- 1 -
PEMODELAN YIELD CURVE DATA OBLIGASI PEMERINTAH INDONESIA DENGAN PENDEKATAN GENERAL REGRESSION NEURAL NETWORK DAN RADIAL BASIS
FUNCTION NETWORK
Yogie Pradhika Y.A.1 dan Suhartono2 1
Mahasiswa Jurusan Statistika FMIPA-ITS ([email protected]) 2
Dosen Jurusan Statistika FMIPA-ITS ([email protected]) ABSTRAK
Ada beberapa metode yang biasanya digunakan untuk pemodelan yield curve di suatu negara, yaitu pendekatan Smooothing Kernel, Spline, Bootstrap Spline, B-Spline, Nelson Siegel Svenson (NSS) dan
Feedforward Neural Network (FFNN). Metode NSS, Smooothing Kernel, Spline, dan FFNN adalah
metode yang telah digunakan untuk pemodelan yield curve obligasi pemerintah Indonesia. Penelitian ini dilakukan dengan tujuan untuk mengembangkan model yield curve obligasi pemerintah Indonesia melalui pendekatan Radial Basis Function Network (RBFN) dan General Regression Neural Network (GRNN). Ada empat arsitektur RBFN dan dua arsitektur GRNN yang diaplikasikan untuk pemodelan
yield curve obligasi pemerintah Indonesia. Evaluasi perbandingan kebaikan model dilakukan berdasarkan
nilai rata-rata dari Mean Squares Errors (MSE) in-sample dan out-sample serta bentuk kurva yang dihasilkan. Hasil perbandingan akurasi model menunjukkan bahwa GRNN dengan spread 0.8 adalah arsitektur jaringan terbaik untuk pemodelan yield curve obligasi pemerintah Indonesia.
Kata kunci : yield curve, obligasi pemerintah Indonesia, RBFN, GRNN 1. Pendahuluan
Obligasi, yang sering dikenal sebagai surat utang mengalami perkembangan yang berarti sebagai instrumen keuangan sejak tahun 2000. Hal ini karena semakin ketatnya prosedur peminjaman di lembaga ke-uangan. Akhirnya, kalangan pebisnis beralih minat terhadap instrumen pendanaan lain yaitu dana masyarakat. Penerbitan obligasi harus melalui prosedur yang ditetapkan oleh Badan Pengawas Pasar Modal (BAPEPAM). Penetapan harga wajar obligasi dilakukan dengan membuat kurva imbal hasil dari obligasi pada tingkat resiko yang sama yaitu berdasarkan peringkat dan jenisnya. YTM (Yield to Maturity) merupakan ukuran yield yang mencerminkan return dengan tingkat bunga majemuk yang diharapkan. Asumsi yang digunakan adalah obligasi tersebut dipertahankan sampai jatuh tempo dan pendapatan kupon akan diinvestasikan kembali pada tingkat YTM. Indonesia memiliki model yield curve yaitu IGSYC yang menggunakan metode nonparametrik dengan Bezier-spline. Ada beberapa penelitian yang berkaitan dengan pengembangan model yield curve, diantaranya Waggoner (1997) dengan menggunakan metode Spline, Deaves dan Parlar (2000) dengan menggunakan metode Bootstrap, Linton et.al. (2000) dengan menggunakan metode Smooothing Kernel, Lin (2002) dengan menggunakan metode B-Spline, Tanaka (2003) dengan menggunakan metode Spline, dan Chadha and Holly (2006) dengan menggunakan metode Calvo-Yun, Hybrid dan Svensson. Selain itu, metode yang berbasis machine learning juga sudah diaplikasikan dalam permodelan yield curve oleh Orr (1994), yaitu metode Radial Basis Function Network (RBFN) untuk data obligasi di negara Jerman.
Kajian model yield curve yang dilakukan tim Jurusan Statistika ITS dan PT. PHEI (2008) menggu-nakan model Nelson Siegel Svenson (NSS), model Spline dan Feedforward Neural Network (FFNN). Penelitian yang dilakukan oleh Yaniar (2009) menggunakan model NSS, model Spline dan Kernel. Penelitian ini dilakukan dengan tujuan untuk menerapkan metode yang berbasis machine learning dalam permodelan yield curve, yaitu model RBFN dan General Regression Neural Network (GRNN) untuk data obligasi pemerintah di Indonesia.
2. Tinjauan Pustaka 2.1. Neural Network
Neural Network (NN) adalah salah satu representasi buatan dari otak manusia yang selalu mencoba untuk mensimulasikan proses pembelajaran pada otak manusia tersebut. Secara umum NN memiliki beberapa komponen, yaitu neuron, lapisan, fungsi aktivasi, dan bobot. Pemodelan NN dilihat pada bentuk jaringan yang
- 2 -
terdiri dari jumlah neuron pada lapisan input, jumlah neuron pada lapisan tersembunyi (hidden layer) dan jumlah neuron pada lapisan output, serta fungsi aktivasi yang digunakan.
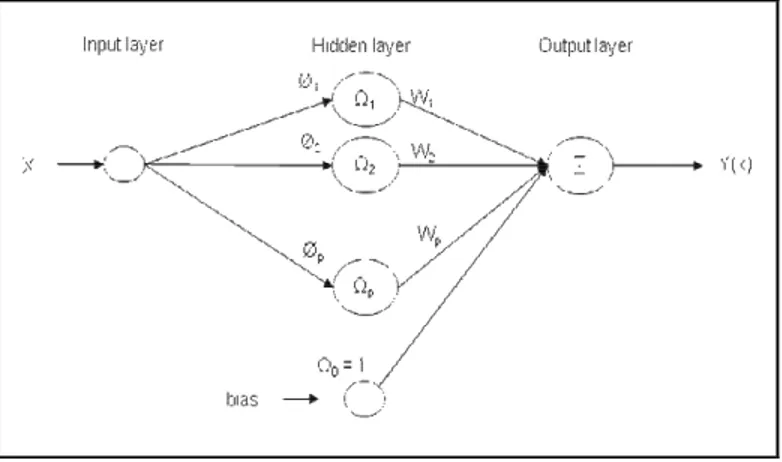
RBFN mempunyai interpolasi awal yang tepat dari sekumpulan nilai data dalam ruang multidi-mensional. RBFN mempunyai arsitektur jaringan yang mirip dengan jaringan regulasi klasik, dimana fungsi dasarnya adalah fungsi Green dari operator Gram dengan stabilisator. Jika stabilator memperlihatkan simetri radial, maka fungsi dasarnya adalah simetri radial dengan baik dan RBFN didapatkan. Nilai estimasi diperoleh dengan menggunakan persamaan berikut
( )
1 ( i ) i p i x Wi i c Y x = =∑
∅ − (1)dengan p sebanyak jumlah output,
( )
wki adalah besaran bobot dari hidden layer ke output, ci adalah center, p hidden unit, dan − menunjukkan aturan Eucledian, dan ∅ −( ) dipilih sebagai fungsi Gaussian. Arsitektur jaringan dari RBFN adalah sebagai berikutGambar 1 Arsitektur Jaringan RBFN
Pembelajaran RBFN biasanya menggunakan dua tahapan strategi. Tahapan pertama adalah mene-tapkan dan memperbarui center ci yang sesuai dan masing-masing standard deviasinya. Tahapan kedua adalah memperbaiki jaringan bobot W. Pembelajaran dari bobot W dikurangi hingga sampai mendapat sebuah optimalisasi permasalahan linear yang dapat diselesaikan dengan menggunakan metode Least Square atau metode gradient-descent. Setelah RBFN center ditetapkan, dilakukan pembelajaran untuk bobot matriks W untuk memperoleh minimalisasi MSE dengan metode Least Square.
( )
†(
)
−1= T T = T T
W Φ Y ΦΦ ΦY (2)
dimana
( )
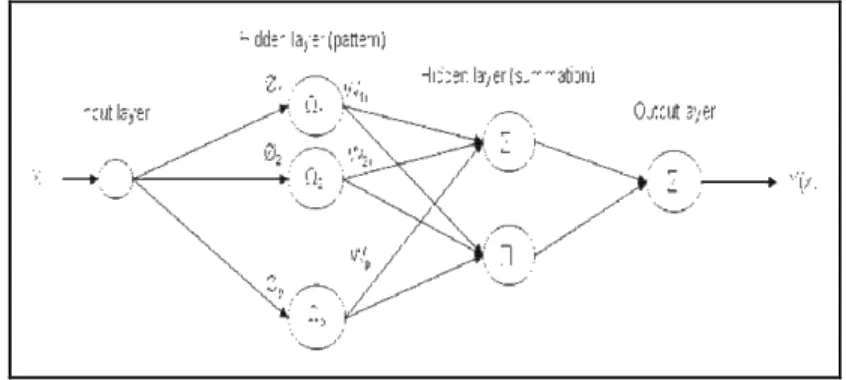
− † adalah pseudoinverse dari matriks yang ada.GRNN diusulkan oleh Donald F. Specht pada tahun 1991 untuk masuk dalam kategori probabilistic neural network. Seperti probabilistic neural network yang lain, GRNN hanya memerlukan sedikit sampel pembelajaran backpropagation neural network. Data yang tersedia dari hasil pengukuran sebuah sistem operasi biasanya tidak pernah cukup untuk backpropagation neural network. Oleh karena itu, penggunaan dari probabilistic neural network lebih menguntungkan karena kemampuannya untuk mempertemukan batas bawah dari fungsi data dengan hanya sedikit sampel pembelajaran yang tersedia. Pemodelan GRNN dilihat pada bentuk jaringan yang terdiri dari jumlah neuron pada lapisan input, jumlah neuron berpola (pattern) dan neuron penyaji (summation) pada lapisan tersembunyi (hidden layer) dan jumlah neuron pada lapisan output, serta fungsi aktivasi yang digunakan. Yang berbeda dari GRNN adalah tidak adanya bobot bias pada lapisan input dan lapisan tersembunyi. Nilai estimasi diperoleh dengan menggunakan persamaan berikut
- 3 -
( )
2 2 1 2 2 1 exp 2 exp 2 n i i i n i i D y y x Dσ
σ
= = − = − ∑
∑
(3)(
) (
)
2 . T i i i D = −x x x−x (4)dimana Di adalah jarak antara sampel pembelajaran dan titik prediksi. Arsitektur jaringan dari GRNN adalah sebagai berikut
Gambar 2 Arsitektur Jaringan GRNN
Pencarian untuk mendapatkan parameter penghalus harus mencakup beberapa aspek tergantung dari penggunaan output prediksi yang digunakan. Nilai σ yang besar hasil kurva prediksi akan semakin datar dan halus secara baik. Pada beberapa kasus hal ini sangat dii-nginkan, contohnya sekumpulan data yang terlalu banyak dengan nilai outlier. Terdapat dua cara untuk mendapatkan parameter penghalus, yaitu metode Holdout dan metode Wiggle.
Alternatif pemilihan model terbaik pada NN biasa disebut dengan cross validation (CV) atau lebih lengkapnya v-leave-out cross validation. Penambahan model yang rumit memerlukan bukan hasil yang lebih baik dalam penjabaran fungsi yang tidak terlihat karena peningkatan estimasi error. Untuk memperoleh tingkat kerumitan yang tepat, dilakukan perbandingan rata-rata kuadrat kesalahan prediksi atau mean square prediction errors (MSPE) dari perbedaan spesifikasi model. Kesalahan prediksi diperoleh dari pembagian sampel menjadi M subsets (himpunan bagian) yang masing-masing terdiri dari n observasi. Model di estimsi ulang secara berulang kali dan menghasilkan satu buah subset setiap perulangannya. Rata-rata dari MSPE dinyatakan sebagai CV. 1 1 CV MSPE p i i p = =
∑
(5)Model dengan nilai CV terkecil yang dipilih sebagai model terbaik. Keuntungan menggunakan CV terletak pada asumsi pe-luang yang saling independent, khususnya keunggulan dari maximum likelihood estimator (MLE). Di sisi lain, pemisahan data memberi hasil pengurangan efisiensi dan perhitungan CV tidak praktis karena seringkali estimasi ulang dari model dipertimbangkan.
2.2. Obligasi
Obligasi didefinisikan sebagai suatu surat utang yang ditawarkan oleh penerbit (issuer) atau peminjam (borrower) untuk membayar kembali kepada investor (lender) sejumlah yang dipinjam ditambah bunga selama tahun yang ditentukan. Ciri utama setiap obligasi adalah jangka waktu jatuh tempo (maturity) yang merupakan tanggal peminjam harus melunasi seluruh jumlah yang dipinjam. Namun secara teknis, maturitas menunjukkan tanggal pinjaman harus dilunasi, sedangkan jangka waktu tempo mengacu kepada jumlah tahun yang tersisa hingga tanggal maturitas. Jumlah yang disetujui untuk dibayarkan peminjam pada tanggal jatuh
- 4 -
tempo disebut nilai par, nilai maturitas atau nilai nominal. Kupon obligasi merupakan pembayaran bunga periodik yang diberikan kepada borrower sepanjang usia obligasi.
Yield merupakan faktor pengukur tingkat pengembalian tahunan yang akan diterima oleh investor atau hasil yang akan diperoleh investor apabila menanamkan dananya pada obligasi. Yield to maturity (YTM) adalah suku bunga yang akan menyamakan nilai sekarang dari sisa arus kas obligasi dengan harga obligasi ditambah bunga yang akan dibayar, jika ada. Secara matematis, YTM bagi obligasi yang membayar bunga setiap 6 bulan dan tidak memiliki bunga akan dibayar dapat ditemukan menggunakan perhitungan sebagai berikut
(
) (
1) (
2)
3(
) (
)
1 1 1 1 n 1 n C C C C M P y y y y y = + + +…+ + + + + + + (6)dengan P adalah harga obligasi pada saat ini, n adalah jumlah tahun sampai dengan jatuh tempo obligasi, C adalah pembayaran kupon untuk obligasi setiap tahunnya, y adalah YTM, dan M adalah nilai maturitas.
Penghitungan YTM yang dapat dilakukan dengan memasukkan semua pembayaran kupon bunga sampai dengan tanggal jatuh tempo dengan mengasumsikan adanya reinvestasi dari kupon yang diterima dengan tingkat bunga yang sama dengan YTM tersebut. Untuk memperoleh nilai YTM, maka dapat digunakan juga penghitungan yield to maturity approximation dengan persamaan berikut
* 100 2 P i P P P C n YTM P P − + = × + (7)
dengan YTM* adalah nilai YTM approximation, P adalah harga obligasi pada saat ini, Pp adalah
harga obligasi pada waktu tertentu, n adalah jumlah tahun sampai dengan jatuh tempo obligasi, Ci
adalah pembayaran kupon untuk obligasi i setiap tahunnya.
Pada Tabel 1 berdasarkan teori penentuan harga obligasi oleh Sharpe (1995) dijelaskan bahwa jika obligasi memiliki nilai pasar yang sama dengan nilai par, maka YTM akan sama dengan suku bunga kuponnya. Namun jika nilai pasar kurang dari nilai par (diskonto) maka obligasi akan memilki YTM yang lebih besar dari suku bunga kupon. Sebaliknya, jika nilai pasar lebih besar dari nilai par (premium) akan memiliki YTM yang lebih rendah dari suku bunga kupon.
Tabel 1 Hubungan antara suku bunga kupon, current yield, YTM dan harga
No Obligasi Suku Bunga Kupon
1 Nilai par/maturitas Suku bunga kupon = current yield = YTM 2 Diskonto Suku bunga kupon < current yield < YTM 3 Premi Suku bunga kupon > current yield > YTM
3. Metodologi Penelitian
Sumber data yang digunakan dalam penelitian ini berasal dari IBPA yang diambil dari transaksi pembelian obligasi pemerintah pada periode Januari sampai April 2009. Data yang digunakan adalah data harian. Trasaksi portofolio obligasi ini diperoleh pihak IBPA dari BAPEPAM. Selain itu jenis obligasi pemerintah yang digunakan adalah yang memiliki nilai kupon tetap. Langkah-langkah analisis yang digunakan adalah sebagai berikut
1. Identifikasi permasalahan tentang pemodelan yield curve obligasi pemerintah Indonesia.
2. Penentuan tujuan dari penelitian yaitu diperoleh model neural network yang sesuai dalam penentuan model yield curve untuk obligasi pemerintah Indonesia.
3. Pengumpulan literatur. 4. Penentuan variabel penelitian.
- 5 - 6. Analisis data dengan metode RBFN dan GRNN.
7. Membandingkan dan memilih model terbaik berdasarkan nilai MSE, nilai Cross Validation, dan hasil dari uji validasi dari masing-masing model.
8. Tahapan terakhir adalah memberikan kesimpulan dan memberikan saran. 4. Pembahasan
Berikut adalah ulasan dan pemaparan hasil penelitian tentang data obligasi pemerintah Indonesia bulan Januari – April 2009 dengan metode neural network.
4.1. Analisis Deskriptif
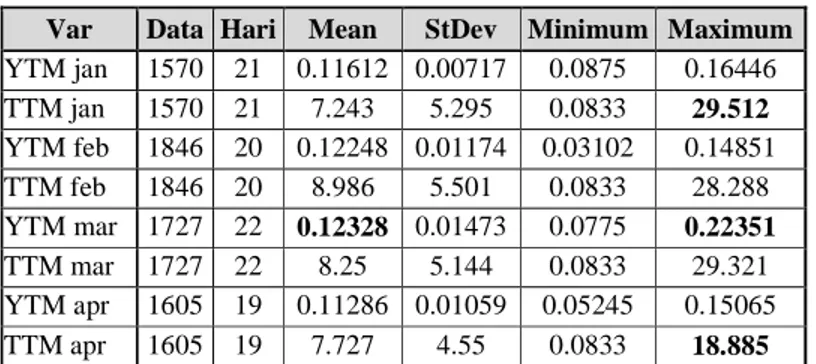
Uraian tentang statistika deskriptif data obligasi pemerintah Indonesia bulan Januari – April 2009 ditunjukkan pada Tabel 2 di bawah ini
Tabel 2 Statistik Deskriptif Data Obligasi per Bulan Var Data Hari Mean StDev Minimum Maximum
YTM jan 1570 21 0.11612 0.00717 0.0875 0.16446 TTM jan 1570 21 7.243 5.295 0.0833 29.512 YTM feb 1846 20 0.12248 0.01174 0.03102 0.14851 TTM feb 1846 20 8.986 5.501 0.0833 28.288 YTM mar 1727 22 0.12328 0.01473 0.0775 0.22351 TTM mar 1727 22 8.25 5.144 0.0833 29.321 YTM apr 1605 19 0.11286 0.01059 0.05245 0.15065 TTM apr 1605 19 7.727 4.55 0.0833 18.885
Berdasarkan Tabel 2 dapat diketahui bahwa jumlah data dan jumlah transaksi untuk setiap bulanya tidak sama. Pada umumnya rata-rata nilai yield to maturity (TTM) antara bulan Januari sampai dengan April 2009 berkisar diantara 0.11 sampai 0.13 dengan rata-rata terbesarnya 0.12328 pada bulan Maret 2009. Bulan Maret 2009 juga memberikan nilai YTM terbesar, yaitu 0.22351. Nilai ini sangat besar selisihnya jika dibandingkan dengan nilai rata-ratanya. Untuk nilai TTM, pada bulan April 2009 tidak melebih 20 tahun padahal secara umum bisa mendekati angka 30 tahun untuk nilai TTM.
4.2. Pemilihan Arsitektur Neural Network
Arsitektur jaringan RBFN yang dibuat untuk penelitian ini secara umum mempunyai satu lapisan input, lapisan tersembunyi yang masing-masing mempunyai jumlah neuron sebanyak data inputan dan satu lapisan output yang menggunakan satu neuron saja. Pada lapisan tersembunyi mempunyai satu neuron tam-bahan yang disebut bias. Fungsi aktivasi yang digunakan untuk lapisan tersembunyi adalah radial basis (radbas) dan purelin adalah fungsi aktivasi pada lapisan outputnya.
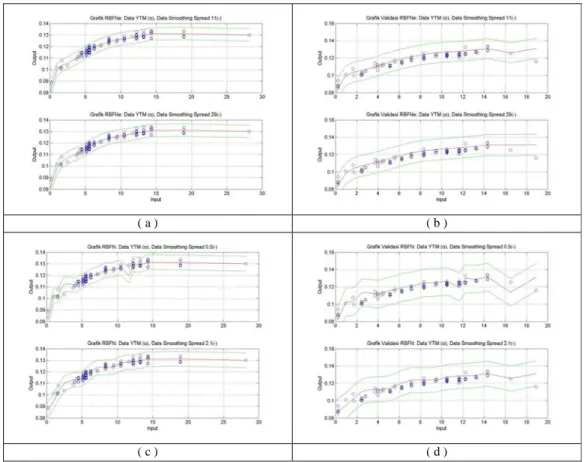
( a ) ( b ) ( c ) ( d )
Gambar 3 Bentuk Kurva Model (a) Arsitektur Jaringan RBFN NEWRBE Command, Spread 11 (b) Arsitektur Jaringan
RBFN NEWRBE Command, Spread 29 (c) Arsitektur Jaringan RBFN NEWRB Command, Spread 0.5 (d) Arsitektur Jaringan RBFN NEWRB Command, Spread 2.1
Pada penelitian ini, dengan bantuan software MATLAB arsitektur RBFN(1,Q,1) dibedakan menjadi dua berdasarkan command (fungsi) yang digunakan, yaitu fungsi newrbe dan fungsi newrb. Perbedaannya terletak pada bobot akhir yang dihasilkan dan jumlah neuron yang digunakan pada lapisan tersembunyi. Pada
- 6 -
fungsi newrbe, jumlah bobot akhir sesuai jumlah data input dan neuron yang digunakan selalu sejumlah data inputan. Sedangkan pada fungsi newrb, jumlah bobot akhir tergantung nilai spread yang digunakan yang artinya jumlah neuron yang digunakan dalam lapisan tersembunyi belum tentu sama dengan jumlah data inputan. Nilai spread berpengaruh di fungsi aktivasi radbas pada lapisan tersembunyi.
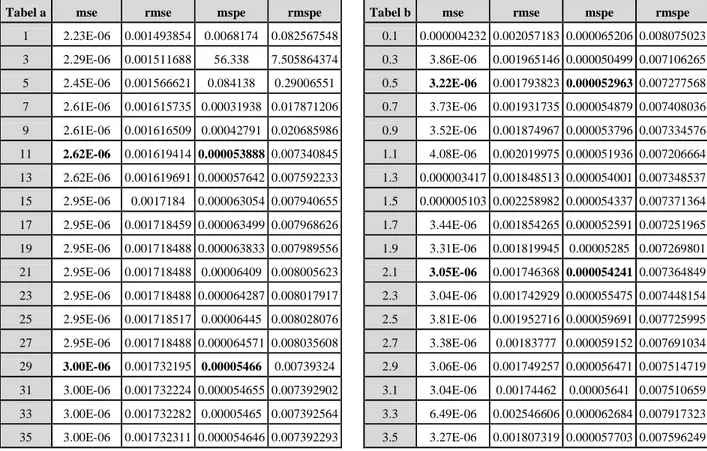
Tabel 3 Nilai MSE dan MSPE (a) NEWRBE Command (b) NEWRB Command
Tabel a mse rmse mspe rmspe Tabel b mse rmse mspe rmspe 1 2.23E-06 0.001493854 0.0068174 0.082567548 0.1 0.000004232 0.002057183 0.000065206 0.008075023 3 2.29E-06 0.001511688 56.338 7.505864374 0.3 3.86E-06 0.001965146 0.000050499 0.007106265 5 2.45E-06 0.001566621 0.084138 0.29006551 0.5 3.22E-06 0.001793823 0.000052963 0.007277568 7 2.61E-06 0.001615735 0.00031938 0.017871206 0.7 3.73E-06 0.001931735 0.000054879 0.007408036 9 2.61E-06 0.001616509 0.00042791 0.020685986 0.9 3.52E-06 0.001874967 0.000053796 0.007334576 11 2.62E-06 0.001619414 0.000053888 0.007340845 1.1 4.08E-06 0.002019975 0.000051936 0.007206664 13 2.62E-06 0.001619691 0.000057642 0.007592233 1.3 0.000003417 0.001848513 0.000054001 0.007348537 15 2.95E-06 0.0017184 0.000063054 0.007940655 1.5 0.000005103 0.002258982 0.000054337 0.007371364 17 2.95E-06 0.001718459 0.000063499 0.007968626 1.7 3.44E-06 0.001854265 0.000052591 0.007251965 19 2.95E-06 0.001718488 0.000063833 0.007989556 1.9 3.31E-06 0.001819945 0.00005285 0.007269801 21 2.95E-06 0.001718488 0.00006409 0.008005623 2.1 3.05E-06 0.001746368 0.000054241 0.007364849 23 2.95E-06 0.001718488 0.000064287 0.008017917 2.3 3.04E-06 0.001742929 0.000055475 0.007448154 25 2.95E-06 0.001718517 0.00006445 0.008028076 2.5 3.81E-06 0.001952716 0.000059691 0.007725995 27 2.95E-06 0.001718488 0.000064571 0.008035608 2.7 3.38E-06 0.00183777 0.000059152 0.007691034 29 3.00E-06 0.001732195 0.00005466 0.00739324 2.9 3.06E-06 0.001749257 0.000056471 0.007514719 31 3.00E-06 0.001732224 0.000054655 0.007392902 3.1 3.04E-06 0.00174462 0.00005641 0.007510659 33 3.00E-06 0.001732282 0.00005465 0.007392564 3.3 6.49E-06 0.002546606 0.000062684 0.007917323 35 3.00E-06 0.001732311 0.000054646 0.007392293 3.5 3.27E-06 0.001807319 0.000057703 0.007596249
Tabel 3 merupakan output dari running program pada software Matlab. Berdasarkan pada tabel terse-but maka nilai MSE dan MSPE yang cukup kecil untuk masing-masing fungsi pada arsitektur RBFN adalah arsitektur RBFN(1,Q,1) dengan fungsi newrbe spread 11 dan 29 dan arsitektur RBFN(1,Q,1) dengan fungsi newrb spread 0.5 dan 2.1. Keempat model arsitektur tersebut yang selanjutnya digunakan untuk pembuatan model dengan data yang sesunguhnya. Hal ini juga didukung dari kurva yang dihasilkan oleh masing-masing model arsitektur seperti yang terlihat pada Gambar 3 dan hasil ini diperoleh dari data simulasi. Kurva yang dihasilkan keempat model arsitektur tersebut dirasa cukup halus dalam menggambarkan data obligasi.
Arsitektur jaringan GRNN hampir sama dengan arsitektur jaringan RBFN namun terdapat perbedaan pada lapisan tersembunyi yang mempunyai dua buah lapisan. Jumlah neuron yang digunakan pada lapisan tersembunyi pertama maksimal sebanyak data inputan yang digunakan untuk membuat model, pada lapisan tersembunyi kedua digunakan dua buah neuron. Pada lapisan tersembunyi arsitektur jaringan GRNN tidak mempunyai bias.
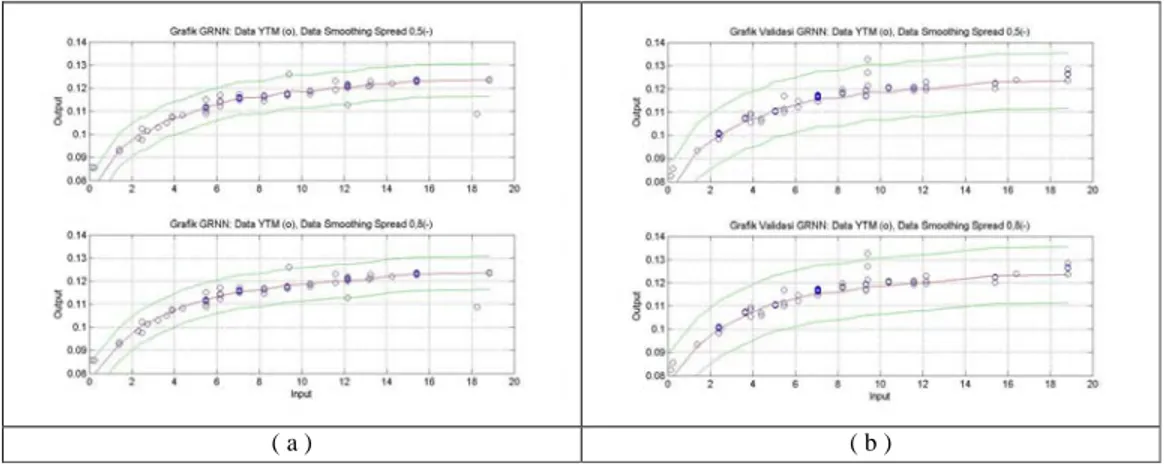
Cara penentuan model terbaik yang akan digunakan untuk model GRNN(1,Q,2,1) sama seperti pada model RBFN(1,Q,1), dengan melihat nilai MSE dan MSPE pada Tabel 4 dan kurva yang dihasilkan seperti pada Gambar 4 maka dipilih model arsitektur jaringan GRNN(1,Q,2,1) dengan spread 0.5 dan 0.8. Kedua model arsitektur tersebut adalah dua model arsitektur terbaik pada arsitektur jaringan GRNN.
- 7 -
( a ) ( b )
Gambar 4 Bentuk Kurva Model (a) Arsitektur Jaringan GRNN Spread 0.5 (b) Arsitektur Jaringan GRNN Spread 0.8
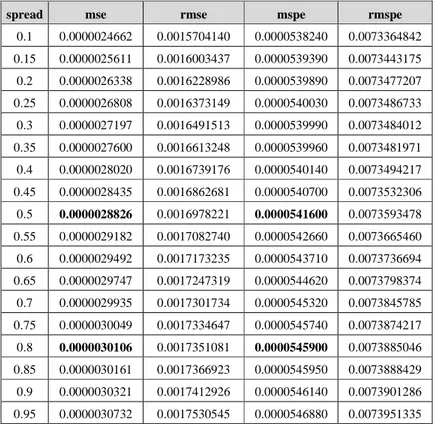
Tabel 4 Nilai MSE dan MSPE NEWGRNN Command spread mse rmse mspe rmspe
0.1 0.0000024662 0.0015704140 0.0000538240 0.0073364842 0.15 0.0000025611 0.0016003437 0.0000539390 0.0073443175 0.2 0.0000026338 0.0016228986 0.0000539890 0.0073477207 0.25 0.0000026808 0.0016373149 0.0000540030 0.0073486733 0.3 0.0000027197 0.0016491513 0.0000539990 0.0073484012 0.35 0.0000027600 0.0016613248 0.0000539960 0.0073481971 0.4 0.0000028020 0.0016739176 0.0000540140 0.0073494217 0.45 0.0000028435 0.0016862681 0.0000540700 0.0073532306 0.5 0.0000028826 0.0016978221 0.0000541600 0.0073593478 0.55 0.0000029182 0.0017082740 0.0000542660 0.0073665460 0.6 0.0000029492 0.0017173235 0.0000543710 0.0073736694 0.65 0.0000029747 0.0017247319 0.0000544620 0.0073798374 0.7 0.0000029935 0.0017301734 0.0000545320 0.0073845785 0.75 0.0000030049 0.0017334647 0.0000545740 0.0073874217 0.8 0.0000030106 0.0017351081 0.0000545900 0.0073885046 0.85 0.0000030161 0.0017366923 0.0000545950 0.0073888429 0.9 0.0000030321 0.0017412926 0.0000546140 0.0073901286 0.95 0.0000030732 0.0017530545 0.0000546880 0.0073951335
4.3. Pembuatan Model Arsitektur Neural Network
Pada pembuatan model neural network dengan menggunakan data yang sesungguhnya, terdapat tiga jenis data yang digunakan untuk membuat satu model. Tiga jenis data tersebut adalah data clean, data asli, dan data hari berikutnya. Data clean adalah data asli yang telah dihilangkan data outliernya. Data asli adalah data yang sesuai dengan fakta di lapangan pada saat itu. Data hari berikutnya adalah data yang digunakan untuk validasi model saat ini untuk hari berikutnya.
Tabel 5 Nilai CV dan Rata-rata MSE model RBFN
spread RBE 11 RBE 29 RB 0.5 RB 2.1
CV per model 10.28798 0.002262 0.105845 1069325
Avg MSE per model 9.65×10-06 1.11×10-05 1.23×10-05 1.32×10-05
Tabel 5 menunjukkan bahwa nilai terkecil untuk kategori CV adalah RBFN(1,Q,1) dengan fungsi newrbe spread 29 yaitu 0.002262 dan rata-rata MSE adalah RBFN(1,Q,1) dengan fungsi newrbe spread 11 yaitu 9.65×10-6. Jika melihat secara keseluruhan dari Tabel 5 maka diketahui bahwa perbedaan nilai untuk
- 8 -
rata-rata MSE sangatlah kecil, namun berbeda dengan nilai CV-nya. Perbedaan nilai CV yang begitu besar diakibatkan karena perbedaan jumlah neuron dan besarnya bobot pada masing-masing lapisan input dan lapisan tersembunyi.
( a ) ( b )
( c ) ( d )
Gambar 5 Bentuk Kurva Model (a) RBFN NEWRBE 19 Maret 2009 (b) Validasi RBFN NEWRBE 20 Maret 2009 (c)
RBFN NEWRB 19 Maret (d) Validasi RBFN NEWRB 20 Maret 2009
Model arsitektur terbaik dari keempat model pada arsitektur RBFN(1,Q,1) adalah arsitektur RBFN (1,Q,1) dengan fungsi newrbe spread 29. Hal ini karena nilai CV yang dihasilkan terkecil dibandingkan de-ngan yang lain serta kurva yang dihasilkan juga relatif lebih halus seperti yang ditunjukkan salah satu contoh-nya pada Gambar 5, meskipun nilai rata-rata MSE-contoh-nya bukan yang terkecil dari keempat arsitektur tersebut.
Tabel 6 Nilai CV dan Rata-rata MSE model GRNN spread GRNN 0.5 GRNN 0.8
CV per model 6.33713×10-05 6.24934×10-05
Avg MSE per model 1.06483×10-05 1.20141×10-05
Berdasarkan Tabel 6, diketahui bahwa perbedaan nilai untuk nilai CV rata-rata MSE sangatlah kecil. Perbedaan kedua nilai tersebut kurang dari sepersepuluhribu. Hal ini sangat berbeda sekali dengan arsitektur RBFN karena pada arsitektur GRNN untuk validasi hari berikutnya menggunakan acuan nilai fits model pada saat itu, sedangkan pada arsitektur RBFN menggunakan acuan nilai bobot dan bias pada lapisan input dan lapisan tersembunyi pada saat itu untuk validasi hari berikutnya. Tabel 6 menunjukkan bahwa nilai CV ter-kecil dihasilkan oleh arsitektur GRNN(1,Q,2,1) dengan spread 0.8 yaitu sebesar 6.24934×10-5 namun rata-rata MSE terkecil dihasilkan oleh arsitektur GRNN(1,Q,2,1) dengan spread 0.5 yaitu sebesar 1.06483×10-5.
- 9 -
( a ) ( b )
Gambar 6 Bentuk Kurva Model (a) GRNN 22 April 2009 (b) Validasi GRNN 23 April 2009
Model arsitektur terbaik dari kedua model pada arsitektur GRNN(1,Q,2,1) adalah arsitektur GRNN (1,Q,2,1) dengan nilai spread 0.8. Arsitektur ini dianggap yang terbaik karena secara keseluruhan hasil yang diberikan oleh arsitektur ini lebih unggul daripada arsitektur GRNN(1,Q,2,1) dengan nilai spread 0.5. Titik berat penilaian terdapat pada nilai CV dan kehalusan kurva.
4.4. Pemilihan Arsitektur Jaringan Terbaik
Setelah melakukan permodelan dengan masing-masing arsitektur jaringan, selanjutnya dilakukan perbandingan semua arsitektur tersebut untuk mendapatan model arsitektur jaringan yang terbaik. Perban-dingan ini dilihat tidak hanya dari perhitungan yang diperoleh, namun juga dari sisi keunggulan yang dimiliki masing-masing model arsitektur. Arsitekur RBFN yang digunakan adalah RBFN(1,Q,1) dengan fungsi new-rbe spread 29, sedang aristektur GRNN yang digunakan adalah GRNN(1,Q,2,1) dengan spread 0.8. Keduanya merupakan model terbaik dari masing-masing arsitektur jaringan yang dimiliki.
( a ) ( b )
Gambar 7 Bentuk Kurva Model (a) RBFN 21-22 April 2009 (b) GRNN 21-22 April 2009
Berdasarkan Tabel 5 dan Tabel 6 dapat dilihat bahwa untuk selisih rata-rata MSE arsitektur RBFN dengan GRNN tidak lebih dari sepersepuluhribu. Hal ini menunjukkan bahwa kedua arsitektur dalam pem-buatan model pada saat itu sama baiknya. Namun hasil yang sangat berbeda secara signifikan ditunjukkan dari nilai CV yang dihasilkan oleh masing-masing arsitektur jaringan. Selisih antara keduanya cukup besar. Arsitektur GRNN masih bisa menghasilkan nilai CV yang lebih kecil dibandingkan arsitektur RBFN. Jika melihat kurva yang dihasilkan maka dengan membandingkan bentuk kurva pada waktu yang sama serta kurva validasi untuk hari berikutnya terlihat bahwa kurva arsitektur GRNN lebih halus dibandingkan arsitektur RBFN. Selain itu kurva arsitektur GRNN lebih stabil untuk menggambarkan kurva validasinya dibandingkan arsitektur RBFN. Kurva validasi RBFN masih tergantung nilai bobot yield to maturity pada time to maturity
- 10 -
tertentu. Jika yield to maturity pada time to maturity tersebut mempunyai nilai bobot yang besar kemudian bobot tersebut digunakan untuk membuat model validasi pada hari berikutnya maka ada kemungkinan bentuk kurva validasi yang dihasilkan terdapat ketidakwajaran bentuk.
Berdasarkan pemaparan sebelumnya maka arsitektur model neural network terbaik yang dapat menjelaskan keadaan data oligasi pemerintah Indonesia adalah arsitektur GRNN (1,Q,2,1) dengan nilai spread 0.8. Hal ini karena nilai rata-rata MSE dan nilai CV yang dihasilkan relatif kecil jika dibandingkan dengan yang lain, kehalusan bentuk kurva pada waktu tertentu dan validasi untuk hari berikutnya lebih halus, dan sifat ketegaran bentuk kurva dalam pembuatan model validasi hari berikutnya.
4.5 Perbandingan Dengan Model Lain
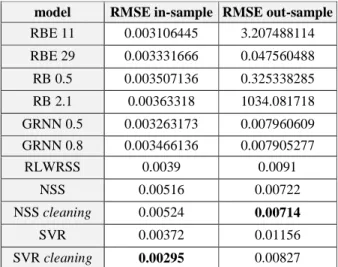
Tabel 7 menunjukkan perbandingan nilai RMSE yang dihasilkan dari 11 model yang digunakan dalam menggambarkan data yield curve obligasi pemerintah Indonesia. RMSE yang dihasilkan dari masing-masing model terbagi menjadi dua jenis, yaitu RMSE in-sample (selisih hasil estimasi data YTM dengan nilai YTM pada hari tersebut) dan RMSE out-sample (selisih hasil prediksi data YTM dengan YTM pada hari berikutnya). Data RMSE selain metode neural network diperoleh dari hasil penelitian yang telah dilakukan oleh Lestari (2009) dan Angraeni (2009). Perbandingan dengan hasil model yang lain dilakukan karena data yang digunakan adalah sama, yaitu data YTM-TTM obligasi peme-rintah Indonesia periode Januari sampai dengan April 2009 yang diperoleh dari IBPA.
Tabel 7 Perbandingan 11 Model Yield Curve model RMSE in-sample RMSE out-sample
RBE 11 0.003106445 3.207488114 RBE 29 0.003331666 0.047560488 RB 0.5 0.003507136 0.325338285 RB 2.1 0.00363318 1034.081718 GRNN 0.5 0.003263173 0.007960609 GRNN 0.8 0.003466136 0.007905277 RLWRSS 0.0039 0.0091 NSS 0.00516 0.00722 NSS cleaning 0.00524 0.00714 SVR 0.00372 0.01156 SVR cleaning 0.00295 0.00827
Berdasarkan tabel 7, dapat diketahui bahwa nilai RMSE in-sample terkecil yang dihasilkan model diperoleh dari model Support Vector Regression (SVR) cleaning yaitu sebesar 0.00295 dan RMSE out-sample terkecil yang dihasilkan model diperoleh dari model Nelson Siegel Svenson (NSS) cleaning yaitu sebesar 0.00714. Jika melihat rata-rata RMSE in-sample yang nilainya 0.003753 maka dapat diketahui bahwa untuk model yang menggunakan metode neural network semua nilainya berada dibawah rata-rata tersebut. Selisih-nya dengan nilai RMSE in-sample terkecil berkisar antara 0.00068 sampai 0.00006 dan selisih tersebut relatif kecil nilainya. Jika melihat selisih RMSE out-sample terkecil dengan RMSE out-sample model GRNN maka nilainya juga relatif kecil yaitu 0.00082 dan 0.00077. Secara umum model GRNN memang bukan model yang terbaik jika melihat dari kriteria RMSE yang dihasilkan, namun model GRNN relatif lebih konstan dalam memberikan nilai estimasi dan nilai prediksi untuk data yield curve obligasi pemerintah Indonesia.
- 11 - 5. Kesimpulan
Berdasarkan analisis dan pembahasan pada bab sebelumnya dapat disimpulkan bahwa metode neural network yang dapat memodelkan yield curve data obligasi pemerintah yang sesuai bagi pasar obligasi di Indonesia adalah arsitektur jaringan RBFN(1,Q,1) dengan spread 29 (tanpa fungsi clustering) dan arsitektur jaringan GRNN(1,Q,2,1) dengan spread 0.8 sedangkan arsitektur jaringan terbaik dari keduanya adalah arsitektur jaringan GRNN(1,Q,2,1) dengan spread 0.8. Kurva imbal hasil obligasi pemerintah yang dibangun pada waktu tertentu dengan arsitektur jaringan GRNN(1,Q,2,1) dengan spread 0.8 dapat berlaku baik untuk menentukan harga wajar obligasi pemerintah pada hari berikutnya, namun dengan arsitektur jaringan RBFN(1,Q,1) dengan fungsi newrbe spread 29 hanya dalam kondisi tertentu saja.
Daftar Pustaka
Andres, U. and Korn, O. (1999). Model Selection In Neural Network. Neural Network 12 No 309-323. Angraeni, D.D. (2009). Pemodelan Yield Curve Obligasi Peme-rintah Indonesia Dengan Robust Locally
Weighted Re-gression Smoothing Scatterplots. Tugas Akhir S-1 ITS Surabaya.
Baeur, M.M. (2000). General Regression Neural Network for Technical Use. Thesis of University of Wisconsin-Madison.
Deaves, R. and Parlar, M. (2000). A Generalized Bootstrap Method to Determine The Yield Curve. Applied Mathematical Finance, vol. 7, issue 4, pages 257-270.
Fabozzi, F. J. (2000a). Investment Management (2 ed.). Prentice-Hall, Inc.
Fabozzi, F. J. (2000b). Bond Market Analysis and Strategies (4 ed.). Prentice-Hall, Inc.
Kusumadewi, S. (2004). Membangun Jaringan Syaraf Tiruan Menggunakan MATLAB dan Excel Link. Yogyakarta: Graha Ilmu.
Kristanto, A. (2004). Jaringan Syaraf Tiruan (Konsep Dasar, Algoritma, dan Aplikasi). Yogyakarta: Gava Media.
Lestari, P. (2009). Aplikasi Metode Support Vector Regression Dalam Pembentukan Model Yield Curve Untuk Govern-ment BondsIndonesia. Tugas Akhir S-1 ITS Surabaya.
Orr, M.L.J. (1994). Extrapolating Uncertain Bond Yield Predictions. Edinburgh University.
Poggio, T. and Girosi, F. (1990). Networks for approximation and learning. Proc IEEE 78(9):1481–1497. Specht, D.F. (1991). A General Regression Neural Network. IEEE Transactions on Neural Networks, Vol 2
pp. 568-576.
Swamy, M.N.S. (2006). Neural Networks in a Softcomputing Framework. Germany: Springer Science and Business Media.
Tim Jurusan Statistika ITS dan PT. PHEI. (2008). Validasi dan Uji Kelayakan Model Pricing PHEI.
Trapletti, A. (2000). On Neural Networks as Statistical Time Series Models. Dissertation of Institute for Statistics Wien University.
Yaniar, R. (2009). Permodelan Yield Curve Untuk Government Bonds Indonesia dengan Metode Parametrik Dan Non-Parametrik. Tugas Akhir S-1 ITS Surabaya.