Willia m St a llings Willia m St a llings
Com put e r Orga niza t ion a nd Arc hit e c t ure
a nd Arc hit e c t ure 8 t h Edit ion
Cha pt e r 4p
Cha ra c t e rist ic s
• Locat ion
C
• Capacit y
• Unit of t ransfer
• Access m et hod
• Perform ance
• Perform ance
• Physical t ype
Ph i l h i i
• Physical charact erist ics
Ca pa c it yp y
• Word size
Th t l it f i t i
—The nat ural unit of organisat ion
• Num ber of words
U nit of T ra nsfe r
• I nt ernal
U ll d b d t b idt h
—Usually governed by dat a bus widt h
• Ext ernal
—Usually a block which is m uch larger t han a word
• Addressable unit
—Sm allest locat ion which can be uniquely addressed
—Word int ernally
Ac c e ss M e t hods (1 )( )
—I ndividual blocks have unique address
—Access is by j um ping t o vicinit y plus sequent ial search
sequent ial search
—Access t im e depends on locat ion and previous locat ion
locat ion
Ac c e ss M e t hods (2 )( )
• Random
I di id l dd id t if l t i t l
—I ndividual addresses ident ify locat ions exact ly
M e m ory H ie ra rc hyy y
• Regist ers
I CPU
—I n CPU
• I nt ernal or Main m em ory
—May include one or m ore levels of cache
—“ RAM”
• Ext ernal m em ory
Pe rform a nc e
• Access t im e
Ti b t t i t h dd d
—Tim e bet ween present ing t he address and get t ing t he valid dat a
M C l t i
• Mem ory Cycle t im e
—Tim e m ay be required for t he m em ory t o “ eco e ” befo e ne t access
“ recover” before next access
—Cycle t im e is access + recovery
T f R
• Transfer Rat e
Physic a l T ype sy yp
• Sem iconduct or
RAM
—RAM
• Magnet ic
—Disk & Tape
• Opt icalp
—CD & DVD
• Ot hersOt hers
—Bubble
Orga nisa t iong
• Physical arrangem ent of bit s int o words
l b
• Not always obvious
H ie ra rc hy Listy
• Regist ers
C h
• L1 Cache
• L2 Cache
• Main m em ory
• Disk cache
• Disk cache
• Disk
O i l
• Opt ical
So you w a nt fa st ?y
• I t is possible t o build a com put er which
uses only st at ic RAM ( see lat er) uses only st at ic RAM ( see lat er)
• This would be very fast
• This would need no cache
—How can you cache cache?
Loc a lit y of Re fe re nc ey
• During t he course of t he execut ion of a
program m em ory references t end t o program , m em ory references t end t o clust er
l
Ca c he
• Sm all am ount of fast m em ory
S b l d
• Sit s bet ween norm al m ain m em ory and
CPU
Ca c he ope ra t ion – ove rvie wp
• CPU request s cont ent s of m em ory locat ion
Ch k h f h d
• Check cache for t his dat a
• I f present , get from cache ( fast )
• I f not present , read required block from
m ain m em ory t o cachea e o y t o cac e
• Then deliver from cache t o CPU
• Cache includes t ags t o ident ify which
• Cache includes t ags t o ident ify which
block of m ain m em ory is in each cache slot
Ca c he De signg
• Addressing
S
• Size
• Mapping Funct ion
• Replacem ent Algorit hm
• Writ e Policy
• Writ e Policy
• Block Size
N b f C h
Ca c he Addre ssingg
—Processor accesses cache direct ly, not t horough physical cache
—Cache access fast er, before MMU address t ranslat ionCache access fast er, before MMU address t ranslat ion
Size doe s m a t t e r
• Cost
M h i i
—More cache is expensive
• Speed
—More cache is fast er ( up t o a point )
Com pa rison of Ca c he Size sp
Processor Type Year of
Introduction L1 cache L2 cache L3 cache IBM 360/85 Mainframe 1968 16 to 32 KB — — IBM 360/85 Mainframe 1968 16 to 32 KB
PDP-11/70 Minicomputer 1975 1 KB — —
VAX 11/780 Minicomputer 1978 16 KB — —
IBM 3033 Mainframe 1978 64 KB — —
IBM 3090 Mainframe 1985 128 to 256 KB — —
Intel 80486 PC 1989 8 KB — —
Pentium PC 1993 8 KB/8 KB 256 to 512 KB —
P PC 601 PC 1993 32 KB
PowerPC 601 PC 1993 32 KB — —
PowerPC 620 PC 1996 32 KB/32 KB — —
PowerPC G4 PC/server 1999 32 KB/32 KB 256 KB to 1 MB 2 MB IBM S/390 G4 Mainframe 1997 32 KB 256 KB 2 MB IBM S/390 G4 Mainframe 1997 32 KB 256 KB 2 MB IBM S/390 G6 Mainframe 1999 256 KB 8 MB —
Pentium 4 PC/server 2000 8 KB/8 KB 256 KB — IBM SP High-end server/
supercomputer 2000 64 KB/32 KB 8 MB — supercomputer
CRAY MTAb Supercomputer 2000 8 KB 2 MB —
Itanium PC/server 2001 16 KB/16 KB 96 KB 4 MB SGI Origin 2001 High-end server 2001 32 KB/32 KB 4 MB —
Itanium 2 PC/server 2002 32 KB 256 KB 6 MB IBM POWER5 High-end server 2003 64 KB 1.9 MB 36 MB
M a pping Func t ionpp g
• Cache of 64kByt e
C h bl k f b
• Cache block of 4 byt es
—i.e. cache is 16k ( 214) lines of 4 byt es
• 16MByt es m ain m em ory
• 24 bit address 24 bit address
Dire c t M a pping
Addre ss St ruc t ure
Tag s-r Line or Slot r Word w
8 14 2
• 24 bit address
• 2 bit word ident ifier ( 4 byt e block)
• 2 bit word ident ifier ( 4 byt e block)
• 22 bit block ident ifier
— 8 bit t ag ( = 22- 14)
— 14 bit slot or line
• No t wo blocks in t he sam e line have t he sam e Tag field
• Check cont ent s of cache by finding line and checking Tag
Dire c t M a pping Ca c he Line T a ble Ca c he Line T a ble
C h li M i M bl k h ld
Cache line Main Mem ory blocks held
0 0, m , 2m , 3m …2s- m
1 1,m + 1, 2m + 1…2s- m + 1, ,
…
Dire c t M a pping Sum m a rypp g y
• Address lengt h = ( s + w) bit s
b f dd bl 2
• Num ber of addressable unit s = 2s+ w
words or byt es
• Block size = line size = 2w words or byt es
• Num ber of blocks in m ain m em ory = 2s+ u be o b oc s a e o y s
w/ 2w = 2s
• Num ber of lines in cache = m = 2r
• Num ber of lines in cache = m = 2r
Dire c t M a pping pros & c onspp g p
• Sim ple
• I nexpensive
• Fixed locat ion for given block
V ic t im Ca c he
• Lower m iss penalt y
b h d d d
• Rem em ber what was discarded
—Already fet ched
—Use again wit h lit t le penalt y
• Fully associat ivey
• 4 t o 16 cache lines
• Bet ween direct m apped L1 cache and next
• Bet ween direct m apped L1 cache and next
Assoc ia t ive M a ppingpp g
• A m ain m em ory block can load int o any
line of cache line of cache
• Mem ory address is int erpret ed as t ag and
d word
• Tag uniquely ident ifies block of m em ory
• Every line’s t ag is exam ined for a m at ch
• Cache searching get s expensive
Assoc ia t ive M a pping from Ca c he t o M a in M e m ory
Assoc ia t ive M a pping Addre ss St ruc t ure
Tag 22 bit Word2 bit
• 22 bit t ag st ored wit h each 32 bit block of dat a
• Com pare t ag field wit h t ag ent ry in cache t o p g g y check for hit
• Least significant 2 bit s of address ident ify which 16 bit word is required from 32 bit dat a block
• e.g.
—Address Tag Dat a Cache line
Assoc ia t ive M a pping Sum m a rypp g y
• Address lengt h = ( s + w) bit s
b f dd bl 2
• Num ber of addressable unit s = 2s+ w
words or byt es
• Block size = line size = 2w words or byt es
• Num ber of blocks in m ain m em ory = 2s+ u be o b oc s a e o y s
w/ 2w = 2s
• Num ber of lines in cache = undet erm ined
• Num ber of lines in cache = undet erm ined
Se t Assoc ia t ive M a ppingpp g
• Cache is divided int o a num ber of set s
h b f l
• Each set cont ains a num ber of lines
• A given block m aps t o any line in a given
set
—e.g. Block B can be in any line of set i
• e.g. 2 lines per set
—2 way associat ive m apping2 way associat ive m apping
Se t Assoc ia t ive M a pping Ex a m plep
• 13 bit set num ber
l k b d l
• Block num ber in m ain m em ory is m odulo
213
• 000000, 00A000, 00B000, 00C000 … m ap
M a pping From M a in M e m ory t o Ca c he : v Assoc ia t ive
M a pping From M a in M e m ory t o Ca c he : k -w a y Assoc ia t ive
Se t Assoc ia t ive M a pping Addre ss St ruc t ure
Word
Tag 9 bit Set 13 bit Word
2 bit
• Use set field t o det erm ine cache set t o
look in look in
• Com pare t ag field t o see if we have a hit
• e.g
—Address Tag Dat a Set
num ber
—1FF 7FFC 1FF 12345678 1FFF
Se t Assoc ia t ive M a pping Sum m a rypp g y
• Address lengt h = ( s + w) bit s
b f dd bl 2
• Num ber of addressable unit s = 2s+ w
words or byt es
• Block size = line size = 2w words or byt es
• Num ber of blocks in m ain m em ory = 2du be o b oc s a e o y d
• Num ber of lines in set = k
• Num ber of set s v 2d
• Num ber of set s = v = 2d
• Num ber of lines in cache = kv = k * 2d
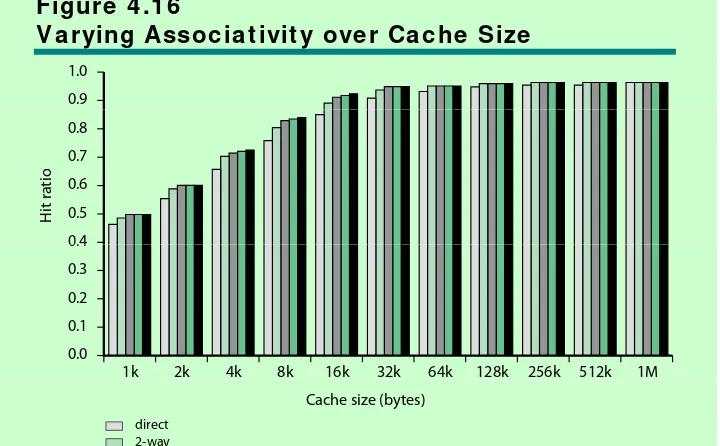
Dire c t a nd Se t Assoc ia t ive Ca c he
• Cache com plexit y increases wit h
associat ivit y
• Not j ust ified against increasing cache t o
8kB or 16kB
8 o 6
• Above 32kB gives no im provem ent
• ( sim ulat ion result s)
Re pla c e m e nt Algorit hm s (1 ) Dire c t m a ppingpp g
• No choice
h bl k l l
• Each block only m aps t o one line
Re pla c e m e nt Algorit hm s (2 ) Assoc ia t ive & Se t Assoc ia t ive
• Hardware im plem ent ed algorit hm ( speed)
l d ( )
• Least Recent ly used ( LRU)
• e.g. in 2 way set associat ive
—Which of t he 2 block is lru?
• First in first out ( FI FO)First in first out ( FI FO)
—replace block t hat has been in cache longest
• Least frequent ly used
• Least frequent ly used
—replace block which has had fewest hit s
R ndom
Writ e Polic yy
• Must not overwrit e a cache block unless
m ain m em ory is up t o dat e m ain m em ory is up t o dat e
• Mult iple CPUs m ay have individual caches
Writ e t hroughg
• All writ es go t o m ain m em ory as well as
cache cache
• Mult iple CPUs can m onit or m ain m em ory
ffi k l l ( C ) h
t raffic t o keep local ( t o CPU) cache up t o dat e
• Lot s of t raffic
• Slows down writ esS o s do s
• Rem em ber bogus writ e t hrough caches!
Writ e ba c k
• Updat es init ially m ade in cache only
d b f h l h
• Updat e bit for cache slot is set when
updat e occurs
• I f block is t o be replaced, writ e t o m ain
m em ory only if updat e bit is set
• Ot her caches get out of sync
• I / O m ust access m ain m em ory t hrough
• I / O m ust access m ain m em ory t hrough
cache
• N B 15% of m em ory references are
• N.B. 15% of m em ory references are
Line Size
• Ret rieve not only desired word but a num ber of adj acent words as well
• I ncreased block size will increase hit rat io at first
—t he principle of localit y
• Hit rat io will decreases as block becom es even
• Hit rat io will decreases as block becom es even bigger
—Probabilit y of using newly fet ched inform at ion becom es less t han probabilit y of reusing replaced
less t han probabilit y of reusing replaced
• Larger blocks
—Reduce num ber of blocks t hat fit in cache
—Dat a overwrit t en short ly aft er being fet ched
—Each addit ional word is less local so less likely t o be needed
• No definit ive opt im um value has been found
• 8 t o 64 byt es seem s reasonable
• For HPC syst em s 64 and 128 byt e m ost
M ult ile ve l Ca c he s
• High logic densit y enables caches on chip
F t t h b
—Fast er t han bus access
—Frees bus for ot her t ransfers
• Com m on t o use bot h on and off chip
cache
—L1 on chip, L2 off chip in st at ic RAM
—L2 access m uch fast er t han DRAM or ROM
—L2 oft en uses separat e dat a pat h
—L2 m ay now be on chip
—Result ing in L3 cache
H it Ra t io (L1 & L2 )
U nifie d v Split Ca c he sp
• One cache for dat a and inst ruct ions or
t wo one for dat a and one for inst ruct ions t wo, one for dat a and one for inst ruct ions
• Advant ages of unified cache
—Higher hit rat e
– Balances load of inst ruct ion and dat a fet ch O l h t d i & i l t
– Only one cache t o design & im plem ent
• Advant ages of split cache
—Elim inat es cache cont ent ion bet ween
inst ruct ion fet ch/ decode unit and execut ion unit
unit
Pe nt ium 4 Ca c he
• 80386 – no on chip cache
• 80486 – 8k using 16 byt e lines and four way set
• 80486 8k using 16 byt e lines and four way set associat ive organizat ion
• Pent ium ( all versions) – t wo on chip L1 caches( ) p
– four way set associat ive
L2 cache
—L2 cache
– Feeding bot h L1 caches
– 256k
128 b t li
– 128 byt e lines
– 8 way set associat ive
I nt e l Ca c he Evolut ion
Problem Solution
Processor on which feature first appears
Add t l h i f t 386 External memory slower than the system bus.
Add external cache using faster memory technology.
386
Increased processor speed results in external bus becoming a p p g Move external cache on-chip, operating at the same speed as the 486 bottleneck for cache access. operating at the same speed as the processor.
Internal cache is rather small, due to limited space on chip
Add external L2 cache using faster technology than main memory
486
Contention occurs when both the Instruction Prefetcher and the Execution Unit simultaneously require access to the cache. In that case, the Prefetcher is stalled while the E ti U it’ d t t k l
Create separate data and instruction caches.
Pentium
Execution Unit’s data access takes place.
Increased processor speed results in external bus becoming a
Create separate back-side bus that runs at higher speed than the main (front-side) external bus. The BSB is
Pentium Pro Increased processor speed results in external bus becoming a
bottleneck for L2 cache access. dedicated to the L2 cache.
Move L2 cache on to the processor chip.
Pentium II
Some applications deal with massive databases and must have rapid access to large amounts of data. The on-chip caches are too small.
Pe nt ium 4 Core Proc e ssor
• Fet ch/ Decode Unit
—Fet ches inst ruct ions from L2 cache
—Fet ches inst ruct ions from L2 cache
—Decode int o m icro- ops
—St ore m icro- ops in L1 cachep
• Out of order execut ion logic
—Schedules m icro- ops
—Based on dat a dependence and resources
—May speculat ively execut e
E t i it
• Execut ion unit s
—Execut e m icro- ops
—Dat a from L1 cache
—Dat a from L1 cache
—Result s in regist ers
• Mem ory subsyst emMem ory subsyst em
Pe nt ium 4 De sign Re a soningg g
• Decodes inst ruct ions int o RI SC like m icro- ops before L1 cache
• Micro- ops fixed lengt h
— Superscalar pipelining and scheduling
• Pent ium inst ruct ions long & com plexPent ium inst ruct ions long & com plex
ARM Ca c he Fe a t ure s
Core Cache Cache Size (kB) Cache Line Size Associativity Location Write Buffer Type (words) Size (words)
ARM720T Unified 8 4 4-way Logical 8
ARM920T Split 16/16 D/I 8 64-way Logical 16 ARM926EJ-S Split 4-128/4-128 D/I 8 4-way Logical 16
ARM1022E Split 16/16 D/I 8 64-way Logical 16 ARM1026EJ-S Split 4-128/4-128 D/I 8 4-way Logical 8
Intel StrongARM Split 16/16 D/I 4 32-way Logical 32 Intel StrongARM Split 16/16 D/I 4 32 way Logical 32
ARM Ca c he Orga niza t iong
• Sm all FI FO writ e buffer
E h it f
—Enhances m em ory writ e perform ance
—Bet ween cache and m ain m em ory
—Processor cont inues execut ion
E t l it i ll l t il t
—Ext ernal writ e in parallel unt il em pt y
—I f buffer full, processor st alls
D t i it b ff t il bl t il it t
—Dat a in writ e buffer not available unt il writ t en