1
1.1 Latar Belakang Masalah
Pengenalan suara merupakan proses identifikasi suara berdasarkan kata yang diucapkan seseorang yang ditangkap oleh perangkat input suara untuk dikenali dan kemudian diterjemahkan menjadi sebuah data yang dipahami oleh komputer. Ketika manusia mengeluarkan suara, saat itulah suara tersebut menyampaikan beberapa informasi di dalam kata yang diucapkan melalui gelombang suara. Informasi suara tersebut dapat diketahui melalui fitur suara itu sendiri, diantaranya dengan pitch dan formant, dimana pitch adalah frekuensi fundamental dari sinyal suara yang dihasilkan karena getaran pita suara, dan formant adalah frekuensi resonansi akustik dari bidang suara manusia [1]. Kedua fitur tersebut merupakan fitur suara yang sangat penting untuk mengidentifikasi suara yang diucapkan dari seseorang [2][3].
Pada penelitian sebelumnya, Yixion Pan, Peipei Shen, dan Liping Shen melakukan pengenalan emosi suara menggunakan Support Vector Machine. Mereka menganalisis emosi suara dari bahasa Jerman dan China, serta mengkombinasikan ekstraksi fitur dengan MFCC+MEDC+Energy menghasilkan akurasi emosi suara bahasa China sebesar 91.3% dan emosi suara bahasa Jerman sebesar 95.1% [5].
Metode Support Vector Machine (SVM) merupakan metode klasifikasi jenis terpandu karena ketika proses pelatihan, diperlukan target pembelajaran tertentu. Meskipun waktu pelatihan SVM kebanyakan lambat, tetapi metode ini sangat akurat karena kemampuannya untuk menangani model-model nonlinear yang kompleks. SVM dapat digunakan untuk prediksi dan klasifikasi [4].
pada pria dan wanita ditinjau dari pitch dan formant menggunakan metode Support Vector Machine.
1.2 Rumusan Masalah
Permasalahan yang ingin dibahas pada skripsi ini adalah bagaimana mengidentifikasi suara tinggi dan rendah pada pria dan wanita ditinjau dari pitch danformantmenggunakan metodesupport vector machine.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan skripsi ini adalah untuk mengidentifikasi suara tinggi dan rendah pada pria dan wanita ditinjau dari pitch dan formant menggunakan metode support vector machine. Tujuan yang ingin dicapai dalam skripsi ini adalah :
1. Untuk mengenali suara berdasarkan nilai frekuensipitchdanformant. 2. Untuk mendapatkan nilai akurasi pendeteksian dari suara pria dan wanita.
1.4 Batasan Masalah
Dalam skripsi ini dibatasi masalah sebagai berikut :
1. Suara yang diteliti adalah suara manusia baik pria maupun wanita yang berumur 20-35 tahun [11].
2. Suara yang digunakan sebagai masukan adalah suara dengan mono channel[4].
3. Inputberupafile *.wav dengan frekuensi pencuplikan 8000 Hz [10]. 4. Panjang suara maksimal 3 detik [9].
5. Jenis suara yang diklasifikasikan adalah Tenor (tinggi) dan Bass (rendah) untuk suara pria, sedangkan Sopran (tinggi) dan Alto (rendah) untuk suara wanita [3].
6. Kata yang diidentifikasi adalah “do-re-mi-fa-sol-la-si-do”. 7. MetodeAutocorrelationuntuk menentukanpitch[9].
9. Kernel Trick RBF (Radial Basis Function) untuk menyelesaikan masalah klasifikasi untuk dataset yang bersifatnon-linear[4].
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metode kuantitatif, yaitu suatu metode yang menggambarkan fakta-fakta dan informasi dalam situasi atau kejadian secara sistematis, faktual dan akurat dengan menggunakan model-model matematis. Metodologi penelitian ini memiliki dua metode, yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Tahap pengumpulan data yang digunakan pada penelitian ini adalah sebagai berikut :
a. Studi Literatur
Studi literatur adalah metode pengumpulan data yang diperoleh dengan mempelajari teori yang berkaitan dengan pengenalan suara, termasuk penerapan pemrosesan sinyal suara dansupport vector machine.
b. Data dan Variabel Penelitian
Data yang digunakan dalam penelitian ini adalah data tentang nilai frekuensi pitch dan formant dari suara pria dan wanita yang diperoleh dengan cara perekaman. Pada penelitian ini, hanya digunakan dua kategori (group), yaitu kategori suara tinggi dan suara rendah.
c. Langkah-langkah Analisis
Langkah-langkah analisis identifikasi suara adalah sebagai berikut :
1. Melakukan pengumpulan data suara pria dan wanita dengan kategori tinggi dan rendah.
Gambar 1.1 Tahapan Analisis Identifikasi Suara
Tahapan analisis identifikasi suara dari gambar di atas dapat dijelaskan sebagai berikut :
1. Pre-processing
Tahap pre-processing merupakan proses memasukkan data suara yang telah disimpan berupa file *.wav yang sebelumnya dilakukan perekaman dengan frekuensi sampling sebesar 8000 Hz menggunakan aplikasi audacity sebanyak rekaman yang dibutuhkan. Kemudian menyaring sinyal suara menjadi bentuk yang lebih halus dan membuang informasi yang tidak dibutuhkan dalam proses ini. Tahappre-processingdibagi menjadi 3 bagian, yaitu pre-emphasis, frame blocking, dan hamming window. Pre-emphasis dilakukan untuk mendapatkan bentuk gelombang frekuensi sinyal suara yang lebih halus. Kemudian setelah dilakukan pre-emphasis, sinyal suara ditempatkan ke dalam frame menjadi beberapa bagian. Setelah dilakukan frame blocking, dilakukan hamming window untuk mengurangi efek diskontinuitas dari potongan-potongan atau bagian-bagian sinyal suara.
2. Feature Extraction
3. Classification
Tahap classification merupakan proses pengklasifikasian data fitur suara dari pitch dan formant dengan menggunakan metode support vector machine untuk menghasilkan informasi suara yang diidentifikasi dari kedua fitur tersebut.
1.5.2 Metode Pembangunan Perangkat Lunak
Metode yang digunakan dalam pembuatan perangkat lunak ini menggunakan modelwaterfallseperti pada Gambar 1.2 di bawah ini.
Gambar 1.2 ModelWaterfall[6]
Model ini adalah model klasik yang melakukan pendekatan secara sistematis, berurutan dalam membangunsoftware berkat penurunan dari satu fase ke fase lainnya. Tahap dari model ini adalah sebagai berikut :
1. Communication
Tahap communication merupakan analisis terhadap kebutuhan simulator dan tahap untuk mengadakan pengumpulan data suara manusia dengan melakukan perekaman suara pria dan wanita usia 20-35 tahun.
2. Planning
3. Modeling
Tahap modeling akan menerjemahkan syarat kebutuhan ke sebuah perancangan simulator yang dapat diperkirakan sebelum dibuat coding. Proses ini berfokus pada rancangan detail (algoritma) prosedural. Tahapan ini akan menghasilkan dokumen yang disebut software requirement. Spesifikasi kebutuhan simulator dilakukan berdasarkan kebutuhan simulator pengidentifikasi suara untuk penerapan analisis algoritma. Spesifikasi kebutuhan perangkat lunak akan dibagi kedalam dua bagian, yaitu SKPL-F (Spesifikasi Kebutuhan Perangkat Lunak Fungsional) dan SKPL-NF (Spesifikasi Kebutuhan Perangkat Lunak Non-Fungsional). 4. Construction
Tahap construction merupakan proses pembuatan kode. Coding atau pengkodean merupakan penerjemahan desain dalam bahasa yang bisa dikenali oleh komputer. Tahapan inilah yang merupakan tahapan secara nyata dalam mengerjakan suatu simulator, artinya dalam tahapan ini penggunaan komputer akan dimaksimalkan. Setelah pengkodean selesai maka akan dilakukan testingterhadap simulator yang telah dibuat. Tujuan testing adalah menemukan kesalahan-kesalahan terhadap simulator tersebut untuk kemudian bisa diperbaiki.
5. Deployment
Tahap deployment bisa dikatakan final dari pembuatan simulator. Setelah melakukan analisis, desain dan pengkodean, maka simulator yang sudah jadi akan digunakan oleh user. Kemudiansoftwareyang telah dibuat harus dilakukan pemeliharaan secara berkala. Pada simulator pengidentifikasian suara ini, tahapdeploymenttidak perlu dilakukan.
1.6 Sistematika Penulisan
BAB 1 PENDAHULUAN
Bab 1 ini membahas tentang latar belakang masalah, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, dan sistematika penulisan untuk menjelaskan pokok-pokok pembahasan skripsi ini.
BAB 2 LANDASAN TEORI
Bab 2 ini membahas tentang teori suara, proses produksi suara, pitch, formant, klasifikasi sinyal berdasarkan eksitasi, sinyal digital, sinyal analog, jenisfile audio digital, elemen dasar sistem pemrosesan sinyal, pengubahan sinyal analog menjadi sinyal digital, pemrosesan sinyal suara, pre-emphasis, frame blocking, hamming window, autocorrelation, linear predictive coding, kecerdasan buatan (AI),machine learning, dansupport vector machine.
BAB 3 ANALISIS DAN PERANCANGAN
Bab 3 ini membahas tentang analisis sistem, analisis metode, analisis spesifikasi kebutuhan perangkat lunak, analisis kebutuhan non-fungsional, analisis kebutuhan perangkat keras, analisis pengguna, analisis perangkat lunak, analisis kebutuhan fungsional, perancangan antarmuka perangkat lunak pengidentifikasi suara. Masalah yang terjadi dalam skripsi ini untuk mengidentifikasi suara tinggi dan rendah pada pria dan wanita, maka itu dilakukan analisis dari penelitian sebelumnya yang berkaitan dengan pengenalan suara. Sistem yang dibuat berbentuk simulator yang dianalisis, yaitu dari tahap pre-processing, feature extraction, dan classification. Hasil akhir yang didapat berupa informasi identifikasi suara.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab 4 ini membahas tentang implementasi data dan antarmuka serta pengujian dengan menggunakan pengujianblack box.
BAB 5 KESIMPULAN DAN SARAN
9
2.1 Teori Umum Suara
Suara adalah fenomena fisik yang dihasilkan oleh getaran suatu benda yang berdupa sinyal analog dengan amplitudo yang berubah secara kontinyu terhadap waktu. Suara berhubungan erat dengan rasa “mendengar”. Suara atau bunyi biasanya merambat melalui udara. Suara atau bunyi tidak bisa merambat melalui ruang hampa [1].
2.2 Proses Produksi Suara
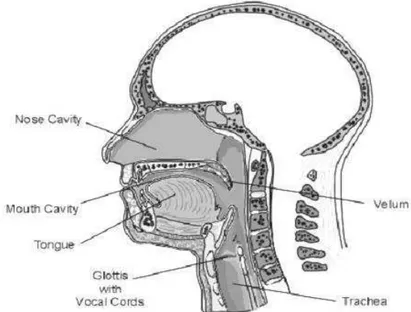
Speech(wicara) dihasilkan dari sebuah kerjasama antaralungs(paru-paru), glottis (dengan vocal cords) dan articulation tract (mouth/mulut dan nose cavity/rongga hidung). Gambar 2.1 menunjukan penampang melintang dari organ wicara manusia. Untuk menghasilkan sebuah voiced sounds(suara ucapan), paru-paru menekan udara melalui epiglottis,vocal cords bergetar, menginterupt udara melalui aliran udara dan menghasilkan sebuah gelombang tekanan quasi-periodic [2].
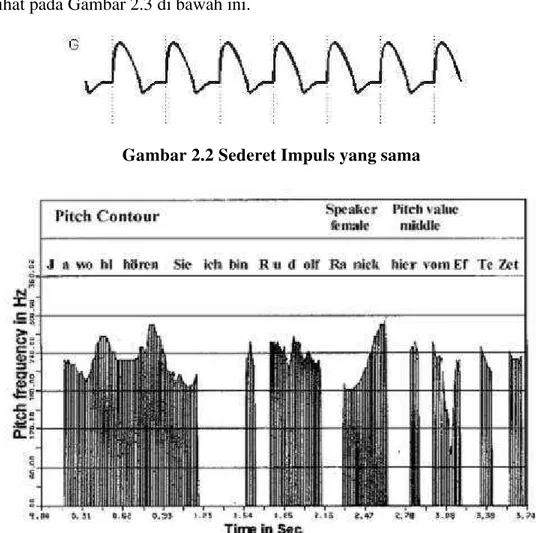
Impuls tekanan pada umumnya disebut sebagai pitch impulses dan frekuensi sinyal tekanan adalahpitch frequencyataufundamental frequency. Pada Gambar 2.2 sederetan impuls (fungsi tekanan suara) dihasikan oleh vocal cords untuk sebuah suara. Ini merupakan bagian dari sinyal voice (suara) yang mendefinisikan speech melody (melodi wicara). Ketika seseorang berbicara dengan sebuah frekuensi pitch konstan, suara sinyal wicara monotonous tetapi dalam kasus normal sebuah perubahan permanen pada frekuensi terjadi. Ketika seseorang berbicara dengan frekuensi pitch constant, maka impuls pitch akan terlihat seperti pada Gambar 2.2. Variasi frekuensipitchdapat dilihat seperti yang terlihat pada Gambar 2.3 di bawah ini.
Gambar 2.2 Sederet Impuls yang sama
Gambar 2.3 Variasi Frekuensi
merupakan sinyal wicara. Kedua rongga beraksi sebagai resonators dengan karakteristik frekuensi resonansi masing-masing, yang disebut formant frequencies. Pada saat rongga mulut dapat mengalami perubahan besar, manusia mampu untuk menghasilkan beragam pola ucapan suara yang berbeda. Mampu pula untuk menghasilkan beragam pola ucapan suara yang berbeda.
Di dalam kasus unvoiced sounds (suara tak terucap), eksitasi pada vocal tract lebih menyerupai noise (derau). Gambar 2.4 menampilkan proses produksi suara-suara “a”, dan “f”. Untuk sementara perbedaan bentuk dan posisi pada organ artikulasi diabaikan saja.
Gambar 2.4 Proses Produksi Suara Ucapan‘a’dan Ucapan‘f’
Berbagai informasi yang dapat diperoleh dari suara yang berasal dari mulut manusia dapat dilihat pada Tabel 2.1 di bawah ini.
Tabel 2.1 Informasi Suara
No Informasi Suara
1 Identitas pengucap
No Informasi Suara
3 Usia
4 Tingkat Kejenuhan
5 Emosi
6 Jarak
7 Pengenalan kata
8 Kondisi kesehatan
9 Logat
10 Laju suara
11 Tingkat kebisingan
12 Kualitas bahasa
Setiap ucapan yang dikeluarkan dari mulut manusia akan mengandung berbagai informasi seperti pada Tabel 2.2, baik itu disadari maupun tidak. Misalkan Wisnu mengucapkan kata “diam” kepada Arif dengan nada keras, maka kata “diam” tersebut dapat diklasifikasikan seperti dalamTabel 2.2 [2].
Tabel 2.2 Jenis Klasifikasi Suara
No Informasi Jenis Klasifikasi/Identifikasi
1 Identitas pengucap Wisnu
2 Jenis gender Pria
3 Usia 20-25 tahun
4 Ekspresi/emosi Marah
5 Jarak sumber suara ± 5 meter
6 Pengenalan kata Diam
7 Dialek/logat/suku Jawa
8 Laju suara Cepat
9 Tingkat kebisingan 0,8 (interval 0-1)
10 Tingkat kejenuhan 0,6 (interval 0-1)
11 Kualitas bahasa Terdidik, pasaran, normal
12 Kondisi kesehatan Normal
2.2.1 Jenis Suara Manusia
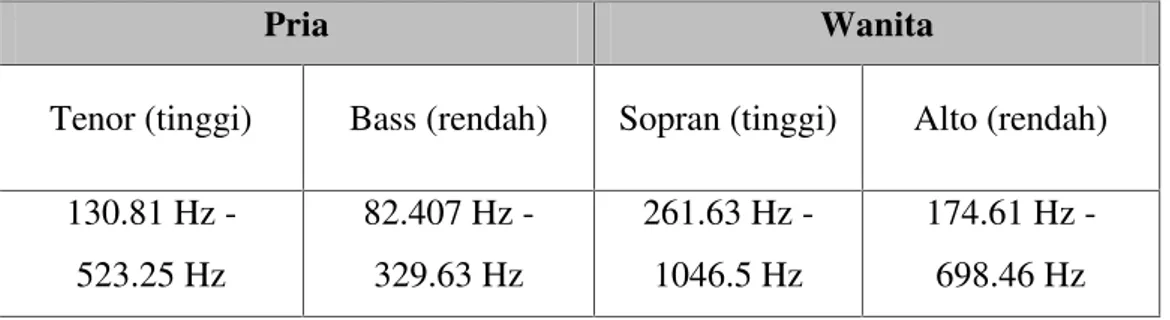
yang tinggi, sedang, dan rendah. Dalam skripsi ini dilakukan penelitian hanya untuk suara tinggi dan rendah yang diantaranya suara pria tinggi (tenor), suara pria rendah (bass), suara wanita tinggi (sopran), dan suara wanita rendah (alto) [19]. Berikut dijelaskan dalam Tabel 2.3 di bawah ini.
Tabel 2.3 Jenis Suara Manusia
Pria Wanita
Tenor (tinggi) Bass (rendah) Sopran (tinggi) Alto (rendah) 130.81 Hz
-523.25 Hz
82.407 Hz -329.63 Hz
261.63 Hz -1046.5 Hz
174.61 Hz -698.46 Hz
2.2.2 Pitch
Pitch merupakan frekuensi fundamental (F0) dari sinyal suara yang
merupakan hasil akustik kecepatan getaran pita suara. Semakin besar getaran pita suara, maka akan semakin tinggi nilai pitch. Periode pitch berkisar antara 10 sampai 20 milidetik. Setiap manusia mempunyai kisaran pitch tersendiri, tergantung dari pangkal tenggorok yang dimiliki. Kisaran pitch yang khas (habitual pitch) dimiliki oleh kebanyakan pria sebesar 50 Hz–250 Hz, sedangkan wanita memiliki pitch (habitual pitch) yang lebih tinggi dibandingkan dengan pria, yaitu berkisar antara 120 Hz – 500 Hz. Frekuensi fundamental ini berubah secara konstan dan memberikan informasi linguistic seseorang seperti pembeda antara intonasi dan emosi.
Pada pria ketika bersuara trakea dan laring pada tenggorokan membuka lebih lebar dibandingkan pada wanita. Ukuran pita suara pada pria berkisar antara 17.5 mm sampai 25 mm, sedangkan pada wanita ukuran pita suaranya berkisar antara 12.5 sampai 17.5 mm. Karena ukuran pita suara wanita lebih kecil, maka suara yang dihasilkan oleh wanita akan lebih tinggi [1][7].
2.2.3 Formant
menyerupai gaung [1]. Frekuensi formant bersifat tidak terbatas namun, untuk mengidentifikasi seseorang paling tidak ada 3 (tiga) format yang dianalisa, yaitu formant 1 (F1), formant 2 (F2), dan formant 3 (F3) [3]. Formant pertama dan
formant kedua berkaitan dengan posisi lidah ketika berbicara, sedangkanformant ketiga berpengaruh terhadap warna suara yang dihasilkan. Nilai formant pertama (F1) berkaitan dengan posisi lidah terhadap langit-langit rongga mulut. Semakin
dekat lidah dengan langit-langit, maka frekuensi yang dihasilkan semakin kecil. Nilai formantkedua (F2) berkaitan dengan posisi lidah depan dan belakang. Nilai
formant(F2) yang tinggi dihasilkan ketika posisi lidah berada di depan, jika posisi
lidah berada di belakang, maka nilai formant kedua (F2) akan lebih kecil
dibandingkan dengan yang posisi lidah di depan.
2.3 Kecerdasan Buatan
Kecerdasan buatan atau Artificial Intelligence (AI) merupakan cabang ilmu yang berusaha memahami kecerdasan manusia. AI berusaha membangun entitas-entitas cerdas yang sesuai dengan pemahaman manusia. Entitas-entitas cerdas yang dibangun AI ini ternyata sangat menarik dan mempercepat proses pemahaman terhadap kecerdasan manusia [13]. Stuart Russel dan Peter Norvig mengelompokan definisi AI ke dalam empat kategori, yaitu :
2.3.1 Thinking Humanly
Pendekatan ini dilakukan dengan dua cara, yaitu :
1. Melalui introspeksi : mencoba menangkap pemikiran kita sendiri pada saat berfikir. Tetapi seorang psikolog barat mengatakan “how do you know that you understand?” bagaimana anda tahu bagaimana anda mengerti? Karena pada saat anda menyadari pemikiran anda, ternyata pemikiran tersebut sudah lewat dan digantikan kesadaran anda. Sehingga definisi ini terkesan mengada-ada dan tidak mungkin dilakukan.
2.3.2 Acting Humanly
Pada tahun 1950, Alan Turing merancang suatu ujian bagi komputer berintelejensia untuk menguji apakah komputer tersebut mampu mengelabuhi seorang manusia yang menginterogasinya melalui teletype (komunikasi berbasis teks jarak jauh).
2.3.3 Thinking Rationally
Terdapat dua masalah dalam pendekatan ini, yaitu :
1. Tidak mudah untuk membuat pengetahuan informasi informal dan menyatakan pengetahuan tersebut ke dalam formal term yang diperlukan oleh notasi logika, khususnya ketika pengetahuan tersebut memiliki kepastian kurang dari 100%.
2. Terdapat perbedaan besar antara dapat memecahkan masalah “dalam prinsip” dan memecahkannya “dalam dunia nyata”.
2.3.4 Acting Rationally
Membuat inferensi yang logis merupakan bagian dari suaturational agent. Hal ini disebabkan satu-satunya cara untuk melakukan aksi secara rasional adalah dengan menalar secara logis. Dengan menalar secara logis, maka bisa didapatkan kesimpulan bahwa aksi yang diberikan akan mencapai tujuan atau tidak. Jika mencapai tujuan, maka agent bisa melakukan aksi berdasarkan kesimpulan tersebut.
Thinking humanly danacting humanlyadalah dua definisi dalam arti yang sangat luas. Sampai saat ini, pemikiran manusia yang diluar rasio, yakni refleks dan intuitif (berhubungan dengan perasaan), belum dapat ditirukan sepenuhnya oleh komputer. Dengan demikian, kedua definisi ini dirasa kurang tepat untuk saat ini. Jika kita menggunakan definisi ini, maka banyak produk komputasi cerdas saat ini yang tidak layak disebut sebagai produk AI.
pemikiran bahwa komputer bisa melakukan penalaran secara logis dan juga bisa melakukan aksi secara rasional berdasarkan hasil penalaran tersebut [13].
2.4 Machine Learning
Komputer dibangun untuk dapat menjalankan tugas atau menyelesaikan masalah berdasarkan instruksi dari pengguna. Dalam proses menjalankan tugas, komputer menggunakan algoritma. Algoritma adalah sekumpulan instruksi yang tersusun secara urut. Fungsi algoritma adalah melakukan transformasi dari data input menjadi dataoutput.Machine learning mempunyai pendekatan agar sebuah komputer tidak lagi hanya bisa menjalankan algoritma, akan tetapi dapat membuat algoritma sendiri. Proses pembuatan algoritma dapat dilakukan dengan proses pembelajaran (learning) dengan mempertimbangkan data yang ada atau dengan kata lain komputer diupayakan untuk dapat mengekstrak algoritma secara otomatis berdasarkan data yang ada untuk menyelesaikan tugasnya [14].
2.4.1 Supervised Learning
Supervised learning adalah teknik pembelajaran mesin dengan membuat suatu fungsi dari data latihan. Data latihan terdiri dari pasangan nilai input dan output yang diharapkan dari input yang bersangkutan. Tugas dari supervised learning adalah untuk memprediksi nilai fungsi untuk nilai semua input yang ada [14].
2.4.2 Unsupervised Learning
2.5 Pattern Recognition
Pattern recognition merupakan salah satu bidang dalam computer sains, yang memetakan suatu data ke dalam konsep tertentu. Konsep tertentu ini disebut class atau category. Aplikasi pattern recognition sangat luas, diantaranya mengenali suara dalam sistem keamanan. Membaca huruf dalam OCR, mengklasifikasikan penyakit, dan lain sebagainya. Berbagai metode yang ada pada pattern recognition, seperti linear discriminant analysis, hidden markov model hingga metode kecerdasan buatan seperti jaringan syaraf tiruan. Salah satu metode yang banyak mendapat perhatian sebagai state of the art dalam pattern recognitionadalahsupport vector machine[15].
2.6 Support Vector Machine
Support vector machine(SVM) muncul pertama kali pada tahun 1992 oleh Vladimir Vapnik bersama rekannya Bernhard Boser dan Isabelle Guyon. Support vector machine (SVM) merupakan metode klasifikasi jenis terpandu (supervised) karena ketika pelatihan, diperlukan target pembelajaran tertentu. SVM dapat digunakan untuk klasifikasi yang dapat diterapkan pada deteksi tulisan tangan, pengenalan obyek, identifikasi suara dan lain-lain [4][16].
SVM adalah metodemachine learningyang bekerja atas prinsipStructural Risk Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buahclasspadainput space.
Berbeda dengan strategi neural network yang berusaha mencari hyperplane pemisah antar class, SVM berusaha menemukan hyperplane yang terbaik padainput space.Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencarihyperplane terbaik berfungsi sebagai pemisah dua buahclass pada input space[16].
2.6.1 Kasus Data yang Terpisah SecaraLinear
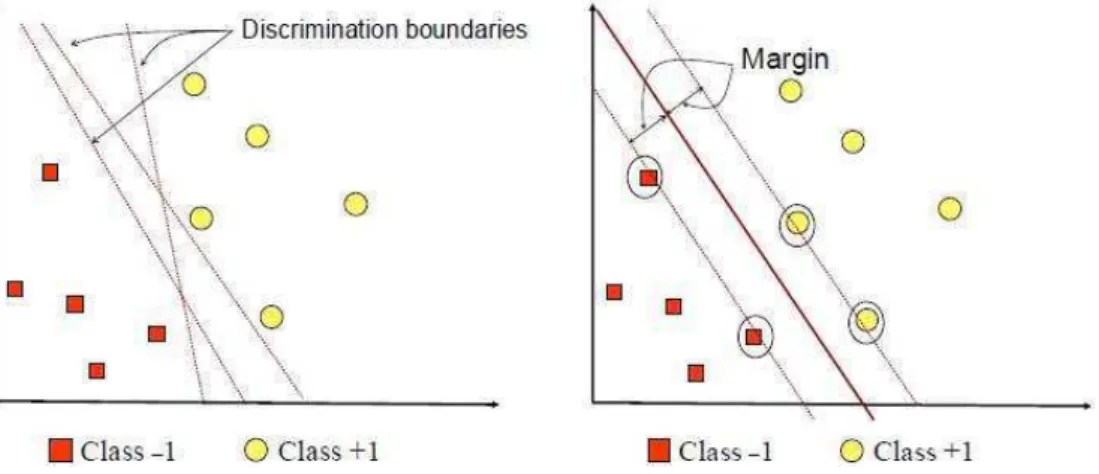
Gambar 2.5 SVM Berusaha MenemukanHyperplanePemisah
Gambar 2.5 memperlihatkan beberapa pattern yang merupakan anggota dari dua buah class : +1 dan -1 yang mempunyai tupel pelatihan 2-D. Pattern yang tergabung pada class -1 disimbolkan dengan kotak berwarna merah sementara patternpada class +1 disimbolkan dengan lingkaran berwarna kuning. Masalah klasifikasi dapat diterjemahkan dengan usaha menemukan hyperplane yang memisahkan antara kedua kelompok tersebut [16].
Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane dengan pattern terdekat masing-masing class. Pattern yang paling dekat ini disebut dengan support vector. Garis solid pada Gambar 2.5 sebelah kanan menunjukan hyperplane terbaik, yaitu yang terletak pada tengah-tengah kedua class, sedangkan titik merah dan kuning yang berada dalam lingkaran hitam adalahsupport vector[16].
Data yang tersedia dinotasikan sebagai sedangkan label
masing-masing dinotasikan untuk yang mana n adalah
banyaknya data. Diasumsikan kedua class dapat terpisah secara sempurna oleh hyperplaneberdimensi , yang didefinisikan pada persamaan 2-1.
(2-2) Pattern yang termasukclass+1 dapat dirumuskan dengan persamaan 2-3.
(2-3) Keterangan :
w = vectorbobot
x = nilai masukan atribut b = bias
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara jarak dan titik terdekatnya, yaitu . Hal ini dapat dirumuskan sebagai quadratic programming (QP) problem, yaitu mencari titik minimal yang dinyatakan dalam persamaan 2-4 dan memperhatikan kondisi yang harus dipenuhi pada persamaan 2-5.
(2-4) (2-5) Problem ini dapat dipecahkan dengan berbagai teknik komputasi, diantaranyalagrange multiplieryang dinyatakan pada persamaan 2-6.
dengan (2-6)
(2-7)
untuk (2-8)
Dengan demikian, maka akan diperoleh yang kebanyakan bernilai positif yang disebut sebagaisupportvector [16].
2.6.2 Kasus Data yang Tidak Terpisah SecaraLinear
Kasus data yang tidak terpisah secara linear diasumsikan bahwa class pada input space tidak dapat terpisah secara sempurna. Hal ini menyebabkan constraint pada persamaan 2-5 tidak dapat terpenuhi, sehingga optimalisasi tidak dapat dilakukan, untuk mengatasi masalah ini SVM dirumuskan ulang dengan memperkenalkan teknik softmargin. Dalam softmargin persamaan 2-5 dimodifikasi dengan menggunakan slack variabel sehingga terlihat pada persamaan 2-9 [16].
(2-9) Dengan demikian persamaan 2-4 diubah menjadi persamaan 2-10.
(2-10) FiturCdigunakan untuk mengontroltradeoff antaramargindan kesalahan klasifikasi .
2.6.3 Kernel TrickdanNon-Linear ClassificationPada SVM
Pada umumnya masalah yang terjadi dalam dunia nyata jarang yang bersifat linear separable. Kebanyakan bersifat non-linear, SVM dimodifikasi dengan memasukan fungsikernel[4].
Dalam non linearSVM, pertama-tama data x dipetakan oleh fungsiΦ (x)
space dapat dipetakan ke feature space yang baru, dimana pattern-pattern tersebut pada probabilitas tinggi dapat dipisahkan secara linear”.
Pemetaan ini dilakukan dengan menjaga topologi data, dalam artian dua data yang berjarak dekat pada input space akan berjarak dekat juga pada feature space, sebaliknya dua data yang berjarak jauh padainput spaceakan juga berjarak jauh padafeature space.
Selanjutnya proses pembelajaran pada SVM dalam menemukan titik-titik support vector, hanya bergantung pada dot product dari data yang sudah ditransformasikan pada ruang baru yang berdimensi lebih tinggi, yaitu
[16].
Karena umumnya transformasi ini tidak diketahui, dan sangat sulit untuk difahami secara mudah, maka perhitungan dot product tersebut sesuai teori Mercer dapat digantikan dengan fungsikernelyang terlihat pada persamaan 2-11.
(2-11) Beberapakernelyang terdapat pada svm meliputi :
1. Polinomial Derajat h
Kernel trick polinomial cocok digunakan untuk menyelesaikan masalah klasifikasi, dimana dataset pelatihan sudah normal. Kernel trick ini dinyatakan dalam persamaan 2-12.
(2-12) 2. Radial Basis Function
Kernel trick radial basis function merupakan kernel yang paling banyak digunakan untuk menyelesaikan masalah klasifikasi untuk dataset yang tidak terpisah secara linear, dikarenakan akurasi pelatihan dan akurasi prediksi yang sangat baik pada kernel ini, dimana kernel radial basis functiondinyatakan dalam persamaan 2-13.
3. Sigmoid
Kernel sigmoid merupakan kernel trick svm yang merupakan pengembangan dari jaringan saraf tiruan, dimana kernel ini dinyatakan dengan persamaan 2-14.
(2-14) Kernel trick memberikan beberapa kemudahan, karena dalam proses pembelajaran SVM, untuk menentukan support vector, pengguna hanya cukup mengetahui fungsi kernel trick yang dipakai, tanpa perlu mengetahui wujud dari fungsinon-linear[4][16].
Dari keseluruhan kernel trick tersebut, kernel trick radial basis function merupakan kernel trick yang memberikan hasil terbaik pada proses klasifikasi khususnya untuk data yang tidak bisa dipisahkan secaralinear[16].
Selain masalah data yang tidak dipisahkan secara linear ada masalah lain yang sering muncul dalam penerapan metode klasifikasi machine learningseperti support vector machine adalah masalah dimensionalitas dataset atau sering disebut sebagai kutukan dimensionalitas (curse of dimensionality), jika dimensi meningkat, data akan meningkat secara halus dalam daerah yang ditempati. Untuk itu diperlukan pengurangan dimensi.
Manfaat dari pengurangan dimensi :
1. Mencegah terjadinya efek dari dimensionalitas.
2. Mengurangi jumlah waktu dan memori yang dibutuhkan oleh machine learning.
3. Membuat data lebih mudah divisualisasikan.
4. Membantu untuk mengurangi fitur-fitur yang tidak relevan atau mengurangi gangguan/derau.
2.7 Standar Deviasi
Standar deviasi disebut juga simpangan baku merupakan metode untuk mencari variasi suatu data dan merupakan metode yang digunakan untuk mengurangi dimensionalitas dari suatu dataset dan mempunyai satuan ukuran yang sama dengan data asal. Singkatnya, standar deviasi mengukur-bagaimana nilai-nlai data tersebar, bisa juga didefinisikan sebagai rata-rata jarak penyimpangan titik-titik. Standar deviasi merupakan hasil akar dari pengurangan dataset dengan nilai rata-rata dari dataset dibagi dengan jumlah dataset. Standar deviasi ini ditulis dengan persamaan 2-15.
(2-15) Keterangan :
= rataan hitung = inputdata n = jumlah data s = standar deviasi
2.8 Klasifikasi Sinyal Berdasarkan Eksitasi
Berdasarkan eksitasi yang dihasilkan pada proses produksi suara, sinyal suara dapat dibagi menjadi tiga bagian, yaitusilence,unvoiced, danvoiced.
1. Sinyalsilence
Sinyal silence merupakan sinyal pada saat tidak terjadi proses produksi suara ucapan dan sinyal yang diterima oleh pendengar dianggap sebagai bising latar belakang.
2. Sinyalunvoiced
3. Sinyalvoiced
Sinyalvoicedterjadi jika pita suara bergetar, yaitu pada saat sinyal eksitasi berupa sinyal pulsa quasi-periodik. Selama terjadinya sinyal voiced ini, pita suara bergetar pada frekuensi fundamental [7].
2.9 Sinyal Digital dan Sinyal Analog
Sinyal itu ialah besaran yang berubah dalam waktu dan atau dalam ruang, dan membawa suatu informasi. Pada umumnya variabel independen untuk sinyal adalah waktu. Jika variabel independennya kontinu, maka sinyal tersebut disebut sebagai sinyal waktu kontinu (continuous-time signal). Jika variabel independennya diskrit, maka sinyal tersebut disebut sebagai sinyal waktu diskrit (discrete-time signal). Sinyal waktu kontinu didefinisikan setiap waktu dalam sebuah interval yang biasanya tidak terbatas, sedangkan sinyal waktu diskrit didefinisikan pada waktu diskrit, dan biasanya berupa urutan angka.
Sinyal waktu kontinu dengan amplitudo kontinu biasanya disebut sebagai sinyal analog. Contoh sinyal analog adalah sinyal suara. Sinyal waktu diskrit dengan amplitudo bernilai diskrit yang direpresentasikan oleh digit angka yang terbatas (finite), biasanya disebut sebagai sinyal digital [8].
2.9.1 Sinyal Digital
Sinyal digital merupakan hasil teknologi yang dapat mengubah sinyal menjadi kombinasi urutan bilangan 0 dan 1 (juga dengan biner), sehingga tidak mudah terpengaruh oleh derau, proses informasinya pun mudah, cepat dan akurat, tetapi transmisi dengan sinyal digital hanya mencapai jarak jangkau pengiriman data yang relatif dekat. Biasanya sinyal ini juga dikenal dengan sinyal diskrit. Sinyal yang mempunyai dua keadaan ini biasa disebut dengan bit. Bit merupakan istilah khas pada sinyal digital. Sebuah bit dapat berupa nol (0) atau satu (1). Kemungkinan nilai untuk sebuah bit adalah 2 buah (21). Kemungkinan nilai untuk 2 bit adalah sebanyak 4 (22), berupa 00, 01, 10, dan 11. Secara umum, jumlah kemungkinan nilai yang terbentuk oleh kombinasi n bit adalah sebesar 2nbuah.
digital dibatasi oleh lebarnya/jumlah bit (bandwidth). Jumlah bit juga sangat mempengaruhi nilai akurasi dan kualitas sinyal digital [8].
2.9.2 Sinyal Analog
Sinyal analog atau sinyal waktu kontinyu adalah sinyal yang memiliki nilai real pada setiap waktu. Sinyal kontinyu merupakan suatu sinyal yang berbentuk gelombang sinusoidal dan merupakan variabel yang berdiri sendiri. Pada sinyal kontinyu, variabel indipendent (yang berdiri sendiri) terjadi terus-menerus dan kemudian sinyal dinyatakan sebagai sebuah kesatuan nilai dari variabel independent. Dengan menggunakan sinyal analog, maka jangkauan transmisi data dapat mencapai jarak yang jauh, tetapi sinyal ini mudah terpengaruh olehnoise.
Gelombang pada sinyal analog yang umumnya berbentuk gelombang sinus memiliki tiga variable dasar, yaitu amplitudo, frekuensi, danphase[8].
1. Amplitudo merupakan ukuran tinggi rendahnya tegangan dari sinyal analog.
2. Frekuensi adalah jumlah gelombang sinyal analog dalam satuan detik. Phaseadalah besar sudut dari sinyal analog pada saat tertentu.
2.10 JenisFile Audio Digital
Setiap bentuk file audio memiliki kelebihan dan kekurangan masing-masing. Formatfileaudio tersebut dapat dirubah sesuai dengan kebutuhan. Format fileaudio bermacam-macam, diantaranya :
1. WAV (Wave),format fileini merupakan dasar dari format audio file yang memiliki kualitas suara terbaik, hanya saja file ini membutuhkan tempat penyimpanan yang besar. Pemilihan format ini sangat tepat apabila membutuhkan kualitas audio yang baik dan memiliki tempat penyimpanan yang besar. Formatfileini mendukung untuk mono atau stereo.
3. Dialogic ADPCM (.VOX), format Dialogic ADPCM ini biasanya ditemui pada aplikasi telepon. Format ini hanya dapat menyimpan audio mono 16-bit, dan seperti format ADPCM lainnyafileini dapat dikompres hingga 4-bit.
4. DiamondWare Digitized (.DWD), ini adalah format audio yang digunakan oleh perangkat DiamondWare's Sound, biasanya format ini digunakan oleh para programmer untuk menghasilkan audio interaktif yang diaplikasikan pada game dan multimedia. Format ini juga medukung baik mono maupun stereo.
5. MPEG Audio Player 3 (.MP3), ini merupakan format audio file yang banyak diminati oleh para pengguna komputer, karena disamping kualitas yang dihasilkan baik file ini juga tidak memerlukan tempat penimpanan yang besar.
6. Real Media (.RM), format audio ini biasanya dapat ditemukan pada jaringan internet.
7. Sound Blaster (.VOC), ini adalah format audio filedari Sound Blaster dan format file suara dari Sound Blaster Pro. Format ini hanya mendukung 8-bit audio, mono hingga 44.1 KHz, dan stereo hingga 22 KHz.
8. Advance Audio Coding (AAC). Sepuluh tahun sejak ditemukannya MP3, sering pula disebut MP4. Apel merupakan vendor yang paling getol menggunakan file suara berlisensi ini. Apel juga merupakan pengembang dari file AAC ini yang bisa dijalankan di iTunes, QuickTime 6, iPod, dan seterusnya.
lainnya, tetapi tidak cocok untuk hasil konversi dari suara analog karena tidak terlaluakurat. File dengan format ini berukuran kecil dan sering digunakan dalam ponsel sebagairingtone[8].
2.11 Elemen Dasar Sistem Pemrosesan Sinyal
Dalam proses pengolahan sinyal analog, sinyal input masuk ke Analog Signal Processing (ASP), untuk kemudian diberi berbagai perlakuan (misalnya pemfilteran, penguatan, dan sebagainya) dan outputnya berupa sinyal analog seperti yang terlihat pada Gambar 2.6.
Gambar 2.6 Sistem Pengolahan Sinyal Analog
Proses pengolahan sinyal secara digital memiliki alur sedikit berbeda. Komponen utama sistem ini berupa sebuahprocessordigital yang mampu bekerja apabila inputnya berupa sinyal digital. Untuk sebuah input berupa sinyal analog perlu proses awal yang bernama digitalisasi melalui perangkat yang bernama analog-to-digital conversion (ADC), dimana sinyal analog harus melalui proses sampling, kuantisasi dan pengkodean (coding). Demikian juga output dari processor digital harus melalui perangkat digital-to-analog conversion (DAC) agar outputnya kembali menjadi bentuk analog. Ini bisa kita amati pada perangkat seperti PC, digital sound system, dan sebagainya. Secara sederhana bentuk blok diagramnya adalah terlihat seperti pada Gambar 2.7.
2.11.1 Pengubahan Sinyal Analog Menjadi Sinyal Digital
Sebagian besar sinyal, seperti sinyal suara merupakan sinyal analog, untuk memproses sinyal analog dengan alat digital, tidak dapat diproses begitu saja atau dengan kata lain sinyal analog harus terlebih dahulu dirubah menjadi sinyal digital. Proses ini dinamakan konversi analog ke digital (A/D) dengan alat yang dinamakananalog to digital converter(ADC).
Terdapat tiga tahap dalam pengubahan sinyal analog menjadi sinyal digital, seperti terlihat pada Gambar 2.8.
Gambar 2.8 Tahapan ADC (Analog to Digital Converter)
Penjelasan tahapan ADC (analog to digital converter) pada Gambar 2.8 adalah sebagai berikut :
1. Sampling
Sampling adalah konversi sinyal kontinu dalam domain waktu menjadi sinyal diskrit melalui proses sampling sinyal pada selang waktu tertentu. 2. Kuantisasi
Kuantisasi merupakan proses pemetaan dari nilai sinyal kontinyu dari hasil sampling menjadi nilai-nilai yang diskrit sehingga didapatkan sinyal nilai diskrit.
3. Coding
Tiap nilai diskrit yang telah didapat, direpresentasikan dengan angka binary n-bit.
2.12 Pemrosesan Sinyal Suara
Pemrosesan sinyal suara bermaksud mengubah karakteristik sinyal suara atau mengambil beberapa informasi yang diinginkan dari sinyal suara.
2.12.1 Pre-emphasis
Pre-emphasis merujuk pada proses memaksimalkan kualitas sinyal dengan meminimalkan efek noise seperti distorsi selama perekaman dan transmisi data, serta memperhalus bentukspectralfrekuensi [9].
Pre-emphasis didasari oleh hubungan input dan output dalam domain waktu yang dinyatakan dalam persamaan 2-16.
) 1 ( ) ( )
(n x n ay n
y (2-16)
Keterangan :
y(n) = sinyal hasilpre-emphasis x(n) = sinyal masukan
y(n-1) = hasilpre-emphasissegmen suara sebelumnya = konstanta filterpre-emphasisyang bernilai 0,9
2.12.2 Frame Blocking
Sinyal suara dibagi-bagi ke dalam frame dengan panjang segmen per-frame adalah Z dan dipisahkan sejauh overlap Y dengan Y<Z [10]. Gambar di bawah ini merupakanframe blocking.
2.12.3 Hamming Window
Windowing diperlukan untuk mengurangi efek diskontinuitas dari potongan sinyal. Dimana jenis windowing ada beberapa macam, yaitu Hamming, Hanning, Bartlet, Rectanguler, dan Blackman. Metode windowing yang dipakai untuk pemrosesan sinyal suara adalah hamming window, dimana hamming window dinyatakan dalam persamaan 2-17 dan perkalian sinyal suara dengan hamming windowdinyatakan dalam persamaan 2-18 [11].
(2-17) )
( * ) ( )
(n x n w n
y (2-18)
Keterangan :
y(n) = hasil perkalian segmen sinyal suara denganhamming window x(n) = inputsegmen suara
w(n) = nilaihamming window = 22/7 atau 3.14
n = nomor segmen suara N = panjang segmen suara–1
2.12.4 MetodeAutocorrelation
x(n) = input sinyal suara N = panjang sinyal suara f0 = frekuensi fundamental
T0 = periode frekuensi fundamental
2.12.5 MetodeLinear Predictive Coding
Linear predictive coding merupakan salah satu metode pemodelan suara yang didasarkan pada teori bahwa sebuah sinyal suara manusia pada waktu n, s(n), dapat diperkirakan sebagai kombinasi linear dari p sinyal suara manusia sebelumnya. Tujuan dari metode lpc adalah untuk memisahkan efek formant dengan pitch atau frekuensi dasar manusia. Hal ini direpresentasikan dengan menggunakan persamaan 2-23 [10].
Levinson Durbin :
Dengan solusi pemecahan terlihat pada persamaan 2-25 sampai dengan persamaan 2-31.
A = persamaan koefisien lpc
Setelah persamaan koefisien didapat, maka selanjutnya adalah mencari nilai r0 atau akar-akar persamaan koefisien A(z) dan kemudian dirubah ke dalam
0
0
2πθ fs
F (2-32)
0
lnr fs B
π
(2-33)
Keterangan :
F = frekuensiformant
fs = frekuensi pencuplikan
π
= konstanta 22/7 atau 3.140
θ = perubahan sudut B = bandwith
0
101
Pada bab ini berisikan kesimpulan dari hasil penelitian yang telah dilakukan dan saran untuk perbaikan dan pengembangan penelitian lebih lanjut.
5.1 Kesimpulan
Dari hasil penelitian ini dapat ditarik kesimpulan mengenai aspek yang menjadi bahasan pada pengidentifikasi suara tinggi dan rendah, yaitu :
1. Simulator dapat mengidentifikasi suara tinggi dan rendah untuk pria dan wanita dengan menggunakan metode klasifikasi support vector machine, dengan ketepatan pelatihan dan prediksi yang baik.
2. Suara tinggi dan rendah wanita lebih mudah diidentifikasi dibandingkan dengan suara tinggi dan rendah pria, ini dibuktikan dengan pengujian sampel suara yang menghasilkan akurasi pengujian sebesar 100% wanita, dan 70% pria dengan fitur suara yang paling dominan mempengaruhi hasil prediksi suara tinggi dan rendah pada pria dan wanita adalahpitch.
5.2 Saran
Nama : Indra Tri Prabowo
Jenis Kelamin : Laki-Laki
Tempat /Tanggal Lahir : Jakarta, 26 Februari 1991
Agama : Islam
Status Pernikahan : Belum Menikah
Alamat Rumah : Pondok Cipta Blok E no.86 RT.010 RW.008 Bintara, Bekasi Barat 17134
Alamat Email : [email protected]
Nomor Telepon : 085721888099
2. RIWAYAT PENDIDIKAN
1997-2003 : SD Negeri Bintara V Bekasi
2003-2006 : SMP Negeri 195 Jakarta
2006-2009 : SMA Negeri 59 Jakarta
2009-2016 : S1 Program Studi Teknik Informatika
Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia
Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung, 27 Februari 2016
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
INDRA TRI PRABOWO
10109276
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
vi
vii
102
Sinyal Ucapan Kata. Prosiding Seminar Nasional Ilmu komputer. Semarang.
[2] Fadlisyah, Bustami, dan Ikhwanus, M, 2013.Pengolahan Suara. Yogyakarta: Graha Ilmu.
[3] Wicaksono, Galieh., Prayudi, Yudi. Teknik Forensika Audio Untuk Analisa Suara Pada Barang Bukti Digital. Universitas Islam Indonesia, Yogyakarta: Pusat Studi Forensika Digital.
[4] Pudjo, Widodo, Prabowo., Trias, Handayanto, Rahmadya., Herlawati. 2013, Penerapan Data Mining dengan Matlab. Bandung: Rekayasa Sains.
[5] Pan, Yixiong., Shen, Peipei., and Shen, Liping. 2012, Speech Emotion Recognition Using Support Vector Machine, International Journal of Smart Home (IJSH).
[6] Roger S. Pressman. 2010.Software Engineering: A Practitioner's Approach, 4th ed. New York: McGraw-Hill Companies.
[7] Bagas, Bhaskoro, Susetyo., Riedho, Altedzar. 2012, Aplikasi Pengenalan Gender Menggunakan Suara. Seminar Nasional Aplikasi Teknologi Informasi.
[8] Suyanto, S.T., Msc. 2007.Artificial Intelegence. Bandung: Informatika. [9] Rabiner, Lawrence., Juang, Bing-Hwang. 1993, Fundamental of Speech
Recognition. New Jersey: Prentince-Hall.
[10] Rabiner, Lawrence., W, Schafer, Ronald. 1978, Digital Processing of Speech Signals. New Jersey: Prentice-Hall, Inc.
103
[14]Alpaydın, Ethem. 2010, Introduction to Machine Learning Second Edition.
London: The MIT Press.
[15] Bernhard E. Boser and Isabelle M. Guyon and Vladimir Vapnik. 1992, A Training Algorithm for Optimal Margin Classifiers. Proceedings of the fifth annual workshop on Computational learning theory (COLT).
[16] Ivanciuc, Ovidiu. 2007, Applications of Support Vector Machines in Chemistry. Reviews in Computational Chemistry, vol. 23.
[17] Hermawati, Astuti, Fajar. 2013.Data Mining. Yogyakarta: Andi.
[18] Kantardzk, Mehmed. 2011. Data Mining (Concepts, Models, Methods, and Algorithms). New Jersey: John Wiley & Sons.
Machine
Indra Tri Prabowo
Teknik Informatika - Universitas Komputer Indonesia Jl. Dipati Ukur No. 112-114 Bandung
Email : [email protected]
ABSTRAK
Pengenalan suara merupakan proses identifikasi suara berdasarkan kata yang diucapkan seseorang yang ditangkap oleh perangkat input suara untuk dikenali dan kemudian diterjemahkan menjadi sebuah data yang dipahami oleh komputer. Ketika manusia mengeluarkan suara, saat itulah suara tersebut menyampaikan beberapa informasi di dalam kata yang diucapkan melalui gelombang suara. Informasi suara tersebut dapat diketahui melalui fitur suara itu sendiri, diantaranya denganpitch dan
formant,dimanapitchadalah frekuensi fundamental dari sinyal suara yang dihasilkan karena getaran pita suara, dan formant adalah frekuensi resonansi akustik dari bidang suara manusia. Kedua fitur tersebut merupakan fitur suara yang sangat penting untuk mengidentifikasi suara yang diucapkan dari seseorang.
Tahapan analisis pengidentifikasian suara ini dengan tahap pre-processing, feature extraction, dan
classification. Tahapan pre-processing dengan pre-emphasis, frame blocking, dan hamming window
dari sinyal suara. Tahapanfeature extractiondengan
autocorrelation untuk menentukan pitch danlinear predictive coding untuk menentukan formant, serta Tahapan classification dengan support vector machine untuk mengklasifikasikan fitur suara yang akan digunakan untuk mengidentifikasi suara tinggi dan rendah.
Berdasarkan hasil pengujian terhadap simulator dengan kesimpulan bahwa rata-rata nilai pitch pria untuk suara tinggi maupun rendah lebih rendah dari wanita, rata-rata nilaiformantke-1 danformantke-2 wanita untuk suara tinggi dan rendah lebih tinggi dari pria, rata-rata formant ke-3 pria untuk suara tinggi dan rendah lebih tinggi dari wanita, fitur suara yang lebih cocok merepresentasikan suara tinggi untuk pria dan wanita adalahpitch,kisaranpitchdan
formant untuk suara pria adalah 191.1435 Hz (F0), 503.9955 Hz (F1), 956.9225 Hz (F2), dan 1561.43 Hz (F3). Untuk suara wanita adalah 268.51 Hz (F0), 534.871 Hz (F1), 1080.4475 Hz (F2), dan 1690.835 Hz (F3). Simulator mampu memprediksi suara tinggi dan rendah baik untuk pria dan wanita dengan
persentase akurasi sebesar 70% untuk suara pria dan 100% untuk suara wanita.
Kata Kunci : Pitch, Formant, Linear Predictive Coding,Support Vector Machine.
1. PENDAHULUAN
Masalah yang dibahas dalam tugas akhir ini mengenai suara tinggi dan rendah manusia. Analisis ini dilakukan atas dasar untuk dapat mengidentifikasi suara tinggi dan rendah dengan melihat nilai-nilai fitur suara, yaitu pitch dan
formant. Nilai pitch dan formant tersebut didapat melalui proses feature extraction. Nilai pitch dan
formantsuara tinggi dan rendah kemudian disimpan sebagai data pelatihan dan dibandingkan dengan nilai pitchdanformantyang ada pada data prediksi untuk diklasifikasikan dengan menggunakan metode
support vector machine (SVM) agar diketahui apakah hasil klasifikasi nilai pitch dan formant
tersebut masuk ke kategori tinggi atau rendah. Hasil penelitian terhadap beberapa pustaka menjelaskan bahwa metodesupport vector machine
merupakan metode klasifikasi jenis terpandu (supervised) yang bekerja menggunakan pemetaan
lineardannon-linierdan sangat baik jika digunakan untuk mengklasifikasikan fitur yang mempunyai dua kelas atau group, dimana kelas atau group disini adalah suara tinggi dan rendah. Solusi yang dihasilkan dari metode support vector machine
untuk penentuan suara tinggi adalah ketepatan pengidentifikasian suara tinggi dari fitur suara yang diuji, dimana fitur suara yang diuji adalahpitchdan
formant.
1.1 Autocorrelation
bahwa bahwa sebuah sinyal suara manusia pada waktu n, sinyal suara dapat diperkirakan sebagai kombinasi linier dari p sinyal suara manusia sebelumnya. Tujuan dari metode lpc adalah untuk memisahkan efek formant dengan pitch atau frekuensi dasar manusia.
1.3 Support Vector Machine
Support vector machine (SVM) merupakan metode klasifikasi jenis terpandu (supervised) karena ketika pelatihan, diperlukan target pembelajaran tertentu. SVM dapat digunakan untuk klasifikasi yang dapat diterapkan pada deteksi tulisan tangan, pengenalan obyek, identifikasi suara dan lain-lain.
SVM adalah metodemachine learningyang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buahclasspadainput space.
Berbeda dengan strategi neural network yang berusaha mencari hyperplane pemisah antar class, SVM berusaha menemukanhyperplaneyang terbaik pada input space. Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari hyperplane
terbaik berfungsi sebagai pemisah dua buah class
padainput space.
2 ISI PENELITIAN
2.1 Metode Pengumpulan Data
Tahap pengumpulan data yang digunakan pada penelitian ini adalah sebagai berikut :
a. Studi Literatur
Studi literatur adalah metode pengumpulan data yang diperoleh dengan mempelajari teori yang berkaitan dengan pengenalan suara, termasuk penerapan pemrosesan sinyal suara dansupport vector machine.
b. Data dan Variabel Penelitian
Data yang digunakan dalam penelitian ini adalah data tentang nilai frekuensi pitchdan
formant dari suara pria dan wanita yang diperoleh dengan cara perekaman. Pada penelitian ini, hanya digunakan dua kategori (group), yaitu kategori suara tinggi dan suara rendah.
c. Langkah-langkah Analisis
Langkah-langkah analisis identifikasi suara adalah sebagai berikut :
1. Melakukan pengumpulan data suara pria dan wanita dengan kategori tinggi dan rendah.
2. Melakukan prediksi klasifikasi kategori suara tinggi dan suara rendah menggunakan metode analisis Support Vector Machine (SVM) dengan langkah-langkah penyelesaian yang
Gambar 1 Tahapan Analisis Identifikasi Suara
2.2 Metode Pembangunan Perangkat lunak
Metode yang digunakan dalam pembuatan perangkat lunak ini menggunakan modelwaterfallseperti pada gambar 2 di bawah ini.
Gambar 2 ModelWaterfall
Model ini adalah model klasik yang melakukan pendekatan secara sistematis, berurutan dalam membangun software berkat penurunan dari satu fase ke fase lainnya. Tahap dari model ini adalah sebagai berikut :
1. Communication
Tahap communication merupakan analisis terhadap kebutuhan simulator dan tahap untuk mengadakan pengumpulan data suara manusia dengan melakukan perekaman suara pria dan wanita usia 20-35 tahun. 2. Planning
Tahap planning merupakan lanjutan dari proses communication (analysis requirement).Tahap ini akan menghasilkan dokumen user requirement atau bisa dikatakan sebagai data yang berhubungan dengan keinginan user dalam rencana pembuatan simulator yang akan dilakukan. Spesifikasi kebutuhan perangkat lunak akan dibagi kedalam dua bagian yaitu SKPL-F (Spesifikasi Kebutuhan Perangkat Lunak Fungsional) dan SKPL-NF (Spesifikasi Kebutuhan Perangkat Lunak Non-Fungsional).
3. Modeling
Tahap modeling akan menerjemahkan syarat kebutuhan ke sebuah perancangan simulator yang dapat diperkirakan sebelum dibuat coding. Proses ini berfokus pada rancangan detail (algoritma) prosedural. Tahapan ini akan menghasilkan dokumen yang disebut software requirement.
Kebutuhan Perangkat Lunak Non-Fungsional).
4. Construction
Tahap construction merupakan proses pembuatan kode.Coding atau pengkodean merupakan penerjemahan desain dalam bahasa yang bisa dikenali oleh komputer. Tahapan inilah yang merupakan tahapan secara nyata dalam mengerjakan suatu simulator, artinya dalam tahapan ini penggunaan komputer akan dimaksimalkan. Setelah pengkodean selesai maka akan dilakukan testing terhadap simulator yang telah dibuat. Tujuan testing adalah menemukan kesalahan-kesalahan terhadap simulator tersebut untuk kemudian bisa diperbaiki.
5. Deployment
Tahap deploymentbisa dikatakan finaldari pembuatan simulator. Setelah melakukan analisis, desain dan pengkodean, maka simulator yang sudah jadi akan digunakan oleh user. Kemudian software yang telah dibuat harus dilakukan pemeliharaan secara berkala. Pada simulator pengidentifikasian suara ini, tahap deployment tidak perlu dilakukan.
2.3 Analisis Metode 2.3.1 Pre-processing
Pre-processing merupakan tahapan untuk mendapatkan data yang dibutuhkan untuk pengidentifikasian suara tinggi dan rendah. Pada tahap ini dilakukan akuisisi sampel sinyal suara dengan merekam suara responden dengan menggunakan perangkat lunak audacity, menghilangkan efek noise dengan filter pre-emphasis, menempatkan sinyal suara kedalam sejumlah frame dengan frame blocking, dan meminimalkan efek diskontinuitas pada potongan
framesinyal suara denganhamming window.
a. Pre-emphasis
Pre-emphasis dilakukan untuk menghilangkan informasi yang tidak relevan dan kebisingan dengan menggunakan perhitungan low pass filter pada sinyal suara. Pre-emphasis merujuk pada proses memaksimakan kualitas sinyal analog dengan meminimalkan efek noise seperti distorsi selama perekaman dan transmisi data.
Pre-emphasis diperlukan dengan tujuan untuk mendapatkan bentuk spectralfrekuensi sinyal suara yang lebih halus.
Sinyal suara hasil pre-emphasis dapat dilihat pada gambar 3.
Gambar 3 Sinyal Suara HasilPre-emphasis
b. Frame Blocking
Sinyal suara hasil pre-emphasis kemudian ditempatkan kedalam frame menjadi beberapa bagian, dimana setiap frame sepanjang 30 milidetik dan dipisahkan sejauh 20 milidetik yang akan memudahkan dalam perhitungan dan analisa suara.
c. Hamming Window
Hamming window diperlukan untuk mengurangi efek diskontinuitas dari potongan - potongan sinyal suara yang berada pada setiapframe.
Sinyal suara hasil perkalian dengan hamming window adalah terlihat seperti pada gambar 4.
Gambar 4 Hasil Perkalian Sinyal Suara dengan Hamming Window
2.3.2 Feature Extraction
Feature extractionatau ekstraksi fitur adalah proses untuk mencari nilai fitur suara, dimana fitur suara yang diambil adalahpitchdanformant. Metode yang dipakai untuk mendapatkan nilai pitch adalah
autocorrelation, sementara untuk mendapatkan nilai
getaran pita suara, semakin besar getaran pita suara, maka akan semakin tinggi nilai pitch. Periodepitch
berkisar antara 10 sampai 20 milidetik. Setiap manusia mempunyai kisaran pitch tersendiri, tergantung dari pangkal tenggorok yang dimiliki. Kisaran pitch yang khas (habitual pitch) dimiliki oleh kebanyakan pria sebesar 50Hz - 250Hz, sedangkan wanita memiliki pitch (habitual pitch) yang lebih tinggi dibandingkan dengan pria, yaitu berkisar antara 120 - 500Hz. Frekuensi fundamental ini berubah secara konstan dan memberikan informasi linguistic seseorang seperti pembeda antara intonasi dan emosi.
Pada laki-laki ketika bersuara trakea dan laring pada tenggorokan membuka lebih lebar dibandingkan pada perempuan. Ukuran pita suara pada laki-laki berkisar antara 17.5 mm sampai 25 mm, sedangkan pada perempuan ukuran pita suaranya berkisar antara 12.5 sampai 17.5 mm. karena ukuran pita suara perempuan lebih kecil, maka suara yang dihasilkan oleh perempuan akan lebih tinggi.
2.3.2.2 Formant
Formant adalah frekuensi resonansi alami yang terjadi didalam rongga bidang suara, tergantung pada bentuk dan ukuran bidang suara dan lebih menyerupai gaung. Frekuensiformantbersifat tidak terbatas namun, untuk mengidentifikasi seseorang paling tidak ada 3 (tiga) format yang dianalisa yaitu,
formant1 (F1),formant2 danformant3 (F3).
2.3.3 Classification
Classification atau klasifikasi adalah proses pengklasifikasian data fitur suara, dimana fitur suara dalam hal ini adalah pitch dan formant akan diklasifikasikan dengan metode klasifikasi support vector machineuntuk menghasilkan informasi suara yang dihasilkan dari kedua fitur suara tersebut.
a. Pelatihan
Pelatihan merupakan tahap yang dilakukan untuk membentuk data model klasifikasi suara, dimana data model ini akan digunakan sebagai data acuan klasifikasi suara dari data latih. Data latih yang digunakan dalam simulator pengideintifikasi suara ini merupakan data fitur suara dan group yang merupakan fitur suara tinggi dan rendah 40 responden yang terdiri dari 20 pria dan 20 wanita.
b. Prediksi
Pada proses ini terlebih dahulu memasukan data yang akan diprediksi yaitu datapitchdan
formant, kemudian dicocokan dengan model yang telah didapat dari hasil proses pelatihan.
a. Pengujian Pemodelan Klasifikasi
Pemodelan klasifikasi merupakan tahap yang dilakukan untuk membentuk data model pelatihan klasifikasi suara, dimana data model ini akan digunakan sebagai data acuan klasifikasi suara dari data latih. Data latih yang digunakan dalam simulator pengideintifikasi suara ini merupakan data fitur suara dangroupyang merupakan fitur suara tinggi dan rendah 40 responden yang terdiri dari 20 pria dan 20 wanita yang disimpan pada file dengan format *.dat.
Gambar 5 Model Klasifikasi Suara
b. Pengujian Pengenalan Suara
Pengujian pengenalan suara dilakukan dengan melakukan ekstraksi fitur suara dan prediksi suara terhadap file suara hasil perekaman suara responden yang berjumlah 10 orang, yang terdiri dari 5 responden pria, dan 5 responden wanita, dimana responden masing-masing mengucapkan satu kalimat.
Gambar 6 Pengenalan Suara
Gambar 8 Hasil Klasifikasi Fitur Suara Wanita
Berdasarkan hasil pengujian terhadap perangkat lunak simulator dapat ditarik kesimpulan bahwa :
1. Rata-rata nilaipitchpria untuk suara tinggi maupun rendah lebih rendah dari wanita. 2. Rata-rata nilai formant ke-1 dan formant
ke-2 wanita untuk suara tinggi dan rendah lebih tinggi dari pria.
3. Rata-rata formant ke-3 pria untuk suara tinggi dan rendah lebih tinggi dari wanita. 4. Fitur suara yang lebih cocok
merepresentasikan suara tinggi untuk pria dan wanita adalahpitch.
5. Kisaranpitchdanformantuntuk suara pria dan wanita adalah sebagai berikut :
Pria : lunak simulator yang dibangun telah cukup memenuhi tujuan awal pembangunan perangkat lunak simulator pengidentifikasi suara, ini dibuktikan dengan pelatihan data dan prediksi data yang menghasilkan persentase akurasi sebesar 70% untuk prediksi fitur suara pria dan 100% untuk prediksi suara wanita.
3 PENUTUP
Pada bab ini berisikan kesimpulan dari hasil penelitian yang telah dilakukan dan saran untuk perbaikan dan pengembangan penelitian lebih lanjut.
3.1 Kesimpulan
Dari hasil penelitian ini dapat ditarik kesimpulan mengenai aspek yang menjadi bahasan pada pengidentifikasi suara tinggi dan rendah, yaitu :
1. Simulator dapat mengidentifikasi suara tinggi dan rendah untuk pria dan wanita dengan menggunakan metode klasifikasi
support vector machine, dengan ketepatan pelatihan dan prediksi yang baik.
2. Suara tinggi dan rendah wanita lebih mudah diidentifikasi dibandingkan dengan suara tinggi dan rendah pria, ini dibuktikan dengan pengujian sampel suara yang menghasilkan akurasi pengujian sebesar 100% wanita, dan 70% pria dengan fitur suara yang paling dominan mempengaruhi hasil prediksi suara tinggi dan rendah pada pria dan wanita adalahpitch.
3.2 Saran
Berdasarkan kesimpulan yang telah diuraikan, diharapkan simulator pengidentifikasi suara ini dikembangkan lebih baik lagi, agar suara yang dikenali lebih banyak.
DAFTAR PUSTAKA
[1] Endah, Sukmawati Nur dan Dinar Mutiara. 2012. Analisis Pitch dan Formant Sinyal Ucapan Kata. Prosiding Seminar Nasional Ilmu komputer. Semarang.
[2] Fadlisyah, Bustami, dan Ikhwanus, M, 2013.
Pengolahan Suara. Yogyakarta: Graha Ilmu. [3] Wicaksono, Galieh., Prayudi, Yudi. Teknik
Forensika Audio Untuk Analisa Suara Pada Barang Bukti Digital. Universitas Islam Indonesia, Yogyakarta: Pusat Studi Forensika Digital.
[4] Pudjo, Widodo, Prabowo., Trias, Handayanto, Rahmadya., Herlawati. 2013,Penerapan Data Mining dengan Matlab. Bandung: Rekayasa Sains.
[6] Roger S. Pressman. 2010. Software Engineering: A Practitioner's Approach, 4th ed. New York: McGraw-Hill Companies. [7] Bagas, Bhaskoro, Susetyo., Riedho, Altedzar.
2012, Aplikasi Pengenalan Gender Menggunakan Suara. Seminar Nasional Aplikasi Teknologi Informasi.
[8] Suyanto, S.T., Msc. 2007. Artificial Intelegence. Bandung: Informatika.
[9] Rabiner, Lawrence., Juang, Bing-Hwang. 1993, Fundamental of Speech Recognition. New Jersey: Prentince-Hall.
[10] Rabiner, Lawrence., W, Schafer, Ronald. 1978, Digital Processing of Speech Signals. New Jersey: Prentice-Hall, Inc.
[11] Hadi, Putra, Prabowo. Penggolongan Suara Berdasarkan Usia dengan Menggunakan Metode K-Means. Surabaya: Institut Teknologi Sepuluh Nopember.
[12] C, Snell, Roy., Milinazzo, Fausto. 1993, Formant Location From LPC Analysis Data.
IEEE Transaction on Speech and Audio Processing, vol. I.
[13] Suyanto. 2011, Artificial Intelligence. Bandung, Indonesia: Informatika.
[14] Alpaydın, Ethem. 2010, Introduction to
Machine Learning Second Edition. London: The MIT Press.
[15] Bernhard E. Boser and Isabelle M. Guyon and Vladimir Vapnik. 1992,A Training Algorithm for Optimal Margin Classifiers. Proceedings of the fifth annual workshop on Computational learning theory (COLT). [16] Ivanciuc, Ovidiu. 2007, Applications of
Support Vector Machines in Chemistry. Reviews in Computational Chemistry, vol. 23. [17] Hermawati, Astuti, Fajar. 2013. Data Mining.
Yogyakarta: Andi.
[18] Kantardzk, Mehmed. 2011. Data Mining (Concepts, Models, Methods, and Algorithms). New Jersey: John Wiley & Sons.
Indra Tri Prabowo
Teknik Informatika - Universitas Komputer Indonesia Jl. Dipati Ukur No. 112-114 Bandung
Email : [email protected]
ABSTRACT
Voice recognition is the process of identifying the sounds by the words spoken by someone who captured the sound input device to be recognized and then translated into a data that is understood by the computer. When humans make a sound, that's when the voice convey some information in spoken words through sound waves. The voice information can be known through the voice feature itself, including the pitch and formant, where the pitch is the fundamental frequency of the sound signal produced by the vibration of the vocal cords, and pre-processing, feature extraction and classification. Stages of pre-processing with pre-emphasis, frame blocking, and hamming window of the sound signal. Stages feature extraction with autocorrelation to determine pitch and linear predictive coding to determine formant, as well as the stages of classification by support vector machine to classify voice features that will be used to identify high and low voices.
Based on the results of testing of the simulator with the conclusion that the average value of a man's voice pitch high and low is lower than women, the average value of formant formant 1st and 2nd women's high and low sounds higher than men, the mean average formant all three men to the sound of high and low is higher than women, the voice feature is better suited to represent the voice high for men and women is the pitch, the range of pitch and formant for a male voice is 191.1435 Hz (F0), 503.9955 Hz (F1) , 956.9225 Hz (F2), and 1561.43 Hz (F3). For a female voice is 268.51 Hz (F0), 534 871 Hz (F1), 1080.4475 Hz (F2), and 1690,835 Hz (F3). Simulator able to predict high and low noise for both men and women with an accuracy percentage of 70% for the voices of men and 100% for the female voice.
Keywords: Pitch, Formant, Linear Predictive Coding, Support Vector Machine.
1. INTRODUCTION
Issues discussed in this thesis regarding the low and high sound human. The analysis was done on the basis to be able to identify high and low sounds by seeing the values of sound features, namely the pitch and formant. Pitch and formant value is obtained through the process of feature extraction. Values pitch and formant sound high and low then stored as training data and compared with the value of pitch and formant contained in the prediction data to be classified by using support vector machine (SVM) in order to know whether the results of the classification value pitch and formant are entered into the high category or lower.
The study of some of the literature explains that the method of support vector machine is a method of classification of types of assisted (supervised), which works using a mapping linear and non-linear and very good if used to classify the features that have two classes or group, where the class or group here is sound high and low. The resulting solution of support vector machine method for determining the high voice is the voice of identifying high accuracy of voice features we tested, which tested sound features are pitch and formant.
1.1 Autocorrelation
Autocorrelation is the cross-correlation of the signal with itself. Autocorrelation value of a speech signal will show how the sound waves that form a correlation to himself. The forms are the same at any given time delay shows the repetition of the pattern of the sound signal. Thus it would be able to estimate the value of the fundamental frequency.
1.2 Linear Predictive Coding
Linear predictive coding is one sound modeling methods that are based on the theory that that a human voice signals at time n, the sound signal can be approximated as a linear combination of previous human voice signal p. The goal of the method is to separate the effects lpc formant pitch or frequency of human nature.
1.3 Support Vector Machine

![Gambar 1.2 Model Waterfall [6]](https://thumb-ap.123doks.com/thumbv2/123dok/650688.79328/5.892.187.761.377.602/gambar-model-waterfall.webp)