MULTIDIMENSIONAL ASSOCIATION RULE
UNTUK MELIHAT
POLA KETERKAITAN ASPEK GANGGUAN
PADA VSAT IP
TANTI NOPIANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Multidimensional Association Rule untuk Melihat Pola Keterkaitan Aspek Gangguan pada VSAT IP adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2014
Tanti Nopianti
ABSTRAK
TANTI NOPIANTI. Multidimensional Association Rule untuk Melihat Pola Keterkaitan Aspek Gangguan pada VSAT IP. Dibimbing oleh ANNISA.
Penelitian ini bertujuan untuk menentukan pola keterkaitan dari gangguan pada divisi VSAT IP (Very Small Aperture Terminal Internet Protocol) dengan menggunakan metode aturan asosiasi multidimensi. Penelitian ini menggunakan kombinasi dari minimum support 40%, 30% dan 20% dan minimum confidence
50%, 60% dan 80%. Hasilnya menunjukkan bahwa aturan menarik dibentuk oleh kejadian item 'USO' (Universal Service Obligation) bersama-sama dengan dimensi 'area' dengan item 'Area-3' yang dihasilkan oleh aturan USOArea-3 dengan support 40% dan confidence 99.6%. Support tertinggi dari seluruh data dibentuk oleh dimensi ‘area’ dengan item ‘Area-3’ dengan nilai support 55.62%. Hal ini berarti lebih dari setengah data gangguan, terjadi di ‘Area-3’ yaitu wilayah Provinsi Kalimantan Timur, Sumatera Utara, Bali, Bengkulu, Jambi, Sumatera Barat, Riau, Kepulauan Riau, Bangka Belitung, Kalimantan Selatan, Kalimantan Tengah dan Kalimantan Barat. Area-3 adalah area yang perlu diperhatikan dalam perbaikan. Pertimbangan hasil aturan asosiasi dapat digunakan dengan mencari pola keterkaitan dari masing-masing dimensi pada data gangguan komunikasi.
Kata kunci: Aturan asosiasi, Multidimensional Association Rule.
ABSTRACT
TANTI NOPIANTI. Multidimensional Association Rule to Discover Interference Relationship Patterns on VSAT IP. Supervised by ANNISA.
This study aimed to give some considerations of interference on VSAT IP (Very Small Aperture Terminal Internet Protocol) by using multidimensional association rule. This study used the combinations of minimum support of 40%, 30% and 20% and minimum confidence of 50%, 60% and 80%. The result showed that the highest value was established by the occurence of itemset 'USO' (Universal Service Obligation) together with the dimension of ‘area’ with the itemset ‘Area-3’ which was produced by rule USOArea-3 with the minimum support of 40% and the confidence of 99.6%. The highest support of the whole data was established by dimension of ‘area’ with the itemset ‘Area-3’ by the support value of 55.62%. This means that on half of the data, interference occurred in Area-3, comprising East Kalimantan, North Sumatera, Bali, Bengkulu, Jambi, West Sumatera, Riau, Riau Archipelago, Bangka Belitung, South Kalimantan, Central Kalimantan and West Kalimantan. Hence, Area-3 is the area that needs to be considered in maintenance. Considerations of the association result can be used to find relationship patterns from each dimension on communications interference data.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
MULTIDIMENSIONAL ASSOCIATION RULE
UNTUK MELIHAT
POLA KETERKAITAN ASPEK GANGGUAN
PADA VSAT IP
TANTI NOPIANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Multidimensional Association Rule untuk Melihat Pola Keterkaitan Aspek Gangguan pada VSAT IP
Nama : Tanti Nopianti NIM : G64086033
Disetujui oleh
Annisa, S.Kom., M.Kom. Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wata’ala atas segala curahan rahmat dan karunia-Nya sehingga penelitian ini berhasil diselesaikan. Shalawat dan salam semoga senantiasa tercurah kepada Nabi Muhammad shalallahu ‘alaihi wassalam, keluarganya, para sahabat, serta para pengikutnya. Karya tulis ini merupakan salah satu syarat memperoleh gelar Sarjana Komputer di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam. Judul dari karya ilmiah ini adalah Multidimensional Association Rule untuk Melihat Pola Keterkaitan Aspek Gangguan pada VSAT IP.
Penyelesaian penelitian ini tidak terlepas dari dukungan dan bantuan berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih sebesar-besarnya kepada:
1 Kedua orang tua tercinta Koesbiyanto dan Ibunda Suwarsih, adik Widya Kusuma Rini, dan segenap keluarga besar penulis atas do’a, dukungan, semangat, kasih sayang, dan perhatian yang tidak pernah berhenti diberikan selama ini.
2 Ibu Annisa, S.Kom., M.Kom. selaku pembimbing, Ibu Dr. Imas Sitanggang, S. Si., M. Kom. dan Bapak Hari Agung Adrianto, S.Kom., M.Kom. selaku dosen penguji, atas waktu, ilmu, kesabaran, nasihat, dan masukan yang diberikan.
3 Teman-teman penulis di Ekstensi Ilmu Komputer Angkatan 3, teman satu bimbingan, serta teman-teman lain yang tidak dapat penulis sebutkan satu per satu atas bantuan, motivasi, kebersamaan, serta semangat kepada penulis.
4 Departemen Ilmu Komputer, Bapak/Ibu Dosen dan Tenaga Kependidikan yang telah begitu banyak membantu baik selama pelaksanaan penelitian ini maupun sebelumnya.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, penulis ucapkan terima kasih banyak. Semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2014
DAFTAR ISI
PRAKATA vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR LAMPIRAN ix
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 1
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Association Rule 2
Multidimensional Association Rule 3
Algoritme Apriori 4
Very Small Aperture Terminal (VSAT) 5
Preventive Maintenance (PM) dan Corrective Maintenance (CM) 6
Signal Quality Factor (SQF) 6
Cross Polarization Interference (CPI) 6
METODE 6
Identifikasi Masalah 6
Pengumpulan Data 7
Praproses 9
Pembangkitan Frequent Predicate Sets 9
Pembangkitan Association Rules 9
Analisis Rules 10
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Seleksi Data 10
Pembersihan Data 10
DataMining 13
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 16
DAFTAR TABEL
1 Contoh dimensi dalam aturan asosiasi 1 dimensi 3
2 Contoh dimensi dalam aturan asosiasi multidimensi 4
3 Data asli yang digunakan untuk awal praproses 8
4 Kategori untuk dimensi CPI 11
5 Kategori untuk dimensi SQF 11
6 Pengelompokan cakupan beberapa wilayah menjadi area 12
7 Pengelompokan beberapa pelanggan menjadi 1 kategori pelanggan 12
8 Large 1-itemset dengan minimum support 40%, 30% dan 20%. 13
9 Large 2-itemset dengan minimum support 40%, 30% dan 20%. 13
10 Empat aturan asosiasi dengan confidence tertinggi untuk minimum
support 20%. 14
11 Aturan asosiasi dengan minimum confidence di atas 50% dengan
hasil PM dan CM 15
DAFTAR LAMPIRAN
1 Sampel data awal sebelum dilakukan pemilihan field yang akan di
mining 17
2 Sampel data yang telah dilakukan pemilihan field yang akan di
mining 17
3 Large itemset dengan minimum support 40%, 30% dan 20% 18
4 Tabel hasil aturan asosiasi dengan minimum support 20% dan minimum confidence 50% 21
5 Tampilan awal masukan minimum support dan minimum confidence
pada sistem. 27
6 Contoh keluaran ketika diberi masukan minimum support 40% dan minimum confidence 80% 27
7 Fungsi untuk membuat kombinasi item dalam array 28
8 Fungsi untuk membuat L1 29
9 Fungsi untuk membuat L2 29
10 Fungsi untuk membuat L3 sampai L7 30
1
PENDAHULUAN
Latar Belakang
Dalam kesehariannya Operation Maintenance di Metrasat, sebuah instansi dalam bidang telekomunikasi, mencatat dan menangani banyak gangguan komunikasi, salah satunya di bagian VSAT IP (Very Small Aperture Terminal Internet Protocol). Gangguan yang terjadi dalam setiap harinya datang dari pelanggan yang beragam. Pihak helpdesk mencatat dan melakukan penanganan pertama atas gangguan yang terjadi, kemudian engineer masing-masing kelompok pelanggan akan menangani lebih lanjut pada tingkatan parameter gangguan tertentu. Pencatatan gangguan, setiap harinya dilakukan oleh helpdesk ke dalam sebuah sistem, begitu pula pencatatan berbagai lokasi yang telah dilakukan kunjungan oleh teknisi untuk pengecekan perangkat.
Dalam catatan gangguan terekam lokasi gangguan, area gangguan serta parameter yang diperlukan. Cara sederhana yang sudah dilakukan oleh perusahaan untuk menganalisis data gangguan tersebut dengan menghitung banyaknya gangguan dalam setiap triwulan dalam area tertentu. Hasil pengolahan aspek-aspek gangguan tersebut tidak dapat memberikan kesimpulan yang dibutuhkan seperti seberapa besar keterkaitan antar aspek-aspek gangguan. Kebijakan dalam penanganan gangguan, masih ditempuh berdasarkan informasi singkat berupa laporan yang didukung intuisi yang dapat mempengaruhi segala keputusan dan strategi yang akan diambil oleh manajer. Oleh sebab itu, diperlukan adanya sistem pendukung yang menerapkan konsep multidimensional berdasarkan data gangguan yang telah tercatat sebelumnya agar dapat diketahui keterhubungan antar aspek gangguan untuk bahan pengambilan keputusan.
Metode yang akan digunakan untuk melihat keterkaitan antar aspek gangguan diharapkan dalam bentuk aturan yang mudah dipahami oleh manajer. Salah satu metode yang sesuai adalah model Multidimensional Association Rule.
Perumusan Masalah
Berdasarkan latar belakang yang disajikan di atas dapat diambil suatu rumusan masalah yaitu:
1 Bagaimana menentukan aturan asosiasi multidimensi dengan menggunakan algoritme Apriori untuk mencari keterkaitan antar aspek gangguan pada VSAT IP.
2 Bagaimana menghasilkan pola keterkaitan antar komponen gangguan komunikasi data sebagai bahan pengambilan keputusan dengan menggunakan algoritme Apriori.
Tujuan Penelitian
2
Manfaat Penelitian
Manfaat dari penelitian ini ialah menghasilkan pola keterkaitan antar-komponen dalam hasil pencegahan penanganan gangguan maupun perbaikan dalam penanganan gangguan komunikasi data. Hasil dari pola keterkaitan tersebut dapat digunakan sebagai bahan pengambilan keputusan.
Ruang Lingkup Penelitian
Data yang digunakan untuk melihat pola keterkaitan antar dimensi adalah data gangguan komunikasi data sejak bulan Mei 2011 hingga September 2012. Data tersebut berisi area lokasi gangguan, kriteria gangguan, serta waktu terjadinya gangguan.
TINJAUAN PUSTAKA
Association Rule
Association rule mining adalah salah satu teknik data mining dan merupakan bentuk paling umum dari penentuan pola dalam unsupervised learning system (Kantardzic 2003). Ukuran kemenarikan yang dapat digunakan dalam
association rule mining adalah (Han dan Kamber 2006):
a Support, suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item atau itemset dari keseluruhan transaksi. Support diperoleh dengan menggunakan persamaan:
support(A⇒B) = P(A B)………….(1)
= ( ) dengan:
support(A⇒B) : support itemA dan B
( ) : jumlah kemunculan itemA bersamaan dengan itemB N : jumlah seluruh transaksi
b Confidence, suatu ukuran yang menunjukkan hubungan antara 2 item secara kondisional. Confidence diperoleh dengan menggunakan persamaan:
confidence(A⇒B)= P(B|A)……...……(2)
= support( support( ) )
dengan:
3
Beberapa model association rule yang selama ini telah digunakan yaitu (Han dan Kamber 2006):
a Single level association rule. Contoh: buys(X, “computer”) ⇒buys(X, “HP printer”
Dalam single level association rule, jika aturan dalam sebuah set himpunan yang diberikan tidak berdasarkan atribut pada level yang berbeda, maka atribut tersebut berisi aturan asosiasi single-level.
b Multilevel association rule. Contoh: buys(X, “laptop computer”) ⇒ buys(X, “HP printer”)
Perbedaan dengan poin sebelumnya, bahwa dalam multilevel association rule menunjuk kepada aturan pada level yang berbeda yakni computer
berada pada tingkatan di atas laptop computer.
c Interdimensional association rule. Contoh: age(X, “20...29”) ⋀ occupation(X, “student”) ⇒buys(X, “laptop”)
Aturan tersebut mengandung 3 predikat (age, occupation, dan buys).
Interdimensional association rule adalah aturan dalam multidimensional association rule dengan tanpa perulangan predikat.
d Hybrid-dimensional association rule. Contoh: age(X, “20...29”) ⋀ buys(X, “laptop”) ⇒buys(X, “HP printer”)
Ada 2 macam model untuk multidimensional association rule, yang membedakan dari keduanya adalah pada interdimensional association rule tidak diperbolehkan adanya pengulangan predikat/dimensi yang sama pada sebuah rule, sementara hybrid-dimensional association rule memperbolehkan terjadinya pengulangan predikat sebuah rule (Han dan Kamber 2006).
Multidimensional Association Rule
Sebuah association rule yang terdiri atas 2 atau lebih dimensi atau predikat dapat disebut multidimensional association rule. Dalam multidimensional association rule, setiap atribut berperilaku sebagai sebuah dimensi. Setiap predikat yang berbeda pada sebuah rule adalah sebuah dimensi yang berbeda pula. Contoh dimensi dalam aturan asosiasi satu dimensi dapat dilihat pada Tabel 1.
Tabel 1 Contoh dimensi dalam aturan asosiasi 1 dimensi
Dimensions Id/Row Itemsets
buy 1 Item1, Item2
buy 2 Item3
buy 3 Item2, Item5
4
Tabel 2 Contoh dimensi dalam aturan asosiasi multidimensi
Dimensi/Predicates Rows
age, buy 1, 2
income 3
buy, occupation 2, 5
Pada aturan multidimensi, pencarian fokus pada frequent predicate set. Pencarian tersebut untuk mengetahui seberapa banyak kemunculan item dalam dimensi tersebut dalam keseluruhan data.
Algoritme Apriori
Algoritme apriori menghitung frequent itemsets dalam basis data melalui beberapa iterasi. Iterasi i menghitung semua frequent i-itemsets (itemsets dengan
element i). Tiap iterasi memiliki 2 langkah: candidate generation dan candidate counting and selection.
Pada fase pertama dalam iterasi pertama, set yang dibangkitkan dari
candidate itemset mengandung semua 1-itemsets (dalam hal ini semua item dalam
dataset). Pada fase candidate counting, algoritme akan menghitung support dan mencari lagi candidate itemset dalam keseluruhan basis data. Kemudian pada akhirnya, hanya 1-itemsets dengan minimum support tertentu yang memenuhi
threshold yang dipilih sebagai 1-frequent item.
Berdasarkan pengetahuan tentang infrequent itemsets yang diperoleh dari iterasi sebelumnya, algoritme Apriori mereduksi set dari candidates itemsets
dengan pruning (menggunakan Apriori) candidate itemsets yang tidak frequent.
Pruning dilakukan berdasarkan observasi bahwa jika sebuah itemset adalah
frequent maka semua subsetnya adalah frequent sehingga sebelum memasuki step
perhitungan kandidat, algoritme ini tidak melihat candidate itemsets yang memiliki subset yang tidak frequent. Proses iterasi Apriori akan berhenti ketika tidak ada lagi kandidat i-itemsets yang dapat disilangkan.
Berikut adalah algoritme Apriori yang digunakan untuk mencari frequent itemsets dengan menggunakan iterasi (Han dan Kamber 2006).
(1)L1 = find_frequent_1-itemsets (D); (2) for (k=2; Lk-1 ≠ Ø; k++) {
(3) Ck = apriori_gen (Lk-1);
(4) for each transaction t D { //scan D for counts
(5) Ct = subset(Ck,t); //get the subsets of t that are
candidates
(6) for each candidate c Ct
(7) c.count++;
(8) }
(9) Lk = {c Ck | c.count min_sup}
(10) }
5
Procedure apriori_gen(Lk-1:frequent (k-1) –itemsets)
(1)for each itemset l1 Lk-1
(2) for each itemset l2 Lk-1
(3) if(l1[1] = l2[1]) (l1[2] = l2[2]) … (l1[k-2] =
l2[k-2]) (l1[k-1] < l2[k-1]) then {
(4) c = l1 x l2; // join step: generate candidates
(5) if has_infrequent_subset(c, Lk-1) then
(6) delete c; //prune step: remove unfruitful
candidate
(7) else add c to Ck;
(8) }
(9)return Ck;
procedure has_infrequent_subset(c: candidate k-itemset;
Lk-1: frequent(k-1)-itemsets); //use prior knowledge
(1)for each(k-1)-subset s of c
(2) if s Lk-1 then
(3) return TRUE;
(4)return FALSE;
Beberapa istilah yang digunakan dalam algoritme Apriori antara lain: a Support untuk aturan asosiasi adalah perbandingan banyaknya kejadian pada
basis data ketika sekumpulan item A dan sekumpulan item B terdapat pada sebuah transaksi. Definisi dari support, yaitu sebagai berikut:
Probabilitas atribut atau kumpulan atribut A dan B yang terjadi secara bersamaan.
b Confidence adalah kuatnya hubungan antar item dalam aturan asosiasi. c Minimum support adalah parameter yang digunakan sebagai batasan
frekuensi kejadian atau support count yang harus dipenuhi suatu kelompok data untuk dapat dijadikan aturan
d Minimum confidence adalah parameter yang digunakan untuk mendefinisikan minimum nilai kepercayaan yang harus dipenuhi.
e Itemset: Kelompok item.
f Support count adalah frekuensi kejadian untuk sebuah kelompok item dari keseluruhan transaksi.
g Candidate itemsets adalah itemset yang akan dihitung support countnya.
h Large itemset adalah itemset yang sudah melewati batas minimum support
yang telah diberikan.
Very Small Aperture Terminal (VSAT)
6
pengiriman/penerimaan data, gambar maupun suara via satelit. Satelit berfungsi sebagai penerus sinyal untuk dikirimkan ke titik lainnya di atas bumi.
Teknologi VSAT pertama kali dikenal di Amerika Serikat pada awal tahun 1980-an. VSAT masuk pertama kali ke Indonesia tahun 1989 seiring dengan bermunculannya bank-bank swasta yang sangat membutuhkan sistem komunikasi online seperti Automated Teller Machine (ATM) (Satkomindo 2008).
Preventive Maintenance (PM) dan Corrective Maintenance (CM)
Preventive Maintenance (PM) dapat diartikan sebagai suatu bentuk penanganan pencegahan gangguan komunikasi. PM dilakukan untuk perawatan dan perbaikan oleh teknisi dalam menangani perangkat dan fasilitas yang ada di lokasi dalam hal memuaskan kondisi pengoperasian dengan cara inspeksi, deteksi dan koreksi galat sebelum terjadi yang lebih mayor. Maintenance termasuk ke dalamnya adalah testing, pengukuran, dan pengecekan perangkat. Corrective Maintenance (CM) dapat diartikan sebagai bentuk tindakan perbaikan karena adanya gangguan di suatu lokasi (Hughes 2006).
Signal Quality Factor (SQF)
Signal Quality Factor (SQF) adalah sebuah ukuran dalam penerimaan kekuatan sinyal yang diterima. Ukurannya berkisar antara 0 point sampai 99 point. SQF merupakan ukuran kualitas, dan tidak mempengaruhi kecepatan jaringan ataupun bandwidth. SQF dapat dipengaruhi oleh cuaca yang sedang terjadi di lokasi, misalnya ketika hujan, nilai SQF yang didapatkan berkisar pada nilai di bawah 60 point. Jika cuaca sangat mendung, ukuran kualitas sinyal berada di nilai minimum 61 point. Ketika cuaca cerah maka nilai ukuran kualitas sinyal yang mungkin didapatkan antara nilai 75 point ke atas. Dengan melakukan pointing
yang baik, maka akan didapatkan SQF yang baik pula dan SQF akan dikatakan sangat baik jika nilainya lebih dari dan sama dengan 85 point (Hughes 2006).
Cross Polarization Interference (CPI)
Cross Polarization Interference (CPI) adalah sebuah pengaturan sudut arah rambat transmisi ke satelit. Pengukuran CPI bertujuan untuk tes pengiriman data atau transmit data dan juga untuk memaksimalkan gelombang, apakah sudah mencapai hasil yang ditetapkan seperti nilai CPI minimal yaitu 30dB (Hughes 2006).
METODE
Identifikasi Masalah
7
Salah satu solusi dalam penanganan permasalahan pada gangguan komunikasi data tersebut adalah dengan membuat suatu aplikasi yang dapat menghasilkan aturan untuk mempermudah analisis terhadap atribut-atribut yang berkaitan dengan penentuan preventivemaintenance atau corrective maintenance.
Pelaksanaan penelitian ini meliputi beberapa tahapan proses yang digambarkan melalui suatu metode penelitian pada Gambar 1.
Gambar 1 Tahapan proses pada metode penelitian
Pengumpulan Data
Data yang digunakan pada penelitian ini adalah data pengecekan CPI dan hasil SQF dari bulan Mei 2011 sampai September 2012 untuk pelanggan yang menggunakan modem HX50, pada ruang lingkup pelanggan, provinsi, CPI dan SQF. Terdapat 2249 record gangguan dari sekitar 4000 titik pelanggan. Pelanggan yang memiliki nilai SQF di bawah 75 dan CPI di bawah nilai 30 sudah termasuk ke dalam data gangguan, dan segera dilakukan PM agar nilai SQF dan CPI normal kembali.
Pengumpulan data dilakukan dengan melakukan transmit dengan memasukkan serial number modem yang digunakan di lokasi tersebut dan di atur dengan frekuensi yang sama pada spektrum, lalu nilai CPI yang tertera pada layar spektrum dilihat. Pengecekan SQF dan CPI terhadap titik pelanggan hanya bisa
Algoritme Apriori Mulai
Pengumpulan Data Praproses Identifikasi Masalah
Selesai AnalisisAturan
Asosiasi Pembangkitan Aturan
Asosiasi Pembangkitan
8
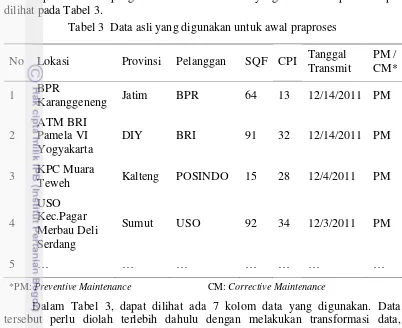
dilakukan ketika titik pelanggan tersebut dalam keadaan menyala atau indikator pada monitoring system terdeteksi warna hijau. Karena ketika keadaan modem tidak menyala, tidak ada transmit ataupun receive pada link tersebut sehingga tidak dapat dilakukan pengukuran. Contoh data asli yang telah dikumpulkan dapat dilihat pada Tabel 3.
Tabel 3 Data asli yang digunakan untuk awal praproses
No Lokasi Provinsi Pelanggan SQF CPI Tanggal Transmit
PM / CM*
1 BPR
Karanggeneng Jatim BPR 64 13 12/14/2011 PM
2
ATM BRI Pamela VI Yogyakarta
DIY BRI 91 32 12/14/2011 PM
3 KPC Muara
Teweh Kalteng POSINDO 15 28 12/4/2011 PM
4
USO Kec.Pagar Merbau Deli Serdang
Sumut USO 92 34 12/3/2011 PM
5 … … … …
*PM: Preventive Maintenance CM: Corrective Maintenance
Dalam Tabel 3, dapat dilihat ada 7 kolom data yang digunakan. Data tersebut perlu diolah terlebih dahulu dengan melakukan transformasi data, sehingga kolom-kolom dalam data asli nantinya akan berubah sesuai dengan transformasi yang dilakukan. Kolom data dalam tabel akan menjadi dimensi dalam data mining.
9
Praproses
Pada tahap praproses dilakukan proses pengolahan data perusahaan ke dalam format yang siap di mining. Dalam tahapan ini dilakukan penggabungan data dalam berbagai dimensi, seperti data pelanggan, data wilayah, data SQF dan CPI. Selain itu, ditentukan pula dimensi-dimensi yang dipilih dan akan digunakan untuk diproses. Keluaran dari praproses ini akan dilanjutkan ke Generate Frequent Predicate Sets.
Pembangkitan Frequent Predicate Sets
Pada tahapan ini dilakukan proses pencarian item yang sering muncul secara bersamaan dan dalam tahapan ini telah ditentukan nilai minimum support yang dijadikan ukuran. Pencarian frequent itemsets/frequent predicate sets dilakukan dengan menggunakan algoritme Apriori dengan iterasi berdasarkan pembentukan kandidat.
Penerapan algoritme Apriori pada masing-masing kandidat digunakan untuk diterapkan pada data pengecekan CPI dan SQF, seperti berikut:
1 Menentukan field yang akan dikorelasikan 2 Menentukan data value
3 Menentukan minimum support dan minimum confidence
4 Membentuk kombinasi berdasarkan field terpilih dengan data value yang ditentukan.
5 Memberikan syarat jika support ≤ minimum support, maka itemset yang tidak memenuhi akan dipangkas.
6 Membangkitkan rules dari tiap korelasi yang memenuhi minimum support
yang ditentukan.
Pembangkitan Association Rules
Pada tahap ini dilakukan proses pembentukan atau pencarian aturan asosiasi dengan masukan hasil dari frequent itemsets dan minimum confidence yang akan menghasilkan aturan asosiasi. Ketika frequent itemsets telah didapatkan, maka akan dibentuk aturan asosiasi kuat yang memenuhi minimum support dan
minimum confidence.
Aturan asosiasi dapat dibentuk dengan algoritme seperti berikut:
1 Dalam setiap frequent itemsetl, bangkitkan semua subset yang tidak kosong dari l.
2 Dalam setiap subset s yang tidak kosong dari l, dihasilkan aturan “s => (l -s)” jika support ount (s)support ount (l) min_conf, min_conf adalah nilai batas minimum dari
10
Analisis Rules
Aturan yang dihasilkan kemudian dianalisis untuk dijadikan bahan pertimbangan dalam penentuan maintenance melalui keterkaitan variabel-variabel yang telah di-mining.
Lingkungan Pengembangan
Lingkungan pengembangan sistem adalah sebagai berikut:
a Perangkat lunak: sistem operasi Windows 8, PHP, MySQL, XAMPP,
Browser, Microsoft Office Excel 2010.
b Perangkat keras: prosesor Intel® Core™ i3 CPU 2.20GHz, memori 4GB,
harddisk 500 GB.
HASIL DAN PEMBAHASAN
Penelitian dilakukan dengan mengacu pada metodologi yang telah disebutkan pada bab sebelumnya, yaitu meliputi tahapan seleksi data, pembersihan data dan transformasi data.
Seleksi Data
Tahap pertama adalah melakukan seleksi data terhadap data yang akan digunakan dalam proses data mining. Data yang digunakan pada penelitian ini adalah data pengecekan gangguan dari bulan Mei 2011 sampai September 2012 sebanyak 2249 record data, mencakup area, kategori pelanggan, CPI, SQF, waktu, tahun, dan kategori PM/CM. Data tersebut didapatkan dari helpdesk maintenance
dalam format Excel.
Dari keseluruhan gangguan yang terjadi, hanya dipilih gangguan dengan lokasi-lokasi yang menggunakan modem jenis HX50 saja. Penentuan akhir dari setiap gangguan yang terjadi adalah pada kolom kategori, yakni apakah akan dilakukan Preventive Maintenance (PM) atau Corrective Maintenance (CM).
Pembersihan Data
Data dalam format Microsoft Excel diubah formatnya menjadi DBMS MySQL untuk memudahkan dalam pengolahan data. Data tersebut dibersihkan dari beberapa hal berikut:
Data yang tidak lengkap. Contohnya, masukan kota yang tidak disertai dengan provinsi harus dilengkapi untuk memenuhi kolom area.
Kesalahan pengetikan. Contohnya, terdapat karakter lebih atau kurang pada penulisan kategori pelanggan
Kesalahan masukan. Contohnya, masukan isian tanggal pada kolom pelanggan.
11
Transformasi Data
Pada tahap ini dilakukan pengkodean data numerik ke kategorik untuk beberapa dimensi data. Data yang dikonversi adalah pada dimensi CPI, SQF, Waktu, dan Tahun. Data pada dimensi CPI yang tersebar antara nilai 1-99, dikonversi menjadi kategorik (Tabel 4).
Tabel 4 Kategori untuk dimensi CPI
Nilai Bawah Nilai Atas Deskripsi
1 19 Kriteria 1
20 24 Kriteria 2
25 29 Kriteria 3
29 99 Normal
Pengelompokkan pada dimensi CPI ditentukan berdasarkan analisis manajer. Kriteria 1, Kriteria 2, Kriteria 3 dan Normal digunakan untuk memudahkan penentuan PM dan CM. Nilai pada Kriteria 1 adalah yang terburuk, dengan nilai CPI antara 1-19, maka titik pelanggan yang memiliki CPI pada Kriteria 1 akan diprioritaskan lebih utama daripada Kriteria 2 dan Kriteria 3 untuk dilakukan maintenance.
Data pada dimensi SQF yang tersebar antara nilai 0-99 dikodekan menjadi kategorik yang dapat dilihat pada Tabel 5.
Tabel 5 Kategori untuk dimensi SQF
Nilai Bawah Nilai Atas Deskripsi
0 30 wrong polarity
31 60 very bad
61 74 bad
75 84 good
85 99 very good
12
Tabel 6 Pengelompokan cakupan beberapa wilayah menjadi area Area Wilayah
Area-1
Jakarta, Bogor, Depok, Tangerang, Bekasi, Jabar, Banten, Jateng, Jatim, Yogyakarta
Area-2
Lampung, Sumsel, Bali, Bengkulu, Jambi, Sumbar, Riau, Kepri, Babel, Batam, Kalsel, Kalteng, Kalbar
Area-3
Kaltim, Sumut, NAD, Sulbar, Sultra, Sulsel, NTB, NTT, Sulut, Sulteng, Gorontalo
Area-4 Maluku
Area-5 Papua
Pengelompokkan area menjadi 5 kategori diambil berdasarkan data internal di Divisi Metrasat. Wilayah tersebut sudah ditentukan berdasarkan persebaran keseluruhan pelanggan yang ada di Divisi Metrasat. Dalam penelitian ini, pelanggan dikategorikan berdasarkan penyebarannya seperti pada Tabel 7.
Tabel 7 Pengelompokan beberapa pelanggan menjadi 1 kategori pelanggan
Kategori Pelanggan Pelanggan
Dephan TNI, Emiliter, Dephan
Kantor Pos Posindo
Kepolisian Polda
Kesehatan Depkes, Askes, Admedika
Oil & Gas Pertagas, Pertamina, Medco, Petrosea,
PT.Metco Pertamina
Pemerintahan
Adminduk, Deptan, Kejari, PLN, Dispenduk, Depag, Bulog, Pajak, BKD, Pemkab Tuban, Pegadaian, Pemkab, Pemprov DKI
Perbankan
BRI Unit, BNI, BTN, BCA Syariah, BPR, BPD Papua, Bank Nisp, BPD Sulteng, BPR Sultra, BII, ATM Niaga, Bank Jatim, BRI, CIMB Niaga, Bank Panin, BNI ATM, BRI Teras, BPD, BRI ATM, BCA, Bank Muamalat
Perkebunan PT. MSL, PT.Inalum
Telekomunikasi Gerai Halo
USO
13
DataMining
Data terdiri atas 7 dimensi (Area, Pelanggan, SQF, CPI, Waktu, Tahun dan Kategori PM/CM) yang digunakan untuk proses mining. Beberapa dimensi pada data, sudah dibuat dengan tipe kategorik. Tabel data asli dan data yang sudah ditransformasi dapat dilihat pada Lampiran 1 dan Lampiran 2. Tahapan asosiasi dibagi menjadi 2 tahap, yaitu mencari frequent itemset dan pembentukan aturan asosiasi.
1 Frequent Itemset
Minimum support yang digunakan dalam penelitian ini adalah 40%, 30% dan 20%. Hal ini digunakan untuk melihat seberapa sering kemunculan itemset dalam data dan dihitung rasio antara kemunculannya dengan total jumlah record
data. Keseluruhan pembentukan large itemset untuk minimum support 40%, 30% dan 20% dapat dilihat pada Lampiran 3.
1.1 Large 1-itemset
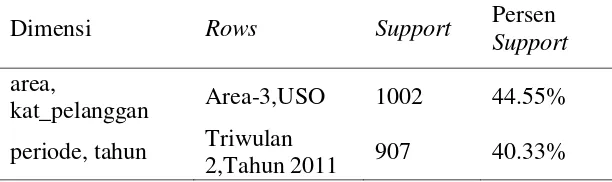
Pada iterasi 1-itemset, support yang memenuhi minimum support 40%, 30% dan 20% dapat dilihat pada Tabel 8. Berdasarkan tabel tersebut, dapat dilihat bahwa dari keseluruhan data, gangguan terbanyak terjadi pada Area-3 di Triwulan 2 dan di Tahun 2011.
Tabel 8 Large 1-itemset dengan minimum support 40%, 30% dan 20%.
Dimensi Rows Support Persen Support
Area Area-3 1251 55.62% tahun Tahun 2011 1245 55.36% periode Triwulan 2 1200 53.36% pm_cm PM 1192 53 % pm_cm CM 1057 47 % kat_pelanggan USO 1006 44.73% tahun Tahun 2012 1004 44.64%
1.2 Large 2-itemset
Pada iterasi 2-itemset untuk minimum support 40%, 30% dan 20%, dihasilkan 2 kombinasi yang dapat dilihat pada Tabel 9.
Tabel 9 Large 2-itemset dengan minimum support 40%, 30% dan 20%.
Dimensi Rows Support Persen Support
area,
kat_pelanggan Area-3,USO 1002 44.55%
periode, tahun Triwulan
14
Berdasarkan hasil pada Tabel 9, kemunculan item Area-3 dalam dimensi area bersamaan dengan kemunculan item USO dalam dimensi kategori pelanggan mencapai support tertinggi untuk iterasi kedua. Hal ini mengindikasikan bahwa untuk kategori pelanggan USO banyak terjadi gangguan di Area-3.
2 Pembentukan Aturan Asosiasi
2.1 Pembentukan Large Itemset dengan Minimum Support 40%, 30% dan 20%
Aturan asosiasi untuk minimum support 20% dan minimum confidence 50% diberikan pada Lampiran 4. Akan tetapi, aturan asosiasi yang dipilih hanya aturan asosiasi dengan confidence yang tinggi dan support yang baik pula, maka diambil contoh untuk 4 aturan teratas dari confidence yang tertinggi (Tabel 10).
Tabel 10 Empat aturan asosiasi dengan confidence tertinggi untuk minimum support 20%.
Dimensi Rules Confidence (%)
area,kat_pelanggan USO Area-3 99.6
area, kat_pelanggan Area-3 USO 80.1
pm_cm, tahun CM Tahun 2011 78.33
pm_cm, tahun Tahun 2012 PM 77.19
Confidence tertinggi dibentuk oleh aturan kemunculan dimensi area karena kemunculan dimensi kategori pelanggan. Confidence aturan ini cukup besar yaitu 99.6%. Dari aturan tersebut dapat dikatakan bahwa untuk melihat seberapa sering sebuah kategori pelanggan muncul di sebuah area, cukup dengan melihat kategori pelanggan USO, karena mayoritas gangguan di Area-3, terjadi karena gangguan pada kategori pelanggan USO.
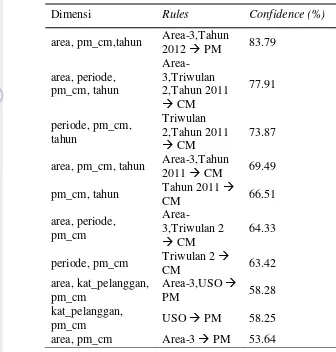
2.2 Aturan asosiasi dengan Minimum Confidence > 50% dengan hasil PM dan CM
Aturan asosiasi dengan minimum confidence di atas 50% yang menghasilkan aturan yang mengandung item PM dan CM dapat dilihat pada Tabel 11. Berdasarkan aturan 1 pada Tabel 11 yaitu Area-3,Tahun 2012 PM, dapat dinyatakan bahwa item Area-3 dalam dimensi area muncul bersamaan dengan
item Tahun 2012 dalam dimensi tahun yang menghasilkan PM. Dalam aturan 1 tersebut menghasilkan confidence tertinggi dengan nilai 83.79%. Serta kemunculan item Area-3 dalam dimensi area bersamaan dengan kemunculan item
15
Tabel 11 Aturan asosiasi dengan minimum confidence di atas 50% dengan hasil PM dan CM
Dimensi Rules Confidence (%)
area, pm_cm,tahun Area-3,Tahun
2012 PM 83.79
area, periode, pm_cm, tahun
Area-3,Triwulan 2,Tahun 2011
CM
77.91
periode, pm_cm, tahun
Triwulan 2,Tahun 2011
CM
73.87
area, pm_cm, tahun Area-3,Tahun
2011 CM 69.49
pm_cm, tahun Tahun 2011
CM 66.51
area, periode, pm_cm
Area-3,Triwulan 2
CM
64.33
periode, pm_cm Triwulan 2
CM 63.42 area, kat_pelanggan,
pm_cm
Area-3,USO
PM 58.28 kat_pelanggan,
pm_cm USO PM 58.25 area, pm_cm Area-3 PM 53.64
Tampilan awal sistem untuk menghasilkan aturan asosiasi pada gangguan VSAT IP dapat dilihat dalam Lampiran 5. Pada halaman tersebut, terdapat masukan mengenai threshold minimum support dan minimum confidence yang telah ditentukan. Proses pembangkitan frequent predicate sets selanjutnya dapat dilihat dalam Lampiran 6. Pada halaman tersebut dapat dilihat list itemset dengan
minimum support yang telah ditentukan serta aturan-aturan asosiasi yang telah terbentuk berdasarkan minimum confidence yang telah ditentukan serta list itemset
yang telah melalui proses pruning. Dalam aturan asosiasi, item dalam itemset
dikombinasikan satu sama lain untuk dilakukan proses pruning dengan memenuhi
threshold nilai minimum support menggunakan fungsi kombinasi yang dapat dilihat dalam Lampiran 7. Setelah proses pruning dilalui, maka proses selanjutnya adalah pembentukan aturan asosiasi berdasarkan list itemset yang memenuhi
16
SIMPULAN DAN SARAN
Simpulan
Setelah percobaan dengan minimum support 40%, 30% dan 20% serta
minimum confidence 50%, 60% dan 80% dilakukan, ditemukan support tertinggi (55.62%) terdapat pada dimensi ‘area’ dengan itemset ‘Area-3’. Berarti lebih dari setengah gangguan terjadi wilayah Provinsi Kalimantan Timur, Sumatera Utara, Bali, Bengkulu, Jambi, Sumatera Barat, Riau, Kepulauan Riau, Bangka Belitung, Kalimantan Selatan, Kalimantan Tengah dan Kalimantan Barat.
Nilai confidence tertinggi sebesar 99.6% didapatkan pada minimum support
40%, yang dihasilkan oleh aturan USO Area-3 . Hal ini dapat bermakna bahwa banyak terjadi gangguan pada Area-3 pada kategori pelanggan USO.
Aturan Area-3,Tahun 2012 PM (support 40% dan confidence 83.79%), menjelaskan bahwa kondisi PM (Preventive Maintenance) banyak terjadi pada Tahun 2012 di Area-3. Disisi lain, kondisi CM (Corrective Maintenance) banyak ditemukan pada Triwulan 2 di Tahun 2011 di Area-3 sebagaimana diperlihatkan oleh aturan Area-3,Triwulan 2,Tahun 2011 CM (confidence 77.91%).
Dengan banyaknya CM pada tahun 2011, dan menurunnya confidence untuk CM di Area-3 di tahun 2012, maka dalam hal ini, penentu kebijakan telah dapat mengambil kesimpulan bahwa Area-3 adalah area yang perlu diperhatikan dalam PM dan CM, dan pelanggan USO adalah pelanggan yang paling sering mengalami gangguan. Penelitian ini sudah dapat menghasilkan aturan asosiasi berdasarkan metode aturan asosiasi multidimensional.
Saran
Untuk penelitian selanjutnya dapat dikombinasikan aturan asosiasi
multidimensional dengan multilevel untuk mendapatkan pola asosiasi yang lebih menarik.
DAFTAR PUSTAKA
Abadi B. 2007. Model Rule: Multilevel and Multidimension Association Rule untuk Analisa Market Basket pada PT. Maha Agung [skripsi]. Surabaya (ID): Universitas Kristen Petra Surabaya.
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques, Ed ke-2. San Fransisco (US): Morgan Kaufmann.
Hughes. 2006. Hughes HX50 Broadband Terminal. Washington (US): Hughes. Kantardzic M. 2003. Data Mining: Concepts, Models, Methods and Algorithms.
New Jersey (US): Wiley.
18
Lampiran 3 Large itemset dengan minimum support 40%, 30% dan 20%
Itemset Dimensi/Fields Rows Support
Persentase
Support
(%)
Minimum Support
1 area Area-3 1251 55.62 40%, 30%, 20%
1 tahun Tahun 2011 1245 55.36 40%, 30%, 20%
1 periode Triwulan 2 1200 53.36 40%, 30%, 20%
1 pm_cm PM 1192 53 40%, 30%, 20%
1 pm_cm CM 1057 47 40%, 30%, 20%
1 kat_pelanggan USO 1006 44.73 40%, 30%, 20%
1 tahun Tahun 2012 1004 44.64 40%, 30%, 20%
1 kat_sqf Very Good 940 41.8 40%, 30%, 20%
1 kat_cpi Normal 786 34.95 30%, 20%
1 kat_sqf Good 737 32.77 30%, 20%
1 kat_cpi Kriteria 3 677 30.1 30%, 20%
1 kat_pelanggan KANTOR POS 674 29.97 20%
1 area Area-1 584 25.97 20%
1 periode Triwulan 3 573 25.48 20%
2 area,
kat_pelanggan Area-3, USO 1002 44.55
40%, 30%, 20%
2 periode, tahun Triwulan 2,
Tahun 2011 907 40.33
40%, 30%, 20%
2 pm_cm, tahun CM, Tahun
2011 828 36.82 30%, 20%
2 pm_cm, tahun PM, Tahun
2012 775 34.46 30%, 20%
2 area, periode Area-3,
Triwulan 2 771 34.28 30%, 20%
2 periode,
19
Lanjutan
Itemset Dimensi/Fields Rows Support
Persentase
2 kat_pelanggan, periode
USO, Triwulan
2 616 27.39 20%
2 kat_pelanggan,
pm_cm USO, PM 586 26.06 20%
2 kat_pelanggan, tahun
USO, Tahun
2011 541 24.06 20%
2 kat_sqf,
pm_cm Very Good, CM 517 22.99 20%
2 kat_pelanggan, kat_sqf
USO, Very
Good 501 22.28 20%
2 kat_cpi,
pm_cm Normal, PM 470 20.9 20%
20
Lanjutan
Itemset Dimensi/Fields Rows Support
Persentase
21
Lampiran 4 Tabel hasil aturan asosiasi dengan minimum support 20% dan minimum confidence 50%
Itemset Dimensi / Fields Rules Confidence
(%)
area, periode, pm_cm, tahun
area, periode, pm_cm, tahun
kat_sqf, pm_cm, tahun Very Good, CM
Tahun 2011
90.72
Triwulan 2, CM, Tahun 2011
periode, pm_cm, tahun Triwulan 2, CM
22
Lanjutan
Itemset Dimensi / Fields Rules Confidence
(%)
area, pm_cm, tahun Area-3, Tahun 2012 PM
83.79
Area-3, Triwulan 2, Tahun 2011
area, periode, tahun Area-3, Tahun 2011 Triwulan 2
82.49
Triwulan 2, CM, Tahun 2011
periode, pm_cm, tahun CM, Tahun 2011
area, periode, pm_cm, tahun
23
Lanjutan
Itemset Dimensi / Fields Rules Confidence
(%)
Area-3, Triwulan 2, Tahun 2011
area, periode, tahun Area-3, Triwulan 2
Tahun 2011
75.75
Triwulan 2, Tahun 2011
periode, tahun Triwulan 2 Tahun 2011
periode, pm_cm, tahun Triwulan 2, Tahun 2011
CM
73.87
Very Good, CM, Tahun 2011
kat_sqf, pm_cm, tahun Very Good, Tahun 2011
CM
73.51
Triwulan 2, Tahun 2011
periode, tahun Tahun 2011 Triwulan 2
area, pm_cm, tahun Area-3, Tahun 2011 CM
69.49
Area-3, Triwulan 2, CM,
Tahun 2011
area, periode, pm_cm, tahun
area, periode, pm_cm Triwulan 2, CM
Area-3
24
Lanjutan
Itemset Dimensi / Fields Rules Confidence
(%)
area, periode, tahun Triwulan 2, Tahun 2011
Area-3
64.39
Area-3, Triwulan 2, CM
area, periode, pm_cm Area-3, Triwulan 2
area, periode, pm_cm, tahun
kat_pelanggan, periode USO Triwulan 2
61.23
Good, Triwulan 2
kat_sqf, periode Good Triwulan 2
area, periode, pm_cm, tahun
Triwulan 2, CM
Area-3, Tahun 2011
25
Lanjutan
Itemset Dimensi / Fields Rules Confidence
(%)
Area-3, CM, Tahun 2011
area, pm_cm, tahun CM, Tahun 2011 Area-3
area, periode, pm_cm, tahun
area, pm_cm, tahun PM, Tahun 2012
Area-3
58.71
Very Good, Triwulan 2
kat_sqf, periode Very Good Triwulan 2
Area-3, Normal area, kat_cpi Normal Area-3
kat_sqf, pm_cm, tahun CM, Tahun 2011 Very
periode, pm_cm, tahun Triwulan 2 CM, Tahun
area, periode, pm_cm, tahun
CM, Tahun 2011 Area-3,
Triwulan 2
26
Lanjutan
Itemset Dimensi / Fields Rules Confidence
(%)
periode, pm_cm, tahun Tahun 2011 Triwulan 2, CM
kat_pelanggan, kat_sqf Very Good USO
kat_pelanggan, periode Triwulan 2 USO
51.33
Very Good, Tahun 2011
kat_sqf, tahun Tahun 2011 Very Good
area, periode, pm_cm, tahun
Triwulan 2, Tahun 2011
Area-3, CM
27
Lampiran 5 Tampilan awal masukan minimum support dan minimum confidence
pada sistem.
28
Lampiran 7 Fungsi untuk membuat kombinasi item dalam array
//fungsi kitemset
//a = awal
//banyak = banyaknya item
//L = array kosong -> index
//po = array yg itemnya mau di kombinasikan
//jml = k itemset
//supp = support
function kitem($a,$banyak,$L,$po,$jml,$supp){
for($L[$a+1]=$L[$a]+1;$L[$a+1]<=$banyak;$L[$a+1]++)
{
$j = count($L);//jumlah array
if ($j == $jml){//ini di pilih sesuai k-itemset
$komb="";//di ulang dengan mengosongkan
$item=$kosong;
foreach ($L as $i){
//echo "<hr> ->".$i."<hr>";
if ($komb=="") $komb=$po[$i];
else $komb=$komb.",".$po[$i];
}
$item = explode(",", $komb);
$kombinasi = mysql_query("SELECT $komb,count(*) as jumlah FROM `t_pmcm` group by $komb");
while ($dt_kombinasi = mysql_fetch_array($kombinasi)){
if($dt_kombinasi[jumlah] >= $supp){
$tampungItem = "";
$item = array_unique($item);
foreach($item as $gabItem){
if
29
else
$tampungItem = $tampungItem.",".$dt_kombinasi[$gabItem];
}
mysql_query("INSERT INTO `t_tampung` (`kolom` ,`isi` ,`jumlah` ,`kombinasi`) VALUES ('$komb', '$tampungItem', '$dt_kombinasi[jumlah]', '$j');");
}
}
}
$b=$a+1;
$c=$banyak;
$R=$L;
kitem($b,$c,$R,$po,$jml,$supp);
}
}
Lampiran 8 Fungsi untuk membuat L1
//L1
//cek kolom
$kolom = mysql_query("DESCRIBE `t_pmcm`");
while ($dt_kolom = mysql_fetch_array($kolom)){
$L1 = mysql_query("SELECT $dt_kolom[Field] as kolom,count( * ) as jumlah FROM `t_pmcm` group by $dt_kolom[Field] ");
while ($dt_L1 = mysql_fetch_array($L1)){
if($dt_L1[jumlah] >= $support)
mysql_query("INSERT INTO `t_tampung` (`kolom` ,`isi` ,`jumlah` ,`kombinasi` ) VALUES ('$dt_kolom[Field]', '$dt_L1[kolom]', '$dt_L1[jumlah]','1');");
}
}
Lampiran 9 Fungsi untuk membuat L2
//L2
$tampung = array();
$tampung[] = 'tampung';
30
while($dt_kolom = mysql_fetch_array($kolom)){
$tampung[] = $dt_kolom[kolom];
}
$banyak = mysql_num_rows($kolom);
if($banyak >= 2) kitem(0,$banyak,$L,$tampung,2,$support);
Lampiran 10 Fungsi untuk membuat L3 sampai L7
//L3 sampai L7
for($t=3;$t<=7;$t++){
if($stop != 1){
$ti = $t - 1;
$kolom = mysql_query("SELECT `kolom` FROM
`t_tampung` WHERE kombinasi = $ti GROUP BY `kolom` ");
$bariskolom = mysql_num_rows($kolom);
if($bariskolom == NULL || $bariskolom ==0) $stop = 1;
else $stop = 0;
$str = "0";
while($dt_kolom = mysql_fetch_array($kolom)){
$str = $str.",".$dt_kolom[kolom];
}
$tampung2 = explode(",", $str);
$tampung2 = array_unique($tampung2);
sort($tampung2);
$banyak = count($tampung2);
$banyak=$banyak-1;
if($banyak >= $t)
kitem(0,$banyak,$L,$tampung2,$t,$support);
}
31
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 25 November 1987 sebagai anak pertama dari dua bersaudara dari Ayah Koesbiyanto dan Ibu Suwarsih. Pada tahun 2005 penulis lulus dari SMU Negeri 2 Bogor. Pada tahun yang sama, penulis diterima sebagai mahasiswa di Institut Pertanian Bogor (IPB) pada Program Diploma 3 Manajemen Informatika melalui jalur reguler.
Penulis menyelesaikan pendidikan D3 selama 3 tahun dari tahun 2005 sampai dengan 2008. Setelah lulus, penulis memutuskan untuk melanjutkan pendidikannya sebagai mahasiswa Program Sarjana Penyelenggaraan Khusus Departemen Ilmu Komputer IPB pada tahun 2008. Selama melaksanakan kuliahnya, penulis juga bekerja sebagai Junior Engineer Provisioning-1VSAT IP di Metrasat oleh PT. Telkom Indonesia, Tbk sejak bulan November 2010 sampai dengan sekarang. Penulis dapat dihubungi melalui alamat email