112
ANALISA BATAS SUDUT KEMIRINGAN
HASIL PEMINDAIAN DOKUMEN MENGGUNAKAN
TEMPLATE MATCHING CORRELATION
Oleh : Teddy Setiady
Manajemen Informatika, Politeknik LP3I Jakarta
Gedung Sentra Kramat Jl. Kramat Raya No. 7-9 Jakarta Pusat 10450 Telp. 021-31904598 Fax. 021-31904599
Email : [email protected]
ABSTRAK
Pemindaian dokumen cetak ke dalam bentuk dokumen digital dapat digunakan untuk konversi karakter optik ke dalam bentuk teks, yang selanjutnya dapat digunakan untuk proses kerja lainnya seperti proses edit, pencarian dan manajemen pemberkasan hasil pemindaian dokumen. Untuk menghasilkan hasil konversi dengan sempurna sering mendapatkan kendalayang diakibatkan oleh berbagai hal, antara lain ukuran huruf, ketebalan, ketajaman cetakan, jenis huruf yang tidak sesuai dengan template, dan posisi hasil pemindaian dokumen yang miring. Penelitian ini menguji kehandalan dari5 (lima) tipe font yang sering digunakan di Politeknik LP3I Jakarta yaitu arial, times new roman, calibri, tahoma dan book antiquadengan ukuran 12pt, 16pt dan 20pt. Posisi karakter diuji dalam sudut kemiringan dari -10o s/d 10o. Metode yang digunakan dalam proses pengenalan karakter optik ini adalah dengan menggunakan template matching correlation,
yaitu teknik untuk mendapatkan nilaiperbandingan karakter pada citra input dan karakter pada citra template. Terdapat kelebihan dan kekurangan pada karakteristik masing-masing tipe font, maka yang dapat dianggap sebagai font yang paling optimal untuk OCR dalam kondisi miring adalah tipe font Arial dan Calibri yang tergabung sebagai kelompok huruf tidak bersirip (sans serif).Sebagai solusi untuk memperbaiki kesalahan pembacaan karakter yang diakibatkan oleh kemiringan dokumen pada sudut tertentu maka dapat dibuat sebuah
tool untuk mendeteksi derajat kemiringan citra input, kemudian angka derajat tersebut digunakan untuk memperbaiki posisi citra sehingga dapat memperbaiki hasil OCR.
Kata kunci : Optical Character Recognition, Template Matching Correlation, Pemindaian Dokumen
PENDAHULUAN
Pada saat ini penggunaan teknologi sudah banyak digunakan untuk mempermudah pekerjaan di perkantoran, termasuk di dalamnya adalah pemindaian dokumen cetak ke dalam bentuk dokumen digital. Hasil pemindaian dokumen sering juga digunakan untuk konversi ke dalam bentuk teks, yang
selanjutnya dapat digunakan untuk proses kerja lainnya seperti proses edit, pencarian dan manajemen pemberkasan hasil pemindaian dokumen. Hasil pemindaian berkas-berkas yang dilakukan pada Unit Data dan Informasi Direktorat Politeknik LP3I Jakartaseperti ijazah, transkrip dan dokumen lainnya tidak mudah untuk diimplementasikan untuk menghasilkan pemindaian yang
113 berkualitas. Konversi hasil pemindaian
dokumen dengan memanfaatkan software peng-konversi karakter citra digital kedalam teks digunakan untuk mengolah bahan tersebut sesuai dengan kebutuhan. Banyaknya hasil pemindaian dokumen yang harus dikonversi menjadi dokumen teks sering mengalami permasalahan yang diakibatkan oleh berbagai hal, antara lain ukuran huruf, ketebalan, ketajaman cetakan, jenis huruf yang tidak sesuai dengan template, dan posisi hasil pemindaian dokumen yang miring, baik diakibatkan oleh posisi kertas ketika dipindai maupun akibat perubahan posisi huruf ketika proses cetak ataupun
fotocopy.
Untuk mengatasi permasalahan yang dikibatkan oleh tingkat kemiringan hasil pemindaian dokumen, maka diperlukan teknik untuk mengetahui batas sudut kemiringan dokumen cetak yang masih dapat memenuhi akurasi pengenalan karakter optik ke dalam teks sesuai dengan isi teks yang sebenarnya, serta solusi untuk mengurangi kesalahan pengenalan karakter optik yang diakibatkan oleh kemiringan hasil pemindaian dokumen. Metode yang digunakan dalam proses pengenalan karakter optik ini adalah dengan menggunakan template matching correlation.
Pada karya ilmiah ini untuk dapat mengetahui batas sudut kemiringan hasil pemindaian dokumen tersebut adalah: menyiapkan dan memindai dokumen cetak yang berisi susunan huruf dan angka dari dari 5 (lima) tipe font yang sering digunakan di lokasi penelitian yaitu arial, times new roman, calibri, tahoma dan book antiquadengan ukuran 12pt, 16pt dan 20pt; pembuatan template
citra biner huruf dari dokumen cetak tersebut melalui preprocessing dan segmentasi ke dalam file huruf dengan ukuran 42 x 24 pixel dan disimpan dalam file *.bmp, pembuatan matriks template
seluruh huruf yang sudah dibuat dalam citra biner secara berurutan dalam satu
file matriks; pembuatan fungsi untuk memberi arti dari urutan huruf matriks dalam bentuk huruf dan angka; pembuatan program untuk mengenali karakter huruf dengan metode template matching correlation yaitu dengan cara membandingkan antara input karakter optik dengan seluruh template huruf yang sudah dibuat. Hasil dari dari perbandingan akan memberikan nilai antara -1 s/d 1, semakin mirip maka akan mempunyai nilai mendekati 1 bahkan dapat mencapai nilai 1; dan terakhir
melakukan percobaan dengan
menggunakan dokumen digital yang digunakan untuk pembuatan template. Hal ini diulangi dengan menggunakan
dokumen yang sudah dirubah
kemiringannya ke kanan ataupun ke kiri dengan interval 1° hingga mencapai batas akurasi pengenalan huruf.
Hasil yang diharapkan pada karya ilmiah ini untuk mendapatkan batas sudut kemiringan tertinggi dengan hasil akurasi pengenalan yang tinggi. Solusi untuk mengatasi kesalahan akibat posisi dokumen yang miring pada derajat tertentu yaitu dengan melakukan koreksi kemiringan dengan teknik skew detection and correction. Sedangkan manfaatnya dapat digunakan sebagai dasar eksperimen berikutnya sehingga proses pengenalan karakter optik tetap memiliki akurasi yang tinggi walaupun posisi dokumen dalam keadaan miring.
LANDASAN TEORI
Optical Character Recognition (OCR)
Optical character recognition (OCR) atau pengenalan karakter optikmerupakansebuah sistem komputer yang dapat membaca karakter,baik yang berasal dari hasil cetakan maupun tulisan
tangan. Aplikasi tersebut
menerjemahkan karakter optik menjadi bentuk teks sesuai dengan pola yang sudah tersimpan dalam basis data sebagai
114 Masyarakat pada umumnya belajar
membaca sejak awal masa
pendidikannya. Secara bertahap kemampuan membaca berkembang hingga dapat mengenali huruf dalam berbagai kondisi yang berbeda, seperti misalnya ketebalan, jenis huruf, posisi huruf, hasil cetak, tulisan tangan hingga simbol-simbol tertentu.
Karakter yang dicetak atau ditulis terkadang terdapat kesalahan, namun berdasarkan pengalaman dan konteks kalimat, kebanyakan manusia masih bisa mengenali maksud dari tulisan tersebut. Sebaliknya, meskipun lebih dari lima dekade penelitian yang intensif, keterampilan komputer untuk mengenali karakter masih jauh dari kemampuan manusia. Kebanyakan sistem OCR masih belum bisa membaca dokumen yang rusak dan tulisan tangan karakter/ kata-kata. Cheriet et.al. (2007:1-2)
Optical Character Recognition (OCR) atau sistem pengenalan karakter optik merupakan salah satu bidang penelitian yang populer sejak tahun 1950 dalam bidang pengenalan pola (pattern recognition) dan kecerdasan buatan (artificial intelligence). (Chandarana dan Kapadia, 2014:219). Pengenalan pola
merupakan suatu ilmu untuk
mengklasifikasikan atau menggambarkan sesuatu berdasarkan pengukuran kuantitatif fitur (ciri) atau sifat utama dari suatu objek. (Hartanto, et.al, 2012:11)
OCR adalah proses konversi dokumen cetak atau hasil pemindaian dokumen ke dalam karakter ASCII yang dapat dikenali komputer. Sistem komputer dengan menggunakan OCR dapat dimanfaatkan untuk meningkatkan kecepatan input, mengurangi kesalahan manusia, pencarian dengan cepat dan manipulasi file lainnya. Aplikasi tersebut dapat digunakan antara lain dalam pengenalan kode pos, entri data secara otomatis ke dalam sistem administrasi, perbankan, peta otomatis dan alat baca bagi orang buta. (Mohammad, et.al, 2014:2088). Sistem pengenalan huruf
yang cerdas sangat membantu usaha besar-besaran yang saat ini dilakukan banyak pihak yakni usaha digitalisasi informasi dan pengetahuan, misalnya dalam pembuatan koleksi pustaka digital, koleksi sastra kuno digital, dan lain-lain. (Hartanto, et.al, 2012:12)
OCR merupakan solusi yang efektif untuk proses konversi dari dokumen cetak ke dalam bentuk dokumen digital. Permasalahan yang muncul dalam melakukan proses pengenalan karakter optik adalah bagaimana sebuah teknik pengenalan dapat mengenali berbagai jenis huruf dengan ukuran, ketebalan, dan bentuk yang berbeda. Secara umum terdapat dua hal utama yang mempengaruhi proses OCR yaitu mekanisme ekstraksi ciri dan mekanisme pengenalan. (Hartanto, et.al, 2012:11)
Beberapa algoritma yang dapat digunakan untuk proses pengenalan antara lain, jaringan syaraf tiruan, logika
fuzzy, k-Nearest Neighbor Algorithm,
sequence alignment, template matching
dan lain-lain. Dari beberapa algoritma tersebut, algoritma template matching
merupakan salah satu algoritma yang efektif untuk diterapkan dalam sistem OCR. (Hartanto, 2012:11)
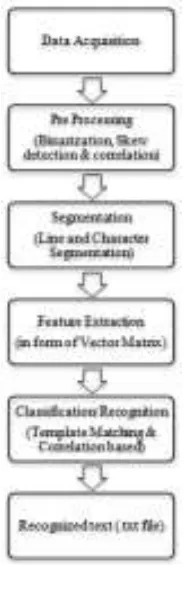
Chandarana dan Kapadia (2014:219) menggambarkan proses OCR dalam gambar sebagai berikut:
115
Gambar 1
Proses Optical Recognition Character
Data Acquisition
File input berupa hasil pemindaian dokumen cetak ke dalam dokumen digital, berupa file BMP, JPG, dan lain-lain. Ada 2 kategori dalam akuisisi untuk OCR yaitu on-line character recognition systems dan off-line character recognition systems. On-line character recognition menangkap data secara langsung dari objek yang bergerak, sedangkan off-line character recognition
menangkap data dari dokumen cetak melalui alat pemindai. (Patil dan Mane, 2013:504)
Pre Processing (Binarization, Skew detection & correlation)
Proses pertama kalinya yaitu konversi citra warna ke dalam citra skala keabuan. Selanjutnya yaitu proses binerisasi yaitu konversi citra skala keabuan (nilai piksel 0 hingga 255) ke dalam citra biner (nilai piksel 0 dan 1) melalui seleksi pengambangan antara nilai 0 hingga 255 dengan nilai pengambangan 128. Bila diperlukan untuk mengatasi kesalahan posisi
dokumen yang miring dapat
menggunakan metode Radon Transform (Skew detection and Correction method)
yaitu deteksi kemiringan, kemudian atas dasar itu dilakukan koreksi posisi
dokumen. (Chandarana dan Kapadia, 2014:220)
Hartanto, et.al. (2012:13) mendefinisikan citra biner sebagai berikut:
Keterangan:
adalah citra hitam putih
adalah citra biner
T adalah nilai ambang yang dispesifikasikan
Segmentation
Suatu citra yang mengandung karakter dipisahkan menjadi cintra individu masing-masing karakter. Langkah segmentasi diawali dengan segmentasi baris (line segmentation) yaitu memisahkan masing-masing baris kalimat. Selanjutnya, dari masing-masing baris dipisah kembali menjadi citra per karakter (character segmentation).
Feature Extraction (In form of Vector Matrix)
Setelah segmentasi karakter, masing-masing citra karakter dikonversi ke dalam bentuk matriks dengan ukuran yang sama dengan prototype, seperti contoh dibawah ini:
Gambar 2 Citra Biner
Classification (Template Matching & Correlation based)
Masing-masing matriks input dibandingkan dengan masing-masing matriks prototype. Perbedaan antara input dan prototype dihitung, prototype dengan nilai korelasi tertinggi dipilih sebagai
116
Recognized text (.txt file)
Hasil proses OCR diuji coba hasilnya dalam sebuah file *.txt.
Template Matching Correlation
Metode korelasi merupakan teknik dasar yang digunakan dalam pengenalan karakter optik yaitu dengan cara menemukan korelasi silang yang cocok dengan template atau pola dalam gambar. Prinsipnya korelasi silang mengukur tingkat kesamaan antara gambar dan
template. Mengukur template T (X × Y) dan citra I (U × V), di mana T lebih kecil dari I, kemudian normalisasi fungsi korelasi silang 2D didefinisikan sebagai :
Di mana (u,v) adalah titik yang terletak pada citra I. Untuk menemukantingkat kesamaan antara template dan citra, korelasi silang harusdihitung atas semua kemungkinan. Cheriet et.al. (2007:66-67)
Sedangkan Hartanto (2012:14) dalam jurnalnya merumuskan nilai korelasi sebagai berikut:
dimana:
Keterangan:
r adalah nilai korelasi antara dua buah matriks (nilainya antara -1 dan +1)
xikadalah nilai piksel ke-k dalam matriks i
xjk adalah nilai piksel ke-k dalam matriks
j
adalah rata-rata nilai piksel matriks i
adalah rata-rata nilai piksel matriks j n menyatakan jumlah piksel dalam suatu matriks
Dalam matlab perintah untuk nilai korelasi antara citra A dan citra B dalam bentuk matriks dalam kondisi ukuran yang sama, yaitu:
corr2(A,B) Algoritma:
Artinya:
merupakan rerata dari A merupakan rerata dari B Sumber :
http://www.mathworks.com/help/images/ref/corr2 .html
Dalam Microsoft Excel untuk menghasilkan nilai koefisien korelasi antara 2 array yaitu menggunakan rumus:
CORREL(array1,array2) Persamaan untuk koefisien korelasi tersebut adalah:
dimana dan adalah rerata dengan persamaan : AVERAGE(array1) dan AVERAGE(array2) Sumber: https://support.office.com/en-us/article/CORREL- function-995dcef7-0c0a-4bed-a3fb-239d7b68ca92
Template matching correlation
dalam proses OCR memiliki kelebihan dan kekurangan. Kelebihannya adalah
117 algoritma ini mudah ditulis ke dalam
bahasa program dan mudah untuk mempersiapkan data referemsinya. Komputasi tidak terlalu besar karena data yang digunakan berupa matriks. Namun, dibalik kelebihannya itu algoritma ini secara umum memiliki kekurangan yaitu membutuhkan data referensi atau basis data yang banyak untuk mendapatkan hasil yang optimal. Basis data bisa berupa citra maupun citra yang telah dijadikan matriks. Semakin banyak jenis huruf yang ingin kita deteksi, maka semakin banyak data referensi yang harus disimpan. (Hartanto, 2012:14)
Kerangka Pemikiran
Kerangka pemikiran analisa batas sudut kemiringan hasil pemindaian dokumen menggunakan template matching correlation pada karya ilmiahini digambarkan dalam 2 buahflowchartyaitu proses pembuatan template karakter dan proses pengujian pengenalan karakter sebagai berikut: Proses Pembuatan Template Karakter
Proses awal dalam penelitian ini adalah pembuatan template karakter yang akan digunakan sebagai pembanding dengan citra input. Adapun urutan pembuatannya seperti di bawah ini.
Gambar 3
Proses Pembuatan Template Citra Karakter
Keterangan:
1. Menyiapkan dokumen cetak dengan warna kertas putih dan teks berwarna hitam yang berisi susunan huruf besar, huruf kecil dan angka dari5 (lima) tipe font yaituarial, times new roman, calibri, tahomadan book antiqua.
2. Pemindaian dokumen cetak ke dalam citra digital dengan resolusi 300 dpi ke dalam file *.jpg
3. Proses pembuatan template citra karakter dengan menggunakan Matlab dengan urutan sbb.:
a. Konversi dari skala warna ke skala keabuan
b. Konversi dari skala keabuan ke citra biner
c. Segmentasi baris dan karakter menjadi citra masing-masing karakter individu
d. Mengubah ukuran citra karakter menjadi 42 x 24 pixel
e. Penyimpanan file karakter ke dalam format BMP secara berurutan sesuai dengan urutan pada dokumen
4. Pengujian citra karakter dengan meliha secara visual, apakah semua karakter sudah sesuai dengan aslinya;
a. Jika sesuai maka lanjut ke proses berikutnya,
b. Jika tidak sesuai maka kembali ke point 3
5. Proses pembuatan dan penyimpanan matriks karakter dengan urutan kerja sebagai berikut:
a. Pembentukan variabel karakter untuk seluruh jenis huruf
b. Penggabungan seluruh variabel ke dalam satu variabel matriks
c. Pembagian matriks dalam
array
d. Penyimpanan dalam file *.mat sebagai template
118 Proses Pengujian Pengenalan
Karakter
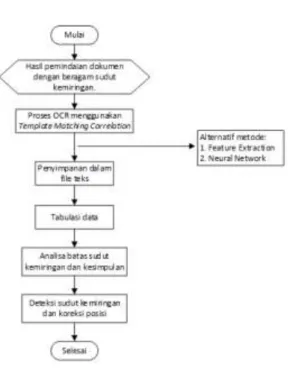
Proses pengujian pengenalan karakter atau yang lebih dikenal dengan OCR (Optical Character Recognition) dilakukan terhadap 5 tipe font dengan ukuran 12pt, 16pt dan 20pt dalam posisi normal dan posisi kemiringan tertentu. Proses pengujian dapat digambarkan sepeti dalam diagram di bawah ini.
KERANGKA PEMIKIRIAN
Gambar 4 Kerangka Pemikiran
Keterangan:
1. Menyiapkan dokumen cetak yang berisi huruf dan angka dengan berbagai kondisi seperti:
a. Jenis huruf : arial, times new roman, calibri, dan tahoma b. Ukuran : 12pt, 16 dan 20pt
c. Tanpa spasi dan 1 spasi
2. Pemindaian dokumen cetak ke dalam citra digital dengan resolusi 300 dpi ke dalam file *.jpg
3. Pengambilan citra input dengan kondisi berspasi dan miring
4. Proses OCR (Optical Character Recognition) menggunakan template
matching correlation dengan urutan proses sebagai berikut:
a. Membaca file hasil pemindaian dokumen
b. Konversi dari RGB ke skala keabuan
c. Konversi dari skala keabuan ke citra biner
d. Segmentasi baris dan karakter menjadi citra masing-masing karakter individu
e. Mengubah ukuran citra input menjadi 42 x 24 pixel agar dapat dibandingkan dengan template yang sudah dibuat
f. Memanggil citra template karakter.
g. Proses komputer untuk
mendapatkan nilai korelasi antara matriks citra template dan citra input dan diulang sebanyak jumlah karakter yang ada dalam template, lalu disimpan dalam suatu variabel secara berurutan h. Pencarian nomor urut template
yang memiliki nilai korelasi tertinggi antara matriks citra input dan citra template sehingga dapat menentukan nama karakter berdasarkan urutan yang didapatkan sesuai dengan variabel karakter yang sudah ditentukan sebelumnya.
5. Penyimpan hasil identifikasi ke dalam file teks *.txt atau ditampilkan dalam form
6. Tabulasi akurasi data hasil pengenalan citra karakter
7. Menentukan tingkat akurasi dengan rumus (jumlah karakter yang benar) / (jumlah citra karakter yang dibaca), sehingga:
a. Jika akurat maka proses berulang ke proses point 6 yaitu untuk mengatur sudut kemiringan dengan interval 1o
b. Jika tidak akurat maka proses berhenti dan berlanjut ke proses berikutnya
119 8. Analisa batas sudut kemiringan
berdasarkan tabulasi yang sudah dibuat.
9. Proses deteksi sudut kemiringan dan koreksi dokumen sebagai alternatif solusi.
METODE PENELITIAN Analisis Kebutuhan
Analisa kebutuhan menjelaskan hal-hal yang dibutuhkan dalam melakukan penelitian. Dalam penelitian yang dilakukan ada beberapa analisa kebutuhan yaitu analisa kebutuhan data dan analisa kebutuhan perangkat, yang dijelaskan seperti berikut ini:
Analisis Kebutuhan Data Jenis Huruf Langkah pertama yang harus disiapkan adalah dokumen cetak yang berisi susunan huruf besar, huruf kecil dan angka. Dokumen tersebut dipindai menjadi citra digital sebagai bahan untukpembuatan template citra karakter sebagai basis data dalam proses pengenalan karakter optik.
Untuk tipe font yang digunakan dalam penelitian yaitu arial, times new roman, calibri, tahoma dan book antiquadengan ukuran 12pt, 16pt dan 20pt. Posisi karakter diuji dalam sudut kemiringan dari -10o s/d 10o.
Analisis Kebutuhan Data Untuk Isi Dokumen
Dokumen yang perlu disiapkan dalam karya ilmiah ini berupa kertas berukuran 16 x 16 cm yang berisi susunan huruf masing-masing tipe font
dengan kombinasi ukuran dan spasi, yaitu:Dokumen Normal Sebelum Dirubah Kemiringan dan Dokumen Yang Sudah Dirubah Kemiringan.
Masing-masing citradigital dengan ukuran 20pt digandakan menjadi citra baru dengan kemiringan 1° hingga 10° ke arah kanan dan kiri. Proses pembuatan citra miring dengan mengguna Matlab,
adapun perintah yang digunakan adalah
imrotate(A,angle), dimana A merupakan nama citra dan angle adalah besar sudut ke arah berlawanan dengan arah jarum jam.
Berikut contoh penamaan citra yang sudah dimiringkan sebanyak 5° ke kanan menjadi sebagai berikut:
Gambar 5
Contoh citra digital font Arial 20pttanpa spasi dengan kemiringan 5° ke arah kanan
(AR20-05.jpg)
Berikut contoh penamaan citra yang sudah dimiringkan sebanyak 5° ke arah kiri menjadi sebagai berikut:
Gambar 6
Contoh citra digital font Times New Roman 20pttanpa spasi dengan kemiringan 5° ke arah kiri
(TN20+05.jpg)
Analisa Kebutuhan Perangkat Lunak Dengan memanfaatkan Matlab perlu dirancang sebuah aplikasi sederhana untuk mempermudah dalam proses penelitian yaitu dengan desain antar muka seperti dalam gambar berikut:
120
Gambar 7
Tampilan Form Uji OCR Menggunakan Template Matching Correlation
Keterangan :
Perancangan Penelitian
Perancangan penelitian merupakan metode yang lebih menekankan pada aspek pemahaman secara mendalam terhadap proses pembuktian dan solusi terhadap pemasalahan Perancangan penelitian dalam karya ilmiah ini dibagi menjadi 3 bagian yautu proses pembuatan template, mencari toleransi sudut kemiringan dan solusi untuk mendapatkan hasil pengenalan karakter optik sesuai dengan yang diharapkan. Proses Pembuatan TemplateKarakter
Proses pembuatan template yaiu menggunakan huruf-huruf yang ada pada citra hasil pemindaian dokumen. Template dibuat menjadi 4 template yaitu template Arial, Times New Roman, Calibri dan Tahoma.
Proses pembuatan template dibagi menjadi 3 bagian utama yaitu proses pembuatan citra per karakter, konversi citra menjadi matriks dan konversi nomor urut dalam matriks ke dalam nama abjad
sesuai dengan citra karakter yang terlihat secara visual.
Untuk mendapatkan masing-masing karakter pada citra hasil pemindaian yaitu dengan proses segmentasi per baris dan per karakter. Kemudian masing-masing karakter dikonversi menjadi 42 x 24 piksel. Selanjutnya penyimpanan citra karakter dengan perintah imwrite().
Setelah citra karakter terbentuk maka perlu diperiksa secara visual apakah citra yang dibuat sesuai dengan yang diinginkan. Jika belum sesuai maka perlu dibuat kembali hingga sesuai dengan karakter yang diharapkan. Selanjutnya citra karakter yang sudah dibuat dikonversi ke dalam kumpulan variabel karakter,dikonversi ke dalam sebuah matriks dan disimpan menjadi sebuah file template.
Untuk keperluan selanjutnya maka dibuat sebuah file untuk dapat menterjemahkan urutan elemen dalam matriks ke dalam penamaan karakter. Pencarian Batas ToleransiSudut Kemiringan
Proses pencarian batas toleransi dilakukan dengan melakukan pengenalan karakter optik atau yang lebih dikenal dengan OCR (Optical Character Recognition) terhadap seluruh citra yang sudah dirubah kemiringannya ke arah kanan dan kiri dari 1° hingga 10° atau berhenti ketika tingkat keberhasilan sudah mencapai 50% atau kurang.
Pengujian ini dilakukan terhadap huruf Arial, Times New Roman, Calibri dan Tahoma dengan ukuran dan spasi yang berbeda.
Teknik Skew Detection and Correction
Sebagai Alternatif Pemecahan Masalah
Sebagai solusi untuk memperbaiki kesalahan pembacaan karakter yang diakibatkan oleh kemiringan dokumen maka perlu dibuat sebuah tool untuk mendeteksi derajat kemiringan citra,
121 kemudian angka derajat tersebut
digunakan untuk memperbaiki posisi citra.
Adapaun teknik yang digunakan adalah transformasi Hough.Dengan asumsi bahwa tiap koordinat pada citra dapat dibentuk garis lurus, maka transformasi Hough menjadi sebuah solusi yang bisa diandalkan. Koreksi dapat dilakukan untuk sebuah citra karakter secara kesulurahan atau bisa juga per-karakter.
Teknik Analisis
Teknik Analisis Korelasi
Cara menghitung nilai korelasi
menggunakan Matlab dengan
menggunakan sintak Corr2(A,B), dimana A merupakan matriks dari citra template dan B meruapakan matriks dari citra input. Citra dengan nilai korelasi tertinggi ditentukan sebagai citra yang paling sesuai dengan template. Contoh tabulasi perhitungan seperti dalam contoh hasil perhitungan nilai korelasi untuk input angka 0 seperti di bawah ini.
Tabel 1
Tabulasi Penentuan Nilai Korelasi Tertinggi
Template citra angka 0, yang berada pada urutan 36 dalam template, memiliki nilai korelasi tertinggi terhadap citra inputangka 0, dibanding template huruf/angka lainnya. Maka citra input 0 dibaca sebagai 0.
Teknik Analisis Batas Sudut Kemiringan
Untuk menentukan batas sudut kemiringan hasil pemindaian dokumen, yaitu dengan membuat tabulasi hasil pengenalan karakter optik untuk semua jenis huruf dengan pergeseran kemiringan dokumen per 1° ke arah kanan dan arah kiri hingga 10o.
Perubahan kemiringan cintra dengan menggunakan Matlab dengan sintak imrotate(A,angle), dimana A merupakan nama citra dan angle adalah besar sudut ke arah berlawanan dengan arah jam.
HASIL DAN PEMBAHASAN Hasil Penelitian
Penelitian yang dilakukan dalam pengenalan karakter optik (OCR) terhadap 5 tipe font telah menghasilkan data-data yang berbeda diantara masing-masing tipe font. Berikut adalah hasil uji coba terhadap masing-masing font yang disajikan berupa ilustrasi dalam gambar dan tabel.
Hasil OCR Tipe Font Arial Tabel 2
Contoh Hasil Uji Coba OCR Font Arial dengan Kemiringan 0o
Tabel 3
Daftar Hasil Pengujian OCR Font Arial Posisi Normal
122 Tipe Font Arial termasuk dalam
tipe font sans serif atau karakter yang tidak bersirip. Kelemahan dari tipe font ini adalah bentuk citra hasil segmentasi untuk karakter huruf I dan l yang sama dan tidak berbentuk sehingga tidak mendapatkan hasil yang spesifik.
Tabel 4
Daftar Hasil Pengujian OCR Font Arial Posisi Miring Ke Kanan
Dalam kondisi miring ke kanan sebesar 5o, tipe font Arial masih terjaga akurasinya hingga 92%. Namun 5 karakter huruf mengalami kesalahan pengenalan yaitu untuk karakter B, I, i, l, dan w.
Tabel 5
Daftar Hasil Pengujian OCR Font Arial Posisi Miring Ke Kiri
Dalam kondisi miring ke kiri sebesar 5o, tipe font Arial terjaga akurasinya hanya 89%. Namun mengalami penyimpangan karakter yang berbeda sebanyak 7 karakter yaitu I, W, X, Z, i, j, dan l.
Hasil OCR Tipe Font Times New Roman
Tabel 6
Daftar Hasil Pengujian OCR Font Times New Roman Posisi Normal
Tipe Font Times New Roman termasuk tipe font serif atau karakter yang bersirip. Kelebihan dari tipe font ini adalah seluruh karakter dapat disegmentasi dengan baik. Berikut adalah hasil uji coba OCR terhadap tipe font Times New Roman dengan ukuran 12pt dan antar karakter terdapat jarak 1 spasi dengan posisi normal.
Tabel 7
Daftar Hasil Pengujian OCR Font Times New Roman Dengan Posisi Miring Ke Kanan
Dalam kondisi miring ke kanan, tipe font Times New Roman dapat terjaga akurasinya maksimal sebesar 2o dengan akurasi sebesar 90%. Namun 5 karakter huruf mengalami kesalahan pengenalan yaitu untuk karakter huruf W, f, g, i, j, dan angka 1. Sedangkan seluruh karakter angka dapat dikenali dengan baik.
Tabel 8
Daftar Hasil Pengujian OCR Font Times New Roman Dengan Posisi Miring Ke Kiri
Sedangkan dalam kondisi miring hingga 5o ke kiri, tipe font Times New Roman terjaga akurasinya hingga 90%.
123 Namun mengalami penyimpangan
karakter yang berbeda sebanyak 5 karakter yaitu huruf U, W, Z, n, dan angka 1, 0.
Hasil OCR Tipe Font Calibri
Tipe Font Calibri termasuk tipe font sans serif atau karakter yang tidak bersirip. Kelemahan dari tipe font ini sama dengan Arial adalah bentuk cintra hasil segmentasi untuk karakter I dan l yang sama dan tidak berbentuk sehingga tidak mendapatkan hasil yang spesifik.
Namun dengan koreksi pada
pemrograman Matlab masih dapat diakali dengan pendefinisian ulang. Berikut adalah hasil uji coba OCR terhadap tipe font Arial dengan ukuran 20pt dan antar karakter terdapat jarak 1 spasi denga posisi normal.
Tabel 9
Daftar Hasil Pengujian OCR Font Calibri Dengan Posisi Normal
Tabel 10
Daftar Hasil Pengujian OCR Font Calibri Dengan Posisi Miring Ke Kanan
Dalam kondisi miring hingga 5o ke kanan, tipe font Calibri masih terjaga akurasinya hingga 90%. Namun 5 karakter huruf mengalami kesalahan pengenalan yaitu untuk karakter huruf I, J, S, W, l, i dan v.
Tabel 11
Daftar Hasil Pengujian OCR Font Calibri Dengan Posisi Miring Ke Kiri
Sedangkan dalam kondisi miring hingga 6o ke kiri, tipe font Calibri terjaga akurasinya hingga 90%. Namun mengalami penyimpangan karakter yang berbeda sebanyak 7 karakter yaitu I, J, V, W, Z, dan l.
Hasil OCR Tipe Font Tahoma
Tipe Font Tahoma termasuk tipe font sans serif atau karakter yang tidak bersirip. Kelemahan dari tipe font ini adalah bentuk cintra hasil segmentasi untuk karakter huruf l karena tidak berbentuk sehingga tidak mendapatkan hasil yang spesifik. Namun dengan koreksi pada pemrograman Matlab masih dapat diakali dengan pendefinisian khusus l. Berikut adalah hasil uji coba OCR terhadap tipe font Tahoma dengan ukuran 20pt dan antar karakter terdapat jarak 1 spasi denga posisi normal.
Tabel 12
Daftar Hasil Pengujian OCR Font Tahoma Dengan Posisi Normal
Tabel13
Daftar Hasil Pengujian OCR Font Tahoma Dengan Posisi Miring Ke Kanan
124 Dalam kondisi miring hingga 5o ke
kanan, tipe font Tahoma hanya terjaga akurasinya sebesar 79%. Terdapat 9 karakter huruf mengalami kesalahan pengenalan yaitu untuk karakter huruf B, S, U, V, Y, i, l, w, dan x.
Tabel 14
Daftar Hasil Pengujian OCR Font Tahoma Dengan Posisi Miring Ke Kiri
Dalam kondisi miring 5o ke kiri, tipe font Tahoma terjaga akurasinya sebesar 87%. Namun mengalami penyimpangan karakter yang berbeda sebanyak 7 karakter huruf yaitu U, W, X, Z, i, l, y dan angka 0.
Hasil OCR Tipe Font Book Antiqua Tipe Font Book Antiqua termasuk tipe font serif atau karakter yang bersirip. Berikut adalah hasil uji coba OCR terhadap tipe font Book Antiqua dengan ukuran 20pt dengan posisi normal.
Tabel 15
Daftar Hasil Pengujian OCR Font Book Antiqua Dengan Posisi Normal
Tabel16
Daftar Hasil Pengujian OCR Font Book Antiqua Dengan Posisi Miring Ke Kanan
Dalam kondisi miring hingga 5o ke kanan, tipe font Book Antiqua hanya terjaga akurasinya sebesar 90%. Terdapat 5 karakter huruf mengalami kesalahan pengenalan yaitu untuk karakter huruf I, J, h, l, dan x.
Tabel17
Daftar Hasil Pengujian OCR Font Book Antiqua Dengan Posisi Miring Ke Kiri
Dalam kondisi miring 5o ke kiri, tipe font Book Antiqua terjaga akurasinya sebesar 85%. Namun mengalami penyimpangan karakter yang berbeda sebanyak 8 karakter huruf yaitu F, I, T, V, X, Z, w, y dan angka 0.
Rekapitulasi Hasil OCR Semua Tipe Font
Berikut ini adalah tabulasi rekapitulasi hasil OCR dari seluruh font yang digunakan, yaitu sebagai berikut:
Tabel 18
Rekapitulasi hasil OCR dari seluruh font
PEMBAHASAN
Berdasarkan hasil penelitian di atas, terdapat beberapa penyimpangan yang akan dibahas berikut ini, yaitu: Kesalahan Baca Yang Diakibatkan Oleh Tidak Mendapatkan Nilai Koefisien Korelasi
Dari hasil pengujian tipe font dengan posisi normal atau 0o terdapat beberapa tipe font salah baca yang diakibatkan oleh tidak diperolehnya nilai koefisien korelasi (r) pada tipe-tipe font sans serif atau tidak bersirip, yaitu
125 karakter I dan l pada font arial, calibri
dan tahoma, serta l pada font tahoma. Seperti contoh hasil penelitian pada font Arial di bawah ini.
Setelah melalui proses pengolahan citra, karakter-karakter I dan l dengan luas piksel sebesar 42 x 24 memiliki nilai 1 pada seluruh pikselnya, seperti contoh karakter I untuk font arial pada gambar di bawah ini:
Gambar 8
Citra Karakter Huruf I dalam tipe font Arial
Jika kita membandingkan karakter tersebut dan karakter template dengan menggunakan rumus koefisien korelasi maka akan mendapatkan hasil yang sama, seperti diuraikan di bawah ini:
Artinya:
dalam hal ini merupakan rerata dari A yaitu 1
m adalah jumlah baris dan n adalah jumlah kolom
Tabel 19
Ilustrasi Penjumlahan Dalam Rumus Koefisien Korelasi
Pada penelitian ini semua karakter disamakan ukurannya menjadi 42 x 24 piksel, sehingga jika diuraikan dalam bentuk tabel maka akan terdapat 1.008 baris penjumlahan, dimana setiap piksel memiliki nilai 1. Dengan nilai rerata A sebesar 1 maka apabila masing-masing nilai pada piksel A jika dikurangi rerata dari A maka akan menghasilkan nilai 0. Nilai 0 jika dikali dengan nilai apapun dari template B maka akan menghasilkan 0, kemudian dihitung dengan akar kuadrat maka akan menghasilkan nilai 0 juga. Akhirnya mengingat pembagi dari rumus tersebut adalah 0 maka hasil dari perhitungan koefisien korelasi menghasilkan nilai tak terhingga, sehingga karakter-karakter tersebut tidak dapat didefinisikan sebagai karakter tertentu.
Namun akan berbeda hasilnya apabila citra dalam posisi miring, misalnya citra input font arial dalam posisi miring ke kanan sebesar 1o saja, maka karakter tersebut di atas akan mendapatkan nilai koefisien korelasi walaupun secara pembacaan masih salah baca, seperti I dan l dibaca sebagai f. (lihat contoh di bawah ini)
Tabel 20
Hasil Uji Coba OCR Arial dengan Kemiringan 1o 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
126 Kesalahan Baca Yang Diakibatkan
Oleh Kemiripan Antar Karakter Pada karakter tipe font serif atau bersirip terdapat kesalahan baca yang diakibatkan oleh kemiripan antar karakter yaitu karakter angka 1 dan huruf l pada font Times New Roman serta huruf I dan huruf l pada font book antiqua.
Secara visual dalam uji coba font Times New Roman seperti tidak ada yang salah, namun sebenarnya terdapat salah baca karakter yaitu angka 1(satu) dibaca huruf l (baca: el kecil) sehingga dalam posisi normal akurasi OCR hanya 98%. Nilai korelasi antar karakter tersebut dapat dilihat dari perbandingan hasil segmentasi citra angka 1 (satu) dengan citra template angka 1 dan huruf l menggunakan perintah corr2(A,B) pada Matlab sebagai berikut:
Tabel 21
Tabel Nilai Korelasi Pada Karakter Angka 1 dan Huruf l
Berdasarkan hasil pencarian nilai korelasi antara citra input angka 1 dengan template ternyata huruf l pada template mempunyai nilai korelasi lebih tinggi dibandingkan angka 1, maka komputer membaca citra input angka 1 sebagai huruf l.
Demikian pula pada uji coba font book antiqua seperti tidak ada yang salah, namun sebenarnya terdapat karakter yang salah baca yaitu huruf I dibaca menjadi l sehingga dalam posisi normal akurasi OCR hanya 98%. Nilai korelasi antar karakter tersebut dapat dilihat dari perbandingan hasil segmentasi huruf I
dengan template dengan menggunakan perintah corr2(A,B) pada Matlab sebagai berikut:
Tabel 22
Tabel Nilai Korelasi Pada Karakter Huruf I dan l
Berdasarkan hasil pencarian nilai korelasi antara citra input huruf I dengan template ternyata huruf l pada template mempunyai nilai korelasi lebih tinggi dibandingkan huruf I pada template, maka komputer membaca huruf I sebagai huruf l.
Kesalahan Baca Yang Diakibatkan Oleh Kegagalan Segmentasi Citra Karakter
Hasil uji coba pada citra dalam kondisi miring terdapat kesalahan baca yang diakibatkan oleh kegagalan segmentasi citra karakter, yaitu dua karakter terbaca menjadi satu karakter pada font serif ata bersirip yaitu font Times New Roman pada karakter “fg” dibaca “m” dan “ij” dibaca “U” dengan posisi miring 2o ke kanan, serta Book Antiqua pada karakter “IJ” dibaca “u” dengan posisi miring 5o ke kanan.
Gambar 9
Hasil Segmentasi Font Times New Roman 2o ke kanan
127
Gambar 10
Hasil Segmentasi Font Book Antiqua 5o ke kanan
Kegagalan segmentasi karakter akan lebih terjaga pada kondisi spasi antar karakter yang lebih renggang, terbukti dengan uji coba font Times New Roman dengan 1 spasi antar karakter dalam posisi 2o ke kanan (lihat Tabel 4.8)
Pada tabel di atas huruf f, g, i dan j dapat dibaca dengan baik, walaupun masih terdapat kegagalan baca pada karakter huruf yang lain.
Demikian juga dengan font Book Antiqua seperti yang diuji pada citra dengan ukuran 20pt dengan 1 spasi antar karakter dalam posisi miring 5o ke kanan (lihat Tabel 4.26)
Walaupun akurasi masih belum optimal, namun dengan uji coba tersebut memperlihatkan bahwa huruf yang
sebelumnya mengalamai gagal
segmentasi dapat dihindari yaitu karakter huruf IJ dapat terbaca dengan benar. Implikasi Penelitian
Berdasarkan hasil uji coba terhadap tipe-tipe font berjenis serif dan sans serif dalam berbagai ukuran dan kemiringan ke kanan dan ke kiri maka dapat ditentukan beberapa implikasi sebagai berikut:
Tipe Font Yang Menghasilkan Akurasi Terbaik Dalam Proses OCR
Keberhasilan dalam pengenalan karakter optik (OCR) diawali dengan keberhasilan dalam segmentasi citra karakter. Dalam kondisi normal atau posisi kemiringan 0o maka seluruh karakter tipe font berjenis serif atau bersirip, yaitu Times New Roman dan
Book Antiqua, berhasil disegmentasi per karakter sehingga berpotensi untuk dapat dikenali dengan baik.
Namun dalam kondisi miring ternyata tipe font sans serif, yaitu Arial, Calibri dan Tahoma, lebih unggul dalam hal akurasi pengenalan karakter.
Sedangkan khusus untuk karakter angka saja, dengan kemiringan citra hingga 5o ke arah kanan maupun kiri maka seluruh tipe font mempunyai keunggulan yang sama yaitu 100% terbaca dengan benar.
Tipe Font Yang Menghasilkan Akurasi Terburuk Dalam Proses OCR
Dalam kondisi normal atau posisi kemiringan 0o maka tipe font berjenis sans serif atau tidak bersirip, yaitu Arial, Calibri dan Tahoma, memiliki kelemahan khususnya pada huruf I dan l. Hal ini diakibatkan adanya kegagalan dalam proses awal pengolahan citra khususnya dalam segmentasi karakter.
Solusi agar mendapatkan akurasi yang lebih baik maka dapat merubah pendefinisian karakter yang tidak dikenal sebagai I untuk pembacaan karakter tipe font Arial seperti di bawah ini:
Tabel 23 Koreksi Pemrograman
Namun dalam posisi miring, maka tipe font berjenis serif atau bersirip cukup rentan dalam pengenalan karakter, sebagai contoh huruf Times New Romans memiliki batas sudut kemiringan 2o dengan akurasi minimal 90%.
Perbaikan OCR dengan Deteksi Sudut Kemiringan dan Koreksi Kemiringan Citra Karakter
Sebagai solusi untuk memperbaiki kesalahan pembacaan karakter yang diakibatkan oleh kemiringan dokumen pada sudut tertentu maka perlu dibuat
128 sebuah tool untuk mendeteksi derajat
kemiringan citra, kemudian angka derajat tersebut digunakan untuk memperbaiki posisi citra. Adapun salah satu teknik yang dapat digunakan adalah transformasi Hough. Dengan asumsi bahwa tiap koordinat pada citra dapat dibentuk garis lurus, makatransformasi Hough menjadi sebuah solusi yang bisa diandalkan.
Namun dalam uji coba masih terdapat beberapa kelemahan yaitu dalam hal kecepatan proses deteksi dan koreksi dokumen yang cukup lama yaitu lebih dari 3 menit serta kegagalan pembacaan sudut sehingga koreksi tidak berhasil.
PENUTUP Kesimpulan
Berdasarkan hasil penelitian pengenalan karakter optik dengan menggunakan metode template matching correlation pada berbagai ukuran, spasi dan kemiringan dokumen maka dapat ditarik kesimpulan sebagai berikut: 1. Karakteristik masing-masing tipe font
yang sudah diuji yaitu: a. Tipe Font Arial
Tipe font Arial merupakan tipe font jenis sans serif yang memiliki kelemahan dalam OCR pada posisi normal untuk mengenali karakter huruf I dan l, karena memiliki anatomi yang sama dan tidak menghasilkan nilai koefisien korelasi. Batas sudut kemiringan hasil pemindaian dokumen untuk mencapai rata-rata akurasi minimal 90% yaitu sebesar 5o ke kanan dan 5o ke kiri.
b. Tipe Font Times New Roman Tipe font Times New Roman merupakan tipe font berjenis serif tidak memiliki kelemahan dalam OCR pada posisi normal untuk mengenali karakter tertentu. Batas
sudut kemiringan hasil
pemindaian dokumen untuk
mencapai rata-rata akurasi minimal 90% yaitu sebesar 2o ke kanan 5o ke kiri.
c. Tipe Font Calibri
Tipe font Calibri merupakan tipe font berjenis sans serif yang memiliki kelemahan dalam OCR pada posisi normal untuk mengenali karakter huruf I dan l, karena memiliki anatomi yang sama dan tidak menghasilkan nilai koefisien korelasi.Batas
sudut kemiringan hasil
pemindaian dokumen untuk mencapai rata-rata akurasi minimal 90% yaitu sebesar 5o ke kanan dan 6o ke kiri.
d. Tipe Font Tahoma
Tipe font Tahoma merupakan tipe font berjenis sans serif yang memiliki kelemahan dalam OCR pada posisi normal untuk mengenali karakter huruf l saja, karena memiliki anatomi yang sama dan tidak menghasilkan nilai koefisien korelasi. Batas
sudut kemiringan hasil
pemindaian dokumen untuk mencapai rata-rata akurasi minimal 90% yaitu sebesar 4o ke kanan dan 4o ke kiri
e. Tipe Font Book Antiqua
Tipe font Book Antiqua merupakan tipe font berjenis serif tidak memiliki kelemahan dalam OCR pada posisi normal untuk mengenali karakter tertentu. Batas
sudut kemiringan hasil
pemindaian dokumen untuk mencapai rata-rata akurasi minimal 90% yaitu sebesar 5o ke kanan dan 4o ke kiri.
2. Dengan mempertimbangkan
kelebihan dan kekurangan pada karakteristik masing-masing tipe font, maka yang dapat dianggap sebagai font yang paling optimal untuk OCR dalam kondisi miring adalah tipe font Arial dan Calibri dengan sudut kemiringan hingga 6o.
129 3. Sebagai solusi untuk memperbaiki
kesalahan pembacaan karakter yang diakibatkan oleh kemiringan dokumen pada sudut tertentu maka dapat dibuat sebuah tool untuk mendeteksi derajat kemiringan citra, kemudian angka derajat tersebut digunakan untuk memperbaiki posisi citra hingga menjadi normal.
Saran
Berdasarkan pembahasan dalam implikasi penelitian di atas, maka saran yang timbul adalah sebagai berikut: 1. Untuk menghasilkan akurasi terbaik
dalam proses OCR maka perlu dilakukan penelitian lebih lanjut untuk jenis font sans serif seperti Arial, Calibri dan Tahoma sehingga dapat menghasilkan akurasi yang lebih baik lagi dalam posisi normal maupun miring.
2. Untuk menghindari akurasi yang rendah dalam OCR maka perlu dilakukan penelitian lebih lanjut dalam hal keberhasilan segmentasi karakter, terutama dalam keadaan miring.
3. Untuk mendapatkan akurasi yang baik dalam OCR pada posisi miring, maka perlu dibuat tool yang dapat mendeteksi kemiringan dan koreksi dokumen. Namun perlu dilakukan penelitian lebih lanjut sehingga proses deteksi dapat dilakukan dengan lebih cepat dan akurat.
DAFTAR PUSTAKA
Adhvaryu, R. V. (2013). Optical Character Recognition Using Template Matching (Alphabet & Numbers). International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR), 3 (4), 227-232.
Away, G. A. (2010). The Shortcut of Matlab Programming. Bandung: Informatika.
Bahri, R. S., & Maliki, I. (2012). Perbandingan Algoritma Template Matching dan Feature Extraction
pada Optical Character
Recognition. Jurnal Komputer dan Informatika (KOMPUTA) , 29-35. Chandarana, J., & Kapadia, M. (2014).
Optical Character Recognition.
International Journal of Emerging Technology and Advanced Engineering, 4 (5), 219-223. Cheriet, M., Kharma, N., Liu, C.-L., &
Suen, C. (2007). Character Recognition Systems: a guide for students and practitioner.
Montreal: Wiley Interscience.
CORREL function - Office Support. (2015). Diambil kembali dari
Office Support:
https://support.office.com/en- us/article/CORREL-function- 995dcef7-0c0a-4bed-a3fb-239d7b68ca92
Fitriawan, H., Pucu, O., & Baptisa, Y. (2012). Identifikasi Plat Nomor Kendaraan Secara Off-Line Berbasis Pengolahan Citra dan Jaringan Syaraf Tiruan.
Electrician: jurnal rekayasa dan teknologi elektro, 6 (2), 123-126. Hartanto, S., Sugiharto, A., & Endah, S.
N. (2012). Optical Character
Recognition Menggunakan
Algoritma Template Matching Correlation. Journal of Informatics and Technology, 1 (1), 11-20. Kadir, A., & Susanto, A. (2013). Teori
dan Aplikasi Pengolahan Citra.
130 Kusrianto, A. (2004). Tipografi
Komputer Untuk Desainer Grafis.
Yogyakarta: Andi.
MathWorks. (2015). Diambil kembali dari Matworks - MATLAB and Simulink for Technical Computing: http://www.mathworks.com
Mohammad, F., Anarase, J., Shingote, M., & Ghanwat, P. (2014). Optical
Character Recognition
Implementation Using Pattern Matching. International Journal of Computer Science and Information Technologies, 5 (2), 2088-2090. Nataliana, D., Anwari, S., & Hermawan,
A. (2011). Pengenalan Plat Nomor Kendaraan Dalam Sebuah Citra Menggunakan Saraf Tiruan. Jurnal Informatika, 2 (3), 48.
Patil, J. M., & Mane, A. P. (2013). Multi Font And Size Optical Character Recognition Using Template Matching. International Journal of Emerging Technology and Advanced Engineering , 3 (1), 504-506.
Rathore, M., & Kumari, S. (2014). Tracking Number Plate From
Vechicle Using Matlab.
International Journal in Foundation of Computer Science & Technology (IJFCST) , 4 (3), 43-53.
Riva, D. A. (2013). Perancangan Aplikasi Konversi File Image Hasil Scan Menjadi Text Dengan Metode Feature Extraction. Pelita Informatika Budi Darma , V (3), 127-132.
Sianipar, R. (2013). Pemrograman Matlab dalam contoh dan
penerapan. Bandung: Informatika.
Supriyono, R. (2010). Desain Komunikasi Visual: teori dan aplikasi. Yogyakarta: Andi.
Webopedia Terms. (2015). Diambil kembali dari Webopedia: Online Tech Dictionary for IT
Professional: