MAHYUS IHSAN
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa Tesis Pengembangan Model Markov Tersembunyi pada Identifikasi Pembicara, adalah karya saya sendiri dan belum diajukan dalam bentuk apapun kepada Perguruan Tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, September 2006
Model Markov Tersembunyi merupakan suatu model yang tersusun dari dua buah proses stokastik, yaitu rantai Markov untuk menampung kemajuan temporal dan proses yang teramati untuk menampung variasi akustik. Model ini dapat digunakan sebagai metode pencocokkan pola pada sistem identifikasi pembicara. Setiap model mewakili referensi pola dari seorang pembicara didalam sistem identifikasi pembicara.
Pada penelitian ini, Model Markov Tersembunyi dibangun terhadap enam kelompok pembagi lebar frame dan overlap yang berasal dari kombinasi tiga lebar frame (20 ms, 30 ms, dan 40 ms) dan 2 overlap antar frame (25% dan 50%). Selanjutnya, tingkat identifikasi dan waktu prosesnya akan diamati terhadap setiap kelompok pembagi tersebut.
HasH eksperimen menunjukkan bahwa sistem identifikasi pembicara yang menggunakan metode Model Markov Tersembunyi memberikan tingkat identifikasi tertinggi dan waktu proses tercepat sebesar 98.9% dan 7.875 detik pada lebar frame 40 ms dan overlap antar frame 25%.
Hidden Markov Model (HMM) is a composition of two stochastic processes, a hidden Markov chain, which accounts for temporal variability, and an observable process, which accounts for spectral variability. This model can be used as a pattern matching method in speaker identification systems. Each model represents the template for each speaker in speaker identification systems.
In this research, Hidden Markov Model was built for six groups of frame segment of the speech signal. These 'groups was generated from combination of three frame wides (20 ms, 30 ms, and 40 ms) and two overlaps between frame (25% and 50%). Then, identification accuracy and process time can be observed for every group of frame segment.
The experiments result of speaker identification give the largest identification accuracy of 98,9% which in a frame segment made by 40 ms and 25%.
MAHYUS IHSAN
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Nama NIM
Mahyus Ihsan G651030034
Disetujui
Komisi Pembimbing
[" Agw
bセGsゥG@
M.KornKetua
Ketua Program Studi
Pascasarjana IImu Komputer
Tanggal ujian : 30 Agustus 2006
Diketahui
Aziz Kustiyo, S.Si, M.Kom Anggota
todiputro, MS
Puji dan syukur penulis panjatkan kepada ALLAH SWT atas segala karuniaNya sehingga karya ilmiah ini berhasil diselesaikan. Topik yang dipilih dalam penelitian yang dilaksanakan sej ak bulan J anuari 2006 ini adalah
Pengembangan Model Ml!rkov Tersembunyi pada Identifikasi Pembicara.
Terima kasih penulis ucapkan kepada Bapak Ir. Agus Buono, M.Si, M.Kom dan Bapak Aziz Kustiyo, S.Si, M.Kom selalru pembimbing yang telah banyak meluangkan waktu dalam memberikan arahan dan masukan serta Bapak Irman Hermadi, S.Kom, MS selaku penguji Iuar komisi yang telah banyak memberikan masukan. Dan tak lupa penulis ucapkan terima kasih kepada ternan-ternan mahasiswa Magister Ilmu Komputer yang telah membantu, baik secara langsung maupun tidak langsung, terutama kepada Pak Agus Hasim, Pak Roni, Bung Jeff, Ria, lin, Ibu Titi, Pak Marsani yang telah memberikan sumbangan suaranya. Ucapan terima kasih juga disampaikan kepada istri Yenni Irawati yang dengan sabar dan penuh pengertian memberi semangat dan dukungan serta seluruh keluarga yang turut mendukung.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2006
Penulis dilahirkan di Banda Aceh pada tanggal 5 Oktober 1970. Putra ketujuh dari delapan bersaudara dari orang tua Mahyuddin dan Murkinah. Penulis beristrikan Yenni Irawati dan mempunyai dua orang anak putri dan putra.
Penulis menempuh pendidikan sarjana sains pada Jurusan Matematika FMIPA Institut Teknologi Sepuluh Nopember Surabaya mulai dari tahun 1990 hingga 1997.
Halaman
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPlRAN ... XIV IPENDAHULUAN 1.1 Latar Belakang ... ... ... ... ... ... ... ... I 1.2 Tujuan Penelitian ... ... ... ... ... ... ... 2
1.3 Ruang Lingkup Penelitian .. ... ... ... ... ... 3
1.4 Manfaat Penelitian ... ... ... ... ... ... ... ... ... 3
2 TINJAUAN PUSTAKA 2.1 Prinsip Dasar Identifikasi Pembicara .. ... ... ... ... 4
2.2 Representasi Sinyal Ucapan ... 6
2.3 Akuisisi Data Ucapan ... 8
2.4 Ekstraksi Inforrnasi ... 9
2.4.1 Pemrosesan Awal ... 10
2.4.2 Frame Blocking and Windowing ... 12
2.4.3 Ekstraksi Ciri ... 14
2.4.4 Pemrosesan Akhir ... 17
2.5 Proses Stokastik ... 18
2.6 Rantai Markov... 19
2.7 Hidden Markov Model .. ... ... ... ... ... 20
2.7.1 Pelatihan pada Model HMM ... ... ... ... 21
2.7.2 Identifikasi Pembicara ... ... ... ... ... .... 24
2.7.3 Pengujian Sistem Identifikasi Pembicara ... 26
3 METODOLOGI PENELITIAN 3.1 Kerangka Pemikiran ... ... ... ... ... ... ... 28
3.1.1 StudiPustaka ... 29
3.1.2 Akuisisi Data Pengucapan ... ... ... ... ... 29
3.1.3 Ekstraksi Inforrnasi .... ... ... ... ... 30
3.1.4 Koefisien Cepstral ... ... ... ... ... ... 30
3.3. Waktu dan Tempat Penelitian ... 31
4 PERANCANGAN DAN IMPLEMENTASI SISTEM 4.1 Data ... 33
4.2 Ekstraksi Informasi ... 33
4.2.1 Deteksi Aktifnya Suara ... 34
4.2.2 Frame Blocking and Windowing ... 35
4.2.3 Ekstraksi Ciri ... .... ... ... ... ... ... ... ... ... ... ... 37
4.2.4 Pernrosesan Akhir ... 37
4.3 Hidden Markov Model ... 38
4.3.1 Pelatihan pada Model HMM ... 38
4.3.2 Identifikasi Pembicara ... 40
4.3.3 Pengujian Sistem Identifikasi Pembicara ... ... ... 40
4.4 Program Aplikasi ... 41
5 HASIL DAN PEMBAHASAN 5.1 Ekstraksi Informasi ... 42
5.2 Pelatihan pada Model HMM ... 44
5.3 Pengujian Sistem ... 45
6 SIMPULAN DAN SARAN 6.1 Simpulan ... 49
6.2 Saran ... :... 50
DAFTARPUSTAKA... 51
2 3 4
Berbagai penerapan metode pencocokkan pola pada sistem identifikasi
pembicara ... ... ... ... ... ... ... ... ... ... 6
Interval frekuensi sampling dan jumlah sampel yang dihasilkan ... . Ketentuan dan struktur sinyal ucapan pada proses V AD ... .. Estimasi jumlahframe dan jumlah sampel pada metode V AD ... .. 33 34 34 5 Iumlahframe danjumlah sampel per frame dari 6 kelompok pembagi . frame ... ,::... 36
6 Inisialisasi posisi pusat cluster pada lebar waktu 20 ms ... 39
7 Inisialisasi posisi pusat cluster pada lebar wakh! 30 ms ... 39
8 Inisialisasi posisi pusat cluster pada lebar wakh!40 ms ... 40
9 Wakh! proses ekstraksi informasi pada enam kelompok pembagi ... 42
10 Waktu proses ekstraksi informasi pada lebar waktu 20 ms ... 43
11 Waktu proses ekstraksi infomlasi pada lebar waktu 30 ms ... 43
12 Waktu proses ekstraksi informasi pada lebar waktu 40 ms ... 44
13 Waktu proses pelatihan model HMM pada enam kelompok pembagi ... 44
14 Hasil pengujian identifikasi pada empat kondisi data pelatihan dan pengujian ... 46
15 Hasil pengujian identifikasi pada tiga kelompok data berbeda dimana data pelatihan dan pengujian tidak ditambahkan noise ... 47
1
2
3
4
5
6
St kt d ru ur asar SIS em I enh I aSI pem Icara ... . . t 'd 'fik' b' St ktu ru r pen a aran pa a slstem I enh I aSI pem lCara ... . d ft d ' 'd 'fik' b' Representasi dalam tiga buah state ... . Spectrogram menggunakan metode Welch dan amplitudo ucapan ... .
Bagian dasar konverter analog ke digital ... . Tahapan-tahapan dalam ekstraksi informasi ... . 7 Suatu sinyal ucapan sebelum dan sesudah dikenakan proses deteksi
4
5
7
7
9
9
aktifnya suara ... ... ... ... ... ... ... ... ... ... ... ... ... ... 11
8 9 Pembentukanframe pada sinyal ucapan ... . Window Hamming untuk 661 sampel (lebarframe 30 ms) ... . 10 Frame pertama sebelum dikenakan window Hamming dan setelah 13 14 dikenakan window Hamming ... 14
II Topologi model HMM jenis kiri ke kanan dengan empat state ... 20
12 Topologi model HMM jenis kiri ke kanan pada kata yang terbentuk dari empat fonem ... 21
13 Tahapan pembentukan satu barisan observasi dari satu sinyal ucapan ... 22
14 Diagram alir prosedur pelatihan untuk pendugaan parameter B(.) ... 24
15 Diagram alir model HMM pada identifikasi pembicara ... ... ... 25
16 Diagram alir penelitian pengembangan model dan prototipe identifikasi pembicara ... ... .... ... ... .... ... ... ... ... ... 28
17 Perancangan model sistem identifikasi pembicara ... 32
Tabel Estimasi jumlah sampel dan lebar ji'ame pada metode V AD ... 54 2 Tabel waktu proses pelatihan dan jumlah iterasi re-estimasi Viterbi untuk
setiap pembicara terhadap enam kelompok pembagi ... 56 3 Tabe! nilai ambang batas (Threshold) pada enam kelompok pembagi
lebar frame dan overlap ... 58 4 Algoritma Viterbi (Rabiner 1989) ... 59 5 Gambar kekonvergenan setiap pembicara untuk enam kelompok pembagi
1.1 Latar Beiakang
Identitas memiliki peranan yang sangat penting dalam kehidupan manusia. Proses pengenalan terhadap identitas seseorang sering dijumpai pada berbagai bentuk aplikasi pelayanan (pengaksesan fasilitas), misalnya pengamanan akses gedung (ruang), sistem komputer, penggunaan mesin ATM, absensi, dan forensik. Penerapan proses tersebut diperlukan untuk memastikan agar fasilitas hanya dapat diakses oleh pengguna yang berhak sehingga terhindar dari pencurian dan manipulasi informasi (data).
Adanya perkembangan teknologi perangkat keras (device) dan pengenalan pola (pattern recognition) telah memotivasi orang-orang untuk melakukan pengalihan proses pengenalan identitas dari cara konvensional (password, PIN, kunci) menjadi secara biometrik (suara, sidik jari, tanda tangan, wajah, retina, dan lain-lain). Pengalihan tersebut disebabkan adanya kelebihan biometrik daripada konvensional, yaitu tidak gampang lupa/hilang dan ditiru. Biometrik merupakan pengenalan seseorang berdasarkan karakteristik fisiologi atau perilaku manusia atau gabungan dari keduanya (Jain et 01. 2004).
Ditinjau dari konteks aplikasi, proses pengenalan identitas terbagi atas dua, yaitu proses identifikasi (identification) dan verifikasi (verification). Pada proses identifikasi, sistem mengenali seseorang dengan cara mencari referensi pola (template) yang sesuai dengannya dari seluruh pengguna di dalam basisdata. Sedangkan pada proses verifikasi, sistem mengesahkan identitas seseorang dengan cara membandingkan data biometrik yang diambil dan template biometrik miliknya yang disimpan di dalam sistem basisdata (Jain et al. 2004).
1990; Cox et at. 2000). Ketahanan (robustness) proses identifikasi dengan suara bergantung pada adanya perhatian terhadap berbagai faktor yang menyebabkan terjadinya variasi sinyal suara, yaitu inkonsistensi ruang akustik (misalnya munculnya noise), perubahan channel transmisi (misalnya menggunakan mikrofon yang berbeda saat pelatihan dan identifikasi), kondisi pembicara (flu atau tidak), kecepatan pengucapan (lambat, sedang, dan cepat), intonasi (berirama, datar, keras, lemah, dan emosional), usia pembicara dan peniruan suara (mimicry) (Campbell 1997; Cox et al. 2000).
Ucapan merupakan rentetan bunyi gelombang suara yang berbentuk sinyal analog. Selanjutnya, sinyal analog dikonversikan menjadi data digital. Rentetan bunyi dapat dipilah-pilah menjadi bagian-bagian yang kecil (frame) berdasarkan satuan ucapan yang dipilih. Kemunculan bagian-bagian tersebut dapat dipandang sebagai kejadian stokastik, yaitu kemunculannya sekuensial dan kemunculan satu bagian memiliki hubungan dengan kemunculan bagian sebelumnya.
Salah satu metode pencocokkan pola yang dapat digunakan di dalam model pengenalan pembicara adalah Hidden Markov Model (HMM). Di samping itu, terdapat pula metode lainnya, yaitu dynamic time warping (DTW), artificial neural networks (NN), dan vector quantization (VQ) (Campbell 1997). Beberapa sistem identifikasi pembicara yang telah dikembangkan dengan menggunakan metode-metode tersebut memiliki tingkat identifikasi mencapai 99% (Campbell
1997).
Di dalam penelitian ini akan digunakan model HMM sebagai metode pencocokan pola pada pengembangan identifikasi pembicara. Pemilihan metode tersebut dikarenakan model HMM merupakan model stokastik temporal sehingga model tersebut cocok untuk digunakan sebagai metode pencocokkan pola pada sis tern identifikasi dengan ucapan.
1.2 Tujuan Penelitian
identifikasi pembicara ini digunakan meta de Linear Predictive Coding (LPC) sebagai metode ekstraksi ciri.
1.3 Ruang Lingkup Penelitian
Ruang lingkup penelitian meliputi:
Identifikasi pembicara dilakukan dengan menggunakan kata yang bersifat text-dependent, yaitu satu kata yang sarna untuk tahap pelatihan sistem dan tahap pengidentifikasian pembicara.
2 Model suara pembicara dibentuk dari 6 orang dewasa yang terdiri atas 3 pria dan 3 wanita.
3 Pembentukan frame sinyal ucapan secara seragam dilakukan terhadap tiga lebar waktu yang berbeda, yaitu 20 ms, 30 ms dan 40 ms. Dan overlap antar frame adalah 25% dan 50%.
4 Pembahasan difokuskan pada pelatihan dan pengujian model HMM. 5 Unit bunyi yang digunakan adalah fonem.
6 Pengujian juga dilakukan terhadap data ucapan yang ditambahkan noise dengan signal-to-noise ratio (SNR) sebesar 10 dB.
7 Sistem yang dikembangkan bam sampai model komputasi yang diimplementasikan dengan menggunakan perangkat lunak Matlab.
1.4 Manfaat Penelitian
2.1 Prinsip Dasar Identifikasi Pembicara
Proses identifikasi pembicara adalah suatu proses untuk mengenali seseorang berdasarkan suara yang direkam (capture). Cara kerja proses ini adalah mencari template ucapan yang sesuai dari seluruh pengguna di dalam basisdata (Jain et al. 2004). Output dari proses ini yaitu seseorang dapat dikenali atau tidak.
Metode identifikasi pembicara dapat dibagi menjadi dua bagian, yaitu text-dependent dan text-independent. Pada metode text-dependent, pembicara diminta mengucapkan satu kata atau rangkaian kata yang sama untuk tahap pelatihan sistem dan pengidentifikasian (Furui 1997b). Pada metode text-independent, rangkaian kata yang diucapkan berbeda antara tahap pelatihan sistem dan pengidentifikasian.
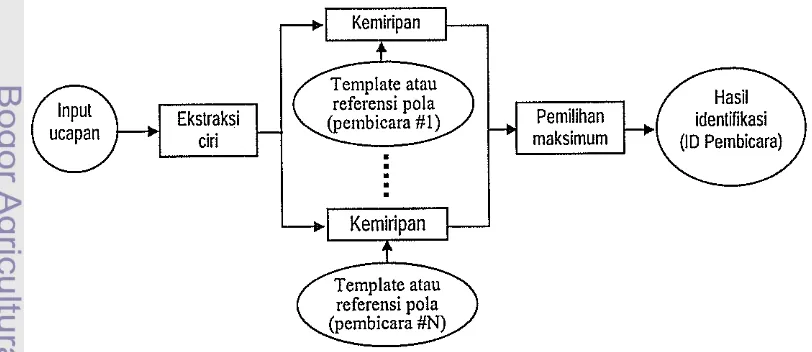
Secara umum, struktur dasar dari sistem identifikasi pembicara terdiri atas dua tahap utama (Gambar I), yaitu tahap ekstraksi ciri dan pencocokkan pola. Ekstraksi ciri merupakan proses mengekstraksi data hasil akuisisi menjadi berukuran lebih kecil. Sebelum proses ini dilakukan, terlebih dahulu data dipilah-pilah dalam sejumlahframe yang berukuran sama agar karakteristik ucapan dapat dipertahankan. Pencocokkan pola adalah proses mencocokkan karakteristik ucapan yang belum dikenal terhadap koleksi template ucapan dari pembicara yang sudah dikenal oleh sistem.
Kemiripan
Template atau
referensi pol a
(pembieara #1)
Template atau referensi pola (pembieara #N)
[image:18.550.74.480.489.665.2]Hasil identifikasi (10 Pembieara)
Sistem identifikasi pembicara juga menyajikan dua sesi yang berbeda, yaitu sesi pertama menunjukkan sesi pendaftaran (fase pelatihan) dan sesi kedua menunjukkan sesi operasi (fase pengujian). Di dalam fase pelatihan (Gambar 2), sistem membangun template untuk setiap pembicara berdasarkan contoh (sampel) suara yang diberikan oleh pembicara yang bersangkutan (Agustini 2006).
Ekstraksi ciri
Pelatihan pola
Templatel referensi pola
Gambar 2 Struktur pendaftaran pada sistem identifikasi pembicara
Tabel I Berbagai penerapan metode pencocokkan pola pada sistem identifikasi pembicara
._---Stmrcc Ala11974 (II
r..f.nkel amJ Duv.i,.. 197')
1J<1}
Org. f」オBャイ」セ@ Method Input T'::)(1
AT&T cBGiiセエイャャュ@ PIIUI,lIH J..f:llch I.ub l)cfX!ndent
---_."""--S-T1 1.1' LtlllC tセョョ@
Srilli!llh."'$
l.:ib hldcpllndcnl
AT&T N0r111alizcd r"n\1crn M,ltch T..:k- ヲI」ャMセエZii|Nャiュ|@
10 i: RoOセセcjNZウZ[[@
v.2%.«fj\,'i.
I () v; O.2%!'iil:-; l=unJi 19HI
(16-) c」ZZーLセエGョャゥャャ@ phone
--·---1----1----4---
---+-+---.
Seh\\llUt .... d"ii.1. 19112' 156] naN
LAH,
Li anll Wnmch ITI' U', 1993 P l) Ccps(rmn
Nm1t)ltr.J1nCll'ic t、・セ@ lrod.:pcndent pdf ph<onc
l.tlb Independent
. = · 1 · · 1 1
-l)()ddillgh")t'I "1 F!)ter-b.'1nk J)TW Uth Dependent 19115 (121
,., i:2.:'i%@2!\
11 i: ZZAGEHサエョセ@ セNMMMᆳ ゥセ@ TBセ_ャQャャセ@
-1---1---_··· .-.--/----..
---.-.-VQ (si..:e 6,1) 'lO.::I..:_ 10 b.Oralc:C 100 i: S%@I, ;'is
MセᄋMiMセセセMMiMMセ@
Soon),:. Hセャ@ .11. ,\'1'&'1' I..P
l')H.'i [S1) l.ikelihood pItOl1!! ctig.llS i: QNUEHセi[NQNウセ@
ョNエエャゥサセ@
IJf!>torti()jl
DTW Ll'Ib
Likclilwod
._----
Ind-cllt:ndC:llt_ ...
_--_._-:=-ihエセ」NゥョNゥ@ and lrr
Wohlford 1 Yllb
p;1j SCllring
1--:--:::--:-+-,.-:::- --. _ .. - --- --.-.
-C---Attili. c-t at RPI CCpsltUnl. Projeclcd Loug ャセlャN「@ J)c:pcnden'
19'88-1:>1 lA', TerrIl
Sllllisth:-s-Aut()corr
Oflicc
f-,.-"-,,,,-,-,jU-:;;.-. -,,-. ,-,,-.
-I--I'=-..--
··LA,,,+·i:)·rw-1991 [22J tP· UkcliJlOOd
Cl.lpstnlm Scoring.
Tishby 1991
[601 AT&'r LP
·::--::--c:::::-1-:-:::::-c-:-·- --.. -.---.
Reyll(lltls 1995 M1T.t..L Mel· [;llq: r\ャケャャッmセ@ gセjャDャイオャャャ@
HMM (AR fIllx.} HMM ((JMM)
----
Tele-phune. OfficI.:and Curbwn
1995 [49]
- - -
---j---+----Chc l:Ind L.ln
1')95 [9'1 RUI(!,cl's
GcpsCrlll1l
- - - - _ ... MNMMセMMM
Colomb;' 0::1 :11.
1996 [l(tJ イ|ャセit@
Office
hmセQ@ OJ)1ce
(kpendo=;ot
--,---HJ isc}illled diJ:iu. Dcp<!ndc,'1
._---_.
Dcpenderlt
d・セhュ、ッuョャ@
1 I v: lO%.t1iP.$"
v: NQNDEHセA[ャサiウ@
nUl YO I LLWEヲNセQQPウ@
'00 v; 7..S",liI'/I}I 5s
'It; oNXBイッ`AjNNUセ@
DR i: ョNウセサNHGjL@ 1 HIセ@
v: O. I ZャGyBGセAh@ fh
- . . ..•
__
..-D8 i: O.56%1l]2. 5h i' O.14%.r.i1I ().Ir
v: O.62%:!!)2.S)'
---t,n i:: 0,220/$2' セ@ ....; 0.28." f,ljlO<;
Ccp.En.c. deep,.
ddCcp
セGセGMセBスMGBMGMBセ、MGMiセNセY\MGKセmMᄋMGtセMセLMNLMNMiMMMmM、M -- MMhMセセBGMᄋM GGGGGMGイMGGMGセMN@
-1-'-"-"-'-"0-"-"-"-"-'+-"-'-.
セvMMiiMEMGMBMGゥBBBGMNTxNィ@I$Oj C:epstrum. (C,MM) pholle ... M' .... 8 .. NLサセセセLAoA\@
Mel- V' jEAZGゥBゥゥNャNサセZSPU@
I dC\:p"-trllln
m:th::hcdfmt:>-'-_______ J _ _ ._. __ ..L .... セ@ ___ .. ___ -'-___ "-__ .. _______ B⦅G⦅LB⦅G⦅ィ⦅セャ⦅G⦅B⦅iQQセセセN⦅@ ..
2.2 Representasi Sinyal Ucapan
Sinyal ucapan dan seluruh karakteristiknya dapat direpresentasikan dalam dua domain nilai yang berbeda, yaitu waktu (time) dan freknensi (Nilsson dan Ejnarsson 2002).
Ada tiga cara untuk merepresentasikan sinyal ucapan yang berdasarkan
salah satu domain nilai
(time
atau frekuensi) (Nilsson dan Ejnarsson, 2002), yaitu:1. Representasi dalam tiga buah
state
Representasi dengan cara ini diilhami dari kondisi yang teljadi pada pita suara
pada saat memproduksi ucapan. Tiga buah state tersebut terdiri atas
Silence
(S),
Unvoiced
(U) danVoiced
(V) (Gambar 3).Silence
berarti tidak ada sinyalucapan yang diproduksikan.
Unvoiced
berarti pita suara tidak bervibrasi yangmengakibatkan bentuk gelombang ucapan tidak periodik (random).
Voiced
[image:21.550.70.468.31.744.2]berarti pita suara menjadi tegang dan bervibrasi secara periodik.
Gambar 3 Representasi dalam tiga buah state
2. Representasi dalam bentuk
spectral
Representasi dengan cara ini merupakan representasi dari sinyal ucapan
berdasarkan intensitasnya terhadap waktu. Salah satu bentuk representasi ini
yang paling populer adalah
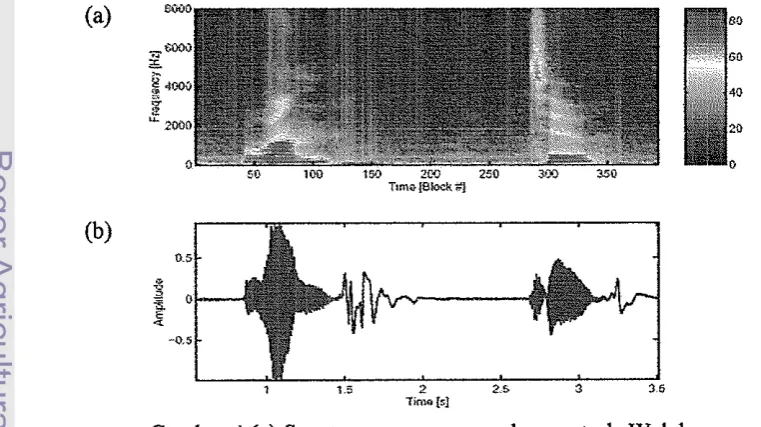
spectrogram
(Gambar 4).(a)
(b)
11010 Is}
Gambar 4 (a) Spectrogram menggunakan metode Welch
[image:21.550.79.460.457.670.2]Pada Gambar 4 (a) diperlihatkan adanya bagian yang bewama biru gelap yang merepresentasikan bagian dari sinyal ucapan di mana ucapan tidak diproduksi. Sedangkan, bagian yang bewama merah merepresentasikan intensitas yang menandakan ucapan diproduksi.
3 Representasi dalam bentuk parameter dari aktivitas spectral
Representasi dalam bentuk ini diilhami dari mekanisme ucapan diproduksi. Rongga pengucapan (Vocal tract) bentuknya menyerupai tabung atau sambungan dari tabung-tabung yang diisi dan dialiri oleh udara. Di dalam teori akustik, fungsi transfer energi yang berasal dari sumber suara (pita suara) menuju output (mulut atau hidung) dapat diuraikan dalam terminologi frekuensi alami atau resonansi dalarn tabung. Resonansi tersebut dikenal dengan istilah formant. Formant merepresentasikan frekuensi yang melewatkan kebanyakan energi akustik dari sumber menuju output.
2.3 Akuisisi Data Ucapan
Sebagian besar sinyal yang digunakan untuk keperluan praktis, seperti sinyal suara, biologis, seismic, radar, sonar, dan berbagai sinyal komunikasi seperti sinyal audio dan video adalah sinyal analog (Proakis dan Manolakis 1997). Untuk memproses sinyal analog dengan alat digital, dibutuhkan sebuah interface yang berfungsi sebagai penterjemah (converter) sinyal analog menjadi bentuk digital. Interface tersebut dinamakan penterjemah analog to digital (AID) (Proakis dan Manolakis 1997). Hasil konversi ini berupa deretan angka yang mempunyai presisi nilai terbatas. Secara konsep, konversi AID melalui tiga tahapan proses dan secara skematis dapat dilihat pada Gambar 5 (Proakis dan Manolakis 1997), yaitu:
2 Kuantisasi, adalah konversi sinyal yang bemilai kontinyu waktu-diskrit
menjadi sinyal yang bemilai diskrit (digital) waktu-diskrit. Nilai setiap sampel
sinyal direpresentasikan oleh sebuah nilai yang dipilih dari himpunan terbatas
dari nilai yang memungkinkan.
3 Pengkodean, adalah proses pengkodean tiap-tiap nilai diskrit ke dalam
kombinasi bemmtan dari bilangan biner.
sinyaJ .1 1
I Sampling I Analog
slnyal .1 c ., I slnyal _ I I
Waktu - tengkUantiSaSi I""T"'er"'ku':::an"'tisa=,i -->1-I Pengkodean I
dlskrit
sinyal 01110111.. ..
digital
Gambar 5 Bagian dasar konverter analog ke digital (Proakis dan Manolakis 1997)
Saat ini, penterjemah analog to digital (AID) yang ditujukan untuk
aplikasi suara (ucapan) menggunakan frekuensi sampling (ft) berkisar antara 8-20
kHz (Campbell 1997). Jika dilakukan proses sampling selama t detik dengan
frekuensi sampling adalah f, maka akan diperoleh suatu vektor sinyal ucapan x(n)
yang memiliki jumlah elemen sebanyak ft, yaitu x(n)
=
[Xl X, x," ·X,,], di manan=ft.
2.4 Ekstraksi Informasi
Ekstraksi infomlasi mempakan tahapan utama dalam membangun vektor
ucapan yang berasal dari sinyal ucapan. Di dalam kebanyakan literatur, tahapan
ini sering disebut sebagai pemrosesan dan analisis sinyal. Menumt Nilsson dan
Ejnarsson (2002), proses ini meliputi pemrosesan awal, pembagian sinyal ke
dalam frame ucapan (frame bloking and windowing), ekstraksi ciri (feature
extraction) dan pemrosesan akhir (lihat Gambar 6).
Pemrosesan Frame blocking Ekstraksi ciri Pemrosesan
awal dan akhir
windowing
2.4.1 Pernrosesan Awal
Tahap ini dibutuhkan untuk memodifikasi sinyaI ucapan menjadi bentuk yang Iebih Iayak untuk analisis ekstraksi cirL Penggunaan pemrosesan awal dapat meningkatkan keandaIan dan akurasi dari sis tern identifikasi pembicara yang akan dibangun. Ada dua pemrosesan awaI yang digunakan di dalam penelitian ini, yaitu:
I Perataan sinyaI (preemphasis), digunakan untuk rneratakan sinyaI ucapan secara spectral dan menjadikan sinyal tersebut Iebih peka terhadap efek presisi terbatas pada proses sinyaI berikutnya (Rabiner dan Juang 1993). Rumus yang digunakan adaIah:
sen) =s(n) -iis(n - I), O.%ii S;I.O (I)
dengan s(ll) adaIah nilai sinyal hasil proses preemphasis yang ke-n, sen) adalah nilai sinyal awal yang ke-n, sen - I) nilai sinyaI awal yang ke-(n-I), dan ii adalah faktor pengali perataan sinyal. Persarnaan (I) akan dikenakan terhadap setiap sinyal mulai dari sarnpel (nilai) yang ke-2 hingga terakhir. Nilai ii yang paling urnum digunakan sekitar 0.95 (Rabiner dan Juang 1993). 2 Deteksi aktifnya suara, digunakan untuk mendeteksi batas-batas dari sinyal
ucapan I. Tujuan dad pemrosesan ini adalah untuk membuang elemen-elemen
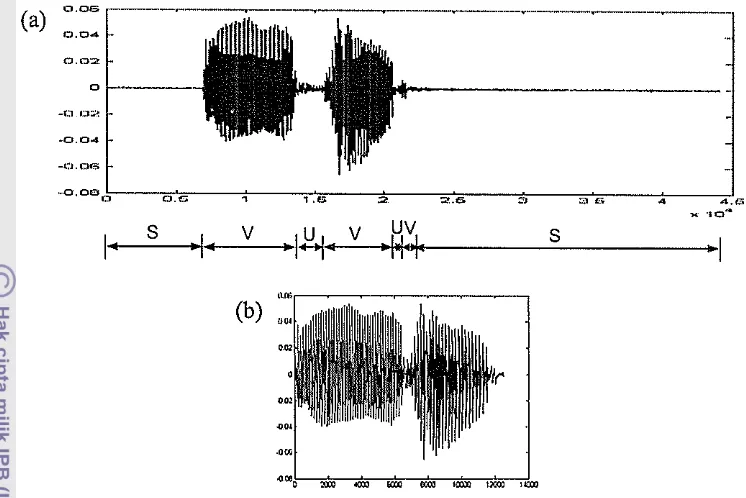
(nilai-nilai) dad suatu sinyal ucapan yang tidak mengandung karakteristik ucapan dari setiap pembicara. Nilai-nilai yang akan dibuang tersebut adaIah nilai-nilai yang berada pada state Silence (S) dan Unvoiced (U) (Gambar 7).
( a) 0 . 0 6 I"--.--... MMNMNMZ[ZMMMMMMMGセZ⦅⦅セMMMMM .. - .. ---... MMMMMMセMMNM .. -.... ---,
0 . 0 4
0 . 0 2
of---x "10"
s V
I
U V uviKᄋNNNNNNNZ]MMᄋセiKᄋM]MMᄋ@
• -I'
-1-1+
s
(b)
Gambar 7 Suatu sinyal ucapan (a) sebelum dan (b) sesudah dikenakan proses deteksi aktifuya suara
Salah satu metode yang dapat digunakan untuk mendeteksi aktifuya suara adalah voice activacy detection (V AD)2. Pada metode ini terdapat asumsi bahwa
200
ms pertama adalah bagian sinyal yang hanya berisi noise (background noise). Setiap sinyal ucapan yang akan dikenakan metode ini dibagi ke dalam lebar frame 5 atau10
ms dan tanpa adanya tumpang-tindih(overlap) antara suatu frame dan frame sebelahnya. Selanjutnya, terhadap setiap frame akan dihitung tenaga (power), banyakuya perubahan tanda (zero crossing rate), dan pembobotan (weight) (secara beliurut-turut persamaan (2), (3) dan (5», yaitu:
dengan:
1 L
P(m)=-Ls2(i)
L
;=,1
f,
Isgn(s(i» -sgn(s(i -1»1Z(m)=-L..
L ;=2 2
sgn(s(i»= . dan m =
1,2, ...
,Jumlahframe{
+1' s(i)2 0 .
-1,
S(/)<0
(2)
(3)
(4)
W(m)=P(m)·(1-Z(m»·S, m=I,2, ... ,jumlahframe (5)
[image:25.550.78.451.54.303.2]dengan S adalah faktor pengali agar hasil perhitungan pada persamaan (5) terhindar dari nilai yang kecil, dalam hal ini dapat diberikan nilai S
=
1000. Langkah berikutnya adalah menentukan sebuah nilai pemicu (trigger) untuk mendukung pengambilan keputusan, yaitu:(6) Pada persamaan (6), flw dan Ow adalah rata-rata (mean) dan varian (variance) dari 10 buah nilai pertama W(m) (WIO
=
{Wei)I
I:s
i:s
10, i E A}).Sedangkan ex diperoleh dari persamaan berikut:
a=0.2-5,;"·'
(7)Langkah terakhir adalah menentukan kriteria keputusan terhadap setiap frame, yaitu:
{
I, W(m):?:tw .
VAD(m)= , m
=
I, 2, ... ,Jumlahframe0, W (m)< tw (8)
Sinyal ucapan hasil proses V AD adalah gabungan dari nilai-nilai sinyal ucapan dari seluruh frame yang memiliki nilai V AD sama dengan 1. Sebalilmya, jika nilai V AD pada suatuframe bernilai 0, maim nilai-nilai sinyal ucapan di dalam frame tersebut dieliminasi.
2.4.2 Frame Blocking and Windowing
Sinyal ucapan sering dipilah-pilah menjadi sejumlah segmen sinyal. Segmen sinyal ucapan ini disebut frame. Tujuan sinyal ucapan dipilah-pilah ke dalam sejumlah frame agar karakteristiknya dapat ditangkap, di mana karakteristilmya tidak berubah dalam rentang waktu yang pendek. Biasanya, lebar frame yang digunakan adalah 10-30 ms (Peacocke dan Graf 1990; Campbell
1997).
posisi awal frame kedua atau sebanyak 2M sampel dari posisi awal frame
pertama. Demikian pula seterusnya hinggaframe terakhir. M dapat diperoleh dari
M =(l/3)N atau M = (aIb)N di mana a dan b adalah bilangan asli, a:S b dan M:S
N. Overlap antara suatuframe denganframe sebelalmya adalah N - M sampel
(Rabiner dan Juang 1993). Adanya overlap dimaksudkan agar pengambilan
sanlpel-sampel dari frame berikutnya dapat bergerak secara halus (smooth)
sehingga karakteristik sinyal ucapan dalam setiap framenya tidak banyalc
berkurang. Ilustrasi tentang pembentukanframe dapat dilihat pada Gambar 8.
1 - - - -N - M - - - - 1 Frame3
Gambar 8 Pembentukanframe pada sinyal ucapan (Rabiner dan Juang 1993)
Tahap selanjutnya dari pemrosesan sinyal adalah membuat window
terhadap tiap-tiap frame dengan tujuan untuk meminimalkan ketidakkontinyuan
pada awal dan akhir setiap frame. Umumnya, window yang digunakan adalall
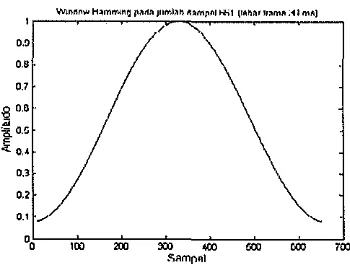
window Hamming. Pembentukan window Hamming menggllilakan formula:
k
w[k+I]=O.S4-0.46cos(2n-);
k=O,···,n-1
n-I (9)
dengan n adalah lebar frame. Pada Gambar 9 diperlihatkan window Hamming
yang berlaku lliltuk setiap frame. Sedangkan pada Gambar 10 diperlihatkan
sampel di dalam frame pertama sebelum dan setelah dikenakan operasi window
/
0.'
o.
0]
0.'
0.2
0.1 , /
DO 100 200 )l) 400 500 COO 700
[image:28.553.73.453.35.771.2]!';Rm['l<ll
[image:28.553.180.355.63.195.2]Gambar 9 Window Hamming untuk 661 sampel (lebarframe 30 ms)
Gambar 10 Frame pertama (a) sebelum dikenakan window Hamming (b) setelah dikenakan window Hamming
Setelah sinyal ucapan dibagi-bagi ke dalamframe dan setiap frame sinyal ucapan tersebut dikenakan operasi window Hamming, yaitu:
X,
(n)= x, (n) w(n), (10)dengan N adalah jumlah sampel dalam setiap ji-ame. Selanjutnya, proses ekstraksi ciri akan dilakukan terhadap setiap ji-ame tersebut.
2.4.3 Ekstraksi Ciri
Tujuan utama dari ekstraksi ciri adalah untuk mereduksi ukuran data tanpa mengubah karakteristik dari sinyal ucapan dalam setiap framenya. Cara keljanya adalah dengan mengkonversikan bentuk sinyal ucapan ke dalam bentuk representasi secara parameter.
beberapa metode lainnya, seperti: filter bank, mel-cepstrum, dan Mel-Frequency Spectral Coefficients (MFSC).
Sebelum digunakan metode LPC, terlebih dahulu dikenakan operasi
analisis autocorrelation untuk setiap frame sinyal ucapan dengan tujuan untuk
mereduksi ukuran data setiap framenya menjadi 8 - 16 buah data yang
merepresentasikannya (Rabiner dan Juang 1993). Selanjutnya, hasil operasi
tersebut dibutuhkan oleh analisis LPC. Rumus yang digunakan adalah sebagai
berikut:
N-I-m
'i (m)=
Ix, (n)x,
(n+m), m=O, 1, ... , p (II)11=0
dengan rl adalah autocorrelation dari setiap frame, N adalah jumlah data dari
setiap frame dan p adalah nilai autocorrelation tertinggi. Pada penelitian ini akan
digunakan nilai p = 8.
Model LPC adalah sebuah model dari sinyal dengan waktu diskrit, sen),
dan pada sejumlah sampel pada waktu n, dapat dilakukan pendekatan sebagai
suatu kombinasi linier dari p sampel ucapan sebelumnya (Roweis 1998):
sen) '" al sen - 1)
+
a2 sen - 2)+ ... +
ap sen - p) (12)dengan koefisien ai, a2, ... , ap diasumsikan konstan di atasframe analisis ucapan.
Persamaan (12) dapat diubah ke dalam bentuk kesamaan dengan menambahkan
selisih antara pendekatan tersebut dan sinyal yang sebenamya, G u(n), diperoleh:
p
sen)
=
Ia, sen-i)+
G u(n) (13)j=!
dengan G u(n) disebut fungsi inovasi (Roweis 1998). Dengan menggunakan
transformasi z sehingga persamaan (13) dapat berubah menjadi:
p
S(z)
=
Ia, z·' S(z)+
G U(z) (14);=1
Selanjutnya dengan melakukan perubahan persamaan (14), diperoleh
fungsi transfer H(z), yaitu:
H(z) S(z)
GU(z)
1 1
Setelah model diperoleh, selanjutnya dilakukan analisis dari model LPC
dengan tujuan untuk menentukan himpunan dari koefisien penduga, {a,}.
Analisis dimulai dengan membentuk persamaan kesalahan pendugaan, e(n), yang
berdasarkan pada model LPC, yaitu:
p
sen)
=
:L:a,
s(n-k)+
G u(n) (16)k=l
p
sen) = L:>k s(n-k) (17)
k=l
Di mana sen) adalah sinyal ucapan yang sesungguhnya dan
s
(n) adalah sinyalucapan hasil estimasi. Selanjutnya, e(n) diperoleh dari:
p
e(n)
=
sen) - sen)=
sen) - La, s(n-k) (18)k=l
Dengan menggunakan transformasi z, persamaan (18) menjadi:
p p
E(z)
=
S(z) - La, z-' S(z)=
S(z) [ 1- La, z-'1
(19)k=1 k=I
Sehingga diperoleh fungsi transfer kesalahan, yaitu:
E(z) P
A(z)
= - - =
1- La,z-'S(z) '=1
(20)
Pendekatan dasar di dalam menemukan koefisien penduga adalah dengan
meminimalkan kesalahan pendugaan mean-squared pada frame sinyal ucapan.
Bentuk persamaan sinyal ucapan untuk setiap frame adalah:
Sn(m) = sen + m)
en(m) = e(n
+
m) (21)Persamaan kesalahan pendugaim mean-squared adalah:
En
=
セ・[HュI@
=
セ{ウLLHュIM
t,akS,,(m-k)r (22)Untuk menemukan koefisien penduga, persamaan (22) diturunkan terhadap setiap
koefisien ak dan hasilnya bernilai 0, yaitu:
(JE" =0, k
=
1,2, ... , PSehingga diperoleh:
p
Ls"(m-i)s,, (m)= Lak Ls,,(m-i)s,,(m-k) (23)
"' k",] III
Dengan memandang bentuk Ls,,(m-i)s,,(m-k) merupakan covariance dari
m
bentuk sn(m), yaitu:
9" (i,k)
=
Ls,,(m-i)s,,(m-k)m
Bentuk persamaan (23) dapat ditulis sebagai:
p
9,,(i,0)= Lak9" (i,k) (24)
k=l
Persamaan (24) merupakan p buah persamaan yang dapat diekspresikan ke dalam bentuk persamaan matriks. Ada tiga metode yang dapat digunakan untuk mencari koefisien penduga, {ak }, dari persamaan (24), yaitu: metode autocorrelation,
covariance, dan rekursi Levinson-Durbin (Nilsson dan Ejnarsson 2002).
2.4.4 Pemrosesan Akhil'
Tahap pemrosesan akhir digunakan untuk mengkonversikan koefisien LPC menjadi koefisien cepstral. Hal ini diyakini dapat meningkatkan keandalan dari aplikasi yang akan dibuat (Rabiner dan Juang 1993). Tahap ini terdiri atas dua proses (Rabiner dan Juang 1993), yaitu:
Konversi dari koefisien penduga (parameter LPC) ke dalam bentuk koefisien
cepstral
Rumus yang digunakan, secara berturut-turut (persamaan (25), (26), dan (27»:
2 '
co=ln(5
m>p
(25)
(26)
(27)
Co
=
-In (E) (28) Tanda negatif disertakan ke dalam persamaan (28) dengan maksud untuk menghindari nilai koefisien Co bernilai negatif, karena energi estimasi error (E) setiapframe sinyal ucapan, memiliki kecenderungan nilai antara 0 < E < 1.2 Pembobotan parameter cepstral
Proses ini dibutuhkan untuk meminimalkan sensitivitas dari koefisien cepstral urutan kecil terhadap seluruh kemiringan spectral dan sensitivitas dari koefisien cepstral urutan besar terhadap noise.
Rumus yang digunakan adalah sebagai berikut:
(29)
(30)
2.5 Proses Stokastik
Proses stokastik dengan waktu clislcrit adalah suatu koleksi {X, :tE T} dari peubah acak yang terurut berdasarkan indeks dislcrit t dengan t adalah bilangan bulat positif. Di dalam proses stokastik secara umum, distribusi dari setiap peubah Xt dapat berubah-ubah dan berbeda untuk setiap waktu t.
Proses stokastik dikatakan bebas dan berdistribusi identik jika memenuhi kondisi berikut ini:
"
p(Xt
=
X" X'+l=
x,+!, ... , Xt+h=
X'+h)=
{=on
p(X =X,+i) (31)untuk semua t; h 2:: 0; semua Xtt+h dan beberapa distribusi p(X = x) yang bebas pada indeks t.
Proses stokastik {X, : t セ@ I} dikatakan seimbang jika dua koleksi peubah acak {X, ,X, , ... ,X, } clan {X,+/t'X, +/t,""X, +/t} memiliki distribusi peluang
I 2 n 1 2 /I
bersama yang sarna untuk seluruh nilai n clan h (Bilmes 1999).
Di dalam kasus waktu-kontinyu, keseimbangan dicapai pada kondisi
Fx (a)=Fx (a) untuk seluruh a di mana F(.) adalah fungsi distribusi
Il:n '1:11 +h
P(Q'I =ql ,Q'2 =q2,· .. ,Q,,, =qn )=P(Q" +h =ql , Q'2 +h =q2 ,···,Q,,,+h =qn} untuk selumh tJ, 1" ... , tn ; n > 0 dan h > 0 (Bilmes 1999).
2.6 Rantai Markov
Rantai Markov (Markov chain) atau sering juga disebut sebagai proses Markov adalah suatu proses stokastik jika memenuhi: kondisi pada saat state s" state berikutnya (S'+I) bebas terhadap state sebelurnnya (S'_I) (Sirl 2005). Menurut Costello (2004), rantai Markov dikatakan sebagai proses stokastik yang memiliki dua buah karakteristik, yaitu:
I Proses terdiri atas finite state di mana indeks dari setiap state adalah bilangan bulat non-negatif.
2 Proses mengikuti bentuk Markovian, yaitu ketika proses sedang berlangsung pada state ke-i, terdapat peluang gabungan antara proses pada saat itu dengan proses peralihannya pada state ke-j, yaitu Pij.
Suatu rantai Markov dikatakan diskret (Diskrete-Time Markov Processes) jika mang dari proses Markov tersebut adalah himpunan yang terbatas (finite) atau tercacah (countable), dengan himpunan indeks adalah T={O, 1,2, ... }. Jika nilai suatu state pada saat tertentu hanya tergantung pada satu state sebelunmya, maka disebut sebagai rantai Markov orde satu (first orde Markov chain) (Buono 2005). Rantai Markov orde satu dapat dimmuskan sebagai:
P(q,
=
jI
q,_1 =i, q<-2 =k, ... )=P(q,=
jI
q'_1 =i) (32) Pada sisi kanan dari persamaan (32) merupakan bentuk yang tidak bergantung terhadap waktu, sehingga memunculkan suatu himpunan dari peluang transisi state, aij, yang berbentuk:aij =Pij =P(q,
=
jI
q,_1 =i), 1 :s; ij :s; N (33)Peluang state, aij memiliki batasan, yailu: N
Vj,i dan
I:aij
=1 Vi (34)j=1
all a12 a'N
A=
a 21 a22 a'N (35)aN' aN' aNN NxN
Suatu proses Markov telah didefinisikan secara lengkap jika telah ditentukan matriks peluang transisi dan inisialisasi vektor distribusi state yang ·merupakan peluang dari setiap state pad a tahap awalnya, yaitu:
1/:=
N
1/:,
=P(q, =1)1/:,
=P(q, =2)1/:
N =P(q, =N) NxIdi mana
L1/:,
=1 dan 11:; = P(q,=
i) untuk I:s
i:S N.;=1
(36)
Sehingga, model rantai Markov dapat direpresentasikan dengan menggunakan parameter A dan 11:.
2.7 Hidden Markov Model
Model Markov tersembunyi atau Hidden Markov Model (HMM) merupakan suatu model yang tersusun dari dua buah proses stokastik, yaitu hidden Markov chain untuk menampung kemajuan temporal dan proses yang teramati untuk menampung variasi akustik. Kemajuan temporal dari ucapan dimodelkan berdasarkan proses Markov, sedangkan variasi akustik dimodelkan melalui distribusi pancaran dari setiap stale di dalam rantai Markov (Hamaker dan Picone 2003). Pada Gambar II diperlihatkan topologi model yang digunakan oleh HMM, yaitu jenis kiri ke kanan dengan empat stale. Pada Gambar 12 diperlihatkan topologi HMM yang lazim digunakan.
MW`MMMMWセ`MMMMW@
セ@ セ@ セ@ セ@
• • • •
[image:34.552.71.460.49.768.2]Gambar 12 Topologi model HMM jenis kiri ke kanan pada kata yang terbentuk dari empatfonem
Model HMM dapat dinotasikan dengan menggunakan parameter-parametemya sebagai berikut:
)..= (A, B, 1t) (37)
Di mana elemen-elemen dari model tersebut terdiri atas (Dugad dan Desai 1996; Tan 2005):
• N : Banyaknya hidden state di dalam model • Kumpulan state, s = {sJ, S2, ... SN}
• State pada waktu t, qt E S
• M: Banyaknya simbol observasi
•
•
•
• Simbol-simbol observasi, v
=
{VI, V2, ... VM} • Observasi pada waktu t, Ot E VA
=
{aij} : distribusi peluang dari transisi state, di mana • aij=
P(qt+1=
Sj Iqt=
s;), I :0 i, j :0 NB
=
{bj (k)} : distribusi peluang dari simbol observasi pada state ke-j • bj (k)=
P(Ot=
vklqt=
Sj), I:OJ
:0 N dan I :0 k:o M1t = {1t;} : distribusi inisialisasi state • 1t;
=
P( ql=
s;), I :0 i :0 N2.7.1 Pelatihan pada Model HMM
Sinyal Frame blocking & Vektor observasi
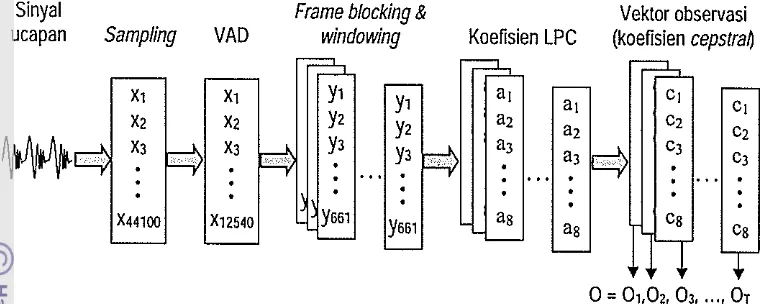
ucapan Sampling VAD windowing Koefisien LPC (koefisien 」・ーウエイ。セ@
Xl Xl Yl Yl al al CI CI
X2 X2 Y2 Y2 a2 a2 C2 C2
セB@
X3 X3 y3 y3 a3a3 C3 C3
X44100 X12540 Y661 Y661 as as Cs Cs
o
= 01,0" 03, ... , OTGambar 13 Tahapan pembentukan satu barisan observasi dari satu sinyal ucapan
Salah satu metode yang dapat dipakai untuk melakukan pelatihan terhadap
model HMM adalah algoritma Segmental K-means (Dugad dan Desai 1996).
Untuk melakukan pelatihan model, metode ini membutuhl<an sejumlah barisan
observasi, misalnya ro barisan. Setiap barisan observasi (0
=
OJ, O2, .. " OT)memiliki T buah simbol observasi. Setiap simbol observasi (Oi) merupakan vektor
yang berdimensi D (dalam penelitian ini, D
=
8).Algoritma Segmental K-means terdiri atas beberapa tahap (Dugad dan
Desai 1996), yaitu;
1 Pemilihan secara acak N buah simbol observasi (vektor berdimensi D) sebagai
pusat cluster untuk seluruh vektor observasi (roT). Pemilihan secara acak
harus memenuhi ketentuan: 1 セ@ PI < P2 < ... < PN セ@ T. Selanjutnya, setiap
vektor observasi akan dikelompokkan ke dalam N pusat cluster dengan cara
mencari jarak minimum terhadap N pusat cluster tersebut. Metode yang
digunakan untuk mencari jarak minimum adalah Euclidean (Gray 1984).
Selanjutnya, setiap vektor observasi, dimulai dari vektor observasi pertama
hingga ke-T, akan diberi indeks sesuai dengan urutan pusat clustemya (1, 2,
.. " N).
2 Menghitung peluang inisial dan transisi state (1 セ@ i セ@ N), yaitu:
Jumlah kemunculan state i di awal (0, E i)
ftj
Jwnlah total kemunculan di awal (OJ) (38)
Untuk 1 セ@ i セ@ N dan 1 セェ@ セ@ N, dihitung:
[image:36.550.79.461.65.217.2]3 Menghitung vektor rata-rata (mean) dan matriks kovarian (covariance) untuk
setiap state, I ::; i ::; N, yaitu:
_ I "
Jii=-L.°,
N; D,ei
Di mana, N; adalah jumlah kemunculan total state ke-i.
(40)
(41)
4 Menghitung distribusi peluang dari simbol observasi untuk setiap vektor
pelatihan terhadap setiap state, I ::; i ::; N, menggunakan distribusi Gaussian,
yaitu:
bi(O,)
I
I_1'12
exp[--21
(0,-fi.yv,-'
(0, -fi.J]
(2,,)DI2
V;
(42)5 Mencari barisan state yang optimal untuk setiap barisan pelatihan dengan
menggunakan model
1,
=
(A"
13"
Jl-,). Barisan yang optimal dapat ditemukandengan menggunakan algoritma Viterbi (Lampiran 4) (Rabiner 1989).
6 Jika ada beberapa vektor yang ditugaskan kembali kepada state baru, maka
proses berulang mulai tahap 2 hingga 6. Sebaliknya, jika tidak ada vektor yang
ditugaskan, maka proses berhenti.
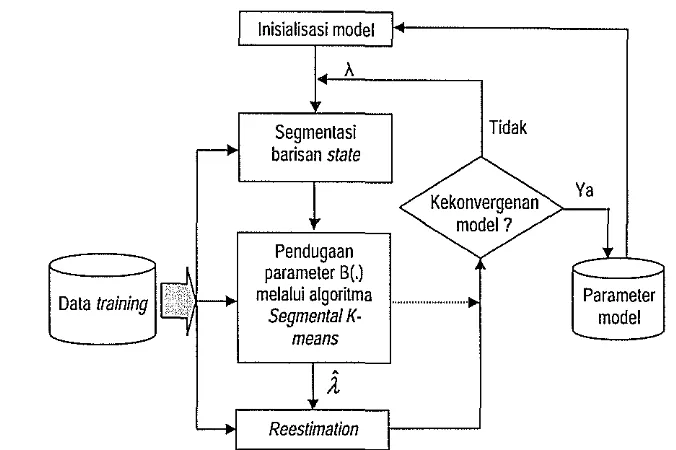
Secara skematis, pelatihan terhadap model HMM dengan algoritma
Inisialisasi model
A
Segmenlasi Tidak
,-
barisan stateKekonvergenan Va
model?
1
Pendugaan
Nセ@
parameter B(.)
Data training
ilE.ili!
セ@ melalui algoritma ... ... セ@ ParameterSegmental K· model
means
i
y
Reestimation I [image:38.553.93.431.73.298.2]I
Gambar 14 Diagram alir prosedur pelatihan untuk pendugaan parameter B(.) J
2.7.2 Identifikasi Pembicara
Sebelum dilakukan identifikasi pembicara, model HMM dibangun untuk setiap orang yang telah melakukan pendaftaran. Parameter model HMM untuk setiap orang diperoleh dari tahap pelatihan sistem.
Pada tahap identifikasi pembicara, barisan observasi yang belum diketahui, 0
=
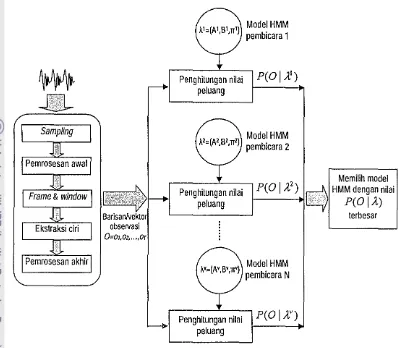
{o" 02, ... , OT}, yang merupakan hasil ekstraksi informasi dariucapan seseorang, dimasukkan ke dalam tiap-tiap model HMM untuk dihitung nilai peluangnya (Likelihood Estimation) dan selanjutnya akan dipilih nilai peluang yang maksimum dari seluruh nilai peluang tersebut. Pemilik ucapan adalah pemilik model HMM yang menghasilkan nilai peluang maksimum.
Pada Gambar 15 diperlihatkan bagaimana model HMM melakukan identifikasi pembicara terhadap suatu ucapan.
Model HMM pembicara 1
Penghitungan nilai P( 0
I
A' ) peluangPenghitungan nilai peluang
Model HMM pembicara 2
P(O
I
A')Model HMM
A'={A',tl',TI'11 pembicara N
Penghitungan nilai peluang
P(OIA')
Memilih model HMM dengan nilai
P(O
I
A) terbesarGambar IS Diagram alir model HMM pada identifikasi pembicara4
Identifikasi pembicara dimulai dengan menentukan nilai peluang P(OIA,) untuk setiap model HMM (Rabiner 1989), yaitu:
P(O I A)= L:P(O I I,A)P(I I A) I
(43)
Pada persamaan (43) terdapat 2T - I perkalian dan NT barisan state yang mungkin berbeda. Dengan melakukan komputasi secara langsung diperoleh 2TN T - I
operasi perkalian dan penjumlahan. Jika N = 5 dan T = 100, maka komputasi yang akan dilakukan sebanyak 1072 perkalian yang membutuhkan waktu cukup
[image:39.556.82.480.69.417.2]lama. Untuk itu dibutuhkan sebuah metode untuk mengatasi kompleksitas komputasi tersebut, yaitu prosedur Forward (Rabiner 1989). Prosedur ini diawali dengan menentukan variabel maju (forward), yaitu:
(44)
Di mana
a,
(i) merupakan peluang dari barisan observasi secara parsial hingga ke-t dan state i pada saat t, yang diberikan oleh model'A.
at
(i) dapat dihitung secara induksi, sebagai 'berikut:Inisialisasi
(45)
2 Induksi
3 Penghitungan peluang
N
P(O
I
,1)=L>r(i)
(47)i=1
2.7.3 Pengujiau Sistem Identifikasi Pembicara
Pengujian sistem dibutuhkan untuk mengetahui tingkat identifikasi (pengenalan) dari sistem yang telah dibangun. Tingkat identifikasi dapat diperoleh dari rasio antara jumlah data pengujian yang berhasil diidentifikasi dan jumlah total data pengujian. Misalkan, M adalah jumlah data pengujian yang berhasil diindentifikasi dan N adalah jumlah total data pengujian, maka tingkat identifikasinya adalah MIN. Sebaliknya, tingkat kesalahan dapat diperoleh dari rasio antara jumlah data pengujian yang tidak berhasil diidentifikasi dan jumlah total data pengujian, yaitu (N-M)/N.
yang digunakan di dalam membangun sistem dibagi menjadi k bagian sama dan terpisah (disjoint), satu bagian menjadi data pengujian dan k-l bagian menjadi data pelatihan sehingga terdapat I< pasang data pelatihan-pengujian (Kustiyo 2005).
3.1 Kerangka Pemildran
Kerangka pemikiran dalam membangun model dan prototipe identifikasi pembicara dapat dituangkan ke dalam suatu diagram alir penelitian, seperti yang diperlihatkan pada Gambar 16.
Mulai
.-
1 . Metode pemrosesan sinyal2. Peraneangan model HMM Studi pustaka
r-
3. Pelatihan model HMM, identifikasipembieara dan pengujian sistem
...
4. Pemrograman MatJabAkuisisi data penqueapan
...
Ekstraksi informasi..
セ@E ;f'...
セ@ ;f'...
セ@ ;f'...
セ@ ;f'...
セ@ ;f'...
セ@ ;f'.セ@ E 0 E セ@ E 0 E セ@ E 0
0 N 0 セ@ 0 N
0 セ@ 0 N 0 セ@
N N M M セ@ セ@
II
Koef.セ@
Koef.セ@
Koef.セ@
Koef. Koef. Koef.eeoslral ceoslral ceoslral cepslral cepslral cepslral
セ@ セ@ セ@ セ@ セ@ セ@
m m m m m
'"
mセ@ セ@
セ@
セ@
'"
セ@セ@ セ@
セ@ セ@ セ@
Nセ@ m Nセ@ = Nセ@ m Nセ@
'"
-\'l'"
'§'"
-\'l'"
-\'l 's'"
-\'l '§'"
-\'lセ@ '§- セ@ セ@ '5- セ@ セ@ セ@
'"
m セ@'"
m'"
セ@1:5
Pelatihan
'"
I
Pelatihan'"
I
Pelatihan'"
I
PelatihanI
Pelatihanf
r
Pelatihanmodel model model model model model
...
...
...
...
...
...
Identifikasi
Identifikasi Identifikasi Identifikasi Identifikasi Identifikasi
セ@ dan dan dan dan dan dan
penqu'ian penqujian penquiian penqu'ian penqujian I penquiian
セ@
Pengembangan
I
prototipe sistem
.
t
I
Pembahasan, dokumentasiI
dan penulisan laporan...
Berikut ini akan dijelaskan beberapa tahap yang ada di dalam diagram alir pada Gambar 16.
3.1.1 Studi Pustaka
Studi pustaka merupakan tahap awal dalam memulai penelitian ini. Tabap ini diperlukan agar peneliti memiliki pengetahuan mendasar dan memadai yang bermanfaat dalam melakukan pemodelan sistem dan prototipe identifikasi pembicara. Studi pustaka yang telah dan sedang dilakukan meliputi:
• Metode pemrosesan sinyal
•
Pada bagian ini dipelajari metode-metode pemrosesan sinyal yang dipergunakan pada berbagai sistem identifikasi pembicara.
Perancangan model HMM
Pada bagian ini dipelajari bagaimana cara membentuk model HMM terhadap kata yang dipilih dan keterkaitan model tersebut terhadap setiap pembicara. • Pelatihan model HMM, identifikasi pembicara dan pengujian sistem
Pada bagian ini dilakukan studi tentang metode-metode yang digunakan untuk pelatihan sistem, identifikasi pembicara dan pengujian sistem.
• Pemrograman Matlab
Sistem dan prototipe identifikasi pembicara yang dikembangkan pada hakikatnya merupakan sebuah perangkat lunak yang mampu melakukan pemrosesan terhadap perangkat keras dan melakukan berbagai perhitungan. Seluruh proses tersebut dapat dibangun dengan menggunakan pemrograman. Dalam hal ini, pemrograman yang dipilih adalah Matlab.
3.1.2 Akuisisi Data Pengucapan
Pada saat akan melakukan perekaman, mikrofon harus sudah terpasang dan perangkat lunak perekaman telah dijalankan. Perekaman dilakukan terhadap pengucapan kata "ujar", selama 2 detik (I detik = 1000 ms), pada frekuensi sampling ifs) sebesar 20 kHz, dan Iingkungan perekamannya "dikondisikan" minim
noise.
wanita. Sepuluh data ucapan dari setiap pembicara akan dijadikan sebagai data pelatihan model, sedangkan lima data sisanya dijadikan sebagai data pengujian (identifikasi pembicara).
Setiap pengucapan disimpan sebagai sebuahfile audio dengan format way. Nama file diberikan berdasarkaninisial pembicara diikuti dengan indeks urutan pengucapan (I s.d. 15), misalnya rial.wav.
3.1.3 Ekstraksi Informasi
Ada 4 tahap yang dilakukan di dalam mengekstraksi informasi dari setiap data ucapan (Gambar 6), yaitu pernrosesan awal,frame blocking and windowing, ekstraksi ciri dan pelmosesan akhir. Pada tahap frame blocking and windowing, setiap data ucapan dibagi berdasarkan 6 kelompok pembagi frame yang dibentuk dari kombinasi 3 lebar waktu (20 ms, 30 ms, dan 40 ms) dan 2 overlap antar frame (25% dan 50%). Keenam kelompok tersebut terdiri atas kelompok I (20 ms
dan 25%), kelompok 2 (20 ms dan 50%), kelompok 3 (30 ms dan 25%), kelompok 4 (30 ms dan 50%), kelompok 5 (40 ms dan 25%) dan kelompok 6 (40 ms dan 50%). Pada tahap ekstraksi ciri, menggunakan metode LPC dengan jumlah koefisien 8.
3.1.4 Koefisien Cepstrai
Setiap data ucapan, baik yang akan digunakan sebagai data pelatihan maupun data pengujian (identifikasi) akan dikonversikan oleh tahap ekstraksi informasi menjadi sebuah barisan koefisien cepstral yang tersusun dari kumpulan vektor di mana setiap vektor memiliki banyaknya elemen 8 buah.
3.1.5 Pelatihan Model
Model HMM untuk setiap pembicara yang dibangun merupakan model HMM jenis kiri ke kanan. Pada tahap ini akan terbentuk 6 buah model HMM untuk setiap kelompok pembagi frame di mana setiap model merepresentasikan pola seorang pembicara. Parameter setiap model (Ap, Bp, 1tp) diperoleh dengan
3.1.6 Identifikasi dan Pengujiau
Identifikasi pembicara dilakukan terhadap suatu data ucapan yang telah disimpan di dalam format file audio (*.wav). Data ucapan yang dipergunakan untuk pengidentifikasian pembicara diperoleh bersamaan dengan pengumpulan data pelatihan. Sedahgkan, pada pengujian melakukan identifikasi pada seluruh data ucapau yaug dijadikan sebagai data pengujian.
3.2 Bahan dan Alat
Bahan pad a penelitian ini berupa sinyal ucapan yang diperoleh pada saat perekaman data ucapan untuk pelatihan dan pengujian. Adapun alat yang digunakan terdiri atas:
• Seperangkat !computer yang memiliki spesifikasi diantaranya prosessor Intel Pentium 4, 1.7 GHz, RAM 256 MB, harddisk 30GB.
• Mikrofon desktop. • Loudspeaker mini.
• Perangkat lunak Matlab versi 7.01.
3.3 Waktu dan Tempat Penelitian
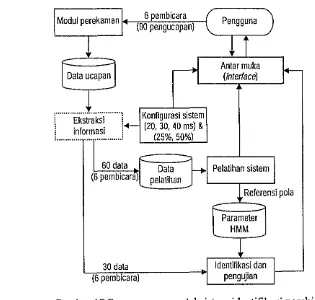
Perancangan model sistem identifikasi pembicara dibangun dengan maksud untuk memudahkan dalam pembuatan aplikasi (perangkat lunak). Aplikasi yang dibuat merupakan gabungan dari berbagai tahap yang ada di dalam sistem lersebut. Di samping ilu, model dirancang sedemikian rupa sehingga dapat memudahkan pengguna dalam menjalankan aplikasi lersebut.
Sistem yang dikembangkan seperti yang diperlihatkan pada Gambar 17, terdiri alas empat modul utama, yaitu modul perekaman, modul konfigurasi sistem, modul pelatihan, dan modul identifikasi (pengujian). Modul perekaman dibuat sebagai suatu aplikasi yang terpisah dari ketiga modul lainnya. Modul pelatihan dan identifikasi (pengujian) diletakkan sebagai submenu dari menu proses. Sedangkan modul konfigurasi sistem diletakkan sebagai submenu dari menu file.
Modul perekaman : 6 pembicara ( Pengguna
(90 pengucapan)
\
!
!
T
Data ucapanJ
1-1
Antar muka
r-(interface)
1 ...
1
"":""""1 Konfigurasi sistemi Ekstraksl. :..- (20 30 40 ms) &
! mformasl i " 0
, ... , (25%.50)(,)
60 data Data
セi@
Pelatihan sistemI
(6 pembicara pelatihan
セ@ Referensi pola
Parameter HMM
!
30 data
J
Identifikasi danI
[image:46.553.86.401.338.638.2](6 pembicara)
'I
pengujian 14.1 Data
Perekaman dilakukan terhadap pengucapan kata "ujar", selama 2 detik, pada frekuensi sampling (ft) sebesar 20 kHz sehingga menghasilkan 44100 sampel setiap pengucapan. Jumlah sampel diperoleh dari perkalian antara lama perekaman dan jumlah sampel per detik dari frekuensi sampling yang dipilih, yaitu 44100 = 2x22050. Pada Tabel 2 diperlihatkan jumlah sampel yang dihasilkan dari frekuensi sampling, seperti yang telah ditentukan oleh perangkat lunak Matlab.
Tabel2 Interval frekuensi sampling danjumlah sampel yang dihasilkan
Interval Jumlah sampel
frekuensi sampling
(Hz) Dalam 1 detik Dalam 2 detik
8000 s.d. 8080 8000 16000
8081 s.d 11135 11025 22050
11136 s.d. 22270 22050 44100
22271 s.d. 44100 44100 88200
Data ucapan yang digunakan di dalam sistem identifikasi pembicara diperoleh dari perekaman 6 orang responden (3 pria dan 3 wanita) dengan masing-masing melakukan 15 kali perulangan. Pengambilan data ucapan sebanyak 15 kaIi untuk setiap pembicara dilakukan dalam rentang waktu yang berurutan. Perekaman dilakukan pada ruangan yang dikondisikan minim noise. Setiap data ucapan disimpan sebagai sebuah file audio dengan format way yang diberi nama sesuai dengan inisial pembicara dan diikuti dengan indeks urutan pengucapan (1 s.d. 15) (Lampiran 1).
4.2 Ekstraksi Informasi
4.2.1 Deteksi Aktifnya Snara
Pada proses deteksi aktifuya suara dilakukan eliminasi terhadap elemen-clemen (nilai-nilai) dari sinyal ucapan apabila elemen-elemen tersebut tidak mengandung karakteristik ucapan seorang pembicara. Metode yang digunakan adalah voice activacy detection (VAD). Metode V AD akan berfungsi secara normal apabila 200 ms pertama dari sinyal ucapan hanya berisi background /loise. Pada metode VAD, setiap sinyal ucapan dibagi ke dalam lebar frame 5 ms dan tanpa adanya overlap antarji-ame (TabeI3).
Tabel 3 Ketentuan dan struktur sinyal ucapan pada proses V AD Ketentuan dan struktur
Keterangan ucapan
Asumsi 200 ms pertama hanya berisi background noise
Lebar frame 5 ms
Overlap Tidak ada
Jumlah frame 401 frame
Jumlah sampel per frame 110 sampel
Jumlah sampel sinyal ucapan setelah melalui proses VAD berbeda untuk setiap pembicara. Hal ini disebabkan, kecepatan pengucapan yang tidak sarna antara seorang pembicara dan pembicara lainnya (Tabel 4). Pada Tabel 4, jumlah sampel diperoleh dari perkalian antara jumlahframe dan jumlah sarnpel per frame (110 sampel). Kepadatan ucapan diperoleh dari rasio antara jumlah sampel ucapan setelah dan sebelum proses VAD. Secara lebih detail, jumlah ji-ame dan sampel setiap sinyal ucapan disajikan pada Lampiran 1.
Tabel4 Estimasijumlahframe danjumlah sampel pada metode VAD
No. Pembicara Jumlah Jumlah Kepadatan
frame sam pel ucapan
1. Mahyus Ihsan 114 12540 28.4%
2. Agus Hasim 170 18700 42.4%
3. Roni Salambue 85 9350 21.2%
4. Titi Ratnasari 60 6600 15.0%
5. Ria Arafiah 70 7700 17.5%
4.2.2 Frame Blocking allil Windowing
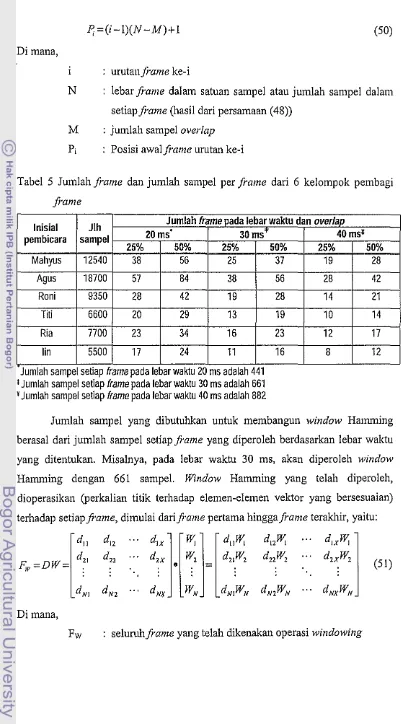
Pada tahap ini, setiap data ucapan dipilah-pilah berdasarkan 6 kelompok pembagi lebar frame dan overlap, yaitu kelompok I (20 ms dan 25%), kelompok 2 (20 ms dan 50%), kelompok 3 (30 ms dan 25%), kelompok 4 (30 ms dan 50%), kelompok 5 (40 ms dan 25%) dan kelompok 6 (40 ms dan 50%). Pada Tabel 5 ditampilkan jumlahframe berdasarkan 6 kelompok pembagiframe.
Untuk mendapatkan jumlah sampel dalam setiap frame, jika diketahui lebar waktuframe, dapat menggunakan persamaan (48), yaitu:
Dimana,
n]ャャセ[oj@
(48)L : lebar waktuframe (20 ms, 30 ms, dan 40 ms) Fs : jumlah sampel dalam satu detik (22050) N : jumlah sampel dalam setiap frame
L
J
Pembulatan ke bawah terhadap nilai bilangan real Uika a<N<a+i, maka N=
a, a adalah bilangan bulat)Selanjutnya, jumlah frame setiap sinyal ucapan dapat dihitung dengan menggunakan persamaan (49), yaitu:
Di mana,
X
J
nData-Ml (49)I
N-M
nData : jumlah total sampel dalam satu sinyal ucapan
N : jumlah sampel dalam setiap frame (hasil dari persamaan (48» M : jumlah sampel overlap, dapat dihitung dari hubungan
M
=
L
NOJ,
di mana 0 adalah overlap antarframe dalam %X : jumlahframe
I l
Pembulatan ke atas terhadap nilai bilangan real Uika a<X <a+ I, maka X=
a+ I, a adalah bilangan bulat)p'=(i-I)(N-M)+I (50)
Di mana,
urutanji-ame ke-i
N lebar frame dalam satuan sampel atau jumlah sampel dalam setiap frame (hasil dari persamaan (48»
M : jumlah sampel overlap Pi : Posisi awalframe urutan ke-i
Tabel 5 Jumlah ji-ame dan jumlah sampel per frame dari 6 kelompok pembagi frame
Inisial Jlh Jumlah frame pada lebar waktu dan overlap
20ms
.
SPュウセ@pembicara sampel
25% 50% 25%
Mahyus 12540 38 56 25
Agus 18700 57 84 38
Rani 9350 28 42 19
Titi 6600 20 29 13
Ria 7700 23 34 16
lin 5500 17 24 11
Jumlah sampel setlap frame pada lebar waktu 20 ms adalah 441
I Jumlah sampel setiap frame pada lebar waktu 30 ms adalah 661
'Jumlah sampel setiap frame pada lebar waktu 40 ms adalah 882
40ms¥
50% 25%
37 19
56 28
28 14
19 10
23 12
16 8
50% 28 42 21 14 17 12
Jumlah sampel yang dibutuhkan untuk membangun window Hamming berasal dari jumlah sampel setiap frame yang diperoleh berdasarkan lebar waktu yang ditentukan. Misalnya, pada lebar waktu 30 ms, akan diperoleh window Hamming dengan 661 sampel. Window Hamming yang telah diperoleh, dioperasikan (perkalian titik terhadap elemen-elemen vektor yang bersesuaian) terhadap setiapframe, dimulai darifi'ame pertama hinggaframe terakbir, yaitu:
dll d" dlx W; dllW; d"W; dlxW;
Fw=DW= d" d" d,x
•
W,=
d"W, d"W, d2XW, (51)dNI dN, dNX WN dNlWN dN,WN dNXWN
Di mana,
[image:50.553.70.471.47.771.2]D data ucapan yang telah terbentuk dalamframe:frame
W window Hamming dengan N sampel
dij elemen data ucapan pada urutan sampel ke-i dariframe ke-j Wi elemen window Hamming pada urutan sampel ke-i
4.2.3 Ekstraksi Ciri
Proses ekstraksi ciri dilakukan terhadap setiap frame sinyal ucapan. Metode yang digunakan adalah LPC dengan jumlah koefisien 8 (p = 8). Hasil proses ini menyebabkan setiap frame sinyal ucapan diisi oleh 8 buah koefisien LPC. Pada tahap ini pula, perlu dihitung estimasi kesalahan pendekatan sinyal ucapan untuk setiap frame dengan menggunakan persamaan (18). Estimasi kesalahan tersebut digunakan untuk mendapatkan energi estimasi kesalahan untuk setiap frame sinyal ucapan, yang nantinya dibutuhkan untuk membangun nilai koefisien pertama cepstral (persamaan (28)) untuk setiapframe sinyal ucapan.
4.2.4 Pemrosesan Akhir
Pada tahap ini akan dilakukan dua proses untuk setiap frame sinyal ucapan, yaitu konversi dari koefisien LPC menjadi koefisien cepstral (persamaan persamaan (26), persamaan (27), dan persamaan (28)) dan pembobotan parameter cepstral (persamaan (29) dan persamaan (30)).
Setelah melalui tahap ini, seluruh koefisien cepstral yang dihasilkan Idmsus untuk data pelatihan yang terdiri atas 10 ucapan untuk masing-masing pembicara disimpan ke dalam sebuah jile data pelatihan yang diberi nama datatraining_lebarframe_overlap.mat. Struktur dari isi jile data tersebut dapat dideskripsikan pada Gambar 18.
セ{cャャ@
C"
/
_ e
21 C22Pembicara 1 U
ll
U" ... U'(IO) :. CSI
en
Pemblcara 2 U2I U" ... U'(IO)
Keterangan gambar: U : satu data ucapan
Pembicara 6 U" U" U6(10) c: koefisien cepstral
X : jumlah frame
4.3 Hidden Markov Model
Model HMM untuk setiap pembicara yang dibangun merupakan model
HMM jenis kiri ke kanan dengan 4 buah state. Setiap state mewakili satu fonem.
Pada Gambar 19 diperlihatkan cara pembentukan model HMM untuk kata yang
dipakai oleh sistem, yaitu kata