Rancang Bangun Perangkat Lunak Penentuan Lokasi Untuk Penelitian
Pendahuluan Usaha Ritel di Surabaya Dengan Jaringan Saraf Tiruan
Damarendra Universitas Ciputra UC Town, CitraLand,
Surabaya 60219
dnugroho@student.ciputra.ac.id
Caecilia Citra Lestari Universitas Ciputra UC Town, CitraLand, Surabaya 60219 caecilia.citra@ciputra.ac.id ABSTRAK
Pemilihan lokasi penjualan yang tepat merupakan salah satu kunci keberhasilan sebuah ritel. Terdapat beberapa faktor-faktor yang mempengaruhi dalam penentuan lokasi, seperti faktor ekonomi dan populasi penduduk suatu daerah. Surabaya sebagai kota kedua terbesar sekaligus salah satu pusat perdagangan di Indonesia merupakan tempat pertumbuhan yang baik bagi usaha ritel. Perangkat lunak pada penelitian ini menggunakan algoritma pembelajaran Jaringan Saraf Tiruan (JST) propagasi balik. JST propagasi balik mampu belajar dari data latihan (training set) yang terdiri atas data masuk dan target. Data latihan yang digunakan diperoleh dari Badan Pusat Statistik (BPS), yang meliputi data kependudukan serta Dinas Pedagangan dan Perindustrian (Disperindag) yang berupa data usaha ritel. Perangkat lunak ini menentukan lokasi ritel berdasarkan jenis ritel, modal usaha yang dibutuhkan, target pendapatan dan populasi penduduk. Lokasi yang dihasilkan berupa kecamatan yang ada di Surabaya yang selanjutnya digunakan sebagai acuan dalam penelitian pendahuluan atau riset pemasaran lebih lanjut.
Kata Kunci: Backpropagation, Bisnis, Jaringan Saraf Tiruan, JST, Java, MySQL, Peluang,
Retail, Surabaya
1. PENDAHULUAN
Ritel atau perdagangan eceran merupakan semua aktifitas dalam menjual barang atau jasa langsung ke konsumen akhir (end user) untuk kebutuhan pribadi dan nonbisnis. Pemilihan lokasi penjualan yang tepat merupakan salah satu kunci keberhasilan usaha ritel.
Salah satu faktor dalam penentuan sebuah lokasi usaha dapat ditinjau melalui
perkembangan ekonomi di daerah itu. Hal ini dapat memberikan pengaruh pada bisnis terutama pada konsumen yang sensitif terhadap harga. Faktor lain yang perlu dipertimbangkan adalah dari segi populasi penduduk, dikarenakan masyarakat adalah pembentuk pasar. Semakin bertumbuh populasi di daerah tersebut maka semakin besar pasar yang dapat dituju dan semakin meningkat pula daya beli di daerah itu.
Dengan data pendukung dari beberapa factor tersebut di atas, pengusaha atau calon pembuka usaha membutuhkan waktu dan keahlian menganalisa sehingga dapat menemukan lokasi usaha yang sesuai. Permasalahan ini dapat dibantu oleh salah satu algoritma kecerdasan buatan, yaitu Jaringan Saraf Tiruan (selanjutnya disingkat JST).
JST bekerja seperti otak manusia sehingga memiliki kemampuan belajar dari sebuah data. JST dibentuk untuk memecahkan suatu masalah seperti pengenalan pola atau klasifikasi karena proses pembelajaran. Terdapat beberapa metode atau algoritma dalam pendekatan JST, salah satunya adalah algoritma pembelajaran JST propagasi balik.
Pembelajaran JST propagasi balik adalah salah satu tipe pembelajaran terawasi atau supervised learning, dimana data yang diberikan (data latihan) atau training set
terdiri atas data masuk dan target yang diinginkan. Pada penelitian ini set data yang digunakan adalah data kependudukan seperti populasi penduduk berdasarkan umur, jenis kelamin, dan pendapatn per bulan tiap kecamatan dengan data kategorisasi berupa lokasi (kecamatan) dan jenis ritel.
2. LANDASAN TEORI 2.1. Ritel
Menurut Kotler (2009: 140) perdagangan eceran/pengeceran (Retailing) adalah semua aktifitas dalam menjual barang atau jasa langsung ke konsumen akhir untuk kebutuhan pribadi dan nonbisnis.
Lokasi adalah faktor yang sangat penting dalam pemasaran ritel. Pada lokasi yang tepat, sebuah gerai akan lebih sukses dibandingkan gerai lainnya yang berlokasi kurang strategis, meskipun keduanya menjual produk yang sama, oleh pramuniaga yang sama banyak dan terampil, dan sama-sama memiliki daya tarik yang bagus. Untuk mendapatkan lokasi yang diinginkan, sangat diperlukan waktu, tenaga, serta biaya untuk melakukan penelitian mengenai lokasi tersebut yang dapat mempertimbangkan beberapa faktor, seperti faktor geografi dan demografi di wilayah tersebut.
Saat sebuah bisnis merencanakan untuk membuka toko maka banyak hal yang dipertimbangkan dalam menentukan lokasi usaha agar tempat tersebut dapat memenuhi permintaan dan tepat sasaran dalam penjualannya. Menurut Kotler (2009:81) kekuatan demografis utama yang diamati pemasar adalah populasi, karena masyarakat adalah pembentuk pasar.
Pertumbuhan populasi memberikan implikasi yang signifikan dalam pertumbuhan usaha bisnis. Populasi sebuah daerah memiliki bauran usia yang beragam. Pemasar biasanya membagi populasi menjadi enam kelompok usia, yaitu: 1) anak-anak (pra sekolah); 2) anak-anak usia sekolah; 3) remaja; 4) pemuda usia 20-40 tahun; 5) dewasa paruh baya usia 40-50 tahun; 6) dewasa lanjut usia 65 tahun ke atas.
Kotler menyebutkan terdapat delapan jenis toko eceran: 1) toko barang khusus; 2) department store; 3) pasar swalayan; 4) toko kelontong; 5) toko diskon; 6) pengecer off-price; 7) superstore; 8) ruang pamer katalog.
2.2 Jaringan Saraf Tiruan Propagasi Balik Jaringan Saraf Tiruan (artificial neural network) atau disingkat JST adalah salah satu cabang dari artificial intelligence yang menirukan cara kerja otak manusia dengan melakukan proses belajar (Fausett, 1994).
Dalam penerapanya, JST digunakan karena memiliki kemampuan untuk melakukan proses pembelajaran atau adaptive learning berdasarkan data latihan yang diberikan.
Seperti halnya sistem saraf otak manusia, jaringan saraf tiruan terdiri atas beberapa komponen utama yakni neuron.
Neuron adalah unit pemroses informasi yang merupakan dasar operasi jaringan saraf tiruan.
Setiap neuron terkoneksi satu sama lain dan memiliki bobot dengan nilai yang berbeda-beda. Istilah bobot (weight connection) terinspirasi dari synapse yang merupakan koneksi antar neuron di dalam sistem saraf otak manusia. Bobot berfungsi menyimpan pola pembelajaran dari sebuah informasi di dalam jaringan. Neuron-neuron tersebut mentransformasikan informasi yang diterima melalui koneksi keluarnya menuju ke neuron lainnya.
JST propagasi balik adalah salah satu bentuk pelatihan yang diawasi (supervised training), dimana di dalam jaringan harus tersedia sampel data masuk (input) dan keluaran target (target output).
Pada proses pembelajaran JST propagasi balik, diperlukan pola data masuk dan target. Setiap pola yang diinputkan akan diolah dan diproses di dalam jaringan, dan hasilnya dibandingkan dengan target yang diinginkan. Aturan belajar dari algoritma ini adalah menggunakan nilai error atau besar perbedaan antara target dengan output (actual output) yang dihasilkan oleh jaringan. Dimana, error tersebut diumpan-balikan (backpropagation) untuk diproses ke koneksi bobot sebelumnya hingga koneksi bobot yang
pertama. Besarnya nilai error ini digunakan sebagai faktor pengubah nilai bobot yang ada pada tiap koneksi di dalam jaringan.
Proses pembelajaran pada JST propagasi balik dilakukan terus hingga keluaran aktual yang dihasilkan sesuai dengan keluaran target, atau memiliki nilai Root Mean Square Error (RMSE) yang dapat diterima. RMSE digunakan sebagai tolok ukur nilai error keseluruhan data latihan (training set) atau penanda cukup atau tidaknya sebuah jaringan mengalami proses pembelajaran (Heaton, 2005). Satu putaran atau proses perulangan belajar JST propagasi balik disebut dengan iterasi atau epoch.
Tujuan dari pembelajaran ini adalah melatih sistem jaringan untuk mencapai suatu keadaan yang memungkinkan JST dapat merespon secara benar model input yang diberikan, dan kemampuan untuk memberikan respon atau jawaban yang masuk akal bagi data masuk yang mirip tetapi tidak identik dengan data masuk yang telah dilatih sebelumnya. Semua keluaran atau kesimpulan yang ditarik oleh jaringan didasarkan pada pengalamannya selama mengikuti proses pembelajaran.
2.2.1. Arsitektur Jaringan Saraf Tiruan Propagasi Balik
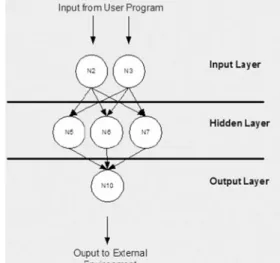
Arsitektur jaringan yang digunakan oleh JST propagasi balik adalah jaringan lapisan banyak (multi layer network), dimana jaringan ini terdiri atas masing-masing satu lapisan masuk (input layer) dan lapisan keluar (output layer) dengan satu atau lebih lapisan tersembunyi (hidden layer). Setiap lapisan terdiri atas satu atau lebih neuron yang saling tekoneksi dengan neuron pada lapisan berikutnya.
Gambar 1. menunjukan jaringan lapisan banyak dengan satu lapisan tersembunyi. Bagian atas sebagai lapisan masuk, bagian tengah sebagai lapisan tersembunyi dan bagian bawah sebagai lapisan keluaran.
Gambar 1. Arsitektur Jaringan Banyak (Heaton, 2005)
Setiap neuron pada lapisan masuk harus terkoneksi dengan neuron pada lapisan tersembunyi. Lapisan tersembunyi selanjutnya
dapat terhubung dengan lapisan tersembunyi lainnya atau langsung menuju pada lapisan keluar.
Jaringan lapisan banyak memiliki minimal satu lapisan tersembunyi. Menggunakan lebih dari satu lapisan tersembunyi diperbolehkan di dalam jaringan, namun, menggunakan satu lapisan tersembunyi sudah cukup memadai.
2.2.2. Algoritma Pembelajaran Jaringan Saraf Tiruan Propagasi Balik
Menurut Fauset, algoritma pembelajaran Jaringan Saraf Tiruan (JST) propagasi balik melibatkan tiga tahap yaitu:
1. Tahap perambatan maju (feedforward) pola input pembelajaran
2. Tahap kalkulasi error dan perambatan mundur (backpropagation)
3. Tahap penyesuaian atau pengubahan bobot Tahap-tahap diatas diberlakukan untuk semua pola data pelatihan (training set) yang telah disediakan sebelumnya.
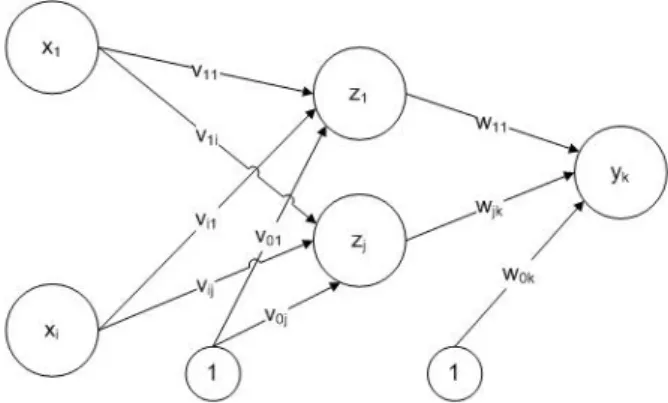
Ilustrasi pada gambar 2. Menunjukan contoh arsitektur dari JST propagasi balik. Dalam gambar tersebut, terdapat dua neuron atau unit masukan x1 dan xi, dua unit
tersembunyi z1 dan zj, dan satu unit keluaran
yk. Untuk tiap unit pada lapisan tersembunyi
dan lapisan keluaran, terdapat satu unit lagi
yang memiliki data masukan dengan nilai 1. Unit ini disebut dengan istilah bias. Bias juga memiliki nilai koneksi sama halnya dengan koneksi bobot.
Gambar 2. Arsitektur JST Propagasi Balik
Tiap neuron atau unit pada lapisan tersembunyi dan lapisan keluar dapat menerima data masuk (input) dan menghasilkan data keluar (output). Berbeda dengan unit yang ada pada lapisan masuk, setiap unit tersebut hanya dapat mengirimkan data masuk untuk kemudian diproses di lapisan berikutnya.
Proses menerima data masuk dapat dihitung dengan menggunakan rumus penjumlahan yang ditulis sebagai berikut.
∑ (1) Sedangkan proses untuk menghasilkan data keluar dihitung dengan menggunakan fungsi aktifasi. Fungsi aktifasi merupakan fungsi pengolah jumlahan data masuk (input) menjadi data output (output). Terdapat 2
fungsi aktifasi yang digunakan dalam penerapan algoritma propagasi balik, yaitu:
1. Fungsi Biner Sigmoid
Fungsi sigmoid memiliki nilai interval (0,1) dan memiliki bentuk fungsi:
(2)
dengan fungsi turunan sebagai berikut:
. 1 (3)
2. Fungsi Bipolar Sigmoid
Fungsi bipolar sigmoid memiliki nilai interval (-1,1) dan memiliki bentuk fungsi:
1 (4)
dengan fungsi turunan sebagai berikut.
(5)
Hasil dari fungsi aktifasi yang dihasilkan oleh tiap unit yang berada di lapisan keluar, merupakan nilai keluaran aktual (actual output) dari sebuah jaringan. Proses pembelajaran dalam JST propagasi balik dapat meningkat apabila menggunakan fungsi bipolar sigmoid.
Seperti yang telah dijelaskan sebelumnya, nilai keluaran aktual akan dibandingkan dengan keluaran target (target output) untuk menghitung nilai kesalahan atau
error. Nilai error ini selanjutnya diproses untuk menghitung seberapa besar koreksi nilai koneksi bobot yang dibutuhkan (weight correction term). Dalam perhitungan itu, terdapat sebuah variabel yang digunakan. Variabel itu disebut dengan istilah learning rate ( atau ketelitian pembelajaran.
Nilai dari learning rate memiliki nilai positif kurang dari 1. Umumnya, memberikan nilai yang terlalu besar akan membuat proses belajar menjadi sangat cepat. Sebaliknya, menggunakan nilai learning rate yang terlalu kecil akan berakibat pada lamanya jumlah iterasi. Tetapi menggunakan nilai learning rate yang terlalu besar mengakibatkan JST tidak akan menuai hasil (Heaton, 2005)
Sebelum JST mengalami proses pembelajaran, koneksi bobot dan bias terlebih dahulu diinisialisasi. Inisialisasi bobot dan bias dapat berupa nilai positif ataupun negatif. Pada umumnya, inisialisasi bobot dan bias dilakukan secara acak dengan nilai yang berkisar antara -0.5 dan 0.5 (Fausett, 1994).
2.2.2.1. Pelatihan Perambatan Maju
Langkah - langkah pelatihan perambatan maju adalah sebagai berikut:
Langkah 0:
Inisialisasi bobot dan bias.
Langkah 1:
Setiap unit masukan (x1, xi, i=1,..n) menerima data xi dan mengantarkan data
ini ke semua lapisan di atasnya (unit tersembunyi).
Langkah 2:
Setiap unit tersembunyi (z1, zj, j=1, ..n) menjumlahkan setiap nilai bobotnya dengan menggunakan fungsi penjumlahan yang telah dituliskan pada persamaan (1).
Tiap unit tersembunyi ini kemudian menghitung nilai dari fungsi aktifasinya dan mengirimkan data keluarnya (zj) ke tiap unit pada lapisan keluaran.
(6)
Langkah 3:
Setiap unit keluaran (y1, yk, k=1,.. n) menjumlahkan setiap nilai bobotnya dengan menggunakan fungsi penjumlahan sebagai berikut.
∑ (7)
Selanjutnya tiap unit pada lapisan keluaran menghitung nilai keluaran aktual (actual output) dengan menggunakan fungsi aktifasi sebagai berikut.
(8)
2.2.2.2. Prosedur Pelatihan Perambatan Mundur
Langkah 1
Setiap unit keluaran (yk, k=1, ..., n) akan memiliki keluaran target atau target output
(tk, k=1, ..., n). Keluaran target ini akan dibandingkan dengan aktual target yang dihasilkan oleh jaringan dan dihitung nilai error yang dikeluarkan (error information term) dengan rumus berikut:
(9)
Selanjutnya, menghitung besarnya koreksi untuk nilai koneksi bobot dan biasnya (weight correction term), dengan rumus berikut:
∆ (10)
∆ (11)
Langkah 2:
Setiap unit pada lapisan tersembunyi (zj,
j=1, ...,n) menjumlahkan hasil perubahan masukannya (dari unit-unit pada lapisan diatasnya) dengan menggunakan rumus berikut:
∑ (12)
Hasil persamaan di atas akan dikalikan dengan nilai turunan dari fungsi aktifasinya guna menghitung besarnya
error yang dikeluarkan (error information term).
(13)
Kemudian, besar koreksi untuk koneksi bobot dan biasnya dihitung dengan rumus berikut
∆ (14)
∆ (15)
2.2.2.3. Prosedur Pengubahan Nilai Bobot dan Bias
Untuk setiap unit keluaran (yk, k=1, ..., n) mengubah nilai bobot dan biasnya (j=0, ..., n) dengan rumus berikut:
∆ (16) Tiap unit pada lapisan tersembunyi (zj, j=1,
...,n) mengubah nilai bobot dan biasnya (i=0, ..., n) dengan menggunakan rumus yang sama yaitu:
∆ (17)
2.2.2.4. Menghitung Root Mean Square Error
Setelah seluruh data latihan (training set) dipelajari oleh jaringan, maka nilai Root Mean Square Error (RMSE) dapat dihitung.
Telah dijelaskan sebelumnya bahwa, RMSE digunakan sebagai tolok ukur nilai
error keseluruhan data latihan. Dengan kata lain, proses belajar pada JST propagasi balik akan berhenti apabila nilai RMSE yang dihasilkan mencapai nilai error yang dapat diterima. Berikut langkah dalam perhitungan RMSE:
1. Menghitung nilai SSE (Sum Square Error) yang di dapatkan dari rumus berikut.
∑ (18)
2. Nilai RMSE selanjutnya dihitung dengan mengakar hasil pembagian dari SSE dengan perkalian jumlah data latihan (N) dengan jumlah unit keluar (K). Rumus RMSE dapat dituliskan sebagai berikut.
∗ (19)
2.2.3 Inisialisasi Pendekatan Nguyen-Widrow
Inisialisasi bobot dan bias dapat dihitung dengan pendekatan nguyen-widrow. Pendekatan ini didasarkan atas analisa dari respon yang diberikan neuron atau unit tersembunyi terhadap unit pada lapisan masuk2, dengan menggunakan nguyen widrow, proses belajar di dalam JST menjadi lebih cepat atau memiliki jumlah iterasi yang
2Fausett, Laurene. 1994. Fundamentals of Neural Networks.
lebih sedikit dengan menggunakan fungsi biner sigmoid ataupun bipolar sigmoid.
Perhitungan atau inisialisasi bobot dan bias dari unit masuk ke unit tersembunyi dirancang untuk meningkatkan kemampuan dari unit tersembunyi melakukan proses pembelajaran. Untuk bobot dan bias dari unit tersembunyi ke unit keluar dilakukan proses inisialisasi secara acak (antara -0.5 dan 0.5).
Adapun pendekatan inisialisasi bobot dan bias (nguyen-widrow), dilakukan sebagai berikut:
. / (20)
dengan faktor pengubah ( ), jumlah unit tersembunyi (p), dan jumlah unit masuk (n).
Selanjutnya dihitung dengan langkah-langkah sebagai berikut, Untuk setiap unit tersembunyi (j=1, ...., n):
Langkah 1:
Inisialisasi bobot dan bias (acak) dari unit pada lapisan masuk dan unit tersembunyi.
0.5 0.5 (21) Langkah 2:
Menghitung jumlah koneksi bobot dan bias dengan cara:
(22)
Langkah 3:
Inisialisasi bobot dan bias.
(23)
3. DESAIN SISTEM
3.1 Pengumpulan dan Pengolahan Data Data didapat dari Disperindag dan BPS Surabaya. Data tersebut adalah:
1. Data usaha ritel.
Data yang digunakan adalah usaha ritel yang berdiri minimal 3 tahun hingga 2010 dan berupa, lokasi kecamatan usaha ritel itu, jenis ritel (pakaian, perhiasan, elektronik, dsb), serta besar modal usaha yang digunakan.
2. Data kependudukan.
Data yang digunakan adalah data pendapatan per kapita dan populasi penduduk per kategori umur untuk tahun 2008-2010. Data primer yang diperoleh dari BPS adalah total populasi penduduk 2008-2010, dan populasi per kategori umur untuk tahun 2010. Penulis kemudian melakukan proyeksi mundur berdasarkan
persentase jumlah per kategori dibandingkan total populasi di tahun 2008 dan 2009.
3.2 Pemetaan Data
3.2.1. Pemetaan Data Kategorikal
Struktur JST menggunakan fungsi aktivasi biner sigmoid sehingga seluruh data kategori dipetakan menjadi biner. Tabel 1. adalah contoh pemetaan biner data jenis usaha ritel. Selain jenis usaha ritel, data kategorikal lain adalah data kecamatan.
3.2.2 Pemetaan Data Numerikal
Untuk data numerikal, seperti modal usaha, pendapatan per kapita, atau populasi, perlu dipetakan untuk normalisasi. Pemetaan tersebut dilakukan dengan persamaan (24) berikut:
(24)
Tabel 2. adalah contoh pemetaan untuk modal usaha.
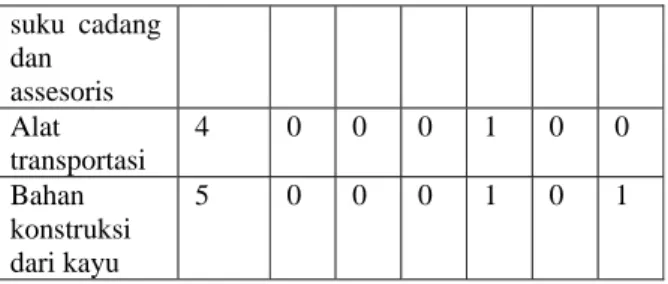
Tabel 1. Contoh Pemetaan Data Jenis Usaha Ritel
Jenis Ritel Num x1 x2 x3 x4 x5 x6
Pencetakan, penerbitan, dan perangkat lunak 1 0 0 0 0 0 1 Bahan-bahan konstruksi 2 0 0 0 0 1 0 Sepeda motor serta 3 0 0 0 0 1 1 suku cadang dan assesoris Alat transportasi 4 0 0 0 1 0 0 Bahan konstruksi dari kayu 5 0 0 0 1 0 1
Tabel 2. Contoh Pemetaan Data Modal Usaha
Modal Usaha Hasil Pemetaan Data
100.000.000 0.09999999800000013 50.000.000 0.019999999199999997 500.000.000 0.019999999919999976 200.000.000 0.04999999949999998 3.3 Arsitektur JST 3.3.1. Neuron
Jaringan yang digunakan dalam perangkat lunak ini memiliki jumlah neuron atau unit masuk (input unit) sebanyak 13 unit, yang terdiri atas 6 bit biner hasil pemetaan jenis ritel, modal dan pendapatan, serta 5 kisaran umur. Jumlah unit pada lapisan tersembunyi atau hidden unit berjumlah 25 unit, sedangkan unit keluar (output unit) yang digunakan sebanyak 5 unit, yaitu berupa hasil pemetaan data biner tiap kecamatan.
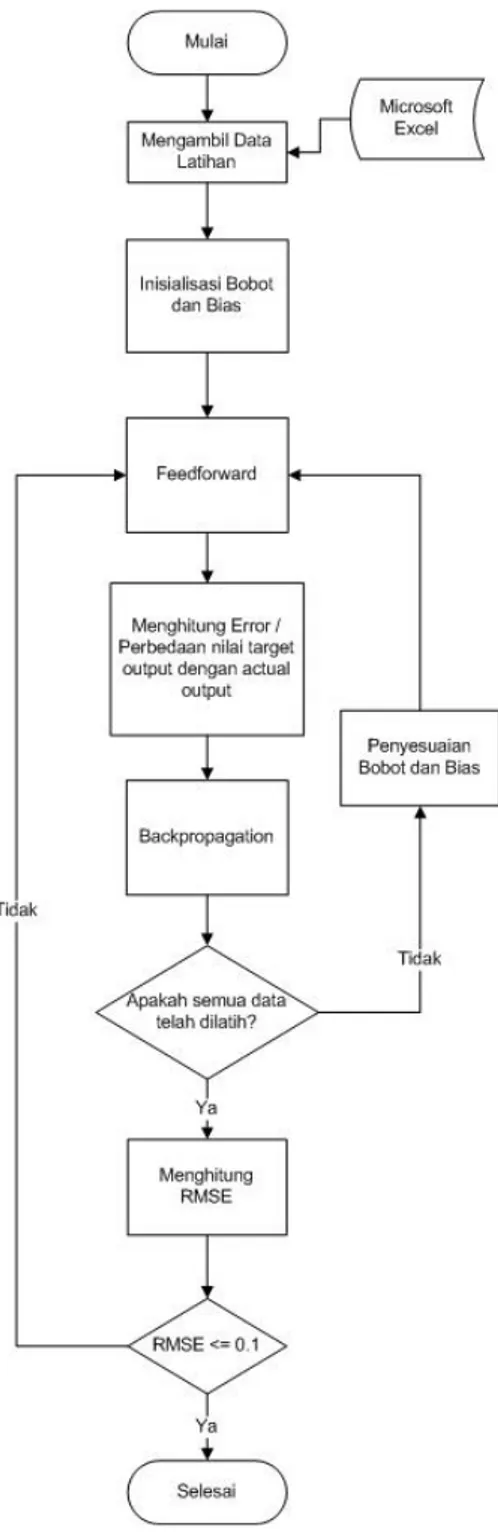
Gambar 3. Diagram Alir Algoritma JST
3.3.2. Learning Rate
Proses pembelajaran JST propagasi balik pada perangkat lunak ini menggunakan nilai learning rate yang sebesar 0.02. Hal ini
dikarenakan pemberian nilai yang terlalu besar akan membuat proses belajar menjadi sangat cepat, namun memberikan dampak pada tidak selesainya pembelajaran atau tidak tercapainya nilai RMSE. Sebaliknya, menggunakan nilai learning rate yang terlalu kecil akan berakibat pada lamanya jumlah iterasi tetapi nilai RMSE tercapai.
3.3.3. Fungsi Aktivasi
Fungsi aktivasi yang digunakan adalah fungsi Biner Sigmoid, yaitu seperti pada persamaan (25) berikut:
(25)
3.3.4. Inisialisasi Bobot dan Bias
Pada pengembangan perangkat lunak proses pelatihan jaringan menggunakan inisialisasi bobot dan bias secara acak yaitu diantara -0.5 dan 0.5 dan dengan inisialisasi pendekatan nguyen-widrow.
Gambar 3. adalah diagram alir dari perangkat lunak ini.
4. IMPLEMENTASI DAN PENGUJIAN 4.1 Struktur Diagram Perangkat Lunak
Struktur diagram perangkat lunak ini terdiri dari beberapa package, yaitu Mapping, Presentation, NeuralNetwork, NNBuilder, dan Runner. Gambar 4. adalah package diagram
adalah NeuralNetwork, Mapping, dan NNBuilder.
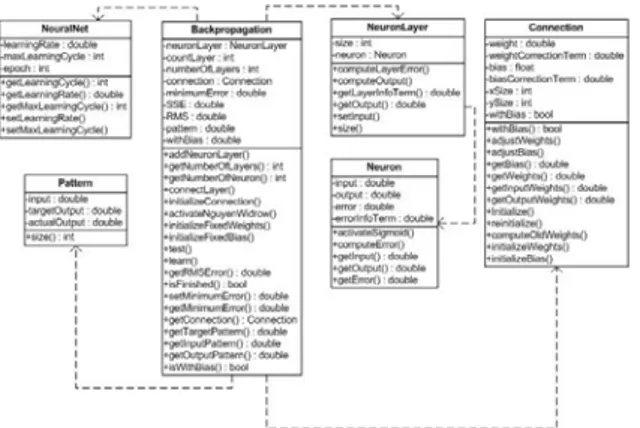
Package NeuralNetwork berisi sejumlah class
yang membentuk arsitektur JST. Gambar 5. merupakan class digram dari NeuralNetwork. Penjelasan singkat tiap-tiap class terdapat pada Tabel 3.
Gambar 4. Package Diagram
Gambar 5. Class Diagram Package NeuralNetwork
Tabel 3. Penjelasan Class pada Package NeuralNetwork
Nama Class Keterangan
Backpropagati on
Merupakan kelas untuk
menjalankan fitur pembelajaran dan pengujian
Neuron Merupakan kelas untuk
melakukan fungsi penjumlahan dan fungsi
aktifasi serta perhitungan error
NeuronLayer Merupakan kelas untuk menyimpan objek neuron ke dalam beberapa lapisan Connection Merupakan kelas untuk
menyimpan bobot dan bias sebuah jaringan
Pattern Menyimpan pola atau
pattern data latihan
NeuralNet Merupakan sebuah abstract class
Pagkage Mapping berisikan sejumlah
class yang berfungsi untuk pemetaan data. Struktur hubungan antar class tersebut direpresentasikan seperti pada Gambar 6., dengan penjelasan seperti pada Tabel 4.
Tabel 4. Penjelasan Class pada Package Mapping
Nama Class Keterangan
MappingData_Angka Merupakan kelas yang berfungsi untuk memetakan data latihan yang berupa angka
MappingData_Kategori Merupakan kelas yang berfungsi untuk memetakan data latihan kecamatan
MappingData_Kategori2 Merupakan kelas yang berfungsi untuk memetakan data latihan jenis ritel
MappingData Merupakan
abstract class
ValueCombination Merupakan kelas untuk
menghasilkan
data kombinasi (jenis kelamin dan umur)
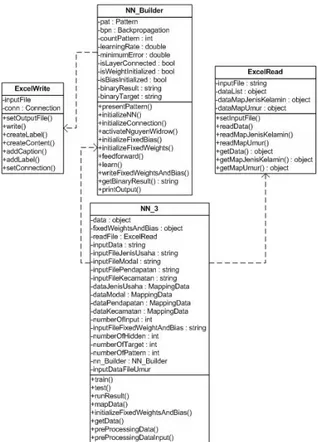
Package NNBuilder berfungsi untuk mengatur jalannya perangkat lunak, pengambilan masukan, pemrosesan data dengan JST, hingga menghasilkan keluaran. Gambar 7. adalah class diagram dari package
ini sedangkan Tabel 5. menjelaskan tiap-tiap class di dalamnya. 4.2. Pengujian
Pengujian ini dilakukan dengan tujuan sebagai berikut:
1) Membandingkan proses pelatihan jaringan menggunakan metode inisialisasi bobot dan bias secara acak (antara -0.5 dan 0.5) dengan metode pendekatan nguyen-widrow.
2) Menguji jaringan dengan bobot dan bias yang telah didapat dari hasil pelatihan, baik pelatihan yang menggunakan inisialisasi bobot dan bias secara acak maupun melalui pendekatan nguyen-widrow untuk mengetahui nilai error atau kesalahan yang dihasilkan.
Tabel 5. Penjelasan Class pada NNBuilder Nama Class Keterangan
ExcelWrite Merupakan kelas yang berfungsi untuk menulis data ke dalam file excel
ExcelRead Merupakan kelas yang berfungsi untuk membaca data dari file excel
NN_Builder Merupakan kelas yang memanggil fungsi-fungsi dari kelas-kelas yang berada di
package neural network
NN_3 Merupakan kelas yang
berfungsi melatih dan menguji pembelajaran pada jaringan
4.2.1. Skenario Pengujian
Untuk mencapai tujuan yang disebutkan diatas, pengujian dilakukan dengan menggunakan 80 persen data, yang terdiri dari data tahun 2008, 2009, dan sebagian 2010. Data dilatih dengan menggunakan dua pendekatan yakni:
1. Inisialisasi bobot dan bias secara acak (antara -0.5 dan 0.5)
2. Inisialisasi bobot dan bias dengan pendekatan nguyen-widrow
Selanjutnya, dilakukan pengujian data dengan menggunakan data yang tidak pernah dipelajari sebelumnya. Data tersebut berupa data dari tahun 2010 dengan jumlah sebesar 20 persen dari data keseluruhan. Pengujian ini dilakukan untuk mengetahui seberapa besar nilai error yang dihasilkan oleh jaringan.
Dalam penerapannya, pengujian ini dilakukan dengan menerapkan algoritma perambatan maju dengan menggunakan bobot dan bias yang didapatkan dari proses pembelajaran baik dengan inisialisasi bobot dan bias secara acak maupun pendekatan
nguyen-widrow.
4.2.2. Hasil dan Analisa Pengujian
4.2.2.1. Perbandingan Antara Inisialisasi Bobot dan Bias Acak dan Pendekatan Nguyen-Widrow
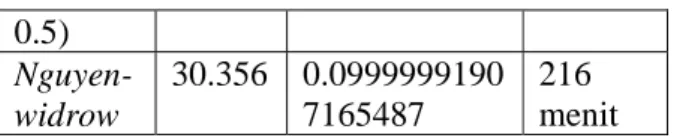
Tabel 6. merupakan tabel perbandingan untuk inisialisasi awal bobot dan bias secara acak dan dengan pendekatan
Nguyen-Widrow. Hasil pengujian ini menyatakan bahwa JST membutukan iterasi lebih banyak dan waktu lebih lama hingga lebih dari dua kali lipat saat bobot dan biasnya diinisialisasi secara acak (antara -0.5 hingga 0.5) dibandingkan dengan ketika diinisialisasi dengan pendekatan Nguyen-Widrow. Namun, apabilai inisialisasi awal bobot dan bias dilakukan dengan pendekatan Nguyen Widrow, JST akan memiliki RMS Error yang lebih besar (selisih 10-6).
Tabel 6. Perbandingan Inisialisasi Awal Bobot dan Bias
Pende-katan
Epoch RMS Error Waktu
Acak (-0.5 sd. 62.280 0.0999900782 6111735 489 menit
0.5) Nguyen-widrow 30.356 0.0999999190 7165487 216 menit
4.2.3.2. Penerapan Data Testing pada JST yang Terlatih
Dengan menggunakan bobot dan bias dari hasil pelatihan, JST diterapkan pada data uji, yaitu sebanyak 20% dari data tahun 2010. Hasil dari pengujian adalah JST mampu menentukan jenis ritel atau lokasi yang sesuai dengan tingkat kesalahan kurang dari 10%, baik dengan inisialisasi acak maupun dengan pendekatan Nguyen-Widrow seperti pada Tabel 7.
Tabel 7. Hasil Pengujian JST Inisialisasi Bobot dan Bias Error Acak (antara -0.5 dan 0.5) 0.09362706530291 11 Pendekatan Nguyen-widrow 0.09716758457907 16
5. KESIMPULAN DAN SARAN
Berdasarkan hasil uji coba yang telah dilakukan dapat disimpulkan bahwa, proses pelatihan jaringan dengan inisialisasi bobot dan bias menggunakan pendekatan nguyen
-widrow memerlukan jumlah iterasi yang lebih
sedikit dibandingkan dengan inisialisasi secara acak.
Perangkat lunak ini telah mampu memberikan jawaban dengan tingkat kebenaran sebesar 90 persen atau memiliki nilai error minimal 0.1. Sehingga, perangkat lunak ini layak digunakan sebagai acuan lokasi untuk melakukan penelitian atau riset pemasaran usaha ritel lebih lanjut. Selain itu, dalam pengembangannya, proses pelatihan data cocok dilakukan dengan menggunakan inisialisasi bobot dan bias melalui pendekatan
nguyen-widrow.
Berikut adalah beberapa rencana atau saran pengembangan untuk perangkat lunak ini:
1. Menentukan lokasi penjualan tidak hanya untuk usaha ritel saja, melainkan untuk usaha lainnya.
2. Dikembangkan di beberapa kota lainnya di Indonesia.
3. Menggunakan data primer atau data survei sebagai data latihan (training set) agar memberikan hasil yang jauh lebih akurat dan dipercaya
6. DAFTAR PUSTAKA
[1] Fausett, Laurene. 1994. Fundamentals of Neural Networks. New Jersey: Prentice Hall. [2] Heaton, Jeff. 2005. Introduction to Neural Networks with Java. USA: Heaton Research, Inc.
[3] Kiki dan Sri Kusumadewi. 2009. Analisa Jaringan Saraf Tiruan dengan Metode
Backpropagation untuk Mendeteksi Gangguan Psikologi. Laboratorium Komputasi dan Sistem Cerdas Jurusan Teknik Informatika Fakultas Teknologi Industri Universitas Islam Indonesia.
[4] Kotler, Philip dan Kevin L. Keller. 2009. Manajemen Pemasaran. Edisi 13. Jakarta: Erlangga.
[5] Ma’aruf, Hendri. 2005. Pemasaran Ritel. Jakarta: PT Gramedia Pustaka Utama.
[6] Pang-Ning Tan, Micheal Steinbach, and Vipin Kumar. 2006. Introduction to Data Mining. Pearson Education , Inc.
[7] Pressman, Roger S. 2005. Software Engineering, A Practitioner’s Approach, 6th Ed., NY:McGraw-Hill.