SKRIPSI
RIZQI MULKI
091402001
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah
Sarjana Teknologi Informasi
RIZQI MULKI
091402001
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : PENERAPAN SPARSE MATRIX PADA
REKOMENDASI BERITA PERSONAL UNTUK PENGGUNA ANONIM
Kategori : SKRIPSI
Nama : RIZQI MULKI
Nomor Induk Mahasiswa : 091402001
Program Studi : SARJANA (S-1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI
Diluluskan di
Medan, Agustus 2014
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Mardiningsih, M.Si Romi Fadillah Rahmat, B.Comp.Sc.,M.Sc NIP. 19630405 198811 2 001 NIP. 19860303 201012 1 004
Diketahui/Disetujui Oleh
Program Studi Teknologi Informasi Ketua,
PERNYATAAN
PENERAPAN SPARSE MATRIX PADA REKOMENDASI BERITA PERSONAL UNTUK PENGGUNA ANONIM
SKRIPSI
Saya mengakui bahwa skripsi adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringakasan yang masing – masing telah disebutkan sumbernya.
Medan, Agustus 2014
PENGHARGAAN
Puji dan syukur dihadiahkan kehadirat Allah SWT, serta selawat kepada Nabi
Muhammad SAW, karena atas anugerah dari-Nya lah penulis dapat menyelesaikan skripsi ini. Rasa syukur yang sangat besar kepada Allah SWT, karena kemudahan yang Allah anugerahkan sehingga skripsi ini bisa diselesaikan.
Dalam menyelesaikan skripsi ini penulis banyak mendapatkan bantuan dan motivasi dari luar diri. Pada kesempatan ini dengan kerendahan hati, penulis mengucapkan terima kasih banyak kepada :
1. Kedua orang tua penulis, yaitu Bunda, Nuraini.S.Pd dan Ayahanda, Abdullah.S.Pd, karena berkat dukungan baik secara moril maupun materil secara terus menerus sehingga penulis dapat menyelesaikan skripsi ini. Kepada saudara penulis Khairurrijal, Linil Masthura, Muhibuddin, Nurkhalidah, dan seluruh keluarga besar kami.
2. Kepada Bapak Romi Fadillah Rahmat, B.Comp.Sc.,M.Sc dan Ibu Dr. Mardiningsih, M.Si yang terus mendukung dalam penyelesaian skripsi ini.
3. Ketua Jurusan sekaligus penasehat akademik M. Anggia Muchtar, ST. MM.IT dan Sekretaris Jurusan M. Fadly Syahputra, B.Sc, M.Sc.IT.
4. Seluruh Dosen yang mengajar pada Program Studi Teknologi Informasi Universitas Sumatera Utara.
5. Teman – teman Teknologi Informasi Stambuk 2009, ranap, satria, ari, zizi, yogi, wildan, fithra, gilberth, aang dan kawan – kawan SRC yang telah banyak membantu selama masa studi dan penyelesaian skripsi ini.
6. Rekan – rekan kerja saya Kak Adri Arianti, Buk Tapi Rondang, Pak Yassin, Vero, Kak Feby, Kak Nita, Kak Ica dan Pak Naqosya Asrori yang selalu mendukung untuk menyelesaikan skripsi.
ABSTRAK
Tautan berita online disebar melalui social media oleh pihak portal berita supaya masyarakat tertarik untuk membaca berita ke portal berita mereka. Supaya user yang sudah masuk ke dalam sebuah portal berita, terus membaca berita lain karena menemukan ada berita yang berkaitan dan disukai pada daftar rekomendasi berita personal. Namun, saat ini rekomendasi secara personal bisa diberikan jika sudah memiliki banyak riwayat penjelajahan dan harus dipastikan user sudah login ke portal berita tersebut. Hal ini akan menjadi masalah jika yang membaca berita adalah pengguna anonim dan tidak memiliki riwayat penjelajahan yang banyak, sehingga akan menyulitkan bagi pemilik portal berita untuk menambah jumlah pembaca baru di portal berita mereka, jika pelayanan yang ingin diberikan adalah berupa rekomendasi berita secara personal. Maka dari itu, dibutuhkan sistem rekomendasi secara personal untuk pengguna anonimyang baru sekali atau beberapa kali mengakses berita dan bisa diberikan rekomendasi secara personal dengan menerapkan metode yang memanfaatkan sparse matrix yaitu CSR Sparse Matrix Vector Multiplication dan proximity processing. Bayesian framework for user interest yang merupakan metode untuk sistem rekomendasi personal akan digunakan juga, namun dengan memodifikasi penerapannya yaitu pada term. Penelitian ini menunjukkan bahwa walaupun riwayat penjelajahan sedikit, rekomendasi berita secara personal tetap bisa diberikan kepada pembaca berita.
SPARSE MATRIX APPLICATION IN PERSONAL NEWS RECOMMENDATION FOR ANONYMOUS USER
ABSTRACT
Online news links are being spread through the social media by news agencies in order to encourage people to read news from their site. After users have logged in to their site, users will keep on reading news that is relevant to their personalized news recommendation. But, nowadays personalized recommendation could be provided to users only if the site has recorded much of users browsing history and it‟s mandatory that users have to log in to the site. This could be problematic if the news readers are
anonymous users and the site hasn‟t record enough browsing history from those users.
It would be difficult for news agencies to increase their daily readers to their site if
they‟re going to compete with other agencies in the aspect of providing good personalized recommendation. Therefore, personalized recommender system is necessary for anonymous users who „ve only visited the news site occasionally, so that the site could recommend the news they‟re likely to read by implementing CSR Sparse Matrix Vector Multiplication and proximity processing as sparse matrix applied method. Bayesian framework for user interest will also be implemented with
the modification in its term. This research will prove that even though news site hasn‟t
recorded enough browsing history, personalized news recommendation could still be provided to the readers.
DAFTAR ISI
Halaman
PERSETUJUAN ... i
PERNYATAAN ... ii
PENGHARGAAN ... iii
ABSTRAK ... iv
ABSTRACT ...v
DAFTAR ISI ... vi
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... xi
BAB 1 PENDAHULUAN ...1
1.1. Latar Belakang ...1
1.2. Rumusan Masalah ...2
1.3. Tujuan Penelitian ...2
1.4. Batasan Masalah...3
1.5. Manfaat Penelitian ...3
1.6. Metodelogi Penelitian ...3
1.7. Sistematika Penulisan ...4
BAB 2 LANDASAN TEORI ...6
2.1. Rekomendasi Berita ...6
2.2. Pengguna Anonim ...6
2.3. Content Based Recommendation ...7
2.4. Sparse Matrix ...7
2.5. Information Filtering ...8
2.6. Information Retrieval ...8
2.7. CSR SpMV(Sparse Matrix Vector Multiplication) ...9
2.8. Proximity Processing... 10
2.9. Rekomendasi Berita Personal ... 11
2.10. Stopword Removal ... 11
2.11. Stemming ... 12
BAB 3 ANALISIS DAN PERANCANGAN ... 16
3.1. Analisis Data ... 16
3.2. Tahapan Eliminasi ... 17
3.3. CSR SpMV ... 19
3.4. Proximity Processing... 23
3.5. Bayesian Framework for User Interest ... 25
3.6. Perancangan General Architecture ... 28
3.7. Perancangan Use Case ... 29
3.7.1. Definisi Aktor... 29
3.7.2. Definisi Use Case ... 29
3.7.3. Skenario Use Case ... 30
3.7.4. Diagram Use Case ... 33
1.8 Diagram Kelas... 33
1.9 Diagram Objek ... 35
1.10 Diagram Sekuen ... 35
1.10.1. Konversi berita ... 35
1.10.2. Catat akses berita ... 36
3.10.3. Rekomendasi akses berita... 36
3.11. Diagram Aktivitas ... 37
3.12. Diagram Komponen ... 38
3.13. Diagram Deployment ... 39
3.14. Perancangan Database ... 40
3.15. Perancangan Antarmuka ... 41
BAB 4 HASIL DAN PEMBAHASAN ... 42
4.1 Implementasi Sistem ... 42
4.1. 1 Spesifikasi Perangkat Keras dan Perangkat Lunak yang Digunakan .. 42
4.2. Tampilan Implementasi Sistem ... 43
3.2.1. Pada daftar item plugin ... 43
3.2.2. Menu untuk pengaturan... 43
3.2.3. Halaman pengaturan batas pengambilan berita rekomendasi ... 44
3.2.4. Halaman pengaturan lama sesi aktif ... 44
4.3. Uji Sistem dan Analisis dengan Satu Pengguna Anonim ... 45
4.3.1. Uji coba akses berita ... 46
4.4 Analisis Penerapan Sparse Matrix ... 50
4.5 Uji Coba dan Analisis dengan Banyak Pengguna Anonim ... 51
BAB 5 KESIMPULAN DAN SARAN ... 55
5.1 Kesimpulan ... 55
5.2 Saran ... 55
DAFTAR PUSTAKA ... 56
LAMPIRAN I ... 58
LAMPIRAN II ... 65
DAFTAR TABEL
Tabel 2.1 Aturan untuk inflectional particle 13
Tabel 2.2 Aturan untuk inflectional possesive pronoun 13 Tabel 2.3 Aturan untuk first order derivational prefix 13 Tabel 2.4 Aturan untuk second order derivational prefix 13 Tabel 2.5 Aturan untuk second order derivational prefix (lanjutan) 14
Tabel 2.6 Aturan untuk derivational suffix 14
Tabel 2.7 Penelitian sebelumnya 14
Tabel 3.1 Contoh kumpulan dokumen serta keterangan 18 Tabel 3.2 Hasil dokumen setelah melalui tahapan eliminasi 19
Tabel 3.3 Tf (term frequency) 20
Tabel 3.4df dan idf 20
Tabel 3.5 Sparse matrix yang ditampilkan dalam bentuk tabel 21 Tabel 3.6 Hasil relevansi dokumen menggunakan algoritma csr spmv 22 Tabel 3.7 Hasil pengurutan nilai akhir secara descending. 22 Tabel 3.8 Term frequency untuk proximy processing 23 Tabel 3.9Hasil dari menjalankan algoritma proximty processing 25 Tabel 3.10 Nilai untuk rekomendasi setelah diterapkan proximity processing 25
Tabel 3.11 Frekuensi akses term terhadap waktu 27
Tabel 3.12 Penambahan nilai dari penerapan bayesian framework for user interest 28
Tabel 3.13 Hasil rekomendasi 28
Tabel 3.14 Mendeskripsikan secara singkat aktor dalam sistem 29
Tabel 3.15 Mendeskripsikan setiap use case 29
Tabel 3.16 Skenario konversi berita 30
Tabel 3.17 Skenario stemming 31
Tabel 3.18 Skenario stopword removal 31
Tabel 3.19 Skenario ambil kata dan angka 31
Tabel 3.20 Skenario catat akses berita 32
Tabel 3.21 Skenario rekomendasi akses berita 32
Tabel 4.2 Nilai yang didapatkan masing – masing dokumen 48
Tabel 4.3 Nilai masing – masing dokumen setelah 49
DAFTAR GAMBAR
Gambar 2.1 contoh sparse matrix 8
Gambar 2.2 Contoh hasil format kompresi csrdari sparse matrix gambar 2.1 8 Gambar 2.3 Algoritma CSR SpMV (goharian, et al. 2001). 9
Gambar 2.4 Algoritma untuk proximity processing 10
Gambar 2.5 Flowchart algoritma porter (Budhi, 2006) 12
Gambar 3.1 Alur tahapan eliminasi 17
Gambar 3.2 Alur tahapan csr spmv 19
Gambar 3.3 Format csr dari sparse matrix tabel 3.5 21
Gambar 3.4 Format vektor query 21
Gambar 3.5 Alur tahapan proximity processing 23
Gambar 3.6 CSR untuk proximity processing 24
Gambar 3.7 Modifikasi query untuk proximity processing 24 Gambar 3.8 Alur tahapan bayesian framework for user interest 26
Gambar 3.9 Diagram arsitektur 29
Gambar 3.10 Diagram use case 33
Gambar 3.11 Diagram kelas 34
Gambar 3.12 Diagram objek 35
Gambar 3.13 Diagram sequence untuk konversi berita 36 Gambar 3.14 Diagram sequence catat akses berita oleh user 36 Gambar 3.15 Diagram sequence memberikan rekomendasi pada saat akses berita 37 Gambar 3.22 Diagram aktivitas yang menggambarkan kerja sistem 38
Gambar 3.23 Diagram komponen 39
Gambar 3.24 Diagram deployment 39
Gambar 3.25 Perancangan database untuk sistem rekomendasi 40 Gambar 3.26 Prancangan database untuk sistem rekomendasi (lanjutan) 41
Gambar 3.30 Rancangan halaman untuk rekomendasi 41
Gambar 4.1 Plugin setelah dilakukan instalasi 43
Gambar 4.4 Halaman bagian pengaturan lama sesi aktif untuk pengguna anonim 44 Gambar 4.5 Bagian pengaturan untuk menajemen stopword 45
Gambar 4.6 Halaman untuk pengaturan widget 45
Gambar 4.7 Hasil rekomendasi pada halaman web untuk akses berita 50
ABSTRAK
Tautan berita online disebar melalui social media oleh pihak portal berita supaya masyarakat tertarik untuk membaca berita ke portal berita mereka. Supaya user yang sudah masuk ke dalam sebuah portal berita, terus membaca berita lain karena menemukan ada berita yang berkaitan dan disukai pada daftar rekomendasi berita personal. Namun, saat ini rekomendasi secara personal bisa diberikan jika sudah memiliki banyak riwayat penjelajahan dan harus dipastikan user sudah login ke portal berita tersebut. Hal ini akan menjadi masalah jika yang membaca berita adalah pengguna anonim dan tidak memiliki riwayat penjelajahan yang banyak, sehingga akan menyulitkan bagi pemilik portal berita untuk menambah jumlah pembaca baru di portal berita mereka, jika pelayanan yang ingin diberikan adalah berupa rekomendasi berita secara personal. Maka dari itu, dibutuhkan sistem rekomendasi secara personal untuk pengguna anonimyang baru sekali atau beberapa kali mengakses berita dan bisa diberikan rekomendasi secara personal dengan menerapkan metode yang memanfaatkan sparse matrix yaitu CSR Sparse Matrix Vector Multiplication dan proximity processing. Bayesian framework for user interest yang merupakan metode untuk sistem rekomendasi personal akan digunakan juga, namun dengan memodifikasi penerapannya yaitu pada term. Penelitian ini menunjukkan bahwa walaupun riwayat penjelajahan sedikit, rekomendasi berita secara personal tetap bisa diberikan kepada pembaca berita.
SPARSE MATRIX APPLICATION IN PERSONAL NEWS RECOMMENDATION FOR ANONYMOUS USER
ABSTRACT
Online news links are being spread through the social media by news agencies in order to encourage people to read news from their site. After users have logged in to their site, users will keep on reading news that is relevant to their personalized news recommendation. But, nowadays personalized recommendation could be provided to users only if the site has recorded much of users browsing history and it‟s mandatory that users have to log in to the site. This could be problematic if the news readers are
anonymous users and the site hasn‟t record enough browsing history from those users.
It would be difficult for news agencies to increase their daily readers to their site if
they‟re going to compete with other agencies in the aspect of providing good personalized recommendation. Therefore, personalized recommender system is necessary for anonymous users who „ve only visited the news site occasionally, so that the site could recommend the news they‟re likely to read by implementing CSR Sparse Matrix Vector Multiplication and proximity processing as sparse matrix applied method. Bayesian framework for user interest will also be implemented with
the modification in its term. This research will prove that even though news site hasn‟t
recorded enough browsing history, personalized news recommendation could still be provided to the readers.
1.1. Latar Belakang
Perkembangan internet mendorong tumbuhnya media pemberitaan online, sehingga menjadikan media online (portal berita) tidak lagi hanya menjadi media sekunder tetapi juga media utama untuk menyampaikan informasi atau berita dari kebanyakan instansi, karena berita sudah menjadi kebutuhan bagi pengguna internet untuk mengetahui kabar terkini dan teraktual (Wardhana, 2012). Tantangan penggunaan media online adalah memberikan layanan yang terbaik, salah satunya yaitu membantu pengguna internet yang selanjutnya disebut user menemukan berita yang mereka sukai. Untuk menyelesaikan masalah tersebut sudah ada penelitian sebelumnya dengan cara user diberikan rekomendasi untuk membantu menemukan berita yang disukai dengan mengakses riwayat penjelajahan dan user profile lalu menggunakan
information filtering serta information collaboration untuk diimplementasikan pada
google news (Liu, et al. 2010). Dalam penelitian tersebut rekomendasi berita secara personal hanya bisa diberikan kepada member user dan memiliki riwayat penjelajahan yang (lebih dari 1 bulan) di google news. Sedangkan untuk user yang baru pertama kali atau beberapa kali mengakses berita di portal tersebut tidak bisa diberikan rekomendasi secara personal dan hanya diberikan rekomendasi dari
information collaboration yang artinya rekomendasi berita diberikan berdasarkan berita – berita yang disukai oleh member user lain. Hal ini menjadi masalah bagi pemilik portal berita yang ingin menambah jumlah pembaca baru di portal berita
selanjutnya disebut pengguna anonim (pengguna anonim) lebih cenderung membuka
link berita dari yang didapatkan dari orang lain atau dari media lain, hal ini disebabkan karena portal berita online sudah banyak menggunakan social media seperti Twitter,
Facebook dan lainnya untuk menyampaikan berita singkat dan link untuk menuju ke halaman portal berita online (Rafita, 2013).
Supaya pengguna anonim yang sudah mengakses link tersebut tertarik untuk tetap membaca berita lainnya yang mungkin akan dia sukai pada suatu portal berita, maka dari itu penulis mengambil judul “PENERAPAN SPARSE MATRIX PADA
REKOMENDASI BERITA PERSONAL UNTUK PENGGUNA ANONIM”. Tujuan
utama dari sistem rekomendasi adalah untuk memberikan rekomendasi terhadap apa yang tersedia pada sistem dan apa yang diinginkan oleh user, karena dalam penelitian ini fokusnya pada pengguna anonim yang notabene tidak memiliki user profile dan riwayat akses berita yang banyak maka akan mengalami masalah data, menerapkan
sistem rekomendasi content based yang akan mencari kesamaan secara detail pada setiap dokumen bisa dijadikan solusi untuk memberikan rekomendasi secara personal (Lops, 2011). Sparse matrix vector multiplication merupakan metode yang mampu mencari relevansi atau kesamaan dokumen terhadap query (Goharian, et al. 2001). Dalam penelitian tersebut dapat dibuktikan bahwa sparse matrix vector multiplication
mampu digunakan untuk mendapatkan hasil relevansi yang diberikan secara ranking
dengan konsep content based, hal ini yang menyebabkan penulis memilih sparse matrix vector multiplication supaya hasil penelitian penulis dapat dimanfaatkan dengan baik oleh pemilik portal berita online.
1.2. Rumusan Masalah
Bagaimana memberikan rekomendasi berita secara personal untuk pengguna anonim.
1.3. Tujuan Penelitian
1.4. Batasan Masalah
Batasan masalah dalam penelitian ini adalah :
1. Menggunakan berita Berbahasa Indonesia
2. Menggunakan PHP dan penerapannya pada plugin WordPress 3. Database menggunakan MySQL
1.5. Manfaat Penelitian
Manfaat penelitian yang bisa didapatkan dari penelitian ini yaitu :
1. Bisa mengundang ketertarikan pembaca baru pada portal berita online, untuk membaca berita lainnya.
2. Dari sudut pandang pemilik portal berita online bisa meningkatkan kunjungan pembaca berita pada portal berita online mereka.
1.6. Metodelogi Penelitian
Untuk penelitian ini, penulis melakukan beberapa metode untuk mendapatkan data untuk mendukung dalam penyelesaian penelitian. Metode yang dilakukan tersebut antara lain :
1. Studi Literatur
Studi literatur atau juga disebut dengan studi pustaka yaitu mengumpulkan bahan
– bahan referensi baik dari artikel, makalah, paper, jurnal maupun dari media internet.
2. Analisis
Analisis yang dilakukan adalah sebagai berikut :
- Menganalisis tahapan untuk memberikan rekomendasi secara personal beserta komponen – komponen penyusunnya.
- Menganalisis penerapan sparse matrix vector multiplication dalam
- Menganalisis sistem rekomendasi personal yang menggunakan bayesian
framework for user interest supaya bisa dikombinasikan dengan content based recommendation system.
3. Perancangan
Perancangan yang dilakukan untuk menghasilkan rancangan arsitektur, alur data dan perancangan antarmuka pemakai untuk menerapkan sistem rekomendasi. 4. Pengkodean
Tahap penkodean yaitu menerapkan hasil rancangan ke dalam bahasa pemrograman PHP dan dikombinasikan dengan framework pada WordPress untuk membuat plugin.
5. Pengujian
Pada pengujian akan dilakukan pengujian program untuk menyesuaikan dengan rancangan yang telah dibuat, sehingga bisa mencapai solusi yang didapatkan.
6. Penyusuan Laporan
Pada tahap ini akan dilakukan penyusunan laporan hasil analisis dan implementasi.
1.7. Sistematika Penulisan
Sistematika penulisan skripsi ini akan dibagi menjadi 5 bab yaitu : Bab 1 Pendahuluan
Bab 1 mencakup konsep dasar untuk penyusuan skripsi. Bab 2 Landasan Teori
Pada bab 2 akan dibahas beberapa teori supaya mendukung pembahasan pada bab selanjutnya.
Bab 3 Analisis dan Perancangan
Pada bab 3 akan dibahas tentang analisis dan perancangan perangkat lunak yang akan dibuat, sehingga bisa tergambar secara keseluruhan tentang apa saja yang akan dilakukan oleh sistem nantinya.
Bab 4 Hasil dan Pembahasan
WordPress lalu dilakukan uji coba untuk menguji kesesuaian program dengan desain yang telah dibuat pada bab sebelumnya.
Bab 5 Kesimpulan dan Saran
2.1. Rekomendasi Berita
Portal berita online saat ini menjadi popular yang bisa menyediakan berita yang dapat diakses melalui internet, tantagannya adalah membantu user menemukan berita yang disukai secara personal (Liu, et al. 2010). Rekomendasi berita menjadi solusi dari tatangan tersebut, karena bisa memberikan bantuan kepada user untuk menemukan lebih banyak berita yang mereka inginkan.
Salah satu rekomendasi berita telah dilakukan oleh peneliti Google untuk diterapkan pada google news yang memberikan rekomendasi berita secara personal kepada user yang sudah login ke dalam sistem google news. Sehingga google news
bisa mengambil jejak penjelajahan yang lebih banyak untuk bisa memberikan rekomendasi yang lebih tepat kepada user.
2.2. Pengguna Anonim
Pengguna anonim merupakan pengakses suatu situs atau service yang tidak membutuhkan untuk mengisi username dan password dalam mengakses dan tidak tervalidasi (Janssen, 2014). Tipe user ini belum menetap untuk akses disuatu situs. Karena pengguna anonim tidak memiliki identitas yang spesifik dan bersifat unik yang bisa dicatat secara permanen, sehingga mengalami kesulitas dari sistem untuk mencatat setiap jejak penjelajahan berita dari pengguna anonim. Yang bisa dicatat
nantinya hanya selama cookie pada browsernya tidak terhapus dan belum expired.
2.3. Content Based Recommendation
Content based recommendation merupakan sistem rekomendasi yang diberikan kepada user dengan cara menganalisa sekumpulan dokumen dan dibandingkan dengan apa yang telah diakses sebelumnya atau user profile dari masing – masing user. Salah satu metode yang bisa digunakan untuk content based recommendation adalah model relevansi yang menggunakan vector space model dengan basis nilai TF-IDF (Lops, 2011). Metode vector space model yang penulis gunakan adalah sparse matrix vector
multiplication yang akan penulis bahas pada bagian 2.7.
2.4. Sparse Matrix
Sparse matrix adalah sebuah matriks yang didalamnya didominasi oleh nilai 0. Secara lebih jelas, jika jumlah nilai non-zero lebih sedikit dari jumlah nilai 0, maka itu disebut sparse matrix, akan tetapi jika nilai 0 lebih sedikit dari jumlah nilai non-zero, maka itu disebut dense martix (Stoer, et al. 2002).
Menurut Bank (2001) penyimpanan data pada sparse matrix sama seperti penyimpanan data matriks pada umumnya. Setiap item di dalam sparse matrix akan diakses melalui Ai,j, I = menyatakan baris dan j = menyatakan kolom. Unutk efisiensi dalam penyimpanan, ada 5 jenis format kompresi dalam sparse matrix yaitu COO (coordinate storage), CSR (Compressed Sparse Row), CCS (Compressed Column Storage ), JDS (Jagged Diagonal Storage) dan TJDS (Transposed Jagged Diagonal
Storage) (Shahnaz, et al. 2006).
Dalam penelitian ini, penulis menggunakan format kompresi CSR yang akan menempatkan nilai non-zero dalam 1 baris vector. Pada CSRterdapat 3 vektor yaitu
val, col_ind, row_ptr. Val merupakan vektor untuk menyimpan nilai non-zero dari
sparse matrix dengan proses pengambilannya dimulai dari kiri atas lalu kekanan sampai ke baris paling bawah dan akan disimpan dalam 1 baris. Col_ind merupakah vektor yang menyimpan kolom pada sparse matrix dari setiap item val dan disimpan dalam 1 baris. Row_ptr merupakan vektor yang menyimpan indeks baris dengan cara
al. 2001). Diberikan contoh matriks pada gambar 2.1 yang selanjutnya akan dibentuk dalam format CSR yang ditunjukkan pada gambar 2.2.
1 0 2 0
0 0 0 1
1 0 1 0
Gambar 2.1 Contoh sparse matrix
Gambar 2.2 Contoh hasil format kompresi CSRdari sparse matrix gambar 2.1
2.5. Information Filtering
Information filtering (IF) adalah penyaringan informasi berdasarkan user profile yang dibentuk dengan menanyakan kepada user atau dengan memonitor perilaku user
terhapat sistem (Smirnov, et al. 2008). Dalam penelitian penulis metode untuk
Information filtering yang akan digunakan adalah bayesian framework for user
interest prediction dan lebih spesifik pada rekomendas berita personal yang merupakan pengembangan dari rumus Naïve Bayes yang akan penulis bahas pada bagian 2.9.
2.6. Information Retrieval
Information retrieval dalam arti sederhana mencari informasi, sedangkan dalam pengertian teknis adalah mendapatkan informasi yang relevan dengan informasi yang
dibutuhkan dari sekumpulan dokumen dengan menggunakan algoritma yang mampu mengetahui ukuran kesamaan antara query dan dokumen (Goker, 2009).
Saat ini, user menginginkan hasil relevansi dalam bentuk ranking, maka dari itu penggunaan information retrieval dengan model vektor dan probabilitas menjadi
pilihan utama (Kneepkens, 2009). Algoritma information retrieval yang akan penulis gunakan dalam penelitian ini adalah CSR SpMV (Sparse Matrix Vector
Multiplication) dan proximity processing. CSR SpMV penulis jelaskan pada bagian 2.7 dan proximity processing penulis jelaskan pada 2.8.
2.7. CSR SpMV(Sparse Matrix Vector Multiplication)
CSR SpMV merupakan perkalian antara sparse matrix dengan vector pengali dengan melakukan perhitungan y = y + A * x, dimana A menyatakan sparse matrix, y menyatakan baris dan x vector pengali yang sudah banyak diaplikasikan pada bidang ilmu science dan engineering untuk melakukan efisiensi pemrosesan (Liu, et al. 2013). Salah satu penerapan sparse matrix untuk information retrieval, dengan membentuk format kompresi CSR lalu melakukan perkalian dengan query yang dibentuk dalam vector, sehingga untuk setiap baris memiliki nilai penjumlahan dari setiap perkalian (Goharian, et al. 2001).
Gambar 2.3 Algoritma CSR SpMV (Goharian, et al. 2001).
Sebelum dilakukan proses CSR SpMV ada beberapa tahapan proses yang akan dilakukan (Goharian, et al. 2001) yaitu :
1. Mengubah dokumen yang berisi term menjadi term frequency (tf)
2. Mengindefikasi setiap jumlah term yang unik pada masing – masing dokumen untuk mendapatkan document frequency (df)
3. Menghitung nilai inverse document frequency (idf) untuk setiap term dengan rumus log(d/df),d menyatakan jumlah dokumen.
4. Membuat dokumen vektor dan query dengan panjang kolom n, dengan n
menyatakan jumlah term yang unik yang tersedia secara kesuluruhan.
for(count = 0; count < D; count++) temp = 0;
for(row_ind=row_vector[count]; row_ind <= (row_vector[count+1] - 1); row_ind++) col_ind = col_vector[row_ind];
temp = temp + non_zero_vector[row_ind] * Q[col_ind]; end for
5. Membentuk sparse matrix dengan cara memasukkan term sesuai kolom setiap baris matrix dengan masing – masing dokumen
6. Membuat vector untuk query dengan mengikuti kolom dari 7. Lakukan kompresi sparse matrix ke dalam format CSR.
8. Lakukan algoritma CSR SpMV sesuai algoritma pada gambar 2.3.
2.8. Proximity Processing
Proximity processing yang merupakan pengembangan dari CSR SpMV. Metode
proximity processing dikembangkan oleh Goharian dkk pada tahun 2001 dalam
jurnalnya “On the Enhancements of a Sparse Matrix Information Retrieval Approach”. Tujuan utama dari proximity processing dalam penelitian ini untuk memberikan hasil rekomendasi yang akurat dan term yang sesuai urutan antara query
dan dokumen (Goharian, et al. 2001).
Gambar 2.4 Algoritma untuk proximity processing
Untuk melakukan proximity processing yang merupakan lanjutan setelah melakukan CSR SpMV yang telah penulis jelaskan pada bagian 2.7 diharuskan untuk memodifikasi format CSR dengan menambahkan vektor yang kelima dan keenam, yaitu offset_vector dan offset_marker. Tujuan dari penambahan tersebut adalah untuk mencatat posisi setiap dari setiap term pada masing – masing dokumen (Goharian, et al 2001).
FOR each document ranked with the highest similary score in the query processing using sparse matrix vector multiplication DO
Find from row_vector the element (term id) and the number of elements in col_vector belonging to that document and the start position in col_vector IF the element (term id) mathes to any query term id Then DO
FOR each found position in col_vector DO
Find the corresponding element in offset_marker Find the corresponding elements in offset_vector END
Build pairs (in the order of query terms) between the elements found in offset_vector across each col_vector
FOR each pair DO
Compute the difference between the elements of the pair IF the difference >= 1 and <= query window size
Then mark the pair for selection END
2.9. Rekomendasi Berita Personal
Rekomendasi berita personal merupakan bagian dari sistem rekomendasi yang memberikan rekomendasi berita yang berbeda untuk setiap pembaca berita, sesuai dengan kesukaan berita yang pernah dibaca (Liu, et al. 2010).
Rekomendasi berita personal dikembangkan dari Naïve Bayes untuk memprediksi
news interest dari setiap pembaca berita. Dalam penelitian ini penulis menggunakan
bayesian framework for user interest yang telah dikembangkan dalam penelitian Liu dkk pada tahun 2010.
� = � � ) =
0 � =
� � �(� = �= � ) �)
� (2.1)
Keterangan
0 � =
� = probabilitas akses kategori pada waktu terakhir terhadap total click di semua kategori
� = � � ) = probabilitas akses kategori i dalam pada waktu t.
sebelum dihitung akan dijabarkan lebih dahulu,
maka = � � = �) ( � = �)
( � )
� = � = probabilitas akses kategori padat waktu t terhadap total click disemua kategori pada waktu t
� = total click pada waktu t
2.10. Stopword Removal
Stopword adalah kata – kata yang tidak memberikan pengertian yang signifikan terhadap kalimat atau pernyataan yang disampaikan (Dragut, et al 2009). Kata – kata
2.11. Stemming
Stemming merupakan proses transformasi dari kata ke kata dasarnya (root word)
menggunakan aturan – aturan tertentu. Contohnya seperti kata bersama, kebersamaan, menyamai memiliki satu kata dasar (root word) yaitu “sama”. Proses stemming dalam Bahasa Indonesia memiliki perbedaan dengan stemming yang ada dalam Bahasa Inggris. Dalam Bahasa Inggris, proses stemming yang diperlukan hanya proses menghilangkan sufiks, sedangkan untuk Bahasa Indonesia selain sufiks, prefiks dan konfiks juga dihilangkan (Agusta, 2009). Dalam penelitian penulis menggunakan algoritma porter. Langkah – langkah algoritma porter (Agusta, 2009) adalah sebagai berikut :
1. Hapus Particle,
2. Hapus prosessive Pronoun
3. Hapus awalan pertama. Jika tidak ditemukan lanjutkan ke langkah 4a, jika ada cari maka lanjutkan ke langkah 4b
4. a. Hapus awalan kedua, lanjutkan ke langkah 5a.
b. Hapus akhiran, jika tidak ditemukan amaka kata tersebut diasumsikan sebagai
root word. Jika ditemukan maka lanjutkan ke langkah 5b
5. a. Hapus akhiran. Kemudian akata akhir diasumsikan sebagai root word
b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word
kataç Kata yang akan di-stem
kataçRemove partikel(kata)
kataç Remove kata ganti milik/ possesive pronouns(kata)
If kata=temp_kata kataçRemove 2nd_order_prefix(kata)
kataçRemove suffix(kata) kataçRemove suffix(kata)
If kata<>temp_kata kataçRemove 2nd_order_prefix(kata)
Ada 5 aturan yang akan penulis jabarkan dalam bentuk tabel, dimulai dari tabel 2.13 sampai tabel 2.17 (Agusta, 2009).
Tabel 2.1 Aturan untuk inflectional particle
Akhiran Replacement Measure
Condition
Tabel 2.2 Aturan untuk inflectional possesive pronoun
Akhiran Replacement Measure
Condition
Tabel 2.3 Aturan untuk first order derivational prefix
Awalan Replacement Measure
Condition
Tabel 2.4 Aturan untuk second order derivational prefix
Awalan Replacement Measure
Tabel 2.5 Aturan untuk second order derivational prefix (lanjutan)
Awalan Replacement Measure
Condition
Tabel 2.6 Aturan untuk derivational suffix
Akhi-2.12. Penelitian Sebelumnya
Penelitian yang pernah dilakukan terkait dengan sistem rekomendasi personal adalah dengan memanfaat collaborative filtering (Das, et al. 2007) merekomendasikan secara personal dengan parameter lokasi sebagai panduan utama, berita akan
direkomendasikan kepada user berdasarkan berita yang disukai oleh user lain dilokasi yang sama. Selain penelitian tersebut, ada juga menggunakan News Interest dari Click Behavior (Liu, et al. 2010) memberikan rekomendasi berita berdasarkan kategori yang pernah dikunjungi oleh user.
Tabel 2.7Penelitian sebelumnya
Penulis Judul Penelitian Teknik Kelemahan
Tabel 2.7Penelitian sebelumnya (lanjutan)
Penulis Judul Penelitian Teknik Kelemahan
Liu et al. 2010
Personalized News Recommendation
Based On Click Behavior
Menggunakan bayesian framework for user
interest untuk memberikan prediksi
rekomendasi berita berdasarkan riwayat penjelajahan dalam 1
kategori
Membutuhkan banyak riwayat
penjelajahan berita, karena
memberikan rekomendasi berdasarkan kategori, yang
Dalam bab ini penulis akan membahas tentang analisis data, tahapan eliminasi, CSR SpMV, proximity processing, bayesian framework for user interest dan perancangan sistem untuk memudahkan pembaca dalam memahami cara kerja sistem rekomendasi secara bertahap.
3.1.Analisis Data
Dalam penelitian ini ada sekumpulan data yang digunakan untuk mencapai tujuan dari penelitian. Hasil analisis dan keterangan data adalah sebagai berikut :
- Menggunakan 265 judul serta isi berita yang diambil dari kompas.com, liputan6.com, merdeka.com, beritateknologi.com dan okezone.com mengandung karakter ASCII (American Standard Code for Information Interchange).
- Judul berita diambil yang terbit pada bulan april, mei dan agustus. - Dokumen (bagian dari proses dalam rekomendasi) adalah judul berita.
- Karakter huruf dalam ASCII (65 – 90 dan 97 - 122), angka dalam ASCII (48 -
57) dan spasi dalam ASCII (32) hanya yang akan diambil dari dokumen, selain ketiga jenis karakter tersebut akan dieliminasi dari proses rekomendasi.
- Riwayat click dari user yang mengakses url berita supaya bisa diberikan rekomendasi secara tepat pada user.
- Stopword yang merupakan daftar kata yang akan dihilangkan dari berita, karena jika kata – kata yang ada di dalam stopword tidak dihilangkan, maka akan memberikan hasil yang kurang efektif untuk rekomendasi (Tala, 2003).
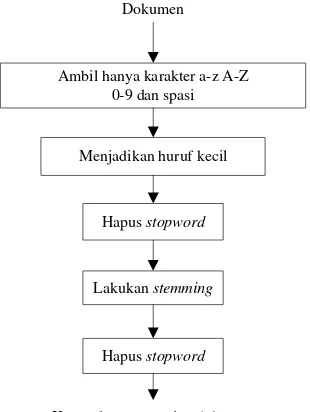
3.2. Tahapan Eliminasi
Untuk menghapus kata dan karakter yang tidak dibutuhkan akan dilakukan beberapa tahapan berikut ini :
1. Melakukan eliminasi dengan mengganti karakter selain dari karakter a-z, A – Z, 0 – 9 dan spasi akan diganti dengan karakter spasi menggunakan regular
expression, yaitu :
- [^a-zA-Z0-9\s] = yang karakter a-z, A-Z, 0-9 dan spasi digantikan jadi spasi - [/\s+/] = melakukan penghapusan jika ada spasi yang lebih banyak dari 1
diantara kedua kata
2. Menjadikan semua karakter huruf menjadi huruf kecil.
3. Melakukan stopword removal berdasarkan daftar kata yang tersedia pada lampiran 2 akan dihapus dari data yang akan diproses untuk rekomendasi.
4. Melakukan stemming, untuk mendapatkan setiap kata dasar dari setiap masing – masing kata.
5. Melakukan stopword removal sekali lagi setelah proses stemming dilakukan, hal ini dilakukan supaya jika ada kata yang belum berhasil dihapus dikarenakan kata tersebut tidak tersedia dalam daftar stopword, maka setelah dilakukan stemming
dan mendapatkan kata dasarnya. Jika kata dasar tersebut tersedia dalam daftar
stopword maka akan dihapus.
Dokumen
Ambil hanya karakter a-z A-Z 0-9 dan spasi Menjadikan huruf kecil
Hapus stopword
Lakukan stemming
Hapus stopword
Kumpulan term setiap dokumen
Untuk memperjelas penjelasan penulis tentang tahapan – tahapan dalam penelitian serta manfaat dari setiap tahapan, maka penulis menjelaskan melalui contoh.
Ada 6 dokumen yang merupakan judul berita dengan diberikan identias D0, D1, D2, D3, Q untuk query dan N berita pernah akses. Karena contoh ini akan berlanjut sampai kepada sistem rekomendasi personal maka contoh ini penulis buat secara lengkap, walaupun pada bagian 3.2 tidak diperlukan semuanya namun pada bagian 3.3 sampai 3.5 akan dibutuhkan.
Tabel 3.1 Contoh kumpulan dokumen serta keterangan
Urutan Isi Ket
D0 Seberapa bagus system yang menggunakan System Recommendation dengan tujuan Recommendation
akan dinilai
D1 System untuk recommendation saat ini adalah system recommendation
akan dinilai
D2 News system recommendation merupakan news system untuk tujuan recommendation
akan dinilai
D3 news retrieval merupakan hal sederhana akan dinilai Q
N1
system recommendation yang lebih baik tidak dinilai, karena sedang diakses N2 news recommendation saat ini ! tidak dinilai,
karena pernah akses
Dari tabel 3.1 ada dokumen yang akan dinilai (D0,D1,D2,D3) untuk proses rekomendasi dan ada yang tidak diproses, hal ini karena untuk yang sedang diakses (Q) akan dijadikan query dan yang pernah diakses (N1,N2) akan dijadikan pertimbangan dalam memberikan nilai pada bagian 3.5 (bayesian framework for user
interest). Penggunaan query akan digunakan pada Algoritma CSR SpMV dan juga Algoritma proximty processing dan berita yang pernah diakses akan menggunakan
Tabel 3.2 Hasil dokumen setelah melalui tahapan eliminasi
Urutan Isi
D0 system system recommendation recommendation D1 system recommendation system recommendation D2 news system recommendation news system
recommendation D3 news retrieval
Q N1
system recommendation
N2 news recommendation
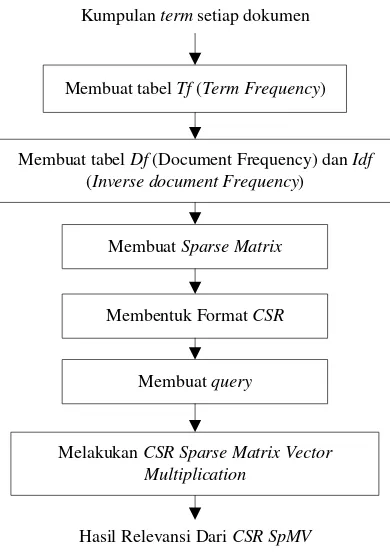
3.3. CSR SpMV
CSR SpMV digunakan untuk mencari tingkat relevansi dokumen. Sesuai algoritma CSR SpMV yang telah dibahas pada bagian 2.7 tahapan – tahapan yang akan dilalui ditunjukkan pada gambar 3.2.
Kumpulan term setiap dokumen
Membuat tabel Tf (Term Frequency)
Membuat tabel Df (Document Frequency) dan Idf
(Inverse document Frequency)
Membuat Sparse Matrix
Membentuk Format CSR
Melakukan CSR Sparse Matrix Vector Multiplication
Hasil Relevansi Dari CSR SpMV
Membuat query
Gambar 3.2 Alur tahapan CSR SpMV
dibuat tabel df untuk menampilkan frekuensi dokumen yang memiliki term tertentu. Untuk lebih lengkapnya akan penulis jabarkan berikut ini :
tf = frekuensi term pada masing – masing dalam sebuah dokumen
df = frekuensi dukumen yang memiliki suatu term
d = Jumlah dokumen yang yang dijadikan pembanding, dalam hal ini = 4
idf = log( )
Tabel 3.3 Tf (term frequency)
Tabel 3.4 df dan idf
Term_id Term Df Idf
0 system 3 0.12
1 recommendation 3 0.12
2 news 2 0.30
3 retrieval 1 0.60
Setelah tabel tf, df dan idf dibentuk selanjutnya akan diimplementasi ke dalam
sparse matrix, kolom merupakan term dan baris merupakan nomor dokumen yang dimulai dengan angka 0. Nilai yang ada di dalam sparse matrix merupakah nilai dari hasil tf*idf untuk setiap term pada masing – masing dokumen.
DOCS Tf
D0
system 2
recommendation 2 D1
system 2
recommendation 2 D2
news 2
system 2
recommendation 2 D3
news 1
Tabel 3.5 Sparse matrix yang ditampilkan dalam bentuk tabel
term
doc
System Recommendation News Retrieval
0 0.24 0.24 0 0
1 0.24 0.24 0 0
2 0.24 0.24 0.60 0
3 0 0 0.30 0.60
Dari tabel 3.5 yang merupakan sparse matrix akan dibentuk dalam format kompresi CSR yang akan ditampilkan pada gambar 3.3 .
Gambar 3.3 Format CSR dari sparse matrix tabel 3.5
Untuk query, dibentuk berdasarkan kolom term yang tersedia pada tabel 3.5.
Query yang dimasukkan dalam kasus ini adalah “system recommendation”. Untuk
term “system” berada pada kolom ke- 0 dan untuk term “recommendation” berada pada kolom ke-1. Sedangkan untuk nilai diambil dari idf dari masing – masing term. Term “system” bernilai 0.12 dan term“recommendation” bernilai 0.30. Jika dibentuk dalam bentuk vector, maka hasilnya seperti pada gambar 2.2.
Gambar 3.4 Formatvektorquery
Vektor query yang terdapat pada gambar 3.4 akan menjadi vektor pengali terhadap nilai sparse matrix dengan kolom yang sama, kolom disini yang berarti term
yang sama antara pada sparse matrix dan pada vektor query, hal ini yang menjadi kunci dari hubungan CSR SpMV dengan information retrieval. Yang artinya hasil dari masing – masing dokumen akan memberikan hasil relevansi berupa nilai jika pada
suatu kolom antara sparse matrix dan vektor query keduanya tidak bernilai 0. val_vector = < 0.24, 0.24, 0.24, 0.24, 0.24, 0.24, 0.6, 0.3, 0.6 > col_vector = < 0, 1, 0, 1, 0, 1, 2, 2, 3 >
row_ptr_vector = < 0, 2, 4, 7, 9 >
Berdasarkan algoritma pada gambar 2.3, akan dijabarkan hasil perhitungan untuk masing – masing dokumen (D0 – D3) pada tabel 3.6 untuk memaparkan secara jelas tentang jalannya algoritma.
Tabel 3.6 Hasil relevansi dokumen menggunakan algoritma CSR SpMV
Dokumen Iterasi Nilai Nilai Akhir
D0 0 0 + (0.24 * 0.12) = 0.0288 0.0576
1 0.0288 + (0.24 * 0.12) = 0.0576
D1 0 0 + (0.24 * 0.12) = 0.0288 0.0576
1 0.0288 + (0.24 * 0.12) = 0.0576
D2 0 0+(0.24 * 0.12) = 0.0288 0.0576
1 0.0288 + (0.24 * 0.12) = 0.0576
D3 0 0 + (0.30 * 0.00) = 0.00 0.00
1 0.00 + (0.60 * 0.00) = 0.00
Nilai relevansi dokumen dari tabel 3.6 diurutkan secara descending berdasarkan nilai akhir yang didapatkan masing – masing dokumen, untuk mengetahui dokumen yang paling relevan diantara keempat dokumen. Tingkat relevansi ditunjukkan dari nilai akhir masing – masing dokumen setelah dijalankan algoritma dari Gambar 2.3.
Tabel 3.7 Hasil pengurutan nilai akhir secara descending.
Dokumen Nilai Akhir
D0 0.0576
D1 0.0576
D2 0.0576
D3 0.00
Dari hasil relevansi yang ditunjukkan pada Tabel 3.7, menunjukkan bahwa dokumen D0, D1 dan D2 menunjukkan nilai relevansi yang sama, padahal jika kita lihat pada Tabel 3.2 yang memaparkan daftar dokumen, seharusnya dokumen D1 dan D2 memberikan nilai relevansi yang lebih tinggi dari pada D0, karena query yang
dimasukkan adalah “system recommendation” dan yang paling relevan jika kita
melihat secara manual pada dokumen D1 dan D2 yang memiliki kalimat “system
3.4.Proximity Processing
Seperti yang telah dijelaskan pada bagian 2.8 tentang proses dalam menjalankan
proximity processing yaitu dengan menambahkan 2 vektor tambahan yaitu
offset_vector dan offset_marker pada CSR. Tahapan dari proximity processing
ditunjukkan pada gambar 3.5.
Membuat tabel Tf (Term Frequency) + kolom Offset
Membuat tabel Df (Document Frequency) dan Idf (Inverse document Frequency)
Membuat Sparse Matrix
Membentuk Format CSR + Offset_vector + Offset_marker
Membentuk query , v1 dan v2
Proximity Processing
Hasil Relvenasi dari Proximity Processing + hasil dari CSR SpMV untuk setiap dokumen
Kumpulan term setiap dokumen
Gambar 3.5 Alur tahapan proximity processing
Untuk memperjelas penjelasan tentang metode proximity processing, penulis akan menjabarkan dalam bentuk contoh yang merupakan sambungan dari contoh pada bagian 3.3 yang memiliki masalah dalam keakuratan menampilkan hasil. Kumpulan dokumen yang ada pada tabel 3.8 akan dibuat kembali tabel frekuensi dengan dilengkapi offset.Tujuan utama melampirkan offset, untuk mengetahui posisi dari term
pada setiap dokumen.
Tabel 3.8Term frequency untuk proximy processing
Dokumen Term Tf Offset
D0 system 2 0,1
recommendation 2 2,3
D1 system 2 0,2
recommendation 2 1,3
D2
news 2 0,3
system 2 1,2
Tabel 3.8 Term frequency untuk proximity processing (lanjutan)
Dokumen Term Tf Offset
D3 news 1 0
retrieval 1 1
Dari tabel 3.8 akan dibentuk sparse matrix yang sama seperti pada tabel 3.5, khusus unutk proximity processing yang akan berbeda hanya pada saat dibentuk format CSR (Compressed Sparse Row). Pada gambar 3.6 ditunjukkan format CSR
yang dilengkapi dengan offset (posisi term dalam dokumen).
Gambar 3.6 CSR untuk proximity processing
Query untuk proximity processing yang berbeda dengan query pada gambar 3.4 yang ditambahkan 1 baris query lagi untuk menyimpan posisi dari term query pada kolom sparse matrix.
Gambar 3.7 Modifikasi query untuk proximity processing
Berdasarkan gambar 3.7, v1 menyatakan query seperti yang telah dijelaskan pada bagian 3.4, sedangkan v2 merupakan posisi kata pada query terhadap kolom
term. Karena dalam contoh ini menggunakan query “system recommendation”, kata
“system” berada pada kolom 0 dan posisi urutan dari query juga berada pada posisi 0, untuk “recommendation” berada pada kolom 1 dan posisi urutan dari query juga berada pada poisisi 1. Mengikuti hasil dari bagian 3.3 selanjutnya untuk mendapatkan
hasil yang akurat maka akan dilakukan algoritma proximity processing yang telah ditunjukkan pada gambar 2.4.
Tujuan utama dari algoritma pada gambar 2.4 untuk mendapatkan posisi term
pada masing – masing dokumen yang didapatkan berdasarkan query, lalu setiap posisi tersebut dihitung jaraknya, jika hasilnya sama dengan 1, maka untuk dokumen akan ditambahkan nilai relevansinya 1 (Goharian, et al. 2001). Untuk lebih jelasnya penulis jabarkan pada tabel 3.9.
Non_zero_vector = <0.24, 0.24, 0.24, 0.24, 0.24, 0.24, 0.6, 0.3, 0.6> Col_vector = < 0, 1, 0, 1, 0, 1, 2, 2, 3 >
Row_vector = < 0, 2, 4, 7, 9>
Offset_vector = <0, 1, 2, 3, 0, 2, 1, 3, 1, 4, 2, 5, 0, 3, 0, 1> Offter_marker = <0, 2, 4, 6, 8, 10, 12, 14, 15, 16>
Tabel 3.9 Hasil dari menjalankan algoritma proximty processing toleransi jarak = 1
yang menghasilkan 1 hanya ada 1 dari (1,2)
tolerenasi jarak = 1 yang menghasilkan 1 ada 2 dari (0,1) dan (2,3)
toleransi jarak = 1 yang menhasilkan 1 ada 2 dari (1,2) dan (4,5)
D0 tingkat relevansinya lebih kecil dari pada D1
D1 menjadi lebih tinggi tingkat relevansi dari pada D0
D1 dan D2 menjadi lebih tinggi tingkat relevansi dari pada D0
Setelah proximity processing dijalankan maka setiap dokumen yang memiliki
term seperti yang ada pada query yang jaraknya 1, maka akan memiliki nilai baru pada dokumen tersebut. Tabel 3.10 memperlihatkan hasil nilai sebelumnya yang didapatkan dari CSR SpMV dan nilai sekarang adalah nilai yang ditambahkan berdasarkan hasil dari proximity processing.
Tabel 3.10 Nilai untuk rekomendasi setelah diterapkan proximity processing
Dokumen Nilai Sebelumnya Nilai Sekarang
D0 0.0576 0.0576 + 1 = 1.0576
D1 0.0576 0.0576 + 2 = 2.0576
D2 0.0576 0.0576 + 2 = 2.0576
D3 0.00 0.00
Tabel 3.10 sudah memperlihatkan hasil rekomendasi setelah melewati dua proses, namun hasil yang didapatkan belum memberikan rekomendasi yang secara personal. Tabel 3.2 menunjukkan bahwa ada berita yang pernah diakses dengan term
“news recommendation” yang artinya bisa menjadi pertimbangan untuk melakukan rekomendasi supaya lebih personal.
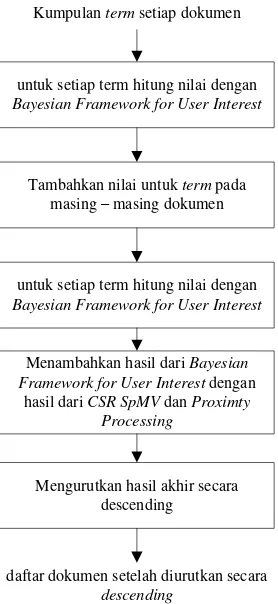
3.5. Bayesian Framework for User Interest
Kumpulan term setiap dokumen
untuk setiap term hitung nilai dengan
Bayesian Framework for User Interest
Tambahkan nilai untuk term pada masing – masing dokumen
untuk setiap term hitung nilai dengan
Bayesian Framework for User Interest
Menambahkan hasil dari Bayesian Framework for User Interest dengan
hasil dari CSR SpMV dan Proximty Processing
Mengurutkan hasil akhir secara descending
daftar dokumen setelah diurutkan secara
descending
Gambar 3.8 Alur tahapan bayesian framework for user interest
Persamaan yang digunakan untuk bayesian framework for user interest
menggunakan persamaan 3.1, karena untuk kasus penulis, category akan diterjemahkan menjadi term dan untuk click diganti dengan term frequency untuk memberikan penilaian terhadap berita yang tertarik dibaca oleh user. Hal ini penulis lakukan karena konteks sistem rekomendasi penulis menggunakan content based
recommendation yang fokus utama rekomendasi pada detail setiap dokumen yang akan direkomendasikan.
= � ) =
0 =
� � ( =�= ) �)
� (3.1)
Keterangan :
0 =
= � ) = probabilitas term terhadap freq pada waktu t.
sebelum dihitung akan dijabarkan lebih dahulu,
maka = = �) ( =�) memilah akses berdasarkan waktu akses, namun karena kasus saat ini hanya memiliki 1 waktu akses maka hanya memiliki 1 tabel akses.
Tabel 3.11 Frekuensi akses term terhadap waktu
Term Waktu
0
news 1
recommendation 1
Dengan menggunakan persamaan 3.1 maka perhitungan untuk masing – masing term adalah sebagai berikut :
1. news
2. recommendation
Untuk memberikan nilai pada masing dokumen berdasarkan nilai dari perhitungan menggunakan persamaan 3.1 akan ditampilkan pada tabel 3.12.
Tabel 3.12 Penambahan nilai dari penerapan bayesian framework for user interest
Dokumen news recommendation Hasil
D0 0 2x0.5 1.0576 + 1 = 2.0576
D1 0 2x0.5 2.0576 + 1 = 3.0576
D2 2x0.5 2x0.5 2.0576 + 2 = 4.0576
D3 0.5 0 0.00 + 0.5 = 0.5
Tabel 3.12 menujukkan hasil setelah menggunakan CSR SpMV, proximity
processing dan bayesian framework for user interest. Untuk mendapatkan hasil rekomendasi, setiap dokumen akan diurutkan secara descending (dari besar ke terkecil) berdasarkan hasil yang didapatkan masing – masing dokumen. Hasil pengurutan secara descending ditunjukkan pada tabel 3.13.
Tabel 3.13 Hasil rekomendasi
Dokumen Hasil Isi
D2 4.0576 news system recommendation news system recommendation
D1 3.0576 system recommendation system recommendation D0 2.0576 system system recommendation recommendation D3 0.5 news retrieval
3.6. Perancangan General Architecture
General archichecture yang digunakan untuk merepresentasikan komponen – komponen pada sistem (Pressman, 2012), akan menggambarkan komponen penyusun pada sistem rekomendasi yang akan dikembangkan dalam penelitian penulis. Sistem
rekomendasi yang akan dikembangkan untuk rekomendasi pada saat akses 1 berita. Memberikan rekomendasi dengan cara mengambil judul berita yang sedang diakses dan menjadikannya query untuk mencari relevansi menggunakan CSR SpMV dan
Pengguna
Gambar 3.9 Diagram arsitektur
3.7. Perancangan Use Case
Use case yang bermanfaat untuk mendeskripsikan ringkasan interaksi antara pengguna (aktor) dan sistem (Eriksson, et al. 2000) yang akan penulis jelaskan secara ringkas tentang sistem yang akan dikembangkan.
3.7.1. Definisi Aktor
Untuk mendefinisikan aktor yang akan menggunakan sistem nantinya serta peran dari masing – masing aktor pada bagian – bagian sistem.
Tabel 3.14 Mendeskripsikan secara singkat aktor dalam sistem
No Aktor Deskripsi
1 Admin Orang yang memasukkan berita – berita baru dan mengatur pengaturan rekomendasi berita personal
2 Pembaca berita Orang yang mengakses berita – berita dan yang menjadi target memberikan
rekomendasi
3.7.2. Definisi Use Case
Mendefinisikan setiap use case yang akan digunakan dan menjadi pendukung sistem rekomendasi.
Tabel 3.15 Mendeskripsikan setiap use case
No Use Case Deskripsi
1 Konversi berita Menkonversi berita menjadi total frekuensi setiap term dan dokumen
2 Stemming Menggunakan algoritma porter untuk mencari
kata dasar
3 Stopword removal Menghapus kata – kata yang tidak memberikan arti
Tabel 3.15 Mendeskripsikan setiap use case (lanjutan)
No Use Case Deskripsi
5 Catat akses berita Mencatat setiap berita yang diakses oleh pembaca berita
6 Rekomendasi Akses berita
Melakukan proses rekomendasi dengan
mempertimbangkan apa yang pernah diakses dan apa yang sedang diakses oleh pembaca berita 7 Manajemen Stopword Untuk menambah jumlah kata yang tidak
penting, supaya hasil rekomendasi lebih bagus
3.7.3. Skenario Use Case
Skenario use case yang digunakan untuk memberikan deskripsi dalam bentuk teks tentang apa yang dikerjakan oleh aktor dan rekasi yang diberikan oleh sistem. Ada 15
use case yang akan dijelaskan dalam bagian skenario use case, yaitu : 1. Konversi berita
Untuk melakukan konversi berita ada 7 tahapan dari skenario normal yang akan terjadi, 1 tahapan dari aktor dan 6 tahapan dari reaksi sistem. Untuk skenario alternatif tidak ada.
Tabel 3.16 Skenario konversi berita
Aksi Aktor Reaksi Sistem
Skenario Normal 1. Menerima judul
2. Memilah perkata
3. Melakukan stopword removal
4. Setiap suku kata dilakukan stemming
5. Melakukan stopword removal sekali lagi 6. Membentuk frekuensi term
7. Menyimpan hasil ke database
2. Stemming
Skenario stemming tidak dibahas sampai bagaimana melakukan stemming karena proses stemming sudah terlihat pada gambar 2.5. Ada 3 tahapan untuk skenario
Tabel 3.17 Skenario stemming
Aksi Aktor Reaksi Sistem
Skenario Normal 1. Mengirim kalimat
2. Memotong kalimat berdasarkan spasi 3. Mencari kata dasar tiap suku kata
3. Stopword removal
Skenario stopword removal yang berguna untuk menhapus kata – kata yang tidak memberikan arti, ada 3 tahapan dari skenario normal 1 dari aksi aktor dari 2 dari reaksi sistem. Untuk Skenario alternatif tidak ada.
Tabel 3.18 Skenario stopword removal
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Mengirim kalimat
2. Mengambil semua daftar stopword dari database
3. Mengecek untuk setiap suku kata yang ada dalam kalimat, apakah ada di dalam daftar stopword, jika ada maka dihapus
4. Ambil kata dan angka
Skenario pengambilan kata dan angka menggunakan regular expression untuk mendapatkan huruf dan angka saja. Ada 2 tahapan dari skenario ambil kata dan angka yang berasalah dari skenario normal, sedangkan dari skenario alternatif tidak ada.
Tabel 3.19 Skenario ambil kata dan angka
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Mengirim Kalimat
2. Menggunakan Reguler Expression (a-z A-Z 0-9) untuk mengambil hanya huruf dan angka
5. Catat akses berita
yang berasal dari skenario normal, 1 dari aksi aktor dan 2 dari reaksi sistem. Sedangkan untuk skenario alternatif tidak ada.
Tabel 3.20 Skenario catat akses berita
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Membuka url berita diakses
2. Mengambil identitas berita diakses 3. Mencatat identitas berita ke database
6. Rekomendasi akses berita
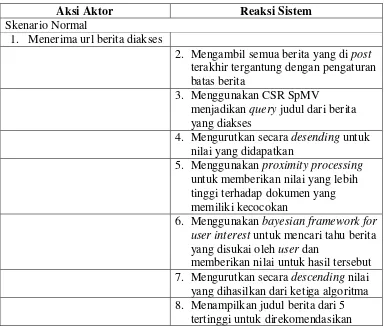
Skenario rekomendasi akses berita yang berguna untuk memberikan rekomendasi
dengan cara mengambil judul berita yang sedang diakses dijadikan query dan jika ada berita yang pernah diakses sebelumnya dijadikan pertimbangan pada perhitungan bayesian framework for user interest. Ada 8 tahapan dari skenario normal, 1 dari aktor dari 7 dari reaksi sistem. Sedangkan untuk skenario alternatif tidak ada.
Tabel 3.21 Skenario rekomendasi akses berita
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Menerima url berita diakses
2. Mengambil semua berita yang di post
terakhir tergantung dengan pengaturan batas berita
3. Menggunakan CSR SpMV
menjadikan query judul dari berita yang diakses
4. Mengurutkan secara desending untuk nilai yang didapatkan
5. Menggunakan proximity processing
untuk memberikan nilai yang lebih tinggi terhadap dokumen yang memiliki kecocokan
6. Menggunakan bayesian framework for user interest untuk mencari tahu berita yang disukai oleh user dan
memberikan nilai untuk hasil tersebut 7. Mengurutkan secara descending nilai yang dihasilkan dari ketiga algoritma 8. Menampilkan judul berita dari 5
3.7.4. Diagram Use Case
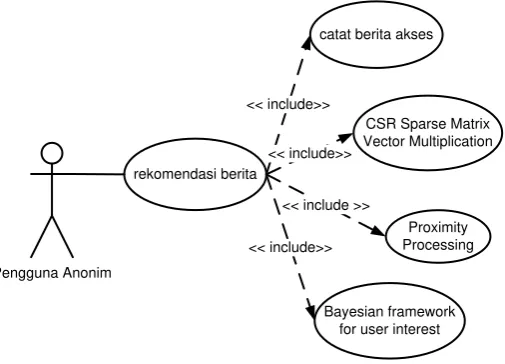
Pada tabel 3.14 telah penulis paparkan tentang tipe aktor. Dibagian ini penulis paparkan ulang secara lebih detail secara teknis. Hanya ada 1 jenis aktor :
1. Pengguna Anonim
Pengguna anonim yang merupakan pembaca berita, mengakses halaman berita lalu sistem rekomendasi memberikan rekomendasi ke pembaca berita dengan memasukkan tiga proses di dalamnya yaitu CSR SpMV, proximity processing dan
bayesian framework for user interest. Ketiga proses tersebut akan memberikan nilainya masing – masing terhadap judul berita yang akan direkeomendasikan, 5 tertinggi akan direkomendasikan kepada pembaca berita.
Pada gambar 3.2 ditampilkan secara grafik dalam bentuk use case untuk mendeskripsikan gambaran secara teknis.
Pengguna Anonim
rekomendasi berita
catat berita akses
CSR Sparse Matrix Vector Multiplication
Proximity Processing
Bayesian framework for user interest << include>>
<< include>>
<< include >>
<< include>>
Gambar 3.10 Diagram use case
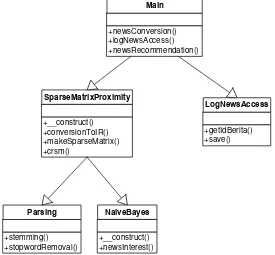
1.8 Diagram Kelas
Sistem nantinya akan dikembangkan menggunakan object oriented programming. Kelas yang akan digunakan dibagi ke dalam 7 kelas, setiap kelas memiliki fungsi
1. Class Main
Tugas utama yaitu menggabungkan kelas – kelas dalam menjalankan fungsi – fungsi tertentu seperti newsConversion, logNewsAccess dan newsRecommendation.
2. Class SparseMatrixProximity
Tugas utama yaitu untuk menjalankan proses CSR SpMV dan proximity
processing.
3. Class LogNewsAccess
Tugas utama yaitu melakukan pencatatan pengaksesan berita. 4. Class Parsing
Tugas utama yaitu melakukan eliminasi terhadap karakter – karakter selain dari karakter huruf, angka dan spasi.
5. Class NaïveBayes
Tugas utama yaitu menyimpulkan news interest dari pembaca berita dengan cara mengambil jejak penjelajahan sebelumnya. Jejak penjelajahan yang disimpan hanya berupa ID, sistem mengambil judul berita melalui ID lalu menjadikannya
term dan frekuensi, setelah itu baru dimasukan ke dalam rumus (2.1) .
+newsConversion() +logNewsAccess() +newsRecommendation()
Main
+__construct() +conversionToIR() +makeSparseMatrix() +crsm()
SparseMatrixProximity
+getIdBerita() +save()
LogNewsAccess
+stemming() +stopwordRemoval()
Parsing
+__construct() +newsInterest()
NaiveBayes
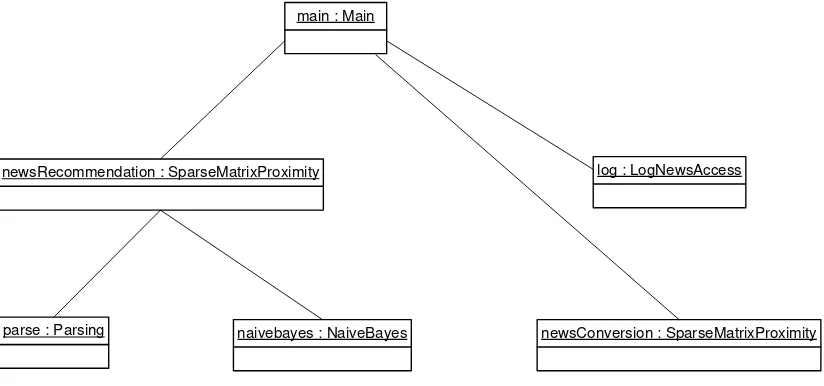
1.9 Diagram Objek
Supaya bisa menjalankan sistem yang dibuat dengan object oriented programming
dibutuhkan objek untuk memanggil kelas. Gambar 3.4 menunjukkan diagram objek yang struktur organisasinya sama seperti diagram kelas pada gambar 3.3 karena sistemnya tidak terlalu besar dan tidak terlalu banyak membutuhkan kombinasi dari kelas.
main : Main
newsRecommendation : SparseMatrixProximity log : LogNewsAccess
newsConversion : SparseMatrixProximity naivebayes : NaiveBayes
parse : Parsing
Gambar 3.12 Diagram objek
1.10 Diagram Sekuen
Untuk menampilkan interaksi dan proses yang dikerjakan dari use case maka perlu digambarkan dalam diagram sekuen. Tidak semua use case akan dibuat masing – masing diagram sekuen, jika sifatnya masuk dalam diagram sekuen yang lain, maka tidak akan dibuat sendiri diagram sekuennya. Yang tidak dibuat diagram sekuen yaitu
stemming, stopword removal, ambil kata dan huruf.
1.10.1.Konversi berita
Tugas dari admin memasukkan judul dan isi berita selanjutnya sistem melakukan konversi dalam bentuk term dan frekuensi untuk disimpan ke database melalui kelas
Admin main : Main conversion : SparseMatrixProximity
judul dan isi berita
inistilizeConversion() << create >>
<<destroy>> conversionToIR()
Gambar 3.13 Diagram sequence untuk konversi berita
1.10.2.Catat akses berita
Anonyomous atau pembaca berita tanpa login yang mengakses halaman berita sistem akan mencatat ID berita yang diakses oleh pengguna anonim.
Anonymous main : Main lga : logNewsAccess
url
<< create >>
logUrl()
<< destroy >>
Gambar 3.14 Diagram sequence catat akses berita oleh user
3.10.3.Rekomendasi akses berita
Sistem akan memberikan rekomendasi akses berita pada saat pembaca berita sedang mengakses suatu berita dengan menjadikan judul berita sebagai query selanjutnya menjalani tahap – tahapan proses rekomendasi. Tahap pertama menjalani proses CSR SpMV, tahap kedua menjalani proximity processing dan terakhir menjalani proses