BAB II
LANDASAN TEORI
Bab ini berisi landasan teori dalam penelitian mengenai aplikasi algoritma spasial
clustering pada data mahasiswa baru. Pembahasan diawali dengan penjelasan secara umum mengenai data mining. Pembahasan dilanjutkan dengan penjelasan secara terperinci mengenai algoritma clustering yang digunakan dalam penelitian. Algoritma tersebut yaitu algoritma Density-based Spatial Clustering of Application with Noise (DBSCAN).
2.1 Penjelasan Umum Data Mining
Data yang tersimpan di dalam suatu basis data biasanya berupa data mentah yang tidak dapat memberikan informasi-informasi berharga secara langsung. Untuk melakukan ekstraksi informasi yang terkandung, perlu dilakukan langkah-langkah pemrosesan tertentu. Metode pemrosesan data dengan tujuan untuk mendapatkan informasi penting yang terkandung di dalamnya dapat dilakukan dengan proses
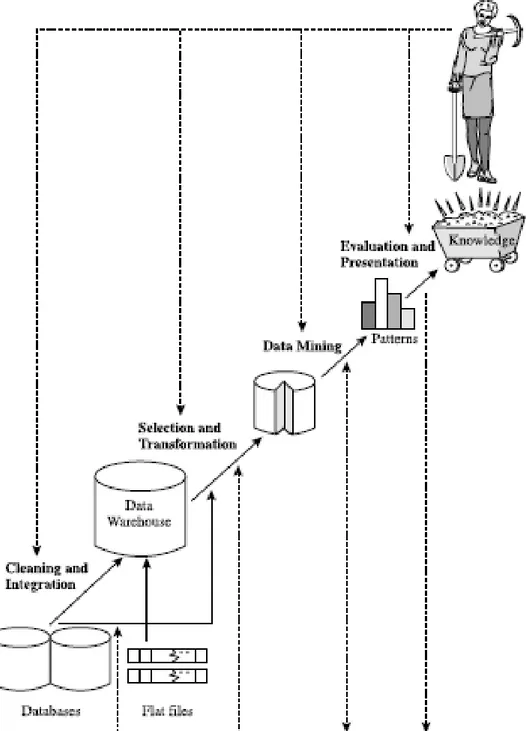
data mining. “Secara sederhana, data mining sebagai proses ekstraksi atau penggalian informasi-informasi penting yang terkandung dalam sejumlah data” (Han & Kamber, 2006, p. 5). Proses penggalian informasi tersebut terdiri dari langkah-langkah pemrosesan data. Langkah-langkah dan metode pemrosesan data disesuaikan dengan tujuan dan karakteristik data yang akan diproses. Langkah-langkah tersebut dapat dilihat di gambar di bawah ini.
Gambar 2.1 Data mining sebagai salah satu langkah Knowledge Discovery Sumber: (Han & Kamber, 2006, p. 6)
Di gambar tersebut, data mining menjadi salah satu langkah dalam proses
knowledge discovery. Meskipun demikian, dalam knowledge discovery, data mining merupakan inti dalam proses tersebut. Beberapa pakar memberikan definisi yang sama terhadap kedua terminologi ini. Di dalam penelitian ini, terminologi data mining dan knowledge discovery selanjutnya disebut sebagai
data mining. Jiawei Han dan Micheline Kamber membagi proses data mining ke dalam tujuh langkah (Han & Kamber, 2006).
Pembersihan data (data cleaning), merupakan proses pembersihan data dari
noise dan dari data yang tidak konsisten;
Integrasi data (data integration), merupakan proses intergrasi data dari berbagai sumber data yang dapat dikombinasikan;
Seleksi data (data selection), merupakan proses pengambilan data-data dari basis data yang relevan dengan penelitian;
Transformasi data (data transformation), merupakan proses transformasi atau konsolidasi data ke dalam bentuk yang sesuai dengan proses analisis data mining;
Data mining, merupakan proses inti yang melakukan ekstraksi atau penggalian pola (pattern);
Evaluasi pola (pattern evaluation), merupakan proses menemukan pola yang menarik berdasarkan pengukuran-pengukuran kemenarikan tertentu;
Presentasi pengetahuan (knowledge presentation) merupakan proses visualisasi dengan menggunakan teknik-teknik representasi untuk menampilkan informasi kepada pengguna.
Langkah satu sampai dengan langkah empat disebut juga sebagai data preprocessing. Data preprocessing dilakukan untuk menyiapkan data dan memodifikasi data sedemikian rupa agar dapat dilakukan data mining. Metode-metode yang sering digunakan dalam data preprocessing antara lain normalisasi, agregasi data, seleksi fitur dan ekstraksi fitur. Spasial data mining merupakan bentuk data mining yang melakukan analisis terhadap data spasial.
Data spasial diambil dari tempat tertentu (spasial), dimana dalam . Dengan demikian, setiap titik pengamatan dalam area tersebut mengandung sequential data. Dalam analisis spasial data mining, data-data tersebut dianalisis untuk menemukan pola-pola menarik yaitu pola kemiripan antara satu titik pengamatan dengan titik pengamatan lain. Pola-pola tersebut dicari dengan fungsionalitas tertentu yang ada dalam spasial data mining. Berikut beberapa fungsionalitas dalam data mining (Han & Kamber, 2006, pp. 21-27).
a. Deskripsi konsep atau kelas, terdiri dari karakterisasi dan diskriminasi
Karakterisasi data merupakan proses menemukan ciri-ciri umum yang terdapat di dalam data. Proses karakterisasi dilakukan untuk mengumpulkan ciri-ciri yang ada dalam suatu kelas atau suatu konsep data. Sementara itu, diskriminasi data merupakan proses perbandingan antara ciri-ciri umum dalam suatu kelas dengan kelas lain.
b. Pattern mining, assoiciation rule dan korelasi
Pattern mining merupakan proses menemukan pola-pola yang terjadi secara spesifik atau berulang-ulang. Pola tersebut antara lain pola dalam itemset,
subsequence, atau substructure. Dalam association rule, hubungan antardata dihitung berdasarkan probabilitasnya. Support dan confidence merupakan dua unsur yang ada dalam association rule. Jika di dalam suatu basis data D terdapat dua kumpulan data, kumpulan data A dan kumpulan data B, support
didefinisikan sebagai persentase jumlah transaksi di D yang
mengandung A dan B atau ( ) , sedangkan confidence
didefinisikan sebagai persentase jumlah transaksi di D yang memiliki hubungan kondisional jika ada A maka ada B atau ( ). Hubungan antardata tersebut dianggap menarik jika support dan confidence melebihi
minimumsupport threshold dan minimum confidence threshold.
c. Klasifikasi dan prediksi
Klasifikasi dan prediksi merupakan proses menemukan model (atau
classifier) yang membedakan antara satu kelas dengan kelas yang lain. Model atau classifier dalam metode klasifikasi dibangun untuk memprediksi label yang berbentuk kategorial. Sementara itu, model atau classifier dalam metode prediksi digunakan untuk memprediksi fungsi bernilai kontinu. Baik klasifikasi maupun prediksi berguna untuk memberi label kepada data yang masih belum terlabelkan.
d. Analisis cluster
Analisis cluster atau clustering merupakan proses pengelompokkan data-data ke dalam cluster tertentu tanpa ada infomasi label secara langsung dalam data.
cluster tersebut dan berbeda dengan data yang ada di cluster lain. Kemiripan dalam analisis cluster dihitung dengan fungsi jarak.
e. Analisis pencilan
Analisi pencilan (outlier) merupakan proses menemukan data pencilan atau data yang memiliki perilaku yang berbeda dengan perilaku data pada umumnya.
2.2 Spasial Clustering
Penelitian ini akan berfokus kepada analisis spasial clustering yaitu analisis pengelompokkan data spasial menggunakan algoritma clustering yang sudah ada. Berbeda dengan klasifikasi, dalam analisis spasial clustering tidak memiliki label atau tidak memasukkan label data tersebut ke dalam proses clustering. Dengan kata lain, analisis spasial clustering merupakan proses unsupervised. Untuk data spasial berukuran besar, biaya komputasi spasial clustering biasanya lebih mahal karena harus menemukan label-label masing-masing profil dalam data tersebut. Untuk itu diperlukan algoritma komputasi yang efektif dan efisien untuk memproses data spasial yang berukuran besar dengan dimensi data yang tinggi tersebut. Profil merupakan istilah untuk satu baris data sepanjang jumlah dimensi data. Adapun beberapa kebutuhan-kebutuhan umum yang mendorong penelitian dalam algoritma clustering antara lain sebagai berikut (Han & Kamber, 2006, pp. 385-386):
skalabilitas,
kemampuan untuk menangani berbagai jenis atribut,
kemampuan menemukan cluster dalam data yang acak,
hanya membutuhkan pengetahuan minimal terhadap domain pengetahuan asal data untuk menentukan parameter masukkan,
kemampuan untuk menangani noisy data,
clustering bersifat inkremental dan tidak sensitif terhadap urutan masukkan data,
kemampuan menangani data berdimensi tinggi,
hasil clustering dapat diinterpretasikan dan digunakan.
Setiap algoritma yang digunakan dalam analisis clustering dapat memberikan hasil yang baik untuk suatu bentuk data, namun dapat memberikan hasil yang tidak baik apabila diimplementasikan terhadap data yang lain. Untuk mengetahui metode yang memberikan akurasi paling baik, diperlukan langkah-langkah tertentu. Langkah-langkah yang umum dilakukan dalam analisis clustering adalah sebagai berikut (Jain, Murty, & Flynn, 1999, hal. 266):
pattern representation (termasuk proses ekstraksi atau proses seleksi fitur),
pendefinisian cara menghitungan kedekatan atau jarak dalam pola yang sesuai dengan domain data,
clustering,
proses abstraksi data (opsional), dan
peninjauan hasil (opsional).
Pattern representation merupakan proses menentukan parameter-parameter masukkan dalam analisis clustering. Proses tersebut antara lain proses menentukan jumlah cluster yang diharapkan dan proses identifikasi jenis, jumlah dan skala atribut-atribut yang dimiliki data. Tidak semua atribut yang dimiliki data perlu diikutsertakan dalam proses analisis spasial clustering. Hanya atribut-atribut tertentu yang relevan terhadap tujuan spasial clustering yang diperlukan dalam clustering. Seleksi atribut merupakan langkah memilih atribut-atribut yang sesuai dengan tujuan clustering. Meskipun demikian, dalam kasus-kasus tertentu, atribut yang diperlukan tidak secara eksplisit tersedia dalam data. Perlu dilakukan ekstraksi fitur atau atribut terlebih dahulu untuk mendapatkan atribut tersebut. Ekstraksi atribut melakukan pengolahan terhadap data dan menghasilkan atribut baru bedasarkan masukkan dari atribut-atribut yang sudah ada. Penghitungan kedekatan atau jarak antarprofil digunakan untuk menentukan kemiripan dalam profil-profil tersebut. Bisanya perhitungan ini menggunakan rumus jarak tertentu. Rumus perhitungan jarak yang umum digunakan dalam analisis clustering antara lain jarak Euclidean, jarak Minkowski, jarak Manhattan, dan jarak Mahalanobis.
( ) √( ) ( ) ( )
Dengan ( ) dan ( ) merupakan dua profil berdimensi . Adapun dalam bentuk matriks, perhitungan jarak Euclidean dapat dilakuan dengan cara sebagai berikut (Jain, Murty, & Flynn, 1999, hal. 271):
( ) (∑ ( ) )
‖ ‖
b. Rumus pengukuran jarak Manhattan atau dikenal juga dengan city block (Han & Kamber, 2006, p. 388)
( ) | | | | | |
c. Rumus pengukuran jarak menggunakan jarak Minkowski (Han & Kamber, 2006, p. 389)
( ) (| | | | | | )
Adapun dalam bentuk matriks, perhitungan jarak Minkowski dapat dilakukan dengan cara sebagai berikut (Jain, Murty, & Flynn, 1999, hal. 372)
( ) (∑ ( ) ) ‖ ‖
d. Rumus pengukuran jarak menggunakan jarak Mahalanobis (Jain, Murty, & Flynn, 1999, hal. 372)
( ) ( ) ∑ ( )
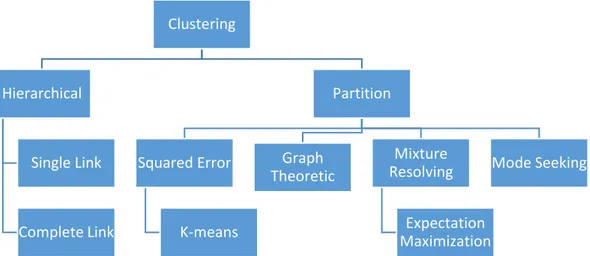
Dalam melakukan clustering, untuk bentuk data tertentu digunakan pendekatan algoritma clustering yang berbeda dengan bentuk data yang lain. Dalam jurnal “Data Clustering: A Review” (Jain, Murty, & Flynn, 1999), terbentuk satu
clustering dibagi menjadi dua pendekatan utama, yaitu pendekatan secara hirarki dan pendekatan secara partisi.
Gambar 2.2 Taksonomi Pendekatan Clustering Sumber: Jain, Murty, & Flynn, 1999, hal. 275 (telah diolah kembali)
Pembentukan taksonomi tersebut berdasarkan beberapa kriteria yang membedakan antara satu algoritma dengan algoritma yang lain. Dibawah ini dijelaskan kriteria-kriteria pembeda yang dimaksud (Jain, Murty, & Flynn, 1999, hal. 274-275).
a. Pendekatan agglomerative dibandingkan dengan pendekatan divisive
Dalam pendekatan agglomerative, mula-mula setiap profil dianggap sebagai satu cluster tersendiri. Dengan menggunakan perhitungan kemiripan, profil-profil yang memiliki kemiripan kemudian digabung sampai memenuhi kriteria tertentu. Sebaliknya, dalam pendekatan divisive, mula-mula seluruh profil dianggap sebagai satu cluster yang sama. Dengan menggunakan perhitungan kemiripan, cluster tersebut kemudian dipecah menjadi beberapa cluster
sampai memenuhi kriteria tertentu.
b. Pendekatan monothetic dibandingkan dengan pendekatan polythetic
Dalam pendekatan monothetic, perhitungan kemiripan profil menggunakan atribut yang dimasukkan secara bertahap. Dalam hal ini, setiap kali tambahan
Clustering Hierarchical Single Link Complete Link Partition Squared Error K-means Graph Theoretic Mixture Resolving Expectation Maximization Mode Seeking
atribut dimasukkan, cluster kemudian dipecah sesuai masukkan atribut baru tersebut. Berbeda dengan pendekatan monothetic, dalam pendekatan polythetic, semua atribut dimasukkan dalam perhitungan kemiripan secara bersama-sama. Metode clustering yang ada pada umumnya menggunakan pendekatan
polythetic.
c. Pendekatan hardclustering dibandingkan dengan pendekatan fuzzyclustering
Dalam pendekatan hard clustering, satu profil menjadi anggota satu cluster
saja. Sementara itu, dalam pendekatan fuzzy clustering, satu profil memiliki derajat keanggotaan di semua cluster. Pendekatan fuzzy clustering dapat diubah menjadi hard clustering dengan memilih derajat keanggotaan paling tinggi sebagai cluster data tersebut.
d. Pendekatan deterministic dibandingkan dengan pendekatan sthocastic
Dalam pendekatan secara deterministic, optimisasi fungsi squared error
dilakukan dengan teknik tradisional, sedangkan dalam pendekatan secara
stochastic, optimisasi fungsi squared error dilakukan dengan random search
terhadap state space yang terdiri dari keseluruhan label yang mungkin. e. Pendekatan non-inkremental dibandingkan dengan pendekatan inkremental
Dalam pendekatan non-inkremental, seluruh profil yang akan dianalisis diproses secara bersama-sama. Hal ini berkaitan dengan kemampuan dari komputasi, alokasi waktu, dan alokasi memori yang harus disediakan. Dengan pendekatan inkremental, jumlah profil yang diproses disesuaikan dengan batasan kemampuan komputasi, memori dan waktu tersebut.
2.3 Algoritma DBSCAN
Density-based Spatial Clustering of Application with Noise atau lebih dikenal dengan sebutan DBSCAN termasuk ke dalam algoritmas clustering berbasis kepadatan (density-based). DBSCAN mencari kumpulan data dengan kepadatan yang tinggi untuk dijdikan sebagai cluster. Bentuk cluster yang dihasilkan oleh DBSCAN bergantung kepada kepadatan tersebut. Sehingga dengan algoritma ini dimungkinkan untuk menghasilkan bentuk cluster yang sembarang. Suatu cluster
dalam DBSCAN didefinisikan sebagai sekumpulan maksimum data yang terhubung di dalam kepadatan tersebut (density-connected). Keanggotaan dari
setiap profil dihitung berdasarkan rumus jarak. DBSCAN termasuk ke dalam
unsupervised clustering karena jumlah cluster yang dihasilkan ditentukan oleh bentuk persebaran data itu sendiri, bukan diinisialisasi di awal.
Gambar 2.3 Contoh Clustering dengan algoritma DBSCAN Sumber: (Ester, Kriegel, Sander, & Xu, August 1996)
Algoritma DBSCAN pertama kali diperkenalkan dalam jurnal ilmiah yang berjudul “A Density-Based Algorithm for Discovering Clusters in Large Spatial Database with Noise”. Dalam jurnal ilmiah tersebut diperkenalkan beberapa
komponen baru dalam proses analisis clustering yang ada di dalam DBSCAN. Komponen-komponen tersebut antara lain (Ester, Kriegel, Sander, & Xu, August 1996):
a. Epsilon
Epsilon kekerabatan dari sebuah profil atau Eps-neigborhood dari sebuah profil, ( ), didefinisikan sebagai
( ) * ( ) +
D adalah basis data yang dianalisis, q adalah profil lain. Eps adalah nilai ambang jarak antarprofil untuk dapat dimasukkan ke dalam cluster yang sama. Dari definisi tersebut, profil p dapat berkerabat dengan profil q (berada dalam satu cluster yang sama) jika jarak dari p ke q tidak lebih dari nilai Eps.
b. Minimum Points
Meskipun p berada dalam Eps-neigborhood dari q, akan tetapi jika hanya dua profil itu saja yang berkerabat, maka akan ada kasus dimana terdapat banyak
diperkenalkan istilah minimum points atau MinPts. MinPts merupakan nilai ambang yang merepresentasikan jumlah minimal profil yang berada dalam Eps-neigborhood profil p agar dapat terbentuk cluster. Dengan nilai ambang ini, maka ada tiga klasifikasi jenis profil di DBSCAN, yaitu profil yang berada di berada di luar daerah padat disebut outlier, profil yang berada di pangkal daerah padat disebut border point, dan profil yang berada di dalam daerah padat disebut core point.
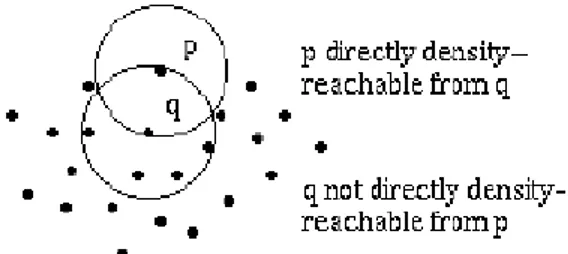
c. Directly density-reachable
Sebuah profil p dikatakan directly density-reachable terhadap profil q jika
( ), dan
| ( )| (q merupakan core point)
Dari definisi tersebut dapat diketahui bahwa agar profil p directly density-reachable terhadap profil q, maka harus memenuhi dua syarat yaitu profil p
berada pada Eps-neighborhood profil q dan profil q merupakan core poin.
Directly density-reachable bersifat simetris jika p dan q keduanya adalah core point. Artinya, jika p directly density-reachable terhadap q, maka q directly density-reachable terhadap p.
Gambar 2.4 Contoh sepasang profil yang directly density-reachable Sumber: Ester, Kriegel, Sander, & Xu, August 1996 (telah diolah kembali)
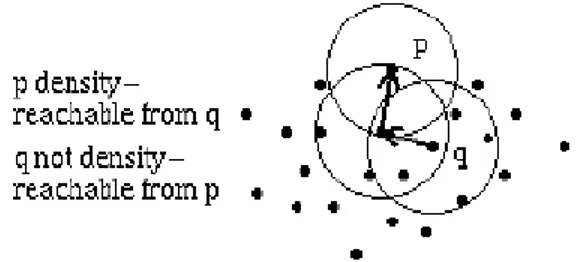
d. Density-reachable
Sebuah profil p dikatakan density-reachable terhadap profil q jika terdapat rantai , dengan dan , sedemikian sehingga bersifat
directly density-reachable terhadap . Dari definisi tersebut dapat diketahui bahwa dua buah profil dikatakan density-reachable jika ada satu rantai profil
sedemikian sehingga dari profil satu ke profil lain di dalam rantai tersebut bersifat directly density-reachable. Sifat density-reachable tidak menjamin dua border point bersifat density-reachable.
Gambar 2.5 Contoh sepasang profil yang density-reachable Sumber: Ester, Kriegel, Sander, & Xu, August 1996 (telah diolah kembali) e. Density-connected
Sebuah profil p dikatakan density-connected terhadap profil q jika terdapat profil o sedemikian sehingga profil p dan profil q bersifat density-reachable
terhadap poin o. Dengan demikian, setidaknya dua profil di dalam satu cluster
bersifat density-connected. Density-connected bersifat simetris dan refleksif. Artinya, jika profil p bersifat density-connected terhadap poin q, maka profil q
bersifat density-connected terhadap profil p.
Gambar 2.6 Contoh sepasang profil yang density-connected Sumber: Ester, Kriegel, Sander, & Xu, August 1996 (telah diolah kembali)
Nilai eps dan MinPts harus diketahui untuk dapat menjalankan algoritma DBSCAN. Algoritma DBSCAN dimulai dengan memilih satu profil p secara acak, kemudian mencari profil-profil lain yang density-reachable terhadap profil p. Jika
p merupakan core point, maka terbentuk suatu cluster. Akan tetapi jika p adalah border point, maka DBSCAN akan mengambil profil lain dari basis data. Dalam
proses tersebut, terdapat kemungkinan dua cluster bergabung jika kedua custer
tersebut dekat. Berikut pseudocode dari algoritma DBSCAN:
DBSCAN (SetOfPoints, Eps, MinPts) // SetOfPoints is UNCLASIFIED
ClusterId := nextId(NOISE)
FOR i FROM 1 TO SetOfPoints.size DO Point = SetOfPoints.get(i)
IF Point.ClID = UNCLASSIFIED THEN
IF ExpandCluster(SetOfPoints, Point, ClusterId,
Eps, MinPts) THEN
ClusterId := nextId(ClusterId) END IF
END IF END FOR END; // DBSCAN
Algoritma 2.1 Pseudocode fungsi DBSCAN untuk algoritma DBSCAN Sumber: (Ester, Kriegel, Sander, & Xu, August 1996)
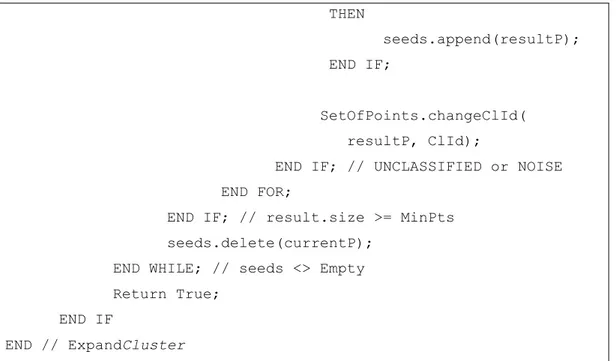
ExpandCluster(SetOfPoints, Point, ClID, Eps, MinPts) : Boolean;
seeds:= SetOfPoints.regionQuery(Point, Eps);
IF seeds.size < MinPts THEN // no core point SetOfPoints.changeClIds(Point, NOISE); RETURN False
ELSE // all points in seeds are density- // reachable from point
SetOfPoints.changeClID(seeds, ClId); seeds.delete(Point);
WHILE seeds <> Empty DO
currentP := seeds.first();
result := SetOfPoints.regionQuery(currentP, Eps);
IF result.size >= MinPts THEN
FOR i FROM 1 TO result.size DO resultP := result.get(i);
IF resultP.ClId IN {UNCLASSIFIED, NOISE}
THEN
THEN seeds.append(resultP); END IF; SetOfPoints.changeClId( resultP, ClId);
END IF; // UNCLASSIFIED or NOISE END FOR;
END IF; // result.size >= MinPts seeds.delete(currentP);
END WHILE; // seeds <> Empty Return True;
END IF
END // ExpandCluster
Algoritma 2.2 Pseudocode fungsi ExpandCluster untuk algoritma DBSCAN Sumber: (Ester, Kriegel, Sander, & Xu, August 1996)
Dan berikut flowchart dari algoritma DBSCAN:
Berdasarkan gambar diatas, dalam algoritma DBSCAN dilakukan input data yang akan digunakan, kemudian dilakukan proses loop. Pada proses loop ini dilakukan pengecekan tiap nilai yang density reachable. Jika data yang dicek ini merupakan titik inti maka akan dibentuk cluster. Jika tidak,maka akan dicek apakah titik itu merupakan titik tepi, jika iya maka titik itu akan melakukan proses pengecekan kembali. Jika tidak, maka akan dimasukkan kedalam kategori noise. Proses ini berlanjut hingga semua titik diperiksa.
2.4 Metode Silhouette Index
Setiap algoritma clustering memiliki kelebihan dalam menganalisis cluster untuk jenis data tertentu, namun belum tentu lebih baik jika diaplikasikan terhadap data lain. Dengan demikian, perlu ada satu metode khusus yang dapat membandingkan secara objektif hasil-hasil analisis clustering tersebut. Dalam clustering, perbandingan tersebut dikenal sebagai cluster evaluation atau cluster validation. Evaluasi clustering dilakukan dengan memvalidasi hasil analisis clustering. Pelabelan keanggotaan terhadap setiap profil dievaluasi dengan menggunakan teknik validasi tertentu. Validasi diperlukan untuk menghitung nilai akurasi dari hasil cluster tersebut. Nilai akurasi tersebut diperlukan antara lain untuk membandingkan akurasi hasil clustering dengan menggunakan beberapa algoritma terhadap data yang sama. Dalam penelitian ini, metode validasi hasil analisi spasial clustering yang digunakan adalah metode Silhouette index. Metode
Silhouette index pertama kali diperkenalkan oleh Rousseeuw (1987) dalam jurnal ilmiah yang berjudul “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis”. Dalam jurnal tersebut, Rousseeuw
memperkenalkan metode validasi dengan mengukur kesamaan atau ketidaksamaan antara profil yang ada dalam satu cluster dengan cluster lain hasil analisis clustering. Pengukuran kesamaan atau ketidaksamaan tesebut dihitung dengan rumus jarak. Jika diketahui data yang dianalisis * + jumlah profil dalam data, dan diketahui A adalah salah satu cluster yang dihasilkan, maka dapat dicari:
Jika diketahui terdapat cluster C dimana , maka dapat dicari
( ) jarak rata-rata profil ke terhadap profil yang ada dalam cluster C.
Jika terdapat lebih dari satu cluster lain selain cluster A, maka perlu dicari cluster
yang paling dekat dengan cluster A dengan menghitung
( ) ( )
Silhouette index terhadap profil ke yaitu ( ) didefinisikan sebagai berikut (Rousseeuw, 1987, hal. 56):
( ) * ( ) ( )+ ( ) ( )
Gambar 2.8 Ilustrasi Silhouette indeks
Contoh elemen yang terlibat dalam perhitungan ( ). Profil i berada di cluster A Sumber: (Rousseeuw, 1987, hal. 55)
Rentang nilai ( ) yang diperoleh dari perhitungan tersebut adalah ( ) . Nilai ( ) lebih dekat ke 1 menunjukkan bahwa data tersebut sudah well clustered. Artinya, kemiripan data tersebut dengan data lain yang ada dalam
cluster yang sama jauh lebih besar dibandingkan dengan kemiripan data tersebut dengan data dari cluster lain yang berdekatan. Nilai ( ) lebih dekat ke 0 menunjukkan bahwa data tersebut termasuk dalam intermediate case. Artinya, kemiripan data tersebut dengan data lain yang ada dalam cluster yang sama relatif sama besar dibandingkan dengan kemiripan data tersebut dengan data dari cluster
lain yang berdekatan. Data yang berada pada intermediate case dapat dipindah ke
tersebut misclassified. Artinya, kemiripan data tersebut dengan data lain yang ada di cluster yang sama dibandingkan dengan data di cluster yang berdekatan jauh lebih mirip terhadap data dari cluster yang berdekatan. Setelah menghitung masing-masing nilai Silhouette index dalam data, maka dapat diketahui yaitu
rata-rata nilai Silhouette index dari data:
∑ ∑ ( )
menyatakan cluster ke-i, menyatakan data ke dalam
cluster ke , dan ( ) menyatakan nilai Silhouette index data ke dalam cluster
ke . Nilai dari menyatakan akurasi hasil analisi clustering.
2.5 Studi Literatur
Dalam studi literatur ini akan dijabarkan tiga buah penelitian yang telah dilakukan menggunakan algoritma DBSCAN. Penelitian pertama yaitu “Aplikasi Algoritma Spasial dan Temporal Clustering pada Data Curah Hujan”, penelitian kedua “Pengembangan Aplikasi berbasis Clustering dan Prediksi Untuk Pemetaan Potensi Sumberdaya Perikanan Ikan Tuna di Indonesia”, dan penelitian ketiga “Comparative Study Between Density Based Clustering - DBSCAN and OPTICS”.
TAHUN PENELITI JUDUL DATA METODE HASIL
2012 Wawan Setiawan Aplikasi Algoritma Spasial dan Temporal Clustering pada Data Curah Hujan Data curah hujan Penelitian yang dilakukan untuk mendapatka n algoritma spasial clustering dan algoritma temporal Dari hasil eksperimen, disimpulkan bahwa algoritma paling akurat dalam proses spasial clustering adalah algoritma DBSCAN dan algoritma paling akurat dalam
clustering yang akurat dan cepat terhadap data curah hujan. Implementa si yang dilakukan adalah melakukan perbandinga n akurasi dan waktu komputasi terhadap masing-masing algoritma. proses temporal clustering adalah algoritma Iterative K-means. Waktu komputasi algoritma Iterative K-means hampir 20 kali lebih cepat dibandingkan dengan algoritma K-means. Selain perbandingan hasil clustering, penelitian juga menghasilkan pola-pola persebaran curah hujan yang diperoleh dari hasil clustering. 2013 Dr.Achmad Nizar Hidayanto, S.Kom., M.Kom, Prof. Dr. Aniati Murni Arymurthy, M.Sc, Devi Fitrianah, S.Kom., MTI Dina Chahyati, Pengembang an Aplikasi berbasis Clustering dan Prediksi Untuk Pemetaan Potensi Sumberdaya Perikanan Ikan Tuna di Indonesia Data tangkap an ikan dilaut Peneiti melakukan integrasi data cluster spatio-temporal tangkapan ikan dengan data oseanografi Algoritma spatio-temporal clustering yang digunakan untuk menentukan area penangkapan ikan dilakukan dengan 2 skema, skema 1 secara berjenjang, yaitu spasial terlebih dahulu baru kemudian
S.Kom., M.Kom algoritma temporal, skema 2 yaitu dengan cara bersamaan, dimana data spasial dan temporal diproses secara bersamaan. Untuk skema 1, algoritma spasial yang digunakan adalah algoritma DBSCAN yang ditambahkan modifikasi berupa threshold untuk menentukan area penangkapan dengan jumlah tangkapan tertinggi. Kemudian dari hasil identifikasi area tangkapan tertinggi dilakukan algoritma temporal untuk melihat periode tangkapan tertinggi. 2016 Pranjal Dubey, Anand rajavat Comparative Study Between Data Yang Diguna Peneliti mencoba melakukan Hasilnya pada kerapatan dengan DBSCAN, boolean
Density Based Clustering - DBSCAN and OPTICS kan Data Rando m analisa perbandinga n clustering dengan DBSCNA dan OPTICS
valuenya itu high atau low. Dan keanggotaan clusternya, boolean valuenya itu yes atau no.
Sedangkan, dengan OPTICS, hasil kerapatannya memiliki numerical value yaitu core dan distance. Dan keanggotaan clusternya memiliki numerical value reachable distance. 2017 Rizky Algian Kurniaputra, Dr. Devi Fitrianah, S.Kom., MTI Analisa Spasial Clustering Dengan Menggunaka n Algoritma DBSCAN. Data koordin at mahasis wa universi tas mercu buana Peneliti melakukan penerapan algoritma spasial clustering yaitu DBSCAN pada data koordinat mahasiswa universitas mercubuana Peneliti mendapatkan hasil clustering dengan beberapa parameter yang berbeda. Dan peneliti mendapatkan kesimpulan dari hasil clustering, validasi clustering, index.