Algoritma Modified K-MEANS Clustering Pada Penentuan Cluster Centre Berbasis Sum Of Squared Error (SSE)
Teks penuh
Gambar



Dokumen terkait
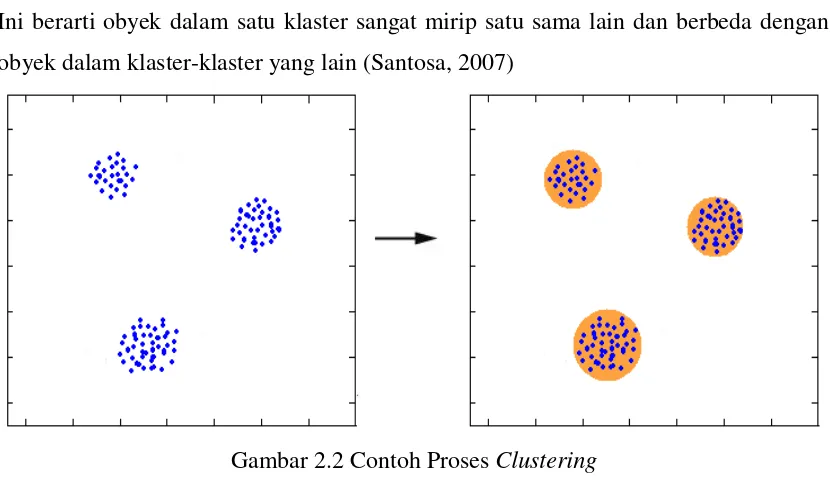
K-Means Clustering dan K-Nearest Neighbor adalah algoritma dalam data mining yang tergolong dalam unsupervised algorithm yang digunakan dalam proses pengelompokan
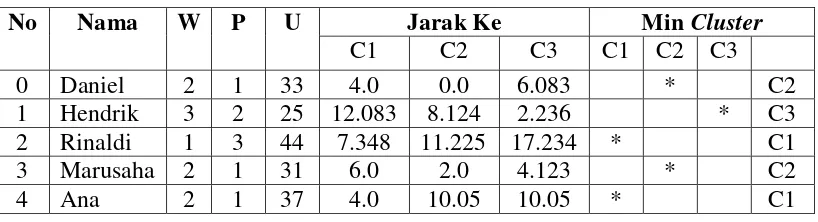
Aplikasi RapidMiner digunakan oleh peneliti untuk mempermudah proses data mining dalam menghasilkan informasi, dimana hasil clustering terbaik adalah 5 cluster, yaitu
Tugas Akhir yang berjudul Analisis Cluster dengan Algoritma K-Means dan Fuzzy C-Means Clustering untuk Pengelompokan Data Obligasi Korporasi ini disusun sebagai salah satu syarat
Metode analisis yang akan digunakan dalam penelitian ini adalah K-Means Cluster Analysis, merupakan keilmuan dalam data mining yang mengelompokkan data (objek) didasarkan hanya pada
Tujuan pengelompokan dengan K- Means Clustering adalah untuk meminimalkan fungsi objektif yang dilakukan dalam proses pengelompokan, dengan tujuan meminimalkan variasi di
Berdasarkan kualitas ketepatan pengelompokan menggunakan rasio simpangan baku dalam cluster dan antar cluster (rasio Sw/Sb), pengelompokan data obligasi korporasi
Manfaat Clustering Kuliah 13 - Hierarchical and K-means Clustering ANR – Data Mining & Knowledge Management - 2022 Keuntungan penggunaan metode hierarki dalam analisis Cluster adalah
Implementasi algoritma k-means clustering ke dalam sistem informasi clustering memberikan hasil klasifikasi pengelompokan data yang efektif dan proses setiap iterasi rotasi jarak
