6
1. Pendahuluan
Lembaga Penjaminan Mutu dan Audit Internal (LPMAI) merupakan lembaga penjaminan mutu Univeritas, yang mempunyai tanggung jawab menyusun sistem manajemen mutu, menjamin pelaksanaan sistem manajemen mutu, dan melakukan evaluasi ditingkat Universitas hingga Program Studi dan sumber daya dosen. Seluruh kegiatan kepegawaian baik dosen maupun staff di Universitas Kristen Satya Wacana, selalu melibatkan LPMAI. Seperti halnya dalam informasi golongan pangkat dari masing- masing dosen dan staff.
Seiring perkembangan jaman, cara manual seperti masih mencari satu per satu data yang menumpuk di ruang arsip lalu dicocokkan dengan basis data yang dipunyai oleh admin LPMAI untuk mencari info pangkat dan golongan ini harus ditinggalkan dan harus dibuat sebuah sistem informasi digital yang bisa diakses dimana saja. Salah satunya dengan menggunakan media website. Dewasa ini semakin banyak tools dan algoritma yang memudahkan programmer untuk membuat sebuah website yang tidak hanya responsive secara penggunaan tapi juga memiliki tampilan antarmuka yang cantik. Dalam penelitian kali ini algoritma Boyer Moore dipilih karena merupakan salah satu algoritma yang paling efisien dalam aplikasi pencarian string dengan menggunakan natural language (bukan binary language). Algoritma ini sering diimplementasikan untuk fungsi “Search”
dan “Subtitute” pada text editor. Algoritma ini melakukan pencarian data secara cepat dan signifikan dengan melakukan perbandingan pattern dari kiri ke kanan [1].
Aplikasi ini menggunakan Framework Codeigniter dan framework ini bisa diterapkan melalui cara atau desain MVC (Model View Controller) atau juga HMVC (Hierarchial Model View Controller) yang tentunya masing- masing punya keunggulan sendiri dalam hal penggunaan. Akan tetapi HMVC memiliki keunggulan lebih yaitu lebih fleksibel karena bisa bebas menambah atau mengurangi module dan library baru sesuai yang diinginkan seorang programmer.
Algoritma Boyer Moore ini diterapkan ke dalam fungsi pencarian data.
Menurut data LPMAI, data dosen dan karyawan internal Universitas Kristen Satya Wacana berjumlah 450 orang. Oleh karena itu dengan data sebanyak itu, akan lebih mempermudah apabila ditambahkan sebuah fungsi pencarian data dikarenakan data dicari dengan waktu yang lebih cepat dibandingkan algoritma pencarian lain, dan juga cara kerja algoritma ini yang unik serta efisien membuat kombinasi antara HMVC dari Codeigniter yang memudahkan programmer untuk mendokumentasikan dan mengkodekan sistem dalam bentuk modul modul yang lebih spesifik dan membuat aplikasi menjadi fleksibel dalam pengerjaan. Membuat fungsi pencarian menggunakan algoritma Boyer Moore akan melengkapi dan mempermudah fungsionalitas sebuah sistem informasi penggolongan kepegawaian di Universitas Kristen Satya Wacana Salatiga.
7
2. Tinjauan Pustaka
Pada penelitian berjudul Analisis Perbandingan Algoritma Boyer Moore dan Algoritma Knuth Morris Pratt pada Aplikasi Tripelka Foodshop Kendari Berbasis Android dilakukan perbandingan antara kedua algoritma tersebut untuk menentukan algoritma terbaik untuk diimplementasikan pada aplikasi Tripelka Foodshop Kendari. Parameter yang digunakan untuk membandingkan adalah waktu pencarian dan tingkat keakurasian data yang ditampilkan. Hasil dari penelitian ini menunjukkan bahwa algoritma Boyer Moore dan algoritma Knuth Morris Pratt memiliki tingkat keakurasian yang sama tetapi algoritma Boyer Moore lebih unggul dikarenakan waktu pencarian yang lebih cepat dibandingkan algoritma Knuth Morris Pratt [2].
Pada penelitian berjudul Implementasi Algoritma Boyer Moore Pada Web E-katalog Flora dan Fauna Pulau Jawa dan Sumatera dilakukan implementasi algoritma Boyer Moore ke dalam aplikasi pengarsipan katalog dalam fungsi pencarian data. Algoritma ini difungsikan untuk mencari dan mengumpulkan informasi flora dan fauna endemik Indonesia secara akurat berdasarkan wilayah atau provinsi. Sehingga data yang dihasilkan akurat serta pencarian bisa dilakukan dengan efisien[3].
Algoritma Boyer Moore
Algoritma ini pertama kali dipublikasikan oleh Robert S. Boyer dan J.
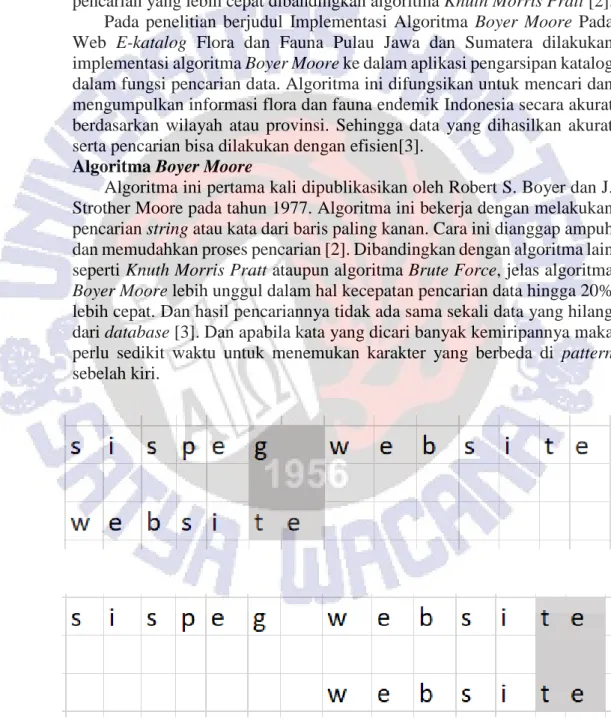
Strother Moore pada tahun 1977. Algoritma ini bekerja dengan melakukan pencarian string atau kata dari baris paling kanan. Cara ini dianggap ampuh dan memudahkan proses pencarian [2]. Dibandingkan dengan algoritma lain seperti Knuth Morris Pratt ataupun algoritma Brute Force, jelas algoritma Boyer Moore lebih unggul dalam hal kecepatan pencarian data hingga 20%
lebih cepat. Dan hasil pencariannya tidak ada sama sekali data yang hilang dari database [3]. Dan apabila kata yang dicari banyak kemiripannya maka perlu sedikit waktu untuk menemukan karakter yang berbeda di pattern sebelah kiri.
Gambar 1. Alur Pergeseran Algoritma Boyer Moore
Gambar 1 menunjukkan bahwa ecara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada saat mencocokkan string atau kata
8
adalah dengan melakukan pembandingan dari posisi paling akhir string dapat dilihat bahwa karakter “t” pada string “website” tidak cocok dengan karakter “g” pada string “sispeg” yang dicari, dan karakter “t” tidak pernah ada dalam string “sispeg” yang dicari sehingga string “website” dapat digeser melewati string “sispeg” selanjutnya karakter “e” tidak cocok dengan karakter “t” tetapi ada pada string “website” tetapi terdapat pada string “website” sehingga digeser sedemikian rupa agar karakter “t” sejajar sehingga teks yang cocok akhirnya ditemukan.
Codeigniter dan HMVC
Codeigniter atau lebih sering disebut CI merupakan sebuah aplikasi framework website berbasis php yang memiliki dokumentasi jelas dan cukup lengkap. CodeIgniter dapat berjalan pada php versi 4 dan versi 5, tujuan utama dari CodeIgniter adalah untuk memudahkan programmer dalam mengembangkan aplikasi secara cepat dan efisien tanpa harus membangun aplikasi atau pengkodean dari awal[4].Pengembang atau programmer awal yang sedang mempelajari pembuatan website akan mampu beradaptasi dengan mudah. Penggunaan di dalam struktur framework CodeIgniter lebih ringkas dibandingkan dengan HTML biasa, dimana pada framework CodeIgniter dilakukan pemisahan komponen utama yang dijadikan menjadi model, view, controller. Model merupakan bagian dari penanganan yang berhubungan dengan pengolahan atau manipulasi database, view merupakan bagian yang menangani halaman UI (User Interface), dan controller merupakan kumpulan intruksi aksi yang menghubungkan model dan view. Seiring perkembangan teknologi, muncullah teknologi baru yang disebut HMVC (Hierarchical Model View Controller) yang merupakan pengembangan dari teknologi MVC (Model View Controller). HMVC (Hierarchical Model View Controller) adalah model teknologi pengembangan dari teknologi MVC (Model View Controller). HMVC merupakan hirarki atau susunan dari pola MVC yang tersusun menjadi satu kesatuan aplikasi [5].
Gambar 2. Arsitektur teknologi HMVC
9
HMVC ini mengurangi beban kerja yang sebelumnya terdapat pada teknologi MVC dengan cara membuat sebuah hirarki atau lebih tepatnya memperjelas sebuah batasan dimana masing-masing seperti yang digambarkan pada Gambar 3. MVC tersimpan dalam modul-modul tertentu, sehingga nanti akan menjadi ringkas dan mempermudah programmer dalam mengatur ulang source code yang sedang dikerjakan [6].
HMVC juga mengurangi ketergantungan antara bagian-bagian yang berbeda dari sourcecode program [7].
3. Metode Penelitian
Penelitian mengenai Perancangan dan Implementasi Aplikasi Sistem Informasi Golongan Kepegawaian berbasis website menggunakan algoritma Boyer Moore ini memiliki beberapa tahapan, yaitu : 1) Analisis kebutuhan dan Pengumpulan data, 2) Perancangan sistem (Perancangan UML, Database dan Interface Aplikasi), 3) Perancangan aplikasi, 4) Implementasi dan pengujian serta analisis Hasil Pengujian.
Gambar 3. Tahapan Penelitian [8]
Berdasarkan Gambar 3, dapat dijelaskan bahwa tahapan penelitian yang dilakukan adalah sebagai berikut : tahap pertama yaitu analisis kebutuhan dan pengumpulan data, pengumpulan data dilakukan dengan cara wawancara langsung kepada Supervisor Divisi IT LPMAI UKSW.
Berdasarkan hasil wawancara tersebut Lembaga Penjaminan Mutu dan Audit Internal UKSW belum terdapat sistem informasi yang untuk pencatatan dan menaikan golongan dosen secara otomatis karena masih menggunakan teknik peng-inputan data secara manual dengan admin divisi IT. Tahap kedua yaitu Perancangan Sistem, pada tahap ini dilakukan rancangan sistem informasi berdasarkan permasalahan atau proses bisnis di LPMAI yang didapat pada tahap pertama. Pada tahap ini perancangan sistem menggunakan Unifed Modelling Language (UML), ada beberapa UML yang akan digunakan, yaitu : Use Case Diagram, Class Diagram, dan Activity Diagram. Pada tahap ketiga yaitu Pembuatan Sistem, pada tahap ini dilakukan pembuatan sistem yang sudah dirancang sebelumnya. Sistem informasi kepegawaian ini dirancang menggunakan bahasa pemrogaman Hypertext Prepocessor (PHP) dan menggunakan framework Codeigniter menggunakan arsitektur HMVC. Tahap selanjutnya adalah pengujian dan implementasi sistem, dalam tahap ini pengujian akan menggunakan metode
Analisis Kebutuhan dan Pengumpulan Data
Perancangan Sistem
Perancangan Aplikasi / Program
Implementasi dan Pengujian Sistem Serta Analisi Hasil Pengujian
Penulisan Laporan Hasil Penelitian
10
blackbox untuk menguji sistem. Blackbox Testing adalah pengujian yang berfokus pada spesifikasi umum dan fungsional dari sebuah perangkat lunak [9]. Tahap terakhir adalah Penulisan Hasil Penelitian, pada tahap ini dilakukan pembuatan dokumentasi proses perancangan dan mengimplementasi sistem yang telah dibuat.
Aplikasi Sistem Informasi Golongan Kepegawaian berbasis website menggunakan algoritma Boyer Moore ini disusun dengan metode SSM (Soft System Methodology). Metode SSM(Soft System Methodology) ini digunakan untuk membantu memodelkan masalah yang tidak terstruktur.
Karena selama ini penggolongan jabatan di LPMAI belum terstruktur dan perlu adanya sistem terstruktur yang menangani hal itu dalam satu tempat.
Pengembangan metode ini dilakukan secara unik karena selalu bergerak dari dua level keadaan yaitu reality dan actually [1]. Keadaan reality adalah keadaan dimana memasuki tahap mengkonstruksikan semua data dari dunia nyata di sekitar, sedangkan keadaan actually adalah keadaan mengkonstruksikan data dari dunia nyata ke dalam otak melalui sistem berfikir alami otak atau disebut juga system thinking about reality. Tahap ini juga bertahap mulai dari Identifikasi Masalah hingga Tahap Maintenance atau Perbaikan masalah.
Gambar 4. Tujuh Langkah Dasar SSM [10]
Gambar 4 menjelaskan bahwa langkah-langkah metode SSM (Soft System Methodology) sebagai berikut: 1) Memahami situasi masalah yang bersifat problematik, yaitu dengan proses mengumpulkan data dari klien, dimana pihak LPMAI (Lembaga Penjaminan Mutu dan Audit Internal) dalam hal ini bertindak sebagai klien. Proses ini diambil dengan cara wawancara pada Supervisor Divisi IT dari LPMAI UKSW. 2) Menggambarkan situasi masalah, yaitu proses dimana mengidentifikasi tentang keadaan yang mendesak agar perlu atau tidaknya dibuat sistem.
Karena pada faktanya, selama ini proses penggolongan kepegawaian masih dilakukan secara manual. 3)Menentukan sistem aktifitas, tahap ini
11
dilakukan dengan mengidentifikasi stakeholder yang terlibat yang dibutuhkan untuk memperbaiki situasi masalah. Dalam hal ini yang terlibat adalah seluruh dosen dan pegawai Universitas Kristen Satya Wacana. 4) Membangun prototype berdasarkan root definition, yaitu membangun prototype konseptual yang dibutuhkan untuk mencapai tujuan dari setiap elemen yang didefinisikan. Dengan cara mulai membangun sebuah kerangka aplikasi sistem informasi kepegawaian yang masih sederhana atau prototype. 5) Membandingkan model dengan dunia nyata, yaitu kerangka aplikasi sistem informasi kepegawaian yang sudah dibuat dalam tahap 4 akan coba dibandingkan dengan kenyataan yang terjadi di dunia nyata. 6) Melakukan perubahan yang diinginkan secara layak dan sistematis, yaitu, melakukan komunikasi antara programmer dengan seluruh stakeholder yang terlibat dalam rangka mengidentifikasi perubahan apa saja yang mungkin terjadi pada aplikasi sistem informasi kepegawaian tersebut. 7) Melakukan tindakan untuk memperbaiki situasi masalah, yaitu tahap maintenance atau perubahan-perubahan desain dari kerangka yang dibuat untuk memenuhi kriteria-kriteria yang diinginkan klien berdasarkan dunia nyata. Semua metode ini akan saling berkesinambungan hingga stakehokder merasa semua kebutuhan sudah terpenuhi.
Perancangan Sistem Informasi Kepegawaian LPMAI dimulai dengan merancang proses pada sistem menggunakan Unifed Modelling Language (UML) yang meliputi Use Case Diagram, Class Diagram, dan Acativity Diagram.
Gambar 5. Use Case Diagram Sistem Informasi Kepegawaian LPMAI
Gambar 5 merupakan Use Case diagram dari sistem informasi kepegawaian LPMAI yang menjelaskan proses dan alur sistem. Pada Use Case ini mempunyai 2 User yaitu : Superadmin, Admin. Superadmin memiliki semua akses pada sistem yaitu hak CRUD (Create Read Update dan Delete) pada data Dosen,. Kedua adalah admin hanya dapat melihat data keseluruhan sistem.
12
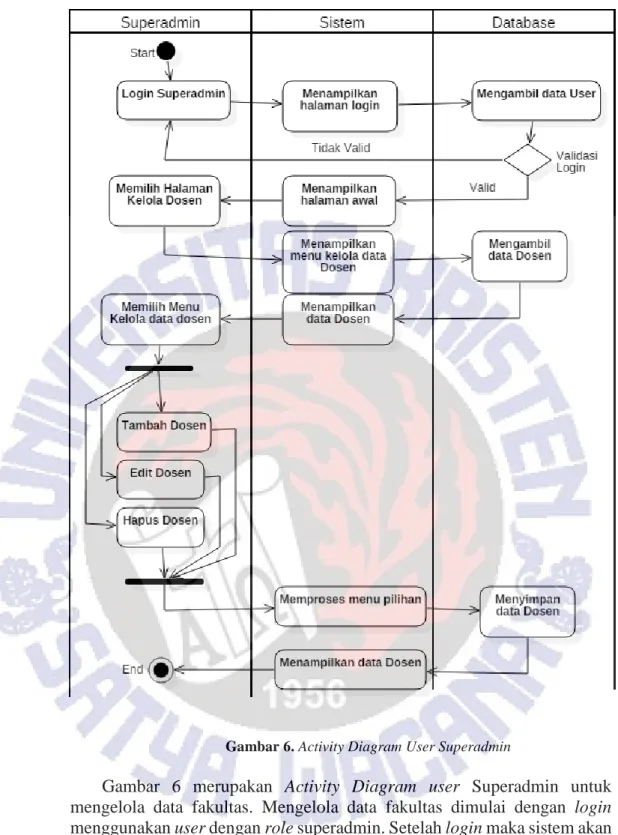
Gambar 6. Activity Diagram User Superadmin
Gambar 6 merupakan Activity Diagram user Superadmin untuk mengelola data fakultas. Mengelola data fakultas dimulai dengan login menggunakan user dengan role superadmin. Setelah login maka sistem akan melihat user valid atau tidak, jika tidak maka akan kembali ke halaman login, jika berhasil maka akan menampilkan menu utama halaman superadmin. Sebelum mengelola data fakultas harus memilih menu dosen untuk menampilkan data fakultas. Superadmin dapat menambah, mengubah atau menghapus dosen, yang kemudian diproses oleh database dan menampilkan data yang sudah diproses.
13
Gambar 7. Class Diagram Sistem Informasi Kepegawaian LPMAI
Gambar 7 merupakan gambar class diagram yang menggambarkan class yang ada pada sistem yaitu : controller , model dan view class pada sistem. Fungsi-fungsi masing masing class berbeda-beda. Pertama adalah model class yang berfungsi sebagai penghubung dan pengelola data dalam database. Kedua, controller class adalah class yang berfungsi untuk mengeksekusi fungsi yang berhubungan dengan model class. Ketiga adalah view class adalah class yang berfungsi menggabungkan dan menampilkan fungsi-fungsi yang terdapat pada controller dan model class. Class diagram pada sistem ini mempunyai 5 controller class yang masing masing mempunyai model class dan view class. Class utama yaitu mengelola data dosen, mengelola data progdi, mengelola data fakultas, mengelola data golongan dan data inpasing.
4. Hasil dan Pembahasan
Hasil dari penelitian ini adalah sistem informasi kepegawaian yang membantu LPMAI (Lembaga Penjaminan Mutu dan Audit Internal) untuk mengakses dan mencari informasi mengenai kepegawaian internal Universitas Kristen Satya Wacana. Sistem Informasi ini memiliki 4 pengguna atau user. User yang pertama adalah Admin, Admin memiliki
14
akses untuk melihat secara keseluruhan data kepegawaian dari semua fakultas dan program studi yang ada di lingkungan Universitas Kristen Satya Wacana. User yang kedua adalah Fakultas. Masing-masing dari perwakilan fakultas akan mendapat 1 akses melalui user Fakultas ini. User ini hanya bisa melihat informasi kepegawaian tentang fakultas tempat user bernaung. User yang ketiga adalah Progdi. Sama halnya dengan user Fakultas, user Progdi ini akan diberikan kepada masing-masing perwakilan dari sebuah progdi dalam satu fakultas tersebut. Hak akses yang diberikan juga hanya mencakup program studi dimana user tersebut bernaung. User terakhir adalah Superadmin. Superadmin memiliki hak akses untuk menambah, mengubah, dan menghapus seluruh data kepegawaian di lingkungan Universitas Kristen Satya Wacana.
Pada user Admin, halaman pertama setelah melakukan login adalah halaman Dashboard. Halaman ini berisi tentang informasi dari keseluruhan halaman yang ada. Karena memang halaman dashboard difungsikan untuk membuat user mengerti secara sekilas tentang keseluruhan data yang ada dalam sebuah sistem informasi tersebut.
Gambar 8. Tampilan antarmuka halaman Dashboard di website SISPEG
Pada penelitian ini, Sistem Informasi Kepegawaian Internal (SISPEG) menerapkan algoritma Boyer Moore pada metode pencarian data untuk setiap halaman yang memerlukan akses data cepat. Berikut adalah proses penerapan algoritma Boyer Moore untuk mencari string target dari string input.
1. Deklarasi string input dan string target.
A S B E Z A
M I C H A E L B E Z A L E L
Diketahui, string input adalah ‘ASBEZA’. Langkah pertama yang dilakukan adalah mencocokan huruf ‘A’ pada ‘ASBEZA’ dengan huruf ‘L’
pada ‘MICHAEL’. Proses ini dilakukan dengan menghitung panjang string
15
target n dan kemudian karakter terakhir dari string target disesuaikan dengan karakter ke n dari string input. Tampak pada proses diatas, huruf ‘A’
!= ‘E’ maka proses berikutnya adalah menguji huruf ‘E’ pada ‘MICHAEL’
dengan semua huruf pada string input ‘ASBEZA’ Karena tidak ada huruf yang sesuai maka string target bergeser ke kanan sesuai jumlah karakter string input.
2. Langkah kedua setelah pergeseran string target dikarenakan ketidaksesuaian karakter, maka hasilnya sebagai berikut:
A S B E Z A
M I C H A E L B E Z A L E L
Pada langkah ini, pencarian dimulai dengan membandingkan karakter
“ASBEZA” dan dicocokkan dengan karakter “L BEZA”. Proses pencarian dimulai dari sebelah kanan kata. Huruf “A” pada “ASBEZA” dicocokkan dengan huruf “A” pada “BEZALEL”, hasilnya cocok lalu pencarian dilanjutkan ke belakang (berjalan ke kiri) dengn membandingkan “Z” pada
“L BEZA” dengan huruf “Z” pada “BEZALEL” , hasilnya cocok lalu pencarian dilanjutkan lagi ke sebelah kiri, hingga karakter dominan yaotu
“BEZA” sudah ditemukan, dan pencarian berhenti. Hal ini dikarenakan string input sudah cocok dengan string target. Kata “BEZA” ditemukan pada salah satu data nama dosen yaitu “MICHAEL BEZALEL”, karena ada kecocokan antara karakter “BEZA” dengan nama belakang “BEZALEL”
maka proses pencarian kata menggunakan algoritma ini akan berhenti.
Sementara huruf “AS” tidak dilanjutkan pencariannya, dikarenakan salah satu string target sudah sesuai dengan data dosen yang ada. Proses pencarian kata ini membutuhkan waktu lebih cepat karena algoritma Boyer Moore hanya mencocokkan antara kedua karakter saja, yakni antara string target dengan string pada input bukan keseluruhan huruf yang terkandung dalam karakter yang ada pada string target. Perbedaan waktu yang signifikan ini dapat dilihat pada Grafik Pengujian Waktu algoritma Boyer Moore. Dari pengujian inilah akan diketahui seberapa efisien dan cepat algoritma pencarian apabila menggunakan Boyer Moore dan pencarian menggunakan kode SQL biasa
Proses pencarian Boyer Moore tersebut diimplementasikan langsung pada kolom pencarian data yang tersedia di website SISPEG. Proses ini menghasilkan pencarian kata yang sesuai datanya dengan string input yang dicari. Berikut adalah implementasi prosesnya:
16
Gambar 9. Implementasi Algoritma Pencarian Boyer Moore di website SISPEG
Gambar 8 merupakan tampilan halaman Dosen ketika dilakukan pencarian data menggunakan string input ‘ASBEZA’ lalu didapatkan hasil
‘MICHAEL BEZALEL’ karena terdapat karakter yang cocok yaitu karakter
‘BEZA’ maka proses pencarian akan berhenti dan menampilkan data hasil pencarian ke halaman hasil pencarian.
Pseudocode 1. Fungsi pencarian data dari database menggunakan SQL biasa
Pseudocode 1 merupakan kode proses pengambilan data dari database menggunakan parameter fungsi pencarian SQL seperti umumnya. Disini terdapat fungsi where untuk menjelaskan tabel apa yang di select dan
1.Program Cari_SQLbiasa
--- 2.Kamus
3.Word : string 4.Input word 5.Deskripsi
--- 6.Open(database)
7.Select(all data from table) 8.Select(3 data like word) 9.Return(hasil)
17
dimana data tersebut dicari untuk ditampilkan ke halaman hasil pencarian.
Kode program ini jauh berbeda dengan kode program menggunakan algoritma Boyer Moore yang menggunakan perhitungan khusus karena sifatnya yang melakukan pencarian dari kanan atau belakang dan akan berhenti apabila terdapat string atau kata yang cocok dengan string input.
Sedangkan pencarian dengan SQL biasa dimulai dari kata sebelah kanan atau yang paling depan, satu persatu huruf dicari hingga selesai lalu ditampilkan datanya ke halaman hasil pencarian.
Pseudocode 2. Implementasi Algoritma Boyer Moore kedalam perhitungan PHP
Pseudocode 2 merupakan inti dari implementasi algoritma Boyer Moore ke dalam kode PHP. Pada baris kode 3 (tiga) sampai dengan baris kode 8 (delapan) terjadi proses pengambilan data dari database yang
Program Cari_BoyerMoore
--- 1.Kamus
2.Nama : string 3.Count: int 4.Input word 5.Deskripsi
--- 6.Open(database)
7.Select(all data from table) 8.Select(3 data nama like word) 9.If(jumlah count bukan 0) maka, 10.Proses(data)
11.Tampilkan(hasil) 12.Else
13.Lakukan Perulangan data = masukkan ke array()
14.Select(nama,ambil 1 karakter dari belakang)
15.Untuk(karakter, apabila = word, karakter +1)
16.Else(masukkan ke persen) 17.Tampilkan(hasil)
18.If(arraypersen = karakter) 19.Else(arraypersen = persen) 20.LakukanPencarian()
21.If cari = (data dari karakter) 22.Else
23.Cari = (data dari persen) 24.If count=0, maka
25.Select(all data from table) 26.Select(3 data nama like word) 27.Ulang(arraypersen)
28.Else
29.Ulang(karakter) 30.Else
31.Hasil=0
32.Return(hasil)
18
berdasarkan parameter nama dari tabel ‘dosenbiodata’. Lalu masing-masing huruf yang ditemukan dari proses pencarian akan ditampung sementara di array. Proses akan berjalan terus hingga string input dan string target cocok.
Pada baris kode 14 (empat belas) hingga 29 (dua puluh sembilan) akan berjalan apabila string input dan string target tidak ketemu. Disini proses akan dilanjutkan dengan cara menampung ke array sementara hasil pencarian dari kanan huruf yang cocok lalu digabungkan dengan ‘%’ untuk huruf yang tidak cocok sebagai sugesti string target, lalu dibandingkan dengan string input. Apabila ada string input yang cocok dengan string target ataupun sugesti string target maka proses akan berhenti dan menampilkan hasil pencarian ke dalam halaman hasil pencarian data.
Grafik 1. Pengujian Waktu Algoritma Boyer Moore
Pada Grafik 1, garis ‘x’ menerangkan string kata yang dicari.
Sedangkan garis ‘y’ menerangkan waktu yang dibutuhkan untuk mencari string kata tersebut dalam satuan waktu ms (milisecond). Pengujian waktu ini membuktikan bahwa algoritma Boyer Moore selalu lebih cepat apabila dibandingkan dengan pencarian menggunakan kode program SQL biasa.
Pada grafik tersebut, pencarian diuji dengan data dosen yang berjumlah 450 data. Pada saat di input data ‘ade’ maka algoritma Boyer Moore hanya membutuhkan waktu 332ms dibandingkan dengan pencarian dengan kode SQL biasa yang membutuhkan waktu 2030ms atau apabila di konversikan ke waktu detik menjadi 2 detik lebih. Pada saat di input kata ‘chris’ waktu pencarian dari SQL biasa membutuhkan waktu 3377ms atau 3 detik lebih, sedangkan pencarian menggunakan algoritma Boyer Moore hanya membutuhkan waktu 270ms. Semakin banyak data yang mempunyai data kata dan huruf yang sama, maka akan semakin membutuhkan waktu untuk algoritma bekerja. Hal ini terjadi dikarenakan kemungkinan kata yang penyusunan dan peletakan huruf sama yang ditemukan dalam data dosen ini juga tinggi, contoh kasus adalah apabila algoritma ini sedang bekerja menemukan kata “chris” maka yang akan tampil pada halaman pencarian tidak hanya nama dosen “chris”, tetapi nama dosen seperti “christine” juga akan muncul, oleh sebeb itu pencarian menggunakan algoritma Boyer Moore bisa dilakukan dalam waktu yang cepat karena hanya mencocokkan antara karakter saja bukan keseluruhan karakter yang ada pada string target
0 1000 2000 3000 4000
ade joko chris yoga arga
Pengujian Waktu Pencarian menggunakan algoritma Boyer Moore dan SQL biasa
Boyer Moore SQL biasa
19
yang dicari. Berbeda dengan pencarian menggunakan metode SQL yang harus mencari keseluruhan string input sampai ketemu. Tentunya pencarian dengan algoritma Boyer Moore ini sangat bisa diandalkan apabila data yang dicari berjenis big data atau sangat besar sehingga bisa lebih mempersingkat waktu yang dibutuhkan.
5. Simpulan dan Saran
Berdasarkan penelitian yang dilakukan, maka dapat disimpulkan bahwa Algoritma Boyer Moore sangat bisa diandalkan dalam hal pencarian data.
Dikarenakan proses kerjanya yang hanya mencocokkan antara karakter input saja, bukan keseluruhan karakter yang ada pada string target yang dicari. Hal ini dapat meringkas waktu pencarian data, apabila algoritma ini di implementasikan dengan data yang lebih kompleks lagi dan mempermudah user (dalam hal ini LPMAI) untuk mencari kata yang dibutuhkan tanpa harus menunggu lama serta tepat sasaran. Untuk penelitian dan pengembangan lebih lanjut, bisa ditambahkan opsi sugesti tentang kata yang dicari sehingga proses pencarian data bisa lebih kompleks dan lebih tepat sasaran lagi. Karena tidak jarang juga user mencari data dengan kondisi pengetikkan kata dan huruf yang salah atau kurang tepat sasaran dengan data yang dimiliki database. Dengan adanya penambahan fungsi berupa pemberian saran pencarian kata, maka sistem informasi yang dibuat menjadi semakin ringkas tetapi kompleks dan yang paling utama adalah lebih mempermudah pencarian.
6. Daftar Pustaka
[1] Tinus Waruwu, Fince & Mandala, Rila 2016. Perbandingan Algoritma Knuth Morris dan Boyer Moore dalam Pencocokan String pada Aplikasi Kamus Bahasa Nias. Padang : Universitas Putra Indonesia (YPTK).
[2] Maghfirah Parenrengi, Andi., Adi Saputra, Rizal., Tajidun, LM 2017. Analisis Perbandingan Algoritma Boyer Moore dan Algoritma Knuth Morris Pratt Pada Aplikasi Tripelka Foodshop Kendari berbasis Android. Kendari : Universitas Halu Oleo.
[3] Hakim, Lukman., Vivi Juliana 2016. Implementasi Algoritma Boyer Moore Pada Web E-Katalog Flora dan Fauna Pulau Jawa dan Sumatera.
[3] Sagita, Vina & Irmina Prasetiyowati, Maria 2013. Studi Perbandingan Implementasi Algoritma Boyer-Moore, Turbo Boyer- Moore, dan Tuned Boyer-Moore dalam pencarian string. Tangerang : Universitas Multimedia Nusantara.
[4] Maghfirah Parenrengi, Andi., Adi Saputra, Rizal., Tajidun, LM 2017. Analisis Perbandingan Algoritma Boyer Moore dan Algoritma Knuth Morris Pratt Pada Aplikasi Tripelka Foodshop Kendari berbasis Android. Kendari : Universitas Halu Oleo.
20
[5] Tanjung, Maulana Iqbal. 2011. Analisis dan Perancangan Sistem Informasi Berbasis Website Menggunakan Arsitektur MVC dengan Framework Codeigniter. Yogyakarta : STMIK AMIKOM.
[6] Wahyu Hidayat, Eka 2013. Penerapan Pola Hierarchical Model View Controller Pada Rekayasa Sistem Berbasis Web Framework.
Tasikmalaya : Universitas Siliwangi.
[7]Muzakir, Ari 201. Implementasi Manajemen Perpustakaan menggunakan Framework Codeigniter (CI) Dengan Teknik Hierarchial model-view-controller (HMVC). Sumatera Selatan : Universitas Bina Dharma.
[8] Dwi Nastiti Mulyaningsih, Meika., Juli Andi Gani, Abdul., Said, Abdullah 2017. Perencanaan Perlindungan dan Pengelolaan Lingkungan Hidup di Kabupaten Kediri dengan Pendekatan Soft System Methodology. Malang : Universitas Brawijaya.
[9]Sidi Mustaqbal, M., Fajri Firdaus, Roeri., Rahmadi, Hendra 2015.
Pengujian Aplikasi Menggunakan Black Box Testung Boundary Value Analysis. Bandung : Universitas Widyatama.
[10] Dwi Nastiti Mulyaningsih, Meika., Juli Andi Gani, Abdul., Said, Abdullah 2017, 66. Perencanaan Perlindungan dan Pengelolaan Lingkungan Hidup di Kabupaten Kediri dengan Pendekatan Soft System Methodology. Malang : Universitas Brawijaya.
![Gambar 3. Tahapan Penelitian [8]](https://thumb-ap.123doks.com/thumbv2/123dok/3825358.3950447/4.892.150.752.323.928/gambar-tahapan-penelitian.webp)
![Gambar 4. Tujuh Langkah Dasar SSM [10]](https://thumb-ap.123doks.com/thumbv2/123dok/3825358.3950447/5.892.149.750.327.934/gambar-tujuh-langkah-dasar-ssm.webp)