MARYAM NOVIYANA BAHI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
XML RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA
MARYAM NOVIYANA BAHI
Skripsi
sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
MARYAM NOVIYANA BAHI
Skripsi
sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
MARYAM NOVIYANA BAHI. XML Retrieval for Document in Bahasa Indonesia. Under direction of JULIO ADISANTOSO.
XML (eXtensible Markup Language) retrieval is the content based retrieval of documents structured with XML and aims to implement focused retrieval strategies aiming at returning document components, which is XML elements instead of whole documents in response to a user query. Query languages for XML retrieval can be classified into content only (CO) and content and structure (CAS) query languages. Content only queries usually used for information retrieval where user does not know structure of a document but can get a specific answer from the query. Whereas, for content and structure queries used for XML retrieval systems which aims to answering user query on retrieve specific part of a document from content and structure XML documents. In this research queries are use content and structure (CAS) character with XML query additional fragments tagging of documents structured with XML. The purpose of this reasearch is to implement XML retrieval for document in Bahasa Indonesia using XML query additional fragments tagging with SIMNOMERGE similarity. The testing used 2 documents i.e. agricultural document and medicinal plants document. For the testing agricultural documents used 30 queries and 1000 documents. Whereas for medicinal plants documents used 13 queries and 93 documents. The testing result showed that the perfomance of information search engine is better when we use the medicinal plants documents than agricultural document. However, the performance of search engine with XML query additional fragment tagging with content and disease in madicinal plants document gave good result with around 0.8589 average precision and for XML query additional fragment tagging with text in agricultural document gave result with around 0.6156 average precision.
1. Ahmad Ridha, S.Kom, MS
Nama : Maryam Noviyana Bahi
NRP : G64060199
Menyetujui:
Pembimbing,
Ir. Julio Adisantoso, M.Kom NIP. 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si, M.Kom. NIP. 19660702 199302 1 001
PRAKATA
Alhamdulilahirobbil'alamin, segala puji syukur penulis panjatkan ke hadirat Allah subhanallah wata'ala atas segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Topik tugas akhir yang dipilih dalam penelitian ini adalah XML Retrieval untuk Dokumen Bahasa Indonesia.
Penulis sadar bahwa tugas akhir ini tidak akan terwujud tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada :
1 Orang tua tercinta, adikku Muhammad Nasir Bahi serta segenap keluarga besar, terima kasih atas doa dan dukungan yang tiada henti.
2 Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima Kasih atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3 Bapak Ahmad Ridha, S.Kom, MS dan Bapak Sony Hartono Wijaya, S.Kom, M.Kom selaku dosen penguji, Dr. Ir. Agus Buono, M.Si, M.Kom. selaku Kepala Departemen Ilmu Komputer serta seluruh staf Departemen Ilmu Komputer FMIPA IPB.
4 Teman-teman satu bimbingan Ilkom 43 dan Ilkom 44 Yucan, Hendrex, Tina, Awet, Eka, Wildan, Rio, Adit, Woro, Dhina, Devi, Agus, Nova, Isna, Fandi dan Nutri. Terima Kasih atas semangat dan kebersamaannya selama penyelesaian tugas akhir ini.
5 Sahabat-sahabatku Uut, Mames, Iki, Syamsul Bachri, dan seluruh sahabatku di Ilkomerz 43. Terima kasih atas motivasi dan kebersamaannya selama ini.
6 Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempunaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Maret 2012
Halaman
DAFTAR TABEL...v
DAFTAR GAMBAR...v
DAFTAR LAMPIRAN...v
PENDAHULUAN Latar Belakang...1
Tujuan...1
Ruang Lingkup...1
TINJAUAN PUSTAKA Information Retrieval (Temu-Kembali Informasi)...1
XML Retrieval...1
Vector Space Model untuk XML Retrieval...2
Recall dan Precision...2
METODE PENELITIAN Evaluasi Sistem...3
Asumsi...3
Lingkungan Implementasi...3
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian...3
Pemrosesan Dokumen...4
Pengindeksan...4
Pemrosesan Kueri...4
Hasil Temu Kembali...4
Pengujian Kinerja Sistem...5
KESIMPULAN DAN SARAN Kesimpulan...7
Saran...8
DAFTAR PUSTAKA...8
LAMPIRAN...9
DAFTAR TABEL
Halaman
1 Deskripsi koleksi dokumen...3
2 Hasil perhitungan average precision pada dokumen pertanian...6
3 Hasil perhitungan average precision pada dokumen tanaman obat ...7
DAFTAR GAMBAR
Halaman 1 Diagram alur penelitiaan...22 Format dokumen dokumen pertanian...4
3 Format dokumen tanaman obat ...4
4 Contoh tree pada kueri...4
5 Grafik R-P untuk tagging title...5
6 Grafik R-P untuk tagging text...5
7 Grafik R-P untuk tagging title and text ...5
8 Grafik R-P untuk dokumen pertanian ...6
9 Grafik R-P untuk tagging penyakit...6
10 Grafik R-P untuk tagging content...6
11 Grafik R-P untuk tagging content dan penyakit...7
12 Grafik R-P untuk dokumen tanaman obat ...7
DAFTAR LAMPIRAN
Halaman 1 Antarmuka implementasi sistem pertanian...102 Antarmuka implementasi sistem tanaman obat...11
3 Daftar kueri dan jumlah dokumen relevan pada sistem pertanian...12
4 Daftar kueri dan jumlah dokumen relevan pada sistem tanaman obat...13
5 Hasil perhitungan precision pada elevent standard recall untuk sistem pertanian...14
6 Hasil perhitungan precision pada elevent standard recall untuk sistem tanaman obat...15
PENDAHULUAN
Latar Belakang
Pada saat ini, informasi dapat diperoleh secara cepat dan mudah dengan menggunakan metode kembali informasi. Sistem temu-kembali mendapatkan informasi dengan menggunakan kueri tertentu. Dengan kueri tersebut, sistem akan melakukan proses temu-kembali sehingga menemukan informasi atau dokumen yang dicari sesuai urutan relevansinya.
Dalam sistem temu kembali informasi, data semi terstruktur dapat direpresentasikan menjadi dua bagian, yaitu sistem temu-kembali informasi biasa dan sistem XML
retrieval. Sistem temu kembali informasi biasa membandingkan semua kumpulan dari term
yang ada berupa gambar, kata-kata, ciri-ciri, dan lain-lain, sedangkan sistem XML retrieval
membandingkan kata yang digambarkan dengan suatu struktursehingga lebih fleksibel (Manning et al. 2008).
Permasalahan di XML retrieval adalah pengguna ingin mengembalikan bagian dari dokumen pada elemen XML bukan dokumen secara keseluruhan dan membedakan konteks yang berbeda dari setiap term dalam pemeringkatan (Manning et al., 2008).
Immaneni dan Thirunarayan (1999) melakukan penelitian terhadap bahasa kueri yang fleksibel dan mengembangkan semantik intuitif dengan ekstraksi dari potongan-potongan dokumen XML yang relevan. Carmel et al. (2002) menambahkan vector space model untuk menemukan dokumen XML dengan menggunakan kueri pada potongan tagging XML dan menghasilkan peringkat sesuai relevansi yang terurut. Fuhr dan Gövert (2002) menggunakan content and structure (CAS) queries dan content only
(CO) queries serta dianalisis menggunakan
recall dan precision. Lalmas (2009) telah melakukan pendekatan terhadap kueri pada
potongan tagging XML dan
merepresentasikan hasil peringkat dokumen XML yang terurut secara relevan.
Penelitian yang telah dilakukan dengan menggunakan metode XML retrieval baru diterapkan menggunakan koleksi bahasa Inggris. Untuk itu, penelitian kali ini akan menerapkan metode XML retrieval
menggunakan koleksi dokumen bahasa Indonesia dengan menggunakan kueri XML dengan potongan tagging dari dokumen
sehingga dokumen dihasilkan lebih spesifik dari sebuah jawaban kueri yang diberikan.
Tujuan
Tujuan dari penelitian ini ialah mengimplementasikan XML retrieval pada dokumen bahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini ialah menggunakan korpus berupa dokumen bahasa Indonesia dengan menggunakan struktur tag
XML yang sama untuk setiap dokumen.
TINJAUAN PUSTAKA
Information Retrieval (Temu Kembali Infomasi)
Temu-kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu, pengguna harus mentransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses oleh mesin pencari
sehingga kueri tersebut akan
merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, sistem akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto, 1999).
XML Retrieval
XML singkatan dari Extensible Markup Language. Extensible mengandung arti bahasa XML dapat diperluas sendiri sehingga tag-tag
atau kode-kode di dalamnya dapat didefinisikan sendiri. Markup berarti bahasa ini berisi kode-kode instruksi yang harus diterjemahkan oleh suatu aplikasi lain untuk menjalankan proses eksekusi yang sesungguhnya (Siregar, 2003). Sebuah dokumen XML adalah sebuah tree yang terurut dan terlabeli. Setiap node dari tree
adalah sebuah elemen XML yang ditandai dengan sebuah tag pembuka dan tag penutup. Sebuah elemen dapat memiliki satu atau lebih atribut (Manning et al.,2008).
mengimplementasikan temu-kembali yang berfokus pada strategi pengembalian komponen dokumen yaitu pada elemen XML yang merupakan jawaban dari sebuah kueri. Bahasa kueri pada XML retrieval dapat direpresentasikan menjadi dua, yaitu content and structure (CAS) queries dan content only
(CO) queries. (CAS) queries merupakan kata kunci yang sifatnya berstruktur sehingga informasi yang didapat lebih spesifik berupa isi dan struktur dari dokumen XML, sedangkan (CO) queries merupakan kata kunci yang sifatnya tidak berstruktur yang biasa dimasukkan dalam sistem temu-kembali biasa (Lalmas, 2009).
Vector Space Model untuk XML Retrieval
Dalam temu-kembali vector space model, dokumen dan kueri direpresentasikan sebagai vektor (Ogilvie, 2010). Term frequency (tf) merupakan frekuensi kemunculan suatu term t
pada dokumen d. Document frequency (df) merupakan banyaknya dokumen dalam korpus yang mengandung kata tertentu (Manning et al., 2008).
Pembobotan tf-idf memberikan bobot pada
term t dalam dokumen d dengan nilai:
tft,d ×idft
dengan idft =log
N dft
, tft,d adalah frekuensi
term t pada dokumen d, N adalah jumlah dokumen dalam koleksi, dan dft
adalah jumlah
dokumen yang mengandung termt.
Vector space model untuk XML Retrieval
dapat ditentukan dengan menghitung SIMNOMERGE similarity yang nilai kemiripannya dapat lebih besar dari 1. Dalam SIMNOMERGE similarity, terdapat nilai
context resemblance yang merupakan ukuran sederhana dari kemiripan setiap context query
dan context document (Manning et al., 2008) yang dirumuskan sebagai berikut:
CRcq,cd=
{
1∣cq∣
1∣cd∣
jika cqcocok dengan cd
0 jika cqtidak cocok dengan cd
}
dengan |cq| adalah banyaknya node pada kueri
dan |cd| adalah banyaknya node pada
dokumen.
Oleh karena itu, SIMNOMERGE
similarity dapat dirumuskan sebagai berikut (Manning et al., 2008):
SIMNOMERGEq ,d=∑
cq∈Bcd∈∑B
CRcq,cd∑ t∈V
weightq ,t , cq
weightd, t , cd
∑c∈B, t∈Vweight 2d , t ,c
dengan V adalah himpunan kata yang unik, B
adalah kumpulan semua konteks XML, cq
adalah panjang konteks pada kueri, cdadalah
panjang konteks pada dokumen, weight(q,t,cq)
merupakan bobot term t pada konteks kueri,
weight(d,t,cd) adalah bobot term t pada
konteks dokumen, dan
∑c∈B, t∈Vweight2
d , t ,c adalah normalisasi panjang dokumen.
Recall dan Precision
Recall adalah perbandingan antara dokumen relevan yang ditemukembalikan
∣Ra∣dengan dokumen relevan yang ada
pada korpus ∣R∣.
Recall=∣Ra∣ ∣R∣
Precision adalah perbandingan antara dokumen relevan yang ditemukembalikan
∣Ra∣ dengan dokumen yang
ditemukembalikan ∣A∣ (Baeza-Yates & Ribeiro-Neto, 1999).
Precision=∣Ra∣ ∣A∣
Average precision (AVP) adalah suatu ukuran evaluasi kinerja temu-kembali yang diperoleh dengan menghitung average precision menggunakan eleven standardrecall
yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1 (Baeza-Yates & Ribeiro-Neto, 1999).
METODE PENELITIAN
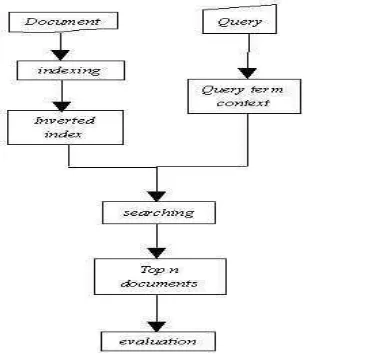
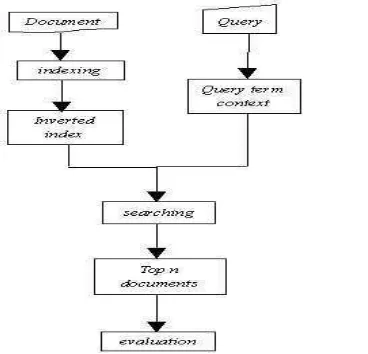
Gambaran umum sistem penelitian yang dikembangkan dapat dilihat pada Gambar 1.
Tahap awal dari penelitian ini adalah mengambil koleksi dokumen terstruktur XML yang terdapat pada satu direktori, kemudian dilakukan pembuangan kata-kata yang tidak penting (stopwords) dan indexing terhadap dokumen. Dari hasil pengindeksan, dilakukan pembentukan inverted index dan terbentuk pencarian dokumen dengan kueri yang diberikan dapat dilakukan.
Evaluasi Sistem
Evaluasi dilakukan terhadap 30 dokumen teratas untuk sistem pertanian, sedangkan untuk sistem tanaman obat evaluasi dilakukan terhadap 20 dokumen teratas untuk setiap hasil temu-kembali sistem berdasarkan kueri yang diberikan.Pengujian sistem dilakukan dengan melakukan perhitungan terhadap recall dan
precision dalam menentukan tingkat keefektifan proses hasil temu-kembali. Dalam perhitungan recall, digunakan eleven standard recall yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1. Perhitungan ini dilakukan untuk masing-masing jenis kueri dengan potongan tagging XML yang berbeda dari sistem pertanian dan sistem tanaman obat .
Hasil perhitungan recall dan precision
untuk masing-masing pembobotan akan dibandingkan dalam bentuk grafik recall-precision. Selain itu, juga akan dihitung nilai
average precision dari jenis kueri dengan potongan tagging XML yang berbeda dari sistem pertanian dan sistem tanaman obat untuk memperoleh sistem yang lebih baik dalam metode XML retrieval mengunakan dokumen bahasa Indonesia.
Lingkungan Implementasi
Perangkat lunak yang digunakan untuk penelitian, yaitu:
Microsoft Windows XP Professional sebagai sistem operasi.
Apache di dalam XAMPP-win32-1.7.1 sebagai web server.
Notepad++ sebagai program editor.
Perangkat keras yang digunakan untuk penelitian, yaitu:
Prosesor Intel Celeron 2.0 GHz.
RAM 2 GB.
Harddisk 80 GB.HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
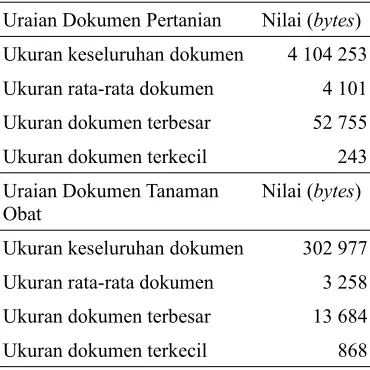
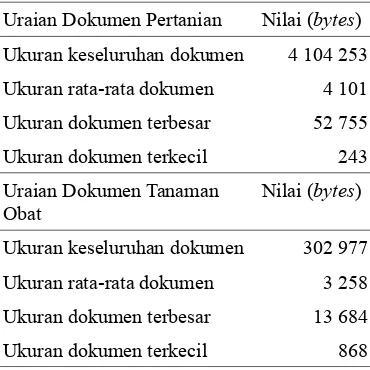
Penelitian ini menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat. Dokumen-dokumen ini berasal dari Laboratorium Temu Kembali, Departemen Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1.
Tabel 1 Deskripsi koleksi dokumen
Uraian Dokumen Pertanian Nilai (bytes) Ukuran keseluruhan dokumen 4 104 253
Ukuran rata-rata dokumen 4 101
Ukuran dokumen terbesar 52 755
Ukuran dokumen terkecil 243
Uraian Dokumen Tanaman Obat
Nilai (bytes)
Ukuran keseluruhan dokumen 302 977
Ukuran rata-rata dokumen 3 258
Ukuran dokumen terbesar 13 684
Ukuran dokumen terkecil 868
Dokumen-dokumen ini memiliki bentuk XML yang seragam untuk setiap dokumen. Format struktur XML dapat dilihat pada Gambar 2 untuk dokumen pertanian dan Gambar 3 untuk dokumen tanaman obat.
Dokumen pertanian dikelompokkan ke dalam tag-tag berikut:
•
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag yang lebih spesifik.•
<DOCNO></<DOCNO>, tag ini menunjukkan ID dari dokumen.•
<TITLE></TITLE>, tag ini menunjukkan judul dokumen yang diberitakan.•
<AUTHOR></AUTHOR>, tag ini menunjukkan nama pengarang berita tersebut.•
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.•
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.•
<content></content>, tag ini mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya.•
<fam></fam>, tag ini menunjukkan nama family dari tanaman obat.•
<penyakit></penyakit>, tag ini menunjukkan nama penyakit yang berkaitan dengan tanaman obat.Gambar 2 Format dokumen dokumen pertanian.
Gambar 3 Format dokumen tanaman obat.
Pemrosesan Dokumen
Sebelum dilakukan proses pengindeksan koleksi, dokumen terlebih dahulu dipisahkan berdasarkan jenis tag. Dokumen pertanian dibedakan dalam tiga tagging: title, text, dan
title & text sedangkan untuk dokumen tanaman obat adalah penyakit, content, dan
content & penyakit dengan menggunakan fungsi preg_split.
Pengindeksan
Pengindeksan dokumen dimulai dengan melakukan parsing terhadap setiap file yang
dibedakan berdasarkan pemisahan tagging, kemudian dilakukan pembuangan stopwords
yang terdapat pada file “stopwords.txt”. File
ini terdiri atas 661 kata yang dipisahkan dengan newline. Selanjutnya, term diubah ke lower case dengan fungsi preg_match.
Pengindeksan 1000 dokumen pertanian dan 93 dokumen tanaman obat pada setiap tagging
menghasilkan jumlah kata unik dan frekuensi total setiap kata.
Pemrosesan Kueri
Untuk menjalankan proses evaluasi, kueri dimasukkan pada sistem mesin pencari (Lampiran 1 dan Lampiran 2). Jumlah kueri yang digunakan pada penelitian ini ialah 30 untuk dokumen pertanian (Lampiran 3) dan 13 untuk dokumen tanaman obat (Lampiran 4). Kueri-kueri ini tersedia di Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer. Kueri pada sistem ini menggunakan kueri XML, yaitu berupa kueri yang dipasangkan dengan potongan tagging
XML yang bersifat terstruktur. Pada kueri XML, potongan tagging yang dipakai pada dokumen pertanian adalah
1. <title>kueri</title>
2. <text>kueri</text>
3. <title><text>kueri</text></t itle>
Tagging yang dipakai pada dokumen tanaman obat adalah
1. <penyakit>kueri</penyakit>
2. <content>kueri</content>
3. <content><penyakit>kueri</pe nyakit></content>
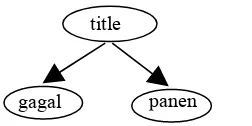
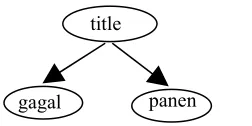
Penghitungan panjang konteks pada kueri dapat dicontohkan sebagai berikut:
“<title> gagal panen</title>”
Kueri tersebut diilustrasikan menjadi tree
yang digambarkan pada Gambar 4. Gambar 4 menunjukkan bahwa panjang konteks pada kueri ialah 3.
Gambar 4 Contoh tree pada kueri.
Hasil Temu Kembali
Pada penelitian ini, pembobotan yang <?xml version="1.0" encoding="utf-8"?> <DOC> <DOCNO>017</DOCNO> <nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal>
<content>Famili : Crassulaceae. Nama Lokal : Cakar itek (Sunda); dan sosor bebek....</content> <fam>Crassulaceae</fam> <penyakit>Kulit</penyakit> </DOC> title panen gagal <?xml version="1.0" encoding="utf-8"?> <DOC> <DOCNO>suaramerdeka1201 04</DOCNO>
<TITLE>Pemerintah Larang Impor Beras pada Pra dan Pascapanen Raya </TITLE>
<AUTHOR> (ant-82) </AUTHOR> <SOURCE>suaramerdeka</SOURCE> <DATE>12/1/2004</DATE>
digunakan yaitu tf-idf. Jumlah dokumen teratas yang diambil adalah 30 untuk sistem dokumen pertanian dan 20 untuk sistem dokumen tanaman obat.
Pengujian Kinerja Sistem
Proses evaluasi dalam penelitian ini dilakukan pada dua koleksi dokumen yaitu dokumen pertanian dan dokumen, tanaman obat beserta kueri uji yang berbeda.
1 Pengujian pada Dokumen Pertanian
Proses evaluasi pada dokumen pertanian menggunakan 30 kueri uji yang telah ada sebelumnya berikut dokumen yang relevan. Pencarian dengan kueri uji ini dilakukan dengan tujuan mendapatkan nilai recall dan
precision untuk 30 dokumen teratas yang ditemukembalikan oleh sistem dan dilakukan perhitungan interpolasi terhadap maksimum untuk mendapatkan nilai average precision
(AVP).
Pengujian terhadap kueri XML pada dokumen pertanian terdapat tiga jenis potongan tagging dari struktur dokumen XML di koleksi, yaitu :
a Kueri XML dengan potongan tagging title
Gambar 5 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging title. Nilai average precision dari pencarian kueri XML dengan potongan tagging title
sebesar 0.5005.
Gambar 5 Grafik R-P untuk tagging title.
b Kueri XML dengan potongan tagging text
Gambar 6 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging text. Nilai average precision dari pencarian kueri XML dengan potongan tagging text
sebesar 0.6156 atau meningkat 12% dari kueri XML dengan potongan tagging title. Hal ini menyebabkan kata konteks kueri banyak yang sama dengan konteks dokumen yang menyebabkan nilai average precision
meningkat sebesar 12%.
Gambar 6 Grafik R-P untuk tagging text.
c Kueri XML dengan potongan tagging title andtext
Gambar 7 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging title dan text.
Gambar 7 Grafik R-P untuk potongan tagging title & text.
Nilai average precision dari pencarian kueri XML dengan potongan tagging title and text sebesar 0.6153 atau lebih rendah 0.0003 dari kueri XML dengan potongan tagging text
dan meningkat 12% dari kueri XML dengan potongan tagging title. Average precision
masing-masing potongan tagging pada kueri XML dapat dilihat pada Tabel 2. Kinerja temu-kembali diilustrasikan dengan grafik
recall-precision yang ditunjukan pada Gambar 8.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re ci si o n
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re c is io n
Gambar 8 Grafik R-P untuk dokumen pertanian.
Gambar 8 menunjukkan bahwa untuk perbedaan jenis potongan tagging telah memiliki perbedaan yang signifikan terhadap penambahan potongan tagging XML dan panjangnya kata pada suatu konteks di dokumen pertanian.
Tabel 2 Hasil perhitungan average precision
pada dokumen pertanian
Jenis Tagging AVP
Title 0.5005
Text 0.6156
Title & Text 0.6153
Tabel 2 menunjukkan bahwa kinerja sistem
pada pembobotan tf-idf dengan
SIMNOMERGE similarity memberikan temu-kembali lebih baik yaitu pada kueri XML dengan potongan tagging text dan tagging title and text sebesar 62%. Berarti, secara rata-rata pada tiap recall point, 62% hasil temu-kembali relevan dengan kueri dan meningkat sebesar 12% dari kueri XML dengan potongan
tagging title.
2 Pengujian pada Dokumen Tanaman Obat
Proses evaluasi pada dokumen tanaman obat menggunakan 13 kueri uji yang telah ada sebelumnya berikut dokumen-dokumen yang relevan. Pengujian yang dilakukan sama seperti sebelumnya, yaitu melakukan perhitungan recall-precision terhadap kueri XML dan dilakukan tahap perhitungan interpolasi masksimum untuk mendapakan nilai average precision (AVP) yang akan menggambarkan nilai kinerja pada sistem secara keseluruhan.
Pada pengujian sistem dilakukan untuk
pencarian dokumen dengan kueri XML dengan mengambil 20 dokumen teratas. Pengujian terhadap kueri XML pada dokumen tanaman obat terdapat tiga jenis potongan
tagging dari struktur dokumen XML di koleksi dokumen pertanian, yaitu :
a Kueri XML dengan potongan tagging
penyakit
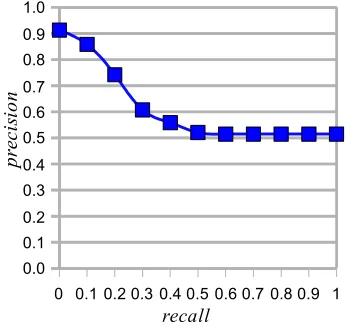
Gambar 9 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging
penyakit. Pada pengujian sistem pada pencarian kueri XML dengan potongan
tagging penyakit, nilai average precision yang didapat sebesar 0.5968. Pengaturan skala sumbu y pada Gambar 9 dimulai dengan skala minimum 0.5750 dan skala maksimum 0.6150. Hal ini dilakukan untuk melihat grafik R-P potongan tagging penyakit telah relevan.
Gambar 9 Grafik R-P untuk tagging penyakit. b Kueri XML dengan Potongan tagging content
Gambar 10 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging content.
Gambar 10 Grafik R-P untuk tagging content. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.5750 0.5800 0.5850 0.5900 0.5950 0.6000 0.6050 0.6100 0.6150 recall p re ci si o n
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Recall P re ci si o n
Nilai average precision dari pencarian kueri XML dengan potongan tagging content
sebesar 0.6273 atau lebih tinggi sebesar 0.0305 dari kueri XML dengan potongan
tagging penyakit.
c Kueri XML dengan potongan tagging content dan penyakit
Gambar 11 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging content dan penyakit. Nilai average precision
dari pencarian kueri XML dengan potongan
tagging content dan penyakit sebesar 0.8589. Perbedaan kinerja sistem pada kueri potongan
tagging content dan content & penyakit di sistem tanaman obat diilustrasikan pada grafik recall-precision yang dapat dilihat Gambar 12 dan uraian masing-masing nilai
average precision terhadap kueri XML di tanaman obat dapat dilihat pada Tabel 3.
Gambar 11 Grafik R-P untuk tagging content
dan penyakit.
Gambar 12 Grafik R-P untuk dokumen tanaman obat.
Dari Gambar 12, dapat dilihat bahwa terjadi perubahan signifikan terhadap
penyatuan potongan tagging pada sistem tanaman obat, yaitu content dan penyakit. Di potongan tagging tersebut, terdapat banyak kueri yang dicari oleh pengguna sehingga banyak terambil dokumen yang relevan pada pengujian kueri XML dengan potongan
tagging content dan penyakit.
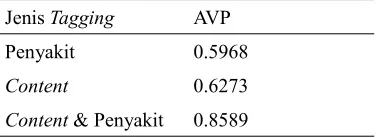
Tabel 3 Hasil perhitungan average precision
pada dokumen tanaman obat
Jenis Tagging AVP
Penyakit 0.5968
Content 0.6273
Content & Penyakit 0.8589
Hasil pada Tabel 3 menunjukkan bahwa kinerja sistem untuk tanaman obat dengan nilai average precision yang sangat baik mencapai 86% pada kueri XML dengan potongan tagging content dan penyakit. Berarti, secara rata-rata pada tiap recall point,
86% hasil temu-kembali relevan dengan kueri. Kinerja pengujian kueri XML dengan potongan tagging content dan penyakit meningkat 23% dari potongan tagging content
atau meningkat 26% dari potongan tagging
penyakit.
Hasil pengujian pada dokumen tanaman obat lebih baik daripada pengujian dokumen pertanian. Hal ini dikarenakan isi konteks dokumen banyak yang sama dengan representasi dari kueri uji yang dilakukan. Hal ini mengakibatkan sistem dapat menghasilkan dokumen yang spesifik dari kueri XML dengan potongan tagging di dokumen tanaman obat. Selain itu, dokumen tanaman obat juga bersifat berbeda antar dokumennya. Setiap dokumen pada setiap tagging memiliki penciri yang berbeda dari dokumen lainnya sehingga membuat hasil temu-kembali menjadi semakin baik.
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian ini menunjukkan bahwa:
1 Kinerja kueri XML pada sistem dokumen tanaman obat lebih baik daripada dokumen pertanian.
2
Kueri XML dengan potongan tagging content dan penyakit di dokumen tanaman obat mendapatkan nilai average precisionyang baik yaitu sebesar 0.8589, sedangkan pada dokumen pertanian nilai 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re ci si o n
average precision maksimumnya mencapai 0.6156 pada kueri XML dengan potongan tagging text.
Saran
Terdapat beberapa hal yang dapat ditambahkan atau diperbaiki untuk penelitian ke depannya, seperti:
1 Membandingkan kinerja pada sistem ini menggunakan pembobotan dan similarity
lainnya yang ada pada metode di XML
retrieval.
2 Menggunakan dokumen XML dengan struktur yang lebih kompleks.
DAFTAR PUSTAKA
Anbiana ED. 2009. Pseudo-Relevance Feedback pada temu kembali menggunakan segmentasi dokumen [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information Retrieval. New York: Addison Wesley.
Carmel D, Efraty N, Landau GM, Maarek YS, Mass Y. 2002. An Extension of the Vector Space Model for Querying XML Documents via XML Fragments. Haifa: Haifa University.
Fuhr N, Gövert N. 2002. INEX: Initiative for the Evaluation of XML Retrieval. London: University of Dortmund, Germany and Queen Mary University of London, UK.
Immaneni T, Thirunarayan K. 1999. Flexible Querying of XML Documents. Ohio: Department of Computer Science and Engineering Wright State University.
Lalmas M. 2009. XML Information retrieval. Glasgow: University of Glasgow.
Manning CD. Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Ogilvie P. 2010. Retrieval Using Document Structure and Annotations. Pittsburgh: Language Technologies Institute.
Lampiran 3 Daftar kueri dan jumlah dokumen relevan pada Sistem Pertanian
No Kueri Jumlah dokumen relevan
1 Bencana kekeringan 39
2 Dukungan pemerintah pada pertanian 29
3 Flu burung 21
4 Gabah kering giling 24
5 Gagal panen 48
6 Harga komoditas pertanian 57
7 Impor beras indonesia 43
8 Industri gula 19
9 Institut pertanian bogor 40
10 Kelangkaan pupuk 20
11 Kelompok masyarakat tani 32
12 Laboratorium pertanian 21
13 Musim panen 40
14 Pembangunan untuk sektor pertanian 46
15 Penerapan bioteknologi di indonesia 42
16 Penerapan teknologi pertanian 39
17 Penyakit hewan ternak 13
18 Penyuluhan pertanian 27
19 Perdagangan hasil pertanian 30
20 Pertanian organik 24
21 Petani tebu 20
22 peternak unggas 20
23 Produk usaha peternakan rakyat 19
24 Pupuk organik 20
25 Riset pertanian 69
26 Swasembada pangan 30
27 Tadah hujan 18
28 Tanaman obat 29
29 Tanaman pangan 43
Lampiran 4 Daftar kueri dan jumlah dokumen relevan pada Sistem Tanaman Obat
No Kueri Jumlah dokumen relevan
1 Batuk rejan 6
2 Diabetes mellitus 16
3 Gangguan pencernaan 19
4 Kencing manis 16
5 Kronis 9
6 Kulit 10
7 Masuk angin 12
8 Muntah darah 15
9 Nyeri radang demam 19
10 Pencernaan 19
11 Perawatan 24
12 Pernapasan 5
Lampiran 5 Hasil perhitungan precision pada eleven standard recall untuk Sistem Pertanian
Recall
Precision
Tagging Title Tagging Text Tagging Title + Text
0 0.7762 0.9125 0.9144
0,1 0.6106 0.8581 0.8674
0,2 0.5294 0.7418 0.7400
0,3 0.4754 0,6075 0.6126
0,4 0.4643 0.5580 0.5537
0,5 0.4451 0.5203 0.5174
0,6 0.4431 0.5148 0.5125
0,7 0.4405 0.5148 0.5125
0,8 0.4405 0.5148 0.5125
0,9 0.4405 0.5148 0.5125
1 0.4405 0.5148 0.5125
Lampiran 6 Hasil perhitungan precision pada eleven standard recall untuk Sistem Tanaman Obat
Recall
Precision
Tagging Penyakit Tagging Content Tagging Content + Penyakit
0 0.6154 0.7194 0.9308
0,1 0.6000 0.7066 0.9308
0,2 0.6000 0.6874 0.9308
0,3 0.5962 0.6617 0.9308
0,4 0.5962 0.6468 0.9212
0,5 0.5962 0.6426 0.8931
0,6 0.5962 0.6356 0.8658
0,7 0.5911 0.5898 0.8073
0,8 0.5911 0.5604 0.7722
0,9 0.5911 0.5552 07671
1 0.5911 0.4949 0.6983
MARYAM NOVIYANA BAHI. XML Retrieval for Document in Bahasa Indonesia. Under direction of JULIO ADISANTOSO.
XML (eXtensible Markup Language) retrieval is the content based retrieval of documents structured with XML and aims to implement focused retrieval strategies aiming at returning document components, which is XML elements instead of whole documents in response to a user query. Query languages for XML retrieval can be classified into content only (CO) and content and structure (CAS) query languages. Content only queries usually used for information retrieval where user does not know structure of a document but can get a specific answer from the query. Whereas, for content and structure queries used for XML retrieval systems which aims to answering user query on retrieve specific part of a document from content and structure XML documents. In this research queries are use content and structure (CAS) character with XML query additional fragments tagging of documents structured with XML. The purpose of this reasearch is to implement XML retrieval for document in Bahasa Indonesia using XML query additional fragments tagging with SIMNOMERGE similarity. The testing used 2 documents i.e. agricultural document and medicinal plants document. For the testing agricultural documents used 30 queries and 1000 documents. Whereas for medicinal plants documents used 13 queries and 93 documents. The testing result showed that the perfomance of information search engine is better when we use the medicinal plants documents than agricultural document. However, the performance of search engine with XML query additional fragment tagging with content and disease in madicinal plants document gave good result with around 0.8589 average precision and for XML query additional fragment tagging with text in agricultural document gave result with around 0.6156 average precision.
PENDAHULUAN
Latar Belakang
Pada saat ini, informasi dapat diperoleh secara cepat dan mudah dengan menggunakan metode kembali informasi. Sistem temu-kembali mendapatkan informasi dengan menggunakan kueri tertentu. Dengan kueri tersebut, sistem akan melakukan proses temu-kembali sehingga menemukan informasi atau dokumen yang dicari sesuai urutan relevansinya.
Dalam sistem temu kembali informasi, data semi terstruktur dapat direpresentasikan menjadi dua bagian, yaitu sistem temu-kembali informasi biasa dan sistem XML
retrieval. Sistem temu kembali informasi biasa membandingkan semua kumpulan dari term
yang ada berupa gambar, kata-kata, ciri-ciri, dan lain-lain, sedangkan sistem XML retrieval
membandingkan kata yang digambarkan dengan suatu struktursehingga lebih fleksibel (Manning et al. 2008).
Permasalahan di XML retrieval adalah pengguna ingin mengembalikan bagian dari dokumen pada elemen XML bukan dokumen secara keseluruhan dan membedakan konteks yang berbeda dari setiap term dalam pemeringkatan (Manning et al., 2008).
Immaneni dan Thirunarayan (1999) melakukan penelitian terhadap bahasa kueri yang fleksibel dan mengembangkan semantik intuitif dengan ekstraksi dari potongan-potongan dokumen XML yang relevan. Carmel et al. (2002) menambahkan vector space model untuk menemukan dokumen XML dengan menggunakan kueri pada potongan tagging XML dan menghasilkan peringkat sesuai relevansi yang terurut. Fuhr dan Gövert (2002) menggunakan content and structure (CAS) queries dan content only
(CO) queries serta dianalisis menggunakan
recall dan precision. Lalmas (2009) telah melakukan pendekatan terhadap kueri pada
potongan tagging XML dan
merepresentasikan hasil peringkat dokumen XML yang terurut secara relevan.
Penelitian yang telah dilakukan dengan menggunakan metode XML retrieval baru diterapkan menggunakan koleksi bahasa Inggris. Untuk itu, penelitian kali ini akan menerapkan metode XML retrieval
menggunakan koleksi dokumen bahasa Indonesia dengan menggunakan kueri XML dengan potongan tagging dari dokumen
sehingga dokumen dihasilkan lebih spesifik dari sebuah jawaban kueri yang diberikan.
Tujuan
Tujuan dari penelitian ini ialah mengimplementasikan XML retrieval pada dokumen bahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini ialah menggunakan korpus berupa dokumen bahasa Indonesia dengan menggunakan struktur tag
XML yang sama untuk setiap dokumen.
TINJAUAN PUSTAKA
Information Retrieval (Temu Kembali Infomasi)
Temu-kembali informasi berkaitan dengan cara merepresentasikan, menyimpan, mengorganisasikan, dan mengakses informasi. Merepresentasikan dan mengorganisasikan suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya. Akan tetapi, mengetahui informasi yang diinginkan pengguna bukan merupakan suatu hal yang mudah. Untuk itu, pengguna harus mentransformasikan informasi yang dibutuhkan ke dalam suatu kueri yang akan diproses oleh mesin pencari
sehingga kueri tersebut akan
merepresentasikan informasi yang dibutuhkan oleh pengguna. Dengan kueri tersebut, sistem akan menemukembalikan informasi yang relevan dengan kueri (Baeza-Yates & Ribeiro-Neto, 1999).
XML Retrieval
XML singkatan dari Extensible Markup Language. Extensible mengandung arti bahasa XML dapat diperluas sendiri sehingga tag-tag
atau kode-kode di dalamnya dapat didefinisikan sendiri. Markup berarti bahasa ini berisi kode-kode instruksi yang harus diterjemahkan oleh suatu aplikasi lain untuk menjalankan proses eksekusi yang sesungguhnya (Siregar, 2003). Sebuah dokumen XML adalah sebuah tree yang terurut dan terlabeli. Setiap node dari tree
adalah sebuah elemen XML yang ditandai dengan sebuah tag pembuka dan tag penutup. Sebuah elemen dapat memiliki satu atau lebih atribut (Manning et al.,2008).
mengimplementasikan temu-kembali yang berfokus pada strategi pengembalian komponen dokumen yaitu pada elemen XML yang merupakan jawaban dari sebuah kueri. Bahasa kueri pada XML retrieval dapat direpresentasikan menjadi dua, yaitu content and structure (CAS) queries dan content only
(CO) queries. (CAS) queries merupakan kata kunci yang sifatnya berstruktur sehingga informasi yang didapat lebih spesifik berupa isi dan struktur dari dokumen XML, sedangkan (CO) queries merupakan kata kunci yang sifatnya tidak berstruktur yang biasa dimasukkan dalam sistem temu-kembali biasa (Lalmas, 2009).
Vector Space Model untuk XML Retrieval
Dalam temu-kembali vector space model, dokumen dan kueri direpresentasikan sebagai vektor (Ogilvie, 2010). Term frequency (tf) merupakan frekuensi kemunculan suatu term t
pada dokumen d. Document frequency (df) merupakan banyaknya dokumen dalam korpus yang mengandung kata tertentu (Manning et al., 2008).
Pembobotan tf-idf memberikan bobot pada
term t dalam dokumen d dengan nilai:
tft,d ×idft
dengan idft =log
N dft
, tft,d adalah frekuensi
term t pada dokumen d, N adalah jumlah dokumen dalam koleksi, dan dft
adalah jumlah
dokumen yang mengandung termt.
Vector space model untuk XML Retrieval
dapat ditentukan dengan menghitung SIMNOMERGE similarity yang nilai kemiripannya dapat lebih besar dari 1. Dalam SIMNOMERGE similarity, terdapat nilai
context resemblance yang merupakan ukuran sederhana dari kemiripan setiap context query
dan context document (Manning et al., 2008) yang dirumuskan sebagai berikut:
CRcq,cd=
{
1∣cq∣
1∣cd∣
jika cqcocok dengan cd
0 jika cqtidak cocok dengan cd
}
dengan |cq| adalah banyaknya node pada kueri
dan |cd| adalah banyaknya node pada
dokumen.
Oleh karena itu, SIMNOMERGE
similarity dapat dirumuskan sebagai berikut (Manning et al., 2008):
SIMNOMERGEq ,d=∑
cq∈Bcd∈∑B
CRcq,cd∑ t∈V
weightq ,t , cq
weightd, t , cd
∑c∈B, t∈Vweight 2d , t ,c
dengan V adalah himpunan kata yang unik, B
adalah kumpulan semua konteks XML, cq
adalah panjang konteks pada kueri, cdadalah
panjang konteks pada dokumen, weight(q,t,cq)
merupakan bobot term t pada konteks kueri,
weight(d,t,cd) adalah bobot term t pada
konteks dokumen, dan
∑c∈B, t∈Vweight2
d , t ,c adalah normalisasi panjang dokumen.
Recall dan Precision
Recall adalah perbandingan antara dokumen relevan yang ditemukembalikan
∣Ra∣dengan dokumen relevan yang ada
pada korpus ∣R∣.
Recall=∣Ra∣ ∣R∣
Precision adalah perbandingan antara dokumen relevan yang ditemukembalikan
∣Ra∣ dengan dokumen yang
ditemukembalikan ∣A∣ (Baeza-Yates & Ribeiro-Neto, 1999).
Precision=∣Ra∣ ∣A∣
Average precision (AVP) adalah suatu ukuran evaluasi kinerja temu-kembali yang diperoleh dengan menghitung average precision menggunakan eleven standardrecall
yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1 (Baeza-Yates & Ribeiro-Neto, 1999).
METODE PENELITIAN
Gambaran umum sistem penelitian yang dikembangkan dapat dilihat pada Gambar 1.
Tahap awal dari penelitian ini adalah mengambil koleksi dokumen terstruktur XML yang terdapat pada satu direktori, kemudian dilakukan pembuangan kata-kata yang tidak penting (stopwords) dan indexing terhadap dokumen. Dari hasil pengindeksan, dilakukan pembentukan inverted index dan terbentuk pencarian dokumen dengan kueri yang diberikan dapat dilakukan.
Evaluasi Sistem
Evaluasi dilakukan terhadap 30 dokumen teratas untuk sistem pertanian, sedangkan untuk sistem tanaman obat evaluasi dilakukan terhadap 20 dokumen teratas untuk setiap hasil temu-kembali sistem berdasarkan kueri yang diberikan.Pengujian sistem dilakukan dengan melakukan perhitungan terhadap recall dan
precision dalam menentukan tingkat keefektifan proses hasil temu-kembali. Dalam perhitungan recall, digunakan eleven standard recall yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1. Perhitungan ini dilakukan untuk masing-masing jenis kueri dengan potongan tagging XML yang berbeda dari sistem pertanian dan sistem tanaman obat .
Hasil perhitungan recall dan precision
untuk masing-masing pembobotan akan dibandingkan dalam bentuk grafik recall-precision. Selain itu, juga akan dihitung nilai
average precision dari jenis kueri dengan potongan tagging XML yang berbeda dari sistem pertanian dan sistem tanaman obat untuk memperoleh sistem yang lebih baik dalam metode XML retrieval mengunakan dokumen bahasa Indonesia.
Lingkungan Implementasi
Perangkat lunak yang digunakan untuk penelitian, yaitu:
Microsoft Windows XP Professional sebagai sistem operasi.
Apache di dalam XAMPP-win32-1.7.1 sebagai web server.
Notepad++ sebagai program editor.
Perangkat keras yang digunakan untuk penelitian, yaitu:
Prosesor Intel Celeron 2.0 GHz.
RAM 2 GB.
Harddisk 80 GB.HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
[image:30.595.324.509.212.397.2]Penelitian ini menggunakan 1000 dokumen pertanian dan 93 dokumen tanaman obat. Dokumen-dokumen ini berasal dari Laboratorium Temu Kembali, Departemen Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1.
Tabel 1 Deskripsi koleksi dokumen
Uraian Dokumen Pertanian Nilai (bytes) Ukuran keseluruhan dokumen 4 104 253
Ukuran rata-rata dokumen 4 101
Ukuran dokumen terbesar 52 755
Ukuran dokumen terkecil 243
Uraian Dokumen Tanaman Obat
Nilai (bytes)
Ukuran keseluruhan dokumen 302 977
Ukuran rata-rata dokumen 3 258
Ukuran dokumen terbesar 13 684
Ukuran dokumen terkecil 868
Dokumen-dokumen ini memiliki bentuk XML yang seragam untuk setiap dokumen. Format struktur XML dapat dilihat pada Gambar 2 untuk dokumen pertanian dan Gambar 3 untuk dokumen tanaman obat.
Dokumen pertanian dikelompokkan ke dalam tag-tag berikut:
•
<DOC></DOC>, tag ini mewakili keseluruhan dokumen dan melingkupi tag-tag yang lebih spesifik.•
<DOCNO></<DOCNO>, tag ini menunjukkan ID dari dokumen.•
<TITLE></TITLE>, tag ini menunjukkan judul dokumen yang diberitakan.•
<AUTHOR></AUTHOR>, tag ini menunjukkan nama pengarang berita tersebut.•
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.•
<namal></namal>, tag ini menunjukkan nama latin dari tanaman obat.•
<content></content>, tag ini mewakili isi dari dokumen meliputi deskripsi tanaman dan kegunaannya.•
<fam></fam>, tag ini menunjukkan nama family dari tanaman obat. [image:31.595.93.300.49.828.2]•
<penyakit></penyakit>, tag ini menunjukkan nama penyakit yang berkaitan dengan tanaman obat.Gambar 2 Format dokumen dokumen pertanian.
Gambar 3 Format dokumen tanaman obat.
Pemrosesan Dokumen
Sebelum dilakukan proses pengindeksan koleksi, dokumen terlebih dahulu dipisahkan berdasarkan jenis tag. Dokumen pertanian dibedakan dalam tiga tagging: title, text, dan
title & text sedangkan untuk dokumen tanaman obat adalah penyakit, content, dan
content & penyakit dengan menggunakan fungsi preg_split.
Pengindeksan
Pengindeksan dokumen dimulai dengan melakukan parsing terhadap setiap file yang
dibedakan berdasarkan pemisahan tagging, kemudian dilakukan pembuangan stopwords
yang terdapat pada file “stopwords.txt”. File
ini terdiri atas 661 kata yang dipisahkan dengan newline. Selanjutnya, term diubah ke lower case dengan fungsi preg_match.
Pengindeksan 1000 dokumen pertanian dan 93 dokumen tanaman obat pada setiap tagging
menghasilkan jumlah kata unik dan frekuensi total setiap kata.
Pemrosesan Kueri
Untuk menjalankan proses evaluasi, kueri dimasukkan pada sistem mesin pencari (Lampiran 1 dan Lampiran 2). Jumlah kueri yang digunakan pada penelitian ini ialah 30 untuk dokumen pertanian (Lampiran 3) dan 13 untuk dokumen tanaman obat (Lampiran 4). Kueri-kueri ini tersedia di Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer. Kueri pada sistem ini menggunakan kueri XML, yaitu berupa kueri yang dipasangkan dengan potongan tagging
XML yang bersifat terstruktur. Pada kueri XML, potongan tagging yang dipakai pada dokumen pertanian adalah
1. <title>kueri</title>
2. <text>kueri</text>
3. <title><text>kueri</text></t itle>
Tagging yang dipakai pada dokumen tanaman obat adalah
1. <penyakit>kueri</penyakit>
2. <content>kueri</content>
3. <content><penyakit>kueri</pe nyakit></content>
Penghitungan panjang konteks pada kueri dapat dicontohkan sebagai berikut:
“<title> gagal panen</title>”
Kueri tersebut diilustrasikan menjadi tree
[image:31.595.354.480.644.707.2]yang digambarkan pada Gambar 4. Gambar 4 menunjukkan bahwa panjang konteks pada kueri ialah 3.
Gambar 4 Contoh tree pada kueri.
Hasil Temu Kembali
Pada penelitian ini, pembobotan yang <?xml version="1.0" encoding="utf-8"?> <DOC> <DOCNO>017</DOCNO> <nama>Sosor Bebek</nama> <namal>Kalanchoe pinnata Lamk.</namal>
<content>Famili : Crassulaceae. Nama Lokal : Cakar itek (Sunda); dan sosor bebek....</content> <fam>Crassulaceae</fam> <penyakit>Kulit</penyakit> </DOC> title panen gagal <?xml version="1.0" encoding="utf-8"?> <DOC> <DOCNO>suaramerdeka1201 04</DOCNO>
<TITLE>Pemerintah Larang Impor Beras pada Pra dan Pascapanen Raya </TITLE>
<AUTHOR> (ant-82) </AUTHOR> <SOURCE>suaramerdeka</SOURCE> <DATE>12/1/2004</DATE>
digunakan yaitu tf-idf. Jumlah dokumen teratas yang diambil adalah 30 untuk sistem dokumen pertanian dan 20 untuk sistem dokumen tanaman obat.
Pengujian Kinerja Sistem
Proses evaluasi dalam penelitian ini dilakukan pada dua koleksi dokumen yaitu dokumen pertanian dan dokumen, tanaman obat beserta kueri uji yang berbeda.
1 Pengujian pada Dokumen Pertanian
Proses evaluasi pada dokumen pertanian menggunakan 30 kueri uji yang telah ada sebelumnya berikut dokumen yang relevan. Pencarian dengan kueri uji ini dilakukan dengan tujuan mendapatkan nilai recall dan
precision untuk 30 dokumen teratas yang ditemukembalikan oleh sistem dan dilakukan perhitungan interpolasi terhadap maksimum untuk mendapatkan nilai average precision
(AVP).
Pengujian terhadap kueri XML pada dokumen pertanian terdapat tiga jenis potongan tagging dari struktur dokumen XML di koleksi, yaitu :
[image:32.595.328.507.165.330.2]a Kueri XML dengan potongan tagging title
Gambar 5 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging title. Nilai average precision dari pencarian kueri XML dengan potongan tagging title
[image:32.595.333.508.428.590.2]sebesar 0.5005.
Gambar 5 Grafik R-P untuk tagging title.
b Kueri XML dengan potongan tagging text
Gambar 6 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging text. Nilai average precision dari pencarian kueri XML dengan potongan tagging text
sebesar 0.6156 atau meningkat 12% dari kueri XML dengan potongan tagging title. Hal ini menyebabkan kata konteks kueri banyak yang sama dengan konteks dokumen yang menyebabkan nilai average precision
meningkat sebesar 12%.
Gambar 6 Grafik R-P untuk tagging text.
c Kueri XML dengan potongan tagging title andtext
Gambar 7 mengilustrasikan kinerja sistem pada XML kueri dengan potongan tagging title dan text.
Gambar 7 Grafik R-P untuk potongan tagging title & text.
Nilai average precision dari pencarian kueri XML dengan potongan tagging title and text sebesar 0.6153 atau lebih rendah 0.0003 dari kueri XML dengan potongan tagging text
dan meningkat 12% dari kueri XML dengan potongan tagging title. Average precision
masing-masing potongan tagging pada kueri XML dapat dilihat pada Tabel 2. Kinerja temu-kembali diilustrasikan dengan grafik
recall-precision yang ditunjukan pada Gambar 8.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re ci si o n
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re c is io n
Gambar 8 Grafik R-P untuk dokumen pertanian.
Gambar 8 menunjukkan bahwa untuk perbedaan jenis potongan tagging telah memiliki perbedaan yang signifikan terhadap penambahan potongan tagging XML dan panjangnya kata pada suatu konteks di dokumen pertanian.
Tabel 2 Hasil perhitungan average precision
pada dokumen pertanian
Jenis Tagging AVP
Title 0.5005
Text 0.6156
Title & Text 0.6153
Tabel 2 menunjukkan bahwa kinerja sistem
pada pembobotan tf-idf dengan
SIMNOMERGE similarity memberikan temu-kembali lebih baik yaitu pada kueri XML dengan potongan tagging text dan tagging title and text sebesar 62%. Berarti, secara rata-rata pada tiap recall point, 62% hasil temu-kembali relevan dengan kueri dan meningkat sebesar 12% dari kueri XML dengan potongan
tagging title.
2 Pengujian pada Dokumen Tanaman Obat
Proses evaluasi pada dokumen tanaman obat menggunakan 13 kueri uji yang telah ada sebelumnya berikut dokumen-dokumen yang relevan. Pengujian yang dilakukan sama seperti sebelumnya, yaitu melakukan perhitungan recall-precision terhadap kueri XML dan dilakukan tahap perhitungan interpolasi masksimum untuk mendapakan nilai average precision (AVP) yang akan menggambarkan nilai kinerja pada sistem secara keseluruhan.
Pada pengujian sistem dilakukan untuk
pencarian dokumen dengan kueri XML dengan mengambil 20 dokumen teratas. Pengujian terhadap kueri XML pada dokumen tanaman obat terdapat tiga jenis potongan
tagging dari struktur dokumen XML di koleksi dokumen pertanian, yaitu :
a Kueri XML dengan potongan tagging
penyakit
Gambar 9 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging
penyakit. Pada pengujian sistem pada pencarian kueri XML dengan potongan
tagging penyakit, nilai average precision yang didapat sebesar 0.5968. Pengaturan skala sumbu y pada Gambar 9 dimulai dengan skala minimum 0.5750 dan skala maksimum 0.6150. Hal ini dilakukan untuk melihat grafik R-P potongan tagging penyakit telah relevan.
Gambar 9 Grafik R-P untuk tagging penyakit. b Kueri XML dengan Potongan tagging content
[image:33.595.331.508.306.459.2]Gambar 10 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging content.
Gambar 10 Grafik R-P untuk tagging content. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.5750 0.5800 0.5850 0.5900 0.5950 0.6000 0.6050 0.6100 0.6150 recall p re ci si o n
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Recall P re ci si o n
[image:33.595.328.508.552.734.2]Nilai average precision dari pencarian kueri XML dengan potongan tagging content
sebesar 0.6273 atau lebih tinggi sebesar 0.0305 dari kueri XML dengan potongan
tagging penyakit.
[image:34.595.105.301.167.825.2]c Kueri XML dengan potongan tagging content dan penyakit
Gambar 11 mengilustrasikan kinerja sistem untuk kueri XML dengan potongan tagging content dan penyakit. Nilai average precision
dari pencarian kueri XML dengan potongan
tagging content dan penyakit sebesar 0.8589. Perbedaan kinerja sistem pada kueri potongan
tagging content dan content & penyakit di sistem tanaman obat diilustrasikan pada grafik recall-precision yang dapat dilihat Gambar 12 dan uraian masing-masing nilai
average precision terhadap kueri XML di tanaman obat dapat dilihat pada Tabel 3.
Gambar 11 Grafik R-P untuk tagging content
dan penyakit.
Gambar 12 Grafik R-P untuk dokumen tanaman obat.
Dari Gambar 12, dapat dilihat bahwa terjadi perubahan signifikan terhadap
penyatuan potongan tagging pada sistem tanaman obat, yaitu content dan penyakit. Di potongan tagging tersebut, terdapat banyak kueri yang dicari oleh pengguna sehingga banyak terambil dokumen yang relevan pada pengujian kueri XML dengan potongan
tagging content dan penyakit.
Tabel 3 Hasil perhitungan average precision
pada dokumen tanaman obat
Jenis Tagging AVP
Penyakit 0.5968
Content 0.6273
Content & Penyakit 0.8589
Hasil pada Tabel 3 menunjukkan bahwa kinerja sistem untuk tanaman obat dengan nilai average precision yang sangat baik mencapai 86% pada kueri XML dengan potongan tagging content dan penyakit. Berarti, secara rata-rata pada tiap recall point,
86% hasil temu-kembali relevan dengan kueri. Kinerja pengujian kueri XML dengan potongan tagging content dan penyakit meningkat 23% dari potongan tagging content
atau meningkat 26% dari potongan tagging
penyakit.
Hasil pengujian pada dokumen tanaman obat lebih baik daripada pengujian dokumen pertanian. Hal ini dikarenakan isi konteks dokumen banyak yang sama dengan representasi dari kueri uji yang dilakukan. Hal ini mengakibatkan sistem dapat menghasilkan dokumen yang spesifik dari kueri XML dengan potongan tagging di dokumen tanaman obat. Selain itu, dokumen tanaman obat juga bersifat berbeda antar dokumennya. Setiap dokumen pada setiap tagging memiliki penciri yang berbeda dari dokumen lainnya sehingga membuat hasil temu-kembali menjadi semakin baik.
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian ini menunjukkan bahwa:
1 Kinerja kueri XML pada sistem dokumen tanaman obat lebih baik daripada dokumen pertanian.
2
Kueri XML dengan potongan tagging content dan penyakit di dokumen tanaman obat mendapatkan nilai average precisionyang baik yaitu sebesar 0.8589, sedangkan pada dokumen pertanian nilai 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 recall p re ci si o n
[image:34.595.323.512.199.268.2]MARYAM NOVIYANA BAHI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
XML RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA
MARYAM NOVIYANA BAHI
Skripsi
sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
MARYAM NOVIYANA BAHI
Skripsi
sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
average precision maksimumnya mencapai 0.6156 pada kueri XML dengan potongan tagging text.
Saran
Terdapat beberapa hal yang dapat ditambahkan atau diperbaiki untuk penelitian ke depannya, seperti:
1 Membandingkan kinerja pada sistem ini menggunakan pembobotan dan similarity
lainnya yang ada pada metode di XML
retrieval.
2 Menggunakan dokumen XML dengan struktur yang lebih kompleks.
DAFTAR PUSTAKA
Anbiana ED. 2009. Pseudo-Relevance Feedback pada temu kembali menggunakan segmentasi dokumen [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Baeza-Yates R, Ribeiro-Neto B. 1999.
Modern Information Retrieval. New York: Addison Wesley.
Carmel D, Efraty N, Landau GM, Maarek YS, Mass Y. 2002. An Extension of the Vector Space Model for Querying XML Documents via XML Fragments. Haifa: Haifa University.
Fuhr N, Gövert N. 2002. INEX: Initiative for the Evaluation of XML Retrieval. London: University of Dortmund, Germany and Queen Mary University of London, UK.
Immaneni T, Thirunarayan K. 1999. Flexible Querying of XML Documents. Ohio: Department of Computer Science and Engineering Wright State University.
Lalmas M. 2009. XML Information retrieval. Glasgow: University of Glasgow.
Manning CD. Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Ogilvie P. 2010. Retrieval Using Document Structure and Annotations. Pittsburgh: Language Technologies Institute.
Lampiran 3 Daftar kueri dan jumlah dokumen relevan pada Sistem Pertanian
No Kueri Jumlah dokumen relevan
1 Bencana kekeringan 39
2 Dukungan pemerintah pada pertanian 29
3 Flu burung 21
4 Gabah kering giling 24
5 Gagal panen 48
6 Harga komoditas pertanian 57
7 Impor beras indonesia 43
8 Industri gula 19
9 Institut pertanian bogor 40
10 Kelangkaan pupuk 20
11 Kelompok masyarakat tani 32
12 Laboratorium pertanian 21
13 Musim panen 40
14 Pembangunan untuk sektor pertanian 46
15 Penerapan bioteknologi di indonesia 42
16 Penerapan teknologi pertanian 39
17 Penyakit hewan ternak 13
18 Penyuluhan pertanian 27
19 Perdagangan hasil pertanian 30
20 Pertanian organik 24
21 Petani tebu 20
22 peternak unggas 20
23 Produk usaha peternakan rakyat 19
24 Pupuk organik 20
25 Riset pertanian 69
26 Swasembada pangan 30
27 Tadah hujan 18
28 Tanaman obat 29
29 Tanaman pangan 43
Lampiran 4 Daftar kueri dan jumlah dokumen relevan pada Sistem Tanaman Obat
No Kueri Jumlah dokumen relevan
1 Batuk rejan 6
2 Diabetes mellitus 16
3 Gangguan pencernaan 19
4 Kencing manis 16
5 Kronis 9
6 Kulit 10
7 Masuk angin 12
8 Muntah darah 15
9 Nyeri radang demam 19
10 Pencernaan 19
11 Perawatan 24
12 Pernapasan 5
Lampiran 5 Hasil perhitungan precision pada eleven standard recall untuk Sistem Pertanian
Recall
Precision
Tagging Title Tagging Text Tagging Title + Text
0 0.7762 0.9125 0.9144
0,1 0.6106 0.8581 0.8674
0,2 0.5294 0.7418 0.7400
0,3 0.4754 0,6075 0.6126
0,4 0.4643 0.5580 0.5537
0,5 0.4451 0.5203 0.5174
0,6 0.4431 0.5148 0.5125
0,7 0.4405 0.5148 0.5125
0,8 0.4405 0.5148 0.5125
0,9 0.4405 0.5148 0.5125
1 0.4405 0.5148 0.5125
Lampiran 6 Hasil perhitungan precision pada eleven standard recall untuk Sistem Tanaman Obat
Recall
Precision
Tagging Penyakit Tagging Content Tagging Content + Penyakit
0 0.6154 0.7194 0.9308
0,1 0.6000 0.7066 0.9308
0,2 0.6000 0.6874 0.9308
0,3 0.5962 0.6617 0.9308
0,4 0.5962 0.6468 0.9212
0,5 0.5962 0.6426 0.8931
0,6 0.5962 0.6356 0.8658
0,7 0.5911 0.5898 0.8073
0,8 0.5911 0.5604 0.7722
0,9 0.5