PEMODELAN DATASET
WHOLESALE CUSTOMERS
DENGAN METODE
CLUSTERING
Galuh Indah Zatadini1, Adhistya Erna Permanasari2, Noor Akhmad Setiawan3 Departemen Teknik Elektro dan Teknologi Informasi
Fakultas Teknik, Universitas Gadjah Mada Jl. Grafika 2 Yogyakarta 55281
E-mail: [email protected] , [email protected] , [email protected]
ABSTRAKS
Data mining merupakan suatu pengetahuan yang digunakan untuk menggali informasi dalam sebuah data. Di dalam teknik data mining ada banyak metode yang dapat digunakan dalam pengolahan sebuah data dimana salah satu metode yang dapat digunakan untuk pengolahan datanya adalah dengan metode Clustering. Paper ini membahas tentang pemodelan suatu data set yaitu Wholesale Customers dimana dataset tersebut mengacu pada data klien dari distributor yang mencakup pengeluaran tahunan dalam satuan moneter pada berbagai macam produk. Pemodelan dataset tersebut dilakukan dengan menggunakan metode clustering dengan membandingkan 3 algoritma yaitu Simple K-Means, Expectation Maximization (EM) dan X-Means. Tujuan mebandingkan 3 algoritma tersebut untuk mengetahui algoritma yang paling baik dalam pengolahan Wholesale custumer dataset. Hasil yang didapatkan pada perbandingan 3 algoritma clustering tersebut menunjukkan bahwa algoritma EM menunjukkan hasil yang cukup baik dengan error rate lebih sedikit, namun untuk efisiensi waktu algoritma X-Means jauh lebih cepat dibandingkan dengan algoritma yang lain.
Kata Kunci: Data mining, Clustering, Wholesale Customers
1. PENDAHULUAN
Pesatnya perkembangan teknologi komputer dan teknologi komunikasi membawa masyarakat ke dalam era informasi dimana dengan kematangan database dan popularitas aplikasi data. Kita hidup di dunia dimana jumlah data yang dikumpulkan oleh manusia semakin cepat dan semakin banyak setiap harinya dan menganalisis data tersebut merupakan sebuah kebutuhan yang sangat penting karena dalam menghadapi jumlah data yang semakin besar dengan beberapa struktur data, tidak semua data tersebut memiliki pengetahuan yang dibutuhkan. Oleh karena itu dibutuhkan sebuah teknologi yang dapat membantu menggali dan menganalisis data yang sangat besar tersebut untuk mendapatkan informasi yang dibutuhkan yang nantinya akan berguna dalam proses pengambilan keputusan.
Data mining dapat dilihat sebagai hasil dari evolusi alami dari teknologi informasi. Perkembangan database dan industri management data memiliki beberapa fungsi penting diantaranya adalah data collection and database creation, data management (termasuk penyimpanan dan pengambilan data dan pengolahan transaksi database) serta advanced data analysis (melibatkan data warehousing dan data mining). Dalam data mining, perlu menemukan knowledge dalam bentuk pattern yang nantinya akan diekstrak menjadi informasi yang akan bermanfaat untuk selanjutnya dilakukan pemahaman terhadap data tersebut. Memahami data yang akan diolah dalam data mining sangat penting karena pemahaman tersebut
bisa menjadi kunci berhasil atau tidaknya proses data mining yang akan dilakukan. Dengan memahami data yang akan diolah, kita bisa menentukan mulai dari input yang diperlukan untuk pengolahan data, output apa yang bisa kita peroleh dari proses data mining, perlu atau tidaknya melakukan pre-processing terhadap data yang kita miliki, apakah seluruh data telah lengkap ataukah ada nilai-nilai yang hilang (missing value), apakah setiap instance sudah memiliki atribut yang sama, dan lain sebagainya (Han, Kamber, and Pei 2011).
Di dalam data mining ada banyak metode yang bisa digunakan untuk menganalisis datanya, salah satu metode analisis yang bisa digunakan adalah analisa dengan metode clustering atau pengelompokan data (Garima, Gulati, and Singh 2015).
Analisa clustering merupakan salah satu bidang penelitian dalam data mining yang merupakan sebuah proses pengelompokan data dan juga partisi data (Hailong Chen and Chunli Liu 2013). Sebuah cluster merupakan sekumpulan objek data yang mirip satu dengan yang lain namun akan berbeda antara satu cluster dengan cluster lain. Hal tersebut dikarenakan sekelompok objek data dapat diperlakukan secara kolektif sebagai satu kelompok dan hal tersebut dapat dianggap sebagai kompresi data. Clustering juga dapat disebut sebagai proses segmentasi data (Aouf, Lyanage, and Hansen 2008).
Dalam paper penelitian ini akan dibahas sebuah proses pemodelan dengan metode analisis clustering dengan beberapa algoritma untuk mengetahui
algoritma mana dalam metode clustering yang lebih baik digunkan pada dataset sejenis ini. Data set yang digunakan dalam paper ini adalah Wholesale Customers dataset yang diambil dari UCI Machine Learning
(https://archive.ics.uci.edu/ml/datasets/Wholesale+c ustomers)
.
Data ini mengacu pada data klien dari distributor yang mencakup pengeluaran tahunan dalam satuan moneter pada berbagai macam produk. Ada 8 atribute dan 440 instances yang dimiliki oleh dataset ini. Parameter dari attribute tersebut adalah : 1. FRESH (pengeluaran tahunan pada produk
segar) dengan tipe data numerik
2. MILK (pengeluaran tahunan pada produk susu) dengan tipe data numeric
3. GROCERY (pengeluaran tahunan pada produk bahan makanan) dengan tipe data numeric 4. FROZEN (pengeluaran tahunan pada produk
beku) dengan tipe data numeric
5. DETERGENTS_PAPER ( pengeluaran tahunan pada produk sabun dan kertas) dengan tipe data numeric
6. DELICATESSEN (pengeluaran tahunan pada produk toko makanan) dengan tipe data numeric 7. CHANNEL (pelanggan dari industri dan
eceran) dengan tipe data numeric
8. REGION (pelanggan dari daerah) dengan tipe data numeric
Dari data yang didapat dari link tersebut memiliki 8 buah attribute dengan 6 attribute perta-ma merupakan pengeluaran tahunan sedangkan 2 attribute terakhir menunjukkan darimana customer berasal. Untuk channel attribute dibagi menjadi 2 kelas yaitu industri dan eceran. Sedangkan untuk region attribute dibagi menjadi 3 kelas yaitu Lisnon, Oporto dan Other.
Analisis data set dalam paper ini menggunakan tools WEKA yang merupakan salah satu paltform yang menyediakan beberapa algoritma sebagai perbandingan dan dapat membandingkan hasil-hasil pengolahan tersebut dari beberapa algoritma yang tersedia. Selain itu, WEKA juga merupakan perangkat lunak open source yang berada dibawah pengawasan GNU dengan general lisensi publik (Shah and Jivani 2013).
2. PEMBAHASAN
Analisis clustering merupakan jenis metode statistic multivariant yang akan membuat objek data sesuai dengan berbagai karakteristik untuk mengambil klasifikasi yang komprehensif (Hailong Chen and Chunli Liu 2013). Pengelompokkan data sesuai dengan tingkat kemiripan diantara data-data tersebut yang kemudian akan dibagi menjadi beberapa kelompok sehingga objek yang mirip akan menjadi sebuah set ini disebut dengan clustering (Rani and Parthipan 2012). Sehingga clustering merupakan kumpulan dari satu set objek data yang mirip antara satu dengan yang lainnya namun sama
sekali berbeda antara satu kelompok dengan kelompok yang lainnya. Analisis clustering biasanya digunakan untuk mencari link berharga antara objek data dari satu set data yang diberikan. Dalam banyak aplikasi, semua objek dalam cluster sering diperlakukan sebagai objek yang akan diproses atau dianalisis.
Penggunaan clustering sangat luas. Dalam proses bisnis, pengelompokan dapat membantu analisis pasar untuk membedakan kelompok konsumen dan meringkas pola konsumsi atau kebiasaan masing-masing jenis konsumen. Sebagai salah satu bagian dari data mining, dapat digunakan sebagai alat untuk menemukan beberapa informasi mendalam dalam database dan generalisasi karakteristik masing-masing kategori ataupun fokus pada kelas khusus untuk analisis lebih lanjut. Selain itu, analisis clustering dapat digunakan sebagai langkah preprocessing algoritma analisis data mining lainnya (Kanellopoulos et al. 2007).
Tujuan dari penggunaan metode clustering dalam paper ini adalah selain untuk menggali informasi yang dimiliki oleh dataset tersebut adalah untuk membandingkan algoritma yang dimiliki oleh metode clustering yaitu algoritma Simple K-Means, Expectation Maximization dan X-Means. Dari perbandingan tersebut dapat dilihat algoritma mana yang lebih baik digunakan dalam dataset ini.Data yang digunakan adalah data Wholesale Customers dari UCI Machine Learning Repository yang memiliki 8 attribute dan 440 instances. Missing value tidak terdapat dalam dataset Wholesale Customers ini. Tabel 1 menunjukkan statistic attribute pada dataset Wholesale Customer.
Attribute Nilai Min Nilai Maks Nilai Rerata Standar Deviasi Fresh 3 112151 12000.3 12647.3 Milk 55 73498 5796.27 7380.4 Grocery 3 92780 7951.28 9503.2 Frozen 25 60869 3071.93 4854.7 Detergent 3 40827 2881.49 4767.8 Delicatess en 3 47943 1524.87 2820.10
Tabel 1. Statistic attribute pada dataset
Dilihat dari nilai statistik (nilai minimum, nilai maksimum, rerata dan standar deviasi) masing-masing attribute, maka disimpulkan tidak adanya noise ataupun outlier dari dataset tersebut sehingga semua instances dapat digunakan untuk clustering
.
Hal ini dibuktikan dengan sebaran data yang tidak terlalu meluas dilihat dari nilai standart deviasinya serta rentang antar nilai maksimum dan minimum. Dengan begitu, dataset tersebut hanya memerlukan pengubahan bentuk yang dapat dikenali oleh WEKA untuk proses perhitungan clustering, dalam hal ini format file .arff.
Dataset tersebut selanjutnya diuji dengan menggunakan metode clustering dengan beberapa algoritma didalamnya untuk melihat algoritma mana yang akan menunjukkan hasil terbaik dengan melihat error rate dan efisiensi waktu pengelom-pokannya.
2.1Simple K-Means
K-Means merupakan salah satu algoritma analisis data pada data mining yang melakukan proses pemodelan unsupervised dan merupakan salah satu algoritma yang melakukan clustering atau pengelompokan data dengan system partisi (Abidi and Ong 2000).
K-Means merupakan salah satu algoritma data mining yang paling populer karena sederhana, terukur dan mudah dimodifikasi untuk berbagai konteks dan domain aplikasi. Masalah utama dari algoritma K-Means adalah kinerjanya yang tergantung pada inisialisasi dari Centroid (Prabha and Visalakshi 2014).
Dasar algoritma K-Means adalah metode clustering dimana dalam algoritma K-Means dibagi menjadi tiga langkah utama. Langkah pertama adalah secara acak memilih mean awal. Langkah kedua adalah menghitung jarak antara Centroid dan objek data. Langkah ketiga adalah menetapkan objek data ke dalam cluster dengan masing-masing jarak minimum. Untuk langkah kedua dan ketiga akan diulang sampai mean tidak berubah (Khandare 2015).
Salah satu kelebihan yang dimiliki oleh algoritma K-Means adalah dapat meminimalkan variasi antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya (Han, Kamber, and Pei 2011). 2.1.1 Perhitungan jarak Euclidean Distance
Euclidean Distance space sering digunakan dalam perhitungan jarak, hal ini dikarenakan hasil yang diperoleh merupakan jarak terpendek antara titik yang diperhitungkan (Prabha and Visalakshi 2014). Euclidean distance menghitung akar dari kuadrat perbedaan 2 vektor. Rumus dari Euclidean distance :
(1)
Dari algoritma simple K-Means dengan perhitungan jarak Euclidean Distance, hasil clustering data didapatkan sebagai berikut :
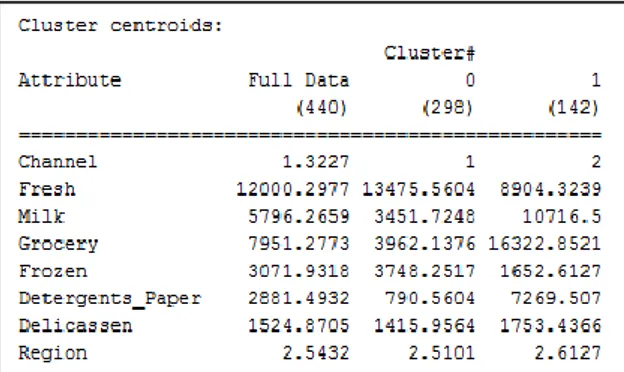
Gambar 1. Hasil Clustering dengan Euclidean Distance
Gambar 1 menunjukkan bahwa error rate dengan algoritma Simple K-Means perhitungan jarak Euclidean Distances sebesar 13.116 %. Ditinjau dari segi efisiensi waktu yang dibutuhkan untuk perhitungan, metode ini membutuhkan 2 kali iterasi dengan lama waktu build 0.04 sec. Sedangkan penyebaran centroid dari masing-masing attribute ditunjukkan pada Gambar 2
Gambar 2. Centroid masing-masing attribute
per-Cluster pada Euclidean Distance
2.1.2 Perhitungan jarak Manhattan Distance
Perhitungan jarak menggunakan Manhattan distance sering digunakan karena kemampuannya dalam mendeteksi keadaan khusus seperti keberadaan outliers dengan lebih baik (Khandare 2015). Outliers adalah data yang menyimpang terlalu jauh dari data yang lainnya dalam suatu rangkaian data. Adanya data outliers ini akan membuat analisis terhadap serangkaian data menjadi bias atau tidak menunjukkan knowledge yang sesungguhnya. Rumus dari algoritma Manhattan distance :
(2) Algoritma Manhattan Distance menggunakan jumlah perbedaan absolute dari setiap variable namun mungkin mengarah pada cluster yang invalid apabila variable yang di cluster terkolerasi tinggi. Hal inilah yang mebedakan algoritma Manhattan Distance dengan algoritma Euclidean Distance.
Dari algoritma simple K-Means dengan perhitungan jarak Manhattan Distance, hasil clustering data ditunjukkan pada Gambar 3.
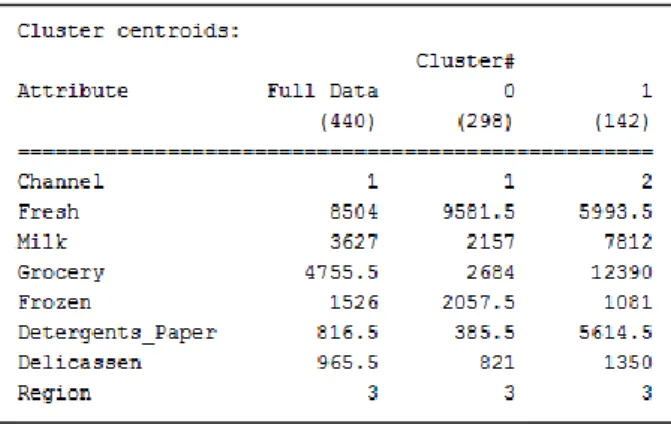
Gambar 3. Hasil Clustering dengan Manhattan Distance
Dari hasil cluster diatas menunjukkan persamaan dengan algoritma simple K-Means dengan perhitungan jarak Euclidean Distance. Namun perbedaannya terletak pada sebaran centroid dari cluster nya yang ditunjukkan pada gambar 4.
Gambar 4. Centroid masing-masing attribute
per-Cluster pada Manhattan Distance
Dari hasil analisis weka diatas, menunjukkan bahwa analisis dengan algoritma Simple K-Means dengan perhitungan jarak Manhattan Distance menunjukkan bahwa jumlah error rate nya men-capai 21.67 %. Ditinjau dari segi efisiensi waktu yang dibutuhkan untuk pehitungan dengan metode ini membutuhkan 2 kali iterasi dengan lama waktu build 0.39 sec.
2.2 EM (Expectation Maximization)
Algoritma EM (Expectation Maximization) merupakan algoritma clustering yang melakukan estimasi Maximum Likelihood (ML) dari parameter dalam sebuah objek data termasuk data yang mengalami missing value (Dempster, Laird, and Rubin 1977).
Pada prosesnya terdapat 2 tahap yang dilakukan secara berulang-ulang dalam pembentukan cluster tersebut, yaitu tahap Expectation (E step) dan tahap Maximization (M step). Pada E step dilakukan penghitungan nilai ekspektasi dari parameter data, dan M step menghitung nilai estimasi parameter dengan menggunakan nilai ekspektasi yang ditemukan pada
E step sebelumnya. Kedua tahap tersebut akan terus dilakukan sampai mencapai nilai konvergen atau nilai toleransi yang telah ditentukan (Dempster, Laird, and Rubin 1977).
Dalam proses menangani nilai missing value, nilai estimasi pada M step akan digunakan sebagai solusinya yang mana pada setiap proses, nilai estimasi pada M step akan terus menerus diisikan sampai proses algoritma mencapai konvergen.
Dari algoritma EM (Expectation Maximization) didapatkan hasil yang ditunjukkan pada gambar 5.
Gambar 5. Hasil Clustering dengan EM (Expectation Maximization)
Hasil tersebut menunjukkan bahwa ada 4 pengelompokkan dari dataset nya. Ditinjau dari segi waktu, metode EM memerlukan 7.2 sec untuk full training data dengan error rate 12.76%
.
2.3X-Means
Salah satu algoritma untuk clustering adalah K-Means seperti yang sudah digunakan sebelumnya. K-Means dinilai sebagai algoritma yang handal dengan waktu eksekusi yang cukup cepat ketika melakukan clustering. Namun K-Means masih memiliki beberapa kekurangan yaitu masalah penentuan jumlah cluster yang masih dilakukan dengan input dari user dan inisialisasi centroid atau pusat cluster (Pelleg and Moore 2000).
Kekurangan K-Means ini dijawab oleh penemuan algoritma X-Means oleh Dan Pelleg dan Andrew Moore. Algoritma ini kemudian akan menambah jumlah cluster secara rekursif hingga jumlahnya sama dengan nilai atas range yang dimasukkan user (upper bound). Hasil akhir dari X-means adalah kelompok-kelompok (cluster) data, dan jumlah cluster terbaik berdasarkan perhitungan uji model yang dilakukan ketika proses eksekusi berlangsung (Pelleg and Moore 2000).
Dari metode X-Means yang digunakan untuk analisis data set tersebut didapatkan hasil seperti yang ditunjukkan pada Gambar 6.
Gambar 6. Hasil Clustering dengan X-Means Dari hasil analisis yang dilakukan oleh Weka menunjukkan bahwa ada 4 cluster centers dengan 1 kali iterasi dan membutuhkan 0.06 sec untuk melakukan full data training.
3. KESIMPULAN
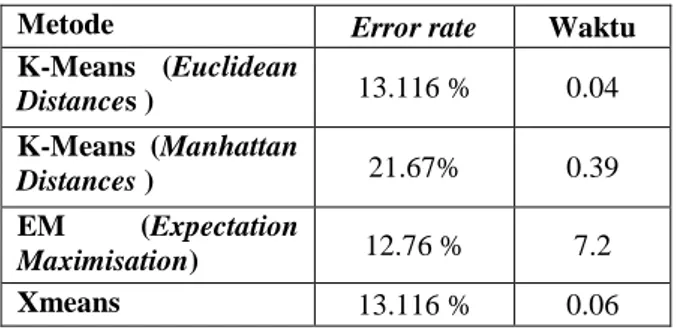
Hasil pengujian keempat metode clustering menggunakan dataset Wholesale Customers, dapat dilihat pada Tabel 2
Tabel 2. Hasil pengujian dataset dengan
Clustering
Dari hasil yang ditunjukkan pada Tabel 2 maka dapat diambil kesimpulan bahwa untuk dataset yang digunakan (Wholesale Customers) metode clustering EM memberikam hasil terbaik dengan error rate 12.76%. Sedangkan jika dilihat dari segi efiesiensi waktu dan hasil clustering, K-Means Euclidean Distances memberikan hasil terbaik (0,04 detik), walaupun tidak terlalu signifikan dibandingkan dengan XMeans (0.06).
Walaupun ada banyak metode yang bisa digunakan pada analisis data mining, namun analisis dengan menggunakan metode clusteing cukup membantu untuk mengetahui knowledge yang ada pada sebuah dataset. Untuk penelitian selanjutnya bisa menggunakan metode yang ada pada analisis data mining seperti menggunakan metode classificatiom, regression ataupun association.
PUSTAKA
Abidi, S.S.R., and J. Ong. 2000. “A Data mining Strategy for Inductive Data Clustering: A Synergy between Self-Organising Neural Networks and K-Means Clustering Techniques.” In TENCON 2000. Proceedings, 2:568–73 vol.2. doi:10.1109/TENCON.2000.888802.
Aouf, M., L. Lyanage, and S. Hansen. 2008. “Review of Data mining Clustering Techniques to Analyze Data with High Dimensionality as Applied in Gene Expression Data (June 2008).” In 2008 International Conference on Service Systems and Service Management, 1–5. doi:10.1109/ICSSSM.2008.4598505.
Dempster, A. P., N. M. Laird, and D. B. Rubin. 1977. “Maximum Likelihood from Incomplete Data via the EM Algorithm.” Journal of the Royal Statistical Society. Series B (Methodological) 39 (1): 1–38.
Garima, H. Gulati, and P.K. Singh. 2015. “Clustering Techniques in Data mining: A Comparison.” In 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), 410–15. Hailong Chen, and Chunli Liu. 2013. “Research and
Application of Cluster Analysis Algorithm.” In , 575–79. IEEE. doi:10.1109/MIC.2013.6758030. Han, Jiawei, Micheline Kamber, and Jian Pei. 2011.
Data mining: Concepts and Techniques. Elsevier.
Kanellopoulos, Yiannis, Panos Antonellis, Christos Tjortjis, and Christos Makris. 2007. “K-Attractors: A Clustering Algorithm for Software Measurement Data Analysis.” In , 358–65. IEEE. doi:10.1109/ICTAI.2007.31.
Khandare, A.D. 2015. “Modified K-Means Algorithm for Emotional Intelligence Mining.” In 2015 International Conference on Computer Communication and Informatics (ICCCI), 1–3. doi:10.1109/ICCCI.2015.7218088.
Pelleg, Dan, and Andrew W. Moore. 2000. “X-Means: Extending K-Means with Efficient Estimation of the Number of Clusters.” In Proceedings of the Seventeenth International Conference on Machine Learning, 727–34. ICML ’00. San Francisco, CA, USA: Morgan
Kaufmann Publishers Inc.
http://dl.acm.org/citation.cfm?id=645529.657808 .
Prabha, K.A., and N.K. Visalakshi. 2014. “Improved Particle Swarm Optimization Based K-Means Clustering.” In 2014 International Conference on Intelligent Computing Applications (ICICA), 59–63. doi:10.1109/ICICA.2014.21.
Rani, A.J.M., and L. Parthipan. 2012. “Clustering Analysis by Improved Particle Swarm Optimization and KMeans Algorithm.” In , 83– 88. Institution of Engineering and Technology. doi:10.1049/cp.2012.2195.
Metode Error rate Waktu
K-Means (Euclidean Distances ) 13.116 % 0.04 K-Means (Manhattan Distances ) 21.67% 0.39 EM (Expectation Maximisation) 12.76 % 7.2 Xmeans 13.116 % 0.06
Shah, C., and A. Jivani. 2013. “Comparison of Data mining Clustering Algorithms.” In 2013 Nirma University International Conference on Engineering (NUiCONE), 1–4. doi:10.1109/NUiCONE.2013.6780101.