Pairwise Clustering with
t
-PLSI
He Zhang, Tele Hao, Zhirong Yang, and Erkki Oja
Department of Information and Computer Science⋆
Aalto University School of Science, Espoo, Finland
{he.zhang,tele.hao,zhirong.yang,erkki.oja}@aalto.fi
Abstract. In the past decade, Probabilistic Latent Semantic Indexing (PLSI) has become an important modeling technique, widely used in clustering or graph partitioning analysis. However, the original PLSI is designed for multinomial data and may not handle other data types. To overcome this restriction, we generalize PLSI tot-exponential family
based on a recently proposed information criterion calledt-divergence. Thet-divergence enjoys more flexibility than KL-divergence in PLSI such that it can accommodate more types of noise in data. To optimize the generalized learning objective, we propose a Majorization-Minimization algorithm which multiplicatively updates the factorizing matrices. The new method is verified in pairwise clustering tasks. Experimental results on real-world datasets show that PLSI with t-divergence can improve
clustering performance in purity for certain datasets.
Keywords: clustering, divergence, approximation, multiplicative update
1
Introduction
Probabilistic clustering has been obtaining promising results in many applica-tions (e.g. [1, 3]). Especially, Probabilistic Latent Semantic Indexing (PLSI) [10] that provides a nice factorizing structure for optimization and statistical in-terpretation has attracted much research effort in the past decade. PLSI was originally used for topic modeling and later also found a good application in clustering (e.g. [5]).
Despite its success in many tasks, PLSI is restricted to multinomial data -originally, word counts in documents. That is, it assumes that data is generated from a multinomial distribution. Besides the nonnegative integer limitation, the multinomial assumption may not hold for other data with different types of noise.
In this paper we generalize PLSI with a more flexible formulation based on nonnegative low-rank approximation. Maximizing the PLSI likelihood is equiv-alent to minimizing the Kullback-Leibler (KL) divergence between the input matrix and its approximation. KL-divergence was recently generalized to a fam-ily calledt-divergence for measuring the approximation error. Thet-divergence
⋆This work is supported by the Academy of Finland in the project Finnish Center of
is more flexible than KL-divergence in the sense that more types of noise model, e.g. data with a heavy-tailed distribution, can be accommodated [8]. Here we integrate t-divergence in our new PLSI formulation and name the generalized method t-PLSI.
As the algorithmic contribution, we propose a Majorization-Minimization algorithm to solve the t-PLSI optimization problem. The t-divergence is con-structed through the Fenchel dual of the log-partition function oft-exponential family distributions [8]. The resulting convexity facilitates developing convenient multiplicative variational algorithms for t-PLSI.
We applyt-PLSI to pairwise clustering analysis. Fourteen real-world datasets are selected for comparing PLSI and the generalized method. Experimental re-sults show that PLSI based on KL-divergence (t= 1) is not always the best. For many selected datasets,t-PLSI can achieve better purities with othert values.
The rest of the paper is organized as follows. Section 2 reviews the PLSI model and gives its formulation for the pairwise clustering framework. In Section 3, we present the generalized PLSI based ont-divergence, including its learning objective and optimization algorithm. Section 4 gives the experimental settings and results. Conclusions and some future work are given in Section 5.
2
Probabilistic Latent Semantic Indexing (PLSI)
PLSI [10] was originally developed for text document analysis. LetCbe anm×n word-document matrix, whereCijis the number of times theith word appears in thejth document. PLSI assumes that the data is generated from a multinomial distribution and maximizes the likelihood
m Y
i=1
n Y
j=1
P(w=i, d=j)Cij. (1)
The multinomial parametersP(w=i, d=j) are factorized by
P(w=i, d=j) = r X
k=1
P(w=i|z=k)P(d=j|z=k)P(z=k), (2)
with conditional independence between the word variable wand the document variable d given the latent class variable z. In the following, we rewrite the probabilities by matrix notations for convenience: Xb = W SH, where Xijb = P(w=i, d=j),Wik=P(w=i|z=k),Hkj=P(d=j|z=k) andSa diagonal matrix withSkk=P(z=k).
GivenX as the normalized version ofC, i.e.Xij = PCij
abCab, maximizing the likelihood in Eq. (1) is equivalent to minimizing the Kullback-Leibler divergence
DKL(X||Xb) =
X
ij
Xijlog Xij
subject to W ≥ 0,H ≥0, Pmi=1Wik = 1,
Pr
k=1Skk = 1,
Pn
j=1Hjk = 1 (for
details, see [5]).
In this paper we focus on the symmetric form of PLSI for pairwise clustering, where X is taken as the affinity matrix of a weighted undirected graph that represents pairwise similarities between data samples. No distinction between “words” and “documents” is made like in the original PLSI, but data can be of any type. In this case,H =WT.
3
PLSI with
t
-Divergence
Data in real-world applications is not necessarily multinomially distributed. Dif-ferent types of data may contain difDif-ferent types of noise (e.g. [9]). We therefore argue that, for certain data, the approximation error inX≈Xb should be mea-sured by more suitable divergences than the Kullback-Leibler.
To capture different statistical properties of data, e.g. for heavy-tailed distri-butions, the exponential family can be generalized to the t-exponential family by replacing the exponential function with the t-exponential function (see e.g. [7]). Correspondingly, there are several ways to generalize the KL-divergence for approximate inference. Here we adopt thet-divergence proposed by Ding et al. [8] because it can maintain the Fenchel duality int-exponential family.
Thet-divergence for two densitiespand ˜pis defined as
Dt(p||p) =˜ Z
q(x) logtp(x)−q(x) logtp(x)dx,˜ (4)
where q(x) = Rp(x)t
p(x)tdx is a normalization term called the escort distribution of p(x), and logt is the inverse oft-exponential function (see e.g. [7]):
logt(x) =
x1−t−1
1−t (5)
for t ∈ (0,2)\{1}. When t = 0, logt(x) = x. When t = 2, logt(x) = 1x. When t → 1, logt(x) = log(x) and thet-divergence (4) reduces to KL-divergence. It is worth noticing that the logt decays towards 0 more slowly than the usual log function for 1< t <2, which leads to the heavy-tailed nature oft-exponential family and is desired for robustness.
3.1 Learning objective
We now generalize the PLSI model by usingt-divergence. The discrete version of t-divergence between a normalized nonnegative matrix X and its approximate
b
X is given by
Dt(X||Xb) =X i,j
qijlogtXij−qijlogtXijb
whereqij =PXijt
abXabt . Recall that we use b
X=W SWT for symmetric inputs. The resultingt-PLSI optimization problem for pairwise clustering is
minimize
W,S Dt(X||X) =b
1−PijXijtXb
1−t ij (1−t)PabX
t ab
(7)
subject to X i
Wik= 1, for allk, and X k
Skk= 1. (8)
3.2 Optimization
Thet-divergence in Eq. (7) is convex inXijb fort∈[0,2]. We can therefore ap-ply Jensen’s inequality to develop a Majorization-Minimization algorithm which iterates the following update rules:
Wik∝
Wik
A⊘ W SWTt
W 1
2t−1
ik 0< t <1 WikA⊘ W SWTtW
ik 1< t <2,
(9)
Skk∝SkkWTA⊘ W SWTtW
1
t
ik, (10)
where Aij = X t ij
P
abXtab and ⊘ denotes the element-wise division between two matrices of equal size.
Theorem 1 The t-PLSI objective in Eq. (7) monotonically decreases by using the multiplicative update rules (9) and (10).
The proof is given in the appendix. It is a basic fact that a lower-bounded monotonically decreasing sequence is convergent. Becauset-divergence is lower-bounded by zero, the monotonicity shown in the above theorem guarantees that the objective function in Eq. (7) converges to a local minimum.
4
Experiments
We have compared the clustering performances on a number of undirected graphs between the original PLSI and the proposed PLSI based on t-divergence. The graphs have ground-truth classes. The evaluation criterion that we adopt is the clustering purity = n1Prk=1max1≤l≤qnlk, wheren
l
k is the number of vertices in the partition k that belong to ground-truth class l. A larger purity in general corresponds to a better clustering result.
We have used fourteen datasets to evaluate the two compared methods. These datasets can be retrieved from Pajek database1, Newman’s collection2, or UCI3
1
http://vlado.fmf.uni-lj.si/pub/networks/data/
2
http://www-personal.umich.edu/~mejn/netdata/
3
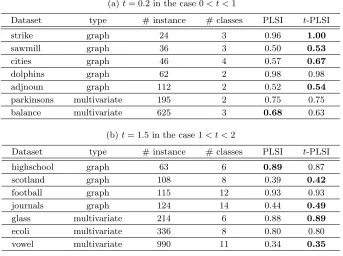
Table 1: Clustering performances measured bypurity for the two methods.
(a)t= 0.2 in the case 0< t <1
Dataset type # instance # classes PLSI t-PLSI
strike graph 24 3 0.96 1.00
sawmill graph 36 3 0.50 0.53
cities graph 46 4 0.57 0.67
dolphins graph 62 2 0.98 0.98
adjnoun graph 112 2 0.52 0.54
parkinsons multivariate 195 2 0.75 0.75
balance multivariate 625 3 0.68 0.63
(b)t= 1.5 in the case 1< t <2
Dataset type # instance # classes PLSI t-PLSI
highschool graph 63 6 0.89 0.87
scotland graph 108 8 0.39 0.42
football graph 115 12 0.93 0.93
journals graph 124 14 0.44 0.49
glass multivariate 214 6 0.88 0.89
ecoli multivariate 336 8 0.80 0.80
vowel multivariate 990 11 0.34 0.35
machine learning repository. Nine datasets are sparse graphs and the remaining five are multivariate data. We preprocessed the latter type into sparse similarity matrices by symmetrizing theirK-Nearest-Neighbor graphs (K= 15).
We set the number of clusters as the true number of classes for the two clustering algorithms on all datasets. The parametersW andS were initialized by following theFresh Startprocedure proposed by Ding et al. [6]. Table 1 shows the clustering performances of the compared algorithms.
5
Conclusions
We have studied the generalization of Probabilistic Latent Semantic Indexing with t-divergence family. The generalized PLSI was formulated as a nonnega-tive low-rank approximation problem. The formulation is more flexible and can accommodate more types of noise in data. We have proposed a Majorization-Minimization algorithm for optimizing the constrained objective. Empirical com-parison shows that clustering performance in purity can be improved by using the generalized method with suitablet-divergences other than KL-divergence.
The proposed generalization is not restricted to PLSI. Thet-divergence could be used in other nonnegative approximation problems with, for example, other matrix factorization/decomposition or other constraints, where the flexibility might also help to improve the performance.
An interesting question raised with thet-exponential family is whether we can find its conjugate prior. The multinomial distribution that underlies PLSI has Dirichlet as its conjugate prior. This conjugacy mainly accounts for the success of generative topic modeling in recent years. Inference based on t-exponential family might also benefit from its conjugate prior if they exist. That is, if we could find a conjugate prior for t-PLSI, we may also apply the nonparametric Bayesian treatment similar to Latent Dirichlet Allocation and thus avoid overfitting.
The t-divergence is related to two other divergence families, α-divergence and R´enyi divergence (see e.g. [3, 4, 13]). One of the major differences is nor-malization on the input: α-divergence involves no normalization and could be problematic when combined with prior information; R´enyi divergence normal-izes the input before the power operation while t-divergence employs t-power before normalization. The latter has the ability to smooth nonzero entries (for 0< t <1) or exclude outliers (for 1< t <2). More thorough comparison among these divergence families should be carried out in the future.
Another important and still open problem is how to select among various t-divergences. This strongly depends on the nature of the data to be analyzed. Usually a largertleads to more exclusive approximation while a smallertto more inclusive approximation. Automatic selection among parameterized divergence family generally requires extra information or criterion, for example, ground truth data [2] or cross-validations with a fixed reference parameter [12].
Appendix: Proof of Theorem 1
The development follows the Majorization-Minimization steps proposed by Yang and Oja [11, 13]. In the derivation, we use W and S for the current estimates whileWfandSefor the variables.
Proof. Introducing Lagrangian multipliers{λk}r k=1,
e
J(fW , S)≡J(fW , S) +X k
λk X i
f Wik−1
!
(Majorization)
Similarly we can prove the monotonicity overS. Let Je(W,S)e ≡ J(W,S) +e λPkSkke −1, which is tightly upper bounded by
G(S, S)e ≡ 1
t−1 X
ij
AijX k
φijkWikSkkWjke
1−t
+λ X k
e Skk−1
! .
Zeroing the derivative of G(S, S) givese Sqqe =λ−1
t P
ijAijφijqW
1−t iq W
1−t jq
1
t .
UsingPqSqqe = 1, we obtainλ
1
t =P
a P
ijAijφijaW
1−t ia W
1−t ja
1
t
. Insertingλ1t
back toSqqe gives the update rule (10).
References
1. Arora, R., Gupta, M., Kapila, A., Fazel, M.: Clustering by left-stochastic matrix factorization. In: International Conference on Machine Learning (ICML). pp. 761– 768 (2011)
2. Choi, H., Choi, S., Katake, A., Choe, Y.: Learning alpha-integration with partially-labeled data. In: Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing. pp. 14–19 (2010)
3. Cichocki, A., Lee, H., Kim, Y.D., Choi, S.: Non-negative matrix factorization with
α-divergence. Pattern Recognition Letters 29, 1433–1440 (2008)
4. Cichocki, A., Zdunek, R., Phan, A.H., Amari, S.: Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-way Data Analysis. John Wiley (2009)
5. Ding, C., Li, T., Peng, W.: On the equivalence between non-negative matrix factor-ization and probabilistic latent semantic indexing. Computational Statistics and Data Analysis 52(8), 3913–3927 (2008)
6. Ding, C., Li, T., Jordan, M.: Convex and semi-nonnegative matrix factorizations. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(1), 45–55 (2010)
7. Ding, N., Vishwanathan, S.: t-logistic regression. In: Advances in Neural Informa-tion Processing Systems 23, pp. 514–522 (2010)
8. Ding, N., Vishwanathan, S., Qi, Y.A.: t-divergence based approximate inference. In: Advances in Neural Information Processing Systems 24, pp. 1494–1502 (2011) 9. F´evotte, C., Bertin, N., Durrieu, J.L.: Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Computation 21(3), 793–830 (2009)
10. Hofmann, T.: Probabilistic latent semantic indexing. In: Proceedings of the 22nd Annual International Conference on Research and Development in Information Retrieval (SIGIR). pp. 50–57. ACM (1999)
11. Hunter, D.R., Lange, K.: A tutorial on MM algorithms. The American Statistician 58(1), 30–37 (2004)
12. Mollah, M., Sultana, N., Minami, M.: Robust extraction of local structures by the minimum of beta-divergence method. Neural Networks 23, 226–238 (2010) 13. Yang, Z., Oja, E.: Unified development of multiplicative algorithms for linear and