BAB 2
LANDASAN TEORI
2.1. Ekstraksi Kata Kunci
Dalam bahasa Inggris, kata kunci sering disebut kedalam 2 istilah yaitu keyphrase dan
keyword. Istilah keyphrase dan keyword mengandung satu pengertian sebagai sebuah kata kunci yang penting dalam menjelaskan dan memberi gambaran terhadap isi suatu
dokumen. Keyphrase merujuk kepada kata kunci yang terdiri dari gabungan kata/multiword (contoh: Demam Berdarah, Bahasa Isyarat, Kotak Hitam Pesawat, dll), sedangkan untuk istilah keyword sering ditujukan untuk kata kunci yang terdiri dari satu kata saja (Contoh: Bahasa, Demam, Kotak, dll) (Siddiqi,et al. 2015). Ekstraksi kata kunci penting dilakukan terutama dalam pengolahan aplikasi text
mining. Beberapa aplikasi text mining yang menerapkan tahapan ekstraksi kata kunci yaitu aplikasi peringkasan teks otomatis, pengelompokkan dokumen, clustering, dan lain sebagainya. Terdapat 2 pendekatan dalam ekstraksi kata kunci yang umum
digunakan dalam pemodelan algoritma ekstraksi kata kunci yaitu unsupervised dan
supervised. Perbedaan umum dari pendekatan supervised dan unsupervised adalah dari ada atau tidaknya data latihnya. Pendekatan unsupervised tidak membutuhkan data latih sedangkan pada pendekatan supervised untuk mendapatkan kata kuncinya dibutuhkan pemrosesan data latih. Berikut beberapa pendekatan yang biasa digunakan
untuk pemrosesan ekstraksi kata kunci dalam pengolahan aplikasi text mining
berdasarkan beberapa penelitian sebelumnya :
a. Pendekatan Unsupervised
Pendekatan unsupervised terbagi kedalam 4 kategori yaitu perankingan berbasis graf (graph-based ranking), topic-based, simultaneous learning, dan
b. Pendekatan Supervised
Beberapa metode yang menggunakan pemodelan algoritma berdasarkan
pendekatan supervised ini seperti metode KEA(Keyprhase Extraction
Algorithm), KEA++, N-Gram, CRF(Conditional Random Field), dan lain sebagainya. Pendekatan ini berfokuskan pada 2 hal yaitu perumusan tugas(task
reformulation) dan pendesainan fitur (Hasan, et al.2014). c. Pendekatan pembelajaran mesin (machine learning)
Pendekatan ini menggunakan konsep pembelajaran seperti metode Supervised
(Siddiqi & Sharan, 2015). Beberapa metode yang termasuk kedalam bagian
pendekatan ini seperti metode support vector machine(SVM), Naive Bayes,
linear logistic regression (LLR), dan lain sebagainya. d. Pendekatan Statistikal
Pendekatan statistik didasarkan pada linguistic corpus dan fitur statistikal yang berasal dari korpus (Siddiqi & Sharan 2015). Salah satu metode yang termasuk
kedalam pendekatan ini yaitu TF-IDF.
2.2. Part-Of-Speech Tagging
Part-of-speech (POS) tagging merupakan salah satu tahapan awal pemrosesan pada aplikasi text mining. POS tagging digunakan untuk melabeli kata yang ada pada suatu kalimat dengan kelas katanya masing-masing. Label-label kata tersebut seperti kata
benda (noun), kata kerja(verb), kata keterangan(adverb), kata sifat(adjective) dan lain sebagainya. POS tagging biasa digunakan untuk pemfilteran kata pada tahapan
pre-processing dari text mining. Seperti pada tahapan ekstraksi kata kunci, POS tagging
dapat digunakan untuk mengambil kata yang hanya merupakan kata benda atau hanya
merupakan kata sifat ataupun mengambil dan memfilter semua jenis kata untuk
perhitungan kata sebagai kata kunci begitupun fungsinya pada aplikasi text mining
lainnya. Terdapat beberapa pendekatan pada POS tagging seperti pendekatan berbasis aturan (rule based), probabilistik, dan pendekatan transformasional (Wicaksono & Purwarianti 2010). Pada bahasa Indonesia ada beberapa kelas kata yang dapat
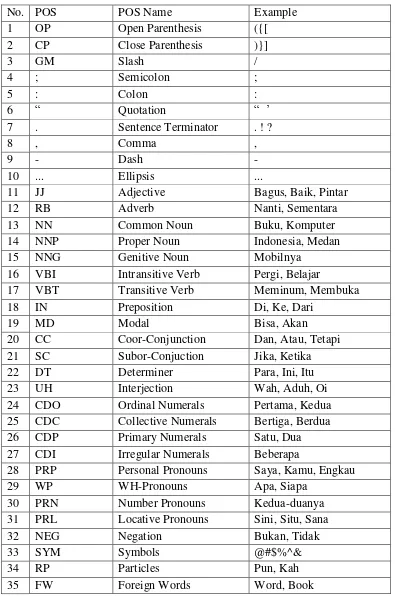
Tabel 2.1. Label Kata untuk Bahasa Indonesia (Wicaksono & Purwarianti 2010)
No. POS POS Name Example
1 OP Open Parenthesis ({[
2 CP Close Parenthesis )}]
3 GM Slash /
4 ; Semicolon ;
5 : Colon :
6 “ Quotation “ ‟
7 . Sentence Terminator . ! ?
8 , Comma ,
9 - Dash -
10 ... Ellipsis ...
11 JJ Adjective Bagus, Baik, Pintar
12 RB Adverb Nanti, Sementara
13 NN Common Noun Buku, Komputer
14 NNP Proper Noun Indonesia, Medan
15 NNG Genitive Noun Mobilnya
16 VBI Intransitive Verb Pergi, Belajar
17 VBT Transitive Verb Meminum, Membuka
18 IN Preposition Di, Ke, Dari
19 MD Modal Bisa, Akan
20 CC Coor-Conjunction Dan, Atau, Tetapi
21 SC Subor-Conjuction Jika, Ketika
22 DT Determiner Para, Ini, Itu
23 UH Interjection Wah, Aduh, Oi
24 CDO Ordinal Numerals Pertama, Kedua
25 CDC Collective Numerals Bertiga, Berdua
26 CDP Primary Numerals Satu, Dua
27 CDI Irregular Numerals Beberapa
28 PRP Personal Pronouns Saya, Kamu, Engkau
29 WP WH-Pronouns Apa, Siapa
30 PRN Number Pronouns Kedua-duanya
31 PRL Locative Pronouns Sini, Situ, Sana
32 NEG Negation Bukan, Tidak
33 SYM Symbols @#$%^&
34 RP Particles Pun, Kah
2.3. Multiword Expression
Multiword expression (MWEs) adalah gabungan kata yang antar kata penyusunnya saling terhubung dan membentuk susunan kata yang baru . Sebagai contoh gabungan
beberapa kata seperti : „Kecerdasan Buatan‟,‟Raja Hutan‟, ‟Rumah Sakit‟, „Kotak Hitam‟, ‟Demam Berdarah‟, dan lain sebagainya. Konsep multiword expression untuk bahasa Inggris dan bahasa Indonesia tidaklah jauh berbeda. Menurut Sag et al.(2002) makna semantik dari Multiword tidak dapat berasal dari gabungan makna semantik kata-kata penyusunnya. Untuk melakukan proses ekstraksi Multiword expression
(MWEs) ada beberapa teknik yang dapat diklasifikasikan kedalam 4 tipe (S.Agrawal,
et al.2014) yaitu:
Metode Statistikal (Cruys & Moiron, 2007)
Metode Symbolic, semantic or linguistic (Vitar & Fiser, 2008)
Metode Hybrid (Duan, et al. 2009 ; Boulaknadel, et al. 2008)
Metode Word alignment ( Moiron & Tiedemann, 2006).
Untuk ekstraksi multiword expression (MWEs) pada dokumen berbahasa Indonesia dapat digunakan suatu aturan metode multiword expression candidate
dimana metode ini memanfaatkan pemfilteran stopword dan tanda baca(Gunawan,et
al. 2016) yang pada penelitian ini penulis gunakan untuk mendapatkan kandidat kata kunci multiword yang selanjutnya akan diolah dengan algoritma textrank. Tahapan utama metode ini yaitu setiap kata yang telah ditokenisasi selanjutnya dideteksi dan
difilter kata mana saja yang merupakan stopword ataupun tanda baca. Kata-kata yang merupakan stopword atau tanda baca akan dihapus ataupun bisa juga diganti dengan tanda baca tertentu seperti tanda baca titik (.) . Kata-kata yang didahului tanda baca
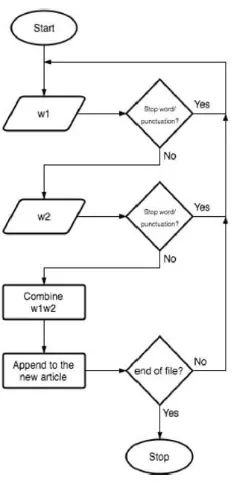
ataupun stopword tersebut kemudian akan digabungkan menjadi satu kata baru sesuai dengan persamaan 2.1 berikut (Gunawan, et al. 2016):
MWE Candidates = w1w2 w2w3 w3w4... wnw(n+1) (2.1)
Alur kerja selengkapnya dari aturan ekstraksi multiword expression candidate ini
Gambar 2.1. Flowchart Metode Multiword Expression Candidates (Gunawan, et al. 2016)
2.4. Algoritma TextRank
TextRank merupakan metode yang termasuk kedalam pendekatan unsupervised dan menggunakan pemodelan berbasis graf. Metode ini dikembangkan berdasarkan dari
metode PageRank (Brin & Page,1998 ; Mihalcea & Tarau,2004). Dasar dari model
berbasis perankingan graf yang diajukan oleh Mihalcea & Tarau(2004) ini yaitu
dengan mengimplementasikan tahapan “voting” pada setiap kata(vertex) dalam graf. Suatu vertex akan dianggap penting jika vertex tersebut di „vote’ lebih banyak dibandingkan dengan vertex lainnya. Nilai skor pada tiap vertex didalam graf ditentukan dari Persamaan 2.2 (Brin and Page,1994 ; Mihalcea, et al.2004) berikut :
S(Vi) = (1 - d) + d ∑
S(Vj) (2.2)
dimana nilai S(Vi) sebagai nilai score vertex Vi, dengan nilai d sebagai damping factor yang biasanya di set dengan nilai 0.85.
Menurut Mihalcea,et al.(2004) Persamaan 2.2 diatas dapat juga diterapkan untuk melakukan perankingan pada graf yang berbobot dengan menggunakan nilai
WS(Vi) = (1 - d) + d ∑ ∑
WS(Vj) (2.3)
dimana dalam rumus diatas terdapat wji yaitu sebagai bobot edge dari vertex Vj yang
berelasi dengan vertex Vi . wjijuga disebut sebagai bobot frekuensi kemunculan vertex
Vj dan Vi yang saling co-occurrence di dalam ukuran window dengan maksimum
L-kata. TextRank menggunakan hubungan kemunculan bersama satu kata dengan kata
yang lainnya (co-occurrence relation) dalam window maksimum L kata tersebut dimana ukuran L bisa di set antara 2 – 10 kata.
Pada metode textrank ini kandidat kata kunci didapat dengan filter kata
menggunakan part-of-speech tagging. Setiap kata yang akan dijadikan vertex dalam graf akan difilter berdasarkan filter kelas katanya seperti kata benda, gabungan kata
benda dan kata kerja, atau filter semua jenis kata. Dari hasil penelitian sebelumnya
hasil terbaik didapatkan dari filter kata berupa kata benda dan kata sifat saja. Untuk
metode TextRank oleh Mihalcea & Tarau (2004) ini frase atau kandidat kata kunci
berbentuk multiword di proses pada tahapan post-processing untuk menghindari besarnya hubungan relasi didalam graf. Berdasarkan hal itu Li & Wang (2014)
menyebutkan bahwasanya cara ini tidak bisa menjamin semua kata kunci yang
dihasilkan merupakan kata-kata yang sudah benar dalam satuan leksikal bahasanya
dan tidak semua kata-kata yang ada didalam kombinasi kata kunci bisa didapat dari k -ranking teratas. Untuk itu Li & Wang (2004) lalu menjalankan algoritma textrank
didalam konsep jaringan frase(phrase network) yaitu dengan meranking langsung kandidat kata kunci berbentuk frase ataupun multiword. Biasanya vertex dalam graph
pada algoritma textrank sebelumnya hanya berupa satu kata saja, tetapi dengan
jaringan frase ini maka akan diperluas hubungan co-occurrence kata menjadi berupa kata dan frase. Kandidat kata kunci atau vertex yang digunakan pada penelitian
tersebut didapat dengan memanfaatkan metode Document Frequency Accessor Variety (DF-AV) dikarenakan pada bahasa Cina pemfilteran menggunakan POS-tagging tidak menunjukkan hasil yang cukup baik.
Umumnya algoritma perankingan berbasis graf memiliki beberapa tahapan
Identifikasi satuan unit teks yang akan digunakan dan tambahkan setiap katanya sebagai vertex dalam graf.
Identifikasi hubungan yang terbentuk untuk setiap unit teks untuk menggambarkan edge dalam graf. Edge dapat berupa berarah atau tidak berarah (directed or undirected) ,berbobot atau tidak berbobot (weighted or unweighted).
Iterasi algoritma perankingan berbasis graf tersebut hingga konvergen (Convergence). Konvergen didapatkan ketika rata-rata nilai error untuk setiap
vertex di dalam graf berada dibawah nilai threshold yang diberikan.
Urutkan vertex yang terbentuk berdasarkan skor bobot akhirnya. Gunakan nilai skor bobot tiap kata tersebut sebagai urutan ranking.
Pada penelitiannya yang berkaitan dengan ekstraksi kata kunci, setiap vertex
didalam graf hanya berupa satu kata dan penentuan jumlah kata dengan bobot textrank
tertinggi yang akan menjadi kata kunci potensial tidak ditentukan secara statis
sehingga jumlahnya bisa ditentukan secara bebas yang dalam penerapannya jumlah
kata kunci potensial ditentukan sebanyak sepertiga dari jumlah teks didalam relasi
graf. Pada tahapan post-processing dari algoritma textrank, kata kunci satu kata akan dibentuk menjadi multiword dengan melihat apakah kata-kata tersebut saling berdekatan atau ber-adjacent didalam teks yang diolah.
2.5. Penelitian Terdahulu
Ekstraksi kata kunci selalu menjadi hal yang menarik untuk diteliti terutama dalam
menyelesaikan persoalan mengenai kata kunci yang terdiri dari beberapa kata
(multiword keyword). Banyak penelitian terdahulu telah mengembangkan beragam metode dan mengolah beragam sumber data untuk diteliti dan dicari kata kuncinya.
Akurasi kata kunci yang dihasilkan oleh penelitian terdahulupun sudah mencapai
tingkat akurasi yang sangat baik terutama untuk artikel berbahasa Inggris.
Bhaskar et al.(2012) menggunakan pendekatan supervised seperti Conditional Random Fields (CRF) yang menghasilkan nilai performansi untuk precision sebesar
32.34%, recall sebesar 33.09% dan F-measure sebesar 32.71%. Data yang digunakan merupakan dokumen ilmiah berbahasa Inggris sejumlah 144 dokumen untuk data
Ali et al.(2014) mencoba menggabungkan metode pembelajaran mesin (machine learning) seperti halnya linear logistic regression, linear discriminant
analysis dan support vector machines serta metode statistikal hybrid untuk proses ekstraksi keyphrase dokumen berbahasa Arab. Pada penelitian ini, terdapat 4 tahapan penentuan kata kunci yaitu document preprocessing, noun phrase extraction,
candidate feature extraction, dan klasifikasi. Pada tahapan dari penentuan kandidat frasa kunci hanya dikategorisasikan kedalam dua kategori yaitu kata benda dan frase
kata benda saja. Penelitian ini mencapai akurasi sebesar 88.31% menggunakan
algoritma SVM.
Figueroa et al.(2014) yang menggunakan HybridRank yaitu metode gabungan TextRank dan KEA untuk ekstraksi frase kunci dari abstrak jurnal berbahasa Inggris.
Pada penelitian ini menggunakan koleksi dokumen dari IEEE Xplore sebanyak 1606
dokumen dan koleksi dokumen Hulth 2003 sebanyak 2000 dokumen yang didalamnya
mengandung bagian abstrak. Pada penelitiannya ini dapat menghasilkan daftar
keyphrase dengan kualitas terbaik untuk artikel pendek berupa abstrak tersebut. Li et al.(2014) mencoba meningkatkan algoritma Textrank menggunakan domain pengetahuan untuk artikel ilmiah bahasa Cina. Pada penelitiannya ini,
algoritma textrank dimodifikasi pada bagian preprocessingnya dimana pada penentuan kandidat kata kuncinya menggunakan metode Document Frequency Accessor Variety (DF-AV) karena menurutnya jika menggunakan POS tagging tidak cukup akurat untuk diaplikasikan pada jurnal ilmiah bahasa Cina. Kemudian pada
penelitiannya ini digunakan pengetahuan terhadap kata kunci yang sudah dikenali
pada beberapa domain pengetahuan dengan menghitung panjang kata kunci,
komponen kata kuncinya, dan juga frekuensi tertinggi kata kunci untuk menggantikan
fungsi thesaurus seperti pada domain pengetahuan beberapa penelitian sebelumnya. Akurasi yang didapatkan ternyata mampu lebih tinggi dari algoritma TF-IDF.
Farizi (2015) membuat sistem rekomendasi tag pada berita online berbahasa
Indonesia dengan menggunakan metode TF-IDF dan Collaborative Tagging yang
menghasilkan persentase relevansi tag sekitar 79,97% dan 80,6%. Penggunaan metode
TF-IDF dan collaborative tagging sangat bergantung pada berita-berita yang telah dipublikasikan sebelumnya. Hasil Pengujian sistem menggunakan 9 berita masukan
kata yang menyusun frasa tersebut diawali dengan huruf kapital. Jika kata tersebut
tidak diawali oleh huruf kapital, maka kata tersebut dianggap sebagai kata biasa dan
bukan frase.
Paymard(2015) menggunakan metode neural network untuk menyelesaikan masalah ekstraksi frasa kunci dari dokumen berbahasa Persia secara
otomatis. Pada penelitian ini, Preprocessing yang dilakukan dengan menggunakan metode neural network mampu maningkatkan akurasi ekstraksi diatas 80%. Salah satu tahapan penting yang digunakan yaitu tahapan pembelajaran jaringan (network
learning) dengan memperhatikan parameter jumlah waktu pada network training. Tahapan preprocessing yang ada pada penelitian ini menjadi tahapan yang harus lebih diperhatikan karena akan meningkatkan akurasi kata kunci yang dihasilkan oleh
metode neural network.
Horita et al.(2016) melakukan penelitian untuk ekstraksi kata kunci untuk proses wikifikasi dimana yang menjadi data sumbernya yaitu artikel di dalam web
wikipedia untuk dokumen berbahasa asia seperti halnya dokumen bahasa Jepang
dengan menggunakan metode Top Consecutive Nouns Cohesion (TCNC) untuk proses ekstraksi kandidat kata kuncinya dan menggunakan Dice Coefficient atau
Keyphraseness untuk meranking kata kunci hasil ekstraksi. Wikifikasi merupakan metode untuk ekstraksi kata kunci secara otomatis dari sebuah dokumen dan
me-linknya kedalam artikel wikipedia yang sesuai. Pada penelitian ini digunakan artikel
wikipedia bahasa Jepang dimana jumlah data ujinya yaitu 296 link teks.
Penelitian terdahulu yang telah dijelaskan diatas akan diuraikan secara singkat pada
Tabel 2.2 berikut:
Tabel 2.2 Penelitian Terdahulu
No. Peneliti Tahun Metode Keterangan
1. Pinaki Bhaskar, Kishorjit
Nongmeikapam & Sivaji Bandyopadhyay
2012 Conditional Random Fields (CRF)
Data yang digunakan merupakan dokumen ilmiah berbahasa Inggris
Membutuhkan
tahapan training data.
Tabel 2.2 Penelitian Terdahulu (Lanjutan)
No Peneliti Tahun Metode Keterangan
dan 80,6% untuk
No Peneliti Tahun Metode Keterangan
6 Seyyede Fateme Paymard
2015 Metode neural network Data yang digunakan yaitu
Berdasarkan beberapa penelitian sebelumnya tersebut, maka pada penelitian
ini penulis memanfaatan algoritma textrank untuk diuji pada teks berbahasa Indonesia
dengan memodifikasi pada tahapan preprocessing-nya dimana pada tahapan ekstraksi kandidat kata kuncinya akan menggunakan aturan multiword expression candidate. Pada penelitian ini juga untuk setiap kata kunci yang diekstraksi kemudian akan
diperhitungkan komponen katanya yang akan dijalankan pada tahapan