DAFTAR PUSTAKA
1. Algifari. 2000. Analisis Regresi. Edisi ke-2. Yogyakarta: BPFE.
2. Aritonang, I dan Subaris, B. 2005. Aplikasi Statistika. Yogyakarta: Media Pressindo.
3. Arthanari, T. S dan Dodge, Y. 1981. Mathematical Programming in Statistics. Canada: John Willey & Sons.
4. Dudewicz, J. E dan Mishra, S. N. 1988. Modern Mathematical Statistics. Canada: John Willey & Sons.
5. Gujarati, D dan Zain, S. 1978. Ekonometrika Dasar. Jakarta: Erlangga.
6. Hasan, M. I. 1999. Pokok-Pokok Materi Statistik 2. Jakarta: Bumi Aksara.
7. Pawitan, Y. 2001. In All Likelihood, Statistical Modelling and Inference using Likelihood. New York: Clarendon Press OXPORD.
8. Spiegel, M. R. 1994. Statistika. Edisi ke-2. Jakarta: Erlangga.
9. Subagyo, P dan Djarwanto. 2005. Statistika Induktif. Yogyakarta: BPFE.
10.Sudjana. 1992. Metoda Statistika. Edisi ke-6. Bandung: Tarsito.
11.Suparman, I. A. 1989. Statistik Matematik. Jakarta: Rajawali.
12.Supranto, J. 2001. Statistik Teori dan Aplikasi. Edisi ke-6. Jakarta: Gelora Aksara Pratama.
13.Surjadi, P. A. 1980. Pendahuluan Teori Kemungkinan dan Statistika. Bandung: ITB.
14.Usman, H dan Akbar, P. S. 1995. Pengantar Statistika. Yogyakarta: Bumi Aksara.
15.Wonnacott, T. H dan Wonnacott, R. J. 1976. Introductory Statistics. Canada: John Willey & Sons.
16.google, 2009. Maximum Likelihood Parameter Estimation.
http://www.weibull.com/AccelTestWeb/mle_maximum_likelihood_parameter _estimation.htm. Diakses tanggal 18 Februari, 2009.
17.google, 2009. Multiple Regresi.
http://www.psppr-ugm.net/jurnalpdf/multiple-reg-1.pdf. Diakses tanggal 3 Maret, 2009
18.wikipedia,2009. Maximum Likelihood.
http://en.wikipedia.org/wiki/Maximum_Likelihood. Diakses tanggal 22 Februari, 2009.
19.yahoo, 2009. Analisis Regresi.
ESTIMASI PARAMETER PADA MULTIPLE REGRESI
MENGGUNAKAN MAKSIMUM LIKELIHOOD
SKRIPSI
SITI MAISAROH RITONGA
070823013
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
2009
ESTIMASI PARAMETER PADA MULTIPLE REGRESI
MENGGUNAKAN MAKSIMUM LIKELIHOOD
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
SITI MAISAROH RITONGA
070823013
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ESTIMASI PARAMETER PADA MULTIPLE
REGRESI MENGGUNAKAN MAKSIMUM LIKELIHOOD
Kategori : SKRIPSI
Nama : SITI MAISAROH RITONGA
Nomor Induk Mahasiswa : 070823013
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juni 2009
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dra. Elvina Herawati, M. Si. Drs. Marwan Harahap, M. Eng.
NIP 131 945 361 NIP 130 422 443
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
Dr. Saib Suwilo, M.Sc. NIP 131 796 149
PERNYATAAN
ESTIMASI PARAMETER PADA MULTIPLE REGRESI MENGGUNAKAN MAKSIMUM LIKELIHOOD
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juni 2009
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Allah SWT, karena dengan limpahan rahmat dan kurnia-Nya kertas kajian ini berhasil diselesaikan dalam waktu yang telah ditetapkan.
Ucapan terima kasih saya sampaikan kepada Drs. Marwan Harahap, M. Eng. dan Dra. Elvina Herawati, M. Si. selaku pembimbing pada penyelesaian skripsi ini yang telah memberikan panduan dan penuh kepercayaan kepada saya untuk menyempurnakan kajian ini. Panduan ringkas, padat dan profesional telah diberikan kepada saya agar penulis dapat menyelesaikan tugas ini. Ucapan terima kasih juga ditujukan kepada Ketua dan Sekretaris Departemen Dr. Saib Suwilo, M. Sc. dan Drs. Henry Rani Sitepu, M. Si., Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara, semua dosen pada Departemen Matematika FMIPA USU, pegawai di FMIPA USU, dan rekan-rekan kuliah. Akhirnya, tidak terlupakan kepada ayah, ibu, kedua kakanda dan semua ahli keluarga yang selama ini memberikan bantuan dan dorongan yang diperlukan. Semoga Allah SWT akan membalasnya.
ABSTRAK
Didalam upaya penentuan persamaan estimasi linier dengan metode garis lurus akan menghasilkan persamaan yang baik, jika semua titik yang mencerminkan pasangan data berada di sekitar garis lurus tersebut. Namun, jika titik-titik pasangan data tersebar satu sama lain, maka persamaan linier yang baik untuk mengestimasi nilai variabel bebas adalah persamaan linier yang kurvanya mempunyai kesalahan yang minimum antara titik estimasi dengan titik sebenarnya. Maka dari pada itu, penelitian ini menerangkan bagaimana cara untuk mendekati garis regresi dengan metode maksimum likelihood. Estimasi maksimum likelihood berguna untuk menentukan parameter yang memaksimalkan kemungkinan dari data sampel. Dari sudut pandang statistik, metode maksimum likelihood dianggap lebih kuat pada hasil estimator dengan sifat statistik.
Bentuk umum persamaan multiple regresi linier yang menunjukkan hubungan antara lebih dari satu variabel X sebagai variabel bebas dengan Y sebagai variabel terikat adalah:
ε β
β
β + + + +
= X kXk
Y 0 1 1 dimana:
Y = variabel terikat
X1,…, Xk = variabel bebas pada variabel ke-1 sampai variabel ke-k
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
THE PARAMETER ESTIMATION OF MULTIPLE REGRESSION
USING MAXIMUM LIKELIHOOD
ABSTRACT
In the effort determination of linear estimation with straight line method will yield good equation, iff all point expressing data couple to reside in around the straight line. But, if point of data couples spread over one another, hence equation of linear which good to estimating variable value dependent is equation of linier which is the curve having mistake which a minimum of between point of estimation with pointactually. Hence from at that, this research explains how to come near regression line with linear programming technique. The idea behind maximum likelihood parameters that maximize the probability (likelihood) of the sample data. From a statistical point of view, the method of maximum likelihood is considered to be more robust of yields estimators with good statistical properties.
Form of equation public of simple linear regression showing relation between two variable, that is variable X as independent variable and variable Y as dependent variable is:
ε β
β
β + + + +
= X kXk
Y 0 1 1 where:
Y = dependent variable
X1,…, Xk = independent variable from variable of 1 to variable of k
k β β
β0, 1,..., = regression parameters
ε = error
Maximum likelihood is correct methods in determining multiple regression coefficient models.
DAFTAR ISI
Halaman
Pesetujuan ii
Pernyataan iii
Penghargaan iv
Abstak v
Abstact vi
Daftar Isi vii
Daftar Tabel ix
Daftar Gambar x
Bab 1 Pendahuluan 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Tujuan Penelitian 3
1.4 Kontribusi Penelitian 3
1.5 Tinjauan Pustaka 3
1.6 Metode Penelitian 6
Bab 2 Landasan Teori 7
2.1 Analisis Rgresi 7
2.1.1 Regresi Linier Sederhana 8
2.1.2 Multiple Regresi 11
2.2 Estimasi 12
2.2.1 Estimasi Maksimum Likelihood 14
2.2.2 Maksimum Likelihood dalam Multiple Regresi 14
3.2 Menentukan Persamaan Multiple Regresi dengan Matriks 22
3.3 Estimasi Interval untuk Parameter Multiple Regresi 24
3.4 Pengujian Hipotesis 27
Bab 4 Kesimpulan dan Saran 30
4.1 Kesimpulan 30
4.2 Saran 31
Daftar Pustaka 32
DAFTAR TABEL
Halaman
Tabel 3.1 Penyajian Data 18
Tabel 3.2 Maksimum Likelihood pada Multiple Regresi Y dalam X1 dan X2 21
Tabel 3.3 Penentuan Nilai e2 25
DAFTAR GAMBAR
Halaman
Gambar 2.1 Diagram Pencar 9
Gambar 2.2 Suatu Pengamatan (Data) yang Tidak Tepat pada Garis Regresi 10
ABSTRAK
Didalam upaya penentuan persamaan estimasi linier dengan metode garis lurus akan menghasilkan persamaan yang baik, jika semua titik yang mencerminkan pasangan data berada di sekitar garis lurus tersebut. Namun, jika titik-titik pasangan data tersebar satu sama lain, maka persamaan linier yang baik untuk mengestimasi nilai variabel bebas adalah persamaan linier yang kurvanya mempunyai kesalahan yang minimum antara titik estimasi dengan titik sebenarnya. Maka dari pada itu, penelitian ini menerangkan bagaimana cara untuk mendekati garis regresi dengan metode maksimum likelihood. Estimasi maksimum likelihood berguna untuk menentukan parameter yang memaksimalkan kemungkinan dari data sampel. Dari sudut pandang statistik, metode maksimum likelihood dianggap lebih kuat pada hasil estimator dengan sifat statistik.
Bentuk umum persamaan multiple regresi linier yang menunjukkan hubungan antara lebih dari satu variabel X sebagai variabel bebas dengan Y sebagai variabel terikat adalah:
ε β
β
β + + + +
= X kXk
Y 0 1 1 dimana:
Y = variabel terikat
X1,…, Xk = variabel bebas pada variabel ke-1 sampai variabel ke-k
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
THE PARAMETER ESTIMATION OF MULTIPLE REGRESSION
USING MAXIMUM LIKELIHOOD
ABSTRACT
In the effort determination of linear estimation with straight line method will yield good equation, iff all point expressing data couple to reside in around the straight line. But, if point of data couples spread over one another, hence equation of linear which good to estimating variable value dependent is equation of linier which is the curve having mistake which a minimum of between point of estimation with pointactually. Hence from at that, this research explains how to come near regression line with linear programming technique. The idea behind maximum likelihood parameters that maximize the probability (likelihood) of the sample data. From a statistical point of view, the method of maximum likelihood is considered to be more robust of yields estimators with good statistical properties.
Form of equation public of simple linear regression showing relation between two variable, that is variable X as independent variable and variable Y as dependent variable is:
ε β
β
β + + + +
= X kXk
Y 0 1 1 where:
Y = dependent variable
X1,…, Xk = independent variable from variable of 1 to variable of k
k β β
β0, 1,..., = regression parameters
ε = error
Maximum likelihood is correct methods in determining multiple regression coefficient models.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Metode analisis yang telah dibicarakan hingga sekarang adalah analisis terhadap data
mengenai sebuah karakteristik atau atribut (jika data itu kualitatif) dan mengenai
sebuah variabel diskrit atau kontinu (jika data itu kuantitatif). Tetapi, sebagaimana
disadari, banyak persoalan atau fenomena yang meliputi lebih dari sebuah variabel.
Misalnya, berat orang dewasa laki-laki sampai taraf tertentu bergantung pada
tingginya, tekanan semacam gas bergantung pada temperatur, hasil produksi padi
tergantung pada jumlah pupuk yang digunakan, banyak curah hujan, cuaca dan
sebagainya. Akibatnya, terasa perlu untuk mempelajari analisis data yang terdiri atas
banyak variabel. Jika kita mempunyai data yang terdiri atas dua variabel atau lebih
variabel, adalah sewajarnya untuk mempelajari cara bagaimana vaiabel-variabel itu
berhubungan. Hubungan yang didapat pada umumnya dinyatakan dalam bentuk
persamaan matematik yang menyatakan hubungan fungsional antara variabel-varibel.
Studi yang menyangkut masalah ini dikenal dengan analisis regresi.
Analisis regresi dibedakan atas dua jenis variabel yaitu variabel bebas atau
variabel prediktor dan variabel terikat atau variabel respon. Penentuan variabel bebas
dan terikat dalam beberapa hal tidak mudah dilaksanakan. Studi yang cermat, diskusi
yang seksama, berbagai pertimbangan, kewajaran masalah yang dihadapi dan
pengalaman akan memudahkan penentuan. Variabel yang mudah didapat atau tersedia
sering dapat digolongkan kedalam variabel bebas, sedangkan variabel yang terjadi
variabel bebas akan dinyatakan dengan X1, X2,…, Xk
(
k ≥1)
, sedangkan variabelterikat akan dinyatakan dengan Y.
Statistika bermaksud menyimpulkan populasi yang pada umumnya dengan
menggunakan hasil analisis data sampel. Khusus mengenai regresi dalam menentukan
hubungan fungsional yang diharapkan berlaku untuk populasi berdasarkan data
sampel yang diambil dari populasi yang bersangkutan. Seperti dikatakan di atas,
hubungan fungsional ini akan dituliskan dalam bentuk persamaan matematik yang
disebut dengan persamaan regresi dan bergantung pada parameter-parameter.
Regresi linier merupakan suatu metode analisis statistik yang mempelajari pola
hubungan antara dua atau lebih variabel. Pada kenyataan sehari-hari sering dijumpai
sebuah kejadian dipengaruhi oleh lebih dari satu variabel, oleh karenanya
dikembangkan analisis multiple regresi. Multiple regresi adalah perluasan dari simple
regresi yang mempunyai lebih dari satu variabel bebas X. Multiple regresi digunakan
untuk memodelkan hubungan antara variabel repon (terikat) dan variabel pediktor
(bebas). Untuk mendapatkan estimasi β0, β1,…, βk digunakan metode maksimum
likelihood, dimana metode ini secara prinsip dapat meminimumkan jumlah kuadrat
kesalahan.
Suatu cara yang penting untuk mendapat penaksir yang baik adalah metode
maksimum likelihood, yang telah diperkenalkan oleh seorang ahli genetika dan
statistik Sir R.A. Fisher antara tahun 1912 sampai 1922 dan memiliki aplikasi yang
luas diberbagai bidang. Cara memaksimumkan likelihood berkaitan dengan metode
estimasi dalam statistik. Estimasi maksimum likelihood berguna untuk menentukan
parameter yang memaksimalkan kemungkinan dari data sampel. Dari sudut pandang
statistik, metode maksimum likelihood ini dianggap lebih kuat pada hasil estimator
dengan sifat statistik. Selain itu, metode ini juga lebih efisien untuk ketidakpastian
pengukuran melalui batas keyakinan. Meskipun metodologi untuk estimasi maksimum
likelihood sangat sederhana namun pelaksanaan matematiknya sangat kuat. Parameter
yang diperoleh dari fungsi estimasi maksimum likelihood merupakan nilai yang
sebenarnya. Jelas bahwa ukuran sampel menentukan ketelitian dari estimator. Jika
ukuran sampel sama dengan populasi, maka estimator memiliki sifat tidak bias,
konsisten dan efisien.
1.2Perumusan Masalah
Masalah dalam penelitian ini adalah bagaimana menentukan model koefisien regresi
multiple variabel dengan menggunakan maksimum likelihood.
1.3Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menguraikan cara mengestimasi parameter
multiple regresi dengan meminimumkan error menggunakan maksimum likelihood.
1.4Kontribusi Penelitian
a. Menambah wawasan dan memperkaya literatur dalam bidang statistika yang
berhubungan dengan multiple regresi dan maksimum likelihood.
b. Dengan diketahuinya bagaimana cara mengestimasi parameter multiple regresi
menggunakan maksimum likelihood diharapkan dapat meminimumkan jarak
antara titik data dan garis regresi.
c. Untuk mengetahui besarnya pengaruh dari setiap variabel bebas (yang
tercakup dalam persamaan) terhadap variabel tak bebas.
1.5Tinjauan Pustaka
Dalam penelitian ini penulis menggunakan buku-buku berikut sebagai sumber utama,
1. Supranto, J (12): apabila variabel mempunyai hubungan linier dengan n buah
variabel X, maka model matematika multiple regresinya adalah:
ε β
β
β + + + +
= X kXk
Y 0 1 1 dimana:
Y = variabel terikat
X1,…, Xk = variabel bebas pada variabel ke-1 sampai variabel ke-k
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
2. Wonnacott, T. H dan Wonnacott, R. J (15): jika X dikurangi dengan
rata-ratanya, maka akan diperoleh variabel baru x
(
xi = Xi−X)
. Dan persamaanmultiple regresinya menjadi:
ε β β
β + + + +
= i k ki
i x x
Y 0 1 1 dimana:
Yi = variabel terikat ke-i
x1i,…, xki = selisih antara variabel bebas X dengan nilai rata-
ratanya pada pengamatan ke-i
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
Secara umum, andaikan kita mempunyai sampel berukuran n dan kita ingin
mengetahui kemungkinan sampel yang diamati. Diperlihatkan fungsi nilai
kemungkinan untuk β0,β1,...,βk: p
(
Y1,Y2,...,Yn β0,β1,...,βk)
. Untuk nilai Y bebas dengan mengalikan semua kemungkinan bersama, dimana:(
Y Y Yn k)
p 1, 2,..., β0,β1,...,β
( ) ( ) = − + + + − − + + + − 2 1 1 0 2 2 1 1 0 1 2 1 2 1 2 1 2 1 σ β β β σ β β β π σ π σ ki k i ki k
i x Y x x
x Y e e ( )
∏
= − + + + − = n i x xYi i k ki
e 1 2 1 2 1 1 0 2
1 β β σ β
π σ
Dengan
∏
=
n
i 1
menyatakan hasil kali n kemungkinan bersama untuk nilai Yi
yang penggunaannya dikenal untuk eksponensial. Hasil di atas dapat
diperlihatkan dengan penjumlahan eksponen:
(
)
( ) ( ) 2 1 1 1 0 2 1 1 0 2 1 2 1 ,..., , ,..., , ∑= − − + + + = n i ki k i i x xY n k n e Y Y Y p σ β β β π σ β β β
Mengingat Yi amatan yang diberikan dipertimbangkan untuk berbagai nilai
k β β
β0, 1,..., . Sehingga persamaan di atas dinamakan fungsi likelihood:
(
)
(
)
∑ = = − − − − − n i ki k i i x xY n k e L 1 2 1 1 0 2 1 1 0 2 1 ,..., , σ β β β π σ β β β dimana:
(
k)
L β0,β1,...,β = fungsi maksimum likelihood pada parameter β0,β1,...,βk
σ = parameter yang merupakan simpangan baku untuk
distribusi
π = nilai konstan (π = 3,1416)
n = banyak data sampel
e = bilangan konstan (e = 2,7183)
1.6Metode Penelitian
Uraian metode yang digunakan dalam penelitian secara rinci meliputi:
a. Membentuk persamaan dari jumlah deviasi kuadrat.
b. Menganalisis persamaan dengan menggunakan maksimum likelihood.
c. Mengambil kesimpulan dari analisa yang diperoleh.
BAB 2
LANDASAN TEORI
2.1 Analisis Regresi
Perubahan nilai suatu variabel tidak selalu terjadi dengan sendirinya, namun
perubahan nilai variabel itu dapat pula disebabkan oleh berubahnya variabel lain yang
berhubungan dengan variabel tersebut. Untuk mengetahui pola nilai suatu variabel
yang disebabkan oleh variabel lain diperlukan alat analisis yang memungkinkan kita
untuk membuat perkiraan nilai variabel tersebut pada nilai tertentu variabel yang
mempengaruhinya.
Teknik yang umum digunakan untuk menganalisis hubungan antara dua atau
lebih variabel dalam ilmu statistik adalah analisis regresi. Analisis regresi adalah
teknik statistik yang berguna untuk memeriksa dan memodelkan hubungan diantara
variabel-variabel. Analisis regresi berguna dalam menelaah hubungan dua variabel
atau lebih dan terutama untuk menelusuri pola hubungan yang modelnya belum
diketahui dengan sempurna, sehingga dalam penerapannya lebih bersifat eksploratif.
Persamaan regresi yang digunakan untuk membuat taksiran mengenai nilai
variabel terikat disebut persamaan regresi estimasi, yaitu suatu formula matematis
yang menunjukkan hubungan keterkaitan antara satu atau beberapa variabel yang
nilainya sudah diketahui dengan satu variabel yang nilainya belum diketahui. Sifat
hubungan antarvariabel dalam persamaan regresi merupakan hubungan sebab akibat.
Regresi yang berarti peramalan, penaksiran atau pendugaan pertama kali
dengan penelitiannya terhadap manusia. Penelitian tersebut membandingkan antara
tingggi anak laki-laki dan tinggi badan orang tuanya. Istilah regresi pada mulanya
bertujuan untuk membuat perkiraan nilai suatu variabel (tinggi badan anak) terhadap
suatu variabel yang lain (tinggi badan orang tua). Pada perkembangan selanjutnya,
analisis regresi dapat digunakan sebagai alat untuk membuat perkiraan nilai suatu
variabel dengan menggunakan beberapa variabel lain yang berhubungan dengan
variabel tersebut.
2.1.1 Regresi Linier Sederhana
Regresi linier sederhana adalah analisis regresi yang melibatkan hubungan fungsional
antara satu variabel terikat dengan satu variabel bebas. Variabel terikat merupakan
variabel yang nilainya selalu bergantung dengan nilai variabel lain. Dalam hal ini
variabel terikat yang nilainya selalu dipengaruhi oleh variabel bebas, sedangkan
variabel bebas adalah variabel yang nilainya tidak bergantung pada nilai variabel lain.
Dan biasanya variabel terikat dinotasikan dengan Y, sedangkan variabel bebas
dinotasikan dengan X. Hubungan-hubungan tersebut dinyatakan dalam model
matematis yang memberikan persamaan-persamaan tertentu.
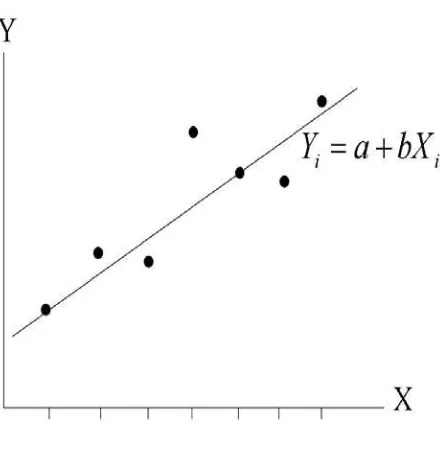
Bentuk umum persamaan regresi linier sederhana yang menunjukkan
hubungan antara dua variabel, yaitu variabel X sebagai variabel bebas dan variabel Y
sebagai variabel terikat adalah
i
i a bX
Y = + (2.1)
dimana:
Yi = variabel terikat ke-i
Xi = variabel bebas ke-i
a = intersep (titik potong kurva terhadap sumbu Y)
b = kemiringan (slope) kurva linier
Gambar 2.1 Diagram pencar
Metode kuadrat terkecil adalah suatu metode untuk menghitung a dan b
sebagai perkiraan A dan B, sedemikian rupa sehingga jumlah deviasi kuadrat
(
=∑
2)
i
e
SSD memiliki nilai terkecil.
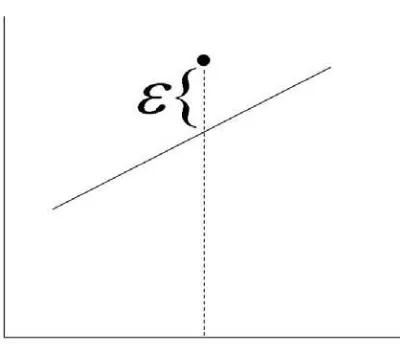
Model sebenarnya : Y = A + BX + ε
Model perkiraan : Y = a + bX + e
Dimana a, b merupakan perkiraan / taksiran atas A, B.
Jika X dikurangi dengan rata-ratanya
(
xi = Xi−X)
akan diperoleh variabelbaru x dengan
∑
xi =0. Maka persamaannya menjadi:(
i)
i i
i i i
bx a Y e
e bx a Y
+ − =
+ + =
(
)
[
]
∑
=∑
− += 2 2
i i
i Y a bx
e
SSD (2.2)
Metode meminimumkan jumlah deviasi kuadrat (regresi kuadrat terkecil) yang
Gambar 2.2 Suatu pengamatan (data) yang tidak tepat pada garis regresi
Kemudian akan ditaksir a dan b sehingga jika taksiran ini disubstitusikan ke
dalam persamaan (2.2), maka jumlah deviasi kuadrat menjadi minimum. Dengan
mendifferensialkan persamaan (2.2) terhadap a dan b dengan menetapkan derivatif
parsial yang dihasilkan sama dengan nol, diperoleh:
(
)
2 0 02
∑
∑
∑
∑
∑
− − = − − = → =∂ ∂ = ∂ ∂
i i
i i
i i
x x
b na Y bx
a Y a a
e
Y
n Y a= i =
⇒ ˆ
∑
(2.3)(
)
2 2 0 02
= →
= −
− =
− − ∂
∂ = ∂ ∂
∑
∑
∑
∑
∑
∑
i i
i i
i i
i i
x x
b x a Y x bx
a Y b b
e
∑
∑
=⇒ ˆ 2
i i i
x Y x
b (2.4)
Nilai aˆ dan bˆ yang diperoleh dengan cara ini disebut taksiran kuadrat terkecil
masing-masing dari a dan b. Dengan demikian, taksiran persamaan regresi dapat
ditulis sebagai, Yˆ =aˆ+bˆX yang disebut persamaan prediksi.
Garis regresi berguna untuk menentukan hubungan pengaruh perubahan
variabel yang satu terhadap variabel yang lainnya. Selanjutnya dari hubungan dua
variabel ini dapat dikembangkan untuk analisa tiga variabel atau lebih.
2.1.2 Multiple Regresi
Multiple regresi (regresi linier ganda) merupakan regresi linier yang melibatkan
hubungan fungsional antara sebuah variabel terikat dengan dua atau lebih variabel
bebas. Semakin banyak variabel bebas yang terlibat dalam suatu persamaan regresi
semakin rumit menentukan nilai statistik yang diperlukan hingga diperoleh persamaan
regresi estimasi. Regresi linier berganda berguna untuk mendapatkan pengaruh dua
variabel kriteriumnya atau untuk mencari hubungan fungsional dua variabel prediktor
atau lebih dengan variabel kriteriumnya, atau untuk meramalkan dua variabel
prediktor atau lebih terhadap variabel kriteriumnya.
Hubungan linier lebih dari dua variabel yang bila dinyatakan dalam bentuk
persamaan matematis adalah:
ε β
β
β + + + +
= X kXk
Y 0 1 1 dimana:
Y = variabel terikat
X1,…, Xk = variabel bebas pada variabel ke-1sampai variabel ke-k
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
Metode kuadrat terkecil dari estimasi β yang terdiri dari minimum
∑
εi2yang berkenaan dengan β, dimana minimum ε'ε = Y −Xβ 2 mengenai β, yaitu:
(
) (
)
β β β
β β
ε ε
X X Y X Y
Y
X Y X Y
' ' ' ' 2 '
'
'
+ −
=
− −
=
Perbedaan ε'ε mengenai β dan persamaan ' =0
∂ ∂
β ε ε
, diperoleh:
0 '
2 '
2 + =
(
X'X)
X'Yˆ= −1
β (2.6)
Kemudian untuk β,
(
) (
)
[
(
)
]
[
(
)
]
(
) (
) (
)
(
)
(
β) (
β)
β β β
β β β
β β β β
β β β
β
ˆ '
ˆ
ˆ ' ' ˆ ˆ '
ˆ
ˆ ˆ '
ˆ ˆ '
X Y X Y
X X X
Y X Y
X X Y X
X Y X Y X Y
− −
≥
− −
+ − −
=
− + − −
+ − = − −
Minimum dari
(
Y −Xβ) (
' Y −Xβ)
adalah(
Y −Xβˆ) (
' Y−Xβˆ)
dicapai pada β =βˆ. Solusi ini untuk melihat minimum ε'ε.2.2 Estimasi
Estimasi adalah menaksir ciri-ciri tertentu dari populasi atau memperkirakan nilai
populasi (parameter) dengan memakai nilai sampel (statistik). Dengan statistika kita
berusaha menyimpulkan populasi. Dalam kenyataannya, mengingat berbagai faktor
untuk keperluan tersebut diambil sebuah sampel yang representatif dan berdasarkan
hasil analisis terhadap data sampel kesimpulan mengenai populasi dibuat. Cara
pengambilan kesimpulan tentang parameter berhubungan dengan cara-cara menaksir
harga parameter. Jadi, harga parameter sebenarnya yang tidak diketahui akan
diestimasi berdasarkan statistik sampel yang diambil dari populasi yang bersangkutan.
Sifat atau ciri estimator yang baik yaitu tidak bias, efisien dan konsisten:
1. Estimator yang tidak bias
Estimator dikatakan tidak bias apabila ia dapat menghasilkan estimasi yang
mengandung nilai parameter yang diestimasikan. Misalkan, estimator θˆ dikatakan estimator yang tidak bias jika rata-rata semua harga θˆ yang
mungkin akan sama dengan θ. Dalam bahasa ekspektasi ditulis E
( )
θˆ =θ .2. Estimator yang efisien
Estimator dikatakan efisien apabila hanya dengan rentang nilai estimasi yang
kecil saja sudah cukup mengandung nilai parameter. Estimator bervarians
minimum ialah estimator dengan varians terkecil diantara semua estimator
untuk parameter yang sama. Jika θˆ1 dan θˆ2 dua estimator untuk θ dimana
varians untuk θˆ1 lebih kecil dari varians untuk θˆ2, maka θˆ1 merupakan
estimator bervarians minimum.
3. Estimator yang konsisten
Estimator dikatakan konsisten apabila sampel yang diambil berapa pun
besarnya, pada rentangnya tetap mengandung nilai parameter yang sedang di
estimasi. Misalkan, θˆ estimator untuk θ yang dihitung berdasarkan sebuah sampel acak berukuran n. Jika ukuran sampel n makin besar mendekati ukuran
populasi menyebabkan θˆ mendekati θ, maka θˆ disebut estimator konsisten.
Estimasi nilai parameter memiliki dua cara, yaitu estimasi titik (point estimation) dan estimasi selang (interval estimation).
a. Estimasi titik (point estimation)
Estimasi titik adalah estimasi dengan menyebut satu nilai atau untuk
mengestimasi nilai parameter.
b. Estimasi interval (interval estimation)
Estimasi interval dengan menyebut daerah pembatasan dimana kita
menentukan batas minimum dan maksimum suatu estimator. Metode ini
memuat nilai-nilai estimator yang masih dianggap benar dalam tingkat
2.2.1 Estimasi Maksimum Likelihood
Suatu cara yang penting untuk mendapat estimator yang baik adalah metode
maksimum likelihood yang diperkenalkan oleh R. A. Fisher. Maksimum likelihood
merupakan suatu cara mendapat estimator a untuk parameter b yang tidak diketahui
dari populasi dengan memaksimumkan fungsi kemungkinan.
Untuk data sampel x1,…, xn dari distribusi yang kontinu dengan fungsi padat
f(x ; α) ditentukan fungsi likelihood sebagai L(x1,…, xn; α) = f(x1;α) … f(xn; α).
Untuk data sampel distribusi yang diskrit dengan nilai kemungkinan p(X = xi)
= pi(α), i = 1,…r dan frekuensi f1,…,fr ditentukan dengan fungsi likelihood sebagai:
(
)
(
( )
)
(
( )
)
∑
=
=
= n
i i f
r f i
n p p f n
x x
L r
1
1,..., ; ... ,
1 α
α α
Karena ln L merupakan transformasi yang monoton naik daripada L, maka ln
L mencapai maksimumnya pada nilai α yang sama. Menurut hitung differensial
persamaannya menjadi ln =0
∂ ∂
α
L
. Suatu akar persamaan ini αˆ =a
(
x1,...,xn)
yangmemaksimumkan L, disebut estimasi maksimum likelihood untuk α.
2.2.2 Maksimum Likelihood dalam Multiple Regresi
Maksimum likelihood adalah metode yang dapat digunakan untuk mengestimasi suatu
parameter dalam regresi.
Jika X dikurangi dengan rata-ratanya, maka akan diperoleh variabel baru x
(
xi = Xi−X)
dan selisih antara Xidengan X merupakan perhitungan yangsederhana karena jumlah dari nilai xi tersebut adalah sama dengan nol
∑
==
0
1 n
i i
x .
Dan persamaan multiple regresinya menjadi:
ε β β
β + + + +
= k k
i x x
Y 0 1 1 (2.7)
dimana:
Yi = variabel terikat ke-i
x1i,…, xki = selisih antara variabel bebas X dengan nilai rata-ratanya pada
pengamatan ke-i
k β β
β0, 1,..., = parameter regresi
ε = nilai kesalahan (error)
Teknik estimasi maksimum likelihood mempertimbangkan berbagai populasi
yang mungkin dengan perpindahan garis regresi dan regresi tersebut mengelilingi
distribusi untuk semua posisi yang mungkin. Perbedaan posisi yang berhubungan
dengan perbedaan nilai percobaan untuk β0,β1,...,βk. Dalam hal ini, pengamatan
likelihood Y1, Y2,…, Yn akan di estimasi. Untuk estimasi maksimum likelihood
dipilih hipotesis populasi yang maksimum dalam likelihood. Secara umum, andaikan
kita mempunyai sampel berukuran n dan kita ingin mengetahui kemungkinan sampel
yang diamati. Diperlihatkan fungsi nilai kemungkinan untuk β0,β1,...,βk:
(
Y Y Yn k)
p 1, 2,..., β0,β1,...,β (2.8)
Mengingat kemungkinan nilai pertama Y adalah:
( )
( )2 1
1 0 1
2 1
1
2
1 − − + + +
= σ
β β β
π σ
ki k i x
x Y
e Y
p
(2.9)
Hal di atas adalah distribusi normal sederhana dengan rata-rata
ki k
i x
x β
β
β0 + 1 1 ++ dan varians
( )
σ2 yang disubstitusi ke dalam( )
2
2 1
2
1 − −
= σ
µ
π σ
x
e x
p . Kemungkinan nilai kedua Y sama dengan (2.9), kecuali
Untuk nilai Y bebas dengan mengalikan semua kemungkinan bersama dalam
(2.8), dimana:
(
Y Y Yn k)
p 1, 2,..., β0,β1,...,β
( ) ( ) = − + + + − − + + + − 2 1 1 0 2 2 1 1 0 1 2 1 2 1 2 1 2
1 β β σ β β β σ β
π σ π σ ki k i ki k
i x Y x x
x Y e e ( )
∏
= − + + + − = n i x xYi i k ki
e 1 2 1 2 1 1 0 2
1 β β σ β
π σ
(2.10)
Dengan
∏
=
n
i 1
menyatakan hasil kali n kemungkinan bersama untuk nilai Yi
yang penggunaannya dikenal untuk eksponensial. Hasil (2.10) dapat diperlihatkan
dengan penjumlahan eksponen:
(
)
( ) ( ) 2 1 1 1 0 2 1 1 0 2 1 2 1 ,..., , ,..., , ∑= − − + + + = n i ki k i i x xY n k n e Y Y Y p σ β β β π σ β β β (2.11)
Mengingat Yi amatan yang diberikan dipertimbangkan untuk berbagai nilai
k β β
β0, 1,..., . Sehingga persamaan (2.11) dinamakan fungsi likelihood:
(
)
(
)
∑ = = − − − − − n i ki k i i x xY n k e L 1 2 1 1 0 2 1 1 0 2 1 ,..., , σ β β β π σ β β β (2.12) dimana:
(
k)
L β0,β1,...,β = fungsi maksimum likelihood pada parameter β0,β1,...,βk σ = parameter yang merupakan simpangan baku untuk distribusi π = nilai konstan (π = 3,1416)
n = banyak data sampel
e = bilangan konstan (e = 2,7183)
Yi = variabel terikat ke-i
i
β = parameter regresi ke-i
Dari persamaan (2.12) diperoleh ln L(β0,β1,...,βk), yaitu:
(
)
( )
∑
= − − − − − − − = = Λ n i ki k i i k x x Y n n L 1 2 1 1 0 1 0 2 1 ln 2 ln 2 ,..., , ln σ β β β σ π β ββ (2.13)
Dengan mendifferensialkan Λ terhadap setiap parameter β0,β1,...,βk dan
menetapkan derivatif parsial yang dihasilkan sama dengan nol, diperoleh:
(
)
0 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 0 2 0 = = → = − − − − = = − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i ki n i i n i ki k n i i n i i n i ki k i i x x x x n Y x x Y β β β β β β σ β Y n Y n i i = =⇒
∑
=10
ˆ
β (2.14)
(
)
0 0 0 1 1 1 1 1 1 2 1 1 1 1 0 1 1 1 1 1 0 1 2 1 = → = + + + + − = = − − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i i n i ki i k n i i n i i n i i i n i ki k i i i x x x x x Y x x x Y x β β β β β β σ β 0 1 1 1 2 1 1 11 + + + =
− ⇒
∑
∑
∑
= = = n i ki i k n i i n i iiY x x x
x β β (2.15)
(
)
0 0 0 1 1 1 2 1 1 1 1 0 1 1 1 1 0 2 = → = + + + + − = = − − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i ki n i ki k n i ki i n i ki n i i ki n i ki k i i ki k x x x x x Y x x x Y x β β β β β β σ β 0 1 2 1 1 1 1 = + + + − ⇒∑
∑
∑
= = = n i ki k n i ki i n i ikiY x x x
x β β (2.16)
Maka hasil yang diperoleh dari penurunan parsial di atas dapat dihitung nilai
BAB 3
PEMBAHASAN
3.1 Estimasi Parameter Menggunakan Maksimum Likelihood
Andaikan suatu persoalan penentuan model multiple regresi diberikan data sebagai
[image:33.595.169.459.367.561.2]berikut:
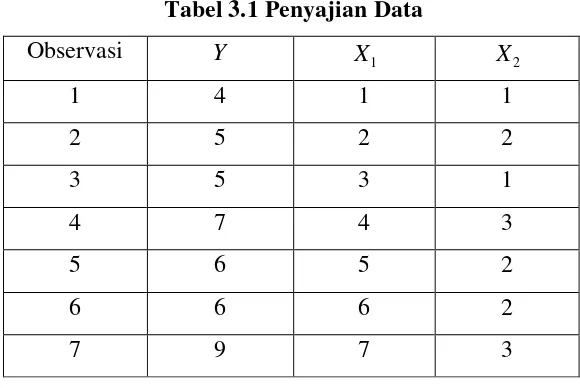
Tabel 3.1 Penyajian Data
Observasi Y X1 X2
1 4 1 1
2 5 2 2
3 5 3 1
4 7 4 3
5 6 5 2
6 6 6 2
7 9 7 3
dengan menentukan regresi yang terdiri dari Yˆ =βˆ0+βˆ1X1+βˆ2X2. Fungsi nilai
kemungkinan untuk β0,β1,β2: p
(
Y1,Y2,...,Yn β0,β1,β2)
. Untuk nilai Y bebas dengan mengalikan semua kemungkinan bersama, dimana:(
Y1,Y2,...,Yn β0,β1,β2)
p
( ) ( )
=
− + +
−
− + +
−
2 2 2 1 1 0 2 2
2 2 1 1 0 1
2 1 2
1
2 1 2
1 β βσ β β βσ β
π σ π
σ
i i i
i x Y x x
x Y
e e
( )
∏
= − + + − = n i x xYi i i
e 1 2 1 2 2 2 1 1 0 2
1 β βσ β
π
σ
Dengan
∏
=
n
i 1
menyatakan hasil kali n kemungkinan bersama untuk nilai Yi yang
penggunaannya dikenal untuk eksponensial. Hasil di atas dapat diperlihatkan dengan
penjumlahan eksponen:
(
)
( ) ( ) 2 1 2 2 1 1 0 2 1 2 1 0 2 1 2 1 , , ,..., , ∑ − + + − = = n i i i i x xY n n e Y Y Y p σ β β β π σ β β
β (3.1)
Mengingat Yi amatan yang diberikan dipertimbangkan untuk berbagai nilai β0,β1,β2.
Sehingga persamaan (3.1) di atas dinamakan fungsi likelihood:
(
)
=(
)
∑= − − − − n i i i i x xY n e L 1 2 2 2 1 1 0 2 1 2 1 0 2 1 , , σ β β β π σ β β
β (3.2)
dimana:
(
β0,β1,β2)
L = fungsi maksimum likelihood pada parameter β0,β1,β2
σ = parameter yang merupakan simpangan baku untuk distribusi π = nilai konstan (π = 3,1416)
n = banyak data sampel
e = bilangan konstan (e = 2,7183)
Yi = variabel terikat ke-i
i
β = parameter regresi ke-i
Maka ln L
(
β0,β1,β2)
adalah:(
)
( )
∑
= − − − − − − = = Λ n i i ii x x
Y n n L 1 2 2 2 1 1 0 2 1 0 2 1 ln 2 ln 2 , , ln σ β β β σ π β β
Setelah diperoleh nilai Λ maka perhitungan differensialnya untuk β0,β1,β2
dan menetapkan derivatif parsial yang dihasilkan sama dengan nol, yaitu:
(
)
0 0 0 1 1 2 1 1 1 2 2 1 1 1 0 1 1 2 2 1 1 0 2 0 = = → = − − − = = − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i i n i i n i i n i i n i i n i i i i x x x x n Y x x Y β β β β β β σ β Y n Y n i i = =⇒
∑
=10
ˆ
β (3.4)
(
)
0 0 0 1 1 1 1 2 1 2 1 2 1 1 1 1 0 1 1 1 2 2 1 1 0 1 2 1 = → = + + + − = = − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i i n i i i n i i n i i n i i i n i i i i i x x x x x Y x x x Y x β β β β β β σ β 0 1 2 1 2 1 2 1 1 11 + + =
− ⇒
∑
∑
∑
= = = n i i i n i i n i iiY x x x
x β β (3.5)
(
)
0 0 0 1 1 2 1 2 2 2 1 2 1 1 1 2 0 1 2 1 2 2 1 1 0 2 2 2 = → = + + + − = = − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i i n i i n i i i n i i n i i i n i i i i i x x x x x Y x x x Y x β β β β β β σ β 0 1 2 2 2 1 2 1 1 12 + + =
− ⇒
∑
∑
∑
= = = n i i n i i i n i iiY x x x
x β β (3.6)
Dari persoalan di atas diperoleh:
Substitusi nilai-nilai tabel di atas ke dalam persamaan (3.4), (3.5) dan (3.6): 6 ˆ 1 0 0 = = = ⇒ ∂ Λ ∂
∑
= Y n Y n i i β β( )
28( )
7 018 1 2
1 2 1 2 1 2 1 1 1 1 1 = + + − = + + − = ∂ Λ ∂
∑
∑
∑
= = = β β β β β n i i i n i i n i iiY x x x
x
⇒28β1+7β2 =18 (3.7)
( )
7( )
4 07 1 2
1 2 2 2 1 2 1 1 1 2 2 = + + − = + + − = ∂ Λ ∂
∑
∑
∑
= = = β β β β β n i i n i i i n i iiY x x x
x
⇒7β1+4β2 =7 (3.8)
Dengan menggunakan persamaan (3.7) dan (3.8) diperoleh nilai βˆ1= 0,3651dan
1111 , 1 ˆ 2 = β .
Maka persamaan multiple regresinya menjadi:
(
)
(
)
2 1 2 1 2 1 1111 , 1 3651 , 0 3174 , 2 2 1111 , 1 4 3651 , 0 6 1111 , 1 3651 , 0 6 ˆ X X X X x x Y + + = − + − + = + + =3.2 Menentukan Persamaan Multiple Regresi dengan Matriks
= = 9 6 6 7 5 5 4 , 3 7 1 2 6 1 2 5 1 3 4 1 1 3 1 2 2 1 1 1 1 Y X Diperoleh: = 3 2 2 3 1 2 1 7 6 5 4 3 2 1 1 1 1 1 1 1 1 T X = 32 63 14 63 140 28 14 28 7 X XT
(
)
441det XTX =
(
)
− − − − − − = 196 49 196 49 28 14 196 14 511 X X Adj T(
)
(
)
− − − − − − = = − 4444 , 0 1111 , 0 4444 , 0 1111 , 0 0635 , 0 0317 , 0 4444 , 0 0317 , 0 1587 , 1 1 X X X X Adj X X T T T = 91 186 42 Y XT(
)
= = − 1111 , 1 3695 , 0 3288 , 2 ˆ 1 Y X X XT Tβ
Maka persamaan multiple regresinya adalah:
2 1 1,1111
3695 , 0 3288 , 2
ˆ X X
Y = + +
Hasil pencarian nilai βˆ0,βˆ1,βˆ2 dengan menggunakan maksimum likelihood
dan matriks didapati angka yang cenderung sama. Pada perhitungan dengan
maksimum likelihood diperoleh βˆ0 =2,3174, βˆ1 = 0,3651 dan βˆ2 =1,1111.
Sedangkan hasil perhitungan secara matriks diperoleh βˆ0 =2,3288, βˆ1 = 0,3695
dan βˆ2 =1,1111. Tampak bahwa nilai βˆ0 hingga satu angka dibelakang koma dan
nilai βˆ1 hingga dua angka dibelakang koma tidak terdapat perbedaan, sedangkan nilai
0
ˆ
β hingga dua angka dibelakang koma dan nilai βˆ1 hingga tiga angka dibelakang
koma mulai ada perbedaan. Perbedaan ini sifatnya tidak substansial karena munculnya
perbedaan itu sendiri akibat dari pembulatan. Dengan demikian dapat disimpulkan
bahwa, mencari βˆ0,βˆ1,βˆ2 dengan maksimum likelihood dan matriks akan
menghasilkan nilai yang sama.
3.3 Estimasi Interval untuk Parameter Multiple Regresi
Pada dasarnya, nilai-nilai dari koefisien regresi βi bervariasi dan variansnya dari βi
dalam bentuk vektor matriks adalah sebagai berikut:
( )
2(
)
−1= X X
Var β σ T (3.9)
Karena umumnya σ2 tidak diketahui, maka σ2 diduga dengan se2, sehingga perkiraan
varians (β) adalah:
( )
(
)
1
2 2
1 2
2
− − = ⇒ =
= −
∑
k n
e s
X X s s
Var T e i
e
β
dimana:
2 e
s = varians dari kesalahan pengganggu
n = banyak observasi
k = banyak variabel bebas
(
)
∑
2 =∑
− 2ˆ
i i
i Y Y
e dapat dihitung langsung dari Yi−Yˆi yaitu selisih antara nilai
[image:39.595.100.534.288.494.2]observasi Yi dengan nilai regresi Yˆi =βˆ0+βˆ1X1+βˆ2X2.
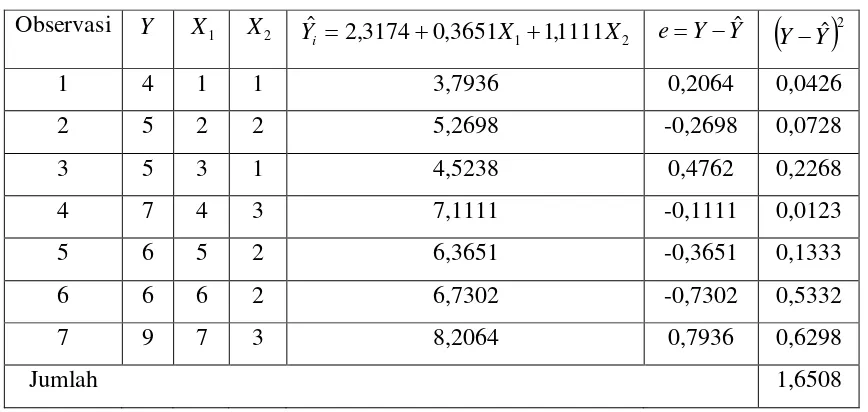
Tabel 3.3 Penentuan Nilai e2
Observasi Y X1 X2
2 1 1,1111
3651 , 0 3174 , 2
ˆ X X
Yi = + + e=Y−Yˆ
( )
Y−Yˆ 21 4 1 1 3,7936 0,2064 0,0426
2 5 2 2 5,2698 -0,2698 0,0728
3 5 3 1 4,5238 0,4762 0,2268
4 7 4 3 7,1111 -0,1111 0,0123
5 6 5 2 6,3651 -0,3651 0,1333
6 6 6 2 6,7302 -0,7302 0,5332
7 9 7 3 8,2064 0,7936 0,6298
Jumlah 1,6508
dari hasil perhitungan tabel di atas diperoleh:
4127 , 0 1 2 7 6508 , 1 1 2 2 = − − = − − =
∑
k n e se iPerkiraan
( )
= 2 = 2(
)
−1X X s s
Var β β e T dan apabila D=
(
XTX)
−1 dan s sedii i2
2 =
β ,
dimana dii adalah matriks dari baris ke i dan kolom i terletak pada diagonal pokok,
maka:
(
)
− − − − − − = = − 4444 , 0 1111 , 0 4444 , 0 1111 , 0 0635 , 0 0317 , 0 4444 , 0 0317 , 0 1587 , 1 1 X X D T(
)
(
)
(
0,4444)
0,1834 0,1834 0,42834127 , 0 1619 , 0 0262 , 0 0262 , 0 0635 , 0 4127 , 0 6915 , 0 4782 , 0 4782 , 0 1587 , 1 4127 , 0 2 2 1 1 0 0 33 2 2 22 2 2 11 2 2 = = ⇒ = = = = = ⇒ = = = = = ⇒ = = = β β β β β β s d S s s d s s s d s s e e e
Untuk menghitung estimasi interval untuk β0, β1, β2 digunakan taraf
signifikan α = 0,05.
( 1) 0,052(7 2 1) 2,7765
2 − − =t − − =
tα n k
1. 2,3174, 0,6915 0
0 = β =
β s
(
)
(
)
2373 , 4 3975 , 0 9199 , 1 3174 , 2 9199 , 1 3174 , 2 6915 , 0 7765 , 2 3174 , 2 6915 , 0 7765 , 2 3174 , 2 0 0 0 025 , 0 0 0 025 , 00 0 0
≤ ≤ + ≤ ≤ − + ≤ ≤ − + ≤ ≤ − β β β β β
β t sβ t sβ
Dengan taraf signifikan α = 0,05, bahwa interval antara 0,3975 dan 4,2373
akan memuat β0.
2. 0,3651, 0,1619
1
1 = β =
β s
(
)
(
)
8146 , 0 0844 , 0 4495 , 0 3651 , 0 4495 , 0 3651 , 0 1619 , 0 7765 , 2 3651 , 0 1619 , 0 7765 , 2 3651 , 0 1 1 1 025 , 0 1 1 025 , 01 1 1
≤ ≤ − + ≤ ≤ − + ≤ ≤ − + ≤ ≤ − β β β β β
β t sβ t sβ
Dengan taraf signifikan α = 0,05, bahwa interval antara -0,0844 dan 0,8146
3. 1,1111, 0,4283 2
2 = β =
β s
(
)
(
)
3003 , 2 0781
, 0
1892 , 1 1111 , 1 1892
, 1 1111 , 1
4283 , 0 7765 , 2 1111 , 1 4283
, 0 7765 , 2 1111 , 1
2 2 2
025 , 0 2 2 025
, 0
2 2 2
≤ ≤ −
+ ≤
≤ −
+ ≤
≤ −
+ ≤ ≤ −
β β β
β β
β t sβ t sβ
Dengan taraf signifikan α = 0,05, bahwa interval antara -0,0781 dan 2,3003
akan memuat β2.
3.4 Pengujian Hipotesis
Hipotesis berasal dari kata hipo dan tesis yang berasal dari bahasa Yunani. Hipo
berarti dibawah, kurang atau lemah dan tesis berarti teori atau proposisi. Jadi, secara
umum hipotesis dapat didefinisikan sebagai asumsi atau dugaan atau pernyataan
sementara yang masih lemah kebenarannya tentang karakteristik populasi. Oleh
karena itu, hipotesis perlu di uji kebenarannya. Pengujian hipotesis dilakukan
berdasarkan hasil penelitian pada sampel yang diambil dari populasi tersebut. Berikut
ini adalah hipotesis yang diperoleh pada persoalan di atas.
1) Hipotesis:
Ho : Tidak terdapat hubungan fungsional yang signifikan antara
variabel X1 dan X2 dengan variabel Y.
Ha : Terdapat hubungan fungsional yang signifikan antara variabel
X1 dan X2 dengan variabel Y.
2) Diperoleh perhitungan berikut:
• Cari Rhit dengan rumus:
( )
8968 , 0
16
) 7 ( 1111 , 1 ) 18 ( 3651 , 0
2 2 2 1 1 2
2 , 1
=
+ =
+ =
∑
∑
∑
y
y x y
x
Ry β β
3) Hitung Fsign hitung dengan menggunakan rumus:
( )
(
)
( )(
)
(
)
(
)
3798 , 17
8968 , 0 1 2
1 2 7 8968 , 0
1
1
2 2 , 1 2
2 , 1
=
−
− − =
− − − =
y y reg
R k
k n R F
4) Taraf signifikansi α = 0,05
5) Hitung Ftabel dengan menggunakan rumus:
( , 1) = 0,05(2,7 2 1) ⇒6,94
= F − − F − −
Ftabel αkn k
6) Kriteria pengujian H0, yaitu:
H0 : tidak signifikan
Ha : signifikan
Jika Fhit≥ Ftabel, maka H0 ditolak atau signifikan.
Ternyata 17,3798 ≥ 6,94 atau Fhit > Ftabel, sehingga H0 ditolak atau signifikan.
7) Kesimpulan
Karena H0 ditolak maka Ha diterima yang berarti bahwa, terdapat hubungan
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil perhitungan dan penganalisaan data yang telah dilakukan, maka
dapat diambil kesimpulan sebagai berikut:
1. Persamaan multiple regresi linier dengan menggunakan metode maksimum
likelihood:
2 1 1,1111
3651 , 0 3174 , 2
ˆ X X
Y = + +
2. Nilai interval dengan taraf signifikan α = 0.05 untuk parameter multiple regresi
diperoleh:
a. 0,3975≤ β0 ≤4,2373
b. −0,0844≤β1 ≤0,8146
c. −0,0781≤β2 ≤2,3003
3. Maksimum likelihood merupakan metode estimasi yang tepat dalam
menentukan model koefisien multiple regresi.
4. Metode maksimum likelihood bertujuan untuk meminimumkan jarak antara
titik estimasi dengan titik sebenarnya.
4.2 Saran
Untuk menentukan model multiple regresi gunakanlah maksimum likelihood dalam
mengestimasi parameternya, karena metode ini lebih sederhana dan mudah untuk
dihitung. Selain itu, metode maksimum likelihood memiliki sifat estimator yang