PENERAPAN SYNTHETIC MINORITY OVERSAMPLING
TECHNIQUE (SMOTE) TERHADAP DATA TIDAK SEIMBANG
PADA PEMBUATAN MODEL KOMPOSISI JAMU
ROSSI AZMATUL BARRO
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan Synthetic Minority Oversampling Technique (SMOTE) terhadap Data Tidak Seimbang pada Pembuatan Model Komposisi Jamu adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, September 2013
Rossi Azmatul Barro
ABSTRAK
ROSSI AZMATUL BARRO. Penerapan Synthetic Minority Oversampling Technique (SMOTE) terhadap Data Tidak Seimbang pada Pembuatan Model Komposisi Jamu. Dibimbing oleh ITASIA DINA SULVIANTI dan FARIT MOCHAMAD AFENDI.
Seiring perkembangan zaman banyak orang menggunakan obat herbal (jamu) untuk mengatasi masalah kesehatan. Jamu dibuat dari tanaman-tanaman dengan komposisi tertentu untuk menghasilkan khasiat tertentu, sehingga diperlukan model komposisi yang tepat untuk membuat jamu dengan khasiat tertentu. Pada penelitian ini yang diteliti sebagai respon adalah jamu yang berkhasiat dalam mengatasi gangguan suasana hati dan perilaku. Model dibangun dengan menggunakan regresi logistik. Tingkat akurasi model dapat dilihat dari
Area Under Curve (AUC). Amatan pada masing-masing kategori peubah respon yang tidak seimbang dapat menyebabkan nilai AUC rendah. Salah satu cara mengatasi data tidak seimbang adalah dengan menggunakan Synthetic Minority Oversampling Technique (SMOTE). Dari penelitian ini diperoleh nilai R2 Nagelkerke yang dihasilkan model dengan SMOTE lebih rendah 3.2% dibanding dengan R2 Nagelkerke yang dihasilkan model tanpa SMOTE. Meskipun demikian, model dengan SMOTE lebih akurat karena nilai AUC yang dihasilkan lebih tinggi daripada model tanpa SMOTE. Model dengan SMOTE memiliki nilai AUC sebesar 0.976 sedangkan model tanpa SMOTE memiliki nilai AUC sebesar 0.908. Hasil tersebut menunjukkan bahwa SMOTE dapat menaikkan tingkat akurasi model pada data tidak seimbang.
Kata kunci: data tidak seimbang, regresi logistik, SMOTE
ABSTRACT
ROSSI AZMATUL BARRO. Application of Synthetic Minority Oversampling Technique (SMOTE) toward Imbalanced Data on Jamu Ingredient Model. Supervised by ITASIA DINA SULVIANTI dan FARIT MOCHAMAD AFENDI.
the model with SMOTE and 0.908 for model without SMOTE. The results show that SMOTE can increase the accuracy of the model for imbalanced data.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
PENERAPAN SYNTHETIC MINORITY OVERSAMPLING
TECHNIQUE (SMOTE) TERHADAP DATA TIDAK SEIMBANG
PADA PEMBUATAN MODEL KOMPOSISI JAMU
ROSSI AZMATUL BARRO
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Penerapan Synthetic Minority Oversampling Technique (SMOTE) terhadap Data Tidak Seimbang pada Pembuatan Model Komposisi Jamu
Nama : Rossi Azmatul Barro NIM : G14090075
Disetujui oleh
Dra Itasia Dina Sulvianti, MSi Pembimbing I
Dr Farit Mochamad Afendi, MSi Pembimbing II
Diketahui oleh
Dr Ir Hari Wijayanto, MSi Ketua Departemen
PRAKATA
Puji syukur kehadirat Allah SWT yang telah memberikan segala karunia-Nya sehingga karya tulis yang berjudul “Penerapan Synthetic Minority Oversampling Technique (SMOTE) terhadap Data Tidak Seimbang pada
Pembuatan Model Komposisi Jamu” dapat terselesaikan. Penulis menyadari
bahwa karya tulis ini tidak lepas dari bantuan dan dukungan pihak lain. Oleh karena itu, penulis mengucapkan terima kasih kepada : Ibu Dra Itasia Dina Sulvianti, MSi dan Bapak Dr Farit Mochamad Afendi, MSi selaku dosen pembimbing yang telah menuntun penulis selama penulisan karya tulis ini, abi dan umi serta saudara-saudara yang telah memberi doa dan dukungannya, para dosen statistika yang turut memberi ilmu dan masukan, staf departemen yang turut membantu dalam administrasi, teman-teman statistika dan kosan yang selalu setia memberi dukungan selama penulisan karya tulis ini. Segala sesuatu memiliki kekurangan, begitu pula dengan karya ini sehingga diharapkan masukan dan kritik untuk perbaikan di masa yang akan datang.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan 1
TINJAUAN PUSTAKA 2
SMOTE (Synthetic Minority Oversampling Technique) 2
Analisis Regresi Logistik 3
Evaluasi Model 4
METODOLOGI 4
Data 4
Metode 5
HASIL DAN PEMBAHASAN 5
Deskripsi Tanaman Komposisi Jamu dan Khasiatnya 5
Model Tanpa SMOTE 7
Model dengan SMOTE 8
Perbandingan Model 9
SIMPULAN 10
DAFTAR PUSTAKA 10
LAMPIRAN 11
DAFTAR TABEL
1 Kesesuaian klasifikasi 4
2 Hasil signifikansi model tanpa SMOTE 7
3 Ketepatan klasifikasi model tanpa SMOTE 8
4 Hasil signifikansi model dengan SMOTE 9
5 Ketepatan klasifikasi model dengan SMOTE 9
6 Perbandingan model 10
DAFTAR GAMBAR
1 Persentase jamu berdasarkan banyaknya tanaman pada jamu yang berkhasiat dalam mengatasi gangguan suasana hati dan perilaku 6 2 Banyaknya tanaman pada jamu yang berkhasiat dalam mengatasi
gangguan pencernaan 6
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Peningkatan aktivitas yang tidak diimbangi dengan asupan gizi yang cukup akan menyebabkan tubuh lebih mudah terserang penyakit. Perkembangan zaman juga membuat banyak orang mudah mengalami stres atau suasana hati yang tidak baik. Untuk mengurangi risiko terserang penyakit maupun suasana hati yang tidak baik, beberapa orang memilih untuk mengkonsumsi obat dan tidak sedikit yang memilih jamu. Jamu dipilih karena dianggap alami dan tidak memiliki efek samping yang berbahaya.
Badan Pengawas Obat dan Makanan (BPOM) menyatakan bahwa jamu adalah obat tradisional Indonesia. Obat tradisional adalah bahan atau ramuan yang berupa bahan tumbuhan, bahan hewan, bahan mineral, sediaan sarian (galenik) atau campuran dari bahan tersebut, yang secara turun-temurun telah digunakan untuk pengobatan berdasarkan pengalaman. Hal tersebut tercantum pada Pasal 1 Peraturan Kepala Badan POM No. HK.00.05.4.1384 Tahun 2005. Sebagian besar jamu dibuat menggunakan berbagai macam tanaman dengan khasiat yang bermacam-macam. Oleh karena itu, diperlukan model agar ditemukan formulasi yang pas untuk membuat jamu dengan khasiat tertentu. Pada penelitian ini khasiat yang diteliti sebagai respon model adalah adanya khasiat dalam mengatasi gangguan suasana hati dan perilaku.
Penelitian ini menggunakan model yang dibangun dengan regresi logistik. Metode tersebut cocok digunakan karena respon yang diamati berskala kategorik. Salah satu hal yang perlu diperhatikan dalam evaluasi model adalah tingkat akurasi sebuah model dalam memprediksi respon dengan benar. Kebaikan model dipengaruhi salah satunya oleh adanya keseimbangan antara kelas mayor dengan kelas minor. Kelas mayor adalah data yang ukuran kelasnya (jumlah amatan) lebih besar dari kelas minor berdasarkan peubah respon. Jika data yang digunakan untuk membuat model tidak seimbang maka akan meningkatkan salah klasifikasi kelas minor. Oleh karena itu, salah satu alternatif untuk meningkatkan akurasi model adalah melakukan Synthetic Minority Oversampling Technique (SMOTE) pada praposes.
Tujuan
2
TINJAUAN PUSTAKA
SMOTE (Synthetic Minority Oversampling Technique)
Ketidakseimbangan data terjadi jika jumlah objek suatu kelas data lebih banyak dibandingkan dengan kelas lain. Kelas data yang objeknya lebih banyak disebut kelas mayor sedangkan lainnya disebut kelas minor. Pengaruh penggunaan data tidak seimbang untuk membuat model sangat besar pada hasil model yang diperoleh. Pengolahan algoritma yang tidak menghiraukan ketidakseimbangan data akan cenderung diliputi oleh kelas mayor dan mengacuhkan kelas minor (Chawla et al 2004).
Chawla et al (2002) mengusulkan metode SMOTE sebagai salah satu solusi dalam menangani data tidak seimbang yang berbeda dengan metode oversampling
sebelumnya yaitu menduplikat data secara acak. Metode SMOTE menambah jumlah data kelas minor agar setara dengan kelas mayor dengan cara membangkitkan data buatan. Data buatan atau sintesis tersebut dibuat berdasarkan
k-tetangga terdekat (k-nearest neighbor). Jumlah k-tetangga terdekat ditentukan dengan mempertimbangkan kemudahan dalam melaksanakannya. Pembangkitan data buatan yang berskala numerik berbeda dengan kategorik. Data numerik diukur jarak kedekatannya dengan jarak Euclidean sedangkan data kategorik lebih sederhana yaitu dengan nilai modus. Perhitungan jarak antar contoh kelas minor yang peubahnya berskala kategorik dilakukan dengan rumus Value Difference Metric (VDM) yaitu (Cost dan Salzberg 1993):
y∑ i yi r
r : bernilai 1 (jarak Manhattan) atau 2 (jarak Euclidean)
3 Prosedur pembangkitan data buatan untuk :
1. Data Numerik
a. Hitung perbedaan antar vektor utama dengan k-tetangga terdekatnya. b. Kalikan perbedaan dengan angka yang diacak di antara 0 dan 1.
c. Tambahkan perbedaan tersebut ke dalam nilai utama pada vektor utama asal sehingga diperoleh vektor utama baru.
2. Data Kategorik
a. Pilih mayoritas antara vektor utama yang dipertimbangkan dengan k -tetangga terdekatnya untuk nilai nominal. Jika terjadi nilai sama maka pilih secara acak.
b. Jadikan nilai tersebut data contoh kelas buatan baru. Analisis Regresi Logistik
Analisis ini dapat mengetahui hubungan antar respon dengan satu atau lebih peubah penjelas. Tujuan penggunaan regresi logistik sama halnya dengan teknik membangun model dalam statistika (Hosmer dan Lemeshow 2000). Regresi logistik dapat juga disebut model logit karena fungsi transformasinya menggunakan logit. Untuk respon biner peubah Y dan peubah penjelas X, maka
π P | - P(Y=0|X=x). Model regresi logistik adalah
π
yang setara dengan log odd, disebut logit, yaitu
logit[π ] -
Hosmer dan Lemeshow (2000) menyatakan bahwa metode umum pendugaan parameter regresi logistik adalah metode kemungkinan maksimum. Untuk menerapkan metode ini, yang pertama harus dilakukan adalah membentuk fungsi kemungkinan:
l β ∏ -
-Prinsip dari metode kemungkinan maksimum adalah dengan memaksimumkan fungsi kemungkinan yang secara matematis lebih mudah dengan memaksimumkan logaritma fungsi kemungkinan:
L β ln[l β ] ∑ { ( - ) - }
untuk mendapatkan nilai dugaan koefisien regresi logistik ( ) dilakukan dengan
penurunan L β terhadap β dan disamakan dengan nol.
Kesesuaian model digunakan untuk mengetahui peubah penjelas yang
berpengaruh nyata terhadap respon. Pengujian parameter β secara bersama dengan
uji-G yaitu uji nisbah kemungkinan. Uji-G untuk pengujian parameter βj dengan hipotesis :
H0 : β1 β2 ... βp = 0
H1 : minimal salah satu βi 0, dengan i=1, 2,...p Statistik uji untuk uji G adalah :
G = -2ln
Jika H0 benar, statistik G akan berdistribusi 2 dengan derajat bebas p. Oleh karena itu, jika H0 ditolak, maka selanjutnya dilakukan uji Wald untuk menguji
4
H0: βj = 0
H1 : βj 0, dengan j=1, 2,...p
Uji Wald dihitung dengan membandingkan pendugaan slope parameter maksimum kemungkinan dengan dugaan standar erornya, sebagai berikut :
W =
̂
Evaluasi Model
Area Under Curve (AUC)
AUC adalah luas di bawah kurva yang dalam hal ini merupakan kurva
Receiver Operating Characteristic (ROC). Menurut Fawcett (2006) bahwa kurva ROC menggambarkan performa pengklasifikasi secara dua dimensi. Kurva tersebut adalah plot peluang salah negatif (1-spesifitas) dengan prediksi benar positif (sensitifitas). Nilai sensitifitas dan spesifitas dapat dilihat pada Tabel 1. Jika ingin membandingkan beberapan performa pengklasifikasi maka ROC dapat diubah ke dalam bentuk skalar salah satunya menjadi AUC. AUC adalah suatu bagian dari daerah satuan persegi yang nilainya antara 0 hingga 1. Nilai AUC semakin mendekati satu maka akurasi model atau klasifikasi semakin tinggi. AUC dapat dihubungkan dengan koefisien Gini dengan persamaan Gini + 1 = 2 x AUC.
Tabel 1 Kesesuaian klasifikasi
R2 Nagelkerke mengukur tingkat keragaman respon yang dapat dijelaskan model dalam regresi logistik (Nagelkerke 1991). Rumus yang digunakan yaitu
R2=1-(
METODOLOGI
Data
5 dengan kategori (1) jamu berkhasiat dalam mengatasi gangguan suasana hati dan perilaku dan kategori (0) jamu berkhasiat dalam mengatasi gangguan pencernaan. Seluruh peubah penjelas bersifat kategorik dengan dua kategori yaitu tanaman komposisi jamu dan bukan tanaman komposisi jamu. Terdapat 22 jamu atau sekitar 2.2% jamu yang memiliki khasiat dalam mengatasi gangguan suasana hati dan perilaku sedangkan 980 jamu sisanya tidak memiliki khasiat tersebut. Penelitian ini lebih memfokuskan pada model dalam memprediksi khasiat jamu untuk mengatasi gangguan suasana hati dan perilaku.
Metode
Tahapan metode yang dilakukan adalah:
1. Melakukan deskripsi data untuk mengetahui gambaran umum data jamu yang diperoleh melalui diagram lingkaran dan batang.
2. Membangun model dengan regresi logistik dengan mencari nilai dugaan parameternya.
3. Melakukan pengujian parameter.
4. Mengevaluasi model dengan melihat nilai AUC dan R2 Nagelkerke. 5. Melakukan SMOTE pada tahap praproses data jamu, yaitu:
a. Menghitung jarak antar amatan pada kelas minor menggunakan rumus VDM.
b. Menentukan nilai k yaitu 5 dan persentase oversampling sebesar 4200%.
c. Dipilih satu contoh dari kelas minor secara acak.
d. Menentukan amatan k tetangga terdekat dengan mengurut jarak contoh terpilih dengan semua amatan pada kelas minor.
e. Data sintesis dibuat dengan menentukan nilai per peubah penjelasnya. Nilai tersebut diperoleh dari mayoritas nilai pada k tetangga terdekat. Jika semua peubah telah dibuat maka diperoleh satu amatan baru.
f. Langkah c hingga e dilakukan berulang hingga banyaknya
oversampling yang diinginkan telah tercapai.
6. Membangun model dengan data yang telah melalui tahap SMOTE. 7. Menguji parameternya.
8. Mengevaluasi tingkat akurasi model.
9. Membandingkan hasil model yang dihasilkan tanpa SMOTE dan dengan SMOTE dari AUC dan R2 Nagelkerkemasing-masing model.
HASIL DAN PEMBAHASAN
Deskripsi Tanaman Komposisi Jamu dan Khasiatnya
6
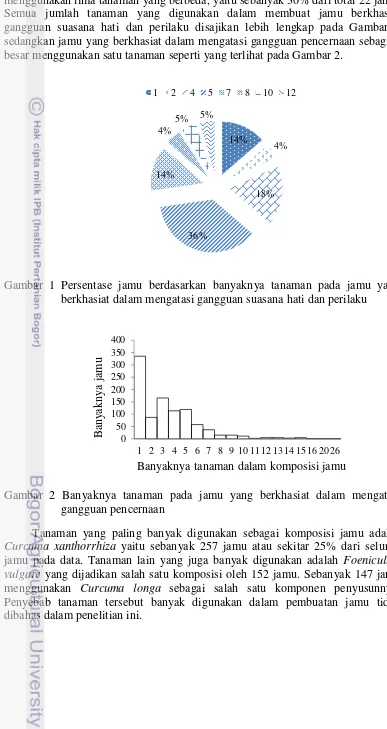
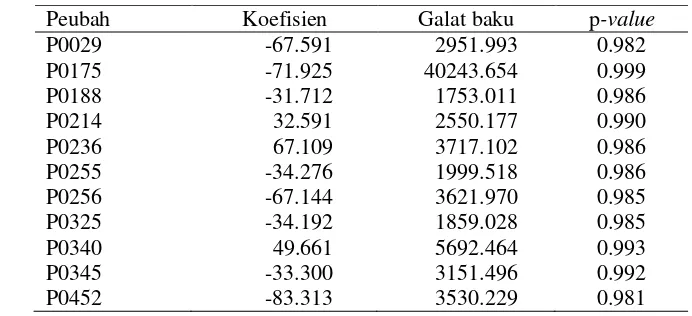
Mayoritas jamu yang berkhasiat dalam mengatasi gangguan suasana hati menggunakan lima tanaman yang berbeda, yaitu sebanyak 36% dari total 22 jamu. Semua jumlah tanaman yang digunakan dalam membuat jamu berkhasiat gangguan suasana hati dan perilaku disajikan lebih lengkap pada Gambar 1 sedangkan jamu yang berkhasiat dalam mengatasi gangguan pencernaan sebagian besar menggunakan satu tanaman seperti yang terlihat pada Gambar 2.
Gambar 1 Persentase jamu berdasarkan banyaknya tanaman pada jamu yang berkhasiat dalam mengatasi gangguan suasana hati dan perilaku
Gambar 2 Banyaknya tanaman pada jamu yang berkhasiat dalam mengatasi gangguan pencernaan
Tanaman yang paling banyak digunakan sebagai komposisi jamu adalah
7 Model Tanpa SMOTE
Regresi logistik dapat digunakan untuk membuat model menurut Hosmer dan Lemeshow (2002). Metode tersebut diterapkan pada data jamu dengan respon biner yaitu khasiat jamu untuk mengatasi gangguan pencernaan (0) dan untuk mengatasi gangguan suasana hati dan perilaku (1). Data dibagi menjadi dua yaitu data pemodelan sebesar 70% (701 amatan) dan data prediksi sebesar 30% (301 amatan). Dugaan parameter yang dihasilkan dengan memaksimumkan fungsi kemungkinan diuji secara bersama menggunakan uji G. Hasil uji G menunjukkan p-value bernilai 0.0 yang artinya ada parameter beta yang berpengaruh nyata terhadap model.
Pengujian dilanjutkan dengan uji parsial menggunakan uji Wald yang sebelumnya dilakukan pereduksian peubah menggunakan forward stepwise. Hasil yang diperoleh dapat dilihat pada tabel yang menunjukkan tidak ada tanaman yang berpengaruh nyata pada model. Hal tersebut terlihat pada p-value peubah penjelas yang lebih dari taraf nyata yaitu 5%. Pada penelitian ini terjadi ketidakkonsistenan antara uji bersama dan uji parsial. Uji bersama menunjukkan bahwa terdapat peubah yang signifikan pada taraf nyata 5%. Akan tetapi, setelah dilakukan uji parsial tidak ditemukan tanaman yang berpengaruh pada taraf nyata 5%. Hal ini disebabkan galat baku yang dihasilkan pada dugaan parameter sangat tinggi yang dapat dilihat pada Tabel 2. Peubah yang tercantum pada Tabel 2 merupakan kode peubah penjelas tanaman sebagaimana yang terlampir pada Lampiran 1 dan tidak menunjukkan apa pun kecuali untuk mempermudah penyebutan peubah.
Tabel 2 Hasil signifikansi model tanpa SMOTE Peubah Koefisien Galat baku p-value
P0029 -67.591 2951.993 0.982
8
98.3%. Ketepatan prediksi berimplikasi pada akurasi model yang ditunjukkan oleh nilai AUC. Nilai AUC model tanpa SMOTE adalah 0.908.
Tabel 3 Ketepatan klasifikasi model tanpa SMOTE
Observasi
persentase keseluruhan 99.9 98.3
Model dengan SMOTE
Persentase awal jumlah amatan pada kelas minor sebesar 2% ditambahkan data buatan melalui tahap SMOTE sehingga persentasenya menjadi sekitar 50% jumlah amatan. Hal tersebut diperoleh dari oversampling sebanyak 4200% sehingga jumlah kelas minor menjadi 946 amatan. Jumlah amatan menjadi 1926 setelah melalui tahap SMOTE. Data tersebut kemudian dibagi menjadi data pemodelan dan data prediksi. Data pemodelan yang digunakan merupakan data asli dan data buatan hasil SMOTE sedangkan data prediksi pada model tanpa SMOTE sama dengan data prediksi pada model dengan SMOTE.
Reduksi peubah penjelas dengan forward stepwise dilakukan sebelum menduga parameter. Kemudian dugaan parameter dilakukan dengan memaksimumkan fungsi kemungkinan. Pengujian dugaan parameter secara simultan menggunakan uji G diperoleh p-value 0.0 yang artinya ada tanaman yang berpengaruh nyata terhadap model. Setelah itu, dilakukan uji parsial (uji Wald) yang menghasilkan peubah-peubah yang berpengaruh nyata terhadap model. Terdapat 17 tanaman yang berpengaruh nyata pada model komposisi jamu yang berkhasiat dalam mengatasi gangguan suasana hati dan perilaku karena memiliki p-value kurang dari taraf nyata (0.05). Tanaman tersebut terdapat pada peubah dalam Tabel 4. Peubah tersebut merupakan kode tanaman untuk mempermudah penyebutan peubah dan daftar kode tersebut dapat dilihat pada Lampiran 1.
9 Tabel 4 Hasil signifikansi model dengan SMOTE
Peubah Koefisien Galat baku p-value
P0001 -2.289 0.549 0.000
Tabel 5 Ketepatan klasifikasi model dengan SMOTE
Observasi
10
Tabel 6 Perbandingan model
Model
Kriteria Tanpa SMOTE Dengan SMOTE
R2 Nagelkerke 98.3% 95.1%
Sensitifitas (true positive rate) 57.1% 85.7% Spesifitas (true negative rate) 99.3% 96.9%
AUC 0.908 0.976
SIMPULAN
Ukuran kebaikan model ditunjukkan oleh nilai R2 Nagelkerke. Nilai R2 Nagelkerke yang dihasilkan model dengan SMOTE lebih rendah 3.2% dibandingkan dengan R2 Nagelkerke yang dihasilkan model tanpa SMOTE. Meskipun demikian, model dengan SMOTE lebih akurat karena nilai AUC yang dihasilkan lebih tinggi daripada model tanpa SMOTE. Model dengan SMOTE memiliki nilai AUC sebesar 0.976 sedangkan model tanpa SMOTE memiliki nilai AUC sebesar 0.908. Hasil tersebut menunjukkan bahwa SMOTE dapat menaikkan tingkat akurasi model pada data tidak seimbang.
DAFTAR PUSTAKA
Chawla VN, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic Minority Over-Sampling Technique. Journal of Artificial Intelligence Research [Internet]. [diunduh 2013 Mei 31]; 16:321-357. Tersedia pada: http://arxiv.org/pdf/1106.1813.pdf.
Cost S, Salzberg S. 1993. A weighted Nearest Neighbor Algorithm for Learning with Symbolic Features. Machine Learning [Internet]. [diunduh pada 2013 Juli 17] 10:57-58. Boston (US) : Kluwer Academic Publisher. Tersedia pada :http://parati.dca.fee.unicamp.br/media/Attachments/courseIA368Q1S 2012/Monografia/cost_1993.pdf.
Fawcett Tom. 2006. An introduction to ROC analysis. Pattern Recognition Letter
[Internet]. [diunduh pada 2013 September 6] 27:861-874. Tersedia pada: https://ccrma.stanford.edu/workshops/mir2009/references/ROCintro.pdf Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression Second Edition.
New Jersey (US): John Wiley dan Sons.
11 Lampiran 1 Daftar peubah penjelas
Kode peubah Peubah (Nama latin tanaman) Kode peubah Peubah (Nama latin tanaman)
P1 Foeniculum vulgare P237 Phoenix dactylifera
P2 Clausena anisum-olens P238 Brucea javanica
P4 Glycyrrhiza uralensis P240 Sechium edule
P5 Acacia sieberiana P241 Piper nigrum
P6 Imperata cylindrica P242 Piperis Albi
P9 Cichorium intybus P243 Ocimum sanctum
P10 Vitis vinifera P244 Alpinia galanga
P11 Pterocarpus indica P245 Vetiveria zizanioides
P12 Artemisia annua P246 Gentiana macrophylla
P14 Malus domestica P247 Lavandula angustifolia
P15 Persia americana P248 Litchi chinensis
P18 Clematis armandii P249 Ledebouriella divaricata
P19 Cynara scolimus P251 Zingiber amaricans
P21 Tamarindus indica P252 Zingiber zerumbet
P22 Angelica keiskei P253 Zingiber littoralis
P24 Astragalus membranaceus P254 Zingiber aromaticum
P25 Amomum kravanh P255 Languas galanga
P26 Atractylodis Macrocephala P256 Leucas lavandulifolia
P28 Pinella ternata P257 Alpinia officinarum
P29 Zingiber purpureum P258 Polygala glomerata
P30 Hordeum vulgare P259 Aloe vera
P33 Allium cepae P262 Raphanus sativus
P34 Allium sativum P265 Boswellia carteri
P35 Sisyrinchium striatum P266 Phaleria papuana
P36 Spinacia oleracea P267 Swietenia mahagoni
P37 Amaranthus spinosus P268 Swietenia macrophylla
P39 Allium ursinum P269 Galla lusitania
P40 Pluchea indica P270 Quercus lusitanica
P41 Scurrula atropurpurea P273 Mangifera indica
P42 Pachyrrhizus erosus P274 Garcinia mangostana
P44 Strychnos ligustrina P275 Nothopanax scutellarium
P45 Merremia mammosa P276 Massoia aromatica
P46 Vaccinium myrtillus P278 Rosa chinensis
P47 Beta Vulgaris P279 Jasminum sambac
P49 Ribes nigrum P280 Morinda citrifolia
P50 Averrhoa bilimbi P281 Phyllanthus urinaria
P51 Plantago ovata P282 Mentha piperita
P53 Tinospora tuberculata P285 Azadirachta indica
P54 Brassica oleracea P287 Terminalia chebula
P55 Pandanus conoideus P291 Carum copticum
P56 Phaseolus vulgaris P292 Artemisia cina
P57 Platycodon grandiflorus P293 Morus australis
P58 Helianthus annuus P294 Aucklandiae lappae
P60 Oroxylum indicum P295 Messua ferrea
P61 Piper retrofractum P296 Homalomena occulta
P62 Capsicum annum P297 Ananas comosus
P66 Santalum album P299 Pogostemon cablin
P68 Syzygium aromaticum P300 Panax pseudoginseng
P70 Physalis peruviana P302 Ophiopogon japonicus
12
Lanjutan Lampiran 1 Daftar peubah penjelas
Kode peubah Peubah (Nama latin tanaman) Kode peubah Peubah (Nama latin tanaman)
P73 Phyllanthus acidus P308 Oryza sativa
P74 Bupleurum falcatum P309 Sophora japonica
P76 Ziziphus jujuba P310 Selaginella doederlinii
P77 Chlorella vulgaris P311 Myristica fragrans
P78 Ligustici wallichi P314 Pandanus amaryllifolius
P79 Ligusticum chuanxiong P316 Momordica charantia
P82 Cola nitida P318 Eurycoma longifolia
P84 Anemarrhena asphodeloides P319 Euphorbia thymifolia
P89 Angelica dahurica P320 Euphorbia hirta
P91 Gynura segetum P321 Prunus persica
P92 Desmodium triquetrum P323 Hydrocotyle asiatica
P94 Plectranthus amboinicus P325 Carica papaya
P95 Achillea santolina P326 Perilla frutescens
P97 Plantago major P328 Areca catechu
P98 Punica granatum P330 Musa paradisiaca
P102 Acorus calamus P331 Musa balbisianna
P105 Eucommia ulmoides P334 Mentha arvensis
P106 Syzygium cumini P337 Saussurea Lappa
P107 Echinacea purpurea P338 Calvatia gigantea
P108 Saposhnikovia divaricata P339 Lepiniopsis ternatensis
P109 Tanacetum parthenium P340 Alstonia scholaris
P111 Dioscorea opposite P341 Rauvolvia serpentina
P114 Uncaria rhynchophylla P342 Pimpinella pruatjan
P115 Gaultheria punctata P345 Helicteres isora
P119 Garcinia cambogia P347 Notopterygium incisum
P121 Gastrodia elata P348 Taraxacum officinale
P124 Ginkgo biloba P349 Ceiba pentandra
P126 Panax ginseng P354 Paeonia veitchii
P128 Angelica sinensis P355 Hibiscus sabdariffa
P129 Eleutherococcus senticosus P359 Lophatherum gracile
P131 Coptis chinensis P360 Laminaria japonica
P132 Equisetum debile P361 Physalis minima
P134 Rubus rosaefolius P362 Hedyotis corymbosa
P135 Gymnema sylvestre P363 Abrus precatorius
P136 Asarum sieboldii P364 Syzygium polyanthum
P138 Magnolia officinalis P365 Vernonia cinerea
P139 Coleus scutellarioides P368 Salvia miltiorrhiza
P142 Zea mays P369 Hemigraphis colorata
P143 Coix lacryma-jobi P370 Andrographis paniculata
P144 Zingiber officinale P371 Moschosma polystachium
P146 Eugenia cumini P372 Sindora sumatrana
P147 Psidium guajava P374 Symplocos odoratissima
P148 Syzygium jambos P376 Brassica juncea
P149 Anacardium occidentale P377 Brassica nigrae
P150 Ganoderma lucidum P378 Nasturtium indicum
P151 Schizonepeta tenuifolia P379 Schisandra chinensis
P155 Guazuma ulmifolia P381 Ocimum polystachyon
P158 Citrus reticulata P382 Apium graveolens
P159 Citrus amblycarpa P383 Prunella vulgaris
P160 Citrus sinensis P384 Hydrocotyle sibthorpioides
13 Lanjutan Lampiran 1 Daftar peubah penjelas
Kode peubah Peubah (Nama latin tanaman) Kode peubah Peubah (Nama latin tanaman) P164 Cuminum cyminum P386 Blumea balsamifera
P166 Nigella sativa P389 Cassia angustifolia
P168 Terminalia bellirica P390 Cymbopogon nardus
P170 Simmondsia chinensis P394 Rehmannia preparata
P171 Baeckea frutescens P396 Polygonatum sibiricum
P172 Gardenia Jasminoides P398 Woodfordia floribunda
P173 Phaseolus radiatus P400 Silybum marianum
P174 Ipomoea aquatica P403 Cinnamomum sintok
P175 Ipomoea reptana P404 Piper betle
P176 Amomum compactum P405 Annona muricata
P179 Alpinia katsumadai P407 Talinum paniculatum
P181 Usnea misaminensis P410 Spirulina
P182 Aquilaria sinensis P412 Stephania tetrandra
P184 Archangelisia flava P413 Stevia rebaudiana
P186 Cinnamomum burmani P414 Fragaria vesca
P188 Melaleuca leucadendra P417 Bixa orellana
P189 Parameria laevigata P419 Codonopsis pilosula
P190 Caesalpinia sappan P420 Catharanthus roseus
P191 Grewia salutaris P421 Elephantopus scaber
P193 Psophocarpus tetragonolobus P424 Theae sinensis
P195 Brugmansia candida P425 Matricaria chamomilla
P198 Parkia roxburghii P426 Melaleuca alternifolia
P199 Soya max P427 Cyperus rotundus
P200 Strobilanthes crispus P428 Thymus vulgaris
P201 Typhonium flagelliforme P430 Scaphium affinis
P202 Cocos nucifera P431 Sonchus arvensis
P203 Rheum tanguticum P432 Curcuma heyneana
P206 Carthamus tinctorius P434 Curcuma aeruginosa
P208 Leucaena glauca P435 Kaempferia pandurata
P210 Piper cubeba P436 Curcuma xanthorrhiza
P211 Murraya paniculata P437 Curcuma mangga
P213 Canarium commune P438 Curcuma zedoaria
P214 Kaempferia galanga P441 Gynura pinnatifida
P217 Sterculia foetida P443 Solanum lycopersicum
P221 Coriandrum sativum P444 Tetranthera brawas
P222 Lindera strychnifolia P447 Tribulus terrestris
P224 Trigonella foenum-graecum P449 Wolfiporia extensa
P225 Brassica napus P451 Manihot utilissima
P226 Cola acuminata P452 Valeriana javanica
P228 Coffea arabica P453 Hibiscus mutabilis
P229 Litsea cubeba P454 Hibiscus tiliaceus
P230 Chrysanthemum morifolium P455 Paeonia lactiflora
P233 Orthosiphon stamineus P458 Ziziphus spina-christi
P234 Kaempferia angustifolia P459 Daucus carota
P235 Kaempferia rotunda P460 Corydalis yanhusuo
14
RIWAYAT HIDUP
Penulis lahir di Kabupaten Pasuruan pada tanggal 19 Mei 1991. Penulis juga merupakan anak kedua dari pasangan Fanani Husein dan Masniari Simarmata serta memiliki dua saudara.
Tahun 2009 penulis lulus dari SMA Darul Ulum 2 Jombang dan berhasil masuk perguruan tinggi. Institut Pertanian Bogor menerimanya sebagai mahasiswa melalui jalur beasiswa utusan daerah yang disponsori oleh Kementrian Agama Republik Indonesia. Penulis diterima di jurusan Statistika Fakultas Matematika dan IPA.