ABSTRACT
CLARA. Application of Mel Frequency Cepstrum Coefficients (MFCC) as Feature Extraction on Phoneme Recognition with Probabilistic Neural Network (PNN) as Classifier. Supervised by AGUS BUONO.
Voice recognition (speech recognition) is one field of study in voice processing. This technology can convert voice signals into a form of written information (text). With this technology, people can interact with a computer. MFCC feature extraction computes the cepstral coefficients by considering the human hearing. This research is a phoneme recognition using feature extraction MFCC and PNN as feature matching model. This study compares the coefficient, overlap, and the test data without noise and with noise. MFCC is used with 13, 20, 26 coefficients and 0%, 25%, 50% overlap. Noise is added by 30 dB, 20 dB and 10 dB. From the comparison of the three overlaps, produced the best accuracy at 50% overlap with an accuracy of 94,71%. From comparing the three coefficients, better accuracy resulting in coefficients of 20 and 26 with an accuracy of 97,12% at 50% overlap. After comparing between the coefficients of 20 and 26 with overlap of 25% then the coefficient 26 is obtained that better accuracy of 94,23%. This shows that in this study the coefficient 26 is the best. In this research, there are three noise variables. The variables are 10 dB, 20 dB, and 30 dB. The best accuracy reached when the noise variable is 30 dB rather than 10 dB or 20 dB because the accuracy has the closest accuracy compared by the accuracy when noise was not added into the data. When the noise variable is 30 dB, the percentage of accuracy is 85,3%.
PENDAHULUAN
Latar Belakang
Perkembangan teknologi menuntut manusia untuk mengembangkan teknologi yang dapat melakukan berbagai keperluan dengan mudah. Pengenalan suara (speech recognition) merupakan salah satu teknologi yang saat ini sedang dikembangkan.
Pengenalan suara (speech recognition) adalah salah satu bidang kajian dalam pemrosesan suara. Teknologi ini dapat mengubah sinyal suara menjadi sebuah informasi berupa tulisan (teks). Dengan teknologi ini, manusia dapat berinteraksi dengan komputer.
Pengenalan suara hanya membutuhkan alat tambahan berupa mikrofon dan kartu suara sedangkan pengenalan lain misalnya sidik jari atau wajah membutuhkan alat tambahan seperti scanner. Hal ini sedikit banyak menekan biaya pengembangan sistem.
Beberapa ekstraksi ciri untuk pengenalan suara antara lain Linear Predictive Coding, Perceptual Linear Prediction, Mel-Frequency Cepstrum Coefficients (MFCC), dan Wavelet. Tujuan ekstraksi ciri adalah mengubah vektor suara yang dihasilkan dari digitalisasi yang memiliki vektor yang besar menjadi vektor ciri, tanpa menghilangkan karakteristik suara tersebut.
Beberapa model pengenalan pola yang dapat digunakan untuk pengenalan suara antara lain Jarak Euclid, Distribusi Normal, dan Probabilistic Neural Network (PNN).
Pada penelitian ini dilakukan pengenalan fonem menggunakan ekstraksi ciri MFCC dan PNN sebagai pengenalan pola. Hal ini dikarenakan PNN telah terbukti memiliki akurasi yang tinggi pada penelitian yang telah dilakukan oleh Fransiswa (2010).
Berbasis fonem dalam pengenalan kata sangat diperlukan agar bersifat large vocabulary. Jika sebuah kata ingin dikenali dengan baik maka diperlukan penelitian pengenalan fonem.
Tujuan Penelitian
Penelitian ini bertujuan menerapkan Mel- Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri pada pengenalan fonem dengan Probabilistic Neural Network (PNN) sebagai classifier.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah : 1. Menggunakan sebelas kata yaitu coba, fana,
gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat yang merepresentasikan fonem /a/ sampai /z/.
2. Setiap kata diucapkan sebanyak 16 kali. 3. Semua kata diucapkan oleh satu orang. 4. Pengaturan ekstraksi ciri MFCC dengan
nilai sampling rate 12000 Hz direkam selama 1 detik, time frame 30 ms, overlap 0%, 25%, dan 50%, koefisien 13, 20, dan 26.
Manfaat Penelitian
Penelitian ini diharapkan memberikan informasi tingkat akurasi pengenalan fonem tunggal menggunakan Probabilistic Neural Network (PNN). Selain itu diharapkan model yang dihasilkan dalam penelitian ini dapat dikembangkan untuk pengenalan kata berbasis fonem yang bersifat large vocabulary.
TINJAUAN PUSTAKA Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang longitudinal yang merambat melalui media (zat perantara). Batas frekuensi bunyi yang dapat didengar oleh manusia berkisar antara frekuensi 20 Hz sampai dengan 20 KHz, dan frekuensi yang dapat didengar dengan baik dan jelas oleh telinga manusia yaitu di atas 10.000 Hz (Pelton 1993).
Berdasarkan pada peubah bebas waktu (t) sinyal dibedakan menjadi dua jenis yaitu: a. Sinyal Analog
Sinyal analog adalah suatu besaran yang berubah dalam waktu atau dalam ruang dan yang memiliki semua nilai untuk setiap nilai waktu (atau setiap nilai ruang). Sinyal analog sering disebut sinyal kontinu untuk menggambarkan bahwa besaran itu memiliki nilai yang kontinu (tak terputus). Sinyal analog dapat dilihat pada Gambar 1.
Gambar 1 Sinyal analog. b. Sinyal Diskret
1 PENDAHULUAN
Latar Belakang
Perkembangan teknologi menuntut manusia untuk mengembangkan teknologi yang dapat melakukan berbagai keperluan dengan mudah. Pengenalan suara (speech recognition) merupakan salah satu teknologi yang saat ini sedang dikembangkan.
Pengenalan suara (speech recognition) adalah salah satu bidang kajian dalam pemrosesan suara. Teknologi ini dapat mengubah sinyal suara menjadi sebuah informasi berupa tulisan (teks). Dengan teknologi ini, manusia dapat berinteraksi dengan komputer.
Pengenalan suara hanya membutuhkan alat tambahan berupa mikrofon dan kartu suara sedangkan pengenalan lain misalnya sidik jari atau wajah membutuhkan alat tambahan seperti scanner. Hal ini sedikit banyak menekan biaya pengembangan sistem.
Beberapa ekstraksi ciri untuk pengenalan suara antara lain Linear Predictive Coding, Perceptual Linear Prediction, Mel-Frequency Cepstrum Coefficients (MFCC), dan Wavelet. Tujuan ekstraksi ciri adalah mengubah vektor suara yang dihasilkan dari digitalisasi yang memiliki vektor yang besar menjadi vektor ciri, tanpa menghilangkan karakteristik suara tersebut.
Beberapa model pengenalan pola yang dapat digunakan untuk pengenalan suara antara lain Jarak Euclid, Distribusi Normal, dan Probabilistic Neural Network (PNN).
Pada penelitian ini dilakukan pengenalan fonem menggunakan ekstraksi ciri MFCC dan PNN sebagai pengenalan pola. Hal ini dikarenakan PNN telah terbukti memiliki akurasi yang tinggi pada penelitian yang telah dilakukan oleh Fransiswa (2010).
Berbasis fonem dalam pengenalan kata sangat diperlukan agar bersifat large vocabulary. Jika sebuah kata ingin dikenali dengan baik maka diperlukan penelitian pengenalan fonem.
Tujuan Penelitian
Penelitian ini bertujuan menerapkan Mel- Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri pada pengenalan fonem dengan Probabilistic Neural Network (PNN) sebagai classifier.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah : 1. Menggunakan sebelas kata yaitu coba, fana,
gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat yang merepresentasikan fonem /a/ sampai /z/.
2. Setiap kata diucapkan sebanyak 16 kali. 3. Semua kata diucapkan oleh satu orang. 4. Pengaturan ekstraksi ciri MFCC dengan
nilai sampling rate 12000 Hz direkam selama 1 detik, time frame 30 ms, overlap 0%, 25%, dan 50%, koefisien 13, 20, dan 26.
Manfaat Penelitian
Penelitian ini diharapkan memberikan informasi tingkat akurasi pengenalan fonem tunggal menggunakan Probabilistic Neural Network (PNN). Selain itu diharapkan model yang dihasilkan dalam penelitian ini dapat dikembangkan untuk pengenalan kata berbasis fonem yang bersifat large vocabulary.
TINJAUAN PUSTAKA Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang longitudinal yang merambat melalui media (zat perantara). Batas frekuensi bunyi yang dapat didengar oleh manusia berkisar antara frekuensi 20 Hz sampai dengan 20 KHz, dan frekuensi yang dapat didengar dengan baik dan jelas oleh telinga manusia yaitu di atas 10.000 Hz (Pelton 1993).
Berdasarkan pada peubah bebas waktu (t) sinyal dibedakan menjadi dua jenis yaitu: a. Sinyal Analog
Sinyal analog adalah suatu besaran yang berubah dalam waktu atau dalam ruang dan yang memiliki semua nilai untuk setiap nilai waktu (atau setiap nilai ruang). Sinyal analog sering disebut sinyal kontinu untuk menggambarkan bahwa besaran itu memiliki nilai yang kontinu (tak terputus). Sinyal analog dapat dilihat pada Gambar 1.
Gambar 1 Sinyal analog. b. Sinyal Diskret
penurunan sifat matematikanya biasanya jarak antar titik waktu adalah sama. Sinyal diskret dapat dilihat pada Gambar 2.
Gambar 2 Sinyal diskret.
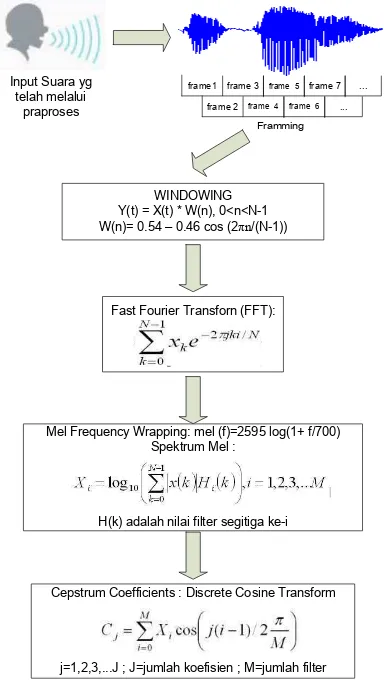
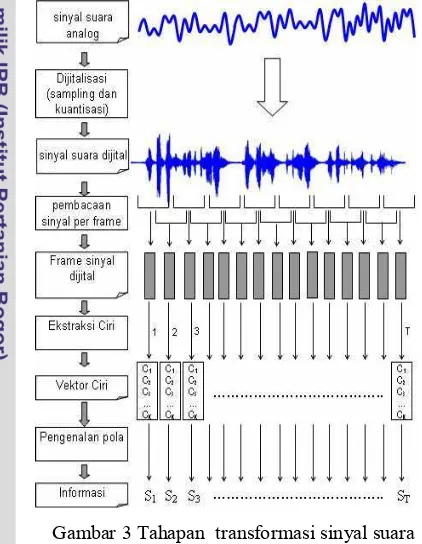
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009). Pada proses transformasi terdapat tahapan yang perlu dilakukan di antaranya digitalisasi sinyal analog, ekstraksi ciri, dan pengenalan pola, seperti yang diilustrasikan pada Gambar 3.
Gambar 3 Tahapan transformasi sinyal suara menjadi informasi (Buono 2009). Digitalisasi Gelombang Suara
Gelombang suara yang ditangkap berupa sinyal analog. Sinyal analog harus diubah menjadi sinyal digital yang disebut proses digitalisasi. Proses digitalisasi suara terdiri atas dua tahap yaitu sampling dan kuantisasi (Jurafsky & Martin 2000). Sampling adalah pengambilan nilai-nilai dalam jangka waktu tertentu. Sampling rate yang biasanya digunakan pada pengenalan suara ialah 8000 Hz sampai dengan 16.000 Hz (Jurafsky & Martin 2000). Hubungan panjang vektor yang dihasilkan, sampling rate dan panjang data suara yang digitalisasi dinyatakan dengan persamaan 1.
S = Fs x T (1)
Keterangan: S = panjang vektor
Fs = sampling rate yang digunakan (Hertz)
T = panjang suara (detik)
Setelah tahap sampling maka proses selanjutnya adalah proses kuantisasi. Proses ini menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC)
Ekstraksi ciri merupakan proses untuk menentukan vektor yang dapat digunakan sebagai penciri objek atau individu. Ciri yang biasa digunakan adalah koefisien cepstral. MFCC merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. MFCC memiliki tahapan yang terdiri atas (Do 1994):
1.
Frame Blocking. Tahap ini sinyal suara continous speech dibagi ke dalam beberapa frame serta dilakukan overlapping frame agar tidak kehilangan informasi.2.
Windowing. Windowing merupakan salah satu jenis filtering untuk meminimalisasikan distorsi antar frame. Proses ini dilakukan dengan mengalikan antar frame dengan jenis window yang digunakan. Penelitian suara banyak menggunakan window hamming karena kesederhanaan formulanya dan nilai kerja window. Dengan pertimbangan tersebut, maka penggunaan window Hamming cukup beralasan. Persamaan window Hamming adalah :w(n)=0.54-0.46cos(2 n/N-1) (2) Keterangan:
n = 0,.., N-1
3.
Fast Fourier Transform (FFT). Tahapan selanjutnya ialah mengubah tiap frame dari domain waktu ke dalam domain frekuensi. FFT adalah algoritme yang mengimplementasikan Discrete Fouries Transform (DFT). Hasil DFT ialah bilangan kompleks dengan Persamaan 3 untuk mencari nilai real dan Persamaan 4 untuk mencari nilai imaginer.(3)
3 Keterangan:
N = jumlah data k = 0, 1, 2,..., N/2 x[i] = data pada titik ke i
Proses selanjutnya ialah menghitung nilai magnitudo FFT. Magnitudo dari bilangan kompleks adalah
.
4.
Mel-Frequency Wrapping. Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara ternyata tidak hanya bersifat linear. Penerimaan sinyal suara untuk frekuensi rendah (<1000) bersifat linear, sedangkan untuk frekuensi tinggi (>1000) bersifat logaritmik. Skala inilah yang disebut dengan skala mel-frequency yang berupa filter. Pada Persamaan 5 ditunjukkan hubungan skala mel dengan frekuensi dalam Hz:(5) Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan menggunakan persamaan 6.
(6)
Keterangan:
Xi = nilai frequency wrapping pada filter
i=1,2 sampai n jumlah filter. X(k) = nilai magnitudo frekuensi pada k
frekuensi.
Hi(k) = nilai tinggi pada filter i segitiga dan
k frekuensi, dengan k=0, 1 sampai N-1 jumlah magnitudo frekuensi.
5.
Cepstrum. Tahap ini merupakan tahap terakhir pada MFCC. Pada tahap ini mel- frequency akan diubah menjadi domain waktu menggunakan Discrete Cosine Transform (DCT) dengan persamaan 7.(7)
Keterangan :
Cj = nilai koefisien C ke j.
j = 1, 2, sampai jumlah koefisien yang diharapkan
Xi = nilai X hasil mel-frequency wrapping
pada frekuensi i= 1, 2 sampai n
Mel Frequency Wrapping: mel (f)=2595 log(1+ f/700) Spektrum Mel :
H(k) adalah nilai filter segitiga ke-i
Cepstrum Coefficients : Discrete Cosine Transform
j=1,2,3,...J ; J=jumlah koefisien ; M=jumlah filter
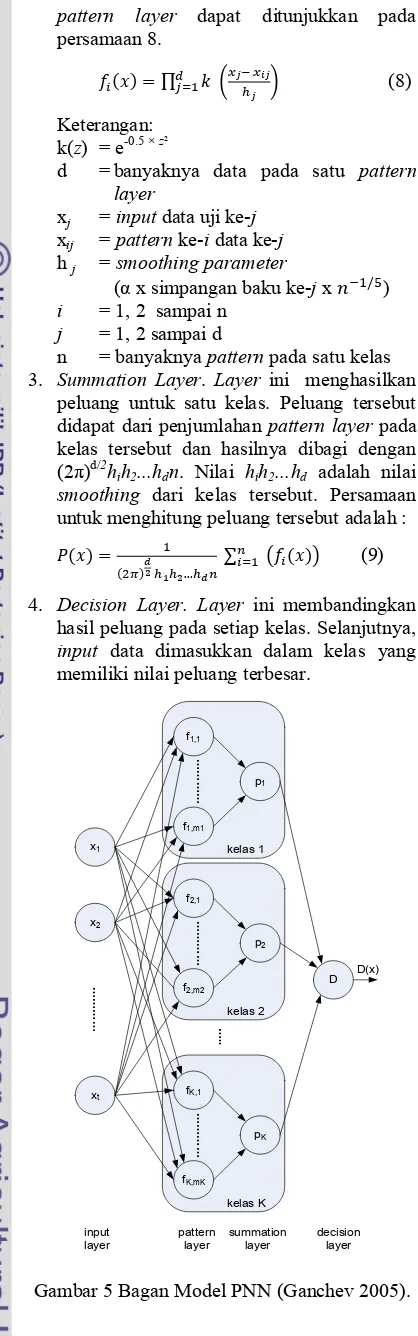
Gambar 4 Diagram Alur MFCC (Buono 2009). Pengenalan Pola Probabilistic Neural Network (PNN)
Donald F. Specht membuat tulisan yang
berjudul “Probabilistic Neural Network” pada tahun 1990 sebagai penyempurnaan idenya pada tahun 1966 (Fausett 1994). Probabilistic Nural Network menggunakan data pelatihan (supervised learning) untuk mengklasifikasi. PNN dirancang menggunakan ide dari teori probabilitas klasik yaitu pengklasifikasi Bayesian dan estimator pengklasifikasi Parzen untuk Probability Density function. Dengan menggunakan pengklasifikasi Bayesian dapat ditentukan bagaimana sebuah data masukan diklasifikasi sebagai anggota suatu kelas dari beberapa kelas yang ada, yaitu yang mempunyai nilai maksimum pada kelas tersebut.
PNN memiliki struktur yang terdiri atas empat layer yaitu:
1. Input layer. Layer ini untuk input data pada PNN
pattern layer dapat ditunjukkan pada
peluang untuk satu kelas. Peluang tersebut didapat dari penjumlahan pattern layer pada kelas tersebut dan hasilnya dibagi dengan
(2 )d/2
hih2...hdn. Nilai hih2...hd adalah nilai
smoothing dari kelas tersebut. Persamaan untuk menghitung peluang tersebut adalah :
(9) 4. Decision Layer. Layer ini membandingkan
hasil peluang pada setiap kelas. Selanjutnya, input data dimasukkan dalam kelas yang memiliki nilai peluang terbesar.
Gambar 5 Bagan Model PNN (Ganchev 2005).
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (Depdikbud 2003). Fonem dibagi menjadi dua yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
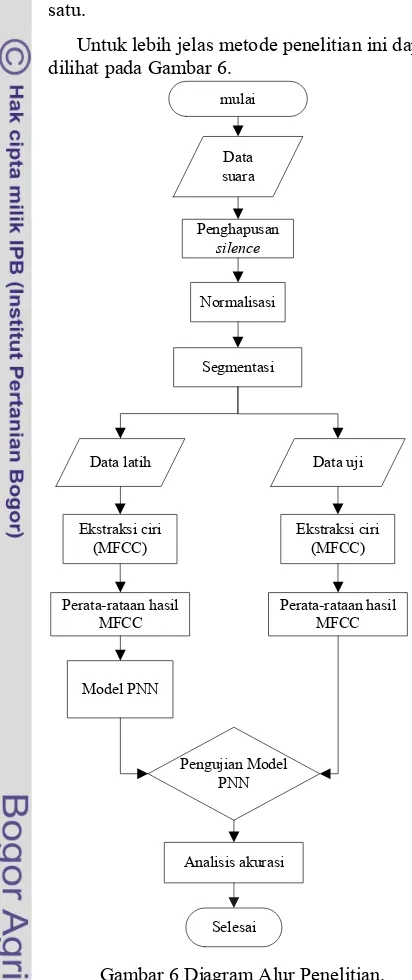
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dilakukan dengan mengambil data suara dari satu orang dengan mengucapkan satu kata sebanyak 16 kali. Bagian silence pada data suara akan dihapus. Proses selanjutnya yaitu normalisasi dan segmentasi. Data dibagi menjadi dua yaitu data latih dan data uji. Kemudian data akan diolah dengan proses MFCC. Hasil MFCC dirata-ratakan pada setiap data suara.
Data Suara
Penelitian ini akan menggunakan data yang telah didigitalisasi dan direkam dari satu orang pembicara yang mengucapkan satu kata sebanyak 16 kali. Setiap suara direkam dengan rentang waktu satu detik dengan sampling rate 12000 Hz. Kata yang digunakan dalam penelitian ini dapat dilihat pada Tabel 1. Tabel 1 Kata dalam penelitian.
Kata Fonem Kata Fonem
Tahap ini sinyal yang memiliki bagian yang silence akan dihapus baik di depan atau di belakang menggunakan Audacity 1.2.6 pada data latih dan data uji.
4 pattern layer dapat ditunjukkan pada
persamaan 8.
peluang untuk satu kelas. Peluang tersebut didapat dari penjumlahan pattern layer pada kelas tersebut dan hasilnya dibagi dengan
(2 )d/2
hih2...hdn. Nilai hih2...hd adalah nilai
smoothing dari kelas tersebut. Persamaan untuk menghitung peluang tersebut adalah :
(9) 4. Decision Layer. Layer ini membandingkan
hasil peluang pada setiap kelas. Selanjutnya, input data dimasukkan dalam kelas yang memiliki nilai peluang terbesar.
Gambar 5 Bagan Model PNN (Ganchev 2005).
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (Depdikbud 2003). Fonem dibagi menjadi dua yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dilakukan dengan mengambil data suara dari satu orang dengan mengucapkan satu kata sebanyak 16 kali. Bagian silence pada data suara akan dihapus. Proses selanjutnya yaitu normalisasi dan segmentasi. Data dibagi menjadi dua yaitu data latih dan data uji. Kemudian data akan diolah dengan proses MFCC. Hasil MFCC dirata-ratakan pada setiap data suara.
Data Suara
Penelitian ini akan menggunakan data yang telah didigitalisasi dan direkam dari satu orang pembicara yang mengucapkan satu kata sebanyak 16 kali. Setiap suara direkam dengan rentang waktu satu detik dengan sampling rate 12000 Hz. Kata yang digunakan dalam penelitian ini dapat dilihat pada Tabel 1. Tabel 1 Kata dalam penelitian.
Kata Fonem Kata Fonem
Tahap ini sinyal yang memiliki bagian yang silence akan dihapus baik di depan atau di belakang menggunakan Audacity 1.2.6 pada data latih dan data uji.
Normalisasi
Normalisasi dilakukan dengan mengabsolutkan nilai-nilai data suara dan mencari nilai maksimumnya. Selanjutnya, setiap nilai data tersebut dibagi dengan nilai maksimumnya. Hal ini dilakukan agar menormalkan suara sehingga memiliki amplitudo maksimum satu dan minimum minus satu.
Untuk lebih jelas metode penelitian ini dapat dilihat pada Gambar 6.
mulai
Gambar 6 Diagram Alur Penelitian. Segmentasi Sinyal
Tahap segmentasi sinyal merupakan tahap dimana setiap fonem dari kata-kata yang ada akan dipisahkan secara manual menggunakan Audacity. Hasil dari banyaknya segmentasi dari
kata yang digunakan sebagaimana dijelaskan pada Tabel 1 maka jumlah data dari tiap fonem dijelaskan dalam Tabel 2.
Tabel 2 Jumlah data tiap fonem.
Fonem Jumlah Fonem Jumlah
Data Latih dan Data Uji
Data dibagi menjadi data latih dan data uji. Proporsi data latih dan data uji yaitu 75%:25%. Data uji yang digunakan yaitu tanpa noise dan data uji yang ditambah noise 30 dB, 20 dB, dan 10 dB. Noise yang ditambahkan pada sinyal perekaman suara dalam penelitian ini menggunakan Gaussian white noise dengan maksud untuk mengetahui sinyal mana yang memberikan generalisasi yang lebih baik pada testing identifikasi yang dibuat terhadap sinyal yang tanpa ditambahkan noise. Lebih detail banyaknya data latih dan data uji untuk masing-masing fonem dapat dilihat pada Tabel 3. Tabel 3 Jumlah data latih dan data uji.
6 Ekstraksi Ciri (MFCC)
Tahap ekstraksi ciri merupakan tahap untuk menentukan vektor penciri dan biasanya menggunakan koefisien cepstral. Proses yang dilakukan pada tahap ini adalah Framing, windowing, Fast Fourier Transform, Mel-Frequency Wrapping, dan Cepstrum. Proses MFCC dilakukan dengan menggunakan toolbox yang tersedia yaitu Auditory Toolbox yang dikembangkan oleh Slaney (1998) dimana membutuhkan lima parameter yaitu :
1. Input yaitu suara yang merupakan masukan dari setiap pembicara.
2. Sampling rate yaitu banyaknya nilai yang diambil dari setiap detik. Penelitian ini menggunakan sampling rate sebesar 12000 Hz.
3. Time frame yaitu waktu yang digunakan untuk satu frame (dalam milidetik). Time frame yang digunakan adalah 30 ms. 4. Lap yaitu overlaping yang diinginkan (harus
kurang dari 100%). Lap yang digunakan pada penelitian ini adalah 0%, 25%, dan 50%.
5. Cepstral coefficient yaitu jumlah cepstrum yang diinginkan sebagai output. Cepstral coefficient yang digunakan sebanyak 13, 20, dan 26.
Setiap data suara dilakukan proses framing dimana masing-masing frame berukuran 30 ms dengan overlap 0%, 25%, dan 50% tanpa noise. Penelitian ini menggunakan 13, 20, dan 26 koefisien mel cepstrum untuk masing-masing frame. Hasil matriks ini yang merupakan masukan untuk Probabilistic Neural Network (PNN). maka dilakukan proses perata-rataan koefisien pada setiap baris.
Pemodelan PNN
Data uji digunakan sebagai input data. Input data tersebut diidentifikasikan dengan pattern layer pada Persamaan 8. Parameter h pada Persamaan 8 digunakan nilai 1,14 × (simpangan baku) × n-1/5. Nilai ialah nilai hasil pattern layer ke i, dimana i=1, 2 sampai banyaknya observasi pada satu kelas. Setelah memperoleh selisih jarak antara nilai data input dengan data pada pattern layer, maka nilai tersebut dibagi dengan nilai smoothing parameter. Nilai
smoothing didapat dari simpangan baku data setiap pattern ke j=1, 2 sampai jumlah koefisien yang digunakan.
Pengujian Model PNN
Setiap data uji (matriks n×1) dimasukkan ke dalam setiap kelas pada model PNN. Perhitungan pada pengujian setiap kelas menggunakan Persamaan 9, sehingga nilai peluang p(x) diperoleh dari setiap kelas pada pengujian model PNN. Nilai p(x) terbesar pada satu kelas merupakan pemenang, sehingga input data dikenali sebagai kelas tersebut.
Perhitungan Nilai Akurasi
Perhitungan dilakukan dengan membandingkan banyaknya hasil kata yang benar dengan kata yang diuji. Persentase tingkat akurasi dihitung dengan fungsi berikut:
Hasil = (10)
Lingkungan Pengembangan
Sistem ini diimplementasikan dengan MATLAB 7.0 yang dijalankan pada sistem operasi Windows 7, sedangkan perangkat keras yang digunakan adalah Intel Atom M 1.66 GHz, 1 GB RAM.s.
Ekstraksi Ciri (MFCC)
Tahap ekstraksi ciri merupakan tahap untuk menentukan vektor penciri dan biasanya menggunakan koefisien cepstral. Proses yang dilakukan pada tahap ini adalah Framing, windowing, Fast Fourier Transform, Mel-Frequency Wrapping, dan Cepstrum. Proses MFCC dilakukan dengan menggunakan toolbox yang tersedia yaitu Auditory Toolbox yang dikembangkan oleh Slaney (1998) dimana membutuhkan lima parameter yaitu :
1. Input yaitu suara yang merupakan masukan dari setiap pembicara.
2. Sampling rate yaitu banyaknya nilai yang diambil dari setiap detik. Penelitian ini menggunakan sampling rate sebesar 12000 Hz.
3. Time frame yaitu waktu yang digunakan untuk satu frame (dalam milidetik). Time frame yang digunakan adalah 30 ms. 4. Lap yaitu overlaping yang diinginkan (harus
kurang dari 100%). Lap yang digunakan pada penelitian ini adalah 0%, 25%, dan 50%.
5. Cepstral coefficient yaitu jumlah cepstrum yang diinginkan sebagai output. Cepstral coefficient yang digunakan sebanyak 13, 20, dan 26.
Setiap data suara dilakukan proses framing dimana masing-masing frame berukuran 30 ms dengan overlap 0%, 25%, dan 50% tanpa noise. Penelitian ini menggunakan 13, 20, dan 26 koefisien mel cepstrum untuk masing-masing frame. Hasil matriks ini yang merupakan masukan untuk Probabilistic Neural Network (PNN). maka dilakukan proses perata-rataan koefisien pada setiap baris.
Pemodelan PNN
Data uji digunakan sebagai input data. Input data tersebut diidentifikasikan dengan pattern layer pada Persamaan 8. Parameter h pada Persamaan 8 digunakan nilai 1,14 × (simpangan baku) × n-1/5. Nilai ialah nilai hasil pattern layer ke i, dimana i=1, 2 sampai banyaknya observasi pada satu kelas. Setelah memperoleh selisih jarak antara nilai data input dengan data pada pattern layer, maka nilai tersebut dibagi dengan nilai smoothing parameter. Nilai
smoothing didapat dari simpangan baku data setiap pattern ke j=1, 2 sampai jumlah koefisien yang digunakan.
Pengujian Model PNN
Setiap data uji (matriks n×1) dimasukkan ke dalam setiap kelas pada model PNN. Perhitungan pada pengujian setiap kelas menggunakan Persamaan 9, sehingga nilai peluang p(x) diperoleh dari setiap kelas pada pengujian model PNN. Nilai p(x) terbesar pada satu kelas merupakan pemenang, sehingga input data dikenali sebagai kelas tersebut.
Perhitungan Nilai Akurasi
Perhitungan dilakukan dengan membandingkan banyaknya hasil kata yang benar dengan kata yang diuji. Persentase tingkat akurasi dihitung dengan fungsi berikut:
Hasil = (10)
Lingkungan Pengembangan
Sistem ini diimplementasikan dengan MATLAB 7.0 yang dijalankan pada sistem operasi Windows 7, sedangkan perangkat keras yang digunakan adalah Intel Atom M 1.66 GHz, 1 GB RAM.s.
7 PNN. Model PNN ini yang selanjutnya diuji
dengan data pengujian yang telah diolah. Perbandingan Overlap 0%, 25%, dan 50%
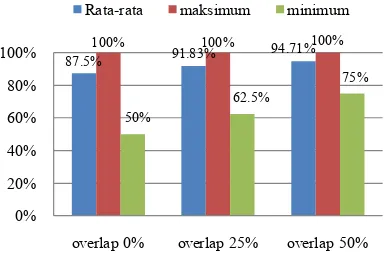
Kehilangan informasi dapat dihindari dengan melakukan overlapping frame yang satu dengan frame tetangganya. Perbandingan tingkat keakurasian model pengenalan fonem dapat dilihat pada overlap yang berbeda, baik pada overlap 0%, 25%, maupun 50%.
Gambar 7 Perbandingan akurasi sistem pada overlap 0%, 25%, dan 50%. Pada Gambar 7 ditunjukkan bahwa rata-rata akurasi, pengenalan fonem maksimum, dan pengenalan fonem yang minimum memiliki akurasi yang paling baik pada overlap 50%. Hal ini berarti informasi yang diambil dari tetangganya yang paling baik adalah overlap 50% pada pengenalan fonem. Jika tidak diambil informasi dari tetangganya atau overlap 0% maka akurasi menurun sangat drastis. Semakin besar overlap bukan berarti hasilnya pasti semakin baik tetapi dapat juga tergantung dengan kecepatan berbicara dan lebar frame namun pada kasus ini overlap 50% yang paling baik.
Perbandingan Koefisien 13, 20, dan 26 Jumlah koefisien yang berbeda dapat mengindikasikan cocok atau tidaknya jumlah matriks ciri pada model. Perbandingan tingkat keakurasian model pengenalan fonem dapat dilihat pada jumlah koefisien yang berbeda, baik pada koefisien 13, 20 maupun 26. Hasil rata-rata akurasi model pada koefisien 13, 20, dan 26 dapat dilihat pada Gambar 8.
Koefisien 20 dan 26 memiliki akurasi yang sama, sedangkan koefisien 13 hanya mencapai 94,71%. Hal ini berarti informasi ciri pada koefisien 20 dan 26 lebih baik daripada koefisien 13 pada pengenalan fonem. Untuk semua koefisien beberapa fonem telah berhasil dikenali sebesar 100% sedangkan fonem yang dikenali paling kecil akurasinya sebesar 75%.
Gambar 8 Perbandingan akurasi sistem pada koefisien 13, 20, dan 26.
Hasil Akurasi Pengenalan Fonem
Fonem yang teridentifikasi dengan benar oleh model PNN menghasilkan rata-rata akurasi yang paling baik pada peneltian ini yaitu sebanyak delapan namun hanya satu fonem /n/ dikenali sebagai fonem /w/ begitu pula dengan fonem /t/ yang dikenali sebagai fonem /i/. Hal ini disebabkan terdapat kesamaan pola dan karekteristik sehingga sistem salah mengenali fonem.
Semua fonem pada overlap 50% akurasinya tidak ada yang di bawah overlap 25%. Overlap 50% akurasinya hampir semua fonem di atas overlap 0% kecuali pada fonem /d/ dan /t/. Pada overlap 0% terdapat tiga fonem yang memiliki selisih akurasi cukup jauh dengan overlap 50%, yaitu fonem /f/, /k/, dan /q/. Hal ini berarti informasi yang diambil dari tetangganya yang paling baik adalah overlap 50%. Grafik perbandingan tingkat akurasi per fonem pada overlap 0%, 25%, dan 50% dapat dilihat pada Lampiran 1.
Akurasi untuk semua fonem koefisien 20 dan 26 sama persis sedangkan koefisien 13 pada fonem /p/, /t/ dan /y/ akurasinya selisih cukup jauh. Hal ini berarti bahwa fonem /p/, /t/, dan /y/ lebih cocok dengan jumlah matriks ciri 20 dan 26. Grafik perbandingan tingkat akurasi per fonem pada koefisien 13, 20, dan 26 dapat dilihat pada Lampiran 2.
Hasil Pengujian dengan Noise
Percobaan ini menambahkan noise jenis Gaussian white noise sebesar 30 dB, 20 dB, dan 10 dB pada data uji. Pada Gambar 9 ditunjukkan bahwa MFCC dengan pemodelan PNN hasil akurasi pada data uji yang diberi noise 30 dB terjadi penurunan yang tidak begitu
87.5% 91.83% 94.71%
overlap 0% overlap 25% overlap 50%
Rata-rata maksimum minimum
jauh dari akurasi fonem tanpa noise sedangkan jika ditambahkan noise 20 dB dan 10 dB terjadi penurunan sangat drastis. Dibandingkan teknik lain, dalam mengekstraksi sinyal suara yang bersifat low noise (>30 dB) teknik MFCC relatif lebih baik (Buono 2009). Hal ini dikarenakan cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga mampu merepresentasikan sinyal suara sebagaimana manusia merepresentasikan.
Gambar 9 Perbandingan data uji tanpa noise dan dengan noise.
Dari perbandingan yang telah dilakukan fonem /a/ merupakan fonem yang paling stabil karena data pelatihannya yang banyak. Pada Gambar 10 ditunjukkan perbedaan sinyal fonem /a/ tanpa noise dengan sinyal yang telah diberi noise 10 dB. Fonem /w/ tidak dikenali pada noise 30 dB. Pada noise 20 dB Ada enam fonem yang tidak dapat dikenali yaitu /j/, /o/, /q/, /v/, /w/, dan /y/. Pada noise 10 dB fonem yang tidak dikenali sebanyak 21 fonem .
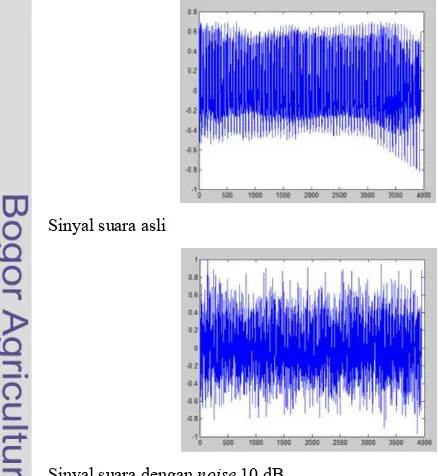
Sinyal suara asli
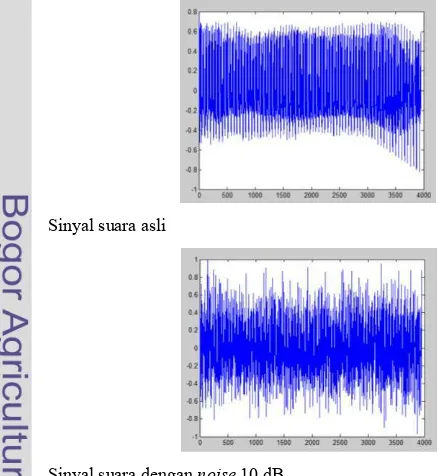
Sinyal suara dengan noise 10 dB
Gambar 10 Sinyal suara asli dan sinyal suara dengan noise 10 dB.
Perbandingan Koefisien, Overlap, dan Data Uji
Perbandingan antara koefisien, overlap, dan data uji dengan noise dan tanpa noise dapat dilihat pada Gambar 11. Terlihat bahwa akurasi pada data uji tanpa noise dan data uji yang ditambah noise 30 dB masih di atas 70% pada setiap overlap dan koefisien.
Gambar 11 Perbandingan koefisien, overlap, dan jenis data uji.
Pada Gambar 11 ditunjukkan bahwa akurasi pada data uji tanpa noise yang paling baik yaitu pada overlap 50% dan dengan koefisien 20 dan 26 sebesar 97,12%. Akurasi pada data uji yang ditambah noise 30 dB yang paling baik adalah overlap 50% dan koefisien 26 sebesar 85,26%. Akurasi pada data uji yang ditambah noise 20 dB yang paling baik adalah overlap 50% dan koefisien 26 sebesar 58,75%. Akurasi pada data uji yang ditambah noise 10 dB yang paling baik adalah overlap 25% dan koefisien 26 sebesar 13,39%. Dari perbandingan ini dapat dilihat bahwa overlap 50% memperlihatkan akurasi yang paling baik karena baik pada data uji tanpa noise maupun data uji yang ditambah noise 30 dB dan 10 dB memiliki akurasi yang paling baik. Koefisien 26 memiliki akurasi yang paling baik pada data uji tanpa noise maupun data uji yang ditambah noise 30 dB, 20 dB, dan 10 dB. Pada Lampiran 3 ditunjukkan secara detail hasil akurasi perbandingan koefisien, overlap, dan jenis data uji.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini telah berhasil dalam pengenalan fonem menggunakan metode PNN. Dari perbandingan ketiga overlap, akurasi terbaik dihasilkan pada overlap 50% dengan akurasi sebesar 94,71%. Untuk perbandingan ketiga koefisien, akurasi yang lebih baik
Tanpa noise Noise 30 dB Noise 20 dB Noise 10 dB
0%
9 dihasilkan pada koefisien 20 dan 26 dengan
akurasi sebesar 97,12% pada overlap 50%. Setelah dilakukan perbandingan antara koefisien 20 dan 26 dengan overlap 25% maka didapatkan hasil bahwa koefisien 26 yang lebih baik akurasinya sebesar 94,23%. Hal ini menunjukkan bahwa pada penelitian ini koefisien 26 yang paling baik.
Untuk perbandingan besarnya penambahan noise, akurasi terbaik dihasilkan pada noise 30 dB karena akurasinya yang paling dekat dengan akurasi tanpa noise. Akurasi penambahan noise 30 dB sebesar 85,3%. Dari hasil penelitian ini ditunjukkan bahwa jumlah data latih tidak harus sama untuk semua kelas karena akurasi yang dihasilkan sudah baik.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih baik lagi, saran untuk pengembangan selanjutnya ialah:
1. Jumlah kata yang lebih banyak agar dapat mewakili untuk tiap fonem yang berada di depan, di tengah, dan di belakang.
2. Jumlah pembicara yang lebih banyak. 3. Segmentasi secara otomatis menggunakan
auto corelation.
4. Menggunakan noise removing agar tahan terhadap noise.
5. Dapat dikembangkan lagi lebih lanjut ke tahap pengenalan kata berbasis fonem.
DAFTAR PUSTAKA
Buono, A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
[Depdikbud] Departemen Pendidikan dan Kebudayaan, Pusat Pembinaan dan Pengembangan Bahasa. 2003. Kamus Besar Bahasa Indonesia. Ed ke-3. Jakarta:Balai Pustaka.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of Technology. Fausett L. 1994. Fundamentals of Neural
Networks Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Fransiswa RR. 2010. Pengembangan Model
Probabilistic Neural Network (PNN) pada
Pengenalan Kisaran Usia dan Jenis Kelamin Berbasis Suara [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Ganchev,T Dimitrov. 2005. Speaker Recognition. University of Patras, Greece. Jurafsky D, Martin JH. 2000. Speech and
Language Processing: An Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey:Prentice Hall. Kudang B, Buono A, Sukin TP. 2005. Desain
dan Uji Komputasi Paralel Penentuan Nilai
Penghalus ( ) Algoritma Jaringan Syaraf
Probabilistik (PNN) untuk Klasifikasi Bunga Iris [ulasan]. Jurnal Ilmiah Ilmu Komputer 2005;3(1):19-31.
jauh dari akurasi fonem tanpa noise sedangkan jika ditambahkan noise 20 dB dan 10 dB terjadi penurunan sangat drastis. Dibandingkan teknik lain, dalam mengekstraksi sinyal suara yang bersifat low noise (>30 dB) teknik MFCC relatif lebih baik (Buono 2009). Hal ini dikarenakan cara kerja MFCC didasarkan pada perbedaan frekuensi yang dapat ditangkap oleh telinga manusia sehingga mampu merepresentasikan sinyal suara sebagaimana manusia merepresentasikan.
Gambar 9 Perbandingan data uji tanpa noise dan dengan noise.
Dari perbandingan yang telah dilakukan fonem /a/ merupakan fonem yang paling stabil karena data pelatihannya yang banyak. Pada Gambar 10 ditunjukkan perbedaan sinyal fonem /a/ tanpa noise dengan sinyal yang telah diberi noise 10 dB. Fonem /w/ tidak dikenali pada noise 30 dB. Pada noise 20 dB Ada enam fonem yang tidak dapat dikenali yaitu /j/, /o/, /q/, /v/, /w/, dan /y/. Pada noise 10 dB fonem yang tidak dikenali sebanyak 21 fonem .
Sinyal suara asli
Sinyal suara dengan noise 10 dB
Gambar 10 Sinyal suara asli dan sinyal suara dengan noise 10 dB.
Perbandingan Koefisien, Overlap, dan Data Uji
Perbandingan antara koefisien, overlap, dan data uji dengan noise dan tanpa noise dapat dilihat pada Gambar 11. Terlihat bahwa akurasi pada data uji tanpa noise dan data uji yang ditambah noise 30 dB masih di atas 70% pada setiap overlap dan koefisien.
Gambar 11 Perbandingan koefisien, overlap, dan jenis data uji.
Pada Gambar 11 ditunjukkan bahwa akurasi pada data uji tanpa noise yang paling baik yaitu pada overlap 50% dan dengan koefisien 20 dan 26 sebesar 97,12%. Akurasi pada data uji yang ditambah noise 30 dB yang paling baik adalah overlap 50% dan koefisien 26 sebesar 85,26%. Akurasi pada data uji yang ditambah noise 20 dB yang paling baik adalah overlap 50% dan koefisien 26 sebesar 58,75%. Akurasi pada data uji yang ditambah noise 10 dB yang paling baik adalah overlap 25% dan koefisien 26 sebesar 13,39%. Dari perbandingan ini dapat dilihat bahwa overlap 50% memperlihatkan akurasi yang paling baik karena baik pada data uji tanpa noise maupun data uji yang ditambah noise 30 dB dan 10 dB memiliki akurasi yang paling baik. Koefisien 26 memiliki akurasi yang paling baik pada data uji tanpa noise maupun data uji yang ditambah noise 30 dB, 20 dB, dan 10 dB. Pada Lampiran 3 ditunjukkan secara detail hasil akurasi perbandingan koefisien, overlap, dan jenis data uji.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini telah berhasil dalam pengenalan fonem menggunakan metode PNN. Dari perbandingan ketiga overlap, akurasi terbaik dihasilkan pada overlap 50% dengan akurasi sebesar 94,71%. Untuk perbandingan ketiga koefisien, akurasi yang lebih baik
Tanpa noise Noise 30 dB Noise 20 dB Noise 10 dB
0%
9 dihasilkan pada koefisien 20 dan 26 dengan
akurasi sebesar 97,12% pada overlap 50%. Setelah dilakukan perbandingan antara koefisien 20 dan 26 dengan overlap 25% maka didapatkan hasil bahwa koefisien 26 yang lebih baik akurasinya sebesar 94,23%. Hal ini menunjukkan bahwa pada penelitian ini koefisien 26 yang paling baik.
Untuk perbandingan besarnya penambahan noise, akurasi terbaik dihasilkan pada noise 30 dB karena akurasinya yang paling dekat dengan akurasi tanpa noise. Akurasi penambahan noise 30 dB sebesar 85,3%. Dari hasil penelitian ini ditunjukkan bahwa jumlah data latih tidak harus sama untuk semua kelas karena akurasi yang dihasilkan sudah baik.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih baik lagi, saran untuk pengembangan selanjutnya ialah:
1. Jumlah kata yang lebih banyak agar dapat mewakili untuk tiap fonem yang berada di depan, di tengah, dan di belakang.
2. Jumlah pembicara yang lebih banyak. 3. Segmentasi secara otomatis menggunakan
auto corelation.
4. Menggunakan noise removing agar tahan terhadap noise.
5. Dapat dikembangkan lagi lebih lanjut ke tahap pengenalan kata berbasis fonem.
DAFTAR PUSTAKA
Buono, A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
[Depdikbud] Departemen Pendidikan dan Kebudayaan, Pusat Pembinaan dan Pengembangan Bahasa. 2003. Kamus Besar Bahasa Indonesia. Ed ke-3. Jakarta:Balai Pustaka.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of Technology. Fausett L. 1994. Fundamentals of Neural
Networks Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Fransiswa RR. 2010. Pengembangan Model
Probabilistic Neural Network (PNN) pada
Pengenalan Kisaran Usia dan Jenis Kelamin Berbasis Suara [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Ganchev,T Dimitrov. 2005. Speaker Recognition. University of Patras, Greece. Jurafsky D, Martin JH. 2000. Speech and
Language Processing: An Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey:Prentice Hall. Kudang B, Buono A, Sukin TP. 2005. Desain
dan Uji Komputasi Paralel Penentuan Nilai
Penghalus ( ) Algoritma Jaringan Syaraf
Probabilistik (PNN) untuk Klasifikasi Bunga Iris [ulasan]. Jurnal Ilmiah Ilmu Komputer 2005;3(1):19-31.
PENERAPAN
MEL FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC)
SEBAGAI EKSTRAKSI CIRI PADA PENGENALAN FONEM DENGAN
PROBABILISTIC NEURAL NETWORK
(PNN) SEBAGAI
CLASSIFIER
CLARA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
9 dihasilkan pada koefisien 20 dan 26 dengan
akurasi sebesar 97,12% pada overlap 50%. Setelah dilakukan perbandingan antara koefisien 20 dan 26 dengan overlap 25% maka didapatkan hasil bahwa koefisien 26 yang lebih baik akurasinya sebesar 94,23%. Hal ini menunjukkan bahwa pada penelitian ini koefisien 26 yang paling baik.
Untuk perbandingan besarnya penambahan noise, akurasi terbaik dihasilkan pada noise 30 dB karena akurasinya yang paling dekat dengan akurasi tanpa noise. Akurasi penambahan noise 30 dB sebesar 85,3%. Dari hasil penelitian ini ditunjukkan bahwa jumlah data latih tidak harus sama untuk semua kelas karena akurasi yang dihasilkan sudah baik.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih baik lagi, saran untuk pengembangan selanjutnya ialah:
1. Jumlah kata yang lebih banyak agar dapat mewakili untuk tiap fonem yang berada di depan, di tengah, dan di belakang.
2. Jumlah pembicara yang lebih banyak. 3. Segmentasi secara otomatis menggunakan
auto corelation.
4. Menggunakan noise removing agar tahan terhadap noise.
5. Dapat dikembangkan lagi lebih lanjut ke tahap pengenalan kata berbasis fonem.
DAFTAR PUSTAKA
Buono, A. 2009. Representasi Nilai HOS dan Model MFCC sebagai Ekstraksi Ciri pada Sistem Indentifikasi Pembicara di Lingkungan Ber-noise Menggunakan HMM. [disertasi]. Depok: Program Studi Ilmu Komputer, Universitas Indonesia.
[Depdikbud] Departemen Pendidikan dan Kebudayaan, Pusat Pembinaan dan Pengembangan Bahasa. 2003. Kamus Besar Bahasa Indonesia. Ed ke-3. Jakarta:Balai Pustaka.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of Technology. Fausett L. 1994. Fundamentals of Neural
Networks Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Fransiswa RR. 2010. Pengembangan Model
Probabilistic Neural Network (PNN) pada
Pengenalan Kisaran Usia dan Jenis Kelamin Berbasis Suara [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Ganchev,T Dimitrov. 2005. Speaker Recognition. University of Patras, Greece. Jurafsky D, Martin JH. 2000. Speech and
Language Processing: An Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey:Prentice Hall. Kudang B, Buono A, Sukin TP. 2005. Desain
dan Uji Komputasi Paralel Penentuan Nilai
Penghalus ( ) Algoritma Jaringan Syaraf
Probabilistik (PNN) untuk Klasifikasi Bunga Iris [ulasan]. Jurnal Ilmiah Ilmu Komputer 2005;3(1):19-31.
PENERAPAN
MEL FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC)
SEBAGAI EKSTRAKSI CIRI PADA PENGENALAN FONEM DENGAN
PROBABILISTIC NEURAL NETWORK
(PNN) SEBAGAI
CLASSIFIER
CLARA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENERAPAN
MEL FREQUENCY CEPSTRUM COEFFICIENTS
(MFCC)
SEBAGAI EKSTRAKSI CIRI PADA PENGENALAN FONEM DENGAN
PROBABILISTIC NEURAL NETWORK
(PNN) SEBAGAI
CLASSIFIER
CLARA
Skripsi
Sebagai salah suatu syarat untuk memperoleh gelar Sarjana Komputer pada
Program Studi Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
CLARA. Application of Mel Frequency Cepstrum Coefficients (MFCC) as Feature Extraction on Phoneme Recognition with Probabilistic Neural Network (PNN) as Classifier. Supervised by AGUS BUONO.
Voice recognition (speech recognition) is one field of study in voice processing. This technology can convert voice signals into a form of written information (text). With this technology, people can interact with a computer. MFCC feature extraction computes the cepstral coefficients by considering the human hearing. This research is a phoneme recognition using feature extraction MFCC and PNN as feature matching model. This study compares the coefficient, overlap, and the test data without noise and with noise. MFCC is used with 13, 20, 26 coefficients and 0%, 25%, 50% overlap. Noise is added by 30 dB, 20 dB and 10 dB. From the comparison of the three overlaps, produced the best accuracy at 50% overlap with an accuracy of 94,71%. From comparing the three coefficients, better accuracy resulting in coefficients of 20 and 26 with an accuracy of 97,12% at 50% overlap. After comparing between the coefficients of 20 and 26 with overlap of 25% then the coefficient 26 is obtained that better accuracy of 94,23%. This shows that in this study the coefficient 26 is the best. In this research, there are three noise variables. The variables are 10 dB, 20 dB, and 30 dB. The best accuracy reached when the noise variable is 30 dB rather than 10 dB or 20 dB because the accuracy has the closest accuracy compared by the accuracy when noise was not added into the data. When the noise variable is 30 dB, the percentage of accuracy is 85,3%.
Judul Skripsi : Penerapan Mel Frequency Cepstrum Coefficients (MFCC) Sebagai Ekstraksi Ciri pada Pengenalan Fonem dengan Probabilistic Neural Network (PNN) Sebagai Classifier
Nama : Clara
NIM : G64086025
Menyetujui:
Pembimbing
Dr. Ir. Agus Buono, M.Si, M.Kom NIP. 19660702 199302 1 001
Mengetahui: Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 10 Mei 1987 di Jakarta. Penulis merupakan anak kedua dari tiga bersaudara.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Terima kasih penulis ucapkan kepada Bapak Dr. Ir. Agus Buono, M.Si, M.Kom selaku pembimbing. Adapun penulis mengucapkan terima kasih kepada:
1. Kedua orang tua, kakak, dan adik yang telah memberikan dukungan spiritual dan material, sehingga penulis dapat menyelesaikan studi di departemen Ilmu Komputer IPB.
2. Dosen penguji, Bapak Aziz Kustiyo, S.Si, M.Kom dan Bapak Mushthofa, S.Kom, M.Sc atas saran dan bimbingannya.
3. Teman-teman satu bimbingan atas bantuan sample suara dan kerjasamanya. 4. Teman-teman Ekstensi ILKOM angkatan 3, atas kerjasamanya selama penelitian. Semoga penelitian ini bermanfaat bagi kemajuan teknologi, khususnya di bidang ilmu komputer.
Bogor, Maret 2011
DAFTAR ISI
Halaman DAFTAR TABEL ... v DAFTAR GAMBAR ... v DAFTAR LAMPIRAN ... v PENDAHULUAN
Latar Belakang ... 1 Tujuan Penelitian ... 1 Ruang Lingkup Penelitian... 1 Manfaat Penelitian ... 1 TINJAUAN PUSTAKA
Pemrosesan Sinyal Suara ... 1 Digitalisasi Gelombang Suara ... 2 Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC)... 2 Pengenalan Pola Probabilistic Neural Network (PNN)... 3 Fonem ... 4 METODE PENELITIAN
Kerangka Pemikiran ... 4 Data Suara ... 4 Penghapusan Silence ... 4 Normalisasi ... 5 Segmentasi Sinyal ... 5 Data Latih dan Data Uji ... 5 Ekstraksi Ciri (MFCC) ... 6 Perata-rataan Hasil MFCC ... 6 Pemodelan PNN ... 6 Pengujian Model PNN ... 6 Perhitungan Nilai Akurasi... 6 Lingkungan Pengembangan ... 6 HASIL DAN PEMBAHASAN
Perbandingan Overlap 0%, 25%, dan 50% ... 7 Perbandingan Koefisien 13, 20, dan 26 ... 7 Hasil Akurasi Pengenalan Fonem ... 7 Hasil Pengujian dengan Noise ... 7 Perbandingan Koefisien, Overlap, dan Data Uji ... 8 KESIMPULAN DAN SARAN
v DAFTAR TABEL
Halaman 1 Kata dalam penelitian. ... 4 2 Jumlah data tiap fonem... 5 3 Jumlah data latih dan data uji. ... 5
DAFTAR GAMBAR
Halaman 1 Sinyal analog. ... 1 2 Sinyal diskret. ... 2 3 Tahapan transformasi sinyal suara menjadi informasi (Buono 2009). ... 2 4 Diagram Alur MFCC (Buono 2009). ... 3 5 Bagan Model PNN (Ganchev 2005). ... 4 6 Diagram Alur Penelitian. ... 5 7 Perbandingan akurasi sistem pada overlap 0%, 25%, dan 50%. ... 7 8 Perbandingan akurasi sistem pada koefisien 13, 20, dan 26. ... 7 9 Perbandingan data uji tanpa noise dan dengan noise. ... 8 10 Sinyal suara asli dan sinyal suara dengan noise 10 dB. ... 8 11 Perbandingan koefisien, overlap, dan jenis data uji. ... 8
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Perkembangan teknologi menuntut manusia untuk mengembangkan teknologi yang dapat melakukan berbagai keperluan dengan mudah. Pengenalan suara (speech recognition) merupakan salah satu teknologi yang saat ini sedang dikembangkan.
Pengenalan suara (speech recognition) adalah salah satu bidang kajian dalam pemrosesan suara. Teknologi ini dapat mengubah sinyal suara menjadi sebuah informasi berupa tulisan (teks). Dengan teknologi ini, manusia dapat berinteraksi dengan komputer.
Pengenalan suara hanya membutuhkan alat tambahan berupa mikrofon dan kartu suara sedangkan pengenalan lain misalnya sidik jari atau wajah membutuhkan alat tambahan seperti scanner. Hal ini sedikit banyak menekan biaya pengembangan sistem.
Beberapa ekstraksi ciri untuk pengenalan suara antara lain Linear Predictive Coding, Perceptual Linear Prediction, Mel-Frequency Cepstrum Coefficients (MFCC), dan Wavelet. Tujuan ekstraksi ciri adalah mengubah vektor suara yang dihasilkan dari digitalisasi yang memiliki vektor yang besar menjadi vektor ciri, tanpa menghilangkan karakteristik suara tersebut.
Beberapa model pengenalan pola yang dapat digunakan untuk pengenalan suara antara lain Jarak Euclid, Distribusi Normal, dan Probabilistic Neural Network (PNN).
Pada penelitian ini dilakukan pengenalan fonem menggunakan ekstraksi ciri MFCC dan PNN sebagai pengenalan pola. Hal ini dikarenakan PNN telah terbukti memiliki akurasi yang tinggi pada penelitian yang telah dilakukan oleh Fransiswa (2010).
Berbasis fonem dalam pengenalan kata sangat diperlukan agar bersifat large vocabulary. Jika sebuah kata ingin dikenali dengan baik maka diperlukan penelitian pengenalan fonem.
Tujuan Penelitian
Penelitian ini bertujuan menerapkan Mel- Frequency Cepstrum Coefficients (MFCC) sebagai ekstraksi ciri pada pengenalan fonem dengan Probabilistic Neural Network (PNN) sebagai classifier.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah : 1. Menggunakan sebelas kata yaitu coba, fana,
gajah, jaya, malu, pacu, quran, tip-x, visa, weda, dan zakat yang merepresentasikan fonem /a/ sampai /z/.
2. Setiap kata diucapkan sebanyak 16 kali. 3. Semua kata diucapkan oleh satu orang. 4. Pengaturan ekstraksi ciri MFCC dengan
nilai sampling rate 12000 Hz direkam selama 1 detik, time frame 30 ms, overlap 0%, 25%, dan 50%, koefisien 13, 20, dan 26.
Manfaat Penelitian
Penelitian ini diharapkan memberikan informasi tingkat akurasi pengenalan fonem tunggal menggunakan Probabilistic Neural Network (PNN). Selain itu diharapkan model yang dihasilkan dalam penelitian ini dapat dikembangkan untuk pengenalan kata berbasis fonem yang bersifat large vocabulary.
TINJAUAN PUSTAKA Pemrosesan Sinyal Suara
Sinyal suara merupakan gelombang longitudinal yang merambat melalui media (zat perantara). Batas frekuensi bunyi yang dapat didengar oleh manusia berkisar antara frekuensi 20 Hz sampai dengan 20 KHz, dan frekuensi yang dapat didengar dengan baik dan jelas oleh telinga manusia yaitu di atas 10.000 Hz (Pelton 1993).
Berdasarkan pada peubah bebas waktu (t) sinyal dibedakan menjadi dua jenis yaitu: a. Sinyal Analog
Sinyal analog adalah suatu besaran yang berubah dalam waktu atau dalam ruang dan yang memiliki semua nilai untuk setiap nilai waktu (atau setiap nilai ruang). Sinyal analog sering disebut sinyal kontinu untuk menggambarkan bahwa besaran itu memiliki nilai yang kontinu (tak terputus). Sinyal analog dapat dilihat pada Gambar 1.
Gambar 1 Sinyal analog. b. Sinyal Diskret
2 penurunan sifat matematikanya biasanya
jarak antar titik waktu adalah sama. Sinyal diskret dapat dilihat pada Gambar 2.
Gambar 2 Sinyal diskret.
Pemrosesan sinyal suara merupakan teknik mentransformasi sinyal suara menjadi informasi yang berarti sesuai dengan yang diinginkan (Buono 2009). Pada proses transformasi terdapat tahapan yang perlu dilakukan di antaranya digitalisasi sinyal analog, ekstraksi ciri, dan pengenalan pola, seperti yang diilustrasikan pada Gambar 3.
Gambar 3 Tahapan transformasi sinyal suara menjadi informasi (Buono 2009). Digitalisasi Gelombang Suara
Gelombang suara yang ditangkap berupa sinyal analog. Sinyal analog harus diubah menjadi sinyal digital yang disebut proses digitalisasi. Proses digitalisasi suara terdiri atas dua tahap yaitu sampling dan kuantisasi (Jurafsky & Martin 2000). Sampling adalah pengambilan nilai-nilai dalam jangka waktu tertentu. Sampling rate yang biasanya digunakan pada pengenalan suara ialah 8000 Hz sampai dengan 16.000 Hz (Jurafsky & Martin 2000). Hubungan panjang vektor yang dihasilkan, sampling rate dan panjang data suara yang digitalisasi dinyatakan dengan persamaan 1.
S = Fs x T (1)
Keterangan: S = panjang vektor
Fs = sampling rate yang digunakan (Hertz)
T = panjang suara (detik)
Setelah tahap sampling maka proses selanjutnya adalah proses kuantisasi. Proses ini menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Ekstraksi Ciri Mel-Frequency Cepstrum Coefficients (MFCC)
Ekstraksi ciri merupakan proses untuk menentukan vektor yang dapat digunakan sebagai penciri objek atau individu. Ciri yang biasa digunakan adalah koefisien cepstral. MFCC merupakan ekstraksi ciri yang menghitung koefisien cepstral dengan mempertimbangkan pendengaran manusia. MFCC memiliki tahapan yang terdiri atas (Do 1994):
1.
Frame Blocking. Tahap ini sinyal suara continous speech dibagi ke dalam beberapa frame serta dilakukan overlapping frame agar tidak kehilangan informasi.2.
Windowing. Windowing merupakan salah satu jenis filtering untuk meminimalisasikan distorsi antar frame. Proses ini dilakukan dengan mengalikan antar frame dengan jenis window yang digunakan. Penelitian suara banyak menggunakan window hamming karena kesederhanaan formulanya dan nilai kerja window. Dengan pertimbangan tersebut, maka penggunaan window Hamming cukup beralasan. Persamaan window Hamming adalah :w(n)=0.54-0.46cos(2 n/N-1) (2) Keterangan:
n = 0,.., N-1
3.
Fast Fourier Transform (FFT). Tahapan selanjutnya ialah mengubah tiap frame dari domain waktu ke dalam domain frekuensi. FFT adalah algoritme yang mengimplementasikan Discrete Fouries Transform (DFT). Hasil DFT ialah bilangan kompleks dengan Persamaan 3 untuk mencari nilai real dan Persamaan 4 untuk mencari nilai imaginer.(3)
Keterangan: N = jumlah data k = 0, 1, 2,..., N/2 x[i] = data pada titik ke i
Proses selanjutnya ialah menghitung nilai magnitudo FFT. Magnitudo dari bilangan kompleks adalah
.
4.
Mel-Frequency Wrapping. Persepsi sistem pendengaran manusia terhadap frekuensi sinyal suara ternyata tidak hanya bersifat linear. Penerimaan sinyal suara untuk frekuensi rendah (<1000) bersifat linear, sedangkan untuk frekuensi tinggi (>1000) bersifat logaritmik. Skala inilah yang disebut dengan skala mel-frequency yang berupa filter. Pada Persamaan 5 ditunjukkan hubungan skala mel dengan frekuensi dalam Hz:(5) Proses wrapping terhadap sinyal dalam domain frekuensi dilakukan menggunakan persamaan 6.
(6)
Keterangan:
Xi = nilai frequency wrapping pada filter
i=1,2 sampai n jumlah filter. X(k) = nilai magnitudo frekuensi pada k
frekuensi.
Hi(k) = nilai tinggi pada filter i segitiga dan
k frekuensi, dengan k=0, 1 sampai N-1 jumlah magnitudo frekuensi.
5.
Cepstrum. Tahap ini merupakan tahap terakhir pada MFCC. Pada tahap ini mel- frequency akan diubah menjadi domain waktu menggunakan Discrete Cosine Transform (DCT) dengan persamaan 7.(7)
Keterangan :
Cj = nilai koefisien C ke j.
j = 1, 2, sampai jumlah koefisien yang diharapkan
Xi = nilai X hasil mel-frequency wrapping
pada frekuensi i= 1, 2 sampai n
Mel Frequency Wrapping: mel (f)=2595 log(1+ f/700) Spektrum Mel :
H(k) adalah nilai filter segitiga ke-i
Cepstrum Coefficients : Discrete Cosine Transform
j=1,2,3,...J ; J=jumlah koefisien ; M=jumlah filter
Gambar 4 Diagram Alur MFCC (Buono 2009). Pengenalan Pola Probabilistic Neural Network (PNN)
Donald F. Specht membuat tulisan yang
berjudul “Probabilistic Neural Network” pada tahun 1990 sebagai penyempurnaan idenya pada tahun 1966 (Fausett 1994). Probabilistic Nural Network menggunakan data pelatihan (supervised learning) untuk mengklasifikasi. PNN dirancang menggunakan ide dari teori probabilitas klasik yaitu pengklasifikasi Bayesian dan estimator pengklasifikasi Parzen untuk Probability Density function. Dengan menggunakan pengklasifikasi Bayesian dapat ditentukan bagaimana sebuah data masukan diklasifikasi sebagai anggota suatu kelas dari beberapa kelas yang ada, yaitu yang mempunyai nilai maksimum pada kelas tersebut.
PNN memiliki struktur yang terdiri atas empat layer yaitu:
1. Input layer. Layer ini untuk input data pada PNN
4 pattern layer dapat ditunjukkan pada
persamaan 8.
peluang untuk satu kelas. Peluang tersebut didapat dari penjumlahan pattern layer pada kelas tersebut dan hasilnya dibagi dengan
(2 )d/2
hih2...hdn. Nilai hih2...hd adalah nilai
smoothing dari kelas tersebut. Persamaan untuk menghitung peluang tersebut adalah :
(9) 4. Decision Layer. Layer ini membandingkan
hasil peluang pada setiap kelas. Selanjutnya, input data dimasukkan dalam kelas yang memiliki nilai peluang terbesar.
Gambar 5 Bagan Model PNN (Ganchev 2005).
Fonem
Fonem merupakan satuan bunyi terkecil yang mampu menunjukkan kontras makna (Depdikbud 2003). Fonem dibagi menjadi dua yaitu:
1. Fonem vokal merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru tidak terkena hambatan atau halangan. Jumlah fonem vokal ada lima yaitu a, i, u, e, dan o.
2. Fonem konsonan merupakan bunyi ujaran akibat adanya udara yang keluar dari paru-paru mendapatkan hambatan atau halangan. Jumlah fonem konsonan ada 21 buah yaitu b, c, d, f, g, h, j, k, l, m, n, p, q, r, s, t, v, w, x, y, dan z.
METODE PENELITIAN Kerangka Pemikiran
Penelitian ini dilakukan dengan mengambil data suara dari satu orang dengan mengucapkan satu kata sebanyak 16 kali. Bagian silence pada data suara akan dihapus. Proses selanjutnya yaitu normalisasi dan segmentasi. Data dibagi menjadi dua yaitu data latih dan data uji. Kemudian data akan diolah dengan proses MFCC. Hasil MFCC dirata-ratakan pada setiap data suara.
Data Suara
Penelitian ini akan menggunakan data yang telah didigitalisasi dan direkam dari satu orang pembicara yang mengucapkan satu kata sebanyak 16 kali. Setiap suara direkam dengan rentang waktu satu detik dengan sampling rate 12000 Hz. Kata yang digunakan dalam penelitian ini dapat dilihat pada Tabel 1. Tabel 1 Kata dalam penelitian.
Kata Fonem Kata Fonem
Tahap ini sinyal yang memiliki bagian yang silence akan dihapus baik di depan atau di belakang menggunakan Audacity 1.2.6 pada data latih dan data uji.
Normalisasi
Normalisasi dilakukan dengan mengabsolutkan nilai-nilai data suara dan mencari nilai maksimumnya. Selanjutnya, setiap nilai data tersebut dibagi dengan nilai maksimumnya. Hal ini dilakukan agar menormalkan suara sehingga memiliki amplitudo maksimum satu dan minimum minus satu.
Untuk lebih jelas metode penelitian ini dapat dilihat pada Gambar 6.
mulai
Gambar 6 Diagram Alur Penelitian. Segmentasi Sinyal
Tahap segmentasi sinyal merupakan tahap dimana setiap fonem dari kata-kata yang ada akan dipisahkan secara manual menggunakan Audacity. Hasil dari banyaknya segmentasi dari
kata yang digunakan sebagaimana dijelaskan pada Tabel 1 maka jumlah data dari tiap fonem dijelaskan dalam Tabel 2.
Tabel 2 Jumlah data tiap fonem.
Fonem Jumlah Fonem Jumlah
Data Latih dan Data Uji
Data dibagi menjadi data latih dan data uji. Proporsi data latih dan data uji yaitu 75%:25%. Data uji yang digunakan yaitu tanpa noise dan data uji yang ditambah noise 30 dB, 20 dB, dan 10 dB. Noise yang ditambahkan pada sinyal perekaman suara dalam penelitian ini menggunakan Gaussian white noise dengan maksud untuk mengetahui sinyal mana yang memberikan generalisasi yang lebih baik pada testing identifikasi yang dibuat terhadap sinyal yang tanpa ditambahkan noise. Lebih detail banyaknya data latih dan data uji untuk masing-masing fonem dapat dilihat pada Tabel 3. Tabel 3 Jumlah data latih dan data uji.
6 Ekstraksi Ciri (MFCC)
Tahap ekstraksi ciri merupakan tahap untuk menentukan vektor penciri dan biasanya menggunakan koefisien cepstral. Proses yang dilakukan pada tahap ini adalah Framing, windowing, Fast Fourier Transform, Mel-Frequency Wrapping, dan Cepstrum. Proses MFCC dilakukan dengan menggunakan toolbox yang tersedia yaitu Auditory Toolbox yang dikembangkan oleh Slaney (1998) dimana membutuhkan lima parameter yaitu :
1. Input yaitu suara yang merupakan masukan dari setiap pembicara.
2. Sampling rate yaitu banyaknya nilai yang diambil dari setiap detik. Penelitian ini menggunakan sampling rate sebesar 12000 Hz.
3. Time frame yaitu waktu yang digunakan untuk satu frame (dalam milidetik). Time frame yang digunakan adalah 30 ms. 4. Lap yaitu overlaping yang diinginkan (harus
kurang dari 100%). Lap yang digunakan pada penelitian ini adalah 0%, 25%, dan 50%.
5. Cepstral coefficient yaitu jumlah cepstrum yang diinginkan sebagai output. Cepstral coefficient yang digunakan sebanyak 13, 20, dan 26.
Setiap data suara dilakukan proses framing dimana masing-masing frame berukuran 30 ms dengan overlap 0%, 25%, dan 50% tanpa noise. Penelitian ini menggunakan 13, 20, dan 26 koefisien mel cepstrum untuk masing-masing frame. Hasil matriks ini yang merupakan masukan untuk Probabilistic Neural Network (PNN). maka dilakukan proses perata-rataan koefisien pada setiap baris.
Pemodelan PNN
Data uji digunakan sebagai input data. Input data tersebut diidentifikasikan dengan pattern layer pada Persamaan 8. Parameter h pada Persamaan 8 digunakan nilai 1,14 × (simpangan baku) × n-1/5. Nilai ialah nilai hasil pattern layer ke i, dimana i=1, 2 sampai banyaknya observasi pada satu kelas. Setelah memperoleh selisih jarak antara nilai data input dengan data pada pattern layer, maka nilai tersebut dibagi dengan nilai smoothing parameter. Nilai
smoothing didapat dari simpangan baku data setiap pattern ke j=1, 2 sampai jumlah koefisien yang digunakan.
Pengujian Model PNN
Setiap data uji (matriks n×1) dimasukkan ke dalam setiap kelas pada model PNN. Perhitungan pada pengujian setiap kelas menggunakan Persamaan 9, sehingga nilai peluang p(x) diperoleh dari setiap kelas pada pengujian model PNN. Nilai p(x) terbesar pada satu kelas merupakan pemenang, sehingga input data dikenali sebagai kelas tersebut.
Perhitungan Nilai Akurasi
Perhitungan dilakukan dengan membandingkan banyaknya hasil kata yang benar dengan kata yang diuji. Persentase tingkat akurasi dihitung dengan fungsi berikut:
Hasil = (10)
Lingkungan Pengembangan
Sistem ini diimplementasikan dengan MATLAB 7.0 yang dijalankan pada sistem operasi Windows 7, sedangkan perangkat keras yang digunakan adalah Intel Atom M 1.66 GHz, 1 GB RAM.s.