Hanna Amalia N, 2015
SISTEM REKOMENDASI VARIAN RASA BERDASARKAN KLASIFIKASI PELANGGAN PADA PERUSAHAAN BROWNIES AMANDA
SKRIPSI
Untuk memenuhi sebagian persyaratan mencapai Gelar Sarjana S-1
Program Studi Ilmu Komputer
Oleh:
Hanna Amalia N
0902283
PROGRAM STUDI ILMU KOMPUTER
FAKULTAS PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS PENDIDIKAN INDONESIA
Hanna Amalia N, 2015
SISTEM REKOMENDASI VARIAN RASA BERDASARKAN KLASIFIKASI PELANGGAN PADA PERUSAHAAN BROWNIES AMANDA
Oleh
Hanna Amalia N
0902283
Sebuah skripsi yang diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana pada
Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
© Hanna Amalia N 2014
Universitas Pendidikan Indonesia
Desember 2014
Hak Cipta dilindungi undang-undang.
Hanna Amalia N, 2015
dengan dicetak ulang, difoto kopi, atau cara lainnya tanpa ijin dari penulis.
SISTEM REKOMENDASI VARIAN RASA BERDASARKAN KLASIFIKASI
PELANGGAN PADA PERUSAHAAN BROWNIES AMANDA
HANNA AMALIA N
0902283
DISETUJUI DAN DISAHKAN OLEH PEMBIMBING :
Pembimbing I,
Budi Laksono Putro, M.T.
NIP. 197607102010121001
Pembimbing II,
Wahyudin, M.T.
NIP.197304242008121001
Mengetahui,
Ketua Program Studi Ilmu Komputer
Jajang Kusnendar, M.T.
Hanna Amalia N, 2015
vi
Hanna Amalia N, 2015
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
UCAPAN TERIMA KASIH ... iv
DAFTAR ISI ... vi
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... xi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan Masalah ... 4
1.4 Tujuan Masalah ... 5
1.5 Manfaat Penelitian ... 5
1.6 Metodelogi Penelitian ... 5
1.7 Sistematika Penulisan ... 8
BAB II KAJIAN PUSTAKA ... 10
2.1 Sistem Rekomendasi ... 10
2.2 Definisi Informasi ... 11
2.3 Data Mining... 13
vii
Hanna Amalia N, 2015
2.5 Definisi Klasifikasi ... 17
2.6 Naive Bayes ... 19
2.7 Hypertext Preprocessor ( PHP ) ... 22
2.8 MYSQL ... 24
2.9XAMPP ... 25
2.10 Perangkat Pemodelan Sistem ... 26
2.10.1 Data Flow Diagram Context Level ... 26
2.10.2Data Flow Diagram Levelled ... 27
BAB III METODE PENELITIAN ... 28
3.1 Desain Penelitian ... 28
3.2 Alat dan Bahan Penelitian ... 33
3.2.1 Alat Peneltian ... 33
3.2.2 Bahan Penelitian ... 33
3.3 Metode Pengembangan Perangkat Lunak ... 34
BAB IV HASIL PENELITIAN ... 36
4.1 Hasil Penelitian ... 36
4.1.1 Proses Klasifikasi Data Mining ... 36
4.1.2 Hasil Survey ... 39
4.2 Implementasi Algoritma ... 46
4.2.1 Implementasi Algoritma Naive Bayes ... 46
4.3 Hasil Informasi Survei ... 55
4.4.1 Varian Rasa Coklat ... 56
viii
Hanna Amalia N, 2015
4.4.3 Varian Rasa Blueberry ... 61
4.4 Evaluasi Model ... 64
BAB V PENUTUP ... 75
5.1 Kesimpulan ... 75
5.2 Saran ... 76
DAFTAR PUSTAKA
ix
Hanna Amalia N, 2015
DAFTAR TABEL
Tabel 4.1 Perhitungan Chi Square JenisKelamin-Varian Rasa... 41
Tabel 4.2 Perhitungan Chi Square Usia-Varian Rasa ... 42
Tabel 4.3 Perhitungan Chi Square Status Pekerjaan-Varian Rasa ... 43
Tabel 4.4 Perhitungan Chi Square Hdm-Varian Rasa ... 44
Tabel 4.5 Data Atribut Jenis Kelamin ... 45
Tabel 4.6 Data Atribut Usia ... 45
Tabel 4.7 Data Atribut Status Pekerjaan ... 45
Tabel 4.8 Data Atribut Hari Dominan Membeli ... 46
Tabel 4.9 Data Atribut Varian Rasa ... 46
Tabel 4.10 Contoh Sampel Penelitian ... 47
Tabel 4.11 Hasil prediksi berdasarkan Algoritma Naive Bayes... 51
Tabel 4.12 Script Algoritma Naïve Bayes ... 51
Tabel 4.13 Jumlah Pelanggan Berdasarkan Jenis Kelamin-Coklat... 56
Tabel 4.14 Jumlah Pelanggan Berdasarkan Status Pekerjaan-Coklat ... 57
Tabel 4.15 Jumlah Pelanggan Berdasarkan Hdm-Coklat ... 57
Tabel 4.16 Jumlah Pelanggan Berdasarkan Jenis Kelamin-Keju ... 58
Tabel 4.17 Jumlah Pelanggan Berdasarkan Status Pekerjaan-Keju ... 59
Tabel 4.18 Jumlah Pelanggan Berdasarkan Hdm-Keju ... 60
Tabel 4.19 Jumlah Pelanggan Berdasarkan Jenis Kelamin-Blueberry ... 61
Tabel 4.20 Jumlah Pelanggan Berdasarkan Status Pekerjaan- Blueberry ... 62
x
Hanna Amalia N, 2015
Tabel 4.22 Data Percobaan ... 66
Tabel 4.23 Data Percobaan Lanjutan ... 67
Tabel 4.24 Hasil Percobaan ... 69
Tabel 4.25 Confussion Matrix Hasil Prediksi Algoritma Naive Bayes ... 72
Tabel 4.26 Tabel Producer Accuracy ... 73
xi
Hanna Amalia N, 2015
DAFTAR GAMBAR
Gambar 2.1 Top Level (CD), dan Level 0 ... 27
Gambar 3.1 Desain Penelitian ... 28
Gambar 3.2 Model Sekuensial Linear... 34
Gambar 4.3 Diagram Pemilih Rasa Coklat Pada Jenis Kelamin ... 56
Gambar 4.4 Diagram Pemilih Rasa Coklat Pada Status Pekerjaan... 57
Gambar 4.5 Diagram Pemilih Rasa Coklat Pada Hari Dominan Membeli ... 58
Gambar 4.6 Diagram Pemilih Rasa Keju Pada Jenis Kelamin ... 59
Gambar 4.7 Diagram Pemilih Rasa Keju Pada Status Pekerjaan ... 60
Gambar 4.8 Diagram Pemilih Rasa Coklat Pada Hari Dominan Membeli ... 61
Gambar 4.9 Diagram Pemilih Rasa Blueberry Pada Jenis Kelamin ... 62
Gambar 4.10 Diagram Pemilih Rasa Blueberry Pada Status Pekerjaan ... 63
28 Hanna Amalia N, 2015
BAB III METODE PENELITIAN
3.1 DESAIN PENELITAN
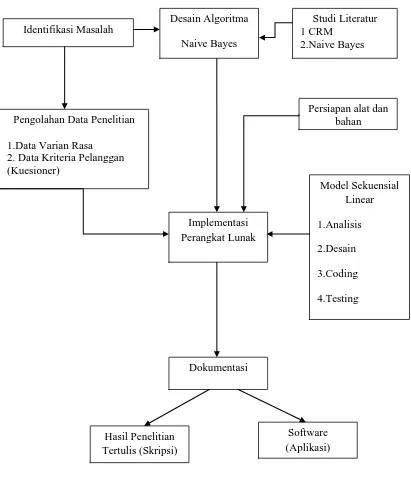
Gambar 3.1. Desain Penelitian
Studi Literatur 1 CRM
2.Naive Bayes
Pengolahan Data Penelitian
29 Hanna Amalia N, 2015
Berikut adalah penjelasan dari desain penelitian, yaitu :
1. Studi Literatur
Studi literatur berisi pengumpulan sumber-sumber teori yang dipelajari dan
dipahami untuk digunakan dalam penelitian.Teori yang akan digunakan seperti
Customer Relationship Management, Metode Naive Bayes.
Pengumpulan data dan materi dengan cara mengumpulkan literatur, jurnal,
websitedan bacaan-bacaan lain yang terkait dengan penelitian.
2. Pengolahan Data Penelitian
Data penelitian merupakan bahan acuan yang dijadikan untuk melakukan
perancangan dan pengembangan perangkat lunak yang diperoleh dari studi
literatur. Dalam penelitian ini data mengenai varian rasa diperoleh dari
Perusahaan Amanda, serta mengunjungi cabang toko kue Amanda.
Untuk menentukan kriteria dari masing-masing himpunan tiap variabel dari
pelanggan dilakukan dengan membuat kuesioner mengenai pelanggan yang
dianggap sesuai dengan himpunan yang ada seperti varian rasa yang disukai
tiap-tiap pelanggan, seperti coklat (original), coklat keju (cheese cream), blueberry.
Untuk penentuan kriteria ini diambil dari jumlah responden yang menjawab
varian rasa apa yang mereka suka, faktor apa yang mempengaruhi mereka
30 Hanna Amalia N, 2015
Metode pengumpulan data yang digunakan adalah Metode Random
Sampling, dengan cara accidental dengan kata lain, Metode Accidental ialah
pengambilan sampel dengan cara mengambil sampel dari sumber yang datang ke
tempat atau lokasi dimana yang akan kita teliti. Pada penelitian ini, karena yang
diteliti adalah konsumen sebuah produk makanan yang dimana konsumen tersebut
datang dan membeli produk makanan tersebut di toko yang khusus menjual
produk itu sendiri.
Pengumpulan data dilakukan dengan cara menyebar kuesioner secara acak
hingga jumlah terpenuhi.Untuk menentukan jumlah sampel yang dibutuhkan,
dikarenakan besar populasi tidak diketahui , maka besar sampel dihitung
menggunakan rumus Lemeshowoleh Stanley Lemeshow (1997) sebagai berikut :
Keterangan :
n = jumlah sampel yang dibutukan
Z = score Z, berdasarkan nilai yang diinginkan
= derajat kepercayaan
31 Hanna Amalia N, 2015
p= proporsi kasus yang diteliti dalam populasi, gunakan p terbesar p=0,5 jika p
tidak diketahui
q= 1- p, yaitu proporsi untuk terjadinya suatu kejadian, Jika p menggunakan p
terbesar maka q= 1-0,5=0,5
Toleransi Kesalahan dinyatakan dalam bentuk persen. Semakin besar
toleransi kesalahan, maka semakin kurang akurat sampel untuk mewakili
populasi, sebaliknya semakin kecil toleransi kesalahan, maka semakin akurat
sampel yang menggambarkan populasinya.. Pada penelitian ini digunakan batas
toleransi kesalahan 5 % sehingga batas toleransi kesalahan adalah 0,05.
Besaran nilai Z ditentukan berdasarkan dengan nilai , jika 5 %,
maka ditetapkan nilai Z ialah 1,96, maka Z2=3,84 dibulatkan menjadi 4. Maka
rumus untuk mengetahui jumlah sampel yang dibutukan dituliskan sebagai berikut
:
dengan class (label) C. P(H) adalah peluang dari hipotesa H, misalkan label untuk
32 Hanna Amalia N, 2015
data sampel yang diamati. P(E|H) adalah peluang data| sampel E, bila diasumsikan
bahwa hipotesa valid. Untuk masalah klasifikasi yang dihitung adalah P(H|E),
yaitu peluang bahwa hipotesa benar untuk data sample E yang diamati.
3. Desain Algoritma Naive Bayes
Pada tahap ini terdapat beberapa proses yang akan menghasilkan suatu
rekomendasi dalam pembelian Brownies sesuai dengan kriteria yang telah dipilih.
a. Menghitung jumlah Class/Label
Menghitung jumlah masing-masing class yang akan dicari terhadap dibagi
dengan jumlah data.
b. Menghitung jumlah kasus yang sama dengan class yang sama
Menghitung salah satu variabel hipotesa terhadap class yang akan dicari
c. Pengkalian semua hasil variabel
Menghitung hasil class berdasarkan perkalian semua variabel yang telah
didapatkan.
d. Pembandingan hasil class yang dicari
Bandingkan hasil class yag dicari untuk menemukan hasilnya berdasarkan
hipotesa
4. Pembangunan Perangkat Lunak
Perancangan perangkat lunak ini dengan model sekuensial linear yang
meliputi analisis, design, coding, dan testing.
5. Dokumentasi
Pembuatan laporan penelitian/skripsi , dokumen teknis dan paper, dan juga
33 Hanna Amalia N, 2015
3.2 ALAT DAN BAHAN PENELITIAN
3.2.1 Alat Penelitian
Alat penelitian menggunakan perangkat keras dan perangkat lunak
dengan rincian sebagai berikut:
1. Komputer dengan spesifikasi sebagai berikut:
a. Processor Intel Core 2 Duo 2,2 Ghz
b. RAM 2 GB
c. Hardisk 320 GB
d. VGA NVIDIA Gforce 512 Mb
e. Resolusi layar 1280 x 800 32 bit color
f. Keyboard dan Mouse
Perangkat lunak dengan spesifikasi sebagai berikut :
a. Sistem Operasi Microsoft Windows 7 Home Premium
b. XAMPP 1.7.2 Win 32 (PhpMyAdmin, MySql)
c. Notepad++
d. Browser Google Chrome dan Mozilla Firefox
3.2.2 Bahan Penelitian
a. Data Varian Rasa Kue Brownies Amanda
34 Hanna Amalia N, 2015
System/Information Engineering
c. Paper/textbook yang didapat dari World Wide Web
3.3 METODE PENGEMBANGAN PERANGKAT LUNAK
Metode Pengembangan Perangkat Lunak yang digunakan dalam penelitian ini
adalah model sekuensial linear. Model ini mengusulkan sebuah pendekatan
kepada perkembangan softwareyang sistematik dan sekuensial yang mulai pada
tingkat dan kemajuan sistem pada seluruh analisis, desain, kode, dan pengujian
(Pressman : 2002).
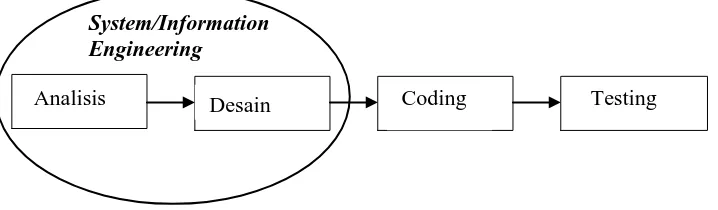
Berikut ini gambar dari model Sekuensial Linear.
as
Berikut penjelasan dari model Sekuensial Linear:
a. Analisis
Tahap ini merupakan tahap awal dalam analisis kebutuhan sistem.
Melakukan analisis terhadap kebutuhan sistem (fungsional dan non
fungsional), kebutuhan pengguna, kebutuhan informasi, dan kebutuhan
antarmuka eksternal. Tujuannya yaitu mengetahui informasi, model, dan
spesifikasi dari sistem yang dibutuhkan. Pada penelitian ini menggunakan
AnaliAnfa Deign Coding Testing
Gambar 3.2 Model Sekuensial Linear
35 Hanna Amalia N, 2015
Data Flow Diagram(DFD), kamus data (data dictionary) dan spesifikasi
proses (process specification) untuk memodelkan sistem.
b. Design
Tahap ini merupakan hasil analisis yang akan dimodelkan pada sistem
tentang bagaimana perangkat lunak dapat berfungsi dan spesifikasi perangkat
lunak. Tahap desain meliputi perancangan data, perancangan arsitektur,
representasi interface, dan perancangan prosedur.
c. Coding
Tahap ini merupakan proses penerjemahan hasil desain kedalam bahasa
pemrograman yang dapat dimengerti oleh komputer (coding). Pada penelitian
ini sistem dibangun nenggunakan bahasa pemrograman PHP dan MySql.
d. Testing
Tahap ini merupakan pengujian dari beberapa tahap sebelumnya. Proses
ini difokuskan pada logika internal dari perangkat lunak yang memastikan
bahwa semua statement telah diuji, dan pada eksternal fungsional. Tujuannya
adalah untuk memastikan bahwa input dan output yang dihasilkan sesuai
dengan yang diharapkan dan mencari apabila terdapat kesalahan-kesalahan
yang belum teratasi sehingga sistem yang telah dibuat sesuai dengan
kebutuhan.Pengujian dilakukan dengan memilih satu variabel dan dua
75 Hanna Amalia N, 2015
BAB V
PENUTUP
1.1KESIMPULAN
Berdasarkan hasil penelitian pada tugas akhir ini didapatkan kesimpulan
bahwa :
1. Berdasarkan hasil survei pada penelitian ini didapatkan klasifikasi
pelanggan berdasarkan varian rasa apa yang paling sesuai dengan kriteria
pelanggan, dengan menggunakan metode klasifikasi Naive Bayes,
berdasarkan jenis kelamin, status pekerjaan, usia, dan hari dominan
membeli. Sebagai contoh wanita berusia 20 tahun, bekerja, dan hari
dominan membeli pada hari kerja, didapat hasil perhitungan bahwa dia
dominan akan membeli rasa keju sesuai dengan perhitungan algoritma
Naive Bayes.
2. Dari data yang sudah dikumpulkan terdapat informasi secara umum bahwa
wanita merupakan pembeli terbanyak pada varian rasa keju, sedangkan
pada pria adalah pembeli varian rasa coklat terbanyak, dari total
keseluruhan ditemukan bahwa pria adalah pembeli terbanyak dalam
pembelian Brownies Amanda tersebut. Dalam prosentase ditemukan
bahwa 58 % pembeli Brownies Amanda ialah pria dan 42 % pembeli ialah
wanita. Pembeli terbanyak pria dapat diasumsikan bahwa pria tersebut
76 Hanna Amalia N, 2015
untuk individu dirinya, sehingga tidak menutup kemungkinan bahwa pria
lebih banyak membeli produk Brownies Amanda tersebut. Selain itu toko
pun harus menyediakan produk yang paling banyak dibeli pada hari
tertentu. Dari data yang diperoleh, dapat diinformasikan bahwa brownies
bervarian rasa keju adalah varian rasa yang paling banyak dicari ataupun
dibeli,sedangkan pada hari biasa coklatlah yang menjadi favorit varian rasa
yang paling sering dibeli.
3. Metode Klasifikasi dengan Algoritma Naive Bayes didukung oleh ilmu
probabilistik khususnya dalam penggunaan data petunjuk untuk
mendukung keputusan pengklasifikasian. Dengan menghitung akurasi
algoritma yang digunakan diperoleh 54 % akurasi sistem, dan error rate
sebesar 46 %. Dengan akurasi tersebut dikarenakan data yang kurang
banyak, sehingga tidak diperoleh akurasi yang sangat tinggi.
1.2SARAN
Untuk pengembangan penelitian selanjutnya penulis menyarankansuatu
hal yaitu pengembangan dengandata yang lebih banyak lebih dari seribu data agar
akurasi dan penggunaan metode dapat tercapai dengan baik. Selain itu, dapat pula
dengan penggunaan metode lain dan membandingkan metode mana yang paling
77 Hanna Amalia N, 2015
Metode yang peneliti terapkan dalam tugas akhir ini merupakan salah satu
upaya untuk mengetahui produk mana yang dijadikan pilihan dalam
pembeliannya pada sebuah produk makanan, yaitu Brownies Amanda.
Namun tidak menutup kemungkinan bahwa ada metode klasifikasi lain
seperti Apriori,Decision Tree dan lain sebagainya, yang lebih baik atau terdapat
pengembangan dan perbaikan terhadap metode yang sudah ada.
Semoga apa yang sudah di peneliti jelaskan dalam penelitian ini dapat
menginspirasi pihak yang lain untuk mengembangkan atau memecahkan suatu