UJI HOMOGENITAS MARGINAL DENGAN MODEL LOG
LINIER PADA TABEL KONTINGENSI
TIGA DIMENSI ATAU LEBIH
SKRIPSI
ELFRIEDE MAHULAE 070823033
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
UJI HOMOGENITAS MARGINAL DENGAN MODEL LOG
LINIER PADA TABEL KONTINGENSI
TIGA DIMENSI ATAU LEBIH
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
ELFRIEDE MAHULAE 070823033
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
ii
PERSETUJUAN
Judul : UJI HOMOGENITAS MARGINAL DENGAN MODEL
LOG LINIER PADA TABEL KONTINGENSI TIGA
DIMENSI ATAU LEBIH
Kategori : SKRIPSI
Nama : ELFRIEDE MAHULAE
Nomor Induk Mahasiswa : 070823033
Program Studi : SARJANA (S1) MATEMATIKA STATISTIK
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN ALAM
(FMIPA) UNIVERSITAS SUMATERA UTARA
Medan, Juni 2009
Komisi Pembimbing:
Pembimbing 2 Pembimbing 1
Drs. H. Haluddin Panjaitan Dra. Rahmawati Pane, M.Si
NIP 130701888 NIP 131 474 682
Diketahui Oleh
Departemen Matematika FMIPA USU
Ketua,
Dr. Saib Suwilo, M.Sc
PERNYATAAN
UJI HOMOGENITAS MARGINAL DENGAN MODEL LOG LINIER
PADA TABEL KONTINGENSI TIGA DIMENSI ATAU LEBIH
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing masing disebutkan sumbernya.
Medan, Juni 2009
ELFRIEDE MAHULAE
070823033
PENGHARGAAN
Puji dan Syukur penulis panjatkan kepada Tuhan Yang Maha Pemurah dan Maha
Penyayang, dengan limpah karunia-Nya kertas kajian ini berhasil diselesaikan dalam
waktu yang telah ditetapkan.
Ucapan terima kasih saya sampaikan kepada Dra. Rahmawati Pane, M.Si dan
Drs. H. Haluddin Panjaitan, selaku pembimbing saya pada penyelesaian skripsi ini
yang telah memberikan panduan dan kepercayaan kepada saya untuk
menyempurnakan kajian ini. Panduan ringkas dan padat serta profesional telah
diberikan kepada saya agar penulis dapat menyelesaikan tugas ini. Ucapan terima
kasih juga ditujukan kepada Ketua dan Sekretaris Departemen Matematika FMIPA
USU Dr. Saib Suwilo, M.Sc dan Drs. Henri Rani Sitepu, M.Si., Dekan dan Pembantu
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatra Utara,
semua Dosen pada Departemen Matematika FMIPA USU, pegawai di FMIPA USU
dan rekan-rekan kuliah. Akhirnya tidak terlupakan kepada Bapak dan Mama serta
semua sanak keluarga yang selama ini memberikan bantuan dan dorongan yang
diperlukan. Semoga Tuhan Yang Maha Esa akan membalasnya
ABSTRAK
Tabel kontingensi dan model log linier merupakan metode statistik yang dapat
diterapkan pada kasus-kasus data kualitatif. Dengan tabel kontingensi dapat diketahui
hubungan antar variabel berskala kualitatif dan dengan analisa log linier dapat
diketahui resiko atau pengaruh dari setiap kategori suatu variabel terhadap variabel
lainnya. Model log linier dapat digunakan untuk mendiskripsikan pola hubungan antar
beberapa variabel kategorik. Dengan pendekatan log linier, angka-angka dalam sel
dapat disusun dalam tabel kontingensi tiga dimensi. Angka-angka tersebut dapat
diselesaikan dalam bentuk perhitungan dan hasil perhitungnnya dapat disajikan dalam
ABSTRACT
Contingency table and log linier model are statistic method can be used in kualitative
case. By used contingency table could known relation among variable kuaitative scale
and log linier analisis could known risk of each category all variable with others. Log
linier models describe pattern among categorical variables. With the log linier
approach, we model cell counts in a contingency table in term of association among
the variables. The result could count and applied by table anova, and then we can see
the relation of all the variables.
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstract vi
Daftar isi vii
Daftar Tabel viii
Bab 1 Pendahulan 1.1 Latar Belakang 1 1.2 Perumusan Masalah 3
1.3 Tujuan Penelitian 3 1.4 Kontribusi Penelitian 3
1.5 Metode Penelitian 3 1.6 Tinjauan Pustaka 6 Bab 2 Landasan Teori 2.1 Data Kategorik 7 2.2 Analisis Berdasarkan Tabel IxJxK 12
2.3 Ukuran Asosiasi Berdasarkan Tabel 2x2x2 12
2.3.1 Selisih Prevalensi atau Proporsi Bersyarat 12
2.4 Model Log Linier 14
2.4.1 Penerapan Model Log Linier 17
Bab 3 Pembahasan 3.1 Kasus 25
3.2 Pembahasan Contoh Kasus 26
Bab 4 Kesimpulan dan Saran 4.1 Kesimpulan 31
4.2 Saran 32
DAFTAR PUSTAKA
LAMPIRAN
DAFTAR TABEL
Tabel 1.1. Tabel Kontingensi bxk 2
Tabel 2.1 Tabel Data Untuk Lapis Pertama 10
Tabel 2.2 Tabel Data Untuk Lapis Kedua 11
Tabel 2.3 Banyaknya Responden Menurut Variabel X1,X2danX3 13
Tabel 3.1 Hasil pengujian efisiensi pemakaian insektisida dan herbisida
pada daerah penanaman tomat. 25
Tabel 3.2 Klasifikasi dua arah Antara Insektisida dengan Herbisida 27
Tabel 3.3 Klasifikasi antara insektisida dan Herbisida dengan Daerah Tomat 28
Tabel 3.4 Klasifikasi Dua Arah Berdasarkan Herbisida dan Daerah Tomat 29
Tabel 3.5 Tabel Anava 30
ABSTRAK
Tabel kontingensi dan model log linier merupakan metode statistik yang dapat
diterapkan pada kasus-kasus data kualitatif. Dengan tabel kontingensi dapat diketahui
hubungan antar variabel berskala kualitatif dan dengan analisa log linier dapat
diketahui resiko atau pengaruh dari setiap kategori suatu variabel terhadap variabel
lainnya. Model log linier dapat digunakan untuk mendiskripsikan pola hubungan antar
beberapa variabel kategorik. Dengan pendekatan log linier, angka-angka dalam sel
dapat disusun dalam tabel kontingensi tiga dimensi. Angka-angka tersebut dapat
diselesaikan dalam bentuk perhitungan dan hasil perhitungnnya dapat disajikan dalam
ABSTRACT
Contingency table and log linier model are statistic method can be used in kualitative
case. By used contingency table could known relation among variable kuaitative scale
and log linier analisis could known risk of each category all variable with others. Log
linier models describe pattern among categorical variables. With the log linier
approach, we model cell counts in a contingency table in term of association among
the variables. The result could count and applied by table anova, and then we can see
the relation of all the variables.
BAB I
PANDAHULUAN
1.1 Latar Belakang
Data merupakan sejumlah informasi yang dapat memberikan gambaran/keterangan
tentang suatu keadaan. Informasi yang diperoleh memberikan keterangan, gambaran,
atau fakta mengenai suatu persoalan dalam bentuk kategori, huruf, atau lambang
disebut data kategorik. Fakta menjadikan suatu penelitian memberikan hasil yang
sesuai harapan bila didukung oleh data yang representatif. Data berupa bilangan
disebut data kuantitatif nilainya berubah-ubah atau bersifat variabel. Dari nilainya,
dikenal dua golongan data kuantitatif yaitu data dengan variabel diskrit atau
singkatnya data diskrit dan dengan variabel kontiniu atau singkatnya data kontinu,
sedangkan data bukan bilangan disebut data kualitatif, ini tiada lain daripada data
yang dikategorikan menurut lukisan kualitas obyek yang dipelajari. Misalnya sembuh,
rusak, gagal, berhasil dsb. Kedua data tersebut diklasifikasikan berdasarkan jenis
datanya, dimana data kualitatif atau data kategorik adalah data yang sifatnya hanya
penggolongan saja.
Data kuantitatif adalah data yang berbentuk angka, atau data yang diukur dalam skala
numerik yang diperoleh dengan perhitungan atau pengukuran. Data tersebut dapat
disajikan, penyajian data dilakukan dalam rangka memperjelas secara visual kondisi
data yang bermanfaat dalam pengambilan kesimpulan yang baik secara deskriptif
maupun inferen banyak cara menyajikan data, seperti dalam tabel maupun gambar
(diagram).
Data kualitatif yang dikumpulkan disajikan menurut kualitas atau kategorik yang
digunakan disertai banyaknya frekuensi yang terjadi atau diperoleh. Jika terdapat
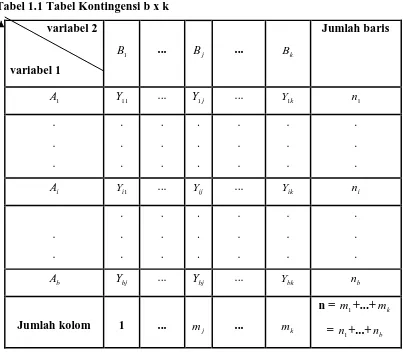
lebih dari satu kategori, biasanya data disajikan dalam daftar baris dan kolom.
Daftar kontigensi bxk, berarti terdapat dua kategori (2 dimensi) masing-masing
memiliki b, k tingkat, dapat ditulis dalam tabel berikut:
Tabel 1.1 Tabel Kontingensi b x k
variabel 2
variabel 1
1
B ... Bj ... B k
Jumlah baris
1
Pada pengujian hipotesa yang menggunakan tabel kontingensi, pertama kali dihitung
kesesuaian frekuensi-frekuensi sel yang diharapkan atau teoritis menurut dasar
hipotesa dalam aturan probabilitas. Jumlah seluruh frekuensi sel yang diharapkan
harus sama dengan jumlah seluruh pengamatan.
Tabel Kontingensi dan Model Log Linier merupakan metode statistik yang dapat
diterapkan pada kasus-kasus data kualitatif. Dengan tabel kontingensi dapat diketahui
hubungan antar variabel berskala kualitatif dengan analisa Log Linier dapat diketahui
resiko atau pengaruh dari setiap kategori suatu variabel terhadap variabel lainnya.
Kelebihan Model log linier adalah dapat menentukan model matematik yang cocok
untuk dependensi lebih dari dua variabel dan dapat digunakan untuk mengetahui ada
merupakan suatu model statistik yang berguna untuk menentukan
depensi/kecenderungan antara beberapa variabel yang berskala nominal, kategorik.
Untuk uji Homogenitas misalkan untuk setiap baris dari tabel, terhadap distribusi
multinomial dengan sampel tertentu yang merupakan jumlah baris n1,n2,...,nb,maka
model untuk uji homogenitas baris ke i, {yi1,yi2,...yik}berdistribusi
multinomialdengan n 1 trial dan probabilitas pi1,pi2,...,pik, i=1,2,...,b
peristiwaA menunjukkan bahwa kita mengambil sampel dari populasi ke i, semua i
sampel {yi1,yi2,...yik},i=1,2,...,b adalah saling independen.
Dari uraian di atas maka penulis tertarik mengambil judul ”UJI HOMOGENITAS
MARGINAL DENGAN MODEL LOG LINIER PADA TABEL KONTINGENSI
TIGA DIMENSI ATAU LEBIH”
1.2 Perumusan Masalah
Berdasarkan latar belakang di atas, maka permasalahannya adalah bagaimana
penyelesaian suatu kasus dengan menggunakan uji homogenitas marginal dengan
model log linier tiga dimensi atau lebih.
1.3 Tujuan Penelitian
Adapun tujuan penelitian ini adalah untuk mengetahui, menganalisa dan
menyelesaikan suatu kasus dengan uji homogenitas marginal dengan model log linier
1.4 Kontribusi Penelitian
Penelitian ini diharapkan bermanfaat bagi siapapun, terutama bagi para peneliti
dalam bidang sosial sehingga lebih mudah mengklasifikasikan data yang ingin diteliti
agar lebih mudah untuk diolah, sehingga jelas tujuannya
1.5 Metodologi Penelitian
Metode yang digunakan pada tugas akhir ini bersifat literatur yaitu di susun
berdasarkan rujukan pustaka dan studi kasus, lalu permasalahan yang akan diteliti di
uji dengan langkah sebagai berikut :
Menyusun atau membuat tabel kontingensi tiga dimensi
a) Tentukan hipotesis H
k
c) Statistik uji yang digunakan adalah
∑
−n observasi pada variabel ke i, j dan k
=
ijk
e frekuensi harapan jika H benar o
Akan mendekati distribusi Chi-Kuadrat dengan derajat bebas
(b-1)(k-1)
d) Daerah kritis
0
H ditolak jika W > χ2((b−1)(k−1);α), dari persoalan kita hitung
statistik penguji W
e) Kesimpulan
Setelah dihitung hasil perhitungan tersebut dapat ditulis dalam bentuk model log
Model log linier dapat digunakan untuk mendeskripsikan pola hubungan antar
variabel kategorik. Dengan pendekatan log linier, angka-angka pada sel tabel
kontingensi dapat dimodelkan sedemikian hingga pada tabel tiga dimensi.
Dapat juga diselesaikan dengan menggunakan analisis varian multiklasifikasi, yang
model log liniernya dapat langsung di dapatkan dari tabel anava. Disini penulis akan
menggunakan analisis varian multiklasifikasi.
ijkl ijk jk
ik ij
k j i ijkl
X =µ +α +β +Γ +(αβ) +(αΓ) +(βΓ) +(αβΓ) +ε
Dengan: =
ijkl
X pengamatan ke 1 (1=1,2,…,n) untuk faktor X yang ke i (i=1,2,…,n), factor
Yyang ke j (j=1,2,…,b), dan faktor z yang ke k (k=1,2,…,c) =
µ rata-rata
= i
α pengaruh faktor X yang ke i
=
j
β pengaruh faktor Y yang ke j
=
Γk pengaruh faktor Z yang ke k
=
ij )
(αβ interaksi faktor X yang ke i dengan faktor Y yang ke j
= Γ)ik
(α interaksi faktor X yang ke i dengan faktor Z yang ke k
(βΓ)jk = interaksi faktor Y yang ke j dengan faktor Z yang ke k
(αβΓ)ijk = interaksi faktor X yang ke i, faktor Y yang ke j dengan faktor Z yang ke k
=
ijkl
ε sesatan pengamatan yang bersangkutan
1.6 Tinjauan Pustaka
Tabel Kontingensi, analisis ini merupakan teknik penyusunan data untuk melihat
hubungan antara beberapa variabel dalam satu tabel. Variabel yang dianalisis
merupakan variabel kategorik yang memiliki skala nominal atau ordinal. Untuk
uji Chi-Square, uji ini digunakan untuk mengetahui adanya hubungan antara variabel
yang diukur tersebut signifikan atau tidak
( Agresti, 1990)
Model Log Linier dapat digunakan untuk menggambarkan pola hubungan antar
variable kategorik. Dengan pendekatan Log linier, angka-angka pada table
kontingensi dapat dimodelkan sedemikian hingga pada tabel kontingensi tiga dimesi
( Agresti, 1990)
Model log-linier mengizinkan pengujian untuk menentukan apakah data dapat
menjadi cocok digambarkan oleh beberapa model tertentu. Untuk contoh ilustrasi, kita
mengikuti prosedur yang relevan untuk pengujian model interaksi orde pertama
BAB II
LANDASAN TEORI
2.1 Data Kategorik
Data statistik yang diperhatikan dalam setiap analisis atau penelitian pada umumnya
memuat banyak variabel numerik maupun variabel kategorik. Sehingga analisis data
juga dapat dilakukan dengan memakai kedua macam ukuran variabel tersebut. Akan
tetapi, dengan mentransformasikan semua variabel numerik menjadi variabel
kategorik (ordinal) maka kita akan mempunyai suatu data baru dengan semua variabel
kategorik, yang akan disebut data kategorik. Manfaat atau keuntungan yang dapat
diperoleh dengan memakai data kategorik antara lain:
a) Ruang yang diperlukan untuk menyimpan data menjadi sangat
sempit/kecil dibandingkan dengan data aslinya atau data primernya
b) Waktu yang diperlukan untuk melakukan analisis data akan menjadi jauh
lebih singkat daripada memakai data primer menjadi sangat kecil
c) Akhirnya, hasil analisis data kategorik dapat dilakukan atau
dipertanggungjawabkan atas dasar pemikiran sebagai berikut
1. Pada dasarnya, analisis statistik dilakukan dengan tujuan untuk
mempelajari perbedaan atau kesamaan kelompok-kelompok individu
yang dibentuk berdasarkan kategori sebuah variabel atau lebih, antara
lain perbedaan proporsi (persentase), prevalensi atau insiden suatu
peristiwa tertentu antara kelompok individu yang ditinjau.
2. mempelajari asosiasi ganda antar variabel kategorik dengan
menerapkan model log linier, atau model regresi logistik yang meliputi
penerapan statistik Rasio Kesamaan atau Rasio Kecenderungan (RK)
3. Model asosiasi (korelasi) antara variabel kategorik, seperti model
regresi logistik t dinyatakan telah mempunyai pola yang standard atau
baku. Sehingga lebih mudah dapat dipahami dan diulang kembali
dengan memakai berbagai macam data kategorik sesuai dengan
4. di pihak lain, kesimpulan yang diperoleh berdasarkan model asosiasi
(empiris) antara variabel numerik kerap kali tidak dapat
dipertanggungjawabkan, karena data yang dipakai pada umumnya
bukanlah data yang sesuai.
Data sering terdiri dari sejumlah objek yang terhitung dengan atribut tertentu yang
dimiliki oleh kategori-kategori tertentu yang disusun dalam tabel satu dimensi, dua
dimensi, tiga dimensi atau bahkan dalam tabel berdimensi lebih tinggi lagi, biasanya
disebut tabel kontingensi satu arah, dua arah dan tiga arah. Masing-masing dimensi
atau arah berhubungan dengan sebuah klasifikasi dalam kategori-kategori yang
menyajikan satu atribut.
Tabel satu arah, pengkategoriannya mungkin tidak relevan untuk setiap analisis
statistik. Seseorang dapat memisalkan pernyataan yang dibuat-buat bahwa datanya
merupakan sampel acak dan memperoleh sebuah perkiraan dari median atau rata-rata
tetapi hasilnya tidak informatif atau sah karena datanya tidak dipilih secara acak,
disini kurang pengacakan juga dapat menimbulkan pertanyaan bagaimana (dalam arti
statistik) setiap kesimpulan populasi yang diterapkan. Pengujian ini sebenarnya bukan
non parametrik jika pengujiannya mengenai sebuah parameter p yang merinci
frekuensi terjadinya setiap angka. Ini adalah sebuah uji kecocokan dan goodness of fit
test.
Tabel dua arah, sama formatnya tetapi berbeda dalam status logikanya. Datanya
terdiri dari dua sampel bebas. Namun demikian dalam dua kasus tersebut masih
digambarkan bahwa pembedaannya dapat diabaikan untuk ukuran sampel yang cukup
yang besar, dan dapat digunakan uji untuk sampel besar yang sama tanpa memandang
apakah pemilihannya menetapkan hanya jumlah keseluruhan yang akan diambil
sampelnya dan kemudian mencatat jumlah masing-masing kelas. Pada suatu keadaan,
kita hanya menetapkan total keseluruhannya pada keadaan lain kita menetapkan tabel
keseluruhan dan total baris. Hal ini juga mungkin untuk menetapkan total keseluruhan
dan total kolom, dan sama dengan pertukaran baris dan kolom. Pendekatan uji sampel
keadaan tersebut, dan merupakan uji terpenting yang tergantung pada total baris dan
kolom pengamatan. Uji sampel besar yang cocok digunakan adalah uji Q Cochran
Tabel multiarah, bila tabel dua arah dengan mudah disajikan pada kertas, tabel tiga
arah atau lebih paling baik disajikan dengan subtabel-subtabel dan lebih dari satu
penyajian selalu mungkin. Setelah data tersebut diberikan dalam tabel lebih baik
untuk analisis selanjutnya dengan memasukkan tabel marginal yang ditunjukkan.
Pembaca dapat menyusun data ini dengan susunan logika yang berbeda meskipun
pengujian untuk kebebasan dapat diperluas dari tabel dua arah sampai multi arah, dan
uji berpasangan mengenai kebebasan dapat digunakan, sehingga analisisnya biasanya
tidak cukup( tidak efisien) dan kita sering tertarik dalam menguji dengan lebih
mengembangkan hipotesis-hipotesis, atau bahkan serangkaian hipotesis.
Banyak eksperimen secara simultan mempelajari lebih dari dua independen variabel
atau lebih dari dua faktor. Misalnya eksperimen bias melibatkan dua kategori atau dua
tingkatan dari satu faktor, tiga kategori dari faktor yang kedua, 5 kategori atau lima
tingkat dari faktor yang ketiga, dengan sejumlah n subjek yang ditarik secara acak
dari masing-masing 2x3x5 kelompok eksperimen tersebut. Ekperimen seperti itu
dikenal dengan nama ‘2x3x5 faktorial eksperimen’. Data yang diperoleh dari
eksperimen seperti itu dapat dikonseptualisasikan sebagai kubus bertiga dimensi, yang
terdiri dari 2 baris, 3 kolom dan 5 lapis, dengan masing-masing n subjek dari 30 sel
yang berbeda dalam eksperimen tersebut.
Analisis dan interpretasi dari data yang dihasilkan dari eksperimen seperti itu adalah
merupakan perluasan langsung dari analisis dan interpretasi dari klasifikasi dua arah.
Dalam suatu eksperimen dua-faktor dengan n subjek dalam setiap sel, jumlah kuadrat
total terbagi dalam empat bagian, yaitu: jumlah kuadrat antar baris, jumlah kuadrat
antar kolom, jumlah kuadrat interaksi dan jumlah kuadrat sel dalam. Setiap jumlah
kuadrat mempunyai sebuah angka yang menjadi angka derajat kebebasan. Jumlah
atau rata-rata kuadrat yang digunakan untuk menguji signifikansi pengaruh utama dan
interaksi.
Umpamakan sejumlah eksperimen yang melibatkan sejumlah R tingkatan dari faktor
pertama, sejumlah C tingkatan dari faktor kedua, dan sejumlah L tingkatan dari faktor
ketiga. Jumlah sel menjadi sebanyak RxCxL yang disingkat menjadi RCL. Misalkan
khusus dalam kasus ini kita mempunyai satu alat pengukuran untuk setiap kombinasi
RCL, jumlah total hasil pengukuran menjadi N. data untuk lapis pertama dari
angka-angka hasil pengukuran itu dapat dituliskan sebagai berikut:
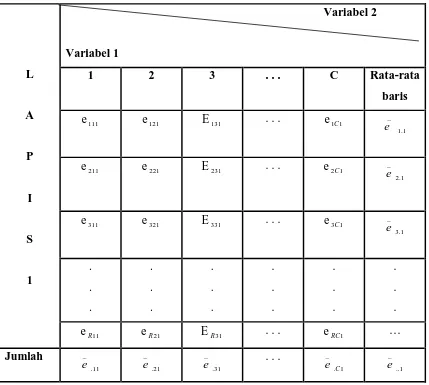
Tabel 2.1 Tabel Data Untuk Lapis Pertama
Dalam subskrip di atas diidentifikasikan, yang pertama sebagai baris, yang kedua
sebagai kolom dan yang ketiga sebagai lapis. Dengan demikian, misalnya e321
menunjukkan observasi pada baris ketiga kolom kedua dari lapis pertama.
_
e .11 adalah
rata-rata dari kolom pertama dari lapis petama, sedang
_
e ..1rata-rata dari semua
observasi yang ada pada lapis pertama.
Adapun notasi pada lapis kedua adalah sebagai berikut:
Tabel 2.2 Tabel Data Untuk Lapis Kedua
Demikian juga halnya dapat ditunjukkan lapis yang ketiga, keempat sampai lapis yang
ke-L. secara umum erc1 menunjukkan yang menunjukkan hasil pengukuran baris yang
ke-r, pada kolom yang ke-c dan pada baris yang ke-1.harus dipahami bahwa R
menunjukkan angka dari baris, C merupakan angka dari kolom dan L merupakan
angka dari lapis. Jumlah r menunjukkan baris yang ke-r, dimana r bias saja berupa
angka 1, 2,…R. demikian juga dengan c dan 1 menunjukkan kolom yang ke c dan
lapis yang ke-1.
Rata-rata dari semua RCL= N adalah ...
_
Χ jumlah kuadrat simpangan total dari
rata-rata umum tadi dapat dituliskan:
2
1 1 1
...)
(Xrcl X
L
l C
c R
r
−
∑
∑
∑
= = =2.2 Analisis Berdasarkan Tabel IxJxK
Berdasarkan data trivariat (V1, V2,V3) dengan berbagai skala ukuran, selalu dapat
dibentuk tabel berdimensi tiga, termasuk tabel 2x2x2. Dengan sendirinya langkah
pertama yang harus dilakukan adalah mentransformasikan atau mengubah ketiga
variabel yang ditinjau menjadi variabel kategorik, berdasarkan kriteria yang
disepakati atau ditentukan.
Disini akan diperhatikan tiga variabel satu-nol, dimana simbol Y dipakai untuk
menyatakan variabel tak bebas atau variabel respon dan kedua variabel lainnya
sebagai variabel bebas yang akan dinyatakan dengan simbol X1 dan X2. Penentuan
variabel tak bebas dan variabel bebas diantara komponen trivariat (V1,V2,V3)
haruslah didukung oleh landasan teori dan substansi, karena pola asosiasi antar
variabel ditentukan secara teoritis. Dipihak lain, secara statistik koefisien asosiasi atau
korelasi antara variabel selalu dapat dihitung walaupun variabel tersebut tidak
berasosiasi secara substansi. Sehingga, analisis statistika berdasarkan data trivariat
statistik yang sesuai dengan pola hubungan teoritis antar ketiga variabel yang ditinjau,
yang akan disebut model teoritis.
2.3 Ukuran Asosiasi Berdasarkan Tabel 2x2x2
2.3.1 Selisih Prevalensi atau Proporsi Bersyarat
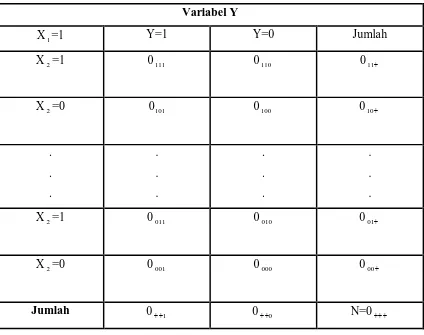
Tabel berikut menunjukkan suatu bentuk tabel 2x2x2. tabel ini menyajikan banyaknya
observasi menurut variabel X1,X2 dan Y yang masing-masing merupakan variabel
satu- nol. Perhatikanlah tabel ini mempunyai empat buah baris dan dua buah kolom
dan banyaknya observasi dalam tiap-tiap sel dinyatakan dengan simbol Oijk untuk
setiap i, j dan k sama dengan satu atau nol
Tabel 2.3 Banyaknya Responden Menurut Variabel X1, X2 dan X3
Variabel Y
X1=1 Y=1 Y=0 Jumlah
X2=1 0111 0110 011+
X2=0 0101 0100 010+
.
.
.
.
.
.
.
.
.
.
.
.
X2=1 0011 0010 001+
X2=0 0001 0000 000+
Sebenarnya tabel ini menggambarkan ruang bedimensi –tiga (kubus) dengan sumbu
X1, X2 dan Y, yang dibagi menjadi 8 (2x2x2) buah kubus kecil yang membentuk
delapan buah sel yang dikemukakan di atas.
2.4 Model Log Linier
Dalam kategorik bivariat dimana diperoleh nilai statistik Chi-kuadrat dari pearson
(Pearson Chi-Kuadrat) dan Rasio Kesamaan. Akan tetapi untuk mempelajari pola
asosiasi ganda berdasarkan data trivariat atau lebih harus diterapkan Model Log
Linier, terlebih-lebih jika model yang ditinjau secara teoritis menunjukkan hubungan
antara demikian banyaknya variabel. Model statistik Model Log Linier akan dipakai
untuk mempelajari apakah data sampel yang akan dipakai mendukung atau tidak
mendukung model asosiasi ganda yang dihipotesiskan dinyatakan atau diasumsikan
berlaku untuk ketiga variabel yang ditinjau.
Analisis yang lebih terinci mengenai tabel kontingensi tiga dimensi atau yang
biasanya menggunakan pengujian pasangan yang tidak sederhana dari kebebasan yang
dapat dilakukan pada bagian-bagian dari tabel-tabel dua arah. Sejumlah besar dari
model-model yang berbeda adalah mungkin dan teknik analitik yang modern sering
didasarkan pada model log-linier. Dalam sebuah buku dasar-dasar statistik, hal ini
cocok hanya untuk memberikan pengenalan singkat untuk model dan pengujian, dan
dijelaskan dengan satu contoh sederhana. Teknik-teknik analitik adalah data diskrit
yang analog dengan analisis varians untuk data kontinu. Pembaca yang belum kenal
dengan analisis varians model linier untuk rancangan percobaan dengan struktur
percobaan faktorial mungkin sulit untuk mengikuti bagian ini, tetapi diharapkan
sebuah penjelasan yang mendasar akan memberikan beberapa indikasi tentang
kekuatan model linier sebagai sebuah alat analitik. Penerapan yang lebih sulit dari
metode ini membutuhkan pengetahuan yang luas mengenai statistik dan tersedianya
program komputer yang cocok.
Misalkan {mijk} merupakan frekuensi harapan, dugalah semua mijk>0 dan misalkan
ijk ijk =logm
η . Tanda dot dibawah merupakan rata-rata, seperti: η.jk =(
∑
iηijk)/I...
Jumlah semua parameter di atas sama dengan nol, yaitu:
∑
=∑
=∑
=∑
=∑
= =∑
=Sehingga bentuk umum model log linier untuk tabel kontingensi tiga dimensi, adalah:
XYZ
Dalam hal pengujian ini juga sama dengan analisis variansi tiga dimensi.
Beberapa model log linier untuk tabel tiga dimensi:
Model log-linier simbol
Z
log (XY,YZ,XZ)
Untuk menunjukkan model log-linier kita cari bentuk marginal dan partialnya dengan
Dengan k dalam Z, hubungan odds ratiosnya:
k
Menunjukkan hubungan X-Y. Sama halnya antara X dan Y didapatkan dari (I-1)(K-1)
Odds ratios {θi(j)k}untuk setiap J pada Y, dan hubungan antara Y dan Z didapatkan
dari (J-1)(K-1) odds ratios {θ(i)jk} untuk setiap I pada X.
Untuk tabel tiga dimensi logmijkdalam log odds ratios, didapat:
ratios antara dua variabel sama dengan tiga variabel. Bentuk umumnya
}
Seperti dalam kasus dua dimensi parameternya sebanding pada log odds ratios. Model
Log linier dapat dikenal dengan menggunakan hubungan odds ratios. Dalam hal
hubungan independent antara X dan Y equivalent terhadap
Kenudian kita berikan satu keadaan yang cukup terhadap X-Y odds ratios menjadi
sama dalam tabel parsial seperti pada tabel marginal. Ketika keadaan sama kita dapat
mempelajari gabungan X-Y dengan cara menyederhanakan menyelesaikan dimensi Z.
selanjutnya, Z akan menjadi variabel tunggal atau multidimensi.
)
Dengan kata lain, gabungan marginal da parsial X-Y disamakan jika Z dan X bebas
(i.e, disimbolkan dengan (XY,YZ)terikat), atau jika Z danY bebas (i.e, bentuknya
(XY,XZ)terikat)
2.4.1 Penerapan Model Log Linier Data Trivariat
Dalam sebuah tabel kontingensi dua dimensi, nilai harapan e untuk sel ij dengan ij
hipotesis kebebasan atau tidak ada asosiasi adalah eij=
N
diagonal adalah sama, atau
1
Sifat perkalian dan harapan untuk kebebasan ini dapat dibandingkan dengan sifat
harapan aditif bila tidak ada interaksi dalam model liniernya. Sebenarnya ada
kesamaan model-model jika kita mengambil logaritma eij dan menulis x lneij
~
= ini
1
adalah sebuah kondisi yang diperlukan untuk kebebasan, maka selanjutnya
setiap hipotesis yang menyebutkan ketergantungan menyatakan sebuah hubungan
yang lebih umum
1
Dengan mengambil logaritmanya kita mempunyai analog model yang berinteraksi.
Perluasan untuk tabel tiga dimensi, modelnya dapat diperluas untuk tabel r x c dan
lebih penting untuk tabel multi arah. Pertama, kita membuat perluasan dari model
linier untuk tiga faktor masing-masing dengan dua level dalam konteks analisis
varians. Pengukuran interaksi telah diperkenalkan dalam model dua faktor yang
disebut sebuah orde pertama atau kadang-kadang disebut sebuah interaksi dua faktor.
Jika kita mempunyai tiga faktor masing-masing pada dua level, kita dapat menyajikan
hasil yang diharapkan dalam sebuah perluasan yang jelas dari notasi xijk
~
i, j, k = 1,2 .
Jika kita mempertimbangkan dua faktor pertama pada level pertama dari faktor ketiga
(ditunjukkan dengan k=1) kita akan mempunyai sebuah interaksi pertama antara
faktor 1 dan faktor 2 pada level tetap faktor 3 ini jika x111+x221−x121−x211 =Ι,Ι≠0
sebagai tambahan, jika kita mempunyai sebuah interaksi orde pertama antara faktor 1
dan faktor 2 pada level kedua dari faktor 3 ( k= 2 ), ini menyatakan
~
x 212= J, J=0. jika I≠J kita katakana tidak ada interaksi orde kedua antara ketiga
faktor. Jika I≠J kita katakan tidak ada sebuah interaksi orde kedua atau orde
ketiga. Jika I= J= 0 mempunyai model tidak ada interaksi. Dalam konteks dari model
log-linier dimana kita tulis
~
x ijk=lneijk dimana eijk adalah harapan untuk level ke-i
klasifikasi 1, untuk level ke-j klasifikasi 2, untuk level ke-k klasifikasi 3, model
dengan tidak ada interaksi berhubungan dengan kebebasan dan eijk menjadi:
Ketergantungan dapat menjadi orde pertama atau kedua (ditunjukkan untuk interaksi
orde pertama atau kedua dalam model log-linier). Untuk interaksi model pertama:
k
Model log-linier mengizinkan pengujian untuk menentukan apakah data dapat
menjadi cocok digambarkan oleh beberapa model tertentu. Untuk contoh ilustrasi, kita
mengikuti prosedur yang relevan untuk pengujian model interaksi orde pertama.
Dalam kasus dalam sebuah tabel kontingensi tiga dimensi, penduga maksimum
likelihood darieijk, yang akan dinotasikan dengan
^
e ijk harus memenuhi kondisi:
(ẽ111ẽ221)/(ẽ121ẽ211)= (ẽ112ẽ222)/(ẽ122ẽ212)
Dengan batasan bahwa
^
e ijk harus juga jumlah untuk total marginal yang diamati
setiap akhiran. Pada umumnya, penduga maksimum likelihood hanya dapat diperoleh
dengan metode yang berulang-ulang( salah satunya dikenal dengan iterative scaling
procedure); akan tetapi dalam kasus khusus dari tabel tiga dimensi dengan model
interaksi orde pertama, perhitungan pertama adalah langsung. Sekali
^
e ijk telah
dihitung, statistik T atau T1untuk tabel tiga dimensi digunakan untuk pengujian nyata.
T1sering lebih disukai karena dari sifat aditif tertentu yang memungkinkan terbagi
kedalam komponen-komponen, analog dengan cara yang dilakukan untuk jumlah
kuadrat orthogonal dalam analisis varians.
Suatu penelitian yang meneliti tiga faktor ( X, Y dan Z ) yang masing-masing
tingkatan dan faktor Z dalam z tingkatan. Percobaan tersebut merupakan percobaan
faktorial xxyxz. Dengan demikian banyak perlakuan yang dicobakan adalah t=xyz.
Andaikan bahwa tiap perlakuan diulang dengan ulangan yang sama sebanyak n
(ukuran contohnya n). tentu saja pada percobaan demikian, data yang diperoleh akan
beragam yang dapat dikaitkan dengan tingkat masing-masing faktornya. Dengan
demikian dapat dituliskan:
ijkl
X pengamatan ke 1 (1=1,2,…,n) untuk faktor X yang ke i (i=1,2,…,n), faktor Y
yang ke j (j=1,2,…,b), dan faktor z yang ke k (k=1,2,…,c)
ε sesatan pengamatan yang bersangkutan
Penduga masing-masing komponen dalam model di atas diduga dengan cara yang
sama seperti yang sudah biasa dilakukan. Penduga yang didapat adalah:
( )ij =
Berbagai penduga ini dengan mudah dapat kita peroleh apabila kita lihat pola untuk
mendapatkannya. Penduga pengaruh suatu tingkat suatu faktor merupakan selisih
antara rerata tingkat faktor tersebut dengan rata-rata keseluruhan data. Perhatikan
notasinya yang ternyata berupa satu indeks saja yang lainnya titik ( i atau j atau k saja,
yang lainnya berupa titik) dan pengurangnya mempunyai indeks yang berupa titik
semua. Pada interaksi dua faktor, penduganya didapat dengan jalan mengurangi
rata-rata gabungan tingkat kedua faktornya dengan rata-rata-rata-rata tingkat masing-masing faktor
dan kemudian ditambah dengan rata-rata keseluruhan data. Menyimak indeksnya,
penduga interaksi dua faktor ini didapat dengan jalan mengurangi rata-rata yang
berindeks dua ( i dan j, i dan k, atau j dan k sedangkan lainnya berupa titik) dengan
rata-rata yang berindeks satu yang persis dengan indeks duanya dan kemudian
ditambah rata-rata keseluruhan data yang semua indeksnya berupa titik.
Seperti halnya dengan analisis varian yang terdahulu, berbagai jumlah kuadrat didapat
tidak dengan menggunakan berbagai penduga diatas tetapi dalam bentuk yang telah
disederhanakan terlebih dahulu. Untuk jumlah kuadrat X
Karena ...
perhatikan bahwa JKX didapat dengan menjumlahkan kuadrat jumlah masing-masing
tingkat faktor X (dijumlah terhadap i) yang dibagi dengan sesuatu yang besarnya
sama dengan batas indeks yang berubah menjadi titik. Dalam hal ini indeks yang
berubah menjadi titik adalah j, k, dan l yang mempunyai batas nilai y, z dan n.
perhatikan bahwa rumus untuk jumlah kuadrat ini bertalian dengan rumus untuk
penduganya. Penduga untuk pengaruh X yang ke i adalah rata-rata dengan indeks i (
yang lainnya berupa titik) dikurangi dengan rata-rata dengan semua indeksnya berupa
titik rumus JKX juga mempunyai indeks i yang dikurangi dengan sesuatu yang tanpa
indeks, yaitu FK. Maka dengan mudah diperoleh JKY dan JKZ, sebagai berikut:
JKY = FK
Sekarang akan kita lihat bagaimana penyederhanaan jumlah kuadrat interaksi dua
faktor. Kita akan simak terlebih untuk interaksi antara X dan Y:
JKXY = 2
Yang apabila disederhanakan akan diperoleh:
Dalam kaitannya dengan rumus untuk penduganya, lihat keterkaitan antara rumus
penduga dan jumlah kuadrat suatu komponen. Rumus penduga komponen interaksi
XY didapat dengan mengurangi rata-rata berindeks dua ( yaitu i dan j untuk X dan Y)
dengan rata-rata berindeks satu untuk X dan berideks satu untuk Y, dan akhirnya
ditambah dengan rata-rata yang semua indeksnya berupa titik ( tidak berindeks).
Penyederhanaan lebih lanjut akan menghasilkan:
JKXY = FK JKX JKY
Perhatikan bahwa jumlah kuadrat interaksi X dan Y didapat dengan menjumlahkan
semua jumlah pada kombinasi X dan Y yang dibagi dengan sesuatu yang merupakan
nilai batas indeks yang berupa titik dalam hal ini indeks yang berupa titik adalah
untuk k dan l yang mempunyai batas z dan n sehingga sebagai pembagi adalah zn,
dikurangi dengan faktor koreksi dan dikurangi lagi dengan jumlah kuadrat
faktor-faktor yang menyusun interaksinya.
Jumlah kuadrat interaksi tiga faktornya didapat dari:
JKXYZ = 2
Yang apabila disederhanakan akan menghasilkan:
JKXYZ =
Derajat bebas berbagai jumlah kuadrat diatas dapat dengan mudah diperoleh dengan
memperhatikan beberapa kali pengkuadratan yang kita jumlahkan dan kurangkan.
sekali untuk memperoleh faktor koreksi yang kemudian kita gunakan untuk
mengurangi. Dengan demikian derajat bebas X adalah ( x-1). Analogi dengan X
adalah untuk Y dan Z.
Untuk interaksi dua faktor, XY misalnya kita mengkuadratkan sebanyak xy kali yang
kemudian kita jumlahkan, kemudian dikurangi dengan FK (yang diperoleh dengan
sekali mengkuadratkan) dan dikurangi lagi dengan JKX dan JKB yang mempunyai
derajat bebas (x-1) dan (y-1). Dengan demikian derajat bebas XY adalah:
xy-1-(x-1)-(y-1)=(x-1)(y-1)
dengan cara yang sama kita dapatkan bahwa interaksi XZ mempunyai derajat bebas
(x-1)(z-1) dan interaksi YZ mempunyai derajat bebas (y-1)(z-1). Derajat bebas
interaksi tiga faktor XY pun diperoleh dengan cara yang sama. Suku pertama pada
rumus jumlah kuadrat XYZ menunjukkan bahwa kita harus mengkuadratkan xyz kali,
sedangkan derajat bebas suku-suku pengurangannya telah kita ketahui. Dengan
demikian derajat bebas untuk interaksi XYZ adalah:
xyz-1-(x-1)(y-1)-(x-1)(z-1)-(y-1)(z-1)-(x-1)-(y-1)-(z-1) yang telah disederhanakan
akan berubah menjadi (x-1)(y-1)(z-1)
BAB III
PEMBAHASAN
Suatu penelitian yang meneliti tiga faktor ( X, Y dan Z ) yang masing-masing
dicobakan dalam berbagai tingkatan. Faktor X dalam x tingkatan, faktor Y dalam y
tingkatan dan faktor Z dalam z tingkatan. Percobaan tersebut merupakan percobaan
faktorial xxyxz. Dengan demikian banyak perlakuan yang dicobakan adalah t=xyz.
Andaikan bahwa tiap perlakuan diulang dengan ulangan yang sama sebanyak n
(ukuran contohnya n). tentu saja pada percobaan demikian, data yang diperoleh akan
beragam yang dapat dikaitkan dengan tingkat masing-masing faktornya.
3.1 Kasus
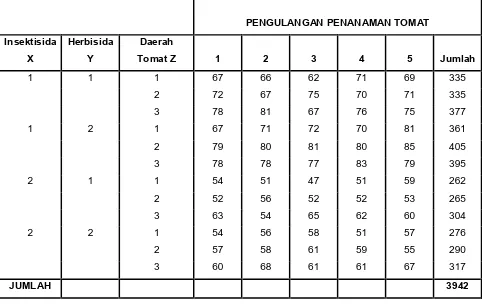
Tabel 3.1 Hasil pengujian efisiensi pemakaian insektisida dan herbisida pada
daerah pertanaman tomat.
PENGULANGAN PENANAMAN TOMAT Insektisida
X
Herbisida Y
Daerah
Tomat Z 1 2 3 4 5 Jumlah
1 1 1 67 66 62 71 69 335
2 72 67 75 70 71 335
3 78 81 67 76 75 377
1 2 1 67 71 72 70 81 361
2 79 80 81 80 85 405
3 78 78 77 83 79 395
2 1 1 54 51 47 51 59 262
2 52 56 52 52 53 265
3 63 54 65 62 60 304
2 2 1 54 56 58 51 57 276
2 57 58 61 59 55 290
3 60 68 61 61 67 317
3.2 Pembahasan Contoh Kasus
Dengan menggunakan tabel anava maka dapat dilihat model log linier dengan
menggunakan langkah-langkah perhitungan sbb:
Menentukan hipotesis:
k
Dengan tingkat signifikansi 5%
H0 ditolak jika Fhit > F0,05;k−1,K(b−1)
Kemudian pecahlah JK sesatan ini atas berbagai jumlah kuadrat faktor-faktornya dan
interaksi-interaksinya. Untuk keperluan ini buatlah tabel penolong, yaitu tabel
klassifikasi dua arah: insektisida dan herbisida , insektisida dengan daerah tomat, dan
herbisida dengan daerah tomat. Mulailah dengan membuat tabel klasifikasi dua arah
insektisida dengan herbisida dengan jalan menjumlah semua data yang berada pada
masing-masing kombinasi tingkatan insektisida dan herbisida.
Tabel 3.2 Klasifikasi dua arah Antara Insektisida dengan Herbisida
Insektisida Herbisida (Y) Jumlah
(X) 1 2 Xi...
1 1067 1161 2228
2 831 883 1714
Jumlah X. j.. 1898 2044 3942
Kemudian hitung JK masing-masing faktor dan JK interaksinya.
JKX = + −FK
) 5 )( 3 ( 2
1714
22282 2
= 263392,7-258989,4
= 4403,3
JKY = + −FK
) 5 )( 3 ( 2
2044
18982 2
= 259344,7-258989,4
= 355,3
Sedangkan jumlah kuadrat interaksinya:
JKXY = + + + −FK−JKX −JKY
) 5 )( 3 (
883 831
1161
10672 2 2 2
= 263777,3- 258989,4- 4403,3-355,3
= 29,3
Karena tabel penolong berbentuk tabel 2x2, maka dapat dihitung berbagai jumlah
JKX =
Sedangkan jumlah kuadrat interaksinya:
JKXY =
Yang bertindak sebagai pembagi untuk berbagai jumlah kuadrat di atas, baik suatu
faktor maupun interaksi, selalu sama ialah banyak data yang ada. Kemudian bentuklah
tabel dua klasifikasi antara insektisida dan herbisida dengan daerah tomat.
Tabel 3.3 Klasifikasi antara insektisida dan Herbisida dengan Daerah Tomat
Insektisida Daerah Tomat (Z) Jumlah
(X) 1 2 3 X i..
1 696 760 772 2228
2 538 555 621 1714
Jumlah X..k. 1234 1315 1393 3942
Seperti halnya dengan tabel penolong sebelumnya, maka akan diperoleh jumlah
kuadrat faktor-faktor klasifikasi ( insektisida pada daerah Tomat) dan interaksinya.
sebelumnya, maka yang dihitung hanya jumlah kuadrat daerah tomat dan jumlah
kuadrat interaksi saja.
JKZ = + + −FK
) 5 )( 2 ( 2
1393 1315
12342 2 2
= 259621,5 – 258989,4
= 632
Sedangkan jumlah kuadrat interaksinya:
JKXZ = + + + −FK−JKX −JKZ
) 5 )( 2 (
621 ... 760
6922 2 2
= 264111,0- 258989,4- 4403,0- 632,1
= 86,2
Yang terakhir buatlah tabel penolong yang merupakan klasifikasi dua arah, yaitu
berdasarkan herbisida dan daerah tomat.
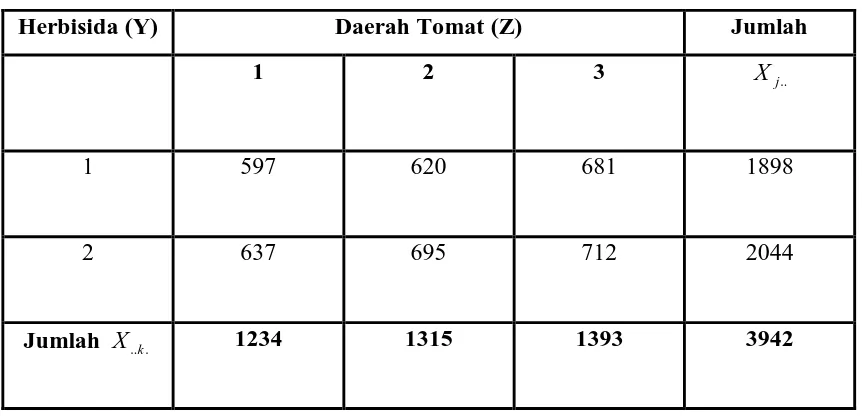
Tabel 3.4 Klasifikasi Dua Arah Berdasarkan Herbisida dan Daerah Tomat
Herbisida (Y) Daerah Tomat (Z) Jumlah
1 2 3 Xj..
1 597 620 681 1898
2 637 695 712 2044
Jumlah X..k. 1234 1315 1393 3942
Karena jumlah kuadrat untuk herbisida dan jumlah kuadrat daerah tomat sudah
dihitung dengan menggunakan dua tabel penolong sebelumnya, maka dari tabel ini
JKYZ = + + + −FK −JKY −JKC
) 5 )( 2 (
712 ... 620
5972 2 2
= 260030,8- 258989,4- 355,3- 632,1
=54,0
Dengan demikian jumlah kuadrat interaksi tiga faktor dapat dihitung dengan jalan
mengurangkan semua jumlah kuadrat masing-masing faktor jumlah kuadrat interaksi
dua faktor ke jumlah kuadrat perlakuan:\
JKXYZ = JK Perlakuan- JKX- JKY- JKZ-JKXY- JKXZ-JKYZ
= 5570,6- 4403,3- 355,3- 632,1-86,2-293- 54,0
= 10,4
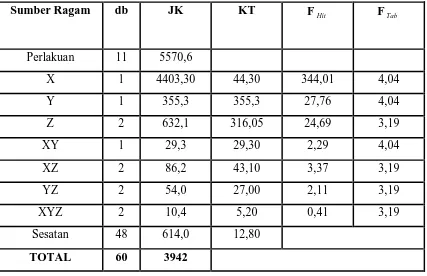
Dengan demikian dapat juga kita susun tabel anavanya:
Tabel 3.5 Tabel Anava
Sumber Ragam db JK KT FHit FTab
Perlakuan 11 5570,6
X 1 4403,30 44,30 344,01 4,04
Y 1 355,3 355,3 27,76 4,04
Z 2 632,1 316,05 24,69 3,19
XY 1 29,3 29,30 2,29 4,04
XZ 2 86,2 43,10 3,37 3,19
YZ 2 54,0 27,00 2,11 3,19
XYZ 2 10,4 5,20 0,41 3,19
Sesatan 48 614,0 12,80
BAB IV
PENUTUP
4.1 Kesimpulan
1. Perhitungan-perhitungan dalam tabel anava dengan jelas menunjukkan
model log linier yaitu hubungan antar variabel yang satu dengan variabel
lainnya.
2. Untuk menyelesaikan persoalan dalam bentuk data, penggunaan tabel
kontingensi akan sangat membantu karena dari tabel tersebut dapat dilihat
hubungan antar variabel-variabelnya.
3. Hasil analisis menunjukkan herbisida tidak berinteraksi baik dengan
insektisida maupun dengan daerah pertanaman tomat dan menunjukkan
pengaruh yang nyata. Jadi di daerah pertanaman tomat mana saja,
herbisida 2 menunjukkan efisiensi yang lebih tinggi dibandingkan dengan
herbisida 1, baik dengan insektisida 1 maupun insektisida 2. Sedangkan
insektisida berinteraksi dengan daerah pertanaman tomat. Ini berarti bahwa
efisiensi insektisida tergantung pada daerah pertanaman tomatnya.
Pengujian pengaruh insektisida menunjukkan hasil yang signifikan
4. Penggunaan insektisida 1 memberikan hasil yang kurang lebih setara pada
daerah pertanaman Tomat 2 dan 3, yang lebih baik daripada daerah hasil
pertanaman tomat 3. namun dengan insektisida 2, hasilnya pada daerah
pertanaman 1 dan 2 kurang lebih serupa, tetapi lebih rendah dari hasil pada
daerah pertanaman 3. Seandainya pengujian pengaruh insektisida
menunjukkan hasil yang tidak nyata, interaksi insektisida dengan daerah
pertanaman tomat merupakan petunjuk bahwa penggunaan insektisida
memberikan pengaruh, hanya pengaruhnya tergantung pada daerah
pertanaman tomatnya seperti yang telah diuraikan. Jadi, apabila interaksi
menunjukkan hasil yang nyata, tidak perlu melihat pada hasil pengujian
4.2 Saran
1. Untuk menggunakan insektisida dan herbisida petani hendaknya terlebih
dahulu melihat keadaan lahan apakah cocok digunakan insektisida maupun
herbisida.
2. Petani lebih baik menggunakan insektisida daripada herbisida karena
DAFTAR PUSTAKA
Agresti, Alan (1990), Categorical Data Analysis, John Wiley & Sons, Inc.,
Canada
Adbul Syani. 1995. Pengantar Metode Statistik Non Parametrik. Jakarta:
Pustaka Jaya
Pearson E.S dan H.O. Hartley. 1970. Biometrical Tables for Statisticians.
Vol. I. Cambridge University Press.
Pollet. A, Nasrullah. Penggunaan Statistika Untuk Ilmu Hayati.
Yogyakarta: UGM-Press
Rahman Ritonga. A. 1997. Statistika Untuk Penelitian Psikologi dan
Pendidikan. FE-UI
Saleh Samsubar. 1990. Statistik Non Parametrik. Jakarta
Sprent. P. 1991. Metode Statistik Nonparametrik Terapan.
Jakarta:UI-Press.
Sudjana.1992. Metoda Statistika. Bandung: Tarsito
Suparman, I.A., M.Sc.1990. Statistik Sosial. Jakarta: Rajawali Press