PERBANDINGAN METODE CLUSTER VALIDITY PADA
JENIS DATA NUMERIK DAN KATEGORIK
RETNO DEWANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Metode Cluster Validity pada Jenis Data Numerik dan Kategorik adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
RETNO DEWANTI. Perbandingan Metode Cluster Validity pada Jenis Data Numerik dan Kategorik. Dibimbing oleh ANNISA.
Clustering merupakan salah satu metode yang penting untuk dapat mengetahui kemiripan dari himpunan objek. Berdasarkan kemiripan ciri tersebut, maka akan terbentuk kelas-kelas dan mendapatkan pola dari kumpulan data yang tidak berlabel. Cluster yang dihasilkan belum dapat dipastikan kebenarannya jika belum dianalisis serta diuji dengan menggunakan metode validitas cluster. Penelitian ini mengimplementasikan algoritme clustering k-means untuk mengelompokan tiga jenis data yaitu numerik, kategorik, dan numerik dan kategorik. Ketiga data tersebut akan divalidasi menggunakan metode validitas cluster indeks Dunn, Hubert’s statistic, dan koefisien silhouette. Hasil ketiga metode tersebut akan dibandingkan berdasarkan tiga jenis data yang digunakan. Berdasarkan hasil penelitian didapatkan bahwa jenis data yang digunakan akan berpengaruh terhadap algoritme validasi cluster yang digunakan. Hasil pengujian ini menunjukkan bahwa metode Hubert’s statistic yang dapat digunakan pada tiga jenis data tersebut. Penelitian dengan melibatkan jumlah data yang lebih banyak masih diperlukan untuk dapat menyimpulkan algoritme validasi yang paling sesuai untuk data numerik, kategorik, atau gabungan keduanya.
Kata kunci: clustering, validitas cluster, Dunn indeks, Hubert’s statistic, koefisien
silhouette
ABSTRACT
RETNO DEWANTI. Comparison of Cluster Validity Methods in Numerical and Categorical Data. Supervised by ANNISA.
Clustering is one of the important methods to determine the similarity of the objects set. Based on the similarity of these characteristics, it will form classes and get a pattern from a collection of unlabeled data. The resulting clusters cannot be ascertained if the accuracy has not been analyzed and tested using the method of cluster validity. This study implements the k-means clustering algorithm to classify three types of data: numerical, categorical, and a combination of numerical and categorical. The three data will be validated using the cluster validity methods: Dunn index, Hubert's statistic, and silhouette coefficient. Results of the three methods will be compared based on the three types of data used. Based on the result of the study, the data type used influences the cluster validation algorithm. The test result showed that Hubert's statistic can be used in the three types of data. Research involving bigger sized data is still needed to be able to conclude the most appropriate algorithm for the validation of numerical data, categorical, or a combination of both.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer pada
Departemen Matematika dan Ilmu Pengetahuan Alam
PERBANDINGAN METODE CLUSTER VALIDITY PADA
JENIS DATA NUMERIK DAN KATEGORIK
RETNO DEWANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Perbandingan Metode Cluster Validity pada Jenis Data Numerik dan Kategorik
Nama : Retno Dewanti NIM : G64090024
Disetujui oleh
Annisa, SKom MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Perbandingan Metode Cluster Validity pada Jenis Data Numerik dan Kategorik. Penulis mengucapkan terima kasih kepada Ibu Annisa, SKom MKom selaku pembimbing yang dengan sabar membimbing dan memberikan saran kepada penulis. Terima kasih juga penulis sampaikan kepada Ibu Dr Imas S. Sitanggang, SKom MKom dan Bapak Hari Agung Adrianto, SKom MSi selaku penguji yang telah memberikan saran dan perbaikan terhadap tugas akhir ini.
Terima kasih kepada kedua orang tua, Bapak Wartoyo dan Ibu Surati yang hingga saat ini selalu memberikan dukungan, semangat, dan doa. Begitu juga dengan ketiga kakak penulis, Mbak Tanti, Mas Toto, dan Mbak yang memacu semangat bagi penulis serta memberikan dukungan.
Terima kasih juga penulis ucapkan kepada semua pihak yang telah membantu menyelesaikan tugas akhir ini, antara lain:
1 Teman-teman satu bimbingan: Lizza, Silviani, Intan, Anggi, kak Ulfa, dan kak Norma atas bantuan dan motivasi yang diberikan.
2 Husnul dan Piput atas kesabaran untuk ditanyai serta membantu dan mengajarkan penulis dalam proses menyelesaikan tugas akhir.
3 Rekan-rekan Mahasiswa Departemen Ilmu Komputer angkatan 46 atas segala bantuan selama menjalani masa studi.
4 Teman-teman kost Aulia: Lena, Sevira, Hanifah, Intan, Alin, Silvi, Elin, Asilah, Siti atas dukungan dan motivasi yang diberikan.
5 Seluruh staf dan karyawan Departemen Ilmu Komputer, serta pihak lain yang telah membantu dalam menyelesaikan penelitian ini.
Penulis menyadari bahwa pelaksanaan penelitian ini masih jauh dari sempurna karena keterbatasan pengalaman dan pengetahuan yang dimiliki penulis. Namun, besar harapan penulis bahwa yang telah dikerjakan dapat memberikan manfaat bagi seluruh pihak.
DAFTAR ISI
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Data 3
Praproses Data 4
Clustering 4
Validitas Cluster 4
Perbandingan Hasil Validitas 6
Analisis Hasil Perbandingan 6
Lingkungan Implementasi 6
HASIL DAN PEMBAHASAN 7
Data 7
Praproses Data 7
Clustering 9
Tiga Metode Validitas Cluster 9
Perbandingan Hasil Validitas Cluster 11
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 16
DAFTAR GAMBAR
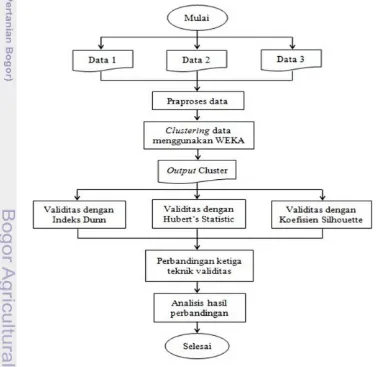
1 Diagram alir metodologi penelitian 3
2 Atribut data numerik sebelum pemilihan atribut yang relevan 8 3 Atribut data numerik setelah pemilihan atribut yang relevan 8 4 Atribut data kategorik sebelum pemilihan atribut yang relevan 8 5 Atribut data kategorik setelah pemilihan atribut yang relevan 8 6 Atribut data numerik dan kategorik sebelum pemilihan atribut yang
relevan 9
7 Atribut data numerik dan kategorik setelah pemilihan atribut yang
relevan 9
8 Grafik hasil clustering data numerik 10
9 Grafik hasil clustering data kategorik 10
10 Grafik hasil clustering data numerik dan kategorik 10
11 Grafik hasil validasi data numerik 11
12 Grafik hasil validasi data kategorik 12
13 Grafik hasil validasi data numerik dan kategorik 13
DAFTAR LAMPIRAN
1 Contoh data numerik 16
2 Contoh data kategorik 18
3 Contoh data numerik dan kategorik 20
4 Langkah perhitungan min-max normalization 22
5 Transformasi data kategorik menjadi biner 23
6 Hasil validasi cluster 24
7 Koding indeks Dunn 25
8 Langkah perhitungan indeks Dunn 26
9 Koding Hubert’s statistic 27
10 Langkah perhitungan Hubert’s statistic 28
11 Koding koefisien silhouette 30
PENDAHULUAN
Latar Belakang
Clustering merupakan salah satu metode penting untuk dapat mengetahui kemiripan dari himpunan objek. Berdasarkan kemiripan ciri tersebut, maka akan terbentuk kelas-kelas dan mendapatkan pola dari kumpulan data yang tidak berlabel. Cluster yang dihasilkan belum dapat dipastikan kebenarannya jika belum dianalisis serta diuji. Kebaikan atau kebenaran dari suatu cluster tergantung dari setiap individu dalam melihatnya. Perkiraan setiap individu akan berbeda dalam merepresentasikan hasil clustering, sehingga cluster perlu untuk diuji. Analisis cluster sangat penting dilakukan pada hasil clustering untuk menguji kebenaran cluster tersebut. Salah satu masalah yang paling penting dalam analisis cluster adalah evaluasi hasil pengelompokan untuk menemukan partisi yang paling sesuai dengan data dasar. Hal ini merupakan subjek utama dari validitas cluster. Jika cluster tidak divalidasi, maka akan berpengaruh pada hasil analisis yang kurang baik dari cluster tersebut. Validitas cluster dilakukan untuk membandingkan algoritme clustering, untuk membandingkan dua set cluster, serta membandingkan dua hasil clustering untuk menentukan yang lebih baik.
Prosedur mengevaluasi hasil dari suatu algoritma clustering dikenal dengan istilah validitas cluster. Secara umum, ada tiga pendekatan untuk menyelidiki validitas cluster. Pendekatan pertama didasarkan pada kriteria eksternal. Ini menyiratkan bahwa mengevaluasi hasil dari suatu algoritma clustering didasarkan pada pra-spesifikasi struktur yang diterima dari sebuah data dan mencerminkan intuisi pengguna tentang struktur pengelompokan dari data. Contoh metode dengan pendekatan eksternal yaitu Rand statistic, Jaccard coefficient, Hubert’s statistic, Q index, dan Folkes and Mallows index. Pendekatan kedua didasarkan pada kriteria internal. Pengguna dapat mengevaluasi hasil algoritma clustering dalam konsep kuantitatif yang didapat dari data. Contoh metode dengan pendekatan internal yaitu coefficient silhouette. Pendekatan ketiga validitas cluster didasarkan pada kriteria relatif. Ide dasarnya adalah evaluasi struktur clustering dengan membandingkan struktur clustering lain yang dihasilkan dari algoritma clustering yang sama tetapi nilai-nilai parameter berbeda. Contoh metode dengan pendekatan relatif yaitu Dunn index, Davies-Bouldin index, root-mean-square standard deviation (RMSSTD) of the new cluster, semi-partial r-squared (SPR), dan r-squared (RS)(Halkidi et al. 2001).
2
bentuk sebaran yang berbeda yaitu cluster pemisahan terbaik, cluster bentuk cincin, dan cluster bentuk tidak beraturan. Hasil dari penelitian ini adalah untuk dataset pertama, empat validitas cluster menghasilkan cluster yang baik. Untuk dataset kedua, hanya indeks Dunn dan S_Dbw yang tepat mengidentifikasi cluster yang optimal. Untuk dataset ketiga, hanya indeks Dunn yang dapat mengidentifikasi cluster yang tepat dalam bentuk sebaran yang tidak beraturan, sedangkan tiga metode validitas cluster yang lain kurang tepat digunakan untuk cluster berbentuk tidak teratur.
Sedangkan penelitian ini akan membandingkan nilai akurasi dari tiga metode validitas cluster yang digunakan untuk tiga jenis data berbeda, dan menggunakan algoritma clustering yang sama. Sehingga dapat dilihat hubungan antara jenis data dengan jenis validitas cluster dari nilai akurasi yang didapat. Perbandingan tersebut akan menghasilkan metode validitas yang tepat sesuai dengan jenis dataset yang digunakan untuk clustering. Penelitian ini menggunakan algoritma clustering k-means pada WEKA 3.6.9 untuk mengelompokkan tiga jenis data yaitu numerik, kategorik, dan numerik dan kategorik. Metode validitas cluster yang akan digunakan adalah indeks Dunn,
Hubert’s statistic, dan koefisien silhouette.
Perumusan Masalah
Perumusan masalah dari penelitian ini yaitu:
1 Apakah ada pengaruh antara jenis data yang digunakan dengan validitas cluster yang digunakan?
2 Metode validitas cluster manakah yang tepat digunakan untuk masing-masing jenis data numerik, kategorik, dan numerik dan kategorik?
Tujuan Penelitian
Tujuan penelitian ini adalah menggunakan beberapa teknik validitas cluster pada beberapa jenis data dan membandingkan hasil validitas cluster untuk mengetahui metode terbaik yang dapat digunakan pada jenis data numerik, kategorik, serta numerik dan kategorik.
Manfaat Penelitian
Manfaat yang diperoleh pada penelitian ini adalah mendapatkan metode validitas cluster yang baik untuk selanjutnya digunakan pada berbagai jenis data.
Ruang Lingkup Penelitian
3
METODE
Penelitian akan dilakukan dalam beberapa tahap. Gambar 1 menunjukkan tahapan dari metode penelitian. Secara umum tahapan penelitian terdiri atas clustering data, validitas clustering dengan indeks Dunn, validitas clustering dengan Hubert’s statistic, validitas clustering dengan koefisien silhouette, perbandingan ketiga teknik validitas, dan analisis hasil perbandingan.
Data
Data numerik adalah data metric atau data yang merupakan hasil pengukuran, yang berupa angka. Data numerik diklasifikasikan menjadi dua yaitu: 1) numerik rasio, data numerik yang mengandung unsur urutan, memiliki jarak ukuran yang sama, serta memiliki nilai nol absolut. Contoh data rasio yaitu jarak tempuh mobil, tinggi badan, usia, dan nilai ujian, 2) numerik interval, yaitu data numerik yang mengandung unsur urutan dan memiliki unsur kesamaan jarak antar urutan, namun tidak memiliki nilai nol yang absolut. Contoh data interval yaitu temperatur dan nomor sepatu. Data yang digunakan untuk jenis data numerik adalah data diabetes.arff (data 1). Jenis data berdasarkan sifat data, yaitu diskret
4
dan kontinu. 1) data diskret adalah data yang memiliki nilai terbatas atau tak terbatas yang jumlahnya dapat dihitung dan biasanya direpresentasikan dengan nilai integer, contoh data diskret yaitu usia, 2) data kontinu adalah data yang memiliki nilai berupa bilangan riil dan biasanya direpresentasikan dalam bentuk pecahan, contoh data kotinu yaitu berat badan.
Data kategorik yaitu data non-numeric (symbolic) yang variabelnya memiliki dua hubungan yaitu sama atau tidak sama. Contoh dari data kategorik seperti warna mata, jenis kelamin, dan kewarganegaraan. Data kategorik biasanya didapat dari hasil pengamatan. Data kategorik diklasifikasikan menjadi dua yaitu : 1) kategorik nominal, yaitu data kategorik yang memiliki nilai atribut berupa
simbol atau “nama-nama benda” sehingga tidak dapat dinyatakan bahwa nilai
atribut (kategori) yang satu lebih baik dari kategori lain, contoh data nominal yaitu pria-wanita, merah-putih, 2) kategorik ordinal, yaitu data kategorik yang memiliki nilai atribut yang mungkin mempunyai urutan berarti atau peringkat, tetapi jarak antar kategori sulit untuk dinyatakan sama. Data ordinal juga dapat diperoleh dari hasil diskretisasi perhitungan data numerik dengan cara membuat rentang nilai ke dalam jumlah kategori yang terbatas. Contoh dari data ordinal yaitu keadaan baik, sedang, dan buruk (Han dan Kamber 2011). Data yang digunakan untuk jenis data kategorik adalah data soybean.arff (data 2). Sedangkan data yang digunakan untuk jenis data numerik dan kategorik adalah data bank-data.arff (data 3).
Praproses Data
Tahap praproses dilakukan sebelum tahap proses. Tahapan yang termasuk dalam praproses yaitu pembersihan data (data cleaning), seleksi data (data selection) yaitu melakukan pemilihan data yang memiliki atribut relevan, sehingga akan membantu tahapan proses clustering dalam menemukan pola data yang berguna, dan transformasi data (data transformation) yaitu mengubah bentuk data. Tahapan praproses data ini dilakukan dengan menggunakan WEKA 3.6.9.
Clustering
Penelitian ini akan dilakukan menggunakan proses data mining. Data mining yang dilakukan adalah clustering. Data yang akan dikelompokkan adalah data diabetes.arff, data soybean.arff dan data bank-data.arff. Cluster yang akan digunakan pada penelitian validitas cluster ini adalah hasil dari clustering yang dilakukan menggunakan software WEKA 3.6.9 dengan algoritme K-Means. Langkah-langkah dalam algoritme k-means adalah (Kantardzic 2003): 1) ditentukan initial partion dengan k cluster berisi sample yang dipilih secara acak, kemudian dihitung pusat cluster dari tiap-tiap cluster,2) dibangkitkan partisi baru dengan penugasan setiap sample terhadap pusat cluster terdekat, 3) hitung pusat-pusat cluster baru, dan 4) ulangi langkah 2 dan 3 sampai nilai optimum dari fungsi kriteria dipenuhi (atau sampai cluster membership telah stabil).
Validitas Cluster
5 kriteria validitas yang didasarkan pada perhitungan geometri dari kekompakan setiap cluster dan pemisahan antar cluster. Indeks Dunn didefinisikan oleh:
min l didefinisikan sebagai maksimum jarak antara sepasang benda dalam cluster l tersebut, yaitu maxi j||xl(i)-xl(j)||. Cluster terbaik dilihat dengan nilai DN yang
terbesar (Vendramin et al. 2009).
Metode validitas cluster kedua adalah menggunakan Hubert’s statistic ( )
tertinggi dari indeks ini menunjukkan kesamaan yang kuat antara X dan Y. Untuk membandingkan partisi diperoleh dengan pengelompokan metode dan partisi nyata yang ada pada dataset, X dan Y merupakan masing-masing partisi tersebut
Indeks lain yang dikenal yaitu koefisien silhouette, yang juga didasarkan pada pertimbangan geometri tentang kohesi dan pemisahan cluster oleh Kaufman dan Rousseeuw. Kohesi digunakan untuk mengukur kedekatan data yang berada pada satu cluster, sedangkan pemisahan digunakan untuk mengukur kedekatan antar cluster yang terbentuk. Untuk menentukan kriteria ini, akan diperhatikan objek ke-j dari himpunan data x(j). Hitung rata-rata jarak setiap objek ke-j dengan semua objek yang ada pada cluster p, cluster yang sama dengan objek j, dilambangkan dengan ap,j. Kemudian, hitung rata-rata jarak dari setiap objek ke-j
dengan semua objek yang ada pada cluster q, dimana p tidak sama dengan q, disebut dq,j. Lalu, cari bp,j dari minimum dq,j, yang menunjukkan perbedaan
rata-rata objek x(j) untuk cluster yang terdekat dengan tetangganya.
Koefisien silhouette dari individu objek x(j) didefinisikan sebagai:
6
Nilai koefisien silhouette yang mendekati 1 adalah yang lebih baik. Nilai silhouette didefinisikan sebagai rata-rata s j , yaitu :
∑s j
j
dimana N adalah jumlah koefisien silhouette yang didapat untuk setiap objek data. Pengelompokkan terbaik dicapai jika SWC maksimal, ini berarti meminimalkan jarak dalam cluster (ap,j) sekaligus memaksimalkan jarak antar kelompok (bp,j)
(Vendramin et al. 2009).
Perbandingan Hasil Validitas
Hasil validitas yang telah dilakukan, akan dipilih cluster yang menghasilkan indeks Dunn maksimal sebagai cluster terbaik. Dari hasil clustering tersebut pula akan dilakukan validitas menggunakan metode Hubert’s statistic dan koefisien silhouette. Hasil seluruh validitas menggunakan indeks Dunn, Hubert’s statistic dan koefisien silhouette akan dibandingkan untuk mendapatkan cluster terbaik.
Analisis Hasil Perbandingan
Analisis akan dilakukan terhadap hasil dari perbandingan ketiga metode validitas cluster. Hasil analisis akan menunjukkan metode validitas cluster yang paling baik digunakan untuk jenis data numerik, kategorik, serta numerik dan kategorik. Hasil analisis mengenai pencarian metode validitas cluster terbaik diharapkan bermanfaat sebagai acuan dalam pengambilan keputusan untuk menggunakan validitas cluster yang tepat sesuai jenis data yang digunakan.
Lingkungan Implementasi
Pada penelitian ini perangkat lunak dan perangkat keras yang digunakan untuk mengembangkan sistem adalah sebagai berikut:
Perangkat lunak:
Sistem operasi: Microsoft Windows 7 Ultimate
WEKA 3.6.9
MATLAB 7.0.7 (R2008b) Perangkat keras:
Prosesor: Intel Core i3 2.1 GHz
Memori 2 GB RAM
Monitor dengan resolusi 1366x768
7
HASIL DAN PEMBAHASAN
Data
Data yang digunakan untuk jenis data numerik adalah data diabetes.arff (data 1) dengan jumlah record kategori setiap atribut dalam dataset yang digunakan sebanyak 768 baris dan 9 atribut, contoh data dapat dilihat pada Lampiran 1. Data yang digunakan untuk jenis data kategorik adalah data soybean.arff (data 2) dengan jumlah record kategori setiap atribut dalam dataset yang digunakan sebanyak 683 baris dan 36 atribut, contoh data dapat dilihat pada Lampiran 2. Data yang digunakan untuk jenis data numerik dan kategorik adalah data bank-data.arff (data 3) dengan jumlah record kategori setiap atribut dalam dataset yang digunakan sebanyak 600 baris dan 12 atribut, contoh data dapat dilihat pada Lampiran 3.
Praproses Data
Data yang digunakan memiliki rentang nilai yang cukup besar, sehingga dilakukan proses normalisasi terlebih dahulu terhadap data sebelum masuk ke tahap proses data mining. Rentang nilai yang cukup besar dapat mempengaruhi hasil dari metode clustering yang berbasis jarak. Normalisasi pada umumnya digunakan untuk menyetarakan nilai atribut agar atribut satu dengan lainnya memiliki ukuran yang sama, memiliki rataan, dan standar deviasi mendekati nol. Normalisasi juga membantu perhitungan jarak menjadi lebih cepat dan efisien karena dapat membuat rentang nilai menjadi lebih kecil.
Normalisasi yang digunakan adalah min-max normalization, yaitu metode normalisasi dengan melakukan transformasi linier terhadap data asli. Metode min-max dapat menyeimbangkan nilai perbandingan antar data saat sebelum dan sesudah proses normalisasi. Persamaan untuk metode Min-Max yaitu seperti berikut:
B ( ( -min )
(ma -min )) ( - )
dengan B adalah hasil normalisasi, A merupakan objek data, min A dan max A merupakan nilai terkecil dan terbesar dari atribut yang akan dinormalisasi, sedangkan C dan D adalah range [0.0, 1.0] (Han dan Kamber 2011). Normalisasi yang dilakukan pada penelitian ini yaitu menggunakan WEKA 3.6.9, contoh perhitungan normalisasi dengan metode min-max normalization disajikan pada Lampiran 4.
Data Numerik
8
digunakan hanya 8 atribut. Penghapusan atribut karena atribut tersebut tidak relevan dengan penelitian yang akan dilakukan, terlihat pada Gambar 2 dan 3. Data Kategorik
Normalisasi untuk data kategorik tidak dilakukan karena data tidak dalam bentuk numerik sehingga tidak diketahui rentang nilainya. Dalam tahap praproses data kategorik, ada beberapa nilai atribut yang kosong sehingga dilakukan pengisian berdasarkan nilai atribut yang paling sering muncul, kemudian data kategorik ditransformasi menjadi data biner. Hal ini dilakukan karena untuk memasukkan data ke dalam rumus validasi cluster diperlukan data berupa angka. Setelah data ditransformasi menjadi biner, normalisasi juga tidak dilakukan karena data akan tetap sama sebelum atau sesudah normalisasi, yaitu bernilai 0 dan 1, tidak memiliki rentang nilai yang besar antar atribut. Transformasi data kategorik menjadi biner, menggunakan WEKA 3.6.9, menghasilkan atribut sebanyak 101 atribut dari yang semula sebanyak 36 atribut sebelum transformasi.
Transformasi dilakukan, dengan cara memisahkan atribut sebanyak jumlah kategori dalam suatu atribut tertentu. Atribut date akan dipisah menjadi tujuh atribut, karena jumlah kategori dalam atribut tersebut berjumlah tujuh, sehingga seluruh kategori dalam atribut date masing-masingakan diwakilkan dengan tujuh digit biner. Hal yang sama dilakukan pada atribut lain yaitu plant-stand, precip, temp, hail, contoh dapat dilihat pada Lampiran 5. Selanjutnya dilakukan pemilihan data dengan menghilangkan atribut class pada data soybean.arff, karena tidak relevan dengan penelitian, sehingga jumlah atribut yang digunakan menjadi 100 atribut, dapat dilihat pada Gambar 4 dan 5.
Data Numerik dan Kategorik
Data gabungan numerik dan kategorik dipraproses seperti cara yang dilakukan pada data numerik dan data kategorik. Jenis atribut dalam data ini berupa numerik dan kategorik, sehingga masing-masing jenis atribut dipraproses dengan cara yang berbeda. Untuk atribut numerik dengan jumlah 3 atribut, dapat langsung dipraproses dan dilakukan normalisasi sama seperti data numerik. Sedangkan atribut kategorik dengan jumlah 8 atribut, sebelumnya akan diubah nilai atributnya agar menjadi numerik, praproses atribut berjenis kategorik ini sama seperti yang sudah dilakukan pada data kategorik. Hasil praproses dari
Gambar 2 Atribut data kategorik sebelum pemilihan atribut yang relevan
Gambar 3 Atribut data kategorik setelah pemilihan atribut yang relevan
Gambar 4 Atribut data numerik sebelum pemilihan atribut yang relevan
9 atribut kategorik yaitu jumlah atribut kategorik menjadi 18 atribut dari yang semula sebanyak 8 atribut. Selanjutnya dilakukan pemilihan data dengan menghilangkan atribut id pada data bank-data.arff, karena tidak relevan dengan penelitian, sehingga jumlah seluruh atribut yang digunakan menjadi 21 atribut, dapat dilihat pada Gambar 6 dan 7.
Clustering
Clustering adalah proses unsupervised karena tidak ada kelas standar dan tidak ada contoh yang akan menunjukkan ciri-ciri pengelompokan dalam kumpulan data. Mayoritas algoritma clustering berperilaku berbeda tergantung pada fitur dari himpunan data dan asumsi awal untuk mendefinisikan kelompok. Oleh karena itu, dalam aplikasi sebagian besar menghasilkan skema pengelompokan yang memerlukan jenis evaluasi terbaik yang berlaku. Mengevaluasi dan menilai hasil pengelompokan dari algoritma adalah subjek utama dari validitas cluster (Halkidi et al. 2002).
Clustering hasil praproses ketiga jenis data akan dilakukan dengan menerapkan algoritme K-means menggunakan WEKA 3.6.9. K-means merupakan algoritme clustering yang bersifat partitional yaitu membagi himpunan objek data ke dalam cluster yang tidak overlap, sehingga setiap objek data berada tepat dalam satu cluster. K-means yang digunakan adalah berdasarkan kriteria sum of square error, tujuan kriteria sum of square error adalah untuk memperoleh partisi (jumlah cluster tetap) yang meminimalkan total sum of square error. Hasil praproses seluruh data selanjutnya dikelompokkan (clustering) dengan jumlah cluster adalah 3, 4, dan 5. Jumlah iterasi yang digunakan yaitu 100, dan mode cluster yang digunakan adalah use training set.
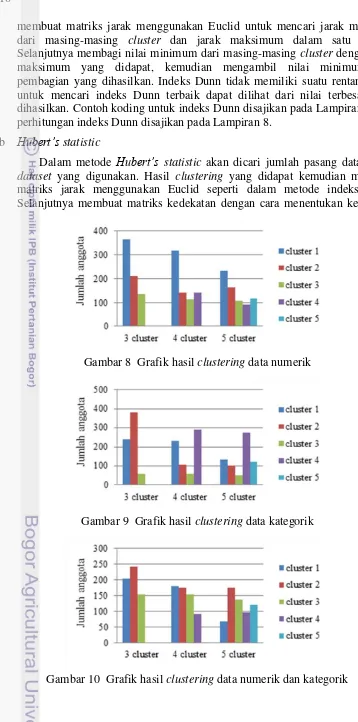
Dari Gambar 8, 9, dan 10 terlihat jumlah anggota pada setiap cluster untuk ukuran cluster 3, 4, dan 5. Ketiga gambar tersebut menunjukan bahwa ukuran cluster 5 merupakan cluster optimal yang dihasilkan oleh clustering ketiga jenis data yang digunakan, karena memiliki nilai sum of square error yang kecil saat jumlah cluster bertambah. Nilai sum of square error untuk hasil clustering terdapat pada Lampiran 6.
Tiga Metode Validitas Cluster
Pada penelitian ini akan dilakukan perbandingan terhadap tiga metode validitas cluster yaitu:
a Indeks Dunn
Dengan menggunakan hasil clustering yang telah didapat kemudian
Gambar 6 Atribut data numerik dan kategorik sebelum pemilihan atribut yang relevan
10
membuat matriks jarak menggunakan Euclid untuk mencari jarak minimum dari masing-masing cluster dan jarak maksimum dalam satu cluster. Selanjutnya membagi nilai minimum dari masing-masing cluster dengan nilai maksimum yang didapat, kemudian mengambil nilai minimum dari pembagian yang dihasilkan. Indeks Dunn tidak memiliki suatu rentang nilai, untuk mencari indeks Dunn terbaik dapat dilihat dari nilai terbesar yang dihasilkan. Contoh koding untuk indeks Dunn disajikan pada Lampiran 7, dan perhitungan indeks Dunn disajikan pada Lampiran 8.
b Hubert’s statistic
Dalam metode Hubert’s statistic akan dicari jumlah pasang data dalam dataset yang digunakan. Hasil clustering yang didapat kemudian membuat matriks jarak menggunakan Euclid seperti dalam metode indeks Dunn. Selanjutnya membuat matriks kedekatan dengan cara menentukan kedekatan
Gambar 8 Grafik hasil clustering data numerik
Gambar 9 Grafik hasil clustering data kategorik
11 antar objek data satu dengan objek data lain. Jika antar dua objek berada dalam cluster yang sama maka diberi nilai nol, dan jika antar dua objek berada dalam cluster yang berbeda maka diberi nilai satu. Diberikan inisialisasi awal sum=0, kemudian dilakukan perkalian terhadap matriks jarak dengan matriks kedekatan. Hasil dari perkalian akan ditambahkan dengan nilai sum, proses perhitungan terus berulang hingga nilai terakhir. Nilai akhir sum selanjutnya dibagi dengan jumlah pasangan dalam dataset. Hasil clustering terbaik berdasarkan nilai Hubert’s statistic adalah yang bernilai besar tanpa adanya rentang nilai. Contoh koding untuk Hubert’s statistic disajikan pada Lampiran 9, dan perhitungan Hubert’s statistic disajikan pada Lampiran 10.
c Koefisien silhouette
Berdasarkan hasil clustering yang didapat, hitung jarak rata-rata setiap objek ke-j dengan semua objek yang berada dalam cluster yang sama. Kemudian mencari nilai minimum dari jarak rata-rata setiap objek ke-j dengan semua objek yang berada dalam cluster yang berbeda. Selanjutnya mencari nilai koefisien silhouette untuk setiap data ke-j, sehingga dihasilkan nilai koefisien yang jumlahnya sama dengan jumlah dataset yang digunakan. Kemudian hasil perhitungan nilai koefisien silhouette dijumlahkan seluruhnya, lalu dibagi dengan jumlah dataset yang digunakan. Contoh koding untuk silhouette disajikan pada Lampiran 11, dan perhitungan silhouette disajikan pada Lampiran 12.
Perbandingan Hasil Validitas Cluster
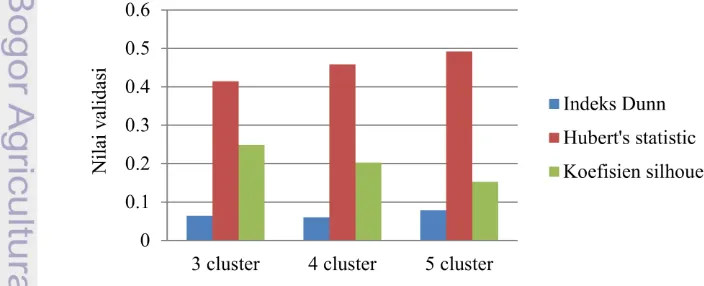
Penelitian ini akan membandingkan hasil perhitungan dari tiga metode validitas cluster indeks Dunn, Hubert’s statistic, dan koefisien silhouette. Validasi cluster hasil clustering data numerik (diabetes.arff), dapat dilihat pada Gambar 11, dengan ukuran cluster 3 menghasilkan nilai indeks Dunn sebesar 0.0639. Hasil clustering dengan ukuran cluster 4, data numerik menghasilkan nilai indeks Dunn sebesar 0.0606. Sedangkan validasi cluster hasil clustering data numerik dengan ukuran cluster 5 menghasilkan nilai indeks Dunn sebesar 0.0788. Metode
Hubert’s statistic untuk data numerik dengan ukuran cluster 3 menghasilkan nilai sebesar 0.4146. Pada ukuran cluster 4 metode Hubert’s statistic untuk data numerik menghasilkan nilai sebesar 0.4579. Sedangkan metode Hubert’s statistic
12
untuk ukuran cluster 5, data numerik menghasilkan nilai sebesar 0.4919.
Metode koefisien silhouette untuk data numerik dengan ukuran cluster 3 menghasilkan jumlah nilai silhouette sebesar 0.2488. Pada metode koefisien silhouette untuk ukuran cluster 4, data numerik menghasilkan jumlah nilai silhouette sebesar 0.2027. Sedangkan metode koefisien silhouette untuk data numerik dengan ukuran cluster 5 menghasilkan jumlah nilai silhouette sebesar 0.1530. Berdasarkan hasil clustering data numerik, cluster yang optimal didapat dengan ukuran cluster 5 karena nilai validasi internalnya atau nilai sum of square error kecil. Hasil validasi yang dapat mengidentifikasi cluster terbaik adalah indeks Dunn dan Hubert’s statistic, sehingga kedua metode tersebut lebih baik digunakan untuk data numerik.
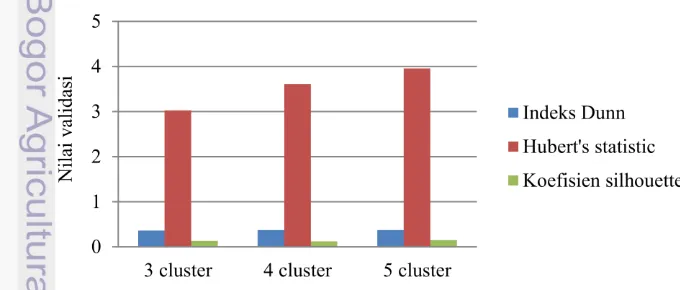
Validasi cluster hasil clustering data kategorik (soybean.arff), dapat dilihat pada Gambar 12, dengan ukuran cluster 3 menghasilkan nilai indeks Dunn sebesar 0.3612. Untuk data kategorik dengan ukuran cluster 4 menghasilkan nilai indeks Dunn sebesar 0.3693. Sedangkan data kategorik dengan ukuran cluster 5 menghasilkan nilai indeks Dunn sebesar 0.3693. Metode Hubert’s statistic untuk data kategorik ukuran cluster 3 menghasilkan nilai sebesar 3.0259. Untuk ukuran cluster 4 data kategorik menghasilkan nilai sebesar 3.6102. Sedangkan data kategorik untuk ukuran cluster 5 menghasilkan nilai sebesar 3.9560.
Metode koefisien silhouette untuk data kategorik ukuran cluster 3 memiliki nilai silhouette sebesar 0.1321. Data kategorik pada ukuran cluster 4 memiliki nilai silhouette sebesar 0.1210, dan data kategorik ukuran cluster5 memiliki nilai silhouette sebesar 0.1471. Berdasarkan hasil clustering data kategorik, cluster yang optimal didapat dengan ukuran cluster 5, sama seperti pada data numerik. Untuk ukuran cluster 4 dan 5 menghasilkan nilai indeks Dunn yang sama sehingga dipilih ukuran cluster 4 yang lebih optimal untuk indeks Dunn. Hasil validasi yang dapat mengidentifikasi cluster terbaik pada data kategorik ini adalah indeks Dunn, Hubert’s statistic dan koefisien silhouette, sehingga ketiga metode tersebut baik digunakan untuk data kategorik.
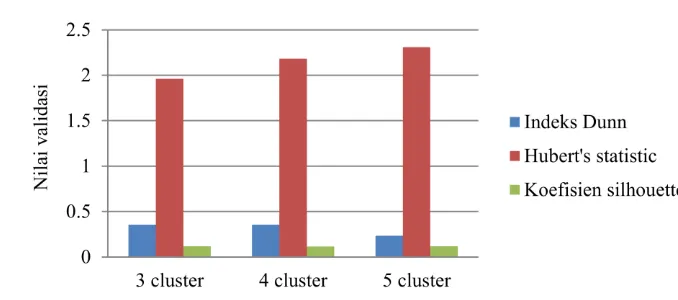
Validasi cluster hasil clustering data numerik dan kategorik (bank-data.arff), dapat dilihat pada Gambar 13, untuk ukuran cluster 3 menghasilkan nilai indeks Dunn sebesar 0.3552. Untuk ukuran cluster 4, data numerik dan kategorik menghasilkan nilai indeks Dunn sebesar 0.3552. Sedangkan untuk data numerik dan kategorik ukuran cluster 5 menghasilkan nilai indeks Dunn sebesar 0.2332. Metode Hubert’s statistic untuk data numerik dan kategorik memiliki nilai
13
Hubert’s statistic sebesar 1.9607. untuk data numerik dan kategorik memiliki nilai sebesar 2.1818. untuk data numerik dan kategorik memiliki nilai Hubert’s statistic sebesar 2.3098.
Metode koefisien silhouette untuk data numerik dan kategorik ukuran cluster 3 memiliki nilai silhouette sebesar 0.1178. Pada ukuran cluster 4, data numerik dan kategorik memiliki nilai silhouette sebesar 0.1155, dan untuk data numerik dan kategorik ukuran cluster 5, memiliki nilai silhouette sebesar 0.1190. Sama seperti clustering data numerik dan data kategorik, clustering data numerik dan kategorik juga menghasilkan cluster yang optimal pada ukuran cluster 5. Hasil validasi yang dapat mengidentifikasi cluster terbaik adalah Hubert’s statistic dan koefisien silhouette, sehingga kedua metode tersebut baik digunakan untuk data numerik dan kategorik.
Analisis Hasil Perbandingan
Dilihat dari sum of square error pada data numerik, cluster optimal pada saat ukuran cluster 5. Berdasarkan teori, ketiga metode validitas cluster yang digunakan akan menghasilkan cluster optimal saat nilai validasi besar. Hal ini menunjukan bahwa data numerik baik digunakan pada metode indeks Dunn dan
Hubert’s statistic, karena nilai validasi terbesar untuk data numerik ukuran cluster 5 didapat dari kedua metode tersebut. Pada data kategorik hal yang sama seperti pada data numerik, yaitu cluster optimal ada pada saat ukuran cluster 5. Nilai validasi terbesar juga terlihat pada metode indeks Dunn, Hubert’s statistic dan koefisien silhouette. Sedangkan data gabungan numerik dan kategorik berdasarkan sum of square error, cluster optimal juga ada pada saat ukuran cluster 5 dan nilai validasi terbesar terlihat pada metode Hubert’s statistic dan koefisien silhouette.
Hasil yang didapat menunjukan bahwa metode Hubert’s statistic baik untuk ketiga jenis data yang digunakan. Hal ini diasumsikan karena adanya matriks jarak dan matriks kedekatan, kedua metode lain pun sama-sama menggunakan matriks jarak namun pada Huberts ini matriks jarak yang didapat kemudian dikalikan dengan matriks kedekatan. Perkalian ini berulang hingga elemen matriks yang terakhir, kemudian dilakukan penjumlahan untuk perkalian tersebut. Hal ini berbeda dengan kedua metode lainnya, karena kedua metode Dunn dan silhouette hanya menghitung matriks jarak kemudian mencari jarak minimum dan maksimum untuk menentukan posisi suatu objek dalam dalam suatu cluster.
14
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini telah diimplementasikan tiga metode validitas cluster yaitu indeks Dunn, Hubert’s statistic, dan koefisien silhouette. Dari hasil clustering terlihat bahwa sum of square error suatu cluster berkurang saat jumlah cluster yang digunakan bertambah. Clustering ketiga jenis data menghasilkan cluster yang optimal pada ukuran cluster 5. Hasil validasi untuk data numerik nilai terbesar terdapat pada metode indeks Dunn sebesar 0.0788 dan Hubert’s statistic sebesar 0.4919. Pada data kategorik nilai terbesar juga terdapat pada metode indeks Dunn sebesar 0.3693, Hubert’s statistic sebesar 3.9560 dan koefisien silhouette sebesar 0.1471. Sedangkan untuk data gabungan numerik dan kategorik nilai terbesar terdapat pada metode Hubert’s statistic sebesar 2.3098 dan koefisien silhouette sebesar 0.1190. Berdasarkan hasil penelitian didapatkan bahwa jenis data yang digunakan akan berpengaruh terhadap algoritme validasi cluster yang digunakan. Hasil pengujian untuk saat ini menunjukkan bahwa metode Hubert’s statistic yang dapat digunakan pada tiga jenis data tersebut.
Saran
Saran untuk penelitian selanjutnya antara lain, yaitu :
1 Penelitian dengan melibatkan jumlah data yang lebih banyak masih diperlukan untuk dapat menyimpulkan algoritme validasi yang paling sesuai untuk data numerik, kategorik, atau gabungan keduanya.
2 Menggunakan metode validitas cluster lain untuk dibandingkan dengan hasil penelitian ini, seperti: Rand statistic, Jaccard coefficient, Folkes and Mallows index, indeks Davies-Bouldin, root-mean-square standard deviation (RMSSTD), r-squared (RS), dan Calinski-Harabas index.
DAFTAR PUSTAKA
Halkidi M, Batistakis Y, Vazirgiannis M. 2001. On clustering validation techniques. Journal of Intelligent Information Systems; 17(2-3):107-145. Han J, Kamber M, Pei J. 2011. Data Mining: Concepts and Techniques. Ed ke-3.
San Francisco (US): Morgan Kaufmann.
Kantardzic M. 2003. Data Mining: Concepts, Models, Methods, and Algorithm. New Jersey (US): J Wiley.
Kovács F, Legány C, Babos A. 2005. Cluster validity measurement techniques. Di dalam: 6th International Symposium of Hungarian Researchers on Computational Intelligence; 2005 Nov 18-19; Budapest, Hungaria.
15 2012 Nov 7]. Tersedia pada: http://citeseer.ist.psu.edu/rd/salazar02 cluster.pdf
16
LAMPIRAN
Lampiran 1 Contoh data numerik
No Pregnant Plasma Pres Skin Insulin Mass Pedigree Age Diskret Diskret Diskret Diskret Diskret Kontinu Kontinu Diskret
1 1 87 68 34 77 37.6 0.401 24
2 1 126 56 29 152 28.7 0.801 21
3 1 89 76 34 37 31.2 0.192 23
4 1 114 80 34 285 44.2 0.167 27
5 1 140 65 26 130 42.6 0.431 24
6 1 138 60 35 167 34.6 0.534 21
7 1 141 84 26 16 32.4 0.433 22
8 1 146 56 35 73 29.7 0.564 29
9 1 71 48 18 76 20.4 0.323 22
10 1 165 90 33 680 52.3 0.427 23
11 1 180 90 26 90 36.5 0.314 35
12 1 109 38 18 120 23.1 0.407 26
13 1 89 24 19 25 27.8 0.559 21
14 1 122 64 32 156 35.1 0.692 30
15 1 94 70 27 115 43.5 0.347 21
16 1 130 60 23 170 28.6 0.692 21
17 1 107 50 19 115 28.3 0.181 29
18 1 173 78 32 265 46.5 1.159 58
17 Lampiran 1 Lanjutan
No Pregnant Plasma Pres Skin Insulin Mass Pedigree Age Diskret Diskret Diskret Diskret Diskret Kontinu Kontinu Diskret
20 1 140 74 26 180 24.1 0.828 23
21 1 198 66 32 274 41.3 0.502 28
22 1 109 58 18 116 28.5 0.219 22
23 1 98 68 35 53 32 0.389 22
24 1 95 60 18 58 23.9 0.26 22
25 1 91 54 25 100 25.2 0.234 23
26 1 179 50 36 159 37.8 0.455 22
27 1 114 66 36 200 38.1 0.289 21
28 1 95 82 25 180 35 0.233 43
29 1 189 104 25 36 34.3 0.435 41
30 1 167 74 17 144 23.4 0.447 33
31 1 106 70 37 148 39.4 0.605 22
32 1 127 80 37 210 36.3 0.804 23
33 1 196 76 36 249 36.5 0.875 29
34 1 139 62 17 210 22.1 0.207 21
35 1 124 74 36 135 27.8 0.1 30
36 1 81 72 18 40 26.6 0.283 24
37 1 137 40 35 168 43.1 2.288 33
38 1 113 64 35 65 33.6 0.543 21
39 1 126 86 27 120 27.4 0.515 21
18 Lampiran 2 Contoh data kategorik
No Date Plant-stand Precip Temp Hail Crop-hist Area-damaged Severity Seed-tmt Germination Nominal Nominal Nominal Nominal Nominal Nominal Nominal Ordinal Nominal Ordinal 1 october normal gt-norm norm yes same-lst-yr low-areas pot-severe none 90-100 2 august normal gt-norm norm yes same-lst-two-yrs scattered severe fungicide 80-89 3 july normal gt-norm norm yes same-lst-yr scattered severe fungicide lt-80
4 july normal gt-norm norm yes same-lst-yr scattered severe none 80-89
19 Lampiran 2 Lanjutan
20 Lampiran 3 Contoh data numerik dan kategorik
No Age Sex Region Income Married Children Car Save_act Current_act Mortgage Pep Diskret Nominal Nominal Kontinu Nominal Diskret Nominal Nominal Nominal Nominal Nominal
1 48 FEMALE INNER_CITY 17546.0 NO 1 NO NO NO NO YES
2 40 MALE TOWN 30085.1 YES 3 YES NO YES YES NO
3 51 FEMALE INNER_CITY 16575.4 YES 0 YES YES YES NO NO
4 23 FEMALE TOWN 20375.4 YES 3 NO NO YES NO NO
5 57 FEMALE RURAL 50576.3 YES 0 NO YES NO NO NO
6 57 FEMALE TOWN 37869.6 YES 2 NO YES YES NO YES
7 22 MALE RURAL 8877.07 NO 0 NO NO YES NO YES
8 58 MALE TOWN 24946.6 YES 0 YES YES YES NO NO
9 37 FEMALE SUBURBAN 25304.3 YES 2 YES NO NO NO NO
10 54 MALE TOWN 24212.1 YES 2 YES YES YES NO NO
11 66 FEMALE TOWN 59803.9 YES 0 NO YES YES NO NO
12 52 FEMALE INNER_CITY 26658.8 NO 0 YES YES YES YES NO
13 44 FEMALE TOWN 15735.8 YES 1 NO YES YES YES YES
14 66 FEMALE TOWN 55204.7 YES 1 YES YES YES YES YES
15 36 MALE RURAL 19474.6 YES 0 NO YES YES YES NO
16 38 FEMALE INNER_CITY 22342.1 YES 0 YES YES YES YES NO
17 37 FEMALE TOWN 17729.8 YES 2 NO NO NO YES NO
18 46 FEMALE SUBURBAN 41016.0 YES 0 NO YES NO YES NO
19 62 FEMALE INNER_CITY 26909.2 YES 0 NO YES NO NO YES
20 31 MALE TOWN 22522.8 YES 0 YES YES YES NO NO
21 61 MALE INNER_CITY 57880.7 YES 2 NO YES NO NO YES
22 50 MALE TOWN 16497.3 YES 2 NO YES YES NO NO
21 Lampiran 3 Lanjutan
No Age Sex Region Income Married Children Car Save_act Current_act Mortgage Pep Diskret Nominal Nominal Kontinu Nominal Diskret Nominal Nominal Nominal Nominal Nominal
24 27 FEMALE TOWN 15538.8 NO 0 YES YES YES YES NO
25 22 MALE INNER_CITY 12640.3 NO 2 YES YES YES NO NO
26 56 MALE INNER_CITY 41034.0 YES 0 YES YES YES YES NO
27 45 MALE INNER_CITY 20809.7 YES 0 NO YES YES YES NO
28 39 FEMALE TOWN 20114.0 YES 1 NO NO YES NO YES
29 39 FEMALE INNER_CITY 29359.1 NO 3 YES NO YES YES NO
30 61 MALE RURAL 24270.1 YES 1 NO NO YES NO YES
31 61 FEMALE RURAL 22942.9 YES 2 NO YES YES NO NO
32 20 FEMALE TOWN 16325.8 YES 2 NO YES NO NO NO
33 45 MALE SUBURBAN 23443.2 YES 1 YES YES YES NO YES
34 33 FEMALE INNER_CITY 29921.3 NO 3 YES YES NO NO NO
35 43 MALE SUBURBAN 37521.9 NO 0 NO YES YES NO YES
36 27 FEMALE INNER_CITY 19868.0 YES 2 NO YES YES NO NO
37 19 MALE RURAL 10953.0 YES 3 YES YES YES NO NO
38 36 FEMALE RURAL 13381.0 NO 0 YES NO YES NO YES
39 43 FEMALE TOWN 18504.3 YES 0 YES YES YES NO NO
22
Lampiran 4 Langkah perhitungan min-max normalization
Setelah normalisasi Sebelum normalisasi
Persamaan min-max normalization
ma min min
Contoh untuk data nomor 1:
B = 0.7222
No A1 A2 A3
1 48 17546 1 2 40 30085.1 3 3 51 16575.4 0 4 23 20375.4 3 5 57 50576.3 0 6 57 37869.6 2 7 22 8877.07 0 8 58 24946.6 0 9 37 25304.3 2 10 54 24212.1 2 Max 58 50576.3 3 Min 22 8877.07 0
No A1 A2 A3
23 Lampiran 5 Transformasi data kategorik menjadi biner
Data awal dengan nilai atribut berupa kategori
Atribut date setelah transformasi
Atribut plant-stand setelah transformasi
Atribut precip setelah transformasi
Atribut temp setelah transformasi
24
Lampiran 6 Hasil validasi cluster
Jenis data Ukuran
cluster
Sum of square error
Indeks Dunn
Hubert’s
Statistic
Koefisien Silhouette
Numerik 3 86.270 0.0639 0.4146 0.2488
4 79.269 0.0606 0.4579 0.2027 5 74.488 0.0788 0.4919 0.1530
Kategorik 3 7510.6 0.3612 3.0259 0.1321
26
Lampiran 8 Langkah perhitungan indeks Dunn k = 3 Mencari jarak antar cluster: Mencari jarak inter cluster:
27 Lampiran 9 Koding Hubert’s statistic
function H = HubertGamma(labels, points)
%jumlah pasangan data dalam dataset (M=N(N-1)/2) a=length(points);
x=a*(a-1)/2; %matriks jarak
p = squareform(pdist(points));
%matriks kedekatan
q = ones(length(points), length(points)); for i = 1:length(points)
for j = 1:length(points) if labels(i) == labels(j) q(i, j) = 0;
end end end
%menghitung nilai Hubert's Statistic sum = 0;
for i = 1:length(points) - 1 for j = i + 1:length(points) sum = sum + p(i, j) * q(i, j); end
28
29 Mencari nilai Hubert’s statistic:
∑ ∑ i j i j
j i
i
M = jumlah pasangan data N = jumlah seluruh data
i j = elemen dari matriks jarak
i j = elemen dari matriks kedekatan
( )
30
Lampiran 11 Koding koefisien silhouette function s = silhouette(X, idx)
%SILHOUETTE Silhouette plot for clustered data. % References:
% [1] Kaufman L. and Rousseeuw, P.J. Finding Groups in Data: An % Introduction to Cluster Analysis, Wiley, 1990
% Copyright 1993-2008 The MathWorks, Inc. % $Revision: 1.2.4.8 $ $Date: 2008/06/20 09:05:32 $
% grp2idx pengelompokan variabel numerik berdasarkan urutan n = length(idx);
p = size(X,2); k = length(cnames); count = histc(idx(:)',1:k);
% membuat daftar anggota untuk setiap cluster mbrs = (repmat(1:k,n,1) == repmat(idx,1,k));
% mencari jarak rata-rata setiap titik dengan titik lain pada setiap cluster myinf = zeros(1,1,class(X)); % 0
31 Lampiran 12 Langkah perhitungan koefisien silhouette
k=2
No A1 A2 A3 A4 A5 A6 A7 A8 Cluster
1 0.000 0.277 0.449 0.293 0.078 0.560 0.136 0.050 1 2 0.000 0.529 0.327 0.239 0.168 0.428 0.307 0.000 1 3 0.000 0.290 0.531 0.293 0.030 0.465 0.046 0.033 1 4 0.000 0.452 0.571 0.293 0.327 0.659 0.036 0.100 1 5 0.000 0.619 0.418 0.207 0.141 0.635 0.149 0.050 2 6 0.000 0.606 0.367 0.304 0.186 0.516 0.193 0.000 1 7 0.000 0.626 0.612 0.207 0.005 0.483 0.149 0.017 1 8 0.000 0.658 0.327 0.304 0.073 0.443 0.205 0.133 2 9 0.000 0.174 0.245 0.120 0.077 0.304 0.102 0.017 1 10 0.000 0.781 0.673 0.283 0.801 0.779 0.147 0.033 2 Membuat matriks jarak menggunakan Euclid
1 1 1 1 2 1 1 2 1 2
1 0.000 0.373 0.163 0.360 0.368 0.367 0.410 0.431 0.388 0.935 1 0.373 0.000 0.437 0.481 0.298 0.182 0.383 0.241 0.461 0.858 1 0.163 0.437 0.000 0.398 0.425 0.420 0.372 0.463 0.396 0.982 1 0.360 0.481 0.398 0.000 0.331 0.375 0.441 0.494 0.643 0.612 2 0.368 0.298 0.425 0.331 0.000 0.182 0.284 0.267 0.594 0.744 1 0.367 0.182 0.420 0.375 0.182 0.000 0.325 0.201 0.549 0.759 1 0.410 0.383 0.372 0.441 0.284 0.325 0.000 0.340 0.621 0.869 2 0.431 0.241 0.463 0.494 0.267 0.201 0.340 0.000 0.564 0.890 1 0.388 0.461 0.396 0.643 0.594 0.549 0.621 0.564 0.000 1.154 2 0.935 0.858 0.982 0.612 0.744 0.759 0.869 0.890 1.154 0.000 Mencari rata-rata jarak inter cluster Mencari rata-rata jarak antar cluster
0.343
Koefisien silhouette untuk data ke-1:
ma
32
RIWAYAT HIDUP
Penulis dilahirkan di Bekasi, Jawa Barat pada tanggal 29 Desember 1990 dan merupakan anak keempat dari 4 bersaudara dengan Ayah bernama Wartoyo dan Ibu bernama Surati. Penulis merupakan lulusan dari Sekolah Menengah Atas Negeri 89 Jakarta (2006-2009), Sekolah Menengah Pertama Negeri 19 Bekasi (2003-2006) dan Sekolah Dasar Negeri Pejuang 3 (1997-2003). Pada tahun 2009 diterima sebagai mahasiswa Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI).