Seminar Nasional Pendidikan Matematika 2016 1 Prosiding PEMODELAN TOPIK DENGAN LATENT DIRICHLET ALLOCATION
Zulhanif
Departemen Staistika FMIPA UNPAD [email protected]
ABSTRAK. Latent Dirichlet Allocation (LDA), model probabilistik generatif pada sekumpulan data teks (corpus) . LDA adalah model Bayesian Hirarki , di mana sekumpulan data teks dimodelkan sebagai model campuran dari berbagai topik. Dalam kontek pemodelan teks, Pengembangan pemodelan LDA senduru merupakan pengembangan pada model topik sebelumnya yang dikenal sebagai Probabilistic Latent Semantic Analysis (PLSA), PLSA sendiri memiliki suatu keterbatasan dalam menentukan suatu topik dari sekumpulan data teks dikarenakan model PLSA tidak memperhatika urutuan kata sehingga suatu teks dengan jumlah kata yang sama akan bermakna lain jika memperhatikan urutannya. Salah satu pemodelan topik yang memperhatikan urutan dari suatu kata adalah model LDA. Model LDA pada penelitian ini merupakan model LDA yang dikembangkan oleh Blei (2003). Model LDA merupakan model probabistik dari sekumpulan latent (Topik) dari sekumpulan data teks (corpus) atau dikatakan model probabilitas topik yang memberikan representasi eksplisit dari sebuah dokumen. Pada penelitian ini menyajikan teknik inferensi berdasarkan algoritma Gibbs, untuk mengestimasi parameter Bayes dalam pemodelan pengelompokkan dokumen teks.
Kata kunci: Text Mining; LDA; Gibbs Sampling
1. PENDAHULUAN
Seminar Nasional Pendidikan Matematika 2016 2 Prosiding
analis untuk menarik suatu kesimpulan dari pengelompokkan yang terbentuk. Secara umum metode PLSA menggabungkan teori klasik tentang vector space model, Singular Value Decomposition (SVD) serta model variabel latent, yang diformulasikan kedalam suatu bentuk model peluang dengan tujuan untuk mendapatkan suatu kelompok (latent) dari sekumpulan teks (bag of words). Aplikasi PLSA ini dapat diterapkan dalam analisis sentiment pada pasar saham, analisis kemiripan dokumen untuk mendeteksi plagiarism, analisis trending topik pada media sosial, Permasalahan yang timbul dalam penggunaan metode LSA ini adalah adanya faktor polysemi dalam pengelompokkan kata (Hofmann, 2001). Permasalahan polysemi pada kata dapat diatasi dengan mengunakan varian dari LSA yang dikenal sebagai Probabilistic Latent Semantic Analysis (PLSA). Latent class Metode PLSA pada dasarnya merupakan model campuran dari model latent class dengan kata lain model latent class untuk data teks, PLSA sendiri merupakan salah satu model based clustering yang bertujuan untuk membentuk cluster berdasarkan model peluang statistik, berbeda dengan metode cluster yang konvensional metode ini dapat dievaluasi berdasarkan ukuran statistik tertentu. Keutamaan metode PLSA sendiri dapat mereduksi dimensi matriks term yang terbentuk dari sekekumpulan teks yang direpresentasikan dalam sebuah variabel latent, sehingga ukuran dimensi matriks kemunculan term pada metode LSA dapat direduksi Hofmann[7]. Baik model LSA dan PLSA mengabaikan urutan kata (word ordering) dalam proses analisisnya, hal ini menjadi masalah dikarenakan beberapa term tertentu akan memiliki makna yang jauh, perkembangan selanjutnya pada analisis teks dalam pemodelan topik adalah seperti yang dikemukan oleh Blei[10] yang mana Blei[10] menggunakan model latent variabel dengan pendekatan bayesian dalam penaksiaran parameter modelnya.
2. METODEPENELITIAN
Latent Dirichlet Allocation (LDA) adalah model probabilistik generatif dari sekumpulan corpus, Ide dasarnya adalah bahwa dokumen dapat direpresentasikan sebagai model campuran dari berbagai topik yang disebut juga laten, di mana setiap topik dikarakateristikan oleh kata. LDA mengasumsikan proses generatif berikut untuk setiap dokumen w dalam sebuah corpus D adalah sbb :
1. Pilih N~Pissson(
) 2. Pilih θ~Dir(
) 3. Untuk setiap N kata wn:a.Pilih Topik zn ~Multinomial(θ) b.Pilih sebuah kata wn dari p(wn|zn,
)Seminar Nasional Pendidikan Matematika 2016 3 Prosiding 1
1 1
1
1 1
)
(
)
(
)
|
(
kk k
i i k
i i
p
(2.1)
Bentuk distribusi bersama dari Topik mixture
dari N topik z dan N kata w bersyarat
dan
adalah :
N
n
n n
n p w z
z p p
p
1
) , | ( ) | ( ) | ( ) , | , ,
(
z w
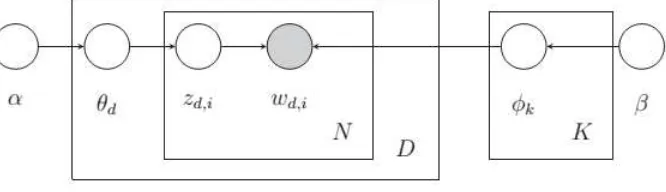
( 2.2) Representasi model LDA jika digambarkan dalam sebuah diagram dapat digambarkan sbb:Gambar 2.1 Representasi Model LDA
Berdasarkan gambar 1 didapat distribusi bersama yang dari parameter pada model LDA sbb:
) , | ( ) | ( ) | ( ) | ( ) , | , , ,
(w z
p
p z
p
p w z
p (2.3)
Pada Persamaan(2.3) diasumsikan bahwa topik setiap dokumen mengikuti distribusi Dirichlet sbb:
Kk k K
k k
k
p
1 1
1
)
(
)
(
)
|
(
(2.4)Sedangkan distribusi peluang dari z untuk semua dokumen dan topik dalam terms dinotasikan nd,kyang merupakan berapa banyak topik k dikelompokan dengan kata dalam dokumen d:
D
d K
k n
k d
k d
z p
1 1 ,
,
) |
Seminar Nasional Pendidikan Matematika 2016 4 Prosiding
Distribusi peluang bersyarat untuk semua corpus
k juga mengikuti distribusi Dirichlet dengan parameter β.
k,v yang diformulasikan pada Persamaan (2.6)
K k V v v k V v v kk kv
p 1 1 1 , 1 , ,. ,
)
(
)
(
)
|
(
(2.6)Selengkapnya distribusi peluang corpus w bersyrat z dan
direpresentasikan sbb:
K k V v n v k v k z w p 1 1 ., , , ) , |(
(2.7)
K k K k n v k Vv kv
k D d K k n k d K k k v k v k k d k z w p p z p p z w p 1 1 1 , 1 , 1 1 1 , 1 , ., , ,. ,
)
(
)
(
)
(
)
(
)
,
|
(
)
|
(
)
|
(
)
|
(
)
,
|
,
,
,
(
(2.8)Dalam proses perhitungannnya dilakukan pengintergrasian (Persamaan 2.8) sehingga bentuk Persamaan (2.8) menjadi sbb:
d d
d d w z p z w p K k K k n v k V
v kv
k D d K k n k d K k k v k v k k d k 1 1 1 , 1 , 1 1 1 , 1 , ., , ,. ,
)
(
)
(
)
(
)
(
)
,
|
,
,
,
(
)
,
|
,
(
(2.9) EstimationProses komputasi pada Persamaan (2.9) menggunakan pendekatan Gibbs sampling, Gibbs Sampling sendiri merupakan pendekatan simulasi untuk mengkonstruk distribusi bersama berdasarkan distribusi marginal, pada proses estimasi parameter LDA, Gibbs sampling untuk LDA memerlukan nilai peluang dari topik z yang diasosiasikan untuk sebuah kata
(term)wi sbb:
)
,
,
,
|
(
z z wSeminar Nasional Pendidikan Matematika 2016 5 Prosiding ) , | , ( ) , | , , ( ) , | , ( ) , | , , ( ) , , , | ( 1 1
1
p z z w p w zw z p w z z p w z z
p i i
i
i
(2.11)
w w i w k w i w k k i k d W w k w k w i w k W w w i w k w w k K k k k d k i k d K k k i k d k k d k i n k d i n d i i i i i i i n n n n n n n n n n n n B n B n B n B w p z w p z w p z p z p z w p z w p w z z p k d
) ( , ) ( , ) ( , 1 , ) ( , 1 ) ( , , 1 , ) ( , 1 ) ( , , ) ( ,. ) ( ,. ) ( ) ( ) ( ) ( ) ()
(
)
(
)
(
)
(
)
(
.
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
|
(
)
|
(
.
)
(
)
(
,
(
)
,
(
)
,
|
(
,. ,. (10) dengan)
(
)
(
)
(
1 1
K k k K k k B
3.HASILPENELITIANDANPEMBAHASAN
Seminar Nasional Pendidikan Matematika 2016 6 Prosiding
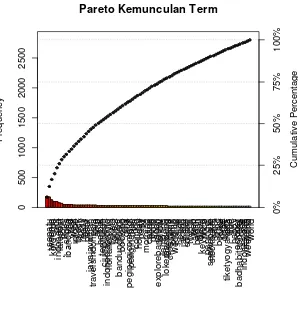
paling tinggi jika dibandingan dengan term kata lainnya hal ini dapat dilihat pada Gambar 3.1 sbb: se p a tu tw e e n ie ko rd e rb e p ict in d o n e si a la te p o st h o te l sh o e s íb an du
ngtred
w e st in fo b e tb la ck to n ly re a d y b a ru p a sa r ja va ja va m a n tr a ve lsi n d o n e si a lo ve a m p h e rb a l te rm u ra h ci u m b u le u it in d o n e si a p ro m o li o n a ir o n lyi n ti cke ts g u e st h o u se bandungj uar a b o o ki n g ci ty g rh a p e g ip e g ico m g tg t p e n g in a p a n vi a co m in g h o li d a y p a rt ytki m o rn in g co ff e e h e ll o p h o to so o n e xp lo re b a n d u n g fo ll o w le m b a n g lo ke rb a n d u n g lo ke rg u ru cr p a rt ti m e p ro m o w e d d in g si ze h e a rt h ja ka rt a si st e r sq u a re to yo ta w e b a la m i
badan dij
u a l ke yw o rd n h cp p e n in g g i se o w e b si te st o ckp a ke t ya ri s zi n c b e ka si n ig h t oct †ti ke tyo g ya ka rt a ti m e fr e e
happyocto
b e r b a d h a b it a p p a re l ca fe in do ne si aâ € m a te ri a l w e e ke n d w o rl d
Pareto Kemunculan Term
[image:6.595.258.407.164.321.2]F re q u e n cy 0 500 1000 1500 2000 2500 0% 25% 50% 75% 100% C u m u la ti ve P e rce n ta g e
Gambar. 3.1 Pareto Terms
Kemunculan term-term yang sering muncul juga dapat dilihat dari gambar wordcloud pada Gambar 3.2 sbb
sepatu
tweenie
pict
in
d
o
n
e
s
ia
latepost
hotel
shoes
íbandung
tred
w
e
s
t
infobe
tblack
to
n
ly
ready
baru
pasar
javajavaman
travelsindonesia
love
amp
herbal termurah ciumbuleuit indonesiapromo lio n a iro n lyi n tickets guest house bandungjuara booking city grha via coming holiday party tki morning coffee hello photo soon follow le m b a n g lokerguru c rp a rt tim e p ro m o wedding size hearth jakarta sister square toyota web alami badan dijual n h c p peninggi stockpaket yaris zinc bekasi oct†ti m e cafe worldGambar. 3.2 WordcloudTerms
[image:6.595.200.428.382.612.2]Seminar Nasional Pendidikan Matematika 2016 7 Prosiding
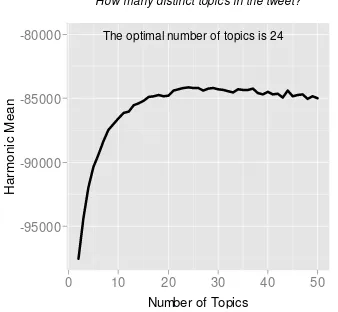
The optimal number of topics is 24
-95000 -90000 -85000 -80000
0 10 20 30 40 50 Number of Topics
H
a
rm
o
n
ic
M
e
a
n
[image:7.595.227.396.135.291.2]Latent Dirichlet Allocation Analysis of Tweet How many distinct topics in the tweet?
Gambar 3.3 Plot jumlah topik terhadap Likelihood
Bentuk Visualisasi dari untuk masing-masing topik dan kata dapat dilihat dalam diagram sbb:
Gambar 3.4 Plot Visualisai LDA 4. SIMPULAN
[image:7.595.118.515.361.552.2]Seminar Nasional Pendidikan Matematika 2016 8 Prosiding
DAFTAR PUSTAKA
[1] Anglin, J. M. (1970) The growth of word meaning. Cambridge, MA.: MIT Press.
[2] Anglin, J. M., Alexander, T. M., & Johnson, C. J. (1996). Word learning and the growth of potentially knowable vocabulary. Submitted for publication.
[3] Dumais, S. T. (1994). Latent semantic indexing (LSI) and TREC-2. In D. Harman (Ed.), The Second Text Retrieval Conference (TREC2) (National Institute of Standards and Technology Special Publication 500-215, pp. 105-116).
[4] Dumais, S. T. & Nielsen, J. (1992). Automating the assignment of submitted manuscripts to reviewers. In N. Belkin, P. Ingwesen, & A. M. Pejtersen (Eds.)
[5] Proceedings of the Fifteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, Association for Computing Machinery.
[6] Hutomo, A. & Zulhanif. 2013. Analisis Keluhan Penumpang PT. Kereta Api Indonesia (Persero) Menggunakan LSA dan Analisis Korespondensi. Univesitas Padjadjaran.
[7] Hofmann. T. 1999, Probabilistic Latent Semantic Indexing, Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval (SIGIR-99).
[8] Hofmann, T., Puzicha, J., & Jordan, M. I. (1999). Unsupervised learning from dyadic data. In Advances in Neural Information Processing Systems, Vol. 11, MIT Press
[9] Saul, L. & Pereira, F. (1997). Aggregate and mixed order Markov models for statistical language processing. In Proceedings of the 2nd International Conference on Empirical Methods in Natural Language Processing, pp. 81-89.