Fakultas Ilmu Komputer
Universitas Brawijaya
905
Implementasi Metode Gabungan Multi-Factors High Order Fuzzy Time
Series dan Fuzzy C-Means Untuk Peramalan Kebutuhan Energi Listrik di
Indonesia
Sigit Pangestu
1, Dian Eka Ratnawati
2,
Candra Dewi
3Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Indonesia merupakan salah satu negara pengkonsumsi listrik yang selalu mengalami kenaikan kebutuhan akan energi listrik setiap tahunnya. Kebutuhan listrik pada sektor rumah tangga dari tahun 2003 sampai 2013 di Indonesia mengalami kenaikan rata-rata sebesar 8% setiap tahunnya. Sedangkan pada sektor komersial rata-rata kenaikannya sebesar 10,1%. Pertumbuhan kebutuhan akan energi listrik sudah selayaknya mendapat penanganan yang tepat agar tidak terjadi kurangnya pasokan energi listrik yang dapat menyebabkan terhambatnya kegiatan perekonomian di Indonesia. Oleh karena itulah dibutuhkan suatu program yang dapat membantu penyuplai energi listrik di Indonesia (PLN) untuk menentukan besarnya energi listrik yang harus dipersiapkan. Metode Gabungan Multi-Factors High
Order Fuzzy Time Series dan Fuzzy C-Means (FCM) dapat digunakan untuk peramalan kebutuhan
energi listrik. Fuzzy C-Means menggantikan salah satu proses yang pada metode Multi-Factors High
Order Fuzzy Time Series yaitu saat pembentukan subinterval. Alur dari metode tersebut yaitu penentuan Universe of Discourse, penentuan jumlah klaster, pembentukan subinterval dengan Fuzzy C-Means,
pembentukan himpunan fuzzy, proses fuzzifikasi, pembentukan Fuzzy Logic Relationship (FLR), dan proses defuzzifikasi. Dari hasil pengujian didapatkan nilai MAPE (Mean Absolute Percentage Error) terkecil sebesar 1,7857%. Hasil MAPE yang diperoleh yaitu kurang dari 10% menunjukkan bahwa Metode Gabungan Multi-Factors High Order Fuzzy Time Series dan Fuzzy C-Means (FCM) sangat baik digunakan untuk melakukan peramalan kebutuhan energi listrik di Indonesia.
Kata kunci:Kebutuhan energi listrik,Multi-Factors High Order Fuzzy Time Series, Fuzzy C-Means, MAPE.
Abstract
Indonesia is one of the countries consuming electricity which always experience the increasing need of electric energy every year. Electricity needs in the household sector from 2003 to 2013 in Indonesia increased by an average of 8% per year. While in the commercial sector the average increase of 10.1%. Growing demand for electrical energy should be properly handled in order to avoid the lack of electricity supply that can lead to inhibition of economic activity in Indonesia. Therefore it is needed a program that can help the supplier of electrical energy in Indonesia (PLN) to determine the amount of electrical energy that must be prepared. The Combined method Multi-Factors High Order Fuzzy Time Series and Fuzzy Means (FCM) can be used to forecast electrical energy requirements. Fuzzy C-Means replaces one of the processes in the Multi-Factors High Order Fuzzy Time Series method when creating subintervals. The path of the method is the determination of the Universe of Discourse, the determination of the number of clusters, the formation of subintervals with Fuzzy C-Means, the formation of fuzzy sets, the fuzzification process, the formation of Fuzzy Logic Relationship (FLR), and the defuzzification process. From the test results obtained the smallest MAPE (Mean Absolute Percentage Error) value of 1.7857%. MAPE results obtained that less than 10% indicate that Combined Methods Multi-Factors High Order Fuzzy Time Series and Fuzzy C-Means (FCM) is very good used to forecast electricity demand in Indonesia.
Fakultas Ilmu Komputer, Universitas Brawijaya
1. PENDAHULUAN
Energi listrik merupakan salah satu sumber energi dasar yang sangat dibutuhkan oleh manusia modern saat ini. Energi listrik digunakan untuk berbagai aktivitas manusia, seperti melakukan pekerjaan kantor, dan lain-lain. Di Indonesia kebutuhan listrik pada sektor rumah tangga dari tahun 2003 sampai 2013 mengalami kenaikan rata-rata sebesar 8% setiap tahunnya. Pada sektor komersial yang meliputi jenis usaha keuangan, perdagangan, pariwisata dan jasa, konsumsi listrik dari tahun 2003 sebesar 49,8% meningkat menjadi 73,4% pada tahun 2013 dengan pertumbuhan rata-rata sebesar 10,1% per tahun (Zed, 2014).
Pertumbuhan kebutuhan akan energi listrik sudah selayaknya mendapat penanganan yang tepat agar tidak terjadi kurangnya pasokan energi listrik yang dapat menyebabkan terhambatnya kegiatan perekonomian di Indonesia. Bila perekonomian bangsa terhambat, maka bisa saja banyak investor asing yang menarik dana investasinya yang telah diinvestasikan di Indonesia, dan hal tersebut tentu saja akan merugikan banyak pihak di Indonesia yang sedang dalam masa pembangunan ini.
Berdasarkan data tingkat kebutuhan energi listrik di Indonesia yang diperoleh dari website resmi World Bank, dapat disimpulkan bahwa perkembangan tingkat kebutuhan energi listrik setiap tahun mengalami kenaikan secara fluktuatif. Kenaikan kebutuhan energi listrik yang berfluktuasi dapat menyebabkan penyuplai energi listrik di Indonesia yaitu PLN (Perusahaan Listrik Negara) kesulitan dalam memperkirakan seberapa besar energi listrik yang harus dipersiapkan dimasa mendatang dalam rangka mencapai ketahanan energi listrik nasional. Oleh karena itulah dibutuhkan suatu program yang dapat membantu penyuplai energi listrik untuk menentukan besarnya energi listrik yang harus dipersiapkan.
Salah satu metode yang dapat digunakan dalam meramalkan suatu keadaan kedepannya yaitu metode fuzzy time series. Metode fuzzy
time series dapat digunakan untuk mempelajari
pola suatu data yang berbentuk time series (runtut waktu). Sistem peramalan dengan fuzzy
time series menangkap pola dari data yang telah
terjadi sebelumnya kamudian digunakan untuk memproyeksikan data yang akan datang (Purwanto, 2013).
Salah satu penelitian yang membahas tentang metode fuzzy time series yaitu pada penelitian yang dilakukan Yupei Lin dan Yiwen (2009) yang melakukan perbandingan antara Metode Multi-Factors High Order Fuzzy Time
Series model dengan Chen’s model. Perbedaan
mendasar kedua model tersebut yaitu pada penentuan subinterval-nya. Dimana pada metode pertama digunakan algoritma Fuzzy C-Means sedangkan yang kedua menggunakan cara membagi himpunan semesta (Universe Of
Discourse) dengan n interval dengan panjang
yang sama. Hasil penelitian ini yaitu Metode
Multi-Factors High Order Fuzzy Time Series model menghasilkan nilai kesalahan peramalan
lebih kecil dari pada Chen’s model yaitu dengan nilai kesalahan terkecil 1,76% dibanding 2,47% (Lin dan Yang, 2009).
Berdasarkan penelitian tersebut penulis mengusulkan peramalan kebutuhan energi listrik dengan menggunakan Metode Gabungan
Multi-Factors High Order Fuzzy Time Series dan Fuzzy C-Means (FCM). Fuzzy C-Means
digunakan untuk klasterisasi data guna mendapatkan k buah letak titik pusat klaster data yang kemudian dijadikan untuk pembentukan subinterval. Fuzzy C-Means menggantikan proses pada metode Multi-Factors High Order
Fuzzy Time Series yaitu saat pembentukan
subinterval. Dengan FCM diharapkan dapat mengatasi permasalahan dari subinterval yang tidak bisa merefleksikan distribusi dari data asli.
2. LANDASAN KEPUSTAKAAN
2.1. Faktor-Faktor Yang Mempengaruhi Tingkat Kebutuhan Energi Listrik
Kebutuhan energi listrik di Indonesia semakin lama semakin meningkat. menurut Mustafa Servet Kıran et al. (2012) dalam penelitian mereka tentang peramalan kebutuhan energi listrik di Turki, faktor-faktor kebutuhan energi listrik yang mempengaruhi antara lain (Kiran et al., 2012):
a) Produk Domestik Bruto (PDB) b) Populasi jumlah penduduk
c) Nilai import produk barang dan jasa d) Nilai eksport produk barang dan jasa
Fakultas Ilmu Komputer, Universitas Brawijaya
2.2. Multi-Factors High Order Fuzzy Time Series
Multi-Factors High Order Fuzzy Time Series dibuat untuk mengatasi permasalahan
pada peramalan fuzzy time series yang hanya bisa meramalkan suatu keadaan time series hanya berdasarkan satu faktor yang dipertimbangkan. Dengan Multi-Factors High
Order Fuzzy Time Series suatu keadaan yang
mempunyai banyak faktor yang menjadi penyebab kejadian dapat diramalkan dengan lebih akurat dikarenakan ada faktor-faktor pendukung yang memperkuat terjadinya suatu kejadian. Langkah-langkah metode
Multi-Factors High Order Fuzzy Time Series yaitu
sebagai berikut (Lee et al., 2006):
1. Penentuan Universe of Discourse (U)
Universe of Discourse terdiri dari 2 nilai
yaitu batas atas dan batas bawah. Batas bawah U ditentukan dengan cara mengurangkan nilai terkecil dari data (𝐷𝑚𝑖𝑛) dengan suatu nilai positif (D1).
Batas atas U ditentukan dengan cara menambahkan nilai terbesar data (𝐷𝑚𝑎𝑥)
dengan suatu nilai positif (D2). Nilai positif
ini berguna agar nilai yang dihasilkan U dapat dibagi dengan jumlah subinterval yang ditentukan sehingga dapat menghasilkan panjang subinterval yang sama.
2. Pembentukan subinterval
Subinterval juga terdapat 2 nilai yaitu batas bawah dan batas atas. Cara untuk membentuk subinterval yaitu sebagai berikut (Abdullah dan Taib, 2011):
a) Mencari panjang dari setiap subinterval dengan cara mengurangkan nilai 𝐷𝑚𝑎𝑥
dan 𝐷𝑚𝑖𝑛 dari U kemudian dibagi dengan
banyaknya subinterval yang ditentukan. b) Menentukan nilai dari masing-masing
subinterval pada setiap fitur data dengan cara pada subinterval pertama (𝑢1)
nilainya yaitu [𝐷𝑚𝑖𝑛− 𝐷1 , ((𝐷𝑚𝑖𝑛− 𝐷1)
+ panjang setiap subinterval)] , kemudian nilai subinterval 2 (𝑢2) nilainya yaitu
[nilai maksimal subinterval sebelumnya , nilai maksimal subinterval sebelumnya + panjang setiap subinterval], demikian penentuan nilai subinterval dengan cara yang sama sampai subinterval yang terakhir (𝑢𝑖).
3. Pembentukan himpunan fuzzy (fuzzy set) didasarkan pada subinterval yang telah terbentuk pada tahap sebelumnya
4. Fuzzifikasi data yang digunakan berdasarkan himpunan fuzzy
5. Pembentukan Fuzzy Logic Relationship (FLR) berdasarkan data yang telah dilakukan proses fuzzifikasi.
6. Defuzzifikasi hasil peramalan.
2.3. Fuzzy C-Means
Fuzzy klastering adalah salah satu teknik
untuk menentukan klaster optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal euclidean untuk jarak antar vektor. Fuzzy
C-Means (FCM) adalah salah satu contoh
metode yang didasari oleh fuzzy klastering. Tujuan dari algoritma FCM yaitu untuk menemukan pusat klaster (centroid) dengan meminimumkan fungsi objektif (Bezdek, 1984). Algoritma dari FCM dijelaskan sebagai berikut (Kusumadewi, 2010):
1. Memasukkan data yang akan diklasterisasi.
2. Menentukan nilai variabel jumlah klaster, bobot, iterasi maksimum, dan eror terkecil yang diharapkan.
3. Membangkitkan bilangan random µ𝑖𝑘; i
=1, 2, 3, ..., n, dan k =1, 2, 3, ..., c (n = jumlah data sampel, c = jumlah klaster (berupa kolom) yang akan dibentuk) sebagai elemen-elemen matriks partisi awal. Untuk menghitung jumlah setiap kolom menggunakan Persamaan (1).
𝑄𝑘= ∑𝑐 µ𝑖𝑘
𝑘=1 (1)
Menghitung normalisasi matris partisi dengan persamaan (2).
µ𝑖𝑘 normalisasi =µ𝑖𝑘 bilangan lama𝑄
𝑘 (2)
Dimana:
𝑄𝑘 = jumlah nilai pada kolom ke-k,
µ𝑖𝑘 = bilangan random pada baris i
dan kolom k.
4. Menghitung pusat klaster ke-k: 𝑉𝑘𝑗, (k =
1, 2, 3 ..., c dan j =1, 2, 3, ..., m) dengan Persamaan (3). 𝑉𝑘𝑗 = ∑𝑛𝑖=1 ((µ𝑖𝑘)𝑤× 𝑥𝑖𝑘) ∑𝑛𝑖=1 (µ𝑖𝑘)𝑤 (3) Dimana:
Fakultas Ilmu Komputer, Universitas Brawijaya 𝑉𝑘𝑗 = jumlah nilai pada klaster ke-k
dan atribut ke-j,
µ𝑖𝑘 = derajat keanggotaan pada
(baris) data ke-i, klaster ke-k, 𝑋𝑖𝑗 = data sampel pada (baris) data
ke-i , atribut ke-j, w = bobot.
5. Menghitung fungsi objektif pada iterasi ke-t: 𝑃𝑡, dengan Persamaan (4).
𝑃𝑡= ∑𝑛𝑖=1 ∑𝑐𝑘=1 ([∑𝑚𝑗=1 (𝑋𝑖𝑗− 𝑉𝑘𝑗)2 ] (µ𝑖𝑘)𝑤) (4)
Dimana:
𝑃𝑡 = fungsi objektif pada iterasi ke-t,
𝑋𝑖𝑗 = data sampel pada (baris) data
ke-i , atribut ke-j,
𝑉𝑘𝑗 = pusat klaster pada klaster ke-k, atribut ke-j
6. Menghitung perbaikan matriks partisi dengan Persamaan (5). µ𝑖𝑘= [∑ (𝑥𝑖𝑗−𝑣𝑘𝑗) 2 ] 𝑚 𝑗=1 −𝑤−11 ∑𝑐𝑘=1 [∑ (𝑥𝑖𝑗−𝑣𝑘𝑗)2 𝑚 𝑗=1 ] −𝑤−11 (5) Dimana:
µ𝑖𝑘 = perbaikan matriks partisi baris
ke-i dan kolom ke-k
𝑋𝑖𝑗 = data sampel pada (baris) data
ke-i , atribut ke-j,
𝑉𝑘𝑗 = pusat klaster pada klaster ke-k, atribut ke-j
𝑤 = bobot
7. Memeriksa kondisi berhenti perulangan
Jika nilai absolut selisih fungsi objektif sekarang (𝑃𝑡) dengan iterasi sebelumnya (𝑃𝑡−1)
kurang dari nilai bobot atau iterasi telah mencapai batas maksimum iterasi maka iterasi berhenti, jika tidak maka iterasi terus berlanjut dimulai dari langkah 4-7.
2.4. Perhitungan Kesalahan Peramalan
Tidak Semua metode peramalan dapat melakukan peramalan dengan ketepatan mencapai 100%, untuk itu maka perlu metode
yang tepat untuk memperoleh peramalan yang hasilnya mendekati benar.
Di dalam penelitian ini, perhitungan kesalahan peramalan menggunakan MAPE (Mean Absolute Percentage Error). Perhitungan MAPE seperti ditunjukkan pada Persamaan (6) (Sungkawa, 2011). 𝑀𝐴𝑃𝐸 =∑ |𝑋𝑡−𝐹𝑡| 𝑋𝑡 𝑛 𝑡=1 x 100% 𝑛 (6) Dimana:
𝑋𝑡 = nilai data aktual pada data sampel
periode t
𝐹𝑡 = nilai peramalan pada data sampel
periode t
𝑛 = jumlah data sampel
2.5. Data Penelitian
Data yang digunakan di dalam penelitian ini yaitu data jumlah kebutuhan energi listrik di indonesia mulai tahun 1971 sampai dengan 2013, data tersebut berinterval 1 kali dalam setahun. Data pendukung lainnya yang digunakan pada penelitian ini yaitu data Produk Domestik Bruto (PDB), data populasi, data nilai impor, dan data nilai ekspor dari negara Indonesia. Semua data didapatkan di situs resmi World Bank.
3. PERANCANGAN
3.1. Alur Penyelesaian Masalah
Menggunakan Metode Gabungan Multi-Factors High Order Fuzzy Time Series Model Dan Fuzzy C-Means
Secara
umum
alur
penyelesaian
permasalahan
pembentukan
subinterval
menggunakan
FCM
untuk
prediksi
kebutuhan energi listrik ditunjukkan pada
Gambar 1.
Metode Gabungan Multi-Factors High
Order Fuzzy Time Series Model (MF HO FTS)
dan Fuzzy C-Means (FCM) adalah metode gabungan antara 2 algoritma yang dikembangkan untuk memperbaiki kelemahan algoritma Multi-Factors High Order Fuzzy Time
Series pada saat pembentukan subinterval yang
tidak bisa merefleksikan distribusi dari data asli.
Fuzzy C-Means menggantikan proses pencarian
subinterval agar subinterval dapat semirip mungkin bisa merefleksikan distribusi dari data asli.
Fakultas Ilmu Komputer, Universitas Brawijaya
Gambar 1 Diagram alir peramalan energi listrik dengan Metode Gabungan Multi-Factors High Order
Fuzzy Time Series dan Fuzzy C-Means
Langkah-langkah metode gabungan ini yaitu sebagai berikut (Lin dan Yang, 2009):
1. Penentuan Universe of Discourse (U)
Universe of Discourse ditentukan
menggunakan Persamaan (7).
𝑈 = [𝐷𝑚𝑖𝑛− 𝜎 , 𝐷𝑚𝑎𝑥+ 𝜎] (7) dimana:
𝐷𝑚𝑖𝑛 = nilai terkecil dari data sampel
𝐷𝑚𝑎𝑥 = nilai terbesar dari data sampel
𝜎 = standar deviasi data
untuk menghitung standar deviasi menggunakan Persamaan (8) (Weisstein, 2015). 𝜎 = √ 1 𝑛−1∑ (𝑥𝑖− 𝑥̅) 2 𝑛 𝑖=1 (8) dimana: 𝜎 = standar deviasi
𝑥̅ = rata-rata dari data sampel 𝑛 = banyak data sampel 𝑥𝑖 = nilai data sampel ke-i
2. Penentuan jumlah klaster data
Klasterisasi bertujuan untuk membagi himpunan semesta U ke dalam beberapa subinterval 𝑢𝑖. Persamaan (9) digunakan
mencari banyaknya klaster.
𝑘 = ||𝐷𝑚𝑖𝑛− 𝐷𝑚𝑎𝑥 | / ∑𝑛𝑡=2|𝑥(𝑡)−𝑥(𝑡−1)|
𝑛−1 | (9)
dimana:
𝑘 = jumlah klaster
𝐷𝑚𝑖𝑛 = nilai terkecil dari data sampel
𝐷𝑚𝑎𝑥 = nilai terbesar dari data sampel
𝑛 = banyaknya data sampel 𝑥(𝑡) = data pada waktu t
𝑥(𝑡 − 1) = data pada waktu sebelum t
(t-1)
Apabila hasil perhitungan 𝑘 bernilai pecahan, maka 𝑘 dibulatkan agar menjadi bilangan bulat.
3. Pembentukan subinterval dengan Fuzzy
C-Means
Terdapat dua proses didalam pembentukan subinterval yaitu proses penentuan pusat klaster dan proses penentuan batas subinterval. Proses penentuan pusat klaster data dilakukan menggunakan FCM untuk mendapatkan k buah titik sebagai pusat klaster. Langkah-langkah dalam membentuk subinterval dengan metode FCM yaitu:
a. Membentuk matriks partisi awal dengan bilangan penyusunnya adalah bilangan random. Ukuran matriks partisi ini yaitu i x k, dimana i adalah jumlah data sampel dan k adalah jumlah klaster yang dibentuk.
b. Melakukan normalisasi matriks partisi awal setiap kolom dengan Persamaan (2).
c. Menghitung pusat klaster (𝑉𝑘𝑖)
menggunakan Persamaan (3).
d. Menghitung fungsi objektif dengan menggunakan Persamaan (4).
e. Menghitung perbaikan matriks partisi menggunakan Persamaan (5).
f. Memeriksa kondisi berhenti perulangan.
Setelah iterasi berhenti dan didapatkan k titik pusat klaster kemudian dilanjutkan dengan proses penentuan batas subinterval dengan cara membagi Universe of
Fakultas Ilmu Komputer, Universitas Brawijaya
Discourse ke dalam k subinterval (𝑢𝑘):
𝑢1: (𝐷𝑚𝑖𝑛, 𝑑1), 𝑢2: (𝑑1, 𝑑2),
𝑢3: (𝑑2, 𝑑3), … , 𝑢𝑘: (𝑑𝑘−1, 𝐷𝑚𝑎𝑥), dimana
𝑑𝑖 (i = 1, 2, ..., k-1) adalah titik tengah antara
dua pusat klaster.
4. Pembentukan himpunan fuzzy (fuzzy set) Himpunan fuzzy 𝐴𝑖 (i = 1, 2, ..., k)
dibentuk seperti pada Persamaan (10).
𝐴1 = 𝑓11/𝑢1 + 𝑓12/𝑢2+ ... + 𝑓1𝑘/𝑢𝑘 𝐴2 = 𝑓21/𝑢1 + 𝑓22/𝑢2 + ... + 𝑓2𝑘/𝑢𝑘
... = ... + ... + ... + ... (10)
𝐴𝑘 = 𝑓𝑘1/𝑢1 + 𝑓𝑘2/𝑢2+ ... + 𝑓𝑘𝑘/𝑢𝑘
Dimana 𝑓𝑖𝑗 menunjukkan derajat
keanggotaan dari 𝑢𝑗 dalam himpunan fuzzy
𝐴𝑖 (i = 1, 2, ..., k; j = 1, 2, ..., k). Tanda “+”
menunjukkan operator himpunan gabungan.
5. Fuzzifikasi
Disini nilai data yang masih berupa bilangan asli dari data sampel diubah menjadi nilai fuzzy dan nilai fuzzy tersebut dalam bentuk derajat keanggotaan. Dari beberapa nilai derajat keanggotaan yang ada, dipilih satu nilai dari himpunan fuzzy yang memiliki derajat keanggotaan paling tinggi.
6. Pembentukan Fuzzy Logic Relationship (FLR)
Data sampel sebanyak n periode (order) dipilih sebagai data latih untuk membentuk
fuzzy time series model. Misal t adalah
periode yang hendak diramal, dengan order = 3 maka tiga periode sebelum periode t adalah t-3, t-2, t-1 dimana t = 4, 5, ..., n.
7. Defuzzifikasi
Defuzzifikasi dilakukan untuk mendapatkan hasil dari peramalan. Disini dilakukan pencocokan dari data latih dengan data uji yang diambil dari FLR. Data latih dinyatakan cocok dengan data uji bila selisih nilai absolut antecedent factor (faktor di ruas kiri FLR) dari kedua data tersebut lebih kecil dari nilai threshold. Kemudian untuk memperoleh nilai hasil peramalan digunakan metode centroid, metode tersebut dinyatakan dengan Persamaan (11).
𝑟𝑇=∑𝑘1𝑖=1𝑐𝑖 ×𝑓𝑖
∑𝑘𝑖𝑖=1𝑓𝑖
(11)
Dimana:
𝑟𝑇 = hasil peramalan hari ke-T
𝑐𝑖 = pusat klaster i dimana A(*, i)
adalah secedent factor dari FLR hasil proses pencocokan.
𝑓𝑖 = frekuensi munculnya A(*, i) pada
saat proses pencocokan.
4. HASIL PENGUJIAN DAN ANALISIS 4.1 Pengujian terhadap pengaruh bobot
pada MAPE
Pengujian ini bertujuan untuk mengetahui pengaruh nilai bobot terhadap MAPE yang dihasilkan. Bobot yang diuji dimulai dari 1,5 hingga 6. Nilai Order yang digunakan 9, konstanta threshold 75, jumlah data latih 32, jumlah data uji 10, iterasi maksimum 10, dan eror terkecil 0,0001.
Gambar 2 Grafik nilai MAPE berdasarkan nilai bobot yang berbeda
Berdasarkan Gambar 2 nilai MAPE dengan bobot 1,5 sampai 2,5 nilainya cenderung turun. Kemudian pada nilai bobot 2,5 sampai 4,5 nilainya cenderung naik. Bobot dengan nilai 2,5 menghasilkan nilai MAPE yang terendah dibandingkan nilai bobot yang lain yaitu dengan nilai MAPE sebesar 1,81%. Nilai MAPE yang naik turun yang ada pada Gambar 2 dikarenakan letak pusat klaster yang dihasilkan pada setiap bobot berbeda-beda sehingga mempengaruhi nilai hasil fuzzifikasi data aktual. Pada nilai bobot 1,5 sampai 2,5 yang menghasilkan MAPE kurang dari 2% disebabkan karena nilai letak pusat klaster yang dihasilkan dari bobot tersebut letaknya lebih tersebar sehingga peramalan yang dihasilkan dapat lebih mendekati data aktualnya.
2,04 1,92 1,81 4,48 7,83 9,54 7,17 7,96 8,31 9,56 1 2 3 4 5 6 7 8 9 10 1,5 2 2,5 3 3,5 4 4,5 5 5,5 6 M A P E ( % ) Bobot
Grafik nilai rata-rata MAPE berdasarkan bobot
Fakultas Ilmu Komputer, Universitas Brawijaya
4.2 Pengujian terhadap pengaruh iterasi maksimum pada MAPE
Pada pengujian ini dilakukan untuk mengetahui pengaruh nilai iterasi maksimum terhadap nilai MAPE yang dihasilkan. Iterasi maksimum yang diuji dari 5 sampai 50. Nilai
Order yang digunakan 9, konstanta threshold 75,
jumlah data latih 32, jumlah data uji 10, bobot 2.5, dan eror terkecil 0,0001. Berdasarkan Gambar 3 nilai iterasi maksimum 5 sampai 20 menghasilkan nilai rata-rata MAPE yang bervariasi kemudian pada iterasi maksimum mulai dari 20 sampai 50 menghasilkan nilai rata-rata MAPE yang konstan, hal ini dikarenakan pada FLR data latih yang cocok dengan data uji memiliki kesamaan nilai fuzzifikasi pada data kebutuhan energi listrik antara iterasi ke-20 hingga iterasi ke-50 sehingga iterasi tersebut memiliki hasil rata-rata MAPE yang sama. Dengan iterasi yang terlalu sedikit maka sistem tidak dapat melakukan eksplorasi pembentukan pusat klaster yang mirip dengan data yang digunakan karena sebelum pusat klaster yang terbentuk memiliki kemiripan dengan data yang digunakan iterasi sudah terlebih dahulu berhenti.
Gambar 3 Grafik nilai MAPE berdasarkan iterasi maksimum yang berbeda
4.3 Pengujian terhadap pengaruh order pada MAPE
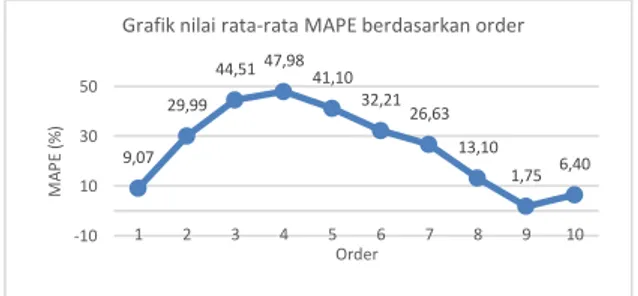
Pada pengujian ini dilakukan untuk mengetahui pengaruh nilai order terhadap nilai MAPE yang dihasilkan. Order yang diuji dari 1 sampai 10. Nilai konstanta threshold yang digunakan 75, jumlah data latih 32, jumlah data uji 10, bobot 2.5, iterasi maksimum 10, dan eror terkecil 0,0001.
Berdasarkan Gambar 4 nilai order yang berbeda menghasilkan nilai MAPE yang berbeda pula. Nilai rata-rata MAPE pada order 1 sampai 4 mengalami kenaikan, kemudian pada order 4 sampai order 9 nilai rata-rata MAPE mengalami penurunan dan kemudian pada order 10 nilai
rata-rata MAPE naik kembali. Nilai rata-rata MAPE yang besar yaitu diatas 10% seperti pada order 2, 3, 4, 5, 6, 7, dan 8 dikarenakan nilai
threshold yang digunakan kurang besar sehingga
menyebabkan ada data latih yang cocok dengan data uji yang seharusnya termasuk data latih yang cocok menjadi tidak cocok karena nilai
threshold yang kecil sehingga menyebabkan
kegagalan peramalan pada satu atau lebih data uji sehingga nilai peramalan dari data uji yang mengalami kegagalan peramalan menjadi 0.
Gambar 4 Grafik nilai MAPE berdasarkan nilai
order yang berbeda
4.4 Pengujian terhadap pengaruh jumlah data latih maksimum pada MAPE
Pada pengujian ini dilakukan untuk mengetahui pengaruh nilai jumlah data latih maksimum terhadap nilai MAPE yang dihasilkan. Jumlah data latih maksimum yang diuji dari 28 sampai 32. Nilai order yang digunakan 9, konstanta threshold 75, jumlah data uji 10, bobot 2.5, iterasi maksimum 10, dan eror terkecil 0,0001.
Gambar 5 Grafik nilai MAPE berdasarkan jumlah data latih maksimum yang berbeda
Berdasarkan Gambar 5 semakin banyak jumlah data latih maksimum maka semakin kecil pula nilai MAPE yang dihasilkan. Penurunan nilai MAPE disebabkan karena proses pencocokan data latih dan uji pada saat defuzzifikasi. Dengan data latih maksimum berada pada FLR 28 dan data uji terakhir berada pada FLR 34 maka selisih antara data uji dan data latih menjadi besar dikarenakan ada jarak
9,41 1,91 1,96 2,00 2,00 2,00 2,00 2,00 2,00 2,00 1 3 5 7 9 11 5 10 15 20 25 30 35 40 45 50 M A P E ( % ) Iterasi Maksimum
Grafik nilai rata-rata MAPE berdasarkan Iterasi Maksimum
9,07 29,99 44,51 47,98 41,10 32,21 26,63 13,10 1,75 6,40 -10 10 30 50 1 2 3 4 5 6 7 8 9 10 M A P E (% ) Order
Grafik nilai rata-rata MAPE berdasarkan order
59,85 41,37 27,85 13,62 2,31 0 20 40 60 28 29 30 31 32 MA PE ( %)
Jumlah data latih maksimum Grafik nilai rata-rata MAPE berdasarkan jumlah
Fakultas Ilmu Komputer, Universitas Brawijaya yang cukup jauh antara data latih maksimum dengan data uji terakhir sehingga dengan
threshold = 120 (didapat dari 5 (jumlah fitur
data) * 9 (order) + 75 (konstanta)) maka ada beberapa data uji yang yang mengalami kegagalan peramalan sehingga nilai peramalannya 0 dan menyebabkan nilai MAPE menjadi sangat tinggi. Kemudian dengan jumlah data latih maksimum = 32 maka jarak antara data latih maksimum dan data uji terakhir menjadi agak dekat sehingga selisih FLR data uji dan latih menjadi lebih kecil dari jumlah data latih maksimum 28 dan dengan threshold 120 maka semua data uji berhasil didapatkan nilai peramalannya yang berefek pada kecilnya nilai MAPE.
4.5 Pengujian terhadap pengaruh threshold pada MAPE
Pada pengujian ini dilakukan untuk mengetahui pengaruh nilai threshold terhadap nilai MAPE yang dihasilkan. Threshold yang diuji dari 110 sampai 200. Nilai order yang digunakan 9, jumlah data latih 32, jumlah data uji 10, bobot 2.5, iterasi maksimum 10, dan eror terkecil 0,0001.
Gambar 6 Grafik nilai MAPE berdasarkan
threshold yang berbeda
Berdasarkan Gambar 6 nilai threshold yang berbeda mempengaruhi nilai dari MAPE yang dihasilkan. Nilai threshold diatas 120 akan menaikan nilai MAPE sedikit demi sedikit sehingga semakin besar nilai threshold semakin besar pula nilai MAPE. Dengan threshold yang terlalu kecil maka batas pencarian FLR yang cocok antara data latih dan uji menjadi sempit sehingga ada data latih yang seharusnya masuk sebagai angka peramalan tetapi tidak termasuk kedalam angka peramalan sehingga ada data uji yang tidak keluar nilai peramalannya karena tidak ada data latih yang cocok dengan data uji sehingga nilai hasil peramalnnya menjadi 0, seperti yang terjadi pada percobaan pertama dengan nilai threshold 110 ada nilai hasil
peramalan data uji yang nilainya 0 sehingga berpengaruh pada nilai MAPE yang tinggi. Nilai
threshold yang terlalu besar juga akan
memperbesar nilai MAPE dikarenakan batas pencarian FLR yang cocok antara data latih dan data uji yang besar sehingga data latih yang seharusnya tidak cocok dengan data uji menjadi cocok sehingga terlalu banyak nilai yang masuk sebagai angka peramalan yang dapat menurunkan kualitas nilai peramalan dan juga meningkatkan MAPE yang dihasilkan.
4.6 Analisis Hasil
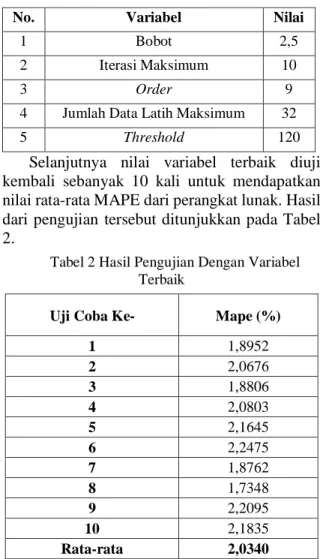
Berdasarkan hasil pengujian didapatkan variabel-variabel terbaik yang dapat digunakan untuk melakukan peramalan kebutuhan energi listrik di Indonesia dengan metode gabungan multi-factors high order fuzzy time series dan fuzzy c-means, variabel-variabel tersebut dapat dilihat pada Tabel 1.
Tabel 1 Variabel Terbaik Hasil Pengujian
No. Variabel Nilai
1 Bobot 2,5
2 Iterasi Maksimum 10
3 Order 9
4 Jumlah Data Latih Maksimum 32
5 Threshold 120
Selanjutnya nilai variabel terbaik diuji kembali sebanyak 10 kali untuk mendapatkan nilai rata-rata MAPE dari perangkat lunak. Hasil dari pengujian tersebut ditunjukkan pada Tabel 2.
Tabel 2 Hasil Pengujian Dengan Variabel Terbaik
Uji Coba Ke- Mape (%)
1 1,8952 2 2,0676 3 1,8806 4 2,0803 5 2,1645 6 2,2475 7 1,8762 8 1,7348 9 2,2095 10 2,1835 Rata-rata 2,0340
Berdasarkan Tabel 2, nilai MAPE terkecil didapatkan pada uji coba ke-8 dengan nilai MAPE sebesar 1,7348%. Sementara nilai MAPE
3,03 1,95 1,97 2,47 3,28 3,73 4,18 5,24 5,80 6,00 1 2 3 4 5 6 7 110 120 130 140 150 160 170 180 190 200 MA PE ( %)
Jumlah data latih maksimum Grafik nilai rata-rata MAPE berdasarkan
Fakultas Ilmu Komputer, Universitas Brawijaya terbesar didapatkan pada uji coba ke-6 dengan nilai MAPE sebesar 2,2475%. Secara umum metode gabungan Multi-Faktor High Order
Fuzzy Time Series dan Fuzzy C-Means
memberikan hasil peramalan yang cukup baik, hal tersebut ditunjukkan dengan rata-rata MAPE dari 10 kali uji coba dengan menggunakan variabel terbaik yang hasil MAPE-nya yaitu sebesar 2,0340%.
5. KESIMPULAN
1. Implementasi Metode Gabungan
Multi-Factors High Order Fuzzy Time Series dan Fuzzy C-Means untuk peramalan kebutuhan
energi listrik di Indonesia dilakukan dengan melalui proses penentuan Universe of
Discourse, proses penentuan jumlah klaster, proses pembentukan subinterval dengan Fuzzy C-Means, proses pembentukan himpunan fuzzy, proses fuzzifikasi, proses pembentukan Fuzzy
Logic Relationship (FLR), dan proses
defuzzifikasi. Hasil dari peramalan kebutuhan energi listrik didapatkan pada akhir proses defuzifikasi.
2. Dari hasil pengujian yang telah dilakukan dapat diketahui bahwa:
a) Nilai bobot yang menghasilkan nilai MAPE paling rendah yaitu bobot dengan nilai 2,5.
b) Nilai order yang menghasilkan nilai MAPE terkecil yaitu dengan order 9. c) Semakin banyak data latih maksimum
yang digunakan maka hasil peramalan semakin baik. Jumlah data latih maksimum yang menghasilkan nilai MAPE terbaik yaitu dengan nilai 32. d) Nilai threshold tidak boleh terlalu
besar karena akan membuat nilai hasil peramalan menjadi lebih buruk, tetapi nilai threshold juga tidak boleh terlalu kecil karena bisa membuat kegagalan dalam peramalan data uji yang digunakan. Rentang nilai threshold yang menhasilkan nilai MAPE tetap dibawah 10% yaitu antara nilai 120 - 200.
3. Tingkat kesalahan dari perangkat lunak Implementasi Metode Gabungan
Multi-Factors High Order Time Series dan Fuzzy C-Means untuk peramalan kebutuhan
energi listrik di Indonesia ditunjukkan dengan nilai MAPE (Mean Absolute
Percentage Error) sebesar 2,0340%. Hasil
perhitungan MAPE yang lebih kecil dari 10% menunjukkan bahwa Implementasi Metode Gabungan Multi-Factors High
Order Fuzzy Time Series dan Fuzzy C-Means sangat baik digunakan untuk
melakukan peramalan kebutuhan energi listrik di Indonesia.
6. DAFTAR PUSTAKA
Abdullah, Lazim., Taib, Imran. 2011. High
Order Fuzzy Time Series for Exchange Rates Forecasting. Faculty Science and Technology. Universiti Malaysia Terengganu.
Bezdek, J. C. 1984. FCM: The Fuzzy C-Means
Clustering Algorithm. Computers & Geoscience, 191-203.
Kiran, Mustafa Servet., Özceylan, Eren., Gunduz, Mesut., Paksoy, Turan. 2012. Swarm intelligence approaches to estimate
electricity energy demand in Turkey.
Department of Computer Engineering, Selcuk University, Turkey.
Kusumadewi, Sri., H. P. 2010. Aplikasi Logika
Fuzzy untuk Pendukung Keputusan.
Yogyakarta: Graha Ilmu.
Lee, L. Wang, L. Chen, S. Leu, Y. 2006.
Handling Forecasting Problems Based on Two-Factors High-Order Fuzzy Time Series. IEEE Transactions On Fuzzy
Sistems. 468- 477.
Lin, Yupei. Yang, Yiwen. 2009. Stock Market
Forecasting Based on Fuzzy Time Sries Model. IEEE Conference Publication,
782-886.
Purwanto, Angga Depi. 2013. Penerapan
Metode Fuzzy Time Series Average-Based
pada Peramalan Data Harian
Penampungan Susu Sapi. S1. Universitas
Brawijaya.
Sungkawa, Iwa., Megasari, Ries Tri. 2011.
Penerapan ukuran ketepatan nilai ramalan data deret waktu dalam seleksi model
peramalan volume penjualan PT
satriamandiri citramulia. School of
Computer Science, Binus University. Wardhani, Dessy Kusuma. 2015. Implementasi
metode Multi-Factors High Order Fuzzy Time Series Model untuk prediksi harga emas. S1. Universitas Brawijaya.
Fakultas Ilmu Komputer, Universitas Brawijaya Weisstein, E. W. 2015. Standart Deviation.
Retrieved Maret 10, 2015. from
MathWorld-A Worfram Web Resource:
http://mathworld.wolfram.com/StandartDev iation.html.
Zed, Farida., Suharyani, Yenny Dwi., Rasyid, Ainur., Hayati, Dwi., Rosdiana, Dian., Mohi, Ervan., Santhani, Fitria., Pambudi, Sadmoko Hesti., Malik, Cecilya., Santosa, Joko., Nurohim, Agus. 2014. Outlook energi
2014. [pdf] Tersedia di:
prokum.esdm.go.id/Publikasi
/Outlook%20Energi%202014.pdf [Diakses 09 Maret 2017].