TINJAUAN PUSTAKA
2.1 Pengunduran Diri Mahasiswa
Hampir tidak ada perguruan tinggi baik negeri maupun swasta (PTN/PTS) yang tidak
pernah mahasiswanya mengundurkan diri sebagai mahasiswa di PTN/PTS tersebut.
Hal ini dibuktikan dengan adanya peraturan pengunduran diri mahasiswa. Sebagai
contoh, Universitas Indonesia (UI) sendiri memiliki peraturan tersebut dan khusus
program studi computer science dapat diakses secara online, dan pada ketentuan
pengunduran mahasiswa Institut Pertanian Bogor (IPB) dicantumkan ketentuan
pengunduran diri mahasiswa baru dan reguler.
Peraturan Akademik STMIK Mikroskil Pasal 37 tentang drop out / putus studi
diberlakukan apabila: telah melewati batas masa studi untuk program sarjana paling
lama 14 semester atau program diploma paling lama 10 semester, tidak memenuhi
persyaratan minimal akademik, mendapat sanksi akibat melanggar tata tertib yang
berlaku (sumber : peraturan Akademik Mikroskil 2011-2015)
Pengunduran diri mahasiswa termasuk drop out di PTS bahkan cukup banyak,
seperti pada STMIK Mikroskil mencapai 88 orang rata-rata per tahun mahasiswa yang
mengundurkan diri dalam periode tahun 2007 hingga 2010 (sumber : SIPT Mikroskil).
Alasan pengunduran diri sangat beragam, seperti orangtua pindah tugas,
mahasiswa pindah kerja, berhenti kuliah, tidak sanggup mengikuti pelajaran, dan lain
sebagainya. Banyak diantara alasan tersebut ternyata hanya karangan belaka setelah
dibuktikan melalui beberapa penelusuran. Sehingga dibutuhkan lebih banyak
penelitian lagi tentang pola tersembunyi, kecenderungan pengunduran diri
mahasiswa. Berbeda dengan pengunduran diri, dropout diakibatkan oleh
ketidakmampuan mahasiswa dalam mencapai sejumlah SKS hingga semester tertentu.
Kecenderungan yang mempengaruhi drop out hampir sama dengan faktor
pengunduran diri.
2.2 Pengertian Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi
dihasilkan diperoleh dengan cara mengekstraksi dan mengenali pola yang penting atau
menarik dari data yang terdapat dalam basisdata.
Data mining adalah suatu istilah yang digunakan untuk menemukan
pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses
semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan,
dan machine learning untuk mengekstraksi dan mengidentifikasi informasi
pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam
database besar. (Turban et al, 2005 ).
Menurut Gartner Group data mining adalah suatu proses menemukan
hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam
sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan
teknik pengenalan pola seperti teknik statistik dan matematika (Larose, 2006).
Data mining adalah sebuah proses secara berulang dimana kemajuan
ditentukan oleh penemuan, baik melalui metode otomatis atau manual. Data mining
sangat berguna dalam sebuah analisis skenario eksplorasi dimana tidak adanya gagasan tentang suatu hasil yang “menarik”. Data mining menemukan informasi yang baru, berharga dalam volume data yang besar yang merupakan upaya kerjasama
manusia dan komputer. Hasil terbaik dicapai dengan menyeimbangkan pengetahuan
para ahli dalam menggambarkan masalah dan tujuan dengan kemampuan pencarian
komputer (Kantardzic, 2003).
“Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya, yang dapat dipahami dan bermanfaat bagi pemilik data.” (Larose, 2006).
“Data mining merupakan bidang dari beberapa keilmuan yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari database yang besar.” (Larose, 2006).
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong
oleh beberapa faktor, antara lain (Larose, 2006).
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Dari definisi-definisi yang telah disampaikan, hal penting yang terkait dengan
data mining adalah:
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin
memberikan indikasi yang bermanfaat.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua
atau lebih dalam satu dimensi. Misalnya dalam dimensi produk, kita dapat melihat
keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu, hubungan
juga dapat dilihat antara dua atau lebih atribut dan dua atau lebih objek.
(Ponniah, 2001).
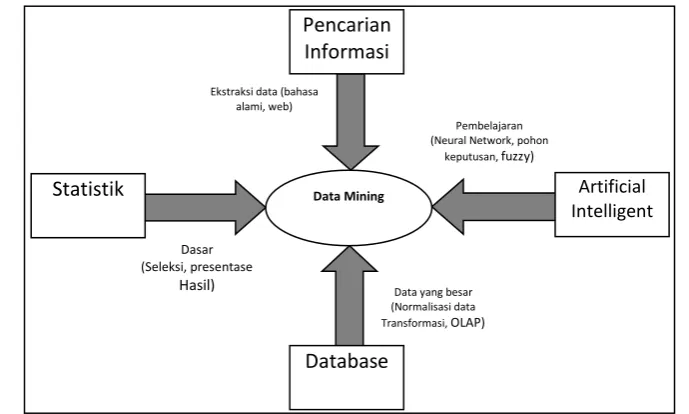
Gambar 2.1 Bidang Ilmu Data Mining
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan
untuk mendefinisikan data mining adalah kenyataan bahwa data mining mewarisi
banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu.
Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang
ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik,
database, dan juga information retrieval (Pramudiono, 2006).
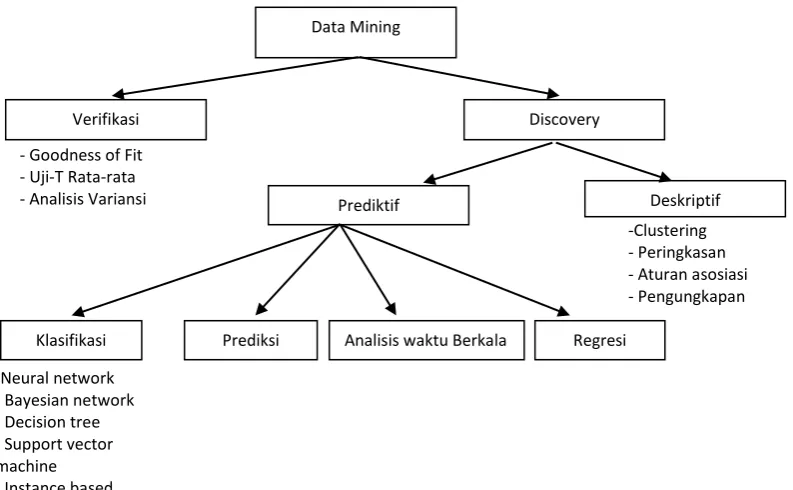
Metode data mining secara garis besar dapat dibagi dalam dua kelompok:
verifikasi dan discover. Metode verifikasi umumnya meliputi teknik-teknik statistic
seperti goodness of fit, Uji-T rata-rata dan analisis variansi. Metode discovery lebih
lanjut dapat dibagi atas model prediktif dan model deskriptif. Model prediktif
melakukan prediksi terhadap data dengan menggunakan hasil-hasil yang telah
diketahui dari data yang berbeda. Model ini dapat dibuat berdasarkan penggunaan data
historis lain. Sementara itu, model deskriptif bertujuan mengidentifikasi pola-pola
atau hubungan dalam data dan memberikan cara untuk mengeksplorasi sifat sifat data
yang diselidiki (Dunham 2003). Taksonomi metode-metode data mining dapat dilihat
pada gambar 2.2.
Gambar 2.2 Taksonomi data mining (Maimon & Last 2000, Dunham 2003)
Data mining terutama digunakan untuk mencari pengetahuan yang terdapat
dalam basis data yang besar sehingga sering disebut Knowledge Discovery in
Database (KDD). Proses pencarian pengetahuan ini menggunakan berbagai
teknik-teknik pembelajaran komputer (machine learning) untuk menganalisis dan
mengekstraksikannya. Proses pencarian bersifat iteratif dan interaktif untuk
-Neural network
menemukan pola atau model yang sahih, baru, bermanfaat dan dimengerti. Dalam
penerapannya data mining memerlukan berbagai perangkat lunak analisis data untuk
menemukan pola dan relasi data agar dapat digunakan untuk membuat prediksi
dengan akurat.
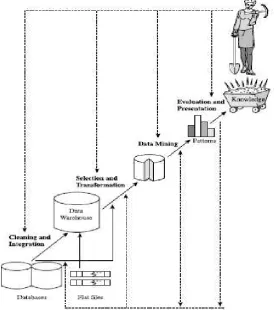
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa
tahap yang diilustrasikan di gambar 2.3. Tahap-tahap tersebut bersifat iterative dan
interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
Gambar 2.3 Tahap-tahap data mining (Han dan Kamber, 2006)
Tahap-tahap data mining ada 6 (enam) yaitu:
1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak
konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik
dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian
yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga
hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak
relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak
mempengaruhi performasi dari teknik data mining karena data yang ditangani
akan berkurang jumlah dan kompleksitasnya. 2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam
satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak
hanya berasal dari satu database tetapi juga berasal dari beberapa database
atau file teks. Integrasi data dilakukan pada atribut-aribut yang
mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis
produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara
cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang
menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai
contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan
produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk
yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena
itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang
membeli dalam kasus market basket analysis, tidak perlu mengambil nama
pelanggan, cukup dengan id pelanggan saja.
4. Transformasi data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam
data mining. Beberapa metode data mining membutuhkan format data yang
khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar
seperti analisis asosiasi dan clustering hanya bisa menerima input data
kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu
dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi
data.
5. Datamining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan
pengetahuan berharga dan tersembunyi dari data.
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang
ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola
yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa
yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai
hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya
umpan balik untuk memperbaiki proses data mining, mencoba metode data
mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang
di luar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang
digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap
terakhir dari proses data mining adalah bagaimana memformulasikan
keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus
melibatkan orang-orang yang tidak memahami data mining. Karenanya
presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami
semua orang adalah satu tahapan yang diperlukan dalam proses data mining.
Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan
hasil data mining (Han dan Kamber, 2006).
2.3 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat di
lakukan, yaitu (Larose, 2006): 1. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara
untuk menggambarkan pola dan kecendrungan yang terdapat dalam data.
Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat
menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional
akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan
kecendrungan sering memberikan kemungkinan penjelasan untuk suatu pola
atau kecendrungan. 2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi
menggunakan record lengkap yang menyediakan nilai dari variabel target
sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai
dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh,
akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit
berdasarkan umur pasien, jenis kelamin, berat badan, dan level sodium darah.
Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam
proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang
dihasilkan dapat digunakan untuk kasus baru lainnya. 3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam
prediksi nilai dari hasil akan ada di masa mendatang.
Contoh prediksi dalam bisnis dan penelitian adalah:
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika
batas bawah kecepatan dinaikan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi
dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Contoh lain klasifikasi dalam bisnis dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosa penyakit seorang pasien untuk mendapatkan termasuk kategori apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
Kluster adalah kumpulan record yang memiliki kemiripan suatu dengan yang
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target
dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan
klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan
tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian
terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki
kemiripan (homogen), yang mana kemiripan dengan record dalam kelompok
lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah:
a. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran
yang besar.
b. Untuk tujuan audit akutansi, yaitu melakukan pemisahan terhadap prilaku finansial dalam baik dan mencurigakan.
c. Melakukan pengklusteran terhadap ekspresi dari gen, dalam jumlah
besar.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul
dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis
keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler
yang diharapkan untuk memberikan respon positif terhadap penawaran
upgrade layanan yang diberikan.
b. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli bersamaan.
2.4 Pengertian Decision Tree
Decision tree merupakan salah satu metode klasifikasi yang menggunakan
representasi struktur pohon (tree) di mana setiap node merepresentasikan atribut,
cabangnya merepresentasikan nilai dari atribut, dan daun merepresentasikan kelas.
Decision tree merupakan metode klasifikasi yang paling populer digunakan.
Selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah
untuk dipahami.
Pada decision tree terdapat 3 jenis node, yaitu:
a. Root Node, merupakan node paling atas, pada node ini tidak ada input dan
bisa tidak mempunyai output atau mempunyai output lebih dari satu.
b. Internal Node, merupakan node percabangan, pada node ini hanya terdapat
satu input dan mempunyai output minimal dua.
c. Leaf node atau terminal node, merupakan node akhir, pada node ini hanya
terdapat satu input dan tidak mempunyai output.
2.5 Algoritma C 4.5
Algoritma C 4.5 adalah salah satu metode untuk membuat decision tree berdasarkan
training data yang telah disediakan. Algoritma C 4.5 merupakan pengembangan dari
ID3. Beberapa pengembangan yang dilakukan pada C 4.5 adalah sebagai antara lain
bisa mengatasi missing value, bisa mengatasi continue data, dan pruning.
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat
dan terkenal. Metode decision tree mengubah fakta yang sangat besar menjadi pohon
keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami
dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam bentuk bahasa basis
data seperti Structured Query Language untuk mencari record pada kategori tertentu.
Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan
tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target.
Karena pohon keputusan memadukan antara eksplorasi data dan pemodelan,
pohon keputusan sangat bagus sebagai langkah awal dalam proses pemodelan bahkan
ketika dijadikan sebagai model akhir dari beberapa teknik lain. Sebuah pohon
keputusan adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan
data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan
menerapkan serangkaian aturan keputusan. Dengan masing-masing rangkaian
pembagian, anggota himpunan hasil menjadi mirip satu dengan yang lain (Berry dan
Linoff, 2004).
Sebuah model pohon keputusan terdiri dari sekumpulan aturan untuk membagi
memperhatikan pada variabel tujuannya. Sebuah pohon keputusan mungkin dibangun
dengan seksama secara manual atau dapat tumbuh secara otomatis dengan
menerapkan salah satu atau beberapa algoritma pohon keputusan untuk memodelkan
himpunan data yang belum terklasifikasi.
Variabel tujuan biasanya dikelompokkan dengan pasti dan model pohon
keputusan lebih mengarah pada perhitungan probability dari tiap-tiap record terhadap
kategori-kategori tersebut atau untuk mengklasifikasi record dengan
mengelompokkannya dalam satu kelas. Pohon keputusan juga dapat digunakan untuk
mengestimasi nilai dari variabel continue meskipun ada beberapa teknik yang lebih
sesuai untuk kasus ini.
Banyak algoritma yang dapat dipakai dalam pembentukan pohon keputusan,
antara lain ID3, CART, dan C4.5 (Larose, 2006).
Data dalam pohon keputusan biasanya dinyatakan dalam bentuk tabel dengan
atribut dan record. Atribut menyatakan suatu parameter yang dibuat sebagai kriteria
dalam pembentukan pohon. Misalkan untuk menentukan main tenis, kriteria yang
diperhatikan adalah cuaca, angin, dan temperatur. Salah satu atribut merupakan atribut
yang menyatakan data solusi per item data yang disebut target atribut. Atribut
memiliki nilai-nilai yang dinamakan dengan instance. Misalkan atribut cuaca
mempunyai instance berupa cerah, berawan, dan hujan (Basuki dan Syarif, 2003)
Proses pada pohon keputusan adalah mengubah bentuk data (tabel) menjadi
model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule
(Basuki dan Syarif, 2003). Berikut ini algoritma dasar dari C4.5:
Input : sampel training, label training, atribut
1. Membuat simpul akar untuk pohon yang dibuat
2. Jika semua sampel positif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (+)
3. Jika semua sampel negatif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (-)
4. Jika atribut kosong, berhenti dengan suatu pohon dengan suatu simpul akar, dengan label sesuai nilai yang terbanyak yang ada pada label training
5. Untuk yang lain, Mulai
a. A --- atribut yang mengklasifikasikan sampel dengan hasil terbaik (berdasarkan Gain rasio)
b. Atribut keputusan untuk simpul akar --- A c. Untuk setiap nilai, vi, yang mungkin untuk A
2) Tentukan sampel Svi sebagai subset dari sampel yang mempunyai nilai vi untuk atrribut A
3) Jika sampel Svi kosong
i. Di bawah cabang tambahkan simpul daun dengan label = nilai yang terbanyak yang ada pada label training
ii. Yang lain tambah cabang baru di bawah cabang yang sekarang C4.5 (sampel training, label training, atribut-[A])
d. Berhenti
Mengubah tree yang dihasilkan dalam beberapa rule. Jumlah rule sama dengan
jumlah path yang mungkin dapat dibangun dari root sampai leafnode.
Tree Pruning dilakukan untuk menyederhanakan tree sehingga akurasi dapat
bertambah. Pruning ada dua pendekatan, yaitu:
a. Pre-pruning, yaitu menghentikan pembangunan suatu subtree lebih awal (yaitu dengan memutuskan untuk tidak lebih jauh mempartisi data training).
Saat seketika berhenti, maka node berubah menjadi leaf (node akhir). Node
akhir ini menjadi kelas yang paling sering muncul di antara subset sampel. b. Post-pruning, yaitu menyederhanakan tree dengan cara membuang
beberapa cabang subtree setelah tree selesai dibangun. Node yang jarang
dipotong akan menjadi leaf (node akhir) dengan kelas yang paling sering
muncul.
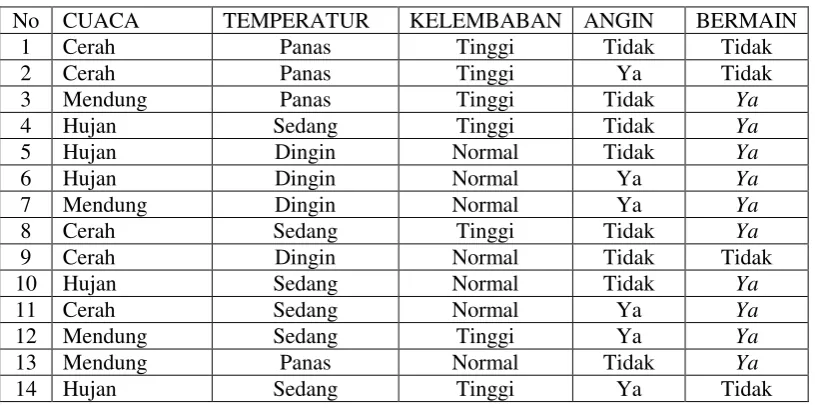
Untuk memudahkan penjelasan mengenai algoritma C4.5 berikut ini contoh
kasus keputusan bermain tenis yang dituangkan dalam Tabel 2.1
Tabel 2.1 Keputusan Bermain Tenis
No CUACA TEMPERATUR KELEMBABAN ANGIN BERMAIN
Dalam kasus yang tertera pada Tabel 2.1 akan dibuat pohon keputusan untuk
menentukan main tenis atau tidak dengan melihat keadaan cuaca, temperatur,
kelembaban dan keadaan angin.
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah
sebagai berikut:
1. Pilih atribut sebagai akar
2. Buat cabang untuk masing-masing nilai 3. Bagi kasus dalam cabang
4. Ulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari
atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera
dalam rumus (2.1) (Craw, 2005).
Gain(S,A) = Entrropy(S) – Expectation(A)
Gain(S,A) = Entrropy(S) –∑ ⃓𝑆𝑖⃓ ⃓𝑆⃓ 𝑛
𝑖=1 * Entropy(Si) (2.1)
Dengan
S : Himpunan Kasus
A : Atribut
N : Jumlah partisi atribut A
|Si| : Jumlah kasus pada partisi ke i
|S| : Jumlah total kasus dalam S
Sedangkan perhitungan nilai Entropy dapat dilihat pada rumus (2.2) berikut
(Craw, 2005):
Entropy(A) = ∑𝑛𝑖=1− 𝑝𝑖 ∗ log2pi (2.2)
Dengan
S : Himpunan Kasus
A : Fitur
n : Jumlah partisi S
pi : Proporsi dari Si terhadap S
Berikut ini adalah penjelasan lebih rinci mengenai masing-masing langkah
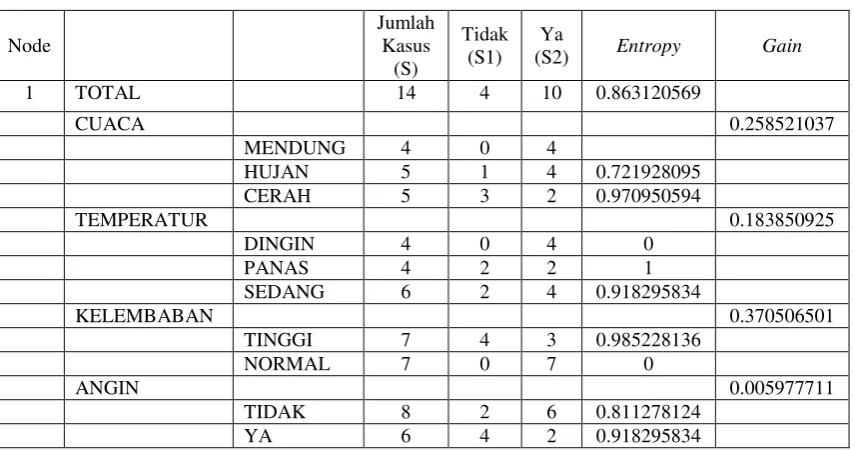
dalam pembentukan pohon keputusan dengan menggunakan algoritma C4.5 untuk
1. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus untuk keputusan Tidak, dan Entropy dari semua kasus dan kasus yang
dibagi berdasarkan atribut cuaca, temperatur, kelembaban dan angin.
Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil
perhitungan contoh kasus keputusan bermain tenis ditunjukkan oleh Tabel
2.2
Baris total kolom Entropy pada Tabel 2.2 dihitung dengan rumus (2.2), sebagai
berikut:
Gain(Total,Cuaca) = Entropy(Total) - ∑ |𝐶𝑢𝑎𝑐𝑎|
|𝑇𝑜𝑡𝑎𝑙| 𝑛
𝑖=1 * Entropy(Cuaca)
Gain(Total,Cuaca) = 0.863120569 – ((4
14*0) + ( 5
14*0.723) + ( 5
14*0.97)) Sehingga didapat Gain(Total,Cuaca) = 0.258521037
Dari hasil pada Tabel 2.2 dapat diketahui bahwa atribut dengan Gain tertinggi
adalah kelembaban yaitu sebesar 0.37. Dengan demikian kelembaban dapat menjadi
nilai atribut tersebut, nilai atribut normal sudah mengklasifikasikan kasus menjadi 1
yaitu keputusannya Ya, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi
untuk nilai atribut tinggi masih perlu dilakukan perhitungan lagi.
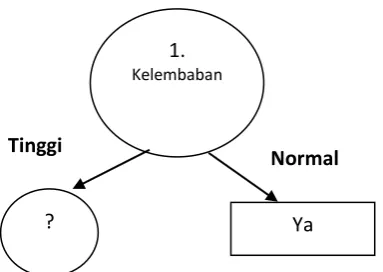
Dari hasil tersebut dapat digambarkan pohon keputusan sementara, tampak
seperti Gambar 2.4
Gambar 2.4 Pohon Keputusan Hasil Perhitungan Node 1
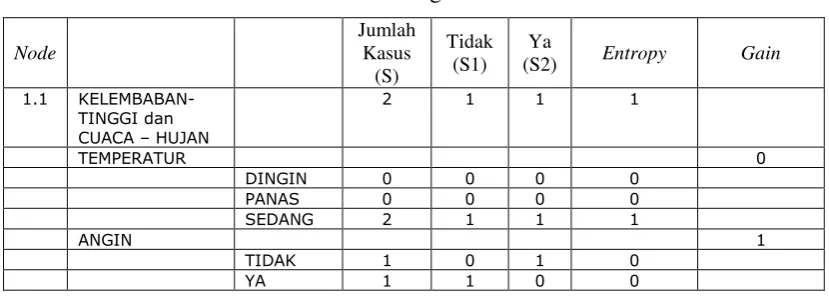
2. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus untuk
keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan
atribut cuaca, temperatur dan angin yang dapat menjadi node akar dari nilai atribut
tinggi. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil
perhitungan ditunjukkan oleh Tabel 2.3
Tabel 2.3 Perhitungan Node 1.1
Node
Dari hasil pada Tabel 2.3 dapat diketahui bahwa atribut dengan Gain tertinggi
adalah cuaca yaitu sebesar 0.699. Dengan demikian cuaca dapat menjadi node cabang
dari nilai atribut tinggi. Ada 3 nilai atribut dari cuaca yaitu mendung, hujan dan cerah.
dari ketiga nilai atribut tersebut, nilai atribut mendung sudah mengklasifikasikan
kasus menjadi 1 yaitu keputusannya Ya dan nilai atribut cerah sudah
mengklasifikasikan kasus menjadi satu dengan keputusan Tidak, sehingga tidak perlu
dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut hujan masih perlu
dilakukan perhitungan lagi.
Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada Gambar
2.5
Gambar 2.5 Pohon Keputusan Hasil Perhitungan Node 1.1
3. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus untuk
keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi
berdasarkan atribut temperatur dan angin yang dapat menjadi node cabang dari
nilai atribut hujan. Setelah itu lakukan penghitungan Gain untuk masing-masing
atribut. Hasil perhitungan ditunjukkan oleh Tabel 2.4
Tabel 2.4 Perhitungan Node 1.1.2
Dari hasil pada Tabel 2.4 dapat diketahui bahwa atribut dengan Gain tertinggi
adalah angin yaitu sebesar 1. Dengan demikian angin dapat menjadi node cabang dari
nilai atribut hujan. Ada 2 nilai atribut dari angin yaitu Tidak dan Ya. Dari kedua nilai
atribut tersebut, nilai atribut Tidak sudah mengklasifikasikan kasus menjadi 1 yaitu
keputusannya Ya dan nilai atribut Ya sudah mengklasifikasikan kasus menjadi satu
dengan keputusan Tidak, sehingga tidak perlu dilakukan perhitungan lebih lanjut
untuk nilai atribut ini. Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan
pada Gambar 2.6
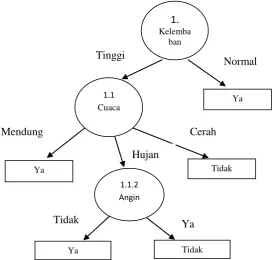
Gambar 2.6 Pohon Keputusan Hasil Perhitungan Node 1.1.2
Dengan memperhatikan pohon keputusan pada Gambar 2.6 diketahui bahwa
semua kasus sudah masuk dalam kelas. Dengan demikian, pohon keputusan pada
Gambar 2.6 merupakan pohon keputusan terakhir yang terbentuk.
2.6 Ekstraksi Rule dari Decision Tree
Pengetahuan yang diperoleh dari decision tree dapat direpresentasikan dalam bentuk
klasifikasi IF-THEN rules. Nilai suatu atribut akan menjadi bagian anticendent
(bagian IF), sedang daun (leaf) dari sebuah decision tree akan menjadi bagian
Ya Tidak
Tidak Ya
1.
Kelemba ban
Ya
1.1
Cuaca
Normal Tinggi
Tidak
1.1.2 Angin
Ya
Cerah
consequent (THEN). Aturan seperti ini akan menjadi sangat membantu manusia
dalam memahami model klasifikasi terutama jika ukuran decisiontree terlalu besar.
2.7 Riset-Riset Terkait
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti berkaitan dengan
seperti yang akan dijelaskan di bawah ini:
Kotsiantis (2009) dalam risetnya mengatakan bahwa mahasiswa drop out
terjadi cukup sering yang menyelenggarakan pendidikan jarak jauh dan tingkat putus
sekolah lebih tinggi dibandingkan pendidikan konvensional. Membatasi mahasiswa
drop out sangat penting dalam pembelajaran jarak jauh dan oleh karena itu
kemampuan untuk memprediksi drop out mahasiswa sangat bermanfaat dengan
sejumlah cara yang berbeda. Menggunakan studi eksperimental metodologi yang
diusulkan local cost sensitive tevhnique. Percobaan berlangsung dalam dua tahap yang
berbeda. Tahap pertama (fase pelatihan) algoritma dilatih dengan menggunakan data
yang dikumpulkan dari tahun ajaran sebelumnya. Atribut yang dikumpulkan antara
lain gender, age, marital status, number of children, occupation, computer literacy,
job associated with computers, face to face meeting, written assignment. Selanjutnya
tutor mengumpulkan sepuluh kelompok data dari tahun ajaran baru. Masing masing
dari sepuluh kelompok digunakan untuk mengukur prediksi akurasi dalam kelompok
ini (fase pengujian)
Kumar dan Vijayalakshmi (2011) dalam risetnya mempelajari data pendidikan
dengan metode klasifikasi seperti decision tree untuk memprediksi perilaku siswa dan
kinerja dalam hasil ujian akhir, hasil prediksi akan membantu tutor untuk
mengidentifikasi siswa yang lemah dan membantu siswa untuk nilai skor yang lebih
baik. Algoritma decision tree 4.5 diterapkan pada data penilaian internal siswa untuk
memprediksi siswa dalam performance ujian akhir. Hasil dari pohon keputusan
memprediksi jumlah siswa yang cenderung gagal atau lulus. Hasilnya diberikan
kepada tutor dan mengambil langkah-langkah untuk meningkatkan performance siswa
yang diprediksi akan gagal. Hasil analisis menyatakan bahwa pembuatan prediksi
telah membantu siswa yang lebih lemah untuk membawa perbaikan dan meningkatkan
keberhasilannya.
Sunjana (2010a) hasil risetnya mengenai teknik klasifikasi menggunakan
menemukan pola yang terjadi pada data mata kuliah mahasiswa. Penerapan algoritma
C 4.5 untuk melihat apakah IPK seorang mahasiswa dapat diperkirakan berdasarkan
nilai beberapa mata kuliah yang dianggap paling signifikan dalam menentukan IPK
seorang mahasiswa. Matakuliah yang diambil merupakan matakuliah yang wajib
diambil oleh setiap mahasiswa di setiap semesternya dan yang saling berhubungan
satu dengan yang lainnya atau matakuliah prasyarat. Hasil uji yang diperoleh
didapatkan prosentase error rate dari data training pada matakuliah. Semakin besar
prosentase nilai error rate yang dihasilkan pada data testing, maka rule yang
dihasilkan pun tidak baik. Begitu juga sebaliknya.
Sunjana (2010b) menjelaskan dalam risetnya tentang klasifikasi data nasabah
sebuah asuransi menggunakan algoritma C 4.5. Dengan algoritma tersebut dapat
diketahui data nasabah mana yang dikelompokkan ke kelas lancar dan data nasabah
mana yang dikelompokkan kekelas tidak lancar. Kemudian pola tersebut dapat
digunakan untuk memperkirakan nasabah yang bergabung, sehingga perusahaan bisa
mengambil keputusan menerima atau menolak calon nasabah tersebut. Atribut yang
digunakan dalam penelitian adalah penghasilan, premi dasar, cara pembayaran, mata
uang dan status sedang. Label yang digunakan untuk pengklasifikasian adalah lancar
dan tidak lancar
Quadri dan Kalyankar (2010) juga menjelaskan tentang performance akademik
mahasiswa sangat penting untuk lembaga pendidikan dan membuat rencana program
strategis yang dapat direncanakan dalam meningkatkan atau mempertahankan
performance siswa selama periode mereka mengikuti pelajaran di perguruan tinggi
tersebut. performance siswa diukur dengan rata-rata IPK setelah lulus. Penelitian ini
menyajikan data mining dalam memprediksi siswa drop out. Menggunakan teknik
decision tree untuk memilih analisis dan prediksi yang terbaik. Daftar mahasiswa
yang sudah diprediksi kemungkinan untuk drop out dengan data mining diserahkan
kepada guru dan manajemen untuk intervensi langsung atau tidak langsung. Analisis
komponen menggabungkan sejumlah metode machine learning secara otomatis
menganalisis data dalam log database. Menggunakan metode decision tree yang
bertujuan untuk mengkarakterisasi motivasi siswa.
Al-Radaideh et al. (2006) menjelaskan dalam risetnya tentang performance
siswa menjadi perhatian besar terhadap pendidikan tinggi dimana ada beberapa faktor
mining khususnya klasifikasi untuk membantu dalam meningkatkan kualitas sistem
pendidikan tinggi dengan mengevaluasi data siswa, mempelajari atribut utama yang
dapat mempengaruhi performance siswa dalam program pendidikan. Tiga metode
klasifikasi algoritma yang berbeda diuji ID3, C 4.5 dan Naïve Bayes. Proses generasi
didasarkan pada decision tree sebagai metode klasifikasi dimana rule yang dihasilkan
dipelajari dan dievaluasi. Rule dibangun yang memungkinkan siswa untuk
memprediksi nilai akhir dalam suatu program studi yang diteliti. Pengetahuan yang
didapat digunakan untuk memberikaan pola pemahaman pendaftaran siswa diteliti,
tindakan untuk memberikan kelas keterampilan kursus dasar tambahan, konseling
akademis.
Adeyemo dan Kuye (2006) menjelaskan dalam risetnya, menyajikan evaluasi
faktor-faktor yang berkontribusi terhadap performance akademik siswa di perguruan
tinggi. Variable kualifikasi untuk masuk dan tipe penerimaan mahasiswa dan
bagaimana faktor-faktor yang mempengaruhi performance akademik siswa. Evaluasi
dilakukan menggunakan perangkat lunak komputer yang mengimplementasikan
algoritma decision tree.
2.8. Persamaan dengan riset-riset lain
Curtis et al (1983) dalam penelitiannya pelajar sekolah menengah yang drop out di
sekolah adalah yang tidak mampu secara sosial dan ekonomi.
Gerben W. Dekker et all (2009) dalam penelitiannya melakukan prediksi
mahasiswa yang drop out dengan mengkalsifikasikan kelompok mahasiswa yang
drop out setelah semester pertama mereka belajar atau memprediksi sebelum mereka
masuk ke program studi serta mengidentifikasi faktor-faktor sukses tertentu.
Hasil penelitian Khoirunnisak dan Iriawan (2010) dalam penelitiannya
tingginya tingkat keberhasilan dan rendahnya tingkat kegagalan mahasiswa
mencerminkan kualitas proses belajar mengajar dari suatu perguruan tinggi. Dan
membuktikan bahwa mahasiswa yang dropout dari ITS Surabaya dipengaruhi oleh
faktor perbedaan usia, perbedaan asal daerah mahasiswa, perbedaan penghasilan
orang tua, perbedaan fakultas mahasiswa, perbedaan jalur masuk, serta perbedaan
nilai IPK dan nilai TPB. menggunakan pendekatan Bayesian mixture survival melalui
Jadric, et all (2010) dalam penelitiannya data diproses dengan aplikasi metode
data mining, regressi logistic, pohon keputusan dan neural network. Model dibangun
menggunakan metodologi SEMMA yang dibandingkan dengan memilih salah satu
prediksi terbaik mahasiswa drop out .
2.9 Perbedaan dengan Riset-Riset lain
Dari beberapa riset yang dilakukan peneliti sebelumnya, terdapat beberapa titik
perbedaan dengan riset yang akan dilakukan ini:
1. Analisis mahasiswa yang mengundurkan diri/pindah, risetnya dilakukan di Sekolah Tinggi Manajemen Informatika dan Komputer (STMIK) Mikroskil
Medan. Yang akan dilakukan penulis adalah mendapatkan model aturan / rule
penyebab mahasiswa pindah/mengundurkan diri dari sekumpulan data set historis
sehingga didapatkan klasifikasi keterhubungan dalam bentuk decision tree.
variabel datanya diolah dari data kuesioner mahasiswa STMIK Mikroskil Medan
seperti fasilitas belajar mahasiswa, lingkungan belajar, interest, disiplin, peraturan
akademik, dukungan orang tua, ekonomi orang tua, biodata mahasiswa dan data
akademik mahasiswa.
Kuesioner dilakukan sebagai alat penting dalam mendapatkan sejumlah
perwakilan orang untuk menjawab pertanyaan dan membuat penilaian dari apa
yang kebanyakan orang pikirkan. Informasi yang diperoleh dari kuesioner dapat
digunakan untuk tren dan perubahan plot pada persepsi publik. 2. Predikat mahasiswa beresiko
Pada riset ini, hasil akhir yang diharapkan pihak manajamen dan program studi
mendapatkan model rule penyebab mahasiswa perguruan tinggi mengundurkan
diri/pindah.
2.10 Kontribusi Riset
Penelitian ini memberikan kontribusi pada pemahaman tentang hubungan data
mahasiswa yang berpotensi berisiko dengan faktor faktor yang mempengaruhi
mahasiswa berhenti studi, berdasarkan predikat berisiko mengundurkan diri/pindah
dan predikat perlunya perhatian ekstra sehingga dapat diberi motivasi dan
Kontribusi lainnya adalah membantu pimpinan perguruan tinggi dalam
membuat suatu rencana yang bersifat strategis. Penelitian ini memperkenalkan suatu
aplikasi metode klasifikasi rule decision tree menggunakan algoritma C4.5 untuk