PENGEMBANGAN MODEL PENDETEKSIAN BAN GANDA (DUAL
TIRE) PADA KENDARAAN TRUK BERGANDAR DUA MENGGUNAKAN
PENGEKSTRAKSI CIRI 2D-PCA DAN SVM SEBAGAI PENGKLASIFIKASI
BAMBANG WAHYUDI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Pengembangan Model Pendeteksian Ban Ganda (Dual Tire) Pada Kendaraan Truk Berganda Dua Menggunakan Pengekstraksi Ciri 2D-PCA dan SVM Sebagai Pengklasifikasi adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, September 2012
Bambang Wahyudi
© Hak Cipta Milik IPB, tahun 2012
Hak Cipta dilindungi Undang-undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB.
PENGEMBANGAN MODEL PENDETEKSIAN BAN GANDA (DUAL
TIRE) PADA KENDARAAN TRUK BERGANDAR DUA MENGGUNAKAN
PENGEKSTRAKSI CIRI 2D-PCA DAN SVM SEBAGAI PENGKLASIFIKASI
BAMBANG WAHYUDI
Tesis
Sebagai Salah Satu Syarat Untuk Memperoleh Gelar Magister Komputer pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Tesis : Pengembangan Model Pendeteksian Ban Ganda (Dual Tire) Pada Kendaraan Truk Bergandar Dua
Menggunakan Pengekstraksi Ciri 2D-PCA dan SVM Sebagai Pengklasifikasi
Nama Mahasiswa : Bambang Wahyudi
Nomor Pokok : G651090354
Program Studi : Ilmu Komputer
Disetujui, Komisi Pembimbing
Dr. Ir. Agus Buono, M.Si, M.Kom Mushthofa, S.Kom, M.Sc
Ketua Anggota
Diketahui,
Ketua Program Studi Dekan Sekolah Pascasarjana
Ilmu Komputer
ABSTRACT
BAMBANG WAHYUDI. The Developing of Dual Tires Detection Model of Two Axles Truck by Using 2D-PCA Feature Extraction and SVM as Classifiers. Under direction of AGUS BUONO and MUSHTHOFA.
Two axles truck is devided into two types i.e truck that uses single tire and dual tires at its back wheels. The use of dual tires at a truck will influnce its classification, so that it is needed a system to detect the use of dual tires. In this study, we develop a model to detect the occurance of dual tires at a two axels truck by using two steps 2D-PCA technique as the feature extraction and SVM as the classifier. In the feature extraction steps by using 2D-PCA, we use the values of precentage 95 %, 90%, and 85 %. While SVM use linear kernel, quadratic, cubic and RBF (sigma = 1, 5, 8, 10, 20, 30). By using the scenario, we obtain 81 models. We performed two phases of testing. The first testing phase measures the accuracy of the detection process without sliding windows. The second testing phase use sliding windows to detect the occurance of dual tires in an image. For the first phase testing, we use a database that consists of 552 dual tires images and 1284 non dual tire images with 150 x 150 pixels, and for the second phase testing, we used 30 images with 640 x 480 pixels. Based on the first phase testing, we obtained 10 best models to be used for second phase testing. The two stage 2D-PCA method successfully reduced the data from 22500 dimensions of image vector to 36. The two phases testing conducted showed that the best kernels for detecting dual tires using SVM is the quadratic and the RBF kernel with the best accuracy of 93.3%.
RINGKASAN
BAMBANG .WAHYUDI. Pengembangan Model Pendeteksian Ban Ganda
(dual tire) Pada Kendaraan Truk Bergandar Dna Menggunakan
Pengekstraksi .Ciri Rdセpca@ dan SVM Sebagai Pengklasifikasi. Dibimbing oleh AGUS BUONO and MUSHTHOFA.
Saat ini jalan tol menjadi suatu jalan alternatif untuk mengatasi kemacetan la1u Hntas ataupun untuk mempersingkat jarak dari satu tempat ke tempat lain. Untuk menikmati layanan jalan tol, para pengguna hams membayar sesuai tarif yang berlaku yang didasarkan pada golongan kendaraan. Proses penggolongan kendaraan ini dilakukan oleh petugas di gerbang tol dengan mengandalkan peng1ihatan. Beberapa hal yang harus diputuskan saat melakukan penggolongan adalah jenis kendaraan bis atau bukan, jumlah gandar dan penggunaan ban ganda pada kendaraan truk. Pekerjaan itu hams dilakukan dalam waktu yang cepat serta dari sudut pandang yang sempit sebingga sangat menyulitkan terutama penentuan jumlah gandar serta penggunaan ban ganda (dual tire). Dengan kondisi ini salah penentuan tarif menjadi sangat potensial teIjadi. Untuk mengatasi hal ini diperlukan sebuah sistem otomatis yang dapat membantu petugas gerbang tol dalam menentukan tarifberdasarkan golongan kendaraan yang telah ditentukan.
Penggunaan teknik-teknik computer vision dan pengenalan pola yang berkembang pesat saat ini memberikan salah satu altematif yang sangat potensial untuk membangun sistem deteksi kendaraan di jalan raya tennasuk jalan tol berbasis vision. Sistem berbasis vision ini memiliki kemudahan dalam instalasi serta pemeliharaan yang tidak mmit.
Selama ini penelitian-penelitian yang berhubungan dengan pengumpulan parameter-parameter laiu lintas seperti volume kendaraan, tipe kendaraan, parameter antrian yang bebasis computer vision sudah banyak dilakukan. Tetapi dalam penelitian-penelitian tersebut belum diteliti teknik untuk mendeteksi penggunaan roda ganda (dual tire) oleh sebuah kendaraan beIjenis truk. Sementara klasiflkasi kendaraan di jalan tol saat ini menggunakan parameter penggunaan ban ganda (dual tire) pada truk bergandar dua sebagai pembeda kelas tarif
Penelitian ini bertujuan membangun model sistem deteksi penggunaan ban ganda (dual tire) pada citra kendaraan beIjenis truk bergandar dua menggunakan metode 2D-PCA dua tahap sebagai pengekstraksi eiri dan SVM sebagai pengklasifIkasi. Model sistem deteksi penggunaan ban gancla pada truk yang diperoleh dapat digabungkan dengan sistem deteksi berbasis vision lain sehingga data laiu lintas yang clapat diperoleh menjadi lebih lengkap. Bagi operator jalan tol, model yang dibangun dapat dikembangkan menjadi sebuah sistem pendeteksi penggunaan ban ganda pada truk untuk meningkatkan akurasi klasifikasi kendaraan.
Untuk kepentingan pelatihan dan pengujian model diambial 165 citra truk yang menggunakan ban ganda dan 315 citra non ban ganda. Citra-citra tersebut ,
diambil 15 citra truk: yang menggunakan ban ganda serta 15 citra non ban ganda untuk keperluan pengujian model tahap kedua. Selanjutnya 150 citra truk yang menggunakan ban ganda dan 300 citra non ban ganda yang tersisa dipakai untuk pembuatan basis data untuk pelatihan model dan pengujian tahap pertama.
Basis data yang digunakan untuk pelatihan dan pengujian model tahap pertama terdiri dati 552 citra ban ganda (positif) dan 1284 citra non ban ganda (negati:t) berukuran 150x150 pixel. Citra-citra ban ganda (positif) diperoleh dari pemotongan citra truk: yang menggunakan ban ganda hasil pengambilan data. Pemotongan dilakukan di sekitar ban ganda dengan ukuran 15Ox150 pixel. Kelompok citra negatif yang terdiri dari 1284 citra bukan ban ganda berukuran 150 x 150 pixel merupakan potongan dati 300 buah citra yang tidak mengandung ban ganda balk kendaraan truk maupun non truk.. Seianjutnya duapertiga bagian citra digunakan untuk proses pelatihan dan sepertiga sisanya digunakan untuk pengujian model tahap 1.
,
Pada tahap pelatihan model, sebelum data citra digunakan untuk melatihj
pengklasifikasi SVM, terlebih dahulu data diproses menggunakan metode 2D-PCA. Langkah ini dimaksudkan untuk mereduksi dimensi dan mengambil komponen ciri dari data. Pengambilan ciri dengan 2D-PCA dilakukan dalam dua tahap. Data latih tereduksi yang diperoleh dari proses ekstraksi ciri ini kemudian
J
divektorkan dan digunakan untuk melatih pengklasifikasi SVM dengan,I
menggunakan kemellinear, polinamial dan RBF.
セ@
セi@ Pada pengujian tahap pertama, setiap citra uji diekstraksi menggunakan matriks transformasi 2D-PCA dua tahap yang diperoleh dari proses pelatihan. Fitur yang diperoleh kemudian divektorkan dan diklasifikasi menggunakan model SVM yang diperoleh dari proses pelatihan, apakah termasuk kelas citra ban ganda ataukah bukan. Akurasi masing-masing model kemudian dihitung berdasarkan jumlah citra yang terklasiftkasi dengan baik.
Berdasarkan akurasi masing-masing model yang diperoleh dari pengujian tahap satu, kemudian diambil beberapa model yang memiliki tingkat akurasi paling baik. Model-model terbaik yang diperoleh selanjutnya diuji pada uji tahap kedua untuk mendeteksi keberadaan ban ganda pada citra-citra truk: menggunakan teknik sliding window.
Hasil penelitian ini menunjukkan bahwa penggunaan metoda 2D-PCA dua tahap berhasil mereduksi data citra sampai 99.8%, dati vektor citra yang berdimensi 22500 menjadi berdimensi 36. Pengujian dua tahap yang dilakukan memperlihatkan bahwa kernel terbaik untuk pengklasifikasian citra ban ganda dan bukan ban ganda menggunakan SVM adalah kernel kuadratik dan RBF. Akurasi terbaik yang dicapai oleh model-model yang dikembangkan mencapai 93.3%.
I
'"":
Kata kunci : klasifikasi truk, deteksi ban ganda, RdMセcaL@ SVMP
RAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT, atas berkat
rahmat dan hidayah-Nya penulis dapat menyelesaikan penelitian dan penulisan
tesis di Program Studi Magister Ilmu Komputer Sekolah Pascasarjana Institut
Pertanian Bogor ini. Tema yang dipilih dalam penelitian yang telah dilaksanakan
pada bulan Desember 2011 sampai dengan Agustus 2012 ini adalah
pengembangan model pendeteksian ban ganda pada kendaraan truk bergandar dua
menggunakan pengekstraksi ciri 2D-PCA dan SVM sebagai pengklasifikasi.
Trima kasih dan penghargaan yang tinggi penulis haturkan kepada Bapak
Dr. Ir. Agus Buono, M.Si, M.Kom dan Bapak Mushthofa, S.Kom, M.Sc. sebagai
komisi pembimbing yang telah memberi banyak arahan dan bimbingan dalam
pelaksanaan penelitian. Ucapan terima kasih juga penulis sampaikan kepada
Bapak Boyke Nurhidayat, S.Kom., M.Kom. selaku penguji pada sidang tesis.
Bagi istri dan putri-putri tersayang serta orang tua tercinta penulis menghaturkan
terima kasih atas semua dorongan moril dan pengorbana yang telah diberikan.
Terima kasih juga penulis sampaikan pada semua pihak yang telah mendukung
dan membantu baik secara langsung maupun tidak langsung.
Semoga penelitian yang telah dilakukan bermanfaat bagi kemajuan ilmu
pengetahuan dan teknologi di masa mendatang.
Bogor, September 2012
RIWAYAT HIDUP
Penulis dilahirkan di Kuningan, pada tanggal 08 Mei 1971 dari ayah
bernama E. Sudrajat dan ibu bernama Zuchriyah. Penulis adalah putra ke tiga dari
enam bersaudara. Menikah dengan Dewi Asri dan dikaruniai satu orang putra
(alm) dan dua orang putri.
Tahun 1990 penulis lulus dari SMA Negeri 1 Kuningan, dan tahun 1991
melanjutkan pendidikan di jurusan Teknik Kimia Fakultas Teknik Universitas
Gadjah Mada Yogyakarta melalui jalur UMPTN. Pendidikan S1 diselesaikan pada
tahun 1998.
Sejak tahun 2003 sampai sekarang penulis tercatat sebagai dosen di program
studi Manajemen Informatika Fakultas Ilmu Komputer Universitas Kuningan.
Pada tahun 2005 penulis diangkat menjadi guru PNS untuk mata pelajaran
Teknologi Informasi dan Komunikasi di Deparetem Agama dan ditempatkan di
RIWAYAT HIDUP
Penulis dilahirkan di Kuningan, pada tanggal 08 Mei 1971 dari ayah
bernama E. Sudrajat dan ibu bernama Zuchriyah. Penulis adalah putra ke tiga dari
enam bersaudara. Menikah dengan Dewi Asri dan dikaruniai satu orang putra
(alm) dan dua orang putri.
Tahun 1990 penulis lulus dari SMA Negeri 1 Kuningan, dan tahun 1991
melanjutkan pendidikan di jurusan Teknik Kimia Fakultas Teknik Universitas
Gadjah Mada Yogyakarta melalui jalur UMPTN. Pendidikan S1 diselesaikan pada
tahun 1998.
Sejak tahun 2003 sampai sekarang penulis tercatat sebagai dosen di program
studi Manajemen Informatika Fakultas Ilmu Komputer Universitas Kuningan.
Pada tahun 2005 penulis diangkat menjadi guru PNS untuk mata pelajaran
Teknologi Informasi dan Komunikasi di Deparetem Agama dan ditempatkan di
PENDAHULUAN
Latar Belakang
Saat ini jalan tol menjadi suatu jalan alternatif untuk mengatasi kemacetan
lalu lintas ataupun untuk mempersingkat jarak dari satu tempat ke tempat lain.
Untuk menikmati layanan jalan tol, para pengguna harus membayar sesuai tarif
yang berlaku yang didasarkan pada golongan kendaraan. Penggolongan kendaraan
di jalan tol yang digunakan berdasarkan Keputusan Presiden nomor 36 tahun 2003
adalah sebagai berikut :
• Golongan 1 – aturan 1 : banyaknya gandar 2, dan tidak dual tires/roda ganda (mobil) .
• Golongan 1 – aturan 2 : banyaknya gandar 2, dual tires/roda ganda , dan kendaraan adalah bis.
• Golongan 2: banyaknya gandar 2, dual tires/roda ganda , bukan bis.
• Golongan 3: banyaknya gandar 3.
• Golongan 4: banyaknya gandar 4.
• Golongan 5: banyaknya gandar 5.
Proses penggolongan kendaraan ini dilakukan oleh petugas di gerbang tol
dengan mengandalkan penglihatan. Beberapa hal yang harus diputuskan saat
melakukan penggolongan adalah jenis kendaraan bis atau bukan, jumlah gandar
dan penggunaan ban ganda pada kendaraan truk bergandar dua. Pekerjaan itu
harus dilakukan dalam waktu yang cepat serta dari sudut pandang yang sempit
sehingga sangat menyulitkan terutama penentuan jumlah gandar serta penggunaan
ban ganda (dual tire) pada kendaraan berjenis truk bergandar dua, karena khusus untuk kendaraan berjenis truk dengan dua gandar, penggunaan ban ganda pada
roda belakang menjdi pembeda kelas. Truk dua gandar dengan empat roda (single tires) dimasukkan ke dalam golongan satu sedangkan truk dua gandar denga enam roda (dual tires) digolongkan ke dalam golongan dua. Tetapi untuk kendaraan berjenis bis penggunaan ban ganda (dual tires) tidak menjadi pembeda kelas karena semua kendaraa bis bergandar dua dimasukkan ke dalam golongan satu.
Untuk mengatasi hal ini diperlukan sebuah sistem otomatis yang dapat membantu
petugas gerbang tol dalam menentukan tarif berdasarkan golongan kendaraan
yang telah ditentukan.
Penggunaan teknik-teknik computer vision dan pengenalan pola yang berkembang pesat saat ini memberikan salah satu alternatif yang sangat potensial
untuk membangun sistem deteksi kendaraan di jalan raya termasuk jalan tol
berbasis vision. Sistem berbasis vision ini memiliki kemudahan dalam instalasi serta pemeliharaan yang tidak rumit (Frenze et al, 2002).
Selama ini penelitian-penelitian yang berhubungan dengan pengumpulan
parameter-parameter lalu lintas seperti volume kendaraan, tipe kendaraan,
parameter antrian yang bebasis computer vision sudah banyak dilakukan. Dalam
penelitian (Chen et al., 2009) telah menggunakan pengklasifikasi SVM dan
teknik-teknik pengolahan citra untuk deteksi kendaraan dan deteksi tipe
kendaraan. Dalam projeknya, Narayanan (Narayanan, 2009) telah berhasil
membangun sistem untuk pengumpulan data lalu lintas menggunakan kamera
pengintai yang tersedia. Beberapa algoritma berbasis computer vision telah
dikembangkan dan diterapkan untuk mengekstrak objek dari video, mendeteksi
keberadaan kendaraan, menghitung jumlah dan panjang kendaraan untuk proses
klasifikasi.
Dalam penelitian lain (Fung, Y. et al. 2006 ), (Frenze et al. 2002) telah
berhasil menggunakan kamera dan teknik-teknik computer vision untuk mendeteksi jumlah gandar pada kendaraan. Penelitian-penelitian tersebut berhasil
mendeteksi keberadaan roda kendaraan secara real time mengunakan kamera berbasis pada deteksi lingkaran dengan teknik Hough transform. Selanjutnya dengan deteksi keberadaa roda tersebut dapat ditentukan jumlah as/gandar dari
sebuah kendaraan. Tetapi dalam penelitian-penelitian tersebut belum diteliti teknik
untuk mendeteksi penggunaan roda ganda (dual tire) oleh sebuah kendaraan berjenis truk. Sementara klasifikasi kendaraan di jalan tol saat ini menggunakan
parameter penggunaan ban ganda (dual tire) pada truk bergandar dua sebagai pembeda kelas tarif. Gambar 1 memperlihatkan dua jenis truk begandar dua
a. Truk single tire b. Truk dual tire
Gambar 1. Dua jenis truk bergandar dua
Principal Component Analisis (PCA) atau juga dikenal sebagai
Karhunen-Loeve merupakan sebuah teknik ekstraksi ciri yang banyak digunakan dalam
bidang pengenalan pola ataupun computer vision. Dalam penelitiannya (Sirovich & Kirby, 1986), (Kirby & Sirovich, 1990) untuk pertama kali menggunakan PCA
guna merepresentasikan citra wajah manusia. Selanjutnya dalam penelitian lain
(Turk, 1991) mengemukakan metoda eigenface yang sangat terkenal untuk
pengenalan wajah. Sejak saat itu, penelitian-penelitian tentang penggunaan PCA
untuk pengenalan wajah (Khelil, M. et al, 2005)(Buono A. et al, 2010) banyak
dilakukan dan memberikan hasil yang bagus. Walaupun demikian PCA tidak
dapat menangkap semua variansi lokal karena adanya proses pem-vektoran citra
wajah. Untuk mengatasi masalah ini Jian Yang (Yang Jian et al, 2004)
mengemukakan metoda baru yang dinamakan 2D-PCA. Pada PCA konvensional
(1D-PCA) citra direpresentasikan sebagai sebuah vektor, sementara pada 2D-PCA
direpresentasikan sebagai sebuah matriks dua dimensi, sehingga variansi lokal
dari citra tidak hilang. Banyak riset yang sudah dilakukan untuk menguji metoda
2D-PCA dalam melakukan ekstraksi ciri, diantaranya (Le, TH., Bui L. 2011)
(Rashad A. et al, 2009) dan menunjukkan hasil yang bagus.
Support Vector Machine (SVM). Sejak saat itu SVM berkembang menjadi metode
yang sangat baik dalam melakukan klasifikasi data. Riset-riset (Le, TH., Bui L.
2011), (Camargo A. et al, 2009), (Lu H. et al, 2011) telah menunjukkan bahwa
SVM merupakan pengklasifikasi yang sangat handal. Pada dasarnya SVM adalah
sebuah pengklasifikasi linear, artinya SVM hanya dapat digunakan pada
kasusu-kasus yang linearly separable. Walaupun demikian kasus-kasus yang non
linearly separable pun dapat menggunakan SVM sebagai pengklasifikasi setelah sebelumnya data ditransformasi ke ruang baru menggunakan sebuah fungsi
kernel.
Pada penelitian ini dibangun model sistem deteksi penggunaan ban ganda
(dual tire) pada citra kendaraan berjenis truk bergandar dua menggunakan metode
2D-PCA dua tahap sebagai pengekstraksi ciri dan SVM sebagai pengklasifikasi.
Model sistem deteksi penggunaan ban ganda pada truk yang diperoleh dapat
digabungkan dengan sistem deteksi berbasis vision lain sehingga data lalu lintas
yang dapat diperoleh menjadi lebih lengkap. Bagi operator jalan tol, model yang
dibangun dapat dikembangkan menjadi sebuah sistem pendeteksi penggunaan ban
ganda pada kendaraan truk bergandar dua untuk meningkatkan akurasi klasifikasi
kendaraan.
Tujuan
Membangun model sistem deteksi penggunaan ban ganda (dual tire) pada kendaraan berjenis truk bergandar dua berbasis vision menggunakan metode
2D-PCA sebagai pengekstraksi ciri dan pengklasifikasi SVM.
Masalah
Permasalahan yang diangkat pada penelitian ini adalah bagaimana
melakukan ektraksi dan pemilihan fitur dari ban ganda menggunakan 2D-PCA
dan bagaimana fitur tersebut bisa diklasifikasikan dengan metode SVM untuk
membangun model sistem pendeteksi penggunaan ban ganda (dual tire) pada
Ruang Lingkup
Berikut adalah batasan-batasan dan ruang lingkup yang berlaku pada tulisan
ini :
1. Pengambilan citra dilakukan siang hari dari jam 10.00 sampai jam 14.00
dengan kondisi cuaca cerah.
2. Citra diambil dari sudut 45O terhadap as roda belakang
3. Pengambilan citra menggunakan kemera digital dengan ukuran 640 x 480
pixel
4. Kendaraan yang dijadikan objek berjenis truk bergandar dua dengan kondisi
factory default.
Manfaat
Model sistem deteksi penggunaan ban ganda pada truk bergandar dua yang
dikembangkan dapat digabungkan dengan sistem deteksi berbasis vision lain
sehingga data lalu lintas yang dapat diperoleh menjadi lebih lengkap. Bagi
operator jalan tol, sistem yang dikembangkan akan meminimumkan kesalahan
TINJAUAN PUSTAKA
Citra Digital
Secara umum citra merupakan gambar pada bidang dua dimensi. Ditinjau
dari sudut pandang matematis, citra merupakan sebuah fungsi kontinu dari
intensitas radiasi pada bidang dua dimensi. Sumber radiasi mengeluarkan radiasi
yang kemudian mengenai objek, objek memantulkan kembali sebagian dari
radiasi tersebut, pantulan radiasi ini ditangkap oleh sensor pada alat-alat optik
seperti mata, kamera, pemindai (scanner) dan sebagainya. Akhirnya bayangan
objek tersebut direkam dalam suatu media tertentu. Citra semacam ini disebut
juga sebagai citra pantulan. Jika objek menghasilkan radiasi sendiri, maka citra
yang tertangkap oleh sensor disebut sebagai citra emisi. Sedangkan jika objek
bersifat transparan, sehingga citra yang dihasilkannya merupakan representasi dari
radiasi yang berhasil diserap oleh partikel-partikel dari objek tersebut, maka citra
tersebut adalah citra absorpsi. Untuk pembahasan selanjutnya pada seluruh bagian
dari riset ini, yang disebut sebagai citra adalah citra pantulan yang ditangkap oleh
sensor pada kamera.
Analisis terhadap sebuah citra dapat dilakukan dengan menggunakan
bantuan komputer melalui sebuah sistem visual buatan yang biasa disebut dengan
computer vision. Secara umum, tujuan dari sistem visual adalah untuk membuat
model nyata dari sebuah citra. Untuk itu citra yang ditangkap oleh sensor yang
masih dalam bentuk fungsi kontinu (analog) harus dirubah terlebih dahulu
menjadi fungsi diskret (digital) yang dapat dibaca oleh komputer. Proses ini
disebut sebagai digitasi, terdiri dari dua sub proses yaitu sampling dan
kuantifikasi. Sampling merupakan proses untuk mengubah sebuah sinyal dalam
ruang kontinu menjadi sinyal dalam ruang diskret, hasil dari proses ini adalah
citra yang terdiri dari piksel-piksel yang tersusun dalam kolom dan baris. Setiap
piksel merupakan hasil penggabungan dari beberapa sinyal yang saling
berdekatan. Sekali sebuah citra mengalami proses sampling, tidak dimungkinkan
untuk mengembalikannya kedalam bentuk kontinu. Setiap piksel biasanya akan
memuat nilai intensitas yang pada awalnya mempunyai range kontinu, artinya
Sehubungan dengan keterbatasan kemampuan komputer untuk memproses
pengkodean nilai-nilai tersebut, dibutuhkan sebuah metode untuk membatasinya.
Kuantifikasi merupakan proses untuk mengubah range nilai intensitas yang
semula kontinu menjadi range nilai yang diskret sedemikian sehingga dapat
diakomodasi oleh sistem pengkodean biner pada komputer. Akhirnya, sebuah citra
yang telah melalui proses digitasi disebut sebagai citra digital.
Representasi Citra Digital
Citra digital biasa direpresentasikan sebagai sebuah fungsi dua dimensi
f(x,y), x dan y adalah koordinat spasial yang menunjukkan lokasi dari sebuah
piksel didalam sebuah citra dan amplitudo dari f pada setiap pasangan koordinat
(x,y) adalah intensitas dari citra pada piksel tersebut [Gonzales, 2004]. Untuk
kebutuhan pengolahan dan analisis, representasi tersebut ditampilkan dalam
bentuk matriks sebagai berikut :
…... (1)
Tipe-Tipe Citra Digital
Tiga tipe citra digital yang sering digunakan adalah citra intensitas, citra
biner, dan citra RGB. Citra intensitas dan citra biner merupakan citra monokrom
(lebih dikenal dengan citra hitam putih) sedangkan citra RGB merupakan citra
berwarna.
a. Citra Intensitas, merupakan sebuah matriks dua dimensi berukuran mxn yang
setiap selnya berisi nilai intensitas antara 0 sampai dengan 255. Intensitas 0
ditangkap sebagai warna hitam pekat, sedangkan intensitas 255 ditangkap sebagai
warna putih terang oleh mata manusia. Nilai intensitas yang ada diantaranya
merupakan gradasi dari warna hitam ke putih, atau lebih sering disebut warna
keabuan (grayscale).
b. Citra biner, merupakan sebuh matriks dua dimensi berukuran mxn yang setiap
atau "salah", disebut juga tipe data boolean. Nilai 0 sering diasosiasikan dengan
warna putih terang (setara dengan nilai 255 pada citra intensitas) sedangkan nilai
1 sering diasosiasikan dengan warna hitam (setara dengan nilai 0 pada citra
intensitas). Namun bagaimanapun, asosiasi tersebut bisa berubah-ubah tergantung
dari asumsi yang digunakan oleh pengguna. Tidak ada kesepakatan baku yang
mengatur bagaimana nilai 0 dan 1 dihubungkan dengan warna hitam dan putih.
Umumnya, citra biner terbentuk dari citra intensitas yang mengalami proses
tresholding. Proses ini sangat sederhana, pertama-tama tetapkan sebuah nilai T
yang terletak diantara range nilai intensitas. Ubah nilai intensitas dari setiap piksel
dengan mengikuti aturan berikut:
…... (2)
c. Citra RGB (red, green, blue), merupakan kumpulan dari 3 buah matriks 2
dimensi yang masing-masing memuat nilai intensitas (0 s.d. 255) untuk warna
merah, hijau dan biru. Sebuah piksel merupakan komposisi dari ketiga nilai
intensitas tersebut (triplet). Jika digunakan sebagai input pada sistem monitor
berwarna, triplet tersebut akan menghasilkan warna-warna yang unik.
Principal Components Analisys (PCA)
Ide utama dari principal component analysis (PCA) adalah mengurangi
dimensionalitas dari set data yang mengandung banyak sekali variabel yang
berinterelasi, dengan tetap mempertahankan sebanyak mungkin informasi
(variansi data). Hal ini dicapai dengan mentransformasikan set data ke set variabel
data yang baru, dinamakan principal component (PC). Principal Component satu
dengan yang lain tidak saling berkorelasi dan diurutkan sedemikian rupa sehingga
Principal Component yang pertama memuat paling banyak variasi dari data set.
Sedangkan Principal Component yang kedua memuat variasi yang tidak dimiliki
oleh Principal Component pertama. (Jolliffe IT, 2002)
Principal Components Analisys 1D (Turk and Pentland, 1991).
Secara matematis ide dasar dari PCA adalah melakukan sebuah transformasi
0, jika f(n)≥T
linear dari Rm ke Rn dimana n <<< m dengan memaksimumkan variansi
data. Misalkan input vector adalah x∈Rm dengan E[x]=0 (zero mean) dan y
adalah vektor berdimensi n, maka transformasi linear dari Rm ke Rn dapat
dinyatakan sebagai :
[
⋯a1T⋯ ⋯a2T⋯⋮ ⋯an T
⋯
]
[
x1 x2 ⋮ xm]
=
[
y1 y2 ⋮ yn]
…... (3)
dengan :
a1=
[
a11 a12 ⋮ a1m]
, a2=
[
a21 a22 ⋮ a2m]
… an=
[
an1 an2 ⋮ anm]
Secara umum transformasi dapat dinyatakan sebagai :
yi=ai T
x ; i = 1,2,...,n …... (4)
sehingga :
varyi = varai T
x
varyi = E [( ai T
xxTai
varyi = ai T
E xxTai
varyi = ai T
∑
ai …... (5) dimana Σ adalah matriks covarian.Selanjutnya harus ditentukan ai yang dapat membuat varyi menjadi
maksimum dengan kondisi batas ∥a∥=1 atau ai T
ai=1 atau ai T
ai−1=0
karena ai adalah sebuah unit vektor. Salah satu teknik memecahkan permasalah
optimisasi seperti ini adalah menggunakan teknik pengganda lagrange.
Penentuan ai dihitung sebagai berikut :
Masalah optimisasi :
Maksimumkan : varyi = aiT
∑
aiKendala : ai T
ai−1=0
f ai = aiT
∑
ai - λ( aiTai−1 )∂F
∂ai=0 = 2Σ ai - 2 λ ai = 0
Σ
ai= λ
ai …... (6)Dari persamaan 6 terlihat bahwa λ adalah nilai-nilai eigen dari matriks Σ, sedang
ai adalah vektor eigen yang bersesuaian dengan masing-masing λ. Jika ruas kiri
dan kanan persamaan tersebut dikalikan dengan ai T
maka akan diperoleh :
ai T
∑
ai
=
ai Tλ ai
kerena ai T
ai=1 , maka :
ai T
∑
ai= λ
varyi = λ …... (7)
Dari persamaan (7) tersebut dapat dilihat bahwa nilai eigen dari matriks covarian
Σ adalah
varyi . Sehingga agar diperoleh varian maksimum maka aiadalah vetor-vektor eigen yang bersesuaian dengan nilai-nilai eigen terbesar dari
matriks Σ.
Principal Components Analisys 2 Dimensi (Yang J. et al, 2004)
Pada teknik pengenalan wajah berbasis 1D PCA, citra wajah 2D akan
dirubah terlebih dahulu menjadi vektor citra 1D. Akibatnya ruang vektor citra
yang terbentuk akan memiliki dimensi sangat besar. Hal ini menyebabkan
perhitungan matriks kovarian secara akurat serta perhitungan nilai eigen dan
vektor eigen dari matriks kovarian tersebut menjadi relatif sulit. Berbeda dengan
1D PCA, pada 2D PCA citra wajah tetap direpresentasikan dengan matriks. Hal
ini menyebabkan matriks kovarian yang terbentuk menjadi jauh lebih kecil.
Dampak dari fakta tersebut, 2D PCA memiliki dua kelebihan dibandingkan
dengan 1D PCA, yaitu :
1. Evaluasi terhadap matriks kovarian lebih akurat.
2. Waktu yang diperlukan untuk menghitung nilai eigen dan vektor eigen
Formulasi 2D PCA
Misalkan X adalah vektor kolom satuan berdimensi n. PCA 2D
melakukan poreksi sebuah matriks acak dari citra A berukuran m x n kepada X
dengan transformasi linear .
Y = A X
Sehingga akan diperoleh vektor Y berdimensi m, dinamakan vektor feature dari
A. Permasalahannya adalah menetukan vektor X yang memaksimumkan total
scatter dari proyeksi data. Secara matematis dapat dinyatakan sebagai :
J(X) = tr (Sx) …... (8)
dimana Sx menyatakan matriks kovarian dari vektor feature data-data training,
dan
tr (Sx) adalah trace dari Sx. Selanjutnya matriks kovarian Sx dapat dinyatakan
sebagai :
Sx = EY−EYY−EYT=E[AX−EAX][AX−EAX]T
= E[A−EAX][A−EAX]T , sehingga :
trSx=XT[E[A−EAT
A−EA]]X ... (9)
Kemudian didefinisikan sebuah matriks
Gt=E[A−EA T
A−EA] …... (10)
Matriks Gt dinamakan matriks kovarian(scatter) citra yang berukuran n x n.
Matriks ini dapat dihitung langsung dari M buah citra-citra training
Ajj=1,2,..., M
Gt= 1 M
∑
j=1M
Aj−AT
Aj− A …... (11)
Maka kriteria pada persamaan (8) dapat dinyatakan sebagai :
JX=XTGtX …...(12)
Kolom vektor satuan X yang memaksimisasi J(X) disebut sumbu proyeksi yang
optimal. Ini berarti total scatter (varians) dari data yang telah diproyeksikan pada
X menjadi maksimum. Sumbu tersebut adalah vektor-vektor eigen dari matriks
Linear Support Vector Machine (SVM)
Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari
hyperplane terbaik yang berfungsi sebagai pemisah dua buah class pada input
space. Gambar berikut memperlihatkan beberapa pattern yang merupakan anggota
dari dua buah kelas : +1 dan –1. Pola yang tergabung pada class –1 disimbolkan
dengan segitiga, sedangkan pola pada class +1, disimbolkan dengan lingkaran.
Problem klasifikasi dapat diterjemahkan dengan usaha menemukan garis
(hyperplane) yang memisahkan antara kedua kelompok tersebut.
Gambar 2 : Support vector, hyperplane dan margin
Hyperplane pemisah dapat dinyatakan dengan persamaan wTxb=0 dimana
w adalah vektor normal dari hyperplane dan b merupakan intercept hyperplane.
Misalkan himpunan n buah data training adalah D={ x , y }, anggotanya
adalah pasangan xi dan label kelasnya yi untuk i=1,2,...,n, dimana dalam
SVM label kelas dinyatakan sebagai +1 dan -1. Selanjutnya linear classifier dapat
dinyatakan sebagai
f xi=signwTxib …... (13)
Permasalahan selanjutnya adalah mencari set parameter w , b sehingga
f xi=w T
xib=yi untuk semua i. SVM berusaha mencari fungsi
pemisah/hyperplane optimum diantara fungsi yang tidak terbatas jumlahnya yang
memisahkan dua kelas objek. Optimal hyperplane kemudian ditentukan terhadap
support vector dengan memaksimumkan margin (ρ). Support vectors adalah data
training yang terletak paling dekat ke hyperplane. Data-data ini merupakan data
saat jarak support vector negatif ke hyperplane sama dengan jarak support vector
positif ke hyperplane ( ρ/2).
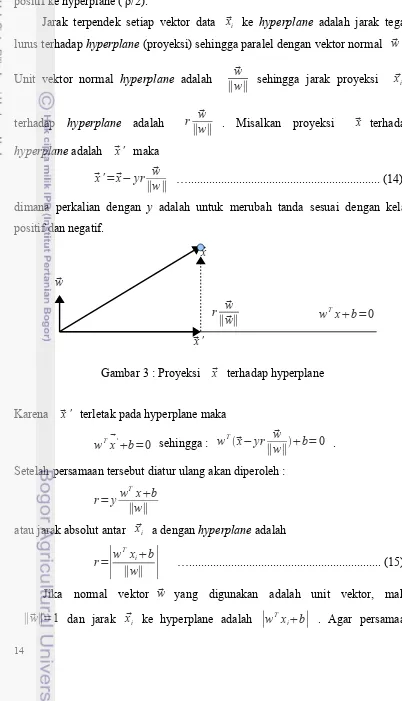
Jarak terpendek setiap vektor data xi ke hyperplane adalah jarak tegak
lurus terhadap hyperplane (proyeksi) sehingga paralel dengan vektor normal w .
Unit vektor normal hyperplane adalah w
∥w∥ sehingga jarak proyeksi xi
terhadap hyperplane adalah r w
∥w∥ . Misalkan proyeksi x terhadap
hyperplane adalah x ' maka
x '=x−yr w
∥w∥ …... (14)
dimana perkalian dengan y adalah untuk merubah tanda sesuai dengan kelas
positif dan negatif.
Gambar 3 : Proyeksi x terhadap hyperplane
Karena x ' terletak pada hyperplane maka
wTx'b=0 sehingga : wTx−yr∥ww∥b=0 .
Setelah persamaan tersebut diatur ulang akan diperoleh :
r=yw T
xb ∥w∥
atau jarak absolut antar xi a dengan hyperplane adalah
r=
∣
w Txib
∥w∥
∣
…... (15)Jika normal vektor w yang digunakan adalah unit vektor, maka
∥w∥=1 dan jarak xi ke hyperplane adalah
∣
wTxib∣
. Agar persamaan xx '
w
r w
menjadi unik, diambil
∣
wT xib∣
=1 untuk setiap support vector xi (vektorterdekat ke hyperplane). Sehingga jarak support vector xi terhadap hyperplane
adalah
∣
w Txib ∥w∥
∣
=1
∥w∥ dan margin ρ = 2 ∥w∥ .
Permasalahan kemudian menjadi bagaimana memilih w dan b agar
2
∥w∥ maksimum dengan kondisi batas :
∣
wT xib∣
≥1 jika xi kelas positif dan∣
wT xib∣
≤1 jika xi kelas negatif. Permasalah ini dapat dirubah menjadi formulasi standar SVM sebagaipermasalahan minimisasi :
Minimumkan fungsi : J w=1 2
∥
w∥
2
Kondisi batas : gi w , b=1−yiwTxib
untuk i = 1, 2 … n
Permasalahan ini merupakan permasalahan optimisasi fungsi kuadrat dengan
kendala linear. Karena J w adalah sebuah fungsi kuadrat, maka akan ada satu
global minimum. Salah satu teknik pemecahannya adalah dengan metoda
Pengganda Lagrange dan Teorema Karush-Kuhn-Tucker. (Smith, 2004),
(Kecman, 2001). Dengan metoda tersebut permasalahan menjadi
maksimumkan : LDλ=
∑
i=1n
λi−1 2
∑
i=1n
∑
j=1 n
λiλjyiyjxiTxj …... (16)
kendala : λi≥0 dan
∑
i=1n
λiyi=0 …... (17)
dimana λ = { λ1,...λn } adalah pengganda lagrange (variabel baru) untuk
masing-masing data. Persamaan (16 ) dapat ditulis menggunakan notasi matriks :
LDλ=
∑
i=1n
λi−1 2
[
λ1 ⋮ λn
]
T
H
[
λ1 ⋮ λn]
…... (18)
dimana H merupakan matiks berukuran n x n, dengan nilai pada baris ke-i dan
kolom ke-j dari matriks H adalah Hij=yiyjxi T
Selanjutnya LDλ dapat dioptimasi menggunakan Quadratic Programming.
Berdasarkan pada λ = { λ1,...λn } optimal yang diperoleh :
• jika λi=0 maka data ke-i adalah bukan support vector
• jika λi≠0 dan yiw T
xib−1=0 maka data ke-i adalah support
vector.
Kemudian w dihitung menggunakan persamaan
w=
∑
i=1 n
λiyixi …... (19)
b dapat dihitung menggunakan sembarang λi0 melalui persamaan
b=1 yi−w
T
xi …... (20)
Persamaan hyperplane optimal yang diperoleh adalah :
f x=
∑
xi∈Sλiyixi
Txib …... (21)
dimana S adalah himpunan support vector
S={ xi | λi≠0 }
Metoda Kernel
Jika suatu kasus klasifikasi memperlihatkan ketidaklinieran, algorithma
linear SVM tidak bisa melakukan klasifikasi dengan baik. Metoda kernel adalah
salah satu teknik untuk mengatasi hal ini. Dengan metoda kernel suatu data xi di
input space dimapping ke feature space F dengan dimensi yang lebih tinggi
melalui map φ sebagai berikut
φ : x → φ(x).
Karena itu data x di input space menjadi φ(x) di feature space.
Dari persamaan (16) terlihat bahwa optimisai fungsi LDa hanya bergantung
pada data xi melalui perkalian titik xiTxj . Jika xi dibawa ke dimensi yang
lebih tinggi oleh φ(x) maka harus dihitung hasil kali titik pada dimensi yang lebih
tinggi tersebut φxi T
LDa=
∑
i=1n ai−1
2
∑
i=1 n∑
j=1 n
aiajyiyjφxiTφxj …... (22)
Sering kali fungsi φ (x) tidak tersedia atau tidak bisa dihitung, tetapi dot
product dari dua vektor dapat dihitung baik di dalam input space maupun di
feature space. Dot product ini dinamakan kernel dan dinotasikan sebagai
Kxi, xj
Sehingga persamaan (19) menjadi :
LDa=
∑
i=1n ai−1
2
∑
i=1 n∑
j=1 n
aiajyiyjKxi, xj …... (23)
Diharapkan pada dimensi yang lebih tinggi data dapat dipisahkan secara linear.
Gambar 4 : Suatu kernel map mengubah problem yang tidak linier menjadi linier dalam space baru
Gambar 4 mendeskrisikan suatu contoh feature mapping dari ruang dua dimensi
ke feature space tiga dimensi. Dalam input space, data tidak bisa dipisahkan
secara linier, tetapi bisa dipisahkan di feature space.
Beberapa fungsi kernel yang umum digunakan adalah : • Linear
Kxi, xj=xi T
xj • Polinamial
Kxi, xj=xi T
xj1 p
• Radial Basis Function (data dibawa ke dimensi tak hingga)
Kxi, xj=exp
−12σ2∥xi−xj∥ 2
METODE PENELITIAN
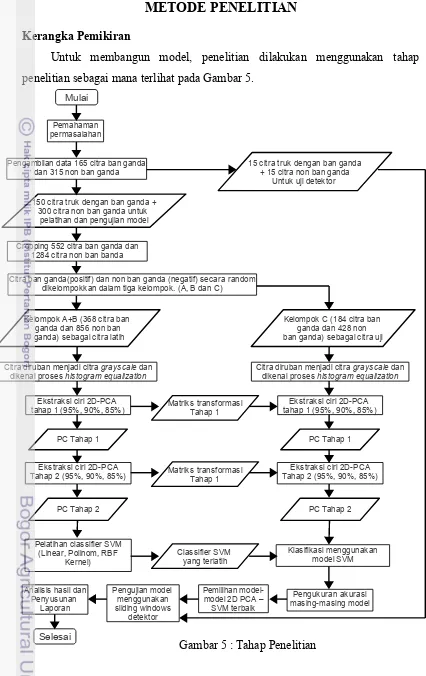
Kerangka PemikiranUntuk membangun model, penelitian dilakukan menggunakan tahap
penelitian sebagai mana terlihat pada Gambar 5.
Gambar 5 : Tahap Penelitian Pemahaman
permasalahan
Pengambilan data 165 citra ban ganda dan 315 non ban ganda
Klasifikasi menggunakan model SVM
Pemilihan model-model 2D PCA –
SVM terbaik Pengujian model menggunakan sliding windows detektor Pengukuran akurasi masing-masing model Kelompok A+B (368 citra ban
ganda dan 856 non ban ganda) sebagai citra latih
Kelompok C (184 citra ban ganda dan 428 non ban ganda) sebagai citra uji Cropping 552 citra ban ganda dan
1284 citra non ban banda
15 citra truk dengan ban ganda + 15 citra non ban ganda
Untuk uji detektor
150 citra truk dengan ban ganda + 300 citra non ban ganda untuk
pelatihan dan pengujian model
Citra ban ganda(positif) dan non ban ganda (negatif) secara random dikelompokkan dalam tiga kelompok. (A, B dan C)
Analisis hasil dan Penyusunan
Laporan
Matriks transformasi Tahap 1 Citra diruban menjadi citra grayscale dan
dikenai proses histogram equalization
Ekstraksi ciri 2D-PCA tahap 1 (95%, 90%, 85%)
Pelatihan classifier SVM (Linear, Polinom, RBF
Kernel) Ekstraksi ciri 2D-PCA Tahap 2 (95%, 90%, 85%)
PC Tahap 1
PC Tahap 2
Matriks transformasi Tahap 1
Classifier SVM yang terlatih
Citra diruban menjadi citra grayscale dan dikenai proses histogram equalization
Ekstraksi ciri 2D-PCA tahap 1 (95%, 90%, 85%)
Ekstraksi ciri 2D-PCA Tahap 2 (95%, 90%, 85%)
PC Tahap 1
PC Tahap 2
Mulai
Tahap Pemahaman Permasalahan
Tahap ini dimulai dengan mengeksplorasi ide-ide dengan membaca
jurnal-jurnal penelitian. Dari eksplorasi ini kemudian diperoleh topik untuk memecahkan
permasalahan penggolongan kendaraan dengan menggunakan computer vision.
Kriteria-kriteria penggolongan kendaraan di jalan tol kemudian ditentukan dari
hasil diskusi dengan beberapa petugas gerbang jalan tol dan dokumen-dokumen
terkait. Selanjutnya ditetapkan masalah-masalah yang harus dipecahkan secara
lebih spesifik. Akhirnya diperoleh gambaran kasar mengenai tujuan penelitian
yang akan dilakukan. Selain itu dilakukan juga studi litertur untuk mengetahui
penelitian-penelitian sejenis yang pernah dilakukan sebelumnya, melakukan
analisis terhadap kelebihan dan kekurangan serta kendala yang dihadapi.
Selanjutnya dikembangkan beberapa alternatif sistem yang diperkirakan dapat
memberikan solusi terhadap permasalahan yang dihadapi. Dengan mengacu pada
fakta-fakta yang ditemukan kemudian dibuat pembatasan permasalahan yang telah
dirumuskan sebelumnya agar penelitian memiliki arah yang jelas serta dapat
diselesaikan dengan biaya dan waktu yang tersedia.
Tahap Pengumpulan Data
Untuk kepentingan pelatihan dan pengujian model diambial 165 citra
trukbergandar dua yang menggunakan ban ganda dan 315 citra non ban ganda.
Citra-citra tersebut diambil menggunakan kamera digital dengan resolusi 640 x
480 pixel. Kemara ditempatkan pada posisi sekitar 45O terhadap as roda belakang
seperti pada Gambar 6.
Gambar 6: Posisi kamera untuk pengambilan citra/video
Ketinggian kamera dari tanah/jalan 0.5 meter (setinggi jari-jari roda). Gambar 7
45O
memperlihatkan beberapa citra hasil pengambilan data.
[image:31.595.104.507.71.825.2]
Gambar 7 : Contoh citra positif hasil pengambilan data
Dari citra-citra yang diperoleh kemudian diambil 15 citra truk yang
menggunakan ban ganda serta 15 citra non ban ganda untuk keperluan pengujian
model tahap kedua. Selanjutnya 150 citra truk yang menggunakan ban ganda dan
300 citra non ban ganda yang tersisa dipakai untuk pembuatan basis data guna
pelatihan model dan pengujian tahap pertama.
Tahap Pembuatan Basis Data
Basis data yang digunakan untuk pelatihan dan pengujian model tahap
pertama terdiri dari 552 citra ban ganda (positif) dan 1284 citra non ban ganda
(negatif) berukuran 150x150 pixel. Citra-citra ban ganda (positif) diperoleh dari
pemotongan citra truk yang menggunakan ban ganda hasil pengambilan data.
Pemotongan dilakukan di sekitar ban ganda dengan ukuran 150x150 pixel. Proses
[image:31.595.118.503.97.239.2]pemotongan citra dapat dilihat pada Gambar 8.
Gambar 8 : Pemotongan bagian citra ban ganda
Gambar 9 memperlihatkan beberapa contoh citra ban ganda (positif) hasil
tahap pertama.
Gambar 9 : Contoh citra positif hasil pemotongan
Kelompok citra negatif yang terdiri dari 1284 citra bukan ban ganda
berukuran 150 x 150 pixel merupakan potongan dari 300 buah citra yang tidak
mengandung ban ganda baik kendaraan truk maupun non truk. Beberapa citra non
ban ganda hasil pengambilan kamera dapat dilihat pada Gambar 10.
Gambar 10 : Contoh citra negatif hasil pengambilan dengan kamera
Pada Gambar 11 dapat dilihat beberapa contoh citra negatif berukuran 150x150
pixel hasil pemotongan yang dipergunakan untuk proses pelatihan dan pengujian
model tahap pertama.
Gambar 11 : Contoh citra negatif hasil pemotongan
Selanjutnya masing-masing kelompok citra (positif dan negatif) dibagi ke
sebagai citra pelatihan sedangkan bagian C dipakai sebagai citra uji. Dengan cara
tersebut maka akan diperoleh 1224 citra pelatihan (368 citra latih positif dan 856
citra latih negatif) dan 612 citra uji (184 citra uji positif dan 428 citra uji negatif).
Semua citra tersebut kemudian dijadikan citra intensitas (grayscale) dan dikenai
proses histogram equalization untuk mengurangi pengaruh perbedaan
pencahayaan.
Tahap Ekstraksi Ciri
Sebelum data diklasifikasi menggunakan model SVM, terlebih dahulu data
diproses menggunakan metode 2D-PCA. Langkah ini dimaksudkan untuk
mereduksi dimensi dan mengambil komponen ciri dari data. Pengambilan ciri
dengan 2D-PCA dilakukan dalam dua tahap. Pada PCA tahap pertama, 368 buah
citra positif berukuran 150 x 150 pixel dan 856 buah citra negatif berukuran 150
x 150 pixel diproses menggunakan algoritma 2D PCA berikut :
Input : - p, jumlah citra pelatihan
- I, matriks citra berukuran m x nx p
- k, jumlah vektor ciri yang dipakai,
Output : - T, matriks transformasi - PC, Principal Components
Algoritma :
1. Hitung matriks citra rata-rata ( I )
I=1
p (I1 + I2 + … + Ip)
6. Hitung matriks covarian
Gt=1
p
∑
j=1p
Ij−IT
Ij−I
7. Hitung dan susun nila ciri matriks covariance : λ1 > λ2 > λ3 > … > λp
8. Hitung vektor ciri yang bersesuaian dengan masing-masing nilai ciri :
u1, u2, u3, … , up
9. Ekstraksi ciri
terbesar. Buat matrix transformasi T yang merupakan gabungan dari k
vektor ciri tersebut
T = [ u1, u2, u3, … , uk]
Kemudian hitung matriks ciri/Principal components (PCi) dari
masing-masing citra Ii.
PCi = Ii.T
Script yang merupakan implementasi dari algoritma di atas dapat dilihat
pada Lampiran 2 untuk fungsi pca2d.
Dimisalkan jumlah nilai ciri yang diambil untuk tahap pertama adalah a
buah. Sehingga dari 2D PCA tahap pertama ini dihasilkan 368 matriks ciri
berukuran 150 x a untuk kelas positif dan 856 matriks ciri berukuran 150 x a
untuk kelas positif.
Selanjutnya setiap matriks ciri yang diperoleh dari PCA tahap pertama,
untuk masing-masing kelas, ditranspose dan di masukan kembali pada algoritma
2D PCA. Dimisalkan untuk tahap kedua ini diambil b buah nilai ciri terbesar,
maka hasil dari PCA tahap kedua ini adalah 368 matriks ciri berukuran a x b
untuk kelas positif 856 matriks ciri berukuran a x b untuk kelas negatif.
Tahap Pelatihan Pengklasifikasi
Data latih tereduksi yang diperoleh dari proses ekstraksi ciri kemudian
divektorkan dan digunakan untuk melatih pengklasifikasi SVM dengan
menggunakan kernel linear, polinamial dan RBF. Untuk keperluan pelatihan
pengklasifikasi SVM digunakan fungsi svmtrain dari Bioinformatics Toolbox
Matlab R2009b.
Tahap Pengujian Model
Pada tahap ini setiap citra uji diekstraksi menggunakan matriks transformasi
2D-PCA dua tahap yang diperoleh dari proses pelatihan. Fitur yang diperoleh
kemudian divektorkan dan diklasifikasi menggunakan model SVM yang diperoleh
dari proses pelatihan, apakah termasuk kelas citra ban ganda ataukah bukan.
Akurasi masing-masing model kemudian dihitung berdasarkan jumlah citra yang
dihitung menggunakan persamaan :
Akurasi= jumlah citra yang terklasifikasi dengan baik jumlah total citra yang diklasifikasi
Selanjutnya hasil pengukuran yang diperoleh dicatat dan dianalisis.
Dari akurasi masing-masing model kemudian diambil beberapa model yang
memiliki tingkat akurasi paling baik. Model-model terbaik yang diperoleh
kemudian diuji pada uji tahap kedua untuk mendeteksi keberadaan ban ganda
pada citra-citra truk menggunakan teknik sliding window.
Model yang Diujikan
Dalam tahap ekstarksi ciri menggunakan 2D-PCA dua tahap, variabel yang
di rubah-rubah adalah presentase nilai ciri (eigen) yang diambil pada
masing-masing tahap. Pada penelitian ini dicobakan variasi persentase nilai ciri yang
diambil untuk masing-masing tahap adalah 95%, 90% dan 85%. Sementara untuk
pengklasifikasi SVM diujikan memakai kernel linear, kuadratik, kubik dan
RBF(sigma=1, 5, 8, 10, 20, 30). Dengan skenario tersebut maka akan diperoleh
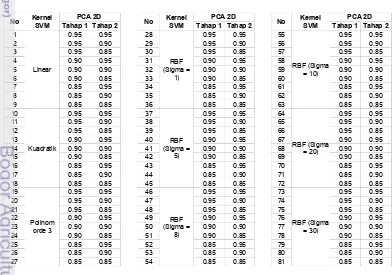
[image:35.595.111.503.436.711.2]sebanyak 81 model yang akan diujikan sebagaimana terlihat pada tabel 1
Tabel 1. Model-model yang akan diujikan
No PCA 2D No PCA 2D No PCA 2D
Tahap 1 Tahap 2 Tahap 1 Tahap 2 Tahap 1 Tahap 2 1
Linear
0.95 0.95 28 0.95 0.95 55 0.95 0.95
2 0.95 0.90 29 0.95 0.90 56 0.95 0.90
3 0.95 0.85 30 0.95 0.85 57 0.95 0.85
4 0.90 0.95 31 0.90 0.95 58 0.90 0.95
5 0.90 0.90 32 0.90 0.90 59 0.90 0.90
6 0.90 0.85 33 0.90 0.85 60 0.90 0.85
7 0.85 0.95 34 0.85 0.95 61 0.85 0.95
8 0.85 0.90 35 0.85 0.90 62 0.85 0.90
9 0.85 0.85 36 0.85 0.85 63 0.85 0.85
10
Kuadratik
0.95 0.95 37 0.95 0.95 64 0.95 0.95
11 0.95 0.90 38 0.95 0.90 65 0.95 0.90
12 0.95 0.85 39 0.95 0.85 66 0.95 0.85
13 0.90 0.95 40 0.90 0.95 67 0.90 0.95
14 0.90 0.90 41 0.90 0.90 68 0.90 0.90
15 0.90 0.85 42 0.90 0.85 69 0.90 0.85
16 0.85 0.95 43 0.85 0.95 70 0.85 0.95
17 0.85 0.90 44 0.85 0.90 71 0.85 0.90
18 0.85 0.85 45 0.85 0.85 72 0.85 0.85
19 0.95 0.95 46 0.95 0.95 73 0.95 0.95
20 0.95 0.90 47 0.95 0.90 74 0.95 0.90
21 0.95 0.85 48 0.95 0.85 75 0.95 0.85
22 0.90 0.95 49 0.90 0.95 76 0.90 0.95
23 0.90 0.90 50 0.90 0.90 77 0.90 0.90
24 0.90 0.85 51 0.90 0.85 78 0.90 0.85
25 0.85 0.95 52 0.85 0.95 79 0.85 0.95
26 0.85 0.90 53 0.85 0.90 80 0.85 0.90
27 0.85 0.85 54 0.85 0.85 81 0.85 0.85
Alat yang digunakan
Untuk pengambilan data citra digunakan kamera digital panasonic 8.1 mega
pixel. Sedangkan untuk pengolahan data digunakan perangkat keras komputer
dengan processor intel Pentium Dual Core 1.6 GHz, memori DDR2 2GB
menjalankan sistem operasi Ubuntu 10.4. Perangakat lunak yang digunakan untuk
pemodelan adalah Matlab R2009b dan untuk pengolahan citra menggunakan
aplikasi GIMP 2.6.
Waktu dan tempat
Penelitian dilaksanakan dari bulan Desember 2011 sampai dengan Agustus
2012 bertempat di Laboratorium Computational Intelegence (CI) Pascasarjana
Departemen Ilmu Komputer, Institut Pertanian Bogor. Data citra diambil di jalan
tol Palikanci Cirebon dan beberapa lokasi penambangan pasir serta jalan raya di
HASIL DAN PEMBAHASAN
Ekstraksi ciri
Citra yang digunakan dalam penelitian ini berukuran 150 x 150 pixel,
sehingga jika divektorkan akan menghasilkan vektor berukuran 22500. Melalui
tahap ekstraksi ciri dengan metode 2D-PCA diharapkan dapat memperkecil
dimensi vektor yang dihasilkan dengan menghilangkan fitur-fitur citra yang tidak
begitu berarti, sehingga proses klasifikasi dapat berjalan lebih cepat. Dengan cara
ini juga diharapkan dapat mengurangi noise pada data sehingga klasifikasi dapat
menjadi lebih akurat.
Ekstraksi 2D-PCA dilakukan dalam dua tahap dengan pengambilan nilai
eigen pada masing-masing tahap sebesar 95%, 90% dan 85%. Hasil yang
diperoleh dapat dilihat pada Tabel 2.
Tabel 2. Jumlah fitur/ciri yang diperoleh dengan metode 2D-PCA dua tahap
Dari tabel di atas terlihat bahwa metoda 2D-PCA dua tahap yang telah
dilakukan cukup berhasil mereduksi dimensi citra yang pada awalnya berukuran
22500 fitur.
Akurasi model
Model yang telah diuji dalam penelitian ini berjumlah 81 model seperti
dapat dilihat dari Tabel 1. Pengujian dilakukan menggunakan perangkat lunak
Matlab serta library-library nya. Hasil pengujian dan pengukuran akurasi yang
telah dilakukan selengkapnya dapat dilihat pada Lampiran 1, dan dirangkum pada
PCA 2D tahap 1 PCA 2D tahp 2
Jml. Fitur
Tahap 1 (%) Jml. PC Tahap 2(%) Jml. PC
95 19 95 18 342
95 19 90 10 190
90 10 95 16 160
95 19 85 7 133
90 10 90 9 90
85 6 95 14 84
90 10 85 7 70
85 6 90 8 48
pada Tabel 3.
Tabel 3. Hasil pengukuran akurasi 81 model pendeteksi ban ganda
Dari hasil pengujian tahap pertama diperoleh fakta bahwa untuk
pengklasifikasi SVM yang menggunakan kernel linear tidak konvergen sampai
jumlah maksimum iterasi. Ini menunjukkan bahwa klasifikasi data ban ganda dan
non ban ganda adalah bukan kasus linear separable. Dengan demikian model
yang menggunakan kernel linear tidak akan diuji pada tahap kedua. Untuk
penggunaan kernel polinamial orde 2 (kuadratik) dan orde 3 (kubik) menunjukkan
akurasi yang bagus, lebih dari 95%. Sementara untuk penggunaan kernel RBF
juga memberikan akurasi yang bagus, kecuali untuk nilai sigma = 1 yang
menunjukkan perilaku yang berbeda, sehingga model yang menggunakan kernel
RBF dengan sigma=1 juga tidak akan diuji pada tahap kedua. Dari tabel hasil di
atas juga terlihat bahwa ada pengaruh dari jumlah fitur yang dihasilkan dari tahap
ekstraksi ciri menggunakan PCA terhadap akurasi model. Ini terlihat lebih jelas
pada model yang menggunakan kernel RBF dengan sigma=5. Untuk memperjelas
pengaruh proses ekstraksi ciri 2D-PCA terhadap akurasi model masing-masing
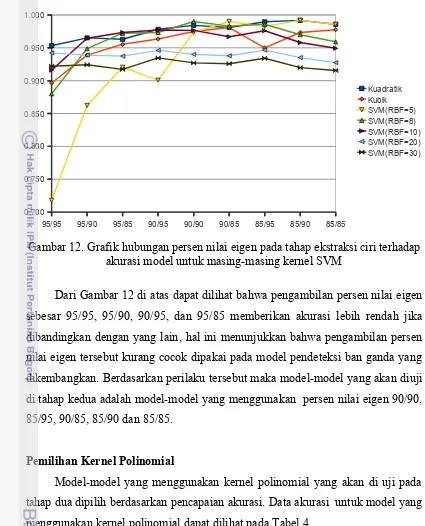
kernel, data pada Tabel 3. ditampilkan sebagai grafik pada Gambar 12.
Kernel
Linear Kubik (%)
PCA
95/95 97.0 95.4 90.4 69.9 71.6 90.8 93.1 94.3 92.3
95/90 T id a k k o n v e rg e n
96.9 93.1 69.9 86.6 95.4 96.4 93.5 92.8
95/85 96.2 95.1 69.9 92.3 97.7 97.5 93.0 91.7
90/95 97.9 95.6 69.9 90.5 97.5 97.9 94.1 93.5
90/90 98.0 97.1 69.9 97.7 99.0 97.7 94.6 93.3
90/85 97.7 97.9 69.9 99.3 98.4 95.9 93.3 92.3
85/95 98.7 94.8 69.9 98.5 98.7 98.4 94.9 93.5
85/90 98.5 96.9 72.4 99.5 96.6 95.3 93.5 92.0
85/85 98.4 97.4 79.9 98.9 95.9 94.6 92.3 91.7
Gambar 12. Grafik hubungan persen nilai eigen pada tahap ekstraksi ciri terhadap akurasi model untuk masing-masing kernel SVM
Dari Gambar 12 di atas dapat dilihat bahwa pengambilan persen nilai eigen
sebesar 95/95, 95/90, 90/95, dan 95/85 memberikan akurasi lebih rendah jika
dibandingkan dengan yang lain, hal ini menunjukkan bahwa pengambilan persen
nilai eigen tersebut kurang cocok dipakai pada model pendeteksi ban ganda yang
dikembangkan. Berdasarkan perilaku tersebut maka model-model yang akan diuji
di tahap kedua adalah model-model yang menggunakan persen nilai eigen 90/90,
85/95, 90/85, 85/90 dan 85/85.
Pemilihan Kernel Polinomial
Model-model yang menggunakan kernel polinomial yang akan di uji pada
tahap dua dipilih berdasarkan pencapaian akurasi. Data akurasi untuk model yang
menggunakan kernel polinomial dapat dilihat pada Tabel 4.
Tabel 4. Akurasi model yang menggunakan kernel polinomial
Dengan menggunakan data tersebut kemudian dipilih model yang
95/95 95/90 95/85 90/95 90/90 90/85 85/95 85/90 85/85
0.700 0.750 0.800 0.850 0.900 0.950 1.000
Kuadratik Kubik SVM(RBF=5) SVM(RBF=8) SVM(RBF=10) SVM(RBF=20) SVM(RBF=30)
2D-PCA
Kubik (%) Tahap 1 (%) Tahap 2 (%)
90 90 98.0 97.1
85 95 98.7 94.8
90 85 97.7 97.9
85 90 98.5 96.9
85 85 98.5 97.4
memberikan akurasi tertinggi yaitu kernel kuadratik pada saat persen nilai eigen
90/90, 85/95, 85/90 dan 85/85 untuk proses 2D-PCA dua tahap. Sedangkan pada
saat persen nilai eigen 90/85 kernel kubik pada klasifikasi dengan SVM
memberikan akurasi lebih tinggi.
Pemilihan Kernel RBF
Data akurasi untuk model yang menggunakan kernel RBF dapat dilihat
pada Tabel 5.
Tabel 5. Nilai akurasi model-model yang menggunakan kernel RBF
Dari Tabel 5 terlihat bahwa untuk PCA 90/90 akurasi tertinggi dicapai pada
saat sigma=8, demikian juga saat PCA 85/95. Tetapi untuk PCA 90/85, 85/90 dan
85/85 akurasi terbaik diberikan oleh model yang menggunakan kernel RBF
dengan sigma=5. Dengan demikian model-model yang menggunakan kernel RBF
yang akan diuji pada tahap dua menggunakan nilai parameter sigma=5 dan
sigma=8.
Pengujian Tahap Dua
Dari pemilihan model-model yang telah dilakukan, maka diperoleh sepuluh
model pendeteksi terbaik seperti terlihat pada Tabel 6.
Tabel 6 : Model-model pendeteksi ban ganda terpilih
2D-PCA
90/90 69.9 97.7 99.0 97.7 94.6 93.3
85/95 69.9 98.5 98.7 98.4 94.9 93.5
90/85 69.9 99.3 98.4 95.9 93.3 92.3
85/90 72.4 99.5 96.6 95.3 93.5 92.0
85/85 79.9 98.9 95.9 94.6 92.3 91.7
RBF (sig=1) (%) RBF (sig=5) (%) RBF (sig=8) (%) RBF (sig=10) (%) RBF (sig=20) (%) RBF (sig=30) (%) PCA 2D Kernel SVM
1 90 90 Kuadratik 98.4
2 85 95 Kuadratik 99.0
3 90 85 Kubik 98.1
4 85 90 Kuadratik 99.2
5 85 85 Kuadratik 98.6
6 90 90 RBF, sig=8 99.0 7 85 95 RBF, sig=8 98.6 8 90 85 RBF, sig=5 99.0 9 85 90 RBF, sig=5 99.2 10 85 85 RBF, sig=5 98.6
Kesepuluh model tersebut kemudian dicobakan untuk mendeteksi
keberadaan ban ganda pada 30 citra yang diambil dengan kamera 640 x 480 pixel
dengan skenario pengambilan seperti telah dipaparkan pada tahap pengambilan
data. Dari 30 citra yang dicobakan, 15 citra mengandung ban ganda dan 15 citra
tidak mengandung ban ganda. Gambar 30 citra uji yang dipergunakan dapat
dilihat selengkapnya pada Lampiran 3.
Proses deteksi dilakukan menggunakan teknik sliding window, dimana
sebuah jendela detektor berukuran 150 x 150 pixel digerakan di seluruh area yang
dimungkinkan terdapat objek ban ganda. Dalam penelitian ini diambil posisi
koordinat awal (1,30) dan posisi akhir di (300,170). Jendela detektor digerakkan
sejauh 10 pixel, sehingga total detektor yang harus diklasifikasi oleh model
berjumlah 450 jendela per citra. Pada Gambar 13 dapat dilihat area pencarian
[image:41.595.91.506.86.817.2]yang dilakukan pada setiap citra uji.
Gambar 13 : Area pencarian ban ganda pada citra uji
Hasil pengujian terhadap sepuluh model terpilih dapat dilihat selengkapnya
pada Tabel 7.
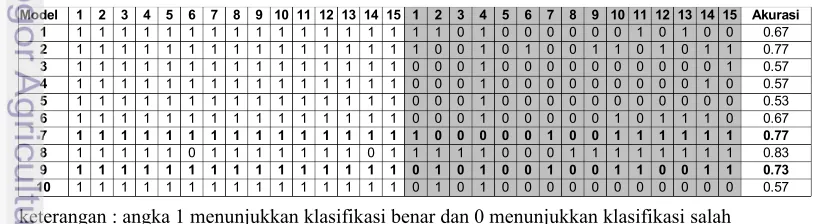
[image:41.595.104.511.604.716.2]keterangan : angka 1 menunjukkan klasifikasi benar dan 0 menunjukkan klasifikasi salah
Tabel 7. Hasil pengujian sepuluh model terpilih
Model 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Akurasi 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 0 0 0 0 1 0 1 0 0 0.67
2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 0 1 0 0 1 1 0 1 0 1 1 0.77
3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0.57
4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0.57
5 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0.53
6 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 1 0 1 1 1 0 0.67
7 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 1 1 1 1 1 1 0.77 8 1 1 1 1 1 0 1 1 1 1 1 1 1 0 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 0.83
Berdasarkan jumlah citra yang terklasifikasi dengan baik kemudian akurasi
dihitung dengan perhitungan
Akurasi= jumlah citra yang terklasifikasi dengan baik
jumlah total citra yang diklasifikasi
[image:42.595.81.467.16.587.2]Hasil perhitungan selengkapnya dapat dilihat pada Tabel 8 berikut :
Tabel 8. Hasil pengujian tahap dua model pendeteksi ban ganda pada citra kendaraan menggunakan teknik sliding windows
Hasil yang diperoleh dari pengujian tahap dua menunjukkan akurasi model
pengklasifikasi yang jauh di bawah akurasi uji tahap pertama. Dari hasil pengujian
pada Tabel 7 juga terlihat bahwa model yang dibangun banyak melakukan salah
klasifikasi pada citra-citra yang tidak mengandung ban ganda yang terdeteksi
sebagai citra yang mengandung ban ganda. Untuk memahami perilaku ini
kemudian nilai fungsi pengklasifikasi dari tiap-tiap jendela detektor pada
taiap-tiap citra uji dianalisis.
Data tersebut menunjukkan bahwa sebuah citra (jendela detektor) akan
diklasifikasikan sebagai ban ganda jika nilai fungsi pengklasifikasi bernilai
negatif (-) dan bukan ban ganda jika positif. Semakin besar nilai negatif
menandakan bahwa model semakin yakin bahwa citra tersebut adalah ban ganda.
Agar semua citra uji yang tidak mengandung ban ganda diklasifikasi secara benar
maka nilai fungsi pengklasifikasi dari semua jendela detektor pada citra-citra uji
yang tidak mengandung ban ganda harus bernilai positif. Hal ini dapat dilakukan
dengan menambahkan sebuah konstanta (threshold) bernilai positif pada fungsi
pengklasifikasi dengan nilai lebih besar dari absolut nilai fungsi pengklasifikasi PCA 2D tahap 1
Kernel SVM
1 90 90 Kuadratik 98.4 67.0 <