SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
APRISAL BUDIANA
10110446
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Asalamualaikum Wr.Wb
Alhamdulillahi rabbil’alamiin, puji dan syukur penulis panjatkan kepada
kehadirat Allah S.W.T karena dengan rahmat dan karunia-Nya sehingga penulis
dengan segala keterbatasannya dapat menyelesaikan penyusunan skripsi yang
berjudul“IMPLEMENTASIDATA MININGPADA PENJUALAN PRODUK
DI PT. FOCUS GAYA GRAHA MENGGUNAKAN METODE
ASSOCIATION RULE” sebagai salah satu syarat dalam menyelesaikan studi
strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer.
Penyusunan laporan skripsi ini merupakan hasil dari usaha yang
berharga serta melalui berbagai dukungan, masukan dan bantuan dari berbagai
pihak. Melalui laporan ini penulis mengucapkan terimakasih yang mendalam
terutama kepada :
1. Kedua orang tua dan keluarga penulis atas do’a, motivasi serta dukungannya
sehingga skripsi ini dapat terselesaikan dengan baik.
2. Ibu Dian Dharmayanti, S.T., M.Kom., selaku pembimbing yang telah banyak
memberikan arahan serta masukan kepada penulis.
3. Bapak Didi Zaenal Abidin yang telah bersedia menerima penulis untuk
melakukan penelitian di PT. Focus Gaya Graha.
4. Bapak Andri Heryandi, S.T., M.T., selaku dosen penguji yang telah
memberikan saran serta kritiknya dalam penyusunan skripsi ini.
5. Ibu Gentisya Tri Mardiani, S.Kom., M.Kom, selaku dosen penguji yang telah
memberikan saran serta kritiknya dalam penyusunan skripsi ini.
6. Teman-teman IF-10 angkatan 2010 yang telah banyak memberikan dukungan
serta bantuan dalam penyusunan skripsi ini.
7.
Semua pihak yang tidak dapat penulis sebut satu persatu yang telah membantuiv
Wassalammu’alaikum Wr.Wb.
Bandung, 1 Agustus 2015
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT... ii
KATA PENGANTAR ... iii
DAFTAR ISI... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL... ix
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN... xiii
BAB I PENDAHULUAN... 1
I.1 Latar Belakang Masalah ... 1
I.2 Perumusan Masalah... 2
I.3 Maksud dan Tujuan ... 2
I.4 Batasan Masalah ... 2
I.5 Metodologi Penelitian ... 3
I.5.1 Metode Pengumpulan Data ... 3
I.5.2 Metode Data Mining... 3
I.5.3 Metode Pembangunan Perangkat Lunak ... 5
I.6 Sistematika Penulisan... 6
BAB II TINJAUAN PUSTAKA ... 9
II.1 Profil Instansi... 9
II.1.1 Logo Instansi ... 9
II.1.2 Struktur Organisasi ... 10
II.2 Landasan Teori ... 11
II.2.1 Data... 11
II.2.2 Basis Data... 11
II.2.3 Database Management System(DBMS)... 12
II.2.4 Data Mining... 14
II.2.4.1 Cross-Industry Standard Process for Data Mining(CRISP-DM) ... 14
vi
II.2.7.1 Entity Relationship Diagram(ERD) ... 22
II.2.7.2 Diagram Konteks... 22
II.2.7.3 Data Flow Diagram(DFD)... 22
II.2.7.4 Kamus Data ... 22
II.2.8 MySQL ... 23
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 25
III.1 Analisis Sistem ... 25
III.1.1 Analisis Masalah ... 25
III.1.2 Pemahaman Bisnis... 26
III.1.2.1 Identifikasi Tujuan Bisnis... 26
III.1.2.2 Penentuan Sasaran Data Mining... 26
III.1.3 Pemahaman Data ... 27
III.1.3.1 Pengumpulan Data Awal ... 27
III.1.3.2 Penjelasan Data ... 27
III.1.4 Persiapan Data ... 28
III.1.4.1 Pemilihan Data ... 28
III.1.4.2 Pembersihan Data ... 28
III.1.4.3 Pembangunan Data ... 28
III.1.4.4 Format Data ... 29
III.1.5 Pemodelan ... 30
III.2 Analisis Spesifikasi Kebutuhan Perangkat Lunak... 32
III.2.1 Analisis Kebutuhan Non-Fungsional ... 33
III.2.1.1 Analisis Kebutuhan Perangkat Keras ... 33
III.2.1.2 Analisis Kebutuhan Perangkat Lunak ... 34
III.2.1.3 Analisis Pengguna (User)... 35
III.2.2 Analisis Kebutuhan Fungsional... 35
III.2.2.1 Analisis Basis Data... 35
vii
III.2.2.3Data Flow Diagram(DFD)... 36
III.2.2.4 Spesifikasi proses ... 40
III.2.2.5 Kamus Data DFD ... 44
III.2.2.6 Skema Relasi ... 46
III.2.2.7 Strktur Tabel ... 46
III.3 Perancangan Arsitektur ... 48
III.3.1 Perancangan Struktur Menu ... 48
III.3.2 Perancangan Antarmuka... 49
III.3.2.1 Perancangan Antarmuka Program ... 49
III.3.2.2 Perancangan Antarmuka Pesan ... 51
III.3.2.3 Jaringan Semantik ... 52
BAB IV IMPLEMENTASI DAN PENGUJIAN... 53
IV.1 Implementasi Sistem ... 53
IV.1.1 Implementasi Perangkat Keras ... 53
IV.1.2 Implementasi Perangkat Lunak ... 53
IV.1.3 Implementasi Antarmuka ... 54
IV.1.4 Implementasi Basis Data ... 54
IV.2 Pengujian Sistem ... 55
IV.2.1 Rencana Pengujian ... 55
IV.2.1.1Pengujian Fungsionalitas... 56
IV.2.1.2Pengujian Sampel ... 57
IV.2.1.3PengujianBeta... 60
BAB V KESIMPULAN DAN SARAN ... 61
V.1 Kesimpulan... 61
V.2 Saran ... 61
63
[1] I. Pramudiono, Pengantar Data Mining : Menambang Permata Pengetahuan di Gunung Data, 2007.
[2] B. Santosa, Data Mining: Teknik Pemanfaatan Data Untuk Keperluan Bisnis, Yogyakarta: Graha Ilmu, 2007.
[3] A. Dodiet, Penelitian Deskriptif, 2009.
[4] D. T. Larose, DISCOVERING KNOWLEDGE IN DATA : An Introduction to DATA MINING, Hoboken, New Jersey: John Wiley & Sons, Inc., 2005.
[5] I. Sommerville, SOFTWARE ENGINEERING 9 Edition, PEARSON, 2011.
[6] Fathayansyah, Buku Teks Komputer : Basis Data, 5th ed., Bandung: Informatika, 2004.
[7] Waljiyanto, Sistem Basis Data: Analisis dan Pemodelan Data, 1st ed., Yogyakarta: Graha Ilmu, 2003.
[8] J. Simarmata dan I. Prayudi, Basis Data, Yogyakarta: Andi Offset, 2006.
[9] Kusrini dan E. T. Luthfi, ALGORITMA DATA MINING Ed : 1, Yogyakarta: Andi, 2009.
[10] D. T. Larose, DATA MINING METHODS AND MODELS, New Jersey: John Wiley & Sons, Inc, 2006.
[11]D. Ulmer, “Mining an Online Auctions Data Warehouse,” The Mid-Atlantic
Student Workshop on Programming Languages and Systems,vol. 19, 2002.
[12] J. Han, M. Kamber dan J. Pei, DATA MINING : Concepts and Techniques 3rd Edition, USA: Morgan Kaufmann Publishers, 2012.
[13] A. B. b. Ladjamudin, Rekayasa Perangkat Lunak, Yogyakarta: Graha Ilmu, 2006.
1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
PT. Focus Gaya Graha merupakan suatu perusahaan perseorangan yang
bergerak dibidang industri furniture. Saat ini, jenis produksi yang ada di PT.
Focus Gaya Graha dibagi menjadi 3 yaitu wood furniture, panel furniture dan
photo frame. Setiap jenis produksi tersebut menghasilkan berbagai produk dengan
berbagai macam tipe, ukuran dan warna yang berbeda-beda. Produk-produk yang
dihasilkan PT. Focus Gaya Graha telah dipasarkan hingga ke luar negeri, hal ini
tentu saja menghasilkan banyak data transaksi penjualan. Saat ini, pemanfaatan
data transaksi penjualan tersebut hanya sebatas pembuatan laporan bagi
perusahaan lalu diarsipkan saja, tidak dimanfaatkan untuk dasar pertimbangan
dalam menentukan produk yang akan diproduksi. Sistem produksi yang berjalan
di PT. Focus Gaya Graha yaitu berdasarkan pesanan dan history penjualan
banyaknya produk yang sering terjual. Sistem produksi berdasarkan history
penjualan banyaknya produk yang sering terjual acap kali mengakibatkan
penumpukan hasil produksi, yang diakibatkan dari kesalahan dalam menentukan
produk yang seharusnya diproduksi.
Data miningadalah serangkaian proses untuk menggali nilai tambah dari
suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara
manual [1]. Dalam bidang keilmuan data mining, terdapat suatu metode yang
dinamakan association rule. Metode ini sering juga dinamakan dengan market
basket analysis karena awal mulanya yang berasal dari studi tentang database
transaksi penjualan [2]. Association rule bertujuan untuk menunjukan nilai
asosiatif antar produk-produk yang dibeli oleh pelanggan sehingga terlihatlah
sebuah pola berupa produk-produk apa saja yang sering dibeli secara bersamaan
dalam sebuah transaksi penjualan. Dengan mengetahui produk apa saja yang
sering dibeli secara bersamaan, dapat dibuat sebuah dasar pengambilan keputusan
Berdasarkan uraian diatas, maka diperlukan perangkat lunak yang
mengimplementasi metode association rulesebagai alat bantu untuk menentukan
nilai asosiatif antar produk-produk. Diharapkan dengan adanya perangkat lunak
ini dapat membantu pihak perusahaan untuk mengetahui pola pembelian
konsumen, yang mana informasi tersebut dapat dimanfaatkan oleh pihak
perusahaan sebagai dasar pertimbangan dalam menentukan produk yang akan
diproduksi.
I.2 Perumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, maka
permasalahan yang terdapat dalam penelitian ini adalah bagaimana
mengimplementasi data mining pada penjualan produk di PT. Focus Gaya Graha
menggunakan metodeassociation rule?
I.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah mengimplementasikan data mining
pada penjualan produk di PT. Focus Gaya Graha menggunakan metode
association rule.
Tujuan yang diharapkan adalah dapat membantu PT. Focus Gaya Graha
untuk mengetahui pola pembelian konsumen, agar dapat mempermudah dalam
menentukan produk apa yang akan diproduksi.
I.4 Batasan Masalah
Batasan masalah pada penelitian yang akan dilakukan adalah sebagai
berikut :
1. Data yang akan dianalisis adalah data laporan transaksi penjualan di PT. Focus
Gaya Graha.
2. Metode yang dipakai dalam penelitian ini adalah metode Association Rule
dengan menggunakan AlgoritmaEclat.
3. Hasil dari analisis adalah terbentuknya pola pembelian konsumen terhadap
3
4. Metode yang digunakan adalah metode aliran terstruktur dimana tools yang
digunakan adalahData Flows Diagram(DFD) danEntity Relational Diagram
(ERD).
5. DBMS yang digunakan adalah MySQL.
6. Aplikasi yang dibangun berbasisdesktop.
I.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metode penelitian
deskriptif, yaitu metode penelitian yang bertujuan untuk memberikan gambaran
atau deskripsi tentang suatu keadaan secara objektif [3]. Metode penelitian ini
memiliki dua metode yaitu metode pengumpulan data dan metode pembangunan
perangkat lunak.
I.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan pada penelitian ini adalah
sebagai berikut :
1. Studi Literatur
Teknik pengumpulan data dengan cara mengumpulkan literatur, jurnal,paper,
dan buku yang berkaitan dengan penelitian yang dilakukan.
2. Wawancara
Teknik pengumpulan data dengan cara berinteraksi atau berkomunikasi secara
langsung kepada responden dengan mengajukan pertanyaan yang sesuai
dengan topik yang diambil.
I.5.2 Metode Data Mining
Metode data mining yang digunakan dalam penelitian ini adalah
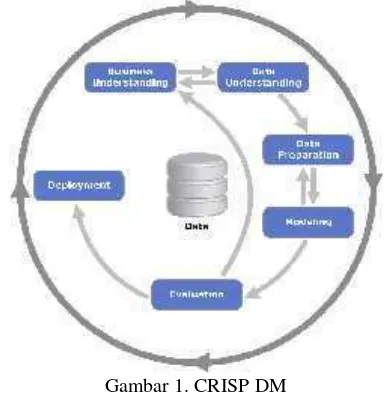
Cross-Industry Standard Process for Data Mining (CRISP-DM), yang digambarkan
pada Gambar I.1. Metode CRISP-DM terbagi dalam enam fase [4]. Keseluruhan
fase berurutan yang ada tersebut bersifat adaptif. Berikut ini adalah enam fase dari
1. Business Understanding Phase
Business Understanding Phase adalah tahapan pendefinisian masalah dan
objektif daridata miningyang akan dilakukan.
2. Data Understanding Phase
Data Understanding Phase adalah tahapan pemahaman struktur data yang
akan dipergunakan.
3. Data Preparation Phase
Data Preparation Phaseadalah tahapan persiapan data.
4. Modelling Phase
Modelling Phase adalah tahapan pemodelan dan implementasi data mining
task.
5. Evaluation Phase
Evaluation phaseadalah tahapan evaluasi hasil dari prosesdata mining.
6. Deployment phase
Deployment phaseadalah tahapan penggunaan hasil dari prosesdata mining.
5
I.5.3 Metode Pembangunan Perangkat Lunak
Model proses pembangunan perangkat lunak yang digunakan dalam
penelitian ini adalah model waterfall. Tahapan-tahapan pada model waterfall
menurut Ian Sommerville adalah sebagai berikut [5]:
Gambar I.2 Waterfall Model
Berikut adalah penjelasan dari tahapan-tahapan tersebut :
1. Requirement Analysis and Definition
Merupakan tahapan penetapan fitur, kendala dan tujuan sistem melalui
konsultasi dengan pengguna sistem. Semua hal tersebut akan ditetapkan secara
rinci dan berfungsi sebagai spesifikasi sistem.
2. System and Software Design
Dalam tahapan ini akan dibentuk suatu arsitektur sistem berdasarkan
persyaratan yang telah ditetapkan. Dan juga mengidentifikasi dan
menggambarkan abstraksi dasar sistem perangkat lunak dan
hubungan-hubungannya.
3. Implementation and Unit Testing
Dalam tahapan ini, hasil dari desain perangkat lunak akan direalisasikan
sebagai satu set program atau unit program. Setiap unit akan diuji apakah
sudah memenuhi spesifikasinya.
4. Integration and System Testing
Dalam tahapan ini, setiap unit program akan diintegrasikan satu sama lain dan
diuji sebagai satu sistem yang utuh untuk memastikan sistem sudah memenuhi
5. Operation and Maintenance
Dalam tahapan ini, sistem diinstal dan mulai digunakan. Selain itu juga
memperbaikierror yang tidak ditemukan pada tahap pembuatan. Dalam tahap
ini juga dilakukan pengembangan sistem seperti penambahan fitur dan fungsi
baru.
I.6 Sistematika Penulisan
Sistematika penulisan laporan akhir penelitian ini disusun untuk
mendeskripsikan secara umum tentang penelitian yang dilakukan. Sistematika
penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang masalah, rumusan
masalah, maksud dan tujuan, batasan masalah, metodologi penelitian serta
sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini membahas tentang profil perusahaan, proses produksi, hasil
produksi serta berbagai konsep dasar dan teori-teori yang berkaitan dengan topik
penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis
permasalahan.
BAB III ANALISIS DAN PERANCANGAN
Bab ini menganalisis masalah dari data hasil penelitian, kemudian
dilakukan pula proses perancangan sistem yang akan dibangun sesuai dengan
analisa yang telah dilakukan.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang implementasi dari tahapan-tahapan penting yang
telah dilakukan sebelumnya kemudian dilakukan pengujian terhadap sistem sesuai
dengan tahapan yang telah dijalani untuk memperlihatkan sejauh mana sistem
7
BAB V KESIMPULAN DAN SARAN
Bab ini berisi mengenai kesimpulan atas tugas akhir yang dibuat serta
berisi saran-saran untuk adanya pengembangan mutu dan kualitas bagi masa yag
9
BAB II
TINJAUAN PUSTAKA
II.1 Profil Instansi
PT. Focus Gaya Graha yang berlokasi di Jalan Leuwigajah No. 106
Cimahi, bergerak dalam bidang industi furniture. Pertama kali didirikan pada
tanggal 21 Mei 1995 oleh Sigit Sasmitapura, PT. Focus Gaya Graha terus
berkembang sampai saat ini. Jenis produksi yang ada di PT. Focus Gaya Graha
dibagi menjadi 3 yaitu wood furniture, panel furniture dan photo frame. Ada
beberapa jenis bahan baku yang digunakan dalam proses produksi, diantaranya
adalah kayu mahoni, kayu albasia, kayu pinus, kayu meranti, kayu jemitri, kayu
bayur, MDF dan partikelboard.
Produk-produk yang dihasilkan oleh PT. Focus Gaya Graha banyak
diminati oleh konsumen dalam negeri maupun luar negeri. Beberapa konsumen
dari negara-negara yang berada di benua Eropa, Amerika dan Asia, telah menjadi
pelanggan tetap perusahaan ini. Saat ini, dengan 450 orang pekerja dan luas
pabrik 12.000m2, PT. Focus Gaya Graha memiliki kapasitas produksi hingga 25
kontainer per bulan.
II.1.1 Logo Instansi
Berikut ini adalah logo dari PT. Focus Gaya Graha yang dapat dilihat
pada Gambar II.1 :
II.1.2 Struktur Organisasi
Berikut ini adalah struktur organisasi PT. Focus Gaya Graha yang dapat
dilihat pada Gambar II.2 :
11
II.2 Landasan Teori
Landasan teori yang berkaitan dengan materi atau teori yang digunakan
sebai acuan dalam melakukan penelitian. Landasan teori yang diuraikan
merupakan hasil studi literatur, buku-buku, maupun situs internet.
II.2.1 Data
Data adalah representasi fakta dunia nyata yang mewakili suatu objek
seperti manusia (pegawai, siswa, pembeli, pelanggan), barang, hewan, peristiwa,
konsep, keadaan, dan sebagainya, yang direkam dalam bentuk angka, huruf,
simbol, teks, gambar, bunyi, atau kombinasinya [6]. Dalam pendekatan basis data
tidak hanya berisi basis data itu sendiri tetapi juga termasuk definisi atau deskripsi
dari data yang disimpan. Definisi data disimpan dalam sistem katalog, yang berisi
informasi tentang struktur tiap berkas, tipe dan format penyimpanan tiap item
data, dan berbagai konstrin dari data. Semua informasi yang disimpan dalam
katalog ini biasa disebut meta-data [7].
II.2.2 Basis Data
Basis data adalah mekanisme yang digunakan untuk menyimpan
informasi atau data. Informasi adalah sesuatu yang kita gunakan sehari-hari untuk
berbagai alasan. Dengan basis data, pengguna dapat menyimpan data secara
terorganisasi. Setelah data disimpan, informasi hasur mudah diambil. Kriterisa
dapat digunakan untuk mengambil informasi. Cara data disimpan dalam basis data
menentukan seberapa mudak mencari informasi berdasarkan banyak kriteria. Data
pun harus mudah ditambahkan ke dalam basis data, dimodifikasi dan dihapus [8].
Menurut Fathansyah [6], basis data sendiri dapat didefinisikan dalam
sejumlah sudut pandang seperti :
1. Himpunan kelompok data (arsip) yang saling berhubungan yang diorganisasi
sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan
mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara bersama
sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk
3. Kumpulan file/tabel/arsip yang saling berhubungan yang disimpan dalam
media penyimpanan elektronis.
II.2.3 Database Management System(DBMS)
“Managemen Sistem Basis Data (Database Management System
/DBMS) adalah perangkat lunak yang di desain untuk membantu dalam hal
pemeliharaan dan utilitas kumpulan data dalam jumlah besar”[6].
Sistem Manajemen Basis data (Database Management System)
merupakan sistem pengoperasian dan sejumlah data pada komputer. Dengan
sistem ini dapat merubah data, memperbaiki data yang salah dan menghapus data
yang tidak dapat dipakai. Sistem manajemen databasemerupakan suatu perluasan
software sebelumnya mengenai software pada generasi komputer yang pertama.
Dalam hal ini data dan informasi merupakan kesatuan yang saling berhubungan
dan berkerja sama yang terdiri dari: peralatan, tenaga pelaksana dan prosedur
data. Sehingga pengolahan data ini membentuk sistem pengolahan data. Peralatan
dalam hal ini berupa perangakat keras (hardware) yang digunakan, dan prosedur
data yaitu berupa perangakat lunak (software) yang digunakan dan dipakai untuk
mengalokasikan dalam pembuatan sistem informasi pengolahandatabase.
Manipulasi basis data meliputi pembuatan pernyataan (query) untuk
mendapatkan informasi tertentu, melakukan pembaharuan atau penggantian
(update) data, serta pembuatan report dari data. Tujuan utama DBMS adalah
untuk menyediakan tinjauan abstrak dari data bagi user. Jadi sistem
menyembunyikan informasi mengenai bagaimana data disimpan dan dirawat,
tetapi data tetap dapat diambil dengan efisien.
Pertimbangan efisiensi yang digunakan adalah bagaimana merancang
struktur data yang kompleks, tetapi tetap dapat digunakan oleh pengguna yang
masih awam, tanpa mengetahui kompleksitas stuktur data. Sistem manajemen
database atau database management system (DBMS) adalah merupakan suatu
sistem software yang memungkinkan seorang user dapat mendefinisikan,
membuat, dan memelihara serta menyediakan akses terkontrol terhadap data.
13
dan memiliki beberapa arti yang saling berpautan. DBMS yang utuh biasanya
terdiri dari :
1. Hardware
Hardware merupakan sistem komputer aktual yang digunakan untuk
menyimpan dan mengakses database. Dalam sebuah organisasi berskala
besar, hardware terdiri : jaringan dengan sebuah server pusat dan beberapa
programclientyang berjalan di komputer desktop.
2. Software
Software beserta utility Software adalah DBMS yang aktual. DBMS
memungkinkan parauseruntuk berkomunikasi dengandatabase. Dengan kata
lain DBMS merupakan mediator antara database dengan user. Sebuah
databaseharus memuat seluruh data yang diperlukan oleh sebuah organisasi.
3. Prosedur
Bagian integral dari setiap sistem adalah sekumpulan prosedur yang
mengontrol jalannya sistem, yaitu praktik-praktik nyata yang harus diikuti
useruntuk mendapatkan, memasukkan, menjaga, dan mengambil data.
4. Data
Data adalah jantung dari DBMS. Ada dua jenis data. Pertama, adalah
kumpulan informasi yang diperlukan oleh suatu organisasi. Jenis data kedua
adalah metadata, yaitu informasi mengenaidatabase.
5. User(Pengguna)
Ada sejumlahuseryang dapat mengakses atau mengambil data sesuai dengan
kebutuhan penggunaan aplikasi-aplikasi dan interface yang disediakan oleh
DBMS, antara lain adalah :
a. Database administrator adalah orang atau group yang bertanggungjawab
mengimplementasikan sistemdatabasedi dalam suatu organisasi.
b. End useradalah orang yang berada di depan workstation dan berinteraksi
secara langsung dengan sistem.
c. Programmer aplikasi, orang yang berinteraksi dengan database melalui
II.2.4 Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan
penemuan pengetahuan di dalam database [9].
Menurut Pramudiono [1], “Data miningadalah serangkaian proses untuk
menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama
ini tidak diketahui secara manual.”
Menurut Larose [4] kemajuan luar biasa yang terus berlanjut dalam
bidang data mining didorong oleh beberapa faktor, antara lain :
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan
memiliki akses ke dalamdatabaseyang andal.
3. Adanya peningkatan akses data melalui navigasiwebdan intranet.
4. Tekanan kompetensi bisnis untuk meningkatkan penguasaan pasar dalam
globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan
teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan
kapasitas media penyimpanan.
II.2.4.1 Cross-Industry Standard Process for Data Mining(CRISP-DM)
CRISP-DM yang dikembangkan tahun 1996 oleh analis dari beberapa
industri seperti Daimler Chrysler, SPSS dan NCR. CRISP-DM menyediakan
standar prosesdata miningsebagai strategi pemecahan masalah secara umum dari
bisnis atau unit penelitian.
Dalam CRISP-DM, sebuah proyek data mining memiliki siklus hidup
yang terbagi dalam enam fase. Keseluruhan fase berurutan yang ada tersebut
bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada keluaran dari
fase sebelumnya. Hubungan antarfase digambarkan dengan panah. Sebagai
contoh, jika proses berada pada fase modelling. Berdasar pada perilaku dan
karakteristik model, proses mungkin harus kembali kepada fase data preparation
15
evaluation. Enam fase yang ada dalam metode CRISP-DM tersebut dapat dilihat
pada Gambar II.3 :
Gambar II.3 CRISP-DM
Fase-fase CRISP-DM [4] :
1. Business Understanding
Business Understanding atau pemahaman domain (penelitian). Pada fase ini
dibutuhkan pemahaman tentang substansi dari kegiatandata miningyang akan
dilakukan, kebutuhan dari perspektif bisnis. Kegiatannya antara lain:
menentukan sasaran atau tujuan bisnis, memahami situasi bisnis, menentukan
tujuandata miningdan membuat perencanaan strategi serta jadwal penelitian.
2. Data Understanding
Data Understanding atau pemahaman data adalah fase mengumpulkan data
awal, mempelajari data untuk bisa mengenal data yang akan dipakai. Fase ini
mencoba mengidentifikasikan masalah yang berkaitan dengan kualitas data,
3. Data Preparation
Data preparation atau persiapan data. Fase ini sering disebut sebagai fase
yang padat karya. Aktivitas yang dilakukan antara lain memilihtabledanfield
yang akan ditransformasikan ke dalam database baru untuk bahandata mining
(set data mentah).
4. Modelling
Modeling adalah fase menentukan tehnik data mining yang digunakan,
menentukan tools data mining, teknik data mining, algoritma data mining,
menentukan parameter dengan nilai yang optimal.
5. Evaluation
Evaluationadalah fase interpretasi terhadap hasildata miningyang ditunjukan
dalam proses pemodelan pada fase sebelumnya. Evaluasi dilakukan secara
mendalam dengan tujuan menyesuaikan model yang didapat agar sesuai
dengan sasaran yang ingin dicapai dalam fase pertama.
6. Deployment
Deployment atau penyebaran adalah fase penyusunan laporan atau presentasi
dari pengetahuan yang didapat dari evaluasi pada proses data mining.
II.2.4.2 Metode-Metode Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang
dapat dilakukan, yaitu [10] :
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara
untuk menggambarkan pola dan kecenderungan yang terdapat dalam data.
Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat
mengumpulkan keterangan atau fakta bahwa siapa yang tidak cukup
profesional akan sedikit didukung dalam pemilihan presiden. deskripsi dari
pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk
17
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih
kearah numerik daripada ke arah kategori. Model dibangun dengan record
lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi.
Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien
rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan
level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel
prediksi dalam proses pembelajaran akan menghasilkan model estimasi.
Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam
prediksi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi dalam
bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas
bawah dinaikan.
4. Klasifikasi
Dalam klasifikasi, terdapat terget variabel kategori. sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu:
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain
klasifikasi dalam bisnis dan penelitian adalah :
1. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan.
2. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk
kategori penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target
dalam pengklusteran. pengklusteran tidak mencoba untuk melakukan
klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan
tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian
terhadap keselurahan data menjadi kelompok-kelompok yang memiliki
kemiripan (homogen), yang mana kemiripan record dalam suatu kelompok
akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok
lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian
adalah :
1. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari
suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran
yang besar.
2. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap
perilaku finansial dalam baik maupun mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul
dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang
pasar. Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respon positif terhadap penawaran upgrade
layanan yang diberikan.
2. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan
barang yang tidak pernah dibeli secara bersamaan.
II.2.5 MetodeAssociation Rule
Association rule adalah teknik data mining untuk mencari hubungan
antar-item dalam suatu dataset yang ditentukan. Contoh aturan asosiatif bisa kita
ambil dari suatu transaksi penjualan di sebuah toko, kita dapat mengetahui berapa
besar kemungkinan seorang konsumen membeli suatu item bersamaan dengan
item lainnya. Metode ini sering juga dinamakan dengan market basket analysis
19
Bila kita ambil contoh dalam sebuah transaksi pembelian barang di
sebuah toko didapat bentuk association rule roti → selai. Yang berarti bahwa
konsumen yang membeli roti ada kemungkinan konsumen tersebut juga akan
membeli selai.
Association rulememiliki dua tahap pengerjaan, yaitu [11]:
1. Mencari kombinasi yang paling sering terjadi dari suatu itemset.
2. Mendefinisikan Condition dan Result (untuk conditional association rule).
Dalam menentukan suatu association rule, terdapat suatuinterestingness
measure (ukuran kepercayaan) yang didapat dari hasil pengolahan data dengan
perhitungan tertentu. Umumnya ada dua ukuran, yaitu :
1. Support : suatu ukuran yang menunjukkan seberapa besar tingkat dominasi
suatu item/itemsetdari keseluruhan transaksi. Ukuran ini menentukan apakah
suatu item/itemsetlayak untuk dicari confidence-nya (misal, dari keseluruhan
transaksi yang ada, seberapa besar tingkat dominasi suatu item yang
menunjukkan bahwaitemA danitemB dibeli bersamaan).
2. Confidence: suatu ukuran yang menunjukkan hubungan antara 2 item secara
conditional (misal, menghitung kemungkinan seberapa sering item B dibeli
oleh pelanggan jika pelanggan tersebut membeli sebuahitemA).
Kedua ukuran ini nantinya berguna dalam menentukan kekuatan suatu
pola dengan membandingkan pola tersebut dengan nilai minimum kedua
parameter tersebut yang ditentukan oleh pengguna. Bila suatu pola memenuhi
kedua nilai minimum parameter yang sudah ditentukan sebelumnya, maka pola
tersebut dapat disebut sebagaiinteresting ruleataustrong rule.
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap [9] :
1. Analisis pola frekuensi tertinggi
Tahap ini mencari kombinasiitem yang memenuhi syarat minimum dari nilai
support dalam database. Nilai support sebuah item diperoleh dengan rumus
berikut.
Sementara itu, nilaisupportdari 2itemdiperoleh dari rumus berikut.
Persamaan (II-2)
Persamaan (II-3)
2. Pembentukan aturan asosiasi
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari
aturan asosiatif yang memenuhi syarat minimum untuk confidence dengan
menghitung confidence aturan assosiatif A -> B dari support pola frekuensi
tinggi A dan B, menggunakan rumus :
% Persamaan (II-4)
II.2.6 AlgoritmaEquivalence Class Transformation(Eclat) [12]
Baik Apriori dan FP-growth keduanya merupakan metode frequent
mining dari kumpulan transaksi dengan menggunakan bentuk TID-itemset,
dimana TID merupakan ID transaksi dan itemset merupakan kumpulan dari
barang yang dibeli pada transaksi TID. Ini dikenal dengan format data horizontal.
Selain itu, data dapat direpresentasikan dalam bentuk item-TID_set, dimana item
merupakan nama item, dan TID_set adalah kumpulan ID transaksi yang
mengandung item. Ini dikenal dengan format data vertikal. Algoritma Eclat adalah
algoritma yang menggunakan format data vertikal untuk merepresentasikan
datanya.
21
Berikut ini merupakan ilustrasi proses mining frequent itemset dengan
menggunakan algoritma Eclat :
1. Representasikan data ke dalam bentuk format data vertikal.
2. Tentukan nilaiminimum support.
3. Tentukan nilaiminimum confidence.
4. Cari data kandidat k-itemset(Ck) lalu hitung masing-masing nilaisupport-nya.
5. Hilangkanitemsetyang nilaisupport-nya kurang dari nilaiminimum support.
6. Setelah mendapatkan data yang memenuhi nilai minimum support (frequent),
lakukan kombinasi pada itemset berdasarkan TID_set yang sama pada
data-data tersebut sehingga menciptakan k-itemset.
7. Ulangi langkah ke 4 sampai dengan langkah ke 6 sampai tidak menghasilkan
itemsetbaru.
8. Cari aturan asosiatifnya dengan cara menentukan nilaiconfidence-nya,
9. Hilangkan data yang nilai confidence-nya kurang dari nilai minimum
confidence.
Kelebihan yang dimiliki oleh algoritma Eclat yang digunakan pada
penelitian ini adalah tidak memerlukan perhitungan nilai support, karena nilai
support dari itemset telah direpresentasikan oleh TID_set dari itemset tersebut.
Pekerjaan utama dari Eclat adalah mengkombinasikan item berdasarkan
TID_set-nya, sehingga ukuran dari TID_set merupakan salah satu faktor utama yang
mempengaruhi jumlah waktu dan memori yang diperlukan. Semakin besar
TID_set maka semakin besar pula waktu dan memori yang diperlukan.
II.2.7 Alat-Alat Pemodelan Sistem
Alat-alat pemodelan sistem adalah alat dan metode yang akan digunakan
untuk memodelkan perancangan perangkat lunak dalam skripsi ini. Adapun tools
pemodelan yang digunakan adalah :
1. Entity Relationship Diagram(ERD)
2. Diagram Konteks
3. Data Flow Diagram(DFD)
II.2.7.1 Entity Relationship Diagram(ERD)
ERD adalah suatu model jaringan yang menggunakan susunan data yang
disimpan dalam sistem secara abstrak [13]. Basis data relasional adalah kumpulan
dari relasi-relasi yang mengandung seluruh informasi berkenaan suatu entitas/
objek yang akan disimpan di dalam database. Tiap relasi disimpan sebagai sebuah
filetersendiri. Perancangan basis data merupakan suatu kegiaatan yang setidaknya
bertujuan sebagai berikut:
1. Menghilangkan redundansi data.
2. Meminimumkan jumlah relasi di dalam basis data.
3. Membuat relasi berada
4. Dalam bentuk normal, sehingga dapat meminimumkan permasalahan
berkenaan dengan penambahan, pembaharuan dan penghapusan.
II.2.7.2 Diagram Konteks
Diagram konteks adalah diagram yang terdiri dari suatu proses dan
menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level
tertinggi dari DFD yang menggambarkan seluruh input ke sistem dan outputdari
sistem. Ia akan membuat gambaran tentang keseluruhan sistem. Sistem dibatasi
oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks
hanya ada satu proses. Tidak boleh adastoredalam diagram konteks [13].
II.2.7.3 Data Flow Diagram(DFD)
Diagram aliran data merupakan model dari sistem untuk
menggambarkan pembagian sistem ke modul yang lebih kecil. Salah satu
keuntungan menggunakan diagram aliran data adalah memudahkan pemakai atau
user yang kurang menguasai bidang komputer untuk mengerti sistem yang akan
dikerjakan [13].
II.2.7.4 Kamus Data
Kamus data berfungsi membantu pelaku sistem untuk mengartikan
aplikasi secara detail dan mengorganisasi semua elemen data yang digunakan
23
dasar pengertian yang sama tentang masukan, keluaran, penyimpanan dan proses
[13].
II.2.8 MySQL
MySQL merupakan salah satu contoh produk RDBMS yang sangat
populer di lingkungan Linux, tetapi juga tersedia pada Windows. Banyak situs 19
web yang menggunakan MySQL sebagai database server (server yang melayani
permintaan akses terhadapdatabase). MySQL sebagaidatabase serverjuga dapat
diakses melalui program yang dibuat dengan menggunakan Borland Delphi.
Dengan cara seperti ini databasedapat diakses secara langsung melalui program
61
BAB V
KESIMPULAN DAN SARAN
V.1 Kesimpulan
Berdasarkan hasil implementasi dan pengujian yang telah dilakukan
pada aplikasi yang telah dibangun, maka dapat diambil kesimpulan bahwa
aplikasi yang dibangun dapat membantu PT. Focus Gaya Graha untuk mengetahui
pola pembelian konsumen, sehingga dapat membantu perusahaan untuk
menentukan produk yang akan diproduksi.
V.2 Saran
Adapun saran untuk pengembangan aplikasi lebih lanjut adalah sebagai
berikut :
1. Hasil aturan asosiatif (rule) yang dihasilkan dapat dikelompokkan berdasarkan
periode penjualan dan diurutkan berdasarkan nilai confidence-nya agar dapat
memudahkan dalam pemilihan produk mana yang akan masuk ke proses
produksi.
2. Optimalisasi dalam hal waktu danmemory, karena semakin banyak data yang
diproses maka semakin banyak juga waktu danmemoryyang diperlukan untuk
RIWAYAT HIDUP PENULIS
Nama : Aprisal Budiana
NIM : 10110446
Tempat/Tanggal Lahir : Bandung/10 April 1992
Jenis Kelamin : Laki-laki
Agama : Islam
Alamat : Jalan Ciroyom Gg. Ikhlas No. 37/77 Rt. 02/11
Kota : Bandung Kode POS : 40183
Telepon : 085795358882
Email : [email protected]
PENDIDIKAN
1. 1998–2004 : SD Angkasa 1 Kota Bandung
2. 2004–2007 : SMP Angkasa Kota Bandung
3. 2007–2010 : SMK Negeri 2 Kota Bandung
4. 2010–2015 : Program Studi S1 Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia, Bandung
Dengan ini Penulis menyatakan bahwa semua informasi yang diberikan dalam dokumen ini adalah benar
Bandung, 18 Agustus 2015
Penulis
PRODUK DI PT. FOCUS GAYA GRAHA MENGGUNAKAN
METODE
ASSOCIATION RULE
Aprisal Budiana
Teknik Informatika - Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
ABSTRAK
PT. Focus Gaya Graha merupakan suatu perusahaan perseorangan yang bergerak dibidang industri furniture. Saat ini, jenis produksi yang ada di PT. Focus Gaya Graha dibagi menjadi 3 yaitu
wood furniture, panel furniture dan photo frame. Setiap jenis produksi tersebut menghasilkan produk-produk dengan berbagai macam tipe, ukuran dan warna yang berbeda-beda. Sistem produksi di PT. Focus Gaya Graha dibagi menjadi 3 yaitu berdasarkan pesanan dan history penjualan banyaknya produk. Sistem produksi berdasarkan history penjualan banyaknya produk yang sering terjual acap kali mengakibatkan penumpukan hasil produksi, yang diakibatkan dari kesalahan dalam menentukan produk yang seharusnya diproduksi.
Dalam bidang keilmuandata mining, terdapat suatu metode yang dinamakan association rule. Association rule bertujuan untuk menunjukan nilai asosiatif antar produk yang dibeli oleh pelanggan sehingga terlihatlah sebuah pola berupa produk-produk apa saja yang sering dibeli secara bersamaan dalam sebuah transaksi penjualan. Dengan mengetahui produk-produk yang sering dibeli secara bersamaan, dapat dibuat sebuah dasar keputusan untuk menentukan produk-produk yang efektif bila diproduksi.
Dari hasil pengujian dapat disimpulkan bahwa metode data mining association rule dapat membantu PT. Focus Gaya Graha untuk mengetahui pola pembelian konsumen, sehingga dapat membantu perusahaan menentukan produk yang akan diproduksi.
Kata kunci:Data mining, association rule.
1. PENDAHULUAN 1.1. Latar Belakang
PT. Focus Gaya Graha merupakan suatu perusahaan perseorangan yang bergerak dibidang industri furniture. Saat ini, jenis produksi yang ada di PT. Focus Gaya Graha dibagi menjadi 3 yaitu
wood furniture, panel furniture dan photo frame.
Setiap jenis produksi tersebut menghasilkan berbagai produk dengan berbagai macam tipe, ukuran dan warna yang berbeda-beda. Produk-produk yang dihasilkan PT. Focus Gaya Graha telah dipasarkan hingga ke luar negeri, hal ini tentu saja menghasilkan banyak data transaksi penjualan. Saat ini, pemanfaatan data transaksi penjualan tersebut hanya sebatas pembuatan laporan bagi perusahaan lalu diarsipkan saja, tidak dimanfaatkan untuk dasar pertimbangan dalam menentukan produk yang akan diproduksi. Sistem produksi yang berjalan di PT. Focus Gaya Graha yaitu berdasarkan pesanan dan
history penjualan banyaknya produk yang sering terjual. Sistem produksi berdasarkan history
penjualan banyaknya produk yang sering terjual acap kali mengakibatkan penumpukan hasil produksi, yang diakibatkan dari kesalahan dalam menentukan produk yang seharusnya diproduksi.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual [1]. Dalam bidang keilmuan
data mining, terdapat suatu metode yang dinamakan
association rule. Metode ini sering juga dinamakan denganmarket basket analysiskarena awal mulanya yang berasal dari studi tentang database transaksi penjualan [2]. Association rule bertujuan untuk menunjukan nilai asosiatif antar produk-produk yang dibeli oleh pelanggan sehingga terlihatlah sebuah pola berupa produk-produk apa saja yang sering dibeli secara bersamaan dalam sebuah transaksi penjualan. Dengan mengetahui produk apa saja yang sering dibeli secara bersamaan, dapat dibuat sebuah dasar pengambilan keputusan untuk menentukan produk mana saja yang efektif bila diproduksi.
Berdasarkan uraian diatas, maka diperlukan perangkat lunak yang mengimplementasi metode
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
1.2. Maksud dan Tujuan
1.2.1. Maksud
Maksud dari penelitian ini adalah mengimplementasikan data mining pada penjualan produk di PT. Focus Gaya Graha menggunakan metodeassociation rule.
1.2.2. Tujuan
Tujuan yang diharapkan adalah dapat membantu PT. Focus Gaya Graha untuk mengetahui pola pembelian konsumen, agar dapat mempermudah dalam menentukan produk apa yang akan diproduksi
1.3. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database [9].
Menurut Pramudiono [1], “Data mining
adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara
manual.”
Menurut Larose [4] kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor, antara lain :
1. Pertumbuhan yang cepat dalam kumpulan data. 2. Penyimpanan data dalam data warehouse,
sehingga seluruh perusahaan memiliki akses ke dalamdatabaseyang andal.
3. Adanya peningkatan akses data melalui navigasi
webdan intranet.
4. Tekanan kompetensi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi. 5. Perkembangan teknologi perangkat lunak untuk
data mining(ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
1.4. Cross-Industry Standard Process for Data
Mining(CRISP-DM)
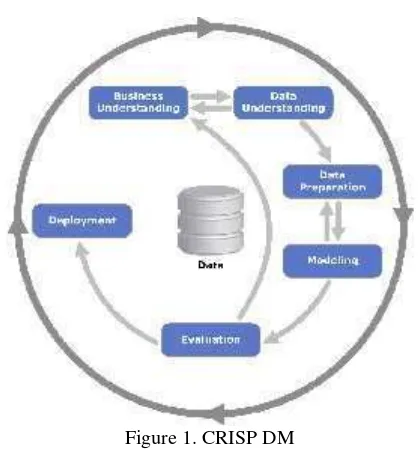
CRISP-DM yang dikembangkan tahun 1996 oleh analis dari beberapa industri seperti Daimler Chrysler, SPSS dan NCR. CRISP-DM menyediakan standar proses data mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit penelitian.
Dalam CRISP-DM, sebuah proyek data mining memiliki siklus hidup yang terbagi dalam enam fase. Keseluruhan fase berurutan yang ada tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada keluaran dari fase sebelumnya. Hubungan antarfase digambarkan dengan panah. Sebagai contoh, jika proses berada pada fase modelling. Berdasar pada perilaku dan karakteristik model, proses mungkin harus kembali kepada fasedata preparationuntuk perbaikan lebih
lanjut terhadap data atau berpindah maju kepada fase
evaluation. Enam fase yang ada dalam metode CRISP-DM tersebut dapat dilihat pada Gambar 1 :
Gambar 1. CRISP DM
Fase-fase CRISP-DM [4] : 1. Business Understanding
Business Understanding atau pemahaman
domain (penelitian). Pada fase ini dibutuhkan pemahaman tentang substansi dari kegiatandata mining yang akan dilakukan, kebutuhan dari perspektif bisnis. Kegiatannya antara lain: menentukan sasaran atau tujuan bisnis, memahami situasi bisnis, menentukan tujuan
data miningdan membuat perencanaan strategi serta jadwal penelitian.
2. Data Understanding
Data Understanding atau pemahaman data adalah fase mengumpulkan data awal, mempelajari data untuk bisa mengenal data yang akan dipakai. Fase ini mencoba mengidentifikasikan masalah yang berkaitan dengan kualitas data, mendeteksi subset yang menarik dari data untuk membuat hipotesa awal.
3. Data Preparation
Data preparation atau persiapan data. Fase ini sering disebut sebagai fase yang padat karya. Aktivitas yang dilakukan antara lain memilih
tabledan fieldyang akan ditransformasikan ke dalam database baru untuk bahan data mining
(set data mentah). 4. Modelling
Modeling adalah fase menentukan tehnik data miningyang digunakan, menentukantools data mining, teknik data mining, algoritma data mining, menentukan parameter dengan nilai yang optimal.
5. Evaluation
menyesuaikan model yang didapat agar sesuai dengan sasaran yang ingin dicapai dalam fase pertama.
6. Deployment
Deployment atau penyebaran adalah fase penyusunan laporan atau presentasi dari pengetahuan yang didapat dari evaluasi pada proses data mining.
1.5. MetodeAssociation Rule
Association rule adalah teknikdata mining
untuk mencari hubungan antar-item dalam suatu dataset yang ditentukan. Contoh aturan asosiatif bisa kita ambil dari suatu transaksi penjualan di sebuah toko, kita dapat mengetahui berapa besar kemungkinan seorang konsumen membeli suatuitem
bersamaan dengan item lainnya. Metode ini sering juga dinamakan dengan market basket analysis
karena awal mulanya yang berasal dari studi tentang database transaksi penjualan.
Bila kita ambil contoh dalam sebuah transaksi pembelian barang di sebuah toko didapat bentuk association rule roti → selai. Yang berarti
bahwa konsumen yang membeli roti ada kemungkinan konsumen tersebut juga akan membeli selai.
Association rule memiliki dua tahap pengerjaan, yaitu [11]:
1. Mencari kombinasi yang paling sering terjadi dari suatu itemset.
2. Mendefinisikan Condition dan Result (untuk conditional association rule).
Dalam menentukan suatu association rule, terdapat suatu interestingness measure (ukuran kepercayaan) yang didapat dari hasil pengolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran, yaitu :
1. Support : suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu
item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu item/itemset layak untuk dicari confidence-nya (misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item yang menunjukkan bahwaitemA danitemB dibeli bersamaan). 2. Confidence : suatu ukuran yang menunjukkan
hubungan antara 2 item secara conditional
(misal, menghitung kemungkinan seberapa sering item B dibeli oleh pelanggan jika pelanggan tersebut membeli sebuahitemA).
Kedua ukuran ini nantinya berguna dalam menentukan kekuatan suatu pola dengan membandingkan pola tersebut dengan nilai minimum kedua parameter tersebut yang ditentukan oleh pengguna. Bila suatu pola memenuhi kedua nilai minimum parameter yang sudah ditentukan sebelumnya, maka pola tersebut dapat disebut sebagaiinteresting ruleataustrong rule.
menjadi dua tahap [9] :
1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support
dalam database. Nilai support sebuah item
diperoleh dengan rumus berikut.
(1)
Sementara itu, nilai support dari 2 item
diperoleh dari rumus berikut.
(2)
(3)
2. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari aturan asosiatif yang memenuhi syarat minimum untukconfidencedengan menghitungconfidenceaturan assosiatif A -> B dari
support pola frekuensi tinggi A dan B, menggunakan rumus :
.
x100% (4)
1.6. Algoritma Equivalence Class
Transformation (Eclat) [12]
Baik Apriori dan FP-growth keduanya merupakan metode frequent mining dari kumpulan transaksi dengan menggunakan bentuk TID-itemset, dimana TID merupakan ID transaksi dan itemset
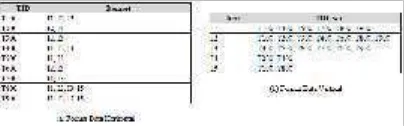
merupakan kumpulan dari barang yang dibeli pada transaksi TID. Ini dikenal dengan format data horizontal. Selain itu, data dapat direpresentasikan dalam bentuk item-TID_set, dimana item merupakan nama item, dan TID_set adalah kumpulan ID transaksi yang mengandung item. Ini dikenal dengan format data vertikal. Algoritma Eclat adalah algoritma yang menggunakan format data vertikal untuk merepresentasikan datanya.
Gambar 2. Format Data Horizontal dan Vertikal .
Berikut ini merupakan ilustrasi proses
mining frequent itemset dengan menggunakan algoritma Eclat :
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033 2. Tentukan nilaiminimum support.
3. Tentukan nilaiminimum confidence.
4. Cari data kandidat k-itemset (Ck) lalu hitung
masing-masing nilaisupport-nya.
5. Hilangkan itemset yang nilai support-nya kurang dari nilaiminimum support.
6. Setelah mendapatkan data yang memenuhi nilai
minimum support(frequent), lakukan kombinasi pada itemset berdasarkan TID_set yang sama pada data-data tersebut sehingga menciptakan k-itemset.
7. Ulangi langkah ke 4 sampai dengan langkah ke 6 sampai tidak menghasilkanitemsetbaru. 8. Cari aturan asosiatifnya dengan cara
menentukan nilaiconfidence-nya,
9. Hilangkan data yang nilai confidence-nya kurang dari nilaiminimum confidence.
Kelebihan yang dimiliki oleh algoritma Eclat yang digunakan pada penelitian ini adalah tidak memerlukan perhitungan nilai support, karena nilai support dari itemset telah direpresentasikan oleh TID_set dari itemset tersebut. Pekerjaan utama dari Eclat adalah mengkombinasikan item berdasarkan TID_set-nya, sehingga ukuran dari TID_set merupakan salah satu faktor utama yang mempengaruhi jumlah waktu dan memori yang diperlukan. Semakin besar TID_set maka semakin besar pula waktu dan memori yang diperlukan.
2. ISI PENELITIAN 2.1. Analisis Sumber Data
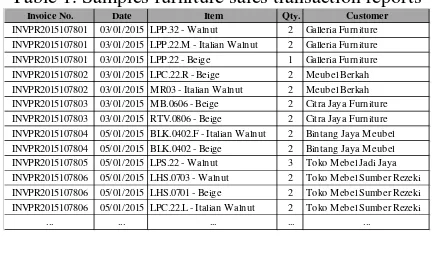
Data yang digunakan adalah laporan transaksi penjualan furniturepada bulan Januari 2015 sampai dengan Februari 2015. Data laporan transaksi penjualan furniture yang digunakan merupakan gabungan dari data produk dan data transaksi penjualan. Data laporan transaksi penjualan furniture yang digunakan tersebut berformat excel (*.xls).
Tabel 1. Sampel laporan transaksi penjualan furniture
Invoice No. Date Item Qty. Customer
INVPR2015107801 03/01/2015 LPP.32 - Walnut 2 Galleria Furniture
INVPR2015107801 03/01/2015 LPP.22.M - Italian Walnut 2 Galleria Furniture
INVPR2015107801 03/01/2015 LPP.22 - Beige 1 Galleria Furniture
INVPR2015107802 03/01/2015 LPC.22.R - Beige 2 Meubel Berkah
INVPR2015107802 03/01/2015 MR03 - Italian Walnut 2 Meubel Berkah
INVPR2015107803 03/01/2015 MB.0606 - Beige 2 Citra Jaya Furniture
INVPR2015107803 03/01/2015 RTV.0806 - Beige 2 Citra Jaya Furniture
INVPR2015107804 05/01/2015 BLK.0402.F - Italian Walnut 2 Bintang Jaya Meubel
INVPR2015107804 05/01/2015 BLK.0402 - Beige 2 Bintang Jaya Meubel
INVPR2015107805 05/01/2015 LPS.22 - Walnut 3 Toko Mebel Jadi Jaya
INVPR2015107806 05/01/2015 LHS.0703 - Walnut 2 Toko Mebel Sumber Rezeki
INVPR2015107806 05/01/2015 LHS.0701 - Beige 2 Toko Mebel Sumber Rezeki
INVPR2015107806 05/01/2015 LPC.22.L - Italian Walnut 2 Toko Mebel Sumber Rezeki
... ... ... ... ...
2.2. Analisis Persiapan Data
Adapun langkah-langkah persiapan data dalam penelitian ini adalah sebagai berikut :
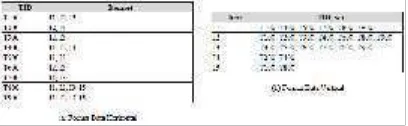
1. Pemilihan Data
Tahap pemilihan data memiliki tugas meliputi pemilihan table dan field. Table yang dipilih
adalah table laporan transaksi penjualan. Field
yang dipilih adalah fieldInvoice No. dan item.
Fieldtersebut dipilih karena dari field tersebut dapat dilihat apa saja produk yang sering dibeli konsumen secara bersamaan. Hasil pemilihan data dapat dilihat pada tabel 2.
Tabel 2. Hasil pemilihan data
Invoice No. Item
INVPR2015107801 LPP.32 - Walnut INVPR2015107801 LPP.22.M - Italian Walnut INVPR2015107801 LPP.22 - Beige
INVPR2015107802 LPC.22.R - Beige INVPR2015107802 MR03 - Italian Walnut INVPR2015107803 MB.0606 - Beige INVPR2015107803 RTV.0806 - Beige
INVPR2015107804 BLK.0402.F - Italian Walnut INVPR2015107804 BLK.0402 - Beige
INVPR2015107805 LPS.22 - Walnut INVPR2015107806 LHS.0703 - Walnut INVPR2015107806 LHS.0701 - Beige INVPR2015107806 LPC.22.L - Italian Walnut
... ...
2. Pembersihan Data
Pada proses ini dilakukan proses pembersihan data dari data-data yang tidak relevan. Kriteria data tidak relevan adalah data yang hanya memiliki satu item tunggal didalam sebuah transaksi, karena dapat dipastikan data tersebut tidak akan memiliki keterkaitan dengan data lainnya. Hasil pembersihan data dapat dilihat pada tabel 3.
Tabel 3. Hasil Pembersihan Data
Invoice No. Item
INVPR2015107801 LPP.32 - Walnut INVPR2015107801 LPP.22.M - Italian Walnut INVPR2015107801 LPP.22 - Beige
INVPR2015107802 LPC.22.R - Beige INVPR2015107802 MR03 - Italian Walnut INVPR2015107803 MB.0606 - Beige INVPR2015107803 RTV.0806 - Beige
INVPR2015107804 BLK.0402.F - Italian Walnut INVPR2015107804 BLK.0402 - Beige
INVPR2015107806 LHS.0703 - Walnut INVPR2015107806 LHS.0701 - Beige INVPR2015107806 LPC.22.L - Italian Walnut
... ...
3. Pembangunan Data
Tabel penjualan merupakan tabel yang menyimpan data tentang transaksi penjualan, struktur tabel dapat dilihat pada tabel 4.
Tabel 4 Struktur Tabel penjualan
Field Tipe Data Ukuran Definisi
Invoice No. Varchar 25 No transaksi pada nota penjualan. Customer Varchar 30 Konsumen yang membeli produk.
b. Tabel detailpenjualan
Tabel detailpenjualan merupakan tabel yang menyimpan data tentang transaksi penjualan, struktur tabel dapat dilihat pada tabel 5.
Tabel 5. Struktur Tabel detailpenjualan
Field Tipe Data Ukuran Definisi
Invoice No. Varchar 25 No transaksi pada nota penjualan.
Date Date - Tanggal transaksi penjualan.
Item Varchar 30 Produk yang dibeli oleh konsumen.
Qty. Int 4 Jumlah produk yang dibeli oleh konsumen.
c. Tabel preprocessing
Tabel produk merupakan tabel yang berisi tentang informasi produk, struktur tabel dapat dilihat pada tabel 6.
Tabel 6 Struktur Tabel preprocessing
Field Tipe Data Ukuran Definisi
Invoice No. Varchar 25 No transaksi pada nota penjualan. Item Varchar 30 Produk yang dibeli oleh konsumen.
4. Format Data
Tahap format data merupakan tahap akhir dari persiapan data sebelum memulai tahap pemodelan. Tahap ini memiliki akhir berupa format data yang akan digunakan dalam proses mining seperti yang dapat dilihat pada tabel 7.
Tabel 7. Format Data untuk Proses Mining
Invoice No. Item
INVPR2015107801 LPP.32 - Walnut
INVPR2015107801 LPP.22.M - Italian Walnut INVPR2015107801 LPP.22 - Beige
INVPR2015107802 LPC.22.R - Beige
... ...
2.3. Analisis Pemodelan
Tahapan ini terdiri dari 2 tahapan, yaitu : a. Teknik Pemodelan
Teknik pemodelan yang digunakan sesuai dengan tujuan awal yaitu untuk menentukan produk yang akan diproduksi. Model yang digunakan yaitu algoritma Equivalence Class Transformation(Eclat).
Kasus yang akan diuji dengan menggunakan algoritma Eclat ini adalah sebagai berikut : 1. Data yang digunakan adalah laporan transaksi
penjualan furniture periode Januari sampai dengan Februari 2015 yang telah diformat sesuai dengan kebutuhan proses mining. 2. Representasikan data laporan transaksi
penjualan furniture yang telah diformat tersebut ke dalam format data vertikal.
Tabel 8. Format Data Vertikal
Item TID_1 TID_2 TID_3 TID_4 TID_5 LPP.32 - Walnut INVPR2015107801 INVPR2015107844 INVPR2015107876 INVPR2015107883 INVPR2015107896 LPP.22.M - Italian Walnut INVPR2015107801
LPP.22 - Beige INVPR2015107801 INVPR2015107896
3. Tentukan nilai minimum support. (Minimum Support= 3)
4. Tentukan nilaiminimum confidence. (Minimum Confidence= 50%)
5. Dari format data vertikal dapat diketahui kandidat 1-itemset (C1). Data tersebut dapat dilihat pada tabel dibawah ini.
Tabel 9. Calon Kandidat 1-itemset(C1)
Item TID_1 TID_2 TID_3 TID_4 TID_5
LPP.32 - Walnut INVPR2015107801 INVPR2015107844 INVPR2015107876 INVPR2015107883 INVPR2015107896 LPP.22.M - Italian Walnut INVPR2015107801
LPP.22 - Beige INVPR2015107801 INVPR2015107896
LPC.22.R - Beige INVPR2015107802 INVPR2015107810 INVPR2015107846 INVPR2015107852 INVPR2015107866 MR03 - Italian Walnut INVPR2015107802 INVPR2015107811 INVPR2015107820 INVPR2015107837 INVPR2015107839 MB.0606 - Beige INVPR2015107803 INVPR2015107872
RTV.0806 - Beige INVPR2015107803 BLK.0402.F - Italian Walnut INVPR2015107804 INVPR2015107848 BLK.0402 - Beige INVPR2015107804 INVPR2015107833 INVPR2015107879
6. Data kandidat 1-itemset(C1) yang nilaisupport -nya tidak memenuhi nilai minimum support
dihapus, maka akan didapatkan frequent
1-itemset (L1). Data tersebut dapat dilihat pada tabel dibawah ini.
Tabel 10.Frequent1-itemset(L1)
Item TID_1 TID_2 TID_3 TID_4 TID_5
LPP.32 - Walnut INVPR2015107801 INVPR2015107844 INVPR2015107876 INVPR2015107883 INVPR2015107896 LPC.22.R - Beige INVPR2015107802 INVPR2015107810 INVPR2015107846 INVPR2015107852 INVPR2015107866 MR03 - Italian Walnut INVPR2015107802 INVPR2015107811 INVPR2015107820 INVPR2015107837 INVPR2015107839 BLK.0402 - Beige INVPR2015107804 INVPR2015107833 INVPR2015107879
LHS.0703 - Walnut INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107847 INVPR2015107851 LHS.0701 - Beige INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107861 INVPR2015107870 LPC.32.R - Walnut INVPR2015107806 INVPR2015107810 INVPR2015107822 INVPR2015107831 INVPR2015107852 RB01 - Walnut INVPR2015107811 INVPR2015107815 INVPR2015107828 INVPR2015107831 INVPR2015107835 MB.0602 - Beige INVPR2015107812 INVPR2015107816 INVPR2015107843 INVPR2015107862 INVPR2015107874
7. Setelah mendapatkan data frequent 1-itemset, untuk mendapatkan kandidat 2-itemset (C2) maka lakukan kombinasi antar item pada L1 berdasarkan TID_k item-item tersebut. Jika hasil kombinasi menghasilkan nilai support
kurang dari nilai minimum support, maka
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033 Tabel 11. Kandidat 2-itemset (C2)
Item_1 Item_2 TID_1 TID_2 TID_3 TID_4 LPP.32 - Walnut MR03 - Italian Walnut INVPR2015107896
LPP.32 - Walnut MR02 - Italian Walnut INVPR2015107883
LPP.32 - Walnut LPP.22 - Italian Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 LPC.22.R - Beige MR03 - Italian Walnut INVPR2015107802
LPC.22.R - Beige LHS.0703 - Walnut INVPR2015107846 LPC.22.R - Beige LHS.0701 - Beige INVPR2015107846
LPC.22.R - Beige LPC.32.R - Walnut INVPR2015107810 INVPR2015107852 INVPR2015107884 LPC.22.R - Beige RB01 - Walnut INVPR2015107866
LPC.22.R - Beige MT0901 - Walnut INVPR2015107890 LPC.22.R - Beige RTV.0802 - Italian Walnut INVPR2015107866 LPC.22.R - Beige LHS.0703 - Italian Walnut INVPR2015107878
Tabel 12. Frequent 2-itemset(L2)
Item_1 Item_2 TID_1 TID_2 TID_3 TID_4 Support
LPP.32 - Walnut LPP.22 - Italian Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 LPC.22.R - Beige LPC.32.R - Walnut INVPR2015107810 INVPR2015107852 INVPR2015107884 3 MR03 - Italian Walnut MR02 - Italian Walnut INVPR2015107820 INVPR2015107839 INVPR2015107845 INVPR2015107864 4 LHS.0703 - Walnut LHS.0701 - Beige INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 MB.0602 - Beige MB.0603 - Beige INVPR2015107843 INVPR2015107862 INVPR2015107893 3
8. Lakukan proses ke-7 secara berulangan pada setiap item hingga tidak menghasilkan itemset
yang baru. Hasil dapat dilihat pada tabel dibawah ini.
Tabel 13. Frequent 2-itemset(L2)
Item_1 Item_2 TID_1 TID_2 TID_3 TID_4 Support
LPP.32 - Walnut LPP.22 - Italian Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 LPC.22.R - Beige LPC.32.R - Walnut INVPR2015107810 INVPR2015107852 INVPR2015107884 3 MR03 - Italian Walnut MR02 - Italian Walnut INVPR2015107820 INVPR2015107839 INVPR2015107845 INVPR2015107864 4 LHS.0703 - Walnut LHS.0701 - Beige INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 MB.0602 - Beige MB.0603 - Beige INVPR2015107843 INVPR2015107862 INVPR2015107893 3
9. Dari hasil pembentukan itemset yang memenuhi nilai minimum support, maka langkah selanjutnya adalah hitung nilai confidence untuk setiap itemset yang dihasilkan.
Tabel 14. Hasil Perhitungan Nilai Confidence
TID_1 TID_2 TID_3 TID_4 Support Confidence (% ) LPP.32 - Walnut →LPP.22 - Italian Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 60 LPC.22.R - Beige →LPC.32.R - Walnut INVPR2015107810 INVPR2015107852 INVPR2015107884 3 37,5 MR03 - Italian Walnut →MR02 - Italian Walnut INVPR2015107820 INVPR2015107839 INVPR2015107845 INVPR2015107864 4 36,36 LHS.0703 - Walnut →LHS.0701 - Beige INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 66,67 MB.0602 - Beige →MB.0603 - Beige INVPR2015107843 INVPR2015107862 INVPR2015107893 3 50 LPP.22 - Italian Walnut →LPP.32 - Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 100 LPC.32.R - Walnut →LPC.22.R - Beige INVPR2015107810 INVPR2015107852 INVPR2015107884 3 42,85 MR02 - Italian Walnut →MR03 - Italian Walnut INVPR2015107820 INVPR2015107839 INVPR2015107845 INVPR2015107864 4 44,44 LHS.0701 - Beige →LHS.0703 - Walnut INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 66,67 MB.0603 - Beige →MB.0602 - Beige INVPR2015107843 INVPR2015107862 INVPR2015107893 3 60
Itemset
10. Setelah mendapatkan data hasil perhitungan nilai confidence dari setiap itemset, langkah selanjutnya ialah hapus data yang tidak memenuhi nilaiminimum confidence.
Tabel 15. Data yang Memenuhi Aturan Asosiasi
TID_1 TID_2 TID_3 TID_4 Support Confidence (%)
LPP.32 - Walnut →LPP.22 - Italian Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 60 LHS.0703 - Walnut →LHS.0701 - Beige INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 66,67 MB.0602 - Beige →MB.0603 - Beige INVPR2015107843 INVPR2015107862 INVPR2015107893 3 50 LPP.22 - Italian Walnut →LPP.32 - Walnut INVPR2015107844 INVPR2015107876 INVPR2015107883 3 100 LHS.0701 - Beige →LHS.0703 - Walnut INVPR2015107806 INVPR2015107842 INVPR2015107846 INVPR2015107898 4 66,67
Itemset
2.4. Diagram Konteks
Diagram konteks menggambarkan proses input dan output data pada sistem. Berikut adalah diagram konteks dari aplikasi yang dibangun :
Marketing Aplikasi Data Mining
PT. Focus Gaya Graha Data Alamat File Laporan Transaksi Penjualan
Data Minimum Support Data Minimum Confidence
Info Laporan Transaksi Penjualan Info Data Detail Penjualan
Info Data Preprocessing
Gambar 3. Digaram Konteks
2.5.Data Flow Diagram(DFD)
DFD adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari sistem. Berikut adalah DFD level 1 dari sistem yang dibangun :
Gambar 4. DFD level 1
Berikut adalah DFD level 2 dari proses Import Data :
Gambar 5. DFD level 2 untuk proses Import Data