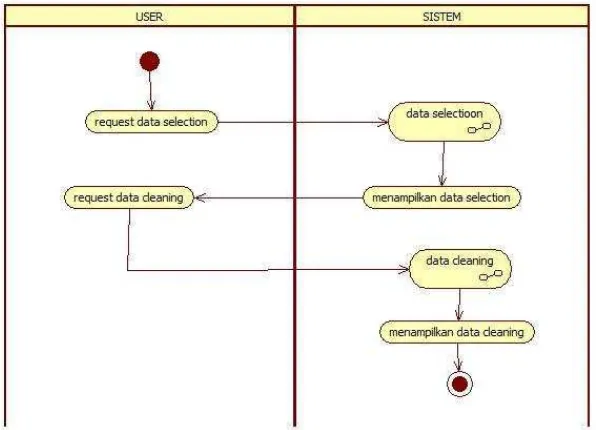
2. Skenario Use Case Preprocesing
Skenario use case preprocessing menjelaskan langkah-langkah user terhadap sistem untuk melakukan proses data selection dan data cleaning. Skenario use case preprocesing dapat dilihat pada table III.11 Requirement A.2 dan tabel III.12 Skenario Use Case Preprocesing.
Tabel III. 11 Requirement A.2
Requirement A.2
Sistem menyediakan fasilitas preprocesing untuk melakukan data selection dan data cleaning
Tabel III. 12 Skenario UseCasePreprocesing
Use case Name Preprocesing
Related Requirements Requirement A.1, Requirement A.2
Goal In Context Sistem melakukan proses data selection dan data cleaning
Precondition Data transaksi telah disimpan didalam database Successful End
Condition
Sistem berhasil melakukan proses data selection dan data cleaning
Failed End Condition Sistem tidak berhasil melakukan proses data selection dan data cleaning
Actors User
Triger User melakukan request proses data selection dan data cleaning kepada sistem
Included Cases Data selection dan data cleaning
Main Flow Step Action
1 User melakakukan request data selection 2 Sistem melakukan proses data selection 3 Sistem menampilkan data hasil data
selection
4 User melakakukan request data cleaning 5 Sistem melakukan proses data cleaning 6 Sistem menampilkan data hasil data
cleaning
Extension Step Branching Action
44
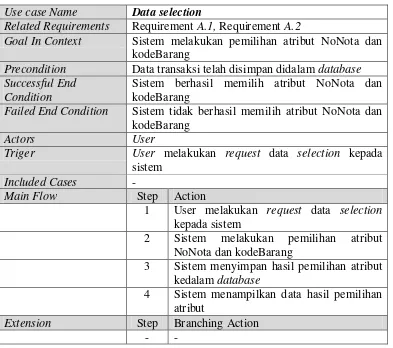
3. Scenario Use Case Data Selection
Skenario use case data selection menggambarkan langkah-langkah user terhadap sistem melakukan pemilihan atribut terhadap data transaksi yang telah melewati proses import data. Skenario use case data selection dapat dilihat pada tabel III.13.
Tabel III. 13Skenario Use Case Data Selection
Use case Name Data selection
Related Requirements Requirement A.1, Requirement A.2
Goal In Context Sistem melakukan pemilihan atribut NoNota dan kodeBarang
Precondition Data transaksi telah disimpan didalam database Successful End
Condition
Sistem berhasil memilih atribut NoNota dan kodeBarang
Failed End Condition Sistem tidak berhasil memilih atribut NoNota dan kodeBarang
2 Sistem melakukan pemilihan atribut NoNota dan kodeBarang
3 Sistem menyimpan hasil pemilihan atribut kedalam database
4 Sistem menampilkan data hasil pemilihan atribut
Extension Step Branching Action
- -
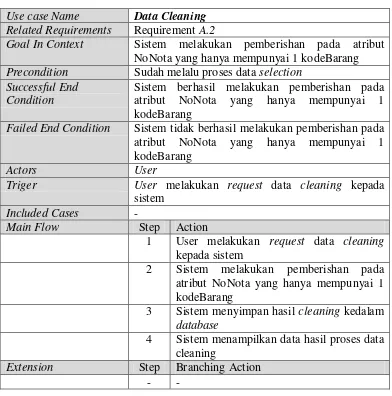
4. Skenario Use Case Data Cleaning
45
Tabel III. 14Skenario Use Case Data Cleaning
Use case Name Data Cleaning
Related Requirements Requirement A.2
Goal In Context Sistem melakukan pemberishan pada atribut NoNota yang hanya mempunyai 1 kodeBarang Precondition Sudah melalu proses data selection
Successful End Condition
Sistem berhasil melakukan pemberishan pada atribut NoNota yang hanya mempunyai 1 kodeBarang
Failed End Condition Sistem tidak berhasil melakukan pemberishan pada atribut NoNota yang hanya mempunyai 1
2 Sistem melakukan pemberishan pada atribut NoNota yang hanya mempunyai 1 kodeBarang
3 Sistem menyimpan hasil cleaning kedalam database
4 Sistem menampilkan data hasil proses data cleaning
Extension Step Branching Action
- -
5. Skenario Use Case Proses Asosiasi
Skenario use case proses assosiasi menggambarkan langkah-langkah aksi user terhadap sistem dalam melakukan proses frequent itemset, rule, dan melihat hasil asosiasi. Skenario use case proses asosiasi dapat dilihat pada tabel III.15 Requirement A.3 dan tabel III.skenario 16 Use Case Proses Asosiasi
Tabel III. 15 Requirement A.3
Requirement A.3
46
Tabel III. 16 Skenario Use Case Proses Asosiasi
Use case Name Proses Asosiasi
Related Requirements Requirement A.1, Requirement A.2, Requirement A.3
Goal In Context Sistem mendapatkan rule lalu menampilkan rule tersebut
Precondition telah melakukan proses import data dan preprocessing
Successful End Condition
Sistem berhasil mendapatkan rule lalu menampilkan rule tersebut
Failed End Condition Sistem tidak berhasil mendapatkan rule untuk dijadikan informasi
Actors User
Triger User memasukan nilai minimum support dan
minimum confidence
Included Cases Input parameter, Frequent itemset, rule, lihat hasil asosiasi, dan rekomendasi produksi
Main Flow Step Action
1 Userinput nilai minimum support 2 Userinput nilai minimum confidence 3 Sistem melakukan proses pencarian
frequent itemset sesuai nilai minimum support
4 Sistem melakukan proses seleksi rule sesuai nilai minimum confidence
5 Sistem melakukan proses lihat hasil asosiasi
6 Sistem melakukan proses menampilkan informasi
Extension Step Branching Action
1.1 Sistem menampilkan notifikasi nilai minimum support yang diinputkan tidak sesuai
2.1 Sistem menampilkan notifikasi nilai minimum confidence yang diinputkan tidak sesuai
3.1 Sistem tidak mendapatkan frequentitemset 4.1 Sistem tidak mendapatkan rule
47
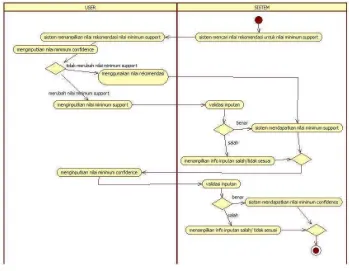
6. Skenario UseCaseInput Parameter
Skenario use case input parameter menggambarkan langkah-langkah aksi user terhdap sistem dalam melakukan input nilai minimum support sebagai parameter dalam pencarian frequent itemset. Skenario use case minimum support dapat dilihat pada tabel III.17
Tabel III. 17Skenario Use CaseMinimum Support
Use case Name Minimum support
Related Requirements Requirement A.3
Goal In Context Sistem mendapatkan nilai minimum support dan minimum confidence
Precondition User menginputkan nilai minimum support dan minimum confidence
Successful End Condition
Sistem berhasil mendapatkan nilai minimum support dan minimum confidence
Failed End Condition Sistem tidak berhasil mendapatkan nilai minimum support dan minimum confidence
Actors User
Triger User menginputkan nilai minimum support dan minimum confidence
Included Cases Frequent itemset
Main Flow Step Action
1 Sistem mencari nilai rekomendasi minimum support
2 Sistem menampilkan rekomendasi nilai minimumsupport
3 User dapat menggunakan rekomendasi nilai minimum support
4 User dapat mengubah nilai minimum support dan dapat menginputkan nilai minimum support
5 Validasi inputan
6 Sistem mendapatkan nilai minimum support
7 User menginputkan nilai minimum confidence
8 Sistem melakukan validasi inputan nilai minimum confidence
48
Extension Step Branching Action
6.1 Sistem menampilkan notifikasi nilai minimum support yang diinputkan tidak sesuai
9.1 Sistem menampilkan notifikasi nilai minimum confidence yang diinputkan tidak sesuai
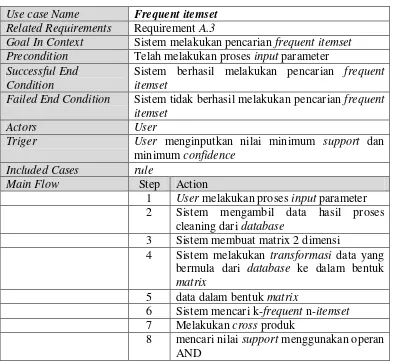
7. Scenario Use CaseFrequent Itemset
Skenario use case frequent itemset menggambarkan langkah-langkah aksi user terhadap sistem dalam melakukan proses pencarian frequent itemset. Skenario use case frequent itemset dapat dilihat pada tabel III.18
Tabel III. 18 Skenario Use Case Frequent Itemset
Use case Name Frequent itemset Related Requirements Requirement A.3
Goal In Context Sistem melakukan pencarian frequent itemset Precondition Telah melakukan proses input parameter Successful End
Condition
Sistem berhasil melakukan pencarian frequent itemset
Failed End Condition Sistem tidak berhasil melakukan pencarian frequent itemset
1 User melakukan proses input parameter 2 Sistem mengambil data hasil proses
cleaning dari database
3 Sistem membuat matrix 2 dimensi
4 Sistem melakukan transformasi data yang bermula dari database ke dalam bentuk matrix
5 data dalam bentuk matrix
6 Sistem mencari k-frequent n-itemset 7 Melakukan cross produk
49
Main Flow Step Action
9 menghitung nilai support count dari setiap kolom dan count setiap barisnya
10 mengeleminasi setiap kolom yang jumlah support countnya < minimum support dan menghapus setiap baris yang jumlah barisnya <= n
11 Sistem melakukan cek matrix
12 Sistem mendapatkan frequent n-itemset 13 Proses pencarian frequent itemset selesai
Extension Step Branching Action
1.1 Sistem menampilkan notifikasi nilai minimum support yang diinputkan tidak sesuai
12.1 Ulangi step 6 sampai step 11 jika matrix not null
12.2 Tidak mendapatkan frequent n-itemset
8. Skenario Use CaseRule
Skenario use case rule menggambarkan langkah-langkah aksi user untuk melakukan proses pembuatan rule. Skenario use case rule dapat dilihat pada tabel III.19
Tabel III. 19 Skenario Use Case Rule
Use case Name Rule
Related Requirements Requirement A.3
Goal In Context Sistem mendapatkan rule
Precondition Sudah melewati proses frequent itemset Successful End
Condition
Sistem berhasil mendapatkan rule Failed End Condition Sistem tidak berhasil mendapatkan rule
Actors User
Triger User menginputkan nilai minimum confidence Included Cases Lihat hasil asosiasi