19
PERUMUS AN PEN ELITIAN 3.1 Blok Diagram
Gambar 3.1 Blok Diagram secara Umum
Secara umum tujuan penelitian ini akan mencari dictionary yang akan menghasilkan sinyal rekonstruksi lebih baik daripada hasil rekonstruksi menggunakan basis seperti Discrete Fourier Transform (DCT) dan Haar yang umum digunakan. Penelitian ini juga memberi sedikit fokus pada pencarian metode penggunaan yang efektif, karena terdapat banyak metode dalam sparse
coding menggunakan dictionary dan masing-masing menghasilkan rekonstruksi
yang berbeda-beda.
Penelitian akan dilakukan dengan cara memasukan sinyal yang berupa citra abu-abu untuk kemudian dilakukan sparse coding menggunakan dictionary yang
Signal Sparse Coding Reconstruction Dictionary Reconstructed Signal Assessment
dibangun dari basis-basis umum yang orthonormal. Hasil outputnya adalah sebuah sinyal atau citra rekonstruksi yang diharapkan memiliki kualitas mendekati citra asli. Untuk mengetahui kualitas citra rekonstruksi, pada penelitian akan dilihat nilai Peak Signal to Noise Ratio atau PSNRnya.
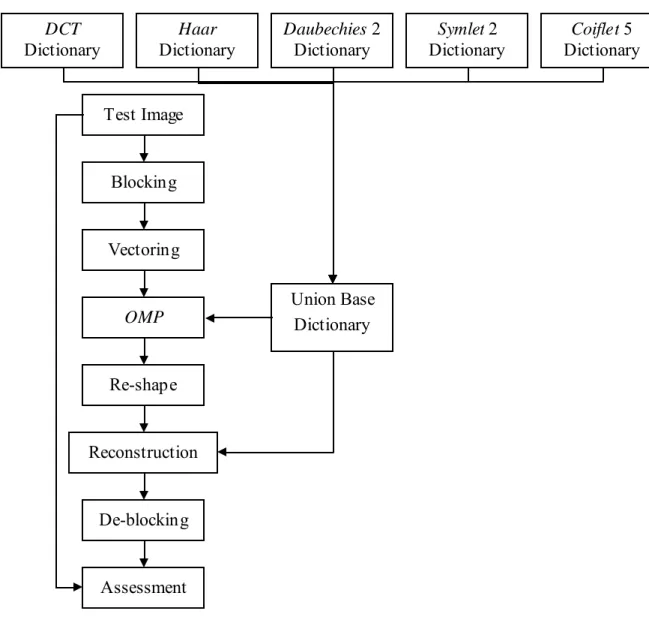
Gambar 3.2 Blok Diagram Test Image Blocking Vectoring Reconstruction De-blocking Assessment Haar Dictionary Daubechies 2 Dictionary Union Base Dictionary Symlet 2 Dictionary OMP Re-shape DCT Dictionary Coiflet 5 Dictionary
Untuk lebih rincinya, pertama-tama test image diinput. Test image yang digunakan ada 5 buah yaitu lena_g.jpg, baboon_g.jpg, barbara.jpg, peppers_g.jpg dan cameraman.jpg.
(a) (b) (c)
(d) (e)
Gambar 3.3 Test image yang digunakan yaitu (a)lena_g.jpg, (b)baboon_g.jpg, (c)barbara.jpg, (d)peppers_g.jpg dan (e)cameraman.jpg
Kemudian selanjutnya dilakukan proses blocking. Pada penelitian ini, pengolahan citra tidak langsung secara utuh melainkan dipecah-pecah dahulu,
inilah yang disebut proses blocking. Misal diinput sebuah citra lena_g.jpg dengan ukuran 512 x 512 pixel dan dilakukan blocking 256 x 256 pixel :
Gambar 3.4 Ilustrasi Blocking
M aka akan gambar 512 x 512 pixel tersebut akan terbagi menjadi 4 buah blok image 256 x 256 pixel. Blok tersebut yang nanti akan diolah dalam sparse
coding. Data citra dibuat menjadi blok yang lebih kecil untuk mempercepat proses
komputasi sparse coding. Dalam penelitian ini, ukuran blocking yang digunakan adalah 8 x 8 pixel karena setelah percobaan dengan beberapa macam ukuran
blocking yakni 2 x 2 pixel, 4 x 4 pixel, 8 x 8 pixel, 16 x 16 pixel, 32 x 32 pixel,
diperoleh data ukuran 8 x 8 pixel memiliki waktu yang paling cepat ketika dilakukan sparse coding. Untuk blocking dengan ukuran 32 x 32 pixel (untuk sebagian test image) dan ukuran lebih dari 32 x 32 pixel, tidak dapat dilakukan percobaan menghitung waktu karena keterbatasan hardware.
Setelah itu dilakukan proses vectoring untuk tiap bloknya, yaitu proses untuk mengubah data dari 2 dimensi menjadi 1 dimensi. Perubahan dimensi data ini
untuk memudahkan pengolahannya dalam sparse coding. Proses pengubahannya dilakukan dengan menginput data daripada blok citra kedalam koefisien yang akan mengambil nilai tiap kolomnya dan menderetkannya menjadi 1 kolom panjang. Contoh :
M isal ada sebuah matriks
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ 9 8 7 6 5 4 3 2 1 sebagai input.
M aka setelah proses vectoring, akan menjadi
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 9 6 3 8 5 2 7 4 1
Lalu berikutnya, proses dalam memperoleh overcomplete dictionary yang diinginkan, pertama akan dibuat basis-basis yang diperlukan. Basis yang digunakan dalam penelitian ini adalah DCT dan Wavelet. Pemilihan 2 macam basis tersebut karena sudah umum digunakan serta memiliki sifat orthonormal. M emiliki sifat orthonormal berarti basis tersebut mempunyai inverse yang sama dengan transposenya, serta tiap-tiap atom dalam basis tersebut unik. Sifat ini diperlukan pada basis yang akan digunakan dalam penelitian karena akan memudahkan proses perhitungan dalam sparse coding.
Wavelet memiliki macam-macam tipe, dan tidak semua tipe Wavelet
memiliki sifat orthonormal Beberapa tipe Wavelet yang memiliki sifat orthonormal dan dipakai dalam penelitian adalah Haar, Daubechies, Coiflet dan Symlet. Untuk
masing-masing tipe Wavelet yang ada (Haar, Daubechies, Coiflet dan Symlet), terbagi lagi menjadi orde-orde. Dalam penelitian ditentukan orde yang digunakan adalah orde 2 untuk Daubechies, orde 5 untuk Coiflet dan orde 5 untuk Symlet. Pemilihan orde dan tipe Wavelet ini tidak berdasarkan alasan khusus, penulis memilih tipe Wavelet yang orthonormal dan umum dipakai secara arbitrary.
Untuk membuat basis DCT, dapat diperoleh dari persamaan (2.3) akan tetapi dalam program digunakan fungsi transformasi DCT di M ATLAB. Fungsi transformasi DCT secara umum adalah :
Dictionary · Koefisien = Sinyal
( Untuk memudahkan selanjutnya Basis disebut sebagai D, koefisien disebut sebagai X dan Sinyal disebut sebagai Y. )
D · X = Y (3.1)
Tetapi fungsi transformasi DCT yang ada dalam MATLAB akan memperoleh koefisiennya sebagai hasil dan sinyal sebagai input, maka persamaannya adalah sebagai berikut:
Jadi untuk memperoleh basis DCT, dapat diinput sebuah matriks identitas sebagai sinyal ke dalam persamaan (3.2).
X = DI · I Æ X = DI (3.3)
Suatu matriks yang dikali dengan matriks identitas sama dengan matriks itu sendiri, maka setelah diinput matriks identitas sebagai sinyal di persamaan (3.2), akan diperoleh hasil koefisien adalah inverse basis DCT (3.3). Dan terakhir untuk diperoleh basis DCT akan dilakukan inverse pada inverse basis DCT. Akan tetapi karena basis DCT adalah dictionary yang orthonormal, maka hasil inversenya akan sama dengan hasil transposenya. Jadi setelah diperoleh inverse basis DCT dari persamaan (3.3), untuk mendapatkan basis DCT cukup dilakukan transpose. Berikut adalah contoh matriks basis DCT ukuran 8x8 yang diperoleh:
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − − − − − − − − − − − − − − − − − − − − − 0975 . 0 2778 . 0 4157 . 0 4904 . 0 4904 . 0 4157 . 0 2778 . 0 0975 . 0 1913 . 0 4619 . 0 4619 . 0 1913 . 0 1913 . 0 4619 . 0 4619 . 0 1913 . 0 2778 . 0 4904 . 0 0975 . 0 4157 . 0 4157 . 0 0975 . 0 4904 . 0 2778 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 4157 . 0 0975 . 0 4904 . 0 2778 . 0 2778 . 0 4904 . 0 0975 . 0 4157 . 0 4619 . 0 1913 . 0 1913 . 0 4619 . 0 4619 . 0 1913 . 0 1913 . 0 4619 . 0 4904 . 0 4157 . 0 2778 . 0 0975 . 0 0975 . 0 2778 . 0 4157 . 0 4904 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0 3536 . 0
Lalu untuk memperoleh basis macam-macam Wavelet, Wavelet menggunakan persamaan fungsi (lihat persamaan (2.6)) dalam transformasinya, tetapi dalam prakteknya digunakan high pass dan low pass filter (lihat gambar 2.2). Ini karena proses komputasi menghitung persamaan Wavelet sangat
membutuhkan waktu, sehingga untuk mengurangi waktu komputasi digunakan gabungan high pass dan low pass filter yang hasilnya ekuivalen dengan persamaan fungsinya.
Fungsi standar M ATLAB hanya tersedia fungsi untuk menghasilkan nilai
low pass dan high pass filter suatu tipe Wavelet. Sehingga untuk mencari
koefisiennya digunakan fungsi tambahan inverse Wavelet transform yang diperoleh dari toolbox UVi_wave version 3.0. Ke dalam fungsi tersebut dimasukkan input sinyal dan high pass serta low pass filternya. Karena hasil yang diperoleh sama seperti fungsi DCT di MATLAB yakni koefisiennya (lihat persamaan (3.2)) maka untuk memperoleh Basisnya, dimasukkan matriks identitas sebagai sinyal input (persamaan (3.3)). Terakhir, sama seperti pada memperoleh basis DCT, basis yang diperoleh adalah inversenya, karena itu perlu dilakukan
inverse terhadap inverse basis tersebut. Karena tipe Wavelet yang dipilih juga
bersifat orthonormal seperti DCT maka untuk memperoleh inversenya cukup dilakukan transpose. Langkah-langkah tersebut dilakukan serupa untuk tiap tipe dan orde Wavelet yang diinginkan, cukup mengubah parameter tipe Wavelet pada saat menghasilkan nilai low pass dan high pass filter, jika ingin dihasilkan Haar
Wavelet maka input parameternya adalah ‘Haar’, untuk menghasilkan Daubechies-2 digunakan ‘db2’, untuk menghasilkan Coiflet-5 digunakan ‘coif5’
dan untuk menghasilkan Symlet-5 digunakan ‘sym5’.
Setelah tersedia basis yang diperlukan, selanjutnya basis tersebut akan digabungkan secara berderet dalam sebuah matriks. Urutan penderetan tidak mempengaruhi hasil akhir dalam sparse coding.
Contoh, diperoleh basis DCT adalah matriks sebagai berikut : ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ DCT DCT DCT DCT DCT DCT DCT DCT DCT
atau disederhanakan menjadi
[
DCT]
Dan basis Wavelet Haar yang diperoleh sebagai berikut :
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ 1 1 1 1 1 1 1 1 1 DB DB DB DB DB DB DB DB DB
atau disederhanakan menjadi
[
Haar]
M aka ketika dilakukan penderetan akan menjadi sebagai berikut :
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ 1 1 1 1 1 1 1 1 1 DB DB DB DCT DCT DCT DB DB DB DCT DCT DCT DB DB DB DCT DCT DCT
atau disederhanakan menjadi
[
DCT Haar]
Dan seterusnya bila ditambah basis lain atau bahkan basis yang sama :
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ 5 5 5 · · · 1 2 1 5 5 5 · · · 1 1 1 5 5 5 · · · 1 1 1 SYM SYM SYM DB DB DB DCT DCT DCT SYM SYM SYM DB DB DB DCT DCT DCT SYM SYM SYM DB DB DB DCT DCT DCT
[
D1 D2 D3 · · · Dn]
Penderetan ini akan menghasilkan bentuk matriks yang berubah dari bujur sangkar menjadi sebuah persegi panjang, perbedaan jumlah kolom dan baris dan matriks menyebabkan dictionary ini disebut sebagai overcomplete dictionary, karena mempunyai penyelesaian yang lebih dari 1. Hal ini dapat dimisalkan, sebuah kasus dimiliki 3 buah persamaan dengan 3 buah koefisien :
(i) X+ Y =1 (ii) 2X+ Z = (iii) 3Y + Z =
M aka penyelesaian pasti hanya 1 buah yaitu X =0, 1Y = , dan Z =2, tidak
mungkin dengan nilai lain. Akan tetapi ketika kasus lain dimiliki 3 buah koefisien tetapi dengan 5 buah persamaan :
(i) X+ Y =1 (ii) 2X+ Z = (iii) 3Y + Z = (iv) 13X −Y = (v) 4X + Z =5
Penyelesaiannya tidak dapat ditemukan, karena penyelesaiannya bisa lebih dari 1, seperti X = 0, 1Y = dan 2Z = untuk persamaan (i), (ii) dan (iii); X =1,
2 =
Y , 1Z = untuk persamaan (ii), (iii), (iv) dan (v); dan seterusnya tanpa ada
penyelesaian yang pasti.
Dapat diandaikan jumlah persamaan adalah dictionary dan jumlah koefisien adalah sinyal input serta penyelesaian adalah koefisien. M aka kasus pertama yang memiliki 1 penyelesaian dapat dianalogikan sebagai complete
dictionary, contohnya seperti basis DCT yang akan selalu menghasilkan nilai
koefisien yang sama setiap kali dilakukan transformasi.
Untuk kasus yang memiliki banyak penyelesaian dapat dianalogikan dengan
overcomplete dictionary. Dengan panjang dictionary yang lebih banyak daripada
sinyal input maka akan diperoleh pilihan koefisien yang lebih banyak. Dalam
sparse coding nanti akan dibuat algoritma dalam memilih koefisien yang hasil
rekonstruksinya paling mendekati test image, atau dalam kasus di atas, memiliki penyelesaian paling mendekati semua persamaan. Dalam sparse coding nilai koefisien yang dihasilkan bergantung pada jumlah pengulangan dalam proses
OMP.
Kemudian dengan tersedianya dictionary yang diinginkan, dilakukan pencarian koefisien dari dictionary gabungan tersebut dengan metode Orthogonal
Matching Pursuit (OMP). Pertama-tama akan dicari nilai dot product antara tiap atom dictionary dengan residu. Residu adalah perbedaan nilai antara data asli
dengan data rekonstruksi. Image secara digital pada dasarnya adalah data berbentuk matriks berukuran sesuai dengan jumlah pikselnya, maka proses pengurangan data dilakukan layaknya pengurangan antar matriks. Nilai awal residu yang digunakan adalah data blok yang sedang dilakukan proses sparse
coding.
Setelah dihitung semua nilai dot productnya, pilih yang memiliki nilai terbesar, lalu menyimpan nilai index dari atom yang menghasilkan nilai dot
product tesebut. Nilai index tersebut yang akan dipakai untuk memilih index dari
koefisien sementara yang diperoleh dari perkalian inverse overcomplete dictionar y dengan data blok yang sedang diproses.
Koefisien memang mudah dicari menggunakan cara seperti itu, tetapi aproksimasi koefisien ini tidak dilakukan seperti pada koefisien complete
dictionary. Karena pada overcomplete dictionary walaupun tiap basisnya memiliki
sifat orthonormal, atom-atom antar basis yang berbeda tidak orthonormal, ada kemungkinan terjadinya pengulangan. Sehingga aproksimasi non linear biasa tidak bisa menjadi solusi. Untuk itu digunakan dot product untuk memperoleh kombinasi atom-atom antar basis yang unik
Koefisien yang diperoleh kemudian akan ditransform kembali menggunakan
overcomplete dictionary yang ada menjadi blok image rekonstruksi. Residu lalu
diupdate dengan mengurangkan nilai blok asli dengan nilai blok rekonstruksi. Residu akan berpengaruh pada pemilihan index, karena index yang sudah terpilih secara tidak langsung tereliminasi.
Selanjutnya proses dilakukan berulang sesuai dengan jumlah aproksimasi koefisien yang ditentukan yaitu 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%,55%, 60%, 65%, 70%, 75%, 80%, 85%, 90% atau 95% daripada jumlah koefisien yang seharusnya ada.
Gambar 3.5 Ilustrasi Rekonstruksi; D adalah Dictionary, x adalah Aproksimasi Koefisien dan y adalah Sinyal Rekonstruksi
Dilihat pada gambar 3.5, contoh ilustrasi cara kerja proses yang terjadi dalam OM P secara sederhana adalah, misal dictionary overcomplete yang diperoleh: ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1
Sinyal yang diinput adalah :
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20
Selanjutnya akan dicari atom dictionary yang paling tinggi keterkaitannya dengan sinyal. Ini dilakukan dengan mencari nilai dot product terbesar antara residu dan atom-atom dictionary. Karena residu adalah beda antara sinyal asli
dengan sinyal rekonstruksi, dan sinyal rekonstruksi belum diperoleh pada langkah paling awal maka residu pertama adalah sinyal asli.
Contoh perhitungan atom pertama dictionary dengan residu awal :
[
1 1 1 1]
· ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 = 140 Perhitungan berikutnya :[
2 2 2 2]
· ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 = 280Dan dihitung seterusnya hingga atom terakhir.
Dilihat dari contoh matriks yang ada, misalkan setelah selesai dicari nilai-nilai dot product tiap atom ternyata pada atom ke-5 merupakan nilai-nilai tertinggi, maka atom tersebut adalah atom terpilih yang akan digunakan untuk mencari koefisien.
Caranya adalah, atom tersebut akan dipisahkan dari dictionary yang ada kemudian diinverse, dan hasilnya dikalikan dengan sinyal asli. Contoh :
M isal hasil inverse atom ke 5 adalah ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − 5 5 5 5
[
−5 −5 −5 −5]
· ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 = − 700Nilai tersebut kemudian akan dimasukkan ke dalam matriks koefisien disesuaikan dengan index atom dictionary yang digunakan, dalam contoh sebelumnya, indexnya adalah 5. Dapat dilihat pada gambar 3.5, matriks koefisien ukurannya sesuai dengan jumlah atom dictionary maka :
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − 0 0 0 0 0 0 0 700 0 0 0 0
Koefisien yang diperoleh lalu direkonstruksi menggunakan overcomplete dictionary yang ada, hasil rekonstruksi digunakan untuk mencari residu baru.
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 · ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − 0 0 0 0 0 0 0 700 0 0 0 0 = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − 3500 3500 3500 3500
Residu baru : ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − 3500 3500 3500 3500 = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 3550 3540 3530 3520
Lalu kemudian proses diulang ke mencari dot product terbesar selanjutnya. Yakni antara residu baru dengan tiap atom dictionary. M isalkan pada proses berikutnya ditemukan bahwa atom ke-3 dictionary memiliki nilai dot product terbesar. M aka atom ini akan digabungkan dengan atom terpilih sebelumnya, dalam contoh sebelumnya adalah atom ke-5. M aka matriks yang terbentuk adalah :
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 3 5 3 5 3 5 3 5
Langkah selanjutnya diinverse kemudian dikalikan dengan sinyal asli untuk diperoleh koefisien.
M isal inverse matriks atom pilihan adalah
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − 3 5 3 5 3 5 3 5
M aka koefisien yang diperoleh adalah :
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − − − − − − − − 3 3 3 3 5 5 5 5 · ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − − 520 700
Sama seperti sebelumnya, nilai tersebut kemudian akan dimasukkan ke dalam matriks koefisien pada index yang sesuai dengan index dimana atom dictionary tersebut ditemukan, dalam contoh kali ini indexnya adalah 5 dan 3.
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − 0 0 0 0 0 0 0 700 0 520 0 0
Proses selanjutnya adalah mencari residu baru dengan cara merekonstruksi koefisien yang ditemukan dengan dictionary dan dicari selisih nilai akhirnya dengan sinyal asli.
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 12 11 10 9 8 7 6 5 4 3 2 1 · ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − 0 0 0 0 0 0 0 700 0 520 0 0 = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − 5060 5060 5060 5060
Residu baru : ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 50 40 30 20 − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − 5060 5060 5060 5060 = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 5110 5100 5090 5080
Dan seterusnya proses berulang hingga jumlah koefisien yang ditemukan sesuai dengan aproksimasi yang diinginkan. Contoh jika aproksimasi yang ditentukan adalah 25% maka perulangan akan dilakukan hingga jumlah koefisien yang memiliki nilai berjumlah, 25% × 12 = 3, tiga buah. Dalam contoh di atas, perulangan cukup dilakukan 1 kali lagi. Bila aproksimasi yang ditentukan adalah 30% maka jumlah koefisien yang diperlukan adalah 30% × 12 = 3.6, ketika angka yang diperoleh tidak bulat maka perlu dilakukan pembulatan ke atas, sehingga jumlah koefisien yang diperlukan menjadi 4.
Setelah blok image rekonstruksi yang terakhir diperoleh, dilakukan
reshaping yaitu kebalikan daripada vectoring, mengubah data dari 1 dimens i
menjadi 2 dimensi. Dan terakhir dilakukan deblocking yang merupakan kebalikan proses blocking, menggabungkan potongan-potongan kecil tersebut ke kembali ke dimensi awal. Image rekonstruksi hasil dictionary baru tersebut nanti akan dibandingkan dengan test image awal secara objektif, yakni dilihat nilai PSNR-nya.
3.2 Diagram Alir 3.2.1 Umum Overcomplete
Gambar 3.6 Diagram Alir Umum Start Generate DCT Matrix Generate Daubechies-2 Matrix Generate Coiflet-5 Matrix Generate Symlet-2 Matrix Dictionary Unification M enghitung PSNR A A Generate Haar Matrix
Melakukan proses Blocking pada image input
Melakukan proses OMP pada block-block image
Proses De-blocking Inisialisasi Input Image Display Image Display Image End
Proses yang dilakukan oleh program penelitian ini pertama-tama adalah dilakukan inisialisasi jumlah dimensi blocking yang digunakan dan jumlah aproksimasi non-zero, lalu menginput citra yang akan dilakukan sparse coding menggunakan syntax imread ke dalam variabel I. Citra-citra yang akan diinput dapat dilihat pada gambar 3.3. Contoh, misal akan diinput citra cameraman.jpg maka dibuatkan syntax
I = imread(cameraman.jpg);
Selain menginput citra yang akan dipakai, diinput juga ukuran citra yang digunakan ke dalam variabel v_size dan h_size. Variabel v_size untuk ukuran citra secara vertikal dan h_size untuk ukuran citra secara horizontal. Ukuran ini nanti akan dipakai dalam proses blocking dan deblocking. Citra lalu dimunculkan menggunakan imshow untuk perbandingan visual dengan citra rekonstruksi pada akhir proses.
Selanjutnya dibuat basis-basis yang akan digabungkan sebagai
overcomplete dictionary. Basis tersebut antara lain adalah DCT, Haar, Daubechies, Coiflet dan Symlet. Basis tersebut diperoleh dari hasil transformas i
dengan matriks indentitas seperti pada persamaan (3.3) yang kemudian dilakukan
inverse. M asing-masing basis tersebut akan ditampung dalam variabel D1, D2,
D3, D4 dan D5. Dapat dilihat pada source code, syntax yang digunakan untuk
DCT adalah sebagai berikut : D1=dct(eye(b*b))';
Syntax dct merupakan fungsi bawaan daripada M ATLAB, yang akan
menghasilkan koefisien DCT dari sinyal yang diinput, dct(sinyal_input). Sinyal yang diinput ke dalam fungsi DCT tersebut adalah eye(b*b). Eye merupakan
fungsi M ATLAB yang akan menghasilkan matriks identitas berukuran input × input ( eye(input) ) , dalam baris program kali ini akan dibuat matriks identitas sebesar dimensi bloking kuadrat. Terakhir hasil DCT tersebut akan ditranspose untuk diperoleh inversenya.
Lalu untuk syntax wavelet adalah sebagai berikut :
c=log2(b*b); Haar [L,H]=wfilters('Haar','R'); D2=iwt(eye(b*b),L,H,c)'; Daubechies-2 [L,H]=wfilters('db2','R'); D3=iwt(eye(b*b),L,H,c)'; Coiflet-5 [L,H]=wfilters('coif5','R'); D4=iwt(eye(b*b),L,H,c)'; Symlet-2 [L,H]=wfilters('sym2','R'); D5=iwt(eye(b*b),L,H,c)';
Dapat dilihat syntax yang digunakan untuk membangun basis tipe-tipe
wavelet mempunyai kemiripan, yang membedakan adalah parameter yang
digunakan pada waktu mencari koefisien high pass dan low pass filternya.
Langkah pertama dalam mencari basis wavelet adalah mencari dahulu koefisien high pass dan low pass filternya yang ekuivalen dengan persamaannya. Ini dilakukan dengan syntax wfilter yang akan ditampung nilainya ke dalam variabel L dan H. Syntax wfilter akan menghasilkan koefisien sesuai dengan tipe wavelet yang diinginkan, untuk Haar digunakan ‘haar’, untuk Daubechies-2 digunakan ‘db2’, untuk Coiflet-5 digunakan ‘coif5’ dan untuk Symlet-2 digunakan ‘sym2’. Parameter lain yang diperlukan adalah ‘R’ karena yang diperlukan adalah koefisien rekonstruksi.
Langkah berikutnya adalah menggunakan fungsi tambahan iwt dari Toolbox
UVi_wave version 3.0. Syntax iwt ini berfungsi sama seperti syntax dct yakni
memperoleh koefisien dari sinyal asli. Akan tetapi parameter yang perlu dimasukkan adalah sinyal input, koefisien low pass dan high pass serta level DWT. Pada penelitian digunakan level DWT maksimum. Sinyal input yang dimasukkan adalah matriks identitas, sama seperti pada dct. Dan terakhir dilakukan transpose untuk diperoleh inversenya.
Basis yang sudah diperoleh kemudian digabungkan untuk menjadi sebuah dictionary dengan cara dideretkan. Hasil penderetan basis tersebut akan ditampung dalam variabel D, syntaxnya adalah D = [ D1 D2 D3 D4 D5 ]. Setelah sudah diperoleh dictionary yang diinginkan, dilakukan juga penghitungan ukuran dimensi dictionary yang dimasukkan ke dalam variabel vd dan hd. Variabel vd
untuk ukuran jumlah baris dictionary dan hd untuk ukuran jumlah kolom
dictionary. Variabel tersebut akan digunakan dalam proses OMP.
Selanjutnya dilakukan proses blocking. Proses blocking menggunakan fungsi yang terpisah dari program utama, lebih lengkapnya dapat dilihat pada subbab 3.2.2 Blocking. Proses lalu masuk ke dalam pengulangan sesuai dengan jumlah blok dalam baris dan kolom.
M asing-masing blok tersebut pertama akan dilakukan proses vectoring untuk mengubah data blok tersebut dari 2 dimensi menjadi 1 dimensi. Kemudian dilakukan proses sparse coding dengan algoritma Orthogonal Matching Pursuit (OMP), lihat subbab 3.2.4 Orthogonal Matching Pursuit (OMP) untuk lebih lengkap.
Blok-blok yang sudah diproses kemudian akan dilakukan proses
de-blocking, lihat subbab 3.2.3 De-de-blocking, menjadi sebuah citra rekonstruksi. Citra
rekonstruksi ini lalu dimunculkan dengan imshow seperti pada citra input di baris-baris awal program.
Terakhir dilakukan penghitungan Peak Signal to Noise Ratio atau PSNR antara citra awal dengan citra rekonstruksi. Hasil PSNR lalu ditunjukkan dalam layar.
Jadi program pada akhirnya akan menghasilkan 3 buah output, yakni citra awal, citra rekonstruksi dan nilai PSNR antara keduanya.
3.2.2. Blocking
J, K : indeks blok
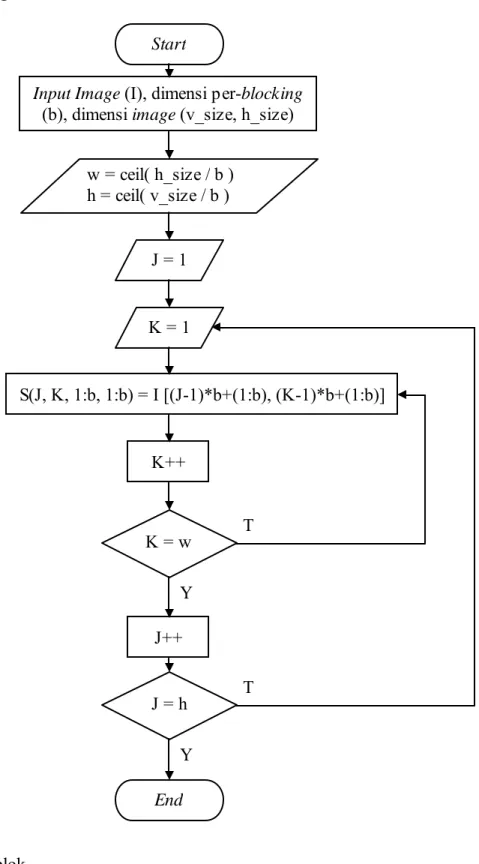
Gambar 3.7 Diagram Alir Blocking
Start
Input Image (I), dimensi per-blocking
(b), dimensi image (v_size, h_size)
w = ceil( h_size / b ) h = ceil( v_size / b ) J = 1 K = 1 S(J, K, 1:b, 1:b) = I [(J-1)*b+(1:b), (K-1)*b+(1:b)] J = h K = w J++ K++ End Y T Y T
Proses blocking dalam program dibuat dalam fungsi secara compact. Pemanggilan fungsi terdapat beberapa parameter yang harus dimasukkan yakni input image, dimensi blocking yang diinginkan, dimensi image asli. Lalu fungs i akan mencari jumlah blok yang akan dibuat berdasarkan dimensi blok yang diinginkan dan dimensi image asli. Bila image asli berukuran 512 x 512 pixel dan ingin dibuat blocking 256 x 256 pixel maka akan didapat nilai w = 512 ÷ 256 = 2 dan nilai h = 512 ÷ 256 = 2. w adalah jumlah baris dan h adalah jumlah kolom. karena itu nanti akan dibuatkan pembagian sebesar 2 baris dan 2 kolom yang berarti ada 4 blok.
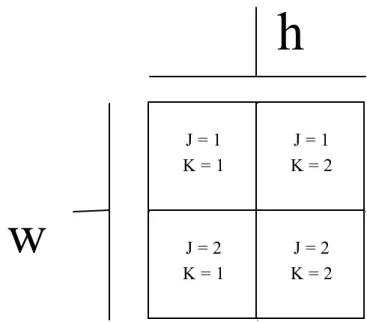
Gambar 3.8 Ilustrasi w dan h serta J dan K
Setelah itu proses masuk ke dalam perulangan sesuai dengan jumlah kolom dan baris. Dalam tiap perulangan terdapat proses yang sama yakni menghasilkan output S(J, K, 1:b, 1:b). Parameter J, K bertindak sebagai inde x blok, misal blok pada baris dan kolom pertama maka akan memiliki index 1, 1 (J = 1 dan K = 1), lalu 2 parameter terakhir adalah index matriks data yang akan
w
h
J = 1 K = 1 J = 1 K = 2 J = 2 K = 1 J = 2 K = 2dimasukkan. Data yang dimasukkan adalah I [(J-1)*b+(1:b), (K-1)*b+(1:b)]. I adalah data dari image asli, diberi beberapa koefisien tambahan pada inde x matriksnya sehingga bisa dilakukan perulangan, sehingga nanti pada saat pengisian data akan terjadi peristiwa sebagai berikut :
M isal I asli berukuran 8 x 8 :
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Dilakukan proses blocking 4 x 4, karena itu nilai w = 8÷4 = 2 dan h = 8 ÷4 = 2 sehingga nanti I akan terbagi menjadi 4 buah blok kecil. Pada tiap bloknya, pada saat penginputan data, pertama-tama J = 1 dan K = 1, S(1, 1, 1:4, 1:4) = I((1-1)×4 + (1:4), (1-1) ×4 + (1:4)). Jadi untuk S(1, 1, 1:4, 1:4) akan diinput data I (1:4, 1:4). I(1:4, 1:4) berarti diambil data I(1, 1) sampai I(4, 4), angka parameter tersebut adalah index dalam matriks, I(1, 1) berarti nilai pada matriks I di baris 1 dan kolom 1. Begitu pula untuk S.
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 28 27 26 25 20 19 18 17 12 11 10 9 4 3 2 1
Selanjutnya J = 1 dan K = 2 maka S (1, 2, 1:4, 1:4) = I((1-1) ×4 + (1:4), (2-1) ×4 + (1:4)) Æ S (1, 2, 1:4, 1:4) = I (1:4, 5:8). ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 32 31 30 29 24 23 22 21 16 15 14 13 8 7 6 5
Untuk J = 2 dan K = 1 maka S (1, 2, 1:4, 1:4) = I((2-1) ×4 + (1:4), (1-1) ×4 + (1:4)) Æ S (2, 1, 1:4, 1:4) = I (5:8, 1:4). ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 60 59 58 57 52 51 50 49 44 43 42 41 36 35 34 33
Untuk J = 2 dan K = 2 maka S (2, 2, 1:4, 1:4) = I((2-1) ×4 + (1:4), (2-1) ×4 + (1:4)) Æ S (2, 2, 1:4, 1:4) = I (5:8, 5:8). ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 56 55 54 53 48 47 46 45 40 39 38 37
Jadi : ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 56 55 54 53 48 47 46 45 40 39 38 37 60 59 58 57 52 51 50 49 44 43 42 41 36 35 34 33 32 31 30 29 24 23 22 21 16 15 14 13 8 7 6 5 28 27 26 25 20 19 18 17 12 11 10 9 4 3 2 1
[ ]
I
⎥
⎦
⎤
⎢
⎣
⎡
)
2
,
2
(
)
1
,
2
(
)
2
,
1
(
)
1
,
1
(
S
S
S
S
3.2.3 De-Blocking
J, K : indeks blok
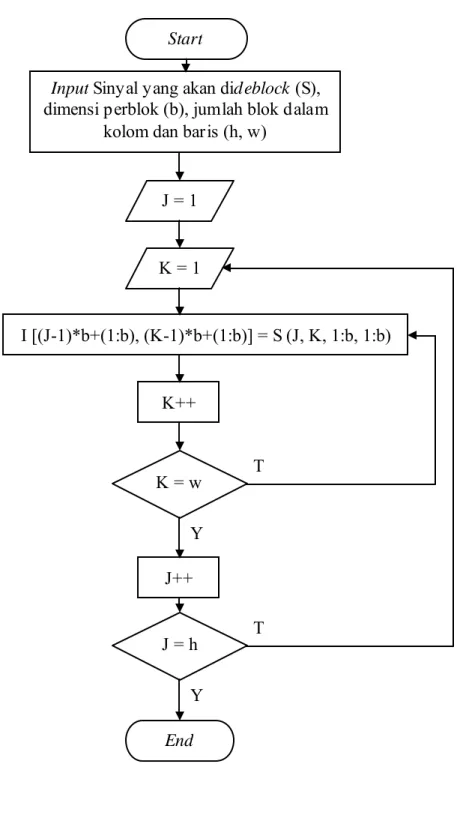
Gambar 3.9 Diagram Alir De-blocking
Start
Input Sinyal yang akan dideblock (S),
dimensi perblok (b), jumlah blok dalam kolom dan baris (h, w)
J = 1 K = 1 I [(J-1)*b+(1:b), (K-1)*b+(1:b)] = S (J, K, 1:b, 1:b) J = h K = w J++ K++ End Y Y T T
Proses deblocking pada program ini pada dasarnya adalah pembalikan dari proses blocking, yakni blok-blok kecil yang ada digabungkan kembali berdasarkan indexnya (J dan K) menjadi ukuran awal image.
Proses de-blocking ini, sama seperti blocking, dibuat menjadi sebuah fungsi. Dalam menggunakan fungsi ini perlu dimasukkan beberapa parameter sebagai berikut yaitu, blok-blok yang akan di deblocking (S), ukuran blockingnya (b), dan jumlah blocking per kolom dan baris (w dan h). Jumlah blocking ini akan digunakan sebagai jumlah perulangan sesuai index blok-blok. Jadi bila nilai w = 2 dan h = 2 maka akan dilakukan perulangan sebanyak 2 kali untuk kolom sesuai nilai w dan perulangan sebanyak 2 kali untuk baris sesuai nilai h (lihat gambar 3.7).
Setelah diinput parameter yang diperlukan, program lalu akan masuk ke dalam proses perulangan baris dan setiap perulangan baris terdapat perulangan kolom. Dalam perulangan kolom terjadi proses sebagai berikut, I [(J-1)*b+(1:b), (K-1)*b+(1:b)] = S (J, K, 1:b, 1:b).
Proses yang terjadi kurang lebih sama dengan proses blocking, hanya saja terjadi kebalikannya. M isal menyesuaikan dengan contoh kasus pada proses blocking, blok-blok hasil blocking sebagai berikut :
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 28 27 26 25 20 19 18 17 12 11 10 9 4 3 2 1 ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 32 31 30 29 24 23 22 21 16 15 14 13 8 7 6 5 ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 60 59 58 57 52 51 50 49 44 43 42 41 36 35 34 33 ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 56 55 54 53 48 47 46 45 40 39 38 37
Dengan indeks, sesuai urutan, sebagai berikut J = 1 dan K = 1, J = 1 dan K = 2, J = 2 dan K = 1, J = 2 dan K = 2. Akan dilakukan proses deblocking menjadi image asli I.
M aka sewaktu perulangan memiliki nilai J = 1 dan K = 1, dimasukkan nilai S (1, 1, 1:4, 1:4) ke dalam I (1:4, 1:4). ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − 28 27 26 25 20 19 18 17 12 11 10 9 4 3 2 1
(menyesuaikan dengan index pada gambar 3.7)
Selanjutnya pada waktu nilai J = 1 dan K = 2 maka dimasukkan nilai S (1, 2, 1:4, 1:4) ke dalam I (1:4, 5:8). ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Ketika nilai J = 2 dan K = 1 maka dimasukkan nilai S (2, 1, 1:4, 1:4) ke dalam I (5:8, 1:4). ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − − − − − − − − − 60 59 58 57 52 51 50 49 44 43 42 41 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Terakhir ketika J = 2 dan K = 2 maka dimasukkan nilai S (2, 2, 1:4, 1:4) ke dalam I (5:8, 5:8). ⎥ ⎥⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Jadi : ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 56 55 54 53 48 47 46 45 40 39 38 37 60 59 58 57 52 51 50 49 44 43 42 41 36 35 34 33 32 31 30 29 24 23 22 21 16 15 14 13 8 7 6 5 28 27 26 25 20 19 18 17 12 11 10 9 4 3 2 1 = ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ 64 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
⎥
⎦
⎤
⎢
⎣
⎡
)
2
,
2
(
)
1
,
2
(
)
2
,
1
(
)
1
,
1
(
S
S
S
S
[ ]
I
3.2.4 Orthogonal Matching Pursuit (OMP)
i : variable looping xk : image rekonstruksi
r : residu
Gambar 3.10 Diagram Alir Orthogonal Matching Pursuit (OMP)
Start
M embuat matriks X berdimensi [hd x 1] dengan nilai tiap elemen 0 (nol)
X = zeros(hd, 1)
M erubah matriks image menjadi 1 dimensi
r = x( : )
i = 1
M encari innerproduct antara atom-atom dictionary dan residu
temp = DT * r
A
A
M engambil nilai dan index dari
absolute hasil innerproduct terbesar, index merepresentasikan index atom
dictionary
[value, index] = max{ abs(temp) }
M encari koefisien sementara dengan DI · Sinyal
M emasukan nilai dari koefisien sementara, sesuai dengan index yang
terpilih, ke dalam koefisien akhir
M engupdate residu r = x( : ) - xk i = M M elakukan proses rekonstruksi Reshape End T Y
Proses algoritma Orthogonal Matching Pursuit (OMP) dalam program tidak dipisah seperti pada blocking dan de-blocking. Proses ini dimasukkan dalam proses perulangan yang jumlahnya disesuaikan dengan jumlah blok yang dihasilkan dari blocking. Langkah awal yang dilakukan adalah melakukan
vectoring pada data blok yang bersangkutan kemudian memasukkannya ke dalam
residu, variabel r, lalu menginisialisasi nilai koefisien awal dengan 0 pada variabel X yang berupa matriks 1 kolom dengan jumlah baris sebanyak hd.
Selanjutnya proses masuk ke dalam pengulangan sebanyak M kali. M adalah jumlah maksimal elemen non-zero disesuaikan dengan aproksimasi yang diinput pada awal program. Kemudian dalam tiap perulangan, pertama-tama diinisialisas i dengan menghapus variabel temp. Lalu dicari hasil innerproduct antara masing-masing atom dictionary dengan residu, nilainya akan dimasukkan ke dalam variabel temp. Untuk memperolehnya dilakukan dengan cara melakukan perkalian antara transpose dictionary dengan residu.
Nilai dari variabel temp kemudian diambil nilai absolut yang terbesar beserta dengan index baris dimana nilai tersebut ditemukan. Contoh jika nilai temp adalah
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − 9 8 7 6
, maka yang akan terpilih adalah 9 dengan nilai index baris 4. Nilai tersebut
akan dimasukkan ke dalam variabel value dan index.
Lalu proses membuat sebuah koefisien sementara dari dictionary. Ini dilakukan sesuai dengan persamaan 3.2. Untuk memperoleh inverse dictionary, tidak dilakukan dengan cara transpose seperti pada basis-basis. Karena walaupun
tiap basis yang digunakan dalam dictionary bersifat orthonormal, hubungan antar basis-basis yang digabungkan tidak memiliki sifat tersebut. Karena itu dalam program digunakan pseudo inverse untuk mencari inversenya dengan syntax pinv. Nilainya akan dimasukkan ke dalam variabel temp.
Setelah sudah diperoleh koefisien sementara (temp), maka proses selanjutnya akan memilih satu koefisien di index yang sesuai dengan nilai variabel index dan memasukkannya ke dalam variabel untuk koefisien akhir yaitu X pada baris sesuai variabel index.
Koefisien akhir (X) kemudian akan direkonstruksi kembali dan dimasukkan ke dalam variabel xk. Hasil rekonstruksi akan digunakan untuk mengupdate residu dengan cara mengurangkan nilai data blok yang sedang dilakukan proses OMP (x) dengan data rekonstruksi (xk). Terakhir proses akan mengulang ke proses pengulangan awal hingga jumlah elemen dalam koefisien akhir (X) sesuai dengan jumlah maksimal elemen non-zero yang diinginkan.
Setelah perulangan selesai maka akan diperoleh koefisien akhir yang jumlah non-zeronya sesuai dengan jumlah aproksimasi yang diinginkan. Koefisien akhir ini akan dilakukan rekonstruksi terakhir untuk memperoleh nilai blok rekonstruksi. Akan tetapi data blok tersebut masih berupa 1 dimensi, perlu dilakukan reshaping untuk mengubahnya kembali menjadi data 2 dimensi.
3.3 Tampilan User Interface
User interface dibuat untuk memudahkan dalam memproses data-data tanpa
perlu mengedit nilai variabel dalam baris program secara manual. Berikut adalah gambar user interface yang dibuat untuk penelitian ini :
Komponen-komponen yang terdapat pada user interface di atas adalah sebagai berikut :
1. File Input
Gambar 3.12 File Input Box
Komponen ini ketika dilakukan klik pada tombol ‘...’ akan membuka window baru untuk seleksi image secara langsung dari file-file yang ada di dalam komputer.
Agar hasil optimum, image yang diinput diharapkan grayscale dengan dimensi yang square yang berukuran 512 x 512.
Apabila tidak ada image yang diinput atau path image yang dipilih tidak sesuai sehingga file tidak ditemukan, maka ketika proses dijalankan akan terdapat pesan error sebagai berikut :
Gambar 3.14 Pesan Error 2. Blocking Size Input
Gambar 3.15 Blocking Size Selection
Komponen ini akan menentukan jumlah dimensi blocking yang akan dilakukan dalam proses, secara default terpilih 8. Pilihan yang tersedia adalah 2, 4, 8, 16, 32, 64, 128, 256 dan 512.
3. Input Aproksimasi
Gambar 3.16 Slider Aproksimasi
Komponen ini akan menentukan jumlah aproksimasi yang digunakan dalam proses. Untuk mengubahnya cukup digeser dari kiri ke kanan. Kiri untuk menurunkan jumlah aproksimasi yang diinginkan dengan minimum aproksimasi 5% dan arah kanan untuk menaikkan jumlah aproksimasi yang diinginkan dengan jumlah maksimum aproksimasi 95%.
4. Pilihan Dictionary/Basis
Gambar 3.17 Daftar Basis/Dictionary
Komponen ini berisikan pilihan basis atau dictionary yang akan digunakan dalam proses, basis yang disediakan hanya 2 yaitu DCT dan
Haar Wavelet (dengan label Wavelet). Dan untuk dictionary hanya
5. Pilihan Jumlah Basis
Gambar 3.18 Slider Basis
Komponen ini menentukan jumlah basis yang digunakan dalam proses. Komponen ini hanya aktif ketika dictionary yang digunakan adalah
Overcomplete. Bila dipilih basis DCT atau Wavelet maka komponen ini
akan didisabled.
Gambar 3.19 Slider Basis Disabled
6. Save Image Checkbox
Gambar 3.20 Save Image Checkbox
Checkbox ini apabila aktif maka setelah tombol Process diklik, image
yang direkonstruksi akan disimpan ke dalam folder /product/. Apabila belum ada folder /product/ maka akan dibuatkan secara otomatis. Bila
checkbox non-aktif maka image hasil rekonstruksi tidak disimpan.
7. Process Button
Gambar 3.21 (a) Process Button Enabled (b) Process Button Disabled
Process Button bila ditekan akan menjalankan proses yang sudah
ditentukan berdasarkan input dari komponen-komponen lain. Ketika
process button ditekan maka akan dibuat sebuah loading window yang
menyatakan proses sedang berjalan. Tombol process didisabled ketika ada loading bar.
Gambar 3.22 Loading Bar
Setelah proses selesai maka akan dimunculkan window baru yang menunjukkan image asli bersebelahan dengan image rekonstruksi. Image asli berada di kiri dan image rekonstruksi di kanan.
Pada judul window image result akan terdapat informasi dictionary yang digunakan.
Gambar 3.24 Title
Setelah proses selesai juga dikeluarkan output perhitungan ke komponen output.
8. Output
Gambar 3.25 Tampilan SNR, PSNR, Time