PENENTUAN
MENGGU
DEP
FAKULTAS MATE
IN
AN KEMIRIPAN DATA KARYA ILM
GGUNAKAN ALGORITME LEVENSHTEI
WIKHDAL KHUSNAINI
EPARTEMEN ILMU KOMPUTER
TEMATIKA DAN ILMU PENGETAHU
INSTITUT PERTANIAN BOGOR
BOGOR
2012
LMIAH IPB
SHTEIN
PENENTUAN KEMIRIPAN DATA KARYA ILMIAH IPB
MENGGUNAKAN ALGORITME LEVENSHTEIN
WIKHDAL KHUSNAINI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
ABSTRACT
WIKHDAL KHUSNAINI. Determining Similarity of IPB Scientific Data Using Levenshtein algorithm. Supervised by FIRMAN ARDIANSYAH.
IPB Scientific Data is documented periodically. This data can be used for academics and researchers to get a reference of particular research study. In this research, Levenshtein algorithm was implemented to determine the similarity between titles. The concept for calculating Levenshtein distance is minimum number of edit operations required to transform a string into another string that consists of 3 operations: 1) insertion, 2) substitution, and 3) deletion.
The research shows that implementation of Levenshtein distance to determine the similirity of scientific data is difficult to be able to obtain high persentage of similarity. And the similarity rate of 34% can be used as a threshold to determine the similarity of scientific data with the title as identifier. This is able to increase AVP curve.
Keywords: edit distance, Levenshtein algorithm, Levenshtein distance.
Penguji:
Endang Purnama Giri,S.Kom., M.Kom.
Judul Skripsi : Penentuan Kemiripan Data Karya Ilmiah IPB Menggunakan Algoritme Levenshtein
Nama : Wikhdal Khusnaini NIM : G64053204
Menyetujui
Pembimbing,
Firman Ardiansyah, S.Kom., M.Si. NIP: 19790522 200501 1 003
Mengetahui
Ketua Departemen,
Dr. Ir. Agus Buono, M.Si., M.Kom. NIP. 19660702 199302 1 001
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahuwata’ala atas segala limpahan nikmat dan karunia-Nya sehingga penulis dapat menyelesaikan penelitian ini. Tulisan ini merupakan hasil penelitian penulis sebagai salah satu syarat untuk meraih gelar sarjana komputer. Bidang kajian ini berjudul Penentuan Kemiripan Menggunakan Algoritme Levenshtein pada Data Karya Ilmiah IPB.
Ucapan terima kasih penulis sampaikan kepada pihak-pihak yang telah membantu dan memberikan dukungan dalam menyelesaikan penelitian ini, khususnya kepada kedua orang tua tercinta, Ayahanda Suharmanu dan Ibunda Ellyk Zuhriana, serta keempat adik tersayang yang telah memberikan inspirasi dan motivasi penulis dalam mengarungi samudera kehidupan ini, Nia Qonitat, Hafidlotun Nafisah, Zakiyah Dzaki, dan Abdurrahman Awwab. Pakpuh Zubaidi dan Budhe Ernie yang telah banyak membantu dan mengarahkan penulis di saat menjalani masa-masa sulit. Terima kasih tak terhingga kepada rekan-rekan seperjuangan atas inspirasi dan keceriaan yang telah diberikan sehingga penulis berani menggantungkan, mengejar, dan meraih impian di biru langit nan jauh di sana meski dalam kondisi sesulit medan perang di jurang bebatuan terjal. Teristimewa Adinda Mardiana yang tiada pernah lelah mengubah kerikil-kerikil tajam di jalanan panjang penuh onak menjadi hamparan mutiara berkilau indah berpendar bening oase sahara nan luas.
Penulis juga ingin berterima kasih kepada semua dosen Ilmu Komputer IPB, khususnya Ibu Annisa, S.Kom., M.Kom., Bapak Wisnu Ananta Kusuma, ST., MT., Bapak Endang Purnama Giri, S.Kom., M.Kom., dan Bapak Firman Ardiansyah, S.Kom., M.Si. selaku dosen PA dan pembimbing TA yang telah sabar membimbing, memotivasi, dan berbagi ilmu kepada penulis. Ucapan terima kasih tidak lupa penulis sampaikan kepada teman-teman Ilkomerz42 yang tidak bosan-bosannya mengingatkan dan memberikan support dalam menyelesaikan tugas penulis sebagai mahasiswa.
Penulis menyadari bahwa pelaksanaan penelitian ini masih jauh dari kesempurnaan, namun penulis berharap semoga apa yang telah dikerjakan dapat bermanfaat bagi semua pihak.
Bogor, Februari 2012
RIWAYAT HIDUP
Penulis dilahirkan di Kediri pada tanggal 10 Desember 1986 dari Ayah Suharmanu dan Ibu Ellyk Zuhriana. Penulis merupakan putra sulung dari 6 bersaudara. Penulis menyelesaikan studi Sekolah Menengah Atas (SMA) di SMA 1 Kediri pada tahun 2005, kemudian di tahun yang sama berhasil masuk Institut Pertanian Bogor (IPB) melalui jalur SPMB. Di tahun kedua, penulis berhasil masuk Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor setelah melalui Tingkat Persiapan Bersama selama satu tahun.
v DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1
String ... 1
Kemiripan Antara Dua Dokumen ... 2
Evaluasi Temu Kembali Informasi ... 2
Levenshtein Distance ... 2
METODE PENELITIAN ... 3
Pengumpulan Data dan Analisis ... 3
Pembuatan Aplikasi dengan Algoritme Levenshtein ...
3
Percobaan dan Evaluasi Hasil ... 4
Evaluasi Kinerja Program ... 4
HASIL DAN PEMBAHASAN ... 4
Pengumpulan data ... 4
Pembuatan Aplikasi dengan Algoritme Levenshtein ... 4
Percobaan ... 5
Evaluasi kinerja program ... 6
KESIMPULAN DAN SARAN ... 8
Kesimpulan ... 8
Saran ... 8
DAFTAR PUSTAKA ... 8
vi DAFTAR TABEL
Halaman
1 Matriks Levenshtein ... 3
2 Jumlah string judul percobaan berdasar substring yang terdapat di dalamnya ... 5
3 Sebaran jumlah dokumen ditemukan berdasar persentase kemiripan dari 10 query judul terhadap semesta 100 dokumen relevan random ... 5
4 Rataan dokumen relevan berdasar tingkat threshold ... 6
5 Rataan dokumen yang ditemukan berdasar tingkat threshold ... 6
6 Rataan recall dan precision berdasar tingkat threshold ... 7
DAFTAR GAMBAR Halaman 1 Kesamaan string A = “tarik” dengan string B = “tari” dengan jumlah perbedaan maksimum satu perbedaan. ... 2
2 String A = “tarik” tidak sama dengan string B = “taro” pada k = 1. ... 2
3 Deskripsi model sistem. ... 3
4 Pembandingan 5 x 5 utuh ... 4
5 Pembandingan 5 x 5 setelah diseleksi ... 4
6 Kurva recall-precision tanpa threshold. ... 7
7 Kurva AVP berdasar tingkat threshold. ... 7
8 Kurva perbandingan AVP sebelum dan sesudah dilakukan threshold. ... 8
DAFTAR LAMPIRAN Halaman 1 Sebaran jumlah judul berdasar persentase kemiripan dari 10 dokumen random ... 10
2 Dokumen yang ditemukan pada uji 10 query judul random ... 11
3 Dokumen relevan dari 10 queryrandom ... 11
4 Nilai recall-precision sebelum dilakukan threshold ... 11
1
PENDAHULUAN Latar Belakang
Institut Pertanian Bogor (IPB) sebagai sebuah institusi pendidikan tinggi tidak dapat dipisahkan dengan data karya ilmiah. Semakin bertambah usia, semakin berlimpah data yang dilahirkan dan harus dikelola dengan rapi. Untuk itu, IPB secara berkala mendokumentasikan data tersebut dalam bentuk digital repository demi menunjang kemudahan dalam berbagi informasi antar institusi dan antar peneliti. Dengan Digital Repository yang terintegrasi dengan baik, setiap mahasiswa, dosen, dan peneliti yang ada di perguruan tinggi bisa menjadi lebih produktif dalam berkarya. Hal ini dikarenakan mereka dapat saling mempublikasikan, saling menelusuri, dan saling mempelajari informasi arsip hasil penelitian, arsip jurnal, dan arsip lainnya di setiap institusi pendidikan (Raditya 2010).
Kumpulan data karya ilmiah ini dapat dimanfaatkan untuk melihat maupun menelusuri judul-judul yang memiliki kemiripan terhadap suatu judul tertentu. Dengan diolah sedemikian rupa, seharusnya data ini dapat dimanfaatkan oleh peneliti-peneliti dan civitas akademika IPB khususnya, untuk dilakukan penelitian lebih mendalam terhadap suatu kajian tertentu, misalnya untuk mencari seberapa dalam suatu topik tertentu sudah diteliti di kampus ini.
Penentuan tingkat kemiripan dilakukan dengan menggunakan algoritme Levenshtein. Levenshtein distance, atau biasa disebut dengan algoritme edit distance, secara umum merupakan sebuah algoritme untuk menghitung tingkat perbedaan dua string. Algoritme ini menghitung jumlah minimum yang dibutuhkan untuk mentransformasikan satu string ke string yang lain dengan operasi pengeditan yang diizinkan menggunakan penyisipan, penghapusan, atau substitusi karakter tunggal.
Penelitian tentang penentuan kemiripan dengan menggunakan algoritme Levenshtein pernah dilakukan oleh Limbong (2011), pada pengaturan format skripsi. Arumsari (1998) menggunakan jarak edit untuk memeriksa ejaan bahasa Indonesia. Sutisna (2009) melakukan koreksi ejaan query bahasa Indonesia menggunakan algoritme Damerau Levenshtein.
Tujuan
Tujuan dari penelitian ini adalah mengimplementasikan algoritme Levenshtein untuk menentukan tingkat kemiripan data karya ilmiah IPB, dalam hal ini judul skripsi.
Ruang Lingkup
Penelitian ini terbatas pada implementasi algoritme Levenshtein untuk menentukan nilai kemiripan data (judul) karya ilmiah.
Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan referensi dalam proses penggalian informasi kemiripan antar data karya ilmiah IPB sehingga nantinya civitas akademika IPB dapat dengan mudah mencari judul-judul karya ilmiah yang mirip dengan suatu judul tertentu.
TINJAUAN PUSTAKA String
String merupakan rangkaian beberapa
karakter, yang dapat berupa angka, huruf, tanda baca, operator, dan lain-lain. Sebagai contoh ‘a’, ‘2’, dan ‘+’ merupakan suatu karakter, sedangkan “abc” dan “2a” merupakan suatu string (Arumsari 1998).
Kumpulan karakter yang digunakan untuk membentuk string disebut gugus ∑. Misalnya ∑ , , maka string yang dapat dibuat adalah “a”, “b”, “ab”, “ba”, “aba”, “bab”, dan seterusnya.
Hopcroft et al. (1979) mendefinisikan
string sebagai rangkaian terbatas dari simbol-simbol yang dipilih dari beberapa alfabet. Misalnya, 01101 merupakan string alfabet biner ∑ {0,1}.
Panjang string w dinyatakan dengan |w|, yaitu jumlah karakter yang tersusun di dalam
string. Sebagai contoh, “abcde” memiliki
panjang 5 dan panjang string kosong (| |) adalah 0(Arumsari 1998).
Panjang string dapat ditentukan dengan menghitung jumlah posisi dari masing-masing simbol dalam sebuah string. Dengan kata lain, panjang string merupakan “jumlah simbol” dalam sebuah string (Hopcroft & Ullman 1979).
2
lima sehingga secara lebih aman definisi panjang string lebih pada “jumlah posisi simbol” dalam string.
Dua string dikatakan sama apabila
keduanya memiliki panjang dan susunan karakter yang sama. String A dan string B
dikatakan sama apabila susunan karakter
string A sama dengan susunan karakter pada
string B. Karakter pertama pada stringA sama persis dengan karakter pertama pada string B. Karakter kedua pada string A sama persis dengan karakter kedua pada string B. Demikian juga dengan karakter ketiga, keempat, dan seterusnya hingga karakter ke-n string A harus sama dengan karakter pada ke-n string B (Arumsari 1998).
Kemiripan Antara Dua Dokumen
Suatu string dikatakan memiliki kesamaan dengan jumlah perbedaan karakter maksimum
k apabila ada maksimum k karakter yang berbeda dari susunan karakter yang terdapat pada kedua string tersebut dan selisih panjang dari kedua string yang akan dibandingkan lebih kecil atau sama dengan k. Sebagai contoh, k = 1, A = “tarik”, dan B = “tari”.
String A dikatakan sama dengan string B
dengan jumlah perbedaan karakter maksimum satu perbedaan. Karena string B tepat sama dengan empat karakter dari string A, jumlah perbedaannya bisa diperoleh dari selisih panjang kedua string tersebut.
Gambar 1 Kesamaan string A = “tarik” dengan string B = “tari” dengan jumlah perbedaan maksimum satu perbedaan.
Dari Gambar 1, dapat diperhatikan bahwa karakter “k” atau karakter ke-5 dari string A
tidak mempunyai karakter pembanding pada
string B. karakter pembanding pada string B.
Evaluasi Temu Kembali Informasi
Manning (2008) menjelaskan dasar pengukuran keefektifan temu kembali informasi adalah recall dan precision. Recall
merupakan jumlah dokumen relevan yang ditemukembalikan, sementara precision
adalah jumlah dokumen relevan dari dokumen-dokumen yang ditemukembalikan.
Average Precision (AVP) adalah suatu
ukuran evaluasi temu kembali yang diperoleh dengan menghitung rata-rata precision pada berbagai tingkat recall yang ditemukembalikan. Tingkat recall standar yang digunakan adalah eleven standard recall,
yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.
Precision yang diinterpolasi maksimum
pada standar recall level ke-j adalah precision
maksimum pada suatu level recall antara level
j dan level (j+1). Sebaliknya, interpolasi minimum adalah precision minimum pada suatu level recall antara level j dan level (j-1). Levenshtein Distance
Jika diberikan dua buah string s1 dan s2, jarak edit antara keduanya adalah jumlah minimum operasi edit yang diperlukan untuk mengubah s1 ke s2. Pada umumnya, operasi mengedit dilakukan untuk: (i) menyisipkan karakter menjadi string, (ii) menghapus karakter dari suatu string, dan (iii) mengganti karakter string dengan karakter lain. Oleh karena itu, operasi menghitung jarak ini biasa dikenal dengan Levenshtein distance (jarak Levenshtein). Sebagai contoh, jarak edit antara cat dan dog adalah 3.
Berikut adalah algoritme pemrograman dinamis untuk menghitung jarak edit antara
3
Tabel 1 Matriks Levenshtein
k i t t e n perhitungan jarak Levenshtein antara kata “kitten” dan “sitting”. Antara keduanya memiliki jarak edit sebesar 3. Pengubahan dari kata “kitten” ke “sitting” meliputi tiga kali operasi edit. Angka 3 merupakan angka terkecil untuk mengubah “kitten” menjadi “sitting”.
“kitten” “sitten” (subtitusi ‘k’ dengan ‘s’)
“sitten” “sittin” (subtitusi ‘e’ dengan ‘i’)
“sittin” “sitting” (menambahkan ‘g’ pada karakter terakhir)
Dalam bahasa singkatnya, Jokinen (1988) menjelaskan bahwa jarak edit antara dua
string, A dan B pada alfabet ∑, dapat didefinisikan sebagai jumlah terkecil dari banyaknya operasi perubahan yang dilakukan untuk mengubah string A menjadi string B. Masing-masing langkah operasi edit adalah (penghapusan), (penyisipan), atau (penggantian) dengan a,b anggota ∑ dan merupakan string kosong.
METODE PENELITIAN
Metode yang digunakan dalam penelitian ini dilakukan dengan tahap-tahap sebagai berikut.
1 Pengumpulan data dan analisis 2 Pembuatan aplikasi
3 Percobaan dan evaluasi hasil 4 Evaluasi kinerja program
Gambar 3 Deskripsi model sistem.
PengumpulanData dan Analisis
Pada tahap ini, data dikumpulkan kemudian dianalisis pola dan struktur datanya untuk dilakukan proses pembuatan aplikasi pada tahap selanjutnya.
Pembuatan Aplikasi dengan Algoritme Levenshtein
Tahap ini merupakan inti dari penelitian, yaitu mengimplementasikan algoritme Levenshtein untuk menentukan tingkat kemiripan antarjudul karya ilmiah di IPB. Alur kerja aplikasi penentuan kemiripan antar judul ini seperti digambarkan pada Gambar 3.
Data karya ilmiah tidak hanya memuat informasi judul saja. Selain itu terdapat informasi mengenai tahun dan nama penulis. Dalam penelitian ini, hanya judul saja yang dilakukan pembandingan dengan operasi Levenshtein. Oleh karena itu diperlukan sebuah indeks yang memuat informasi hasil pembandingan antar judul.
4
Indeks yang telah tersimpan dalam pangkalan data tersebut dapat diolah untuk memberikan informasi kemiripan antar judul karya ilmiah berikut dengan persentase kemiripan, nama penulis, dan tahun penulisan.
Percobaan dan Evaluasi Hasil
Percobaan dilakukan untuk mengamati kinerja algoritme Levenshtein dalam menentukan tingkat kemiripan antar string
(dalam hal ini judul skripsi). Dalam penelitian-penelitian sebelumnya, algoritme Levenshtein digunakan untuk menentukan kemiripan antar string yang tidak terlalu panjang (kata), sementara dalam penelitian ini digunakan untuk menentukan kemiripan antar judul yang tersusun dari beberapa kata.
Percobaan dilakukan dengan memasukkan data karya ilmiah yang telah dipilih secara acak, kemudian dilakukan pembandingan antar judul dari semua judul yang ada.
Evaluasi Kinerja Program
Evaluasi dilakukan dengan pengamatan. Hal ini dilakukan untuk mengetahui kinerja algoritme Levenshtein dalam menemukan
string (judul) dengan tingkat kemiripan paling tinggi hingga paling rendah. Threshold dan besaran yang dapat digunakan untuk memotong list judul yang ditampilkan. Asumsi
Asumsi yang digunakan dalam penelitian ini antara lain:
• Pembandingan operasi Levenshtein hanya diterapkan pada dokumen judul. • Jumlah dokumen yang dianggap relevan
sudah diketahui sebelumnya.
• Algoritme Levenshtein pada penelitian ini bersifat case sensitive.
HASIL DAN PEMBAHASAN Pengumpulan data
Penelitian ini menggunakan data skripsi IPB. Data diambil dari data digital repository
IPB dalam bentuk file teks dengan format CSV. Data berasal dari tahun 1956 hingga tahun 2011. Jumlah data skripsi adalah 22833 dokumen.
Penelitian ini lebih difokuskan pada pengamatan kinerja algoritme Levenshtein dalam memberikan informasi tingkat kemiripan antarjudul karya ilmiah di IPB. Saat dilakukan percobaan, beberapa data diubah
seperlunya untuk melihat pola yang berkembang saat diterapkan algoritme ini.
Pembuatan Aplikasi dengan Algoritme Levenshtein
Dalam penelitian ini, pembuatan aplikasi belum difokuskan pada penerapan konsep-konsep Interaksi Manusia dan Komputer (IMK), namun lebih difokuskan pada penerapan algoritme Levenshtein.
(J1,J1) (J2,J1) (J3,J1) (J4,J1) (J5,J1)
Aplikasi menentukan kemiripan data karya ilmiah dengan membandingkan antar judul. Apabila suatu data yang dimasukkan memiliki 100 judul, akan ada 100x100 atau 10000 kali pembandingan antar judul. Sebagai gambaran, misalnya pada data yang dibandingkan terdapat 5 judul. Jika J adalah himpunan seluruh judul, terdapat judul-judul J1, J2, J3, J4,
dan J5, operasi Levenshtein akan
membandingkan kombinasi judul sebagaimana digambarkan pada Gambar 4.
Dapat dipastikan, nilai Levenshtein (Ji, Ji) adalah nol (sama persis) karena merupakan pembandingan terhadap diri sendiri.
Demikian pula dengan kasus pembandingan antara J1 terhadap J2 dapat dipastikan memiliki tingkat kemiripan sama dengan J2 terhadap J1. Pembandingan ini bersifat kombinasi dengan (J1, J2) = (J2, J1), (J1, J3) = (J3, J1), dan seterusnya. Dengan demikian, tidak perlu dilakukan pembandingan dua kali. Artinya, apabila ingin mengetahui Levenshtein (J1, J2) dan (J2, J1), jika telah didapatkan nilai Levenshtein (J1, J2), tidak perlu dicari lagi nilai Levenshtein (J2, J1) sehingga kombinasi operasi pembandingan antar judul sebagaimana pada Gambar 5.
5
Apabila indeks telah diperoleh dan disimpan dalam pangkalan data, list judul dapat ditampilkan, termasuk menampilkan list
judul yang mirip dengan suatu judul tertentu berikut informasi penulis dan tahun penulisan dengan diurutkan berdasar tingkat kemiripan judul dari yang paling mirip hingga yang kurang mirip. Judul yang memiliki tingkat kemiripan paling tinggi akan otomatis berada di daftar list paling atas, sementara yang
Dihasilkan kombinasi jarak edit sebagai berikut:
levenshtein(J1,J2) = 15 levenshtein(J1,J3) = 10 levenshtein(J1,J4) = 18 levenshtein(J1,J5) = 25
Apabila didapatkan hasil perhitungan nilai Levenshtein sebagaimana kombinasi di atas, maka judul yang memiliki tingkat kemiripan paling tinggi hingga yang paling kurang dari judul J1 adalah J3, J2, J4, dan yang terakhir J5.
Semakin besar nilai jarak edit, semakin rendah tingkat kemiripan antara kedua string
(judul). Besar dan kecil nilai jarak edit menjadi relatif dalam persentase kemiripan terhadap string yang lain. Oleh karena itu, LevenCom menampilkan tingkat kemiripan antar judul pada antar muka dalam bentuk persentase kemiripan. Rumus yang digunakan untuk mendapatkan nilai persentase kemiripan dua buah stringA dan string B adalah:
Persentase Kemiripan (A,B)=
1 levenshtein(A,B)
max panjang A, panjang B) ×100%
Percobaan
Percobaan dilakukan menggunakan 100 dokumen acak. Seratus dokumen acak ini merupakan gabungan dari masing-masing 10 dokumen yang dianggap relevan.
Dalam percobaan ini, dipilih secara acak masing-masing 10 dokumen yang memiliki judul dengan substring “aktivitas antibakteri”, “aktivitas antioksidan”, “analisis kelayakan finansial”, “analisis kepuasan pelanggan”, “analisis strategi bisnis”, “biologi reproduksi”, “ayam kampung”, “benih jagung”, “daging ayam broiler”, dan “pengaruh pemupukan nitrogen”. Terdapat 10 substring yang
digunakan sebagai identifier data relevan, masing-masing memiliki 10 dokumen sehingga jumlah semesta dokumen adalah 100. Rinciannya sebagaimana tertera pada Tabel 2.
Tabel 2 Jumlah string judul percobaan berdasar substring yang terdapat di dalamnya
Substring Jumlah
Aktivitas antibakteri 10 Aktivitas antioksidan 10 Analisis kelayakan finansial 10 Analisis kepuasan pelanggan 10 Analisis strategi bisnis 10 Biologi reproduksi 10
Ayam kampung 10
Benih jagung 10
Daging ayam broiler 10 Pengaruh pemupukan nitrogen 10
Percobaan dilakukan dengan mengambil 10 dokumen judul random sebagai quey. Masing-masing judul tersebut mewakili 10
substring yang ada dan terdapat dalam
himpunan semesta dokumen. Satu judul mewakili “aktivitas antibakteri”, satu judul dengan substring “aktivitas antioksidan”, satu judul “analisis kelayakan finansial”, dan seterusnya. Pada sepuluh dokumen tersebut, dilakukan pembandingan terhadap 100 dokumen semesta.
Dari uraian tersebut, hasil yang diharapkan muncul dari setiap proses pembandingan Levenshtein adalah 10 dokumen relevan yang akan muncul di urutan paling atas.
Tabel 3 Sebaran jumlah dokumen ditemukan berdasar persentase kemiripan dari 10
6
Sebagaimana uraian pada Gambar 4 dan Gambar 5, dari pembandingan 100 dokumen terhadap dokumen itu sendiri dihasilkan 1000 hasil pembandingan. Masing-masing query
judul memiliki 100 kombinasi hasil pembandingan. Hasil yang diperoleh pada percobaan 10 query judul yang mewakili 10
substring sebagaimana ditunjukkan pada
Tabel 3.
Dari Tabel 3 (untuk detailnya lihat Lampiran 1), sebaran banyak terpusat di range
20 hingga 30 persen dengan rataan 72.2 dokumen judul, kemudian diikuti range 10 sampai 20 persen sebanyak 11.9 judul dari 100 judul yang ada, kemudian range 30 hingga 40 persen sebanyak rata-rata 11.7 judul mengikuti di urutan ketiga. Selebihnya, tidak ada yang memiliki rataan lebih dari atau sama dengan 1. Bahkan, pada kasus ini, tidak ditemukan satupun judul yang memiliki persentase kemiripan lebih dari 70 persen, kecuali hasil pembandingan terhadap dokumen query judul itu sendiri. Selain itu, tidak ditemukan judul yang memiliki persentase kemiripan kurang dari 10 persen di antara judul-judul yang lain.
Tabel 4 Rataan dokumen relevan berdasar tingkat threshold
Threshold Rataan Dokumen Ditemukan
0% 100.0
Dalam percobaan ini, rataan dokumen yang ditemukan dalam proses pencarian pada 10 kueri percobaan sebagaimana dirincikan pada Tabel 4 (detail rincian dapat dilihat pada Lampiran 2). Sementara, dengan asumsi dokumen dianggap relevan apabila judul memiliki substring (Tabel 2) yang sama dengan substring pada query judul, rataan dokumen relevan yang muncul sebagaimana ditunjukkan pada Tabel 5. Uraian lebih rinci dapat dilihat pada Lampiran 3.
Tabel 5 Rataan dokumen yang ditemukan berdasar tingkat threshold
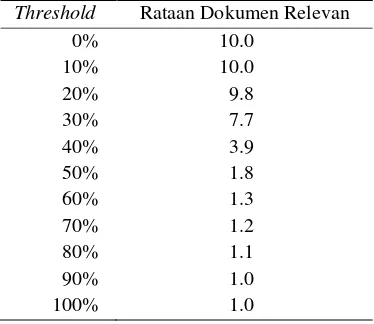
Threshold Rataan Dokumen Relevan
0% 10.0 yang terjadi dengan penggunaan threshold,
mulai dari 0 persen hingga 100 persen kemiripan. Percobaan pada beberapa tingkat
threshold ini digunakan untuk melakukan
evaluasi pemotongan angka kemiripan minimal yang perlu ditampilkan pada sistem.
Penggunaan threshold kurang dari 10% tidak mempengaruhi kinerja program. Jumlah dokumen yang dihasilkan tidak berubah dengan atau tanpa penggunaan threshold. Demikian halnya dengan threshold di atas 90%. Penggunaan threshold justru menyebabkan sistem tidak dapat menemukan dokumen yang memiliki kemiripan terhadap dokumen kueri judul yang dimasukkan, kecuali penemuan pada judul itu sendiri. Penggunaan threshold efektif pada rentang 20% hingga 80%.
Evaluasi kinerja program
Dari hasil percobaan, penggunaan algoritme Levenshtein untuk menentukan kemiripan antar judul karya ilmiah tidak dapat dikatakan benar-benar efektif. Hal ini dapat ditinjau dari sebaran tingkat persentase kemiripan yang dihasilkan. Sebaran sebagian besar terpusat di rentang kemiripan 10 hingga 40 persen. Persentase kemiripan tidak terlalu tinggi. Hanya sedikit yang berada di atas angka persentase tersebut.
7
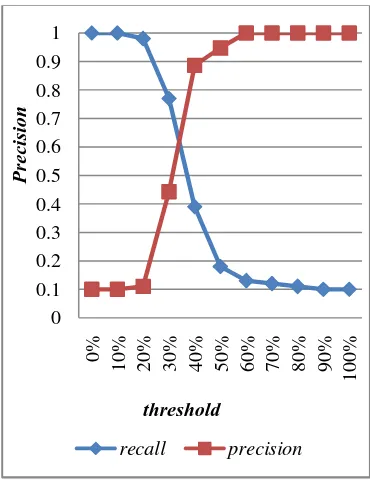
Gambar 6 Kurva recall-precision tanpa
threshold.
Dengan menggunakan eleven standard
recall, diperoleh kurva AVP sebagaimana
terlihat pada Gambar 6.
Tabel 6 Rataan recall dan precision berdasar
Penentuan threshold mempengaruhi jumlah dokumen yang ditemukan oleh sistem. Demikian juga dengan jumlah dokumen relevan yang dapat ditemukan. Dengan nilai
recall dan precision, dihasilkan rataan sebagaimana terinci pada Tabel 6. Kurva AVP berdasar tingkat threshold disajikan pada
Gambar 7. Secara lebih rinci, nilai precision
pada tiap-tiap tingkat recall dapat dilihat pada Lampiran 4.
Demikian halnya dengan range lebih dari 60 persen. Nilai threshold juga tidak dapat diterapkan pada selang ini. Meskipun nilai
precision yang diperoleh sangat tinggi, nilai
recall-nya sangat rendah. Bahkan, nilai
precision pada selang 90 persen ke atas, nilai
recall yang dihasilkan hanya 0.1.
Selang kemiripan yang memungkinkan untuk dijadikan sebagai threshold adalah di antara 20 persen dan 60 persen. Threshold 30 persen memiliki recall 0.77, namun nilai
precision hanya 0.4425287. Sebaliknya,
threshold 40 persen memiliki precision
0.8863636 namun recall-nya hanya 0.39. Dengan menghitung titik potong persamaan linier yang dibentuk oleh keempat titik pada selang 30 dan 40 persen, diperoleh angka 33.974962% atau dapat dibulatkan menjadi 34%. Pada titik tersebut, kedua kurva bertemu dengan nilai precision 0.6189514. Dibandingkan angka 30 dan 40 persen, nilai ini relatif lebih baik untuk dijadikan threshold. Titik threshold 30 persen memiliki ketepatan kurang dari 0.5. Sementara 40 persen memiliki perolehan yang cukup rendah meskipun memiliki ketepatan yang relatif tinggi.
Gambar 7 Kurva AVP berdasar tingkat
8
Gambar 8 Kurva perbandingan AVP sebelum dan sesudah dilakukan threshold.
Dilihat dari kurva AVP yang telah diinterpolasi minimum pada Gambar 8, penggunaan threshold pada selang kemiripan 34% mampu menaikkan nilai precision.
Secara lebih detail, nilai precision pada tiap tingkat recall dapat dilihat pada Lampiran 5.
KESIMPULAN DAN SARAN Kesimpulan
Dengan menggunakan algoritme Levenshtein untuk membandingkan nilai kemiripan antar judul karya ilmiah yang relatif panjang, cukup sulit untuk bisa diperoleh nilai persentase kemiripan yang tinggi. Sistem berjalan efektif dengan pemotongan list
dokumen judul yang ditampilkan sistem pada ambang batas minimal kemiripan 34%.
Saran
Saran penelitian selanjutnya antara lain:
1 Perlu diteliti lebih mendalam mengenai penerapan metode ini dengan memecah satu string judul menjadi substring yang lebih pendek saat dilakukan pembandingan.
2 Perlu penelitian lebih lanjut untuk memperhatikan jumlah kata penyusun substring penanda relevansi dokumen.
3 Menggunakan algoritme lain untuk menentukan kemiripan data karya ilmiah.
DAFTAR PUSTAKA
Arumsari KN. 1998. Penggunaan metode kesamaan string pada pemeriksaan ejaan bahasa Indonesia [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
Horpcroft, Motwani R, Ullman JD. 2001.
Introduction to Automata Theory,
Languages, and Computation. New
York: Addison-Wesley.
Jokinen P, Tarhio J, Ukkonen E. 1996. A comparison of approximate string matching algorithms. Software - Practice and Experience 26(12): 1439-1458. Limbong SOO. 2011. Pengembangan
framework dan fungsionalitas dasar add-in Microsoft Office Word 2007 untuk pengecekan format skripsi [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
Manning CD, Prabhakar R, Hinrich S. 2008.
An Introduction to Information Retrieval. New York: Cambridge University Press.
Raditya MR. 2010. Penerapan open archive standard dan database caching pada pengembangan jaringan digital repository [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
Sutisna U. 2009. Koreksi ejaan query bahasa Indonesia menggunakan algoritme Damerau Levenshtein [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
10
Lampiran 1 Sebaran jumlah judul berdasar persentase kemiripan dari 10 dokumen random
% Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Total Rata-rata > 90 1 1 1 1 1 1 1 1 1 1 10 1 > 80 - 90 0 0 0 0 0 0 0 0 0 0 0 0 > 70 - 80 0 0 0 0 0 1 0 0 0 0 1 0.1 > 60 - 70 0 0 0 0 0 0 0 0 0 0 0 0 > 50 - 60 1 0 0 0 1 2 0 0 0 0 4 0.4 > 40 - 50 3 0 6 6 3 1 0 0 6 2 27 2.7 > 30 - 40 6 8 16 16 5 7 24 3 16 16 117 11.7 > 20 - 30 70 76 69 69 71 77 69 77 69 75 722 72.2 > 10 - 20 19 15 8 8 19 11 6 19 8 6 120 11.9 < 10 0 0 0 0 0 0 0 0 0 0 0 0
Q1 = Aktivitas antibakteri Daun Senggugu (Clerodendron serratum [L.] Spr.)
Q2 = Aktivitas antioksidan dan immunostimulan ekstrak Buah Andaliman (Zanthoxylum acanthopodium DC.)
Q3 = Analisis kelayakan finansial budidaya jamur tiram(Pleurotus sp) pada usaha agribisnis supa tiram mandiri, Bogor
Q4 = Analisis kepuasan pelanggan di taman bacaan quadrant
Q5 = Analisis strategi bisnis ekpor ikan hias air tawar di PT Nusantara Aquatik Exporindo Bumi Bintaro Permai, Jakarta Selatan
Q6 = Biologi reproduksi dan kebiasaan makan ikan lampam (Barbonymus schwanenfeldii) di Sungai Musi, Sumatera Selatan
Q7 = Analisis Saluran Pemasaran Ayam Kampung (Gallus domesticus) di Jakarta Selatan, Propinsi DKI Jakarta
Q8 = Aplikasi Beberapa Cara Penyiapan Lahan dengan Modifikasi Penggunaan Herbisida Metsulfuron Metil dan Glifosat pada Produksi Benih Jagung (Zea Mays L.), Kacang Tanah (Arachis Hypogaea L.) dan Kedelai (Glycine max (L.) Merr)
Q9 = Analisis permintaan daging ayam broiler konsumen rumah tangga di Kecamatan Pamulang Tangerang
11
Lampiran 2 Dokumen yang ditemukan pada uji 10 query judul random
Threshold Dokumen Ditemukan Rataan
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10
0% 100 100 100 100 100 100 100 100 100 100 100 10% 100 100 100 100 100 100 100 100 100 100 100 20% 81 85 92 93 81 89 94 81 97 94 88.7 30% 11 9 23 25 10 12 25 4 36 19 17.4 40% 5 1 7 12 4 5 1 1 5 3 4.4 50% 2 1 1 5 1 4 1 1 2 1 1.9 60% 1 1 1 2 1 2 1 1 2 1 1.3 70% 1 1 1 1 1 2 1 1 2 1 1.2 80% 1 1 1 1 1 1 1 1 2 1 1.1
90% 1 1 1 1 1 1 1 1 1 1 1
100% 1 1 1 1 1 1 1 1 1 1 1
Lampiran 3 Dokumen relevan dari 10 queryrandom
Threshold Dokumen Relevan
Rataan Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10
0% 10 10 10 10 10 10 10 10 10 10 10 10% 10 10 10 10 10 10 10 10 10 10 10 20% 10 10 10 10 10 10 8 10 10 10 9.8 30% 8 4 10 10 10 9 2 4 10 10 7.7 40% 5 1 6 9 4 4 1 1 5 3 3.9 50% 2 1 1 5 1 3 1 1 2 1 1.8 60% 1 1 1 2 1 2 1 1 2 1 1.3 70% 1 1 1 1 1 2 1 1 2 1 1.2 80% 1 1 1 1 1 1 1 1 2 1 1.1 90% 1 1 1 1 1 1 1 1 1 1 1 100% 1 1 1 1 1 1 1 1 1 1 1
Lampiran 4 Nilai recall-precision sebelum dilakukan threshold
Recall Precision AVP
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10
0.1 1 1 1 1 1 1 1 1 1 1 1
0.2 1 1 1 1 1 1 0.13 1 1 1 0.91333
0.3 1 1 1 1 1 1 0.10 1 1 1 0.91071
12
Lampiran 5 Nilai recall-precision setelah dilakukan threshold
Recall Precision AVP
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10
0.1 1 1 1 1 1 1 1 1 1 1 1
0.2 1 1 1 1 1 1 1 1 1 1 1
0.3 1 1 1 1 1 1 1 1 1 1 1
0.4 1 1 1 1 1 1 1 1 1 1 1
0.5 1 1 1 1 1 1 1 1 1 1 1