KAJIAN MODEL
HIDDEN
MARKOV UNTUK MENDUGA
VOLATILITAS INDEKS HARGA SAHAM
ABDUL BAIST
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Kajian Model Hidden Markov untuk Menduga Volatilitas Indeks Harga Saham adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir Tesis ini.
Bogor, Januari 2013
Abdul Baist
ABDUL BAIST. The Study of Hidden Markov Model for Estimating Stocks Index Volatility. Supervised by BERLIAN SETIAWATY and N. K. KUTHA ARDANA.
Volatility is a measure of uncertainty, which is useful for investor to plan a good investment strategy. The problem is that volatility is unobservable, and estimating volatility is not a trivial task. Hidden Markov model is, a model which is consisted of two processes, i.e. observation and a Markov process. The Markov process is assumed to be unobserved (hidden). In this thesis, LQ45 index is considered as the observation process and the unobserved hidden Markov is the volatility. To estimate the volatility of LQ45 index, the model proposed by Rossi and Gallo (2006) is used. The result of the study shows that volatility estimation of the LQ45 index using the model performs well. This is shown by the calculated error using symmetric mean absolute percentage error, which is only about 13.62%.
RINGKASAN volatilitas stokastik ditulis dalam format ruang–state:
(1)
, (2)
di mana adalah bentuk autoregresi sederhana
. (3)
dan diasumsikan bebas, di mana merupakan perubahan return yang diasumsikan menyebar Student’s-t dengan varians satu dan derajat kebebasan , sedangkan merupakan representasi semi-martingale, , varians berada pada regime (state) volatilitas terendah, dan varians berada pada
regime (state) volatilitas tertinggi.
Untuk menggambarkan keadaan di mana volatilitas dibangkitkan oleh return pada waktu t, maka matriks transisi didefinisikan sebagai berikut:
{ [
Elemen matriks didefinisikan sebagai berikut:
{
∑ [ ] [ ] | |
,
di mana > 0 ( adalah parameter yang menggambarkan korelasi antara return
dan perubahan volatilitas), dan
| | , ( adalah parameter time-varying)
untuk beberapa koefisien a dan b, di mana () menyatakan fungsi sebaran normal baku.
Pasangan merupakan model Hidden Markov, dan berdasarkan persamaan (1)-(6), model Hidden Markov untuk volatilitas tersebut dicirikan oleh
.
Fungsi log-likelihood didefinisikan sebagai
( )
| | | | | |
∑ | ,
dengan .
Untuk pendugaan parameter yang memaksimumkan fungsi log-likelihood
digunakan algoritma Berndt, Hall, Hall, Hausman (BHHH).
Pendugaan volatilitas untuk satu langkah ke depan adalah
̂ | ∑ | |
Dari 1375 data yang tersedia, sebanyak 917 (sekitar dua pertiga dari keseluruhan) digunakan untuk pendugaan model (in-sample), sementara itu sisanya sebanyak 458 digunakan untuk analisis out-of-sample (prediksi yang akan datang).
Dari data in-sample yang digunakan, dengan data nilai awal
,
menghasilkan parameter model sebagai berikut:
̂ ̂ ̂ ̂ ̂ ̂
̂ ̂ .
Pendugaan volatilitas untuk satu langkah ke depan diterapkan pada data in-sample
SMAPE { ∑
| |
di mana At nilai aktual, dan Ft nilai dugaan.
Perhitungan SMAPE dari volatilitas dugaan in-sample menghasilkan nilai rataan galat sebesar 13.79%, nilai galat maksimum sebesar 67.28%, dan nilai galat minimum sebesar 0.00%, serta kuartil ke-1 (Q1), kuartil ke-2 (Q2), dan kuartil
ke-3 (Q3) masing-masing sebesar 4.80%, 11.24%, dan 20.09% serta jarak
inter-kuartil sebesar 15.29%.
Perhitungan SMAPE dari volatilitas dugaan out-of-sample menghasilkan nilai rataan galat sebesar 13.62%, nilai galat maksimum sebesar 60.07%, dan nilai galat minimum sebesar 0.004%, serta kuartil ke-1 (Q1), kuartil ke-2 (Q2), dan kuartil
ke-3 (Q3) masing-masing sebesar 5.71%, 11.32%, dan 20.06% serta jarak
inter-kuartil sebesar 14.35%.
Hak Cipta milik IPB, tahun 2013
Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB
KAJIAN MODEL HIDDEN MARKOV UNTUK MENDUGA VOLATILITAS INDEKS HARGA SAHAM
ABDUL BAIST
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Matematika Terapan
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Tesis : Kajian Model Hidden Markov untuk Menduga Volatilitas Indeks Harga Saham
Nama : Abdul Baist NRP : G551090371
Disetujui
Komisi Pembimbing
Dr. Berlian Setiawaty, M.S. Ir. N. K. Kutha Ardana, M.Sc.
Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana
Matematika Terapan
Dr. Ir. Endar H. Nugrahani, M.S. Dr. Ir. Dahrul Syah, M.Sc.Agr.
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini ialah model hidden Markov, dengan judul Kajian Model Hidden
Markov untuk Menduga Volatilitas Indeks Harga Saham.
Terima kasih penulis ucapkan kepada Ibu Dr. Berlian Setiawaty, M.S. dan Bapak Ir. N. K. Kutha Ardana, M.Sc. selaku pembimbing. Ungkapan terima kasih juga disampaikan kepada bapak, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2013
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 8 Mei 1979 dari bapak H. Muhammad Ali dan ibu Hj. Asiah. Penulis merupakan putra ke lima dari enam bersaudara.
Pendidikan sarjana ditempuh di Program Studi Pendidikan Matematika, Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam Universitas Pendidikan Indonesia Bandung, lulus pada tahun 2005. Pada tahun 2009, penulis diterima di Program Studi Matematika Terapan pada Program Pascasarjana Institut Pertanian Bogor.
xi
Halaman
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiii
1 PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Tujuan Penelitian ... 3
2 LANDASAN TEORI 2.1 Ruang Contoh, Kejadian dan Peluang ... 4
2.2 Peubah Acak dan Fungsi Sebaran ... 5
2.3 Penduga ... 8
2.4 Proses Stokastik ... 8
2.5 Vektor ... 11
3 MODEL HIDDEN MARKOV 3.1 Model Hidden Markov ... 14
3.2 Dugaan Maksimum Likelihood ... 16
3.3 Algoritma Pemrograman ... 22
4 PENDUGAAN VOLATILITAS INDEKS HARGA SAHAM 4.1 Indeks Harga Saham ... 25
4.2 Volatilitas ... 25
4.3 Pendugaan Volatilitas ... 26
5 SIMPULAN DAN SARAN ... 31
DAFTAR PUSTAKA ... 32
xii
DAFTAR GAMBAR
Halaman
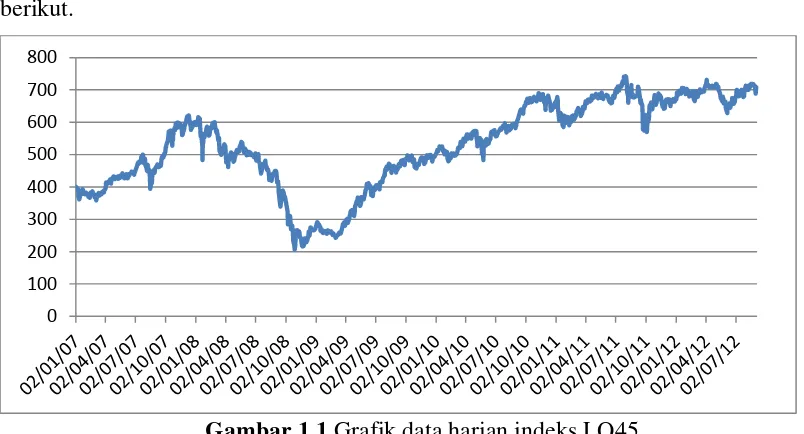
1 Grafik data harian indeks LQ45 ... 2
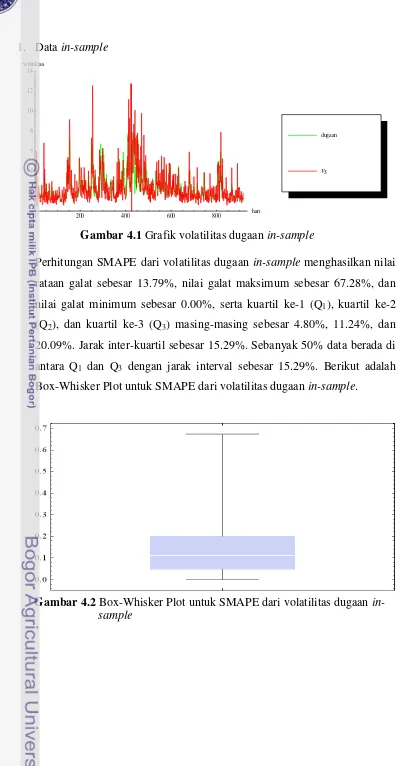
2 Grafik volatilitas dugaan in-sample ... 28
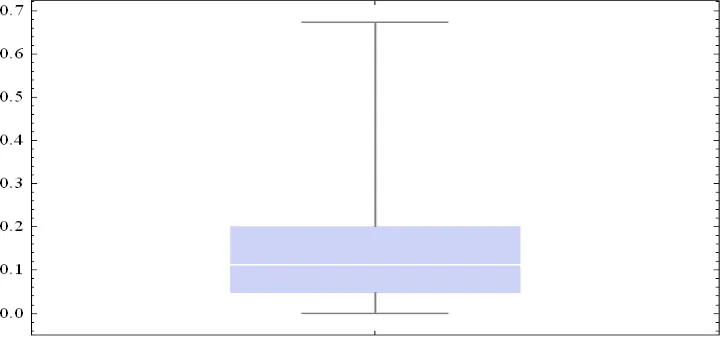
3 Box-Whisker Plot untuk SMAPE dari volatilitas dugaan in-sample ... 28
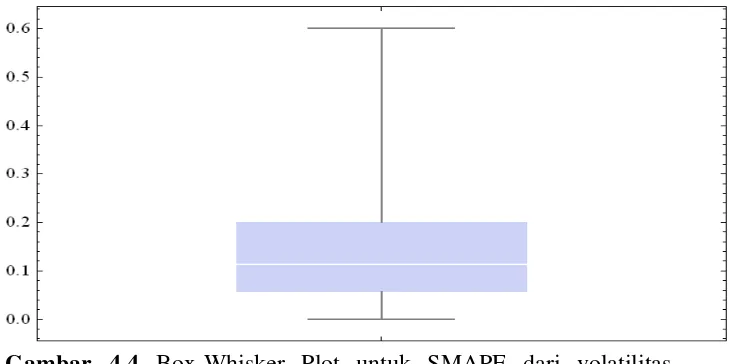
4 Grafik volatilitas dugaan out-of-sample ... 29
xiii
Halaman
1 Pembuktian sebaran Student’s-t konvergen ke sebaran normal
ketika ... 36
2 Proses penurunan turunan pertama fungsi sebaran return terhadap parameter yang berkaitan ... 39
3 Penurunan turunan pertama fungsi log-Likelihood ... 45
4 Pemrograman menggunakan software MATLAB 7.7 ... 51
BAB I
PENDAHULUAN
1.1 LatarBelakangVolatilitas adalah ukuran ketidakpastian perubahan pada nilai sebuah sekuritas. Volatilitas yang lebih tinggi berarti nilai sekuritas berpotensi menyebar dalam rentangan nilai yang lebih besar. Ini berarti bahwa harga sekuritas dapat berubah secara dramatis dalam periode waktu yang pendek pada arah manapun. Volatilitas yang lebih rendah berarti nilai sekuritas tidak berfluktuasi secara dramatis, tetapi terjadi perubahan nilai pada langkah yang tetap dalam suatu periode waktu. (http://www.investopedia.com)
Volatilitas menjadi perhatian besar bagi para investor atau orang yang menanamkan uangnya dalam dunia investasi. Para investor ingin mengetahui seberapa besar volatilitas terjadi. Dengan mengetahui volatilitas, investor dapat memperkirakan keuntungan yang akan didapat, atau bahkan kerugian yang akan diderita.
Permasalahannya adalah volatilitas tidak dapat diamati secara langsung, dan bukan pekerjaan yang mudah untuk menduganya. Sebagaimana yang diungkapkan oleh Cvitanic et al. (2005) “Estimating volatility from observed stock prices is not a trivial task in either complete or incomplete models, in part because the prices are observed at discrete, possibly random time points. Since volatility itself is not observed, it is natural to apply filtering methods to estimate the volatility process from historical stock price observations.”
Tipe GARCH memiliki kelemahan yang berkaitan dengan persistensi volatilitas (kondisi di mana volatilitas tinggi pada suatu hari diikuti dengan volatilitas tinggi, dan volatilitas rendah diikuti dengan volatilitas rendah). Lamoureux dan Lastrapes (1990) menyatakan bahwa persistensi yang sangat besar yang diindikasikan oleh GARCH sebagai ketidakmampuan menangkap perubahan struktural dalam varians tak bersyarat return aset. Sedangkan pada tipe SWARCH terdapat kelemahan yang berkaitan dengan banyaknya state. Sebagaimana yang diungkapkan oleh Hamilton dan Susmel (1994) bahwa maksimum global fungsi
likelihood spesifikasi SWARCH tidak terdeteksi ketika jumlah state rantai Markov di atas tiga.
Model yang penulis kaji di sini adalah sebuah model Hidden Markov untuk menduga volatilitas yang diajukan oleh Rossi dan Gallo (2006). Rossi dan Gallo (2006) menyatakan bahwa model yang diajukan dapat mengatasi permasalahan bertambahnya jumlah state, dan dapat mengakomodasi persistensi volatilitas dengan mudah.
Model Hidden Markov yang dikaji dalam penelitian ini diaplikasikan pada data harian (close-to-close) dari indeks LQ45. Data pengamatan yang didapat sebanyak 1375, dimulai dari 2 Januari 2007 hingga 3 September 2012. Data diambil dari http://www.finance.yahoo.com. Grafik dapat dilihat pada gambar berikut.
Gambar 1.1 Grafik data harian indeks LQ45.
Menggunakan data tersebut, parameter model diduga dengan metode maksimum likelihood yang melibatkan filtering untuk state. Filtering untuk state
3
yang tak diamati menggunakan filtering rekursif yang diajukan oleh Hamilton (1994). Setelah didapatkan dugaan parameter, selanjutnya dilakukan peramalan varians dengan menggunakan algoritma yang diajukan oleh Rossi dan Gallo (2006) sehingga dapat diduga volatilitas. Untuk smoothing menggunakan
smoother yang diajukan oleh Kim (1994). Untuk menghitung dan menganalisis data tersebut dibuat suatu program komputasi dengan menggunakan software
MATLAB 7.7.
1.2 TujuanPenelitian
Tujuan penelitian ini adalah:
1. Mengkaji model Hidden Markov yang diajukan oleh Rossi dan Gallo (2006).
BAB II
LANDASAN TEORI
2.1 Ruang Contoh, Kejadian dan PeluangDalam suatu percobaan seringkali dilakukan pengulangan yang biasanya dilakukan dalam kondisi yang sama. Semua kemungkinan hasil yang akan muncul dapat diketahui, tetapi hasil pada percobaan berikutnya tidak dapat diduga dengan tepat. Percobaan semacam ini, yang dapat diulang dalam kondisi yang sama, disebut percobaan acak. (Hogg & Craig 1995)
Definisi 2.1.1 (Ruang Contoh dan Kejadian)
Himpunan dari semua kemungkinan hasil dari suatu percobaan acak disebut ruang contoh, dinotasikan dengan . Suatu kejadian A adalah himpunan bagian dari . (Grimmet & Stirzaker 1992)
Definisi 2.1.2 (Medan-)
Medan- adalah suatu himpunan yang anggotanya terdiri atas himpunan bagian ruang contoh , yang memenuhi kondisi berikut:
1.
2. Jika A1, A2, … maka
� �
3. Jika maka (Grimmet & Stirzaker 1992)
Definisi 2.1.3 (Ukuran Peluang)
Misalkan adalah medan- dari ruang contoh . Ukuran peluang adalah suatu fungsi pada yang memenuhi:
1. .
2. Jika adalah himpunan yang saling lepas yaitu �
untuk setiap pasangan , maka
� � ∑� � .
5
Definisi 2.1.4 (Kejadian Saling Bebas)
Misalkan adalah ruang peluang dan Kejadian A dan B dikatakan saling bebas jika .
Misalkan I adalah himpunan indeks. Himpunan kejadian � dikatakan
saling bebas jika ( i) ( )i i j i j
P A P A
untuk setiap himpunan bagian berhingga Jdari I. (Grimmet & Stirzaker 1992)
Definisi 2.1.5 (Peluang Bersyarat)
Misalkan sehingga P(A1) > 0. Misalkan pula A2 adalah sebarang
himpunan dalam . Peluang bersyarat dari A2 jika diketahui A1, dinotasikan
dengan , ialah
(Hogg & Craig 1995)
2.2 Peubah Acak dan Fungsi Sebaran Definisi 2.2.1 (Peubah Acak)
Misalkan adalah medan- dari ruang contoh . Suatu peubah acak X adalah suatu fungsi dengan sifat untuk setiap . (Grimmet & Stirzaker 1992)
Catatan:
Peubah acak dinotasikan dengan huruf besar seperti X, Y, Z, sedangkan nilai peubah acak dinotasikan dengan huruf kecil seperti x, y, z.
Definisi 2.2.2 (Fungsi Sebaran)
Misalkan adalah ruang peluang. Fungsi sebaran dari peubah acak X
Definisi 2.2.3 (Peubah Acak Diskret)
Peubah acak X dikatakan diskret jika nilainya hanya pada himpunan bagian yang terhitung dari . (Grimmet & Stirzaker 1992)
Catatan:
Suatu himpunan bilangan C disebut terhitung jika C terdiri atas himpunan bilangan berhingga atau anggota C dapat dikorespondensikan 1-1 dengan bilangan bulat positif.
Definisi 2.2.4 (Fungsi Massa Peluang)
Misalkan adalah ruang peluang. Fungsi massa peluang dari peubah acak diskret X adalah fungsi � yang diberikan oleh
� . (Grimmet & Stirzaker 1992)
Definisi 2.2.5 (Nilai Harapan)
Jika X adalah peubah acak diskret dengan fungsi massa peluang � , maka nilai harapan dari X adalah ∑ � asalkan jumlah di atas konvergen
mutlak.
(Hogg & Craig 1995)
Lemma 2.2.6 (Sifat Nilai Harapan)
Beberapa sifat nilai harapan, antara lain:
1) Jika k adalah suatu konstanta, maka E[k] = k.
2) Jika k adalah suatu konstanta dan V adalah peubah acak, maka E[kV] = kE[V]. 3) Jika k1, k2 adalah konstanta dan V1, V2 adalah peubah acak, maka
E[k1V1 + k2V2] = k1E[V1] + k2E[V2].
(Bukti lihat Hogg & Craig 1995)
Definisi 2.2.7 (Fungsi Sebaran Bersama Dua Peubah Acak)
Fungsi sebaran bersama dari dua peubah acak X dan Y adalah suatu fungsi yang didefinisikan oleh � .
7
Definisi 2.2.8 (Fungsi Gamma)
Fungsi gamma, , didefinisikan sebagai
∫ � .
(Grimmet & Stirzaker 1992)
Definisi 2.2.9 (Sebaran Student’s-t)
Peubah acak X memiliki sebaran Student’s-t dengan k derajat kebebasan, X ~ tk,
jika fungsi kepekatan peluangnya
√
(Kvam & Vidakovic 2007)
Definisi 2.2.10 (Sebaran Normal Baku)
Peubah acak X disebut normal baku jika fungsi sebarannya adalah Φ, yaitu jika
Φ
√ ∫
�
(Ghahramani 2005)
Definisi 2.2.11 (Sebaran Normal)
Peubah acak X disebut normal dengan parameter dan � , jika fungsi kepekatannya adalah
�√
(Ghahramani 2005)
Definisi 2.2.12 (Peubah Acak yang Dibakukan)
Misalkan X sebuah peubah acak dengan nilai harapan dan simpangan baku �.
Peubah acak disebut sebagai X yang dibakukan. (Ghahramani 2005)
Definisi 2.2.13 (Metode Transformasi)
. Misalkan bahwa inverse dari y = h(x) adalah fungsi x = h-1(y), yang terdiferensialkan untuk semua nilai . Maka , fungsi kepekatan Y, yaitu
, .
(Ghahramani 2005)
2.3 Penduga
Definisi 2.3.1 (Statistik)
Statistik adalah suatu fungsi dari satu atau lebih peubah acak yang tidak bergantung pada parameter (yang tidak diketahui). (Hogg & Craig 1995)
Definisi 2.3.2 (Penduga/estimator dan Dugaan/estimate)
Misalkan X1, X2, …, Xn adalah peubah acak. Suatu statistik
yang digunakan untuk menduga fungsi parameter
g(), dikatakan sebagai penduga (estimator) bagi g(). Nilai amatan dari U dengan nilai amatan disebut sebagai dugaan (estimate) bagi g(). (Hogg & Craig 1995)
2.4 Proses Stokastik Definisi 2.4.1 (Ruang State)
Misalkan merupakan nilai dari barisan peubah acak, maka S disebut ruang
state. (Grimmet & Stirzaker 1992)
Definisi 2.4.2 (Proses Stokastik)
Proses Stokastik � yang terdefinisi pada ruang peluang adalah suatu himpunan dari peubah acak yang memetakan suatu ruang contoh ke ruang stateS. (Ross 1996)
Definisi 2.4.3 (Proses Stokastik dengan Waktu Diskret dan Kontinu)
Suatu proses stokastik � disebut proses stokastik dengan waktu diskret jika himpunan indeks T adalah himpunan terhitung (countable set), sedangkan � disebut proses stokastik dengan waktu kontinu jika T adalah suatu
9
Catatan:
Contoh himpunan indeks T pada proses stokastik dengan waktu diskret adalah T =
{0, 1, 2, …}, sedangkan contoh himpunan indeks T pada proses stokastik dengan
waktu kontinu adalah T = [0, ), atau himpunan bilangan nyata.
Definisi 2.4.4 (Filtrasi)
Misalkan adalah barisan submedan- dari , disebut filtrasi jika untuk semua .
(Grimmet & Stirzaker 1992)
Definisi 2.4.5 (Measurable/Terukur)
Misalkan adalah ruang peluang. Jika fungsi memiliki sifat untuk setiap maka X dikatakan terukur- (Grimmet & Stirzaker 1992)
Definisi 2.4.6 (Adapted)
Misalkan adalah ruang peluang. Barisan peubah acak � dikatakan adapted ke filtrasi jika � merupakan terukur- untuk semua t. (Grimmet & Stirzaker 1992)
Definisi 2.4.7 (Martingale)
Proses Stokastik � disebut proses Martingale jika � untuk semua t dan � � �. (Ross 1996)
Definisi 2.4.8 (Variasi Hingga)
Misalkan merupakan proses CADLAG (kontinu kanan dengan limit kiri). Variasi A didefinisikan sebagai proses naik V yaitu
� { ∑| � ⋀ � � ⋀ �|
}
Sebuah proses A disebut memiliki variasi hingga jika proses variasi bersama V
Definisi 2.4.9 (Waktu Acak)
Misalkan adalah ruang peluang. . T disebut waktu acak dari proses � jika kejadian {T = t} ditentukan oleh peubah acak X1, …, Xt. Artinya dengan mengetahui X1, …, Xt maka diketahui apakah T = t atau tidak.
Jika , maka waktu acak T disebut sebagai stopping time. (Ross 1996)
Definisi 2.4.10 (Lokal Martingale)
{ t, t, 0 t }
M M adalah lokal martingale jika dan hanya jika terdapat
barisan stopping time Tn yang menuju tak hingga sedemikian sehingga MTn
merupakan martingale untuk setiap n. (Bain 2009)
Definisi 2.4.11 (Semimartingale)
Sebuah proses X adalah semimartingale jika X proses adapted CADLAG (kontinu kanan dengan limit kiri) yang memiliki dekomposisi
X = X0 + M + A,
di mana M lokal martingale, null pada saat nol dan A proses null pada saat nol, dengan jalur variasi hingga. (Bain 2009)
Catatan:
Null pada saat nol untuk proses stokastik X(t) maksudnya adalah meskipun pada saat t > 0 nilai dari X(t) itu acak, pada saat t = 0 (waktu mulai) diketahui/ditetapkan nilainya adalah nol: X(0) = 0 (atau, secara lebih formal, bahwa P(X(0) = 0) = 1). Contoh khusus ini merupakan proses random walk paling dasar.
Definisi 2.4.12 (Rantai Markov dengan Waktu Diskret)
Misalkan adalah ruang peluang dan S adalah ruang state. Proses stokastik � dengan ruang state S disebut rantai Markov dengan waktu diskret jika berlaku:
� � � � � � �
11
Definisi 2.4.13 (Matriks Transisi)
Misalkan �� adalah rantai Markov dan S adalah ruang state yang berukuran N. Matriks transisi � berukuran adalah matriks dari peluang
transisi �� �� � � �� � �� �� untuk i = 1, 2, …, N.
(Rossi & Gallo 2006)
Definisi 2.4.14 (Nilai Harapan Bersyarat)
Misalkan adalah ruang peluang dan adalah submedan- dari . Jika
X adalah peubah acak tak negatif dan terintegralkan, maka didefiniskan sebagai peubah acak yang terukur- dan bersifat tunggal kecuali pada kejadian berpeluang nol, serta memenuhi:∫ ∫ .
(Elliot et al. 1995)
2.5 Vektor
Definisi 2.5.1 (Ruang Vektor)
V disebut ruang vektor, jika untuk setiap vektor dan sebarang skalar k
dan l dipenuhi aksioma berikut: 1. Jika maka . 2. u + v = v + u.
3. u + (v + w) = (u + v) + w.
4. Ada sehingga 0 + u = u + 0 = u, .
5. Untuk , ada yang dinamakan negatif u sehingga
u + (–u ) = (–u ) + u = 0.
6. Jika k adalah sebarang skalar dan , maka . 7. k(u + v) = ku + kv.
8. (k + l)u = ku + lu. 9. k(lu) = (kl)u. 10. 1u = u. (Anton 1997)
Definisi 2.5.2 (Perkalian Dalam)
. (Anton 1997)
Definisi 2.5.3 (Ruang Hasil Kali Dalam)
Sebuah hasil kali dalam pada ruang vektor real V adalah fungsi yang mengasosiasikan bilangan real dengan masing-masing pasangan vektor u
dan v pada V sedemikian rupa sehingga aksioma-aksioma berikut dipenuhi untuk semua dan skalar k:
1. .
2. . 3. .
4. dan jika dan hanya jika v = 0.
Sebuah ruang vektor real dengan sebuah hasil kali dalam dinamakan ruang hasil kali dalam real. (Anton 1997)
Definisi 2.5.4 (Hadamard Product)
Hadamard product, dengan simbol operator , merupakan perkalian elemen dengan elemen dari dua buah matriks. Oleh karena itu, jika A [ � ] dan
B [ � ] adalah dua buah matriks yang berukuran , maka
[
].
(Schott 1997)
Definisi 2.5.5 (Matriks Hessenberg)
Matriks � berukuran disebut matriks Hessenberg atas jika � untuk i > j + 1:
[
]
.
13
Definisi 2.5.6 (Matriks Tridiagonal)
Matriks � berukuran , yang merupakan Hessenberg atas dan bawah, disebut matriks tridiagonal jika � , ketika :
[
]
.
BAB III
MODEL
HIDDEN
MARKOV
3.1 Model Hidden Markov
Misalkan � harga sebuah aset pada waktu t. Return atas aset tersebut, yaitu �� � � , dianggap sebagai peubah acak yang dapat diamati pada waktu t,
untuk t = 1,…,T. Volatilitasnya dikendalikan oleh 3-state rantai Markov �� dengan ruang state � � � dengan �� adalah vektor satuan di . Model volatilitas stokastik ditulis dalam format ruang–state:
�� � � �� � (1)
�� � �� �, (2)
di mana � adalah bentuk autoregresi sederhana:
� �� . (3)
� dan � diasumsikan bebas, di mana � merupakan perubahan return yang
diasumsikan menyebar Student’s-t dengan varians satu dan derajat kebebasan ,
sedangkan � merupakan representasi semi-martingale, � �� � �� � � dan � adalah filtrasi yang dibangkitkan oleh � �
� �� adalah nilai volatilitas yang terjadi pada waktu t, dengan σ() sebuah
fungsi penskalaan bernilai positif yang bernilai � ketika �� = � , � ketika ��=� ,
dan � ketika �� = � . Jika � ( � �
� ), maka � �� �
�� �.
Misalkan �� �� dan �� �
, di mana i = 1, 2, 3,
maka
� �� {
� � �
�� � �
� �
,
di mana dan adalah konstanta. Ketika positif, � dapat diartikan bahwa varians berada pada regime (state) volatilitas terendah, dan � varians berada pada
regime (state) volatilitas tertinggi.
15
��
{
�� � �� �
�� � �� �
�� � �� �
. (4)
� pada persamaan (2) adalah matriks transisi berukuran 33 dari rantai Markov
�� dengan elemennya:
� �� �� � �� �� �� � �� , (5)
dengan � adalah filtrasi yang dibangkitkan oleh � � , yang
menggambarkan peluang transisi rantai Markov. Entri dari � memenuhi �� ≥ 0, dan ∑ � �� = 1, untuk setiap 1 ≤ i, j≤ 3 dan t.
Untuk menggambarkan keadaan di mana volatilitas dibangkitkan oleh
return pada waktu t, maka matriks transisi didefinisikan sebagai berikut:
� { �
[ �� ] ��
� [ �� ] ��
, (6)
dengan
�
(�
� �� �� � �� ) dan � (�� �� �� � �� ).
Keadaan model ini menunjukkan return dan perubahan volatilitas berkorelasi negatif. Jika pada waktu t harga aset turun, maka peluang bahwa suatu vektor state bergerak menuju tingkat volatilitas yang lebih tinggi harus lebih tinggi dari pada kasus harga aset naik. Jadi syarat untuk adalah :
� (�� �� �� � �� )
�� �� �� � ��
� .
Sementara itu untuk hal sebaliknya harus muncul ketika . Sehingga elemen matriks didefinisikan sebagai berikut:
��
{
�
�[ � ]
�[ � ]
� persamaan (1)-(8), model Hidden Markov untuk volatilitas tersebut dicirikan oleh .
3.2 Dugaan Maksimum Likelihood
17
diketahui � adalah
�� � ∑ �� �� �
� �
∑� �� �� �� � �� �� � . (9)
Sementara itu, dengan menggunakan hukum total peluang, bentuk �� �� � dirinci sebagai
�� �� � ∑ �� ��
�� � �
∑ (�� ��|�� � �� ) �� � � . (10)
Sehingga persamaan (10) menjadi
�� � ∑ ∑� �� �� �� � (�� ��|�� � �� )
�� � � (11)
Dari persamaan (1),
�� � � �� �,
di mana � merupakan perubahan return yang diasumsikan menyebar Student’s-t. Asumsi tersebut didasarkan pada penelitian Bollerslev (1987) bahwa sebaran
Student’s-t lebih tepat untuk menggambarkan tingkat return.
Diketahui fungsi kepekatan peluang dari sebaran Student’s-t adalah ,
dengan , dan
. (Kvam & Vidakovic 2007).
Misalkan �
adalah sebaran Student’s
-t yang
dibakukan dan misalkan pula, . Maka
� � dan � .
Dengan menggunakan metode transformasi, maka fungsi kepekatan peluang dari
� adalah
� � �
�
Dengan menggunakan metode transformasi, maka fungsi kepekatan peluang dari �� adalah
yang konvergen ke fungsi kepekatan sebaran normal, yaitu
� �� � � � �� � �
ketika .
Bagian kedua dari persamaan (11) yaitu (�� ��|�� � �� ) � � ,
sedangkan (�� � | � ) persamaan (11) merupakan filtrasi dugaan state
yang didapat dengan memproses pengamatan masa lalu dan sekarang. Rekursif
filter yang digunakan di sini adalah mengadaptasi rekursif filter yang diajukan oleh Hamilton dan Susmel (1994).
�� �� � . (16)
Sehingga berdasarkan persamaan (14), (15), dan (16) maka diperoleh
�� �� � �� � �� �� � � �
di mana �� �� � merupakan �� � � . Oleh karena itu
�
� � ( ( ) ) . (17)Dari persamaan (2) didapat
�� � � �� � � �
� �� �
� �� �
�� � � �� � (18)
yang merupakan harapan �� berada pada suatu state dengan diberikan pengamatan sebelumnya.
Sehingga persamaan (17) menjadi
�� � ( ( ) ) . (19)
Menggunakan persamaan (11) dan mengamati bahwa
�� �� � ��[
�� � �
�� � �
�� � �
]
�� � �� � � � �� � � � �� � �
��[∑ �� (�� � | �)]
�� �� � ���� �,
maka bentuk umum fungsi likelihood dari proses return yang diamati adalah
�� � ∑ ∑ �� �� �� �
�
� � � �
� �
�� �� � � [ � � �� � � � �� � � � �� � ]
�� �� � � [ � � �� � � � �� � � � �� � ]
21
(20)
dengan � � � � , jika �� atau � � � � , jika �� . Fungsi log-likelihood didefinisikan sebagai
( � � �� )
�� �� �� � �� �� �� � � � �
� � �� �
∑�� �� � ,
dengan � �� �� � .
Untuk pendugaan parameter yang memaksimumkan fungsi log-likelihood
digunakan algoritma Berndt, Hall, Hall, Hausman (BHHH). Langkah algoritma BHHH pada penelitian ini mengadapatasi langkah algoritma BHHH yang diuraikan oleh Arneric dan Rozga (2009). Berikut langkah algoritma tersebut:
Langkah 1
Tentukan vektor parameter awal dan kriteria kekonvergenan tol > 0, dengan
maka coba dengan dan seterusnya hingga didapatkan di mana
Jika kriteria kekonvergenan terpenuhi maka hentikan algoritma, jika tidak maka
ii + 1, kembali ke langkah 2.
Kriteria kekonvergenan yang digunakan adalah
| | .
Algoritma ini diimplementasikan dengan menggunakan software pemrograman MATLAB 7.7.
3.3 Algoritma Pemrograman
Penerapan algoritma BHHH memerlukan turunan pertama dari fungsi
23
Turunan tersebut diadaptasi dari pencarian turunan pertama dari fungsi
log-likelihood yang diuraikan oleh Gable et al. (1997).
�� � didapat dari perhitungan smoother yang diajukan oleh Kim (1994) yang
diuraikan kembali oleh Hamilton (1994). Sedangkan �� � didapat dari perhitungan rekursi filter yang diajukan oleh Hamilton (1994).
Berikut adalah rekursi filter yang diajukan oleh Hamilton (1994)
�� � ( ( � �� � ) � � �� � ) �
Berikut adalah rekursi smoother yang diajukan oleh Kim (1994) �� � �� � { �[�� � ( ��� �)]}
Hitung dan
Jika ( ) maka coba dengan .
Jika ( ) maka coba dengan dan seterusnya
hingga didapatkan di mana ( )maksimum.
Langkah 3
Uji kriteria kekonvergenan | |
Jika terpenuhi, hentikan proses, kemudian cetak dan ( ) .
Langkah 4
Jika kriteria kekonvergenan belum terpenuhi, lanjutkan untuk iterasi
berikutnya, yaitu i = i + 1.
Pilih
Hitung � � (∑
�
� | � )
∑�
� | �
Hitung dan
Jika ( ) maka coba dengan .
Jika ( ) maka coba dengan dan seterusnya
hingga didapatkan di mana ( )maksimum.
Langkah 5
Uji kriteria kekonvergenan | |
Jika terpenuhi, hentikan proses, kemudian cetak � dan ( ) , jika
BAB IV
PENDUGAAN VOLATILITAS INDEKS HARGA SAHAM
4.1 Indeks Harga SahamSaham merupakan salah satu investasi yang menjanjikan bagi investor pada saat ini. Pertumbuhan ekonomi Indonesia yang cukup baik, menambah gairah perdagangan saham. Banyak investor, baik dari luar maupun dalam negeri berkecimpung dalam kegiatan ini.
Indeks harga saham, sebagai salah satu panduan dalam berinvestasi sangat diperlukan oleh investor untuk menentukan strategi dalam berinvestasi. Salah satu indeks harga saham yang ada di Indonesia adalah indeks LQ45.
Indeks LQ45 merupakan indeks harga saham yang dihitung dari 45 saham yang memiliki likuiditas tinggi. Setiap enam bulan sekali dilakukan peninjauan kembali, yaitu pada bulan Februari dan Agustus. Artinya bahwa indeks LQ45 terdiri dari saham-saham pilihan, yaitu saham-saham yang memiliki kualitas baik.
4.2 Volatilitas
Perubahan return dari suatu indeks harga saham memiliki ketidakpastian. Terkadang bernilai positif, terkadang bernilai negatif. Untuk mengetahui seberapa besar ketidakpastian hal tersebut digunakan sebuah ukuran yang disebut dengan volatilitas.
Volatilitas dianggap sebagai suatu hal yang tak dapat diamati (unobservable). Seseorang tak dapat mengetahui secara pasti berapa nilai volatilitas sesungguhnya. Oleh karena itu, perhitungan volatilitas merupakan sebuah dugaan.
Volatilitas biasanya dihitung dengan menggunakan ragam atau simpangan baku. Seiring dengan perkembangan zaman, banyak peneliti mengajukan cara lain untuk menghitung volatilitas.
Terdapat beberapa cara untuk menghitung volatilitas harian, yaitu:
1. Realized Volatility
Volatilitas diukur dengan menggunakan rumus
di mana �� � merupakan kuadrat return ke-i pada perdagangan hari ke-t
dan n merupakan banyaknya data. Biasanya digunakan data return tiap 5 menit pada perdagangan hari ke-t. Perhitungan ini diajukan oleh Andersen dan Bollerslev (1998).
2. Range Based Volatility
Terdapat beberapa cara yang diajukan peneliti untuk menghitung volatilitas dengan pendekatan ini, salah satunya adalah yang diajukan oleh Alizadeh et al. (2002). Volatilitas diukur dengan menggunakan rumus
� � � (2)
di mana Ht merupakan harga tertinggi, dan Lt merupakan harga terendah
pada perdagangan hari ke-t.
3. Squared Return
Cara ini disebut sebagai cara tradisional, karena cara ini telah digunakan sebelum cara ke-1, dan ke-2 ada. Rumus squared return adalah
� �� (3)
di mana �� merupakan kuadrat return pada perdagangan hari ke-t.
Di antara ketiga cara perhitungan tersebut, cara ke-1 adalah yang terbaik, sedangkan cara ke-3 adalah yang paling tidak akurat (Blair et al. 2001).
Volatilitas dianggap tak dapat diamati sehingga diperlukan pembanding (de Vilder & Visser, 2007). Penelitian ini menggunakan cara ke-2 sebagai daily volatility proxy (wakil volatilitas harian), sebagai acuan atau pembanding dalam perhitungan galat. Pemilihan cara ke-1 tidak dapat dilakukan, dikarenakan tidak tersedianya data return untuk tiap 5 menit pada indeks LQ45.
4.3 Pendugaan Volatilitas
Perhitungan pendugaan volatilitas dari model yang diajukan oleh Rossi dan Gallo (2006) untuk satu langkah ke depan, menggunakan bentuk berikut
�� � � � �� �
� �� �
∑� �� �� � �
27
�� �� � ∑ (�� ��|�� � �� )
�� �� �
Oleh karena itu, pendugaan volatilitas untuk satu langkah ke depan adalah ̂� � ∑� �� �� � � � ��� � (4)
Data yang digunakan dalam penelitian ini sebanyak 1375, di mana sebanyak 917 (sekitar dua pertiga dari keseluruhan) digunakan untuk pendugaan model ( in-sample), sementara itu sisanya sebanyak 458 digunakan untuk analisis out-of-sample (prediksi yang akan datang). Data didapat dari situs yahoo finance http://www.finance.yahoo.com
Dari data in-sample yang digunakan, dibuat sebuah program dengan menggunakan software MATLAB 7.7 untuk mendapatkan parameter yang memaksimumkan fungsi log-likelihood. Program tersebut membangkitkan data nilai awal
yang menghasilkan parameter model sebagai berikut:
̂ ̂ ̂ ̂ ̂ ̂ ̂ ̂ .
Penggunaan bentuk (4) dalam menduga volatilitas untuk satu langkah ke depan diterapkan pada data in-sample dan out-of-sample. Perhitungan galat menggunakan Symmetric Mean Absolute Percentage Error (SMAPE) dengan rumus
SMAPE { ∑
� � �
� �
(5)
di mana At nilai aktual, dan Ft nilai dugaan. Nilai SMAPE pada (5) berada pada
interval [0%, 100%]. Semakin kecil nilai SMAPE, maka semakin akurat pendugaan volatilitas.
Perhitungan pendugaan volatilitas satu langkah ke depan untuk masing-masing data, dibuat sebuah program dengan menggunakan software Mathematica
1. Data in-sample
Gambar 4.1 Grafik volatilitas dugaan in-sample
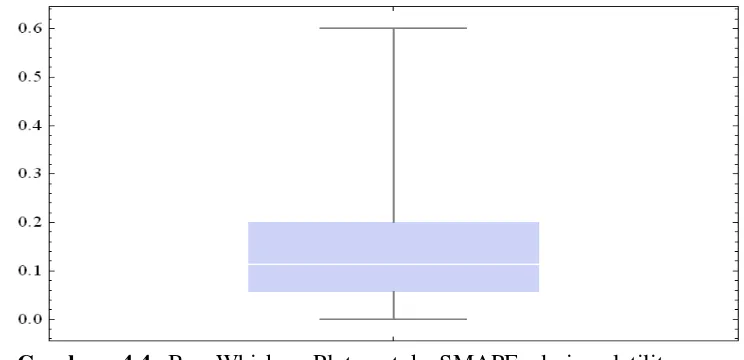
Perhitungan SMAPE dari volatilitas dugaan in-sample menghasilkan nilai rataan galat sebesar 13.79%, nilai galat maksimum sebesar 67.28%, dan nilai galat minimum sebesar 0.00%, serta kuartil ke-1 (Q1), kuartil ke-2
(Q2), dan kuartil ke-3 (Q3) masing-masing sebesar 4.80%, 11.24%, dan
20.09%. Jarak inter-kuartil sebesar 15.29%. Sebanyak 50% data berada di antara Q1 dan Q3 dengan jarak interval sebesar 15.29%. Berikut adalah
Box-Whisker Plot untuk SMAPE dari volatilitas dugaan in-sample.
Gambar 4.2 Box-Whisker Plot untuk SMAPE dari volatilitas dugaan in-sample
0 200 400 600 800 hari 2
4 6 8 10 12 14 volatilitas
VS
29
2. Data out-of-sample
Gambar 4.3 Grafik volatilitas dugaan out-of-sample
Perhitungan SMAPE dari volatilitas dugaan out-of-sample menghasilkan nilai rataan galat sebesar 13.62%, nilai galat maksimum sebesar 60.07%, dan nilai galat minimum sebesar 0.004%, serta kuartil ke-1 (Q1), kuartil
ke-2 (Q2), dan kuartil ke-3 (Q3) masing-masing sebesar 5.71%, 11.32%,
dan 20.06%. Jarak inter-kuartil sebesar 14.35%. Sebanyak 50% data berada di antara Q1 dan Q3 dengan jarak interval sebesar 14.35%. Berikut
adalah Box-Whisker Plot untuk SMAPE dari volatilitas dugaan out-of-sample.
Gambar 4.4 Box-Whisker Plot untuk SMAPE dari volatilitas dugaan out-of-sample
Dari Gambar 4.2 dan Gambar 4.4, dapat dilihat bahwa sebaran nilai galat tampak menjulur ke kanan, yang berarti sebagian besar nilai mengumpul
0 100 200 300 400 hari 2
4 6 8 10 12 volatilitas
VS
BAB V
KESIMPULAN DAN SARAN
Kesimpulan
Kesimpulan hasil penelitian adalah sebagai berikut.
1. Model hidden Markov yang diajukan oleh Rossi dan Gallo (2006) telah dikaji dan diimplementasikan pada indeks LQ 45.
2. Pendugaan parameter model hidden Markov menggunakan algoritma BHHH dan diimplementasikan dengan pemrograman MATLAB 7.7.
3. Pendugaan volatilitas pada indeks LQ 45 cukup baik. Hal ini dapat dilihat dari hasil perhitungan galat dengan menggunakan SMAPE sebesar 13.62%.
Saran
DAFTAR PUSTAKA
Alizadeh S, Brandt M, Diebold F. 2002. Range-based Estimation of Stochastic Volatility Models. Journal of Finance, 57, 1047-1091.
Andersen, Bollerslev. 1998. Answering the Skeptics: Yes, Standard Volatility Models Do Provide Accurate Forecasts. International Economic Review, 39: 885-905.
Anton H. 1997. Aljabar Linear Elementer.Ed. ke-5.Terjemahan Pantur Silaban dan I Nyoman Susila. PenerbitErlangga. Jakarta.
Arneric J, Rozga A. 2009. Numerical Optimization within Vector of Parameters Estimation in Volatility Models. International Journal of Human and Social Sciences 4:16.
Bain A. 2009. Stochastic Calculus.http://www.chiark.greenend.org.uk/~alanb/ [10 Mar 2011]
Blair BJ, Poon SH, Taylor SJ. 2001. Forecasting S&P 100 Volatility: The Incremental Information Content of Implied Volatilities and High-Frequency Index Returns. Journal of Econometrics, 105, 5-26.
Bollerslev, T. 1986. Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics, 31, 307-327.
Bollerslev, T. 1987. A Conditionally Heteroskedastic Time Series Model for Speculative Prices and Rates of Return. The Review of Economics and Statistics, 69, 542-547.
Cvitanic J, Liptser RS, Rozovskii BL. 2005. A Filtering Approach to Tracking Volatility from Prices Observed at Random Times. The Annals of Applied Probability 16, No.3, 1633-1652.
33
Elliot JR, Aggoun L, dan Moore JB. 1995. Hidden Markov Models Continuous. Springer-Verlag. New York.
Gable J, van Norden S, Vigfusson R. 1997. Analytical Derivatives for Markov Switching Models. Computational Economics, 10, 187-194.
Ghahramani, S. 2005. Fundamentals of Probability with Stochastic Processes. Ed. ke-3 Pearson Education International. New Jersey.
Grimmet GR, Stirzaker DR. 1992. Probability and Random Processes. Ed. ke-2. Oxford University Press. Oxford.
Hamilton JD. 1994. Time Series Analysis. Princeton University Press.
Hamilton JD, Susmel R. 1994. Autorgressive Conditional Heteroskedasticity and Changes in Regimes, Journal of Econometrics 64, 307-333.
Hogg RV, Craig AT. 1995. Introduction to Mathematics Statistics. Ed. ke-5.Prentice Hall, Englewood Cliffs. New Jersey.
Horn RA, Johnson CR. 1990. Matrix Analysis. Cambridge University Press. Cambridge.
Kim CJ. 1994. Dynamic Linear Models with Markov Switching, Journal of Econometrics 60, 1-22.
Kvam PH, Vidakovic B. 2007. Nonparametric Statistics with Applications to Science and Engineering. John Wiley & Sons, New jersey.
Lamoureux CG, Lastrapes WD. 1990. Persistence in Variance, Structural Changes, and the GARCH Model, Journal of Business and Economic Statistics 8, No. 2, 226-234.
Ross SM. 1996. Stochastic Processes. Ed. ke-2. John Wiley & Sons. New York.
Rossi A, Gallo G. 2006. Volatility Estimation via Hidden Markov Models, Journal of Empirical Finance, 13, 203-230.
Schott JR. 1997. Matrix Analysis for Statistics. John Wiley & Sons. Canada.
Stirling formula. Encyclopedia of Mathematics. URL: http://www.encyclopedia ofmath.org/index.php?title=Stirling_formula&oldid=24807
Lampiran1 Pembuktian sebaran Student’s-t konvergen ke sebaran normal ketika
Dengan menggunakan formula Stirling (Encyclopedia of Mathematics), yaitu
� √ �� , maka
[ ] [ ] √ ( ) ( )
37
dan
[
] √ (
) (
)
, sehingga
Oleh karena itu
� ��
��
��
��
�� .
Uraikan bentuk
menjadi
.
Misalkan , maka
, dan .
Sehingga
.
� �� � �� � �� .
Jadi,
�� �� �� � ��
39
Lampiran 2 Proses penurunan turunan pertama fungsi sebaran return terhadap parameter yang berkaitan
Diketahui fungsi sebaran returnyang menyebar Student’s-t
�� �� �� � � �� ��� � �� �
Turunan pertama terhadap parameter adalah
�� �� � �
Turunan pertama terhadap parameter adalah
�� �� � �
�� �� ��
�� �� ��
Untuk mendapatkan turunan pertama terhadap parameter dan , fungsi sebaran
return ditulis kembali menjadi
Proses mendapatkan turunan pertama terhadap parameter dengan �� � dan
41
Untuk mencari turunan pertama terhadap parameter , dimisalkan
Turunan pertama terhadap parameter adalah
�� �� � �
Terlebih dahulu akan dicari
43
Jadi, turunan pertama terhadap parameter adalah
Lampiran 3 Penurunan turunan pertama fungsi log-likelihood
Turunan berikut hampir serupa prosesnya dengan proses di atas.
45
Berikut adalah turunan terhadap parameter yang berkaitan dengan peluang transisi.
Turunan terhadap a adalah
�
Turunan terhadap b adalah
Turunan terhadap adalah
kepekatan peluang dari sebaran normal baku. Oleh karena itu,
�
Turunan terhadap a adalah
47
Turunan terhadap b adalah
�
merupakan fungsi sebaran kumulatif normal baku.
Turunan Fungsi log-Likelihood
Berikut turunan fungsi log-likelihood yaitu
.
Mengadaptasi pencarian turunan pertama dari fungsi log-likelihood yang diuraikan Gable et al. (1995), turunan fungsi log-likelihood adalah sebagai
dengan menganggap bahwa peluang awal state diberikan sebagai nilai awal,
49 perhitungan rekursi filter yang diajukan oleh Hamilton (1994).
Berikut adalah rekursi filter yang diajukan oleh Hamilton (1994)
�� � ( ( � �� � ) � � �� � ) �
Berikut adalah rekursi smoother yang diajukan oleh Kim (1994)
�� � �� � { �[�� � ( ��� �)]}
�� ��
Lampiran 4 Pemrograman menggunakan software MATLAB 7.7
Program ini hanya untuk model Hidden Markov yang diajukan oleh Rossi dan Gallo (2006) dengan stateN = 3 dan parameter .
%Script file: dlmtm1_da.m
%Tujuan: untuk menghitung turunan pertama peluang transisi terhadap
y1=[ye/(1ye1) ye/ye1 0;ye/ye1 ye/(1ye1) ye/ye1;0 ye/ye1 -ye/(1-ye1)];
%Tujuan: untuk menghitung turunan pertama peluang transisi terhadap
abs(r(t))*(ye/ye1);0 abs(r(t))*(ye/ye1) -abs(r(t))*(ye/ye1)];
y2=[-abs(r(t))*(ye/(p-ye1)) abs(r(t))*(ye/ye1) 0;abs(r(t))*(ye/ye1) -abs(r(t))*...
51
if (r(t)<=0) y=y1;
else y=y2;
end
---
%Script file: dlmtm1_dpsi.m
%Tujuan: untuk menghitung turunan pertama peluang transisi terhadap
% parameter psi
% Record of revisions:
% Date Programmer Description of change % ==== ========== ===================== % 07/16/12 Abdul Baist Original code
function y=dlmtm1_dpsi(a,b,p,t)
ye=normcdf(a+b*abs(r(t)),0,1);
y1=zeros(3);
y2=[ye/((p-ye)*p) 1/p 0;-1/p ((1-p^2)/(2*p^2-p^3*ye-p*ye))*ye 1/p;0 -1/p -ye/(1-p*ye)];
if (r(t)<=0) y=y1;
else y=y2;
end
---
%Script file: dlogfrt_dalp.m
%Tujuan: untuk menghitung turunan pertama log fungsi sebaran return
% terhadap parameter alpha
% Record of revisions:
% Date Programmer Description of change % ==== ========== ===================== % 07/16/12 Abdul Baist Original code
function y=dlogfrt_dalp(m,g,n,s,t)
y=1/2*((n*(r(t)-m-g*r(t-5))^2-s*(n-2))/(s*(n-2)+(r(t)-m-g*r(t-5))^2));
---
%Script file: dlogfrt_dg.m
%Tujuan: untuk menghitung turunan pertama log fungsi sebaran return
% Record of revisions:
%Tujuan: untuk menghitung turunan pertama log fungsi sebaran return
%Tujuan: untuk menghitung turunan pertama log fungsi sebaran return
53 fprintf('mu= %10.4f',teta(1));fprintf(' g= %10.4f',teta(2)); fprintf(' alp= %10.4f',teta(3));
fprintf(' dlt= %10.4f\n',teta(4));fprintf(' a= %10.4f',teta(5)); fprintf(' b= %10.4f\n',teta(6));
fprintf(' p= %10.4f',teta(7));fprintf(' nu= %10.4f\n',teta(8));
%---while ((kkonv >= tol) && (i<=maxit)); % Memulai loop iterasi.
tes_NaN=isnan(rcond(op_grad(teta(1),teta(2),teta(3),teta(4),teta(5 ),teta(6),teta(7),teta(8),te)));
if (tes_NaN==1),fixseed(teta,alpa,te);end;
va=mat_ex(teta(1),teta(2),teta(3),teta(4),teta(5),teta(6),teta(7), teta(8),te)\ones(te,1); % Vektor arah dihitung dengan menggunakan least square.
% ---% Memilih langkah(step) terbesar yang meningkatkan nilai fungsi. j=0;
deltf =-1;
while (deltf<0) && (j<=10); % Memulai loop reduksi langkah
(step).
step=(0.5)^j; % Mereduksi langkah.
teta1=teta+(step*va);% Mencoba vektor parameter baru. if (teta1(7)<1)||(teta1(8)<2),fixseed(teta1,alpa,te);end;
logl=floglh(teta1(1),teta1(2),teta1(3),teta1(4),teta1(5),teta1(6),
...
% Mencetak hasil iterasi ke-i.
stderr = sqrt(diag(mk)); % Menghitung standar error.
% Mencetak Output
if (i>maxit), fixseed(teta,alpa,te), end; fprintf('\n');
fprintf(' teta\t Std. Error\n '); fprintf('---\n');
for h=1:8;
fprintf([h,'%12.5f %12.8f \n'], [teta(h) stderr(h)]); fprintf('\n');
end;
clear global;
---
%Script file: estimatepar.m
%Tujuan: menampilkan tampilan awal proses pendugaan parameter dari % fungsi loglikelihood
disp('Program ini untuk menduga parameter dari fungsi loglikelihood');
disp('dengan menggunakan algoritma BHHH'); fprintf('\n');
alpa=input('Masukkan angka untuk SeedRandom: '); % Prompt the user to enter a number.
te=input('Banyaknya data: '); % Prompt the user to enter a number. stream=RandStream('mcg16807', 'Seed',alpa); % Membangkitkan nilai acak.
beta=[-5+10*rand(stream,1,6) 1+5*rand(stream,1,1)
2+8*rand(stream,1,1)]'; % Nilai awal yang dibangkitkan dengan seed random.
espar2(beta,te,alpa); % Memanggil file pendugaan parameter.
---
55
%Tujuan: untuk menghitung fungsi sebaran return menyebar Student's-t
%Tujuan: menampilkan tampilan awal proses pendugaan parameter dari % fungsi loglikelihood
fprintf('Parameter sebelumnya:%10.5f\n', [pmtr1(1) pmtr1(2) pmtr1(3) pmtr1(4) pmtr1(5) pmtr1(6) pmtr1(7) pmtr1(8)]); fprintf('Angka SeedRandom sebelumnya:%2.0f\n',snumb);
stream=RandStream('mcg16807', 'Seed',snumb+1); % Membangkitkan nilai acak.
y=[-5+10*rand(stream,1,6) 1+5*rand(stream,1,1)
function y=floglh(mu,g,alp,dlt,a,b,p,nu,t)
%Tujuan: untuk menghitung vektor gradien pada waktu t>1
% Record of revisions:
57
dlogf_db(i,j)=zet0(j)*(pkim(i)/zet(i))*db(i,j); end
dlogf_dp(i,j)=zet0(j)*(pkim(i)/zet(i))*dp(i,j); end
%Tujuan: untuk menghitung vektor gradien pada waktu t=1
for i=1:3
dlogf_da(i,j)=zet01(j)*(pkim(i,1)/zet(i))*da(i,j); end
dlogf_db(i,j)=zet01(j)*(pkim(i,1)/zet(i))*db(i,j); end
59
else m1=[1-y3/p p*y2 0;y3/p 1-(p+1/p)*(y2) p*y3;0 y2/p 1-p*y3];
% Date Programmer Description of change
grad_an(m,g,alp,dlt,a,b,p,n,zet(:,i),zet0,pkim(:,i),i)';
end
y=grad_an1(m,g,alp,dlt,a,b,p,n)*grad_an1(m,g,alp,dlt,a,b,p,n)'+y1;
---
%Script file: sum_grad.m
%Tujuan: untuk menghitung total vektor gradien dari t=1 s/d t=T
61
va=mat_ex(m,g,alp,dlt,a,b,p,n,t)\ones(t,1); % Vektor arah dihitung dengan menggunakan least square.
---
%Script file: zet_t.m
%Tujuan: untuk menghitung rekursi filter Hamilton
% Record of revisions:
% Date Programmer Description of change % ==== ========== ===================== % 07/16/12 Abdul Baist Original code
function y=zet_t(m,g,alp,dlt,a,b,p,n,t)
format long
ye=[1/4;1/2;1/4]; y=zeros(3,t);
if (t==0),y=ye;
end
for k=1:t,
ye=((mat_trans(a,b,p,k- 1)*ye).*fgs_rt(m,g,alp,dlt,n,k))/(ones(1,3)*((mat_trans(a,b,p,k-1)*ye).*fgs_rt(m,g,alp,dlt,n,k)));
y(:,k)=ye;
end
ABSTRACT
ABDUL BAIST. The Study of Hidden Markov Model for Estimating Stocks Index Volatility. Supervised by BERLIAN SETIAWATY and N. K. KUTHA ARDANA.
Volatility is a measure of uncertainty, which is useful for investor to plan a good investment strategy. The problem is that volatility is unobservable, and estimating volatility is not a trivial task. Hidden Markov model is, a model which is consisted of two processes, i.e. observation and a Markov process. The Markov process is assumed to be unobserved (hidden). In this thesis, LQ45 index is considered as the observation process and the unobserved hidden Markov is the volatility. To estimate the volatility of LQ45 index, the model proposed by Rossi and Gallo (2006) is used. The result of the study shows that volatility estimation of the LQ45 index using the model performs well. This is shown by the calculated error using symmetric mean absolute percentage error, which is only about 13.62%.
ABDUL BAIST. Kajian Model Hidden Markov untuk Menduga Volatilitas volatilitas stokastik ditulis dalam format ruang–state:
�� � � �� � (1)
�� � �� �, (2)
di mana � adalah bentuk autoregresi sederhana
� �� . (3)
� dan � diasumsikan bebas, di mana � merupakan perubahan return yang
diasumsikan menyebar Student’s-t dengan varians satu dan derajat kebebasan , sedangkan � merupakan representasi semi-martingale, � �� � �� , varians berada pada regime (state) volatilitas terendah, dan � varians berada pada
regime (state) volatilitas tertinggi.
Untuk menggambarkan keadaan di mana volatilitas dibangkitkan oleh return pada waktu t, maka matriks transisi didefinisikan sebagai berikut:
� { �
Elemen matriks didefinisikan sebagai berikut:
� �
{
∑� � �� � [ � ]
[ � ]
,
di mana > 0 ( adalah parameter yang menggambarkan korelasi antara return
dan perubahan volatilitas), dan
� �� , ( � adalah parameter time-varying)
untuk beberapa koefisien a dan b, di mana () menyatakan fungsi sebaran normal baku.
Pasangan �� �� merupakan model Hidden Markov, dan berdasarkan persamaan (1)-(6), model Hidden Markov untuk volatilitas tersebut dicirikan oleh .
Fungsi log-likelihood didefinisikan sebagai ( � � �� )
�� �� �� � �� �� �� � � � �
� � �� �
∑�� �� � ,
dengan � �� �� � .
Untuk pendugaan parameter yang memaksimumkan fungsi log-likelihood
digunakan algoritma Berndt, Hall, Hall, Hausman (BHHH).
Pendugaan volatilitas untuk satu langkah ke depan adalah
̂� � ∑� �� �� � � � ��� �
Dari 1375 data yang tersedia, sebanyak 917 (sekitar dua pertiga dari keseluruhan) digunakan untuk pendugaan model (in-sample), sementara itu sisanya sebanyak 458 digunakan untuk analisis out-of-sample (prediksi yang akan datang).
Dari data in-sample yang digunakan, dengan data nilai awal
, menghasilkan parameter model sebagai berikut:
̂ ̂ ̂ ̂ ̂ ̂
̂ ̂ .
Pendugaan volatilitas untuk satu langkah ke depan diterapkan pada data in-sample
SMAPE { ∑
� � �
� �
di mana At nilai aktual, dan Ft nilai dugaan.
Perhitungan SMAPE dari volatilitas dugaan in-sample menghasilkan nilai rataan galat sebesar 13.79%, nilai galat maksimum sebesar 67.28%, dan nilai galat minimum sebesar 0.00%, serta kuartil ke-1 (Q1), kuartil ke-2 (Q2), dan kuartil
ke-3 (Q3) masing-masing sebesar 4.80%, 11.24%, dan 20.09% serta jarak
inter-kuartil sebesar 15.29%.
Perhitungan SMAPE dari volatilitas dugaan out-of-sample menghasilkan nilai rataan galat sebesar 13.62%, nilai galat maksimum sebesar 60.07%, dan nilai galat minimum sebesar 0.004%, serta kuartil ke-1 (Q1), kuartil ke-2 (Q2), dan kuartil
ke-3 (Q3) masing-masing sebesar 5.71%, 11.32%, dan 20.06% serta jarak
inter-kuartil sebesar 14.35%.