Directory UMM :wiley:Public:college:hill:
Teks penuh
Gambar
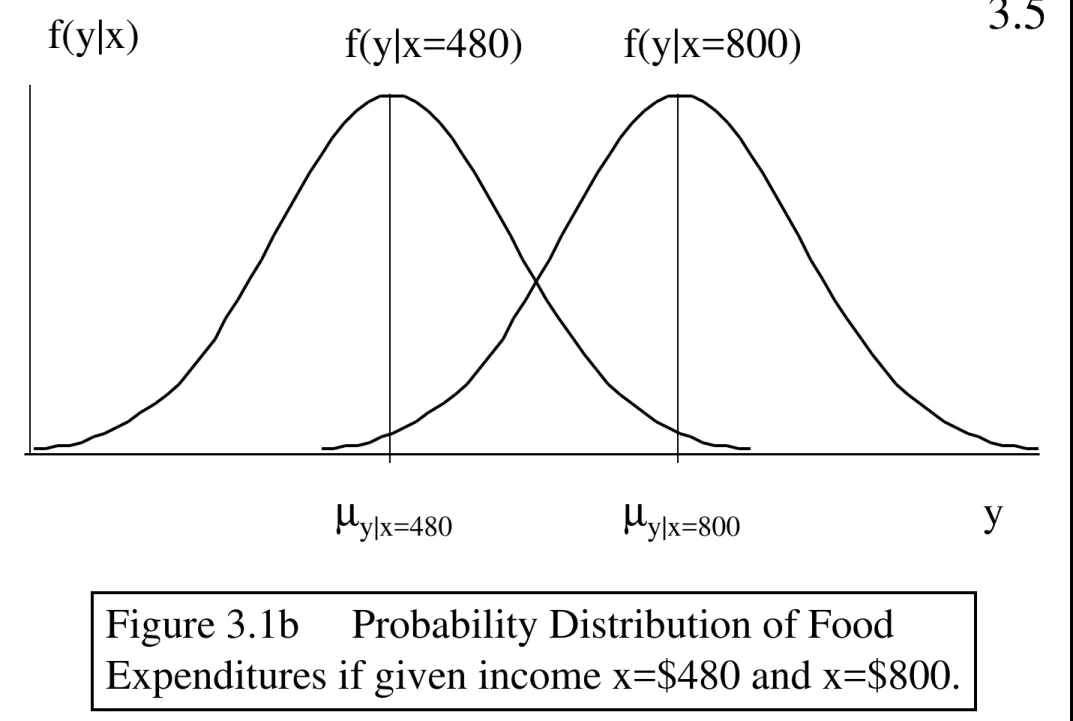
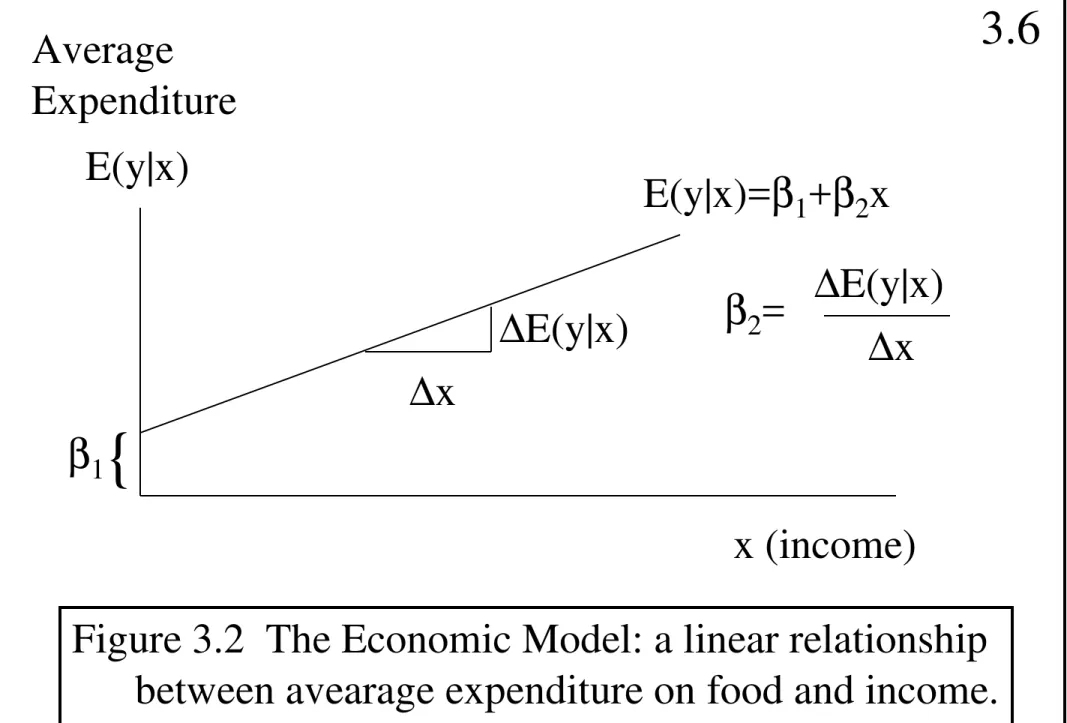
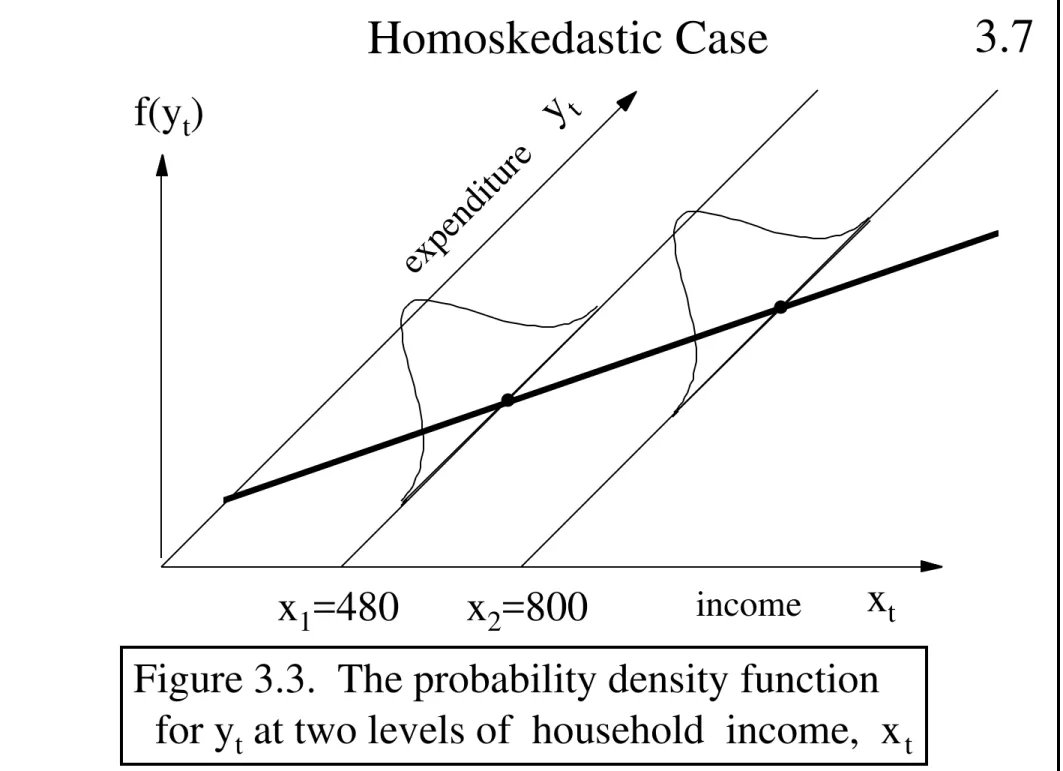

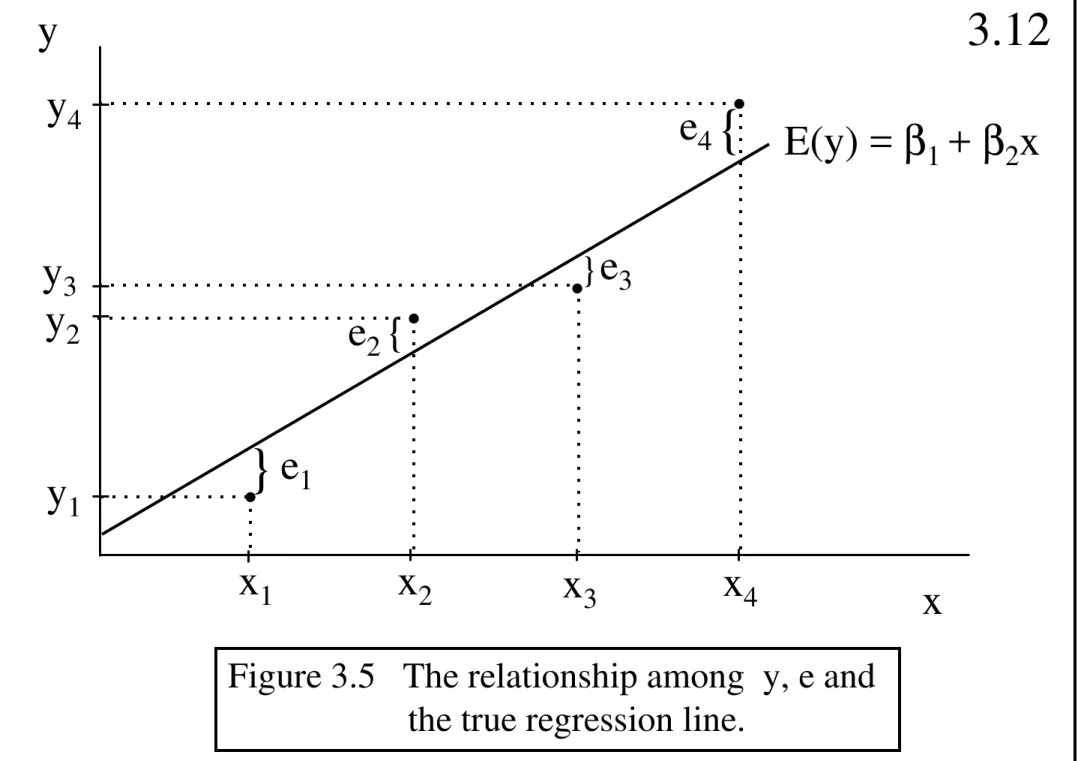
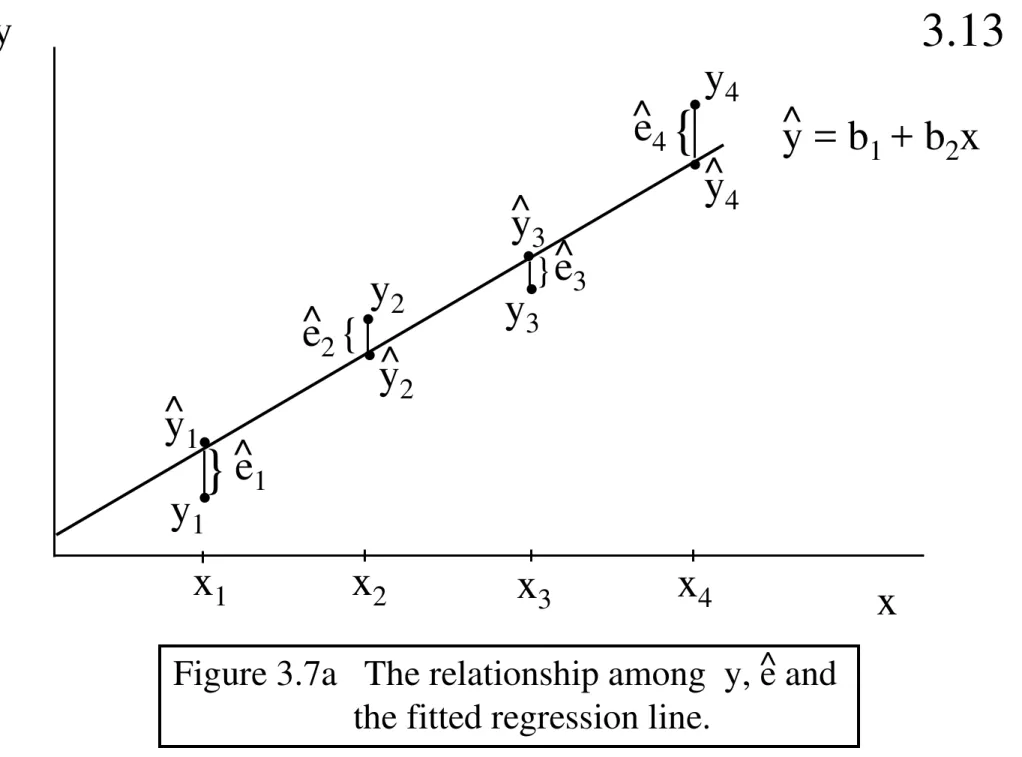
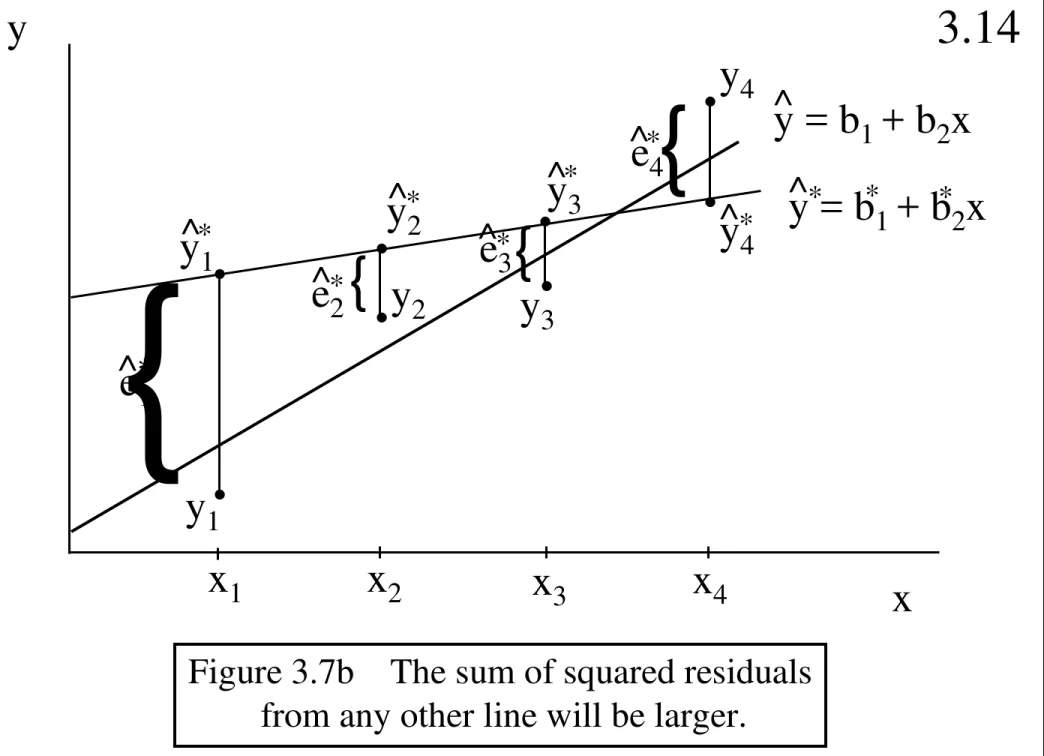


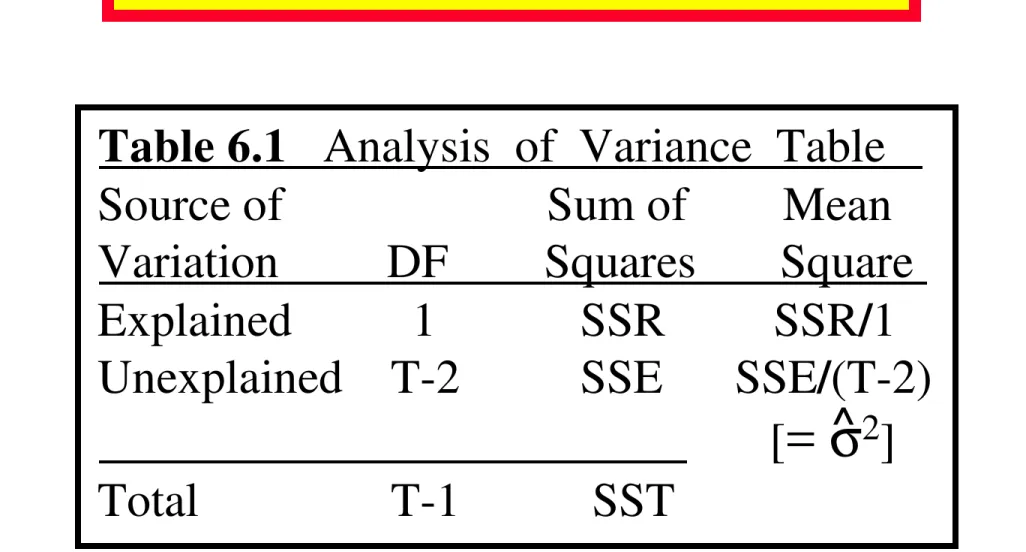
Garis besar
Dokumen terkait
Section 117 of the 1976 United States Copyright Act without the express written permission of the copyright owner
16.40 Copyright 1996 Lawrence C. All rights reserved. Reproduction or translation of this work beyond that permitted in Section 117 of the 1976 United States Copyright Act
permitted in Section 117 of the 1976 United States Copyright Act without theexpress written permission of the copyright owner is unlawful.. Request
Reproduction or translation of this work beyond that permitted in Section 117 of the 1976 United States Copyright Act without the express written permission of the copyright owner
Journal of Vacation Marketing; Apr 2008; 14, 2; ProQuest Central pg... Reproduced with permission of the
Reproduced with permission of the copyright owner.. Further reproduction prohibited
The Journal of Consumer Affairs; Winter 2007; 41, 2; ProQuest Central pg... Reproduced with permission of the
Journal of Global Business Issues; Spring 2009; 3, 1; ProQuest Central pg... Reproduced with permission of the
