Fakultas Ilmu Komputer
3258
Pembangkitan Aturan Pengenalan Emosi Pada Twitter Menggunakan
Metode Fuzzy-C Means
Farid Rahmat Hartono1,Yuita Arum Sari2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Di era digital saat ini, pengguna media sosial berkembang semakin pesat dan semakin banyak aplikasi media sosial. Salah satu media sosial yang banyak digunakan saat ini adalah Twitter, dengan pengguna mencapai lebih dari ratusan juta orang di dunia. Twitter merupakan aplikasi mobile maupun dekstop
dimana pengguna dapat membuat suatu tulisan yang dapat mencerminkan emosinya melalui sebuah status berupa teks singkat dengan maksimal sebayak 280 karakter. Dengan banyaknya pengguna aktif hingga saat ini maka pada setiap sebuah status yang dibuat oleh pengguna Twitter dapat mencerminkan emosinya. Dibutuhkan seorang pesikolog untuk melihat suatu emosi dari status orang di media sosial dikarenakan belum adanya sistem otomatis untuk menentukan emosi seseorang melalui statusnya di Twitter. Sistem dalam penelitian ini dibuat dengan menggunakan metode Fuzzy C-Means (FCM). Metode FCM dapat digunakan untuk membangkitkan aturan-aturan yang dapat menggantikan peran dari seorang psikolog untuk menentukan emosi seseorang dari suatu status yang dia buat di media sosial Twitter. Metode Term Frequency & Index Document Frequency (TF-IDF) pada text mining digunakan untuk mengolah data tekstual menjadi data numerik agar mampu diolah oleh FCM. Berdasarkan hasil pengujian, sistem ini menghasilkan akurasi tertinggin sebesar 70% sehingga dapat disimpulkan bahwa metode FCM bisa digunakan dalam pembentukan aturan penentuan emosi seseorang dari suatu status pada media sosial Twitter.
Kata kunci: Twitter, pembangkitan aturan, Fuzzy C-Means
Abstract
In this digital era, social media users are growing more rapidly and more mediasocial applications. One of the most widely used social media today is Twitter, with users reaching over hundreds of millions of people in the world. Twitter is a mobile or desktop application where users can create an article that can reflect their emotions through a short text form status with a maximum of 280 characters. With so many active users up to now then on every status created by Twitter users can reflect their emotions. It takes a pesikolog to see an emotion from the status of people in social media because there is no automatic system to determine one's emotions through its status on Twitter. The system in this research is made using Fuzzy C-Means (FCM) method. The FCM method can be used to generate rules that can replace the role of a psychologist to determine a person's emotions from a status he or she creates on Twitter's social media. The Term Frequency & Index Document Frequency (TF-IDF) method in text mining is used to process textual data into numerical data to be able to be processed by FCM. Based on the test results, this system produces an highest accuracy of 70% so it can be concluded that the FCM method is can be used in the formation of a person's emotional determination of a status on social media Twitter.
Keywords: Twitter, rule generation, Fuzzy C-Means
1. PENDAHULUAN
Media sosial adalah media yang mendukung terjadinya interaksi sosial antar manusia dengan menggunakan koneksi internet. Media sosial
Mayfield adalah media yang dapat memudahkan pengguna untuk berpartisipasi di dalamnya, seperti berbagi dan membuat pesan seperti aplikasi messaging. Media sosial memiliki fungsi utama yakni untuk memperluas interaksi sosial manusia menggunakan internet (Mayfield, 2008).
Twitter merupakan media sosial yang populer di Indonesia sejak awal diperkenalkan dengan jumlah pengguna menurut data PT Bakrie Telecom mencapai 19,5 juta pengguna aktif pada tahun 2013. Indonesia pada tahun 2017 menjadi negara ke-5 pengguna Twitter di dunia dengan jumlah yang tidak disebutkan dengan pengguna global mencapai 328 juta. Twitter merupakan media sosisal yang unik karena memiliki perbedaan mencolok dari media sosial lain yakni maksimal karakter pada Twitter dibatasi hanya 280 karakter sehingga saat seseorang meng-update status yang disebut
tweet atau kicauan (Twitter, 2017).
Pada tahun 2016 sebuah penelitian tentang klasifikasi emosi dilakukan oleh dua mahasiswa Turki dari Selcuk University yakni Demircan & Kahramanli. Penelitian tersebut menggunakan
Fuzzy C-Means yang digabung dengan metode
suport vector machine (SVM) dan menghasilkan akurasi sebesar 92,86% (Demircan & Kahramanli, 2016). Pada tahun 2012 dilakukan sebuah penelitian untuk mengetahui apakah 140 karakter pada pengguna Twitter mengambarkan emosi dari seseorang tersebut. Penelitian ini dilakukan di Singapura dengan jumlah sampel sebanyak 142 orang yang mengisi kuisioner dan hasil penelitian hanya menghasilkan 2 jenis emosi yang dapat dideteksi oleh sistem yaitu keramahan dan neurotisisme (Qiu, 2012).
Dengan banyaknya pengguna maka tak jarang media sosial digunakan sebagai tempat untuk mencurahkan hati dan keadaan emosi seseorang terkadang sulit ditebak karena biasanya hanya berisi tag(#) dan emoticon serta isi kicauan atau tweet yang singkat sehingga dibutuhkan sistem yang dapat melakukan pengenalan emosi pada Twitter dengan berdasarkan dari kicauan atau tweet pengguna.
Berdasarkan latar belakang tersebut dengan memanfaatkan metode yang dapat membantu untuk membuat sistem yang dapat menentukan emosi seseorang pada kicauan di Twitter adalah metode fuzzy. Metode fuzzy merupakan metode yang melakukan penalaran menggunakan nilai kekaburan atau kesamaran. Dengan beberapa algoritme tertentu dan didukung dengan data serta pakar yang layak maka dapat dibangkitkan
aturan. Salah satu metode yang dapat mengekstraksi aturan fuzzy adalah Metode Fuzzy C-Means (FCM). FCM merupakan adaptasi metode K-means yang menggunakan derajat keanggotaan untuk menentukan klasternya.
2. TINJAUAN PUSTAKA
2.1. Twitter
Twitter merupakan media sosial berlogo burung biru yang pertama kali diperkenalakan oleh pendirinya yakni Jack Dorsey pada tahun 2006. Twitter mengalami pertumbuhan signifikan pada tahun 2013 dimana penggguna Twitter meningkat drastis sehingga menjadi populer dan menyebar cepat di seluruh dunia tak terkecuali di indonesia. Perbedaan mencolok Twitter dengan media sosial yang lain adalah Twitter merupakan media sosial yang unik karena memiliki perbedaan mencolok dari media sosial lain yakni maksimal karakter pada Twitter dibatasi hanya 280 karakter sehingga saat seseorang membuat status maka disebut tweet atau kicauan (Twitter, 2017).
2.2. Text Mining
Text mining merupakan suatu metode yang berhubungan dengan mengolah suatu dokumen yang berisi kata atau huruf untuk diurutkan atau hal lainnya. Text mining atau permrosesan teks pertama kali muncul pada pertengahan tahun 1980 dan pemrosesan teks masih dalam dalam satu lingkup dengan data mining, sistem temu kembali, statistik dan bahasa komputer. Terdapat beberapa proses-proses dalam melakukan pemrosesan teks yakni case folding, tokenisasi,
filtering, dan stemming (Agusta, 2009).
2.3. Pra-Pemrosesan
Pra-Pemrosesan dilakukan untuk mengubah data dari dokumen yang semula berjenis tekstual menjadi numerik. Pada proses ini juga dilakukan pembagian jenis emosi yang ada pada dokumen dan jenis emosi akan dibagi menjadi lima emosi yakni senang, sedih, marah, cinta dan takut. Setelah dibagi ke jenis emosinya masing-masing maka selanjutnya dilakukan proses pembobotan menggunakan TF-IDF.
2.4. Pembobotan TF-IDF
besar. Berikut ini adalah persamaan untuk menghitung bobot TF yang dapat dilihat pada Persamaan 1.
(𝑡𝑖) {1 + log(𝑇𝐹( 𝑡𝑖)) , 𝑇𝐹 0 (𝑡𝑖) > 0 (1)
Inverse Document Frequency (IDF) merupakan sebuah perhitungan dari bagaimana
term didistribusikan secara luas pada koleksi dokumen yang bersangkutan. IDF menunjukkan hubungan ketersediaan sebuah term dalam seluruh dokumen. Semakin sedikit jumlah dokumen yang mengandung term yang dimaksud, maka nilai IDF semakin besar. untuk menghitung IDF menggunakan persamaan 2.
𝐼𝐷𝐹(𝑡𝑖) = log( |𝐷|𝐷𝐹(𝑡𝑖)) (2) 2.5. Algoritme Fuzzy C-Means
Algoritme Fuzzy C-Means adalah sebagai
berikut (Kusumadewi, 2010).
1. Input n data yang akan diclustering
menjadi clusterX, berupa matriks berukuran n x m dengan n merupakan jumlah seluruh data dan m merupakan atribut dari data.
2. Penentuan awal fuzzy c-means: Jumlah dari cluster = c; Nilai pangkat = w;
Maksimal iterasi yang diperbolehkan =
MaxIter;
Epsilon (errorI terkecil) = ξ;
Nilai fungsi obyektif awal: P0 = 0; Nilai Iterasi awal: t = 1;
3. Membangkitkan angka random berupa matriks µik berdimensi c x n.
selanjutnya menghitung jumlah setiap kolom dengan Persamaan 3.
𝒬𝑖 = ∑𝑐𝑘=1𝜇𝑖𝑘
(3) Keterangan Persamaan 2.3
𝒬𝑖= jumlah kolom tiap c
𝜇𝑖𝑘= Matriks angka random
Selanjutnya menentukan derajat keanggotaan awal dengan memakai Persamaan 4.
𝜇𝑖𝑘 = 𝜇𝒬𝑖𝑘𝑖 (4)
4. Menghitung nilai pusat cluster ke-k (Vkj)
berdasarkan dengan menggunakan Persamaan 5.
dengan k=1,2, …,c; dan j=1, 2, …, m.
𝑉𝑘𝑗 =∑ ((𝜇𝑖𝑘)∗(𝑋𝑖𝑗)
𝑛 𝑖=1
∑𝑛𝑖=1(𝜇𝑖𝑘) (5)
Keterangan Persamaan 5 𝑉𝑘𝑗= Pusat cluster
𝜇𝑖𝑘= Matriks keanggotaan
𝑋𝑖𝑗= Matriks input
5. Menghitung nilai fungsi obyektif pada setiap iterasi ke-t (Pt) sesuai dengan Persamaan 6.
𝑃𝑡 = ∑𝑐𝑘=1([∑ (𝑋𝑚𝑗=1 𝑖𝑗 −
𝑉𝑖𝑗)2]( 𝜇𝑖𝑘)𝑤) (6)
Keterangan Persamaan 6
𝑃𝑡 = Fungsi Objektif setiap iterasi ke t
𝑉𝑖𝑗 = Pusat cluster data ke i
𝜇𝑖𝑘 = Matriks keanggotaan
𝑋𝑖𝑗 =Matriks input
𝑤 = Pangkat
6. Perbaikan matiks U berdasarkan Persamaan 2.7.
𝜇𝑖𝑘 = [∑ (𝑋𝑖𝑗−𝑉𝑖𝑗) 𝑚
𝑗=1 2]−1(𝑤−1)
∑[∑𝑚𝑗=1(𝑋𝑖𝑗−𝑉𝑖𝑗)2]−1(𝑤−1)
(7)
Keterangan Persamaan 2.7 𝜇𝑖𝑘 = Matriks keanggotaan
𝑉𝑖𝑗 = Pusat cluster data ke i
𝑋𝑖𝑗 =Matriks input
𝑤 = Pangkat
7. Memeriksa kondisi untuk iterasi dihentikan.
apabila: (|Pt – Pt-1| < ξ) atau (t > MaxIter) maka iterasi berhenti.
apabila tidak: t = t+1, ulangi langkah ke-4.
Keterangan
3. METODOLOGI
Metodologi berisi tentang uraian dari metodologi penelitian dan tahapan dalam penyelesaian sistem pembangkitan aturan untuk pengenalan emosi pada Twitter menggunakan metode Fuzzy C-Means.
Sistem yang dikembangkan pada penelitian ini adalah pembangkitan aturan dengan menggunakan metode Fuzzy C-Means. Metode
Fuzzy C-Means bergantung dari data yang akan dimasukkan yang berupa matriks [i][j] yang berasal dari hasil pembobotan menggunakan TF-IDF. Perancangan sistem yang dibuat dapat dilihat pada Gambar 1.
Gambar 1 Diagram Perancangan
4. PENGUJIAN DAN ANALISIS
Dalam penelitian ini dilakukan pengujian dengan menggunakan data uji yang berupa beberapa status orang pada aplikasi Twitter. Data uji berjumlah 50 dan danta latih berjumlah 500 data.
4.1. Pembangkitan Aturan Dari Data Latih Untuk mendapatkan aturan dari data latih maka dilakukan proses seperti yang dijelaskan pada bagian dua yaitu proses text mining dan pembobotan TF-IDF untuk mengubah data tekstual menjadi numerik. Peroses selajutnya dilakukan perhitungan FCM mulai dari proses penentuan jumlah cluster hingga perhitunggan fungsi objektif sampai iterasi dihentikan.
Agar aturan dapat di ekstraksi. Dilakukan langkah-langkah setelah dilakukan proses
clustering yakni malkukan analisis varian untuk melihat kualitas cluster yang dihasilkan dan selanjutnua membentuk aturan dari pusat cluster
yang didapat yang disesuaikan berdasarkan atribut yang ada pada proses FCM. Pada penelitian ini digunakan data latih sebanyak N yang menghasilkan aturan sebanyak lima sesuai dengan jumlah cluster yang dibuat. Contoh hasil aturan yang dihasilkan dapat dilihat pada Tabel 1.
Tabel 1 Hasil Aturan yang Dihasilkan Cluster
4.2. Pembentukan Fungsi Gauss
Fungsi Gauss digunakan untuk melakukan penghitunggan fuzzyfikasi data uji Untuk membuat fungsi Gauss, maka nilai dari standar deviasi dan pusat cluster harus diketahui. Langkah-langkah untuk membentuk fungsi Gauss adalah sebagai berikut.
1. Mengambil nilai pusat cluster dari proses FCM
2. Menghitung nilai dari standar deviasi tiap cluster
Studi Kepustakaan
Analisis
Kebutuhan
Pengumpulan Data
Perancangan Sistem
Implementasi
Analisis
3. Membentuk fungsi Gauss sesuai jumlah atribut pada tiap cluster.
4.3. Perhitungan Koefisien Output
Perhitungan utnuk koefisien output akan dilakukan dengan menggunakan metode kuadrat terkecil (least square). Kudarat terkecil digunakan karena matriks yang digunakan tidak berbentuk persegi (square). Langkah-langkah untuk menghitung koefisien output adalah:
1. Membentuk matriks Dkij ternormalisasi
dari matriks input dikali derajat keanggotaan.
2. Membentuk matrik U berdasarkan matriks Dkij yang dirubah dimensinya.
Malkukan operasi matriks yakni U transpose (Ut), U x Ut menghasilkan (Uxt), Uxt invers, Uxt x Ut dan terakhir dikalikan dengan matriks Y
yang merupakan target output dari data laih.
4.4. Pengujian Aturan Dengan Data Uji Pada pengujian digunakan data uji berjumlah N untuk menguji akurasi dari aturan yang dihasilkan sistem. Pengujian akan menunjukkan emosi yang ada pada tiap data uji dan juga dicocokkan dengan kedekatan aturan yang sesuai. Langkah-langkah pengujian adalah sebagai berikut.
1. Melakukan perhitungan derajat keanggotaan melalui proses fuzzyfikasi berdasarkan fungsi keanggottan Gauss. 2. Menghitung fire strenght dengan cara
mengkalikan tiap derajat keanggotaan yang telah didapat tiap cluster.
3. Menghitung nilai Z pada tiap aturan berdasarkan persamaan U = k x Z. 4. Melakukan proses Defuzzyfikasi.
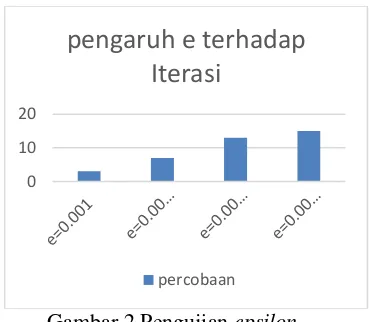
4.4.1. Pengujian Pengaruh Epsilon pada Iterasi
Pada bagian ini merupakan pembahasan dari hasil pengujian data uji. Pengujian dilakukan sebanyak empat kali dan pada tiap penggujian memilki nilai epsilon/error yang berbeda-beda. Nilai epsilon akan berpengaruh terhadap banyaknya iterasi yang akan dijalankan.
Gambar 2 Pengujian epsilon
4.4.2. Analisis Pengujian Pengaruh Epsilon
Terhadap Iterasi
Nilai epsilon sangat berpengaruh terhadap kualitas cluster yang dihailkan juga jumlah iterasi yang akan dilakukan. Hal ini dikarenakan nilai epsilon adalah reprsentasi dari target pendekatan nilai fungsi objektif yang merupakan salah satu syarat berhentinya iterasi. Nilai
epsilon juga berpengaruh terhadap hasil dari nilai varian cluster dimana nilai tersebut merupakan pedoman terhadap penilaian kualitas suatu cluster. Semakin kecil nilai varian cluster maka kualitas cluster yang dihasilkan akan semakin baik sehingga saat nilai varian cluster minimum didapat maka persebaran data latih pada proses clustering akan semakin bagus dan kluster tersebutlah yang akan dipakai sebagai pembentuk aturan.
Pada Gambar 2 hasil pengujian nilai epsilon (e) terhadap hasil clustering pada pengujian pertama nilai e = 0.001 dan iterasi pada proses FCM berhenti pada iterasi ke-3. Pada percobaan kedua nilai e = 0.0001 dan iterasi berhenti pada iterasi ke-7. Pada percobaan ketiga nilai e = 0.00001 dan iterasi berhenti pada iterasi ke-13 . Pada percobaan keempat nilai e = 0.000001 dan iterasi berhenti pada iterasi ke-15. Semakin banyak iterasi maka cluster yang dihasilkan akan semakin homogen dan tidak baik Sehingga dapat diketahui bahwa nilai e sangat berpengaruh terhadap hasil clustering yang akan dijalankan pada proses FCM.
4.4.3. Pengujian Kedekatan Defuzzyfikasi Dengan Z Aturan
Pengujian ini bertujuan untukm melihat hasil dari proses defuzzyfikasi yang digunakan sebagai tahap ahir pengujian untuk dilihat kedekatannya terhadap nilai Z setiap aturan. kedekatan hasil defuzzyfikasi setiap data latih dengan Z setiap aturan akan menentukan aturan mana yang sesuai dengan data yang diuji.
0 10 20
pengaruh e terhadap
Iterasi
Pada pengujian ini digunakan 50 jumlah data latih yang menghasilkan 50 nilai defuzzyfikasi dan juga Z sebanyak 50 dengan nilai Zsenang,Zsedih,Zmarah,Zcinta dan Ztakut
pada tiap Z. pengujian kedektan Z dilakukan saat hasil aturan FCM memiliki nilai varian cluster minimum yakni dengan nilai epsilon sebesar 0.00001 pada proses pelatihan data dan pembentukan aturan dari proses clustering.
Gambar 3 Kedekatan Data Uji Terhadap Z
4.4.4. Analisis Pengujian Kedekatan Defuzzyfikasi Dengan Z Aturan
Kedekatan nilai defuzzyfikasi setiap data uji dengan Z aturan dapat emnunjukkan hasil dari emosi yang terdapat pada setiap dokumen uji. Hal ini dapat dilakukan karena nilai deffuzyfikasi didapat dari proses fuzzyfikasi terlebih dahulu yang menggunakan fungsi Gauss dengan variabel yang bersesuaian. Fungsi Gauss didapat dari nilai standar deviasi dan nilai pusat
cluster yang terdapat pada proses clustering. Pada Gambar 3 dapat dilihat hasil kedekatan nilai defuzzyfikasi setiap data uji terhadap nilai Z setiap aturan dengan jumlah data 50 menunjukkan emosi cinta dengan nilai kedekatan paling banyak dengan jumlah 16. Dari hasil tersebut dapat dilakukan sebuah pengujian akurasi dengan menggunakan confusionmatrix.
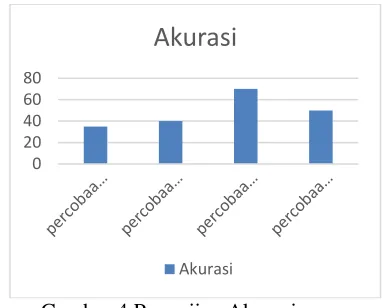
4.4.5. Pengujian Akurasi
Nilai akurasi dihitung menggunakan
confusion matrix dengan skala multi-class
karena terdiri dari lima jenis emosi. Convension matrix menggunakan perbandingan dari hasil kedekatan defuzzyfikasi setiap data uji dengan Z aturan dengan nilai emosi sebenarnya yang telah ditentukan pada tiap dokumen uji. Dengan melakukan empat kali percobaan pada aturan yang berbeda didapatkan hasil akurasi terbesar pada percobaan ke tiga yakni sebesar 70%.
Gambar 4 Pengujian Akurasi
4.4.6. Analisis Pengujian Akurasi
Pada Gambar 4 dapat dilihat hasil pegujian akurasi data uji terhadap aturan yang tealh dihasilkan dari proses FCM. Dilakukan percobaan sebanyak empat kali dengan nilai epsilon yang telah dijelaskan pada Gambar 2. hasil akurasi pada percobaan petama menghasilkan akurasi sebesar 35%. Pada percobaan kedua hasil akurasi yang didapatkan sebesar 40%. Pada percobaan ketiga hasil akurasi yang didapatkan sebesar 70% dan pada percobaan keempat hasil akurasi yang didapat adalah 50%.
5. KESIMPULAN
Dari hasil perancangan, implementasi, pengujian dan analisis pada penelitian pembangkitan aturan pengenalan emosi pada Twitter menggunakan metode Fuzzy C-Means
maka dapat diambil simpulan sebagai berikut. 1. Metode Fuzzy C-Means dapat
diimplementasikan pada pembangkitan aturan pengenalan emosi pada Twitter. Data Twitter didapat langsung dari aplikasi Twitter. Pra-pemrosesan yang dipakai adalah tokenesasi, filtering, stemming, dan metode TF-IDF pada text mining. Penggunaan metode fuzzy C-means untuk melakukan clustering
tergolong bagus dikarenakan persebaran data yang merata yang hampir sesuai dengan data aktual dengan catatan nilai varian cluster sudah yang terbaik. Metode stemming Nazief & Adriani untuk teks bahasa indonesia menghasilkan hasil stemming yang kurang baik sehingga terdapat beberapa
0 10 20
senang sedih marah cinta takut
Kedekatan
Zd
dengan
Z
tiap Aturan
Z tiap Aturan
0 20 40 60 80
Akurasi
term yang masih belum sesuai dengan kata dasar yang diharapkan.
2. Algoritme Fuzzy C-Means untuk pembangkitan aturan pengenalan emosi pada Twitter menghasilkan akurasi tertinggi sebesar 70% dengan menggunakan jumlah data latih sebesar 500 dan jumlah data uji sebesar 50 data dengan nilai epsilon sebesar 0.00001. Pada akurasi tertinggi dari 50 jumlah data uji didapatkan emosi terbanyak adalah emosi dengan kategori cinta, hal ini disebabkan banyaknya kata-kata yamg mengandung emosi cinta baik pada data latih maupun data uji. Dari hal tersebut maka dapat diketahui bahwa semakin banyak term atau kata yang mengandung unsur emosi tertentu maka emosi tersebut akan cenderung dominan pada tiap pengujian dari aturan yang dihasilkan.
6. SARAN
Untuk meningkatkan hasil yang didapat dari penelitian ini, diharapkan pada penelitian selanjutnya dapat melakukan beberapa perbaikan sebagai berikut:
1. Diharapkan pada penelitian selanjutnya untuk mengoptimasi fitur atau stemming menggunakan metode lain agar hasil akurasi yang didapat lebih maksimal. 2. Diharapkan pada perhitungan least
square dilakukan dengan metode lain agar dapat dilakukan proses yang lebih benar supaya hasil lebih baik.
7. DAFTAR PUSTAKA
Agusta, L. 2009, Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia, KNS: Bali.
Antony, Mayfield. 2008, What Is Social Media?, London: ICrossing.
Demircan, S & Kahramanli, H. 2016, Application of Fuzzy C-Means Clustering Algorithm to Spectral Features for Emotion Classification From Speech, Turki: Selcuk University.
Kusumadewi, Sri & Purnomo, Hari. 2010, Aplikasi Logika Fuzzy, Cetakan Pertama, Garaham Ilmu, Yogyakarta.
Qiu, L., Lin, H., Ramsay, J & Yang, F., 2012. You Are What You Tweet: Personality Expression and Perception on Twitter, Journal of Research in Personality: Singapore.
Sari, Y., & Ridok, A., 2012, Penentuan Lirik Lagu Berdasarkan Emosi Menggunakan Sistem Temu Kembali Informasi Dengan Metode Latent Semantic Indexing. Malang: Universitas Brawijaya.