ABSTRAK
Dalam organisasi yang berorientasi pada profit, kegiatan usaha yang dilakukan diharapkan dapat berlangsung secara terus menerus untuk jangka waktu yang lama, bahkan kegiatan usaha tersebut diharapkan juga mengalami peningkatan dari segi aktivitas operasi maupun laba yang diperoleh. Salah satu cara untuk membuat produksi yang baik dalam suatu perusahaan adalah dengan melakukan estimasi terhadap pasar potensial yang dikuasai oleh perusahaan. Sebelum perusahaan menanamkan investasi untuk perluasan usaha baru, maka terlebih dahulu perlu diketahui apakah proyek atau investasi yang akan dilakukan dapat mengembalikan uang yang telah diinvestasikan dalam proyek tersebut, dengan jangka waktu tertentu.
Dari data penjualan produk helm tersebut bisa dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan algoritma naïve bayesian. Algoritma naïve bayesian akan menghitung probabilitas posterior untuk setiap nilai kejadian dari atribut target pada setiap kasus (sampel data). Selanjutnya, naïve bayesian akan mengklasifikasikan sampel data tersebut ke kelas yang mempunyai nilai probabilitas posterior tertinggi.
Keluaran sistem adalah rekomendasi wilayah pendistribusian produk helm perusahaan xyz. Peneliti melakukan pengujian pada data set dengan jumlah 834 record data dan menggunakan fold bernilai 2 sampai 10 cross validation dengan tingkat rata-rata nilai akurasi yang dihasilkan dari data pengujian tersebut, yaitu sebesar 93 %.
ABSTRACT
In a profit oriented organization, business activities are carried out is expected to take place continuously for a long period of time, even the expected business activities also experienced an increase in terms of operating activities nor the profit obtained. One way to make a good production in a company is validation imation against potential market that is controlled by the company. Before implanting the company investments for the expansion of the new venture, so first I need to know whether the project or investment is going to do can return the money that has been invested in the project, with a specific time period.
From the helmet product sales data can be used for data mining techniques using with naïve bayesian algorithm uses. Naïve bayesian algorithm will calculate the posterior probability for each value of the target attribute occurrences in each case (sample data). Furthermore, the naïve bayesian will classify the sample data to the class that has the highest value of the posterior probability.
The output of the system is the recommendation product distribution area helmet company xyz. Researchers conduct tests on the data set with a total of 834 record data and use provisions 2 fold to 10 fold cross validation, with the average rate value accuracy resulting from the testing data, namely amounting to 93%.
PREDIKSI PENJUALAN HELM MENGGUNAKAN
ALGORITMA
NAÏVE BAYESIAN
(Studi Kasus : Distribusi Perusahaan XYZ di Wilayah Jawa
Tengah dan Daerah Istimewa Yogyakarta)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun oleh :
Carolus Benny Dwi Setiawan 115314018
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
i
HELMET SELLING PREDICTION USING
NAÏVE BAYESIAN
ALGORITHMS
(Case Study : Distribution Of Xyz Company In Central Java And
Special Region Of Yogyakarta)
Thesis
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree
In Informatics Engineering
By :
Carolus Benny Dwi Setiawan 115314018
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
ii
iii
iv
v
vi
HALAMAN PERSEMBAHAN
Karya Skripsi ini Saya persembahan kepada :
1. Tuhan Yesus Kristus, yang selalu mendampingiku dalam menyelesaikan karya
skripsi ini.
2. Keluargaku, antara lain Alm. Bapak, Mamah, Om, Tante, Kakak, dan
Adikku yang selalu mendukungku baik berupa doa dan materi.
3. Calon pendamping hidupku dan keluarganya yang selalu mendoakan dan
memberikan semangat.
4. Para Dosen dan Teman-Teman Mahasiswa Teknik Informatika Universitas
Sanata Dharma yang menjadi relasi dan penolong selama Saya menjalankan
studi.
5. Keluarga besar Universitas Sanata Dharma yang telah memberikan segala
pengalaman berharga dalam hidupku, yaitu ilumu atau pembelajaran dalam
vii
HALAMAN MOTTO
Jika iman tidak disertai perbuatan
Maka iman itu pada hakekatnya adalah mati
( Yakobus 2:17 )
Jika pikiran saya bisa membayangkannya,
hati saya bisa meyakininya,
saya tahu saya akan mampu menggapainya
( Jesse Jackson )
Seberapa besar kesuksesan Anda bisa diukur dari seberapa kuat
keinginan Anda, setinggi apa mimpi-mimpi Anda, dan bagaimana
Anda memperlakukan kekecewaan dalam hidup Anda
( Robert Kiyosaki )
“Mintalah, maka akan diberikan kepadamu; Carilah, maka kamu akan mendapat;
Ketoklah, maka pintu akan dibukakan bagimu. Karena setiap orang yang
meminta, menerima, dan setiap orang yang mencari, mendapat, dan setiap orang
viii
ABSTRAK
Dalam organisasi yang berorientasi pada profit, kegiatan usaha yang dilakukan diharapkan dapat berlangsung secara terus menerus untuk jangka waktu yang lama, bahkan kegiatan usaha tersebut diharapkan juga mengalami peningkatan dari segi aktivitas operasi maupun laba yang diperoleh. Salah satu cara untuk membuat produksi yang baik dalam suatu perusahaan adalah dengan melakukan estimasi terhadap pasar potensial yang dikuasai oleh perusahaan. Sebelum perusahaan menanamkan investasi untuk perluasan usaha baru, maka terlebih dahulu perlu diketahui apakah proyek atau investasi yang akan dilakukan dapat mengembalikan uang yang telah diinvestasikan dalam proyek tersebut, dengan jangka waktu tertentu.
Dari data penjualan produk helm tersebut bisa dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan algoritma naïve bayesian. Algoritma naïve bayesian akan menghitung probabilitas posterior untuk setiap nilai kejadian dari atribut target pada setiap kasus (sampel data). Selanjutnya,
naïve bayesian akan mengklasifikasikan sampel data tersebut ke kelas yang mempunyai nilai probabilitas posterior tertinggi.
Keluaran sistem adalah rekomendasi wilayah pendistribusian produk helm perusahaan xyz. Peneliti melakukan pengujian pada data set dengan jumlah 834
record data dan menggunakan fold bernilai 2 sampai 10 cross validation dengan tingkat rata-rata nilai akurasi yang dihasilkan dari data pengujian tersebut, yaitu sebesar 93 %.
ix
ABSTRACT
In a profit oriented organization, business activities are carried out is expected to take place continuously for a long period of time, even the expected business activities also experienced an increase in terms of operating activities nor the profit obtained. One way to make a good production in a company is validation imation against potential market that is controlled by the company. Before implanting the company investments for the expansion of the new venture, so first I need to know whether the project or investment is going to do can return the money that has been invested in the project, with a specific time period.
From the helmet product sales data can be used for data mining techniques using with naïve bayesian algorithm uses. Naïve bayesian algorithm will calculate the posterior probability for each value of the target attribute occurrences in each case (sample data). Furthermore, the naïve bayesian will classify the sample data to the class that has the highest value of the posterior probability.
The output of the system is the recommendation product distribution area helmet company xyz. Researchers conduct tests on the data set with a total of 834 record data and use provisions 2 fold to 10 fold cross validation, with the average rate value accuracy resulting from the testing data, namely amounting to 93%.
x
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yang Maha Esa yang telah mengaruniakan
berkat dan rahmat-Nya sehingga penulis dapat menyelesaikan tugas akhir ini.
Dalam proses penulisan tugas akhir ini ada banyak pihak yang telah
memberikan bantuan dan perhatian dengan caranya masing-masing sehingga tugas
akhir ini dapat diselesaikan. Oleh karena itu penulis mengucapkan terima kasih
kepada :
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
2. Ridowati Gunawan, S.Kom., M.T. selaku dosen pembimbing yang telah
mendampingi dan memberikan banyak nasihat dan masukan untuk tugas
akhir ini.
3. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. dan Bapak Robertus Adi
Nugroho, S.T., M.Eng. selaku panitia penguji yang telah memberikan
banyak kritik dan saran untuk tugas akhir ini.
4. Seluruh Dosen program studi Teknik Informatika Universitas Sanata
Dharma yang telah memberikan bekal ilmu, arahan, dan pengalaman selama
penulis menempuh studi.
5. Seluruh staff Sekretariat Fakultas Sains dan Teknologi yang banyak
membantu penulis dalam urusan administrasi akademik terutama menjelang
ujian tugas akhir dan yudisium.
6. Alm. Bapak Agustinus Sutarno, S.Pd. dan Ibu Theresia Sri Marsinah, S.E.,
FX Andy Prasetya, S.Teo. dan Fr. Cornelius Pandu Tri Waluyo, Pr, Bapak
xi
yang merupakan keluarga saya, terima kasih untuk setiap cinta, kasih
xii
DAFTAR ISI
Halaman Judul
Halaman Judul (Bahasa Inggris) ... i
Halaman Persetujuan ... ii
Halaman Pengesahan ... iii
Halaman Pernyataan ... iv
Halaman Persetujuan Publikasi Karya Ilmiah ... v
Halaman Persembahan ... vi
Halaman Motto ... vii
Abstrak ... viii
Abstract ... ix
Kata Pengantar ... x
Daftar Isi ... xii
Daftar Gambar ... xv
Daftar Tabel ...xvii
Daftar Lampiran ... xviii
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 3
1.3 Tujuan ... 3
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 4
1.6 Sistematika Pembahasan ... 5
BAB II LANDASAN TEORI 2.1 Penambangan Data ... 6
2.1.1 Pengertian Penambangan Data ... 6
2.1.2 Pengelompokan Penambangan Data ... 8
2.1.3 Klasifikasi ... 10
xiii
2.2.1 Pengertian Teorema Bayesian ... 11
2.2.2 Klasifikasi NaïveBayesian ... 12
2.2.3 Contoh Kasus Klasifikasi Naïve Bayesian ... 14
2.2.4 Karakteristik Klasifikasi Naïve Bayesian ... 16
2.2.5 Kelebihan dan Kekurangan Klasifikasi Naïve Bayesian... 17
2.3 K-Fold Cross Validation ... 17
BAB III ANALISA DAN PERANCANGAN SISTEM 3.1 Analisis Sistem ... 18
3.2 Tahap-Tahap KDD ... 18
3.3 Analisis Kebutuhan Pengguna ... 21
3.3.1 Diagram Model Use Case ... 21
3.3.2 Tabel Ringkasan Use Case ... 21
3.3.3 Narasi Use Case ... 22
3.4 Diagram Aktivitas ... 29
3.4.1 Diagram Aktivitas Cetak Hasil Prediksi ... 29
3.4.2 Diagram Aktivitas Evaluasi Sistem ... 29
3.4.3 Diagram Aktivitas Prediksi Helm (Data Kelompok) .... 30
3.4.4 Diagram Aktivitas Prediksi Helm (Data Tunggal) ... 31
3.4.5 Diagram Aktivitas Input Data Training ... 32
3.5 Perancangan Struktur Data ... 32
3.5.1 Matriks Dua Dimensi ... 32
3.6 Penerapan Contoh Perhitungan Naïve Bayesian ... 34
3.7 Perancangan Antar Muka ... 36
3.7.1 Perancangan Halaman Awal ... 36
3.7.2 Perancangan Halaman Utama ... 36
3.7.3 Perancangan Halaman Input Data Training ... 37
3.7.4 Perancangan Halaman Prediksi Helm (Data Kelompok)... 38
xiv
3.7.6 Perancangan Halaman Bantuan Sistem ... 39
3.7.7 Perancangan Halaman Hitung Akurasi ... 40
3.7.8 Perancangan Halaman Tentang Sistem ... 40
BAB IV IMPLEMENTASI DAN ANALISA HASIL SISTEM 4.1 Spesifikasi Software dan Hardware ... 42
4.2 Implementasi Use Case... 42
4.2.1 Implementasi Halaman Awal ... 42
4.2.2 Implementasi Halaman Utama ... 43
4.2.3 Implementasi Halaman Input Data Training ... 44
4.2.4 Implementasi Halaman Prediksi Helm ... 48
4.2.5 Implementasi Halaman Bantuan Sistem... 56
4.2.6 Implementasi Halaman Hitung Akurasi Data ... 61
4.2.7 Implementasi Halaman Tentang Sistem ... 64
4.3 Implementasi Struktur Data ... 65
4.3.1 Implementasi Kelas NaiveBayesian.java ... 65
4.3.2 Implementasi Kelas Model_NB.java ... 66
4.4 Implementasi Kelas ... 68
4.5 Pengujian Hasil Sistem... 69
4.5.1 Penentuan Jumlah Kelompok Data... 69
4.5.2 Pengujian dan Hasil Perhitungan Akurasi ... 72
BAB V PENUTUP 5.1 Kesimpulan ... 75
5.2 Saran ... 75
DAFTAR PUSTAKA... 76
xv
DAFTAR GAMBAR
Gambar 2.1 Langkah-langkah Penambangan Data ... 6
Gambar 3.1 Use case sistem ... 21
Gambar 3.2 Diagram Aktivitas : Cetak Hasil Prediksi Kelompok ... 29
Gambar 3.3 Diagram Aktivitas : Evaluasi Sistem... 29
Gambar 3.4 Diagram Aktivitas : Prediksi Helm (Data Kelompok) ... 30
Gambar 3.5 Diagram Aktivitas : Prediksi Helm (Data Tunggal) ... 31
Gambar 3.6 Diagram Aktivitas : Input Data Training ... 32
Gambar 3.7 Contoh Representasi Matriks ... 33
Gambar 3.8 Contoh Representasi Matriks Multidimensi ... 33
Gambar 3.9 Desain Halaman Awal ... 36
Gambar 3.10 Desain Halaman Utama... 37
Gambar 3.11 Desain Halaman Input Data Training ... 37
Gambar 3.12 Desain Halaman Prediksi Helm (Data Kelompok) ... 38
Gambar 3.13 Desain Halaman Prediksi Helm (Data Tunggal) ... 39
Gambar 3.14 Desain Halaman Bantuan Sistem ... 39
Gambar 3.15 Desain Halaman Hitung Akurasi ... 40
Gambar 3.16 Desain Halaman Tentang Sistem... 41
Gambar 4.1 Antarmuka Halaman Awal ... 43
Gambar 4.2 Antarmuka Halaman Utama ... 44
Gambar 4.3 Antarmuka Halaman Input Data Training... 45
Gambar 4.4 Antarmuka Pilih FileTraining ... 45
Gambar 4.5 Antarmuka Input Data Training saat isi file tampil pada tabel training ... 46
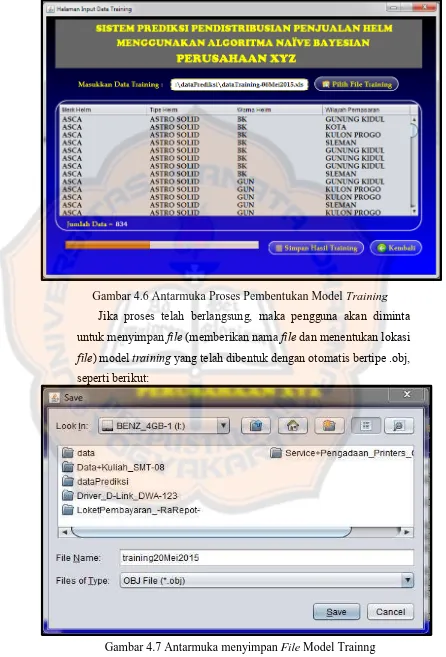
Gambar 4.6 Antarmuka Proses Pembentukan Model Training ... 47
Gambar 4.7 Antarmuka Menyimpan File Model Training ... 47
Gambar 4.8 Antarmuka Proses Training Berhasil ... 48
Gambar 4.9 Antarmuka Proses Training Gagal ... 48
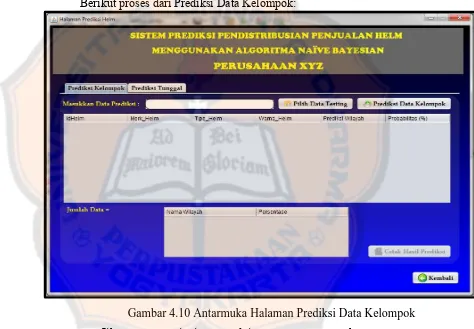
Gambar 4.10 Antarmuka Halaman Prediksi Data Kelompok ... 49
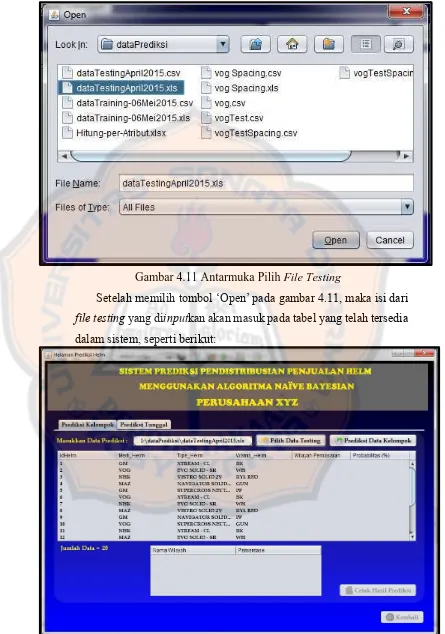
Gambar 4.11 Antarmuka Pilih FileTesting ... 50
xvi
testing ... 50
Gambar 4.13 Antarmuka Pilih Model FileTraining ... 51
Gambar 4.14 Antarmuka Proses Prediksi Data Kelompok ... 51
Gambar 4.15 Antarmuka Halaman Setelah Proses Prediksi Kelompok Selesai ... 52
Gambar 4.16 Antarmuka Halaman Mencetak Hasil Prediksi Kelompok ... 53
Gambar 4.17 Antarmuka HalamanPrediksi Data Tunggal ... 53
Gambar 4.18 Antarmuka contoh field-field terisi ... 54
Gambar 4.19 Antarmuka Prediksi Data Tunggal Gagal ... 54
Gambar 4.20 Antarmuka Pilih Model FileTraining ... 55
Gambar 4.21 Antarmuka Pemberitahuan Proses Prediksi Data Tunggal... 55
Gambar 4.22 Antarmuka Prediksi Tunggal Berhasil ... 56
Gambar 4.23 Antarmuka Pemberitahuan ErrorPemilihan File ... 56
Gambar 4.24 Antarmuka HalamanBantuan Sistem ... 57
Gambar 4.25 Contoh Antarmuka Hitung Akurasi Data 2 fold ... 62
Gambar 4.26 Antarmuka Pilih File data set ke-3... 63
Gambar 4.27 Antarmuka Proses Perhitungan Akurasi Data dengan 2 fold .... 63
Gambar 4.28 Antarmuka Hasil Perhitungan Akurasi Data dengan 2 fold ... 64
Gambar 4.29 Antarmuka Halaman Tentang Sistem ... 65
Gambar 4.30 Atribut-Atribut Kelas Model_NB.java ... 66
Gambar 4.31 Penentuan Jumlah 2 Kelompok Data (2 fold) ... 69
Gambar 4.32 Penentuan Jumlah 3 Kelompok Data (3 fold) ... 69
Gambar 4.33 Penentuan Jumlah 4 Kelompok Data (4 fold) ... 69
Gambar 4.34 Penentuan Jumlah 5 Kelompok Data (5 fold) ... 70
Gambar 4.35 Penentuan Jumlah 6 Kelompok Data (6 fold) ... 70
Gambar 4.36 Penentuan Jumlah 7 Kelompok Data (7 fold) ... 70
Gambar 4.37 Penentuan Jumlah 8 Kelompok Data (8 fold) ... 71
Gambar 4.38 Penentuan Jumlah 9 Kelompok Data (9 fold) ... 71
xvii
DAFTAR TABEL
Tabel 2.1 Langkah-langkah Penambangan Data ... 14
Tabel 3.1 Ringkasan Use Case ... 21
Tabel 3.2 Narasi Use Case : Input data training ... 22
Tabel 3.3 Narasi Use Case : Evaluasi Sistem ... 23
Tabel 3.4 Narasi Use Case : Prediksi Helm (Data Kelompok) ... 25
Tabel 3.5 Narasi Use Case : Prediksi Helm (Data Tunggal) ... 26
Tabel 3.6 Narasi Use Case : Cetak Hasil Prediksi ... 28
Tabel 4.1 Implementasi Kelas ... 68
Tabel 4.2 Daftar Tools yang digunakan dalam Sistem ... 68
xviii
DAFTAR LAMPIRAN
Lampiran 1 Listing Program Algoritma Naïve Bayesian ... 78
Lampiran 2 Ringkasan Hasil Hasil Perhitungan Akurasi Data ... 83
1
BAB I
PENDAHULUAN
Pada bab pendahuluan dijelaskan mengenai latar belakang masalah dari penelitian. Tujuan pengerjaan tugas akhir memberikan penjelasan mengenai hasil yang ingin diketahui serta batasan dalam pengerjaan. Tahapan dalam metodologi penelitian dan sistematika penulisan laporan.
1.1 Latar Belakang Masalah
Dalam persaingan industri yang hypercompetitive seperti sekarang ini, semua perusahaan dituntut untuk merencanakan produksinya seefektif mungkin agar dapat memaksimalkan keuntungan. Kelangsungan sebuah usaha sangat diperlukan oleh setiap organisasi, baik yang berorientasi pada
profit ataupun yang nonprofit. Dalam organisasi yang berorientasi pada profit, kegiatan usaha yang dilakukan diharapkan dapat berlangsung secara terus menerus untuk jangka waktu yang lama, bahkan kegiatan usaha tersebut diharapkan juga mengalami peningkatan dari segi aktivitas operasi maupun laba yang diperoleh. Salah satu cara untuk membuat produksi yang baik dalam suatu perusahaan adalah dengan melakukan estimasi terhadap pasar potensial yang dikuasai oleh perusahaan. Sebelum perusahaan menanamkan investasi untuk perluasan usaha baru, maka terlebih dahulu perlu diketahui apakah proyek atau investasi yang akan dilakukan dapat mengembalikan uang yang telah diinvestasikan dalam proyek tersebut, dengan jangka waktu tertentu (Sugiharto, 2002).
berorientasi pada profit, distributor helm diharapkan dapat terus meningkatkan keuntungan, salah satunya dengan menyediakan helm sesuai dengan permintaan pasar agar tidak terjadi kekurangan atau kelebihan helm yang dipasarkan. Jadi diperlukan suatu sistem otomasi yang dapat memprediksi atau meramalkan jumlah helm yang akan dipasarkan sesuai dengan permintaan dengan suatu metode tertentu.
Data penjualan yang sudah ada akan diolah atau dianalisis untuk mengetahui tingkat kecenderungan konsumen di setiap tempat tujuan pemasaran produk pada faktor ketertarikannya. Dari pengolahan data tersebut akan diperoleh suatu pola konsumsi masyarakat terhadap produk dari perusahaan tersebut. Ketersediaan data yang cukup banyak, kebutuhan akan informasi (atau pengetahuan) sebagai pendukung pengambilan keputusan untuk membuat solusi bisnis serta dukungan infrastruktur di bidang teknologi informasi menciptakan lahirnya suatu teknologi data mining salah satunya
naïve bayesian. Data mining yang dimaksud untuk memberikan solusi nyata bagi para pengambil keputusan di dunia bisnis untuk mengembangkan bisnis mereka.
Naïve bayesian merupakan salah satu metode data mining yang digunakan pada persoalan klasifikasi berdasarkan pada penerapan teorema
bayesian. Algoritma naïve bayesian akan menghitung probabilitas posterior untuk setiap nilai kejadian dari atribut target pada setiap sampel data. Selanjutnya, naïve bayesian akan mengklasifikasikan sampel data tersebut ke kelas yang mempunyai nilai probabilitas posterior tertinggi. Kelebihan metode naïve bayesian sendiri adalah mudah diimplementasi serta memberikan hasil yang baik untuk banyak kasus. Teorema Bayesian adalah teorema yang digunakan dalam statistika untuk menghitung peluang suatu hipotesis, bayes optimal classifier menghitung peluang dari suatu kelas dari masing-masing kelompok atribut yang ada, dan menentukan kelas mana yang paling optimal.
efektif (mendapatkan hasil yang tepat) dan efisien (memanfaatkan input yang ada dengan cara yang relatif cepat) khususnya kinerja dari seorang sales (Zhang, 2007). Sistem ini dengan algoritma naïve bayesian diharapkan membantu menghitung probabilitas posterior pada sampel data untuk menentukan pendistribusian dari produk helm dari perusahan XYZ berdasarkan warna, merk, dan tipe dari produk helm tersebut.
1.2 Rumusan Masalah
Perumusan masalah yang akan diselesaikan dalam penelitian tugas akhir ini sebagai berikut:
1. Bagaimana mengimplementasikan algoritma naïve bayesian untuk memprediksi pendistribusian produk helm di wilayah perusahaan XYZ dengan berdasarkan warna, merk, dan tipe dari produk helm tersebut? 2. Berapakah tingkat keakuratan prediksi yang dihasilkan dalam
memprediksi pendistribusian produk helm di wilayah perusahaan XYZ dengan berdasarkan warna, merk, dan tipe dari produk helm tersebut?
1.3 Tujuan
Tujuan dari penelitian tugas akhir ini adalah bagaimana menerapkan algoritma naïve bayesian sebagai salah satu algoritma dalam data mining
untuk membantu memberikan estimasi atau prediksi dalam pendistribusian produk helm di wilayah perusahaan XYZ.
1.4 Batasan Masalah
Dalam prediksi yang akan dilakukan dalam tugas akhir ini memiliki batasan-batasan masalah, sebagai berikut:
1. Dalam mengimplementasi prediksi ini, algoritma yang digunakan memakai algoritma naïve bayesian.
3. Data yang digunakan sebagai atribut adalah data pendistribusian penjualan produk helm yang sudah ditetapkan oleh perusahaan XYZ, yaitu berdasarkan merk, tipe, dan warna dari produk helm tersebut.
4. Berdasarkan input data pendistribusian penjualan produk helm di perusahaan XYZ tahun 2014, output program ini adalah prediksi pendistribusian produk helm di suatu wilayah perusahaan XYZ dengan berdasarkan merk, tipe, dan warna dari produk helm tersebut, serta tingkat keakuratan prediksi yang dihasilkan.
5. Program yang digunakan untuk mengimplementasi adalah Java.
6. Pengguna sistem adalah bagian pemasaran produk helm di perusahaan XYZ.
1.5 Metodologi Penelitian
Metodologi penelitian dilakukan dengan menerapkan proses KDD (Knowledge Discovery in Databases) dengan tahapan sebagai berikut:
1. Pembersihan data, menghilangkan noise, dan data yang tidak konsisten. 2. Integrasi data, menggabungkan data dari berbagai sumber data yang
berbeda.
3. Seleksi data dan transformasi data, untuk menentukan kualitas dari hasil
data mining, sehingga data diubah menjadi bentuk sesuai untuk di-mining. 4. Penerapan teknik data mining
Penerapan teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Ada beberapa teknik data mining yang sudah umum dipakai. Teknik yang akan digunakan oleh penulis adalah teknik
naïve bayesian.
5. Evaluasi pola yang ditemukan
6. Presentasi pengetahuan
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data mining adalah menformulasikan keputusan atau aksi dari hasil analisa yang didapat.
1.6 Sistematika Pembahasan Bab I. Pendahuluan
Dalam bab ini berisi tentang latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, serta sistematika penulisan.
Bab II. Landasan Teori
Dalam bab ini berisi tentang teori yang dapat menunjang penelitian, yaitu berupa pengertian penambangan data, proses penambangan data, klasifikasi, dan algoritma naïve bayesian.
Bab III. Analisa dan Perancangan Sistem
Dalam bab ini berisi tentang cara penerapan konsep dasar yang telah diuraikan pada Bab II untuk menganalisis dan merancang tentang sistem sesuai tahap-tahap penyelesaian masalah tersebut dengan menggunakan algoritma naïve bayesian.
Bab IV. Implementasi dan Analisa Sistem
Dalam bab ini berisi tentang implementasi ke program komputer berdasarkan hasil perancangan yang dibuat, analisis perangkat lunak yang telah dibuat, serta kelebihan dan kekurangan pada sistem.
Bab V. Penutup
6
BAB II
LANDASAN TEORI
Pada bab ini dijelaskan analisis sistem yang akan dibuat dan perancangan untuk melakukan prediksi dalam pendistribusian produk helm di perusahaan XYZ dengan menggunakan algoritma naïve bayesian.
2.1. Penambangan Data
2.1.1. Pengertian Penambangan Data
Penambangan Data, sering juga disebut Knowledge Discovery in Database (KDD), adalah serangkaian kegiatan dari data yang jumlahnya besar berupa input yang diproses dengan tujuan mendapatkan ouput, tidak sekedar informasi tetapi berupa pengetahuan (knowledge) yang sering diperoleh, tidak diketahui atau tersembunyi, serta tujuannya untuk pengambilan keputusan atau
decision making (Han & Kamber, 2006).
Gambar 2.1 Langkah-langkah Penambangan Data
Sumber: Tan, Steinbach, Kumar (2004)
Penemuan pengetahuan ini merupakan sebuah proses seperti ditunjukkan pada gambar 2.1 dan terdiri dari urutan-urutan sebagai berikut (Han & Kamber, 2006):
1. Pembersihan data (data cleaning)
ketidakcocokan. Ketidakcocokan tersebut dapat disebabkan oleh beberapa faktor antara lain desain form masukan data yang kurang baik sehingga menyebabkan munculnya banyak field, adanya kesalahan petugas ketika memasukkan data, dan adanya kesalahan yang disengaja dan adanya data yang rusak.
2. Integrasi data (data integration)
Pada langkah ini akan dilakukan penggabungan data. Data dari bermacam-macam tempat penyimpanan data akan digabungkan ke dalam satu tempat penyimpanan data yang koheren. Macam-macam tempat penyimpanan data tersebut termasuk multiple database, data cube, atau file flat. Pada langkah ini, ada beberapa hal yang perlu diperhatikan yaitu integrasi skema dan pencocokan objek, redundansi data, deteksi dan resolusi konflik nilai data. Selama melakukan integrasi data, hal yang perlu dipertimbangkan secara khusus adalah masalah struktur data. Struktur data perlu diperhatikan ketika mencocokkan atribut dari satu basis data ke basis data lain.
3. Seleksi data (data selection)
Data yang relevan akan diambil dari basis data untuk dianalisis. Pada langkah ini akan dilakukan analisis korelasi untuk analisi fitur. Atribut-atribut data akan dicek apakah relevan untuk dilakukan penambangan data. Atribut yang tidak relevan ataupun atribut yang mengalami redundansi tidak akan digunakan. Atribut yang diharapkan adalah atribut yang bersifat independen. Artinya, antara atribut satu dengan atribut yang lain tidak saling mempengaruhi.
4. Transformasi data (data transformation)
primitif atau data level rendah menjadi data level tinggi, normalisasi (normalization) yaitu mengemas data atribut ke dalam skala yang kecil, sebagai contoh -1.0 sampai 1.0, dan konstruksi atribut atau fitur (attribute construction atau feature construction) yaitu mengkonstruksi dan menambahkan atribut baru untuk membantu proses penambangan.
5. Penambangan data (data mining)
Langkah ini adalah langkah yang penting di mana akan diaplikasikan metode yang tepat untuk mengekstrak pola data. 6. Evaluasi pola (pattern evaluation)
Langkah ini berguna untuk mengidentifikasi pola yang benar dan menarik. Pola tersebut akan direpresentasikan dalam bentuk pengetahuan berdasarkan beberapa pengukuran yang penting. 7. Presentasi pengetahuan (knowledge presentation)
Pada langkah ini informasi yang sudah ditambang akan divisualisasikan dan direpresentasikan kepada pengguna. Langkah 1 sampai dengan langkah 4 merupakan langkah praproses data di mana data akan disiapkan terlebih dahulu untuk selanjutnya dilakukan penambangan.
Pada langkah penambangan data, pengguna atau basis pengetahuan bisa dilibatkan. Kemudian pola yang menarik akan direpresentasikan kepada pengguna dan akan disimpan sebagai pengetahuan yang baru.
2.1.2. Pengelompokan Penambangan Data
Penambangan data dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005):
1. Deskripsi
tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali atribut target lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari atribut target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari atribut target dibuat berdasarkan atribut prediksi.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. 4. Klasifikasi
Dalam klasifikasi, terdapat target atribut kategori. Sebagai contoh, menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
5. Pengklusteran
6. Asosiasi
Tugas asosiasi dalam penambangan data adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis market basket.
2.1.3. Klasifikasi
Klasifikasi merupakan model atau classfier yang dikonstruksikan untuk memprediksi kategori label (categorical labels). Contoh kasusnya adalah aman atau berbahaya untuk sebuah data aplikasi, ya dan tidak untuk data penjualan. Klasifikasi dan prediksi numerik adalah dua tipe utama dari masalah-masalah prediksi (prediction problems). Cara klasifikasi bekerja, di mana klasifikasi data (data classification) terdiri dari dua langkah proses, yaitu:
Langkah-1 : Penggolong (classifier) mendiskripsikan pembangunan himpunan dari kelas-kelas data atau konsep- konsep yang telah ditetapkan. Bagian ini merupakan langkah pembelajaran atau fase pelatihan (learning step atau
training phase), di mana algoritma klasifikasi yang dibangun digolongkan melalui menganalisa atau dari mana pembelajaran itu berasal (learning from), sebuah training set akan dibuat dari database tuples dan label-label kelas yang berhubungan satu dan lainnya. Sebuah tuple, X, dinyatakan sebagai sebuah n- dimensional
Langkah-2 : Tingkat akurasi dari suatu klasifikasi. Model langsung akan langsung digunakan untuk diklasifikasi. Pertama, akan ditaksir seberapa akurat prediksi yang dibuat oleh
classifier. Jika kekuatan classifier diukur dengan menggunakan data pelatihan, maka taksiran ini akan baik karena classifier cenderung overfit data. Maka dari itu, perlu digunakan sekumpulan data uji. Data tersebut dipilih secara acak dari sekumpulan data umum. Data yang diuji ini bersifat independen atau berdiri sendiri dari data pelatihan, artinya data yang diuji tersebut tidak lagi digunakan untuk membuat classifier.
2.2. Teorema Bayesian
2.2.1. Pengertian Teorema Bayesian
Teori keputusan Bayes atau sering disebut teorema Bayes adalah pendekatan statistic yang fundamental dalam pengenalan pola atau
pattern recognition (Santosa, 2007). Pendekatan teorema Bayes ini didasarkan pada kuantifikasi trade-off antara berbagai keputusan klasifikasi dengan menggunakan probabilitas dan nilai yang muncul dalam keputusan-keputusan tersebut.
Jika X adalah bukti atau kumpulan data pelatihan, � adalah hipotesi, dan jika class variable memiliki hubungan tidak
deterministic dengan atribut, maka dapat diperlukan X dan � sebagai atribut acak dan menangkap hubungan peluang menggunakan �� � �. Peluang bersyarat ini juga dikenal dengan probabilitas posterior untuk
�, dan P( �) adalah probabilitas prior.
kelas bersyarat � � dan bukti ( �) seperti pada rumus 2.1 berikut: (Han & Kamber, 2006)
... (2.1)
dalam hal ini:
X = Himpunan data training.
Y = Hipotesis.
( �| �) = Probabilitas posterior, yaitu probabilitas bersyarat dari hipotesis Y berdasarkan kondisi X.
( �) = Probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa hipotesis Y bernilai benar sebelum data X muncul.
( �) = Probabilitas dari data X.
( �| �) = Probabilitas bersyarat dari X berdasarkan kondisi pada hipotesis Y, dan biasa disebut dengan likelihood. Likelihood ini mudah untuk dihitung ketika memberikan nilai 1 saat X dan Y konsisten, dan memberikan nilai 0 saat X dan Y tidak konsisten.
2.2.2. Klasifikasi Naïve Bayesian
Klasifikasi Naïve Bayesian merupakan salah satu metod pengklasifikasian yang berdasarkan pada penerapan teorema Bayes
dengan asumsi antara atribut penjelas saling bebas (independen). Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman dimasa sebelumnya. Klasifikasi naïve bayesian diasumsikan dimana nilai atribut dari sebuah kelas dianggap terpisah dan independen dengan nilai atribut lainnya, kondisi seperti ini dinyatakan dengan rumus 2.2 seperti berikut ini: (Han & Kamber, 2006)
... (2.2) Keterangan:
Y = Hipotesis.
( �| �) = Probabilitas posterior, yaitu probabilitas bersyarat dari hipotesis Y berdasarkan kondisi X
( �) = Probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa hipotesis Y bernilai benar sebelum data X muncul.
( �) = Probabilitas dari data X.
( �1| �), ( �2| �), ( ���| �) = Probabilitas dari X1, X2, Xn untuk hipotesis Y, biasa disebut dengan likelihood. Karena P(X) irrelevant, maka untuk mencari peluang hanya menggunakan rumus berikut ini: (Han & Kamber, 2006)
... (2.3) Jika ada P(Xn|Y) yang memiliki nilai 0, maka P(Y\X) = 0. Maka klasifikasi naïve bayesian tidak bisa memprediksi record yang salah satu atributnya memiliki probabilitas bersyarat (likelihood) = 0. Untuk mengatasi hal itu, dilakukan penambahan nilai 1 ke setiap evidence
dalam perhitungan sehingga probabilitas tidak akan bernilai 0. Langkah ini sering disebut laplace estimator dengan rumus sebagai berikut: (Santosa, 2007)
... (2.4) dimana:
n = total jumlah instances dari kelas Yj.
nc = jumlah contoh training dari Yj yang menerima nilai Xi.
m = parameter yang dikenal sebagai ukuran sampel ekuivalen. Cara kerja klasifikasi naïve bayesian: (Santosa, 2007)
1. Misalkan � adalah kumpulan data pelatihan dari tuple dan � berhubungan dengan label kelas.
2. Andaikan ada �� kelas, �1, �2, … , ���. Jika disediakan tuple x,
klasifikasi naïve bayesian memprediksi x ke dalam kelas yang mempunyai probabilitas posterior tertinggi. Maka penggolong
naïve bayesian memprediksi tuple x termasuk ke dalam kelas ���
... (2.5) Dengan demikian (y��|x) akan dimaksimalkan. Kelas ��� untuk
setiap (y��|x) yang dimaksimalkan dinamakan maximum posteriori hypothesis. Berdasarkan teorema bayes adalah:
... (2.6) 3. Selama P(x) konstan untuk semua kelas maka hanya P(x|yi)P(y)
yang dimaksimalkan. Jika kelas probabilitas prior tidak diketahui, maka kelas-kelas tersebut diasumsikan sama, yaitu P(y1) = P(y2) =
… = P(yn). Oleh karena itu, P(x|yi) akan dimaksimalkan. Jika tidak,
P(x|yi)P(y) yang akan dimaksimalkan.
2.2.3. Contoh Kasus Klasifikasi Naïve Bayesian
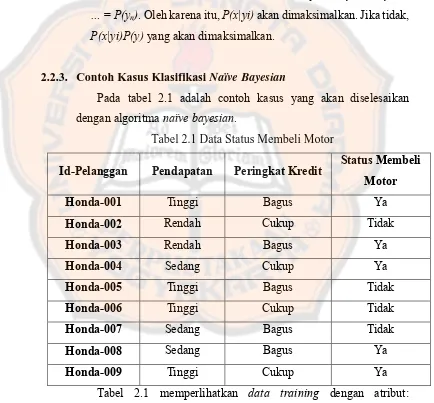
[image:35.595.101.535.264.667.2]Pada tabel 2.1 adalah contoh kasus yang akan diselesaikan dengan algoritma naïve bayesian.
Tabel 2.1 Data Status Membeli Motor
Id-Pelanggan Pendapatan Peringkat Kredit Status Membeli Motor
Honda-001 Tinggi Bagus Ya
Honda-002 Rendah Cukup Tidak
Honda-003 Rendah Bagus Ya
Honda-004 Sedang Cukup Ya
Honda-005 Tinggi Bagus Tidak
Honda-006 Tinggi Cukup Tidak
Honda-007 Sedang Bagus Tidak
Honda-008 Sedang Bagus Ya
Honda-009 Tinggi Cukup Ya
Tabel 2.1 memperlihatkan data training dengan atribut:
Terdapat dua kelas dari klasifikasi yang dibentuk, yaitu: C1 = Membeli Motor = Ya
C2 = Membeli Motor = Tidak
Data yang akan diklasifikasikan adalah X = (Pendapatan = “Tinggi”, Peringkat Kredit = “Cukup”).
Langkah-langkah Perhitungan, sebagai berikut: 1. Mencari P(Ci), sebagai berikut:
P(Ci) merupakan prior probability untuk setiap kelas berdasar data, yaitu:
P(Ci) = a � a a �C a � a � a a
P(C1) = 5/9 = 0.556 P(C2) = 4/9 = 0.444
2. Untuk menghitung �� � ��� , untuk i=1,2 akan dihitung
probabilitas bersyarat (likelihood), sebagai berikut: P(Xj|Ci) = � � ∩� �� �
� �
Likelihood Untuk atribut Pendapatan (X1) = “Tinggi”.
P(X1|C1) =
2� 9
9
= 2= 0.400
P(X1|C2) =
2� 9
9
= 2= 0.500
Likelihood Untuk atribut Peringkat Kredit (X2) = “Cukup”.
P(X2|C1) =
2� 9
9
= 2= 0.400
P(X2|C2) =
2� 9
9
= 2= 0.500
Laplace Estimator
3. Menghitung P(X|Ci), sebagai berikut:
P(X| Membeli Motor = “Ya”) = 0.400 x 0.400 = 0.160 P(X| Membeli Motor = “Tidak”) = 0.500 x 0.500 = 0.250
4. Dari probabilitas-probabilitas tersebut, maka dilanjutkan dengan menghitung P(X|Ci) x P(Ci), sebagai berikut:
P(X|Membeli Motor = “Ya”) x P(Membeli Motor = “Ya”) = 0.160 x 0.556 = 0.089
P(X|Membeli Motor = “Tidak”) x P(Membeli Motor = “Tidak”) = 0.250 x 0.444 = 0.111
5. Hasil persentasi kedua prediksi diatas, sebagai berikut:
Untuk membeli motor =”Ya” adalah: 0.089/(0.089+0.111) x 100% = 44.5%
Untuk membeli Motor =”Tidak” adalah: 0.111/(0.111+0.089+) x 100% = 55.5%
6. Kesimpulan, sebagai berikut:
Dari hasil P(X|Ci) x P(Ci) di atas dapat disimpulkan bahwa data X termasuk ke dalam kelas membeli motor = “Tidak”, karena data yang digunakan adalah data yang memiliki nilai peluang terbesar atau maksimal yaitu = 0.111.
2.2.4. Karakteristik Klasifikasi Naïve Bayesian
Naïve bayesian Classifier umumnya memiliki karakteristik sebagai berikut: (Santosa, 2007)
1. Kokoh untuk atribut irrelevant, jika Xi adalah atribut yang
irrelevant, maka ( �i| �) menjadi hampir didistribusikan seragam. Peluang kelas bersyarat untuk �i tidak berdampak pada keseluruhan perhitungan peluang posterior.
2.2.5. Kelebihan dan Kekurangan Klasifikasi Naïve bayesian
Algoritma naïve bayesian memiliki beberapa kelebihan dan kekurangan yaitu sebagai berikut: (Santosa, 2007)
Kelebihan naïve bayesian, antara lain: 1. Menangani kuantitatif dan data diskrit.
2. Hanya memerlukan sejumlah kecil data pelatihan (training) untuk mengestimasi parameter yang dibutuhkan untuk klasifikasi.
3. Kokoh terhadap atribut yang tidak relevan.
Kekurangan naïve bayesian, antara lain: (Santosa, 2007)
1. Tidak berlaku jika probabilitas kondisionalnya adalah nol, apabila nol maka probabilitas prediksi akan bernilai nol juga.
2. Mengasumsikan variabel bebas.
2.3. K-Fold Cross Validation
Cross Validation adalah salah satu metode yang bisa digunakan untuk mengukur kinerja dari sebuah model prediktif. Dalam k-fold cross validation, data akan dipartisi secara acak ke dalam k partisi, D1,
D2,…,Dk, masing-masing D mempunyai jumlah yang sama. Pada iterasi
ke-i partisi Di digunakan sebagai data uji, sedangkan sisa partisi
digunakan sebagai data pelatihan. Pada iterasi pertama, D1 digunakan
sebagai data uji dan D2, D3,….,Dk digunakan sebagai data pelatihan.
Pada iterasi kedua, D2 digunakan sebagai data uji, sedangakan D1,
D3,….,Dk digunakan sebagai data pelatihan. Pada iterasi ketiga, D3
digunakan sebagai data uji, sedangkan D1, D3,….,Dk digunakan sebagai
data pelatihan dan seterusnya. Setiap sample D, hanya digunakan sekali sebagai data uji dan berkali-kali sebagai data pelatihan. Untuk pengklasifikasian, pengukuran keakurasian dapat dihitung dengan rumus, sebagai berikut:
18
BAB III
ANALISA DAN PERANCANGAN SISTEM
Pada bab ini dijelaskan analisis sistem yang akan dibuat dan perancangan untuk melakukan prediksi dalam pendistribusian produk helm di perusahaan XYZ dengan menggunakan algoritma naïve bayesian.
3.1 Analisis Sistem
Sistem yang dibuat memiliki kemampuan untuk memprediksi pendistribusian suatu produk helm di perusahaan XYZ berdasarkan wilayah, warna, merk, dan tipe. Sistem prediksi pendistribusian penjualan produk helm ini menggunakan algoritma naïve bayesian. Data penjualan yang dibutuhkan adalah data penjualan helm di perusahaan XYZ di tahun 2014. Data-data penjualan ini akan diubah menjadi data berbentuk nominal pada saat tahap
pre-processing sehingga dapat diolah dengan teknik naïve bayesian. Selanjutnya, data penjualan akan masuk ke dalam proses training dan testing, serta pada akhirnya akan mendapatkan keputusan atau output berupa daerah atau wilayah pemasaran dari suatu produk helm yang ditentukan. Sistem ini akan diimplementasikan ke sebuah aplikasi dengan menggunakan bahasa pemrograman Java.
3.2 Tahap-Tahap KDD (Knowledge Discovery in Database)
Setelah data mentah diperoleh maka selanjutnya dilakukan proses KDD (Knowledge Discovery in Database) dengan tahapan seperti berikut ini: 1. Pembersihan data (Data Cleaning)
Pada tahap ini juga dilakukan penyeleksian atribut-atribut pada data penjualan yang tidak relevan terhadap penelitian yang dilakukan, seperti satuan, size, harga jual, quantity, discount, harga satuan, sisa pesan, status
adalah 834 records untuk data penjualan yang telah berlangsung di tahun 2014 di atas dapat dilihat pada lampiran3 dalam tugas akhir ini.
2. Seleksi data (Data Selection) dan Integrasi data (Data Integration)
Tahap selanjutnya akan dilakukan penyeleksian terhadap data-data penjualan yang kurang relevan dengan penelitian yang dilakukan. Setelah dilakukan proses penyeleksian data kemudian tahap selanjutnya dilakukan penggabungan seluruh data yang telah diperoleh yang dikenal dengan integrasi data. Data mentah yang diperoleh disajikan secara terpisah, yaitu data penjualan dan data penjualan kanvaser. Data penjualan yang sama disatukan dalam satu file yang berekstensi .csv atau .xls sesuai dengan atribut-atribut yang sesuai dari penelitian. Setelah disatukan dalam satu
file, maka data penjualan dapat disimpan dalam tabel pada database. Hasil pada tahap ini yaitu sample data penjualan tahun 2014 yang telah dilakukan disimpan dalam file dataTraining_dataSet.csv atau dataTraining_dataSet.xls.
3. Transformasi data
Pada tahap transformasi data, data penjualan diklasifikasikan menjadi wilayah-wilayah tertentu sesuai dengan hasil yang pernah didapatkan. Untuk memudahkan proses penambangan data, maka sample data yang telah digabungkan pada proses intergrasi data akan dikelompokkan berdasarkan wilayah atau daerah yang sudah ditetapkan oleh perusahaan. 4. Penerapan teknik data mining
Data-data penjualan yang telah diolah pada tahap sebelumnya kemudian akan diolah menggunakan algoritma naïve bayesian. Data penjualan yang digunakan untuk penelitian terbatas pada beberapa hasil dari transaksi penjualan yang telah dilakukan oleh perusahaan XYZ. a. Variabel Input
Variabel-variabel yang menjadi variable input dalam sistem ini, antara lain merk, tipe, dan warna dari produk suatu helm.
b. Variabel Output
penelitian ini, keterangan wilayah atau daerah akan menjadi hasil atau keluaran yang berupa prediksi pendistribusian penjualan suatu produk helm.
5. Evaluasi pola yang ditemukan
Pada tahap ini akan dilakukan proses untuk mengukur akurasi sistem yang telah dibuat. Proses pengukuran akan dilakukan menggunakan teknik
k-fold cross validation. K-fold cross validation merupakan salah satu metode yang bisa digunakan untuk mengukur kinerja dari sebuah model
prediktif. Dalam k-fold cross validation, data akan dikelompokkan ke dalam k buah partisi atau kelompok dengan ukuran yang sama. Masing-masing kelompok akan mengalami posisi sebagai data testing dan sebagai data training. (Han&Kamber, 2001). Metode pengukuran cross validation
dengan nilai fold = 10.
Akhir dari tahap ini adalah diperolehnya presentase akurasi antara data training dengan data testing, sehingga dapat ditentukan tingkat keberhasilan proses penambangan data yang telah dilakukan. Rumus untuk menghitung akurasi dapat dilihat pada rumus (3.1), sebagai berikut:
3.3 Analisis Kebutuhan Pengguna 3.3.1 Diagram Model Use Case
Gambar 3.1 Use case sistem
Pada gambar 3.1 direpresentasikan semua aktivitas yang dilakukan oleh user dalam sistem ini, yaitu input data training, prediksi helm, cetak hasil prediksi, dan evaluasi sistem. Dalam gambar 3.1 terdapat keterangan sebelum user melakukan prediksi helm, maka user wajib melakukan input data training terlebih dahulu. Sementara itu, sebelum melakukan cetak hasil prediksi, maka user
wajib melakukan prediksi helm terlebih dahulu. 3.3.2 Tabel Ringkasan Use Case
Tabel 3.1 Ringkasan Use Case
Nama Use Case Keterangan Pelaku
Input Data Training
Use case ini merupakan proses memasukkan data training berupa data penjualan yang kemudian akan digunakan untuk pre-processing dan menghasilkan model training yang digunakan untuk proses prediksi.
User
Evaluasi Sistem Use case ini merupakan proses penggambaran
Prediksi Helm
Use case ini merupakan proses memasukan data penjualan berupa data tunggal atau data kelompok ke dalam sistem.
User
Cetak Hasil Prediksi Use case ini merupakan proses mencetak dari
hasil prediksi helm yang dilakukan. User
[image:43.595.102.571.101.754.2]3.3.3 Narasi Use Case
Tabel 3.2 Narasi Use Case : Input Data Training
Author (s) : Carolus Benny Dwi Setiawan Date : 17 Desember 2014
Aktor : User sistem Versi : 02
Nama Use Case Input data training
Use case type :
Use Case ID UCPrediksiHelm001
Prioritas High
Aktor Utama User
Aktor Lain yang
berperan
-Interested stakeholders User sistem
Diskripsi Use casememasukkan data ini mendiskripsikan proses dimana training yang kemudian akan digunakan untuk User sistem proses prediksi.
Prakondisi User trainingsistem di halaman utama dan telah menyiapkan yang akan dimasukkan sebagai data training. file data Post Kondisi User sistem telah siap untuk melakukan prediksi dari data training
yang dimasukkan.
Langkah Umum Aksi Aktor Reaksi Sistem
- Langkah 2
User sistem memilih menu
“Input Data Training”.
- Langkah 4
User sistem memilih data atau file yang ingin dimasukkan dengan memilih tombol “Pilih File
Training”.
- Langkah 6
User sistem melakukan pencarian file yang sesuai pada direktori yang dipilihnya.
- Langkah 1
Sistem menampilkan halaman home User sistem.
- Langkah 3
Sistem menampilkan halaman input data training.
- Langkah 5
Sistem menampilkan file chooser yang memudahkan untuk memasukkan file.
- Langkah 7
- Langkah 8
User sistem memilih tombol
“Simpan Hasil Training”.
- Langkah 10
User memberikan nama dan menentukan lokasi penyimpanan file model training yang dihasilkan sistem. User Memilih tombol “Save”.
- Langkah 9
Sistem akan melakukan proses pembentukan model training dari data-data yang telah diinputkan. Sistem menampilkan file chooser
yang memudahkan untuk menyimpan file model training bertipe .obj.
- Langkah 11
Sistem menampilkan status (berhasil atau gagal) dari pembentukan file training yang telah dilakukan.
Bidang alternatif Alt-Langkah 7 : kolom yang tidak sesuai dengan tabel yang tersedia dalam sistem.Sistem akan menampilkan peringatan jika jumlah
Kesimpulan Use casememasukkan seluruh isi dari ini akan berhenti apabila file yang dimasukkan pada tabel yang User sistem telah berhasil tersedia dalam sistem, dan dijadikan sebagai data training.
Aturan bisnis
-Batasan dan spesifikasi
inplementasi Akses sistem dalam keadaan stabil dan harus berbentuk .csv atau .xls. file yang akan dimasukkan
Assumptions File dengan ketentuan dalam sistem.yang dijadikan sebagai data training telah tersedia dan sesuai
[image:44.595.98.571.76.765.2]Masalah terbuka Usertraining sistem harus paham memasukan . file untuk menjadi data
Tabel 3.3 Narasi Use Case : Evaluasi Sistem
Author (s) : Carolus Benny Dwi Setiawan Date : 17 Desember 2014
Aktor : User sistem Versi : 02
Nama Use Case Evaluasi sistem
Use case type :
Use Case ID UCPrediksiHelm002
Prioritas High
Aktor Utama User
Aktor Lain yang
berperan
-Interested stakeholders User sistem
Diskripsi Use case ini mendiskripsikan proses pengukuran akurasi.
Prakondisi User data trainingsistem di halaman utama dan telah berhasil meng. inputkan Post Kondisi User sistem telah mendapatkan hasil perhitungan akurasi dari
proses input data training sebelumnya.
Langkah Umum Aksi Aktor Reaksi Sistem
- Langkah 2
User sistem memilih menu
“Akurasi Data”.
- Langkah 4
User menentukan berapa
fold dengan memilih nilai pada dropdown field yang akan digunakan untuk melakukan perhitungan akurasi data.
- Langkah 6
User sistem memilih tombol
“Hitung Akurasi Data”
untuk memulai proses perhitungan akurasi data.
- Langkah 8
User sistem melakukan pencarian file data set pengujian yang sesuai pada direktori yang dipilihnya, dan user memilih tombol
“Open” untuk melanjutkan proses perhitungan akurasi data.
Sistem menampilkan halaman home User sistem.
- Langkah 3
Sistem menampilkan halaman perhitungan akurasi data.
- Langkah 5
Sistem menampilkan nilai
fold yang telah ditentukan oleh user.
- Langkah 7
Sistem menampilkan file chooser yang memudahkan untuk memasukkan file data set pengujian.
- Langkah 9
Sistem melakukan perhitungan akurasi data berdasarkan nilai fold yang ditentukan.
- Langkah 10
Sistem menampilkan status dari hasil perhitungan akurasi data.
Bidang alternatif
-Kesimpulan
Use case ini akan berhenti apabila sistem telah berhasil menampilkan hasil perhitungan akurasi data, berupa jumlah data benar, jumlah data salah, rata-rata data benar, dan rata-rata data salah.
Aturan bisnis
-Batasan dan spesifikasi
inplementasi Akses sistem dalam keadaan stabil dan akan dimasukkan harus berbentuk .csv atau .xls.file data set pengujian yang
Assumptions Ketentuan perhitungan akurasi data telah tersedia dan dapat digunakan secara maksimal.
Tabel 3.4 Narasi Use Case : Prediksi Helm (Data Kelompok)
Author (s) : Carolus Benny Dwi Setiawan Date : 17 Desember 2014
Aktor : User sistem Versi : 02
Nama Use Case Prediksi helm (data kelompok)
Use case type :
Use Case ID UCPrediksiHelm003
Prioritas High
Aktor Utama User (bagian pemasaran)
Aktor Lain yang
berperan
-Interested stakeholders User sistem
Diskripsi Use casehelm. ini mendiskripsikan proses memprediksi pendistribusian
Prakondisi User prediksi yang akan dimasukkan sebagai data prediksi.sistem di halaman utama dan telah menyiapkan file data Post Kondisi User sistem telah mendapatkan hasil prediksi.
Langkah Umum Aksi Aktor Reaksi Sistem
- Langkah 2
User sistem memilih menu
“Prediksi Helm”.
- Langkah 4
User sistem memilih submenu “Prediksi Kelompok”.
- Langkah 5
User sistem memilih data atau file testing yang ingin dimasukkan untuk prediksi kelompok dengan memilih tombol “Pilih Data
Testing”.
- Langkah 7
User sistem melakukan pencarian file yang sesuai pada direktori yang dipilihnya dan memilih tombol “Open” untuk membuka file testing
tersebut.
- Langkah 9
User sistem memilih tombol
“Prediksi Data
- Langkah 1
Sistem menampilkan halaman home User sistem.
- Langkah 3
Sistem menampilkan halaman prediksi helm.
- Langkah 6
Sistem menampilkan file chooser yang memudahkan untuk memasukkan file testing.
- Langkah 8
Sistem menampilkan data pada tabel yang tersedia berdasarkan id-helm, merk, tipe, dan warna produk – produk helm.
- Langkah 10
Sistem menampilkan bahwa proses prediksi berlansung. Sistem menampilkan file chooser yang memudahkan untuk memasukkan file
model training yang berbentuk .obj.
Kelompok” untuk memulai proses prediksi kelompok.
- Langkah 11
User sistem melakukan pencarian file yang sesuai pada direktori yang dipilihnya dan memilih tombol “Open” untuk membuka file model
training.
Secara bertahap sistem akan melakukan perhitungan
prior, perhitungan
likelihood, perhitungan
laplace estimator, dan perhitungan posterior.
- Langkah 13
Sistem menampilkan status dari prediksi kelompok yang dilakukan dan menampilkan hasil presiksi produk-produk helm (data-data pada kolom wilayah pemasaran dan kolom probabilitas) pada tabel yang tersedia.
Bidang alternatif
Alt-Langkah 8 : Sistem akan menampilkan peringatan jika jumlah kolom yang tidak sesuai dengan tabel yang tersedia dalam sistem.
Alt-Langkah 13 : Sistem akan menampilkan pesan peringatan
“Proses Prediksi Gagal” apabila proses prediksi gagal dilakukan.
Kesimpulan Use casemenampilkan hasil prediksi. ini akan berhenti apabila sistem telah berhasil
Aturan bisnis
-Batasan dan spesifikasi inplementasi
Akses sistem dalam keadaan stabil, file data testing yang akan dimasukkan harus berbentuk .csv atau .xls, dan file model training
harus berbentuk .obj.
Assumptions File model yang dijadikan sebagai data kelompok untuk prediksitraining telah tersedia dan sesuai dengan ketentuan dalam dan file sistem.
[image:47.595.105.579.83.758.2]Masalah terbuka Userdengan data berupa data kelompok. sistem harus paham melakukan prediksi pendistribusian helm
Tabel 3.5 Narasi Use Case : Prediksi Helm (Data Tunggal)
Author (s) : Carolus Benny Dwi Setiawan Date : 17 Desember 2014
Aktor : User sistem Versi : 02
Nama Use Case Prediksi helm (data tunggal)
Use case type :
Use Case ID UCPrediksiHelm004
Prioritas High
Aktor Utama User
Aktor Lain yang
berperan
-Interested stakeholders User sistem
Diskripsi Use casehelm. ini mendiskripsikan proses memprediksi pendistribusian
Langkah Umum Aksi Aktor Reaksi Sistem
- Langkah 2
User sistem memilih menu
“Prediksi Helm”.
- Langkah 4
User sistem memilih sub menu “Prediksi Tunggal”.
- Langkah 5
User sistem mengisikan data-data id-helm, merk, tipe, dan warna dari suatu produk helm yang ingin diprediksi.
- Langkah 6
User sistem memilih tombol
“Prediksi Data Tunggal”.
- Langkah 8
User sistem melakukan pencarian file yang sesuai pada direktori yang dipilihnya dan memilih tombol “Open” untuk membuka file model
training.
- Langkah 1
Sistem menampilkan halaman home User sistem.
- Langkah 3
Sistem menampilkan halaman prediksi helm.
- Langkah 7
Sistem menampilkan bahwa proses prediksi berlangsung. Sistem menampilkan file chooser yang memudahkan untuk memasukkan file
model training yang berbentuk .obj.
- Langkah 9
Secara bertahap sistem akan melakukan perhitungan
prior, perhitungan
likelihood, perhitungan
laplace estimator, dan perhitungan posterior.
- Langkah 10
Sistem menampilkan status dari prediksi kelompok yang dilakukan dan menampilkan hasil presiksi produk-produk helm (data-data pada kolom wilayah pemasaran dan kolom probabilitas) pada tabel yang tersedia.
Bidang alternatif
Alt-Langkah 7 : Sistem akan menampilkan peringatan berupa
“Prediksi Gagal, Silahkan Cek data-data yang diInputkan”
apabila User sistem belum memasukkan isi dari fields yang mewakili atribut-atribut tersebut.
Kesimpulan Use casemenampilkan hasil prediksi. ini akan berhenti apabila sistem telah berhasil
Aturan bisnis
-Batasan dan spesifikasi inplementasi
Akses sistem dalam keadaan stabil, file data testing yang akan dimasukkan harus berbentuk .csv atau .xls, dan file model training
Assumptions File model yang dijadikan sebagai data kelompok untuk prediksitraining telah tersedia dan sesuai dengan ketentuan dalam dan file sistem.
Masalah terbuka Userdari suatu data tunggal yang ditentukan. sistem harus paham melakukan prediksi pendistribusian helm
Tabel 3.6 Narasi Use Case : Cetak Hasil Prediksi
Author (s) : Carolus Benny Dwi Setiawan Date : 17 Desember 2014
Aktor : User sistem Versi : 02
Nama Use Case Cetak hasil prediksi
Use case type :
Use Case ID UCPrediksiHelm005
Prioritas High
Aktor Utama User (bagian pemasaran)
Aktor Lain yang
berperan
-Interested stakeholders User sistem
Diskripsi Use casependistribusian helm. ini mendiskripsikan proses mencetak hasil prediksi
Prakondisi User prediksi.sistem di halaman utama dan telah berhasil melakukan proses Post Kondisi User sistem telah mendapatkan review laporan hasil prediksi yang
dilakukan.
Langkah Umum Aksi Aktor Reaksi Sistem
- Langkah 2
User sistem memilih tombol
“Cetak Hasil Prediksi”.
- Langkah 1
Sistem berhasil melakukan proses prediksi data kelompok helm.
- Langkah 3
Sistem akan menampilkan
review laporan hasil prediksi pendistribusian helm dan
User sistem dapat lansung mencetak laporan tersebut.
Bidang alternatif
-Kesimpulan Use casemenampilkan ini akan berhenti apabila sistem telah berhasil review laporan hasil prediksi yang dilakukan.
Aturan bisnis
-Batasan dan spesifikasi
inplementasi Akses sistem dalam keadaan stabil dan melakukan proses prediksi. User sistem telah berhasil
Assumptions Hasil dari proses prediksi pendistribusian helm telah tersedia.
3.4 Diagram Aktivitas
3.4.1 Diagram Aktivitas Cetak Hasil Prediksi Kelompok
Gambar 3.2 Diagram Aktivitas : Cetak Hasil Prediksi Kelompok 3.4.2 Diagram Aktivitas Evaluasi Sistem
Gambar 3.3 Diagram Aktivitas : Evaluasi sistem
User sistem memilih tombol “Cetak Hasil Prediksi”.
Berhasil melakukan proses prediksi data
kelompok helm.
Selesai Mulai
Menampilkan review laporan hasil prediksi pendistribusian helm dan dapat lansung Mencetak laporan
tersebut.
Memilih menu
“Akurasi Data” perhitungan akurasi data.Menampilkan halaman Menentukan berapa fold
dengan memilih nilai pada dropdown field.
Menampilkan nilai fold yang telah ditentukan oleh user.
Selesai Mulai
Memilih tombol “Hitung
Akurasi Data” untuk memulai
proses perhitungan akurasi data. Menampilkan file chooser yang memudahkan untuk memasukkan file data set
pengujian. Melakukan pencarian file data
set pengujian yang sesuai pada direktori yang dipilihnya, dan Memilih tombol “Open” untuk melanjutkan proses perhitungan
akurasi data. Melakukan perhitungan akurasi data berdasarkan nilai fold yang ditentukan.
Menampilkan status dari hasil perhitungan
3.4.3 Diagram Aktivitas Prediksi Helm (Data Kelompok)
Gambar 3.4 Diagram Aktivitas : Prediksi Helm (Data Kelompok) Memilih menu
“Prediksi Helm”.
Menampilkan halaman prediksi helm. Selesai Mulai Memilih submenu “Prediksi Kelompok”.
Memilih data atau file testing dengan memilih tombol
“Pilih Data Testing”.
Menampilkan halaman prediksi
kelompok.
Menampilkan file chooser yang memudahkan untuk memasukkan file testing. Melakukan pencarian file yang sesuai
pada direktori yang dipilihnya dan Memilih tombol “Open” untuk
membuka file testing. Menampilkan data pada tabel
yang tersedia berdasarkan id-helm, merk, tipe, dan warna
produk–produk helm. Memilih tombol “Prediksi
Data Kelompok” untuk memulai proses prediksi
kelompok. Menampilkan bahwa proses prediksi berlansung dan Menampilkan file chooser yang memudahkan untuk
memasukkan file model training yang berbentuk .obj. Melakukan pencarian file yang sesuai
pada direktori yang dipilihnya dan memilih tombol “Open” untuk
membuka file model training. Melakukan perhitungan prior,
perhitungan likelihood, perhitungan laplace estimator,
dan perhitungan posterior.
3.4.4 Diagram Aktivitas Prediksi Helm (Data Tunggal)
Gambar 3.5 Diagram Aktivitas : Prediksi Helm (Data Tunggal) Memilih menu
“Prediksi Helm”.
Menampilkan halaman prediksi helm.
Selesai Mulai
Memilih submenu
“Prediksi Tunggal”.
Mengisikan data-data id-helm, merk, tipe, dan warna dari suatu produk helm yang
ingin diprediksi.
Menampilkan halaman sub menu
prediksi tunggal.
Memilih tombol “Prediksi
Data Tunggal”.
Menampilkan bahwa proses prediksi berlansung dan Menampilkan file chooser yang memudahkan untuk memasukkan file model training
yang berbentuk .obj. Melakukan pencarian file yang sesuai
pada direktori yang dipilihnya dan Memilih tombol “Open” untuk
membuka file model training. Melakukan perhitungan prior,
perhitungan likelihood, perhitungan laplace estimator,
dan perhitungan posterior.
3.4.5 Diagram Aktivitas Input Data Training
Gambar 3.6 Diagram Aktivitas : Input data training
3.5 Perancangan Struktur Data
Perancangan struktur data dalam sistem ini dimaksudkan untuk menyimpan dan mengorganisasikan atau mengkonstruksi informasi yang tersedia. Struktur data membantu pengolahan data yang lebih efisien. Penelitian ini digunakan konsep struktur data dengan matriks 2 dimensi. 3.5.1 Matriks Dua Dimensi
Matriks dua di