Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
1
ANALISIS SENTIMEN REVIEW APLIKASI TIK-TOK DENGAN ALGORITMA K-NEAREST NEIGHBOR, NAIVE
BAYES DAN SUPPORT VECTOR MACHINE
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer (M.Kom)
FANNY FATMA WATI 14002213
Program Studi Ilmu Komputer (S2)
Sekolah Tinggi Manajemen Informatika Dan Komputer Nusa Mandiri
Jakarta 2020
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
ii
BAYES DAN SUPPORT VECTOR MACHINE
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer (M.Kom)
FANNY FATMA WATI 14002213
Program Studi Ilmu Komputer (S2)
Sekolah Tinggi Manajemen Informatika Dan Komputer Nusa Mandiri
Jakarta 2020
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
iii Yang bertanda tangan di bawah ini:
Nama : Fanny Fatma Wati
NIM : 14002213
Perguruan Studi : Ilmu Komputer Jenjang : Strata Dua (S2) Konsentrasi : Data Mining
Dengan ini menyatakan bahwa tesis yang telah saya buat dengan judul: “ Analisis Sentimen Review Aplikasi Tik-Tok Dengan Algoritma K-Nearest Neighbor, Naive Bayes Dan Support Vector Machine” adalah hasil karya sendiri, dan semua sumber baik yang dikutip maupun yang dirujuk telah saya nyatakan dengan benar dan tesis belum pernah diterbitkan atau dipublikasikan dimanapun dan dalam bentuk apapun.
Demikianlah surat pernyataan ini saya buat dengan sebenar-benarnya. Apabila dikemudian hari ternyata saya memberikan keterangan palsu dan atau ada pihak lain yang mengklaim bahwa tesis yang telah saya buat adalah hasil karya milik seseorang atau badan tertentu, saya bersedia diproses baik secara pidana maupun perdata dan kelulusan saya dari Progam Studi Ilmu Komputer (S2) Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri dicabut/dibatalkan.
Jakarta, 05 Agustus 2020 Yang menyatakan,
Fanny Fatma Wati
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
iv
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
v
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER NUSA MANDIRI
NIM : 14002213
Nama Lengkap : Fanny Fatma Wati Dosen Pembimbing : Dr. Windu Gata, M.Kom
Judul Skripsi : Analisis Sentimen Review Aplikasi Tik-Tok Dengan Algoritma K-Nearest Neighbor, Naive Bayes Dan Support Vector Machine
NO Tanggal
Bimbingan Pokok Bahasan Paraf Dosen
Pembimbing
1 11 April 2020 Pengajuan Judul
2 20 April 2020 Revisi Judul dan Pengajuan Bab 1 3 27 April 2020 Revisi Bab 1 dan Pengajuan Bab II 4 4 Mei 2020 Revisi Bab II
5 14 Mei 2020 Revisi Bab II dan Pengajuan Bab III 6 08 Juni 2020 Revisi Bab III dan Pengajuan Bab IV 7 29 Juni 2020 Revisi Bab IV
8 13 Juli 2020 Revisi Bab IV dan Pengajuan Bab V 9 3 Agustus 2020 Acc Keseluruhan
Catatan untuk Dosen Pembimbing.
Bimbingan Skripsi
• Dimulai pada tanggal : Maret 2020
• Diakhiri pada tanggal : Agustus 2020
• Jumlah pertemuan bimbingan : 9 Kali
Disetujui oleh, Dosen Pembimbing
Dr. Windu Gata, M.Kom
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
vi
telah melimpahkan rahmat dan karunia-Nya, sehingga pada akhirnya penulis dapat menyelesaikan tesis ini tepat pada waktunya. Dimana tesis ini penulis sajikan dalam bentuk buku yang sederhana. Adapun judul tesis, yang penulis ambil sebagai berikut “Analisis Sentimen Review Aplikasi Tik-Tok Dengan Algoritma K-Nearest Neighbor, Naive Bayes Dan Support Vector Machine”.
Tujuan penulisan tesis ini dibuat sebagai salah satu syarat untuk mendapatkan gelar Magister Ilmu Komputer (M.Kom) pada Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri (STMIK Nusa Mandiri).
Tesis ini diambil berdasarkan data dari review aplikasi yang ada di google playstore. Penulis juga mencari dan menganalisa berbagai macam sumber referensi, baik dalam bentuk jurnal ilmiah, buku-buku literatur, internet, dll yang terkait dengan pembahasan pada tesis ini.
Penulis menyadari bahwa tanpa bimbingan dan dukungan dari semua pihak dalam pembuatan tesis ini, maka penulis tidak dapat menyelesaikan tesis ini tepat pada waktunya. Untuk itu ijinkanlah penulis pada kesempatan ini untuk mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Bapak Dr. Windu Gata, M.Kom selaku pembimbing tesis yang telah menyediakan waktu, pikiran dan tenaga dalam membimbing penulis dalam menyelesaikan tesis ini.
2. Ibu Dr. Dwiza Riana,S.Si.,MM.,M.Kom Selaku Ketua STMIK Nusa Mandiri.
3. Bapak Ir. Naba Aji Notoseputro yang telah memberikan kesempatan kepada penulis untuk menempuh pendidikan hingga S2.
4. Bapak Sudadi dan Ibu Siti Fatonah yang selalu memberikan dukungan material dan moral kepada penulis.
5. M.Haikal Riziq dan keluarga besar yang selalu memberikan semangat dan motovasi untuk penulis.
6. Seluruh staf pengajar (dosen) Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri yang
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
vii
7. Seluruh staf dan karyawan Program Pascasarjana Magister Ilmu Komputer Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri yang telah memberikan pelayanan terbaik selama penulis duduk di bangku kuliah.
8. Seluruh staf dan karyawan Universitas Bina Sarana Informatika Kampus Kota Tegal yang selalu memberikan motivasi dan dukungan kepada penulis.
9. Rekan-rekan seperjuangan lain yang tidak bisa penulis sebutkan satu-persatu.
Serta semua pihak yang terlalu banyak untuk penulis sebutkan satu persatu sehingga terwujudnya penulisan tesis ini. Penulis menyadari bahwa penulisan tesis ini masih jauh sekali dari sempurna, untuk itu penulis mohon kritik dan saran yang bersifat membangun demi kesempurnaan karya ilmiah yang penulis hasilkan untuk masa yang akan datang.
Akhir kata semoga tesis ini dapat bermanfaat bagi penulis pada khususnya dan bagi para pembaca pada umumnya.
Jakarta, 05 Agustus 2020
Fanny Fatma Wati Penulis
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
viii Yang bertanda tangan di bawah ini, saya:
Nama : Fanny Fatma Wati
NIM : 14002213
Program Studi : Ilmu Komputer Jenjang : Strata Dua (S2) Konsentrasi : Data Mining Jenis Karya : Tesis
Demi pengembangan ilmu pengetahuan, dengan ini menyetujui untuk memberikan ijin kepada pihak Program Studi Ilmu Komputer (S2) Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri (STMIK Nusa Mandiri) Hak Bebas Royalti Non-Eksklusif (Non-exclusive Royalti-Free Right) atas karya ilmiah kami yang berjudul : “Analisis Sentimen Review Aplikasi Tik-Tok Dengan Algoritma K-Nearest Neighbor, Naive Bayes Dan Support Vector Machine” beserta perangkat yang diperlukan (apabila ada).
Dengan Hak Bebas Royalti Non-Eksklusif ini pihak STMIK Nusa Mandiri berhak menyimpan, mengalih-media atau bentuk-kan, mengelolaannya dalam pangkalan data (database), mendistribusikannya dan menampilkan atau mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari kami selama tetap mencantumkan nama kami sebagai penulis/pencipta karya ilmiah tersebut.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak STMIK Nusa Mandiri, segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini .
Demikian pernyataan ini saya buat dengan sebenarnya.
Jakarta, 05 Agustus 2020 Yang menyatakan,
Fanny Fatma Wati
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
ix Nama : Fanny Fatma Wati
NIM : 14002213
Program Studi : Magister Ilmu Komputer Jenjang : Strata Dua (S2)
Konsentrasi : Data Mining
Judu : “Analisis Sentimen Review Aplikasi Tik-Tok Dengan Algoritma K-Nearest Neighbor, Naive Bayes Dan Support Vector Machine”
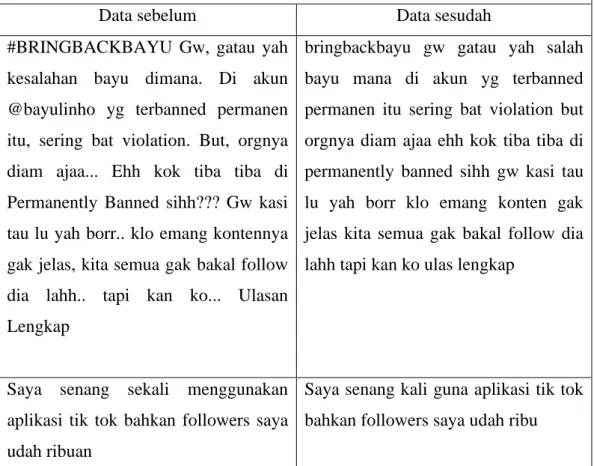
Tik-Tok merupakan aplikasi yang dapat digunakan untuk membuat video yang berdurasi kurang lebih 30 detik. Banyaknya pengguna aplikasi Tik-Tok menyebabkan banyaknya penilaian baik positif ataupun negatif, di perlukan metode untuk dapat mengklasifikasikan suatu ulasan secara otomatis dengan analisis sentimen. Tujuan dari penelitian ini adalah mengklasifikasikan analisis review aplikasi Tik-tok dengan mengunakan algoritma KNN, SVM, dan NB untuk menentukan nilai akurasi terbaik dengan menggunakan 2 Model Percobaan Cross Validation dan Partitioning. Penelitian ini menggunakan data 500 positif dan 500 negatif. Hasilnya menunjukan dengan model Partitioning menggunakan metode SVM menghasilkan nilai accuracy 87,667 %, dengan NB nilai accuracy 51,00%, dan KNN (K-3) 82,667%, sedangkan dengan model Cross Validation dengan algoritma SVM menghasilkan accuracy 85,872%, NB sebesar 50,1% dan dengan KNN (K-3) 80,561%. Dapat di simpulkan bahwa algoritma SVM dengan model partitioning merupakan algortima terbaik dibandingkan dengan KNN, SVM dan NB.
Algoritma SVM mendapatkan nilai accuracy sebesar 87,667 % dengan nilai AUC 0,9482.
Kata Kunci: Tik-Tok, Analisa Sentimen, K-Nearest Neighbor, Support Vector Machine, Naive Bayes.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
x Name : Fanny Fatma Wati NIM : 14002213
Study of Program : Master of Computer Science Levels : Strata Dua (S2)
Concentration : Data Mining
Titel : “Sentiment Analysis Review of Tik-Tok Application with K-Nearest Neighbor, Naive Baye and Support Vector Machine Algorithm”
Tik-Tok is an application that can be used to make videos that are approximately 30 seconds long. The large number of Tik-Tok application users causes many positive and negative ratings, a method is needed to be able to classify a review automatically with sentiment analysis. The purpose of this study is to classify a review analysis of the Tik-tok application by using the KNN, SVM, and NB algorithm to determine the best accuracy value by using 2 Cross Validation and Partitioning Experiment Models. This study uses 500 positive and 500 negative data. The results show that the Partitioning model using the SVM method produces an accuracy value of 87.667%, with an NB accuracy value of 51.00%, and KNN (K-3) 82.667%, whereas with the Cross Validation model the SVM algorithm produces an accuracy of 85.887%, NB of 50, 1% and with KNN (K-3) 80.561%. It can be concluded that the SVM algorithm with partitioning models is the best algorithm compared to KNN, SVM and NB. SVM algorithm get an accuracy value of 87.667% with AUC value of 0.9482.
Keywords: Tik-Tok, Sentiment Analysis, K-Nearest Neighbor, Support Vector Machine, Naive Bayes.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xi
HALAMAN SAMPUL ... i
HALAMAN JUDUL... ... ii
HALAMAN PERNYATAAN ORISINALITAS ... iii
HALAMAN PERSETUJUAN TESIS... iv
LEMBAR KONSULTASI BIMBINGAN TESIS... . v
KATA PENGANTAR... .... vi
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS... ... viii
ABSTRAK... ... ix
ABSTRCT... ... x
DAFTAR ISI... ... xi
DAFTAR TABEL ... xiii
DAFTAR GAMBAR... .... xv
DAFTAR LAMPIRAN... ... xvii
BAB 1. PENDAHULUAN... ... 1
1.1. Latar Belakang Penulisan... 1
1.2. Identifikasi Masalah ... 3
1.3. Tujuan Penelitian ... 3
1.4. Ruang Lingkup Penelitian... 3
1.6.Sistematika Penulisan ... . 4
BAB II. LANDASAN TEORI ... 5
2.1. Tinjauan Pustaka ... 5
2.1.1 Analisis Sentimen ... 5
2.1.2. Aplikasi Tik-Tok ... 6
2.1.3. Text Mining ... 7
2.1.4. Data Mining ... 11
2.1.5. Klasifikasi ... 13
2.1.5.1. Support Vector Machine... 14
2.1.5.2. Naive Bayes... ... 15
2.1.5.3. K-Nearest Neighboor... 16
2.1.6. TF- IDF ... 16
2.1.7. Cross Validation ... 17
2.1.8. Confution Matrix ... 17
2.1.9. ROC (Receiver Operating Characteristic) ... 19
2.1.10. KNIME ... 20
2.1.11. GataFramework ... 21
2.1.12. Web Scraping ... 23
2.2.Tinjauan Studi ... 24
2.2.1. Penelitian Terkait ... 24
2.3. Tinjauan Objek Penelitian ... 33
2.4. Kerangka Pemikiran ... 34
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xii
3.2. Pengolahan Data Awal ... 36
3.3. Metode yang di usulkan ... 36
3.4. Eksperimen dan Hasil Pengujian ... 37
3.5. Evaluasi dan Hasil Validasi ... 37
3.6. Penerapan (Deployment)... 40
BAB IV. HASIL DAN PEMBAHASAN ... 41
4.1. Business Understanding ... 41
4.2. Data Understanding ... 41
4.3.Data Preparation ... 44
4.3.1. @Anotation Removal ... 47
4.3.2. Tokenization (RegExp) dan Normalization Emoticon... 47
4.3.3. Stemming... 48
4.3.4. Transformation Not (Negative)... 49
4.3.5. Indonesia Stop Word Removal... .. 50
4.3.6. N-Chart Filter ... ... 50
4.3.7. Stop Word Filter ... ... 51
4.3.8. Bag Of Word Creator ... ... 52
4.3.8. TF-IDF ... ... 53
4.4. Modelling ... ... 53
4.4.1. Desain Model Partitioning ... ... 60
4.4.2. Desain Model Cross Validation... 62
4.5. Evaluation ... ... 64
4.5.1. Hasil Evaluasi dengan metode SVM... ... ... 64
4.5.2. Hasil Evaluasi dengan metode NB ... 66
4.5.3. Hasil Evaluasi dengan metode KNN... ... .... 68
4.5.4. Rangkuman... ... .... 74
4.6. Deployment ... ... 76
BAB V. PENUTUP ... 81
5.1. Kesimpulan ... 81
5.2. Saran ... 81
DAFTAR PUSTAKA... ... 82
DAFTAR RIWAYAT HIDUP... .. 86
LAMPIRAN-LAMPIRAN... .. 87
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xiii
Tabel 2.1. Model Confution Matrix ... 18
Tabel 2.2. Kategori Klasifikasi dengan menggunakan hasil AUC ... 19
Tabel 2.3. Penelitian Terkait... 27
Tabel 3.1. Jadwal Kegiatan (TimeLine) ... 40
Tabel 4.1..Tabel Review Aplikasi Tik-Tok ... 42
Tabel 4.2. Tabel Hasil Proses Pelabelan ... 45
Tabel 4.3. Perbandingan Sebelum dan Sesudah Dilakukan Proses @Anotation Removal. ... 46
Tabel4.4. Perbandingan Teks Sebelum dan Sesudah Dilakukan Proses Regex Filter ... 47
Tabel 4.5 Perbandingan Teks Sebelum dan Sesudah Dilakukan Proses Stemming ... 48
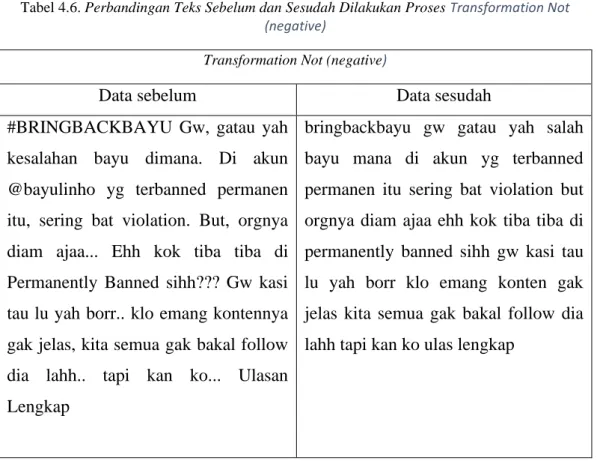
Tabel 4.6 Perbandingan Teks Sebelum dan Sesudah Dilakukan Proses Transformation Not Negative... 49
Tabel 4.7. Perbandingan Teks Sebelum dan Sesudah Dilakukan Proses Stop Word Removal... 49
Tabel 4.8. Perbandingan Teks Sebelum dan Sesudah Dilakukan Proses N-Chart Filter... 50
Tabel 4.9. Text Stop Word Removal ... 51
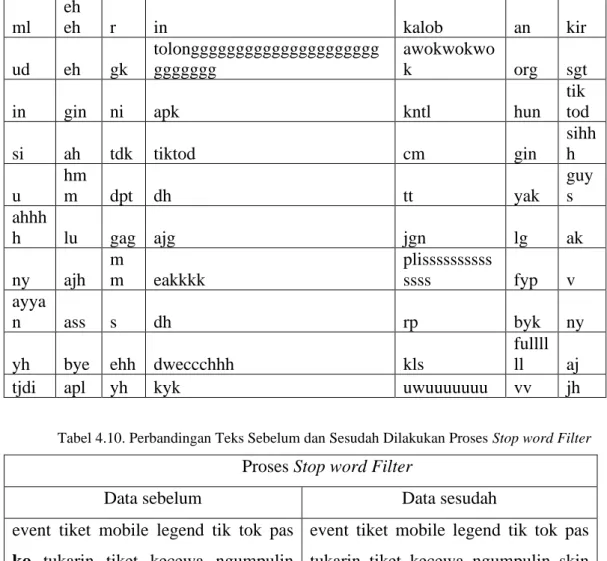
Tabel 4.10. Perbandingan Teks Sebelum dan sesudah dilakukan Proses Stop Word Filter... 51
Tabel 4.11. Term yang terbentuk dari proses Bag Of Word Ceator... 52
Tabel 4.12. Pembobotan TF IDF... 52
Tabel 4.13. Confussion matrix dengan metode SVM Partitioning... 64
Tabel 4.14. Confussion matrix dengan metode SVM Cross Validation... . 65
Tabel 4.15. Confussion matrix dengan metode NB Partitioning... 66
Tabel 4.16. Confussion matrixdengan metode NB Cross Validation... 67
Tabel 4.17. Confussion matrix dengan metode KNN Partitioning... 68
Tabel 4.18. Confussion matrix dengan metode KNN Cross Validation... 71 Tabel 4.19 Perbandingan Accuracy, Precision, Recall dan
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xiv
Validation... 75
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xv
Gambar 2.1. Tampilan Aplikasi Tik-Tok ... 7
Gambar 2.2. CRISP-DM Conceptual Model ... 11
Gambar 2.3. Kurva ROC ... 20
Gambar 2.4. Tampilan Aplikasi KNIME ... 21
Gambar 2.5. User Interface Gata Framework ... 23
Gambar 2.6. Tampilan Web Harvy ... 24
Gambar 2.7. Rating ulasan aplikasi tik-tok ... 33
Gambar 2.8. Kerangka Pemikiran ... 34
Gambar 3.1. Metode Penelitan ... 38
Gambar 4.1. Proses preprocessing dengan gataframework ... 45
Gambar 4.2. Proses preprocessing dengan KNIME ... 45
Gambar 4.3. Model Penelitian pengolahan data review aplikasi tik-to... 54
Gambar 4.4 Hasil Output tabel Read Data Excel ... 55
Gambar 4.5. Hasil Output tabel String to document ... 55
Gambar 4.6 .Hasil Output preprocessing ... 56
Gambar 4.7. Hasil Output Document Vector ... 56
Gambar 4.8. Hasil Output Category To Class ... 57
Gambar 4.9. Hasil Output dari column Filter ... 57
Gambar 4.10. Hasil Output First Partition ... 58
Gambar 4.11. Hasil Output Secon Partition ... 58
Gambar 4.12. Hasil Output X-Partitioning data training ... 59
Gambar 4.13. Hasil Output X-Partitioning data testing ... 59
Gambar 4.14. Model Partitioning ... 60
Gambar 4.15 Desain Model Proses SVM ... 60
Gambar 4.16. Desain Model Proses NB ... 61
Gambar 4.17. Desain Model Proses KNN ... 61
Gambar 4.18. Desain Model Proses SVM ... 62
Gambar 4.19. Desain Model Proses NB ... 63
Gambar 4.20. Desain Model Proses KNN ... 63
Gambar 4.21. ROC curve dari algoritma SVM Partitioning ... 64
Gambar 4.22. ROC curve dari algoritma SVM Cross Validation ... 65
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xvi
Gambar 4.25.. ROC curve dari algoritma KNN Partitioning ... 70
Gambar 4.26. ROC curve dari algoritma KNN Cross Validation ... 73
Gambar 4.27. Grafik Perbandingan Hasil Evaluasi ... 75
Gambar 4.28. Flowchart Aplikasi Sentimen Aplikasi Tik-Tok ... 76
Gambar 4.29. Halaman Home Aplikasi Analisa Sentimen Tik-Tok ... 77
Gambar 4.30. Halaman Login ... 77
Gambar 4.31. Tampilan Menu Dashboard ... 78
Gambar 4.32. Tampilan Halaman Input Teks Sentimen ... 78
Gambar 4.33. Tampilan Halaman Hasil Prepocessing ... 79
Gambar 4.34. Tampilan Halaman Hasil Sentimen... 79
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
xvii
Halaman Lampiran 1. Contoh Dataset Review Aplikasi Tik-Tok di Google Playstore ..87 Lampiran 2. Contoh Prepocessing Dataset ...91 Lampiran 3 Korpus Data Algoritma SVM Partitioning ...93 Lampiran 4 Percobaan Aplikasi ...124
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
1 BAB 1 PENDAHULUAN
1.1. Latar Belakang Penulisan
Pesatnya perkembangan ilmu pengetahuan dan teknologi, kemunculan dan perkembangan media semakin mempercepat kecepatan pengiriman informasi.
normatif dan non normatif kepada individu tertentu atau non mayoritas khusus orang oleh individu dengan alat elektronik, dan modern. Berbeda dari saluran tradisional, pesan media pribadi dapat berasal dari individu atau organisasi mana pun, dan keakuratan pesan tidak dapat dijamin. Pada saat yang sama, dengan bantuan Internet, penyebarannya berita sangat cepat, ruang lingkup pengaruhnya sangat besar, dan kadang-kadang akan menimbulkan dampak sosial [1].
Dalam beberapa tahun terakhir, platform self-media video pendek menghasilkan nilai komersial yang tinggi. Menurut statistik pada bulan Mei 2019, aktivitas harian platform video pendek itu mencapai lebih dari 1 miliar, dan volume interaksi video pujian dan komentar telah mencapai 100 miliar[2].
Pertumbuhan konten video sendiri dapat dengan mudah diunggah ke internet hal ini di dukung dengan kemajuan kecepatan internet. Banyak platform maupun aplikasi yang menyediakan dukungan pembuatan video dan dengan hal menarik pada pengguna smartphone. Salah satunya terdapat pada aplikasi Tik-Tok yang berasal dari perusahaan teknologi asal Singapura, Bytemod, menghadirkan aplikasi edit video bernama ”Tik Tok”. Pada aplikasi Tik-Tok ini pengguna dapat membuat video yang hanya berdurasi kurang lebih 30 detik dengan memberikan special effects yang unik dan menarik serta memiliki dukungan musik yang banyak sehingga penggunanya dapat melakukan performa dengan beragam gaya ataupun tarian, dan masih banyak lagi sehingga mendorong kreativitas penggunanya menjadi content creatore [3].
Google Play adalah layanan konten digital milik Google yang melingkupi produk-produk seperti musik/lagu, buku, aplikasi, permainan, ataupun pemutar media. Layanan produk yang dapat ditemui di Google Play adalah aplikasi Tik- tok. Layanan ini dapat diakses baik melalui web, aplikasi android (Play Store), dan Google. Dalam Google Play, selain toko produk-produk online juga
2
dilengkapi adanya fitur penilaian bagi pelanggan untuk memberikan ulasan tentang kelebihan ataupun kekurangan dalam penggunaan aplikasi Tik-tok. Ulasan pengguna bisa bermacam-macam bentuknya, mulai dari kalimat yang halus sampai kalimat yang kasar, selain memberikan ulasan para pengguna juga memberikan skor bintang (antara 1-5) tergantung penilaian yang diberikan oleh pengguna tersebut dan terakhir pengguna juga bisa memberikan skor “like”
terhadap komentar seseorang yang mewakili kepuasan atau kekecewaan seseorang terhadap aplikasi Tik tok tersebut.
Ulasan dari pengguna digunakan sebagai alat yang efektif dan efisien dalam menemukan informasi terhadap suatu produk atau jasa. Data hasil dari penelitian dapat diolah dan digunakan oleh perusahaan, sehingga perusahaan dapat memahami sentimen apa yang mendominasi pemikiran konsumen tentang perusahaan atau aplikasi mereka, memahami konsumen atau pelanggan merupakan cara agar perusahaan dapat terus melihat feedback maupun jasa yang diberikan dari konsumen terhadap aplikasi untuk perusahaan.
Permasalahan yang berkaitan dengan beberapa ulasan tentang aplikasi Tik-tok di Google Playstore fokus utamanya adalah review pengguna aplikasi Tik-tok yang ada di situs google play dimana untuk pengambilan datanya pada bulan januari-April (kurun waktu 4 bulan). Ulasan pengguna aplikasi Tik tok bisa dipengaruhi oleh beberapa hal yang belum menjadi perhatian baik dari pihak Tik- tok. Hal ini mungkin terjadi karena adanya beberapa faktor yang harus diperbaiki dan belum diketahui oleh pihak Tik-tok.
Berdasarkan dari penjelasan di atas di perlukan sebuah metode untuk dapat mengklasifikasikan dari suatu ulasan tersebut secara otomatis, apakah positif atau negatif yang nantinya akan menghasilkan suatu akurasi dari pengolahan data ulasan dalam aplikasi Tik-tok. Hal tersebut di mungkinkan dengan analisa sentimen.
Analisis sentimen atau yang sering disebut dengan opini mining merupakan sebuah proses menemukan gagasan seseorangmengenai beberapa ide atau pokok yang disampaikan pengguna tersebut, opini yang dimuat di media sosial jumlahnya terlalu banyak untuk diproses secara manual [4]. Oleh sebab itu dalam
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
penelitian ini ingin mengetahui sejauh mana analisis review pengguna aplikasi Tik-tok pada aplikasi setelah menggunakan aplikasi tersebut.
Berdasarkan pada uraian latar belakang yang telah di paparkan maka dalam penelitian ini akan melakukan analisis sentimen terhadap review pengguna aplikasi Tik-tok. Dimulai dari tahap preprocessing sampai tahap analisa sentimen dengan menggunakan metode data mining di antaranya K-Nearest Neighbor, Naïve Bayes dan Support Vector Machine dengan percobaan dua model diantaranya partitioning dan cross validation serta bagaimana mengukur kualitas hasil analisis dari masing-masing algoritma klasifikasi ulasan aplikasi Tik-tok.
1.2.Identifikasi Masalah
Review pengguna aplikasi Tik-tok yang ada pada google playstore sangat beragam dalam mengekspreiskan berbagai macam pendapat baik review positif ataupun negatif terhadap suatu aplikasi. Berdasarkan hal tersebut penelitian ini dilakukan untuk menentukan algortima manakah yang lebih efektif diantara KNN, NB Dan SVM dalam melakukan analisis sentimen aplikasi Tik-Tok? Dan Bagaimana hasil akurasi dari tiap-tiap algortima kalsifikasi data mining dalam mengkalsifikasikan sentimen aplikasi Tik-Tok?
1.3.Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah mengklasifikasikan analisis review aplikasi Tik-tok dengan mengunakan metode algoritma K-Nearest Neighbor ,Support Vector Machine, and Naïve Bayes sehingga dapat menghasilkan classifier yang terbaik dalam menentukan akurasi dengan menggunakan dua percobaan model yaitu partitioning dan Cross Validation sehingga dapat membantu pengembangan dan penerapan teori para peneliti lainnya yang berkaitan dengan analisis review pengguna Tik-tok pada google play berdasarkan review yang diberikan pengguna terhadap apliaksi Tik-tok.
1.4.Ruang Lingkup Penelitian
Ruang lingkup masalah dalam penelitian ini di batasi pada proses analisa sentimen untuk mengklasifikasi review pengguna aplikasi Tik-tok pada google play. Review pada aplikasi yang akan di klasifikasikan adalah teks berbahasa
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
indonesia (meliputi bahasa formal dan non formal). Sedangkan Metode yang di gunakan untuk analisis review menggunakan algoritma K-Nearest Neighbor, Support Vector Machine,dan Naïve Bayes dengan menggunakan model partitioning dan Cross Validation sehingga mampu mengetahui algoritma manakah yang memiliki tingkat akurasi paling tinggi beserta hasil analisisnya berdasarkan hasil perhitungan dari ketiga algortima.
1.5. Sistematika Penulisan
Sistematika penelitian ini terdiri dari 5 (lima) bab, dimana tiap bab sendiri terdiri dari beberapa sub bab sebagai berikut:
BAB 1 PENDAHULUAN
Pada Bab ini membahas tentang Latar Belakang Penulisan, Identifikasi Masalah, Tujuan Penelitian, Ruang Lingkup Penelitian, Hipotesis dan Sistematika Penulisan.
BAB 2 LANDASAN/KERANGKA PEMIKIRAN
Pada bab ini dibahas teori yang melandasi penelitian, dalam bab ini juga diuraikan Tinjauan Pustaka, Tinjauan Studi dan Obyek Penelitian dari penelitian.
BAB 3 METODOLOGI PENELITIAN
Pada bab ini membahas metodologi penelitian. Berisi tentang pembahasan pengumpulan data yang di gunakan dalam penelitian. Pada bab ini juga di bahas mengenai pengolahan data review aplikasi dengan menggunakan metode data mining.
BAB 4 HASIL PENELITIAN DAN PEMBAHASAN
Pada bab ini menampilkan hasil dari pembahasan yang penulis lakukan, membahas metode, mengukur hasil akurasi dengan algoritma klasifikasi.
Hasil dari penerapan metode KNN, NB dan SVM pada dataset yang di ambil dari review aplikasi Tik tok.
BAB 5 PENUTUP
Pada bab ini membahas kesimpulan dari penelitian, dan saran untuk penelitian selanjutnya.
5 BAB II
LANDASAN TEORI
2.1. Tinjauan Pustaka
Tinjauan pustaka dilakukan dengan menggunakan referensi dari buku- buku ataupun artikel yang penulis dapatkan melalui media internet sebagai acuan penulisan ini, berikut adalah pengertian-pengertian mengenai penulisan yang akan dibahas.
2.1.1. Analisis Sentimen
Analisis sentimen adalah proses mendeteksi polaritas teks secara kontekstual yang memiliki makna positif, negatif atau natural yang merupakan pendapat dari sikap orang yang bersangkutan [5]
Analisis sentimen atau opinion mining merupakan proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi sentimen yang terkandung dalam suatu kalimat opini. Analisis sentimen dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah masalah atau objek oleh seseorang, apakah cenderung berpandangan atau beropini negatif atau positif. Salah satu contoh penggunaan analisis sentimen dalam dunia nyata adalah identifikasi kecenderungan pasar dan opini pasar terhadap suatu objek barang. Besarnya pengaruh dan manfaat dari analisis sentimen menyebabkan penelitian dan aplikasi berbasis analisis sentimen berkembang pesat. Bahkan di Amerika terdapat sekitar 20-30 perusahaan yang memfokuskan pada layanan analisis sentimen [6].
Sentimen analisis juga dapat menyatakan perasaan emosional sedih, gembira, atau marah. D. Osimo, and F. Mureddu (2010) mengungkapkan dalam [6] bahwa sentimen analisis memiliki banyak aplikasi domain termasuk akuntansi, hukum, penelitian, hiburan, pendidikan, teknologi, politik, dan pemasaran.
Menurut [7] Analisis Sentimen dapat dianggap sebagai proses klasifikasi yang memiliki 3 tingkat klasifikasi utama adalah tingkat dokumen, pada tingkat kalimat dan pada tingkat aspek.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2.1.2. Aplikasi Tik-tok
Tik-Tok merupakan aplikasi yang dapat digunakan untuk membuat video yang hanya berdurasi kurang lebih 30 detik dengan memberikan special effects yang unik dan menarik serta memiliki dukungan musik yang banyak sehingga penggunanya dapat melakukan performa dengan beragam gaya ataupun tarian, dan masih banyak lagi sehingga mendorong kreativitas penggunanya menjadi content creatore [3]. Kelebihan Aplikasi Tik-tok dengan aplikasi pembuatan vidioa lainnya adalah sebagai berikut:
1. Perlu akun untuk melihat vidio di aplikasi Tik-tok
Tidak perlu memiliki akun sendiri untuk bisa melihat video-vdeo yang ada di tik-tok.
2. Menyajikan Vidio Pendek 15 detik
Durasi vidio di tik-tok berdurasi 15 detik saja, sehingga orang lebih tertarik untuk menggunakan karna hemat kuota. Vidio singkat juga tidak akan membuat orang bosan.
3. Filter yang dimiliki aplikasi beragam
Fitur yang ada di tik-tok beragam dan berbeda dengan aplikasi serupa lainnya sehingga banyak dinikmati oleh semua kalangan.
4. Memiliki Challenge
Challenge yang ada di tik-tok sangat beragam contohnya yang viral
#TaktahuMalu, #FilterSwipe dll.
5. Bisa menggunakan background musik pilihan
Pada aplikasi TikTok sendrii pengguna bisa menambahkan musik latar untuk membuat video yang dibuat lebih hidup. Pilihan musik latar yang ditawarkan pun bisa dibilang cukup banyak dan up to date.
6. Tidak ada iklan pada aplikasi Tik-tok
Aplikasi ini tidak memiliki iklan. Dengan tidak adanya iklan, maka pengalaman pengguna menggunakan aplikasi tentu akan semakin puas.
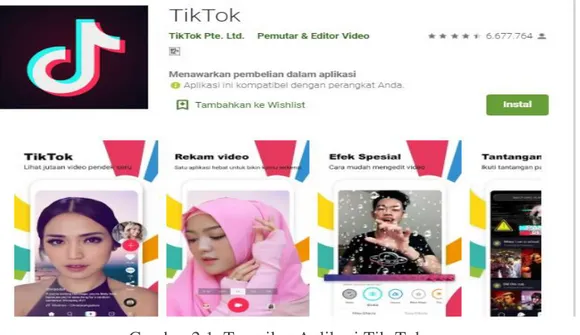
Kelemahan dari aplikasi Tik-Tok adalah Sistem keamanan aplikasi tersebut dapat di bobol, serta informasi pribadi pengguna bisa diubah hacker. Tik-Tok merupakan salah satu platform media sosial yang populer. Berikut ini adalah tampilan apliaksi tik-tok yang ada di google Playstore.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 2.1. Tampilan Aplikasi Tik-Tok
Sumber:https://play.google.com/store/apps/details?id=com.ss.android.ugc.trill&hl
=in
2.1.3. Text Mining
Text mining umumnya mencakup kategorisasi informasi atau teks, mengelompokkan teks, ekstraksi entitas atau konsep, pengembangan dan perumusan taksonomi umum. Text mining berkenaan dengan informasi terstruktur atau tekstual ekstraksi informasi yang bermakna dan pengetahuan dari jumlah besar teks [8].
Text mining juga dikenal dengan text data mining atau pencarian pengetahuan di basis data tekstual adalah proses yang semi otomatis melakukan ekstraksi dari pola data. Tipe pekerjaan text mining meliputi kategorisasi, text clustering, ekstraksi konsep/entitas, analisis sentimen, document summarization, dan entity-relation modeling (yaitu, hubungan pembelajaran antara entitas).
Sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur. Text mining dapat di artikan sebagai penemuan informasi baru yang belum di ketahui sebelumnya oleh komputer, dan secara otomatis mengekstrak informasi dari beberapa sumber yang berbeda [9].
Text mining adalah salah satu bidang khusus dari data mining. Hanya saja, yang membedakannya adalah pada sumber datanya, dimana text mining bersumber dari kumpulan dokumen atau teks. Pada proses klasifikasi ini,
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
dokumen akan dikelompokkan ke dalam kategori yang sesuai berdasarkan pola yang dibuatpada proses training.
Ada empat tahap proses pokok dalam text mining, yaitu pemrosesan awal terhadap teks (text preprocessing), transformasi teks (text transformation), pemilihan fitur (feature selection), dan penemuan pola (pattern discovery) sebagai berikut:
1. Text Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik (kebenaran susunan) terhadap teks. Tujuan dari pemrosesan awal adalah untuk mempersiapkan teks menjadi data yang akan mengalami pengolahan lebih lanjut.
Teknik yang biasa dilakukan dalam penelitian di Indonesia pada tahap preprocessing antara lain :
a. Annotation removal, bertujuan untuk menghapus dan menghilangkan karakter yang dianggap tidak perlu dan tidak penting.
b. Regex filter, digunakan untuk mencocokan string teks, seperti karakter tertentu, kata-kata, atau pola karakter dan mengelompokkannya.
c. Remove emoticon,digunakan untuk mengkonversi bahkan menghilangkan simbol emoticon.
d. Indonesian Stemming, digunakan untuk mencari kata dasar dari kata-kata berbahaa Indonesia.
e. Transformation Not, prosesnya tidak menghapus kata melainkan mengambil untuk menilai bahwa kalimat yang diproses mengandung kalimat negatif. Selanjutnya akan ditambahkan ke sebuah variabel yang sudah ditentukan untuk dihitung. Misalnya kasus sentimen analisis yang membutuhkan penilaian pada kalimat positif dan negatif.
f. Stopword Removal, biasanya digunakan untuk menghilangkan kalimat tidak penting seperti kata penghubung.
g. Punctuation,bertujuan menghapus semua karakter non alphabet misalnya simbol, spasi dan lain-lain.
h. N-chars filter,berfungsi untuk menetapkan batasan minimal karakter yang dimiliki oleh sebuah kata.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2. Text Transformation
Transformasi teks atau pembentukan atribut mengacu pada proses untuk mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi dokumen yang lazim digunakan oleh model “bag of words” dan model ruang vector (vector space model).Transformasi teks sekaligus juga melakukan pengubahan kata-kata ke bentuk dasarnya dan pengurangan dimensi kata di dalam dokumen. Tindakan ini diwujudkan dengan menerapkan stemming dan menghapus stop words.
3. Feature Selection
Pemilihan fitur (kata) merupakan tahap lanjut dari pengurangan dimensi pada proses transformasi teks. Walaupun tahap sebelumnya sudah melakukan penghapusan kata-kata yang tidak deskriptif (stopwords), namun tidak semua kata-kata di dalam dokumen memiliki arti penting. Oleh karena itu, untuk mengurangi dimensi, pemilihan hanya dilakukan terhadap kata-kata yang relevan yang benar-benar merepresentasikan isi dari suatu dokumen.Ide dasar dari pemilihan fitur adalah menghapus kata-kata yang kemunculannya di suatu dokumen terlalu sedikit atau terlalu banyak. Algoritma yang digunakan pada text mining, biasanya tidak hanya melakukan perhitungan pada dokumen saja, tetapi juga pada feature . Empat macam feature yang sering digunakan:
a. Character, merupakan komponan individual, bisa huruf, angka, karakterspesial dan spasi, merupakan block pembangun pada level paling tinggi pembentuk semantik feature, seperti kata, term dan concept.
b. Words.
c. Terms merupakan single word dan multiword phrase yang terpilih secara langsung dari corpus. Representasi term-based dari dokumen tersusun dari subset term dalam dokumen.
d. Concept, merupakan feature yang di-generate dari sebuah dokumen secara manual, rule-based, atau metodologi lain.
e. Pattern Discovery
Pattern discovery merupakan tahap penting untuk menemukan pola atau pengetahuan (knowledge) dari keseluruhan teks.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
4. Ekstraksi Dokumen
Ekstrasksi Dokumen ini bertujuan untuk menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen. Sebelum menentukan fitur- fitur yang mewakili, diperlukan tahap preprocessing yang dilakukan secara umum dalam teks mining pada dokumen, yaitu case folding, tokenizing, filtering, stemming, tagging dan analyzingantara lain [10]:
a. Transform Case / Case Folding
Pada tahap ini di lakukan penyeragaman jenis huruf pada dokumen atau mengubah semua huruf menjadi huruf kecil, pada tahap ini juga di lakukan pembersihan atau penghapusan pada semua dokumen yang berisi angka, url (http;//), username (@), hastag (#), delimiter seperti koma (,), dan titik (.) serta tanda baca lainya.
b. Tokenizing
Pada tahap ini dilakukan pemenggalan kata menjadi kalimat atau proses memecahkan dokumen menjadi kata perkata.
c. Filtering
Pada tahap ini berfungsi untuk membuang kata-kata yang di anggap tidak penting dan berfungsi untuk mereduksi dimensi data sehingga tidak terlalu besar.
d. Stopword Removal
Proses menghilangkan kata yang tidak mendiskripsikan sesuatu yang tidak perlu digunakan.
e. Stemming
Pada tahap terakhir prepocessingini dilakukan proses pengambilan kata dasar dengan membuang imbuan kata.Kata imbuhan yang dihilangkan terdiri dari awalan (prefix),akhiran (suffix), sisipan (infix), dan gabungan awalan-akhiran (confix).
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2.1.4. Data Mining
Data mining adalah proses mencari informasi atau pola yang menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu[11].
Pengelompokan dalam data mining terbagi menjadi empat kategori yaitu metode asosiasi, metode clustering, metode klasifikasi, metode prediksi, dan metode estimasi [12].
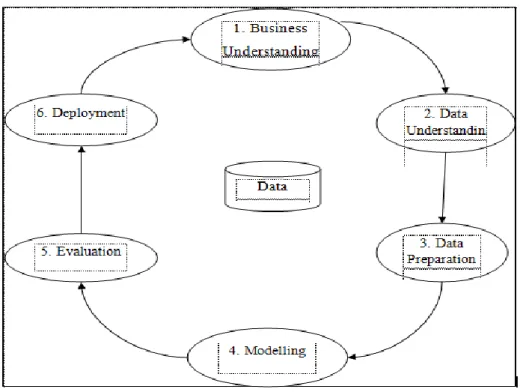
Data Miningmerupakanpenerapan metode statistik dan logika untuk mengolah dataset yang sangat besar [10]. Pada tahun 1980 bidang data mining mulai ada dan terus berkembang berkembang pada tahun 1990 hingga saat ini.
Pada tahun 1999 beberapa perusahaan besar seperti perusahaan otomotif Daimler- Benz, penyedia asuransi OHRA, produsen perangkat keras dan perangkat lunak NCR Corp dan statistik pembuat software SPSS, Inc mulai bekerja sama membuat suatu standarisasi pendekatan untuk data mining. Standarisasi yang dibentuk dari hasil kerjasama adalah pendekatan untuk data mining dengan nama CRISP-DM, the CRoss-Industry Standard Process for Data Mining. Adapun tahapan dalam CRISP-DM terdapat pada Gambar 2.2.
Sumber:[10]
Gambar 2.2. CRISP-DM Conceptual Model
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Terdapat 6 langkah dalam standarisasi pendekatan CRISP-DM untuk melakukan pengolahan data yaitu:
1. Business Understanding
Pada tahapan ini peneliti menterjemahkan tujuan dari penelitian yang akan dilakukan. Perspektif dari bisnis juga harus benar-benar dipahami. Tahapan ini juga akan mengungkap faktor penting dari tahapan awal yang akan mempengaruhi hasil proyek. Tahapan ini dapat dilakukan dengan mengumpulkan data awal dan hasil dengan kegiatan untuk memperoleh data yang terintegrasi, melakukan identifikasi terhadap masalah kualitas data, dan menemukan wawasan pertama untuk subset menarik yang terkait dengan pembentukan hipotesis.
2. Data Understanding
Tahapan ini dapat terselesaikan dengan mengumpulkan data. Ketika terdapat data yang diperoleh lebih dari satu dataset, maka diperlukan proses integrasi.
Analisis perlu dikembangkan terhadap penyelidikan data untuk mengenal lebih lanjut mengenai data dan pencarian pengetahuan di awal.
3. Data Preparation
Tahapan persiapan data mencakup koleksi data, penilaian, konsolidasi dan pembersihan, pilihan data, dan transformasi. Pembangunan dataset akhir dari data mentah awal juga dilakukan dalam tahapan ini. Peneliti juga dapat melakukan perubahan pada variabel ketika diperlukan. Persiapan data awal dilakukan hingga siap untuk menerapkan permodelan.
4. Modeling
Model dalam data mining adalah representasi terkomputerisasi dari pengamatan dunia nyata. Model merupakan aplikasi algoritma untuk mencari, mengidentifikasi, dan menampilkan pola atau pesan dalam data. Ada dua jenis dasar atau jenis model dalam penggalian data yaitu mereka yang mengklasifikasikan dan mereka yang memprediksi.
5. Evaluation
Tahapan ini melakukan evaluasi terhadap satu atau lebih model yang digunakan dalam fase permodelan. Evaluasi juga dapat dilakukan untuk menerapkan apakah suatu model sudah sesuai dengan tujuan pada fase awal.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Selain itu, evaluasi juga digunakan untuk menentukan permasalahan penting dari bisnis atau penelitian yang tidak dapat ditangani dengan baik.
Pengambilan keputusan yang terkait dengan penggunaan hasil dari data mining juga dapat diputuskan setelah melihat hasil dari evaluasi.
6. Deployment
Tahap ini menjadi tahap akhir dalam CRISP-DM untuk menentukan manfaat dari hasil data. Pada tahap ini dapat diambil hasil evaluasi dan menyimpulkan strategi terbaik agar penelitian dapat diimplementasikan. Dokumentasi prosedur penelitian juga dapat dilakukan untuk penggunaan model selanjutnya.
2.1.5. Klasifikasi
Klasifikasi merupakan suatu proses yang bertujuan untuk menentukan suatu obyek kedalam suatu kelas atau kategori yang sudah ditentukan sebelumnya.
Menurut klasifikasi adalah proses dari pembangunan terhadap suatu model yang mengklasifikan suatu objek sesuai dengan atribut-atributnya. Klasifikasi data ataupun dokumen juga dapat dimulai dari membangun aturan klasifikasi tertentu yang menggunakan data training yang sering disebut sebagai tahapan pembelajaran dan pengujian digunakan sebagai data testing [13].
Klasifikasi adalah salah satu pembelajaran yang paling umum di data mining. Klasifikasi didefinisikan sebagai bentuk analisis data untuk mengekstrak model yang akan digunakan untuk memprediksi label kelas. Kelas dalam klasifikasi merupakan atribut dalam satu set data yang paling unik yang merupakan variabel bebas dalam statistik[12].
Klasifikasi data terdiri dari dua proses yaitu tahap pembelajaran dan tahap pengklasifikasian. Tahap pembelajaran merupakan tahapan dalam pembentukan model klasifikasi, sedangkan tahap pengklasifikasian merupakan tahapan penggunaan model klasifikasi untuk memprediksi label kelas dari suatu data.
Contoh sederhana dari teknik data mining klasifikasi adalah pengklasifikasian hewan berdasarkan atribut jumlah kaki, habitat dan organ pernafasannya akan diklasifikasikan ke dalam dua label kelas yaitu unggas dan ikan. Label kelas unggas adalah data yang memiliki jumlah kaki dua, habitatnya di darat, dan organ pernafasannya menggunakan paru-paru, sedangkan label kelas ikan adalah data
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
yang memiliki jumlah kaki nol (tidak memiliki kaki), habitat di air, dan organ pernafasannya menggunakan insang. Banyak algoritma yang dapat digunakan dalam pengklasifikasian data, namun dalam penelitian ini hanya akan membandingkan dua algoritma saja, yakni Naive Bayes dan SupportVector Machine. Berikut ini algoritma klasifikasi yang akan digunakan dalam penelitian ini antara lain:
2.1.5.1.Support Vector Mechine
Support Vector Machine (SVM) adalah metode yang digunakan untuk menganalisa data dan mengenali pola yang bisa digunakan utnuk pengklasifikasian. Berbagai penelitian menggunakan algoritma SVM juga terkait dengan keunggulan yang dimiliki. SVM mempunyai kelebihan dibandingkan dengan algoritma lain yaitu proses training dapat dilakukan sekali saja sehingga tidak mengalami overfitting dan mendapatkan solusi optimal [14].
Teknik SVM termasuk dalam pembelajaran mesin yang sangat populer untuk klasifikasi dan analisis regresi, yang telah diterapkan di berbagai bidang seperti kategorisasi teks dan pengenalan pola [15] SVM membuat hyperplane untuk memaksimalkan margin antara kelas yang berbeda dan masalah optimisasi.
dapat diungkapkan sebagai berikut:
{
Maximize 2
||w||
subject to 𝑦𝑖(w. 𝑥𝑖 − b) ≥ 1 for any 𝑖 ∈ {1,2, … . . , n}
Dimana {(x1,y1),...,(xn,yn)}, xi Rn, yi {-1,1} berdiri untuk data set dari n data instances dengan penjelasan kelas yang sesuai.
SVM pertama kali diperkanalkan pada tahun 1992 oleh Vapnik sebagai rangkaian dari beberapa konsep – konsep unggulan dalam bidang pattern recognition dan SVM secara umum memiliki karakteristik, Kelebihan dan Kekurangan sebagai berikut [16]:
1. Karakteristik SVM
a. Secara prinsip SVM adalah linear classifier.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
b. Pattern recognition pada SVM dilakukan dengan mentransformasikan data pada input space ke ruang yang memiliki dimensi yang lebih tinggi. Proses tersebut juga yang membedakan SVM dari solusi pattern recognition pada umumnya.
c. Menerapkan strategi Structural Risk Minimization (SRM).
d. Prinsip kerja SVM pada dasarnya hanya mampu menangani klasifikasi dua kelas.
2. Kelebihan SVM
a. Generalisasi Generalisasi didefinisikan sebagai kemampuan suatu metode untuk mengklasifikasikan suatu pattern, yang tidak termasuk data yang dipakai dalam fase pembelajaran metode tersebut.
b. Curse of Dimensionality Curse of Dimensionality didefinisikan sebagai masalah yang dihadapi suatu metode pattern recognition dalam mengestimasikan parameter misal jumlah hidden neuron pada neural network, stopping criteria dalam proses pembelajaran, dsb dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional ruang vektor data tersebut. Semakin tinggi dimensi dari ruang vector informasi yang diolah, membawa konsekuensi dibutuhkannya jumlah data dalam proses pembelajaran.
c. Easibility SVM dapat diimplementasikan realtif mudah, karena proses penentuan support vector dapat dirumuskan dalam QP problem Quadratic Progamming.
3. Kekurangan SVM
a. Sulit dipakai dalam problem berskala besar. Skala besar dalam hal ini dimaksudkan dengan jumlah sample yang diolah.
b. SVM secara teorik dikembangkan untuk problem klasifikasi dengan dua class atau lebih.
2.1.5.2.Naive Bayes
Algoritma NB merupakan algoritma klasifikasi berdasarkan probabilitas dalam statistik yang dikemukakan oleh Thomas Bayes yang memprediksi peluang di masa depan berdasarkan peluang di masa sebelumnya (teorema
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Bayes). Metode ini kemudian dikombinasikan dengan “naive” dimana kondisi antar atribut saling bebas tidak berhubungan satusama lain [17].
Metode yang digunakan adalah metode NB yang mempunyai tahapan- tahapan antara lain: proses pembersihan data (Data Cleaning), integrasi data (Data Integration), seleksi data (Data Selection), transformasi data (Data Transformation), proses mining, evaluasipola (Patterin Evaluation), presentasi pengetahuan (Knowledge Presentation) [18].
Algoritma NB merupakan teknik prediksi yang berbasis probabilistik sederhana yang berdasar pada penerapan Teorema Bayes yang memiliki asumsi dengan independensi (ketidak tergantungan) yang kuat (naif) [19]. Penamaan algoritma tersebut dilakukan oleh Thomas Bayes yang mendalilkan dua jenis probabilitas, yaitu [20]:
- Probabilitas Posterior H dikondisikan pada X: [P (H / X)]; dan
- Kemungkinan Sebelumnya H terlepas dari pengamatan atau kondisi atau informasi
Dimana:
X adalah data Bukti dan H adalah hipotesis. Oleh karena itu, probabilitas yang dimiliki hipotesis H
Mengingat "bukti" atau data yang diamati X diberikan sebagai
P (X | Y) = P (Y | X) P (X ... (2.1) P(Y)
Keterangan:
Y = data dengan kelas yang belum diketahui
X = hipotesis data Y merupakan suatu kelas spesifik P (X | Y) = probabilitas hipotesis X berdasarkan kondisi Y P(X) = probabilitas hipotesis X
P(Y | X) = probabilitas Y berdasarkan kondisi pada hipotesis X P(Y) = probabilitas dari Y
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Kelebihan Naive Bayes :
a. Menangani kuantitatif dan data diskrit
b. Kokoh untuk titik noise yang diisolasi, misalkan titik yang dirata – ratakan ketika mengestimasi peluang bersyarat data.
c. Hanya memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (rata – rata dan variansi dari variabel) yang dibutuhkan untuk klasifikasi.
d. Menangani nilai yang hilang dengan mengabaikan instansi selama perhitungan estimasi peluang
e. Cepat dan efisiensi ruang Kekurangan Naive Bayes :
a. Tidak berlaku jika probabilitas kondisionalnya adalah nol, apabila nol maka probabilitas prediksi akan bernilai nol juga
b. Mengasumsikan variabel bebas 2.1.4.3 K- Nearest Neighboor
K-Nearest Neighboor (KNN) adalah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat atau memiliki persamaan ciri paling banyak dengan objek tersebut [21].
Prinsip kerja KNN adalah mencari jarak terdekat anatar data yang akan dievaluasi dengan K tetangga terdekatnya dalam data pelatihan. Data pelatihan diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menajdi bagian-bagian berdasarkan klasifikasi data pelatihan.Langkah – langkah untuk menghitung algoritmaKNN, sebagai berikut [21]:
a. Menentukan nilai k
b. Menghitung kuadrat jarak euclid (query instance) masing – masing objek terhadap training data.
c. Mengurutkan objek – objek tersebut ke dalam kelompok yang mempunyai jarak euclid terkecil
d. Mengumpulkan label class Y (klasifikasi Nearest Neighborhood)
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Kelebihan KNN memiliki beberapa kelebihan yaitu bahwa dia tangguh terhadap training data yang noisy dan efektif apabila data latih nya besar.
Kelemahan KNN adalah sebagai berikut:
a. KNN perlu menentukan nilai dari parameter K (jumlah dari tetangga terdekat) b. Pembelajaran berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus
digunakan dan atribut mana yang harus digunakan untuk mendapatkan hasil yang terbaik
c. Biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap sample uji pada keseluruhan sample latih
2.1.6. TF-IDF
TF-IDF merupakan suatu metode untuk mencari pembobotan kata (term weighting). Fungsi dari term weighting ini adalah untuk menggantikan nilai sel VSM yang awalnya adalah jumlah frekuensi kemunculan terms untuk masing- masing dokumen dengan nilai perhitungan term weighting dengan TF-IDF. Proses TF-IDF diawali dengan input matriks yang merepresentasikan dokumen dengan term. Lalu untuk mendapatkan nilai TF-IDF setiap term terhadap dokumen maka dilakukan proses nilai frekuensi kemunculan kata pada sutau dokumen yang di sebut dengan Term Frequency (TF) dikali dengan Inverse Document Frequncy (IDF) yang merepresentasikan sedikit tidaknya jumlah dokumen yang memiliki kata tersebut dengan penambahan fungsi log dalam prosesnya. TF-IDF Tidak hanya melihat dari jumlah kemunculan setiap kata saja tapi juga pengaruh pentingnya kata tersebut dalam suatu korpus [22].
2.1.7. Cross Validation
Pendekatan standar untuk mengukur daya prediksi adalah cross validation yang dilakukan dengan membagi data tersedia menjadi train set, kemudian digunakan untuk melatih model, dan test set. Prosedur tidak terlihat oleh model selama pelatihan dan digunakan untuk menghitung kesalahan prediksi[23].
Metode ini merupakan suatu metode statistik yang digunakan menganalisis dan mengukur keakuratan hasil percobaan pada data yang independen. Metode ini membagi sebuah data menjadi beberapa subdata yang selanjutnya subdata satu digunakan untuk mengkonfirmasi kebenaran subdata yang lain.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Salah satu subbagian data pada cross validation dijadikan sebagai validator dan testing sedangkan K-1 data digunakan sebagai data training. Proses akan dilakukan berulang sebanyak K kali untuk setiap subbagian data. Hasil dari pengujian adalah rata-rata dari K kali pengujian yang dilakukan pada data. Teknik validasi silang yang sering digunakan adalah 10 fold cross validation dan menjadi teknik yang terbaik [24].10-fold cross validation akan memperkirakan model 10 kali (90% dari data setiap kali) dan hasilnya diterapkan pada 10% sisanya dari contoh [25].
2.1.8. Confution Matrix
Confusion matrix digunakan sebagai indikasi aturan sifat klasifikasi (diskriminan). Confusion matrix ini berisi jumlah elemen yang telah dikelompokkan dengan benar atau tidak benar untuk setiap kelas. Salah satu manfaat dari confusion matrix adalah mudah untuk melihat sistem confusion dua kelas. Untuk setiap contoh di test set, akan membandingkan kelas yang sebenarnya dengan kelas classifier. Contoh positif (negatif) yang diklasifikasikan dengan benar oleh classifier disebut True Positive (true negative), contoh positif (negatif) yang salah diklasifikasikan adalah disebut False Negative (false positive) Rokach et,al. 2015 dalam [17].
Metode ini menggunakan tabel matrix, jika dataset hanya terdiri dari dua kelas, kelas yang satu di anggap sebagai positif dan yang lainnya negatif.
Tabel 2.1. Model Confution Matrix
Kenyataan Diprediksi sebagai
+ -
+ True Positive False Positive
- False Negative True Negative
True Positive adalah jumlah record positif yang diklasifikasikan sebagai positif, false positive adalah jumlah record negatif yang diklasifikasikan sebagai positif, false negative adalah jumlah record positif yang diklasifikasikan sebagai negatif, true negative adalah jumlah record negative yang diklasifikasikan sebagai negatif, kemudian masukkan data uji. Setelah data uji dimasukkan ke dalam confusion matrix, nilai-nilai yang telah dimasukkan tersebut untuk dihitung jumlah
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
sensitivity (recall), specificacy, precission, dan accuracy. Sensitivity digunakan untuk membandingkan jumlah true positive terhadap jumlah record yang positif sedangkan specificity adalah perbandingan jumlah true negatives terhadap jumlah record yang negatif. Untuk menghitung akurasi digunakan persamaan di bawah Accuracy = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 ... (2.2) Keterangan:
TP = jumlah true positive TN = jumlah true negative FP = jumlah false positive FN = jumlah false negative
Precision adalah rasio jumlah parameter yang benar yang termasuk ke dalam true positive dan jumlah parameter yang salah tetapi benar (false positive). Recall adalah rasio jumlah parameter yang benar (true positive) dengan jumlah parameter yang benar true positive dan jumlah parameter yang salah (false negative).
Adapun rumus untuk menghitung precision dan recall sebagai berikut:
Precision = 𝑇𝑃
𝑇𝑃+𝐹𝑃 ... (2.3) Recall = 𝑇𝑃
𝑇𝑃+𝐹𝑁 ... (2.4)
2.1.9. ROC (Receiver Operating Characteristic).
Analisis selanjutnya dilakukan dengan Kurva ROC (Receiver Operating Characteristic). ROC adalah sebuah grafik yang digunakan untuk menilai hasil dari suatu prediksi. Dalam model klasifikasi ROC adalah suatu teknik visualisasi, pengaturan dan pemilihan klasifikasi berdasarkan hasil performance. Grafik ROC akan membentuk garis yang menunjukkan hasil prediksi dari model klasifikasi yang digunakan terhadap data. Apabila garis tersebut berada di atas diagonal grafik maka hasil klasifikasi bernilai baik (good classification), sedangkan garis yang berada di bawah diagonal grafik menghasilkan nilai klasifikasi yang buruk (poor classification). Garis yang menempel pada sumbu Y menunjukkan grafik tersebut menunjukkan klasifikasi yang baik [26].
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Dari grafik ROC akan diperoleh nilai AUC (Area Under the ROC Curve) untuk menganalisis hasil prediksi klasifikasi.Penentuan hasil prediksi klasifikasi dilihat dari batasan nilai AUC pada tabel 2.2, sebagai berikut [26]:
Tabel 2.2. Kategori Klasifikasi dengan menggunakan hasil AUC
Nilai AUC Kategori
0.90 – 1.00 Excellent classification
0.80 – 0.90 Good classification
0.70 – 0.80 Fair classification
0.60 – 0.50 Poor classification
0.50 – 0.60 Failur classification
Kurva Receiver Operation Charactheristic (ROC) menjelaskan pengukuran lain menggunakan kurva ROC yang menggambarkan trade off antara true positive terhadap false positive.
Sumber : [26]
Gambar 2.3. Kurva ROC
Kurva ROC di mana sumbu X mewakili tingkat false positive dan Y –axis merupakan tingkat true positive. Titik ideal pada ROC Kurva akan menjadi (0,100), Artinya, semua contoh positif diklasifikasikan dengan benar dan tidak ada contoh negatif yang salah klasifikasi sebagai positif.
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2.1.10. KNIME
KNIME merupakan landasan menggabungkan ratusan node pengolahan data input/output, Preprocessing dan pembersihan, pemodelan analsisi dan data mining serta berbagai tools interaktif, seperti plot pancar koordinat pararel dan lain lain [27].
KNIME atau Konstanz Information Miner Merupakan Sofware analis data yang bersifat open source. Knime banyak di gunakan untuk proses Data mining karena sangat memberikan kemudahan dalam pengolahan data skala besar secara cepat. KNIME juga dapat di gunakan untuk mengolah big data secara cepat sehingga dapat menghemat waktu pengerjaan. Berikut adalah tampilan dari aplikasi KNIME:
Gambar 2.4. Tampilan Aplikasi KNIME
2.1.11. Gata Framework
Pada tahun 2018, seorang pribadi bernama Windu Gata mengembangkan aplikasi berbasis web untuk pra-pemrosesan seperti penghapusan stopwords Indonesia, bahasa Indonesia, akronim Indonesia, bahasa gaul Indonesia dan lainnya dimaksudkan untuk membantu dalam melakukan penelitian di bidang penambangan teks Bahasa Indonesia. Aplikasi ini dibangun menggunakan kerangka kerja yang disebut Kerangka Kerja GATA
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
(http://www.gataframework.com). Aplikasi ini merupakan alternatif dalam teks pra-pemrosesan Indonesia, aplikasi juga menyediakan fitur antarmuka program aplikasi (API) untuk mengirim data dari aplikasi eksternal. Sedangkan kerangka kerja GATA adalah kerangka kerja yang didasarkan pada pemrograman PHP bahasa yang dikembangkan dengan nama MTG Framework pada tahun 2012 dan mengubah namanya menjadi Kerangka kerja GATA pada tahun 2017. Kerangka kerja GATA telah mampu mengatasi berbagai masalah eksternal, yaitu kegunaan, kemampuan, respons, keamanan, keberadaan, dan keandalan, serta faktor internal, yaitu kemudahan sintaks atau kode yang mudah digunakan dan telah menggunakan Model View Controller (MVC) pola pemrograman. Saat ini, perangkat aplikasi dapat memproses pra-pemrosesan dalam bentuk aformulir tunggal, atau unggah data dalam bentuk file Ms. Excell dengan templat dan layanan web [28].
Dalam aplikasi KNIME sudah ada fasilitas kamus untuk mengubah akronim, dan stopwords, tetapi masih terbatas pada bahasa Inggris, Cina, dan Arab, sedangkan untuk bahasa Indonesia masih belum tersedia. Tahap pemrosesan teks bahasa Indonesia untuk menghapus tagar, @, HTTP, Bahasa Indonesia akronim, Stopwords Indonesia, dan stemming bahasa Indonesia dapat menggunakan aplikasi Kerangka GATA seperti yang ditunjukkan pada Gambar 2.3. Teknik yang biasa digunakan untuk pra-pemrosesan teks bahasa Indonesia adalah @annotation, Hapus URL, Tokenisasi: REGEXP, Transformasi Tidak (Negatif), Bahasa Indonesia stemming, dan Penghapusan Stopwords Indonesia.
Penjelasan tentang setiap opsi teknik di GATA Kerangka penambangan teks antara lain sebagi berikut [28]:
1. @ Annotation Removal
@ Annotation Removal digunakan untuk menghapus tanda @ dan deskripsi yang sering digunakan untuk menyapa atau tandai akun lain.
2. Transformation: Remove URL
Remove URL digunakan untuk menghapus URL dari komentar yang digunakan.
3. Tokenization: Regexp
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Digunakan untuk menghapus tanda selain huruf dan juga menghilangkan angka.
4. Transformation NOT
Pada tahap ini proses mubungkan kata-kata yang memiliki makna terbalik seperti "tidak", "tidak", dll.
5. Indonesian Stemming
Indonesai Stemming merupakan proses mengembalikan kata menjadi kata dasar.
6. Indonesian Stopword Removal
Proses menghapus kata-kata yang tidak memiliki arti.
Dengan menggunakan aplikasi Gata Framework kita dapat menginport file yang berisi text review aplikasi tik-tok yang sudah di save dengan format excel 2003. Berikut adalah tampilan dari aplikasinya:
Gambar 2.5. User InterfaceGataFramework Sumber: http://www.gataframework.com/textmining/
2.1.12. Web Scraping
Web scraping adalah teknik yang di gunakan untuk menuai informasi dari halaman website. Teknik scraping web sering di manfaatkan untuk menghimpun data penting berupa teks. Untuk mengotomatisasi proseng scraping salah satunya
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
adalah dengan memanfaatkan perangkan lunak yang menyediakan antar muka untuk merekam informasi pada website [29]. Salah satu aplikasi yang bisa digunakan untuk proses scraping adalah web harvy.WebHarvy adalah web Scraping perangkat lunak cerdas yang secara otomatis dapat mengakses data dari halaman web dan menyimpan konten diekstrak dalam format yang berbeda.
Dengan menggunakan software ini, dapat mengikis teks, gambar, URL, dan email dari situs web, dan menyimpannya dalam berbagai format otomatis, cepat dan mudah. Berikut adalah tampilan dari WebHarvy :
Gambar 2.6. Tampilan WebHarvy
2.2.Tinjauan Studi
Studi literatur mengenai pembahasan text mining telah banyak di lakukan pada peneltiian sebelumnya, Berikut adalah penelitian sebelumnya yang dilakukan untuk mendukung teoritis dari peneltian ini adalah sebagi berikut:
2.2.1. Penelitian Terkait
Beberapa penelitian terkait dengan pemberian klasifikasi terhadap analisa sentimen yang telah dilakukan.Tinjauan dari studi literatur yang terkait dengan pembahasan penggunaanalgoritma klasifikasi untuk analisa review pengguna aplikasi menggunakan algoritma KNN, NB dan SVM .Sebuah analisa sentimen banyak dipakai pada penelitian sebelumnya dengan menggunakan metode-metode algoritma lainya. Berikut hasil penelitian algoritma klasifikasi text mining berdasarkan literatureyang berhasil dikumpulkan: