PEMODELAN KLASIFIKASI SMS BERINDIKASI TINDAK PENIPUAN MENGGUNAKAN TEXT MINING
PRITASARI PALUPININGSIH
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Pemodelan Klasifikasi SMS Berindikasi Tindak Penipuan Menggunakan Text Mining adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Maret 2013
Pritasari Palupiningsih
ii
ABSTRACT
PRITASARI PALUPININGSIH. A Classification Modelling for Fraud SMS Identification using Text Mining. Supervised by TAUFIK DJATNA and HARI AGUNG ADRIANTO.
Nowadays the presence of fraudulence based on SMS is increasing in the
society. Those SMS use unsuspicious sentences, so people could be misled. We
propose a classification model which indicates the presence of fraud and use the
pattern to predict the new SMS. This research use ROCK algorithm to cluster
data and Naive Bayes algorithm to build classifier. Moreover, semantic word
correction technique was applied. SMS which have indication of fraud, used in
this research are SMS containing request of handphone voucher to certain phone
number, offering to be voucher agent, and interest in the activities of buying and
selling land. 5 cluster with threshold 0.08 are resulted from clustering phase and
result from training data phase is classifier with accuracy 80,93%. Finally, the classifier are successfully implemented on the Android phone.
RINGKASAN
PRITASARI PALUPININGSIH. Pemodelan Klasifikasi SMS Berindikasi Tindak Penipuan Menggunakan Text Mining. Dibimbing oleh TAUFIK DJATNA dan HARI AGUNG ADRIANTO.
Saat ini, tindak penipuan melalui SMS semakin marak terjadi. Terkadang, kalimat yang digunakan untuk tindak penipuan tidak menimbulkan kecurigaan bagi penerima SMS. Akan tetapi, ketika SMS tersebut ditindak lanjuti, ternyata SMS itu mengarah ke tindak penipuan. Tahapan ini membutuhkan penyaringan SMS dalam bahasa Indonesia secara real time yang dapat mengenali SMS yang memiliki indikasi tindak penipuan.
Pada penelitian ini terdapat tiga tujuan utama. Tujuan 1 adalah membentuk klaster terhadap data SMS berbasis algoritma ROCK dan memilih ukuran jumlah klaster dan nilai ambang yang memberikan klaster terbaik. Tujuan 2 adalah membentuk sebuah model klasifikasi berbasis algoritma Naive Bayes dengan menggunakan fitur kata yang ada dalam SMS. Tujuan 3 adalah mengimplementasikan model klasifikasi ke perangkat seluler berbasis Android.
Pembentukan klaster menggunakan algoritma ROCK dilakukan berulang dengan mengubah masukan ukuran jumlah klaster dan nilai ambang. Jumlah klaster yang digunakan adalah 2, 3, 4, dan 5. Nilai ambang yang digunakan adalah 0,01 sampai 0,18. Selain itu juga digunakan teknik word approximation yang digunakan untuk melakukan perbaikan kata yang disingkat atau salah ketik. Hasil yang diperoleh dari proses ini adalah klaster dengan ukuran 5 dan nilai ambang 0,08 merupakan klaster terbaik.
Klaster dengan ukuran 5 dan nilai ambang 0,08 digunakan untuk memberi label pada data SMS. Data SMS yang telah memiliki label digunakan pada pembentukan model klasifikasi dengan menggunakan Naïve Bayes. Akurasi yang diperoleh dari model yang terbentuk adalah 80,93%.
Implementasi model klasifikasi telah dilakukan pada perangkat seluler berbasis Android dengan modul yang dimiliki daftar SMS yang termasuk indikasi penipuan, nomor telepon yang termasuk blacklist, dan nomor telepon yang termasuk whitelist.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Ilmu Komputer
PEMODELAN KLASIFIKASI SMS BERINDIKASI TINDAK PENIPUAN MENGGUNAKAN TEXT MINING
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Tesis : Pemodelan Klasifikasi SMS Berindikasi Tindak Penipuan Menggunakan Text Mining
Nama : Pritasari Palupiningsih
NIM : G651100071
Disetujui oleh Komisi Pembimbing
Dr. Eng. Taufik Djatna, S.TP, M.Si Ketua
Hari Agung Adrianto, S.Kom, M,Si Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr. Yani Nurhadryani, S.Si, M.T
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, MSc.Agr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat dan karunia, sehingga penulis dapat menyelesaikan tugas akhir dengan judul Pemodelan Klasifikasi SMS Berindikasi Tindak Penipuan Menggunakan Text Mining. Penelitian ini dilaksanakan mulai Agustus 2011 sampai dengan Januari 2013, bertempat di Departemen Ilmu Komputer.
Ucapan terima kasih penulis sampaikan kepada kepada Bapak DR.Eng. Taufik Djatna, S.TP, M.Si selaku pembimbing pertama dan Bapak Hari Agung Adrianto, S.Kom, M.Si selaku pembimbing kedua atas bimbingan dan arahannya selama pengerjaan tugas akhir ini. Di samping itu terima kasih juga penulis ucapkan kepada orangtua dan keluarga tercinta atas doa dan dukungannya selama mengerjakan tugas akhir ini. Penulis juga mengucapkan terima kasih kepada teman-teman Magister Ilmu Komputer Angkatan 12. Semoga tulisan akhir ini dapat bermanfaat, amin.
Bogor, Februari 2013
2
RIWAYAT HIDUP
3
GLOSARIUM ISTILAH
Istilah Pengertian
Cohesion Ukuran kebaikan klaster yang menentukan seberapa dekat objek-objek di dalam klaster (Tan et al. 2005).
Goodness function Ukuran kemiripan antara dua klaster yang digunakan pada algoritma ROCK.
Jaccard coefficient Ukuran jarak antara dua objek.
link Ukuran kemiripan antara dua objek
yang digunakan pada algoritma ROCK.
Separation Ukuran kebaikan klaster yang menentukan perbedaan atau seberapa jauh suatu klaster dengan klaster lainnya (Tan et al. 2005).
Short Message Service (SMS) Sebuah layanan dasar yang membolehkan pertukaran pesan teks singkat antarpelanggan perangkat seluler (Bodic 2005).
Tetangga Objek lain yang dianggap paling mirip
dengan suatu objek (Guha et al. 2000).
Token Kata, rangkaian huruf dengan angka,
4
Istilah Pengertian
5
GLOSARIUM NOTASI
Notasi Pengertian
θ Nilai ambang untuk menentukan
kemiripan antara dua objek
sim , Nilai yang merepresentasikan kemiripan
antara dua objek dengan menggunakan ukuran jarak
link , Jumlah tetangga yang dimiliki oleh
dan
g , Nilai goodness function antara dua
klaster
P(Cl |X) Nilai posterior probability dari X
terhadap Cl
P(Cl) Nilai Class prior probability dari Cl
6
Algoritma ROCK (Robust Clustering using links) ... 10
Evaluasi Klaster ... 12
Pembentukan Klaster Data Teks dan Pemilihan Klaster Terbaik ... 21
Representasi Pesan ... 24
Pembentukan Dataset ... 24
Pembentukan Model Klasifikasi ... 24
Penentuan Data Latih dan Data Uji ... 24
Klasifikasi ... 25
Implementasi Model Klasifikasi ke Perangkat Seluler ... 26
BAB IV HASIL DAN PEMBAHASAN Pembentukan Klaster Data SMS ... 27
Praproses ... 27
Pembentukan Klaster Data SMS dan Pemilihan Klaster Terbaik ... 28
Pembentukan Model Klasifikasi ... 33
7 BAB V KESIMPULAN DAN SARAN
Kesimpulan ... 43
Saran ... 43
DAFTAR PUSTAKA……… 45
8
5 Klaster Hasil dari Jumlah Klaster= 5 dan Nilai ambang= 0,08 ... 31
6 Class prior probability ... 33
7 Conditional probability untuk 5 token ... 33
8 Confusion matrix dari model klasifikasi untuk 140 data ... 34
9 Akurasi dari 20 Perulangan ... 34
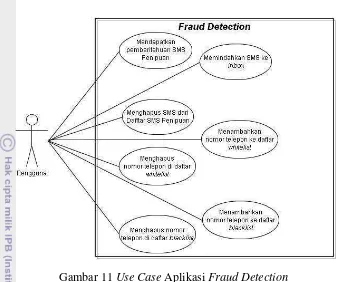
10 Daftar Use Case pada Aplikasi Fraud Detection ... 35
DAFTAR GAMBAR
1 Arsitektur SMS pada Jaringan GSM (Bodic 2005) ... 72 Arsitektur Android (Xie et al, 2012) ... 15
3 Tahapan Pembentukan Klaster Data ... 17
4 Tahapan Praproses ... 18
5 Tahapan Pembentukan Model Klasifikasi. ... 25
6 Grafik Cohesion jumlah klaster 2, 3, 4, dan 5 ... 28
7 Grafik Separation jumlah klaster 2, 3, 4, dan 5 ... 28
8 Grafik waktu proses pembentukan klaster untuk jumlah klaster 5 ... 30
9 Grafik jumlah klaster yang memiliki sms yang termasuk penipuan untuk jumlah klaster 5 ... 30
10 Use Case Aplikasi Fraud Detection ... 36
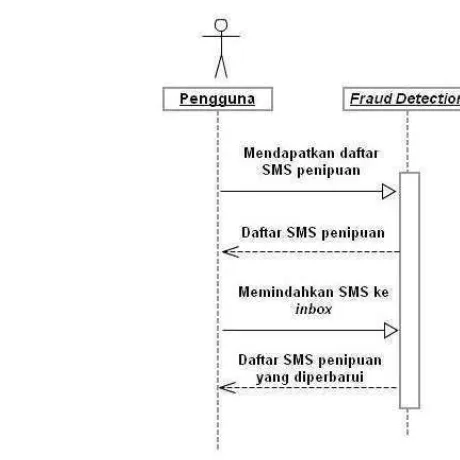
11 Sequence diagram untuk Mendapatkan Pemberitahuan SMS Penipuan ... 36
12 Sequence diagram untuk Memindahkan SMS ke inbox ... 37
13 Sequence diagram untuk Menghapus SMS dari Daftar SMS Penipuan ... 38
14 Sequence diagram untuk Menambahkan Nomor Telepon ke Daftar
18 Implementasi Model Klasifikasi pada Perangkat Seluler ... 41
19 Proses Klasifikasi Data SMS Baru ... 41
DAFTAR LAMPIRAN
1 Cohesion dan Separation untuk 2 Klaster ... 492 Cohesion dan Separation untuk 3 Klaster ... 50
3 Cohesion dan Separation untuk 4 Klaster ... 51
9 BAB 1
PENDAHULUAN
Latar Belakang
Short Message Service (SMS) merupakan salah satu media komunikasi yang banyak digunakan saat ini karena praktis untuk digunakan dan biaya pengirimannya murah. Namun, seiring dengan semakin populernya penggunaan SMS, muncul tindakan menggunakan layanan SMS untuk tujuan yang tidak tepat. SMS dengan tujuan malfungsi ini biasanya disebut SMS spam. Contoh dari SMS
spam adalah SMS yang digunakan sebagai media iklan, SMS yang berisi pesan porno, SMS dengan tujuan menipu dan sebagainya. SMS seperti ini cenderung mengganggu penerima SMS. Bahkan SMS dengan tujuan menipu dapat merugikan orang yang menerima SMS tersebut. Saat ini, tindak penipuan melalui SMS semakin marak terjadi. Dengan menggunakan SMS sebagai media tindak penipuan, keberadaan penipu akan sulit untuk dilacak. Ada beberapa macam tindak penipuan yang dilakukan melalui SMS. Salah satu tindak penipuan yang saat ini marak terjadi di masyarakat adalah SMS yang berisi permintaan pulsa telepon seluler ke nomor tertentu, dengan mengatasnamakan keluarga. Terkadang, kalimat yang digunakan untuk tindak penipuan tidak menimbulkan kecurigaan bagi penerima SMS. Akan tetapi, ketika SMS tersebut ditindak lanjuti, ternyata SMS itu mengarah ke tindak penipuan. Oleh karena itu, dibutuhkan penyaringan SMS yang memiliki indikasi tindak penipuan.
10
menimbulkan kesulitan jika dilihat dari sisi hardware. Dimana perangkat lunak yang dibuat tidak bisa menggunakan banyak memori di dalam perangkat seluler dan harus dapat bekerja dalam waktu yang relatif cepat.
Klasifikasi adalah bentuk analisis data yang dapat digunakan untuk mengekstrak model yang mendeskripsikan data yang berisi kelas-kelas atau untuk memprediksi trend data di masa depan (Han & Kamber 2011). Pemodelan klasifikasi akan menghasilkan model klasifikasi yang akan digunakan untuk memprediksi label berbentuk kategori.
11 yang spesifik, fitur baru seperti nomor telepon singkat, dan di mana ruang fitur secara intuitif lebih besar (Cormack 2007b).
Hidalgo et al. (2006) melakukan penelitian penggunaan Bayesian Filtering yang telah berhasil digunakan pada identifikasi email spam untuk digunakan pada identifikasi SMS. Dari penelitian yang dilakukannya, mereka memperoleh hasil bahwa teknik Bayesian Filtering dapat digunakan pada SMS spam secara efektif. Khemapatapan (2010) melakukan penelitian tentang penyaringan SMS spam
dengan menggunakan algoritma Support Vector Machine (SVM) dan Naïve Bayes. Proses analisis semantik diterapkan pada penelitian ini untuk menangani masalah kata yang salah diketik. Salah satu hasil yang diperoleh adalah SVM memberikan akurasi yang lebih tinggi dari Naïve Bayes, akan tetapi waktu pemrosesan klasifikasi dengan menggunakan SVM jauh lebih lama dibandingkan dengan Naïve Bayes. Deng & Peng (2006) melakukan penelitian tentang pembangunan sistem penyaringan SMS terdistribusi menggunakan algoritma Naïve Bayes. Selain menggunakan kata sebagai atribut dari SMS, penelitian ini juga menggunakan panjang pesan dan beberapa aturan sebagai atribut dari SMS. Hasil penelitian yang diperoleh menunjukkan, penggunaan panjang pesan dan aturan sebagai atribut SMS dapat meningkatkan akurasi klasifikasi SMS.
12
oleh aplikasi penyaringan SMS di perangkat seluler. Apabila ternyata aplikasi penyaringan SMS salah melakukan klasifikasi, pengguna masih tetap dapat membaca isi dari SMS tersebut.
Data SMS yang beredar di masyarakat dapat dianalisis menggunakan teknik
text mining. Salah satu teknik dalam text mining adalah klasifikasi (Feldman & Sanger 2007). Masalah penyaringan SMS spam dapat dipandang sebagai klasifikasi teks, yang biasanya dimodelkan sebagai tugas pembelajaran yang diawasi dimana pengklasifikasi biner dilakukan pada kelompok pesan pelatihan yang diberi label dan kemudian digunakan untuk memprediksi kelas dari masing-masing pesan pada kelompok pesan pengujian yang tidak berlabel (Sebastiani 2002). Teknik klasifikasi akan menghasilkan model klasifikasi yang dapat digunakan untuk menentukan apakah sebuah SMS yang baru masuk memiliki indikasi tindak penipuan atau tidak. Salah satu tantangan yang harus dihadapi adalah struktur dari SMS. Selain masalah keterbatasan pada struktur SMS yang telah dijelaskan di atas, terdapat beberapa hal yang penting pada proses penyaringan SMS spam yaitu :
1. Aplikasi penyaringan SMS membutuhkan pemrosesan real time pada lingkungan sumber daya terbatas, seperti ponsel, untuk mengklasifikasikan pesan karena itu pengguna tidak bisa menunggu. Umumnya kurang dari 5 detik yang dibutuhkan, sehingga memerlukan pendekatan penyaringan cepat untuk melakukan hal ini (Deng & Peng 2006).
2. Adanya interaksi dengan pengguna, dimana pengguna dapat memberikan
feedback, yaitu apakah sms tersebut merupakan SMS spam atau SMS sah. 3. Tidak hanya menggunakan kata sebagai atribut. Tetapi juga menggunakan
beberapa rangkaian angka atau angka dengan huruf yang memiliki makna tertentu. Misalnya rangkaian angka yang merupakan nomor telepon, seperti 085697851845. Kemudian rangkaian angka dan huruf yang merupakan jumlah uang, seperti Rp.50.000.
Perumusan Masalah
13 1. Bagaimana melakukan pengelompokkan data SMS yang memiliki indikasi
tindak penipuan dan tudak memiliki indikasi tindak penipuan? Jumlah klaster dan nilai ambang berapa yang memberikan pengelompokkan data SMS yang terbaik?
2. Bagaimana mengetahui pola SMS yang memiliki indikasi tindak penipuan? 3. Bagaimana pengguna perangkat seluler dapat mengetahui sebuah SMS
memiliki indikasi tindak penipuan atau tidak? Tujuan Penelitian
Penelitian ini bertujuan untuk :
1. Membentuk klaster terhadap data SMS berbasis algoritma ROCK (Guha et al. 2000) dan memilih ukuran jumlah klaster dan nilai ambangyang memberikan klaster terbaik.
2. Membentuk sebuah model klasifikasi berbasis algoritma Naive Bayes (Deng & Peng 2006) dengan menggunakan fitur kata yang ada dalam SMS tersebut. 3. Mengimplementasikan model klasifikasi ke perangkat seluler berbasis
Android (Google 2012). Ruang Lingkup Penelitian
BAB II
TINJAUAN PUSTAKA
Short Message Service (SMS)
Short Message Service (SMS) adalah sebuah layanan dasar yang membolehkan pertukaran pesan teks singkat antarpelanggan. Pesan ini dapat dikirim dari perangkat mobile GSM/UMTS tetapi bisa juga dikirim dari perangkat lain dengan cakupan yang lebih luas seperti internet host, telex, dan faksimili SMS. Internet host, telex, dan faksimili SMS adalah teknologi yang didukung 100% oleh perangkat GSM dan sebagian besar jaringan GSM di seluruh dunia yang sudah sangat matang (Bodic 2005).
Arsitektur SMS yang disediakan oleh jaringan GSM ditunjukkan pada Gambar 1. Sebagai tambahan, terdapat sebuah elemen yang disebut short message entity, biasanya dalam wujud sebuah aplikasi perangkat lunak dalam perangkat
mobile, yang penting dalam menangani pesan (pengiriman, penerimaan, penyimpanan, dan lain-lain). Short message entity tidak ditampilkan pada Gambar 1.
8
Elemen yang dapat mengirim dan menerima pesan singkat dinamakan short message entities (SME). Sebuah SME dapat berupa aplikasi perangkat lunak dalam sebuah perangkat mobile tetapi juga bisa berupa perangkat faksimili, peralatan telex, remote internet server, dan lain-lain. Sebuah perangkat mobile
harus diatur supaya bekerja dengan baik dalam jaringan mobile. Sebuah SME dapat berupa server yang saling berhubungan langsung atau melalui sebuah gateway yaitu SMS center. Sebuah SME juga dikenal sebagai sebuah External
SME (ESME). Sebuah ESME menggambarkan sebuah WAP proxy/server, sebuah email gateway, atau sebuah voice mail server. Untuk pertukaran pesan singkat, SME yang membangkitkan dan mengirim pesan singkat dikenal sebagai
originator SME sedangkan SME yang menerima pesan singkat dikenal sebagai
recipient SME.
Service Center (SC) atau SMS Center (SMSC) memainkan peran penting dalam arsitektur SMS. Fungsi utama dari SMSC adalah menyiarkan pesan singkat diantara SME dan menyimpan dan meneruskan pesan singkat (penyimpanan pesan jika SME penerima tidak tersedia). SMSC mungkin terintegrasi sebagai bagian dari jaringan mobile (misalnya, terintegrasi dengan MSC) atau entitas jaringan yang berdiri sendiri. SMSC mungkin juga dapat ditempatkan diluar jaringan dan diatur oleh organisasi ketiga. Operator jaringan mobile biasanya mempunyai perjanjian komersial yang saling menguntungkan untuk membolehkan pertukaran pesan antarjaringan. Hal ini berarti sebuah pesan yang dikirim dari sebuah SME yang ada di jaringan A dapat dikirim ke SME lain yang ada di jaringan mobile B. Hal ini memungkinkan pengguna untuk bertukar pesan walaupun mereka tidak terdaftar dalam jaringan yang sama dan terkadang berada di negara yang berbeda, inilah salah satu fitur kunci yang membuat SMS sangat sukses (Bodic 2005).
Text Mining
9 berguna dari sumber data melalui identifikasi dan eksplorasi pola yang menarik. Dalam kasus text mining, bagaimanapun, sumber data merupakan koleksi dokumen, dan pola yang menarik yang ditemukan tidak diantara record basis data yang tersusun tetapi dalam data teks tidak terstruktur dalam dokumen yang ada dalam koleksi (Feldman & Sanger 2007).
Karena data mining mengambil data yang tersimpan dalam format terstruktur, sebagian besar dari praproses fokus pada dua kegiatan : scrubbing dan
normalizing data dan membuat sejumlah tabel penggabungan. Secara berlawanan, untuk sistem text mining, pusat operasi praproses terjadi pada identifikasi dan ekstrasi fitur representatif untuk dokumen bahasa alami. Operasi praproses ini bertanggung jawab untuk mengubah data tidak terstruktur yang tersimpan dalam koleksi dokumen ke dalam format terstruktur lanjutan yang lebih eksplisit, yang merupakan masalah yang tidak relevan untuk sebagian besar sistem data mining
(Feldman & Sanger 2007).
Metode yang digunakan pada text mining hampir sama dengan metode dalam data mining. Sekali data ditransformasi menjadi format numerik biasa, metode data mining standar dapat diterapkan (Weiss et al. 2005). Klasifikasi, klastering, dan information extraction merupakan metode yang banyak diterapkan dalam text mining.
Tema yang mungkin dalam menganalisa data yang kompleks adalah klasifikasi atau kategorisasi. Secara abstrak diuraikan, tugasnya adalah mengklasifikasikan sebuah instance data yang diberikan ke dalam sebuah kategori. Berlaku untuk bidang dari manajemen dokumen, tugas ini dikenal dengan kategorisasi teks, dimana diberikan kumpulan kategori (subyek, topik) dan sebuah koleksi dari dokumen teks, proses menemukan topik yang sesuai untuk setiap dokumen (Feldman & Sanger 2007).
Beberapa teknik yang dapat digunakan pada klasifikasi dokumen adalah
probabilistic classifier, decision tree classifier, decision rule classifier, nearest-neighbor classifier, dan support vector machine classifier.
10
mirip untuk membentuk klaster yang koheren, sedangkan dokumen yang berbeda terpisah menjadi klaster yang berbeda (Huang 2008).
Algoritma ROCK (Robust Clustering using links)
ROCK adalah algoritma klastering hirarki aglomeratif untuk mengelompokkan data kategorik. Algoritma ROCK membangun link untuk menggabungkan klaster dan tidak menggunakan jarak seperti algoritma klastering pada umumnya (Guha et al. 2000). Parameter yang digunakan dalam algoritma ROCK adalah :
1. Tetangga
Tetangga dari suatu objek adalah objek lain yang dianggap paling mirip dengan objek tersebut. Diberikan suatu nilai ambang (θ) yang bernilai antara 1 dan 0. Dua objek dan yyyy, sim , ≥θ. θ merupakan parameter yang ditentukan oleh pengguna yang dapat digunakan untuk mengontrol seberapa dekat hubungan dan yyyy sehingga kedua objek tersebut dapat dikatakan sebagai tetangga. Ukuran kemiripan antarpasangan objek dihitung dengan
Jaccard Coefficient
2. Link
Algoritma ROCK menggunakan informasi link sebagai ukuran kemiripan antarobjek. Jika merupakan tetangga dari dan merupakan tetangga dari maka dikatakan memiliki link dengan walaupun bukan tetangga dari . Didefinisikan :
Link( , ) = ∑tetangga yang dimiliki sekaligus oleh dan
11 3. Goodness Function
Algoritma ROCK menggunakan informasi nilai goodness sebagai ukuran kemiripan antarklaster, dan menggabungkan objek/klaster yang memiliki kemiripan terbesar. Didefinisikan ukuran goodness antara klaster dan :
g , = link( , ) ( + )1+2f(θ)- 1+2f(θ)- n1+2f(θ)] (2) Dimana link , = ∑ , link( , ) menyatakan banyaknya cross link
(jumlah link dari semua kemungkinan pasangan objek yang ada dalam dan , dan masing-masing menyatakan jumlah anggota klaster dan jumlah anggota klaster , dan f θ = 1 ⁄1 .
Langkah-langkah dalam algoritma ROCK yaitu :
1. Menentukan inisialisasi untuk masing-masing data poin sebagai klaster pada awalnya.
2. Menghitung similaritas antarklaster dengan klaster lainnya, menggunakan
jaccard coefficient.
3. Menentukan nilai matrik tetangga A dengan menggunakan nilai nilai ambang (θ).
A[x,y] bernilai 1 jika sim(x,y) ≥θ dan bernilai 0 jika sim(x,y) ≤θ.
4. Menghitung link antarklaster dengan klaster lainnya. Link(Ti, Tj) antarobjek diperoleh dari jumlah tetangga antara Ti dan Tj
5. Menghitung nilai goodness measure untuk setiap klaster dengan klaster lainnya jika link !=0 yang disebut local heap.
6. Memilih nilai maksimum goodness measure antarkolom di baris ke i yang disebut global heap.
7. Ulangi langkah 5 dan 6 hingga mendapatkan nilai maksimum di global heap
dan local heap.
8. Selama ukuran data > k, dengan k adalah jumlah kelas yang ditentukan lakukan penggabungan klaster yang memiliki nilai local heap terbesar menjadi satu klaster, tambahkan link antarklaster yang digabungkan, hapus klaster yang digabungkan dari local heap dan update nilai global heap dengan nilai hasil penggabungan.
12
Evaluasi Klaster
Evaluasi klaster adalah kemampuan untuk mendeteksi ada atau tidaknya suatu struktur tidak acak dalam data. Beberapa aspek penting dalam evaluasi klaster yaitu (Tan et al. 2005):
1. Menentukan kecenderungan klaster dari suatu data. 2. Menentukan jumlah klaster yang tepat.
3. Mengevaluasi seberapa baik hasil analisis klaster tanpa diberikan informasi eksternal.
4. Membandingkan hasil analisis klaster terhadap hasil eksternal yang diketahui, misalnya label kelas eksternal.
5. Membandingkan dua himpunan klaster untuk menentukan klaster yang lebih baik.
Perhitungan evaluasi dapat digolongkan menjadi tiga jenis yaitu: 1. Unsupervised
Teknik unsupervised mengukur goodness dari struktur klaster tanpa informasi eksternal. Ukuran yang digunakan dalam teknik unsupervised dibagi menjadi dua, yaitu : cohesion dan separation. Cohesion merupakan ukuran kebaikan klaster yang menentukan seberapa dekat objek-objek di dalam klaster.
Separation merupakan ukuran kebaikan klaster yang menentukan perbedaan atau seberapa jau suatu klaster dengan klaster lainnya.
2. Supervised
Teknik supervised mengukur kecocokan struktur hasil pembentukan klaster dengan struktur eksternal.
3. Relative
Teknik relative membandingkan klaster yang berbeda. Ukuran evaluasi klaster relative merupakan teknik unsupervised dan supervised yang digunakan untuk perbandingan.
Pada aspek evaluasi klaster kesatu, kedua, dan ketiga termasuk teknik
13 Algoritma Naive Bayes
Klasifikasi Naive Bayes dapat diuraikan sebagai berikut :
Asumsi bahwa setiap instance direpresentasikan dengan sebuah vektor X=(x1,x2,…,xn), dimana x1,x2,…,xn adalah ukuran dari atribut A1,A2,…,An.
Andaikan terdapat kelas sejumlah m yaitu C1,C2,…,Cm. Diberikan suatu instance X yang belum diketahui kelasnya, dengan menggunakan teorema Bayesian,
posterior probability dari X terhadap Cl adalah :
P(Cl |X) = | ⁄ = | ⁄ ∑ ! | (3)
Class prior probability dapat diduga dengan P(Cl)=" "⁄ , dimana s
ladalah
jumlah dari data pelatihan dengan kelas Cl dan s adalah jumlah total data pelatihan. Naive Bayes menduga conditionally independent antara satu atribut dan atribut lainnya dengan :
P(X|Cl)= ∏% ! $ | (4)
P(x
k|Cl) dapat diduga dari data. Sehingga didapatkan
P(Cl|X)= ∏% ! $ | ⁄ ∑' ! & $ | ' (5)
Untuk menggolongkan sebuah data X yang belum diketahui kelasnya,
P(Cl|X) dievaluasi untuk setiap kelas Cl. Data X akan dimasukkan dalam kelas Cl
jika dan hanya jika P(Cl|X) > P(Cj|X), 1 ≤ j ≤ m, j≠l (Deng & Peng 2006).
Proses belajar mengambil sebagai masukan pengumpulan pelatihan, dan terdiri atas langkah-langkah berikut (Sebastiani 2002):
1. Preprocessing. Penghapusan elemen-elemen yang tidak relevan (misalnya, HTML), dan pemilihan segmen yang sesuai pengolahan (misalnya header, tubuh, dan lain-lain).
2. Tokenization. Membagi pesan ke segmen semantik yang koheren (misalnya, kata, string karakter lain, dan lain-lain).
14
4. Selection. Penghapusan atribut yang kurang prediktif (menggunakan ukuran kualitas misalnya seperti information gain).
5. Learning. Secara otomatis membangun model klasifikasi (classifier) dari koleksi pesan, karena mereka sebelumnya telah diwakili.
Word Approximation
Word approximation merupakan teknik yang digunakan untuk menyelesaikan kesalahan typographical dari query dengan menggunakan teknik pencarian yang rapi. Dalam word approximation dilakukan penghitungan nilai kekeliruan sebuah query dari pengguna dengan membandingkan query dari pengguna dengan kata yang terdapat pada kamus. Kata dengan nilai kekeliruan paling sedikit yang akan dikembalikan. Modul word approximation dilakukan berdasarkan penghitungan jarak mengubah string masukan dengan kata kunci yang dikenal. Jika string masukan sama persis dengan sebuah kata kunci, maka kata kunci ini digunakan secara langsung. Selainnya, kata kunci terdekat dipilih sebagai perbaikan kata (Angkawattanawit et al. 2008).
Confusion Matrix
Confusion matrix merupakan sebuah tabel yang berisi jumlah banyaknya
record uji yang diprediksi secara benar dan tidak benar oleh model klasifikasi. Bentuk dari confussion matrix terlihat pada Tabel 1. Setiap entri pada f
ij pada
tabel ini menyatakan banyaknya record dari kelas i yang diprediksi ke dalam kelas
j.
15 Akurasi= f11 f00 f
11 f10 f01 f00
⁄ (6)
Android
Android adalah perangkat lunak yang menyertakan sistem operasi,
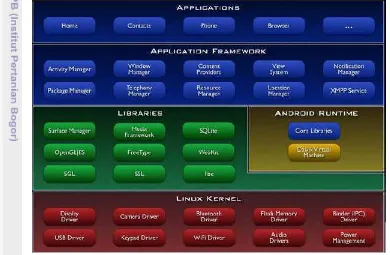
middleware, dan kunci aplikasi perangkat seluler dengan sekumpulan Application Programming Interface (API) library untuk pembuatan aplikasi perangkat seluler sesuai kebutuhan (Meier 2009). Google mengembangkan sistem operasi Android untuk platform di perangkat mobile atau netbook. Struktur sistem dari Android terdiri dari lapisan aplikasi, lapisan kerangka aplikasi, lapisan runtime sistem, dan lapisan kernel Linux (Xie et al, 2012). Arsitektur Android dapat dilihat pada Gambar 2.
Gambar 2 Arsitektur Android (Xie et al. 2012) Penelitian Terkait
16
processing center. Sedangkan bagian penyaringan SMS diletakkan pada SMS
filter agent yang terdapat pada mobile phone. Pembaruan pengetahuan penyaringan dilakukan secara berkala, dengan cara SMS filter agent akan melaporkan SMS yang salah diklasifikasikan ke SMS processing center. Kemudian SMS processing center akan menggunakan informasi tersebut untuk melakukan pembelajaran untuk mendapatkan pembaruan pengetahuan penyaringan. Pembaruan pengetahuan penyaringan ini akan diunduh oleh SMS
filter agent untuk kemudian digunakan pada penyaringan SMS selanjutnya. Terdapat atribut baru yang digunakan pada penelitian ini, yaitu panjang pesan dan beberapa aturan yang dibentuk oleh penulis.
BAB III
METODOLOGI PENELITIAN
Terdapat tiga tahapan utama dalam penelitian ini. Ketiga tahapan tersebut yaitu, pembentukan klaster data SMS, pembentukan model klasifikasi, serta implementasi model klasifikasi ke perangkat seluler.
Pembentukan Klaster Data SMS
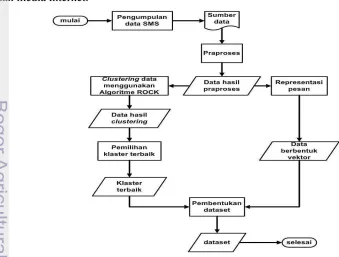
Pada Gambar 3 ditunjukkan tahapan pembentukan klaster data yang digunakan. Pada tahap ini, akan dilakukan pembentukan klaster data dan pembentukan dataset dari data SMS. Terdapat lima subtahap dari tahapan pembentukan klaster data, yaitu subtahap pengumpulan data SMS, subtahap praproses, subtahap pembentukan klaster data teks dan pemilihan klaster terbaik, subtahap representasi pesan, dan subtahap pembentukan dataset.
Pengumpulan data SMS dilakukan untuk memperoleh sumber data yang akan digunakan pada penelitian ini. SMS yang dikumpulkan adalah SMS berindikasi tindak penipuan yang beredar di masyarakat pada tahun 2010-2011. Kumpulan SMS tersebut diperoleh dari penulis, beberapa orang kolega penulis, dan media internet.
18
Struktur Praproses
Tahap praproses dapat dipecah lagi menjadi beberapa tahap. Rincian lengkap tahap praproses dapat dilihat pada Gambar 4.
Gambar 4 Tahapan Praproses
Tahapan praproses data yang dilakukan adalah sebagai berikut :
1. Tokenizing: Pada proses tokenizing dilakukan pemotongan untuk setiap kata, rangkaian angka dan rangkaian angka dengan huruf yang memiliki makna tertentu, yang terdapat dalam SMS. Karakter selain huruf, rangkaian angka, atau rangkaian angka dengan huruf akan dihilangkan. Setiap kata, rangkaian angka, maupun rangkaian angka dengan huruf disebut sebagai token.
Ilustrasi dari proses tokenizing dapat dilihat di bawah ini. Data awal :
Hasil proses tokenizing :
2. Filtering: Proses filtering merupakan proses pembuangan token yang termasuk dalam daftar stop word. Beberapa kata yang termasuk dalam daftar
stop word adalah yang, di, ke, dari, adalah, dan, atau, dan lain sebagainya. tolong belikan dlu mama pulsa nominal di no yang baru ini nomortelepon mau pakai nelpon pnting orng
19 Ilustrasi dari proses filtering dapat dilihat di bawah ini.
Data hasil proses tokenizing :
Hasil proses filtering :
3. Stemming: Pada proses stemming dilakukan penghapusan awalan dan akhiran yang terdapat pada setiap token yang mengandung imbuhan. Proses ini dilakukan untuk mendapatkan kata dasar dari setiap token.
Ilustrasi dari proses stemming dapat dilihat di bawah ini. Data hasil proses filtering :
Hasil proses stemming :
4. Word Approximation: Proses word approximation merupakan proses perbaikan token yang salah ketik atau token yang disingkat (Angkawattanawit
et al. 2008). Karena token yang salah ketik atau token yang disingkat tidak akan memiliki makna. Padahal bisa saja token tersebut memiliki makna yang dapat digunakan dalam mengenali kategori suatu SMS.
20
penggantian satu karakter, atau penukaran dari dua karakter yang berdekatan.
Pseudocode dari algoritma Damerau Levenshtein ditunjukkan pada Gambar 5.
Gambar 5 Pseudocode Algoritma Damerau Levensthein
Data hasil proses stemming dan daftar kata dasar dalam Bahasa Indonesia digunakan sebagai masukan pada proses ini. Proses word approximation dilakukan perbandingan kata dengan memperhatikan empat jenis kesalahan pengetikan, yaitu :
a. Penyisipan sebuah huruf. b. Penghapusan sebuah huruf.
c. Penggantian sebuah huruf dengan huruf lain. d. Penukaran dua karakter yang berdekatan.
Tahapan yang dilakukan pada proses word approximation dengan menggunakan algoritma Damerau Levenshtein adalah sebagai berikut :
a. Menghitung jarak antara token dengan setiap kata yang terdapat pada daftar kata dasar dengan menggunakan ukuran jarak Damerau Levenshtein.
21 c. Mengganti token tersebut dengan kata dari daftar kata dasar,
dimana jarak antara token dengan kata tersebut merupakan jarak paling kecil.
Ilustrasi dari proses word approximation dapat dilihat di bawah ini. Data hasil proses stemming :
Hasil proses word approximation :
Pembentukan Klaster Data Teks dan Pemilihan Klaster Terbaik
Proses pembentukan klaster data dilakukan untuk mendapatkan pengelompokkan dari seluruh data SMS yang ada (Huang 2008). Proses ini dilakukan menggunakan data hasil tahap praproses. Pada penelitian ini dilakukan percobaan membentuk klaster menggunakan algoritma ROCK dengan merubah masukan jumlah klaster dan nilai ambang. Jumlah klaster yang digunakan adalah 2, 3, 4, dan 5. Sedangkan nilai ambang yang digunakan antara 0.01 sampai 0.18.
Tahapan dari pembentukan klaster data menggunakan algoritma ROCK adalah (Guha et al. 2000):
1. Menentukan inisialisasi untuk masing-masing data poin sebagai klaster pada awalnya.
2. Menghitung similaritas antara suatu klaster dengan klaster lainnya, menggunakan rumus jaccard coefficient berikut :
sim , = | ∩ | |⁄ ( |
| ∩ | menyatakan banyaknya item yang sama pada dan , sedangkan | ( | menyatakan banyaknya gabungan item pada dan .
Sebagai contoh penghitungan jaccard coefficient, diberikan dua SMS )! dan )* sebagai berikut :
tolong beli dulu mama pulsa nominal nomor baru ini nomortelepon mau pakai telepon penting orang
22
)! = { baru, beli, dulu, ini, mama, mau, nominal, nomor, nomortelepon, orang, pakai, penting, pulsa, telepon, tolong}
)* = { ada, baru, ini, jangan, kantor, kirim, lagi, masalah, nominal, nomor, nomortelepon, papa, polisi, pulsa, telepon, tolong}
sim , = 8 23⁄ =0,35
3. Menentukan nilai matrik tetangga A dengan menggunakan nilai nilai ambang (θ).
A[x,y] bernilai 1 jika sim(x,y) ≥θ dan bernilai 0 jika sim(x,y) ≤θ.
Sebagai contoh penentuan nilai matrik tetangga A dapat dilihat berikut ini : nilai ambang (θ) = 0,3
+,- )!, )* = 0,35
A[)!, )*] = 1, maka )! dan )* merupakan tetangga.
4. Menghitung link antara suatu klaster dengan klaster lainnya menggunakan persamaan 1. Link(Ti, Tj) antarobjek diperoleh dari jumlah tetangga antara Ti
dan Tj.
Link(Ti, Tj) = |tetangga(Ti) ∩ tetangga(Tj)|.
Sebagai contoh penentuan Link(Ti,Tj) dapat dilihat berikut ini :
23 5. Menghitung nilai goodness measure untuk setiap klaster dengan klaster
lainnya jika link != 0 yang disebut local heap, dengan menggunakan Persamaan 2.
Sebagai contoh penghitungan nilai goodness measure dapat dilihat berikut ini :
7. Ulangi langkah 5 dan 6 hingga mendapatkan nilai maksimum di global heap dan
local heap
8. Selama ukuran data > k, dengan k adalah jumlah kelas yang ditentukan lakukan penggabungan klaster yang memiliki nilai local heap terbesar menjadi satu klaster, tambahkan link antarklaster yang digabungkan, hapus klaster yang digabungkan dari local heap dan update nilai global heap dengan nilai hasil penggabungan.
9. Lakukan langkah 8 hingga menemukan jumlah klaster yang diharapkan atau tidak ada lagi link antara klaster-klasternya
Setelah itu dilakukan pemilihan klaster terbaik dari semua klaster yang terbentuk dengan menggunakan ukuran kebaikan klaster. Ukuran kebaikan klaster yang digunakan adalah cohesion dan separation. Semakin tinggi nilai cohesion
24
Pengelompokkan dari klaster terbaik yang akan menjadi kategori kelas dari data SMS.
Representasi Pesan
Setiap SMS yang telah melalui tahap praproses diubah menjadi bentuk vektor numerik yang elemennya adalah nilai 1 atau 0 (Sebastiani 2002). Dimana nilai 1 menunjukkan bahwa suatu token dimiliki oleh SMS dan nilai 0 menunjukkan suatu token tidak dimiliki oleh SMS.
Pembentukan Dataset
Dataset dibentuk dengan menggabungkan data berbentuk vektor yang dihasilkan dari proses representasi data dengan kategori kelas yang merupakan hasil dari proses pembentukan klaster data. Dataset ini yang akan digunakan pada tahapan selanjutnya, yaitu tahapan pembentukan model klasifikasi.
Pembentukan Model Klasifikasi
Tahapan setelah pembentukan dataset adalah tahapan pembentukan dan pemilihan model. Tahapan pembentukan dan pemilihan model dapat dilihat pada Gambar 6.
Penentuan Data Latih dan Data Uji
25
Gambar 6 Tahapan Pembentukan Model Klasifikasi. Klasifikasi
Terdapat dua proses dalam klasifikasi, yaitu proses pelatihan data latih untuk membentuk model klasifikasi dan proses penghitungan akurasi dari model klasifikasi yang terbentuk menggunakan data uji. Klasifikasi dilakukan menggunakan algoritma Naive Bayes (Deng & Peng 2006) pada dataset yang telah melalui proses seleksi fitur. Pada proses pelatihan data, dilakukan penghitungan class prior probability menggunakan dan conditional probability
untuk setiap token menggunakan Persamaan 4.
26
evaluasi confusion matrix (Han & Kamber 2011). Akurasi akhir adalah rata-rata akurasi dari semua akurasi yang diperoleh dari 20 perulangan.
Implementasi Model Klasifikasi ke Perangkat Seluler
Model klasifikasi yang telah diperoleh pada tahap sebelumnya akan diimplementasikan ke perangkat seluler berbasis Android. Sistem ini dibuat menggunakan bahasa pemrograman Java (Eclipse 2010) dan basis data SQLite (Hipp et al. 2010). Berdasarkan arsitektur Android (Xie et al. 2012), aplikasi penyaringan SMS berindikasi tindak penipuan yang akan dikembangkan berada pada lapisan aplikasi pada arsitektur Android. Sedangkan SQLite merupakan salah satu library yang dapat digunakan dalam pengembangan aplikasi untuk
framework Android.
Dalam penentuan label dari SMS baru, dilakukan penghitungan posterior probability dengan menggunakan persamaan (5).
Sebagai contoh penghitungan posterior probability adalah sebagai berikut : Contoh data disajikan pada Tabel 2.
Tabel 2. Contoh data
Id_data Token1 Token2 Token3 Token4 Kelas
27
P(Token4=1 | C1) = 2⁄3=0,67
P(Token4=0 | C1) = 1⁄3=0,33 P(Token4=1 | C2) = 2⁄2=1 P(Token4=0 | C2) = 0⁄2=0
Data Baru : X = Token1=1 , Token2=0, Token3=0, Token4=1
Class-conditional Probability untuk kelas C1
P(X | C1)= P(Token1=1 | C1) * P(Token2=0 | C1) * P(Token3=0 | C1) * P(Token4=1 | C1)
= 0,67 * 0,33 * 0,33 * 0,67 = 0,048
Class-conditional Probability untuk kelas C1
P(X | C2)= P(Token1=1 | C2) * P(Token2=0 | C2) * P(Token3=0 | C2) * P(Token4=1 | C2)
= 0,5 * 0,5* 0,5 * 1 = 0,125
Posterior Probability untuk kelas C1
P(C1 | X)= P(C1) * P(X | C1) /( [P(C1) * P(X | C1)] + [P(C2) * P(X | C2)]) = 0,6 * 0,048 /( [0,6 * 0,048] + [0,4 * 0,125])
= 0,0288 / 0,0788 = 0,365
Posterior Probability untuk kelas C2
P(C2 | X)= P(C2) * P(X | C2) /( [P(C1) * P(X | C1)] + [P(C2) * P(X | C2)]) = 0,4 * 0,125/( [0,6 * 0,048] + [0,4 * 0,125])
= 0,05/ 0,0788 = 0,635
BAB IV
HASIL DAN PEMBAHASAN
Pembentukan Klaster Data SMS
Data yang digunakan pada penelitian ini berjumlah 140 data sms, yang terdiri dari 70 data SMS yang berindikasi tindak penipuan dan 70 data SMS yang tidak berindikasi tindak penipuan. Berikut ini dapat dilihat contoh data SMS yang digunakan pada penelitian ini.
Tolong belikan Mama dlu pulsa Rp 50 di No,nya Mama yng baru ini No,nya 081313779293 MAMA mau pkai Nelpon pnting.! ini No,nya orng MAMA pakai Praproses
Tahap praproses dilakukan terhadap 140 data tersebut dan dilakukan penghitungan jumlah token yang diperoleh pada setiap subtahap. Jumlah token sebagai hasil yang diperoleh dari tahap praproses dapat dilihat pada Tabel 2. Pada subtahap filtering dan stemming, jumlah token yang dihasilkan lebih sedikit disbanding jumlah token dari subtahap sebelumnya. Hal ini disebabkan adanya penghapusan token pada subtahap filtering dan stemming. Sedangkan pada subtahap word approximation, jumlah token yang dihasilkan sama dengan jumlah token dari subtahap sebelumnya yaitu stemming. Jumlah token pada subtahap
word approximatioin tidak berubah karena pada subtahap ini hanya dilakukan perbaikan token dan tidak dilakukan penghapusan token.
Tabel 3 Hasil Tahapan Praproses
Tahap Jumlah Token yang Diperoleh
Tokenizing 2949
Filtering 2662
Stemming 2406
Word Approximation 2406
28
kata yang sama, dimana token dengan kata sama tetapi terdapat pada instance sms yang berbeda akan dihitung lebih dari satu kali. Sedangkan jumlah token unik, yaitu jika kemunculan setiap token hanya dihitung satu kali adalah 266 token. Jumlah token unik inilah yang digunakan dalam tahap selanjutnya.
Pembentukan Klaster Data SMS dan Pemilihan Klaster Terbaik
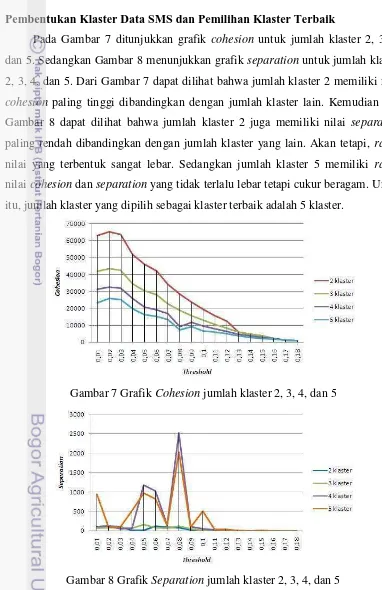
Pada Gambar 7 ditunjukkan grafik cohesion untuk jumlah klaster 2, 3, 4, dan 5. Sedangkan Gambar 8 menunjukkan grafik separation untuk jumlah klaster 2, 3, 4, dan 5. Dari Gambar 7 dapat dilihat bahwa jumlah klaster 2 memiliki nilai
cohesion paling tinggi dibandingkan dengan jumlah klaster lain. Kemudian dari Gambar 8 dapat dilihat bahwa jumlah klaster 2 juga memiliki nilai separation
paling rendah dibandingkan dengan jumlah klaster yang lain. Akan tetapi, range
nilai yang terbentuk sangat lebar. Sedangkan jumlah klaster 5 memiliki range
nilai cohesion dan separation yang tidak terlalu lebar tetapi cukur beragam. Untuk itu, jumlah klaster yang dipilih sebagai klaster terbaik adalah 5 klaster.
Gambar 7 Grafik Cohesion jumlah klaster 2, 3, 4, dan 5
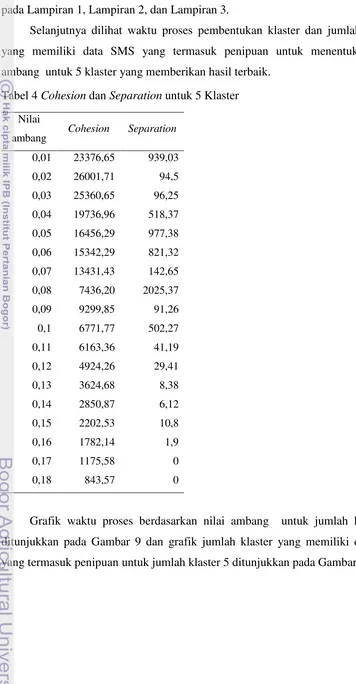
29 Nilai cohesion dan separation untuk 5 klaster ditunjukkan pada Tabel 3. Untuk nilai cohesion dan separation untuk jumlah klaster 2, 3, dan 4 ditunjukkan pada Lampiran 1, Lampiran 2, dan Lampiran 3.
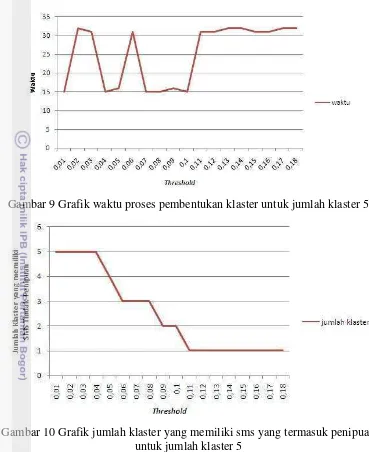
Selanjutnya dilihat waktu proses pembentukan klaster dan jumlah klaster yang memiliki data SMS yang termasuk penipuan untuk menentukan nilai ambang untuk 5 klaster yang memberikan hasil terbaik.
Tabel 4 Cohesion dan Separation untuk 5 Klaster
Nilai
ambang Cohesion Separation
30
Gambar 9 Grafik waktu proses pembentukan klaster untuk jumlah klaster 5
Gambar 10 Grafik jumlah klaster yang memiliki sms yang termasuk penipuan untuk jumlah klaster 5
Jika melihat dari nilai cohesion, separation, waktu proses, dan jumlah klaster yang memiliki data sms yang termasuk penipuan untuk jumlah klaster 5, makanilai ambang yang dipilih adalah 0,08. Dimana klaster yang terbentuk dari jumlah klaster 5 dan nilai ambang 0,08 memiliki nilai cohesion sebesar 7436,2 , nilai separation sebesar 2025,37 , waktu proses 15 ms, dan jumlah klaster yang memiliki data sms yang termasuk penipuan adalah 3 klaster. Maka klaster yang terbentuk dari kombinasi jumlah klaster 5 dengan nilai ambang 0,08 dipilih sebagai klaster terbaik yang akan digunakan dalam pemberian label kelas pada
dataset. Label kelas yang digunakan adalah C1, C2, C3, C4, dan C5. Klaster yang
31 klaster 5 dengan nilai ambang 0,08 ditunjukkan pada Lampiran 4.
Tabel 5 Klaster Hasil dari Jumlah Klaster= 5 dan Nilai ambang= 0,08
Kelas Anggota
Karakteristik dari setiap klaster adalah sebagai berikut :
1. Token unik yang dimiliki anggota klaster 1 adalah nomor, baru, papa, tolong kirim, pulsa, nominalpulsa, nomortelp, lagi, kantor, polisi, ada, masalah, jangan, telepon
32
cara, daftar, kota, bisnis, master, jam, murah, mudah, bagai, daerah, untung, bagi, format, krim, sentra, selamat, salam, sukses, jalan, kamu, berangkat, menit, abis, alhamdulillah, baik, apa, tinggal, dimana, tadi, kapan, sana, kuliah, bulan, libur, bayang, materi, harus, selesai, mepet, kenapa, kaget, bilang, siapa, tau, lebih, tangguh, daripada, jarang, laptop, sama, modem, buka, kok, sampai, amplop, coklat, baju, hijau, gelang, tengah, isolasi, kali, makan, baca, buku, komunikasi, kontak, fisik, minum, dan kopi.
3. Token unik yang dimiliki anggota klaster 3 adalah kita, nanti, lama, aku, anti, temu, tidak, kabar, alhamdulillah, baik, apa, tinggal, dan ketemu.
4. Token unik yang dimiliki anggota klaster 4 adalah nomor, baru, tolong, pulsa, nominalpulsa, nomortelp, lagi, ada, masalah, jangan, mama, isi, kena, sekarang, rumah, saudara, pak, ya, yang, beli, nanti, ganti, soal, cuma, ikut, mah, bapak, as, saat, jadi, saya, aku, hubung, uang, kami, besok, anti, kasih, maaf, ribu, ibu, hari, sudah, harga, suami, terimakasih, karena, liat, minat, bu, mobil, kemarin, tidak, bandara, kabar, endang, ingin, bicara, bisa, masuk, mungkin, langsung, saja, gunawan, iklan, aja, silah, biro, ratna, arif, terima, cari, cara, guna, jalan, kamu, abis, baik, apa, dimana, hampir, habis, masih, macet, banget, tadi, kapan, pulang, masak, ayam, sore, kuliah, bulan, libur, bayang, materi, harus, selesai, mepet, kenapa, kaget, bilang, siapa, tau, lebih, tangguh, daripada, jarang, laptop, sama, modem, bawa, tidur, nih, buka, pintu, berisik, dong, kok, sampai, hormat, pesan, beritahu, bahwa, gerangan, acap, dan kali.
5. Token unik yang dimiliki anggota klaster 5 adalah ada, isi, pak, ya, saat, saya, lihat, mobil, ingin, bisa, langsung, apa, tarik, kijang, tadi, pagi, kondisi, apakah, siang, dan datang.
Dari karakteristik setiap klaster di atas dapat diketahui bahwa anggota klaster C1, C2, dan C4 lebih banyak memiliki token unik dari SMS berindikasi
penipuan. Sedangkan anggota klaster C3, dan C5 lebih banyak memiliki token
33 Pembentukan Model Klasifikasi
Hasil yang diperoleh dari proses pelatihan data menggunakan algoritma Naive Bayes adalah class prior probability dan conditional probability untuk setiap token. Pada Tabel 5 ditunjukkan class prior probability untuk setiap kelas. Tabel 6 Class prior probability
ditunjukkan conditional probability untuk 5 token sebagai contoh dari conditional probability.
Tabel 7 Conditional probability untuk 5 token
Token C1 C2 C3 C4 C5
Nilai conditional probability untuk setiap token diperoleh dari kemunculan token tersebut pada setiap instance dengan kelas tertentu. Nilai class prior probability dan conditional probability merupakan model klasifikasi yang akan digunakan dalam klasifikasi suatu sms baru yang masuk ke dalam perangkat seluler.
Evaluasi model klasifikasi dilakukan menggunakan tabel confusion matrix
34
Tabel 8 Confusion matrix dari model klasifikasi untuk 140 data
C1 C2 C3 C4 C5 Akurasi akhir yang diperoleh untuk model klasifikasi yang terbentuk adalah 80,93%, yang merupakan akurasi rata-rata bergerak dari 20 perulangan.
Tabel 9 Akurasi dari 20 Perulangan
35 Implementasi Model Klasifikasi ke Perangkat Seluler
Dalam pengembangan aplikasi perangkat seluler yang mengimplementasi model klasifikasi digunakan kerangka spesifik UML. Diagram UML yang digunakan adalah use case diagram dan sequence diagram. Daftar use case pada aplikasi fraud detection dapat dilihat pada Tabel 8.
Tabel 10 Daftar Use Case pada Aplikasi Fraud Detection
Nama Use Case Deskripsi Use Case Pelaku
Mendapatkan Pemberitahuan
Memindahkan SMS ke Inbox Memindahkan SMS yang terdapat
di daftar SMS penipuan ke inbox
Pengguna
Menambahkan nomor telepon ke
dalam daftar whitelist, yaitu daftar
nomor telepon yang diijinkan
untuk melewati aplikasi fraud
detection
Menambahkan nomor telepon ke
dalam daftar blacklist, yaitu daftar
nomor telepon yang langsung
36
Gambar 11 Use Case Aplikasi Fraud Detection
Pengguna aplikasi fraud detection memiliki sequence diagram untuk masing-masing use case pada aplikasi fraud detection yang dapat dilihat di bawah ini :
1. Mendapatkan Pemberitahuan SMS Penipuan
Sequence diagram untuk Mendapatkan Pemberitahuan SMS Penipuan dapat dilihat pada Gambar 12. Dari Gambar 12 dapat dilihat rangkaian interaksi ketika pengguna mendapatkan pemberitahuan SMS penipuan. Ketika sebuah SMS baru masuk ke dalam perangkat seluler pengguna, aplikasi fraud detection akan melakukan klasifikasi terhadap sms tersebut. Jika SMS tersebut diklasifikasikan sebagai SMS penipuan, maka pengguna akan mendapatkan pemberitahuan di layar perangkat selulernya.
37 2. Memindahkan SMS ke inbox
Sequence diagram untuk Memindahkan SMS ke inbox dapat dilihat pada Gambar 13. Untuk memindahkan SMS ke inbox, pengguna harus membuka aplikasi fraud detection dan membuka tab logs yang akan menampilkan daftar SMS penipuan. Kemudian pengguna memilih salah satu SMS dan memilih pilihan move to inbox. Setelah itu aplikasi akan menampilkan daftar SMS penipuan yang telah diperbarui, dimana SMS yang telah dipilih tadi sudah tidak ada di dalam daftar SMS penipuan.
Gambar 13 Sequence diagram untuk Memindahkan SMS ke inbox
3. Menghapus SMS dari Daftar SMS Penipuan
38
Gambar 14 Sequence diagram untuk Menghapus SMS dari Daftar SMS Penipuan 4. Menambahkan Nomor Telepon ke Daftar Whitelist
Sequence diagram untuk Menambahkan Nomor Telepon ke Daftar Whitelist
dapat dilihat pada Gambar 15. Untuk menambahkan nomor telepon ke daftar
whitelist, pengguna membuka aplikasi fraud detection dan membuka tab
allow. Kemudian pengguna memilih add number dan memasukkan nomor telepon yang ingin ditambahkan. Setelah itu aplikasi akan menampilkan daftar nomor telepon whitelist yang telah diperbarui, dimana terdapat nomor telepon yang telah ditambahkan tersebut.
Gambar 15 Sequence diagram untuk Menambahkan Nomor Telepon ke Daftar
39 5. Menghapus Nomor Telepon di Daftar Whitelist
Sequence diagram untuk Menghapus Nomor Telepon di Daftar Whitelist
dapat dilihat pada Gambar 16. Untuk menghapus nomor telepon di daftar
whitelist, pengguna membuka aplikasi fraud detection dan membuka tab
allow. Kemudian pengguna memilih nomor telepon yang ingin dihapus dan memilih delete. Setelah itu aplikasi akan menampilkan daftar nomor telepon
whitelist yang telah diperbarui, dimana tidak terdapat nomor telepon yang telah dihapus tersebut.
Gambar 16 Sequence diagram untuk Menghapus Nomor Telepon di Daftar
Whitelist
6. Menambahkan Nomor Telepon ke Daftar Blacklist
Sequence diagram untuk Menambahkan Nomor Telepon ke Daftar Blacklist
40
Gambar 17 Sequence diagram untuk Menambahkan Nomor Telepon ke Daftar
Blacklist
7. Menghapus Nomor Telepon di Daftar Blacklist
Sequence diagram untuk Menghapus Nomor Telepon di Daftar Blacklist
dapat dilihat pada Gambar 18. Untuk menghapus nomor telepon di daftar
blacklist, pengguna membuka aplikasi fraud detection dan membuka tab
block. Kemudian pengguna memilih nomor telepon yang ingin dihapus dan memilih delete. Setelah itu aplikasi akan menampilkan daftar nomor telepon
blacklist yang telah diperbarui, dimana tidak terdapat nomor telepon yang telah dihapus tersebut.
Gambar 18 Sequence diagram untuk Menghapus Nomor Telepon di Daftar
Contoh tampila
ambar 20 Proses Klasifikasi Data SMS Baru baru yang masuk ke perangkat seluler akan aplikasi yang dibuat. Tahap awal yang di . Hasil dari praproses akan digunakan dalam pr kan data class prior probability dan conditional
am basis data SQLite. Pada proses klasifika tungan posterior probability untuk setia amaan 5. Klasifikasi dilakukan berdasarkan m
42
BAB V
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang telah dilakukan, diperoleh simpulan sebagai berikut :
1. Algoritma ROCK dapat digunakan untuk mengelompokkan data SMS. Jumlah klaster 5 dengan nilai ambang 0.08 merupakan klaster terbaik. 2. Pembentukan model klasifikasi berhasil dilakukan dengan akurasi sebesar
80,93%.
3. Implementasi model klasifikasi pada perangkat seluler berbasis Android dengan modul yang dimiliki daftar SMS yang termasuk indikasi penipuan, nomor telepon yang termasuk blacklist, dan nomor telepon yang termasuk
whitelist.
Saran
DAFTAR PUSTAKA
Angkawattanawit N., Haruechaiyasak C., Marukatat S. 2008. Thai Q-Cor:
Integrating Word Approximation and Soundex for Thai Query Correcction.
In Proceeding of ECTI-CON.
Bodic G.L. 2005. Mobile Messaging Technologies and Services SMS, EMS and
MMS. Wiley.
Cormack G.V., Hidalgo J.M.G., Sánz E.P. 2007. Spam Filtering for Short Messages. In Proceedings of the sixteenth ACM conference onConference on information and knowledge management.
Cormack G., Hidalgo J.M.G., Sánz E.P. 2007. Feature Engineering for Mobile
(SMS) Spam Filtering. In 30th ACM SIGIR Conference on Research and Development on Information Retrieval.
Deng W.W., Peng H. 2006. Research on A Naive Bayesian Based Short Message Filtering System, In Proceeding of the Fifth International Conference on Machine Learning and Cybernetics.
Eclipse. 2010. Eclipse IDE for Java Developers [internet], [Diacu 11 Februari 2012], Tersedia dari: http://www.eclipse.org/downloads/packages/eclipse-ide-java-developers/heliossr2.
Feldman R., Sanger J. 2007. The Text Mining Handbook : Advances Approaches in Analyzing Unstructures Data. Cambridge University Press.
Google. 2012. Android the world's most popular seluler platform [internet],
[Diacu 10 Agustus 2012], Tersedia dari:
http://www.developer.android.com/sdk/index.html.
Guha S., Rastogi R., Shim K. 2000. ROCK: A Robust Clustering Algorithm for Categorical Attributes. In Proc.ofthe15thInt.Conf.onDataEngineering. Han J., Kamber M. 2011. Data Mining Concepts and Techniques, Third Edition.
46
Hidalgo J.M.G., Bringas G.C., Sánz E.P. 2006. Content Based SMS Spam Filtering, In Proceedings of the 2006 ACM symposium on Document engineering.
Hipp D.R., Kennedy D., Mistackhin J. 2010. About SQLite [internet], [Diacu 10 Agustus 2012], Tersedia dari: http://www.sqlite.org/about.html.
Huang A. 2008. Similarity Measures for Text Document Clustering, In New Zealand Computer Science Research Student Conference.
Khemapatapan C. 2010. Thai-English Spam SMS Filtering, In Proceeding Asia-Pacific Conf. Communications (APCC) 16: 226-230.
Meier R. 2009. Professional Android 2 Application Development, Indianapolis: Wiley Publishing, Inc.
Navarro G. 2001. A Guided Tour to Approximate String Matching. In ACM Computing Surveys 33: 1.
Sebastiani F. 2002. Machine Learning in Automated Text Categorization, In ACM Computing Surveys 34: 1.
Tan P.N., Steinbach M., Kumar V. 2005. Introduction to Data Mining, Boston : Pearson Education, Inc.
Weiss S.M., Indurkhya N., Zhang T., Damerau F.J. 2005. Text Mining : Predictive Methods for Analyzing Unstructured Information, Springer.
Witten I.H., Frank E., Hall M.A. 2011. Data Mining: Practical Machine Learning Tools and Techniques, Third Edition. Morgan Kaufman Publishers.
49 Lampiran 1 Cohesion dan Separation untuk 2 Klaster
Nilai
ambang Cohesion Separation
50
Lampiran 2 Cohesion dan Separation untuk 3 Klaster
Nilai
ambang Cohesion Separation
51 Lampiran 3 Cohesion dan Separation untuk 4 Klaster
Nilai
ambang Cohesion Separation
52
ii
ABSTRACT
PRITASARI PALUPININGSIH. A Classification Modelling for Fraud SMS Identification using Text Mining. Supervised by TAUFIK DJATNA and HARI AGUNG ADRIANTO.
Nowadays the presence of fraudulence based on SMS is increasing in the
society. Those SMS use unsuspicious sentences, so people could be misled. We
propose a classification model which indicates the presence of fraud and use the
pattern to predict the new SMS. This research use ROCK algorithm to cluster
data and Naive Bayes algorithm to build classifier. Moreover, semantic word
correction technique was applied. SMS which have indication of fraud, used in
this research are SMS containing request of handphone voucher to certain phone
number, offering to be voucher agent, and interest in the activities of buying and
selling land. 5 cluster with threshold 0.08 are resulted from clustering phase and
result from training data phase is classifier with accuracy 80,93%. Finally, the classifier are successfully implemented on the Android phone.
RINGKASAN
PRITASARI PALUPININGSIH. Pemodelan Klasifikasi SMS Berindikasi Tindak Penipuan Menggunakan Text Mining. Dibimbing oleh TAUFIK DJATNA dan HARI AGUNG ADRIANTO.
Saat ini, tindak penipuan melalui SMS semakin marak terjadi. Terkadang, kalimat yang digunakan untuk tindak penipuan tidak menimbulkan kecurigaan bagi penerima SMS. Akan tetapi, ketika SMS tersebut ditindak lanjuti, ternyata SMS itu mengarah ke tindak penipuan. Tahapan ini membutuhkan penyaringan SMS dalam bahasa Indonesia secara real time yang dapat mengenali SMS yang memiliki indikasi tindak penipuan.
Pada penelitian ini terdapat tiga tujuan utama. Tujuan 1 adalah membentuk klaster terhadap data SMS berbasis algoritma ROCK dan memilih ukuran jumlah klaster dan nilai ambang yang memberikan klaster terbaik. Tujuan 2 adalah membentuk sebuah model klasifikasi berbasis algoritma Naive Bayes dengan menggunakan fitur kata yang ada dalam SMS. Tujuan 3 adalah mengimplementasikan model klasifikasi ke perangkat seluler berbasis Android.
Pembentukan klaster menggunakan algoritma ROCK dilakukan berulang dengan mengubah masukan ukuran jumlah klaster dan nilai ambang. Jumlah klaster yang digunakan adalah 2, 3, 4, dan 5. Nilai ambang yang digunakan adalah 0,01 sampai 0,18. Selain itu juga digunakan teknik word approximation yang digunakan untuk melakukan perbaikan kata yang disingkat atau salah ketik. Hasil yang diperoleh dari proses ini adalah klaster dengan ukuran 5 dan nilai ambang 0,08 merupakan klaster terbaik.
Klaster dengan ukuran 5 dan nilai ambang 0,08 digunakan untuk memberi label pada data SMS. Data SMS yang telah memiliki label digunakan pada pembentukan model klasifikasi dengan menggunakan Naïve Bayes. Akurasi yang diperoleh dari model yang terbentuk adalah 80,93%.
Implementasi model klasifikasi telah dilakukan pada perangkat seluler berbasis Android dengan modul yang dimiliki daftar SMS yang termasuk indikasi penipuan, nomor telepon yang termasuk blacklist, dan nomor telepon yang termasuk whitelist.
9 BAB 1
PENDAHULUAN
Latar Belakang
Short Message Service (SMS) merupakan salah satu media komunikasi yang banyak digunakan saat ini karena praktis untuk digunakan dan biaya pengirimannya murah. Namun, seiring dengan semakin populernya penggunaan SMS, muncul tindakan menggunakan layanan SMS untuk tujuan yang tidak tepat. SMS dengan tujuan malfungsi ini biasanya disebut SMS spam. Contoh dari SMS
spam adalah SMS yang digunakan sebagai media iklan, SMS yang berisi pesan porno, SMS dengan tujuan menipu dan sebagainya. SMS seperti ini cenderung mengganggu penerima SMS. Bahkan SMS dengan tujuan menipu dapat merugikan orang yang menerima SMS tersebut. Saat ini, tindak penipuan melalui SMS semakin marak terjadi. Dengan menggunakan SMS sebagai media tindak penipuan, keberadaan penipu akan sulit untuk dilacak. Ada beberapa macam tindak penipuan yang dilakukan melalui SMS. Salah satu tindak penipuan yang saat ini marak terjadi di masyarakat adalah SMS yang berisi permintaan pulsa telepon seluler ke nomor tertentu, dengan mengatasnamakan keluarga. Terkadang, kalimat yang digunakan untuk tindak penipuan tidak menimbulkan kecurigaan bagi penerima SMS. Akan tetapi, ketika SMS tersebut ditindak lanjuti, ternyata SMS itu mengarah ke tindak penipuan. Oleh karena itu, dibutuhkan penyaringan SMS yang memiliki indikasi tindak penipuan.