Abstract—Berdasarkan perkembangan studi Process Mining dari tiap tahun ke tahunnya, hingga akhirnya ditemukanlah banyak Algoritma Discovery untuk mengubah informasi data berupa Event Log menjadi data process model bentuk Petri Net yang lebih mudah dimengerti. Beberapa contoh Algoritma tersebut adalah Alpha, Alpha++, Genetic dan Heuristic. Kemudian untuk menilai performa dari tiap algoritma itu dilakukanlah Conformance Checking dengan metode Recall dan Precision yang dapat diukur dengan nilai pasti. Dalam makalah ini, akan dibahas bagaimana menilai Algoritma itu dengan menggunakan tools ProM.
Keywords—Process Mining, Quality Assesment, Algoritma Discovery, ProM Tools.
I. LATAR BELAKANG
alam suatu organisasi di masa sekarang, bisnis proses akan mempunyai banyak record data dengan jumlah besar yang di dalam data itu akan terekam pula berbagai aktivitas tiap hari dari bisnis tersebut baik informasi data maupun pegawai yang mengerjakannya. Dan biasanya record itu dibuat menjadi suatu bentuk Event Log.
Pendapatan informasi dari event log yang ada dalam suatu perusahaan tersebut biasa disebut dengan Process Mining. Ilmu ini pada dasarnya berada di antara pembelajaran proses bisnis berdasarkan Data Mining dan Business Process Management. Dalam pengembangannya, Process Mining telah dapat digunakan dengan berbagai macam teknik atau algoritma dalam proses mencari informasi/proses Discovery-nya.
Yang menjadi ciri dari suatu Process Mining adalah dapat divisualisasikannya bisnis proses yang diidentifikasi tersebut sehingga dapat dengan mudah untuk meng-extract informasi yang ada di dalamnya.
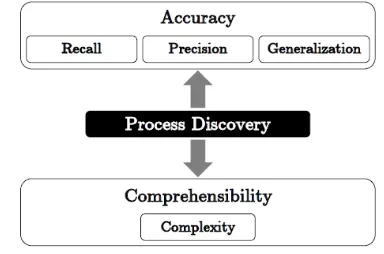
Penilaian utama dalam penggunaan Process Mining adalah Accuracy dan Comprehensibility. Dimana accuracy bertitik berat pada ketepatan dari visualisasi proses bisnis yang terekstraksi dari Event Log, sedangkan Comprehensibility adalah kemudahan untuk memahami proses bisnis yang terjadi dari Event Log.
Gambar 1. Model Quality Assesment proses Discovery Algoritma
II. TINJAUAN PUSTAKA
A. Quality Assesment pada Algoritma Discovery Process Mining
Conformance Checking merupakan cara yang paling populer digunakan dalam menetukan performa dari suatu Algoritma. Dalam pengembangannya nilai Conformance dapat diukur dengan dua pendekatan, yakni dengan pendekatan Accuracy
dan kedua pendekatan Comprehensibility. Yang dimana
Accuracy bertitik berat pada ketepatan dari visualisasi proses bisnis yang terekstraksi dari Event Log, sedangkan
Comprehensibility adalah kemudahan untuk memahami proses bisnis yang terjadi dari Event Log.
Pada tools ProM sendiri terdapat suatu plugin untuk menghitung Accuracy (Recall dan Precision) bernama Conformance Cheker plugin sehingga tidak harus menghitungnya nilainya secara manual. Untuk menggunkan plugin ini tentunya harus terlebih dahulu melakukan proses Discovery Event Log dengan algoritma yang diinginkan hingga mendapatkan Model Process Bisnis berbentuk Petri Net dan kemudian akan dihitung nilai Recall dan Precisionnya.
A.1. Evaluating Accuracy
Secara garis besar nilai accuracy dari Proses Model yang dihasilkan Discovery Algorithm tersebut dapat berbeda-beda
Quality Assesment
pada Algoritma-Algoritma
Discovery Process Mining
Moh. Ahmaluddin Zinni, 5110100128 Jurusan Teknik Informatika Fakultas Teknologi Informasi Institut Teknologi Sepuluh Nopember
tergantung perspektif penilaian yang digunakan. Jenis-jenis penilaian accuracy itu sendiri terdiri dari Recall, Precision dan F-Score/Generalitation (Penggabungan Recall dan Precision)
Untuk mengetahui accuracy dari sebuah discovery algorithm untuk process Mining dapat dilakukan dengan beberapa cara, dan cara yang paling sering digunakan adalah dengan membandingkan event log dengan mined process model atau biasa disebut dengan comformane checking.
• Recall
Recall merupakan proses paling penting untuk mengevaluasi hasil dari proses model yang dibuat. Dengan menggunakan recall metrics akan dapat merepresentasikan berapa banyak behaviour yang ada di event log yang telah ditangkap oleh model proses. Recall fitness metrics yang paling dikenal adalah Fitness f. Petri Net based Matrics ini akan menilai accuracy dengan menghitung banyaknya missing dan remaining tokens ketika mengembalikan event log pada Discovered Model. Rumus untuk menghitung fitness itu sendiri adalah :
�=1 Dengan keterangan sbb :
f = nilai fitness. k = banyak log traces.
n = banyak instance process yang terjadi. m = banyak missing token yang terjadi. r = remaining tokens yang tersisa.
p = banyak token yang diproduksi selama log replay. c = banyak token yang dikonsumsi selama log replay.
• Precision
Pada precision evaluation berlangsung dengan melihat dari Process Model yang tidak memasukkan behaviour dari Event Log. Salah satu metode yang digunakan dalam penghitungan Precision adalah menggunakan Advanced Behavioral Appropriateness dengan rumus sebagai berikut :
��′ =�
| ��� ∩ ��� | 2 . | ��� | +
| ��� ∩ ��� | 2 . | ��� | � Dengan keterangan sebagai berikut :
��′ = Nilai Advanced Behavioral Appropriateness
��� = Banyak Sometimes Follow Relation dari Eventlog
��� = Banyak Sometimes Follow Relations dari Model
��� = Banyak Sometimes Precedes Relations dari Eventlog
��� = Banyak Sometimes Precedes Relations dari Model Dan dengan pengertian “Sometimes Follow” Relation dan “Sometimes Precedes” Relation adalah sebagai berikut :
Definition 1 (Follows relations) Two activities (x; y) are in “Always Follows", “Never Follows", or “Sometimes Follows" relation in the case that, if x is executed at least once, then always, never, or sometimes also y is eventually executed, respectively.
Definition 2 (Precedes relations) Two activities (x; y) are in “Always Precedes", “Never Precedes", or “Sometimes Precedes" relation in the case that, Ir y is executed at least once, then always, never, or sometimes also x was executed some time before, respectively.
• Combining Precision and Recall : F-Score / Generalization Metode F-Score merupakan penggabungan antara dua metode sebelumnya yakni Recall dan Precision. Rumus yang digunakan yakni :
��=�
(1 +�)2�����������������
�2����������������� �
Dengan β merupakan tingkat faktor influence kebenaran dari precision dan recall.
A.2. Evaluating Comprehensibility
Evaluating Comprehensibility dapat dilihat pula dalam suatu matriks, yang dideskripsikan dalam tiga bagian yakni, Extended Cardoso Metric (ECM), Extended Cyclomatic Metrics (ECaM) dan Structuredness Metric (SM). Dimana pada ECM angka– angkanya akan didapat dari split dan join dari Process Model.
III. KONTRIBUSI
Kontribusi yang akan saya berikan dalam makalah ini adalah dengan menggunakan data set lain, yang di mana dataset itu saya buat sendiri dengan menggunakan YAWL Engine. Agar lebih mandalami tentang perhitungan Conformance Checking, paper ini akan membandingkan perhitungan dengan cara manual serta perhitungan dengan plugin ProM.
Kemudian dengan melakukan perhitungan Fitness dan Advanced Behavioral Appropriateness pada beberapa Algoritma yaitu, Alpha, Alpha++, Genetic dan Heuristic menggunakan tools ProM akan dieksplorasi dan dianalisis perbedaan dan keunggulan dari tiap masing-masing Algoritma berdasarkan nilai Conformance Checking tersebut.
IV. HASIL UJI COBA A. Skenario Uji Coba
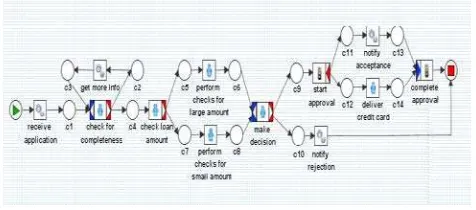
Langkah pertama dalam uji coba yang saya lakukan adalah dengan membuat Event Log sendiri dengan proses model Credit Application Process yang tergambar seperti berikut :
Log yang nantinya akan di lakukan Conformance Cheking, maka process model tadi disimulasikan pada YAWL Engine.
receive_application = A
check_for_completeness = B
get_more_info = C
check_loan_amount = D
perform_checks_for_small_amount = E perform_checks_for_large_amount = F
make_decision = G
notify_rejection = H
start_approval = I
notify_acceptance = J
deliver_credit_card = K
complete_approval = L
Dengan keterangan seperti di atas, berikut adalah Skenario case yang saya buat :
ID Log Traces 13 ABDEGIJKL 12 ABDFGIKJL 9 ABDFGIKJL 8 ABDFGH
7 ABCBCBDFGIJKL 6 ABDFGIKJL 5 ABDFGIJKL 4 ABDEGIKJL 3 ABCBDEGIJL 11 ABDFH
10 ABCBDEGIJKL
Output file Event Log dari proses simulasi YAWL Engine masih berekstensi .xes sehingga agar dapat digunakan untuk proses Discovery dan Conformance Checking file tersebut diubah ke dalam bentuk file berkekstensi .mxml dengan menggunakan tools ProM 6.
Agar nilai fitness tidak selalu bernilai 1 (karena tidak terdapat fraud/kesalahan pada Event Log) maka saya melakukan editing pada Eventlog yang ada sehingga dapat merepresentasikan Real Life Event Log yang memiliki kemungkinan adanya kesalahan pada Event Log. Untuk memudahkan dalam melakukan edit EventLog, file yang sebelumnya berformat .mxml diubah menjadi .csv dengan menggunakan aplikasi Nitro.
Selanjutnya mengubah atau melakukan editing pada Event Log tersebut. Beberapa data yang diubah antara lain.
Case ID Perubahan
3 Menghapus Activity “deliver_credit_card”
11 Menghapus Activity “make_decision”
Setelah itu file yang telah dimodifikasi EventLognya tadi diubah kembali menjadi file berekstensi .mxml dengan Nitro dan memakai cara yang sama.
Selanjutnya adalah melakukan proses Discovery pada Event
Log dengan menggunakan Algoritma yang ada dengan menggunakan Tools ProM 5.2.
Gambar 3. Load Eventlog ke tools ProM 5.2
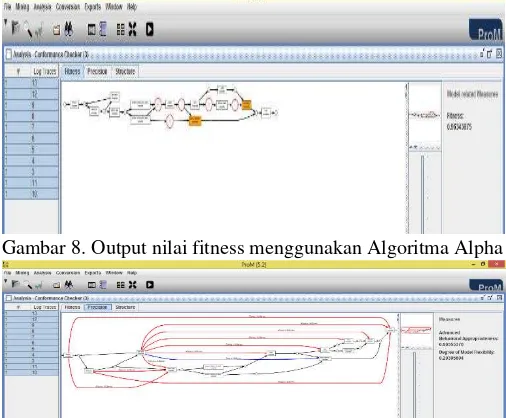
Gambar 4. Pemilihan Algoritma Discovery Process Mining Setelah didapatkan representasi model dalam bentuk Petri Net, dapat dilakukan Conformance Checking pada Algoritma tersebut menggunakan pluggin Conformance Checker untuk kemudian dilihat nilai dari Fitness yang merepresentasikan Recall dan nilai Advanced Behavioral Appropriateness yang merepresentasikan Precision. Atau dapat juga menggunakan metode hitungan lain seperti perhitungan Simple Behavioral Appropriateness sebagai representasi nilai Precision pada Conformance Checking.
Gambar 6. Plugin “Conformance Checker pada tools ProM 5.2”
Gambar 7. Pemilihan metode perhitungan Conformance
Gambar 8. Output nilai fitness menggunakan Algoritma Alpha
Gambar 9. Output nilai Advanced Behavioral Appropriateness
B. Hasil Uji Coba
B.1. Membandingkan Perhitungan Manual dengan menggunakan plugin Conformance Checking pada ProM. Recall:
Untuk mendapatkan nilai dari Recall dapat direpresentasikan dengan nilai fitness.
Rumus fitness sendiri adalah :
�=1 Dengan keterangan sbb :
f = nilai fitness. Berikut adalah data Log Trace yang didapat dari YAWL Simulation :
No. Of Instance Log Traces
3 ABDFGIKJL
Precision :
Untuk mendapatkan nilai Precision dapat pula direpresentasikan dengan nilai Advanced Behavioral Appropriateness dengan rumus sebagai berikut :
��′ =����
��′ = Nilai Advanced Behavioral Appropriateness
��� = Jumlah Sometimes Follow Relation dari Log.
��� = Jumlah Sometimes Follow Relation dari Model.
��� = Jumlah Sometimes Precedes Relation dari Log.
��� = Jumlah Sometimes Precedes Relation dari Model. Proses pertama dalam menghitung Advanced Behavioural Approriatness, yakni membuat matriks “Follows” relation dan “Precedes” relation berdasarkan model serta log traces. “Follows” relation Table dari process Model
Fol A B C D E F G H I J K L
“Precedes” relation Table dari process model.
Pre A B C D E F G H I J K L
“Follows” relation Table dari Event Log
Fol A B C D E F G H I J K L
“Precedes” relation Table dari Event Log.
Pre A B C D E F G H I J K L
Kemudian dari data tabel di atas digunakan dalam rumus Advanced Behavioral Approriatnessnya sebagai berikut :
��′ =����
B.2. Tabel Perbandingan Conformance Checking pada Beberapa Algoritma
f
��′ Alpha Miner 0.96343875 0.86355376 Alpha++ Miner 0.96343875 0.86355376 Genetic Miner 0.98286261 - Heuristic Miner 0.92561984 0.79565215V. KESIMPULAN
Quality Assesment dari Algoritma-Algoritm Discovery yang ada dapat direpresentasikan dalam perhitungan Fitness dan Advanced Behavioral Appropriatness serta perhitungan Generalization dengan menggunakan rumus-rumusnya masing-masing.
Kemudian dari percobaan untuk membandingkan perhitungan manual dan otomatis dengan plugin ProM, terdapat perbedaan hasil fitness dan Advanced Behavioural Appropriatness dikarenakan terdapat beberapa Miss perhitungan yang salah oleh saya.
Dari percobaan yang telah dilakukan sebelumnya terdapat beberapa hasil yang berbeda antara Algoritma satu dengan yang lain. Misal contohnya pada Algoritma Alpha dan Algoritma Genetic. Pada Alpha fitness yang didapat adalah 0.96343875 dan Advanced Appropriateness Behavioralnya 0.86355376 sedangkan pada Genetic Miner mendapatkan fitness yang lebih tinggi dengan nilai 0.98286261. Ini dikarenakan kemungkinan terdapat pattern yang tidak terbaca oleh Algoritma Alpha seperti adanya Short Loop dan Non-Free Choice Behaviour. Sedangkan pada Genetic pattern tersebut terbaca.
REFERENSI
[1] J.D. Weerdt, M.D. Backer, J. Vanthiene and B. Baesens, “A multi-dimensional quality assessment of state-of-the-art process Discovery algorithms using real-life event logs”, Belgium, Universiteit Gent. [2] K.B. Lassen and Wil M.P. van der Aalst, “Complexity Metrics for Work
ow Nets”, Eindhoven, Eindhoven university of Technology. [3] A. Rozinat and W.M.P. van der Aalst, “Conformance Checking of
Processes Based on Monitoring Real Behavior”, Eindhoven, Eindhoven university of Technology.
[4] www.processmining.org