PEMILIHAN DATA TRAINING UNTUK MENINGKATKAN KINERJA
VOTING FEATURE INTERVAL 5 (VFI 5)
DAVID AULIA AKBAR ADHIEPUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PEMILIHAN DATA TRAINING UNTUK MENINGKATKAN KINERJA
VOTING FEATURE INTERVAL 5 (VFI 5)
DAVID AULIA AKBAR ADHIEPUTRA
Skripsi
Sebagai salah satu syarat untuk memperoleh
Gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ii ABSTRACT
DAVID AULIA AKBAR ADHIEPUTRA. Training Data Selection for Improving Performance of Voting Feature Interval 5 (VFI 5). Supervised by SRI NURDIATI and AZIZ KUSTIYO.
Voting Feature Interval 5 (VFI 5) is a supervised algorithm and an inductive learning algorithm for inducing knowledge classification from training information. VFI 5 algorithm is capable of classifying sample very well and can provide an explanation why and how the class groups of new samples from the classification can be predicted in the individual vote that each feature has been assigned to the class. VFI 5 algorithm determines the point interval for the classification process. Point interval is obtained by taking the lowest and the highest value of the sample in each class. In the testing process, if the test data are outside the sample interval they will have zero voting value and will reduce the accuracy of the classification results.
The selection of training data with non-random sampling method uses the purposive sampling technique. The selection process is done by taking a few of the lowest and the highest feature values from each feature data to be training data. The remaining data which are not used as training data will be used as testing data. The propotion of training and testing data is 2:1.
Among the three data used in the VFI 5 algorithm with the selection training data using the lowest and highest feature values, the iris data produced an accuracy of 98.04%, the accuracy of wines data is 96.56% and the acuracy of gender koi data is very high reaching 100%. The result of this study shows that the algorithm VFI 5 data selection method using the lowest and the highest feature values can improve the performance of the algorithm VFI 5.
iii Judul : Pemilihan Data Training untuk Meningkatkan Kinerja Voting Feature Interval5 (VFI 5) Nama : David Aulia Akbar Adhieputra
NRP : G64104105
Menyetujui:
Pembimbing I,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
Pembimbing II,
Aziz Kustiyo, S.Si., M.Kom. NIP. 19700719 199802 1 001
Mengetahui: Ketua Departemen,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
iv
RIWAYAT HIDUP
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT karena hanya dengan rahmat dan karunia-Nya penulis dapat menyelesaikan tugas akhir ini yang merupakan salah satu persyaratan kelulusan pada Program Sarjana Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Tugas akhir ini mengambil judul Pemilihan Data
Training untuk Meningkatkan Kinerja Voting Feature Interval5 (VFI 5).
Pada kesempatan ini, penulis ingin menyampaikan rasa terima kasih yang sebesar-besarnya kepada senua pihak yang telah membantu kelancaran penelitian ini, anatara lain kepada:
1. Orangtua tercinta, Ayahanda Muji Hadiwiyono dan Ibunda Suyatmi atas segala doa, kasih sayang, dan dukungan baik moral maupun spiritual yang telah diberikan selama ini, serta kepada kedua kakak, Didit dan Dewi yang selalu memberi semangat.
2. Ibu Dr. Ir. Sri Nurdiati M.Sc dan Bapak Aziz Kustiyo, S.Si, M.Kom yang senantiasa dengan penuh ketekunan dan kesabaran membimbing penulis hingga selesainya penulisan karya ilmiah ini.
3. Bapak Firman Ardiansyah, S.Kom, M.Si, terima kasih atas kesediaan beliau menjadi moderator pada seminar dan penguji pada sidang tugas akhir.
4. Edho, Yohan, Didit, Indri Puspita, Tresna, Ganang, Reza, Geti, Maul, Lutfi, Onong, Ahyar, anak-anak kos Cemara, dan teman-teman Passing Out lainnya yang selalu memberi dukungan dan mendampingi penulis selama penelitian ini.
5. Intan Dyah, Yuli Fitriyani, Khodijah, Bayu Mahardhika, Rista, dan Radi yang telah menjadi sahabat baik penulis selama ini.
6. Mi-Chan, Oreo, Maze, Onji, Titin, Mong-Mong, Lala, Tete, Bon-Bon, Oski, Candy, Edu, Momo, Plato, Oin, dan Oscar yang selalu menemani penulis selama ini.
7. Pak Soleh, Pak Pendi, Mbak Rahma, Mas Irfan, dan seluruh keluarga besar Ilmu Komputer, FMIPA IPB umumnya, Ilkomers ’39, ’40, ’42, dan ‘41 khususnya.
8. Serta kepada semua pihak yang telah memberikan kontribusi besar selama pengerjaan penelitian ini yang tidak dapat penulis sebutkan satu-persatu.
Sebagaimana manusia yang tidak luput dari kesalahan, penulis menyadari bahwa karya ilmiah ini jauh dari kesempurnaan. Akan tetapi, penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi semua pihak, baik secara langsung maupun tidak langsung termasuk penulis pribadi.
Jazakumullah khairan katsiira.
:
Bogor, Januari 2010
vi
DAFTAR ISI
Halaman
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... vii
DAFTAR LAMPIRAN ... vii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA Pengambilan Sampel ... 1
Teknik Pengambilan Sampel ... 1
Metode k-Fold Cross Validation ... 2
Algoritme Voting Feature Interval 5 ... 2
METODE PENELITIAN Studi Pustaka ... 4
Data ... 4
Klasifikasi Algoritme VFI 5 ... 4
Data Pelatihan dan Data Pengujian ... 4
Pelatihan ... 4
Klasifikasi (Pengujian) ... 4
Akurasi... 5
Lingkungan Pengembangan ... 5
HASIL DAN PEMBAHASAN Pemilihan Data Latih dan Data Uji ... 5
Pengolahan dan Tingkat Akurasi VFI 5 dengan Data Iris ... 5
Pengolahan dan Tingkat Akurasi VFI5 dengan Data Wine ... 8
Pengolahan dan Tingkat Akurasi VFI5 dengan Data Ikan Koi ... 11
KESIMPULAN DAN SARAN Kesimpulan ... 13
Saran ... 13
DAFTAR PUSTAKA ... 14
vii
DAFTAR TABEL
Halaman
1 Spesifikasi Data yang Digunakan ... 4
2 Pembagian Data Iris dengan Nilai Fitur Terendah dan Tertinggi ... 6
3 Hasil Akurasi dengan Nilai Fitur Terendah dan Tertinggi Data Iris ... 6
4 Hasil Pembagian Acak Data Iris ... 6
5 Susunan Data Pelatihan dan Data Pengujian Data Iris ... 6
6 Hasil Akurasi dengan Nilai Acak Data Iris ... 7
7 Pembagian Data Iris dengan Nilai Fitur Terendah ... 7
8 Pembagian Data Iris dengan Nilai Fitur Tertinggi ... 7
9 Pembagian Data Iris Tanpa Nilai Fitur Terendah dan Tertinggi ... 7
10 Perbandingan Akurasi pada Data Iris ... 8
11 Pembagian Data Wine dengan Nilai Fitur Terendah dan Tertinggi ... 8
12 Hasil Akurasi dengan Nilai Fitur Terendah dan Tertinggi Data Wine ... 9
13 Hasil Pembagian Acak Data Wine ... 9
14 Susunan Data Pelatihan dan Data Pengujian Data Wine ... 9
15 Hasil Akurasi dengan Nilai Acak Data Wine ... 9
16 Pembagian Data Wine dengan Nilai Fitur Terendah ... 9
17 Pembagian Data Wine dengan Nilai Fitur Tertinggi ... 10
18 Pembagian Data Wine Tanpa Nilai Fitur Terendah dan Tertinggi ... 10
19 Perbandingan Akurasi pada Data Wine ... 10
20 Pembagian Data Ikan Koi dengan Nilai Fitur Terendah dan Tertinggi ... 11
21 Hasil Akurasi dengan Nilai Fiture Terendah dan Tertinggi Data Ikan Koi ... 11
22 Hasil Pembagian Acak Data ... 11
23 Susunan Data Pelatihan dan Data Pengujian Data Koi ... 12
24 Hasil Akurasi dengan Nilai Acak Data Ikan Koi ... 12
25 Pembagian Data Ikan Koi dengan Nilai Fitur Terendah ... 12
26 Pembagian Data Ikan Koi dengan Nilai Fitur Tertinggi ... 12
27 Pembagian Data Ikan Koi Tanpa Nilai Fitur Terendah dan Tertinggi ... 12
28 Perbandingan Akurasi pada Data Ikan Koi ... 13
DAFTAR GAMBAR
Halaman 1 Diagram Metode Penelitian ... 32 Perbandingan Akurasi pada Data Iris ... 8
3 Perbandingan Akurasi pada Data Wine ... 11
4 Perbandingan Akurasi pada Data Ikan Koi ... 13
DAFTAR LAMPIRAN
Halaman 1 Contoh Pelatihan ... 162 Contoh Klasifikasi ... 17
3 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Iris (Iterasi 1) ... 17
4 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Iris (Iterasi 2) ... 17
5 Normalisasi Akhir dengan Data Latih Acak pada Data Iris (Iterasi 1) ... 18
6 Normalisasi Akhir dengan Data Latih Acak pada Data Iris (Iterasi 2) ... 18
7 Normalisasi Akhir dengan Data Latih Acak pada Data Iris (Iterasi 3) ... 19
8 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah Data Iris ... 19
viii Halaman
10 Normalisasi Akhir Data Latih Tanpa Nilai Fitur Terendah dan Tertinggi Data Iris ... 20
11 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Wine (Iterasi 1) ... 20
12 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Wine (Iterasi 2) ... 21
13 Normalisasi Akhir dengan Data Latih Acak pada Data Wine (Iterasi 1) ... 22
14 Normalisasi Akhir dengan Data Latih Acak pada Data Wine (Iterasi 2) ... 23
15 Normalisasi Akhir dengan Data Latih Acak pada Data Wine (Iterasi 3) ... 25
16 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah Data Wine ... 26
17 Normalisasi Akhir Data Latih dengan Nilai Fitur Tertinggi Data Wine ... 27
18 Normalisasi Akhir Data Latih Tanpa Nilai Fitur Terendah dan Tertinggi Data Wine ... 28
19 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Koi (Iterasi 1) 30 20 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah dan Tertinggi Data Koi (Iterasi 2) 30 21 Normalisasi Akhir dengan Data Latih Acak pada Data Koi (Iterasi 1) ... 31
22 Normalisasi Akhir dengan Data Latih Acak pada Data Koi (Iterasi 2) ... 32
23 Normalisasi Akhir dengan Data Latih Acak pada Data Koi (Iterasi 3) ... 33
24 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah Data Koi ... 34
25 Normalisasi Akhir Data Latih dengan Nilai Fitur Tertinggi Data Koi ... 35
26 Normalisasi Akhir Data Latih Tanpa Nilai Fitur Terendah dan Tertinggi Data Koi ... 36
27 Normalisasi Akhir Data Latih dengan Nilai Fitur Terendah Data Iris ... 36
28 Normalisasi Akhir Data Latih dengan Nilai Fitur Tertinggi Data Iris ... 38
1 PENDAHULUAN
Latar Belakang
Voting Feature Interval 5 (VFI 5) adalah sebuah supervised algorithm dan algoritme pembelajaran secara induktif untuk menginduksi klasifikasi pengetahuan dari informasi suatu pelatihan. Algoritme VFI 5 mampu melakukan proses klasifikasi dengan sangat baik. Algoritme ini dapat memberikan penjelasan mengapa dan bagaimana contoh baru dari klasifikasinya dapat diprediksi golongan kelasnya dalam individual vote yang masing-masing fiturnya telah diberikan ke dalam kelas tersebut.
Setiap contoh training direpresentasikan sebagai sebuah nominal vektor (dengan fungsi diskret) atau linear (dengan fungsi continous) pada nilai fiturnya, ditambah label yang merepresentasikan kelas dari setiap contohnya. Contoh pelatihan menunjukkan bahwa algoritme VFI 5 membangun interval
untuk masing-masing fitur berupa range atau
point interval. Range interval didefinisikan pada sebuah kumpulan nilai yang berurutan yang diberikan oleh data fitur pelatihan, sedangkan point interval didefinisikan pada sebuah nilai tunggal dari fiturnya (Demiröz 1997).
Algoritme VFI 5 menentukan point interval untuk proses klasifikasi. Point interval didapat dari pengambilan nilai fitur terendah dan tertinggi contoh pada masing-masing kelas. Pada proses uji, jika data uji berada di luar interval contoh akan mendapat nilai voting nol dan akan mengurangi akurasi dari hasil klasifikasinya.
Dalam penelitian ini data pelatihan dengan menggunakan nilai fitur terendah dan tertinggi akan dibandingkan dengan beberapa data pelatihan yang dipilih dengan cara lain, dengan pembandingan tersebut diharapkan data pelatihan yang menggunakan nilai fitur terendah dan tertinggi akan mendapatkan akurasi yang lebih baik.
Tujuan
Tujuan dari penelitian ini adalah melakukan pemilihan data training untuk meningkatkan kinerja dari algoritme VFI 5 agar mendapatkan nilai akurasi yang lebih baik dengan menggunakan nilai fitur terendah dan tertinggi, serta menggunakan bobot yang sama pada algoritme VFI 5.
TINJAUAN PUSTAKA Pengambilan Sampel
Dalam rangka pengambilan sampel menurut Nasution (2003) ada beberapa pengertian yang perlu diketahui agar sampel yang diambil mewakili sehingga dapat diperoleh informasi yang cukup , yaitu:
1. Populasi sasaran
Yaitu populasi yang menjadi sasaran pengamatan atau populasi di mana keterangan dapat diperoleh.
2. Kerangka sampel
Yaitu suatu daftar unit-unit yang ada pada populasi yang akan diambil sampelnya. 3. Unit sampel
Yaitu unit terkecil pada populasi yang akan diambil sebagai sampel.
4. Rancangan sampel
Yaitu rancangan yang meliputi cara pengambilan sampel dan penentuan besar sampel.
5. Random
Yaitu salah satu cara pengambilan sampel, di mana setiap unit dalam populasi mempunyai kesempatan yang sama untuk dipilih untuk mejadi anggota sampel.
Teknik Pengambilan Sampel
Pemilihan teknik pengambilan sampel merupakan upaya penelitian untuk mendapat sampel yang representatif yang dapat menggambarkan populasinya. Teknik pengambilan sampel tersebut dibagi atas dua kelompok besar (McLennan 1998), yaitu
probability sampling (random sampling) dan
non probability sampling (non random sampling).
Probability sampling
Pada pengambilan sampel secara acak, setiap unit populasi mempunyai kesempatan yang sama untuk diambil sebagai sampel. Hal ini dapat menghindarkan peneliti dari memilih data sesuai keinginannya yang akan mengakibatkan bias pada kasus tertentu yaitu hasil yang diperoleh tidak sesuai dengan kenyataan. Dengan cara acak bias pemilihan dapat diperkecil sehingga diperoleh sampel yang representatif. Keuntungan pengambilan sampel secara acak adalah sebagai berikut:
• Derajat kepercayaan terhadap sampel dapat ditentukan.
2
• Besar sampel yang dapat diambil dapat dihitung.
Non probability sampling (selected sample)
Pemilihan sampel dengan cara ini tidak menghiraukan prinsip-prinsip probability. Pemilihan sampel secara tidak acak, hasil yang diharapkan adalah gambaran kasar dari suatu keadaan, dan biasanya pengambilan sampel dengan cara ini digunakan jika biaya sangat sediki, hasil yang diminta segera, dan tidak memerlukan ketepatan yang tinggi karena hanya gambaran umumnya saja.
Pada penelitian kali ini, pengambilan sampel pada sampel data pelatihan menggunakan metode non probability sampling. Teknik pengambilan sampel yang digunakan adalah pengambilan sampel dengan maksud (purposive sampling) di mana teknik ini merupakan bagian dari metode pengambilan sampel secara tidak acak dengan cara mengambil unsur-unsur yang dikehendaki untuk pertimbangan penelitian. Dalam hal ini unsur- unsur yang diambil adalah nilai terendah dan tertinggi dari atribut data atau pada algoritme ini biasa disebut minimum fitur dan maksimum fitur. Keduanya digunakan sebagai sampel data pelatihan dengan harapan dapat meningkatkan kinerja algoritme VFI 5.
Metode k-Fold Cross Validation
Validasi silang (cross-validation) merupakan metode untuk memerkirakan error
generalisasi berdasarkan “resampling” (Weiss & Kulikowski 1991; Efron & Tibshirani 1993; Hjorth 1994; Plutowski et al. 1994; Shao & Tu 1995, diacu dalam Sarle 2004). Dalam k-fold cross validation, data dibagi secara acak menjadi k himpunan bagian yang ukurannya hampir sama satu sama lain. Himpunan bagian yang dihasilkan yaitu S1,S2,...,Sk digunakan sebagai pelatihan dan pengujian.
Pengulangan dilakukan sebanyak k kali dan pada setiap ulangan disisakan satu subset
untuk pengujian dan subset lainnya untuk pelatihan. Pada iterasi ke-i, subset Si diperlakukan sebagai data pengujian, dan
subset lainnya diperlakukan sebagai data pelatihan. Pada iterasi pertama S2,...Sk menjadi data pelatihan dan S1 menjadi data pengujian. Selanjutnya pada iterasi kedua S1,S3,...,Sk menjadi data pelatihan dan S2 menjadi data pengujian, dan seterusnya.
Algoritme Voting Feature Interval 5
Voting Feature Intervals 5 (VFI 5)
merupakan algoritme klasifikasi yang dikembangkan oleh Demiröz dan Güvenir (Demiröz, 1997). Semua instance pelatihan diproses bersamaan. Algoritme VFI 5 terdiri atas dua tahap, yaitu tahap pelatihan dan klasifikasi.
Pelatihan
Pada tahap pelatihan, awalnya dicari nilai
end point suatu feature f pada kelas data c.
End point adalah nilai minimum dan nilai maksimum setiap kelas c pada feature f. Nilai end points tersebut kemudian diurutkan menjadi interval untuk feature f. Terdapat dua jenis interval, yaitu point interval dan
range interval. Point interval dibentuk dari setiap nilai yang berbeda dari end points. Range interval dibentuk dari dua nilai end points yang berdekatan tetapi tidak termasuk
end points tersebut (Güvenir 1997).
Tahap selanjutnya ialah menghitung jumlah instance pelatihan setiap kelas c dengan feature f yang nilainya jatuh pada
interval i, direpresentasikan sebagai
interval_class_count [f,i,c]. Untuk setiap
instance pelatihan, dicari interval i di mana nilai feature f dari instance pelatihan e (ef) tersebut jatuh. Jika interval i merupakan point interval dan nilai ef sama dengan nilai pada batas bawah atau batas atas maka jumlah kelas
instance tersebut (ef) pada interval i ditambah 1. Jika interval i merupakan range interval
dan nilai ef jatuh pada interval tersebut, maka jumlah kelas instance ef pada interval i ditambah 1. Hasil dari proses tersebut merupakan jumlah vote kelas c pada interval i.
Jumlah vote kelas c untuk feature f pada
interval i dibagi dengan jumlah instance pada kelas c (class_count[c]) untuk menghilangkan perbedaan distribusi setiap kelas. Hasil normalisasi direpresentasikan dalam
interval_class_vote [f,i,c]. Nilai-nilai pada
interval_class_vote [f,i,c] dinormalisasi sehingga jumlah vote dari beberapa kelas pada setiap feature sama dengan 1. Berikut ini adalah pseudocode olehGüvenir (1997)tahap pelatihan dari algoritme VFI 5.
train (TrainingSet);
begin
for each feature f if f is linear
3
EndPoints[f] = EndPoints[f]U find_end_points(TrainingSet,f, count_instances(f,TrainingSet); for each interval i on feature f for each class c
normalize
interval_class_vote[f,i,c]; /* such that
∑
c interval_class_vote[f,i,c] = 1 */End
Klasifikasi
Klasifikasi merupakan proses menemukan sekumpulan model (atau fungsi) yang menggambarkan dan membedakan konsep-konsep kelas data. Tujuannya adalah agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang lebel kelasnya tidak diketahui (Han & Kamber 2001).
Pada tahap awal klasifikasi, dilakukan proses inisialisasi awal nilai vote masing-masing kelas dengan nilai 0. Untuk setiap
feature f dicari nilai interval i di mana ef jatuh, ef adalah nilai feature f dari instance tes e. Jika ef tidak diketahui, maka feature tersebut tidak disertakan dalam voting
(memberi nilai vote 0 untuk masing-masing kelas). Feature yang nilainya tidak diketahui diabaikan.
Jika ef diketahui maka interval tersebut ditemukan. Interval tersebut dapat menyimpan
instances pelatihan dari beberapa kelas. Kelas-kelas dalam sebuah interval direpresentasikan oleh vote kelas-kelas tersebut pada interval
itu. Untuk setiap kelas c, feature f
memberikan vote yang sama dengan
interval_class_vote[f,i,c]. Notasi tersebut merepresentasikan vote feature f yang diberikan untuk kelas c.
Setiap feature f mengumpulkan nilai vote
kemudian dijumlahkan untuk memeroleh total
vote. Kelas c yang memiliki nilai vote
tertinggi diprediksi sebagai kelas dari instance
tes e. Pseudocode olehGüvenir (1997)untuk tahap klasifikasi dapat dilihat di bawah ini.
classify (e)
interval_class_vote [f,i,c] for each class c
vote[c] = vote[c] +
feature_vote[f,c]*weight[f]; return class c with highes vote[c]; end
METODE PENELITIAN
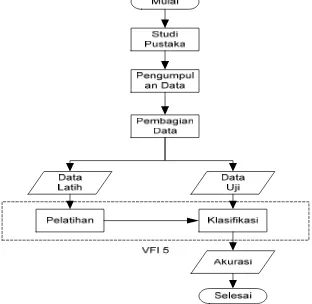
Metode penelitian diawali dengan pengumpulan bahan-bahan penunjang penelitian, pengumpulan data, dan pengolahan data. Metode penelitian yang digunakan disajikan dalam diagram metode penelitian pada Gambar 1.
4 Studi Pustaka
Melakukan studi pustaka yang berhubungan dengan penelitian yang akan dilakukan. Dalam hal ini, studi pustaka mengenai penerapan algoritme VFI 5.
Data
Penelitian ini menggunakan minimal tiga buah data. Data yang digunakan harus memiliki atribut yang memiliki nilai kontinyu agar dapat dibuat range interval. Data yang digunakan pada penelitian ini adalah data iris, data wine, dan data jenis kelamin ikan koi yang masing-masing data memiliki jumlah atribut yang berbeda dan atribut yang memiliki nilai kontinyu jumlahnya juga berbeda. Data bunga iris dan wine diambil dari UCI repository of machine learning database
(http://archive.ics.uci.edu/ml/datasets), sedangkan data jenis kelamin ikan koi diambil dari penelitian sebelumnya.
Data yang diambil dari sumber tersebut untuk penelitian ini, memiliki nilai kontinu dan digunakan untuk penggunaan klasifikasi. Contoh data dapat dilihat pada Lampiran 27, Lampiran 28, dan Lampiran 29. Adapun spesifikasi data, disajikan pada Tabel 1.
Tabel 1 Spesifikasi Data yang Digunakan
No Nama
Klasifikasi Algoritme VFI 5
Tahapan klasifikasi Voting Feature Intervals 5 terdiri atas dua proses yaitu proses pelatihan dan proses klasifikasi (pengujian). Data yang digunakan pada tahapan ini juga dibagi menjadi dua bagian yaitu data pelatihan dan data pengujian. Proses pelatihan akan menghasilkan model klasifikasi yang diturunkan dari data pelatihan. Model ini akan digunakan dalam data pengujian dalam proses klasifikasi.
Data Pelatihan dan Data Pengujian
Pada pemilihan data pelatihan dengan metode non random sampling, teknik yang digunakan adalah purposive sampling. Teknik tersebut dilakukan melalui pemilihan data latih dengan hanya mengambil beberapa nilai
yang terendah dan tertinggi (minimum dan maksimum fitur) dari setiap fitur data untuk dijadikan data latih dan menggunakan sisa data yang belum digunakan sebagai data uji. Perbandingan yang digunakan adalah 2:1, yaitu dua untuk data latih dan satu untuk data uji.
Pelatihan dan pengujian pada pemilihan data pelatihan secara acak menggunakan metode k-fold cross validation. Pada metode ini digunakan 3-fold cross validation. Oleh karena itu, data yang digunakan dibagi menjadi tiga subset secara acak yang masing-masing subset memiliki jumlah instance dan perbandingan jumlah kelas yang hampir sama. Pembagian data ini digunakan pada proses iterasi klasifikasi. Iterasi dilakukan sebanyak tiga kali. Setiap iterasi, satu subset digunakan untuk pengujian sedangkan subset-subset
lainnya digunakan untuk pelatihan.
Data pelatihan dibagi menjadi lima macam pemilihan yaitu :
1. Pemilihan data pelatihan menggunakan nilai fitur terendah dan tertinggi.
2. Pemilihan data pelatihan dilakukan secara acak.
3. Pemilihan data pelatihan hanya menggunakan nilai fitur terendah.
4. Pemilihan data pelatihan hanya menggunakan fitur tertinggi.
5. Pemilihan data pelatihan tanpa menggunakan nilai fitur terendah dan tertinggi.
Pelatihan
Subset data pelatihan digunakan sebagai input bagi algoritmeVoting Feature Intervals 5 pada tahapan pelatihan. Langkah pertama yang dilakukan pada tahapan pelatihan yaitu membuat interval dari masing-masing fitur berdasarkan nilai end point masing-masing fitur untuk setiap kelasnya. Setelah end point
masing-masing fitur terbentuk maka dimulailah proses voting pada algoritme.
Voting yang dilakukan yaitu menghitung jumlah data untuk setiap kelas pada interval
tertentu. Masing-masing kelas pada rentang
interval tertentu memiliki nilai vote yang berbeda-beda. Nilai vote tersebut akan dinormalisasi untuk mendapatkan nilai vote
akhir pada masing-masing fitur. Contoh pelatihan dapat dilihat pada Lmpiran1
Klasifikasi (Pengujian)
5 diperiksa letaknya pada interval. Nilai Vote
setiap kelas untuk setiap fitur pada interval
yang bersesuaian diambil nilainya dan kemudian dijumlahkan. Kelas dengan nilai
vote tertinggi menjadi kelas prediksi dari data pengujian tersebut.
Tahapan pengujian menggunakan data uji yang telah ditentukan sebelumnya dalam proses iterasi. Data uji yang digunakan disesuaikan dengan subset data pelatihan yang digunakan. Contoh pengujian dapat dilihat pada Lampiran2.
Akurasi
Akurasi adalah adalah derajat kedekatan pengukuran terhadap nilai sebenarnya. Pada penelitian ini akan diketahui akurasi yang dicapai algoritme VFI5. Tingkat akurasi dihitung dengan cara :
100%
Tingkat akurasi menunjukkan tingkat kebenaran penglasifikasian data terhadap kelas sebenarnya. Semakin rendah nilai akurasi maka semakin tinggi kesalahan klasifikasi. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati nilai 100%.
Lingkungan Pengembangan
Aplikasi yang digunakan pada penelitian ini dibangun dengan menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
Perangkat keras berupa computer mobile: 1. Processor AMD Sempron M 1,86
GHz
2. RAM kapasitas 512 MB 3. Harddisk kapasitas 40 GB
4. Monitor pada resolusi 1024×768
pixels
5. Keyboard dan Mouse
Perangkat lunak:
1. Sistem Operasi : Microsoft Windows XP Proffesional Edition
2. Visual Basic 6.0
HASIL DAN PEMBAHASAN Pada bab ini akan dipaparkan proses peningkatan kinerja algoritme VFI5 untuk mendapatkan nilai akurasi yang lebih baik dengan menggunakan nilai fitur terendah dan tertinggi, sertamenggunakan bobot yang sama pada algoritme VFI 5.
Pemilihan Data Latih dan Data Uji
Penelitian ini bertujuan untuk melakukan pemilihan data latih guna meningkatkan kinerja dari algoritme VFI 5. Pemilihan data dalam penelitian ini dibagi ke dalam 5 kategori seperti yang sudah dipaparkan pada bagian metode penelitian.
Hasil dari kelima kategori akan dbandingkan satu sama lainnya untuk menunjukkan tingkat akurasi masing-masing. Kategori utama adalah pemilihan data pelatihan menggunakan nilai fitur terendah dan tertinggi. Kategori pemilihan data pelatihan secara acak merupakan pembanding, sedangkan sisanya digunakan sebagai pembanding tambahan. Pemilihan data secara acak dilakukan dengan mengacak suatu kelompok data kemudian diambil proporsi data latih dan data uji sebesar 2:1 pada tiap-tiap kelas.
Pemilihan data dengan menggunakan nilai fitur terendah dan tertinggi dilakukan dengan membagi data latih dan data uji dengan proporsi 2:1. Misal data ikan koi yang memiliki 119 data jika dibagi dengan proporsi 2:1 akan menghasilkan 80 data latih dan 39 data uji serta nilai terendah dan tetinggi setiap fitur terdapat di dalam data latih pada masing-masing fitur pada tiap kelas. Tiap fitur diurutkan berdasarkan nilai fitur terendah dan tertingginya kemudian data tersebut dijadikan data latih.
Pemilihan data dengan tanpa nilai fitur terendah dan tertinggi, data latihnya adalah data yang bukan merupakan nilai fitur terndah dan tertinggi. Dalam hal ini data ujinya menggunakan data yang telah dikelompokkan berdasarkan nilai terendah dan tertinggi pada tiap fitur.
Pemilihan data dengan nilai fitur terendah, data latihnya menggunakan nilai terendah pada masing-masing fitur, sedangkan data ujinya memakai nilai tertinggi pada fitur. Pada pemilihan data dengan nilai fitur tertinggi, digunakan nilai tertinggi pada masing-masing fitur sebagai data latih dan nilai terendah pada fitur digunakan sebagai data uji.
Pengolahan dan Tingkat Akurasi VFI 5 dengan Data Iris
6 1. Pengolahan Data Pelatihan Menggunakan
Nilai Fitur Terendah dan Tertinggi
a. Pemilihan Data
Proses ini dilakukan dengan menggunakan metode non random sampling
dengan teknik purposive sampling. Teknik ini berupa pemilihan data latih dengan hanya mengambil beberapa nilai yang terendah dan tertinggi (minimum dan maksimum fitur) dari setiap fitur data untuk dijadikan data latih dan menggunakan sisa data yang belum digunakan sebagai data uji. Perbandingan yang digunakan adalah mendekati 2:1, yaitu dua untuk data latih dan satu untuk data uji.
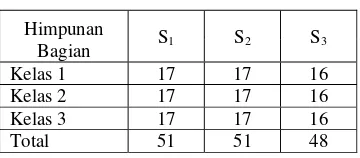
Data iris dibagi menjadi tiga kelas yang tiap kelasnya terdiri atas 50 kasus dengan 4 fitur. Tiap-tiap kelas masing-masing fiturnya diambil 2 nilai terndah dan 2 nilai tertinggi sehingga diperoleh 8 nilai terendah dan 8 nilai tertinggi pada tiap kelasnya. Pembagian tersebut menghasilkan 24 nilai terendah dan 24 nilai tertinggi atau total 48 data yang memiliki nilai nilai fitur terendah dan tertinggi pada keseluruhan data iris. Data tersebut digunakan untuk proses pelatihan pada iterasi pertama. Sisanya adalah 102 data yang sebagian diikutkan sebagai data pelatihan dengan jumlah 51 data dan sebagian lagi sebagai data uji dengan jumlah 51 data. Secara keseluruhan data iris pada iterasi pertama terdiri atas 99 data pelatihan dan 51 data uji. Iterasi kedua dilakukan dengan menukar data pelatihan pada iterasi pertama yang tidak mengandung nilai fitur terendah dan tertinggi dengan data uji pada iterasi pertama. Pembagian data dapat dilihat pada Tabel 2.
Tabel 2 Pembagian Data Iris dengan Nilai Fitur Terendah dan Tertinggi
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada
Lampiran 3 dan Lampiran 4. Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 96,08% dan pada iterasi kedua sebesar 100%. Rata-rata tingkat akurasi adalah sebesar 98,04%. Hasil akurasi ditunjukkan dalam Tabel 3.
Tabel 3 Hasil Akurasi dengan Nilai Fitur Terendah dan Tertinggi Data Iris
Keterangan Nilai Akurasi Iterasi 1 96,08%
Iterasi 2 100%
Rata-rata 98,04%
2. Pengolahan Data Pelatihan Secara Acak
a. Pemilihan Data
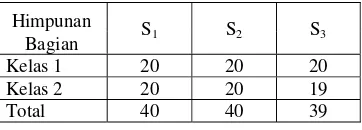
Proses ini dilakukan dengan menggunakan metode 3-fold cross validation
dengan jumlah data keseluruhan 150 kasus. Terlebih dahulu data dibagi menjadi tiga himpunan. Jumlah masing-masing bagiannya hampir sama satu dengan lainnya. Pembagian tersebut menghasilkan bagian S1, S2, dan S3. Hasil pembagian data himpunan secara keseluruhan disajikan dalam Tabel 4.
Tabel 4 Hasil Pembagian Acak Data Iris
Himpunan S
Penelitian ini dilakukan dengan pelatihan dan pengujian data sebanyak tiga kali. Susunan data pelatihan dan data pengujian disajikan dalam Tabel 5.
Tabel 5 Susunan Data Pelatihan dan Data Pengujian Data Iris
Iterasi Pelatihan Pengujian 1 S2 dan S3 S1
2 S1 dan S3 S2 3 S1 dan S2 S3
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan secara acak menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 5, Lampiran 6, dan Lampiran 7. Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 86,28%, pada iterasi kedua sebesar 96,08%, dan pada iterasi ketiga sebesar 97,92%. Rata-rata tingkat akurasi Keterangan Data
7 adalah sebesar 93,43%. Hasil akurasi
ditunjukkan dalam Tabel 6.
Tabel 6 Hasil Akurasi dengan Nilai Acak Data Iris
3. Pengolahan Data Pelatihan Menggunakan Nilai Fitur Terendah.
a. Pemilihan Data
Data yang hanya memiliki nilai fitur terendah ditambah dengan data yang tidak memiliki nilai fitur terendah dan tertinggi dijadikan data latih, sedangkan data ujinya adalah data yang memiliki nilai fitur tertinggi ditambah sisa data yang tidak memiliki nilai fitur nilai fitur terendah dan tertinggi. Data yang dijadikan data latih dan data uji memiliki rasio 2:1, sehingga diperoleh 99 data latih dan 51 data uji. Hasil pembagian data dapat dilihat pada Tabel 7.
Tabel 7 Pembagian Data Iris dengan Nilai Fitur Terendah
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur terendah menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 8. Proses pengujian menghasilkan akurasi sebesar 72,55%.
4. Pemilihan Data Pelatihan Menggunakan Nilai Fitur Tertinggi.
a. Pemilihan Data
Data yang hanya memiliki nilai fitur tertinggi ditambah dengan data yang tidak memiliki nilai fitur terendah dan tertinggi dijadikan data latih, sedangkan data ujinya adalah data yang memiliki fitur terndah ditambah sisa data yang tidak memiliki nilai fitur terendah dan tertinggi. Data yang dijadikan data latih dan data uji memiliki rasio 2:1, sehingga diperoleh 99 data latih dan 51
data uji. Hasil pembagian data dapat dilihat pada Tabel 8.
Tabel 8 Pembagian Iris dengan Nilai Fitur Tertinggi
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 9. Proses pengujian menghasilkan akurasi sebesar 70,59%.
5. Pemilihan Data Pelatihan Tanpa Menggunakan Nilai Fitur Terendah dan Tertinggi.
a. Pemilihan Data
Data yang tidak memiliki nilai fitur terendah dan tertinggi sejumlah 102 kasus digunakan sebagai data latih sedangan data uji adalah data yang memiliki nilai terendah dan tertinggi sebanyak 48. Pembagian data ini dapat dilihat pada Tabel 9.
Tabel 9 Pembagian Data Iris Tanpa Nilai Fitur Terendah dan Tertinggi
Kelas Data Latih Data Uji Kelas 1 34 16 Kelas 2 34 16 Kelas 3 34 16
Total 102 48
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan tanpa menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 10. Proses pengujian menghasilkan akurasi sebesar 72,92%.
6. Analisis dan Perbandingan Akurasi pada Data Iris
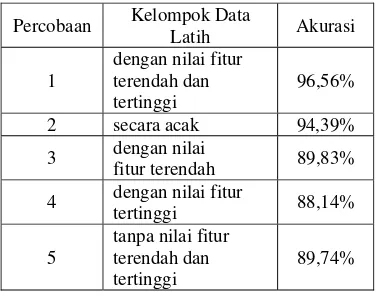
Pelatihan dan Pengujian data iris menunjukkan tingkat akurasi yang bervariasi. Hal ini disebabkan karena cara pemilihan data latih dan data uji yang berbeda-beda. Perbedaan tingkat akurasi masing-masing ditunjukkan pada Tabel 10.
Keterangan Nilai Akurasi Iterasi 1 86,28%
Iterasi 2 96,08% Iterasi 3 97,92%
8 Tabel 10 Perbandingan Akurasi pada Data Iris
Percobaan Kelompok Data
Latih Akurasi
1
dengan nilai fitur terendah dan tertinggi
98,04%
2 secara acak 93,43%
3 dengan nilai
fitur terendah 72,55%
4 dengan nilai fitur
tertinggi 70,59%
5
tanpa nilai fitur terendah dan tertinggi
72,92%
Tabel 10 menunjukkan rata-rata akurasi menggunakan nilai fitur terendah dan tertinggi adalah yang tertinggi di antara lainnya yaitu sebesar 98,04%. Hal ini disebabkan oleh data uji tidak berada ujung selang yang bernilai nol (vote tidak sama dengan nol) sehingga didapatkan tingkat akurasi yang tinggi. Hasil ini berbeda jauh dengan pelatihan data iris secara acak yaitu sebesar 93,43%. Sebagai pembanding tambahan yaitu pelatihan dengan nilai fitur terendah, dengan nilai fitur tertinggi fitur, dan tanpa nilai fitur terendah dan tertinggi menunjukkan tingkat akurasi yang berbeda jauh yaitu masing-masing sebesar 72,55%, 70,59%, dan 72,92%. Hal ini disebabkan oleh adanya kasus-kasus yang berada pada ujung selang yang bernilai nol pada ketiga percobaan tersebut.
Pada penelitian data iris ini, perbandingan tingkat akurasi rata-rata dari hasil kelima percobaan digambarkan dalam Gambar 2.
Gambar 2 Perbandingan Akurasi pada Data Iris.
Pengolahan dan Tingkat Akurasi VFI5 dengan Data Wine
Kelompok data wine ini terdiri atas 178 kasus dengan 13 fitur dan mempunyai 3 kelas data.
1. Pengolahan Data Pelatihan Menggunakan Minimum dan Maksimum Fitur
a. Pemilihan Data
Proses ini dilakukan dengan metode yang sama seperti pada data iris yaitu menggunakan metode non random sampling dengan teknik
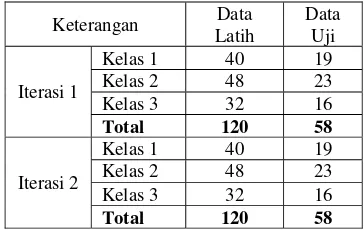
purposive sampling. Perbandingan yang digunakan adalah 2:1 yaitu dua untuk data latih dan satu untuk data uji. Data wine dibagi menjadi tiga kelas dengan kelas 1 berjumlah 59, kelas 2 berjumlah 71, dan kelas 3 berjumlah 48. Tiap kelas memiliki 13 fitur. Tiap-tiap kelas masing-masing fiturnya diambil 1 nilai terendah dan 1 nilai tertinggi sehingga diperoleh 13 nilai terendah dan 13 nilai tertinggi pada tiap kelasnya. Pembagian tersebut menghasilkan 39 nilai terendah dan 39 nilai tertinggi atau total 78 data yang memiliki nilai terendah dan tertinggi pada keseluruhan data wine. Data tersebut digunakan untuk proses pelatihan pada iterasi pertama. Sisanya adalah 100 data yang sebagian diikutkan sebagai data pelatihan dengan jumlah 42 data dan sebagian lagi sebagai data uji dengan jumlah 58 data. Secara keseluruhan data wine pada iterasi pertama terdiri dari 120 data pelatihan dan 58 data uji. Iterasi kedua dilakukan dengan menukar data pelatihan pada iterasi pertama yang tidak mengandung nilai fitur terendah dan tertinggi dengan data uji pada iterasi pertama. Pembagian data dapat dilihat pada Tabel 11.
Tabel 11 Pembagian Data Wine dengan Nilai Fitur Terendah dan Tertinggi
9 b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 11 dan Lampiran 12. Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 94,83% dan pada iterasi kedua sebesar 98,28%. Rata-rata tingkat akurasi adalah sebesar 96,56%. Hasil akurasi ditunjukkan dalam Tabel 12.
Tabel 12 Hasil Akurasi dengan Nilai Fitur Minimum dan Maksimum Data Wine
Keterangan Nilai Akurasi Iterasi 1 94,83% Iterasi 2 98,28%
Rata-rata 96,56%
2. Pengolahan Data Pelatihan Secara Acak
a. Pemilihan Data
Proses ini dilakukan dengan menggunakan metode 3-fold cross validation
dengan jumlah data keseluruhan 178 kasus. Terlebih dahulu data dibagi menjadi tiga himpunan. Jumlah masing-masing bagiannya hampir sama satu dengan lainnya. Pembagian tersebut menghasilkan bagian S1, S2, dan S3. Hasil pembagian data himpunan secara keseluruhan disajikan dalam Tabel 13.
Tabel 13 Hasil Pembagian Acak Data Wine
Himpunan S
Penelitian ini dilakukan dengan pelatihan dan pengujian data sebanyak tiga kali. Susunan data pelatihan dan data pengujian disajikan dalam Tabel 14.
Tabel 14 Susunan Data Pelatihan dan Data Pengujian Data Wine
Iterasi Pelatihan Pengujian 1 S2 dan S3 S1
2 S1 dan S3 S2 3 S1 dan S2 S3
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan secara acak menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 13, Lampiran 14, dan Lampiran 15.
Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 94.83%, pada iterasi kedua sebesar 93.33%, dan pada iterasi ketiga sebesar 95%. Rata-rata tingkat akurasi adalah sebesar 94,39%. Hasil akurasi ditunjukkan dalam Tabel 15.
Tabel 15 Hasil Akurasi dengan Nilai Acak Data Wine
Keterangan Nilai Akurasi Iterasi 1 94.83%
Iterasi 2 93.33% Iterasi 3 95%
Rata-rata 94,39%
3. Pengolahan Data Pelatihan Menggunakan Nilai Fitur Terendah.
a. Pemilihan Data
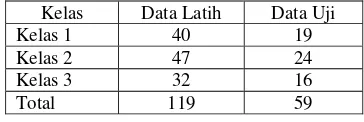
Data yang hanya memiliki nilai fitur terendah ditambah dengan data yang tidak memiliki nilai fitur terendah dan tertinggi dijadikan data latih, sedangkan data ujinya adalah data yang memiliki nilai fitur tertinggi ditambah sisa data yang tidak memiliki nilai fitur terendah dan tertinggi. Data yang dijadikan data latih dan data uji memiliki rasio 2:1, sehingga diperoleh 119 data latih dan 59 data uji. Hasil pembagian data dapat dilihat pada Tabel 16.
Tabel 16 Pembagian Data Wine dengan Nilai Fitur Terendah
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur terendah menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 16. Proses pengujian menghasilkan akurasi sebesar 89,83%.
4. Pemilihan Data Pelatihan Menggunakan Nilai Fitur Tertinggi
a. Pemilihan Data
10 Data yang dijadikan data latih dan data uji
memiliki rasio 2:1, sehingga diperoleh 119 data latih dan 59 data uji. Hasil pembagian data dapat dilihat pada Tabel 17.
Tabel 17 Pembagian Data Wine dengan Nilai Fitur Tertinggi
Kelas Data Latih Data Uji Kelas 1 40 19 Kelas 2 47 24 Kelas 3 32 16
Total 119 59
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 17. Proses pengujian menghasilkan akurasi sebesar 88,14%.
5. Pemilihan Data Pelatihan Tanpa Menggunakan Nilai Fitur Terendah dan Tertinggi
a. Pemilihan Data
Data yang tidak memiliki nilai fitur terendah dan tertinggi sejumlah 100 kasus digunakan sebagai data latih sedangan data uji adalah data yang memiliki nilai fitur terendah dan tertinggi sebanyak 78. Pembagian data ini dapat dilihat pada Tabel 18.
Tabel 18 Pembagian Data Wine dengan Tanpa Menggunakan Nilai Fitur Terendah dan Tertinggi
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan tanpa menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 18. Proses pengujian menghasilkan akurasi sebesar 89,74%.
6. Analisis dan Perbandingan Akurasi pada Data Wine
Pelatihan dan pengujian data wine
menunjukkan tingkat akurasi yang bervariasi. Hal ini disebabkan oleh cara pemilihan data latih dan data uji yang berbeda-beda. Perbedaan tingkat akurasi masing-masing ditunjukkan pada Tabel 19.
Tabel 19 Perbandingan Akurasi pada Data Wine
Percobaan Kelompok Data
Latih Akurasi
1
dengan nilai fitur terendah dan tertinggi
96,56%
2 secara acak 94,39%
3 dengan nilai
fitur terendah 89,83%
4 dengan nilai fitur
tertinggi 88,14%
5
tanpa nilai fitur terendah dan tertinggi
89,74%
Tabel 19 menunjukkan rata-rata akurasi menggunakan nilai fitur terendah dan tertinggi adalah yang tertinggi di antara lainnya yaitu sebesar 96,56%. Hal ini disebabkan oleh data uji yang tidak berada di ujung selang yang bernilai nol (vote tidak sama dengan nol). Hasil ini tidak berbeda jauh dengan tingkat akurasi pada pelatihan data wine secara acak yaitu sebesar 94,39%. Walaupun tidak berbeda jauh, pelatihan menggunakan nilai fitur terendah dan tertinggi menunjukkan angka yang lebih tinggi dibandingkan pada pelatihan data wine secara acak. Sebagai pembanding tambahan yaitu pelatihan dengan nilai fitur terendah, dengan nilai fitur tertinggi, dan tanpa nilai fitur terendah dan tertinggi menunjukkan tingkat akurasi yang lebih rendah yaitu masing-masing sebesar 89,83%, 88,14%, dan 89,74%. Tingkat akurasi tersebut masih dibilang tinggi karena hampir mendekati 90%. Hal ini disebabkan oleh sedikitnya pengaruh nilai nol di ujung selang pada ketiga percobaan tersebut terhadap tingkat akurasi data wine. Sedikitnya pengaruh tersebut dimungkinkan karena nilai fitur tiap kelas berbeda-beda di mana terdapat range nilai yang jauh antar kelas sehingga memengaruhi rataan nilai dari ketiga kelas.
11 Gambar 3 Perbandingan Akurasi pada Data
Wine.
Pengolahan dan Tingkat Akurasi VFI5 dengan Data Ikan Koi
Kelompok data ikan koi ini terdiri atas 119 kasus dengan 13 fitur dan mempunyai 2 kelas data.
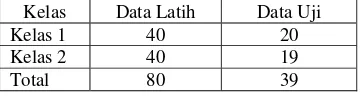
1. Pengolahan Data Pelatihan Menggunakan Nilai Fitur Terendah dan Tertinggi
a. Pemilihan Data
Proses ini dilakukan dengan menggunakan metode seperti pada iris dan
wine. Data ikan koi dibagi menjadi 2 kelas yang tiap kelasnya terdiri atas 60 kasus dan 59 kasus dengan 13 fitur. Tiap-tiap kelas masing-masing fiturnya diambil 1 nilai terendah dan 1 nilai tertinggi sehingga diperoleh 13 nilai terendah dan 13 nilai tertinggi pada tiap kelasnya. Pembagian tersebut menghasilkan 26 nilai terendah dan 26 nilai maksimum atau total 52 data yang memiliki nilai terendah nilai dan tertinggi pada keseluruhan data ikan koi. Data tersebut digunakan untuk proses pelatihan pada iterasi pertama. Sisanya adalah 67 data yang sebagian diikutkan sebagai data pelatihan dengan jumlah 28 data dan sebagian lagi sebagai data uji dengan jumlah 39 data. Secara keseluruhan data ikan koi pada iterasi pertama terdiri dari 80 data pelatihan dan 39 data uji. Iterasi kedua dilakukan dengan menukar data pelatihan pada iterasi pertama yang tidak mengandung nilai fitur terendah dan tertinggi dengan data uji pada iterasi pertama. Pembagian data dapat dilihat pada Tabel 20.
Tabel 20 Pembagian Data Ikan Koi dengan Nilai Fitur Terendah dan Tertinggi
Keterangan Data Latih Data Uji
Iterasi 1
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 19 dan Lampiran 20. Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 100% dan pada iterasi kedua sebesar 100%. Rata-rata tingkat akurasi adalah sebesar 100%. Hasil akurasi ditunjukkan dalam Tabel 21.
Tabel 21 Hasil Akurasi dengan Nilai Fitur Terendah dan Tertinggi Data Ikan Koi
Keterangan Nilai Akurasi Iterasi 1 100% Iterasi 2 100%
Rata-rata 100%
2. Pengolahan Data Pelatihan Secara Acak
a. Pemilihan Data
Proses ini dilakukan dengan menggunakan metode 3-fold cross validation
dengan jumlah data keseluruhan 119 kasus. Terlebih dahulu data dibagi menjadi tiga himpunan. Jumlah masing-masing bagiannya hampir sama satu dengan lainnya. Pembagian tersebut menghasilkan bagian S1, S2, dan S3. Hasil pembagian data himpunan secara keseluruhan disajikan dalam Tabel 22.
Tabel 22 Hasil Pembagian Acak Data Ikan Koi
12 Tabel 23 Susunan Data Pelatihan dan Data
Pengujian Data Koi
Iterasi Pelatihan Pengujian 1 S2 dan S3 S1
2 S1 dan S3 S2 3 S1 dan S2 S3
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan secara acak menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 21, Lampiran 22, dan Lampiran 23. Proses pengujian menghasilkan akurasi pada iterasi pertama sebesar 97,44%, pada iterasi kedua sebesar 95%, dan iterasi ketiga sebesar 95%. Rata-rata tingkat akurasi adalah sebesar 95,81%. Hasil akurasi ditunjukkan dalam Tabel 24.
Tabel 24 Hasil Akurasi dengan Nilai Acak Data Ikan Koi
3. Pengolahan Data Pelatihan Menggunakan Nilai Fitur Terendah.
a. Pemilihan Data
Data yang hanya memiliki nilai fitur terendah ditambah dengan data yang tidak memiliki nilai fitur terendah dan tertinggi dijadikan data latih, sedangkan data ujinya adalah data yang memiliki nilai fitur tertinggi ditambah sisa data yang tidak memiliki minimum dan maksimum fitur. Data yang dijadikan data latih dan data uji memiliki rasio 2:1, sehingga diperoleh 80 data latih dan 39 data uji. Hasil pembagian data dapat dilihat pada Tabel 25.
Tabel 25 Pembagian Data Ikan Koi dengan Nilai Fitur Terendah
Kelas Data Latih Data Uji Kelas 1 40 20 Kelas 2 40 19
Total 80 39
b. Proses Pelatihan dan Klasifikasi
Hasil Hasil pelatihan menggunakan nilai fitur terendah menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 24. Proses
pengujian menghasilkan akurasi sebesar 92,31%.
4. Pemilihan Data Pelatihan Menggunakan Nilai Fitur Tertinggi
a. Pemilihan Data
Data yang hanya memiliki nilai fitur tertinggi ditambah dengan data yang tidak memiliki nilai fitur terendah dan tertinggi dijadikan data latih, sedangkan data ujinya adalah data yang memiliki nilai fitur terendah ditambah sisa data yang tidak memiliki nilai fitur terendah dan tertinggi. Data yang dijadikan data latih dan data uji memiliki rasio 2:1, sehingga diperoleh 80 data latih dan 39 data uji. Hasil pembagian data dapat dilihat pada Tabel 26.
Tabel 26 Pembagian Data Ikan Koi dengan Nilai Fitur Tertinggi
Kelas Data Latih Data Uji Kelas 1 40 20 Kelas 2 40 19
Total 80 39
b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan menggunakan nilai fitur tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 25. Proses pengujian menghasilkan akurasi sebesar 74,36%.
5. Pemilihan Data Pelatihan Tanpa Menggunakan Nilai Fitur Terendah dan Tertinggi
a. Pemilihan Data
Data yang tidak memiliki nilai fitur terendah dan tertinggi sejumlah 67 kasus digunakan sebagai data latih sedangkan data uji adalah data yang memiliki nilai fitur terendah dan tertinggi sebanyak 52. Pembagian data ini dapat dilihat pada Tabel 27.
Tabel 27 Pembagian Data Ikan Koi Tanpa Menggunakan Nilai Fitur Terendah dan Tertinggi
Kelas Data Latih Data Uji Kelas 1 34 26 Kelas 2 33 26
Total 67 52
Keterangan Nilai Akurasi
Iterasi 1 97,44% Iterasi 2 95% Iterasi 3 95%
13 b. Proses Pelatihan dan Klasifikasi
Hasil pelatihan tanpa menggunakan nilai fitur terendah dan tertinggi menghasilkan normalisasi akhir yang dapat dilihat pada Lampiran 26. Proses pengujian menghasilkan akurasi sebesar 61,54%.
6. Analisis dan Perbandingan Akurasi pada Data Ikan Koi
Pelatihan dan Pengujian data ikan koi menunjukkan tingkat akurasi yang bervariasi. Hal ini disebabkan karena cara pemilihan data latih dan data uji yang berbeda-beda. Perbedaan tingkat akurasi masing-masing ditunjukkan pada Tabel 28.
Tabel 28 Perbandingan Akurasi pada Data Ikan Koi
Percobaan Kelompok Data
Latih Akurasi
1
dengan nilai fitur terendah dan tertinggi
100%
2 secara acak 95,81%
3 dengan nilai
fitur terendah 92,31%
4 dengan nilai fitur
tertinggi 74,36 %
5
tanpa nilai fitur terendah dan tertinggi
61,54 %
Tabel 27 menunjukkan rata-rata akurasi menggunakan nilai nilai fitur terendah dan tertinggi adalah yang tertinggi diantara lainnya yaitu sebesar 100%. Hal ini disebabkan oleh data uji tidak berada di ujung selang yang bernilai nol (vote tidak sama dengan nol) sehingga didapatkan tingkat akurasi yang tinggi. Hasil ini jauh lebih tinggi dibandingkan tingkat akurasi pada pelatihan data iris secara acak yaitu sebesar 95,81%. Sebagai pembanding tambahan yaitu pelatihan dengan nilai fitur terendah, dengan nilai fitur tertinggi, dan tanpa nilai fitur terendah dan tertinggi menunjukkan tingkat akurasi yang berbeda jauh yaitu masing-masing sebesar 92,31%, 74,36%, dan 61,54%. Saat pelatihan dengan menggunakan nilai fitur terendah, tingkat akurasi terbilang tinggi. Hal ini dilihat pada tingkat akurasi di atas 90% yang disebabkan oleh sedikitnya pengaruh nilai nol pada ujung selang sterhadap tingkat akurasi dari data ikan koi. Berbeda dengan kedua percobaan terakhir, nilai nol pada ujung selang sangat berpengaruh sehingga mengakibatkan tingkat akurasi yang rendah.
Pada penelitian data ikan koi ini, perbandingan tingkat akurasi rata-rata dari hasil kelima percobaan digambarkan dalam Gambar 4.
Gambar 4 Perbandingan Akurasi pada Data Ikan Koi.
KESIMPULAN DAN SARAN Kesimpulan
Dari ketiga data yang digunakan pada kinerja algoritme VFI 5 dengan pemilihan data latih menggunakan nilai fitur terendah dan tertinggi dengan data iris dihasilkan akurasi lebih tinggi dari metode yang lain yaitu 98,04%, sedangkan pada data wine
dihasilkan akurasi sebesar 96,56%. Pada data jenis kelamin ikan koi akurasi yang diperoleh sangat tinggi yaitu mencapai 100%.
Jika dilihat dari hasil ketiga pengujian tersebut, penelitian ini memerlihatkan bahwa algoritme VFI 5 dengan metode pemilihan data menggunakan nilai fitur terendah dan tertinggi mampu meningkatkan kinerja dari algoritme VFI 5.
Saran
14 DAFTAR PUSTAKA
Demiröz G. 1997. Non-Incremental Classification Learning Algorithms Based on Voting Feature Intervals.
http://www.cs.bilkent.edu.tr/tech-reports/1997/BU-CEIS-9715.pdf
[16 Agustus 2008].
Demiroz G, Guvenir HA. 1997. Classification by Voting Feature Intervals.
http://www.cs.bilkent.edu.tr /tech-reports/1997/BU-CEIS-9708.ps.gz.
[16 Agustus 2008].
Güvenir HA. 1998. A Classification Learning Algorithm Robust to Irrelevant
Features.
http://www.cs.bilkent.edu.tr/tech-report/1998/BU-CEIS-9810.pdf
[16 Agustus 2008].
Han J, Kamber M. 2001. Data Mining Concepts &Techniques. USA: Academic Press.
McLennan W. 1998. Statistics - A Power Edge! Second Edition. Canberra: Australian Bureau of Statistics.
Nasution R. 2003. Teknik Sampling. library.usu.ac.id/download/fkm/fkm-rozaini.pdf [17 Desember 2009].
Sarle W. 2004. What are cross-validation and bootstrapping?.