APLIKASI DATA MINING UNTUK MEMPREDIKSI KELULUSAN MAHASISWA DENGAN ALGORITMA NAIVE BAYES
DI STMIK DUTA BANGSA SURAKARTA
PROPOSAL SKRIPSI
Diajukan Untuk Melengkapi Persyaratan Menyelesaikan Pendidikan Program Strata 1
Program Studi Sistem Informasi
Oleh
ADITYA DHIMAS SULISTYANTO 140101006
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER STMIK DUTA BANGSA
HALAMAN PERSETUJUAN
Proposal ini diajukan oleh :
Nama : Aditya Dhimas Sulistyanto
NIM : 140101006
Program Studi : Sistem Informasi
Judul : Aplikasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Dengan Algoritma Naive Bayes di STMIK Duta Bangsa Surakarta
Telah disetujui oleh Pembimbing Skripsi sebagai bagian persyaratan yang diperlukan untuk Seminar Proposal Skripsi pada Program Studi Sistem Informasi.
Hari/Tanggal :
Menyetujui,
Pembimbing I Pembimbing II
Wijiyanto, S.Kom., M.Pd., M.Kom Herliyani Hasanah, MT
HALAMAN PENGESAHAN
Nama : Aditya Dhimas Sulistyanto
NIM : 140101006
Program Studi : Sistem Informasi
Judul : Aplikasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Dengan Algoritma Naive Bayes di STMIK Duta Bangsa Surakarta
Telah berhasil dipertahankan di hadapan Dewan Penguji dalam Seminar Proposal Skripsi pada Program Studi Sistem Informasi.
Hari/Tanggal :
Mengesahkan,
Penguji I Penguji II
Wijiyanto, S.Kom., M.Pd., M.Kom Herliyani Hasanah, MT
Mengetahui, Ketua Program Studi
Eko Purwanto, M.Kom
1. Judul
“Aplikasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Dengan Algoritma Naive Bayes di STMIK Duta Bangsa Surakarta”
STMIK Duta Bangsa Surakarta merupakan salah satu perguruan tinggi swasta yang mengalami perkembangan yang sangat pesat. Hal itu dibuktikan dengan diraihnya akreditasi B terhadap keempat program studi yang ada. Program studi tersebut diantaranya adalah Sistem Informasi dan Teknik Informatika untuk jenjang strata 1, serta Manajemen Informasi dan Teknik Komputer untuk jenjang diploma 3. Selain itu STMIK Duta Bangsa Surakarta juga meraih penghargaan sebagai “Smart Campus” urutan ke-33 dari Tesca Indonesia.
Namun seiring terjadinya perkembangan, maka jumlah mahasiswa baru yang terdaftar juga semakin banyak. Sebagai contoh mahasiswa angkatan tahun 2014 yang terdaftar sebanyak 379 mahasiswa. Sedangkan pada tahun 2015 sebanyak 431 mahasiswa. Dan untuk tahun 2016 sebanyak 531 mahasiswa (STMIK Duta Bangsa, 2016). Artinya terjadi peningkatan dari tahun ke tahun rata-rata mencapai 14% hingga 20%. Hasil tersebut didapatkan dari jumlah akumulasi terhadap mahasiswa dari keempat program studi.
Dengan terjadinya peningkatan jumlah mahasiswa yang terdaftar, maka dapat dipastikan institusi memiliki jumlah data mahasiswa yang cukup besar. Data mahasiswa tersebut mencangkup mahasiswa yang belum maupun yang sudah lulus. Berdasarkan data yang ada, pada tahun 2015 jumlah kelulusan mahasiswa mencapai 277 mahasiswa. Sedangkan pada tahun 2016 sebanyak 397 mahasiswa. Dan untuk tahun 2017 sebanyak 424 mahasiswa (STMIK Duta Bangsa, 2017).
tidak tepat waktu sebesar 37,5% (STMIK Duta Bangsa, 2018). Artinya perbandingan antara persentase kelulusan yang tepat dan tidak tepat masih bersifat fluktuatif. Sehingga hal tersebut menjadi dasar acuan dilakukannya proses klasifikasi melalui pendekatan data mining.
Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban dan Liang dalam Mujib Ridwan, 2013). Salah satu informasi baru yang dapat digali adalah tentang kelulusan mahasiswa pada angkatan selanjutnya.
Hal ini dapat digunakan sebagai bahan evaluasi bagi mahasiswa untuk dapat mencapai kelulusan tepat waktu dengan nilai optimal dan mempertahankan akreditasi bagi institusi. Mengingat salah satu elemen penting dalam penilaian oleh Badan Akreditasi Nasional Perguruan Tinggi (BAN-PT) adalah tentang presentase kelulusan mahasiswa. Namun pada kenyataannya, institusi belum menerapkan sistem atau aplikasi serupa maupun suatu perhitungan sejenis yang tujuannya untuk memprediksi kelulusan mahasiswa.
3. Perumusan Masalah
Berdasarkan latar belakang masalah diatas, maka dapat dirumuskan permasalahannya adalah bagaimana cara membangun aplikasi data mining
untuk memprediksi kelulusan mahasiswa menggunakan algoritma naive bayes di STMIK Duta Bangsa Surakarta?
4. Batasan Masalah
a. Pendekatan data mining yang akan dilakukan adalah pendekatan klasifikasi melalui algoritma naive bayes untuk memprediksi kelulusan mahasiswa b. Data yang dibutuhkan sebagai data training adalah data kelulusan
mahasiswa dari periode wisuda 9-14 pada keempat program studi di STMIK Duta Bangsa Surakarta.
c. Data uji yang digunakan adalah data mahasiswa angkatan 2014-2015 pada keempat program studi di STMIK Duta Bangsa Surakarta. Dengan batasan untuk angkatan 2014 hanya mencangkup program studi Sistem Informasi dan Teknik Informatika, sedangkan untuk angkatan 2015 mencangkup keempat program studi.
d. Atribut yang digunakan untuk menghitung nilai probabilitas atribut meliputi data mahasiswa mengenai program studi yang dipilih, jenis kelamin, status pekerjaan, dan nilai IPK terakhir.
e. Sedangkan untuk kelas yang digunakan sebagai target klasifikasi adalah status kelulusan yang meliputi tepat waktu dan tidak tepat waktu.
f. Aplikasi ini dirancang dengan teknik permodelan menggunakan Unified Modeling Language (UML) dan didukung pemrograman web.
g. Aplikasi ini dibangun dengan mengacu tahapan metode pengembangan phased development.
h. Tingkat akurasi proses klasifikasi diuji menggunakan RapidMiner versi 8.1 5. Tujuan Penelitian
Berdasarkan rumusan dan batasan masalah diatas, maka dapat dideskripsikan tujuan dari penelitian ini adalah mampu menghasilkan sebuah aplikasi data mining untuk memprediksi kelulusan mahasiswa menggunakan algoritma naive bayes di STMIK Duta Bangsa Surakarta.
a. Manfaat teoritis
Penelitian ini dapat digunakan sebagai bahan referensi pengetahuan, dan pembanding dalam melakukan pengembangan di masa yang akan datang. b. Manfaat praktis
Memberikan suatu solusi dengan merancang, membangun, dan mengimplementasikan aplikasi data mining yang telah dibuat sebagai penunjang proses klasifikasi dan prediksi kelulusan mahasiswa di STMIK Duta Bangsa Surakarta sebagai bahan evaluasi akademik.
7. Tinjauan Pustaka
Beberapa literatur sejenis yang digunakan untuk mendukung penelitian diantaranya :
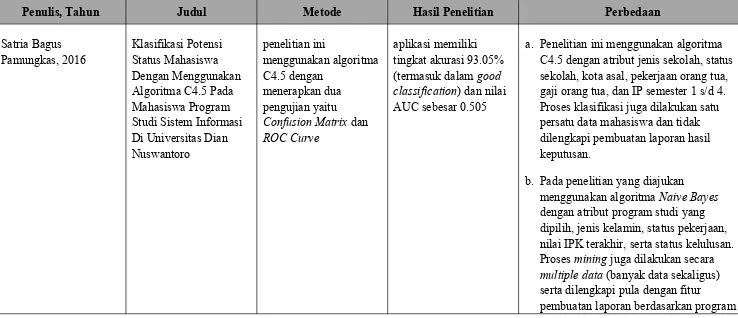
a. Jurnal ilmiah dengan judul “KLASIFIKASI POTENSI STATUS MAHASISWA DENGAN MENGGUNAKAN ALGORITMA C4.5 PADA MAHASISWA PROGRAM STUDI SISTEM INFORMASI DI UNIVERSITAS DIAN NUSWANTORO” oleh Satria Bagus Pamungkas (2016) dari Universitas Dian Nuswantoro. Penelitian ini bertujuan untuk mengklasifikasikan status mahasiswa yang berpotensi mangkir sebagai pemicu menurunnya presentase mahasiswa yang lulus tepat waktu. Pada penelitian ini digunakan algoritma C4.5 dengan menerapkan dua pengujian yaitu Confusion Matrix dan ROC Curve. Dengan dilakukannya penelitian ini dihasilkan prototype aplikasi memiliki tingkat akurasi 93.05% (termasuk dalam good classification) dan nilai AUC sebesar 0.505.
Komputer Indonesia)” oleh Astrid Darmawan (2012) dari Universitas Komputer Indonesia. Penelitian ini bertujuan untuk dapat memprediksi kelulusan dan presentase kelulusan mahasiswa di jurusan Teknik Komputer khususnya S1. Pada penelitian ini digunakan algoritma K-Nearest Neighborhood dengan menghitung nilai Euclidean Distance pada setiap indeks prestasi semester mahasiswa. Hasil penelitian ini menunjukkan nilai k terbaik tergantung dari jumlah data yang digunakan.
Berikut ini tabel perbandingan dari ketiga tinjauan pustaka dengan penelitian yang diajukan.
Tabel 1 Perbandingan Tinjauan Pustaka Dengan Penelitian Yang Diajukan
Penulis, Tahun Judul Metode Hasil Penelitian Perbedaan
Satria Bagus
a. Penelitian ini menggunakan algoritma C4.5 dengan atribut jenis sekolah, status sekolah, kota asal, pekerjaan orang tua, gaji orang tua, dan IP semester 1 s/d 4. Proses klasifikasi juga dilakukan satu persatu data mahasiswa dan tidak dilengkapi pembuatan laporan hasil keputusan.
b. Pada penelitian yang diajukan
menggunakan algoritma Naive Bayes dengan atribut program studi yang dipilih, jenis kelamin, status pekerjaan, nilai IPK terakhir, serta status kelulusan. Proses mining juga dilakukan secara multiple data (banyak data sekaligus) serta dilengkapi pula dengan fitur
studi dan tahun angkatan masuk.
Penulis, Tahun Judul Metode Hasil Penelitian Perbedaan
Astrid Darmawan, 2012 Pembuatan Aplikasi Data Mining Untuk
ukuran nilai k yang besar/kecil belum tentu menjadi nilai k terbaik untuk memprediksi masa studi mahasiswa dengan tingkat
keberhasilan yang tinggi. Tetapi nilai k terbaik tergantung pada jumlah data yang digunakan
a. Penelitian ini menggunakan algoritma K-Nearest Neighborhood dengan atribut IP semester 1 s/d 6. Proses klasifikasi juga dilakukan satu persatu data mahasiswa dan tidak dilengkapi pembuatan laporan hasil keputusan.
b. Pada penelitian yang diajukan
menggunakan algoritma Naive Bayes dengan proses mining multiple data (banyak data sekaligus) dan dilengkapi fitur pembuatan laporan berdasarkan program studi & tahun angkatan masuk.
Yayak Kartika Sari, sebesar 0,01 dan nilai
Mahasiswa Di Program Studi Teknik
Informatika FT UN PGRI Kediri
nilai mata kuliah per semester dan nilai kedekatan nilai mata kuliah terhadap nilai standar sebagai variabelnya
probabilitas akhir dari perdiksi lulus tepat sebesar 0,1485
sedangkan probabilitas terlambat sebesar 0,099
kedekatan nilai mata kuliah terhadap nilai standar sebagai variabelnya.
b. Pada penelitian yang diajukan
8. Landasan Teori a. Data Mining
Data mining adalah teknik untuk menemukan dan mendeskripsikan pola-pola yang ada dalam data sebagai sebuah alat untuk membantu menjelaskan data tersebut dan membuat prakiraan dari data itu (Witten & Eibe Frank dalam Mauriza, Ahmad dan Yusuf Sulistyo, 2014).
Sedangkan menurut Turban dan Liang dalam Mujib Ridwan dkk (2013) menjelaskan bahwa data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar.
Berdasarkan pengertian tersebut, maka dapat disimpulkan bahwa data mining merupakan serangkaian proses ekstraksi dan identifikasi dengan melalui tahap perhitungan untuk mendapatkan informasi baru berdasarkan data yang telah ada.
(1) Pengelompokan data mining
Menurut Larose dalam Kusrini dan Emha Taufiq Luthfi (2009), data mining dikelompokkan dalam beberapa bentuk diantaranya :
(a) Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam data. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
(c) Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa teknik dan metode yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi. (d) Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. (e) Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan tidak memiliki kemiripan dengan record-record dalam kluster lain.
(f) Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja
Menurut Fayyad dalam Riadi, Muchlisin (2014) terdapat beberapa tahapan dalam data mining, diantaranya :
(a) Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
(b) Pre-processing / cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data.
(c) Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
(d) Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
b. Algoritma Naive Bayes
Menurut Prasetyo, Eko (2012) naive bayes adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Naive bayes didasarkan pada teorema Bayes yang memiliki kemampuan klasifikasi serupa dengan decision tree dan neural network. Naive bayes terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar.
Prediksi Bayes didasarkan pada formula teorema Bayes dengan formula umum sebagai berikut :
V
NB= argmax
vjVP(v
j)
P(a
i|
v
j)
Keterangan
P(v) = probabilitas kelas
P(a | v) = probabilitas atribut terhadap kelas c. Prediksi
Sedangkan menurut Anonim (2014), prediksi dapat diartikan kedalam beberapa pengertian yaitu :
(1) Ramalan atau pernyataan bahwa sesuatu akan terjadi sebelum sesuatu itu terjadi sebagaimana dalam ramalan, divinasi, pre-kognisi.
(2) Dan dapat juga diartikan sebagai pengetahuan inferensial yang dnyatakan sebelum terjadi sesuatu yang sungguh-sungguh tiba dan atau diharapkan tiba, yang dibuat berdasarkan kebiasaan-kebiasaan dalam pengalaman-pengalaman lalu.
d. Kelulusan Studi Mahasiswa
Mahasiswa dapat dikatakan lulus apabila telah memenuhi persyaratan pada setiap program studi di masing-masing perguruan tinggi yang ada. Terdapat dua istilah yang terdapat dalam kelulusan studi mahasiswa, diantaranya adalah yudisium dan wisuda. Menurut Anonim (2017) yudisium adalah proses akademik yang menyangkut penerapan nilai dan kelulusan mahasiswa dari seluruh proses akademik. Yudisium juga berarti pengumuman nilai kepada mahasiswa sebagai proses penilaian akhir dari seluruh mata kuliah yang telah di ambil mahasiswa dan penetapan nilai dalam transkrip akademik, serta memutuskan lulus atau tidaknya mahasiswa dalam menempuh studi selama jangka waktu tertentu, yang ditetapkan oleh pejabat berwenang yang dihasilkan dari keputusan rapat yudisium. Sedangkan wisuda adalah proses akhir dalam rangkaian kegiatan akademik pada perguruan tinggi. Yakni sebagai tanda pengukuhan atas selesainya studi yang diadakan prosesi pelantikan melalui rapat senat terbuka dan ditujukan untuk semua lulusan program studi (Anonim, 2017).
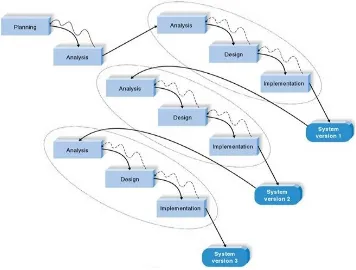
Dennis dalam Konstantinou mengatakan, phased development merupakan metode pengembangan sistem yang membagi keseluruhan bentuk sistem kedalam beberapa seri versi yang dibangun secara berurutan. Pengembangan akan dilakukan setelah versi 1.0 dari sistem berhasil diimplementasikan dengan baik. Kemudian, dilanjutkan pada versi 2.0, dan seterusnya hingga versi terakhir yang merupakan versi terlengkap dari sistem selesai dibangun.
Gambar 1 Phased Development Methodology (Sumber : Dennis, 2006:55)
Namun, perlu diketahui bahwa pengembangan pada metode phased dilakukan dengan memberikan penambahan fungsi pada versi sebelumnya. Sehingga tidak membuat sistem baru dan tidak mengurangi requirements yang terdapat pada versi 1.0.
RapidMiner merupakan perangkat lunak yang bersifat terbuka (open source). RapidMiner adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining, dan analisis prediksi (Dennis Aprilla, 2013). RapidMiner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik. RapidMiner memiliki kurang lebih 500 operator data mining, termasuk operator untuk input, output, data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data dan sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri. RapidMiner ditulis dengan menggunakan bahasa java sehingga dapat bekerja di semua sistem operasi. 9. Tempat Penelitian
Penelitian ini dilakukan di STMIK Duta Bangsa yang beralamat di Jalan Bhayangkara Nomor 55-57, Tipes, Serengan, Surakarta, Jawa Tengah. Telepon (0271) 719552.
10. Metodologi Penelitian
a. Tahapan Penelitian (Kerangka Pikir)
Pada penelitian ini, tahapan penelitian dilakukan melalui beberapa kegiatan
mengacu pada tahapan data mining dengan dikombinasikan metode
pengembangan aplikasi menggunakan metode phased development.
Diantaranya dimulai dari planning yang mencangkup pengumpulan data
dan gambaran struktur project yang dijalankan. Kemudian dilanjutkan
analysis, lalu design, dan terakhir implementasi. Berikut ini gambaran alur
Gambar 2 Tahapan Penelitian b. Jenis dan Sumber Data
Pada penelitian ini, data dikelompokkan berdasarkan cara mendapatkannya diantaranya :
(1) Jenis data primer
Data primer merupakan data yang didapat secara langsung dari sumber data. Dalam hal ini meliputi data akademik mahasiswa aktif, dan data kelulusan mahasiswa yang tujuannya untuk dapat dipelajari guna memberikan informasi untuk dapat mendukung penelitian yang akan dilakukan.
(2) Jenis data sekunder
Beberapa data yang termasuk data sekunder meliputi dokumen dan jurnal terkait yang berguna sebagai bahan pembanding antara penelitian yang sudah ada dengan penelitian yang akan dilakukan.
c. Metode Pengumpulan Data
Metode ini dilakukan dengan mengajukan beberapa pertanyaan kepada staff / karyawan bagian BAAK yaitu Sdr/i Dany Aurin, S.Kom dan Pradita Mei Nuryani, S.Kom yang berkaitan dengan :
(a) Apakah sudah menerapkan sistem atau aplikasi atau perhitungan
serupa untuk memprediksi kelulusan mahasiswa pada setiap angkatan dan program studi yang ada?
(b) Bagaimana perkembangan tingkat kelulusan mahasiswa dari tahun ke
tahun?
(c) Bagaimana perkembangan dan berapa banyak jumlah mahasiswa baru
yang terdaftar selama 3 tahun terakhir? (2) Observasi
Pengamatan secara langsung dilakukan dengan mengamati dan mempelajari tingkat kelulusan mahasiswa untuk mendapatkan aspek apa saja yang dapat dijadikan tolok ukur dalam menentukan atribut-atribut untuk pendekatan data mining .
(3) Dokumentasi
Data mahasiswa, kelulusan, dan akademik merupakan beberapa contoh dokumen yang digunakan dalam melakukan pembangunan aplikasi data mining untuk memprediksi kelulusan mahasiswa menggunakan algoritma naive bayes di STMIK Duta Bangsa Surakarta.
(4) Studi Literatur
Metode ini digunakan dengan mengumpulkan data dan informasi dari
berbagai sumber bacaan seperti paper, jurnal, artikel dan bacaan-bacaan
terkait untuk mendukung proses penulisan kode program maupun dalam
penyusunan laporan akhir.
Aplikasi dibangun dengan menggunakan metode phased dengan tahapan menurut Dennis (2006:12) sebagai berikut :
(1) Planning
Pada tahap ini berfokus pada identifikasi alasan kenapa membangun aplikasi ini dan bagaimana struktur project aplikasi berjalan. Beberapa kegiatannya meliputi identifikasi peluang, menganalisa kemungkinan, membuat workplan, dan menyusun bahan pokok project.
(2) Analysis
Pada tahap ini berfokus pada pertanyaan apa, siapa, dimana, dan kapan aplikasi ini digunakan. Beberapa kegiatannya meliputi membuat analisa strategi, menggambarkan use case model, membuat model proses, dan membuat model data.
(3) Design
Pada tahap ini berfokus pada bagaimana aplikasi ini bekerja termasuk membahas mengenai spesifikasi aplikasi. Beberapa kegiatannya meliputi desain physical system, desain antarmuka, desain program, dan desain basis data serta files.
(4) Implementasi
Pada tahap ini berfokus pada pelepasan dan support system. Beberapa
kegiatannya meliputi penulisan kode program (coding), penerapan
aplikasi, pengujian aplikasi, pemeliharan aplikasi, dan validasi akurasi.
11. Sistematika Penulisan BAB I. PENDAHULUAN
Mencangkup latar belakang, rumusan masalah, batasan masalah, tujuan,
manfaat, tinjauan pustaka, metodologi penelitian dan sistematika penulisan.
Mencangkup teori-teori tentang data mining, algoritma naive bayes,
prediksi, kelulusan studi mahasiswa, metode phased development, dan
RapidMiner.
BAB III. ANALISIS DAN PERANCANGAN SISTEM
Mencangkup analisis permasalahan, prosedur penelitian, dan perancangan
sistem.
BAB IV. IMPLEMENTASI SISTEM
Mencangkup implementasi baik dari segi perancangan basis data sampai
dengan pembuatan desain antarmuka, pembahasan, pengujian, dan
pemeliharaan.
BAB V. PENUTUP
Menguraikan kesimpulan hasil penelitian dan saran-saran sebagai bahan pertimbangan untuk pengembangan di masa yang akan datang.
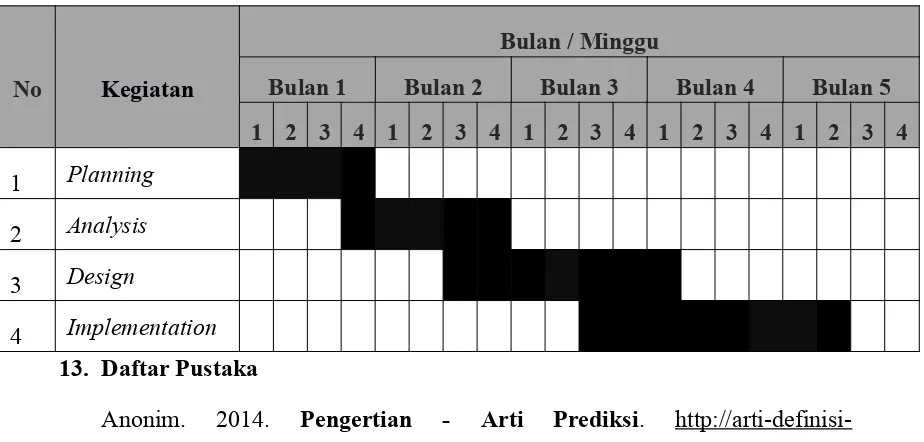
12. Jadwal Penelitian
Tabel 2 Jadwal Penelitian
No Kegiatan
Bulan / Minggu
Bulan 1 Bulan 2 Bulan 3 Bulan 4 Bulan 5
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
1 Planning
2 Analysis
3 Design
4 Implementation
13. Daftar Pustaka
_______. 2017. Yudisium dan Wisuda. https://www.uny.ac.id/akademik/yudisium-dan-wisuda. Tanggal akses 4 Oktober 2017.
Astrid Darmawan. 2012. Pembuatan Aplikasi Data Mining Untuk Memprediksi Masa Studi Mahasiswa Menggunakan Algoritma K-Nearest Neighborhood (Studi Kasus Data Akademik Jurusan Teknik Komputer-S1 Universitas Komputer Indonesia). Skripsi. Universitas Komputer Indonesia. Bandung.
Dennis, A., at al. 2006. System Analysis and Design. 5th. New York : Ed.
John Willey & Sons.
Dennis Aprilla, dkk. 2013. Belajar Data Mining Dengan RapidMiner. Jakarta : Gramedia Pustaka Utama.
Kamus Besar Bahasa Indonesia versi V
Konstantinou, Parthenopi. Rapid Application Development. International Society for Ecological Economics (ISEE). ISAM 5635. Page 2-4.
Kusrini dan Emha Taufiq Luthfi. 2009. Algoritma Data Mining. Yogyakarta : Penerbit ANDI.
Mauriza, Ahmad dan Yusuf Sulistyo. 2014. Implementasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Fakultas Komunikasi dan Informatika UMS Menggunakan Metode Naive Bayes. Skripsi. Universitas Muhammadiyah Surakarta. Surakarta.
Mujib Ridwan dkk. 2013. Penerapan Data Mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier. Jurnal EECCIS Vol. 7, No. 1.
Riadi, Muchlisin. 2014. Data Mining. http://www.kajianpustaka.com/2017/09/data-mining.html. Tanggal akses 29 November 2017.
Satria Bagus Pamungkas. 2016. Klasifikasi Potensi Status Mahasiswa Dengan Menggunakan Algoritma C4.5 Pada Mahasiswa Program Studi Sistem Informasi Di Universitas Dian Nuswantoro. Jurnal Ilmiah. Universitas Dian Nuswantoro. Semarang.
STMIK Duta Bangsa. 2016. DAFTAR MAHASISWA MASUK. BAAK : Surakarta
________________. 2017. DAFTAR LULUS. BAAK : Surakarta
________________. 2018. Mahasiswa lulus-baru sampai angkatan tahun 2013. BAAK : Surakarta