Dewi Eka Putri, S.Kom, M.Kom
METODE NON HIERARCHY ALGORITMA K-MEANS DALAM MENGELOMPOKKAN TINGKAT KELARISAN BARANG
(STUDI KASUS : KOPERASI KELUARGA BESAR SEMEN PADANG)
Dewi Eka Putri, S.Kom, M.Kom
Fakultas Ilmu Komputer, Universitas Putra Indonesia “YPTK” Padang e-mail: [email protected]
ABSTRAK
Pesatnya perkembangan teknologi informasi yang menjadikan semua informasi dapat di simpan dalam jaringan komputer, membuat munculnya sistem basis data yang sangat besar. Data Mining salah satunya, merupakan teknologi yang sangat berguna untuk membantu perusahaan menemukan informasi yang sangat penting dari gudang data (Data warehouse). Clustering merupakan salah metode dalam Data Mining yang bersifat tanpa arahan (unsupervised). Penggunaan algoritma K-Means adalah dapat membantu dalam mengelompokkan data, dan informasi yang ditampilkan berupa nilai centroid dari tiap-tiap cluster, untuk menentukan tingkat kelarisan barang pada Koperasi.
Kata kunci : Data Mining, algoritma K-Means, tingkat kelarisan barang, dan Koperasi.
1. PENDAHULUAN
Data Mining salah satunya, merupakan teknologi yang sangat berguna untuk membantu perusahaan menemukan informasi yang sangat penting dari gudang data (Data warehouse). Banyak pengertian mengenai Data Mining, salah satunya menurut Witten et all (2011), Data Mining adalah melakukan ekstraksi data untuk memperoleh informasi penting yang sifatnya implisit dan sebelumnya tidak di ketahui dari suatu data.
Data Mining erat kaitannya dengan data, informasi dan pengetahuan. Proses Data Mining dimulai dengan mengekstraksi data yang kemudian menghasilkan sebuah informasi. Informasi yang dihasilkan kemudian diolah untuk menghasilkan biasa berbentuk pola (pattern). Pola inilah yang kemudian diterjemahkan menjadi sebuah pengetahuan. Dan pengetahuan yang dihasilkan dapat digunakan untuk mengambil keputusan oleh pimpinan dalam sebuah perusahaan.
Clustering merupakan salah metode dalam Data Mining yang bersifat tanpa arahan (unsupervised). Ada dua metode yang digunakan dalam clustering, yaitu
metode Hierarchy dan metode Non Hierarchy. Yang termasuk kedalam metode Hierarchy adalah complete linkage clustering, single linkage clustering, average linkage clustering dan centroid linkage clustering. Sedangkan yang termasuk metode Non Hierarchy adalah K-means dan Fuzzy K-means.
Koperasi Keluarga Besar Semen Padang, yang bergerak dalam bidang penjualan barang-barang kebutuhan sehari-hari, memiliki Toserba yang menyediakan barang yang lengkap.
Sehingga Pimpinan kesulitan untuk mengetahui barang mana yang lebih di minati dan banyak di beli. Maka perlu di identifikasi dan di kelompokkan produk apa saja yang diminati sehingga bisa menyusun faktor-faktor apa saja yang dapat menarik konsumen baru untuk membeli.
2. KAJIAN LITERATUR
2.1 Metode Non Hierarchy (Clustering)
Dikutip dari salah satu jurnal (Tahta
Alfina dkk, 2011), salah satu teknik yang
di kenal dalam Data Mining yaitu
clustering. Pengertian clustering adalah
pengelompokkan sejumlah data atau objek
kedalam cluster (group) sehingga setiap
Dewi Eka Putri, S.Kom, M.Kom
cluster akan berisi data yang semirip mungkin dan berbeda dengan objek dalam cluster yang lainnya. Ada dua metode clustering yang kita kenal, yaitu Hierarchy dan Non Hierarchy. Metode Hierarchy terdiri dari complete linkage clustering, single linkage clustering, average linkage clustering dan centroid linkage clustering. Sedangkan metode Non Hierarchy terdiri dari k-means dan Fuzzy k-means.
2.2 Algoritma K-Means
Menurut salah satu jurnal nasional (Afrisawati, 2013), K-means merupakan metode penglompokkan data nonhierarki yang berusaha mempartisi data kedalam dua bentuk atau lebih kelompok. Metode ini mempartisi data kedalam kelompok sehingga data berkarakteristik sama dimasukkan ke dalam satu kelompok yang sama dan data yang berkarakteristik berbeda dikelompokkan kedalam kelompok lain.
Tujuan dari pengelompokkan ini adalah untuk meminimalkan fungsi objektif yang diatur dalam proses pengelompokkan, yang pada umumnya berusaha meminimalkan variasi di dalam suatu kelompok dan memaksimalkan variasi antar kelompok (sumber : Eko Prasetyo, “Data Mining:Konsep dan Aplikasi menggunakan MATLAB, 2012:178”).
Berikut adalah flowchart dari algoritma K-means :
Start
Jumlah K (Inisiasi Pusat Cluster)
Hitung jarak objek ke pusat
Kelompokkan objek berdasarkan jarak minimum
Pusat cluster baru
Ada selisih pusat cluster lama dan baru
END Tidak
Pusat cluster = Pusat cluster baru Ya
Gambar 2.1. Flowchart Algoritma K-means
Algoritma K-means :
a) Penetapan jumlah cluster (k) b) Penentuan titik pusat cluster
secara random
c) Hitung jarak setiap data ke pusat cluster
d) Kelompokkan data ke dalam cluster dengan jarak minimal e) Hitung pusat cluster baru
berdasarkan rata-rata jarak terhadap pusat cluster
f) Apakah ada selisih antara pusat cluster lama dengan pusat cluster baru? Jika ada, maka pusat cluster lama=pusat cluster baru
g) Ulangi langkah 2-4 hingga sudah tidak ada lagi selisih pada pusat cluster
3. METODE PENELITIAN
Penelitian ini bertujuan untuk mengetahui tingkat kelarisan suatu produk pada Koperasi Keluarga Besar Semen Padang. Koperasi ini menyediakan banyak produk-produk kebutuhan sehari- hari. Sehingga Pimpinan mengalami kesulitan dalam menyediakan stok barang.
Untuk mengetahui tingkat kelarisan suatu
Dewi Eka Putri, S.Kom, M.Kom
produk, maka penulis menggunakana algoritma K-means. Dalam proses penelitian ini, diperlukan literatur untuk pemahaman konsep dan pendalaman materi dari beberapa jurnal sebagai referensi. Tahap selanjutnya adalah teknik pengumpulan data dengan cara observasi secara langsung.
Kerangka kerja diperlukan dalam acuan langkah-langkah untuk mengerjakan suatu penelitian secara terstruktur dengan membuat sebuah tahapan metodologi penelitian sehingga hasil yang dicapai menjadi lebih maksimal. Kerangka kerja pada penelitian ini dapat dilihat pada Gambar 3.1
Gambar 3.1. Kerangka Kerja Penelitian
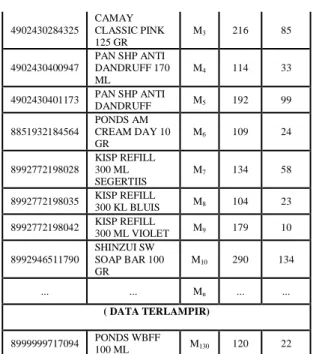
Dalam hal ini penulis mengambil sampel data sebanyak 130 data, sedangkan atribut digunakan 4 yaitu Kode Barang, Nama Barang, Total Stok, Stok Akhir.
Tabel 3.1. Sampel Data Rekapitulasi Penjualan
Kode Barang Nama Barang Item Total Stok
Stok Akhir 4902430284301 CAMAY CHIC
BLACK 125 GR M1 192 102 4902430284318
CAMAY NATURAL WHITE 125 GR
M2 205 120
4902430284325
CAMAY CLASSIC PINK 125 GR
M3 216 85
4902430400947
PAN SHP ANTI DANDRUFF 170 ML
M4 114 33
4902430401173 PAN SHP ANTI
DANDRUFF M5 192 99
8851932184564
PONDS AM CREAM DAY 10 GR
M6 109 24
8992772198028
KISP REFILL 300 ML SEGERTIIS
M7 134 58
8992772198035 KISP REFILL
300 KL BLUIS M8 104 23 8992772198042 KISP REFILL
300 ML VIOLET M9 179 10 8992946511790
SHINZUI SW SOAP BAR 100 GR
M10 290 134
... ... Mn ... ...
( DATA TERLAMPIR)
8999999717094 PONDS WBFF
100 ML M130 120 22
4. HASIL DAN PEMBAHASAN 4.1 Analisa Algoritma K-Means
Percobaan dilakukan dengan menggunakan parameter-parameter berikut :
Jumlah Data : 130
Jumlah cluster : 2 (Barang Paling Laris dan Barang Kurang Laris)
Jumlah Atribut : 4 (Kode Barang, Nama Barang, Total Stok, Stok Akhir)
Proses analisa terhadap tingkat kelarisan yang dikategorikan “Barang Laris” dan “Barang Kurang Laris”
menggunakan Algoritma K-Means, dimana Algoritma tersebut digunakan untuk mengelompokkan barang berdasarkan tingkat kelarisannya yang diambil sebagai sampel berdasarkan parameternya.
Jarak tiap objek (Nama Barang) ke masing-masing centroid menggunakan rumus kolerasi antar dua objek yaitu Euclidean Distance. Untuk menentukan M
ndiambil dari Total Stok (X) dan Stok Akhir (Y).
Asumsi :
1. Semua data akan dikelompokkan ke dalam dua Cluster
2. Center points dari kedua cluster yang di tentukan secara random adalah :
Pusat cluster 1 (C
1) : (170, 50) MelakukanStudiPendahuluan
MelakukanStudiLiteratur
Mengumpulkan Data
MenganalisaMasalah
Mengolah Data denganK-means
Menguji data dengan tools
MembuatKesimpulan
MenentukanTujuan
Dewi Eka Putri, S.Kom, M.Kom
Pusat cluster 2 (C
2) : (325, 150) Iterasi I
Pada tahap ini akan di hitung jarak setiap data ke masing-masing centroid menggunakan rumus Euclidean Distance.
Menghitung jarak masing-masing data ke titik pusat cluster pertama (C1).
Dimulai dari D11 sampe D1130 menggunakan rumus :
D
ik=
Dari hasil pengelompokkan diatas, menggunakan Rumus Euclidean Distance, dapat dilihat bahwa tidak terjadi perubahan anggota untuk masing-masing cluster, maka proses iterasi dihentikan.
Maka dapat disimpulkan bahwa ada 95 anggota pada cluster pertama, yang artinya ada 95 barang masuk kategori LARIS, dan ada 35 anggota pada cluster kedua, yang artinya ada 35 barang masuk kategori KURANG LARIS. Seperti yang terlihat pada grafik persebaran dibawah ini:
Gambar 4.1. Grafik Persebaran
4.2 Implementasi Sistem
Sebelumnya mengimplementasikan sistem terhadap data yang ingin diolah serta mempersiapkan terlebih dahulu data riil nya.
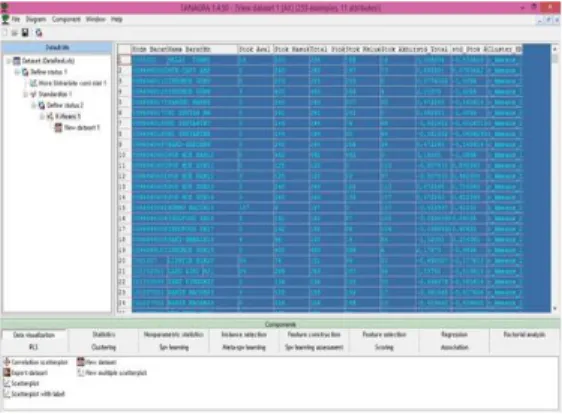
Gambar 4.2. Export Dataset Gambar diatas merupakan cara untuk menginput dataset, jika tidak ada warning, maka export data berhasil. Tahapan selanjutnya adalah set parameter pada define status dan tahapan clustering k- means. Sehingga akan didapat output iterasi I seperti berikut :
Gambar 4.3. View Dataset 1 Setelah mendapat Cluster K-Means Iterasi 1 dengan penentuan nilai C secara random, selanjutnya adalah menghitung Cluster K-Means untuk Iterasi 2. Maka kita akan membuat Define Status 3 pada komponen K-Means. Seperti pada gambar berikut :
Gambar 4.4. Set Parameter Baru Penentuan parameter Iterasi 2 ini adalah
1. Target : C_Kmeans_1
2. Input : Kode barang, Nama barang,
Item, Total Stok, Stok Akhir
Untuk melihat grafik nya, maka
tambahkan komponen Scatterplot pada
tab Data Visualization, tarik ke arah K-
Means 1.
Dewi Eka Putri, S.Kom, M.Kom
Gambar 4.5. Grafik Scatterplot Lalu tambahkan komponen EXPORT
DATASET (tab DATA
VISUALIZATION) kedalam diagram, setting jarak dialog menu pada PARAMETER, Pilih attribut input yang dieksport.
Gambar 4.6. Export Dataset Sehingga hasil output dapat kita lihat di tempat kita menyimpan file input sebelumnya.
Dari 255 data riil yang diujikan menggunakan tools Tanagra, dengan menggunakan 2 cluster, maka didapatkan hasil output Cluster Barang Yang Laris (C2) 194 data dan Cluster Barang Yang Kurang Laris (C1) 61 data yang telah dikelompokkan kedalam 2 tabel.
5. KESIMPULAN
Berdasarkan uraian pada bab-bab sebelumnya, maka penulis dapat mengambil kesimpulan antara lain :
A. Proses akan berlanjut jika perbandingan anggota C
1dan C
2pada iterasi 1 dan iterasi 2 hasilnya berbeda.
B. Proses akan berhenti jika perbandingan anggota C
1dan C
2pada iterasi 1 dan iterasi 2 hasilnya sama.
Dari hasil analisis cluster_k-means dari 130 jenis sampel Perlengkapan Mandi dan Mencuci dapat dikelompokan menjadi dua cluster_k-means yaitu:
a. Cluster_K-means (C1), adalah kelompok barang yang laris, dengan total sampel data 95 item dari 130 sampel data.
b. Cluster_K-means2 (C2), adalah kelompok barang yang kurang laris, dengan total sampel data 35 item dari 130 sampel data.
Hasil yang dicari dengan cara manual equivalen dengan hasil yang diproses dengan menggunakan aplikasi Tanagra 1.4.50.
6. REFERENSI
Afrisawati. (2013). “Jurnal Implementasi Data Mining Pemilihan Pelanggan Potensial Menggunakan Algoritma K- Means.”
Alfina, Tahta., Santosa, Budi., dan Barakbah, Ali Ridho. (2012). “Jurnal Analisa Perbandingan Metode Hierarchical Clustering, K-Means dan Gabungan Keduanya Dalam Cluster Data (Studi Kasus : Problem Kerja Praktek Jurusan Teknik Industri ITS.)”
Dash, Rajashree., Mishra, Debahuti., Rath, Amiya Kumar., and Acharya, Milu. (2010). “Journal A Hybridized K-Means Clustering Approach For High Dimensional Dataset.”
Dua, Sumeet., and Du, Xian. (2011).
“Data Mining And Machine Learning In Cybersecurity.”
Durairaj, M. Dan Vijitha, C. (2014).
“Journal Educational Data Mining For Prediction Of Student Performance Using Clustering Algorithms.”
Fadli, Ari. (2011). “Jurnal Konsep Data Mining.”
Ginting, Selvia Lorena Br. (2010).
“Jurnal Konstruksi Struktur Bayesian Network Dalam Data Mining Untuk Basis Data Incomplete Menggunakan Algoritma CB*.”
Han, Jiawei., Kamber, Micheline., and Pei, Jian. (2012). “Data Mining : Concepts And Techniques.”
Irwan Budiman. (2012). “Data Clustering Menggunakan Metodologi CRISP- DM Untuk Pengenalan Pola Proporsi Pelaksana Tridharma.” Universitas
(X1) Total Stok vs. (X2) Stok Akhir by (Y) Cluster_KMeans_1
c_kmeans_1c_kmeans_2
480 460 440 420 400 380 360 340 320 300 280 260 240 220 200 180 160 140 120 100 360 340 320 300 280 260 240 220 200 180 160 140 120 100 80 60 40 20 0