LANDASAN TEORI
2.1 Optimisasi
Dalam matematika, istilah optimisasi atau program matematika berhubungan dengan masalah pencarian nilai minimum atau maksimum dari fungsi riil dengan memilih nilai dari variabel secara sistematis dari himpunan yang ada. Masalah ini dapat direpresentasikan sebagai berikut.
Diberikan sebuah fungsi f :AR dari himpunan bilangan A ke himpunan bilangan riil. Akan dicari x0dari himpunan A di mana f
x0 f
x untuk semua x pada A (“minimalisasi”) atau f
x0 f
x untuk semua x pada A (”maksimalisasi”).Secara khusus, A adalah himpunan bagian dari dimensi Euclid Rn. Pada A terdapat beberapa kendala berupa persamaan atau pertidaksamaan yang harus dipenuhi oleh anggota himpunan A. Domain dari himpunan A disebut ruang cari dan elemen-elemen dari himpunan A disebuat solusi kandidat atau feasible solution. Fungsi f disebut objective function atau cost function. Sebuah solusi kandidat paling minimal atau paling maksimal dari sebuah objective function disebut solusi optimal.
Pada umumnya, pada objective function yang bersifat konveks terdapat beberapa local minima atau maksima, di mana local minimum x* didefinisikan sebagai berikut.
*x x , di mana 0 sehingga
x f
x f * Local maxima didefinisikan dengan cara yang sama. Untuk mengatasi hal itu, maka dikenal istilah global optimization yang dapat mencari solusi yang konvergen pada permasalahan non konveks dalam waktu yang terbatas.
2.2 Teori Graf
Graf diperkenalkan pertama kali pada tahun 1736 oleh Leonhard Euler pada Seven Bridges of K€nigsberg. Rumus Euler ini berhubungan dengan jumlah verteks, sisi, dan permukaan pada polihedron konveks.
2.2.1 Definisi dan Jenis
Sebuah graf terdiri dari dua bagian, yaitu sebagai berikut.
(i) Sebuah himpunan V = V(G) memiliki elemen-elemen yang dinamakan verteks, titik, atau simpul.
(ii) Sebuah kumpulan E = E(G) merupakan pasangan terurut dari verteks-verteks yang berbeda dinamakan sisi atau edge.
Sebuah multigraf G = G(V,E) terdiri dari suatu himpunan V (verteks) dan suatu himpunan E (edge), kecuali E mengandung edge ganda, yaitu beberapa edge yang menghubungkan titik-titik ujung yang sama. E mungkin mengandung satu atau lebih loop, yaitu sebuah edge yang titik-titik ujungnya adalah verteks yang sama.
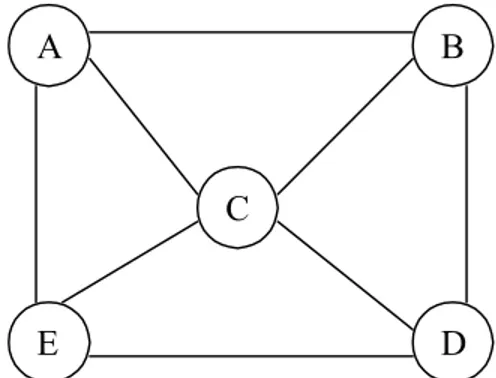
Gambar 2.1 Sebuah multigraf dengan empat simpul dan tujuh edge (sumber: Seymour Lipschutz et al, 2002, p2)
Pada gambar 2.1 , G adalah graf dengan: V = { A, B, C, D }
E = { (A,B), (B,C), (C,D), (A,C), (A,C), (B,D), (D,D)} = { e1, e2, e3, e4, e5, e6, e7}
G mengandung edge ganda, e4dan e5, yang menghubungkan dua verteks yang sama, yaitu A dan C. G juga mengandung sebuah loop e7, yang titik-titik ujungnya sama, yaitu verteks D. Karena itu, graf di atas merupakan multigraf.
Berdasarkan pada orientasi arah pada edge, maka secara umum graf dapat dibedakan atas 2 jenis sebagai berikut.
1. Graf tak berarah (undirected graph)
Graf yang sisinya tidak mempunyai orientasi arah. Gambar 2.1 merupakan gambar graf tak berarah.
2. Graf berarah (directed graph atau di graph)
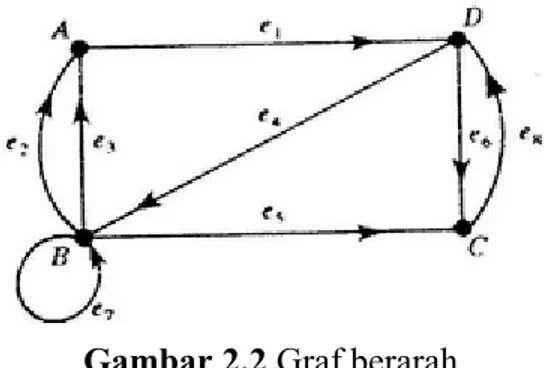
Graf yang sisinya mempunyai orientasi arah. Gambar 2.2 merupakan gambar graf berarah.
Gambar 2.2 Graf berarah
2.2.2 Matriks dan Graf, Perwakilan Hubungan
Misalkan G adalah sebuah graf dengan verteks-verteks v1, v2, ..., vndan edge e1, e2, ..., en, maka didefinisikan dua macam matriks yang berhubungan dengan sebuah graf G.
1. Matriks adjacency
Misalkan A = (aij) adalah matriks m x m yang didefinisikan oleh:
lainnya 0 v erhadap adjacent t yaitu v edge, adalah v} {u, jika 1 aij i j
A disebut matriks adjacency dari G (gambar 2.2 (a)). Karena aij = aji, A adalah sebuah matriks simetris. (Sebuah matriks adjacency didefinisikan untuk sebuah multigraf dengan pemisalan aijmenyatakan jumlah edge {vi, vj}).
2. Matriks incident
Misalkan M = (mij) adalah matriks m x n yang didefinisikan oleh:
lainnya 0 e edge pada incident adalah v verteks 1 m i i
Maka, M disebut matriks incidence dari G (gambar 2.2 (b)).
Contoh:
Maka: v1 v2 v3 v4 v5 e1 e2 e3 e4 e5 e6 e7 e8 v1 0 1 1 1 1 v1 1 1 1 0 1 0 0 0 v2 1 0 1 0 0 v2 1 0 0 1 0 0 0 0 A = v3 1 1 0 1 1 m = v3 0 0 1 1 0 0 1 1 v4 1 0 1 0 1 v4 0 0 0 0 1 1 0 1 v5 1 0 1 1 0 v5 0 1 0 0 0 1 1 0 (a) (b)
Gambar 2.3 Matriks adjacency (a) dan matriks incidence (b) (sumber: Seymour Lipschutz et al, 2002, p36)
2.3 Travelling Salesman Problem
Travelling Salesman Problem (TSP) adalah permasalahan pada matematika diskrit dan optimisasi kombinatorial. TSP pertama kali dikemukakan pada tahun 1800-an oleh seorang matematikawan asal Irlandia, Sir William Howard Hamilton dan seorang matematikawan asal Inggris, Thomas Penyngton Kirkman. Bentuk umum dari TSP pertama dipelajari oleh para matematikawan mulai tahun 1930. Diawali oleh Karl Menger di Vienna dan Harvard. Setelah itu permasalahan TSP dipublikasikan oleh Hassler Whitney dan Merrill Flood di Princeton. Penelitian secara rinci mengenai hubungan antara penemuan Menger dan Whitney, serta perkembangan TSP dapat ditemukan dalam makalah Alexander Schrijver “On the history of combinatorial optimization (till 1960)”.
TSP memerlukan keputusan dari siklus biaya minimal, yang melalui setiap simpul pada graf yang relevan. Jika biaya bersifat simetris, yakni jika biaya antar dua lokasi tidak tergantung pada arah lintasan, maka TSP jenis ini bersifat simetris, sedangkan dalam hal lain bersifat asimetris , yang disebut TSP berarah.
Gambar 2.4 Graf Travelling Salesman Problem dan solusinya (sumber: Massimo Paolucci, 2003, p45)
Solusi-solusi dari berbagai metode dianalisis dan setiap n buah simpul memerlukan sejumlah waktu f(n). Besaran f(n) fungsi waktu dari sebuah metode terhadap jumlah kota n. Untuk membandingkan dua buah metode, cukup dibandingkan fungsi f(n) dari masing-masing metode. Suatu metode mungkin baik tetapi analisisnya buruk, sehingga menghasilkan f(n) yang buruk. Dalam banyak permasalahan komputasi, studi tentang algoritma dan fungsi telah menghasilkan solusi matematika yang sangat bagus, yang penting dalam penyelesaian permasalahan praktis. Hal ini telah menjadi subjek studi yang utama dalam sains komputer.
Untuk setiap masalah TSP fungsi f(n)-nya adalah (n-1)! = (n-1)(n-2)(n-3)…(3)(2)(1) dan jumlah jalur yang mungkin terjadi adalah (n-1)!/2. Hasil yang lebih baik ditemukan pada tahun 1962 oleh Michael Held dan Richard Karp, yang menemukan algoritma dan fungsi yang mempunyai f(n) = n22n, yaitu n x n x 2 x 2 x … x 2. Untuk setiap n bernilai besar, fungsi f(n) Held-Karp akan selalu lebih kecil dibandingkan (n-1)!.
TSP dikenal sebagai salah satu masalah NP-complete. Secara implisit, algoritma polinomial sering digunakan untuk mencari solusi TSP.
2.4 Multi Travelling Salesman Problem
Multiple Travelling Salesman Problem (m-TSP) adalah generalisasi dari TSP, yang merupakan persoalan yang lebih mendekati permasalahan dalam dunia nyata, di mana diperlukan lebih dari satu kendaraan pengangkut untuk pendistribusian barang. Pada m-TSP, kendaraan pengangkut berjumlah m akan mengunjungi semua simpul yang ada dengan total jarak minimum. M-TSP dapat selalu dikonversikan ke dalam TSP yang sama dengan membuat perbanyakan sebanyak M kali dari satu lokasi yang sama, tetapi tidak berhubungan satu sama lain. Beberapa formula m-TSP diturunkan secara independen oleh Bellmore dan Hong (1974), Orloff (1974), Svetska dan Huckfeltz (1973).
Pada m-TSP harus terdapat m≥2 salesman yang mengunjungi n kota yang mengunjungi secara bebas seluruh kota tersebut. Tidak ada kota yang akan dikunjungi oleh lebih dari satu salesman dan setiap m salesman dapat memulai dari kota awal yang berbeda (berakhir pada kota yang sama dengan kota awal masing-masing salesman) atau mulai dari kota yang sama untuk setiap m salesman.
Gambar 2.5 Graf Multi Travelling Salesman Problem (sumber: Gambardella et al., 1999, p34)
Transformasi m-TSP menjadi TSP biasa digunakan pertama kali oleh Bellmore dan Hong yang dilakukan dengan menambah simpul pada graf sejumlah (m-1) buah simpul yang merupakan salinan dari simpul asal. Dengan demikian, hasil transformasi mempunyai (n+m-1) simpul.
2.5 Teori Lintasan dan Siklus
Misalkan v0 dan vn adalah verteks-verteks dalam sebuah graf. Sebuah lintasan dari v0ke vndengan panjang n adalah sebuah barisan berselang-seling dari (n+1) verteks dan n rusuk yang berawal dengan verteks v0dan berakhir dengan verteks vn,
(v0,e1,v1,e2,v2, ... ,vn-1,en,vn), dengan rusuk eiinsiden pada verteks vi-1dan vi(i = 1, 2, ..., n).
Sebuah siklus adalah sebuah lintasan yang mempunyai panjang lintasan tidak nol dari kota pertama sampai kota terakhir yang merupakan kota pertama, di mana tidak terdapat rusuk yang dilalui lebih dari sekali.
Sebuah siklus sederhana adalah siklus dari kota pertama sampai kota terakhir yang merupakan kota terakhir juga pada suatu graf, di mana kecuali kota pertama dan kota terakhir yang sama, tidak terdapat simpul yang berulang.
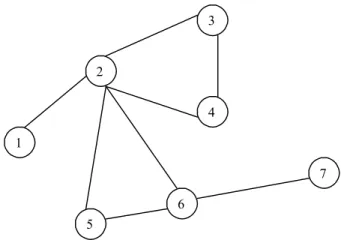
Untuk mengamati perbedaan antara lintasan, siklus, siklus sederhana, dengan contoh graf pada gambar 2.6 di bawah yang akan disajikan dalam bentuk tabel.
1 2 3 4 5 6 7
Gambar 2.6 Graf tidak berarah
(sumber: Seymour Lipschutz et al, 2002, p42)
Tabel 2.1 Perbedaan Lintasan, Siklus, dan Siklus Sederhana (sumber: Seymour Lipschutz et al, 2002, p43)
Lintasan Lintasan Sederhana Siklus Siklus Sederhana
(5, 6, 2, 5) Tidak Ya Ya
(2, 6, 5, 2, 4, 3, 2) Tidak Ya Tidak
(6, 5, 2, 4) Ya Tidak Tidak
(6, 5, 2, 4, 3, 2, 1) Tidak Tidak Tidak
2.6 Siklus Hamilton (Hamiltonian Cycle)
Sebuah graf G = (V,E) yang merupakan sebuah graf yang terhubung dengan n simpul, dikatakan sebagai sebuah Hamiltonian Cycle jika dapat dibentuk suatu jalur yang melalui n buah rusuk pada G, setiap simpul hanya dikunjungi satu kali, dan kembali ke simpul awal. Dengan kata lain, sebuah graf adalah Hamiltonian Cycle jika dimulai dari suatu simpul vi G dan semua simpul dalam G dikunjungi dengan urutan v1, v2, ..., vn+1 dengan rusuk-rusuk yang menghubungkan verteks-verteks tersebut merupakan anggota E dalam G, pada i i n dan semua vi berbeda kecuali v1 dan vn+1 yang merupakan simpul yang sama.
B E D C A B E D C A
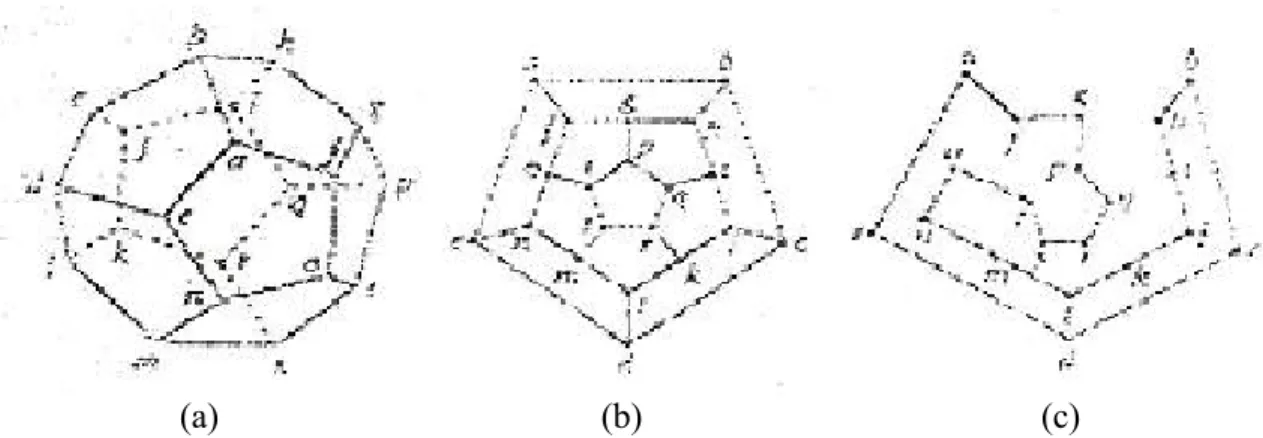
Sir William Rowan Hamilton memasarkan sebuah teka-teki pada pertengahan 1800-an dalam bentuk sebuah dodecahedron (lihat Gambar 2.8). Tiap sudut yang berjumlah 20 tersebut diberi nama sebuah kota. Masalah berawal dari sembarang kota, kemudian menjalani rusuk-rusuk, mengunjungi setiap kota tepat satu kali, dan kembali ke kota semula. Kita sebut siklus dalam graf G yang mengandung setiap verteks di G tepat satu kali, kecuali verteks awal dan akhir yang muncul dua kali disebut siklus Hamilton (Hamiltonian Cycle). Pada gambar 2.7 diperlihatkan sebuah contoh graf yang mempunyai siklus Hamilton. Pada gambar 2.8 diperlihatkan contoh graf yang sebelumnya (gambar 2.7) yang diselesaikan sesuai teka-teki Hamilton, di mana siklus dalam graf G mengandung setiap verteks tepat satu kali (kecuali verteks awal dan akhir yang muncul dua kali).
Gambar 2.7 Sebuah graf yang mempunyai siklus Hamilton (sumber: Massimo Paolucci, 2001, p52)
Gambar 2.8 Sebuah solusi siklus Hamilton (sumber: Massimo Paolucci, 2001, p53)
(a) (b) (c)
Gambar 2.9 (a) Teka-teki Hamilton, (b) Pemodelan Dodecahedron dalam graf, (c) Salah satu penyelesaian berbentuk siklus Hamilton
(sumber: Bentley, 1992, p78)
2.7 Vehicle Routing Problem
Vehicle Routing Problem (VRP) pertama kali diutarakan oleh Dantzig dan Ramser. VRP adalah permasalahan kompleks dari optimisasi kombinatorial, yang merupakan gabungan dari dua permasalahan, yaitu Travelling Salesman Problem (TSP) dan Bin Packing Problem (BPP). VRP merupakan NP-Hard, sehingga permasalahan ini sulit dipecahkan.
VRP berhubungan dengan pengiriman dan/atau pengambilan barang. Masalah kritis VRP adalah rute dan pengaturan kendaraan pengangkut yang ada sehingga dapat melayani permintaan pelanggan seefisien mungkin berdasarkan pada kritera-kriteria yang ada. Sebuah rute adalah serangkaian lokasi yang harus dikunjungi kendaraan pengangkut untuk menyelesaikan pelayanannya, misalnya pelayanan pengiriman barang. Penyelesaian VRP menghasilkan rute, dan dapat juga menghasilkan penjadwalan kendaraan-kendaraan pengangkut dalam rute yang terbentuk.
Permasalahan dalam Vehicle Routing dapat dibedakan menjadi dua, yaitu permasalahan statis dan dinamis. Pada permasalahan statis, permintaan pelanggan telah
diketahui sebelumnya. Sedangkan pada permasalahan dinamis, sebagian ataupun seluruh permintaan pelanggan diketahui ketika kendaraan pengangkut sudah mulai beroperasi, yaitu ketika rute telah diatur, ataupun ada perubahan di tengah perjalanan.
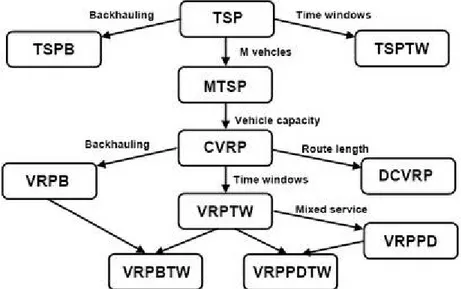
Gambar 2.10 Hubungan VRP dengan TSP dan perkembangannya (sumber: Massimo Paolucci, 2001, p10)
VRP adalah generalisasi dari TSP. Maka, TSP adalah sebuah VRP tanpa batasan seperti depot, pelanggan dan permintaan. M-TSP adalah VRP dengan sebuah depot dan m kendaaran pengangkut, termasuk bila tidak ada permintaan dari pelanggan. MTSP adalah transformasi dari TSP dengan memperbanyak jumlah depot.
Pada kenyataannya, Vehicle Routing digambarkan dengan jaringan jalan, yang kemudian dituangkan dalam sebuah graf, baik graf berarah G = (V, A), graf tidak berarah G = (V, E), maupun graf campuran G = (V, A E). Penggunaan bentuk graf ini disesuaikan dengan daerah yang akan dikunjungi kendaraan pengangkut. Graf tak berarah digunakan jaringan jalan skala besar, meliputi negara dan negara bagian atau propinsi. Sedangkan graf berarah digunakan untuk jaringan jalan skala kecil, misal untuk menggambarkan jalan-jalan dalam satu kota.
Depot
Pelanggan
Verteks menggambarkan depot, pelanggan ataupun persimpangan jalan. Himpunan verteks dilambangkan dengan V = (v0, …, vn). Verteks v0 mewakili pusat, di mana terdapat kendaraan pengangkut identik sejumlah k dengan kapasitas Q. Sedangkan verteks lainnya melambangkan kota atau pelanggan, yang memiliki permintaan di. Arc atau edge menggambarkan jalan-jalan yang ada. Edge dapat bersifat berarah (i,j) A, di mana A = {(v1,vj): i ≠ j, v1,vj V} dan tidak berarah, eE. Biaya dan jarak perjalanan dilambangkan oleh cij, yang didefinisikan pada A, sedangkan waktu non-negatif dilambangkan oleh tij, yang juga didefinisikan pada A.
Setiap verteks vi dalam V diasosiasikan dengan sejumlah barang qi yang akan diantarkan oleh satu kendaraan. VRP bertujuan untuk menentukan sejumlah k rute kendaraan dengan total biaya yang minimum, bermula dan berakhir di sebuah depot. Adapun setiap verteks dalam V dikunjungi tepat sekali oleh satu kendaraan. Jadi, biaya
dari solusi masalah ini S adalah :
k 1 i i VRP(S) C(R ) F .
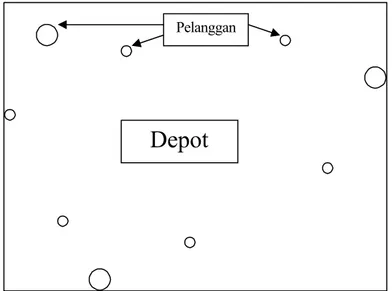
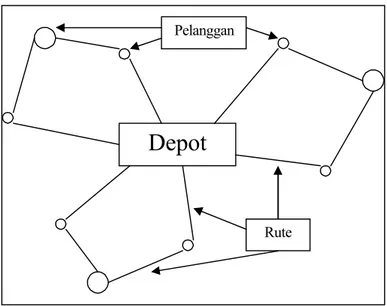
Gambar 2.11 Contoh visualisasi input dari Vehicle Routing Problem (sumber: Massimo Paolucci, 2001, p2)
Depot
Pelanggan
Rute
Gambar 2.12 Salah satu output dari persoalan VRP dari input gambar 2.11 (sumber: Massimo Paolucci, 2001, p5)
Pada perkembangannya, VRP memiliki beberapa karakteristik sehingga dapat dibagi-bagi dalam beberapa kategori masalah, seperti yang dapat ditunjukkan dalam tabel 2.2. Kategori ini dibuat oleh Bodin dan Golden (1981), yang memaparkan berbagai karakteristik umum, yang akan membedakan VRP. Keseluruhan tabel memberikan gambaran singkat tentang masalah routing.
Tabel 2.2 Kategori masalah dalam VRP (sumber: Titiporn Thammapimookkul, 2001, p16)
NO KARAKTERISTIK VARIAN YANG MUNGKIN
1. Jumlah kendaraan pengangkut
Satu kendaraan pengangkut Multi kendaraan pengangkut 2. Tipe kendaraan
pengangkut
Homogen (satu tipe kendaraan pengangkut ) Heterogen (multi tipe kendaraan pengangkut ) Tipe khusus
3. Tempat asal kendaraan (pusat)
Satu pusat Multi pusat
4. Tipe permintaan Permintaan deterministik (telah diketahui sebelumnya) Permintaan stokastik
5. Lokasi permintaan Simpul Garis Campuran 6. Jaringan yang mendasari Tidak berarah Berarah Campuran Euclid 7. Batasan kapasitas kendaraan pengangkut Semuanya sama Jalur yang berbeda Kapasitas tak terbatas 8. Rute maksimum Sama untuk semua rute
Berbeda untuk setiap rute Tidak ditentukan
9. Sistem pengoperasian Pengambilan saja Pengiriman saja
Pengambilan dan pengantaran 10. Biaya Variabel atau biaya rute
Biaya tetap pengoperasian atau biaya tetap kendaraan pengangkut
Biaya pengangkutan umum 11. Tujuan Meminimalkan biaya total rute
Meminimalkan jumlah kendaraan pengangkut yang diperlukan
Meminimalkan fungsi kegunaan berdasarkan pada pelayanan dan kenyamanan
Meminimalkan fungsi kegunaan berdasarkan pada prioritas pelanggan
2.8 Teknik-Teknik Penyelesaian VRP
Ada beberapa teknik penyelesaian VRP, antara lain sebagai berikut. 1. Pendekatan eksak
a. Branch and Bound (1994) 2. Heuristik
a. Constructive Heuristik: Clark and Wright Saving Algorithm (1964), Altinkemer and Gavish Algorithm, dan insertion heuristik
b. Hierarchical Approach (split and TSP): Sweep Algorithm, Fisher and Jaikumar (1981), Petal Heuristik, dan Taillard (1993)
c. Multi-route Improvement Heuristiks: Kinderwater and Salvesbergh (1997)
3. Metaheuristik
a. Tabu Search: Rochat and Taillard (1995), dan Kelly and Xu (1999) b. Granular Tabu: Toth and Vigo (1998)
c. Ant Colony Optimization: Gambardella, al. (1999) d. Genetic Algorithms
e. Greedy Randomized Adaptive Search Procedure f. Simulated Annealing
g. Variable Neighbourhood Search
2.8.1 Pendekatan Eksak A. Dynamic Programming
Dynamic Programming adalah implicit enumerative search method yang dapat dilihat sebagai teknik Divide and Conquer. Untuk menyelesaikan masalah yang besar, dilakukan pemecahan masalah tersebut menjadi bagian-bagian kecil yang serupa dan independen. Bagian-bagian tersebut dapat dipecahkan dengan metode yang serupa dengan masalah induk. Setelah bagian-bagian kecil tersebut diselesaikan maka hasil-hasil yang diperoleh digabung kembali dengan suatu metode tertentu untuk memberi solusi yang sebenarnya pada masalah asal.
B. Branch and Bound
Pendekatan branch and bound terdiri dari dua prosedur dasar. Branching adalah proses mempartisi masalah yang besar menjadi dua atau lebih masalah kecil dan bounding adalah proses menghitung batas bawah pada solusi optimal dari masalah kecil tersebut. Bounding function yang digunakan yaitu, pemrosesan hanya dilakukan pada branch yang baik dan branch yang buruk tidak akan diproses dengan harapan branch yang baik akan memberikan hasil yang optimal pada proses selanjutnya.
C. Branch and Cut
Pendekatan branch and cut merupakan pendekatan yang menggunakan branch and bound dengan penambahan algoritma pemotongan atau cutting pada solusi yang didapatkan. Proses yang dilakukan adalah dengan mengaplikasikan branch and bound pada masalah yang akan menghasilkan suatu solusi yang nantinya akan dipotong dengan algoritma tertentu untuk mendapatkan hasil yang lebih baik. Proses tersebut akan diulangi sampai tidak ada pemotongan lagi.
2.8.2 Heuristik
Heuristik adalah algoritma yang digunakan untuk pencarian solusi optimal dengan cara pembelajaran, sehingga lebih cepat dari pada pendekatan eksak. Dua tujuan dasar dalam pemecahan masalah optimisasi pada ilmu komputer adalah mencari algoritma yang cepat menyelesaikan masalah dan memperoleh hasil yang optimal. Heuristik adalah algoritma yang menghilangkan salah satu atau dua dari tujuan tersebut. Sebagai contoh, pada pemecahan masalah optimisasi, dihasilkan solusi yang cukup optimal, tetapi secara manual, belum tentu solusi yang lebih optimal dapat diperoleh
karena kompleksnya permasalahan yang ada. Atau, dihasilkan solusi pada waktu yang sangat cepat, tetapi secara manual masih dapat ditemukan hasil yang lebih optimal.
Pada permasalah yang kompleks seperti masalah kombinatorial pada NP-hard problem, mencari hasil yang optimal secara manual sangatlah sulit karena harus dicoba semua kemungkinan yang ada. Misalkan ada sebuah kotak besar yang harus diisi dengan barang, maka yang sering dilakukan orang adalah memasukkan barang-barang yang besar terlebih dahulu, lalu memasukkan barang-barang yang kecil pada ruang-ruang yang tersisa. Tentunya ini bukanlah cara yang terbaik, tetapi akan menghasilkan solusi yang cukup baik. Demikianlah gambaran mengenai cara kerja heuristik.
Menurut Judea Peral (April, 1984), metode heuristik bekerja berdasarkan strategi pencarian pintar pada pemecahan masalah dengan komputer dengan menggunakan beberapa pendekatan. Jadi, hasil yang diperoleh belum tentu yang paling optimal. Pada pendekatan eksak, hasil yang diperoleh adalah hasil yang paling optimal Namun, dalam waktu yang sangat lama (polynomial time).
A. Metode Savings
Clarke dan Wright (1964) menemukan sebuah metode sederhana untuk mengoptimalkan rute pengiriman, di mana terdapat banyak kendaraan pengangkut dengan berbagai kapasitas yang berasal dari satu pusat yang akan mengirimkan barang-barang ke banyak tempat. Rute terpendek antara dua titik diberikan pada sistem. Tujuan yang ingin dicapai adalah bagaimana mengalokasikan kendaraan pengangkut, sehingga semua barang dapat terkirim dengan biaya pengiriman serta operasional minimal. Sebenarnya, prosedurnya sederhana, tetapi sangat efektif dalam menghasilkan solusi yang mendekati optimal. Cara heuristik ini disebut metode Savings, di mana terjadi
0 c 0j c j0 c 0i c i0 j i c ij 0 c j0 c 0i j i
perubahan prosedur dalam setiap langkah sehingga menghasilkan yang lebih baik. Langkah-langkahnya adalah sebagai berikut.
1. Pertama, setiap rute menghubungkan pusat dengan satu pelanggan.
2. Kemudian, hubungkan setiap dua pelanggan dalam satu rute jika total permintaannya tidak melebihi kapasitas kendaraan pengangkut. Dengan algoritma ini, dihitung biayanya dan dipilih yang terbesar.
3. Kemudian, rute diperluas lagi dengan mengkombinasikan rute-rute yang ada, penghitungan biaya dilakukan dan biaya terbesar dipilih.
4. Lakukan langkah ini berulang-ulang hingga permintaan melebihi kapasitas kendaraan pengangkut.
Dalam algoritma Savings, kombinasi dari dua pelanggan i dan j ke dalam satu rute dirumuskan sebagai berikut.
S
ij = cio + coj - cij
Di mana c
ij menyatakan biaya rute dari pelanggan i ke j. Pelanggan “0”
merupakan pusat atau awal rute. Contoh ilustrasi digambarkan dalam gambar 2.13.
\
Gambar 2.13 Ilustrasi dari Savings yang telah dihitung (sumber: Titiporn Thammapimookkul, 2001, p34)
Dari prosedur sebelumnya, algoritma dapat digambarkan sebagai berikut. 1. Pertama, setiap n kendaraan pengangkut melayani satu pelanggan
2. Untuk setiap pasang simpul i, j, i… j (baik pelanggan pertama ataupun terakhir dari siklus yang berbeda) hitung savings dengan menggabungkan siklus dengan edge (i,j): Sij= cio+ coj– cij
3. Urutkan savings dari besar ke kecil
4. Ambil edge (i, j) dari bagian paling atas daftar savings. Gabungkan dua siklus yang terpisah dengan edge (i, j), jika:
Simpul-simpul dimiliki oleh siklus terpisah
Permintaan tidak melebihi kapasitas maksimal dari kendaraan pengangkut i dan j adalah pelanggan pertama atau terakhir dari siklus
5. Ulangi langkah keempat hingga semua data pada daftar savings telah dikerjakan atau kapasitas sebuah kendaraan pengangkut sudah penuh untuk melayani pelanggan selanjutnya
Contoh:
Berikut adalah sebuah graf lengkap dengan pusat 0 dan akan mengirimkan barang ke 9 pelanggan dengan kapasitas kendaraan pengangkut = K = 40
Gambar 2.14 Contoh soal penyelesaian VRP dengan Savings Method Tabel 2.3 Tabel simetris dari biaya antarlokasi
Langkah kerja penyelesaian masalah di atas adalah sebagai berikut. 1. Dengan menghitung S
ij = cio + coj - cij, maka diperoleh tabel savings pada tabel 2.4.
Tabel 2.5 Tabel savings setelah diurutkan
2. Urutkan savings dari besar ke kecil: (4,5) = 10+10-3 = 17
(1,2) = 12+11-8 = 15
… (1,3), (1,4), (2,6), (5,7), (4,7), (1,5), (3,4), (2,3), (7,9), (3,5), (8,9), (1,6), (5,9), (6,8), (2,4), dan seterusnya
3. Cari rutenya
Solusi inisialisasi: siklus 0-1-0, 0-2-0, ... , 0-9-0.
Edge (4,5): gabungkan siklus 0-4-0 dengan 0-5-0. Hasil = 0-4-5-0, maka simpan d4 + d5 = 20 < K.
Edge (1,2): gabungkan siklus 0-1-0 dan 0-2-0. Hasil = 0-1-2-0, maka simpan d1 +
d2 = 25 < K.
Edge(1,3): gabungkan siklus 0-1-2-0 dengan 0-3-0, tetapi ternyata melebihi batas kapasitas, karena d1+d2+d3 = 43 > K (tidak mungkin)
Edge(1,4): gabungkan siklus 0-1-2-0 dengan 0-4-0, tetapi ternyata melebihi batas kapasitas, karena d1+d2+d4 = 42 > K (tidak mungkin)
Edge (2,6): simpul 2 sudah termasuk dalam siklus 1-2, maka gabungkan siklus 0-1-2-0 dengan 0-6-0. Hasil: 0-1-2-6-0, maka simpan d1+d2+d6 = 30 < K.
Edge (5,7): simpul 5 sudah termasuk dalam siklus 0-4-5-0, maka gabungkan siklus 0-4-5-0 dan 0-7-0. Hasil: 0-4-5-7-0, maka simpan d4+d5+d7 = 29 < K.
Edge(4,7): Termasuk siklus 0-4-5-7-0 (tidak mungkin)
Edge(1,5): simpul 5 merupakan bagian dalam siklus 0-4-5-7-0 (di bagian tengah), sehingga tidak mungkin bercabang ke lokasi lain (tidak mungkin)
Edge(3,4): gabungkan siklus 0-3-0 dengan 0-4-5-7-0, tetapi batas kapasitas: d3+
d4 +d5+d7 = 47 > K (tidak mungkin)
Edge(2,3): simpul 2 merupakan bagian dalam siklus 0-1-2-6-0 (tidak mungkin)
Edge (7,9): simpul 7 sudah termasuk dalam siklus 0-4-5-7-0, maka gabungkan si-klus 0-4-5-7-0 dengan 0-9-0. Hasil: 0-4-5-7-9-0, maka simpan d4 +
d5+d7+d9 = 35 < K.
Edge(3,5):simpul 5 merupakan bagian dalam siklus 0-4-5-7-9-0 (tidak mungkin)
Edge (8,9): simpul 9 sudah termasuk dalam siklus 0-4-5-7-9-0, maka gabungkan si-klus 0-4-5-7-9-0 dengan 0-8-0. Hasil: 0-4-5-7-9-8-0, maka simpan d4+d5+d7+d9+d8 = 39 < K.
Edge (5,9): baik simpul 5 maupun simpul 9 sudah termasuk ke dalam siklus
Edge (6,8): gabungkan siklus 0-1-2-6-0 dengan 0-4-5-7-9-8-0, tetapi ternyata melebihi kapasitas, karena(d1+d2+d6)+(d4+d5+d7+d9+d8) = 69 > K (tidak mungkin)
4. Diperoleh 3 rute, yaitu:
RUTE MUATAN BIAYA
0 – 3 – 0 18 14
0 – 1 – 2 – 6 – 0 30 37
0 – 4 – 5 – 7 – 9 – 8 – 0 39 46 Total biaya = 97
5. Graf yang terbentuk:
B. Nearest Neighbourhood
Algoritma Nearest Neighbourhood adalah algoritma pertama untuk menyelesaikan masalah TSP. Algoritmanya adalah sebagai berikut.
2. Cari simpul selanjutnya yang memiliki jalur termurah. Adapun simpul tersebut terhubung dengan simpul yang sudah dipilih dan belum terpilih dalam jalar. 3. Set simpul tersebut menjadi simpul sementara dan beri tanda telah terpilih.
4. Jika semua simpul telah terpilih, maka hubungkan simpul terakhir tersebut dengan simpul pertama. Jika belum semua terpilih, ulangi langkah kedua.
Gambar 2.15 Nearest Neighbourhood (sumber: Massimo Paolucci, 2001, p80)
C. Algoritma Heuristik Fisher and Jaikumar
Algoritma ini digunakan apabila tidak ada masalah polinomial dalam persamaan, sehingga masalah penugasan atau General Assignment Problem (GAP) dapat
dipecahkan. Permasalahan pada masalah penugasan adalah sebagai berikut.
Diberikan tugas (T) sebanyak n untuk diselesaikan dengan mesin (M) sebanyak m. Setiap tugas memiliki beban widan setiap mesin kapasitas tertentu C. Biaya dijakan dibebankan apabila ada tugas i yang dikerjakan oleh mesin j. Tujuan dari masalah ini adalah meminimalkan biaya operasi dalam pembagian semua tugas kepada mesin-mesin yang ada dengan memperhitungkan kapasitas mesin.
Berikut adalah pseudocode algoritma heuristik Fisher and Jaikumar (pseudocode ini tidak berlaku apabila ada kendala waktu).
2. Buat cluster untuk setiap rute. Tugaskan setiap pelanggan jkuntuk setiap cluster k.
3. Hitung biaya heuristik dikuntuk setiap pelanggan i pada cluster k.
d
ik= c
0 i+ c
ijk– c
0 jk4. Selesaikan GAP untuk setiap tugas dan cluster yang berhubungan dengan mesin. Biaya dinyatakan dalam dik, beban tugas dinyatakan dengan
permintaan pelanggan didan kapasitas mesin dinyatakan dengan kapasitas kendaraan pengangkut Q.
5. Selesaikan masalah TSP untuk setiap cluster dengan menggunakan metode eksak ataupun heuristik tertentu.
2.8.3 Metaheuristik
Metaheuristik adalah generasi baru pengembangan dari algoritma heuristik. Metaheuristik dikembangkan karena tingginya stingkat kompleksitas masalah kombinatorial pada dunia nyata akibat makin luasnya dimensi kendala, sehingga pendekatan eksak sudah tidak mungkin digunakan.
Filosofi metaheuristik terbagi menjadi dua, yaitu sebagai berikut. 1. Perluasan dari algoritma Local Search (Trajectory Method)
Tujuannya adalah untuk menghindari terjadinya local minima, sehingga dapat melakukan eksplorasi pada ruang pencarian sambil terus mencari local minima yang lebih baik. Trajectory method menggunakan satu atau lebih struktur neoghbourhood. Contoh: Tabu Search, Iterated Local Search, Variable Neighboudhood Search, GRASP, dan Simulated Annealing.
2. Menggunakan komponen pembelajaran (Learning Population-Based Method)
Metode ini secara implisit maupun eksplisit mencoba mempejari korelasi atar variabel keputusan untuk mengidentifikasi area yang berkualitas pada ruang pencarian. Metode ini melakukan sampling maya pada ruang pencarian. Contoh: Ant Colony Optimization, Particle Swarm Optimization, dan Evolutionary Computation (Genetic Algorithm).
Klasifikasi pencarian pada metaheuristik adalah sebagai berikut. 1. Inspirasi oleh alam atau inspirasi oleh non alam.
2. Berbasis populasi atau berbasis satu titik. 3. Objective function yang dinamis atau statis. 4. Satu atau lebih struktur neighbourhood.
5. Penggunaan kapasitas memori yang besar atau sedikit.
A. Ant Colony Optimization (ACO)
Metaheuristik ini terinspirasi dari metafor alami, yaitu komunikasi dan kerja sama antarsemut untuk mencari jalur terpendek dari sarang semut hingga ke makanan. Media komunikasi ini berupa komponen kimia yang disebut feromon, yang disebar di darat. Ketika ada semut yang tertinggal, maka alat pendeteksi feromon pada semut dapat mendeteksi jalur feromon dan mengikutinya dengan beberapa kemungkinan dan diperkuat dengan feromon semut tersebut. Maka, probabilitas semut akan mengikuti jalur feromon yang telah terbentuk akan semakin bertambah dengan banyaknya semut yang kemudian mengikutinya.
Hal ini kemudian mengarah pada pencarian rute terpendek karena akumulasi feromon yang cepat pada jalur yang terbentuk. Karena itu, dibentuk metaphor buatan, di mana sejumlah semut-semut buatan mencari solusi secara acak dalam suatu siklus. Setiap semut memilih elemen selanjutnya yang akan dihubungkan dengan elemen sementara yang telah terbentuk berdasarkan evaluasi heuristik dan jumlah feromon pada elemen tersebut. Feromon ini direpresentasikan dengan bobot. Feromon menggambarkan memori dari sistem. Feromon ini juga berhubungan dengan solusi elemen baik yang sebelumnya telah terbentuk oleh semut-semut. ACO banyak digunakan dalam menyelesaikan TSP, di mana siklus Hamilton terpendek dapat ditemukan dalam graf lengkap.
B. Greedy Randomized Adaptive Search Procedure (GRASP)
Ide dasar dari GRASP adalah menggunakan heuristik pengkonstruksian randomized greedy dalam prosedur banyak awalan untuk menghasilkan solusi yang bervariasi. Pada setiap langkah heuristik pengkonstruksian randomized greedy, elemen-elemen yang belum tergabung dalam solusi sementara dievaluasi dengan fungsi heuristik, dan elemen terbaik disimpan dalam daftar kandidat terbatas. Kemudian, satu elemen dipilih dari daftar tersebut dan digabungkan dengan solusi sementara yang telah terbentuk. Ketika proses pengkonstruksian telah selesai, solusi yang dihasilkan kemudian dikembangkan dengan pencarian lokal hingga diperoleh hasil terbaik.
C. Simulated Annealing (SA)
Metaheuristik ini adalah metode pencarian lokal yang acak, di mana modifikasi untuk solusi sementara, yang mengarah pada hasil yang lebih baik, dapat diterima
dengan beberapa kemungkinan. Mekanisme ini dapat mengantisipasi dari local optima yang buruk. SA berasal dari analogi proses penguatan fisik tanah dengan energi yang rendah.
Pada proses pengentalan materi, penguatan atau annealing adalah sebuah proses mencairkan zat padat dengan cara menaikkan suhu. Kejadian ini kemudian diikuti dengan penurunan suhu secara bertingkat untuk mengembalikan kondisi zat padat dari energi rendah. Penguatan dilakukan perlahan-lahan berdasarkan tingkatan suhu, di mana suhu berada pada tingkat tertentu dalam waktu cukup lama supaya tercapai keseimbangan. Hal ini dilakukan supaya penguatan mengarah pada pembentukan struktur yang solid sehingga dapat berasosiasi dengan zat pada pada energi rendah.
Pada VRP, himpunan rute berhubungan dengan keadaan, sedangkan solusi biaya berhubungan dengan energi. Pada setiap iterasi, solusi sementara dimodifikasi dengan memilih modifikasi acak berdasarkan kelas modifikasi tertentu yang mendefinisikan struktur keterikatan lingkungan atau neighbourhood. Jika solusi terbaru lebih baik daripada yang sementara sudah terbentuk, maka solusi itu yang kemudian terpilih menjadi solusi sementara. Sebaliknya, solusi terbaru dapat diterima berdasarkan kriteria tertentu di mana modifikasi diperoblehkan jika parameter, yang disebut suhu, bersifat tinggi, tetapi peningkatan biaya rendah.
Selama proses berlangsung, parameter suhu diturunkan berdasarkan jadwal pendinginan, dan iterasi dilakukan pada setiap tingkatan suhu. Ketika suhu sudah cukup rendah, hanya modifikasi yang berkembang yang diperbolehkan dan metode berhenti pada local optima.
D. Tabu Search (TS)
Seperti SA, TS adalah metaheuristik yang berdasarkan pencarian lokal, di mana pada setiap iterasi, apabila ditemukan solusi baru yang lebih baik dari yang ada sementara, maka solusi itu kemudian menjadi solusi sementara yang ada, meskipun solusi ini mengarah pada kenaikan biaya. Melalui mekanisme ini, maka metode ini akan terhindar dari local optima. Sebuah memori jangka pendek, yang dikenal sebagai daftar tabu, menyimpan solusi sementara terakhir untuk menghindari siklus jangka pendek. Pencarian berhenti hingga iterasi telah mencapai angka tertentu meskipun belum dihasilkan lagi solusi yang lebih baik dari solusi yang telah ada.
E. Variable Neighbourhood Search (VNS)
VNS adalah metaheuristik pencarian lokal lainnya yang mengambil berbagai kelas transformasi yang lain, atau neighbourhood untuk menghindari local optima. Ketika terjadi local optima, dengan memberitahukan pada neighbourhood yang sudah terbentuk, neighbourhood lain dipilih dan digunakan pada iterasi berikutnya.
Misalkan diberikan himpunan neighbourhood (biasanya berangkai), dan sebuah solusi dihasilkan secara acak dari neighbourhood pertama dari solusi sementara, yang berasal dari keturunan sementara yang telah terbentuk (dapat pula berasal dari neighbourhood yang memiliki struktur yang berbeda). Jika local optima yang terjadi tidak lebih baik dari solusi sementara, maka prosedur diulang pada neighbourhood selanjutnya dalam struktur berangkai. Pencarian ini diulang dari neighbourhood pertama ketika ada solusi yang lebih baik dari atau ketika semua neighbourhood telah dicoba.
2.9 Soft Computing
Soft Computing mengacu pada koleksi dari teknik-teknik komputasi pada ilmu komputer, intelejensia semu, pembelajaran mesin, dan ilmu teknik lainnya, yang bertujuan untuk membuat model dan menganalisis setiap masalah yang kompleks. Pendekatan komputasi yang sebelumnya hanya dapat memodelkan dan menganalisis permasalahan yang relatif sederhana.
Secara umum, soft computing lebih melakukan pendekatan secara biologis daripada pendekatan secara teknis. Adapun ruang lingkup soft computing adalah sebagai berikut.
1. Neural Networks 2. Fuzzy System
3. Evolutionary Computation, yang terdiri dari Evolutionary Algorithm dan Harmony Search
4. Swarm Intelligence 5. Bayesian Network 6. Chaos Theory
2.9.1 Evolutionary Algorithm
Dalam intelejensia semu, Evolutionary Algorithm (EA) adalah himpunan bagian dari Evolutionary Computation, sebuah algoritma optimisasi metaheuristik berbasis populasi. EA menggunakan mekanisme-mekanisme yang terinspirasi dari evolusi biologi, seperti reproduksi, mutasi, rekombinasi, dan seleksi. Kandidat solusi pada masalah optimisasi berperan sebagai individu pada populasi, dan cost function atau
fitness function merupakan lingkungan di mana solusi ada. Evolusi terjadi ketika ada reproduksi populasi yang berulang.
EA dapat menghasilkan solusi pendekatan yang konsisten untuk hampir semua tipe permasalahan pada optimisasi, karena algoritma ini tidak membuat asumsi tentang fitness landscape yang ada.
Terlepas dari penggunaan EA sebagai mesin optimisasi, digunakan juga untuk memvalidasi teori evolusi biologi dan seleksi alam pada model kehidupan semu. Pembatasan pada EA adalah kepunahan dari genotype dan phenotype. Secara alamiah melalui proses embriogenesis, sel telur yang telah dibuahi akan tumbuh menjadi phenotype yang dewasa. Pengkodean ini dipercaya dapat membuat pencarian genetik lebih cepat, karena mengurangi mutasi yang fatal, dan juga dapat meningkatkan kemampuan berevolusi pada organisme.
2.9.2 Genetic Algorithm
Genetic Algorithm (GA) banyak dipengaruhi oleh ilmu Biologi. Sesuai dengan namanya, proses-proses yang terjadi dalam GA sama dengan apa yang terjadi pada evolusi biologi. Dalam biologi, sekumpulan individu yang sama, yang disebut spesies, hidup, bereproduksi, dan mati dalam suatu area, yang disebut populasi. Jika anggota-anggota populasi terpisah, misalkan karena terjadi banjir atau gempa, maka individu-individu tersebut akan membentuk beberapa populasi yang terpisah. Dalam waktu yang cukup lama, mungkin saja akan terjadi proses pembentukan spesies baru atau dikenal dengan istilah speciation. Dalam hal ini, terjadi perubahan hereditas secara bertahap yang membentuk ciri-ciri baru pada spesies tersebut. Perubahan bertahap secara bersamaan pada kedua spesies dikenal sebagai co-evolution.
Konsep yang penting di sini adalah hereditas, yaitu sebuah ide yang menyatakan bahwa sifat-sifat individu dapat dikodekan dengan cara tertentu sehingga sifat-sifat tersebut dapat diturunkan kepada generasi berikutnya. Setiap individu dari suatu spesies membawa sebuah genome yang berisi beberapa kromosom dalam bentuk molekul-molekul DNA (Deoxyribo Nucleic Acid). Setiap kromosom berisi sejumlah gen, di mana unit-unit hereditas dan pengkodean informasi diperlukan untuk membangun dan menjaga suatu individu. Setiap gen dibangun dari suatu urutan bases. Terdapat empat bases dalam kromosom yang dinyatakan sebagai A, C, G, dan T. Jadi, informasi disimpan dalam suatu pola digital, menggunakan keempat simbol tersebut. Selama perkembangan dan juga selama kehidupan suatu individu, DNA dibaca dengan suatu enzim yang disebut RNA (Ribo Nucleic Acid) polymerase. Proses ini dikenal sebagai transcription yang menghasilkan mesenger RNA (mRNA). Selanjutnya, protein dibentuk dalam suatu proses yang disebut translation menggunakan mRNA sebagai sebuah template.
Masing-masing gen dapat memiliki beberapa setting, yang dikenal dengan allele. Selanjutnya, genome yang lengkap dari suatu individu dengan semua setting-nya disebut sebagai genotype. Suatu individu dengan semua sifat-sifat dikenal dengan istilah phenotype.
Konsep penting dalam teori evolusi adalah fitness dan selection untuk proses reproduksi. Pada proses evolusi di dunia nyata, terdapat dua cara reproduksi, yaitu reproduksi seksual dan aseksual. Pada reproduksi seksual, kromosom-kromosom dari dua individu (sebagai orang tua) dikombinasikan untuk menghasilkan individu baru. Artinya, kromosom pada individu baru berisi beberapa gen yang diambil dari orangtua pertama dan beberapa gen lainnya diambil dari orangtua kedua. Hal ini disebut dengan
crossover (pindah silang). Namun demikian, proses pengkopian gen orangtua ini tidak luput dari kesalahan. Kesalahan pengkopian gen ini dikenal dengan istilah mutation (mutasi). Sedangkan pada reproduksi aseksual, hanya satu individu orangtua yang diperhatikan, sehingga tidak terjadi proses crossover. Tetapi proses mutasi juga mungkin terjadi pada reproduksi aseksual.
Sejak pertama kali dirintis oleh John Holland pada tahun 1960-an, genetic algorithm telah dipelajari, diteliti dan diaplikasikan secara kuat pada berbagai bidang. Genetic algorithm sangat berguna dan efisien untuk masalah dengan karakteristik sebagai berikut.
a. Ruang masalah sangat besar, kompleks, dan sulit dipahami.
b. Kurang atau bahkan tidak ada pengetahuan yang memadai untuk merepresentasikan masalah ke dalam tuang pencarian yang lebih sempit.
c. Tidak tersedianya analisis matematika yang memadai.
d. Ketika metode-metode konvensional sudah tidak mampu menyelesaikan masalah yang dihadapi.
e. Solusi yang diharapkan tidak harus paling optimal, tetapi cukup dapat diterima. f. Terdapat batasan waktu, misalnya dalam real time system.
Berikut adalah langkah-langkah dalam genetic algorithm. Inisialisasi populasi, N kromosom
Loop
Loop untuk N kromosom Dekodekan kromosom Evaluasi kromosom End
Buat satu atau dua kopi kromosom terbaik (elitisme) Loop sampai didapatkan N kromosom baru
Pilih dua kromosom Pindah silang Mutasi End
End
Algoritma 2.1 Genetic Algorithm Pseudocode (sumber: Suyanto, 2005, p6)
2.10 Vehicle Routing Problem Pick Up and Delivery with Mixed Vehicles dengan
Dual (VRPPDMV)
Salah satu kelebihan genetic algorithm adalah dapat menjaga kelayakan allele melalui crossover. Hal ini membuat struktur kromosom tetap terjaga setelah proses reproduksi. Banyak terjadi pada kasus lain, setelah melewati fase reproduksi, gen-gen hasil replikasi terdapat pada induk yang satu, dan mengacaukan allele yang ada, seperti pada gambar 2.16. Replikasi ini juga berarti mengunjungi kembali simpul yang telah dikunjungi sebelumnya. Untuk memperbaiki kesalahan ini, diperlukan waktu dan usaha yang lebih, serta memerlukan coding yang cukup banyak dan sulit untuk dicek. Karena itu, metode yang efisien tidak memperbolehkan replikasi dan penghilangan gen pada kromosom.
Gambar 2.16 Contoh replikasi dan pembuangan gen melalui pindah silang (sumber: Arif Volkan Vural, 2003, p26)
Pada genetic algorithm yang efektif, dua tujuan yang bertolak belakang harus dapat tercapai, yaitu eksplorasi dan eksploitasi. Eksplorasi adalah menguasai sebanyak mungkin kemungkinan yang ada, sedangkan eksploitasi adalah memastikan bahwa fitness yang dihasilkan pada iterasi berikutnya lebih baik daripada iterasi sebelumnya. Kontradiksi yang terjadi adalah eksploitasi memerlukan pencarian yang kontinu pada lingkungan yang kecil, sedangkan eksplorasi memerlukan lingkungan yang luas. Karena itu diperlukan random key method.
2.10.1 Random Key Method
Metode yang diperkenalkan oleh Bean (1994) bertujuan untuk mengatasi kesulitan dalam menjaga kelayakan pada keturunan setelah crossover. Random key mengkodekan solusi dengan nilai acak. Nilai ini digunakan untuk mengurutkan kunci (key) untuk mengkodekan solusi kembali. Random keys mengatasi masalah kelayakan pada keturunan dengan menggunakan pengkodean kromosom yang merepresentasikan solusi. Angka acak biasanya bernilai [0,1]n. Angka-angka hasil pengacakan dipetakan pada solusi.
Misalkan, sebuah pabrik harus mengantarkan barang ke lima outlet. Maka, setiap kromosom akan tersusun dari gen-gen yang merupakan konfigurasi dari outlet-outlet yang akan dikunjungi. Dengan menggunakan metode random key, maka susunan allele pada gen berbentuk sebagai berikut.
(0.46 , 0.91, 0.33, 0.75, 0.51)
Pemetaan dilakukan dengan membuat nomor urut allele sebagai berikut. (3 1 5 4 2)
Asumsikan gen di atas adalah gen pada induk pertama. Misal induk kedua berbentuk:
(0.84, 0.32, 0.64, 0.04, 0.48) (4 2 5 3 1)
Apabila crossover dilakukan, maka keturunan yang dihasilkan adalah sebagai berikut.
(0.84, 0.32, 0.33, 0.75, 0.51) (2 3 5 4 1) (0.46, 0.91, 0.64, 0.04, 0.48) (4 1 5 3 2)
Karena setiap konfigurasi dapat dibuat urutan baru, dan tidak terjadi pengulangan ataupun penghilangan gen, maka kelayakan keturunan dapat terjaga.
2.10.2 Pengembangan Dual Genetic Algorithm
Pengembangan ini dikemukakan oleh Topcuoglu dan Sevilmis (2002) untuk masalah penugasan dengan banyak tujuan. Pada metode ini, setiap kromosom diwakili dengan string tunggal dengan panjang yang terdefinisi, yang menyatakan jumlah pekerjaan yang akan ditugaskan. Kemudian, dilakukan crossover pada kromosom. Crossover dilakukan dengan membagi dua kromosom menjadi bagian kiri dan kanan. Kemudian, salin bagian kiri dari induk pertama ke anak pertama. Kemudian,
kekosongan gen pada anak diisi dengan salinan dari induk kedua dengan cara yang sama. Hal serupa juga dilakukan pada anak kedua.
Gambar 2.17 Dua kromosom induk dan hasil crossover (sumber: Arif Volkan Vural, 2003, p30)
Metode pengembangan ini berpotensi untuk mengantarkan informasi dalam membentuk generasi tanpa adanya destruksi. Hal ini terjadi karena selama crossover, pada relokasi dua tahap ini, gen-gen anak mewakili gen-gen terbaik pada induknya, sehingga mengurangi informasi yang hilang dari induk ke keturunan.
Inisialisasi populasi dengan menggunakan random keys
While jumlah generasi < kriteria jumlah generasi
For
Bagi seluruh lintasan yang ada ke dalam subrute
Kembangkan subrute dengan savings based local search Evaluasi kromosom dan hitung fitness
End for: iterasi setiap kromosom
Masukkan kendala dan hitung ulang fitness
Gantikan kromosom yang buruk dengan yang baik dari populasi yang sama
Lakukan crossover Lakukan mutasi
End While: kriteria generasi tidak terpenuhi
Algoritma 2.2 Algoritma Dual Genetic Algorithm (sumber: Vural, Arif Volkan. 2003. Sabanci Univeristy)
2.11 Teori Perancangan Program
Menurut Pressmann (2005, p53), perangkat lunak didefinisikan sebagai berikut. 1. Instruksi-instruksi yang jika dijalankan memberikan fungsi dan kerja yang
diinginkan.
2. Struktur data yang membuat program mampu memanipulasi suatu informasi. 3. Dokumen-dokumen yang menjelaskan operasi dan pemakaian suatu program.
Perangkat lunak dapat dibagi menjadi dua kategori besar, yaitu: a. Sistem operasi, yang mengontrol jalannya komputer
b. Aplikasi, yang dapat mengerjakan berbagai fungsi atau tugas yang diinginkan manusia dalam menggunakan komputer
Perangkat lunak berbeda dengan perangkat keras. Perangkat lunak merupakan suatu elemen sistem yang bersifat logis, bukan fisik dan tidak berwujud nyata. Perangkat lunak memiliki beberapa karakteristik, sebagai berikut.
a. Perangkat lunak dikembangkan dan direkayasa. Perangkat lunak tidak dirakit seperti perangkat keras.
b. Perangkat lunak tidak dapat rusak, tetapi dapat mengalami kegagalan fungsi, walaupun kegagalan ini dapat diperbaiki. Sedangkan perangkat keras dapat rusak karena pengaruh lingkungan, sehingga harus diganti jika sudah tidak mungkin diperbaiki. Pemeliharaan perangkat lunak lebih rumit daripada perangkat keras. c. Perangkat lunak dibuat mulai dari komponen terkecil kemudian digabungkan,
sehingga dapat membentuk suatu fungsi tertentu. Sedangkan perangkat keras dirakit dari berbagai komponen yang sudah ada.
Untuk membuat sebuah perangkat lunak, Turban, et. al. (2001, p477-486), mengusulkan paradigma yang dapat dipakai sebagai pendekatan yang digunakan untuk perancangan perangkat lunak, yaitu Software Development Life Cycle (SDLC). SDLC adalah kerangka terstruktur yang terdiri dari beberapa proses yang berurutan yang diperlukan untuk membangun suatu sistem informasi. Pendekatan waterfall digunakan untuk menggambarkan SDLC. Pendekatan ini merupakan pendekatan paradigma paling kuno dan paling banyak dipakai dalam pembuatan perangkat lunak yang sudah menjadi pola dasar dalam paradigma-paradigma lainnya.
Gambar 2.18 An Eight-stage SDLC (sumber: Turban, et. al., 2001, p477)
Tahap-tahap SDLC adalah sebagai berikut: 1. Systems Investigation
Pembelajaran terhadap segala kemungkinan yang dapat terjadi adalah tahap terpenting dalam tahap ini. Dengan pembelajaran yang benar maka suatu perusahaan dapat terhindar dari kesalahan yang dapat meningkatkan jumlah pengeluaran perusahaan. Pembelajaran tersebut menentukan kemungkinan adanya keuntungan dari proyek pengembangan sistem yang diajukan dan menilai proyek tersebut secara teknik, biaya, dan sifat.
2. System Analysis
Tahap ini menganalisis masalah yang perlu diselesaikan. Tahap ini mendefinisikan permasalahan, mengidentifikasikan penyebab, menspesifikasikan solusi, serta mengidentifikasi informasi-informasi yang diperlukan. Tujuan utama dari tahap ini adalah untuk menggabungkan informasi mengenai sistem yang ada dan menentukan kebutuhan dari sistem yang baru. beberapa hal yang dihasilkan dari tahap analisis adalah:
a. Kelebihan dan kekurangan dari sistem yang telah ada
b. Fungsi-fungsi yang diperlukan oleh sistem yang baru untuk menyelesaikan permasalahan.
c. Kebutuhan informasi mengenai pengguna untuk sistem yang baru. 3. System Design
Tahap ini menjelaskan bagaimana suatu sistem akan bekerja. Yang dihasilkan oleh desain sistem adalah sebagai berikut:
a. Output, input, dan user interface dari sistem
b. Hardware, software, database, telekomunikasi, personel, dan prosedur c. Penjelasan mengenai bagaimana komponen terintegrasi
4. Programming
Tahap ini mencakup penerjemahan spesifikasi desain ke dalam bahasa komputer. 5. Testing
Tahap ini dipergunakan untuk memeriksa apakah pemrograman telah menghasilkan hasil yang diinginkan dan diharapkan atas situasi tertentu. Testing didesain untuk mendeteksi adanya error di dalam coding.
6. Implementation
Implementation adalah proses perubahan dari penggunaan sistem lama ke sitem yang baru. Ada empat strategi yang dapat digunakan oleh suatu perusahaan dalam menghadapi perubahan adalah sebagai berikut.
Parallel conversion: dengan menerapkan dua sistem, yang lama dan yang baru, secara simultan dalam periode waktu tertentu.
Direct conversion: sistem yang baru akan langsung diterapkan dan yang lama akan langsung didisfungsikan.
Pilot conversion: sistem yang baru akan digunakan dalam satu bagian dari organisasi. Apabila sistem baru tersebut berhasil maka akan digunakan pada bagian lain dari organisasi.
Phased conversion: sistem akan digunakan secara bertahap, per komponen atau modul. Satu persatu modul akan dicoba dan dinilai, bila satu modul berhasil maka modul lain akan digunakan sampai seluruh sistem bekerja dengan baik. 7. Operation dan Maintenance
Setelah tahap konversi berhasil maka sistem baru akan dioperasikan dalam suatu periode waktu. Ada beberapa tahap dalam maintenance atau pemeliharaan, diantaranya:
Debugging the program: proses yang berlangsung selama sistem berjalan.
Terus memperbaharui sistem untuk mengakomodasi perubahan dalam situasi bisnis.
2.12 Object Oriented
2.12.1 Object Oriented Analysis and Design (OOAD)
Object Oriented Analysis and Design merupakan suatu penggabungan data dan proses ke dalam suatu konstruksi yaitu object. OOAD sendiri mengenalkan object diagram dari suatu sistem beserta interaksi antar object-nya, di mana diagram-diagram tersebut akan didokumentasikan (Whitten, 2002, p97).
Object adalah representasi dari suatu entitas, baik dalam dunia nyata maupun konseptual. Sebuah object dapat mempresentasikan suatu hal yang konkret, seperti misalnya mahasiswa, mobil, ataupun konsep mengenai transaksi bank dan pemesanan barang. Secara umum, sebuah object adalah sebuah konsep, abstraksi, atau benda dengan batasan yang jelas dan berguna bagi sebuah aplikasi. Setiap object dalam suatu sistem memiliki tiga karakteristik, yaitu state,behavior,dan identity (Whitten, 2002, p247).
Object adalah abstraksi dari sesuatu dalam problem domain, merefleksikan kemampuan sistem untuk menjaga informasi, berinteraksi atau keduanya. Object memiliki dua tujuan yaitu memberikan pengertian tentang dunia nyata dan menyediakan dasar praktik bagi implementasi komputer (Bennett, 2002, p64-65).
Class adalah deskripsi dari sekumpulan object yang berbagi attributes, operations, methods, relationships, dan semantics. Class merupakan suatu template untuk menciptakan object. Operations adalah suatu service yang diminta dari suatu object akibat adanya behavior yang berpengaruh.Attributes secara umum digunakan untuk nilai data murni tanpa identity, seperti number dan string. Methods adalah implementasi dari suatu operations yang mengkhususkan pada algoritma atau prosedur (Booch et. al., 1999, p42).
2.12.2 Konsep dalam OOAD A. Encapsulation
Object-object berkomunikasi dengan cara mengirimkan message. Transfer message adalah cara untuk mengisolasi setiap object dari kebutuhan untuk mengetahui detil dari object lainnya. Object memiliki operation yang digunakan untuk menerima message dari object lainnya. Object hanya mengetahui data dan operasi masing-masing dan tidak perlu mengetahui bagaimana object lain mengirimkan message tetapi mengetahui bagaimana cara merespon message tersebut. Data dalam sebuah object hanya dapat diakses oleh operation dalam object yang bersangkutan. Encapsulations adalah perlindungan terhadap suatu object di mana representasi dari datanya tersembunyi, data yang tersembunyi hanya dapat diakses oleh operation dari object itu sendiri, dan operation dari suatu object hanya dapat dipanggil oleh yang mempunyai signal operation yang valid (Bennett, 2002, p72-73).
B. Inheritance
Inheritance adalah suatu mekanisme untuk mengimplementasikan generalization dan specialization dalam bahasa pemrograman object-oriented. Bila dua class direlasikan dengan mekanisme inheritance, class yang lebih general disebut superclass dan class lainnya yang lebih terspesialisasi disebut dengan subclass. Subclass selalu mewarisi semua karakteristik dari semua superclass dan mempunyai minimal satu karakteristik tersendiri yang tidak didapatkan dari semua superclass tersebut (Bennett, 2002, p74).
C. Polymorphism
Polymorphism adalah kemampuan untuk tampil dalam berbagai bentuk dan mewakili kemampuan dalam mengidentifikasi message yang dikirim dari object pada class-class yang berbeda. Hal ini berarti bahwa dalam mengorganisasikan object tidak perlu harus mengetahui class yang akan menerima message pada berbagai situasi. Kunci dari polymorphism adalah object penerima harus mengetahui bagaimana cara merespon suatu message (Bennett, 2002, p75).
2.13 Unified Modelling Language (UML)
UML adalah bahasa grafikal yang standar untuk memodelkan software object oriented (Lethbridge, 2002, p151).
Menurut Lethbridge (2002, p152), UML mengandung tipe diagram yang bervariasi, yaitu sebagai berikut.
1. Class Diagrams, yang menjelaskan class dan relasinya.
2. Interaction Diagrams, yang mempunyai dua tipe: sequence diagrams dan collaboration diagrams. Keduanya menggambarkan perilaku sistem dalam menangani bagaimana object berinteraksi satu dengan yang lainnya.
3. State Diagrams dan activity diagrams, yang menggambarkan bagaimana sistem berjalan secara internal.
4. Component dan deployment diagrams, yang menggambarkan bagaimana bermacam-macam components dari sistem dibentuk secara logical dan fisikal.
2.13.1 Class Diagram
Class Diagram adalah diagram yang menggambarkan data yang ditemukan di dalam software system (Lethbridge, 2002, p154). Pada class diagram, terdapat simbol-simbol sebagai berikut.
1. Simbol ‘+’ untuk menandakan public. 2. Simbol ’-’ untuk menandakan private. 3. Simbol ’#’ untuk menandakan protected.
Gambar 2.19 Notasi Class (sumber: Lethbridge, 2002, p439)
Relasi pada class diagram adalah sebagai berikut. 1. Generalization
Generalization adalah class induk atau superclass yang menggambarkan property yang sama dari class anak atau subclass.
Gambar 2.20 Class diagram dengan hubungan Generalization (sumber: Lethbridge, 2002, p439)
2. Aggregiation
Aggregiation adalah class induk (superclass) terdiri dari beberapa class lainnya atau hubungan terdiri dari.
Gambar 2.21 Class diagram dengan hubungan Aggregiation (sumber: Lethbridge, 2002, p439)
Menurut Lethbridge (2004, p169), aggregiation dibagi menjadi dua, yaitu sebagai berikut.
a. Agresiasi Dasar (Shared Aggregiation ) adalah bentuk agregasi di mana objek ”whole” lebih besar atau berisi lebih dari satu objek ”part”, dengan kata lain objek ”part” adalah bagian dari kelas objek ”whole” yang lebih besar.
Gambar 2.22 Notasi Agregasi Dasar (sumber: Lethbridge, 2002, p169)
b. Agregasi Komposisi (Composite Aggregation), adalah bentuk agregasi yang kuat, di mana objek “whole” sama sekalibertanggung jawab pada objek “part” dan objek “part” dapat diasosiasikan hanya pada satu objek “whole”
Gambar 2.23 Notasi Agregasi Komposisi (sumber: Lethbridge, 2002, p169)
3. Association
Association adalah menggambarkan bagaimana dua kelas berelasi diantara keduanya (Lethbridge, 2002, p155), atau menggambarkan hubungan diantara beberapa kelas (Lethbridge, 2002, p154).
Multiplicity dinotasikan pada masing-masing ujung dari garis association, yang mengindikasikan berapa banyak instant dari sebuah kelas pada suatu bagian dari asosiasi yang dapat dihubungkan pada instan dari kelas pada sissi lainnya (Lethbridge, 2002, p155).
Gambar 2.24 Class Diagram dengan hubungan Association (sumber: Lethbridge, 2002, p155)
2.13.2 Use Case Diagram
Use Case Diagram adalah notasi UML yang menunjukkan relasi antara kumpulan dari use case-use case dengan actor (Lethbridge, 2002, p237). Use case diagram juga menggambarkan bagaimana user berinteraksi dengan sistem untuk mencapai tujuan tertentu (Lethbridge, 2002, p234). Komponen-komponen yang ada pada use case diagram adalah sebagai berikut.
1. Use Case
Use Case adalah urutan dari aksi yang dilakukan oleh aktor untuk mencapai sebuah tugas yang diberikan (Lethbridge, 2002, p234).
Gambar 2.25 Notasi Use Case (sumber: Lethbridge, 2002, p238)
2. Actor
Actor adalah peranan seorang user atau sistem lain ketika berinteraksi dengan sistem (Lethbridge, 2002, p234), selain itu actor dapat juga diartikan sebagai orang yang melakukan sebuah Use Case (Lethbridge, 2002, p235).
Gambar 2.26 Notasi Actor (sumber: Lethbridge, 2002 , p238) 3. Extensions
Extensions digunakan untuk menyatakan interaksi optional atau untuk meng-handle kasus pengecualian (Exceptional case) (Lethbridge, 2002, p238)
4. Specializations
Specializations digunakan sama seperti subclasses di dalm class diagram (Lethbridge, 2002, p238).
5. Inclusions
Inclusions digunakan untuk mengekspresikan bahwa suatu use case tertentu dapat di-includekan ke dalam use case lainnya (Lethbridge, 2002, p239).
Gambar 2.27 Contoh Use Case Diagram (sumber: Lethbridge , 2002, p241)
2.13.3 Sequence Diagram
Menurut Lethbridge (2002, p270), Sequence diagram menunjukkan urutan penukaran pesan oleh sejumlah objek (dan seorang actor yang optional) di dalam melakukan tugas tertentu.
Gambar 2.28 Notasi Object Lifeline dan Activation (sumber: Lethbridge, 2002, p440)
Gambar 2.29 Contoh Sequence Diagram (sumber: Lethbridge, 2002, p273)