APLIKASI METODE
VARIABLE SELECTION
UNTUK MENENTUKAN
FAKTOR DOMINAN YANG MEMPENGARUHI
PENDIDIKAN DAN KESEHATAN
RIAN MULYANA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
RIAN MULYANA. Aplikasi Metode Variable Selection untuk Menentukan Faktor Dominan yang Mempengaruhi Pendidikan dan Kesehatan. Dibimbing oleh HADI SUMARNO dan I WAYAN MANGKU.
Pendidikan dan kesehatan merupakan komponen utama yang mempengaruhi pembangunan manusia. Derajat pendidikan dan kesehatan dipengaruhi oleh berbagai faktor. Akan tetapi terdapat beberapa faktor yang paling berpengaruh. Oleh karena itu, tujuan dari karya ilmiah ini adalah untuk menentukan faktor dominan yang mempengaruhi pendidikan dan kesehatan dengan menggunakan metode variable selection. Prinsip utama dari metode variable selection adalah menentukan peubah yang dimasukkan ke dalam model regresi, sehingga pada akhirnya diperoleh model regresi terbaik. Metode variable selection yang digunakan adalah metode semua kemungkinan regresi, metode regresi bertatar, metode eliminasi langkah mundur, dan metode substitusi langkah maju. Peubah terpilih merupakan irisan antara metode regresi bertatar, metode eliminasi langkah mundur, dan metode substitusi langkah maju. Kemudian peubah terpilih tersebut dibandingkan dengan peubah yang dihasilkan dari metode semua kemungkinan regresi.
Pada bidang kesehatan, indikator yang digunakan adalah Angka Harapan Hidup dan Angka Kematian Bayi. Proses variable selection pada kedua indikator tersebut menghasilkan faktor dominan yang sama, yaitu dokter dan mantri. Pada bidang pendidikan indikator yang digunakan adalah lama sekolah dan Angka Melek Huruf. Pada indikator lama sekolah, jumlah perguruan tinggi dan Angka Partisipasi Kasar SMP menjadi faktor yang paling berpengaruh. Sementara itu pada indikator Angka Melek Huruf, faktor terpilih adalah Angka Partisipasi Kasar SD. Berdasarkan hasil pemilihan peubah pada setiap metode, metode regresi bertatar dapat diambil sebagai metode terbaik. Pada metode regresi bertatar dapat dilihat kombinasi antara metode substitusi maju dan metode eliminasi mundur. Metode ini juga menghasilkan peubah terpilih yang sama dengan metode semua kemungkinan regresi.
ABSTRACT
RIAN MULYANA. Application of Variable Selection Methods to determine the Dominant Factors that Affect Education and Health. Under supervision of HADI SUMARNO and I WAYAN MANGKU.
Education and health are the main components that affect human development. The degree of education and health is influenced by various factors. However, there are several factors that most influential. Therefore, the aim of this paper is to determine the dominant factors that affect education and health using variable selection methods. The main principle of variable selection method is to determine the variables included in the regression model, in order to obtain the best regression model. Variable selection method that used in this script are all possible regression method, stepwise regression method, backward elimination method, and forward substitution method. Selected variables are intersection between stepwise regression method, backward elimination method and forward substitution method. The selected variables then were compared with variables resulted from all possible regression method.
In the health sector, the indicators used are life expectancy rate and infant mortality rate. The process of variable selection on both indicators produces the same dominant factors, that is doctor and paramedic. In the education sector, the indicators used are years of schooling and the literacy rate. In the years of schooling indicator, the number of colleges and gross enrolment rate of junior high school become the most influential factors. While in the literacy rate indicator, the selected factor is gross enrolment rate of primary school. Based on the results of the variables selections on each method, stepwise regression method can be taken as the best method. In stepwise regression method, combination of forward substitution method and backward elimination method can be seen. This method also produces the same selected variables with all possible regression methods.
APLIKASI METODE
VARIABLE SELECTION
UNTUK MENENTUKAN
FAKTOR DOMINAN YANG MEMPENGARUHI
PENDIDIKAN DAN KESEHATAN
RIAN MULYANA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Sains pada
Departemen Matematika
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi
: Aplikasi Metode
Variable Selection
untuk Menentukan
Faktor Dominan yang Mempengaruhi Pendidikan dan
Kesehatan
Nama
: Rian Mulyana
NIM
: G54080043
Menyetujui,
Pembimbing I,
Dr. Ir. Hadi Sumarno, MS.
NIP.
19590926 198501 1 001Pembimbing II,
Dr.Ir. I Wayan Mangku, M.Sc.
NIP.
19620305 198703 1 001Mengetahui,
Ketua Departemen Matematika,
Dr. Berlian Setiawaty, MS.
NIP. 19650505 198903 2 004
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala limpahan rahmat dan karunia-Nya karya ilmiah berhasil diselesaikan. Shalawat dan salam semoga selalu tercurah kepada Nabi Besar Muhammad SAW beserta seluruh keluarga, sahabat, dan para pengikutnya sampai akhir zaman.
Karya ilmiah ini berjudul “Aplikasi Metode Variable Selection untuk Mengetahui Faktor Dominan yang Mempengaruhi Pendidikan dan Kesehatan” yang disusun sebagai syarat untuk memperoleh gelar Sarjana Sains pada Departemen Matematika. Penyusunan karya ilmiah ini juga tidak lepas dari bantuan berbagai pihak. Untuk itu penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Dr. Ir. Hadi Sumarno, MS. selaku dosen pembimbing I atas waktu, bimbingan, kesabaran, saran, dan bantuan yang diberikan kepada penulis selama penulisan skripsi ini.
2. Dr. Ir. I Wayan Mangku, M.Sc. selaku dosen pembimbing II atas waktu, bimbingan, kesabaran, saran, dan bantuan yang diberikan kepada penulis selama penulisan skripsi ini. 3. Ir. Ngakan Komang Kutha Ardana, M,Sc. selaku dosen penguji atas semua saran yang
diberikan kepada penulis.
4. Dr. Ir. Siswadi, M.Sc. atas saran yang diberikan kepada penulis.
5. Seluruh dosen Departemen Matematika atas semua ilmu dan nasihat yang bermanfaat sehingga membantu penulis dalam menyelesaikan karya ilmiah ini.
6. Bu Susi, Pak Mulyono, Bu Ade, Mas Deni, Mas Heri dan seluruh staf Departemen Matematika FMIPA IPB yang telah membantu penulis selama belajar di Departemen Matematika FMIPA IPB.
7. Keluargaku tercinta: Ibu dan bapak, kakakku dan adikku serta seluruh keluarga atas segala doa, dukungan, serta kasih sayang yang telah diberikan kepada penulis.
8. Ust. Ece Hidayat, Ust. Abdurrahman, dan Ust. Dudi Supiandi selaku pembimbing di Pondok Pesantren Al-ihya atas ilmu dan semangat yang selalu diberikan kepada penulis. 9. Nur Afriyanti, Nur Lasmini, dan Aldi Martiandi atas kesediaannya sebagai pembahas
seminar tugas akhir penulis.
10. Teman-teman Matematika 45 atas doa, bantuan, saran, semangat, dan dukungannya. 11. Kakak-kakak Matematika 44 dan 43 atas doa dan dukungannya.
12. Adik-adik Matematika 46 dan 47 atas doa dan dukungannya.
13. Teman-teman santri dan santriat Pondok Pesantren Al-ihya Dramaga : Asep, Sahlin, Luthfi, Opik, Aji, Uki, Fitra, Eer, Umam, Zimam, Quro, Ajron, Yusuf, Adi, Fitri, Fadholi, Aidah, Hannim, Pipit, Wenny, Velin, Iin, Titis, dan teman-teman santri yang lain atas doa dan dukungannya.
14. Semua pihak yang tidak dapat disebut satu persatu yang telah memberikan dukungan kepada penulis sehingga karya ilmiah ini dapat diselesaikan.
Semoga karya ilmiah ini dapat bermanfaat bagi dunia ilmu pengetahuan dan menjadi inspirasi bagi penelitian-penelitian selanjutnya.
Bogor, November 2012
RIWAYAT HIDUP
Penulis lahir di Cianjur, pada tanggal 13 Oktober 1990 dari pasangan bapak Saeful Sanusi dan ibu Engkam Komariah. Penulis merupakan anak kedua dari tiga bersaudara. Pada tahun 2002 penulis menyelesaikan pendidikan dasar di SDN Bojong Sari, kemudian melanjutkan studi di SMPN 1 Cipanas hingga tahun 2005. Pada tahun 2008 penulis lulus dari SMAN 1 Sukaresmi Kabupaten Cianjur dan pada tahun yang sama penulis diterima sebagai mahasiswa IPB melalui jalur Undangan Seleksi Masuk IPB (USMI). Penulis memilih mayor Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam dengan Statistika Terapan sebagai mata kuliah penunjang.
DAFTAR ISI
Halaman
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... ix
DAFTAR LAMPIRAN ... ix
I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Tujuan ... 1
II LANDASAN TEORI ... 1
2.1 Pendidikan dan Kesehatan ... 1
2.2 Peubah Bebas dan Peubah Terikat ... 2
2.3 Analisis Regresi Berganda ... 2
2.4 Koefisien Korelasi dan Korelasi Parsial ... 3
2.5 Analisis Variansi ... 3
2.6 Hipotesis Statistik dan Taraf Nyata ... 5
2.7 Koefisien Determinasi, Rataan Kuadrat Sisa, dan Cp Mallows ... 5
III DESKRIPSI METODE VARIBLE SELECTION ... 6
3.1 Uji Signifikansi Persamaan Regresi ... 6
3.2 Prosedur Variable Selection ... 7
3.2.1 Metode Seleksi Maju (Forward Substitution) ... 7
3.2.2 Metode Eliminasi Mundur (Backward Elimination) ... 7
3.2.3 Metode Regresi Bertatar (Stepwise Regression) ... 8
3.2.4 Metode Semua Kemungkinan Regresi (All Possible Regression) ... 8
IV APLIKASI METODE VARIABLE SELECTION PADA BIDANG PENDIDIKAN DAN KESEHATAN ... 9
4.1 Formulasi Peubah Bebas dan Peubah Terikat ... 9
4.2 Ilustrasi Pemilihan Peubah Dominan ... 9
4.3 Hasil dan Pembahasan ... 12
SIMPULAN ... 15
DAFTAR TABEL
Halaman
1. Metode backward elimination dengan peubah terikat Angka Harapan Hidup ... ... 9
2. Metode forward elimination dengan peubah terikat Angka Harapan Hidup ... ... 10
3. Metode stepwise elimination dengan peubah terikat Angka Harapan Hidup ... ... 11
4. Metode all possible regression dengan peubah terikat Angka Harapan Hidup ... ... 12
5. Peubah terpilih dari setiap metode dengan peubah terikat Angka Kematian Bayi... ... 13
6. Peubah terpilih dari setiap metode dengan peubah terikat Angka Melek Huruf... ... 13
7. Peubah terpilih dari setiap metode dengan peubah terikat lama sekolah... ... 14
DAFTAR GAMBAR
Halaman 1. Diagram pencar analisis regresi ... 7DAFTAR LAMPIRAN
Halaman 1. Proses pemilihan peubah bebas dari metode backward elimination, forward substitution, stepwise regression, dan all possible regressions dengan peubah terikat Angka Harapan Hidup (AHH) ... ... 182. Proses pemilihan peubah bebas dari metode backward elimination, forward substitution, stepwise regression, dan all possible regressions dengan peubah terikat Angka Kematian Bayi (AKB) ... ... 27
3. Proses pemilihan peubah bebas dari metode backward elimination, forward substitution, stepwise regression, dan all possible regressions dengan peubah terikat Angka Melek Huruf (AMH) ... ... 31
I PENDAHULUAN
1.1 Latar Belakang
Salah satu tujuan suatu negara adalah untuk meningkatkan pembangunan manusia. Untuk mengklasifikasikan suatu negara termasuk negara maju atau negara berkembang dapat digunakan sebuah ukuran perbandingan yang dinamakan Indeks Pembangunan Manusia (IPM). IPM terdiri atas 3 komponen utama, yaitu Pendidikan, Kesehatan, dan Ekonomi. Namun pada pembahasan karya ilmiah ini dibatasi dalam ruang lingkup komponen pendidikan dan kesehatan.
Pembangunan bidang pendidikan bertujuan untuk meningkatkan kecerdasan dan keterampilan manusia, sehingga kualitas sumber daya manusia sangat bergantung pada kualitas pendidikan. Sedangkan pembangunan kesehatan antara lain bertujuan agar masyarakat memperoleh pelayanan secara mudah, murah, dan merata. Dalam mengukur dimensi pendidikan dan kesehatan penduduk digunakan beberapa indikator. Salah satu indikator yang digunakan untuk menentukan derajat pendidikan adalah Angka Melek Huruf dan rata-rata lama sekolah. Sedangkan indikator yang digunakan untuk menentukan derajat kesehatan penduduk adalah Angka Kematian Bayi dan Angka Harapan Hidup (Biro Pusat Statistik 2009).
Derajat pendidikan dan kesehatan penduduk dipengaruhi oleh banyak faktor. Namun dari sekian banyak faktor tersebut, terdapat faktor dominan yang paling berpengaruh. Oleh karena itu diperlukan suatu metode untuk menentukan faktor dominan yang paling berpengaruh. Salah-satu upaya untuk mengatasi permasalahan tersebut adalah dengan menggunakan analisis regresi.
Analisis regresi merupakan sebuah teknik statistika yang digunakan untuk menyelidiki dan memodelkan hubungan antara beberapa peubah. Dalam proses pemilihan peubah dan model regresi terbaik digunakan suatu metode yang dinamakan metode variable selection (Montgomery & Peck 1991).
Prinsip utama dari metode variable selection adalah menentukan peubah yang dimasukkan ke dalam model regresi. Dalam metode ini juga dapat diketahui peubah yang tidak perlu dimasukkan ke dalam model. Sehingga pada akhirnya diperoleh model regresi dengan peubah yang lebih sedikit. Selain keuntungan secara teoritis yaitu menghilangkan peubah yang tidak relevan, model ini memiliki daya tarik dari sisi kesederhanaan serta keuntungan ekonomi (Rawlings et al. 1998).
Metode variable selection yang digunakan pada karya ilmiah ini adalah metode semua kemungkinan regresi (all possible regression), regresi bertatar (stepwise regression), eliminasi langkah mundur (backward elimination), dan eliminasi langkah maju (forward substitution).
1.2 Tujuan
Tujuan dari penulisan karya ilmiah ini adalah : 1. Mempelajari teknik pemilihan peubah
dalam model regresi.
2. Menentukan faktor dominan yang berpengaruh terhadap pendidikan dan kesehatan dengan menggunakan beberapa metode variable selection.
3. Memilih model terbaik dari faktor dominan yang mempengaruhi pendidikan dan kesehatan.
II LANDASAN TEORI
Berikut ini akan dijelaskan beberapa definisi dan teori yang terkait dengan masalah variable selection.
2.1 Pendidikan dan Kesehatan
Definisi Pendidikan
Menurut Undang-undang RI No.2 tahun 1998, pendidikan adalah usaha sadar untuk menyiapkan peserta didik melalui kegiatan bimbingan, pengajaran dan atau latihan untuk peranannya di masa yang akan datang.
Sedangkan pendidikan nasional menurut ayat 2 pasal 1 adalah pendidikan yang berakar pada kebudayaan bangsa Indonesia dan yang berdasarkan pada Pancasila dan Undang-undang Dasar 1945. Selanjutnya pendidikan nasional berfungsi untuk mengembangkan kemampuan serta meningkatkan mutu kehidupan dan martabat manusia Indonesia dalam rangka upaya mewujudkan tujuan nasional.
Definisi Kesehatan
Kesehatan adalah keadaan dinamis atau kondisi organisme manusia yang multidimensi di alam, sumber daya untuk hidup, dan hasil dari interaksi dan adaptasi seseorang dengan lingkungannya. Karena itu, kesehatan dapat berada dalam berbagai derajat dan spesifikasi untuk setiap individu dan situasinya.
( McKenzie et al. 2008) 2.2 Peubah Bebas dan Peubah Terikat
Peubah bebas adalah peubah yang nilainya ditentukan dan diatur, atau nilainya dapat diamati. Perubahan nilai peubah bebas dapat memberikan suatu efek atau pengaruh yang diberikan kepada peubah lain. Peubah tersebut dinamakan peubah terikat.
(Draper & Smith 1985)
2.3 Analisis Regresi Berganda
Analisis regresi berganda merupakan analisis regresi yang digunakan untuk mencari hubungan fungsional dari dua peubah bebas atau lebih terhadap peubah terikat.
Misalkan terdapat n-pengamatan dan k peubah bebas dimana n > k. Sedangkan adalah peubah terikat pada amatan ke-i dan
menunjukkan peubah bebas ke-j pada amatan ke-i. Diasumsikan berdistribusi normal N [0, ] serta tidak berkorelasi. Selanjutnya dapat dibentuk model regresi linear berganda, yaitu :
= + + + …+ +
= + +
dengan = 1,2, …, dan = 1,2, …, . Koefisien , , , …, disebut sebagai koefisien regresi dari setiap peubah bebas ( Montgomery & Peck 1991).
Koefisien adalah sebuah konstanta yang menunjukkan nilai awal persamaan regresi. Sementara β1, β2, … ,βk menyatakan
perubahan rata-rata peubah y untuk setiap peubah ( = 1,2, …, ) sebesar satu satuan. Jika nilai koefisien regresi positif, maka nilai y akan mengalami penambahan atau kenaikan. Sebaliknya jika koefisien regresi bernilai negatif, maka nilai y akan mengalami penurunan.
Untuk menduga nilai dari koefisien regresi β1, β2, … , βk digunakan metode kuadrat terkecil. Misalkan koefisien b1,b2, … , bk adalah penduga bagi koefisien regresi tersebut. Menurut metode kuadrat terkecil, penduga setiap koefisien regresi b1,b2, … , bk dapat diperoleh dengan meminimumkan bentuk kuadrat :
( , ,…, ) =
= ( − )
= ( − + ) .
Penduga kuadrat terkecil bagi β0, β1, … , βk dari persamaan tersebut diperoleh apabila : a.
| , ,…, = 0
↔ −2 ( − + ) = 0
b.
| , ,…, = 0
↔ −2 ( − + ) = 0.
Penyederhanaan dari persamaan tersebut dapat disajikan dalam bentuk persamaan normal :
+ + + … + =
+ + + … + =
⋮ ⋮ ⋮ ⋮ ⋮
+ + + … + = .
Pada pola persamaan tersebut terdapat = ( + 1) persamaan dan untuk masing-masing persamaan telah diketahui koefisien regresinya. Solusi dari persamaan tersebut akan menjadi penduga bagi b1, b2, … , bk.
Jika dituliskan ke dalam bentuk notasi matriks, maka akan terbentuk suatu model regresi sebagai berikut :
= +
y = ⋮ , = 1 … 1 … ⋮ ⋮ ⋮ ⋮ 1 … = ⋮ , = ⋮ .
Menurut metode kuadrat terkecil, penduga setiap koefisien regresi dalam matriks dapat diperoleh dengan meminimumkan :
( ) = ∑ = ′
= ( − ) ( − )
= − − +
= − +
dengan adalah skalar dan memiliki bentuk transpos ( )′= juga berupa skalar. Penduga kuadrat terkecil bagi β diperoleh apabila :
| = ↔ − ′ + = ↔ ′ = dengan = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ … … ⋮ ⋮ ⋮ … ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢
⎡ 1 1 …… 1
… ⋮ ⋮ ⋮ … ⎦⎥ ⎥ ⎥ ⎤ ⋮ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ⋮ ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ .
Jika X’X tak singular, maka dari persamaan = ′ dapat diperoleh :
= ( ) ′
dimana ( ) adalah matriks invers dari X’X.
(Montgomery & Peck 1991)
2.4 Koefisien Korelasi dan Korelasi Parsial
Definisi Koefisien Korelasi
Koefisien korelasi adalah nilai yang menunjukkan besarnya korelasi antara dua
peubah atau lebih yang biasa dilambangkan dengan r. Koefisien korelasi ini digunakan untuk menyatakan keeratan hubungan suatu peubah dengan peubah yang lainnya.
Korelasi merupakan bentuk pembakuan dari kovariansi Sxy, yaitu dengan cara membaginya dengan simpangan baku masing-masing peubah. Jika Sx dan Sy adalah simpangan baku dari peubah x dan y, maka koefisien korelasi r antara x dan y adalah :
= = ∑( − ) ( − ) ∑( − ) ∑( − ) = ∑ − (∑ ) (∑ ) ∑ −(∑ ) ∑ −(∑ ) = ∑ − (∑ ) (∑ ) ∑ −(∑ ) ∑ −(∑ )
dengan i = 1,2,3,…, n.
Nilai r berkisar dari -1 sampai 1 atau dalam bentuk matematis dapat ditulis menjadi -1 ≤ r ≤ 1. Semakin tinggi nilai mutlak r maka semakin tinggi pula keeratan hubungan peubah tersebut. Tanda positif pada koefisien korelasi menandakan bahwa hubungan kedua variabel adalah searah. Sedangkan tanda negatif pada koefisien korelasi menandakan bahwa hubungan kedua peubah berlawanan.
(Sembiring 1995)
Definisi Korelasi Parsial
Korelasi parsial adalah korelasi antara dua peubah dengan mengontrol peubah lainnya. Korelasi parsial digunakan untuk meneliti hubungan antara dua peubah yang diasumsikan bahwa seluruh atau sebagian dipengaruhi oleh peubah ketiga. Dalam hal ini peubah ketiga dijadikan tetap (konstan). Misalkan terdapat peubah x,y, dan z. Korelasi parsial antara x dan y jika z konstan didefinisikan sebagai:
. =
−
1− 1− . (Sembiring 1995)
2.5 Analisis Variansi
= +
( , )
( − )
( − ) ( − )
̅
Gambar 1. Diagram pencar analisis regresi.
dimana :
: Garis rata-rata regresi − : Deviasi residu : Nilai rata-rata − : Deviasi regresi : Nilai rata-rata
− : Deviasi total
Dari diagram pencar di atas dapat dilihat bahwa jumlah deviasi atau penyimpangan total adalah akumulasi dari penyimpangan akibat regresi dan penyimpangan residual atau sisa bagian yang tidak dapat diterangkan oleh regresi. Sehingga dapat dibentuk persamaan sebagai berikut :
( − ) = ( − ) + ( − ) dengan i = 1, 2, 3,…, n.
Jika ruas kiri dan kanan dikuadratkan dan kemudian dijumlahkan, maka diperoleh :
( − )
= {( − ) + ( − ) }
= ( − ) + ( − )
+ 2 ( − ) ( − ) .
Pandang hasil perkalian silang pada suku ketiga persamaan ruas kanan di atas. Persamaan tersebut dapat dituliskan sebagai : 2 ( − ) ( − )
= 2 ( − )−2 ( − ) . Bagian kedua ruas kanan sama dengan nol karena berdasarkan pada syarat minimum persamaan kuadrat terkecil bahwa :
−2 − + = 0
↔ − − ( ) = 0
↔ − ( + ) = 0
↔ − = 0
↔ ( − ) = 0.
Bagian pertama dari ruas kanan juga sama dengan nol, karena
( − )
= ( + ) ( − )
= ( − ) + ( − )
= 0 + ( − + )
= 0.
Jadi persamaan deviasi total di atas dapat ditulis sebagai berikut :
( − ) = ( − ) + ( − ) .
Persamaan di atas merupakan persamaan dasar dalam analisis regresi dan analisis variansi. Ruas kiri disebut sebagai jumlah kuadrat total ( ) atau jumlah variasi total. menyatakan jumlah penyimpangan di sekitar nilai rata-ratanya. Bagian pertama ruas kanan disebut jumlah kuadrat regresi atau regression sum of squares ( ), dan ini adalah variasi respons disekitar nilai rata-ratanya . Bagian ini menyatakan pengaruh regresi peubah x terhadap peubah respons y. Bagian kedua pada ruas kanan disebut jumlah kuadrat galat atau residual sum of squares ( ). Dengan demikian hubungan antara ,
, dan dapat ditulis sebagai : = + .
(Sembiring 1995) Jika x merupakan peubah bebas dan y merupakan peubah terikat dari suatu persamaan regresi, maka jumlah kuadrat total ( ) dapat dinyatakan sebagai :
= ( − )
= ( −2 − )
= − 2 ∑ − (∑ )
= − 2(∑ ) −(∑ )
= 2
= 1
−(∑= 1 ) 2
.
Dalam bentuk matriks dapat dituliskan sebagai berikut:
= − (∑ ) .
Selanjutnya untuk mencari jumlah kuadrat sisa ( ) dari suatu persamaan regresi adalah sebagai berikut :
= − 2
= 1
= ( )2 = 1
= ′ .
Substitusi = − , sehingga = ( − )′( − )
= − − +
= − + .
Karena = , akibatnya
= − .
Untuk mencari formula jumlah kuadrat regresi ( ) dapat digunakan formula umum dari , yaitu :
= + maka
= +
= − (∑ ) − +
= − (∑ ) .
( Montgomery & Peck 1991)
2.6 Hipotesis Statistik dan Taraf Nyata (α) Hipotesis statistik adalah pernyataan atau dugaan mengenai satu atau lebih populasi. Hipotesis yang dirumuskan dengan harapan akan ditolak disebut sebagai hipotesis nol, dilambangkan dengan . Penolakan mengakibatkan penerimaan suatu hipotesis alternatif, yang dilambangkan dengan . Hipotesis nol suatu parameter harus menyatakan suatu nilai dari parameter tersebut, sedangkan hipotesis alternatifnya merupakan kemungkinan nilai lainnya. Jadi bila menyatakan hipotesis nol = 0,5 maka hipotesis alternatifnya adalah ≠0,5.
Taraf nyata adalah besarnya batas toleransi dalam menerima kesalahan hasil hipotesis
terhadap nilai parameter populasinya. Taraf nyata dilambangkan dengan (alpha). Semakin tinggi taraf nyata yang digunakan, semakin tinggi pula penolakan hipotesis nol atau hipotesis yang diuji, padahal hipotesis nol benar. Besarnya nilai bergantung pada keberanian dalam menentukan besarnya kesalahan yang akan ditolerir. Besarnya kesalahan disebut sebagai daerah kritis pengujian (critical region of test) atau daerah penolakan (region of rejection).
(Walpole 1995)
2.7 Koefisien Determinasi ( ), Rataan Kuadrat Sisa (s2), dan -Mallows
Definisi Koefisien Determinasi ( )
Koefisien determinasi ( ) merupakan suatu ukuran kelayakkan model regresi. Nilai menunjukkan besarnya pengaruh peubah bebas secara serempak terhadap peubah terikat. Misalkan adalah koefisien determinasi berganda dengan = banyaknya parameter dalam model, maka dapat didefinisikan sebagai: = = + = ⁄ 1 + . Salah satu kelemahan adalah besarnya nilai dipengaruhi oleh banyaknya peubah bebas di dalam model. Jika banyaknya peubah bebas bertambah maka nilai akan membesar, sehingga sulit untuk memperoleh nilai optimum. Akan tetapi jika model yang dibandingkan mempunyai peubah bebas yang sama maka mudah untuk digunakan. Salah satu cara untuk mengatasi kelemahan adalah dengan menggunakan yang disesuaikan (adjusted ) yang didefinisikan sebagai :
= 1− ⁄( − ) ( −1) ⁄
= 1−( −1) ( − ) 1− = 1−( )
( ) ( 1− ).
Penyesuaian ini membuat tidak selalu membesar apabila banyaknya peubah bebas meningkat.
(Sembiring 1995)
Definisi Rataan Kuadrat Sisa (s2)
kuadrat sisa s2 membesar jika terjadi penurunan dalam akibat penambahan peubah bebas ke dalam model. Penambahan peubah bebas ke dalam model akan menurunkan dan derajat bebasnya. Kuadrat sisa s2 dapat dinyatakan sebagai :
=
− .
(Sembiring 1995)
Definisi Statistik -Mallows
Ukuran statistik ini diperkenalkan oleh Colin L. Mallows yang digunakan untuk menilai kecocokan model regresi yang telah diperkirakan dengan menggunakan kuadrat terkecil biasa. Tujuannya adalah untuk menemukan model terbaik yang melibatkan subset dari semua peubah bebas yang tersedia.
Misalkan menunjukkan jumlah kuadrat sisa ( ) dari model dengan parameter termasuk β0 . Sementara menunjukkan ukuran amatan, dan menunjukan rataan kuadrat sisa. Statistik dapat dinyatakan sebagai
= + 2 − .
Semakin banyak suku yang disertakan ke dalam model biasanya penurunan Cp akan semakin tinggi. Model terbaik ditentukan setelah memeriksa pola perubahan Cp. Selanjutnya cari persamaan regresi dengan nilai Cp terendah yang kira-kira sama dengan Cp = p.
(Sembiring 1995)
III DESKRIPSI METODE VARIABLE SELECTION
Prinsip utama dari metode variable selection adalah menentukan peubah yang akan dimasukkan ke dalam model regresi. Dalam metode ini pula dapat ditentukan peubah yang tidak perlu dimasukkan ke dalam model. Sehingga pada akhirnya diperoleh model regresi dengan peubah yang lebih sedikit ( Rawlings et al. 1998).
3.1 Uji Signifikansi Persamaan Regresi Uji signifikansi persamaan regresi merupakan suatu uji yang digunakan untuk menunjukkan adanya suatu hubungan linear antara peubah respon y dan peubah bebas
, , …, . Hipotesis yang sesuai adalah: H0 : = 0
H1 : ≠0 (minimal ada satu ≠0 ).
Penolakan H0 menandakan bahwa
setidaknya ada satu dari peubah bebas , , …, yang berkontribusi secara signifikan terhadap model. Jumlah kuadrat total dipartisi menjadi jumlah kuadrat regresi dan Jumlah Kuadrat Sisa , yang dapat dinyatakan dalam bentuk:
= + .
Jika H0 : = 0 benar, maka / ~
dimana nilai derajat bebas dari setara dengan banyaknya peubah bebas yang ada di dalam model. Selain itu pula dapat dinyatakan bahwa / ~ , serta dan saling bebas. Prosedur pengujian untuk H0 :
= 0 dilakukan dengan menghitung :
= ⁄
( − −1)
⁄ = .
Penolakkan H0 terjadi jika nilai >
= , , dengan α merupakan taraf
nyata, misalkan α=0.05 atau α=0.1 ( Montgomery & Peck 1991).
Untuk menguji pengaruh setiap peubah bebas terhadap peubah terikat digunakan uji F parsial. Uji F parsial dapat dilakukan terhadap semua koefisien regresi dengan menganggap semua peubah bebas telah masuk ke dalam model kecuali peubah yang ingin diuji pengaruhnya. Uji F parsial juga digunakan untuk memilih peubah bebas yang keberadaannya memberikan sumbangan keragaman yang cukup besar terhadap model regresi. Peubah bebas yang keberadaannya dapat diwakili oleh peubah lain tidak perlu dimasukkan ke dalam model.
Misalkan ∗, ∗, …, ∗ adalah peubah bebas di luar model yang akan diuji pengaruhnya. Sementara , , …, adalah peubah bebas yang telah ada di dalam model. Model regresi penuh (full) dapat ditulis sebagai:
= + + + …+ +
∗ ∗+ ∗ ∗+ …+ ∗ ∗ + . Hipotesis nol yang sesuai dengan Uji F parsial adalah :
H0 : ∗= 0
H1 : ∗≠0 (minimal ada satu ∗= 0).
Tahapan pertama dari uji F parsial adalah mencari jumlah kuadrat akibat penambahan atau pengurangan peubah ∗, ∗, …, ∗ terhadap model. Jumlah kuadrat ini dapat dinyatakan dalam bentuk :
( ∗, ∗, …, ∗| , , …, )
= , , …, , ∗, ∗, …, ∗ − , , …,
= , , …,
− ( , , …, , ∗, ∗, …, ∗).
Dengan menggunakan jumlah kuadrat tambahan di atas, maka nilai dapat ditentukan sebagai berikut :
( ∗, ∗,…, ∗| , , …, ) = [ model penuh− tereduksi]⁄
Kuadrat tengah sisa ( ) model full = [ model tereduksi− model full]⁄
Kuadrat tengah sisa ( ) model full =
∗, ∗, …, ∗ , , …, ⁄ ( ∗, ∗,…, ∗| , ,…, )
Jika > = , ,
maka H0 ditolak dan dapat disimpulkan bahwa
peubah bebas tersebut berpengaruh nyata terhadap model.
(Kleinbaum et al. 2008) 3.2 Prosedur Variable Selection
3.2.1 Metode Seleksi Maju (Forward Elimination)
Menurut metode ini peubah bebas dimasukkan satu demi satu menurut urutan besar pengaruhnya terhadap model dan berhenti jika semua peubah bebas yang memenuhi syarat telah masuk ke dalam model. Didefinisikan k adalah banyaknya peubah bebas x yang akan dimasukkan ke dalam model. Pada keadaan awal model tidak mengandung peubah bebas, sehingga model awal dapat ditulis sebagai = .
Algoritma forward selection : Langkah 0:
Menentukan model regresi awal = . Langkah 1:
Menentukan matriks korelasi R dari semua peubah yang tersedia.
= ⎣ ⎢ ⎢
⎡ 1 1 ⋯⋯
⋮ ⋮ ⋱ ⋮
⋯ 1 ⎦⎥ ⎥ ⎤ .
Langkah 2 :
Memilih peubah bebas , , …, dengan korelasi ( = 1,2, …, ) tertinggi terhadap peubah terikat y.
Langkah 3:
Masukkan peubah bebas terpilih pertama ke dalam model, misalkan . Sehingga membentuk suatu model regresi :
= + Langkah 4:
Uji F terhadap peubah pertama yang terpilih. Jika < maka
peubah terpilih dibuang dan proses dihentikan. Jika > maka peubah terpilih memiliki pengaruh nyata terhadap peubah terikat y, sehingga layak untuk dipertahankan di dalam model. Langkah 5:
Memilih peubah bebas tersisa dengan kuadrat korelasi parsial tertinggi.
Langkah 6:
Masukkan peubah bebas terpilih kedua ke dalam model, misalkan . sehingga membentuk suatu model regresi :
= + +
Langkah 7:
Uji F parsial, jika < maka proses dihentikan dan model terbaik adalah model sebelumnya. Namun jika ≥ peubah bebas layak untuk dimasukkan ke dalam model dan kembali ke langkah 5. Proses berakhir jika tidak ada lagi peubah tersisa yang bisa dimasukkan ke dalam model.
( Montgomery & Peck 1991)
3.2.2 Metode Seleksi Mundur (Backward Elimination)
Metode ini dimulai dengan memasukkan semua peubah bebas ke dalam model sehingga terbentuk suatu model regresi penuh (full). Kemudian satu demi satu peubah bebas tersebut direduksi sampai semua peubah tidak memenuhi patokan keluar model. Misalkan k adalah banyaknya peubah bebas. Maka model lengkap dapat dituliskan dalam bentuk :
= + + + …+ .
Algoritma backward elimination : Langkah 0:
Menentukan model regresi penuh (full)
= + + + …+ .
Langkah 1:
Uji F parsial masing-masing peubah bebas terhadap model.
Langkah 2 :
Memilih peubah bebas , , …, dengan nilai terendah.
Langkah 3:
Jika terendah ≥ maka proses dihentikan dan persamaan regresi tersebut merupakan persamaan terbaik. Tetapi jika nilai terendah < maka peubah bebas yang memiliki nilai F parsial terendah dibuang dari model. Langkah 5:
Kembali ke langkah 1 dengan model awal yang tidak menyertakan peubah yang dibuang ( k-1 peubah bebas).
3.2.3 Metode Seleksi Bertahap ( Stepwise Elimination)
Metode ini merupakan gabungan dari metode seleksi maju dan metode seleksi mundur yang diterapkan secara bergantian. Pada tahap pertama digunakan seleksi maju, dan tahap kedua digunakan seleksi mundur. Pada setiap tahap jika peubah yang ada dalam model tidak berpengaruh setelah dimasukkan peubah baru, maka peubah tersebut akan dikeluarkan dari model. Sebaliknya jika peubah yang ada dalam model masih berpengaruh setelah peubah lain dimasukkan, maka peubah tersebut akan dipertahankan sampai pengujian tahap berikutnya.
Didefinisikan k adalah banyaknya peubah bebas x yang akan dimasukkan ke dalam model. Pada keadaan awal model tidak mengandung peubah bebas, sehingga model awal dapat ditulis sebagai = .
Algoritma stepwise elimination : Langkah 0:
Menentukan model regresi awal = . Langkah 1:
Menentukan matriks korelasi R dari semua peubah yang tersedia.
= ⎣ ⎢ ⎢
⎡ 1 1 ⋯⋯
⋮ ⋮ ⋱ ⋮
⋯ 1 ⎦⎥ ⎥ ⎤ .
Langkah 2 :
Memilih peubah bebas , , …, dengan korelasi ( = 1,2, …, ) tertinggi terhadap peubah terikat y.
Langkah 3:
Masukkan peubah bebas terpilih pertama ke dalam model, misalkan . Sehingga membentuk suatu model regresi :
= + .
Langkah 4:
Uji F terhadap peubah terpilih pertama. Jika < ( ) maka peubah terpilih dibuang dan proses dihentikan. Namun jika > ( ) maka peubah terpilih layak dipertahankan di dalam model.
Langkah 5:
Memilih peubah bebas dengan kuadrat korelasi parsial -parsial tertinggi. Langkah 6:
Masukkan peubah bebas terpilih kedua ke dalam model, misalkan . Sehingga membentuk suatu model regresi :
= + + .
Langkah 7:
Uji F parsial masing-masing peubah bebas yang terdapat di dalam model.
Langkah 8:
Uji F parsial masuk, jika peubah bebas terpilih kedua > ( ) maka proses dihentikan dan model terbaik adalah model sebelumnya. Namun jika
≥ ( ) peubah
bebas terpilih layak untuk dipertahankan dalam model.
Langkah 9:
Uji F parsial ke luar, jika nilai
terendah < ( ) maka peubah bebas yang memiliki F parsial terendah dibuang dari model. Jika terendah ≥ maka peubah bebas dipertahankan.
Langkah 10:
Kembali ke langkah 5 untuk menguji peubah bebas tersisa. Proses dihentikan jika tidak ada lagi peubah bebas yang dapat dimasukan atau dikeluarkan.
(Sembiring 1995)
3.2.4 Metode Semua Kemungkinan Regresi (All Possible Regression)
Sesuai dengan namanya metode ini dirancang untuk menjalankan semua kemungkinan regresi antara peubah terikat dengan semua kombinasi dari peubah bebas. Jika terdapat k peubah bebas yang tersedia, maka ada 2k persamaan. Jika k=10 maka ada 210 = 1024 persamaan yang harus diperiksa. Itulah sebabnya prosedur ini memerlukan komputer berkecepatan tinggi. Dalam menilai kebaikan suatu kombinasi atau pasangan peubah bebas biasanya sering digunakan salah satu patokan dari:
1. Koefisien determinasi R2 2. Rataan kuadrat sisa s2, dan 3. Cp Mallows.
Algoritma all possible regression : Langkah 1:
Mengelompokkan persamaan ke dalam kelompok-kelompok berdasarkan pada banyaknya peubah bebas. Kelompok terdiri dari persamaan yang tidak mengandung peubah bebas sampai persamaan yang mengandung semua peubah bebas. Pengelompokkan persamaan regresi tersebut adalah sebagai berikut :
a. Kelompok 1 terdiri dari persamaan regresi dengan hanya nilai tengah (Model = )
c. Kelompok 3 terdiri dari persamaan regresi dengan 2 peubah bebas (Contoh: = + + ) d. Kelompok ke-n ( = 4,5, …, + 1)
terdiri dari persamaan regresi dengan (n-1) atau semua peubah bebas. (Contoh : = + + ⋯+
). Langkah 2:
Pengamatan terhadap pola perubahan nilai , , dan Cp dari setiap persamaan
setelah ditambahkan peubah. Peubah yang memiliki pengaruh besar akan meningkatkan dan menurunkan , dan Cp yang cukup signifikan. Jika setelah penambahan peubah bebas tidak terjadi perubahan yang cukup signifikan, maka peubah tersebut dianggap tidak terlalu berpengaruh. Sehingga model sebelumnya lebih baik.
(Draper & Smith 1985)
IV APLIKASI METODE
VARIABLE SELECTION
PADA BIDANG
PENDIDIKAN DAN KESEHATAN
4.1 Formulasi peubah bebas dan peubah terikat
Dalam mengukur dimensi pendidikan dan kesehatan penduduk digunakan beberapa indikator. Indikator yang digunakan untuk menentukan derajat kesehatan dalam karya ilmiah ini adalah :
= Angka Harapan Hidup = Angka Kematian Bayi.
Sedangkan peubah bebas atau faktor yang berpengaruh terhadap kedua indikator di atas yaitu :
= Distribusi air = Jumlah bidan = Jumlah dokter = Jumlah mantri = Jumlah puskesmas = Jumlah Rumah Sakit (RS).
Indikator yang digunakan untuk menentukan derajat pendidikan yaitu :
= Rata-rata lama sekolah = Angka Melek Huruf.
Sedangkan peubah bebas atau faktor yang berpengaruh terhadap kedua indikator di atas yang yang digunakan yaitu :
= Jumlah SD (SD) = Jumlah SMP (SMP) = Jumlah SMA (SMA) = Jumlah Perguruan tinggi = Jumlah guru SD
= Jumlah guru SMP = Jumlah guru SMA = Jumlah dosen
= Pendidikan S-1 keatas guru SD = Pendidikan S-1 keatas guru SMP = Pendidikan S-1 keatas guru SMA = Angka Partisipasi Kasar SD = Angka Partisipasi Kasar SMP = Angka Partisipasi Kasar SMA = Angka Partisipasi Murni SD = Angka Partisipasi Murni SMP = Angka Partisipasi Murni SMA.
Data yang digunakan pada karya ilmiah ini adalah data sekunder indikator pendidikan dan kesehatan dari 33 provinsi di Indonesia pada tahun 2008 yang diambil dari Biro Pusat Statistik (BPS).
4.2 Ilustrasi pemilihan peubah dominan Dalam karya ilmiah ini digunakan beberapa metode variable selection, yaitu metode semua kemungkinan regresi (all possible regression), regresi bertatar (stepwise regression), eliminasi langkah mundur (backward elimination), dan substitusi langkah maju (forward regression). Sebagai contoh aplikasi dari metode-metode tersebut, ditentukan peubah yang paling berpengaruh terhadap kesehatan dengan Angka Harapan Hidup (AHH) sebagai peubah terikat. Dalam menyelesaikan permasalahan ini digunakan perangkat lunak R-Stat 2.8.0 dan Minitab 16. Proses pemilihan peubah bebas dengan Angka Harapan Hidup (AHH) sebagai peubah terikat disajikan pada Lampiran 1.
Backward Elimination
Pada tahap pertama semua peubah bebas , , …, dimasukkan, sehingga membentuk model penuh (full). Kemudian peubah bebas direduksi satu persatu dengan menggunakan uji F parsial pada taraf nyata = 0.1 . Proses pereduksian peubah bebas tersebut dapat dilihat pada tabel di bawah ini :
Tabel 1 Metode backward elimination dengan peubah terikat Angka Harapan Hidup
Model Peubah
F parsial terendah
parsial
1 (full) Puskesmas ( ) 0.0012 2.91
2 Air ( ) 0.4422 2.90
Dari tabel di atas dapat dilihat bahwa pada model pertama (full) peubah bebas atau jumlah puskesmas memiliki F parsial terkecil dan tidak nyata ( < ). Sehingga peubah bebas harus dikeluarkan dari model. Pada model kedua, peubah bebas yang harus dikeluarkan dari model adalah atau distribusi air. Pada model ketiga peubah dengan F parsial terendah adalah atau jumlah RS. Akan tetapi nilai dari peubah bebas tersebut lebih besar dari nilai , sehingga peubah tersebut berpengaruh nyata terhadap model. Akibatnya proses pereduksian dihentikan dan model terbaik adalah model ketiga yang dinyatakan dalam bentuk :
= 69.71−0.026 + 0.117 −0.03 + 1.892 .
Nilai keseluruhan dari model di atas adalah 15.63. Nilai ini lebih besar dari nilai pada taraf nyata = 0.1, yaitu sebesar 2.16. Sehingga model tersebut nyata, dengan nilai koefisien determinasi sebesar 69.07%. Dari tabel ANOVA parsial dapat dilihat bahwa nilai F parsial untuk setiap peubah juga nyata, sehingga layak untuk dipertahankan dalam model. Peubah atau jumlah RS memiliki koefisien regresi tertinggi, yaitu sebesar 1.892. Artinya penambahan jumlah dokter sebesar 1 satuan akan menambah Angka Harapan Hidup sebesar 1.982. Sementara peubah bebas atau jumlah dokter memiliki koefisien regresi sebesar 0.117. Peubah dan mempunyai koefisien regresi berturut-turut sebesar -0.026 dan -0.030. Hasil ini bertolak belakang dengan Angka Harapan Hidup yang seharusnya bertambah seiring dengan bertambahnya jumlah bidan dan mantri. Hal ini juga terjadi karena antara peubah dan berkorelasi negatif dengan Angka Harapan Hidup. Dari hasil ini juga dapat diidentifikasi bahwa bertambahnya jumlah bidan dan mantri tidak diikuti dengan kualitas kerja yang seharusnya semakin meningkat. Sehingga berdampak pada menurunnya Angka Harapan Hidup.
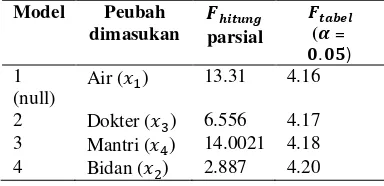
Forward Substitution
Metode ini merupakan kebalikan dari metode eliminasi mundur (backward elimination). Pada metode ini, model regresi awal tidak mengandung peubah bebas atau dengan kata lain hanya mengandung koefisien . Secara umum proses substitusi peubah pada metode ini dapat dilihat pada tabel di bawah ini :
Tabel 2 Metode forward substitution dengan peubah terikat Angka Harapan Hidup
Model Peubah
dimasukan parsial ( =
. )
1 (null)
Air ( ) 13.31 4.16
2 Dokter ( ) 6.556 4.17 3 Mantri ( ) 14.0021 4.18 4 Bidan ( ) 2.887 4.20
Dari matriks korelasi yang terbentuk, peubah atau air memiliki korelasi tertinggi terhadap peubah terikat y. Oleh karena itu peubah tersebut menjadi peubah pertama yang diambil untuk dimasukkan ke dalam model. Pada uji F keseluruhan untuk model tersebut didapatkan nilai sebesar 13.31. Nilai ini lebih besar dari nilai pada taraf nyata = 0.05, yaitu sebesar 4.16. Maka dari itu peubah bebas atau air layak dipertahankan di dalam model. Proses dilanjutkan dengan mencari kuadrat korelasi parsial dari masing-masing peubah bebas. Setelah itu diambil peubah atau jumlah dokter sebagai peubah bebas dengan kuadrat korelasi parsial tertinggi untuk dimasukkan ke dalam model. Dari tabel ANOVA parsial dapat dilihat bahwa nilai parsial untuk peubah bebas adalah sebesar 6.556. Nilai ini lebih besar dari nilai pada taraf nyata = 0.05, yaitu sebesar 4.17. Maka peubah bebas atau jumlah dokter layak untuk dipertahankan di dalam model. Pada model ke-4 iterasi dihentikan karena nilai parsial dari peubah atau jumlah bidan lebih kecil dari nilai pada taraf nyata = 0.05. Akibatnya peubah harus dikeluarkan dari model. Dengan demikian model terbaik yang dihasilkan dengan metode forward substitusion adalah :
Harapan Hidup yang seharusnya bertambah seiring dengan bertambahnya jumlah mantri. Hal ini juga terjadi karena antara peubah atau mantri berkorelasi negatif dengan Angka Harapan Hidup. Dari hasil ini mungkin dapat diidentifikasi bahwa bertambahnya jumlah mantri tidak diikuti dengan kualitas kerja mantri yang seharusnya semakin meningkat. Sehingga berdampak pada menurunnya Angka Harapan Hidup.
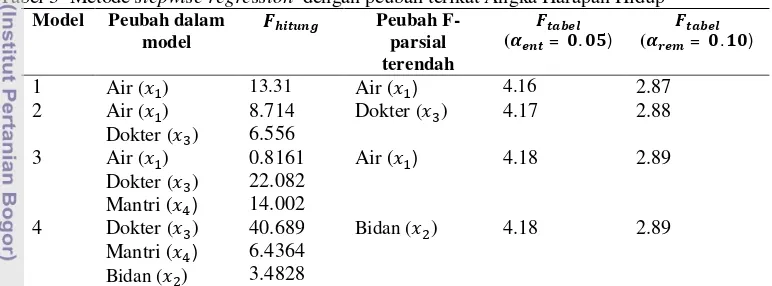
Stepwise Regression
Sebagaimana yang telah dipaparkan sebelumnya, metode ini merupakan gabungan dari metode forward substitution dan backward elimination. Taraf nyata yang digunakan dalam metode ini ada 2, yaitu taraf nyata masuk ( ) untuk forward substitution dan taraf nyata keluar
( ) untuk backward elimination. Adapun nilai taraf nyata yang diberikan dalam menyelesaikan permasalahan ini adalah
= 0.05 dan =0.10.
Pada tahap pertama digunakan forward substitution. Seperti halnya pada metode forward substitution yang telah dijelaskan sebelumnya, model awal tidak mengandung peubah bebas atau hanya mengandung koefisien . Tahap selanjutnya adalah menggunakan metode backward elimination untuk menguji kelayakan semua peubah bebas yang telah ada dalam model. Dalam hal ini digunakan uji F parsial pada taraf nyata = 0.05. Secara umum proses substitusi dan eliminasi pada proses stepwise regression dapat ditunjukkan pada tabel berikut ini :
Tabel 3 Metode stepwise regression dengan peubah terikat Angka Harapan Hidup
Model Peubah dalam
model
Peubah F-parsial terendah
( = . ) ( = . )
1 Air ( ) 13.31 Air ( ) 4.16 2.87
2 Air ( ) Dokter ( )
8.714 6.556
Dokter ( ) 4.17 2.88
3 Air ( ) Dokter ( ) Mantri ( )
0.8161 22.082 14.002
Air ( ) 4.18 2.89
4 Dokter ( ) Mantri ( ) Bidan ( )
40.689 6.4364 3.4828
Bidan ( ) 4.18 2.89
Dari tabel di atas dapat dilihat bahwa peubah pertama yang dimasukkan ke dalam model adalah atau distribusi air. Hal ini karena nilai dari peubah tersebut lebih besar dari nilai ( = 0.05) . Kemudian diikuti oleh atau jumlah dokter pada model kedua. Pada tahap selanjutnya dilakukan uji F parsial terhadap semua peubah yang ada dalam model. Peubah bebas atau jumlah dokter memiliki F parsial lebih kecil dari distribusi air. Akan tetapi nilai dari peubah bebas lebih besar dari ( = 0.05) . Sehingga peubah bebas harus dipertahankan di dalam model. Pada model ketiga dimasukkan peubah atau jumlah mantris. Akan tetapi hasil pengujian F parsial untuk masing-masing peubah bebas menunjukkan bahwa peubah bebas atau distribusi air memiliki F parsial terkecil dan tidak nyata. Maka peubah bebas dikeluarkan dan model terbaik adalah :
= 69.476 + 0.153 −0.040 .
Sehingga berdampak pada menurunnya Angka Harapan Hidup.
All Possible Regression
Pada metode ini diamati pengaruh setiap peubah jika dimasukkan ke dalam model. Perubahan yang diamati pada metode ini adalah pola perubahan R2, s2, dan Cp-Mallows dari setiap kelompok akibat masuknya peubah baru. Karena terdapat 6 peubah bebas, maka akan terdapat 26 atau 64 kombinasi persamaan. Kemudian semua kombinasi persamaan tersebut dibagi berdasarkan jumlah peubah bebas yang terdapat di dalam model. Tahap selanjutnya adalah mengambil beberapa persamaan dari setiap kelompok untuk diamati pola perubahan nilai R2, s2, dan Cp-Mallows.
Analisis untuk metode ini menggunakan software Minitab 16. Dari output Minitab tersebut dihasilkan beberapa persamaan terbaik yang telah diurutkan menurut besarnya nilai R2, s2, dan Cp-Mallows.
Dari setiap kelompok diambil persamaan terbaik yang memiliki nilai R 2 tertinggi dan s2 serta Cp-Mallows terendah. Persamaan-persamaan regresi yang menduduki posisi utama dalam setiap kelompok dapat dilihat pada Tabel 4.
Tabel 4 Pemilihan peubah bebas pada metode all possible regression dengan peubah terikat Angka Harapan Hidup
p Kombinasi Peubah
R2 (%) Cp
1 30.0
25.9 30.8 34.3
43.82 45.43
2 , 60.2 7.0 25.70
3 , , 64.5 5.4 23.52
4 , , , 69.1 3.5 21.81
5 , , , , 69.6 5.0 22.18
6 , , , , , 69.5 7.0 23.04
Pada tabel di atas dapat dilihat bahwa bertambahnya peubah bebas ke dalam model akan diikuti dengan perubahan nilai R2. Pada pemilihan kelompok persamaan dengan 1 peubah bebas, terlihat bahwa peubah bebas dan memiliki R2 yang relatif lebih tinggi. Kemudian diikuti dengan nilai s2 dan Cp -Mallows yang lebih kecil. Akan tetapi pada kelompok selanjutnya peubah tidak berkontribusi secara maksimal. Pada kelompok dengan 2 peubah bebas, Persamaan yang mengandung dan memiliki nilai R2 tertinggi. Hal ini menunjukkan kedua peubah tersebut memiliki hubungan yang erat
terhadap Angka Harapan Hidup. Pada kelompok dengan 3 peubah bebas, terlihat bahwa masuknya peubah tidak memberikan penambahan R2 yang cukup besar. Pada kelompok selanjutnya, jika sebuah peubah ditambahkan ke dalam persamaan yang mengandung peubah dan maka akan memberikan sumbangan nilai R2 yang relatif kecil. Hal ini berlaku untuk besarnya nilai s2 dan Cp-Mallows yang semakin berkurang seiring dengan bertambahnya peubah. Pengurangan kedua patokan tersebut terlihat drastis pada kelompok dengan 2 peubah. Akan tetapi pada kelompok selanjutnya pengurangan relatif kecil. Akibatnya peubah tersebut dianggap tidak terlalu berpengaruh terhadap model. Dengan demikian persamaan yang layak dipilih adalah persamaan yang mengandung peubah dan . Secara umum persamaan tersebut dapat dinyatakan dalam bentuk :
= 69.476 + 0.153 −0.040 . Hasil dari metode ini tidak jauh berbeda dengan hasil pada metode regresi bertatar (stepwise regression). Kedua metode ini melibatkan korelasi antar peubah dalam proses pemilihan peubah. Selain itu juga dapat dilihat pengaruh setiap peubah dalam model. Jika peubah tersebut tidak terlalu berpengaruh atau memberikan kontribusi yang kecil, maka dapat dikeluarkan dari model.
Dari ilustrasi pemilihan peubah bebas di atas, dapat dilihat bahwa peubah bebas dan memiliki pengaruh yang cukup besar terhadap model. Dapat diambil kesimpulan bahwa kedua peubah tersebut merupakan peubah dominan yang mempengaruhi Angka Harapan Hidup (AHH).
4.3 Hasil dan Pembahasan
Proses pemilihan peubah bebas seperti ilustrasi pada subbab 4.2 juga dilakukan terhadap peubah terikat lain, yaitu Angka Kematian Bayi (AKB), Angka Melek Huruf (AMH), dan lama sekolah. Hasil pemilihan peubah bebas dari masing-masing peubah terikat dapat dilihat pada tabel dibawah ini :
Angka Kematian Bayi
Tabel 5 Peubah terpilih dari setiap metode dengan peubah terikat Angka Kematian Bayi (AKB)
Metode Peubah terpilih Koef. regresi P-Value Backward elimination 0.110 -0.445 0.099 -6.665 0.0313 0.0002 0.0083 0.0505 Forward substitution -0.001 -0.521 0.131 0.3737 0.0001 0.0008 Stepwise regression -0.566 0.146
8∙10 2∙10 Tabel di atas menunjukkan peubah terpilih pada setiap metode dengan peubah terikat Angka Kematian Bayi (AKB). Dari tabel tersebut dapat dilihat bahwa peubah bebas dan terpilih pada setiap metode. Ini menunjukkan bahwa kedua peubah tersebut memiliki pengaruh yang sangat kuat terhadap Angka Kematian Bayi. Hal ini juga diperlihatkan dalam pemilihan peubah bebas dengan menggunakan metode all possible regression. Dari output Minitab yang dihasilkan, pada pemilihan kelompok persamaan dengan 1 peubah bebas, terlihat bahwa peubah bebas dan memiliki R2 yang relatif tinggi. Kemudian diikuti dengan nilai s2 dan Cp-Mallows yang lebih kecil. Akan tetapi pada kelompok selanjutnya peubah tidak berkontribusi secara nyata. Pada kelompok dengan 2 peubah bebas, persamaan yang mengandung dan memiliki nilai R2 tertinggi. Pada kelompok selanjutnya, jika suatu peubah ditambahkan ke dalam persamaan yang mengandung peubah dan maka akan memberikan sumbangan nilai R2 yang kecil . Hal ini terlihat juga pada pola besarnya nilai s2 dan Cp-Mallows yang semakin berkurang seiring dengan bertambahnya peubah. Pengurangan kedua patokan tersebut terlihat drastis pada kelompok dengan 2 peubah. Akan tetapi pada kelompok selanjutnya pengurangan relatif kecil. Akibatnya peubah tersebut dianggap tidak terlalu berpengaruh terhadap model. Maka persamaan yang layak dipilih adalah persamaan yang mengandung peubah dan
.
Dengan melihat hasil dari berbagai metode di atas, peubah bebas dan dapat diambil sebagai peubah dominan yang berpengaruh terhadap peubah terikat Angka Kematian Bayi. Secara umum bentuk persamaan yang mengandung dua peubah bebas tersebut adalah :
= 31.054−0.567 + 0.146 . Angka Melek Huruf
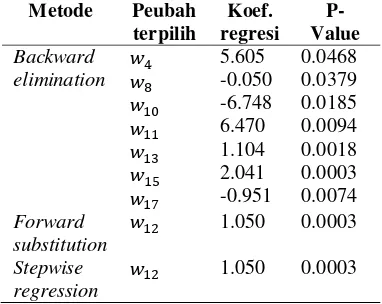
Proses pemilihan peubah bebas dengan peubah terikat Angka Melek Huruf (AMH) dapat dilihat pada Lampiran 3. Rincian peubah terpilih pada setiap metode pemilihan peubah bebas dapat dilihat pada tabel di bawah ini.
Tabel 6 Peubah terpilih dari setiap metode dengan peubah terikat Angka Melek Huruf (AMH)
Metode Peubah terpilih Koef. regresi P-Value Backward elimination 5.605 -0.050 -6.748 6.470 1.104 2.041 -0.951 0.0468 0.0379 0.0185 0.0094 0.0018 0.0003 0.0074 Forward substitution
1.050 0.0003
Stepwise regression
1.050 0.0003
Pada tabel di atas dapat dilihat bahwa pada metode forward substitution dan stepwise regression dihasilkan peubah terpilih yang sama, yaitu atau APK SD. Akan tetapi peubah tersebut tidak terpilih pada metode backward elimination. Pada metode All possible regression, terlihat bahwa pada pemilihan kelompok persamaan dengan 1 peubah bebas, peubah bebas atau APK SD memiliki R2 tertinggi. Kemudian diikuti dengan nilai s2 dan Cp-Mallows yang lebih kecil. Pada persamaan dengan kombinasi 2 peubah bebas terlihat bahwa kombinasi dan memiliki nilai R2 tertinggi. Ini menunjukkan bahwa kedua peubah tersebut memiliki hubungan yang sangat erat. Akan tetapi penambahan nilai R2 tidak terlalu tinggi. Jika suatu peubah dimasukkan ke dalam persamaan yang telah mengandung akan memberikan kontribusi yang keci. Jadi peubah atau APK SD merupakan peubah yang layak untuk diambil sebagai faktor dominan yang paling berpengaruh terhadap Angka Melek Huruf (AMH). Koefisien regresi dari peubah adalah 1.050. Artinya bertambahnya APK SD sebesar 1 satuan akan menambah Angka Melek Huruf sebesar 1.050. Secara umum persamaan regresi yang mengandung peubah tersebut adalah :
Lama sekolah
Proses pemilihan peubah bebas dengan peubah terikat lama sekolah dapat dilihat pada Lampiran 4. Rincian peubah terpilih pada setiap metode pemilihan peubah bebas dapat dilihat pada tabel di bawah ini.
Tabel 7 Peubah terpilih dari masing-masing metode dengan peubah terikat lama sekolah
Metode Peubah terpilih Koef. regresi P-Value Backward elimination 0.048 0.528 -0.002 0.004 0.172 0.0180 0.0019 0.0008 0.0368 8 ∙ 10-5 Forward substitution 0.050 0.466 0.062 0.050 0.466 0.062 Stepwise regression 0.050 0.466 0.062
6 ∙ 10-5 9 ∙ 10-4 0.0371
Pada tabel di atas dapat dilihat bahwa metode forward substitution dan stepwise regression menghasilkan peubah terpilih yang sama. Peubah terpilih tersebut adalah , , dan . Akan tetapi hanya terdapat peubah dan pada metode backward elimination. Pada metode all possible regression terlihat bahwa pada pemilihan kelompok persamaan dengan 1 peubah bebas, peubah bebas atau APK SMP memiliki R2 tertinggi. Kemudian diikuti dengan nilai s dan Cp-Mallows yang lebih kecil. Pada kelompok dengan 2 peubah bebas, persamaan dengan kombinasi antara dan memiliki R2 tertinggi. Pada kelompok dengan 3 peubah bebas, persamaan dengan kombinasi peubah , , dan memiliki R2 tertinggi. Hasil ini sesuai dengan yang diperoleh pada forward substitution dan stepwise regression.
Akan tetapi masuknya peubah hanya memberikan penambahan R2 yang kecil, yaitu sebesar 71.0% – 66.2% = 4.8%. Begitu juga dengan penurunan s2 dan Cp-Mallows yang tidak terlalu besar. Jadi dapat diambil kesimpulan bahwa menurut metode ini persamaan dengan kombinasi dan layak menjadi persamaan terbaik. Dengan demikian menurut peubah dan atau jumlah Perguruan Tinggi dan APK SMP adalah faktor yang paling berpengaruh terhadap lama sekolah. Secara umum persamaan regresi yang mengandung peubah tersebut adalah :
̂ = 2.882 + 0.537 + 0.051 . Dari hasil pemilihan peubah di atas dapat diperoleh beberapa peubah bebas dominan yang layak dimasukkan ke dalam model. Pada bidang kesehatan faktor terpilih yang dihasilkan pada kedua indikator relatif sama, yaitu dokter dan mantri. Ini menunjukkan bahwa dokter dan mantri mempunyai pengaruh yang besar terhadap Angka Harapan Hidup maupun Angka Kematian Bayi. Pada bidang pendidikan dengan indikator lama sekolah, jumlah perguruan tinggi dan APK SMP layak dipilih menjadi faktor dominan yang paling berpengaruh. Sementara pada indikator Angka Melek Huruf faktor dominan terpilih yang paling berpengaruh adalah APK SD.
Pada setiap metode variable selection yang digunakan, terdapat kelebihan dan kekurangan dari masing-masing metode. Berdasarkan hasil pemilihan peubah di atas, metode stepwise regression dapat diambil sebagai metode terbaik. Pada metode stepwise regression dapat dilihat kombinasi antara metode forward substitution dan backward elimination. Pada metode ini juga didapatkan hasil yang tidak jauh berbeda dengan metode all possible regression.
V. SIMPULAN DAN SARAN
5.1 Simpulan
Dalam penulisan karya ilmiah ini telah diperlihatkan bahwa masalah penentuan faktor yang paling berpengaruh terhadap pendidikan dan kesehatan, dapat dipandang sebagai permasalahan yang dapat diselesaikan dengan metode variable selection. Adapun metode yang digunakan adalah backward elimination, forward substitution, stepwise regression, dan all possible regression.
Pada bidang kesehatan digunakan indikator Angka Harapan Hidup dan Angka Kematian Bayi. Faktor terpilih yang dihasilkan pada kedua indikator tersebut sama, yaitu dokter dan mantri. Ini menunjukkan bahwa dokter dan mantri mempunyai pengaruh yang besar terhadap baik untuk Angka Harapan Hidup maupun Angka Kematian Bayi. Pada bidang pendidikan digunakan indikator lama sekolah dan Angka Melek Huruf. Pada indikator lama sekolah, jumlah perguruan tinggi dan APK SMP layak dipilih menjadi faktor yang paling berpengaruh. Sementara pada indikator Angka
Melek Huruf, faktor dominan yang paling berpengaruh adalah APK SD.
Dari beberapa peubah bebas terpilih, dapat dibentuk suatu model yang lebih efisien. Besarnya kontribusi dari setiap peubah dapat dilihat dari perubahan koefisien determinasi dari model tersebut.
Berdasarkan hasil pemilihan peubah pada setiap metode variable selection di atas, metode stepwise regression dapat diambil sebagai metode terbaik. Pada metode stepwise regression dapat dilihat kombinasi antara metode forward substitution dan backward elimination. Pada metode ini juga didapatkan hasil yang tidak jauh berbeda dengan metode all possible regression.
5.2 Saran
DAFTAR PUSTAKA
Biro Pusat Statistik. 2009. Statistik Kesejahteraan Rakyat 2008. Jakarta: PT. Tejokirono Berkah Rahayu.
Draper N, Smith H. 1985. Applied Regression Analysis, 2nd Ed. New York : John Wiley & Sons.
Johansz OI, Sukijo, Iko Piris. 1994. Peranan
Pendidikan dalam Pembinaan
Kebudayaan Nasional di Daerah Kabupaten Dili-Timor Timur. Dili: Depdikbud Propinsi Timor-Timur.
Kleinbaum DG, Kupper LL, Muller KE, Nizam. 2008. Applied Regression Analysis and Other Multivariate Methods, 4rd Ed. California: Duxbury Press.
McKenzie JF, Pinger RR, Kotecki JE. 2008. An Introduction to Community Health, 6th Ed. London: James and Bartlett Publisher. Montgomery DC, Peck EA. 1991.
Introduction to Linear Regression Analysis. New York : John Wiley & Sons. Rawlings JO, Pantula SG, Dickey DA. 1998.
Applied Regression Analysis. New York : Springer.
Sembiring RK. 1995. Analisis Regresi. Bandung: Penerbit ITB.
Walpole RE. 1995. Pengantar Statistik. Edisi ke-3. Bambang Sumantri, Penerjemah. Jakarta: PT Gramedia Pustaka. Terjemahan dari: Introduction to Statistics.
Lampiran 1 Proses pemilihan peubah bebas dari metode backward elimination, forward substitution, stepwise regression, dan all possible regressions dengan peubah terikat Angka Harapan Hidup (AHH)
Backward Elimination
>#Peubah terikat : Angka Harapan Hidup (AHH)
>kesehatan <- read.table("D:/AHH.txt", header=TRUE, sep="\t", na.strings="NA", dec=".", strip.white=TRUE)
>kesehatan
AHH RS Puskes Air Bidan Dokter Mantri 1 69.2 0.82 7.01 326.16 130.60 25.92 81.91 2 71.9 1.00 3.80 1251.13 78.14 22.11 39.20 3 70.7 0.86 0.57 796.69 69.18 23.68 42.03 4 72.0 0.54 3.53 212.73 46.19 19.79 41.78 5 72.4 0.89 4.06 2675.84 44.04 30.62 47.00 6 70.5 0.65 5.67 421.55 60.22 18.43 41.21 7 71.1 0.48 3.90 577.54 57.06 14.39 33.81 8 70.8 0.62 4.45 223.34 36.35 18.44 47.75 9 70.1 0.67 8.65 715.87 99.70 34.11 51.89 10 71.1 0.30 3.42 146.80 41.06 10.36 26.92 11 75.9 1.36 3.84 8494.06 13.22 38.07 2.49 12 70.5 0.35 2.44 454.72 25.43 14.79 18.42 13 69.3 0.28 2.02 768.59 29.36 15.69 15.11 14 72.3 0.56 2.58 600.32 36.75 17.22 29.96 15 75.7 0.98 3.46 626.78 27.27 39.07 29.06 16 71.2 0.46 2.53 814.73 33.00 18.12 25.87 17 74.1 0.97 3.24 2867.41 45.42 37.94 44.85 18 66.3 0.30 3.25 909.72 26.33 11.53 44.39 19 69.4 0.57 6.13 384.91 73.20 16.47 67.31 20 70.4 0.66 5.28 701.49 34.55 12.02 48.48 21 71.8 0.73 8.21 732.37 61.05 19.69 80.54 22 68.7 0.75 6.21 1161.51 52.63 15.58 39.98 23 72.7 1.00 6.62 2110.53 43.69 26.63 68.86 24 74.6 1.00 6.52 942.43 63.13 53.89 92.44 25 69.5 0.41 7.51 475.41 44.54 23.66 57.29 26 68.4 0.78 5.91 637.11 74.93 18.13 72.88 27 70.4 0.79 5.06 713.14 43.23 20.55 53.35 28 70.4 0.10 6.78 541.34 42.33 18.50 59.38 29 69.9 0.72 10.02 445.02 63.66 16.24 78.56 30 69.4 1.44 11.58 349.80 97.75 22.94 111.53 31 68.9 0.83 9.48 513.13 92.64 26.37 69.92 32 69.5 0.88 11.48 738.09 85.53 27.18 127.40 33 69.3 1.37 13.15 0.00 113.57 52.33 172.61 >
> # Backward Elimination
> full <- lm(AHH ~ Air + Bidan + Dokter + Mantri + Puskes + RS , data=kesehatan)
> Anova(full, type="II") Anova Table (Type II tests)
Response: AHH
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 >
> backward <- update(full,.~.-Puskes) > Anova(backward, type="II")
Anova Table (Type II tests)
Response: AHH
Sum Sq Df F value Pr(>F) Air 0.688 1 0.4422 0.5116890 Bidan 8.502 1 5.4659 0.0270490 * Dokter 26.589 1 17.0940 0.0003098 *** Mantri 12.344 1 7.9362 0.0089507 ** RS 6.442 1 4.1416 0.0517676 . Residuals 41.997 27 ---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 >
> backward <- update(backward,.~.-Air) > Anova(backward, type="II")
Anova Table (Type II tests)
Response: AHH
Sum Sq Df F value Pr(>F) Bidan 7.832 1 5.1376 0.0313319 * Dokter 25.949 1 17.0216 0.0002997 *** Mantri 12.280 1 8.0554 0.0083482 ** RS 6.361 1 4.1728 0.0505953 . Residuals 42.685 28 ---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
> Fix <- lm(AHH ~ Bidan + Dokter + Mantri + RS, data = kesehatan) > summary(Fix)
Call:
lm(formula = AHH ~ Bidan + Dokter + Mantri + RS, data = kesehatan)
Residuals:
Min 1Q Median 3Q Max -3.4256 -0.6703 0.0652 0.8237 2.1833
Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 69.711634 0.644313 108.195 < 2e-16 *** Bidan -0.026303 0.011605 -2.267 0.031332 * Dokter 0.117138 0.028392 4.126 0.000300 *** Mantri -0.028083 0.009895 -2.838 0.008348 ** RS 2.008607 0.983293 2.043 0.050595 . ---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.235 on 28 degrees of freedom Multiple R-squared: 0.6907, Adjusted R-squared: 0.6465 F-statistic: 15.63 on 4 and 28 DF, p-value: 7.83e-07
Forward Substitution
>
cor(kesehatan[,c("AHH","Air","Bidan","Dokter","Mantri","Puskes","R S")], use="complete.obs")
AHH Air Bidan Dokter Mantri Puskes AHH 1.0000000 0.5480735 -0.3789178 0.5089975 -0.3072723 -0.3206006 Air 0.5480735 1.0000000 -0.3545265 0.3153974 -0.3324426 -0.2061090 Bidan -0.3789178 -0.3545265 1.0000000 0.2950407 0.7224636 0.6764529 Dokter 0.5089975 0.3153974 0.2950407 1.0000000 0.4331426 0.3237747 Mantri -0.3072723 -0.3324426 0.7224636 0.4331426 1.0000000 0.8607753 Puskes -0.3206006 -0.2061090 0.6764529 0.3237747 0.8607753 1.0000000 RS 0.3594077 0.4119522 0.4049162 0.6773346 0.4664730 0.4179193 RS
AHH 0.3594077 Air 0.4119522 Bidan 0.4049162 Dokter 0.6773346 Mantri 0.4664730 Puskes 0.4179193 RS 1.0000000
>
> forward <- update(null,.~.+Air) > Anova(forward, type="II")
Anova Table (Type II tests)
Response: AHH
Sum Sq Df F value Pr(>F) Air 41.453 1 13.31 0.0009605 *** Residuals 96.546 31 ---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
> partial.cor(kesehatan[,c("AHH","Air","Bidan")], use="complete.obs")
AHH Air Bidan AHH 0.0000000 0.4781320 -0.2360454 Air 0.4781320 0.0000000 -0.1897167 Bidan -0.2360454 -0.1897167 0.0000000
> partial.cor(kesehatan[,c("AHH","Air","Dokter")], use="complete.obs")
AHH Air Dokter AHH 0.0000000 0.47443789 0.42348523 Air 0.4744379 0.00000000 0.05059821 Dokter 0.4234852 0.05059821 0.00000000
> partial.cor(kesehatan[,c("AHH","Air","Mantri")], use="complete.obs")
AHH Air Mantri AHH 0.0000000 0.4968521 -0.1585450 Air 0.4968521 0.0000000 -0.2060829 Mantri -0.1585450 -0.2060829 0.0000000
> partial.cor(kesehatan[,c("AHH","Air","Puskes")], use="complete.obs")
AHH Air Puskes AHH 0.0000000 0.52002038 -0.25368976 Air 0.5200204 0.00000