Computational dynamics of gradient bistable networks
Vladimir Chinarov *, Michael Menzinger
Department of Chemistry,Uni6ersity of Toronto,Toronto Ont.,Canada M5S3H6
Abstract
We describe a neural-like, homogeneous network consisting of coupled bistable elements and we study its abilities of learning, pattern recognition and computation. The technique allows new possibilities of pattern recognition, including the memorization and perfect recall of several memory patterns, without interference from spurious states. When the coupling strength between elements exceeds a critical value, the network readily converges to a unique attractor. Below this critical value one could perfectly recall all memorized patterns. © 2000 Elsevier Science Ireland Ltd. All rights reserved.
Keywords:Real-valued network; Bistable elements; Gradient dynamics
www.elsevier.com/locate/biosystems
1. Introduction
Computational aspects and dynamics of com-plex interacting systems are often simulated and
analyzed using the neural network (NN)
paradigm (Hopfield and Tank, 1986; Amit, 1989; Hoppensteadt and Izhikevich, 1997). NNs are ap-plied routinely to diverse aspects of information science and biology, including the prediction of tertiary structure of proteins (Demchenko and Chinarov, 1999). The problems of learning and pattern recognition are central to these areas of research (Rumelhart, 1986; Chinarov et al., 1999; Haykin, 1999). Hopfield-type models, amongst others, are convenient for pattern recognition since each of its dynamical (fixed-point) attractors corresponds to a stored memory pattern (Pineda, 1988; Amit, 1989; Haken, 1991).
Networks based on principles other than Hopfield’s approach are known and examples include:
1. gradient nets and their generalizations, includ-ing short-range diffusive interactions and
sub-threshold periodic forcing (Bressloff and
Popper, 1998);
2. bistable networks (Chinarov 1998; Chinarov et al., 1999) exploiting the idea that ion channels in biological membranes are self-organized dy-namic systems, functioning in a multistable regime (Chinarov et al., 1992);
3. relaxation oscillators with two time scales modes (Terman and Wang, 1995; Chinarov,
1998). The stochastic bistable oscillator
Hopfield-type network model (Han et al., 1998);
4. oscillatory models (Borisyuk and Hoppen-steadt, 1998).
* Corresponding author. Tel.: +1-416-9786158.
E-mail address:[email protected] (V. Chinarov)
In this paper we propose a novel neural-like network which exploits well-understood principles of nonlinear dynamics, the physics of many-body interactions, and some neurophysiological princi-ples, such as associative memory, learning and adaptation to a changing environment. Its com-putational abilities derive from the relaxation dy-namics of coupled overdamped oscillators that move in a double-well potential. Each node can thus be found in one of two (negative or positive) bistable states. The strength of the interactions between network elements is given by a coupling parameter. Due to its attractive features which include the absence of spurious states and a high memory capacity and the absence of spurious states, we believe that this model may be an effective tool for describing and analyzing differ-ent phenomena that require storage and recall of patterns, including the modeling of protein folding.
2. Model of bistable neural-like network
The model consists ofNbistable elements fully
connected with each other. It is characterized by the multistability and the gradient dynamics of each node. This ensures the rapid convergence to its fixed point attractors. The network dynamics is based on the following equations:
dxi/dt= −#V
o/#xI+aSjwijxj+bi, (1)
where theith component of the network statexiis
considered as an activity of bistable networks’ element andb={b1,..,bi,..,bN} is called bias
vec-tor. The local potential Vo(x1,x2,…,xN) is the
sum (over all nodes, as the net is fully connected) of local double-well potentials
Vo(x1,x2,…,xN)=SiVi(xi) (2)
In contrast to traditional connectionist
Hopfield-type networks which use perceptron-based logic units, this network is governed by the gradient of a potential:
dxi/dt= −#V/#xI,
V=Vo+Vb+Vint (4)
where the interaction term Vint is given by
Vint=1/2aSiSjwijxixj (5)
a is a scaling factor that expresses the global
coupling strength. The linear bias potential Vbis
defined as
Vb=bixi (6)
In Eqs. (1) and (5) the coupling coefficients wij
characterize the pair-wise interactions between
el-ements moving in a potential Vo+Vb. In the
framework of traditional neurodynamics the
cou-pling matrix w may be constructed by Hebb’s
learning rule (Amit, 1989; Haykin, 1999):
w=1/pSkpjkjk (7)
from the p configurations jk, (k=1,...,p) we
want the network to memorize.
Each element of the network is an overdamped nonlinear oscillator moving in a double-well po-tential. All network limit configurations are con-tained within the set of fixed point attractors. For
a given coupling matrix wij, the network evolves
towards such a limit configuration starting from any initial input configuration of bistable ele-ments. Note that the elements are distributed among left and right wells of the potential with negative and positive values, respectively.
The actual values of elements in all the configu-rations are not the bipolar ones with values
re-stricted to equal to −1 or +1, but they are real
values established by the network when it reaches its final state. These values correspond to the minima of the double-well potentials for each element. These fixed-point attractors do not coin-cide, like in all Hopfield-type networks, with the corners of hypercube. Therefore, the network de-scribed above is a real-valued bistable network.
3. Network performance
The configuration ofNelements that have
pos-itive and negative values is taken as a pattern j.
from the stored (desired) patterns by inverting the signs of some of its elements. Fig. 1 shows an example of the network performance. The net-work dynamics is described by Eqs. (1) – (4).
Seven patterns (j1,..,j7) were memorized via
Hebb’s rule (7) in a network consisting of N=8
elements. Only one memorized pattern is given here. Each column represents a pattern where black circles depict the element’s negative values (the left well of the double-well potential is occu-pied) and white circles depict the element’s posi-tive values (the right well is occupied). The first column represents one of the memorized patterns, the second column a distorted, applied pattern in which the signs of four elements were inverted (50% of distortion). The eight remaining columns depict the convergence of this applied pattern to the desired one. Only six iterations are needed to recall the desired configuration. Each iteration corresponds to a rearrangement of configuration in which at least one element changes its sign.
Besides memorized patterns only the patterns that are fully antisymmetrical to them could be recalled. The latter have inverted signs of all elements with respect to the original pattern and therefore have the same energy. No spurious states corresponding to linear combinations of stored patterns arise during the learning and re-trieval process.
A second example of pattern retrieval is shown in Fig. 2. Several patterns were memorized by a
Fig. 2. Example of memorized pattern in a network with 30 coupled bistable units (panel a) and convergence to this state (panel c) from random initial configuration (panel b). White (gray) cells depict positive (negative) values of a pattern.
network with 30 coupled bistable elements. Only one of them is shown (panel a). White (gray) cells correspond to positive (negative) values of the
memorized pattern j — the corresponding
bistable element is in the right (left) well of the potential given by Eq. (3). A random initial configuration (panel b) converges to this state (panel c).
We introduce now useful abbreviations tradi-tionally used to represent the 20 amino acids in proteins. This gives the possibility to analyze con-cisely each configuration. To encode each ‘amino acid’, six bits are used (see Table 1). Unfortu-nately, this encoding scheme gives additional five configurations (called Mut1 – Mut5 in Table 1). For example, the following configurations:
1. 1 – 1111 – 1 1 – 111 – 11 1 – 1 – 111 – 1 – 1 – 11 – 11 – 1 1 – 1 – 11 – 1 – 1 1 – 11 – 11 – 1
2. – 1 – 11 – 11 – 1 – 1 – 1111 – 1 1 – 1111 – 1 – 1 –
111 – 11 – 1 – 11 – 111 1 – 1 – 111 – 1
read as: (a) AlaArgHisValLeuCys and (b)
ValSerAlaThrTyrHis.
We give now the third example of network performance. Seven patterns (P1 – P7) were used
to generate the coupling matrix wij using Hebb’s
rule for the N=36 network. They are listed in
Table 2.
The energies E (arbitrary units) of these
pat-terns were calculated using the following
expression:
E=SiVi(xi)+1/2aSiSjwijxixj+bixi (8)
For the relatively large value of the coupling
constant a=7 only one sequence
(GluMet-IleLysAspGly) is retrieved (E= −109.23),
Table 1
Scheme to encode ‘amino acids’ using six-bit pattern
1 1 1 –1 Ala
ing from any initial random input configuration. This means that, for strong enough coupling, the system has only a single fixed-point attractor. For this case the time course of energy relaxation is shown for binary configurations in Fig. 4 (panel (a)) and the ‘sequence trajectory’ (from initial random pattern to final stable configuration) is given in Table 3 where the initial random
se-quence is PheLeuPhePheIleGly (E= −8.06) and
successive intermediate configurations are shown. The number of time steps that are needed to
achieve a given state is denoted by J. In binary
representation the energy of any intermediate state is constant until the next rearrangement of
network elements occurs (atJ=32, 44, 51,…). At
some moment of time (J=80) the network settles
down at its final, stable configuration. In this concrete case the retrieved sequence is:
GluMet-IleLysAspGly (E= −109.23).
If one adds one or more patterns (sequences) to the training set P1 – P7, the coupling matrix changes and another unique pattern is retrieved
(for the appropriate value of a, say for a=7).
This may be considered as a soft adaptation to a changing environment (see Table 4).
Depending on the coupling strength a one
could either perfectly recall all memorized
pat-terns (aBacr) starting from any random initial
configuration, or retrieve only one stable
configu-ration (a\acr). We anticipate that this last,
re-markable property — fast convergence of the trained network to a unique, stable pattern, the configuration and energy of which depends on the patterns used to train a network, may be used in different applications such as robotic control or protein folding.
Table 2
Memorized patterns and their energies
P1=Pro Gly Leu Tyr Asp His E= −89.39
E= −91.76 P2=ProMet Phe Lys Gln Gly
P3=Asp Val Pro Gly Gly His E= −72.76 P4=GlnMet Asn Glu Glu Lys E= −88.50 P5=Tyr Val Ile Val Leu Glu E= −52.46
E= −68.63 P6=Tyr Phe Gly Tyr Tyr Ile
P7=Phe Asp Tyr Ile Asp Ile E= −72.15
Table 4
Set of additional learned patterns (see Table 2) and retrieved configuration
Additional pattern
Learned set Retrieved pattern P1–P7 TyrTyrTyr- GluLysIleAspAspGly
Intermediate patterns needed to achieve a final configuration
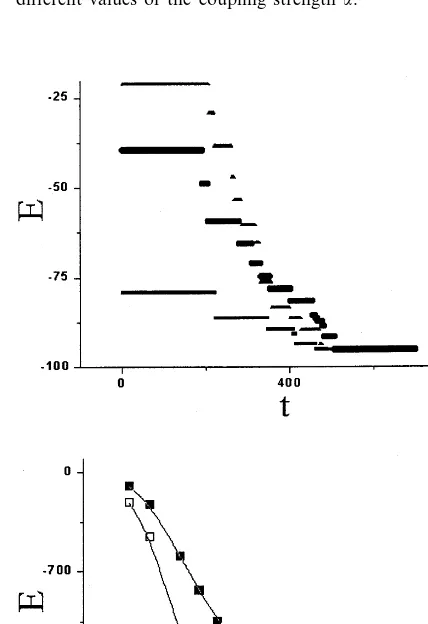
Fig. 3. Time-course of N=36 network mean activity for different values of the coupling strengtha.
This effect is illustrated in detail in Fig. 3 where the time courses of the mean activity (the average
of all activitiesxi) are given for different values of
the coupling strength a. One of the seven
memo-rized patterns (TyrPheGlyTyrTyrIle) was taken as
an input. For a=3, 4 the final patterns are the
same as the input (the resulting activities are
depicted by solid curves). Fora=0.5, 1, 2, on the
other hand, the network relaxes to different
at-tractors, described by the sequences (GluMetIle-AspAspGly), (ProMetIle(GluMetIle-AspAspGly), (ProMet-LeuAspAspGly), respectively. This means that the final, unique configuration is determined not only by the information content of network, contained
in the coupling matrix wij but also by the global
coupling strength which may be considered as an order parameter.
Fig. 4 shows the time course of energy relax-ation for the network described by Eqs. (1) – (4)
with a=7. Panel (a) illustrates the case of binary
configurations — only +1 or −1 values are
used to describe the activities of the right or left wells, respectively. The relaxation proceeds in steps and the plateaus correspond to metastable states including the memorized patterns. As shown in the lower panel (b), however, for real-valued configurations, defined by real rather than binary numbers, the relaxation is monotonic.
4. Conclusion
We described the performance of neural-like gradient network consisting of strongly coupled bistable elements with regard to its abilities of learning and pattern recognition.
The advantages of the proposed approach are: conceptual and physical simplicity, absence of spurious memory states, and arising from it a greatly enhanced memory capacity, high fault tol-erance in recognition of corrupted patterns, and rapid convergence to fixed point attractors (fast recall of memorized patterns). The rapid conver-gence of any random pattern to one of the native states of network is guaranteed by its gradient dynamics.
A problem that occurs in areas such as robotics control is the need to adapt to a changing
ronment. This may be readily achieved by a tracking algorithm that keeps the system’s native state (attractor) focused on a moving target state, subject to a given error criterion.
It was shown that the proposed approach en-sures the network convergence to unique, lowest energy attractor (ground state), rather than to one of the several attractors that the network can store. This change of emphasis on the un-failing flow to the lowest energy attractor, re-gardless of the coexistence of other, higher energy attractors, represents a goal, unrealized up to now, that is of great importance in a number of fields. Examples are: robotics and control applications where a controller must be trained to learn a certain task and to adapt to a slowly changing environment. The problem of protein folding is essentially of the same nature, as are other optimization tasks.
Acknowledgements
This research was funded by the Natural Sci-ences and Engineering Research Council of Canada.
References
Amit, D.J., 1989. Modeling Brain Function: the World of Attractor Neural Networks. Cambridge University Press, Cambridge.
Borisyuk, R.M., Hoppensteadt, F.C., 1998. Memorizing and
recalling spatial-temporal patterns in an oscillator model of the hippocampus. Biosystems 48, 3 – 10.
Bressloff, P.C., Popper, P., 1998. Stochastic dynamics of the diffusive Haken model with subthreshold periodic forcing. Phys. Rev. E 58, 2282 – 2287.
Chinarov, V., 1998. Synchronization and chaos in networks consisting of interacting bistable elements. In: Barbi, M., Chillemi, S. (Eds.), Chaos and Noise in Biology and Medicine. World Scientific Publishers, Singapore, pp. 301 – 304.
Chinarov, V.A., Gaididei, Yu.B., Kharkyanen, V.N., Sit’ko, S.P., 1992. Ion pores in biological membrane as a self-orga-nized bistable system. Phys. Rev. A 46, 5232 – 5241. Chinarov, V., Halici, U., Leblebicioglu, K., 1999. Pattern
recognition in bistable networks. In: Priddy, K.L., Keller, P.E., Fogel, D.B., Bezdek, J.C. (Eds.), Applications and Science of Computational Intelligence II. SPIE Proceedings pp. 3722 – 51, 457 – 463.
Demchenko, A.P., Chinarov, V.A., 1999. Tolerance of protein structures to the changes of amino acid sequences and their interactions. The nature of the folding code. Protein Pept. Lett. 6, 115 – 129.
Haken, H., 1991. Synergetic Computer and Cognition. Springer – Verlag, Berlin.
Haykin, S., 1999. Neural Networks. Macmillan, New York. Han, S.K., Kim, W.S., Kook, H., 1998. Temporal segmentation
of the stochastic oscillator neural network. Phys. Rev. E 58, 2325 – 2334.
Hopfield, J.J., Tank, D.W., 1986. Computing with neural circuits: a model. Science 233, 625 – 633.
Hoppensteadt, F.C., Izhikevich, E.M., 1997. Weakly Connected Neural Networks. Springer – Verlag, New York.
Pineda, F.J., 1988. Dynamics and architecture in neural compu-tation. J. Complexity 4, 216 – 245.
Rumelhart, D., 1986. Learning Internal Representations by Error Propagation. Parallel Distributed Processing: Explo-rations in the Microstructures of Cognition. Foundations, vol. 1. MIT Press, Cambridge, MA.
Terman, D., Wang, D.L., 1995. Global competition and local cooperation in a network of neural oscillators. Physica D 81, 148 – 176.