PERANAN DISTRIBUSI NORMAL PADA KAJIAN UJI
WILCOXON
SKRIPSI
FIRZA UMAYRA
080823013
KEMENTRIAN PENDIDIKAN NASIONAL
UNIVERSITAS SUMATERA UTARA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
DEPARTEMEN MATEMATIKA
PERANAN DISTRIBUSI NORMAL PADA KAJIAN UJI WILCOXON
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
FIRZA UMAYRA 080823013
KEMENTRIAN PENDIDIKAN NASIONAL
UNIVERSITAS SUMATERA UTARA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
DEPARTEMEN MATEMATIKA
PERSETUJUAN
Judul : PERANAN DISTRIBUSI NORMAL PADA KAJIAN UJI WILCOXON
Kategori : SKRIPSI
Nama : FIRZA UMAYRA
Nomor Induk Mahasiswa : 080823013
Program Studi : S1 STATISTIKA EKSTENSI
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (MIPA) UNIVERSITAS SUMATERA
UTARA
NIP. 19461225197403001 NIP. 19500321980303001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU
PERNYATAAN
PERANAN DISTRIBUSI NORMAL PADA KAJIAN UJI WILCOXON
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2010
PENGHARGAAN
Diawali dengan mengucapkan Puji Syukur Kehadirat Allah SWT, yang selama ini telah memberikan Penulis kekuatan dan semangat sehingga penyusunan Skripsi ini dapat diselesaikan dengan baik dan tepat waktu.
Adapun tujuan dari penulisan Skripsi ini adalah merupakan salah satu syarat untuk menyelesaikan Program S1 Statistika Ekstensi pada Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara.
Sebagai salah satu perwujudan dari proses pendidikan kemahasiswaan, penyusunan Skripsi ini disajikan berdasarkan pembahasan oleh penulis dari Uji Wilcoxon.
Selama dalam penyusunan Skripsi ini penulis telah banyak memperoleh bantuan dan bimbingan, untuk itu pada kesempatan ini Penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada :
1. Kepada Almarhum Ayahanda H. Syarifuddin Sayuti dan Ibunda Hj. Ulfa Rahmi yang telah memberikan bantuan materil, ridho dan do’a yang tiada hentinya untuk penulis dari awal perkuliahan sampai selesainya penyusunan Skripsi ini, dan Adinda tersayang Elsya Soraya yang selalu memberi semangat dan motivasi kepada penulis
2. Bapak Prof. Dr. Eddy Marlianto, M.Sc selaku Dekan FMIPA USU
3. Bapak DR. Saib Suwilo, M.Sc selaku Ketua Departemen Matematika FMIPA USU
4. Bapak Drs. Marwan Harahap, M.Eng selaku Ketua Pelaksana Jurusan Program S1 Statistika Ekstensi dan dosen pembimbing 2 pada penulisan Skripsi ini yang telah bersedia memberikan arahan, bimbingan dan petunjuk kepada penulis dalam menyelesaikan Skripsi ini
5. Bapak Drs. Suwarno Arriswoyo, M.Si selaku dosen pembimbing 1 pada penulisan Skripsi ini yang telah bersedia memberikan arahan, bimbingan dan petunjuk kepada penulis dalam menyelesaikan Skripsi ini
7. Seluruh Staff Pengajar di Fakultas Matematika dan lmu Pengetahuan Alam Universitas Sumatera Utara khususnya Jurusan Matematika
8. Semua pihak yang terkait dalam penyelesaian skripsi ini
Sepenuhnya Penulis menyadari bahwa dalam penyusunan Skripsi ini masih banyak terdapat kekurangan. Untuk itu penulis mengharapkan saran dan kritik yang bersifat membangun, dimana saran dan kritik tersebut dapat dimanfaatkan untuk kemajuan ilmu pengetahuan pada saat ini dan yang akan datang.
Semoga Penulisan Skripsi ini dapat memberikan manfaat dan berguna bagi pembaca dan penulis pada khususnya. Akhir kata penulis mengucapkan banyak terima kasih.
Medan, Juli 2010
ABSTRAK
ABSTRACT
DAFTAR ISI
2.2 Transformasi Normal Standar 10
2.3 Tabel Distribusi Normal Standar 12
2.4 Uji Hipotesis 13
2.5 Spesifikasi Hipotesis : Hipotesis Nol dan Hipotesis Alternatif 14
2.6 Tipe Kesalahan I dan Kesalahan II 16
2.7 Aturan Keputusan Pengujian Hipotesis 18
2.8 Distribusi Normal Standar, z untuk Uji Hipotesis 19
2.9 Uji Tanda 20
2.10 Uji Wilcoxon 21
Bab 3 Pembahasan dan Hasil 23
3.1 Pembahasan 23
3.1.1 Untuk Sampel N < 25 24
3.1.2 Untuk Sampel N 25 26
3.2 Penyelesaian 28
3.2.1 Untuk Sampel N < 25 28
3.2.2 Untuk Sampel N 25 30
Bab 4 Penutup 33
4.1 Kesimpulan 33
4.2 Saran 33
Daftar Pustaka 35
DAFTAR TABEL
Halaman
DAFTAR GAMBAR
Halaman
Gambar 2.6.1 Tipe Kesalahan I 17
Gambar 2.6.2 Tipe Kesalahan II 18
ABSTRAK
ABSTRACT
BAB 1
PENDAHULUAN
1.1 Latar belakang
Dalam penelitian seringkali dijumpai kesulitan untuk memperoleh data kontinu yang
menyebar mengikuti distribusi normal. Data penelitian yang diperoleh kebanyakan
hanya berupa kategori yang hanya dapat dihitung frekuensinya atau berupa data yang
hanya dapat dibedakan berdasarkan tingkatan atau rankingnya.
Menghadapi kasus data kategorikal atau data ordinal, jelas peneliti tidak
mungkin mempergunakan metode statistik parametrik. Sebagai gantinya diciptakan
oleh pakar metode statistik lain yang sesuai yaitu metode statistik nonparametrik.
Metode statistik nonparametrik sering juga disebut metode bebas sebaran
(distribution free) karena model uji statistiknya tidak menetapkan syarat-syarat
tertentu tentang bentuk distribusi parameter populasinya. Artinya bahwa metode
statistik nonparametrik ini tidak menetapkan syarat bahwa observasi-observasinya
harus ditarik dari populasi yang berdistribusi normal dan tidak menetapkan syarat
homoscedasticity. Dalam sejumlah uji statistik nonparametrik hanya menetapkan
asumsi/persyaratan bahwa observasi-observasinya harus independen dan bahwa
varibel yang diteliti pada dasarnya harus memiliki kontinuitas. Banyak di antara uji-uji
statistik nonparametrik kadangkala disebut sebagai “uji ranking”, karena teknik-teknik
pengertian keangkaan, melainkan skor yang semata-mata berupa jenjang-jenjang
(ranks).
Hasil pemikiran para pakar untuk menciptakan metode-metode statistik
nonparametrik, ternyata dapat menunjukkan hasil yang cukup baik, tidak jauh berbeda
dengan hasil yang diperoleh dengan metode statistik parametrik. Metode statistik
nonparametrik ternyata mempunyai kelebihan-kelebihan bila dibandingkan dengan
metode statistik parametrik, di samping kekurangan-kekuranganya.
Sebuah uji parametrik tergantung keabsahannya pada asumsi bahwa dalam
menarik sampel secara acak dari sebuah distribusi yang memiliki sebuah aturan
tertentu. Jika terdapat keraguan, maka uji nonparametrik yang sah dengan asumsi
yang lebih lemah dapat digunakan. Metode-metode nonparametrik tidak terhingga
nilainya, tentu saja metode-metode ini biasanya hanya tersedia bila mempunyai data
yang tersusun secara urut atau rank dan tidak teliti nilai pengamatannya.
Hal ini harus ditekankan bahwa asumsi yang lebih lemah tidak berarti bahwa
metode nonparametrik berasumsi bebas. Apa yang dapat disimpulkan tergantung pada
apakah asumsi dapat terbukti secara sah.
Asumsi dasar yang digunakan adalah bahwa sampel berasal dari populasi yang
mengikuti suatu distribusi tertentu, misalnya distribusi normal. Namun dalam banyak
hal, asumsi tersebut sulit dilakukan karena tidak ada informasi yang cukup memberi
petunjuk mengenai bentuk distribusi populasi yang dikaji. Dalam kondisi seperti ini
metode-metode nonparametrik dapat digunakan untuk melakukan suatu uji statistik
parametrik dan nonparametrik dapat digunakan untuk suatu masalah tertentu, prosedur
parametrik akan lebih efisien.
Dengan karakteristik yang dijelaskan diatas, metode nonparametik kebanyakan
dipakai dalam menangani data kualitatif. Metode ini digunakan dalam menangani
situasi berikut:
1. Jika ukuran sampel terlalu kecil sehingga distribusi sampling dari statistik
tidak mendekati distribusi normal dan ketika bentuk distibusi populasi asal
sampel tersebut tidak dapat diasumsikan.
2. Jika digunakan jenis data ordinal (atau data peringkat)
3. Jika digunakan jenis data nominal
Dengan demikian dapat dipahami bahwa metode nonparametrik memberi
keleluasan yang lebih luas dalam melakukan inferensi statistik karena metode ini
dapat digunakan dalam keterbatasan data dari sampel dan keterbatasan informasi
mengenai populasi. Meskipun tidak seefisien metode parametrik, metode ini lebih
mudah dipahami dibandingkan dengan metode parametrik serta melibatkan
perhitungan – perhitungan yang lebih sederhana. Namun terdapat juga beberapa
keterbatasan dari metode ini. Jika jenis data yang digunakan adalah data ordinal atau
data nominal, maka seluruh data hasil pengukuran yang sudah tersedia diabaikan
sehingga kurang begitu kuat dan kurang sensitif dibandingkan dengan hasil dari uji
1.2 Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah menentukan hasil yang lebih
signifikan dengan menggunakan Uji Peringkat Bertanda Wilcoxon untuk beberapa
nilai parameter.
1.3 Tujuan Penelitian
Mengetahui hasil analisis yang menunjukkan bahwa untuk data yang diketahui bentuk
distribusinya, uji parametrik dengan menggunakan uji t memberikan hasil yang lebih
baik daripada uji nonparametrik dengan uji peringkat bertanda Wilcoxon, atau
sebaliknya.
1.4 Kontribusi Penelitian
a. Mengetahui hasil yang lebih baik dalam bentuk distribusi normal pada uji
nonparametrik
b. Mengidentifikasi nilai parameter pada uji nonparametrik
c. Menambah wawasan dan memperkaya literatur dalam bidang statistika yang
1.5 Tinjauan Pustaka
1. Siegel, Sidney, 1992
Dalam melakukan penelitian untuk menetapkan apakah hipotesis yang
bersumber pada teori-teori tentang tingkah laku dapat diterima atau tidak.
Sesudah memilih hipotesis tertentu yang tampaknya penting dalam suatu teori
yaitu mengumpulkan data empiris yang harus menghasilkan informasi
langsung mengenai dapatnya hipotesis tersebut diterima. Keputusan mengenai
arti data itu mungkin dipertahankan, direvisi atau menolak hipotesis tersebut
serta teorinya merupakan sumber hipotesis tersebut.
Dalam rangka mencapai suatu keputusan objektif mengenai apakah
suatu hipotesis tertentu diperkuat oleh seperangkat data, dipergunakan suatu
prosedur objektif untuk menolak atau menerima hipotesis tersebut. Objektifitas
yang ditekankan disini, sebab salah satu yang dituntut dari metode ilmiah
adalah bahwa seseorang harus sampai pada kesimpulan ilmiah melalui
metode-metode yang diketahui umum dan yang dapat diulangi oleh peneliti
lain yang kompeten.
Prosedur objektif ini harus didasarkan atas informasi yang diperoleh
dalam penelitian tersebut, dan didasarkan atas resiko yang sanggup ditanggung
bahwa keputusan sehubungan dengan hipotesis tersebut bisa menjadi tidak
benar.
Suatu tes statistik nonparametrik adalah tes yang modelnya tidak
menetapkan syarat-syarat mengenai parameter-parameter populasi yang
merupakan induk sampel penelitiannya. Anggapan-anggapan tertentu
observasi-observasinya independen dan bahwa variabel yang diteliti pada
dasarnya memiliki kontinuitas. Namun anggapan-anggapan ini lebih sedikit
dan jauh lebih lemah daripada anggapan-anggapan yang berkaitan dengan tes
parametrik. Terlebih lagi tes nonparametrik tidak menuntut pengukuran sekuat
yang dituntut tes-tes parametrik, sebagian besar tes nonparametrik dapat
diterapkan untuk data dalam skala ordinal dan beberapa yang lain juga dapat
diterapkan untuk data dalam skala nominal.
Dalam mempertimbangkan arah dan besar (magnitude) relatif
perbedaan maka dapat dilakukan suatu tes yang lebih besar kekuatannya. Tes
wilcoxon melakukan hal tersebut. Tes wilcoxon memberikan bobot yang lebih
besar kepada pasangan yang menunjukkan perbedaan yang besar untuk kedua
kondisinya, dibandingkan dengan pasangan yang menunjukkan perbedaan
yang kecil.
Tes wilcoxon ini adalah tes yang paling berguna bagi para ilmuwan
sosial. Dengan data tingkah laku, bukannya tidak lazim bahwa peneliti dapat
mengatakan anggota manakah dalam suatu pasangan yang “lebih besar dari”,
yaitu mengatakan tanda selisih observasi dalam setiap pasangan dan membuat
ranking selisih itu dalam urutan harga absolutnya. Artinya dapat membuat
penilaian tentang “lebih besar dari” itu antara dua penampilan dalam
masing-masing pasangan, dan juga dapat membuat penilaian antara dua skor yang
2. Hasan, Iqbal. M, 2001
Uji Wilcoxon pertama kali diperkenalkan oleh Frank Wilcoxon pada tahun
1945. Uji Wilcoxon merupakan pengembangan dari Uji t dengan ketelitian
hasil analisis Wilcoxon dibandingkan Uji t adalah tidak hanya dapat
menunjukkan arah perbedaan tetapi juga dapat menunjukkan perbedaan antara
kelompok – kelompok yang dibandingkan. Uji peringkat bertanda Wilcoxon
digunakan jika besaran maupun arah perbedaan relevan untuk menentukan
apakah terdapat pebedaan yang sesungguhnya antara data yang satu dengan
data yang lainnya. Uji peringkat bertanda Wilcoxon tidak hanya
memanfaatkan informasi tentang arah tetapi juga besarnya perbedaan pasangan
nilai itu.
Langkah – langkah pengujian urutan bertanda Wilcoxon ialah sebagai berikut:
- Menentukan formulasi hipotesis
H0 : Jumlah urutan tanda positif dengan jumlah urutan tanda negatif adalah
sama ( tidak ada perbedaan nyata antara pasangan data )
H1 : Jumlah urutan tanda positif dengan jumlah urutan tanda negatif adalah
berbeda ( ada perbedaan nyata antara pasangan data )
- Menentukan taraf nyata (α) dengan T tabelnya
Pengujian dapat berbentuk satu sisi atau dua sisi
- Menentukan kriteria pengujian
H0 diterima apabila t hitung T tabel
H0 ditolak apabila thitung < T tabel
- Menentukan nilai uji statistik nilai (nilai t hitung)
Tahap – tahap pengujian ialah sebagai berikut:
- Menentukan tanda beda dan besarnya tanda beda antara pasangan data
- Jika terdapat beda yang sama, diambil rata-ratanya
- Beda nol tidak diperhatikan
- Memisahkan tanda beda positif dan negatif atau tanda jenjang
- Menjumlahkan semua angka positif dan angka negatif
- Nilai terkecil dari nilai absolut hasil penjumlahan merupakan nilai t hitung,
yaitu uji nilai statistik
- Membuat kesimpulan
Menyimpulkan H0 diterima atau ditolak
Untuk pasangan data lebih besar dari 25 ( n 25 ), pengujiannya
menggunakan nilai z yaitu :
z =
E
T=
σ
T=
1.6 Metode Penelitian
1. Mengkaji lebih dalam lagi statistik non parametrik khususnya uji peringkat
bertanda Wilcoxon dengan menggunakan beberapa parameter
2. Simulasi data menggunakan paket program Microsoft Excel
BAB 2
LANDASAN TEORI
2.1 Distribusi Normal
Salah satu distribusi frekuensi yang paling penting dalam statistika adalah distribusi
normal. Distribusi normal berupa kurva berbentuk lonceng setangkup yang melebar
tak berhingga pada kedua arah positif dan negatifnya. Penggunaanya sama dengan
penggunaan kurva distribusi lainnya. Frekuensi relatif suatu variabel yang mengambil
nilai antara dua titik pada sumbu datar. Tidak semua distribusi berbentuk lonceng
setangkup merupakan distribusi normal.
Pada tahun 1733 DeMoivre menemukan persamaan matematika kurva normal
yang menjadi dasar banyak teori statistika induktif. Distribusi normal sering pula
disebut Distribusi Gauss untuk menghormati Gauss (1777 – 1855), yang juga
menemukan persamaannya waktu meneliti galat dalam pengukuran yang
berulang-ulang mengenai bahan yang sama.
Sifat dari variabel kontinu berbeda dengan variabel diskrit. Variabel kontinu
dipisahkan satu nilai dengan nilai yang lain. Itulah sebabnya fungsi variabel random
kontinu sering disebut fungsi kepadatan, karena tidak ada ruang kosong diantara dua
nilai tertentu. Dengan kata lain sesungguhnya keberadaan satu buah angka dalam
variabel kontinu jika ditinjau dari seluruh nilai adalah sangat kecil, bahkan mendekati
nol. Karena itu tidak bisa dicari probabilitas satu buah nilai dalam variabel kontinu,
tetapi yang dapat dilakukan adalah mencari probabilitas diantara dua buah nilai.
Distribusi kontinu mempunyai fungsi matematis tertentu. Jika fungsi
matematis tersebut digambar, maka akan terbentuk kurva kepadatan dengan sifat
sebagai berikut:
1. Probabilitas nilai x dalam variabel tersebut terletak dalam rentang antara 0
dan 1
2. Probabilitas total dari semua nilai x adalah sama dengan satu (sama dengan
luas daerah di bawah kurva)
Fungsi kepadatan merupakan dasar untuk mencari nilai probabilitas di antara
dua nilai variabel. Probabilitas di antara dua nilai adalah luas daerah di bawah kurva
di antara dua nilai dibandingkan dengan luas daerah total di bawah kurva. Dapat dicari
luas daerah tersebut dengan menggunakan integral tertentu (definit integral).
Persamaan matematika distribusi peluang peubah normal kontinu bergantung
pada dua parameter μ dan σ yaitu rataan dan simpangan baku. Jadi fungsi padat x akan dinyatakan dengan n (x; μ, σ).
persis sama tapi titik tengahnya terletak di tempat yang berbeda di sepanjang sumbu
datar.
Dengan memeriksa turunan pertama dan kedua dari n(x ; μ, σ) dapat diperoleh lima sifat kurva normal berikut :
1. Modus, titik pada sumbu datar yang memberikan maksimum kurva,
terdapat pada x = μ
2. Kurva setangkup terhadap garis tegak yang melalui rataan μ
3. Kurva mempunyai titik belok pada x = μ σ, cekung dari bawah bila μ – σ
< x < μ + σ, dan cekung dari atas untuk harga x lainnya
4. Kedua ujung kurva normal mendekati asimtot sumbu datar bila harga x
bergerak menjauhi μ baik ke kiri maupun ke kanan
5. Seluruh luas di bawah kurva diatas sumbu datar sama dengan 1
Bila x menyatakan peubah acak distribusi maka P(x1 < x < x2) diberikan oleh
daerah yang diarsir dengan garis yang turun dari kiri ke kanan. Jelas bahwa kedua
daerah yang diarsir berlainan luasnya. Jadi, peluang yang berpadanan dengan
masing-masing distribusi akan berlainan pula.
2.2 Transformasi Normal Standar
Distribusi normal adalah distribusi variabel kontinu dengan fungsi matematis adalah
dengan π = 3,14159… dan e = 2,71828
Selain beberapa konstanta yang tidak akan berubah nilainya (e, π), bentuk
distribusi kurva normal ditentukan oleh tiga variabel, yaitu:
x = nilai dari distribusi variabel
μ = mean dari nilai-nilai distribusi variabel
σ = standar deviasi dari nilai-nilai distribusi variabel
Para ahli statistik telah menyelidiki bentuk distribusi normal dengan
mempelajari fungsi tersebut dan didapatkan sifat-sifat sebagai berikut:
a. Simetris, yaitu mean distribusi terletak di tengah dengan luas bagian
sebelah kiri sama dengan bagian sebelah kanan (berbentuk lonceng)
sehingga total daerah di bawah kurva sebelah kiri = total daerah di bawah
kurva sebelah kanan = 0,5
b. 68% dari nilai variabel terletak dalam jarak 1σ (antara -1σ dan +1σ)
c. 95% dari nilai variabel terletak dalam jarak 1,96σ
d. 99% dari nilai variabel terletak dalam jarak 3σ
Selain menggunakan metode integral, perhitungan probababilitas distribusi
normal juga bisa menggunakan tabel distribusi normal, yaitu tabel yang memuat
probabilitas dari berbagai nilai variabel dalam distribusi normal. Metode ini lebih
praktis untuk keperluan penelitian. Yang menjadi masalah dalam penyusunan tabel
tersebut adalah kenyataan bahwa terdapat banyak sekali macam distribusi normal,
Untuk mengatasi hal tersebut, maka para ahli hanya membuat satu buah tabel
yaitu tabel untuk menghitung nilai-nilai probabilitas distribusi normal standar,
sedangkan jika akan menghitung probabilitas nilai-nilai variabel distribusi normal
yang tidak standar, tetap bisa menggunakan tabel distribusi normal standar tersebut
dengan memakai metode konversi. Yang dimaksud distribusi normal standar adalah
distribusi normal dengan sifat khusus, yaitu distribusi dengan normal yang mean = 0
dan standar deviasi = 1.
Untuk mengatasi kesulitan dalam menghitung fungsi padat normal maka
dibuat tabel luas kurva normal sehingga memudahkan penggunaanya. Akan tetapi,
tidak akan mungkin membuat tabel yang berlainan untuk setiap harga μ dan σ.
Untunglah, seluruh pengamatan dengan setiap peubah acak normal x dapat
ditransformasikan menjadi himpunan pengamatan baru suatu peubah acak normal z
dengan rataan nol dan variansi 1. Hal ini dapat dikerjakan dengan transformasi.
z =
Bilamana x mendapat suatu harga x, harga z padanannya diberikan oleh z = (x
– μ)/σ. Jadi, bila z berharga antara x = x1 dan x = x2, maka peubah acak z akan
berharga z1 = (x1 – μ)/σ dan z2 = (x2 – μ)/σ. Distribusi peubah acak normal dengan
rataan nol dan variansi 1 disebut distribusi normal baku.
Dengan demikian sepanjang diketahui rata-rata dan deviasi standar, maka
dapat ditransformasi setiap distribusi nilai ke dalam nilai-nilai z. Bagaimanapun hanya
sendirinya berdistribusi normal. Dengan kata lain, transformasi ke dalam nilai-nilai z
tidak mengubah bentuk awal dari distribusi itu.
2.3 Tabel Distribusi Normal Standar
Berikut ini beberapa hal tentang distribusi normal standar :
1. Tabel distribusi normal standar disusun untuk menghitung probabilitas
nilai-nilai variabel normal standar, yaitu distribusi normal dengan mean nol (μ = 0) d an standar d ev iasi satu (σ = 1 ). Variabel distribu si normal stand ar
menggunakan lambang z.
2. Karena distribusi normal standar bersifat simetris (kiri-kanan sama), maka
tabel distribusi normal standar dibuat hanya untuk menghitung bagian sebelah
kanan mean dari distribusi tersebut. Untuk menghitung nilai di sebelah kiri,
maka nilai z yang negatif dianggap sama dengan z positif, sehingga tabel
tersebut tetap bisa digunakan.
3. Nilai-nilai probabilitas yang terdapat dalam tabel tersebut adalah nilai
probabilitas antara μ = 0 dan satu nilai z tertentu, bukan antara dua buah nilai z
sembarang.
Nilai z begitu penting karena semua distribusi normal ukuran nilai apapun
dapat ditransformasi kedalam satu distribusi nilai, yaitu distribusi nilai z yang disebut
dengan distribusi normal standar.
Distribusi mempunyai dua sifat penting, yaitu :
1. Rata-rata distribusi z, μ adalah 0
Distribusi asli dan sesudah ditransformasi dikarenakan semua harga x antara x1
dan x2 mempunyai harga z padanan antara z1 dan z2, luas di bawah kurva x antara
ordinat x = x1 dan x = x2 sama dengan luas di bawah kurva z antara ordinat yang telah
ditransformasikan z = z1 dan z = z2. Sekarang banyaknya tabel kurva normal yang
diperlukan telah diperkecil menjadi satu, yaitu distribusi normal baku.
2.4 Uji Hipotesis
Dua unsur utama dalam statistik inferensi adalah estimasi dan pengujian hipotesis.
Pengujian hipotesis merupakan hal sangat penting dalam statistik inferensi. Dua tipe
pengujian hipotesis, yaitu uji t untuk menguji hipotesis pada parameter tunggal
(individual) dan uji F menguji hipotesis pada parameter-parameter secara simultan.
Pengujian hipotesis dilakukan setelah menghitung estimasi terhadap parameter
populasi yang benar dengan serangkaian pertanyaan-pertanyaan yang jauh lebih rumit.
Pengujian hipotesis menentukan apa yang dapat dipelajari tentang alam nyata dari
sampel. Apabila hipotesis ditolak dengan menggunakan hasil yang muncul oleh
sampel yang digunakan maka hipotesis dinyatakan benar, keanehan-keanehan yang
terjadi bahwa sampel tertentu akan teramati.
Pengujian hipotesis digunakan di berbagai bidang. Sebuah perusahaan
memiliki bagian penelitian dan pengembangan yang salah satu tugasnya adalah
menguji produk sebelum dipasarkan. Seorang ahli ekonomi Milton Friedman
Walaupun para peneliti selalu tertarik untuk mempelajari apakah teori yang
dipertanyakan (hipotesis) didukung oleh estimasi-estimasi yang dihasilkan dari sebuah
sampel yang berasal dari pengamatan-pengamatan alam nyata, nampaknya hampir
tidak mungkin untuk membuktikan bahwa suatu hipotesis tertentu adalah benar.
Semua yang dapat dilakukan menyatakan bahwa suatu sampel tertentu cocok atau
sesuai dengan hipotesis tertentu. Walaupun hal tersebut tidak dapat membuktikan
bahwa suatu teori tertentu adalah “benar” dengan menggunakan uji hipotesis dengan
suatu tingkat keyakinan tertentu. Dalam kasus seperti ini, peneliti menyimpulkan
bahwa sangatlah tidak mungkin hasil sampel akan teramati, jika teori yang
dihipotesiskan adalah benar. Jika terdapat bukti yang tidak sesuai dengan validitas
teori, pertanyaan itu sering disimpan sampai data tambahan atau suatu pendekatan
baru memberikan jalan terang bagi persoalan itu.
Ada tiga topik yang sangat penting untuk dibicarakan dalam aplikasi pengujian
hipotesis pada analisis regresi :
1. Spesifikasi hipotesis yang harus diujikan
2. Keputusan yang digunakan untuk menentukan apakah menolak hipotesis
yang dipertanyakan
3. Macam kesalahan yang mungkin dihadapi jika aplikasi keputusan
menghasilkan kesimpulan yang tidak benar.
2.5 Spesifikasi Hipotesis : Hipotesis Nol dan Hipotesis Alternatif
Tahap pertama dalam pengujian hipotesis adalah menyatakan secara eksplisit
hipotesis yang akan diuji. Untuk menjaga rasa kejujuran, peneliti seharusnya
menyatakan spesifikasi hipotesis tersebut sebelum parameter dalam hipotesis itu
hipotesis dengan dasar teori selengkap mungkin. Hipotesis yang disusun setelah
estimasi adalah pembenaran hasil-hasil tertentu daripada menguji validatasinya.
Akibatnya, sebagian besar ahli statistik inferensi harus hati-hati dalam menyusun
hipotesis sebelum estimasi.
Dalam menyusun sebuah hipotesis, peneliti harus menyatakan secara hati-hati
tentang apa yang dipikir tidak benar dan apa yang dipikir benar. Ini mencerminkan
harapan-harapan peneliti tentang suatu parameter atau parameter-parameter tertentu
diringkas dalam bentuk hipotesis nol dan hipotesis alternatif.
Hipotesis nol adalah suatu pernyataan tertentu tentang nilai-nilai dalam suatu
range dari parameter yang akan diharapkan terjadi apabila teori yang dimiliki peneliti
tidak benar. Sedangkan Hipotesis alternatif digunakan untuk menspesifikasi nilai-nilai
dalam suatu range dari parameter yang diharapkan terjadi apabila pernyataan teori
oleh peneliti adalah benar.
Kata nol berarti “kosong” dan hipotesis nol dapat dipertimbangkan sebagai
hipotesis yang mana peneliti tidak dipercaya. Dalam membangun hipotesis nol dan
hipotesis alternatif dengan cara seperti ini supaya dapat menyusun pernyataan yang
kuat apabila menolak hipotesis nol. Ini hanya terjadi apabila didefinisikan hipotesis
nol dengan beranggapan bahwa hal tersebut tidak mengharapkan dapat membatasi
probabilitas menolak secara kebetulan hipotesis nol apabila faktanya memang benar.
Pernyataan sebaliknya tidak berlaku, yaitu bahwa sesungguhnya hal tersebut
tidak pernah mengetahui probabilitas menerima secara kebetulan hipotesis nol apabila
hipotesis nol. Dapat dikatakan bahwa tidak dapat menolak hipotesis nol atau
meletakkan kata menerima dalam permasalahan.
Dalam statistik inferensi, hipotesis biasanya tidak menspesifikasi nilai-nilai
tertentu, namun menyatakan suatu arah atau tanda tertentu yang mana peneliti
mengharapkan statistik hasil estimasi itu akan diperoleh. Dapat dinyatakan hipotesis
suatu parameter tertentu akan positif atau negatif. Dalam kasus-kasus semacam itu
hipotesis nol menunjukkan bahwa apa yang diharapkan tidak terjadi, namun harapan
itu merupakan suatu range nilai hipotesis yang sama (dalam suatu range) untuk
hipotesis alternatif.
Notasi yang digunakan untuk menunjukkan suatu hipotesis nol adalah “H0”
dan notasi ini diikuti oleh suatu pernyataan nilai atau range nilai-nilai yang tidak
diharapkan sebagai parameter yang akan diperoleh. Apabila kita mengharapkan suatu
parameter yang negatif maka hipotesis nol yang benar adalah
H0: μ < 0 (nilai yang tidak diharapkan)
Hipotesis alternatif dinyatakan oleh “H1” diikuti oleh parameter nilai atau
nilai-nilai yang diharapkan teramati :
H1: μ 0 (nilai yang diharapkan benar)
Cara lain untuk menyatakan hipotesis nol dan hipotesis alternatif adalah
menguji hipotesis bahwa μ adalah tidak berbeda secara signifikan dari nol untuk
H0: μ = 0
H1: μ 0
Oleh karena H1 memiliki nilai-nilai pada kedua arah dari hipotesis nol, maka
pendekatan ini disebut uji dua-arah untuk membedakan dengan contoh yang pertama,
yaitu uji satu-arah
2.6. Tipe Kesalahan I dan Kesalahan II
Pengujian dalam statistik inferensi adalah menghipotesiskan suatu arah yang
diharapkan dari parameter atau masing-masing parameter dan kemudian menentukan
apakah menolak atau tidak menolak hipotesis nol. Oleh karena statistik hanyalah
estimasi dari parameter (parameter-parameter) populasi yang benar, maka tidaklah
realistis untuk menduga bahwa kesimpulan yang ditarik dari analisis sampel akan
selalu benar. Ada dua macam kesalahan yang dapat dibuat dalam pengujian hipotesis
semacam itu :
Tipe Kesalahan I : Tidak menolak sebuah hipotesis nol yang benar
Tipe Kesalahan II : Tidak menolak sebuah hipotesis nol yang salah
Dapat diperhatikan kesalahan-kesalahan ini sebagai kesalahan-kesalahan Tipe
I dan Tipe II. Anggaplah memiliki hipotesis nol dan hipotesis alternatif sebagai
berikut :
H0:μ 0
membuat kesalahan Tipe I, namun hanya satu-satunya kesempatan dapat dinolak
kebenaran adalah ketika jatuh di daerah penolakan.
Memperkecil tipe kesalahan I berarti memperbesar tipe kesalahan II. Dapat
dipilih di antara kedua tipe kesalahan tersebut dengan memperhatikan biaya (cost)
membuat satu jenis kesalahan yang secara dramatis lebih besar daripada biaya
membuat kesalahan jenis lain.
2.8 Distribusi Normal Standar, z untuk uji Hipotesis
Uji hipotesis sering menggunakan distribusi normal standar. Untuk kasus-kasus di
mana ukuran jumlah sampel cukup besar dan deviasi standar populasi diketahui
digunakan distribusi normal standar z, sementara untuk ukuran jumlah sampel kecil
dan deviasi standar populasi tidak diketahui digunakan distribusi normal standar.
a. Untuk Sampel Berukuran Besar dan σ Diketahui
z =
dengan :
σ
x=
σ = deviasi standar populasi
= rata-rata sampel
b. Untuk Sampel Berukuran Besar dan σ Tidak Diketahui
z =
dengan :
S
x=
S = deviasi standar data sampel
= rata-rata sampel
μ = rata-rata populasi
2.9 Uji Tanda
Di dalam menggunakan uji t, populasi dari mana sampel diambil harus berdistribusi
normal. Untuk pengujian perbedaan mean dari dua populasi didasarkan pada
anggapan bahwa varians populasinya harus identik/sama. Dalam banyak hal bila salah
satu atau kedua anggapan tersebut tidak diketahui, maka uji t tidak dapat
dipergunakan. Dalam hal demikian dapatlah dipergunakan uji nonparametrik yang
umum dikenal sebagai uji tanda (sign test).
Uji tanda didasarkan atas tanda-tanda, positif atau negatif, dari perbedaan
antara pasangan pengamatan. Bukan didasarkan atas besarnya perbedaan. Uji tanda
dapat dipergunakan untuk mengevaluasi efek dari suatu treatment tertentu. Efek dari
variabel eksperimen atau treatment tidak dapat diukur melainkan hanya dapat diberi
2.10 Uji Wilcoxon
Uji nonparametrik akhir-akhir ini mendapat perhatian yang lebih besar karena
beberapa sebab. Pertama, perhitungannya biasanya singkat dan mudah dikerjakan.
Kedua, datanya tak perlu berupa pengukuran kuantitatif tapi dapat saja berupa respon
kualitatif seperti ‘cacat’ atau ‘tidak cacat’, ‘ya ‘ atau ‘tidak’ atau sering pula nilai skala
ordinal yang dapat diberi rank. Pada skala ordinal datanya di rank menurut aturan
tertentu, dan dengan uji nonparametrik berbagai rank itu dianalisis.
Pada tahun 1945 Frank Wilcoxon mengusulkan suatu cara nonparametrik yang
amat sederhana untuk membandingkan dua populasi kontinu bila hanya tersedia
sampel bebas yang sedikit dan kedua populasi asalnya tidak normal. Cara ini sekarang
dinamakan uji Wilcoxon atau Uji Jumlah Rank Wilcoxon.
Hipotesis nol H0 bahwa μ1= μ2 akan diuji lawan suatu tandingan yang sesuai.
Pertama-tama ambilah sampel acak dari tiap populasi. Misalkan n1 banyaknya
pengamatan dalam sampel yang lebih kecil, dan n2 banyaknya pengamatan dalam
sampel yang lebih besar. Bila sampelnya berukuran sama, maka n1 dan n2 dapat
dipertukarkan. Urutlah semua n1 + n2 pengamatan dengan urutan membesar dan
berikan rank 1, 2, … , n1 + n2 pada tiap pengamatan. Bila terdapat seri (pengamatan
yang besarnya sama), maka pengamatan tersebut diganti dengan rataan ranknya jika
2.11 Uji Wilcoxon untuk pengamatan berpasangan
Uji tanda ditunjukkan dengan pemberian tanda tambah atau kurang, anggota yang
mana dari pengamatan yang berpasangan yang lebih besar, tapi tidak menunjukkan
besarnya selisih tersebut. Suatu uji memperhitungkan tanda dan besarnya selisih telah
dikemukakan oleh Wilcoxon dan sekarang biasa disebut sebagai Uji Wilcoxon untuk
pengamatan berpasangan. Uji wilcoxon lebih peka daripada uji tanda dalam
menentukan perbedaan antara rataan populasi dan karena itu akan dibahas secara
mendalam.
Untuk menguji hipotesis bahwa μ1 = μ2 dengan uji Wilcoxon, mula-mula
kesampingkan semua selisih yang besarnya nol dan kemudian rank bi, yaitu sisanya,
tanpa memperhatikan tandanya. Rank 1 diberikan pada nilai mutlak bi yang terkecil,
rank 2 pada terkecil berikutnya, dan seterusnya. Bila nilai mutlak dari dua atau lebih
selisih sama, berilah pada tiap selisih rata-rata dari yang seharusnya akan diberikan
seandainya selisih tersebut dapat diberikan. Bila tidak ada perbedaaan antara kedua
rataan populasi, maka jumlah ruang dari selisih yang positif seharusnyalah hampir
sama dengan jumlah rank dari selisih yang negatif.
Uji ini digunakan untuk menguji kondisi (variabel) pada sampel yang
berpasangan atau dapat juga untuk penelitian sebelum dan sesudah. Dalam uji ini
ingin diketahui manakah yang lebih besar dari antara pasangan. Misalkan di = selisih
tiap pasangan yang harus dibuat ranking, untuk di tanpa memperhatikan tandanya,
rank 1 diberikan untuk harga mutlak di terkecil dan rank terbesar untuk harga mutlak
di terbesar. Kemudian untuk masing-masing ranking berikan tandanya sesuai dengan
Bila perlakuan pertama sama pengaruhnya dengan perlakuan kedua, yaitu
apabila Ho benar, diharapkan akan dijumpai beberapa di yang bertanda + dan beberapa
yang bertanda – dalam jumlah yang sama. Jika jumlah tersebut berbeda, maka berarti
perlakuan pertama berbeda dengan perlakuan kedua.
Tujuan Penggunaan Uji Peringkat Bertanda Wilcoxon ialah menggunakan arah
dan besar perbedaan untuk mengetahui apakah benar-benar terdapat perbedaan pada
data ordinal pasangan tersebut.
BAB 3
PEMBAHASAN DAN HASIL
3.1 Pembahasan
Setiap data merupakan alat bagi pengambilan keputusan untuk dasar pembuatan
keputusan – keputusan atau untuk memecahkan suatu persoalan. Keputusan yang baik
dapat dihasilkan jika pengambilan keputusan tersebut didasarkan atas data yang baik.
Jumlah data yang akan dianalisis tergantung dari penentuan ukuran sampel yang
diambil.
Penentuan ukuran sampel n, merupakan salah satu hal yang penting dalam
studi penarikan sampel, karena telah diketahui bahwa banyaknya informasi tentang
sifat populasi yang terkandung dalam sampel sangat ditentukan oleh ukuran sampel
yang ada. Pada dasarnya memang berlaku bahwa semakin besar ukuran sampel adalah
semakin baik karena akan menambah informasi, tetapi dari penambahan ukuran
sampel tersebut berkaitan dengan penambahan ongkos, sehingga penentuan ukuran
Dalam metode Wilcoxon memperkenalkan pengujian yang relatif cukup
sederhana dan tidak membutuhkan berbagai macam asumsi yang harus dipenuhi
seperti pengujian-pengujian lainnya, misalnya tentang sifat dan bentuk distribusinya
serta parameter populasinya.
Dalam analisa ini, Wilcoxon mengenalkan pengujian terhadap 2 macam
sampel yang dikenal sebagai Wicoxon Two Sample Test. Pengujian dengan metode
ini sebenarnya ditujukan untuk menguji suatu hipotesa nol (H0). Untuk menguji hal
tersebut diatas, maka pertama kali yang harus dilakukan adalah memilih beberapa
sampel secara random dari tiap populasi yang akan diteliti. Setelah itu diusahakan
untuk membuat ranking yang sesuai dengan pengamatan sampel yang telah diperoleh.
Selanjutnya jumlah ranking yang diperoleh tersebut dari sejumlah pengamatan
n1 pada jenis sampel yang pertama disebut sebagai W1 dan jumlah ranking yang
diperoleh dari sejumlah pengamatan pada jenis sampel kedua n2 sebagai W2.
3.1.1 Untuk sampel n < 25
Jika diberikan sebuah persoalan seperti berikut:
Seorang peneliti ingin menentukan apakah kenaikan gaji akan meningkatkan tingkat
motivasi pegawai. Misalkan X menunjukkan tingkat motivasi pegawai sebelum
Ukuran sampel 20 pekerja dan hasil penelitian sebagai berikut :
Tabel 3.1.1 Tingkat Motivasi Pegawai Sebelum & Sesudah Kenaikan Upah
Pegawai Sebelum (X) Sesudah (Y)
Dari data diatas ujilah hipotesis nol (Ho) bahwa kenaikan upah tidak
mempunyai pengaruh terhadap jumlah output per jam dengan taraf nyata 0,01.
3.1.2 Untuk sampel n 25
Penelitian kinerja sebelum dan sesudah pelaaksanaan otonomi daerah pegawai telah
dilakukan terhadap sampel berukuran 29 pegawai suatu instansi “X”. Hasil
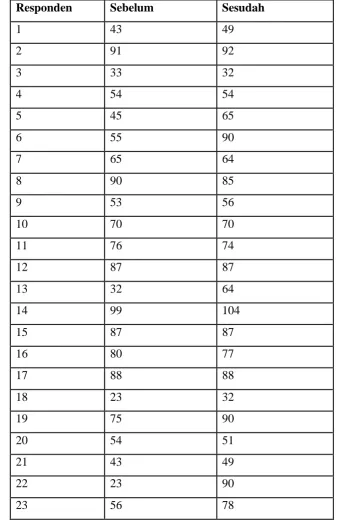
Tabel 3.1.2 Tingkat Kinerja Sebelum & Sesudah Otonomi Daerah
Responden Sebelum Sesudah
24 56 57
Sumber : Nana Danapriatna dan Rony Setiawan (2005)
Dari data diatas ujilah Hipotesis nol (H0) bahwa pelaksanaan otonomi daerah
tidak berpengaruh nyata terhadap kinerja pegawai dengan taraf nyata 0.05
3.2 Penyelesaian
3.2.1 Untuk sampel n < 25
Adapun penyelesaian dari permasalahan diatas adalah sebagai berikut :
1. H0 : Kenaikan upah tidak mempunyai pengaruh terhadap tingkat motivasi
pegawai (jumlah ranking positif = jumlah ranking negatif)
H1 : Kenaikan upah mempunyai pengaruh terhadap tingkat motivasi pegawai
(jumlah ranking positif ≠ jumlah ranking negatif)
2. Taraf nyata a = 0,01; n = 20 pasangan dan akan dikurangi jika terdapat nilai
di = 0. Karena n 25 maka menggunakan tabel Wilcoxon (T tabel)
3. Kriteria daerah kritis : dk = (n1 + n2 – 2)
= (20 + 20 – 2)
dengan α = 0,01 maka t hitung = 37
4. Kriteria uji: H0 ditolak jika t hitung < T tabel atau sebaliknya.
5. Penyelesaian menghitung T
Tabel 3.2.1 Tingkat Motivasi Pegawai Sebelum & Sesudah Kenaikan Upah
S 75 65 -10 20 -19 -19
T 65 67 2 8 6 6
Jumlah 137.5 -72.5
6. Kesimpulan :
T hitung terkecil = 72.5 dan t hitung terbesar = 137.5
Nilai T tabel yang diperoleh adalah 37
Lalu diperoleh t hitung < T tabel
Maka H0 diterima : Kenaikan upah tidak mempunyai pengaruh terhadap
tingkat motivasi pegawai
3.2.2 Untuk sampel n 25
Adapun penyelesaian dari permasalahan diatas adalah sebagai berikut :
1. H0 : pelaksanaan otonomi daerah tidak berpengaruh terhadap kinerja pegawai
atau jumlah ranking positif sama dengan jumlah ranking negatif
H1 : pelaksanaan otonomi daerah berpengaruh terhadap kinerja pegawai
2. Taraf nyata : 0.05, n = 29 dan akan dikurangi jika terdapat nilai di = 0. Sebaran
sampel dari data diatas n 25 maka digunakan pendekatan kurva normal atau
z tabel.
3. Kriteria uji : H0 ditolak jika z hitung > z tabel atau sebaliknya dengan z tabel
= Z0.05 = 1.64
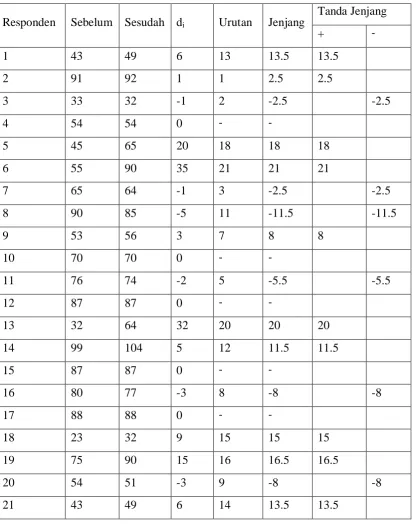
Tabel 3.2.2 Tingkat Kinerja Sebelum dan Sesudah Otonomi Daerah
Responden Sebelum Sesudah di Urutan Jenjang
22 23 90 67 22 22 22
23 56 78 22 19 19 19
24 56 57 1 4 2.5 2.5
25 70 70 0 - -
26 76 78 2 6 5.5 5.5
27 45 60 15 17 16.5 16.5
28 76 80 4 10 10 10
29 54 54 0 - -
Jumlah 215 -38
Dari penyelesaian diatas maka nilai t hitung = 38 dengan Beda (di) = 0 tidak dihitung.
Oleh karena itu n = 29-7 = 22
E
T=
=
= 126.5
σ
T=
=
= 30.802
z =
=
= -2.87
5. Kesimpulan
z hitung yang diperoleh adalah 2.87
Nilai Z tabel yang diperoleh adalah 1.64
Lalu diperoleh z hitung (2.87) > Z tabel (1.64)
Maka H0 ditolak : Pelaksanaan otonomi daerah berpengaruh terhadap kinerja
BAB 4
PENUTUP
4.1 Kesimpulan
Berdasarkan hasil perhitungan dan penganalisaan data yang telah dilakukan, maka
dapat diambil kesimpulan sebagai berikut:
1. Untuk sampel n < 25 maka diperoleh hasil bahwa H0 diterima yang berarti
Kenaikan Upah tidak mempunyai pengaruh terhadap tingkat motivasi pegawai
2. Untuk sampel n 25 maka diperoleh hasil bahwa H0 ditolak yang berarti bahwa
Pelaksanaan Otonomi Daerah Berpengaruh terhadap Kinerja Pegawai
3. Untuk sampel n 25 uji Wilcoxon berperan cukup penting pada Distribusi
Normal
4. Uji Wilcoxon memiliki hasil yang cukup signifikan untuk beberapa nilai
4.2Saran
Dari analisis dan kesimpulan yang telah didapat, ada beberapa saran yang mungkin
dapat membantu dalam melakukan pengambilan sampel sebagai berikut :
1. Jika ingin mengambil sampel haruslah lebih teliti rumus mana yang akan
digunakan agar tidak terjadi kesalahan dalam menentukan penyelesaian.
DAFTAR PUSTAKA
1. Danapriatna, Nana dan Rony Setiawan, ” Pengantar Statistika”, Graha
Yogyakarta, 2005
2. Daniel, W, ” Statistik Nonparametrik Terapan ”, PT. Gramedia, Jakarta, 1989
3. Dixon, J. Wilfrid and Frank J. Massey, Jr, ” Pengantar Analisis Statistik ”,
Universitas Gajah Mada, Yogyakarta, 1997
4. Djarwanto, ” Statistik Nonparametrik ”, Universitas Sebelas Maret Surakarta,
Yogyakarta, 2003
5. Drapper, NR and Harry smith, S, “ Applied Regression Analysis “, Second
Edition. John Wiley & Sons, Inc, New York, 1981
6. Dudewicz, J. Edward dan Satya N. Mishra, “ Statistika Matematika Modern “, ITB
Bandung, 1995
7. Dwi Waluyo, Sihono, “ Statistika Untuk Pengambilan Keputusan “, Ghalia
Indonesia, Jakarta, 2001
8. Hakim, Abdul, “ Statistik Induktif ”, Ekonisia, Yogyakarta, 2002
9. Harinaldi, ” Prinsip – Prinsip Statistik Untuk Teknik dan Sains ”, Erlangga,
Jakarta, 2005
10.Hasan, Iqbal. M, ” Pokok-Pokok Materi Statistik 2 (Statistik Inferensif) ”, Bumi
Aksara, Jakarta, 2001
11.Saleh, Samsubar, ” Statistik Nonparametrik ”, Universitas Gajah Mada,
Yogyakarta, 1996
12.Siegel, Sidney, ” Statistik Nonparametrik ”, PT. Gramedia, Jakarta, 1992
13.Supangat, Andi, ”Statistika dalam Kajian Deskriptif, Inferensi dan
14.Spigel, M, ” Statistik Terjemahan ”, Erlangga, Jakarta, 2004
15.Sprent, P, ” Metode Statistik Nonparametrik Terapan ”, Universitas Indonesia,
Jakarta, 1991
16.Supranto, J, ” Statistik : Teori dan Aplikasi ”, PT. Gelora Aksara Pratama, Jakarta,
1989
17. Walpole, E. Ronald dan Raymond H. Myrers, ” Ilmu Peluang dan Statistika
Untuk Insinyur dan Ilmuwan”, ITB, Bandung, 1986
18. http:// www.google.com
19. http://
/ Kajian Uji Mann-Whitney dan Uji Peringkat Bertanda
Wilcoxon oleh Yelvarina, Bengkulu, diakses pada 02 Maret 2010