PERBANDINGAN MULTIVARIATE ADAPTIVE REGRESSION
SPLINE (MARS) DAN POHON KLASIFIKASI C5.0
PADA DATA TIDAK SEIMBANG
(Studi Kasus: Pekerja Anak di Jakarta)
DIMAS ADIANGGA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Perbandingan Multivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0 pada Data Tidak Seimbang (Studi Kasus: Pekerja Anak di Jakarta)” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, September 2015
RINGKASAN
DIMAS ADIANGGA. Perbandingan Multivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0 pada Data Tidak Seimbang (Studi Kasus: Pekerja Anak di Jakarta). Dibimbing oleh HARI WIJAYANTO dan BAGUS SARTONO.
Pekerja anak merupakan salah satu pelanggaran hak anak karena mendayagunakan anak-anak untuk tujuan ekonomi. Tidak semua anak yang bekerja adalah pekerja anak. Badan Pusat Statistik (BPS) mendefinisikan seorang anak adalah pekerja anak jika memenuhi salah satu kriteria, yaitu anak-anak berumur 5-12 tahun yang bekerja dalam satu minggu terakhir tanpa melihat jam kerja mereka, atau anak-anak berumur 13-14 tahun yang bekerja lebih dari 15 jam dalam satu minggu terakhir, atau anak-anak yang bekerja umur 15-17 tahun yang bekerja lebih dari 40 jam dalam satu minggu terakhir.
Metode klasifikasi digunakan untuk mengetahui faktor-faktor yang berpengaruh terhadap pekerja anak karena peubah respon dalam penelitian ini terdiri dari dua kelas yaitu pekerja anak dan bukan pekerja anak. Metode klasifikasi yang digunakan adalah Mutivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0. MARS merupakan metode regresi non parametrik yang menggabungkan fungsi basis spline dengan algoritma pemilahan rekursif yang bersifat adaptif terhadap data sehingga menghasilkan model dengan tingkat keakuratan tinggi. C5.0 merupakan metode analisis yang mentransformasi data ke dalam bentuk pohon yang mudah dalam interpretasi dengan tingkat keakuratan yang tinggi.
Jumlah pekerja anak diketahui jauh lebih rendah daripada jumlah anak pada suatu wilayah. Ketimpangan proporsi pada kelas peubah respon disebut dengan data tidak seimbang (imbalanced data). Klasifikasi rentan terhadap data yang tidak seimbang karena menghasilkan model dengan akurasi yang rendah pada kelas minoritas. Beberapa metode untuk menangani data yang tidak seimbang yaitu Syntethic Minority Oversampling Technique (SMOTE) dan Cost Sensitive Learning (CSL). SMOTE menyeimbangkan kedua kelas pada peubah respon dengan membuat data sintetis untuk kelas minoritas, sementara CSL memberikan pembobotan pada saat pembangunan model berdasarkan kesalahan klasifikasi.
Penelitian ini bertujuan untuk mencari model klasifikasi terbaik antara metode MARS dan C5.0 setelah penanganan data tidak seimbang dengan SMOTE dan CSL serta mengidentifikasi faktor-faktor yang berpengaruh terhadap pekerja anak di Propinsi DKI Jakarta. Data yang digunakan adalah Survey Sosial Ekonomi Nasional (Susenas) Propinsi DKI Jakarta pada tahun 2013.
Model terbaik berdasarkan nilai luas di bawah Kurva ROC (AUC) tertinggi adalah MARS dengan SMOTE. Beberapa faktor yang berpengaruh terhadap pekerja anak antara lain Partisipasi Sekolah Anak (X1), Tinggal dengan Orang Tua Kandung (X3), Umur Kepala Rumah Tangga (KRT) (X4), Pendidikan KRT (X7), Pengeluaran per Kapita (X12), dan Jumlah Anggota Rumah Tangga (X10).
SUMMARY
DIMAS ADIANGGA. COMPARISON OF MULTIVARIATE ADAPTIVE REGRESSION SPLINE (MARS) AND CLASSIFICATION TREE C5.0 OF IMBALANCED DATA (CASE STUDY: CHILD LABOR IN JAKARTA). Supervised by HARI WIJAYANTO and BAGUS SARTONO.
Child labor is a violation of children's rights as exploiting children for economic purposes. Not all working children are child labor. Statistics Indonesia (BPS) defines a child is child labor if it meets one of the criteria, e.g, children 5-12 years old who worked in the last week without seeing their working hours, children aged 13-14 years who worked more than 15 hours in the last week, and children aged 15-17 years who work who worked more than 40 hours in the last week.
Classification method is used to determine the factors that influence child labor as a response variable in this study consisted of two classes, they are child labor and not child labor. Classification methods used are Mutivariate Adaptive Regression Spline (MARS) and C5.0 classification tree. MARS is a non-parametric regression method which combines the basis function of spline with recursive partitioning algorithm that is adaptive to the data so that results models with a high degree of accuracy. C5.0 is an analysis that transforms the data into a form of trees that is easily in the interpretation with a high degree of accuracy
The number of child labor known to be much lower than the number of children in the region. Inequality response variable proportion of the class is called imbalanced data. Classification is vulnerable to data that is not balanced because it results a model with low accuracy for the minority class. Syntethic Minority Oversampling Technique (SMOTE) and Cost Sensitive Learning (CSL) are known methods to handle imbalanced data. SMOTE will balance both classes on the response variable by making the data synthetic for the minority class, while CSL will consider the cost of misclassification by providing weighting at the time of construction of the model.
This study aimed to find the best classification model between the MARS method and C5.0 after handling the imbalanced data with SMOTE and CSL as well as the identification of factors that influence a child labor in DKI Jakarta. The data used is from the National Socioeconomic Survey (Susenas) DKI Jakarta in 2013.
The best model based on the highest value of the area under the ROC Curve (AUC) is MARS with SMOTE. Some of the factors that influence child labor are
Child’s School Participation (X1), Child That Live with Parents (X3), Age of Household Head (X4), Education of Household Head (X7), Expenditure per Capita (X12), and Number of Household Members (X10).
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika Terapan
PERBANDINGAN MULTIVARIATE ADAPTIVE REGRESSION
SPLINE (MARS) DAN POHON KLASIFIKASI C5.0
PADA DATA TIDAK SEIMBANG
(Studi Kasus: Pekerja Anak di Jakarta)
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Perbandingan Multivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0 pada Data Tidak Seimbang
(Studi Kasus: Pekerja Anak di Jakarta) Nama : Dimas Adiangga
NIM : G152130324
Disetujui oleh Komisi Pembimbing
Dr. Ir. Hari Wijayanto, M.Si Ketua
Dr. Bagus Sartono, M.Si Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr. Ir. Indahwati, M.Si
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M.Sc.Agr
PRAKATA
Segala puji bagi Allah ‘azza wa jalla atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tesis yang berjudul “Perbandingan Multivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0 pada Data Tidak Seimbang (Studi Kasus: Pekerja Anak di Jakarta)”. Keberhasilan ini tidak dapat penulis raih sendiri tetapi dengan bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Penulis mengucapkan terima kasih kepada ketua komisi pembimbing Bapak Dr. Ir. Hari Wijayanto, M.Si, dan Bapak Dr. Bagus Sartono sebagai anggota komisi pembimbing, yang telah memberikan bimbingan, arahan, dan saran kepada penulis dalam menyempurnakan tesis ini. Terima kasih juga Penulis ucapkan kepada Pimpinan Badan Pusat Statistik (BPS) baik di pusat maupun di daerah atas kepercayaan dan kesempatan yang diberikan kepada penulis untuk melanjutkan pendidikan Magister Statistika Terapan. Terima kasih kepada orang tua, kakak, istri dan putri tersayang serta seluruh keluarga besar atas cinta, do’a, dan dukungannya. Tidak lupa ucapan terima kasih kepada seluruh staf Departemen Statistika IPB, dan rekan-rekan S2 dan S3 khususnya dari kelas BPS, atas bantuan dan kebersamaannya. Dan yang terakhir, penulis sampaikan terima kasih kepada semua pihak yang tidak dapat disebutkan satu per satu yang telah membantu dalam penyusunan tesis ini.
Tiada gading yang tak retak, begitu pula penulisan tesis ini yang masih terdapat kekurangan. Oleh karena itu, penelitian selanjutnya diharapkan lebih baik dari penelitian ini. Penulis berharap semoga penelitian ini dapat bermanfaat dan memberikan kontribusi bagi yang membutuhkan.
Bogor, September 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
Pohon Klasifikasi C5.0 3
Multivariate Adaptive Regression Spline (MARS) 5
Data Tidak Seimbang 7
Syntethic Minority Oversampling Technique (SMOTE) 8
Cost Sensitive Learning 8
Ketepatan Klasifikasi 9
3 METODE PENELITIAN 11
Data 11
Metode Analisis 12
4 HASIL DAN PEMBAHASAN 14
Gambaran Umum Pekerja Anak di Jakarta 14
Penanganan Data Tidak Seimbang 18
Pemilihan Model Klasifikasi Terbaik 20
Interpretasi Model Terbaik 21
5 SIMPULAN 26
DAFTAR PUSTAKA 27
LAMPIRAN 29
DAFTAR TABEL
2.1 Tabel klasifikasi dua arah 10
3.1 Peubah penyusun model 11
4.1 Persentase Status Anak menurut kelompok umur 15 4.2 Partisipasi sekolah pekerja anak berdasarkan kelompok umur 15 4.3 Persentase pekerja anak menurut peubah yang digunakan 16 4.4 Persentase perbandingan jumlah anak menurut Status Anak 18
4.5 Hasil SMOTE pada data latih 19
4.6 Perbandingan ketepatan metode klasifikasi 20
DAFTAR GAMBAR
2.1 Contoh pohon klasifikasi 3
2.2 Contoh plot data tidak seimbang 8
3.1 Diagram alir penelitian 13
4.1 Peta persentase persebaran pekerja anak berdasarkan kab/kota 14 4.2 Boxplot Jumlah ART berdasarkan Status Anak 17
4.3 Boxplot Umur KRT berdasarkan Status Anak 17
4.4 Plot Umur KRT dan Jumlah ART berdasarkan Status Anak 18 4.5 Plot hasil SMOTE peubah Umur KRT dan Jumlah ART berdasarkan
Status Anak 19
4.6 Perbandingan nilai AUC pada ketiga model 21
4.7 Tingkat kepentingan tiap peubah 22
DAFTAR LAMPIRAN
1 Pohon Klasifikasi C5.0 29
2 Pohon Klasifikasi C5.0 SMOTE 29
3 Pohon Klasifikasi C5.0 Cost 30
1
1 PENDAHULUAN
Latar Belakang
Anak adalah sebutan untuk penduduk yang berusia dibawah 18 tahun, termasuk mereka yang masih dalam kandungan. Anak-anak sebagai generasi penerus bangsa di masa depan telah mendapat jaminan perlindungan dari Pemerintah dengan perangkat hokum dan perundang-undangan. Salah satu perundangan tersebur adalah Undang-Undang No 35 Tahun 2014 yang merupakan perubahan dari Undang-Undang No 22 Tahun 2002. Dengan undang-undang ini, pemerintah pusat mewajibkan pemerintah daerah untuk mendukung dan melaksanakan kebijakan perlindungan anak di daerah. Penerapan undang-undang pada kenyataannya tidak berjalan sesuai dengan semangat yang diusung karena pelanggaran terhadap hak anak masih terjadi.
Pekerja anak adalah suatu bentuk pendayagunaan anak untuk tujuan ekonomi dan merupakan pelanggaran hak asasi anak untuk hidup, tumbuh, berkembang dan berpartisipasi secara optimal. Tidak semua anak yang bekerja adalah pekerja anak. Badan Pusat Statistik (BPS) mendefinisikan seorang anak adalah pekerja anak bila memenuhi salah satu kriteria yaitu semua anak-anak yang bekerja umur 5-12 tahun tanpa melihat jam kerja mereka, anak-anak berumur 13-14 tahun yang bekerja lebih dari 15 jam dalam satu minggu terakhir, dan anak-anak yang bekerja umur 15-17 tahun yang bekerja lebih dari 40 jam dalam satu minggu terakhir.
Berdasarkan hasil pengolahan Survey Angkatan Kerja Nasional (Sakernas) yang diselenggarakan oleh BPS pada tahun 2011-2014, tingkat pekerja anak di Indonesia mengalami penurunan, mulai dari 4.23 persen pada tahun 2011 yang kemudian turun pada tahun 2014 yaitu 2.77 persen. Penurunan ini merupakan keberhasilan pemerintah yang telah mengeluarkan berbagai kebijakan dan upaya untuk mengurangi jumlah pekerja anak. Penurunan ini seharusnya menjadikan Pemerintah Indonesia lebih semangat dalam pengurangan jumlah pekerja anak kedepannya.
DKI Jakarta sebagai pusat pemerintahan dan ekonomi tidak luput dari permasalahan sosial pekerja anak. Berdasarkan Profil Anak Indonesia tahun 2011-2013, jumlah pekerja anak di Jakarta pada tahun 2010 – 2012 masih cukup tinggi dibanding beberapa propinsi lain. Tingginya jumlah pekerja anak ini berarti bahwa perlindungan anak terhadap eksploitasi secara ekonomi belum berjalan maksimal. Untuk itu perlu metode analisis yang akurat untuk mengidentifikasi faktor-faktor yang menyebabkan seorang anak menjadi pekerja anak agar kebijakan penanganan pekerja anak tidak salah sasaran.
2
Metode mencari faktor-faktor yang menyebabkan seorang anak menjadi pekerja anak adalah dengan regresi atau klasifikasi. Penggunaan regresi jika peubah tak bebas merupakan peubah kontinyu sedangkan penggunaan metode klasifikasi jika peubah tak bebas merupakan peubah kategorik. Penelitian ini menggunakan metode klasifikasi karena peubah tak bebas adalah peubah kategorik. Beberapa metode klasifikasi yang dapat digunakan adalah Regresi Logistik, Support Vector Machine (SVM), Multivariate Adaptive Regression Spline (MARS), Pohon Klasifikasi, dan lainnya. MARS merupakan metode nonparametrik yang dikembangkan oleh Friedman (1991) untuk memecahkan masalah regresi parametrik dengan tujuan utama untuk memprediksi nilai dari peubah respon dari satu atau beberapa peubah penjelas. Prasetyo (2009), Jalaluddin (2009), dan Munoz dan Felicisimo (2004) memberikan kesimpulan yang sama bahwa MARS lebih baik dari beberapa model analisis seperti Regresi Logistik dan Classification And
Regression Tree (CART).
Pohon klasifikasi C5.0 merupakan model prediksi untuk peubah kategorik yang berstruktur seperti pohon dengan Algoritma C5.0 yang dikembangkan oleh Quinlan pada tahun 2011. Algoritma ini merupakan pengembangan dari algoritma ID3 dan C4.5. Kelebihan C5.0 dibanding algoritma sebelumya adalah dalam hal kecepatan, memori, dan efisiensi. Algoritma C5.0 mempunyai tingkat akurasi yang lebih baik daripada CART (Ernawati 2008) dan K-Nearest Neighbor (Nilima et al 2012). Dengan beberapa kelebihan tersebut, maka pada penelitian ini digunakan metode MARS dan Pohon Klasifikasi C5.0.
Model klasifikasi rentan dengan data yang tidak seimbang. Ketidakseimbangan ini terletak pada timpangnya proporsi jumlah antar kategori pada peubah tidak bebas yang cukup jauh sehingga terbentuk kelas data mayoritas dan kelas data minoritas. Kondisi ini akan menyebabkan model klasifikasi akan lemah dalam memprediksi kelas data minoritas, padahal kelas ini sering dijadikan objek analisis pemodelan, misalnya pemodelan pada penderita HIV/AIDS dimana jumlah penderita sangat sedikit dibanding jumlah penduduk di suatu wilayah, dan pemodelan pekerja anak dimana jumlah pekerja anak lebih sedikit dibandingkan jumlah anak di suatu wilayah.
Penanganan data tidak seimbang perlu dilakukan sebelum pemodelan untuk mendapatkan model klasifikasi yang memiliki tingkat keakuratan yang tinggi pada kedua kelas. Dua teknik penanganan data tidak seimbang yaitu Syntethic Minority Oversampling Technique (SMOTE) (Chawla 2002) dan Cost Sensitive Learning (CSL) (Elkan 2001). SMOTE akan menyeimbangkan kedua kelas dengan membuat data sintetis untuk data minoritas, sedangkan Cost Sensitive Learning akan memperhitungkan dampak kesalahan klasifikasi dan memberikan pembobot pada data.
Tujuan Penelitian
3
2 TINJAUAN PUSTAKA
Pohon Klasifikasi C5.0
Salah satu metode prediksi dalam penambangan data (data mining) adalah Pohon Keputusan. Metode ini merupakan salah satu metode penambangan data yang banyak digunakan oleh peneliti karena mudah dalam interpretasi model yang dihasilkan. Pohon Keputusan terbagi menjadi dua, yaitu Pohon Klasifikasi dan Pohon Regresi. Pohon Regresi digunakan pada peubah respon numerik sedangkan Pohon Klasifikasi digunakan pada peubah respon kategorik. Penelitian ini berfokus pada Pohon Klasifikasi karena peubah target yang digunakan berupa peubah biner yaitu Status Anak (Pekerja Anak dan Bukan Pekerja Anak).
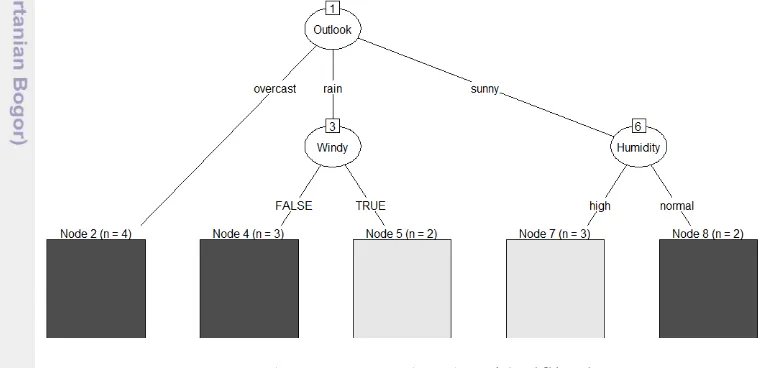
Konsep dasar Pohon Keputusan adalah transformasi data menjadi berstruktur seperti pohon. Pohon Keputusan ini akan menyederhanakan data kompleks dalam sebuah bentuk yang lebih sederhana berupa model pohon kemudian mengubahnya menjadi sekumpulan aturan (rules) sehingga akan mempermudah dalam menarik informasi yang tersembunyi dari sebuah data. Contoh pohon keputusan seperti terlihat pada Gambar 2.1. Pohon ini merupakan model pohon dari data keputusan pelaksanaan pertandingan olahraga (yes atau no) berdasarkan kondisi di lapangan (outlook, windy, humidity, dan temperature).
Gambar 2.1. Contoh pohon klasifikasi
4
Daun merupakan hasil terahir dari percabangan yang memuat nilai dari peubah respon. Pada Gambar 2.1, Daun diwujudkan dengan bentuk kotak yang berbeda warna menurut atribut dari peubah respon. Kotak berwarna gelap (simpul
2,4, dan 8) merupakan atribut peubah respon “yes”, sedangkan kotak berwarna
terang merupakan atribut peubah respon “no”. Pada Daun, juga terdapat informasi jumlah data yang berhasil diklasifikasikan dengan benar yang dinotasikan dengan
“n”.
Pengujian pada Simpul dilakukan untuk mencari pilahan terbaik. Beberapa metode yang digunakan adalah Gini Index, Gain Ratio, Misclassification, dll. Algoritma C5.0 menggunakan konsep Gain Ratio dalam memilih pilahan terbaik. Gain Ratio berdasar pada konsep Entropy dalam penghitungannya. Entropy adalah tingkat kehomogenan data pada himpunan contoh kasus S. Formula Entropy seperti terlihat pada persamaan 1.
= ∑ − � �
�=
= Himpunan kasus = Jumlah partisi
� = Proporsi dari � terhadap
Ketika peubah A memilah himpunan kasus S menjadi subkasus Si maka dihitung information gain yang merupakan selisih dari Entropy sebelum pemilahan dan setelah pemilahan. Formula dari information gain dari peubah A terhadap himpunan contoh S adalah sebagai berikut:
� , = − ∑|| |�| �
Bias Information gain terjadi pada peubah dengan beberapa kategori. Modifikasi information gain menjadi Gain Ratio untuk mengurangi bias yang dihasilkan dengan mempertimbangkan Cabang dalam memilih peubah yang dimasukkan Simpul Internal. Gain Ratio adalah perbandingan information gain dan intrinsic information dari sebuah pilahan. Intrinsic information (IntI) adalah jumlah informasi yang dibutuhkan untuk menentukan Cabang.
5
Pohon klasifikasi dapat berkembang sampai tidak dapat lagi dilakukan pemilahan terhadap data atau sesuai batasan (threshold) tertentu. Pemangkasan (prune) diperlukan untuk menghasilkan pohon yang sederhana. C5.0 menggunakan metode pemangkasan yang sama dengan metode C4.5 yaitu Pemangkasan Berbasis Galat (Error Based Pruning (EBP)). Formula pemangkasan sebagai berikut:
= + + √ − +
+
= tingkat galat pada Daun (error rate)
= nilai invers dari distribusi kumulatif normal baku dengan α=0.25, atau sesuai masukan dari pengguna
= perbandingan jumlah data yang salah dalam klasifikasi dengan jumlah keseluruhan data pada Daun.
= Jumlah data pada Daun.
Pada EBP, Quinlan menyarankan menggunakan batas atas dari selang kepercayaan distribusi kumulatif normal baku sebesar 25% untuk menduga tingkat galat pada Daun (Kuhn 2013). Peningkatan nilai ini akan mengakibatkan pembentukan pohon yang lebih besar. Pemangkasan dilakukan apabila nilai pada Daun lebih besar daripada Simpul Internal sebelum Daun.
Multivariate Adaptive Regression Spline (MARS)
Multivariate Adaptive Regression Spline (MARS) merupakan algoritma pemodelan yang menggabungkan transformasi peubah nonparametrik dan skema pemilahan rekursif (recursive partitioning). Algoritma ini membentuk fungsi basis spline yang terdiri dari fungsi truncated power spline dan memilih knot dengan metode pemilihan model (stepwise regression). MARS terdiri dari dua tahap
seperti pada Pohon Keputusan yaitu “tumbuh” atau pemilihan maju (forward selection) dan “pangkas” atau pemilihan mundur (backward selection).
Pada tahapan pemilihan maju, fungsi basis dibentuk dari interaksi antara basis induk dan transformasi non-parametrik dari peubah numerik dan nominal. Setelah model terbentuk sampai ukuran tertentu, pemilihan mundur dimulai dengan menghapus basis yang berpengaruh kecil atau yang tidak berpengaruh terhadap model. Penghapusan ini berlanjut sampai model mencapai kriteria model terbaik tertentu.
Transformasi peubah non parametrik sebagai berikut:
6
= knot peubah v.
� = pengamatan dari peubah v.
b. Untuk peubah nominal menggunakan transformasi fungsi indikator.
v, = { , jika � ∈ { , … , } , lainnya
v, = { , lainnya , jika � ∈ { , … , }
{ , … , } = subset dari semua kategori pada peubah v.
Diasumsikan model regresi sebagai kombinasi linear dari fungsi basis , dengan basis setiap subregion = , , … , .
= + ∑
=
Dan fungsi basis MARS dapat dinyatakan sebagai berikut:
= ∏ � . Km = derajat interaksi
� = nilainya ± 1
�, = peubah independen
� = nilai knots dari peubah �, .
Bentuk lain dari persamaan (2) diatas adalah
̂ = + ∗ + ∗ + ⋯ + �∗ �
= peubah respon B0 = konstanta
B1, B2,.,Bk = koefisien fungsi basis spline ke 1,2,...,k. BF1, BF2,.,BFk = fungsi basis ke 1,2,...k.
Metode pemilihan model ini dilakukan dengan cara meminimumkan nilai Generalized Cross Validation (GCV). Semakin kecil nilai GCV dari suatu peubah, maka semakin penting peubah tersebut. Persamaan GCV adalah sebagai berikut dimana pembilangnya adalah kuadrat tengah galat, dan penyebutnya merupakan fungsi nilai kompleks.
(7)
7
�
=
∑�= [ �− ̂]∗[ −�(�̂)]
= jumlah pengamatan,
= jumlah fungsi basis pada model MARS, ( ̂) = C(M) + d.M
d = penalty
C(M) = jumlah efektif parameter yang diestimasi,
Klasifikasi dengan MARS berdasarkan pendekatan analisis regresi logistik. Pengklasifikasian ini untuk melihat tingkat keakuratan dalam pengelompokan data sesuai dengan kelompoknya. Peubah respon Y biner (0 dan 1) maka dapat menggunakan model probabilitas sebagai berikut:
� = | = = � = +� �
Fungsi dari model probabilitas diatas dapat dicari dengan menggunakan metode nonparametrik seperti MARS (Friedman, 1991). Pemilihan fungsi basis dilakukan dengan menggunakan kuadrat sisaan berdasarkan loss criterion, dan koefisien fungsi basis untuk model terbaik diestimasi dengan pendekatan regresi logistik terhadap kumpulan basis tersebut (Friedman, 1991). Transformasi model diatas dapat dituliskan sebagai berikut:
ln [ − �� ] = + ∑
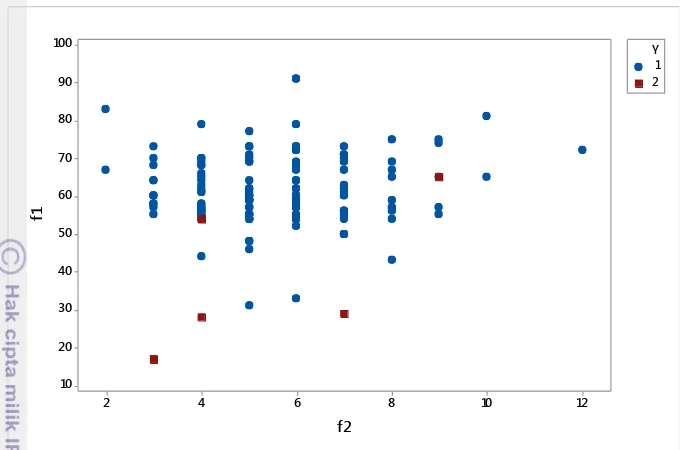
Data tidak seimbang (imbalanced data) terjadi ketika proporsi antar kelas data pada peubah respon mengalami ketimpangan. Bentuk ketidakseimbangan data terjadi pada peubah kategorik dengan dua atau lebih kategori dengan rasio, misal 20:1, 100:1, 1000:1, bahkan sampai 10000:1. Ketidakseimbangan ini berakibat pada tidak sensitifnya klasifikasi pada kelas data minoritas. Kesalahan klasifikasi ini sering dianggap suatu kewajaran karena bisa diartikan sebagai galat dari model klasifikasi. Gambar 2.2 adalah ilustrasi dari data tidak seimbang. Gambar 2.2 merupakan plot peubah respon biner Y dengan dua kelas data (1 dan 2) terhadap peubah f1 dan f2. Terlihat bahwa kelas data 1 lebih mendominasi daripada kelas data
2. Kondisi ini yang disebut dengan data tidak seimbang.
Kesalahan klasifikasi pada kelas minoritas pada kasus tertentu sangat fatal akibatnya dibandingkan kesalahan klasfikasi pada kelas mayoritas. Salah satu contoh kasus data tidak seimbang adalah pada kasus pekerja anak dimana jumlah pekerja anak lebih sedikit daripada jumlah anak. Kesalahan mendeteksi seorang anak adalah bukan pekerja anak padahal sebenarnya dia adalah pekerja anak sangat fatal karena kebijakan yang dilakukan oleh pemerintah untuk menanggulangi pekerja anak dapat menjadi salah sasaran.
(9)
(10)
8
Gambar 2.2. Contoh plot data tidak seimbang
Syntethic Minority Oversampling Technique (SMOTE)
Teknik SMOTE merupakan salah satu metode penanganan data tidak seimbang dengan membangkitkan data buatan untuk kelas data minoritas pada peubah respon sehingga proporsi kelas data mayoritas dan minoritas menjadi lebih seimbang. SMOTE (Synthetic Minority Oversampling Technique) membuat data buatan berdasarkan kedekatan ruang antar data pada kelas minoritas. Prosedur pembangkitan data buatan dengan SMOTE adalah dengan persamaan sebagai berikut:
� = � + ̂� − � ∗ [ , ]
̂�= salah satu K-Nearest Neighbors (KNN) suatu data � yang dipilih secara acak ̂� . KNN dihitung berdasarkan jarak Euclidean antar data seperti pada persamaan 12.
, = √ − ′ − = √∑ �− �
�= [ , ] = Nilai random antara 0 dan 1.
9
1. Jumlah K pada KNN. Chawla (2002) menggunakan nilai K = 5, yang berarti setiap data akan dihitung KNN dengan mempertimbangkan lima tetangga terdekat.
2. Menentukan nilai oversampling dalam satuan ratus persen. Nilai oversampling 300% berarti bahwa setiap data pada kelas minoritas akan dibangkitkan sebanyak tiga data buatan.
3. Menentukan nilai undersampling dalam ratus persen. Nilai undersampling 200% berarti sebanyak dua kali jumlah data minoritas akan digunakan untuk mengambil contoh dari kelas minoritas. Jika nilai undersampling tidak ditentukan maka aplikasi akan menggunakan nilai undersampling 100%. Hal ini berarti bahwa jumlah contoh kelas mayoritas yang diambil secara acak adalah sebanyak nilai oversampling.
4. Data baru akan terdiri dari gabungan seluruh data minoritas ditambah hasil dari SMOTE serta contoh dari kelas mayoritas.
Cost Sensitive Learning (CSL)
Metode Cost Sensitive Learning (CSL) merupakan metode penanganan data tidak seimbang dengan memperhitungkan dampak (costs) yang terkait dengan kesalahan klasifikasi (misclassification). Penentuan cost berdasarkan confusion matrix yang merupakan tabulasi dari ketepatan klasifikasi pada data prediksi dan data aktual. Bentuk cost matrix untuk klasifikasi biner adalah sebagai berikut :
= [ ,, � ,, �]
Fungsi dari matrik ini adalah untuk memboboti data latih. Cost matrix terdiri dari TN (True Negative), FN (False Negative), FP(False Positive) dan TP (True Positive). Pada umumnya, TP dan TN akan bernilai nol (0) karena tidak ada dampak negatif jika model melakukan prediksi dengan benar. Pada kasus tertentu nilai FN umumnya lebih besar daripada FP, karena dampak kesalahan klasifikasi kelas negatif lebih besar daripada dampak kesalahan kelas positif (Elkan 2001).
Ketepatan Klasifikasi
10
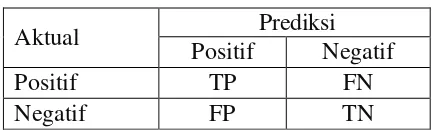
Tabel 2.1. Tabel klasifikasi dua arah
Aktual Prediksi
Positif Negatif
Positif TP FN
Negatif FP TN
Model terbaik dapat diukur dengan nilai berikut, antara lain Accuracy adalah tingkat keakuratan suatu model klasifikasi, sedangkan Sensitivity adalah tingkat keakuratan kelas positif, dan Specificity adalah tingkat keakuratan kelas negatif. Semakin mendekati nilai 1 maka semakin baik model yang dihasilkan.
Accuracy = ��+� ��+��+� +�
;
Sensitivity = �� ��+�� ;
Specificity = � � +�
Luas dibawah kurva ROC (Area Under Curve, AUC) direkomendasikan untuk membandingkan metode klasifikasi. ROC akan membentuk plot persentase dari pengklasifikasian yang benar terhadap pengklasifikasian yang salah. Model dengan nilai AUC mendekati nilai satu berarti model tersebut merupakan model yang sangat baik.
(14)
(15)
11
3 METODE PENELITIAN
Data
Data yang digunakan bersumber dari data rumah tangga Survey Sosial Ekonomi Nasional (Susenas) pada tahun 2013 di provinsi DKI Jakarta. Berdasarkan definisi pekerja anak, unit analisis yang digunakan adalah anak-anak berumur 5-17 tahun, tetapi karena pengumpulan data status pekerjaan pada anak berusia 5-9 tahun tidak tercakup dalam Susenas maka unit analisis dalam penelitian ini terbatas pada anak berusia 10-17 tahun. Jumlah data yang dianalisis sebanyak 2402 jiwa. Peubah respon merupakan peubah kategorik dimana pekerja anak berkode 1 dan bukan pekerja anak berkode 0.
Tabel 3.1. Peubah penyusun model
Peubah Keterangan Kriteria
Y Status Anak 0 = Bukan pekerja anak
1 = Pekerja anak X1 Jenis Kelamin Anak 1 = Laki-laki
2 = Perempuan
X2 Partisipasi Sekolah Anak 1 = Tidak / belum pernah sekolah 2 = Masih sekolah
3 = Tidak bersekolah lagi X3 Tinggal Dengan Orang Tua 1 = Ya
2 = Tidak X4 Umur Kepala Rumah Tangga
(KRT) (tahun)
Numerik X5 Jenis Kelamin KRT 1 = Laki-laki
2 = Perempuan X6 Status Pekerjaan KRT 1 = Tidak bekerja
2 = Informal X10 Jumlah Anggota Rumah
Tangga (ART)
Numerik X11 ART Lain Yang Bekerja 1 = Ya
2 = Tidak X12 Pengeluaran Rumah Tangga
per Bulan
1 = Rendah (≤ 3.233 juta Rupiah) 2 = Sedang (3.233 juta Rupiah - 5.525
juta Rupiah)
12
Metode Analisis
Secara garis besar, langkah-langkah analisis data yang dilakukan pada penelitian ini adalah sebagai berikut:
1. Pemisahan data menjadi dua bagian, yaitu data latih awal (80%) dan data uji (20%). Pemisahan dilakukan secara acak. Data yang terbagi menjadi dua bagian tersebut memiliki proporsi kelas data pada peubah respon yang sama dengan data asli. Pemodelan dilakukan pada data latih, dan data uji untuk validasi model yang dihasilkan.
2. Penanganan data tidak seimbang dengan SMOTE
a. Menentukan jumlah k-tetangga terdekat, yaitu 5 tetangga yang berarti bahwa data bangkitan berasal dari 5 data pada kelas minoritas yang letaknya berdekatan.
b. Menentukan nilai oversampling yaitu 800%, yang berarti bahwa data minoritas yang akan dibangkitkan sebesar delapan kali.
c. Menyimpan data keluaran hasil SMOTE ini untuk digunakan sebagai data latih baru.
3. Pembentukan Pohon Klasifikasi C5.0 dengan data latih awal dan data latih baru.
4. Membentuk pohon klasifikasi dengan menerapkan Cost Matrix pada algoritma C5.0 dengan menggunakan data latih awal. Pembobotan yang digunakan adalah nilai FN=2 dan FP=1. Hal ini berarti bahwa dampak kesalahan klasifikasi seorang anak adalah bukan pekerja anak padahal sebenarnya dia adalah pekerja anak lebih besar dua kali daripada kesalahan klasifikasi seorang anak adalah pekerja anak padahal dia bukan pekerja anak. Bentuk cost matrix adalah sebagai berikut:
= [ � � ]
5. Pemodelan klasifikasi dengan MARS.
a. Pemodelan menggunakan data latih awal dan data latih baru.
b. Menentukan maksimal jumlah fungsi basis yang akan masuk ke model yaitu dua kali jumlah peubah penjelas yang digunakan ditambah satu.
c. Menentukan maksimal jumlah level interaksi, yaitu dua level interaksi. Dua level interaksi berarti bahwa terdapat interaksi antara dua peubah berbeda.
d. Menentukan jumlah penalty pada setiap peubah baru yang masuk ke model. yaitu 0.05. Dengan penalty, maka MARS akan lebih cenderung membentuk knot baru berdasarkan peubah yang telah masuk daripada menggunakan peubah baru yang akan dimasukkan. Hal ini mendukung prinsip kesederhanaan model.
6. Membandingkan ketepatan klasifikasi MARS dan C5.0 dengan confusion matrix dan luas kurva ROC.
13
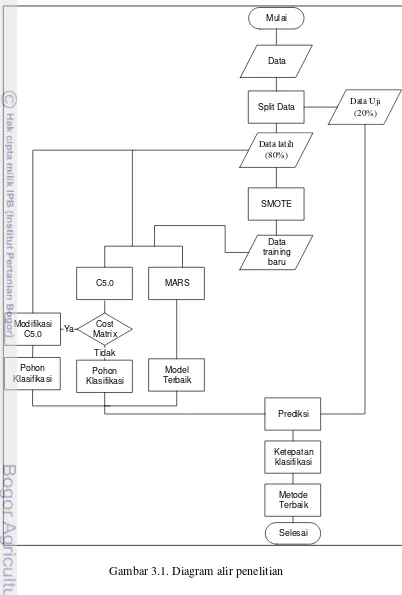
Digram alir dari langkah-langkah diatas tersaji pada Gambar 3.1.
Mulai
Gambar 3.1. Diagram alir penelitian
Data latih (80%)
14
4 HASIL DAN PEMBAHASAN
Tahap berikutnya dalam penelitian ini adalah eksplorasi data. Tahapan ini akan memberikan beberapa gambaran umum terhadap pekerja anak di Jakarta, baik ditinjau berdasarkan wilayah maupun dari sisi internal dan eksternal pekerja anak, misalnya dalam hal pendidikan anak, kondisi Kepala Rumah Tangga (KRT), dan tingkat perekonomian rumah tangga dimana anak tersebut menetap. Eksplorasi data menggunakan hasil estimasi Susenas tahun 2013 di Propinsi Jakarta.
Gambaran Umum Pekerja Anak di Jakarta
Jumlah pekerja anak di Jakarta sebanyak 58609 jiwa atau 4.6% dari total anak berumur 10-17 tahun. Kota dengan jumlah pekerja anak terbanyak adalah di kota Jakarta Barat yaitu sebesar 37.2%, sedangkan Kepulauan Seribu merupakan kabupaten di Jakarta yang mempunyai jumlah pekerja anak paling sedikit yaitu sebesar 0.2% dari total pekerja anak. Gambar 4.1 memuat peta persebaran pekerja anak di Jakarta.
Gambar 4.1. Peta persentase persebaran pekerja anak berdasarkan kab/kota Jakarta Barat merupakan kota dengan PDRB terendah dibandingkan kota lain di Jakarta dan merupakan kota terpadat kedua di Jakarta. Berdasarkan Gambar 4.1, terlihat bahwa Jakarta Barat merupakan daerah konsentrasi pekerja anak di propinsi DKI Jakarta. Selain itu, dari total anak berumur 10-17 tahun yang berada di kota ini, 7.1 % merupakan pekerja anak. Oleh karena itu, kota ini perlu mendapat perhatian lebih dalam dari Pemerintah Propinsi DKI Jakarta dalam rangka mengurangi jumlah pekerja anak.
JAKARTA BARAT
37.2%
JAKARTA UTARA
20.3 %
JAKARTA TIMUR
15
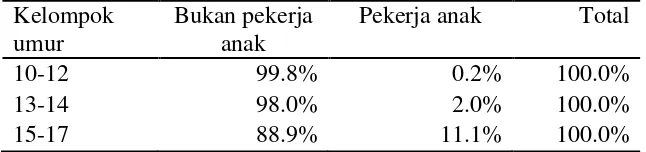
Tabel 4.1. Persentase Status Anak menurut kelompok umur Kelompok
Yang menjadi perhatian serius oleh Pemerintah adalah masih terdapat pekerja anak yang masih berumur 10-12 tahun, yaitu 0.2 persen dari total anak pada umur 10-12 tahun. Sedangkan pada umur 13-14 tahun, terdapat dua persen (2%) pekerja anak dari total anak pada umur tersebut. Pada Tabel 4.2 terlihat bahwa pada umur 10-14 tahun, pekerja anak masih didominasi oleh anak yang sudah tidak bersekolah lagi. Hal ini sangat mengkhawatirkan karena pada kelompok umur ini, anak harus mendapat pembekalan dasar pendidikan dan ketrampilan dasar yang berguna untuk penghidupan mereka di masa mendatang.
Tabel 4.2. Partisipasi sekolah pekerja anak berdasarkan kelompok umur
Kelompok umur
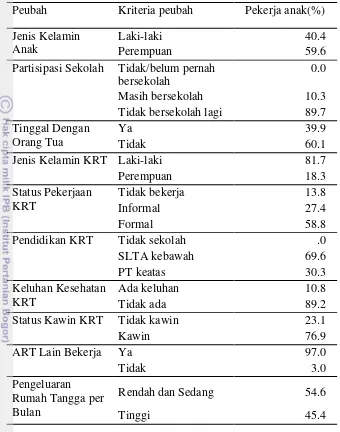
Tabel 4.3 memuat persentase pekerja anak menurut peubah-peubah yang digunakan pada penelitian ini. Berdasarkan Jenis Kelamin Anak, pekerja anak didominasi oleh perempuan, selain itu hampir seluruh pekerja anak di Jakarta berstatus tidak bersekolah lagi. Tidak bersekolah lagi dapat berarti anak tersebut tidak melanjutkan sekolahnya atau berhenti di tengah jalan. Sedangkan sebagian kecil pekerja anak masih menempuh pendidikan dalam bangku sekolah. Tidak ada pekerja anak yang tidak atau belum pernah bersekolah di Jakarta. Ini mengindikasikan bahwa pekerja anak merupakan anak-anak yang pernah mengenyam pendidikan.
16
Tabel 4.3. Persentase pekerja anak menurut peubah yang digunakan
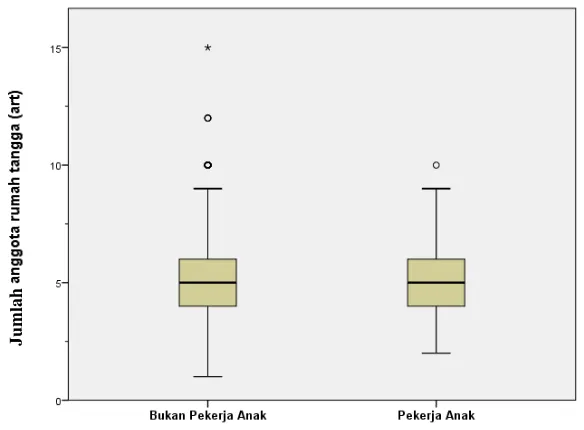
Gambar 4.2 menunjukkan bahwa boxplot pekerja anak dan bukan pekerja anak memiliki beberapa karakteristik yang mirip. Kemiripan tersebut terletak pada nilai Kuartil ke 1, Kuartil ke 2, dan Kuartil ke 3. Sehingga dapat dikatakan bahwa setengah dari anak-anak di Jakarta tinggal di rumah tangga dengan lima atau kurang dari lima orang ART. Selain itu, kedua kelas data ini memiliki kemiripan dalam sebaran data karena ukuran simpangan kuartil yang sama besar. Sebaran data kedua kelas data ini juga sama-sama tidak simetris atau menceng ke arah kanan, hal ini ditandai dengan terdapatnya pencilan pada kedua boxplot dan panjang garis whisker yang tidak sama. Tetapi kemencengan pada data bukan pekerja anak lebih lebar karena terdapat lebih banyak data pencilan. Pada data pekerja anak, terdapat satu pekerja anak yang tinggal pada rumah tangga dengan sepuluh orang ART. Sedangkan pada data bukan pekerja anak, terdapat beberapa anak yang tinggal pada rumah tangga dengan lebih dari sepuluh ART. Banyaknya ART ikut mempengaruhi seorang anak menjadi pekerja anak.
Peubah Kriteria peubah Pekerja anak(%)
Jenis Kelamin Anak
Laki-laki 40.4
Perempuan 59.6
Partisipasi Sekolah Tidak/belum pernah bersekolah
0.0
Masih bersekolah 10.3
Tidak bersekolah lagi 89.7 Tinggal Dengan
Orang Tua
Ya 39.9
Tidak 60.1
Jenis Kelamin KRT Laki-laki 81.7
Perempuan 18.3
Pendidikan KRT Tidak sekolah .0
SLTA kebawah 69.6
Status Kawin KRT Tidak kawin 23.1
Kawin 76.9
Rendah dan Sedang 54.6
17
Gambar 4.2. Boxplot Jumlah ART berdasarkan Status Anak
Gambar 4.3. Boxplot Umur KRT berdasarkan Status Anak
Gambar 4.3 menunjukkan perbandingan boxplot pekerja anak dan bukan pekerja anak berdasarkan Umur KRT dimana anak tersebut tinggal. Terlihat bahwa terdapat kemiripan pada nilai tengah kedua boxplot, hal ini berarti bahwa setengah dari anak-anak di Jakarta tinggal pada rumah tangga dimana Umur KRT nya sekitar 45 tahun atau dibawah 45 tahun. Selain itu, kemiripan lainnya adalah kedua data ini sama-sama tidak simetris atau menceng ke arah kanan, hal ini terlihat dari data pencilan yang terdapat pada kedua boxplot dan garis whisker yang tidak sama panjang. Jika dilihat dari ukuran kotak dalam boxplot atau disebut dengan simpangan kuartil, data umur KRT pada pekerja anak lebih menyebar (ukuran kotak lebih panjang) daripada bukan pekerja anak, sehingga dapat dikatakan Umur KRT lebih bervariasi pada data pekerja anak dibandingkan pada bukan pekerja anak. Hal
J
u
m
la
18
ini mengakibatkan data pencilan lebih banyak terdapat pada data bukan pekerja anak. Kondisi kepala rumah tangga ikut mempengaruhi terdapatnya pekerja anak pada suatu rumah tangga (Syahruddin 2004).
Penanganan Data Tidak Seimbang
` Berikut merupakan perbandingan jumlah pekerja anak dan bukan pekerja anak di Jakarta. Ketidakseimbangan distribusi kelas data peubah respon ini yang disebut dengan data tidak seimbang. Perlu penanganan lebih lanjut karena kondisi ini mengakibatkan kecilnya akurasi pada kelas data minoritas, padahal kelas data ini yang akan kita teliti lebih lanjut.
Tabel 4.4. Persentase perbandingan jumlah anak menurut Status Anak
Kategori Jumlah (%)
1 (pekerja anak) 97 (4.04)
0 (bukan pekerja anak) 2305 (95.96)
Jumlah 2402 (100.00)
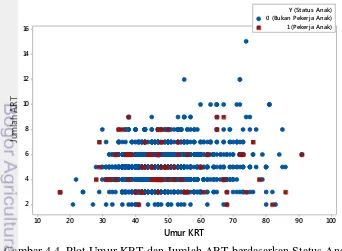
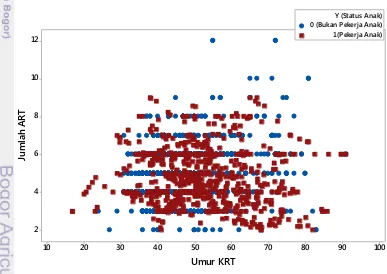
Pada Tabel 4.4 terlihat bahwa antara perbandingan jumlah pekerja anak dan bukan pekerja anak cukup jauh. Hal ini berarti telah terjadi ketidakseimbangan data. Gambar merupakan ilustrasi plot dari peubah respon Status Anak (pekerja anak dan bukan pekerja anak) berdasarkan peubah Umur KRT dan Jumlah Anggota Rumah Tangga. Pada gambar 4.4, kelas pekerja anak (minoritas) diwakili oleh kotak merah, sedangkan kelas bukan pekerja anak (mayoritas) diwakili oleh lingkaran biru. Terlihat bahwa kelas bukan pekerja anak lebih mendominasi daripada kelas pekerja anak. Kondisi ini yang disebut dengan data tidak seimbang.
Gambar 4.4. Plot Umur KRT dan Jumlah ART berdasarkan Status Anak
19
Teknik SMOTE akan digunakan untuk menangani ketidakseimbangan data. Teknik ini membangkitkan data sintesis untuk kelas minoritas sebesar 800 persen yang berarti bahwa data sintesis akan dibangkitkan sebesar (800/100 = 8) delapan kali data latih minoritas, yaitu 8x78 = 624 dan data baru ini akan ditambahkan ke data awal sehingga berjumlah 624+78 = 702. Sedangkan kelas data mayoritas akan diambil sampel secara acak dari data awal sebanyak dua kali dari jumlah data bangkitan kelas minoritas, yaitu 624*2 = 1248. Data latih baru berjumlah 780 yang terdiri dari 312 data kelas minoritas dan 468 data mayoritas. Tabel 4.5 memuat perbandingan data latih dengan data yang telah di-SMOTE.
Tabel 4.5. Hasil SMOTE pada data latih
Kategori Data latih(%) Data SMOTE(%)
1 (pekerja anak) 78 (4.06) 702 (36.00)
0 (bukan pekerja anak) 1844 (95.94) 1248 (64.00)
Jumlah 1922 (100.00) 1950 (100.00)
Perbandingan antara kelas data mayoritas dan minoritas pada tabel diatas menjadi lebih seimbang dengan 36 persen kelas data pekerja anak dan 60 persen kelas data bukan pekerja anak. Ilustrasi kelas data yang telah seimbang dapat dilihat pada Gambar 4.5. Kelas minoritas terlihat bertambah banyak dibandingkan pada Gambar 4.5.
20
Pemilihan Model Klasifikasi Terbaik
Sebelum mendapatkan faktor-faktor yang mempengaruhi seorang anak menjadi pekerja anak, akan dicari terlebih dahulu model yang dapat memberikan ketepatan yang tinggi untuk memprediksi baik pekerja anak maupun bukan pekerja anak. Model yang dibandingkan adalah C5.0 dan MARS, baik dengan data latih awal maupun dengan data latih baru, dan juga C5.0 yang menggunakan Cost Matrix. Hasil yang diperoleh dapat dilihat pada Tabel 4.6. Hasil dari model pada Tabel 4.6 dapat dilihat pada Lampiran 1-4.
Tabel 4.6. Perbandingan ketepatan metode klasifikasi
Metode Accuracy Specificity Sensitivity
C5.0 0.9667 0.9978 0.2105
C5.0 SMOTE 0.9479 0.9458 1.0000
C5.0 Cost 0.9562 0.9566 0.9474
MARS 0.9688 0.9957 0.3158
MARS SMOTE 0.9500 0.9501 0.9474
Pohon klasifikasi sangat rentan terhadap ketidakseimbangan data, termasuk juga metode C5.0. Seperti yang terlihat pada Tabel 4.6, ketepatan klasifikasi untuk pekerja anak (Sensitivity) sangat rendah yaitu 0.2105, yang berarti bahwa diantara 100 pekerja anak, C5.0 hanya benar memprediksi 21 anak saja. Sedangkan sisanya terdapat kesalahan klasifikasi. Pada kelas data bukan pekerja anak, C5.0 memberikan ketepatan yang tinggi, dimana hampir mendekati angka satu. Hal ini berarti bahwa dari 100 anak yang bukan pekerja anak, C5.0 tepat memprediksikan bahwa mereka adalah bukan pekerja anak. Data tidak seimbang terlihat juga berpengaruh signifikan terhadap metode klasifikasi MARS. Ketepatan klasifikasi pada pekerja anak pada model MARS lebih tinggi dibandingkan C5.0 yaitu 0.3158 yang berarti bahwa dari 100 pekerja anak, MARS berhasil memprediksikan tepat sebanyak 31 anak.
Penanganan data tidak seimbang dengan cost sensitive learning memberikan hasil yang sangat baik. Peningkatan signifikan terjadi pada ketepatan klasifikasi pada pekerja anak yaitu sebesar 0.9474, hal ini lebih besar daripada tanpa menggunakan cost. Kenaikan nilai sensitivity tidak diikuti dengan nilai accuracy dan specificity, kedua nilai tersebut mengalami sedikit penurunan. Dengan cost sensitive learning, C5.0 mengklasifikasikan pekerja anak dengan lebih hati-hati dan menghindari kesalahan klasifikasi.
21
Berdasarkan Tabel 4.6, tiga model yang dihasilkan setelah penanganan data tidak seimbang memberikan hasil yang optimal dengan nilai ketepatan klasifikasi yang tinggi pada semua kelas data. Pemilihan model terbaik jika hanya dengan melihat Tabel 4.6 akan sulit karena tidak ada model yang benar-benar memberikan nilai tertinggi. Oleh karena itu pemilihan model terbaik melihat dari nilai AUC. Gambar 4.6 memuat nilai AUC pada ketiga model. Model MARS SMOTE merupakan model terbaik dengan nilai AUC yang tertinggi diantara model lainnya, yaitu 0.9761.
Gambar 4.6. Perbandingan nilai AUC pada ketiga model
Interpretasi Model Terbaik
Berdasarkan Gambar 4.7, Partisipasi Sekolah Anak (X2) merupakan peubah yang paling berpengaruh pada model MARS SMOTE. Hal ini menunjukkan bahwa faktor pendidikan sangat berpengaruh terhadap seorang anak. Berdasarkan Tabel 4.2, pekerja anak masih didominasi oleh anak-anak yang tidak bersekolah lagi. Pemerintah Provinsi DKI Jakarta berusaha untuk mengembalikan anak-anak tersebut ke bangku sekolah dengan mengeluarkan kebijakan wajib belajar 12 tahun bagi warganya, serta pemberian bantuan pendidikan bagi warga miskin berupa Kartu Jakarta Pintar sebagai pendamping Bantuan Operasional Sekolah (BOS) yang dikeluarkan oleh pemerintah pusat. Salah satu harapan dari kebijakan ini adalah mengembalikan para pekerja anak yang putus sekolah untuk kembali ke bangku sekolah dan mengurangi jumlah pekerja anak.
22
Gambar 4.7. Tingkat kepentingan tiap peubah
= . + . ∗ − . ∗ − . ∗ + . ∗ penjabaran dari fungsi basis seperti pada persamaan 18. Interpretasi model diatas adalah sebagai berikut:
a. . * BF1
� = + . . + .+ . = .
23
Dengan asumsi peubah lainnya konstan, seorang anak yang tidak sekolah lagi, putus sekolah atau tidak melanjutkan sekolah ke jenjang lebih tinggi, berpeluang sangat besar menjadi pekerja anak yaitu 0.98.
b. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tinggal dengan orang tua kandung dan pendidikan anak masih sekolah maka anak tersebut memiliki peluang yang sangat kecil untuk menjadi pekerja anak yaitu 0.1.
c. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang masih sekolah, dan anak tersebut tinggal dalam rumah tangga dimana umur KRT diatas 25 tahun, maka anak tersebut berpeluang besar menjadi pekerja anak yaitu 0.7.
d. . ∗
� = + . . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang masih sekolah, dan anak tersebut tinggal dalam rumah tangga dimana umur KRT dibawah 25 tahun, maka anak tersebut berpeluang besar menjadi pekerja anak yaitu 0.9. Hal ini dapat terjadi pada anak yang tidak tinggal dengan orang tua kandung.
e. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tidak sekolah lagi dan tinggal bersama KRT dimana KRT tersebut tidak pernah menempuh sekolah, maka anak tersebut sangat kecil kemungkinannya untuk menjadi pekerja anak, yaitu 0.01.
f. − . ∗
� = +− .− . + .+ . = .
24 menjadi pekerja anak yaitu sebesar 0.7.
h. 3.2708* BF11
� = + . . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tinggal dalam rumah tangga dimana KRT tersebut diatas SLTA, maka anak tersebut berpeluang sangat besar menjadi pekerja anak yaitu sebesar 0.98. Hal ini dapat terjadi pada rumah tangga yang mempunyai usaha sendiri, sehingga anak-anak berusia 10-17 tahun biasanya akan ikut membantu usaha tersebut. Pekerja anak ini dinamakan dengan pekerja keluarga.
i. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tidak sekolah lagi dan tinggal dalam rumah tangga dimana pengeluaran rumah tangga tersebut tergolong sedang, mempunyai peluang menjadi pekerja anak sebesar 0.36.
j. . ∗
� = + .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tidak sekolah lagi dan tinggal dalam rumah tangga dimana terdapat lebih dari dua anggota rumah tangga, maka anak tersebut mempunyai peluang menjadi pekerja anak sebesar 0.76.
k. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tidak sekolah lagi dan tinggal sendiri, maka anak tersebut mempunyai peluang menjadi pekerja anak sebesar 0.86.
l. − . ∗
� = +− .− . + .+ . = .
25
sehingga anak-anak berusia 10-17 tahun biasanya akan ikut membantu usaha tersebut. Pekerja anak ini dinamakan dengan pekerja keluarga.
m. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tinggal di rumah tangga dimana KRT tersebut telah menempuh pendidikan setelah SMA, dan umut KRT tersebut diatas 69 tahun, maka peluang seorang anak menjadi pekerja anak sebesar 0.6.
n. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tinggal di rumah tangga dimana KRT tersebut telah menempuh pendidikan setelah SMA, dan umut KRT tersebut dibawah 69 tahun, maka peluang seorang anak menjadi pekerja anak sebesar 0.7.
o. . ∗
� = + . . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang masih sekolah dan tinggal di rumah tangga dimana KRT tersebut telah berumur diatas 82 tahun, maka anak tersebut dapat dipastikan menjadi pekerja anak.
p. − . ∗
� = +− .− . + .+ . = .
Dengan asumsi peubah lainnya konstan, seorang anak yang tinggal dalam rumah tangga dengan jumlah anggota rumah tangga diatas tiga dan pendidikan KRT tersebut belum sarjana maka anak tersebut berpeluang besar menjadi pekerja anak yaitu sebesar0.7.
q. . ∗
� = + . . + .+ . = .
26
5 SIMPULAN
Data tidak seimbang mempengaruhi ketepatan model klasifikasi yaitu akurasi model untuk salah satu kelas data menjadi rendah. Ketepatan klasifikasi untuk kelas bukan pekerja anak sangat tinggi yaitu 0.9978 untuk C5.0 dan 0.9957 untuk MARS, sedangkan ketepatan klasifikasi pekerja anak pada metode C5.0 dan MARS sangat rendah, yaitu 0.2105 dan 0.3158. Hal ini mengakibatkan model klasifikasi tidak dapat digunakan. Penggunaan metode Syntethic Minority Oversampling Technique (SMOTE) pada tahap pra pengolahan data meningkatkan ketepatan klasifikasi pekerja anak, yaitu 1.0 untuk metode C5.0 dan 0.9474 untuk MARS. Sedangkan metode Cost Sensitive Learning (CSL) meningkatkan ketepatan klasifikasi pekerja anak untuk metode C5.0 sebesar 0.9474.
Model terbaik berdasarkan nilai AUC tertinggi sebesar 0.9761 yaitu MARS SMOTE. Berdasarkan model terbaik, faktor-faktor yang berpengaruh terhadap pekerja anak antara lain Partisipasi Sekolah Anak, Tinggal dengan Orang Tua Kandung, Umur Kepala Rumah Tangga (KRT), Pendidikan KRT, Pengeluaran Rumah Tangga per Bulan, dan Jumlah Anggota Rumah Tangga. Partisipasi Sekolah Anak merupakan pengaruh utama dalam metode MARS SMOTE, dimana anak berumur 10-17 tahun yang tidak bersekolah lagi memiliki kecenderungan tinggi untuk menjadi pekerja anak dibandingkan anak yang masih bersekolah.
SARAN
27
DAFTAR PUSTAKA
[BPS] Badan Pusat Statistik. 2012. Profil Anak Indonesia 2013. Jakarta(ID): Kementrian Pemberdayaan Perempuan dan Perlindungan Anak.
. 2013. Profil Anak Indonesia 2012. Jakarta(ID): Kementrian Pemberdayaan Perempuan dan Perlindungan Anak.
[BPS] Badan Pusat Statistik. 2010. Pekerja Anak di Indonesia 2009. Jakarta(ID): Badan Pusat Statistik.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research 16 (2002) 321–357.
Darusasi R, Pitoyo AJ. Kondisi Demografi dan Sosial Ekonomi Rumah Tangga Pekerja Anak DKI Jakarta (Analisis Data Susenas KOR 2010). Jurnal Bumi Indonesia Volume 2, Nomor 1, Tahun 2013.
Elkan C. 2001. The Foundations of Cost-Sensitive Learning. Proceedings of the Seventeenth International Joint Conference of Artificial Intelligence, 973-978.
Ernawati I. 2008. Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritma C5.0 dan K-Nearest Neighbor [tesis]. Bogor(ID): Institut Pertanian Bogor. Friedman JH. 1991. Multivariate Adaptive Regression Spline. California(US):
Stanford University.
Hastie T, Tibshirani R, Friedman JH. 2008. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. California(US): Stanford Unversity.
He H, Garcia EA. 2009. Learning from Imbalanced Data. IEEE Transactions On Knowledge And Data Engineering, Vol. 21, No. 9, September 2009, 1263-1284
Hugo B, Verner D. 2001. Revisiting The Link Between of Economics, Poverty and Child Labour – The Ghanaian Experience. CLS Working Paper No. 01-03. Denmark(DK): Department of Centre of Labour Market and Social Research.
Jalaluddin M. 2009. Pemodelan Partisipasi Anak dalam Kegiatan Ekonomi di Sumatera Barat Menggunakan Regresi Logistik dan MARS[tesis]. Surabaya(ID): Institut Teknologi Sepuluh November.
James G, Witten D, Hastie T, Tibshirani R. 2013. An Introduction to Statistical Learning with Application in R. New York(US): Springer.
Kuhn M, Johnson K. 2013. Applied Predictive Modeling. New York(US): Springer Ling CX, Sheng VS. 2008. Cost-Sensitive Learning and the Class Imbalance Problem. Encyclopedia of Machine Learning. C. Sammut (Ed.). Canada(CA): Springer.
Munoz J, Felicisimo AM. 2004. Comparison of Statistical Methods commonly used in predictive modelling . Journal of Vegetation Science Vol. 15, pp. 285-292.
Nandi. 2006. Pekerja Anak dan Permasalahannya. Jurnal GEA Jurusan Pendidikan Geografi Vol. 6, No. 2.
28
Prasetyo GC. 2009. Klasifikasi Deteksi Intrusi Menggunakan Pendekatan Classification And Regression Trees(CART) dan Multivariate Adaptive Regression Spline (MARS) [tesis]. Surabaya(ID): Institut Teknologi Sepuluh November.
Syahruddin F. 2004. Determinan Keberadaan Rumah Tangga dengan Pekerja Anak di Kawasan Timur Indonesia [tesis]. Depok(ID): Universitas Indonesia. Witten IH, Frank E, Hall MA. 2011. Data Mining : Practical Machine Learning
29
Lampiran 1. Pohon Klasifikasi C5.0
30
Lampiran 3. Pohon Klasifikasi C5.0 Cost
Lampiran 4. Model MARS
= − . + . ∗ + . ∗ − . ∗ +
. ∗ − . ∗ + . ∗ + . ∗
− . ∗ + . ∗ + . ∗ −
. ∗ − . ∗ + . ∗ − . ∗
− . ∗ + . ∗ + . ∗ −
. ∗
BF0 = 1 BF13 = BF0*MAX(X10 - 5,0)
31
RIWAYAT HIDUP
Penulis lahir di Ponorogo pada tanggal 5 Oktober 1986, sebagai anak kedua dari dua bersaudara dari Bapak Drs. Supriyono dan Ibu Dra. Dewi Noriyati. Penulis menempuh pendidikan sekolah menengah di SMA Negeri 1 Ponorogo Jurusan IPA, lulus pada tahun 2004. Pada tahun yang sama, penulis diterima di Sekolah Tinggi Ilmu Statistik (STIS) Jakarta, dan menyelesaikan kuliah pada tahun 2008. Saat ini penulis bekerja sebagai Pegawai Negeri Sipil di Badan Pusat Statistik (BPS) Kabupaten Buru, Propinsi Maluku.