PEMBUATAN
RESULT SNIPPET
PADA MESIN PENCARI
BERBAHASA INDONESIA DENGAN MENGGUNAKAN
PSEUDO-RELEVANCE FEEDBACK
MUHAMMAD GINANJAR RAMADHAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pembuatan Result Snippet pada Mesin Pencari Berbahasa Indonesia dengan Menggunakan Pseudo-Relevance Feedback adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
MUHAMMAD GINANJAR RAMADHAN. Pembuatan Result Snippet pada Mesin Pencari Berbahasa Indonesia dengan Menggunakan Pseudo-Relevance Feedback. Dibimbing oleh SONY HARTONO WIJAYA.
Snippet atau penggalan dokumen merupakan kutipan ringkas dari sebuah dokumen pada hasil pencarian yang menjelaskan keberadaan kata kunci yang dimasukkan oleh pengguna pada mesin pencari. Snippet yang dihasilkan oleh sebuah mesin pencari harus dapat memberikan informasi yang cukup agar pengguna dapat memutuskan apakah sebuah dokumen relevan atau tidak dengan kebutuhan informasi yang dimilikinya. Penelitian ini mengimplementasikan teknik pseudo-relevance feedback untuk pemilihan kalimat yang akan ditampilkan sebagai sebuah snippet serta menguji akurasi dari snippet yang dihasilkan oleh sistem. Penerapan pseudo-relevance feedback dalam pembuatan snippet ini memberikan akurasi 90.71% dari dokumen-dokumen yang dianggap relevan. Kata kunci: hasil pencarian, kebutuhan informasi, mesin pencari, relevansi, snippet
ABSTRACT
MUHAMMAD GINANJAR RAMADHAN. Result Snippet Generation on Bahasa Indonesia Search Engine with Pseudo-Relevance Feedback. Supervised by SONY HARTONO WIJAYA.
A search result snippet is a quick excerpt from a document retrieved by a retrieval system (search engine) that explains the existence of the keywords entered by a user. Snippets generated by a search engine must be able to provide enough information so that a user can make decision on whether or not a document is relevant based on his/her information needs. This study implements pseudo-relevance feedback techniques for selecting the sentences to be displayed as a snippet and evaluates the accuracy of the snippet generated by the system. Application of pseudo-relevance feedback in this study resulted in an accuracy of 90.71% from the documents that are considered relevant.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
PEMBUATAN
RESULT SNIPPET
PADA MESIN PENCARI
BERBAHASA INDONESIA DENGAN MENGGUNAKAN
PSEUDO-RELEVANCE FEEDBACK
MUHAMMAD GINANJAR RAMADHAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Pembuatan Result Snippet pada Mesin Pencari Berbahasa Indonesia dengan Menggunakan Pseudo-Relevance Feedback
Nama : Muhammad Ginanjar Ramadhan NIM : G64090130
Disetujui oleh
Sony Hartono Wijaya, SKom MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Desember 2012 ini ialah metode pemilihan kalimat snippet pada sistem pencarian berbasis web, dengan judul Pembuatan Result Snippet pada Mesin Pencari Berbahasa Indonesia dengan Menggunakan Pseudo-Relevance Feedback.
Terima kasih penulis ucapkan kepada Bapak Sony Hartono Wijaya selaku pembimbing dan Bapak Agus Buono selaku pimpinan Departemen Ilmu Komputer yang telah membantu selama penyelesaian dan penulisan tugas akhir. Ungkapan terima kasih juga penulis sampaikan kepada orang tua tercinta, Bapak Ahmad Sulaeman dan Ibu Leni Hasnawati, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Tidak lupa pula, terima kasih penulis untuk teman-teman atas bantuan dan semangatnya, khususnya untuk Sapariansyah, Rahmad Syaifullah Gusman, Galih Kenang Avianto, Abdullah Adzkiy Robbani, Rudi Hartomo, Nadiul Haq, dan Muhammad Muhajir Amini yang telah bersedia menjadi penguji sistem yang telah dibuat. Juga kepada Ozi Priawadi, Yuzar Marsyah, Andre Fadila Mulyanto, dan Sapariansyah, teman-teman satu bimbingan.
Terakhir, penulis ucapkan terima kasih kepada Bapak Julio Adisantoso dan Bapak Aziz Kustiyo selaku penguji serta seluruh staf Departemen Ilmu Komputer yang telah melancarkan perjalanan penulis dalam menempuh studi sampai akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat kekurangan dan kelemahan dalam berbagai sisi yang penyebabnya tiada lain adalah keterbatasan kemampuan penulis. Penulis mengharapkan adanya saran ataupun kritik yang bersifat membangun dari pembaca demi kesempurnaan tulisan ini.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Pembobotan Kata Benda dan Pembuatan Kueri Baru 4
Pemeringkatan Kalimat dan Pembuatan Snippet 5
Evaluasi Kualitas Snippet 6
HASIL DAN PEMBAHASAN 6
Pembuatan dan Konfigurasi Mesin Pencari 6
Akuisisi Korpus dan Indeksasi 7
Penerapan POS Tagger pada Dokumen 8
Ekstraksi Kalimat pada Dokumen 9
Ekstraksi Kata Benda pada Dokumen 10
Pemisahan Kalimat Relevan dan Non-Relevan 11
Ekstraksi Kata Benda dari Kalimat Relevan 11
Pembobotan Kata Benda 11
Pembuatan Kueri Baru 13
Perhitungan Salience Score Kalimat 13
Visualisasi Snippet 14
Evaluasi Snippet 15
SIMPULAN DAN SARAN 17
Simpulan 17
Saran 17
LAMPIRAN 19
DAFTAR TABEL
1 Hasil pembobotan untuk kata benda t yang diurutkan berdasarkan TSV 12 2 Hasil pembobotan untuk kata benda t yang diurutkan berdasarkan n 12 3 Hasil pemeringkatan kalimat yang diurutkan berdasarkan RWScore(Si) 13 4 Hasil pemeringkatan kalimat yang diurutkan berdasarkan score(Si) 14
DAFTAR GAMBAR
1 Bagan alur pembuatan sistem 3
2 Konfigurasi sumber data pada Sphinx 6
3 Konfigurasi SphinxClient 7
4 Definisi bagian dokumen yang diindeks oleh Sphinx 7
5 Penerapan POS tagger pada judul dokumen 8
6 Penerapan POS tagger pada isi dokumen 8
7 Kesalahan dalam pemberian tag 9
8 Kegagalan dalam pemisahan kalimat 9
9 Hasil ekstraksi kata benda pada korpus 10
10 Kalimat relevan untuk kueri 'tanaman obat' 11
11 Kata benda dari kalimat-kalimat relevan 11
12 Visualisasi snippet dengan kata kueri 'tanaman obat' berada dalam satu
kalimat 15
13 Visualisasi snippet dengan kata kueri 'tanaman obat' berada dalam
kalimat terpisah 15
14 Pengaruh nilai k terhadap akurasi snippet 16
15 Pengaruh nilai α terhadap akurasi snippet 17
DAFTAR LAMPIRAN
1 Konfigurasi mesin pencari Sphinx 20
2 Contoh dokumen XML dalam koleksi pengujian 22
3 Tagset pada IPOSTagger v1.1 (Wicaksono dan Purwarianti 2010) 24
4 Contoh hasil ekstraksi kalimat pada korpus 25
5 Contoh hasil ekstraksi kata benda pada korpus 27
6 Contoh hasil pembobotan kata benda (TSV) 28
7 Contoh hasil pemeringkatan kalimat 30
8 Contoh hasil pengujian snippet30 kueri untuk nilai α = 0.4 dan k = 7 31
9 Pengaruh nilai α dan k terhadap akurasi snippet (dalam persen) 32
PENDAHULUAN
Latar Belakang
Penggalan isi dokumen, atau snippet, merupakan fitur penting yang harus ada pada sebuah mesin pencari, khususnya yang berhubungan dengan pencarian dokumen, agar proses pencarian menjadi lebih efektif dan lebih efisien. Snippet merupakan kutipan ringkas pada hasil pencarian yang menunjukkan keberadaan kueri pada sebuah dokumen. Snippet bersifat ringkas dan informatif dan pada umumnya terletak di bawah setiap judul dokumen pada halaman hasil pencarian. Keberadaan snippet pada hasil pencarian membantu pengguna dalam memutuskan relevansi dokumen dengan kebutuhan informasinya tanpa harus membuka dan membacanya terlebih dahulu.
Snippet merupakan salah satu bentuk implementasi peringkasan teks. Ringkasan dapat berupa generic summary, yang memberikan gambaran umum isi sebuah dokumen, atau query-relevant summary, yang menerangkan isi yang paling berhubungan dengan kueri pencarian (Goldstein et al. 1999). Snippet merupakan ringkasan bias kueri (query-biased summary) pada sebuah mesin pencari yang menunjukkan kata kueri mana saja yang muncul dalam sebuah dokumen beserta kata-kata di sekitar kata kueri tersebut (McDonald dan Chen 2006). Karena snippet hanya mengambil potongan-potongan kalimat yang kemudian digabungkan tanpa memperhatikan aturan semantik, maka snippet termasuk ringkasan yang bersifat ekstraktif. Kalimat-kalimat yang dipilih untuk dijadikan snippet berdasarkan ada atau tidaknya kata kueri pada kalimat.
Snippet selalu diupayakan agar tetap ringkas namun memiliki kualitas informasi yang baik. Hal ini agar perhatian pengguna tidak terganggu dan keputusan terhadap relevansi dokumen dapat diberikan dengan cepat. Karena snippet menempati ruang yang sangat terbatas, reduksi informasi menjadi semakin besar seiring dokumen yang semakin besar pula. Oleh karena itu, pemilihan kalimat snippet serta visualisasinya perlu dipertimbangkan dengan baik agar snippet yang dihasilkan tetap informatif. Upaya untuk memilih kalimat yang terbaik diantaranya melalui pembuatan kueri baru dengan cara mengekspansi kueri awal.
Pseudo-relevance feedback merupakan salah satu fitur dalam sistem temu kembali informasi (retrieval systems) yang berupaya untuk memperbaiki kueri awal dan memprosesnya tanpa memerlukan intervensi pengguna. Teknik ini dapat diterapkan pada pemeringkatan dokumen, kalimat, maupun gambar. Pseudo-relevance feedback bekerja dengan mengambil beberapa hasil dari pemrosesan kueri awal dan memanfaatkan informasi yang terdapat pada hasil tersebut untuk membuat kueri baru. Dengan diprosesnya kueri baru tersebut, diharapkan hasil-hasil yang menempati peringkat teratas merupakan hasil-hasil yang paling relevan dengan kebutuhan informasi pengguna. Pada peringkasan dokumen, pseudo-relevance feedback diterapkan dalam pemeringkatan dan pemilihan kalimat ringkasan.
pseudo-2
relevance feedback, PRF), kalimat judul, dan kalimat pertama dari dokumen. Penelitian tersebut diimplementasikan ke dalam sebuah web snippet oleh Ko et al. (2008). Hasil yang diperoleh mampu meningkatkan kualitas snippet yang dihasilkan oleh mesin pencari Google dan Naver dengan akurasi paling besar 68.75% (Ko et al. 2008). Penelitian ini berusaha untuk mengimplementasikan pseudo-relevance feedback melalui teknik-teknik yang digagas oleh penelitian Ko et al. (2008) ke dalam sebuah mesin pencari dengan tujuan mengevaluasi kembali sejauh mana metode tersebut dapat memberikan kualitas snippet yang baik, khususnya untuk dokumen-dokumen berbahasa Indonesia.
Perumusan Masalah
Rumusan masalah yang digunakan dalam penelitian ini adalah: 1 Bagaimana ukuran kualitas dari sebuah snippet?
2 Sejauh mana pseudo-relevance feedback mampu meningkatkan akurasi dari snippet yang dibuat?
3 Apakah sistem penghasil snippet yang dibangun dapat memberikan akurasi yang lebih baik untuk dokumen berbahasa Indonesia?
4 Hal apa saja yang dapat mempengaruhi pemilihan kalimat snippet?
Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun dan mengevaluasi sistem penghasil snippet yang diintegrasikan ke dalam sebuah mesin pencari berbasis web dengan menerapkan pseudo-relevance feedback.
Manfaat Penelitian
Penelitian ini diharapkan mampu:
1 Memudahkan pengguna dalam menilai dokumen secara intuitif.
2 Memudahkan pengguna dalam mengambil keputusan relevansi terhadap dokumen hasil pencarian.
3 Meningkatkan efisiensi dan efektivitas dalam melakukan proses pencarian.
Ruang Lingkup Penelitian
Batasan-batasan dalam penelitian ini adalah:
1 Menggunakan korpus berbahasa Indonesia dengan tema 'pertanian'.
2 Menggunakan IPOSTagger v1.1 berbasis JAVA khusus untuk dokumen berbahasa Indonesia.
3 Menggunakan sphinx-2.0.7-id64-release (r3759) dan PHP 5.4.7.
3
METODE
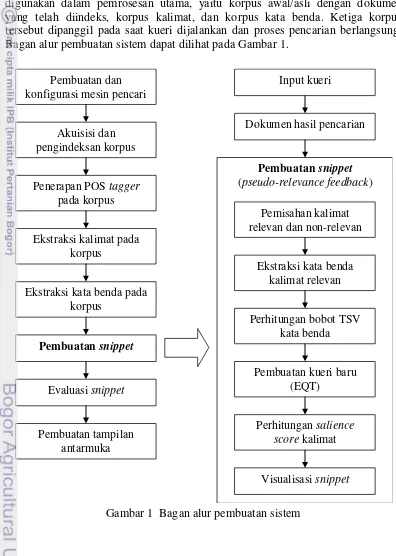
Penelitian mengenai pseudo-relevance feedback bagi sistem penghasil snippet diawali dengan pembuatan dan konfigurasi mesin pencari yang kemudian diikuti oleh pengindeksan korpus. POS tagger lalu diterapkan secara terpisah pada korpus untuk memecah dokumen menjadi kalimat-kalimat tunggal dan untuk mengekstraksi kata benda dari setiap kalimat tersebut. Terdapat tiga korpus yang digunakan dalam pemrosesan utama, yaitu korpus awal/asli dengan dokumen yang telah diindeks, korpus kalimat, dan korpus kata benda. Ketiga korpus tersebut dipanggil pada saat kueri dijalankan dan proses pencarian berlangsung. Bagan alur pembuatan sistem dapat dilihat pada Gambar 1.
4
Mesin pencari menerima input kueri dari pengguna lalu memprosesnya dan mengeluarkan dokumen-dokumen hasil pencarian. Setiap halaman dari hasil pencarian terdiri atas maksimum sepuluh dokumen. Snippet dibuat untuk setiap dokumen pada halaman hasil pencarian yang aktif dan dibuat setiap kali pengguna berganti halaman.
Ide utama dari pseudo-relevance feedback adalah mengambil sejumlah hasil yang diperoleh dari kueri awal dan memanfaatkan informasi yang terdapat pada hasil tersebut untuk membuat kueri baru. Untuk menerapkan pseudo-relevance feedback ke dalam pembuatan snippet, kalimat-kalimat yang relevan dengan kueri awal harus dapat diekstraksi secara otomatis. Untuk setiap dokumen hasil pencarian, kalimat-kalimat dipisah antara kalimat relevan dan kalimat non-relevan berdasarkan ada atau tidaknya kata kueri awal pada kalimat. Kata benda dari semua kalimat relevan dalam dokumen lalu diekstraksi dan diterapkan fungsi pembobotan. Diantara kata benda yang diberi bobot termasuk pula kata kueri awal. Kueri awal lalu diekspansi dengan mengambil sejumlah k kata dengan bobot tertinggi. Kata-kata yang digunakan untuk mengekspansi kueri awal disebut expanded query term (EQT).
Fungsi pemeringkatan diterapkan pada semua kalimat dalam dokumen untuk menentukan kalimat yang dianggap paling penting untuk dijadikan snippet. Peringkat kalimat ditentukan berdasarkan posisi kalimat dalam dokumen dan nilai relevansi kalimat. Nilai kepentingan kalimat yang didapat dari hasil pemeringkatan dikalikan dengan bobot bernilai 1 untuk kalimat relevan dan bobot bernilai 0 untuk kalimat non-relevan. Bobot tersebut digunakan untuk mengeliminasi kalimat-kalimat non-relevan karena bukan kalimat yang ingin dijadikan snippet. Sejumlah m kalimat dengan peringkat teratas diambil, disesuaikan panjangnya, dan digabungkan menjadi sebuah snippet yang ditampilkan di bawah judul dokumen pada halaman hasil pencarian. Terakhir, evaluasi dilakukan dengan mengukur tingkat akurasi snippet yang dihasilkan oleh sistem.
Pembobotan Kata Benda dan Pembuatan Kueri Baru
Semua kata benda diekstraksi dari setiap kalimat relevan dan dijadikan kandidat untuk pembuatan kueri baru. Setiap kata benda diberikan bobot relevansi yang disebut term selection value (TSV) menggunakan Persamaan 1 dengan melihat sebaran kata tersebut pada kalimat relevan dan kalimat non-relevan (Robertson dan Jones 1976). Sejumlah k kata benda dengan bobot tertinggi lalu diambil sebagai expanded query term (EQT) yang bobotnya digunakan dalam pemeringkatan dan pemilihan kalimat snippet.
5 qt : peluang kata t ada pada kalimat non-relevan,
R : jumlah kalimat relevan,
rt : jumlah kalimat relevan yang mengandung kata t, S : jumlah kalimat non-relevan,
st : jumlah kalimat non-relevan yang mengandung kata t.
Pemeringkatan Kalimat dan Pembuatan Snippet
TSV dari setiap kata pada kueri baru digunakan sebagai pembobot pada saat pemeringkatan kalimat. Tujuan dari pemeringkatan untuk mendapatkan kalimat yang mengandung informasi yang paling baik, yaitu kalimat yang mampu menjelaskan keberadaan kueri pengguna beserta informasi di sekitarnya. Selain TSV kata kueri baru, posisi kalimat juga berperan dalam menentukan tingkat kepentingan kalimat (salience rate). Asumsi yang digunakan, bahwa kalimat paling penting umumnya ada pada posisi teratas dalam dokumen setelah judul dan seterusnya sampai dengan kalimat terakhir dalam dokumen atau paragraf (Ko et al. 2008). Pemeringkatan kalimat menggunakan Persamaan 2 dan Persamaan 3 secara bertahap.
re = w t
t (2)
re =α re a re α (3)
Untuk setiap kalimat dalam dokumen, nilai relevansi dihitung dengan menjumlahkan TSV kata kueri (EQT) yang berbeda yang terdapat pada kalimat tersebut. Variabel weqt pada Persamaan 2 menunjukkan TSV dari kata ke-j dari EQT yang terdapat pada kalimat S pada posisi ke-i di dalam dokumen. Nilai relevansi kalimat Si dinyatakan dengan RWscore. Dari Persamaan 3, nilai kepentingan (salience score) setiap kalimat didapatkan melalui kombinasi linear dari RWscore kalimat yang telah dinormalisasi dan nilai posisi kalimat. N adalah jumlah kalimat yang ada di dalam dokumen. Paramater α digunakan untuk memberikan bobot lebih besar pada nilai relevansi ataupun nilai posisi kalimat.
Nilai α yang diuji bakan dari nilai 0.1 sampai dengan 0.9 dengan interval 0.1.
6
Evaluasi Kualitas Snippet
Sepuluh dokumen teratas dari hasil pemrosesan kueri diambil sebagai data uji. Untuk setiap pasangan kueri dan dokumen, tiga orang penguji diminta untuk mengidentifikasi kalimat-kalimat relevan yang terdapat pada dokumen tersebut. Masing-masing penguji lalu diminta untuk memilih paling banyak tiga kalimat yang dianggap paling relevan, sehingga jumlah kalimat yang terpilih paling banyak 9 kalimat untuk setiap pasangan kueri dan dokumen. Snippet dokumen yang dihasilkan oleh sistem kemudian dibandingkan dengan kalimat-kalimat yang dipilih oleh penguji untuk dokumen tersebut. Akurasi snippet dijadikan sebagai ukuran kualitas sistem penghasil snippet yang telah dibuat. Sebuah snippet dianggap akurat kalau di dalam snippet tersebut terdapat paling sedikit satu kalimat dari kalimat-kalimat yang dipilih oleh penguji.
HASIL DAN PEMBAHASAN
Pembuatan dan Konfigurasi Mesin Pencari
Mesin pencari dibangun menggunakan Sphinx 2.07, yaitu sebuah engine pencarian open source berbahasa PHP yang menyediakan fitur-fitur information retrieval, seperti indeksasi, penentuan stopwords, pemeringkatan dokumen, dan pembuatan snippet dokumen hasil pencarian. Konfigurasi mesin pencari dilakukan sebelum pengindeksan. Konfigurasi yang dilakukan diantaranya mendefinisikan sumber data, mendefinisikan indeks, mengatur indexer, dan mengatur daemon pencarian yang disebut 'searchd'. Definisi sumber data penting dalam menentukan data yang dibaca dan diindeks oleh Sphinx. Sumber data yang diindeks berupa fail XML sehingga xmlpipe digunakan sebagai tipe sumber data yang dikenali oleh mesin pencari (Gambar 2). Bagian-bagian dokumen yang diindeks diantaranya id dokumen (docno), judul (title), penulis (author), dan isi (content). Konfigurasi lengkapnya dapat dilihat pada Lampiran 1.
SphinxClient pada Gambar 3 digunakan untuk mengatur pencarian yang dilakukan oleh pengguna. SphinxClient menentukan bagaimana sistem menerima kueri, memprosesnya, dan menampilkan hasil dari kueri tersebut. SphinxClient diatur agar membuat array yang menyimpan hasil pencarian. Metode pencocokan kata yang digunakan adalah SPH_MATCH_ANY, sedangkan metode pemeringkatan
source srcxml {
type = xmlpipe
xmlpipe_command = type C:\Sphinx\corpus\corpus.xml
xmlpipe_field = docno
xmlpipe_field = author
xmlpipe_field = title
xmlpipe_field = content
}
7 dokumen menggunakan SPH_RANK_PROXIMITY_BM25. Dokumen yang telah dilakukan pemeringkatan lalu diurutkan berdasarkan relevansi dokumen dengan SPH_SORT_RELEVANCE. Untuk keperluan penelitian, jumlah dokumen hasil yang ditampilkan sebanyak 10 dokumen yang menempati peringkat teratas dan jumlah maksimum dokumen hasil yang dikeluarkan sistem sebanyak 1000 dokumen. Setelah SphinxClient beserta konfigurasinya dilakukan, barulah pencarian dapat dimulai.
Akuisisi Korpus dan Indeksasi
Korpus yang digunakan dalam penelitian berasal dari Departemen Ilmu Komputer IPB, berjumlah 1000 dokumen, berbahasa Indonesia, dan memiliki satu tema, yaitu pertanian. Korpus yang pada awalnya berupa fail-fail teks terpisah digabungkan menjadi satu fail XML dengan format yang diterima oleh indexer Sphinx, seperti pada Gambar 4 dan Lampiran 2.
Elemen XML yang diterima oleh indexer diantaranya sphinx:docset,
sphinx:schema, sphinx:field, sphinx:attr, sphinx:document, dan
<?xml version="1.0" encoding="utf-8"?> <sphinx:docset>
<sphinx:schema>
<sphinx:field name="docno" attr="string"/> <sphinx:field name="author" attr="string"/> <sphinx:field name="title" attr="string"/> <sphinx:field name="content" attr="string"/>
Gambar 4 Definisi bagian dokumen yang diindeks oleh Sphinx
8
sphinx:killlist. Elemen XML sphinx:schema menyatakan skema
dokumen yang diindeks berupa bagian atau field dan atribut dokumen. Nama field dokumen harus sesuai dengan nama pada xml_pipe_field dari fail konfigurasi (Gambar 2) agar bagian-bagian tersebut dapat diindeks. Korpus yang telah disatukan dan disesuaikan formatnya kemudian diindeks dengan indexer Sphinx untuk digunakan dalam proses pencarian.
Penerapan POS Tagger pada Dokumen
Part-of-speech (POS) tagger diterapkan pada judul dan isi dari setiap dokumen pada korpus (Lampiran 2). POS tagger digunakan untuk memberikan label atau tag fungsi kata pada setiap elemen pembentuk kalimat. POS tagger bekerja secara lebih baik dalam menentukan fungsi kata dalam kalimat dibandingkan dengan hanya menggunakan lexicon atau kamus. POS tagger yang digunakan adalah IPOSTagger v1.1 khusus untuk dokumen berbahasa Indonesia (Wicaksono dan Purwarianti 2010). Gambar 5 dan Gambar 6 merupakan hasil penerapan POS tagger pada dokumen, sedangkan daftar tag yang digunakan oleh IPOSTagger terdapat pada Lampiran 3.
Kekurangan yang dijumpai pada IPOSTagger, diantaranya: konflik dalam memberi tag untuk kata dan simbol yang bersinggungan, ketidaktepatan tag yang diberikan, serta ketidakmampuan dalam menangani morfologi kata. Konflik dalam pemberian tag dapat dilihat pada kata 'obat' pada Gambar 5 dan Gambar 6, dimana tag yang diberikan hanya untuk kata 'obat' saja atau koma dan titik. Kesalahan dalam pemberian tag dapat dijumpai pada Gambar 7 untuk kata 'kelapa' dan 'temulawak', sedangkan kesalahan akibat morfologi terlihat pada kata 'kegigihannya' pada Gambar 6. Penggunaan kata yang tidak baku atau kata yang tidak terdapat pada kamus serta penempatan elemen-elemen kalimat dengan cara yang tidak tepat merupakan penyebab utama kesalahan dalam pemberian tag.
IPOSTagger v1.1 disebutkan memiliki akurasi paling baik sebesar 99.4% untuk in-vocabulary words dan 80.4% untuk out-of-vocabulary words (Wicaksono dan Purwarianti 2010). Untuk kata-kata yang terdapat di dalam kamus atau lexicon, kesalahan dalam pemberian tag hanya sebesar 0.6%,
Dari/IN keuletan/NN dan/CC kegigihannya/VBT dalam/IN usaha/NN tanaman/NN obat,/, Sidik/NN Raharjo/NNP kini/RB mempunyai/VBT koleksi/NN sekitar/CDI 645/CDP tanaman/NN obat/NN dan/CC menguasai/VBT ribuan/CDC jenis/NN tanaman/NN obat./. Pimpinan/NN Merapi/NN Farma/NN ini/DT awalnya/VBT hanya/RB mempunyai/VBT usaha/NN menjual/VBT berbagai/CDI macam/NN bibit/NN tanaman/NN buah./.
Gambar 6 Penerapan POS tagger pada isi dokumen
Sidik/NN Raharjo/NNP Hidupnya/NNP untuk/IN Tanaman/NN Obat./NNP
9 sedangkan untuk kata-kata yang tidak terdapat pada lexicon, tingkat kesalahan tersebut semakin besar. Dapat diperiksa pada Gambar 7 bahwa kata 'jahe', 'temulawak', 'kelapa', dan 'lengkuas' tidak terdapat pada lexicon yang digunakan oleh IPOSTagger.
POS tagger diharapkan mampu memberikan tag fungsi kata secara tepat dengan melihat pola umum pembentukan kalimat. Dengan melihat pola ini diharapkan kata-kata yang tidak terdapat pada lexicon serta iregularitas dalam bahasa dapat ditangani, begitu juga dengan kata-kata yang memiliki dua makna dengan fungsi kata yang berbeda. Kalimat pada Gambar 7 merupakan kalimat dengan tingkat kesalahan tag yang tinggi. Kesalahan dalam pemberian tag yang terdapat pada Gambar 7 terjadi selain karena tidak ada referensi kata jahe, kelapa, dan temulawak di dalam lexicon namun juga karena definisi pola kalimat yang tunggal atau salah.
Ekstraksi Kalimat pada Dokumen
Isi setiap dokumen pada korpus dipecah menjadi kalimat-kalimat dengan memanfaatkan hasil yang didapatkan dari penerapan POS tagger. Pemisahan kalimat pada dokumen berdasarkan tag pengakhir kalimat '/.' (Lampiran 3). Pemisahan dengan cara seperti ini lebih praktis dan lebih akurat meskipun masih terdapat kalimat-kalimat yang tidak terpisah seperti pada Gambar 8. Sebagaimana terlihat pada Gambar 8, penyebab utama kegagalan dalam pemisahan kalimat adalah pemberian tag yang salah sebagai akibat adanya konflik dalam pemberian tag untuk kata dan simbol yang bersinggungan. Belum terlihat adanya kesalahan
dalam pemisahan kalimat, seperti kalimat yang terpotong, selain kegagalan seperti yang telah disebutkan.
Pendapatan/NN tertinggi/JJ diperoleh/VBT dari/IN polatanam/VBT kelapa/CDI +/NN jahe/FW yaitu/SC sebesar/RB Rp/CDP 11/CDP 410/CDP 240/Ha,/, berturut-turut/VBT diikuti/VBT oleh/IN kelapa/CDI +/NN kunyit/NN (Rp/NN 5/CDP 096/CDP 860/Ha),/, kelapa/CDI +/NN temulawak/JJ (Rp/IN 2/CDP 953/CDP 200/Ha),/, ke-lapa/CDI +/NN temuireng/NN (Rp/NN 1/CDP 263/CDP 620/Ha),/, kelapa/CDI +/NN lengkuas/JJ (Rp/IN 1/CDP 206/CDP 960/Ha)./.
Gambar 7 Kesalahan dalam pemberian tag
Begitu/RB menekuni/VBT tanaman/NN buah,/, ia/PRP bisa/MD membiayai/VBT kuliahnya/NNG di/IN Teknik/NN Sipil/NN Universitas/NN Lambung/NN Mangkurat,/NN Lampung./NNP Setelah/SC mampu/MD melakukan/VBT budidaya/NN tanaman/NN buah,/, Sidik/NN tertarik/VBI untuk/IN menekuni/VBT usaha/NN budidaya/NN tanaman/NN obat.
10
Setelah semua kalimat dalam dokumen dipisah, sisa tag yang terdapat pada kalimat dihilangkan dan kalimat dikembalikan kedalam bentuk asalnya. Korpus baru dibuat dengan isi dokumen berupa kalimat-kalimat terpisah yang telah dinormalisasi, seperti pada Lampiran 4, untuk digunakan dalam ekstraksi kalimat relevan, pemeringkatan kalimat, dan visualisasi kalimat snippet.
Ekstraksi Kata Benda pada Dokumen
Kata-kata pada kalimat dipisahkan menjadi dua golongan, yaitu kata benda dan non-kata benda. Kata yang termasuk ke dalam kata benda merupakan kata dengan tag '/NN', '/NNP', '/NNG', dan '/FW' (Lampiran 3), sedangkan kata yang tidak memiliki tag tersebut dianggap bukan kata benda. '/FW' merupakan kata asing yang diputuskan sebagai kata benda karena isi dari dokumen yang digunakan secara garis besar berbahasa Indonesia, sehingga dapat diduga bahwa sebagian besar kata asing yang dikutip dalam dokumen merupakan kata benda yang jumlahnya tidak signifikan. Ekstraksi kata benda diterapkan pada setiap kalimat pada dokumen yang telah diberi tag.
Lexicon kembali digunakan untuk mengatasi kekurangan pada IPOSTagger. Lexicon memiliki peranan yang penting dalam mengevaluasi kata-kata benda yang terekstraksi maupun yang tidak terekstraksi. Lexicon dibagi menjadi lexicon kata benda dan lexicon non-kata benda dengan fungsinya masing-masing. Lexicon non-kata benda digunakan untuk mendeteksi non-kata yang bukan non-kata benda yang terekstraksi berdasarkan IPOSTagger serta mengeliminasinya. Sedangkan, lexicon kata benda digunakan untuk mencari kata benda pada kalimat sesuai perbendaharaan kata pada lexicon. Dengan cara seperti ini, kata yang terekstraksi namun tidak termasuk kata benda dapat dideteksi dan dieliminasi, sedangkan kata yang seharusnya diidentifikasi sebagai kata benda namun tidak terekstraksi dapat digabung dengan kata benda yang sudah diekstraksi.
Hasil ekstraksi kata benda setiap kalimat pada dokumen disimpan sebagai korpus tersendiri yang digunakan pada saat ekstraksi kata benda kalimat-kalimat relevan pada saat pembuatan snippet. Korpus kata benda dapat dilihat pada Gambar 9 dan Lampiran 5.
<title>
<sentence>raharjo hidupnya tanaman obat</sentence> </title>
<content>
<sentence>keuletan usaha tanaman raharjo koleksi obat jenis</sentence><sentence>pimpinan merapi farma usaha macam bibit tanaman buah</sentence><sentence>usaha sman tanjungkarang tetangganya kebanyakan bibit tanaman buah</sentence>
...
</content>
11
Pemisahan Kalimat Relevan dan Non-Relevan
Pemisahan kalimat relevan dan non-relevan merupakan tahap pertama dalam pembuatan snippet dokumen hasil pencarian. Dokumen hasil pemrosesan kueri yang dikeluarkan oleh mesin pencari diambil oleh sistem penghasil snippet untuk dibuatkan snippet. Kalimat-kalimat pada dokumen tersebut diambil dari korpus kalimat yang telah dibuat sebelumnya lalu dipisahkan berdasarkan ada dan tidak adanya kata kueri awal. Kalimat yang mengandung sedikitnya satu kata kueri awal dianggap sebagai kalimat relevan dan selain itu dianggap kalimat non-relevan. Pada tahap ini, kalimat judul juga dimasukkan ke dalam himpunan kalimat relevan atau non-relevan. Gambar 10 merupakan dua kalimat relevan untuk kueri 'tanaman obat'.
Ekstraksi Kata Benda dari Kalimat Relevan
Semua kata benda yang ada pada kalimat-kalimat relevan pada dokumen diekstraksi dan dijadikan kandidat untuk membuat kueri baru. Pada tahap ini, korpus kata benda dipanggil dan kata benda dari semua kalimat relevan disatukan sebagai kandidat kata untuk mengekspansi kueri awal. Gambar 11 merupakan hasil ekstraksi kata benda dari 22 kalimat relevan untuk kueri 'tanaman obat' dan dokumen 'republika020604-003' (Lampiran 5).
Pembobotan Kata Benda
Kata benda yang diekstraksi dari kalimat-kalimat relevan dikasih bobot (TSV) sesuai dengan Persamaan 1. Tabel 1 merupakan hasil perhitungan TSV
alternatif bagaimanapun bahan balai bethesda bibit broto bto buah budidaya bulan dasar-dasar depkes farma gunung guru hargobinangun jakarta jamu jawa jenis juta kali kaliurang kamdanen karyawan kebanyakan kesulitan keuletan koleksi kuliah kuliahnya lainnya lambung lapangan macam magang mangkurat merapi meter modal ngaglik obat orang pabrik pakar pedagang pelatihan pembibitan pengetahuan penguasaan permintaan persegi persen pertanian pimpinan prospek raharjo saat sariharjo sekarang semester seminar sidorejo sleman sman soedibyo standar tahun tanah tanaman tanjungkarang tawangmangu teknik teman temannya tetangganya tren universitas usaha usahanya wilayah yogyakarta
Gambar 11 Kata benda dari kalimat-kalimat relevan
Dari keuletan dan kegigihannya dalam usaha tanaman obat, Sidik Raharjo kini mempunyai koleksi sekitar 645 tanaman obat dan menguasai ribuan jenis tanaman obat. Pimpinan Merapi Farma ini awalnya hanya mempunyai usaha menjual berbagai macam bibit tanaman buah.
12
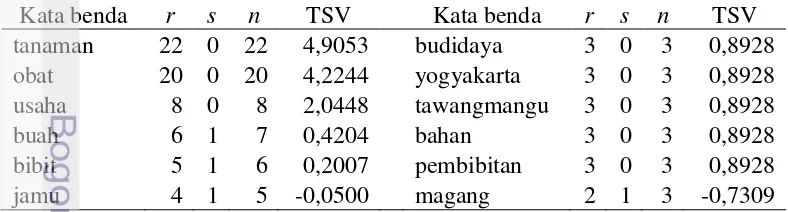
kata benda pada dokumen 'republika020604-003' dengan kueri 'tanaman obat'. TSV kata dipengaruhi oleh jumlah kalimat relevan dan kalimat non-relevan yang mengandung kata tersebut. Kata yang tersebar pada sebagian besar kalimat relevan memiliki TSV yang besar pula. Kata 'tanaman' pada Tabel 1 merupakan kata dengan TSV terbesar diikuti oleh kata 'obat' dan kata 'usaha'. Kata 'tanaman' terdapat pada 22 kalimat relevan (r) dan tidak ada pada kalimat non-relevan (s). Jumlah total kalimat yang mengandung kata 'tanaman' dalam dokumen (n) sebanyak 22 kalimat.
Tabel 2 merupakan TSV kata untuk kueri dan dokumen yang sama yang diurutkan berdasarkan jumlah kalimat dalam dokumen yang mengandung kata tersebut. Keberadaan suatu kata pada kalimat non-relevan menurunkan TSV kata secara signifikan, seperti terlihat pada perbandingan kata 'buah' dengan kata 'budidaya' (Tabel 2). Kata 'buah' terdapat pada 6 kalimat relevan dan 1 kalimat non-relevan, sedangkan kata 'budidaya' hanya terdapat pada 3 kalimat relevan. Meskipun jumlah kalimat yang mengandung kata 'buah' lebih banyak daripada
kata 'budidaya', namun TSV kata 'buah' jauh lebih kecil dari TSV kata 'budidaya', bahkan sangat kontras dengan TSV kata 'usaha' yang memiliki jumlah hampir sama. Daftar lengkap hasil pembobotan kata benda (perhitungan TSV) terdapat pada Lampiran 6.
Tabel 1 Hasil pembobotan untuk kata benda t yang diurutkan berdasarkan TSV Kata benda r s n TSV Kata benda r s n TSV
r: jumlah kalimat relevan yang mengandung kata benda t, s: jumlah kalimat non-relevan yang mengandung kata benda t, n: jumlah kalimat dalam dokumen yang mengandung kata benda t, TSV: bobot kata benda t
Tabel 2 Hasil pembobotan untuk kata benda t yang diurutkan berdasarkan n Kata benda r s n TSV Kata benda r s n TSV
13
Pembuatan Kueri Baru
Kata benda diurutkan berdasarkan TSV yang didapat dari perhitungan sebelumnya. Sejumlah k kata benda dengan TSV terbesar lalu dipilih sebagai expanded query term (EQT) untuk mengekspansi kueri awal. Nilai k menyatakan jumlah EQT dalam kueri baru. Nilai k = 5 berarti kueri baru dibentuk atas kueri awal ditambah lima EQT. EQT sangat mungkin terdapat di dalamnya kata kueri awal. Dengan menggunakan hasil perhitungan TSV pada Tabel 1, kueri baru untuk 'tanaman obat' dengan k = 5 adalah 'tanaman obat' itu sendiri ditambah EQT berupa 'tanaman', 'obat', 'usaha', 'budidaya', dan 'yogyakarta'.
Perhitungan Salience Score Kalimat
Salience score kalimat didapat melalui penjumlahan hasil perkalian parameter α dengan nilai relevansi kalimat dan hasil perkalian invers parameter α dengan nilai posisi kalimat. Pada implementasi, posisi kalimat dimulai dari indeks nol sehingga nilai posisi kalimat pada Persamaan 3 disesuaikan menjadi satu dikurangi hasil bagi i dengan N. Tabel 3 dan Tabel 4 merupakan hasil pemeringkatan kalimat pada dokumen 'republika020604-003' dengan kueri 'tanaman obat'. Tabel 3 diurutkan berdasarkan nilai relevansi kalimat, RWscore(Si), sedangkan Tabel 4 diurutkan berdasarkan salience score kalimat, score(Si).
Nilai relevansi kalimat merupakan penjumlahan TSV dari expanded query term yang ada pada kalimat. Nilai relevansi kalimat dan nilai posisi kalimat merupakan dua nilai yang memiliki pengaruh besar dalam perhitungan salience score atau nilai kepentingan kalimat. Salience score kalimat yang tinggi umumnya terdapat pada kata-kata yang tidak terlalu jauh dari judul. Dengan mengambil contoh kalimat 16 (S16) pada Tabel 3 dan kalimat 1 (S1) pada Tabel 4, terlihat bahwa kalimat dengan RWscore yang tinggi sekalipun menjadi semakin tenggelam seiring indeks kalimat i yang semakin besar.
Kata 'tanaman' dan kata 'obat' berdasarkan Tabel 1 merupakan dua kata dengan TSV yang besar, yaitu 4.90 dan 4.22. Kedua kata tersebut, sebagaimana terlihat pada Tabel 4, mendominasi perhitungan RWscore serta membawa perhitungan salience score ke arah kedua kata tersebut. Kata kueri baru lainnya dengan TSV yang rendah secara individu menjadi lemah. Dapat dipahami pada Tabel 3 dan Tabel 4 bahwa kalimat yang dipilih sebagai snippet untuk dokumen Tabel 3 Hasil pemeringkatan kalimat yang diurutkan berdasarkan RWScore(Si)
Si RWscore(Si) score(Si) num_iqt eqt
14
'republika020604-003' kemungkinan besar adalah kalimat yang berhubungan dengan usaha tanaman obat.
Berdasarkan Persamaan 3, nilai parameter α dapat diatur untuk memberi bobot lebih besar pada relevansi kalimat atau pada posisi kalimat di dalam dokumen. Penentuan nilai α yang optimal hanya bisa dilakukan melalui percobaan. Untuk penelitian ini, nilai α yang optimal adalah 0.7.
Visualisasi Snippet
Hasil dari pemeringkatan kalimat digunakan untuk memutuskan kalimat yang dipilih sebagai snippet. Kalimat dengan salience score yang tinggi dianggap sebagai kalimat yang penting dan relevan dengan kebutuhan informasi pengguna. Selain salience score, kriteria lain yang digunakan dalam pemilihan dan visualisasi kalimat snippet adalah keberadaan kata kueri awal pada kalimat.
Kecenderungan pengguna mesin pencari dalam mengidentifikasi keberadaan kata kueri di dalam dokumen menjadi alasan mengapa keberadaan kata kueri pada snippet perlu diperhatikan. Kalimat diambil dan digabungkan hingga mencakup semua atau sebagian besar kata kueri pengguna. Kalimat yang diutamakan adalah kalimat dengan kata kueri yang lengkap atau yang paling banyak. Dengan cara seperti ini, snippet menjadi lebih ringkas namun padat informasi.
Pada Gambar 12 dan Gambar 13, terlihat bahwa ruang yang tersedia untuk snippet sangat terbatas. Keterbatasan ruang menyebabkan kalimat dan karakter setiap kalimat yang dapat ditampilkan juga terbatas. Karena jumlah kalimat yang ditampilkan terbatas, maka terdapat beberapa informasi yang hilang. Tingkat kompresi informasi dalam pembuatan snippet cukup tinggi dan menjadi semakin tinggi seiring jumlah kalimat relevan yang semakin banyak.
Snippet pada Gambar 12 dan Gambar 13 mencakup semua kata kueri pengguna. Snippet pada Gambar 12 terlihat lebih baik karena cukup ringkas dan langsung memperlihatkan kueri 'tanaman obat' sehingga pengguna lebih cepat dalam memutuskan relevansi dokumen. Jumlah karakter yang ditampilkan untuk masing-masing kalimat pada snippet sebanyak 100 karakter. Jumlah karakter diatur agar pengguna tidak larut dalam membaca kalimat snippet sehingga pengguna dapat dengan cepat memutuskan dokumen mana yang akan diambilnya.
Tabel 4 Hasil pemeringkatan kalimat yang diurutkan berdasarkan score(Si) Si RWscore(Si) score(Si) num_iqt eqt
0 11.1744 0.9704 2 tanaman obat usaha 3 11.1744 0.9104 2 tanaman obat usaha
5 10.9152 0.8618 2 tanaman obat tawangmangu yogyakarta 4 9.1297 0.8226 2 tanaman obat
1 6.9500 0.8104 1 tanaman usaha
15
Tampilan hasil pencarian dibuat dengan memperhatikan kenyamanan pengguna. Judul dokumen di-highlight dan digarisbawahi dan setiap kata kueri dicetak tebal. Pemotongan kalimat juga diupayakan agar kata kueri tetap terlihat dengan mengutamakan intelligibility dari snippet yang ditampilkan.
Evaluasi Snippet
Pengujian dilakukan untuk melihat kualitas snippet yang dibuat oleh sistem. Sebanyak 30 kueri diproses dan dikeluarkan hasilnya. Sepuluh dokumen teratas dari setiap pemrosesan kueri diambil sebagai dokumen uji. Untuk setiap dokumen uji, sebanyak tiga orang dilibatkan untuk menentukan, secara terpisah, kalimat-kalimat relevan yang dianggap paling cocok untuk dijadikan snippet. Hasil sampingan yang didapat dari pemilihan kalimat relevan oleh penguji adalah diketahuinya dokumen-dokumen yang tidak relevan. Dokumen dianggap tidak relevan jika tidak ada satu pun kalimat yang dipilih oleh penguji sebagai kalimat relevan.
Dokumen yang tidak relevan tidak diikutsertakan dalam perhitungan akurasi, sebab snippet yang dihasilkan oleh sistem untuk dokumen tersebut tidak dapat diuji. Untuk memastikan lebih lanjut mengenai relevansi dokumen dengan kueri, pasangan kueri dan dokumen terkait dari Departemen Ilmu Komputer digunakan sebagai rujukan. Dari total 300 dokumen uji, terdapat 20 dokumen tidak relevan, sehingga total dokumen uji yang digunakan sebanyak 280 dokumen.
Snippet yang telah dibuat oleh sistem dibandingkan dengan kalimat-kalimat yang dipilih oleh penguji. Snippet dianggap akurat jika terdapat minimal satu kalimat pada snippet diantara kalimat-kalimat yang dipilih oleh penguji. Untuk memudahkan dalam evaluasi, jumlah kalimat pada snippet dibatasi menjadi satu kalimat. Contoh hasil evaluasi snippet untuk nilai k = 7 dan nilai α = 0.4 dapat dilihat pada Lampiran 8.
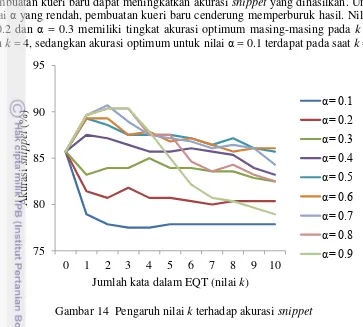
Pengamatan terhadap parameter α dan nilai k dilakukan untuk melihat pengaruh kedua variabel tersebut terhadap akurasi snippet. Gambar 14 merupakan grafik pengaruh nilai k terhadap akurasi snippet untuk setiap parameter α. Nilai k = 0 menunjukkan snippet yang dibuat tidak berdasarkan pseudo-relevance feedback dan hanya menggunakan informasi keberadaan kata kueri awal di dalam
Sidik Raharjo Hidupnya untuk TanamanObat - nri
Pimpinan Merapi Farma ini awalnya hanya mempunyai usaha menjual berbagai macam bibit tanaman buah. Setelah matang dalam penguasaan obat tradisional, ia mulai meracik jamu.
Gambar 13 Visualisasi snippet dengan kata kueri 'tanaman obat' berada dalam kalimat terpisah
Sidik Raharjo Hidupnya untuk TanamanObat - nri
Dari keuletan dan kegigihannya dalam usaha tanaman obat, Sidik Raharjo kini mempunyai koleksi sekitar ...
16
kalimat. Nilai tersebut digunakan sebagai pembanding untuk melihat sejauh mana pembuatan kueri baru dapat meningkatkan akurasi snippet yang dihasilkan. Untuk nilai α yang rendah, pembuatan kueri baru cenderung memperburuk hasil. Nilai α = 0.2 dan α = 0.3 memiliki tingkat akurasi optimum masing-masing pada k = 3 dan k = 4, sedangkan akurasi optimum untuk nilai α = 0.1 terdapat pada saat k = 1.
Nilai α = 0.9 memiliki kenaikan tingkat akurasi yang cukup baik sampai dengan nilai k = 3 yang pada akhirnya turun secara signifikan dengan nilai k yang semakin besar. Secara garis besar, setiap nilai α memiliki nilai optimumnya masing-masing dan penambahan nilai k setelah titik optimum tersebut memperburuk akurasi snippet yang dihasilkan. Nilai α dari 0.7 sampai dengan 0.9 merupakan nilai α yang paling baik. Akurasi tertinggi terdapat pada nilai α = 0.7 dan nilai k = 2 dengan tingkat akurasi snippet sebesar 90.71% (Lampiran 9).
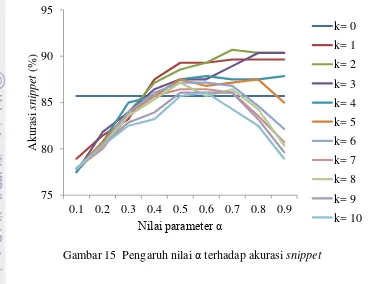
Grafik pada Gambar 15 merupakan transpose dari grafik pada Gambar 14. Pada Gambar 15, pengaruh penambahan nilai α terhadap akurasi snippet dilihat dari sudut pandang nilai k. Nilai k = 0 kembali digunakan sebagai pembanding kualitas snippet yang dihasilkan. Untuk setiap nilai k, dapat dilihat kecenderungan akurasi snippet bergerak ke arah nilai α optimum. Nilai α yang paling baik untuk semua nilai k antara 0.5 sampai dengan 0.7. Dari grafik ini (Gambar 15), terlihat kembali bahwa nilai k paling baik adalah antara satu sampai empat. Tabel tingkat akurasi snippet untuk setiap nilai α dan nilai k dapat dilihat pada Lampiran 9.
Perhitungan TSV dan salience score didasarkan pada informasi statistik dan bukan pada semantik dari kueri yang dimasukkan oleh pengguna. Sedangkan penguji lebih memahami kueri dari segi semantik, sehingga pemilihan kalimat dilaksanakan dengan hati-hati. Beberapa penguji memilih kalimat secara ketat pada kueri tertentu dan longgar pada kueri yang lain. Oleh karena itu, pada Tabel pada Lampiran 8, banyak terjadi mismatch antara snippet yang dibuat oleh sistem dengan kalimat-kalimat yang dianggap paling relevan oleh penguji. Hasil akhir dari pengujian menunjukkan metode pseudo-relevance feedback dengan
17 memanfaatkan informasi TSV dan posisi kalimat memberikan akurasi paling baik 90.71% dari total dokumen yang dianggap relevan.
SIMPULAN DAN SARAN
Simpulan
Sistem penghasil snippet berhasil dibuat dan diintegrasikan dengan mesin pencari dokumen berbahasa Indonesia. Implementasi pseudo-relevance feedback dalam pembuatan snippet pada mesin pencari dokumen berbahasa Indonesia memberikan akurasi paling besar 90.71% dari dokumen-dokumen yang dianggap relevan.
Saran
Sistem penghasil snippet masih dapat dikembangkan, diantaranya dengan: 1 Menggunakan lexicon multi-bahasa dan multi-disiplin serta melakukan proses
lematisasi untuk memerkecil tingkat kesalahan dalam penentuan term kandidat. 2 Melakukan caching untuk menyimpan snippet dan mempercepat waktu
pemrosesan kueri.
3 Optimasi kueri melalui pemrosesan semantik.
18
DAFTAR PUSTAKA
Goldstein J, Kantrowitz M, Mittal V, Carbonell J. 1999. Summarizing text documents: sentence selection and evaluatin metrics. Di dalam: Proceedings of the 22nd Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval. hlm 121-128.
Ko Y, An H, Seo J. 2008. Pseudo-relevance feedback and statistical query expansion for web snippet generation. Information Processing Letters 109(1):18-22. doi:10.1016/j.ipl.2008.08.004.
McDonald DM, Chen H. 2006. Summary in context: searching versus browsing. ACM Transaction on Information Systems (TOIS). 24(1):111-141.
Robertson SE, Jones KS. 1976. Relevance weighting of search terms. Journal of the American Society for Information Science. 27(3):129-148.
19
20
Lampiran 1 Konfigurasi mesin pencari Sphinx
##################################################################
xmlpipe_command = type C:\Sphinx\corpus\corpus.xml
xmlpipe_field = docno
path = C:/Sphinx/data/hasilIndeks
21 Lampiran 1 Lanjutan
client_timeout = 300
max_children = 30
pid_file = C:/Sphinx/log/searchd.pid
max_matches = 1000
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
mva_updates_pool = 1M
max_packet_size = 8M
max_filters = 256
max_filter_values = 4096 max_batch_queries = 32
workers = threads
}
22
Lampiran 2 Contoh dokumen XML dalam koleksi pengujian
<sphinx:document id="388">
<docno>republika020604-003</docno> <author>nri</author>
<title>
Sidik Raharjo Hidupnya untuk Tanaman Obat </title>
<content>
Dari keuletan dan kegigihannya dalam usaha tanaman obat, Sidik Raharjo kini mempunyai koleksi sekitar 645 tanaman obat dan menguasai ribuan jenis tanaman obat. Pimpinan Merapi Farma ini awalnya hanya mempunyai usaha menjual berbagai macam bibit tanaman buah.
Usaha tersebut dimulai sejak dia lulus dari SMAN 2 Tanjungkarang pada 1994. Dia belajar dari tetangganya yang kebanyakan menjual bibit tanaman buah. Begitu menekuni tanaman buah, ia bisa
membiayai kuliahnya di Teknik Sipil Universitas Lambung Mangkurat, Lampung. Setelah mampu melakukan budidaya tanaman buah, Sidik tertarik untuk menekuni usaha budidaya tanaman obat. ''Saya melihat prospek budidaya tanaman obat itu bagus, karena belum banyak yang melakukannya,'' ungkapnya.
Sambil menjual bibit tanaman buah ke wilayah Jawa, Sidik mulai ''berguru'' tentang tanaman obat dari guru ke guru, dari seminar ke seminar, dari pelatihan ke pelatihan ke Jakarta, Malang, Yogyakarta, Tawangmangu, dan lainnya. Selama ''berguru'' ia mengambil cuti kuliah. Setelah mengikuti pelatihan dan banyak seminar ia berharap dapat meracik jamu. ''Tetapi saya malah
semakin bimbang karena tanaman obat tidak ada yang standar, tidak ada guru yang betul-betul mumpuni,'' ungkapnya. Bagaimanapun hati dan pikirannya tetap ingin terjun ke tanaman obat. Sebab, ia melihat di lapangan bahwa pedagang kesulitan mencari bahan obat tradisional, sementara itu tidak ada yang membuat bibit dan menjual tanaman obat. Sidik bahkan sudah mendatangi Tasikmalaya, Purwokerto, dan Cilacap. Di sana ia hanya menemukan bibit
perkebunan dan buah-buahan.
Padahal, dengan tren obat tradisional, permintaan pada tanaman obat akan terus ada. Akhirnya ia magang di Balai Tanaman Obat (BTO) Depkes Tawangmangu secara resmi selama tiga bulan. Tetapi, sebenarnya ia telah magang secara tidak resmi lebih dari setahun. Di sini ia memiliki teman yang suka menjelajah tanaman obat ke berbagai gunung di Jawa. Setelah magang di BTO, ia dipertemukan oleh temannya dengan R Broto Soedibyo, pakar tanaman obat dari RS Bethesda Yogyakarta. ''Pengetahuan tentang dasar-dasar tanaman obat sudah didapatkan dari BTO Tawangmangu, saat menjelajah gunung dan mencari tahu sendiri. Kemudian ilmu peracikan dimatangkan ketika ia bertemu dengan Pak Broto. Di sini saya belajar sekitar sebulan,'' tutur Sidik yang lahir di Tanjungkarang tanggal 19 Januari 1975 ini.
Pada 1998 ia menyewa tanah di Kamdanen, Sariharjo, Ngaglik, Sleman, Yogyakarta seluas sekitar 3.000 meter persegi, tetapi sekarang tinggal 1.500 meter persegi, untuk usaha pembibitan tanaman buah dan beberapa tanaman obat. Dua tahun kemudian Sidik menyewa tanah di Sidorejo, Hargobinangun, Pakem, Sleman seluas 5.000 meter
23 Lampiran 2 Lanjutan
penguasaan obat tradisional, ia mulai meracik jamu. Ada tiga usaha yang dijalankan, yakni bibit tanaman obat, bahan jamu untuk
dipakai sendiri maupun yang disalurkan ke pabrik, dan membuat jamu. Sekarang 90 persen usahanya adalah bahan jamu, tanaman obat, dan jamu. Namun demikian, budidaya tanaman buah tak akan
ditinggalkannya karena itu usahanya yang pertama kali.
Jika saat pertama melakukan pembibitan tanaman obat hanya dibantu oleh dua orang karyawan, maka kini ada sembilan karyawan. Modal usaha untuk tanaman obat di Jl Kaliurang sebesar Rp 80 juta. Saat ini asetnya mencapai sekitar Rp 300 juta. Karena terlalu sibuk mengurusi usaha tanaman obat, Sidik terpaksa berhenti kuliah pada semester tujuh. Dia mempunyai obsesi membuat Merapi Farma menjadi pabrik besar dan bisa menghidupi banyak petani. ''Saya ingin menjadikan tanaman obat sebagai pertanian alternatif,'' katanya. Ia merasa senang dan puas bila bisa mengobati orang sampai sembuh dengan jamu racikannya.
</content>
24
Lampiran 3 Tagset pada IPOSTagger v1.1 (Wicaksono dan Purwarianti 2010)
No POS POS name Example
14 NNP Proper Noun Bekasi, Indonesia 15 NNG Genitive Noun Bukunya
16 VBI Intransitive Verb Pergi 17 VBT Transitive Verb Membeli 18 IN Preposition Di, Ke, Dari
19 MD Modal Bisa
20 CC Coor-Conjunction Dan, Atau, Tetapi 21 SC Subor-Conjunction Jika, Ketika 22 DT Determiner Para, Ini, Itu 23 UH Interjection Wah, Aduh, Oi 24 CDO Ordinal Numerals Pertama, Kedua 25 CDC Collective Numerals Bertiga
26 CDP Primary Numerals Satu, Dua 27 CDI Irregular Numerals Beberapa 28 PRP Personal Pronouns Saya, Kamu 29 WP WH-Pronouns Apa, Siapa 30 PRN Number Pronouns Kedua-duanya 31 PRL Locative Pronouns Sini, Situ, Sana
32 NEG Negation Bukan, Tidak
33 SYM Symbols @#$%^&
34 RP Particles Pun, Kah
25 Lampiran 4 Contoh hasil ekstraksi kalimat pada korpus
<document id="388">
<docno>republika020604-003</docno> <author>nri</author>
<title> <sentence>
Sidik Raharjo Hidupnya untuk Tanaman Obat </sentence>
</title> <content> <sentence>
Dari keuletan dan kegigihannya dalam usaha tanaman obat, Sidik Raharjo kini mempunyai koleksi sekitar 645 tanaman obat dan
menguasai ribuan jenis tanaman obat.</sentence><sentence> Pimpinan Merapi Farma ini awalnya hanya mempunyai usaha menjual berbagai macam bibit tanaman buah..</sentence><sentence> Usaha tersebut dimulai sejak dia lulus dari SMAN 2 Tanjungkarang pada 1994. Dia belajar dari tetangganya yang kebanyakan menjual bibit tanaman buah.</sentence><sentence> Begitu menekuni tanaman buah, ia bisa membiayai kuliahnya di Teknik Sipil Universitas Lambung Mangkurat, Lampung. Setelah mampu melakukan budidaya tanaman buah, Sidik tertarik untuk menekuni usaha budidaya tanaman
obat.</sentence><sentence> ''Saya melihat prospek budidaya tanaman obat itu bagus, karena belum banyak yang melakukannya,''
ungkapnya..</sentence><sentence> Sambil menjual bibit tanaman buah ke wilayah Jawa, Sidik mulai ''berguru'' tentang tanaman obat dari guru ke guru, dari seminar ke seminar, dari pelatihan ke pelatihan ke Jakarta, Malang, Yogyakarta, Tawangmangu, dan lainnya. Selama ''berguru'' ia mengambil cuti kuliah.</sentence><sentence> Setelah mengikuti pelatihan dan banyak seminar ia berharap dapat meracik jamu.</sentence><sentence> ''Tetapi saya malah semakin bimbang karena tanaman obat tidak ada yang standar, tidak ada guru yang betul-betul mumpuni,'' ungkapnya.</sentence><sentence>
Bagaimanapun hati dan pikirannya tetap ingin terjun ke tanaman obat.</sentence><sentence> Sebab, ia melihat di lapangan bahwa pedagang kesulitan mencari bahan obat tradisional, sementara itu tidak ada yang membuat bibit dan menjual tanaman
obat.</sentence><sentence> Sidik bahkan sudah mendatangi
Tasikmalaya, Purwokerto, dan Cilacap. Di sana ia hanya menemukan bibit perkebunan dan buah-buahan..</sentence><sentence> Padahal, dengan tren obat tradisional, permintaan pada tanaman obat akan terus ada.</sentence><sentence> Akhirnya ia magang di Balai Tanaman Obat (BTO) Depkes Tawangmangu secara resmi selama tiga bulan.</sentence><sentence> Tetapi, sebenarnya ia telah magang secara tidak resmi lebih dari setahun.</sentence><sentence> Di sini ia memiliki teman yang suka menjelajah tanaman obat ke berbagai gunung di Jawa. Setelah magang di BTO, ia dipertemukan oleh temannya dengan R Broto Soedibyo, pakar tanaman obat dari RS Bethesda Yogyakarta. ''Pengetahuan tentang dasar-dasar tanaman obat sudah didapatkan dari BTO Tawangmangu, saat menjelajah gunung dan mencari tahu sendiri.</sentence><sentence> Kemudian ilmu
peracikan dimatangkan ketika ia bertemu dengan Pak Broto. Di sini saya belajar sekitar sebulan,'' tutur Sidik yang lahir di
26
Lamipran 4 Lanjutan
Sidik menyewa tanah di Sidorejo, Hargobinangun, Pakem, Sleman seluas 5.000 meter persegi khusus untuk pembibitan tanaman obat.</sentence><sentence> Setelah matang dalam penguasaan obat tradisional, ia mulai meracik jamu.</sentence><sentence> Ada tiga usaha yang dijalankan, yakni bibit tanaman obat, bahan jamu untuk dipakai sendiri maupun yang disalurkan ke pabrik, dan membuat jamu.</sentence><sentence> Sekarang 90 persen usahanya adalah bahan jamu, tanaman obat, dan jamu.</sentence><sentence> Namun demikian, budidaya tanaman buah tak akan ditinggalkannya karena itu usahanya yang pertama kali..</sentence><sentence> Jika saat pertama melakukan pembibitan tanaman obat hanya dibantu oleh dua orang karyawan, maka kini ada sembilan
karyawan.</sentence><sentence> Modal usaha untuk tanaman obat di Jl Kaliurang sebesar Rp 80 juta.</sentence><sentence> Saat ini asetnya mencapai sekitar Rp 300 juta.</sentence><sentence> Karena terlalu sibuk mengurusi usaha tanaman obat, Sidik terpaksa
berhenti kuliah pada semester tujuh.</sentence><sentence> Dia mempunyai obsesi membuat Merapi Farma menjadi pabrik besar dan bisa menghidupi banyak petani.</sentence><sentence> ''Saya ingin menjadikan tanaman obat sebagai pertanian alternatif,''
katanya.</sentence><sentence> Ia merasa senang dan puas bila bisa mengobati orang sampai sembuh dengan jamu
racikannya.</sentence><sentence> </sentence>
27 Lampiran 5 Contoh hasil ekstraksi kata benda pada korpus
<document id="388">
<sentence>keuletan usaha tanaman raharjo koleksi obat
jenis</sentence><sentence>pimpinan merapi farma usaha macam bibit tanaman buah</sentence><sentence>usaha sman tanjungkarang
tetangganya kebanyakan bibit tanaman
buah</sentence><sentence>tanaman kuliahnya teknik universitas lambung mangkurat budidaya usaha buah
obat</sentence><sentence>prospek budidaya tanaman
obat</sentence><sentence>bibit tanaman buah wilayah jawa obat guru seminar pelatihan jakarta yogyakarta tawangmangu lainnya
kuliah</sentence><sentence>pelatihan seminar jamu</sentence><sentence>tanaman obat guru
standar</sentence><sentence>bagaimanapun tanaman
obat</sentence><sentence>lapangan pedagang kesulitan bahan obat bibit tanaman</sentence><sentence>tasikmalaya purwokerto cilacap bibit perkebunan buah-buahan</sentence><sentence>tren obat
permintaan tanaman</sentence><sentence>magang balai tanaman obat depkes tawangmangu bulan</sentence><sentence>magang
setahun</sentence><sentence>teman tanaman obat gunung jawa magang bto temannya broto soedibyo pakar bethesda yogyakarta pengetahuan dasar-dasar tawangmangu</sentence><sentence>ilmu dimatangkan pak broto tutur tanjungkarang januari</sentence><sentence>tanah
kamdanen sariharjo ngaglik sleman yogyakarta meter sekarang usaha pembibitan tanaman buah persegi obat</sentence><sentence>tahun tanah sidorejo hargobinangun sleman meter persegi pembibitan tanaman obat</sentence><sentence>penguasaan obat
jamu</sentence><sentence>usaha bibit tanaman bahan jamu obat pabrik</sentence><sentence>sekarang persen usahanya bahan tanaman jamu obat</sentence><sentence>budidaya tanaman buah usahanya kali</sentence><sentence>saat pembibitan tanaman obat orang karyawan</sentence><sentence>modal usaha tanaman obat kaliurang juta</sentence><sentence>saat juta</sentence><sentence>usaha tanaman kuliah semester obat</sentence><sentence>obsesi merapi farma pabrik petani</sentence><sentence>tanaman obat pertanian alternatif</sentence><sentence>orang
jamu</sentence><sentence></sentence> </content>
28
Lampiran 6 Contoh hasil pembobotan kata benda (TSV)
29 Lampiran 6 Lanjutan
Kata benda r s n TSV Kata benda r s n TSV wilayah 1 0 1 -0.0435 seminar 1 1 2 -1.2852 jakarta 1 0 1 -0.0435 pelatihan 1 1 2 -1.2852 lainnya 1 0 1 -0.0435 broto 1 1 2 -1.2852 standar 1 0 1 -0.0435 pabrik 1 1 2 -1.2852 bagaimanapun 1 0 1 -0.0435 juta 1 1 2 -1.2852
30
Lampiran 7 Contoh hasil pemeringkatan kalimat Si RWscore(Si) score(Si) num_iqt eqt
0 11.1744 0.9704 2 tanaman obat usaha 1 6.9500 0.8104 1 tanaman usaha 2 6.9500 0.7904 1 tanaman usaha 3 11.1744 0.9104 2 tanaman obat usaha 4 9.1297 0.8226 2 tanaman obat
5 10.9152 0.8618 2 tanaman obat tawangmangu yogyakarta
6 0.0000 0.0000 0
7 9.1297 0.7626 2 tanaman obat 8 9.1297 0.7426 2 tanaman obat 9 9.1297 0.7226 2 tanaman obat
10 0.0000 0.0000 0
11 9.1297 0.6826 2 tanaman obat
12 10.0224 0.6922 2 tanaman obat tawangmangu
13 0.0000 0.0000 0
14 10.9152 0.6818 2 tanaman obat tawangmangu yogyakarta
15 0.0000 0.0000 0
16 12.0672 0.6800 2 tanaman obat usaha yogyakarta 17 9.1297 0.5626 2 tanaman obat
18 4.2244 0.3800 1 obat
19 11.1744 0.5904 2 tanaman obat usaha 20 9.1297 0.5026 2 tanaman obat 21 4.9053 0.3426 1 tanaman 22 9.1297 0.4626 2 tanaman obat 23 11.1744 0.5104 2 tanaman obat usaha
24 0.0000 0.0000 0
25 11.1744 0.4704 2 tanaman obat usaha
26 0.0000 0.0000 0
27 9.1297 0.3626 2 tanaman obat
28 0.0000 0.0000 0
29 0.0000 0.0000 0
31
bencana kekeringan 10 10
dukungan pemerintah pada pertanian 9 6
flu burung 10 10
gabah kering giling 10 10
gagal panen 10 10
harga komoditas pertanian 10 9
impor beras indonesia 10 9
industri gula 10 5
institut pertanian bogor 10 8
kelangkaan pupuk 10 10
kelompok masyarakat tani 9 7
laboratorium pertanian 8 3
musim panen 10 10
pembangunan untuk sektor pertanian 9 4
bioteknologi di indonesia 3 2
penerapan teknologi pertanian 10 6
penyakit hewan ternak 9 6
penyuluhan pertanian 10 9
perdagangan hasil pertanian 10 10
sistem pertanian organik 10 7
petani tebu 10 10
peternak ayam 10 9
produk usaha peternakan rakyat 8 8
pupuk organik 9 9
peningkatan pendapatan petani 9 9
Total dokumen 240 280
32
Lampiran 9 Pengaruh nilai α dan k terhadap akurasi snippet (dalam persen)
Jumlah kata dalam EQT (Nilai k)
α 0 1 2 3 4 5 6 7 8 9 10
0.1 85.71 78.93 77.86 77.50 77.50 77.86 77.86 77.86 77.86 77.86 77.86
0.2 85.71 81.43 80.71 81.79 80.71 80.71 80.36 80.00 80.36 80.36 80.36
0.3 85.71 83.21 83.93 83.93 85.00 83.93 83.93 83.57 83.57 82.86 82.50
0.4 85.71 87.50 87.14 86.43 85.71 85.71 86.07 85.71 85.36 83.93 83.21
0.5 85.71 89.29 88.57 87.50 87.50 87.50 87.14 86.43 87.14 86.07 85.71
0.6 85.71 89.29 89.29 87.50 87.86 86.79 87.14 86.43 85.71 86.07 86.07
0.7 85.71 89.64 90.71 88.93 87.50 87.14 86.79 86.07 86.43 86.07 84.29
0.8 85.71 89.64 90.36 90.36 87.50 87.50 84.64 83.57 84.29 83.21 82.50
34
RIWAYAT HIDUP
Muhammad Ginanjar Ramadhan dilahirkan di Sukabumi, Jawa Barat pada tanggal 28 Maret 1991 dan merupakan anak kedua dari enam bersaudara dari pasangan Bapak Ahmad Sulaeman dan Ibu Leni Hasnawati. Pada tahun 2009 penulis menyelesaikan pendidikan menengah atas di MA Husnul Khotimah, Kuningan, Jawa Barat. Pada tahun yang sama, penulis diterima di Institut Pertanian Bogor dengan mayor Ilmu Komputer melalui Seleksi Nasional Masuk Perguruan Tinggi Nasional (SNMPTN).