Fixed-Slope Universal Lossy Data Compression
En-hui Yang, Zhen Zhang,
Senior Member, IEEE, and Toby Berger,
Fellow, IEEEAbstract—Corresponding to any lossless codeword length
func-tion l, three universal lossy data compression schemes are pre-sented: one is with fixed rate, another is with fixed distor-tion, and a third is with fixed slope. The former two universal lossy data compression schemes are the generalization of recent Yang–Kieffer’s results to the general case of any lossless codeword length function l, whereas the third is new. In the case of fixed-slope > 0, our universal lossy data compression scheme works as follows: for any source sequencexn of length n, the encoder first searches for a reproduction sequenceynof lengthn which minimizes a cost function n01l(yn) + n(xn; yn) over all reproduction sequences of length n, and then encodes xn into the binary codeword of length l(yn) associated with yn via the lossless codeword length function l, where n(xn; yn)
is the distortion per sample between xn and yn. Under some mild assumptions on the lossless codeword length function l, it is shown that when this fixed-slope data compression scheme is applied to encode a stationary, ergodic source, the resulting encoding rate per sample and the distortion per sample converge with probability one toRandD, respectively, where(D; R)
is the point on the rate distortion curve at which the slope of the rate distortion function is0. This result holds particularly for the arithmetic codeword length function and Lempel–Ziv codeword length function. The main advantage of this slope universal lossy data compression scheme over the fixed-rate (fixed-distortion) universal lossy data compression scheme lies in the fact that it converts the encoding problem to a search problem through a trellis and then permits one to use some sequential search algorithms to implement it. Simulation results show that this fixed-slope universal lossy data compression scheme, combined with a suitable search algorithm, is promising.
Index Terms—Arithmetic code, distortion rate (rate distortion)
function, ergodic sources, fixed-slope universal source coding, Lempel–Ziv code, search algorithms, stationary, universal lossy data compression.
I. INTRODUCTION
I
T has long been recognized that rate distortion theory [1], [16] in principle provides a theoretical basis for many practically important data compression problems. So far, how-ever, the theory has not yet yielded such profound impact on practice as one might conceive. The limitation on the use of the theory lies in two difficulties: one is that it isManuscript received May 26, 1996; revised February 10, 1997. This work was supported in part by National Science Foundation under Grants NCR-9508282, NCR-9216975, and IRI-9310670. The material in this paper was presented in part at the International Symposium on Information Theory, Whistler, BC, Canada, September 1995.
E.-h. Yang is with the Department of Mathematics, Nan’kai University, Tianjin 300071, P. R. China.
Z. Zhang is with the Department of Electrical Engineering-Systems, Com-munication Sciences Institute, University of Southern California, Los Angeles, CA 90089-2565 USA.
T. Berger is with the School of Electrical Engineering, Engineering Theory Center Building, Cornell University, Ithaca, NY 14853 USA.
Publisher Item Identifier S 0018-9448(97)05015-3.
often very hard to construct suitable and analytically tractable source models for real-world problems; and the other is that no coding algorithms are known to approach asymptotically the rate-distortion limit with low coding complexity. Although universal lossy source coding theory [5] is probably a way to overcome the first difficulty, this theory says much about the existence of universal lossy codes and provides no universal lossy data compression algorithms which are implementable with low complexity.
Yet, in recent years, there has been some progresses beyond the existence proof of universal lossy codes in universal lossy source coding theory. Ziv [30] presented a universal lossy algorithm for coding at a fixed rate level. Ornstein and Shields [13] and Yang [22] each exhibited a universal lossy algorithm for coding at a fixed distortion level; the algorithm of the former authors is based upon empirical types, whereas that of the latter author uses Kolmogorov complexity. These algorithms, however, are still far from being implementable in real time. It is time to construct universal lossy algorithms with low coding complexity.
Recently, attempts have been made to construct universal lossy algorithms with low coding complexity. Cheung and Wei [2] and Yamamoto and Rimoldi [21] extended the move to front algorithm to the lossy case. Morita and Kobayashi [10] proposed a lossy Lempel–Ziv algorithm. Making use of a long training sequence, Steinberg and Gutman [19] proposed a lossy algorithm by extending the method of string matching to the lossy case. Unfortunately, it turns out [25] that all these algorithms are suboptimal. Zhang and Wei [28] devised an algorithm for adaptively changing codebooks which was proved optimal in [29] for stationary, -mixing sources. Based upon the lossless Lempel–Ziv algorithm, Yang and Kieffer [24] recently derived two universal lossy source coding schemes: one for the fixed-rate case and one for the fixed-distortion case, and proved that both schemes are asymptotically optimal for stationary, ergodic sources and for individual sequences.
Following the same line as in [24], in this paper we present three universal lossy data compression schemes, one for the fixed-rate case, one for the fixed-distortion case, and one for the fixed-slope case, based upon any given lossless codeword length function, such as the arithmetic codeword length function and Lempel–Ziv codeword length function. The fixed-rate (fixed-distortion) universal lossy data compression scheme is the extension of the corresponding Yang and Kieffer’s result to the general case of any lossless codeword length function. The fixed-slope universal lossy data compression scheme is new. For any , the fixed-slope universal lossy data compression scheme works as follows: for any source sequence of length , the encoder first
searches for a reproduction sequence of length which minimizes a cost function over all reproduction sequences of length , where is the length of the binary codeword associated with via the lossless codeword length function and is the distortion per sample between and , and then encodes into the binary codeword associated with via the lossless codeword length function. After receiving the binary codeword, the decoder can completely recover and outputs as a reproduction sequence of . In this way, the resulting rate in bits per sample is and the resulting distortion per sample is . It will be shown later in the paper that when this fixed-slope universal lossy data compression scheme is used to encode a stationary, ergodic source, under some mild conditions, the resulting rate in bits per sample and the distortion per sample converge with probability one to and , respectively, where is the point on the rate distortion curve at which the slope of the rate distortion function is .
The motivation for us to consider the fixed-slope universal lossy data compression scheme mentioned above is as follows. The fixed-rate universal lossy data compression scheme given in [24] first picks a codebook consisting of all reproduction sequences of length whose Lempel–Ziv codeword length is , and then uses to encode the entire source sequence -block by -block. Although this fixed-rate encoding scheme is very simple conceptually, at present there is no easy way to implement it. The difficulty lies in the fact that the codebook has not yet been found to have well-behaved structure and the corresponding encoding process may involve a search over a set which grows exponentially in the number of source samples. (As indicated in [24], the codebook might have some kind of tree structure; so far, however, this point is not clear.) On the other hand, the fixed-slope universal encoding scheme mentioned above employs no codebook and converts an encoding problem into a search problem through a trellis. More precisely, let be a source alphabet and a reproduction alphabet. Let be a single-letter fidelity criterion based on these alphabets. Assume is finite. Then can be thought of as a trellis of length
with state set . The main task in the encoding process of the fixed-slope universal encoding scheme is to search for a reproduction sequence which minimizes the cost function over . This kind of feature of the fixed-slope universal encoding scheme permits us to use some sequential search algorithms to perform the encoding job. Actually, later in the paper we shall study the -algorithm. Simulation results for binary sources and for arithmetic codeword length functions show that this fixed-slope universal lossy data compression scheme, combined with suitable search algorithms, might be implementable in practice. This paper is organized as follows. In Section II we develop, in general, the fixed-slope approach in source coding theory as an alternative to the traditional rate approach and fixed-distortion approach in source coding theory with a fidelity criterion [5]. Section III is devoted to formal descriptions of our fixed-rate and fixed-distortion universal data compression schemes, respectively, which are based upon any given lossless
codeword length function. Section IV is devoted to the formal descriptions of our fixed-slope universal data compression scheme and its optimality proof. In Section V we study the
-algorithm, and present some simulation results.
II. FIXED-SLOPE SOURCE CODING
Let be an abstract alphabet and a finite alphabet. The sets and will serve as our source alphabet and reproduction alphabet, respectively. Let be a -field of subsets of , and let be the -field consisting of all subsets of . Let the measurable space
be the infinite Cartesian product of exemplars of the measurable space . The measurable space
is defined similarly. If is a finite or infinite sequence of symbols from or (or of random variables taking their values in these sets), let and for simplicity, write as . We denote the set of all -tuples
drawn from by .
For the purpose of this paper, an information source is a stationary, ergodic process taking values in the source alphabet . If is the shift transformation on defined by , , then can also be regarded as an ergodic, -preserved measure on . Let be a measurable function. Let be the single-letter fidelity criterion generated by , by which
we mean that for each , is
the map in which
for any and . For any stationary, ergodic source , let and denote the rate-distortion function and the distortion-rate function of the source with respect to the fidelity criterion , respectively (as defined in [1] and [3]). Throughout the paper, we shall assume that a reference letter exists for and such that
(1)
To simplify our discussion, we shall assume, without loss of generality, that
(2)
Otherwise, we may replace by
and by the left-hand derivative of at .
Since is the inverse of when ,
where
it is not hard to see that
Therefore, for convenience, we may assume that . For any , define
(3) and
(4)
The following lemma summarizes some properties of which will be used later.
Lemma 1:
i) is a nonincreasing function of over . ii) , as a function of , is left-hand-continuous over
. iii) For any
Proof: Property i) follows from the fact that is a nondecreasing function of . Property ii) follows from the definition of . Property iii) follows from the fact that due to the convexity of as a function of ,
is right-hand-continuous over and the left-hand limit
of is equal to for any .
As surveyed in [5], so far there have been two approaches to source coding with a fidelity criterion: one is the fixed-rate approach and the other is the fixed-distortion approach. In the fixed-rate approach, one seeks to first determine the minimum distortion per sample achievable by a sequence of codes whose rates in bits are less than or equal to a prescribed number and then exhibit such a sequence of codes whose asymptotic distortion per sample is close to the minimum. In the fixed-distortion approach, one seeks to first determine the minimum rate in bits achievable by a sequence of codes whose distortion per sample are less than or equal to a prescribed number, and then exhibit such a sequence of codes whose asymptotic rate is close to the minimum. More precisely, in the fixed-rate approach, one seeks to first determine for each a quantity which is defined to be the infimum of all numbers for which there exists a sequence of block codes with rate such that
where
is the average distortion per sample arising from using to encode , and then exhibit such a sequence of block codes whose asymptotic distortion per sample
is close enough to . In the fixed-distortion approach, one seeks to first determine for each a quantity which is defined to be the infimum of all numbers for which there exists a sequence
of variable length codes such that
1) , where is a prefix set,
is a map from , and is a map from .
2) , where is the average distor-tion per sample arising from using to encode which is defined by
3) , where is the
average rate per sample which is defined by
length of
and then exhibit such a sequence of variable-length codes whose asymptotic rate per sample is close enough to . For any stationary, ergodic source ,
it is well known [5] that and
.
In some applications, however, neither rate nor distortion needs to be fixed. Instead, one might use a flexible strategy which allows both rate and distortion to vary, but minimizes for some fixed the following cost function:
over all variable-length codes . This is the basic idea of one-shot fixed-slope source coding. In the asymptotic fixed-slope source coding, one might want to first determine for each fixed the infimum (denoted by ) of all numbers for which there exists a sequence of variable-length codes such that
and then exhibit such a sequence of variable-length codes whose asymptotic cost
is close enough to .
For stationary, ergodic sources, we have the following fixed-slope source coding theorem.
Theorem 1: Let be fixed. For any stationary, ergodic source satisfying conditions (1) and (2), the following holds:
where and are defined by (3) and (4), respec-tively.
Proof: First note that for any variable-length code
, the point lies above or
on the rate distortion curve of the source . In view of Lemma 1 and the convexity of , it is not hard to see that
From this it follows that . On
[1, ch. 7], there exists for any a sequence of block codes such that
and
Hence
From this
Letting yields
which completes the proof of Theorem 1. Note that in view of Lemma 1
If , then is just the slope
of the rate-distortion curve at the point . This is why the fixed-slope approach gets its name.
Although for a specific stationary, ergodic source , fixed-slope source coding is essentially the same as fixed-rate source coding and fixed-distortion source coding, difference occurs when we deal with universal source coding. There is no way to convert existing fixed-rate (or fixed-distortion) universal codes to fixed-slope universal codes. In this paper, however, we shall give a simple fixed-slope universal lossy data compression scheme.
III. A FIXED-RATE(FIXED-DISTORTION)
UNIVERSAL LOSSYDATA COMPRESSIONSCHEME
In this section, we shall extend the results of [24] to the general case of any lossless codeword length function. The basic idea has already been presented in [11], [22], [24], and [26]; the main purpose of this section is to facilitate our discussion later on. Let denote the set of all finite sequences from . Let be a length function such that for any
(5)
It is easy to see that corresponding to any length function satisfying (5), there exists a prefix code such that for any the length of . (By a prefix code we mean a map from satisfying that for each , is a prefix set.) Conversely, for any prefix code , the length function defined by the length of for any satisfies (5). Henceforth, we shall refer to any length function satisfying (5) as a lossless codeword length function and keep in mind that there is a prefix code associated with it. The following are some examples of lossless codeword length functions.
Example 1–-The Lempel–Ziv Codeword Length Function : For each , we first use the incremental parsing procedure described in [31] to sequentially parse
into substrings so that and for
any , is the longest proper prefix of that is a member of , where denotes the empty word. Then we encode each substring into a binary string of length . (Throughout the paper, if is a finite set, then denotes the cardinality of ; also, all logarithms are to base two.) The total length of the codeword of , denoted by , is then
Example 2–-The Sliding-Window Lempel–Ziv Codeword
Length Function : For each , we first use a
modified incremental parsing procedure to sequentially parse
into substrings so that and
for any , is the longest proper prefix of
that is a member of , where
is the smallest integer such that the total length of is less than or equal to the window length . (Here we adopt the convention that the minimum of an empty set is . Hence when , is simply .) Having determined , it is encoded into a binary string of length , where
The total length of the codeword of , denoted by , is then
(6)
Note that the above encoding procedure is actually a version of the sliding-window Lempel–Ziv algorithm. Other versions of the sliding-window Lempel–Ziv algorithm are also possible, such as the original one described in [32] and the recent one described in [9].
Example 3—The th-Order Arithmetic Codeword Length
Function : For each , is given by
(7)
where denotes the number of occurrences of as a subsequence in the sequence , where is the sequence of length consisting only of one letter . In this and the following example, we drop the requirement that a length function must take integer values.
Example 4—Rissanen’s Stochastic Complexity : For each
(8)
Example 5—Kolmogorov Complexity : For the defi-nition of Kolmogorov complexity, please refer to [33].
We next present two universal lossy data compression schemes, based on any lossless codeword length function
, and .
A Fixed-Rate Universal Lossy Data Compression Scheme:
Fix . Let be the smallest positive integer such
that the set is nonempty for all
. We define to be the
sequence of sets
In our fixed-rate universal lossy data compression scheme, each source sequence is quantized into a closest member of . There are two different ways for the encoder to encode : 1) The encoder can transmit the index of in using a binary string of length ; or 2) the encoder can transmit the binary codeword associated with via the lossless codeword length function , adding some dummy digits to ensure overall codeword length . The resulting distortion per sample is then
A Fixed-Distortion Universal Lossy Data Compression Scheme: Fix . For each , we think of the entire set as a codebook of dimension and list the elements of in order of nondecreasing the lossless codeword length . For each source sequence , the encoder maps into the binary codeword associated with via the lossless codeword length function , where is the first element in the list such that . The resulting rate in bits per sample is then
To guarantee the optimality of the above two lossy data compression schemes, we must impose some conditions on the lossless codeword length function . Accordingly, we shall assume that is a universal lossless codeword length function for all stationary, ergodic sources. That is, satisfies the following condition.
Condition A: For any stationary, ergodic process taking values in , the following holds with probability one:
a.s.
where is the entropy rate of the process . It is well known that the Lempel–Ziv codeword length function [31], Kolmogorov complexity [23], Rissa-nen’s stochastic complexity [15], Ornstein–Shields’s codeword length function described in [13], and Shields’s codeword length function described in [17] all satisfy Con-dition A.
Under Condition A, we have the following optimality results concerning our fixed-rate and fixed-distortion lossy data compression schemes.
Theorem 2: Suppose satisfies Condition A. Then for any stationary, ergodic source and for any and
as almost surely (9) and
as almost surely (10)
Note that when the source alphabet is standard and the source is two-sided, (10) and, hence, (9) have already been proved in [11]. To prove Theorem 2 in the general case where the source alphabet is arbitrary and the source is one-sided, we first need to state some results concerning the sliding-block coding of one-sided sources.
Definition 1: A code is a measurable map from . A code is a sliding-block code if for some positive integer , there exists a measurable map
such that for any
The rate of the foregoing sliding-block code is defined as follows. For each , let be the total number of different -blocks that appear in the sequences in .
Then . The average distortion
per sample arising from using to encode is defined as
When the source alphabet is standard, the one-sided source can be extended to a two-sided one. Therefore, it follows that, in the case of standard source alphabet, the following holds.
Proposition 1: Given a block code and , there exists a sliding-block code such that
and . Hence, for any and
, there exists a sliding-block code such that
and
Actually, it was Proposition 1 that was used in [11] to prove (10).
Interestingly enough, whether the source alphabet is standard or not, Proposition 1 is always true. This can be proved by modifying the argument given in [6] to the case of one-sided sources. Since the argument is lengthy, we omit it here.
Using Proposition 1, We are now ready to prove Theorem 2. As an example, in the following we present only the proof of (9) since (10) can be proved similarly.
Proof of (9): Let and . From Proposition
1, there exists a sliding-block code with a measurable map such that
(11) and
For each , define
Then it is easy to see that is stationary and ergodic. Define random variables appropriately so that is also stationary and ergodic. From (11) and (12), it follows that
(13) and
(14)
Since satisfies Condition A
a.s.
From the ergodic theorem,
a.s.
Therefore, for almost every realization we have for sufficiently large
and
By the construction of the fixed-rate lossy data compression schemes
This implies that with probability one
which, together with the sample converse given in [7] implies
almost surely.
This completes the proof of (9).
Since the th-order arithmetic codeword length function and the sliding-window Lempel–Ziv codeword length function have the property that for any stationary, ergodic process taking values in
a.s.
and
a.s.
from Theorem 2 we get the following corollary.
Corollary 1: For any stationary, ergodic source and for
any and
a.s. (15)
a.s. (16)
a.s. (17)
and
a.s. (18)
IV. A FIXED-SLOPE UNIVERSAL
LOSSY DATA COMPRESSIONSCHEME
We now turn to the case of fixed-slope universal coding. As before, let be a lossless codeword length function. Let be fixed. Our fixed-slope universal lossy data compression scheme works as follows: for each source sequence , the encoder first searches the first element in which
minimizes the cost function over
the whole set , where is assumed to be ordered in some order, and then encodes into the binary codeword associated with via the lossless codeword length function . After receiving the binary codeword, the decoder can completely recover and outputs as a reproduction of . In this way, the resulting rate in bits per sample is then
where is defined to be
where the first minimum is relative to the order of . The resulting distortion per sample is then
The following is our optimality result concerning the fixed-slope lossy data compression scheme.
Theorem 3: Suppose satisfies Condition A. Then for any stationary, ergodic source and for any , the following hold:
1) As
a.s. (19)
where and are defined by (3) and (4), respectively.
2) For almost every realization , all limit points of the set
lie on the rate distortion curve of the source . 3) If is the only point on the rate distortion
curve such that
then, as ,
a.s. (20)
and
For the th-order arithmetic codeword length function and the sliding-window Lempel–Ziv codeword length function
, we have the following result.
Theorem 4: For any stationary, ergodic source and for any , the following hold:
1)
a.s.
2) For almost every realization , all limit points of the set
lie between the rate distortion curve of the source and the curve of the function , where goes to as .
3) If is the only point on the rate distortion curve such that
then
a.s. (22)
and
a.s. (23)
4) Results 1)—3) are still valid if we replace by
and by .
Before we prove Theorems 3 and 4, we need a strong sample converse for variable-length source coding.
Theorem 5: Let be a stationary, ergodic source with alphabet . Then
1) For any and any sequence of
variable-length codes
a.s. (24)
where denotes the length of the binary string .
2) For almost every realization , all limit points of the set
lie above or on the rate distortion curve of the source .
Proof: For convenience, let .
First note that from Theorem 1, it is not hard to see that there exists a sequence of variable-length codes such that
a.s.
(25)
We shall prove (20) by contradiction. Assume that (20) is not true. Then there exists an such that
on a set of positive probability. Consequently, there exists a positive real number such that
(26)
Let be a small real number to be specified later. In view of (25), there exists a positive integer such that
(27)
In view of (26), fix a positive integer and choose so large that
(28)
Let
and
For sufficiently large , define
and (29)
where and are the indicator functions of the measurable subsets and , respectively. Clearly, can be regarded as measurable subset of .
We next use the sample path covering idea originated by Ornstein and Weiss [14] and modified by Shields [18] to obtain for each a sequence of nonoverlapping subintervals of . The sequence is a partition of , i.e., , and can be defined inductively as follows. Assume have been defined and
Step 1: If or , then put .
Step 2: Otherwise, test the membership of in . If , then put , where is the least positive integer such that
Step 3: Otherwise, test whether there exists
such that . If exists, then put ; if
not, put .
Here we make the convention that when , we let . Note also that when Step 3 is executed, must belong to . From the construction of the sequence
we see that the following properties hold.
Property 1: The length of the subinterval is equal to , or , or is in the range .
Property 2: occurs only in the following cases:
, or , or ,
but there exists such that . Since , the union of those for which
and the first case holds has at most positive integers. The union of those for which and the second case holds has at most positive integers if is sufficiently large so that . Since , the union of those for which and the third case holds has also at most positive integers. Consequently, if , the union of those for which has cardinality at most .
Property 3: If , the union of those for which has cardinality at least .
For each , we shall call the sequence
of nonoverlapping subintervals of as the block de-composition of associated with . Since each block decomposition can be determined uniquely by specifying those for which , it is not hard to see that the total number of all possible block decompositions can be upper-bounded by
(30)
where the inequality is used and is given by
Here we assume .
Let be a variable-length code of order
such that for each , and
. Note that the existence of such a variable-length code is guaranteed by Assumptions 1) and 2). For each block decomposition , we now define a variable-length code
of order so that
where
if if if
for . Note that if and
are variable-length codes of order and order , respectively, denotes the product variable=length
code of order such that
and
If has the block decomposition , then from the construction of , it is not hard to see that
(31)
where the last inequality is due to Property 3. Based on variable-length codes , we can construct a variable-length code of order so that
i) for each , if is the block decomposition associated with , then
(32) and
where (32) is due to (30). ii) for each
and
Consequently, in view of (31), we have that for each
which, combined with (33), implies
From the proof of Theorem 1, it follows that
(34)
In view of (27)–(29), the ergodic theorem guarantees that
as
Letting and then letting in (34) yield
This is the desired contradiction which asserts that (24) is valid.
We now turn to the proof of Result ii). From Result i), it follows that for almost every realization
(35)
for every rational . Now let satisfy (35) for every rational . Let be a limit point of the set
Then from (35)
for every rational . In view of Lemma 1 and the continuity of , it is not hard to see that
for every real number . From this, it follows that the point must lie above or on the rate distortion curve of the source . This completes the proof of Result ii) and hence the proof of Theorem 5.
Remark 1: Theorem 5 is the strongest sample converse so far obtained in source coding relative to a fidelity criterion which implies the results of [7] and [8] as corollaries.
We are now in a position to prove Theorems 3 and 4.
Proof of Theorem 3: From Theorem 5, it follows that for any
a.s. (36)
On the other hand, if , then from the description of the fixed-slope universal lossy data compression scheme, it follows that
Note that the quantity on the right-hand side of the above inequality is the cost resulting from the fixed distortion com-pression scheme at . Thus the above inequality simply says that the cost resulting from the fixed-slope com-pression scheme is upper-bounded by the cost resulting from the fixed distortion compression scheme. Using Theorem 2, we get
a.s. (37)
If , then can be
upper-bounded by the cost resulting from the fixed-rate com-pression scheme at , i.e.,
From this and Theorem 2
a.s. (38)
Combining (36) with (37) and (38) yields (19).
From Theorem 5 and (19), it follows that for almost every realization
i) all limit points of the set
lie above or on the rate distortion curve of the source ; ii) all limit points satisfy
(39)
On the other hand, since satisfies
This, together with (39), implies that must lie on the rate distortion curve, that is, . Moreover, from (39) and the convexity of as a function of , it is not hard to see that
Therefore, if is the only point on the rate distortion curve such that
then all limit points must equal . From this, it follows that
as and
as
which completes the proofs of (20) and (21) and hence the proof of Theorem 3.
Proof of Theorem 4: A similar argument to the proof of Theorem 3 can lead to Theorem 4.
V. SEARCHING ALGORITHMS
As mentioned in Section IV, in the fixed-slope universal lossy data compression scheme, the encoding problem is equivalent to a search problem through a trellis. The main task in the encoding process is to find for each source sequence an element in which minimizes the cost
per symbol over the whole set .
Clearly, this is a typical search problem in the trellis or tree coding encountered in channel/source coding except that in our present case, the cost function is not additive in general. If the lossless codeword function has some additive-like property, then the Viterbi algorithm [4], [20] can be used to find the element in which minimizes the cost function over the whole set . Among the existing universal lossless codeword length functions, the arithmetic codeword length function
is most easily computed. In this section, therefore, we confine ourselves to the arithmetic codeword length function
and study the resulting performance when the -algorithm is used as a sequential search algorithm. For further performance analysis of the fixed-slope scheme and its implementation in the standard setup where both and are the real line, please refer to a subsequent paper [27] in this direction.
For each , the arithmetic codeword length function can be computed recursively as follows. We asso-ciate each pair with a counter , where and . Initially, all counters are set to . At each time , the codeword length function and the counters are updated according to the following procedure:
Step 1: Let
Step 2: The counter is incremented by and at
the same time, all the other counters are kept unchanged. Clearly, if we take and let , where
is the sequence of length consisting only of one letter , then computed according to Steps 1 and 2 coincides with (7).
Given the source sequence to be encoded, the -algorithm can be described recursively as follows. Assume that at time , the algorithm retains paths, that is,
sequences of length , where
, . Then at time , the algorithm works as follows.
1) Path Extension: The algorithm extends each se-quence , , by one symbol so that
becomes , where is an arbitrary element in , and computes the corresponding cost function by
that is,
2) Path Selection: Among the total extended se-quences, the algorithm selects the extended paths with the
lowest costs .
After all input source symbols , , are processed, the algorithm outputs the sequence with the lowest cost which serves as the reproduction sequence of the source sequence . In this way, the resulting rate
is
and the resulting distortion is
where is the final output of the -algorithm.
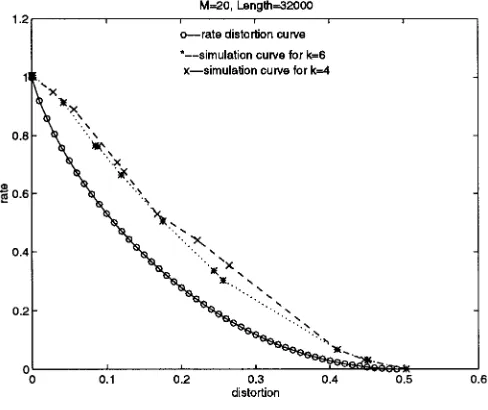
In the binary-symmetric case, where , the source is an independent and identically distributed (i.i.d.) source with uniform distribution over , and the distortion measure is the Hamming distance over , we simulate the fixed-slope universal lossy data compression scheme with the arithmetic codeword length function as a lossless codeword length function and the -algorithm as a sequential search algorithm. Simulation results show that 1) for fixed and , the cost decreases as the length increases; 2) for fixed and sufficiently large , the cost decreases as increases; and 3) for large and sufficiently large , the cost decreases as the order increases. Typical simulation results are shown in Figs. 1 and 2. Detailed simulation results for the standard setup where both and are the real line are presented in [27].
We claim that for any stationary, ergodic source
Fig. 1. Simulation curves for different orders.
Fig. 2. Simulation curves for different lengths.
claim directly, the validity of this claim can be justified by the following observation. In the process of computing
for each , if, instead of using Steps 1 and 2, we use the following procedure:
Step 1 : Let
Step 2 : The counter is incremented by .
Step 3 : If , then the counter is
decremented by . At the same time, all the other counters are kept unchanged, then we can use the Viterbi algorithm to find the optimal element . In this way, it can be proved that for any stationary, ergodic source , the resulting cost per
symbol converges with probability one to as
, and then .
We conclude this paper with pointing out an interesting problem which was suggested to us by one of the referees. In all our preceding discussions regarding the fixed-slope universal algorithm we assumed no constraint on the maximum transmitted bits per unit time. In a real communication system, however, the channel bandwidth is limited and there is an upper limit on the maximum transmitted bits per unit time. An interesting problem then arises: how to use the fixed-slope universal algorithm once there is an upper limit on the maximum transmitted bits per unit time? (A similar problem also occurs in the case of fixed-distortion coding.) For sources with , one can use the algorithm to encode them while keeping fixed. For sources with
, one needs to decrease so that the constraint on the maximum transmitted bits per unit time is satisfied. Although the specific solution to the problem is case-dependent, in general one can use the following two approaches. One approach is to adaptively adjust the value of so that the constraint on the maximum transmitted bits per unit time is satisfied. The other approach is to use some kind of fixed-slope maximum-rate hybrid universal algorithm in which one uses the fixed-slope algorithm to encode sources with
and another fixed-rate algorithm to encode sources with . Both these approaches need to be investigated further.
ACKNOWLEDGMENT
The authors wish to thank Dr. M. Tu for his early pro-gramming support in the implementation of the fixed-slope universal lossy data compression scheme.
REFERENCES
[1] T. Berger,Rate Distortion Theory. Englewood Cliffs, NJ: Prentice-Hall, 1971.
[2] K. Cheung and V. K. Wei, “A locally adaptive source coding scheme,” in Communication, Control, and Signal Processing, Proc. Bilkent Conf. on New Trends in Communication, Control, and Signal Processing, 1990, pp. 1473–1482.
[3] R. M. Gray, Entropy and Information Theory. New York: Springer-Verlag, 1990.
[4] T. Hashimoto, “A list-type reduced constraint generalization of the Viterbi algorithm,”IEEE Trans. Inform. Theory, vol. IT-33, pp. 866–876, 1987.
[5] J. C. Kieffer, “A survey of the theory of source coding with a fidelity criterion,”IEEE Trans. Inform. Theory, vol. 39, pp. 1473–1490, 1993. [6] , “Extension of source coding theorems for block codes to
sliding-block codes,” IEEE Trans. Inform. Theory, vol. IT-26, pp. 679–692, 1980.
[7] , “Sample converses in source coding theory,” IEEE Trans.
Inform. Theory, vol. 37, pp. 263–268, 1991.
[8] , “Strong converses in source coding relative to a fidelity crite-rion,”IEEE Trans. Inform. Theory, vol. 37, pp. 257–262, 1991. [9] H. Morita and K. Kobayashi, “On asymptotic optimality of a sliding
window variation of Lempel–Ziv codes,”IEEE Trans. Inform. Theory, vol. 39, pp. 1840–1846, 1993.
[10] , “An extension of LZW coding algorithm to source coding
subject to a fidelity criterion,” in Proc. 4th Joint Swedish–Soviet Int. Workshop on Inform. Theory(Gotland, Sweden, 1989), pp. 105–109. [11] J. Muramatsu and F. Kanaya, “Distortion-complexity and rate-distortion
[12] , “Dual quantity of the distortion complexity and a universal database for fixed-rate data compression with distortion,”IEICE Trans. Fundamentals. to be published.
[13] D. S. Ornstein and P. C. Shields, “Universal almost sure data compres-sion,”Ann. Prob., vol. 18, pp. 441–452, 1990.
[14] D. S. Ornstein and B. Weiss, “The Shannon-McMillan-Breiman theorem for a class of amenable groups,”Israel J. Math., vol. 44, pp. 53–60, 1983.
[15] J. Rissanen, “Complexity of strings in the class of Markov sources,” IEEE Trans. Inform. Theory, vol. IT-32, pp. 526–532, 1986.
[16] C. E. Shannon, “Coding theorems for a discrete source with a fidelity criterion,” inIRE Nat. Conv. Rec., 1959, pt. 4, pp. 142–163.
[17] P. C. Shields, “Universal almost sure data compression using Markov types,”Probl. Contr. Inform. Theory, vol. 19, no. 4, pp. 269–277, 1990. [18] , “The ergodic and entropy theorems revisit,”IEEE Trans. Inform.
Theory, vol. IT-33, pp. 263–266, 1987.
[19] Y. Steinberg and M. Gutman, “An algorithm for source coding subject to a fidelity criterion based on string matching,”IEEE Trans. Inform. Theory, vol. 39, pp. 877–886, 1993.
[20] A. J. Viterbi and J. K. Omura,Principles of Digital Communication and Coding. New York: McGraw-Hill, 1979.
[21] H. Yamamoto and B. Rimoldi, “A universal data compression scheme with distortion,” submitted for publication.
[22] E.-h. Yang, “Universal almost sure data compression for abstract alpha-bets and arbitrary fidelity criterions,”Probl. Contr. Inform. Theory, vol. 20, no. 6, pp. 397–408, 1991.
[23] , “The proof of Levin’s conjecture,”Chinese Sci. Bull., vol. 34, pp. 1761–1765, Nov. 1989.
[24] E.-h. Yang and J. C. Kieffer, “Simple universal lossy data compression schemes derived from Lempel–Ziv algorithm,” IEEE Trans. Inform. Theory, vol. 42, pp. 239–245, Jan. 1996.
[25] , “On the performance of data compression algorithms based upon string matching,”IEEE Trans. Inform. Theory. to be published. [26] E.-h. Yang and S.-Y. Shen, “Distortion program-size complexity with
respect to a fidelity criterion and rate distortion function,”IEEE Trans. Inform. Theory,vol. 39, pp. 288–292, 1993.
[27] E.-h. Yang and Z. Zhang, “Fixed slope lossification technique and variable rate trellis source coding,” submitted for publication, 1996. [28] Z. Zhang and V. K. Wei, “An on-line universal lossy data compression
algorithm by continuous codebook refinement,” IEEE Trans. Inform. Theory, vol. 42, pp. 803–821, May 1996.
[29] Z. Zhang and E.-h. Yang, “An on-line universal lossy data compression algorithm by continuous codebook refinement—Part two: Optimality for phi-mixing source models,” IEEE Trans. Inform. Theory, vol. 42, pp. 822–836, May 1996.
[30] J. Ziv, “Distortion rate theory for individual sequences,”IEEE Trans. Inform. Theory, vol. IT-26, pp. 137–143, 1980.
[31] J. Ziv and A. Lempel, “Compression of individual sequences via variable rate coding,”IEEE Trans. Inform. Theory, vol. IT-24, pp. 530–536, 1978. [32] , “A universal algorithm for sequential data compression,”IEEE
Trans. Inform. Theory, vol. IT-23, pp. 337–343, 1977.