CI-73
PENENTUAN LIRIK LAGU BERDASARKAN EMOSI
MENGGUNAKAN SISTEM TEMU KEMBALI INFORMASI DENGAN METODE LATENT SEMANTIC INDEXING (LSI)
*Yuita Arum Sari , **Achmad Ridok, Marji
*Teknik Informatika, Institut Teknologi Sepuluh Nopember (ITS), Surabaya **Program Teknik Informatika dan Ilmu Komputer, Universitas Brawijaya (UB), Malang
E-mail: *[email protected], **[email protected], [email protected] Abstrak
Lirik lagu merupakan salah satu elemen yang paling berpengaruh dalam menentukan emosi. Jika dibandingkan dengan elemen yang bersifat audio, representasi makna yang menggambarkan emosi, tampak lebih kuat dalam lirik lagu. Fokus penelitian ini terletak pada lirik lagu yang sifatnya berupa teks, dan dapat diselesaikan dengan proses text
mining. Pada paper ini, sistem temu kembali informasi yang digunakan untuk
menentukan lirik lagu adalah Latent Semantic Indexing (LSI). Teknik dalam LSI mengadopsi proses matematis reduksi dimensi Singular Value Decomposition (SVD). Walaupun dimensi data direduksi, proses tersebut tidak mengganggu keterkaitan makna antara lirik lagu pada corpus dan query. Pada masing-masing lirik lagu dalam corpus dan
query, diberi label emosi secara otomatis yaitu, label religius, sedih, marah, semangat,
takut, dan cinta. Sistem akan menentukan relevansi berdasarkan kecocokan label emosi antara query dan corpus. Sistem dikatakan dapat bekerja dengan baik, ditunjukkan dengan adanya hasil pengujian berupa nilai Mean Average Precision (MAP) pada masing-masing k-rank 300, 200, 100, 50, dan 10 mendekati nilai 1.
Kata kunci : Information Retrieval, Latent Semantic Indexing, Singular Value Decomposition, Natural Language Processing, Text Mining
Abstract
Song lyrics is one of the most influential elements in determining emotion. Compared to audio, lyric can represent meaning of emotion deeper and stronger. This research focuses in song lyrics which use text and text mining can be implemented. In this paper, Latent Semantic Indexing was used as a technique to determine song lyrics. LSI technique adopts Singular Value Decomposition (SVD), which is a mathematics technique to reduce dimension. Although data dimension is reduced, this process does not affect meaning linkage of song lyrics in corpus and query. Each song lyric in corpus and query is labeled automatically with these categories: religious, sad, angry, cheer, fear, and love. This system will determine relevance based on emotion label match between query and corpus. The system run well and it was shown by the result of Mean Average Precision (MAP) in each k-rank 300, 200, 100, 50, and 10 which were almost 1. Keywords : Information Retrieval, Latent Semantic Indexing, Singular Value Decomposition, Natural Language Processing, Text Mining
CI - 74 PENDAHULUAN
Sistem temu kembali informasi merupakan salah satu teknik pencarian untuk mencari informasi yang relevan antara query dan corpus. [1]. Kasus yang paling sering banyak diteliti dalam proses sistem temu kembali adalah teks [2]. Lirik lagu merupakan salah satu betuk teks yang dapat digunakan sebagai objek dalam penelitian sistem temu kembali berdasarkan emosi. Dalam penentuan emosi, lirik lagu merupakan elemen yang memiliki makna yang paling kuat dalam menggambarkan emosi [3]. Pada sebuah dimensi data yang besar, dibutuhkan reduksi dimensi untuk mengurangi adanya proses komputasi. Penelitian dilakukan oleh Kleedorfer, Knees, dan Pohle (2008) [3] menggunakan proses reduksi dimensi matriks
Nonnegative Matrix Factorization (NMF), dan
penelitian Samat, Murad, Abdullah dan Atan (2005) [4] menggunakan metode reduksi matriks Singular Value Decomposition (SVD) untuk proses clustering data. Pada penelitian Peter, Shivapratap, Dyva, dan Soman (2009) [5] melakukan analisis terhadap evaluasi SVD dan NMF untuk proses Latent Semantic
Analysis (LSA) dan menyebutkan rata-rata
nilai interpolated average precission SVD memiliki nilai lebih tinggi dibanding dengan menggunakan NMF dan Vector Space Model (VSM). Proses temu kembali dengan menggunakan konsep SVD disebut dengan LSI [5].
Pada penelitian ini, digunakan proses temu kembali LSI yang memanfaatkan reduksi dimensi SVD dengan menggunakan obyek lirik lagu berbahasa Indonesia dan mengabaikan bahasa yang sifatnya tidak resmi. Proses pengolahan yang pertama dilakukan adalah menggunakan teknik preprocessing pada text mining yang merupakan salah satu cabang ilmu dari Natural Language Processing (NLP). Dalam proses prepocessing, stemming yang digunakan
menggunakan algoritma Nazief-Andriani, karena stemming tersebut mempunyai hasil kebenaran sekitar 93% [6]. Hasil numerik dari proses pembobotan setelah di-prepocessing diolah menggunakan Latent Semantic Indexing (LSI). Hasil dari sistem ini untuk mengetahui akurasi dari LSI dalam proses penentuan lirik lagu berdasarkan emosi.
TINJAUAN PUSTAKA
2.1.Lirik Lagu dalam Menentukan Emosi
Menurut Kamus Besar Bahasa Indonesia
Online (KBBI online) lirik merupakan karya
sastra (puisi) yang berisi curahan perasaan pribadi, atau susunan kata sebuah nyanyian, dan lagu merupakan ragam suara yang berirama. Lirik lagu merupakan salah satu komponen yang ada dalam musik, selain audio. Lirik lagu mempunyai makna emosi yang kental, karena jika menggunakan representasi audio saja terkadang kurang bisa mengetahui makna dari lagu tersebut, sehingga lirik digunakan untuk penelitian ini.
2.2.Proses Temu Kembali Teks
Proses temu kembali teks yang lebih dikenal dengan nama text information
retrieval, merupakan sebuah teknik pencarian
dengan menggunakan algoritma tertentu untuk mendapatkan hasil pencarian yang relevan berdasarkan kumpulan (corpus) informasi yang besar. Sebagian besar penggunaan sistem temu kembali adalah pada teks. Pengguna memasukkan kata kunci berupa teks, dan kemudian sistem mengolahnya hingga mendapatkan informasi semantik yang diinginkan oleh pengguna [1].
2.3.Text Mining
Teknik text mining merupakan sebuah teknik dimana data yang berupa teks dikumpulkan dan diolah, untuk dapat diidentifikasi dengan pola-pola tertentu . Proses text mining termasuk dalam salah satu bidang Natural Language Processing (NLP), karena di dalam text mining, teks akan diolah sehingga dapat dikomputasi dan dapat menghasilkan informasi yang relevan satu dengan yang lainnya. Pengolahan dalam teks
mining tahap awal dikenal dengan nama preprocessing [7]. Teknik yang terdapat dalam preprocessing yaitu case folding, stopword removal, tokenizing, dan stemming. Case foding merupakan proses untuk membuat
semua teks menjadi pola yang seragam (uppercase atau lowercase). Stopword removal menghilangkan kata-kata yang dianggap tidak mempunyai kata penting. Tokenizing atau teknik parsing digunakan untuk memecah kalimat menjadi kata. Selanjutnya, kata-kata tersebut diolah sehingga hanya
didapatkan kata-dasar saja. Teknik tersebut dinamakan dengan stemming. Stemming yang
digunakan pada penelitian ini adalah algoritma Nazief-Andriani.
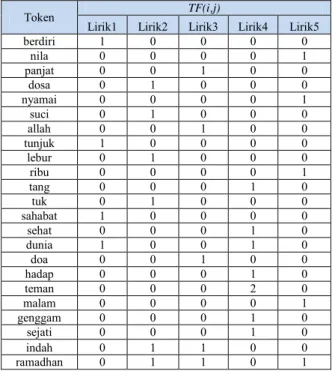
2.4.Inverted Index
Inverted Index merupakan struktur data
berbentuk matriks, yang digunakan untuk mempermudah dalam merepresentasikan banyaknya kata yang muncul dalam dokumen teks [7].
Tabel 1. Contoh penerapan inverted index
Token TF(i,j)
Lirik1 Lirik2 Lirik3 Lirik4 Lirik5
berdiri 1 0 0 0 0 nila 0 0 0 0 1 panjat 0 0 1 0 0 dosa 0 1 0 0 0 nyamai 0 0 0 0 1 suci 0 1 0 0 0 allah 0 0 1 0 0 tunjuk 1 0 0 0 0 lebur 0 1 0 0 0 ribu 0 0 0 0 1 tang 0 0 0 1 0 tuk 0 1 0 0 0 sahabat 1 0 0 0 0 sehat 0 0 0 1 0 dunia 1 0 0 1 0 doa 0 0 1 0 0 hadap 0 0 0 1 0 teman 0 0 0 2 0 malam 0 0 0 0 1 genggam 0 0 0 1 0 sejati 0 0 0 1 0 indah 0 1 1 0 0 ramadhan 0 1 1 0 1
2.5.Pembobotan TF-IDF ternormalisasi Terdapat tiga cara untuk menghitung nilai term frequency (TF), yaitu dengan menghitung frekuensi sebagai bobot, menghitung peluang kemunculan sebagai bobot (TF tanpa ternormalisasi), dan menghitung logaritma dari banyaknya kemunculan term (TF ternormalisasi). Dari ketiga fungsi tersebut , menurut Garcia [8], TF dengan normalisasi menghasilkan nilai pembobotan yang baik, karena dapat mengurangi efek panjang dari dokumen. TF ternormalisasi dihitung sebagai berikut [8] :
𝒇
𝒊,𝒋 = 𝐦𝐚𝐱 𝒕𝒇𝒊,𝒋𝒕𝒇𝒊,𝒋 (1)
dimana fi,j adalah frekuensi ternormalisasi,
tfi,j adalah frekuensi kata i pada dokumen j,
max tfi,j adalah frekuensi maksimum kata i
pada dokumen j. Untuk normalisasi frekuensi dalam query diberikan rumus :
𝒇
𝑸,𝒊 =𝟎,𝟓+ 𝟎.𝟓∗ 𝒕𝒇𝑸,𝒊
𝐦𝐚𝐱 𝒕𝒇𝑸,𝒊
(2) dimana fi,j adalah frekuensi ternormalisasi,
tfi,j adalah frekuensi kata i pada dokumen
j, dan max tfi,j adalah frekuensi maksimum
kata i pada dokumen j. Sehingga, pembobotan TF-IDF pada kata i dan dokumen j dapat ditulis sebagai berikut :
𝑾 𝒊,𝒋 = 𝒕𝒇𝒊,𝒋 𝐦𝐚𝐱 𝒕𝒇𝒊,𝒋 𝒙 𝐥𝐨𝐠𝟐( 𝑫 𝒅𝒇𝒊) (3) dimana Wi,j adalah bobot kata i pada
dokumen j , fi,j adalah frekuensi
ternormalisasi, tfi,j adalah frekuensi kata i
pada dokumen j, max tfi,j adalah frekuensi
maksimum kata i pada dokumen j, D adalah banyaknya dokumen yang diinputkan/ banyaknya dokumen dalam corpus, dan dfi adalah banyaknya dokumen
yang mengandung kata i.
Pembobotan tersebut digunakan untuk pembobotan pada corpus. Pembobotan pada query dapat ditulis sebagai berikut :
𝑾 𝑸,𝒊 =𝟎.𝟓+𝟎.𝟓∗ 𝒕𝒇𝑸,𝒊 𝐦𝐚𝐱 𝒕𝒇𝑸,𝒊 𝒙 𝐥𝐨𝐠𝟐( 𝑫 𝒅𝒇𝒊) (4) dimana Wi,j adalah bobot kata i pada
dokumen j, fi,j adalah frekuensi
ternormalisasi, tfi,j adalah frekuensi kata i
pada dokumen j, max tfi,j adalah frekuensi
maksimum kata i pada dokumen j, D adalah banyaknya dokumen yang diinputkan/ banyaknya dokumen dalam corpus, dan dfi adalah banyaknya dokumen
yang mengandung kata i.
2.6.Singular Value Decomposition (SVD) Singular Value Decomposition (SVD) merupakan model matematis yang digunakan untuk reduksi dimensi data. Proses SVD dilakukan dengan mendekomposisi matriks menjadi tiga bagian [5], seperti pada gambar 1.
CI - 76 Gambar 1. Ilustrasi matriks SVD
Matriks U dan V adalah matriks othonormal, dimana baris pada matriks U menggambarkan banyaknya baris pada matriks A, sementara kolom pada matriks V menggambarkan banyaknya kolom pada matriks A. k-rank digunakan untuk mereduksi dimensi dari matriks A. Matriks S merupakan matriks simetris yang berisi nilai positif di sepanjang diagonal, daerah selain diagonal berisi 0.
2.7.Latent Semantic Indexing (LSI) Penggunaan SVD digunakan dalam LSI. LSI merupakan salah satu bentuk teknik proses temu kembali dengan menggunakan Vector Space Model (VSM), untuk menemukan informasi yang relevan. Keterkaitan makna di dalam LSI sifatnya tersembunyi. Fungsi matematis di dalam LSI mampu menemukan hubungan semantik antar kata [4],[9],[10]. Representasi dari LSI adalah
𝒒′ = 𝒒𝑻. 𝑼
𝒌. 𝑺𝒌−𝟏 (5)
dimana q’ adalah query vector representasi dari LSI, qT adalah transpose
TDM dari pembobotan ternormalisasi TF-IDF query, Uk adalah reduksi dimensi k
dari matriks U, dan 1 k
S adalah inverse dari reduksi dimensi k matriks S
2.8.Vector Space Model (VSM)
VSM adalah cara konvensional yang biasa digunakan dalam proses temu kembali informasi. Prosesnya dengan
menghitung kemiripan dua buah vektor, yaitu antara vektor dari corpus dan vektor dari query [10],[11]. Penghitungan kemiripan dihitungdengan menggunakan rumus cosine similarity [12].
𝒔𝒊𝒎𝒊𝒍𝒂𝒓𝒊𝒕𝒚 = 𝐜𝐨𝐬(𝜽) = ∑ 𝒒.𝒅
‖𝒒‖‖𝒅‖ (6)
= ∑𝒏𝒊=𝟏𝒒𝒊 𝒙 𝒅𝒊
∑𝒏𝒊=𝟏𝒒𝒊𝟐𝒙 ∑𝒏𝒊=𝟏𝒅𝒊𝟐
Dari persamaan 6 nilai q merupakan nilai matriks hasil query SVD. d merupakan nilai dari matriks V, dimana nilai dimensi dari matriks V merupakan hasil input k sesuai dengan nilai reduksi dengan k ≤ min(m x n), dimana m adalah banyaknya kata-kata dan n adalah banyaknya dokumen lirik.
2.9.Tipe Evaluasi
Precision, recall, dan F-Measure merupakan kumpulan evaluasi untuk mengetahui keakuratan sistem temu kembali secara unranked retrieval, atau dengan pengembalian dokumen tanpa perangkingan. Tipe evaluasi yang digunakan untuk mengevaluasi sistem temu kembali dengan ranked retrieval pada penelitian ini digunakan Mean Average Precission (MAP). Dalam konteks sistem temu kembali, dokumen yang dikembalikan dengan memasukkan top-k dokumen yang retrieved. Average Precission (AP) hanya mengambil nilai presisi dari dokumen-dokumen yang relevan dan kemudian hasilnya dibagi dengan jumlah dokumen yang dilibatkan [13]. Pengukuran dari MAP merupakan hasil perhitungan rata-rata dokumen relevan yang retrieved dari setiap query yang terlibat di dalam sistem, sedangkan dokumen yang tidak relevan nilainya adalah 0 [14]. Rumus dari Mean Average Precission adalah sebagai berikut [15]: 𝑴𝑨𝑷(𝑸) = 𝟏 |𝑸|∑ 𝟏 𝒎∑ 𝑷𝒓𝒆𝒄𝒊𝒔𝒊𝒐𝒏 𝑹𝒋𝒌 𝒎𝒋 𝒌=𝟏 |𝑸| 𝒋=𝟏 (7)
CI-77 dimana nilai Q merupakan kumpulan
query atau menyatakan banyaknya query yang diinputkan qj € Q {d1,……dmj} dan Rjk
adalah nilai precission dari kumpulan file lirik lagu retrieved dan relevan yang telah diranking. Nilai MAP mempunyai rentang nilai 0 sampai 1, dan dalam sebuah system dikatakan baik jika nilai MAP mendekati 1 [15].
METODE PENELITIAN
Kumpulan lirik lagu bahasa Indonesia didapatkan dari berbagai sumber yang ada di internet dan kemudian ditentukan emosi-emosi apa saja yang terdapat di dalam sebuah lirik lagu. Label emosi yang digunakan diantaranya religius, sedih, marah, semangat, takut, dan cinta.
Penelitian dilakukan melalui langkah-langkah sebagai berikut:
a. Mengumpulkan lirik lagu berbahasa Indonesia. Kumpulan lirik lagu tersebut disebut sebagai corpus. Inputan sistem terdiri atas corpus dan query yang berupa lirik.
b. Preprocessing file corpus dan query. c. Membentuk struktur data inverted
index pada corpus.
d. Membentuk matriks pembobotan TF-IDF ternormalisasi pada corpus dan query.
e. Mendekomposisi matriks pembobotan corpus dengan SVD.
f. Reduksi dimensi dari hasil dekomposisi matriks SVD.
g. Menghitung query vector yang merupakan representasi dari LSI. h. Mencari kemiripan antara corpus dan
query dengan cosine similarity.
i. Pengurutan nilai cosine similarity secara descending order.
j. Pengambilan top-n teratas nilai cosine similarity hasil pengurutan.
k. Melakukan evaluasi dari hasil penelitian dengan Mean Average Precission (MAP). Hasil yang relevan antara query dan corpus adalah yang memiliki label emosi yang sama.
HASIL PENELITIAN
Analisis hasil secara kesuluruhan dapat dikatakan sistem dapat bekerja dengan baik, dibuktikan dengan nilai MAP yang rata-rata mendekati nilai 1, karena hal tersebut menujukkan sistem dapat mendeteksi kemiripan makna antara query dan corpus lirik lagu. Tabel 2 menujukkan hasil dari evaluasi MAP pada masing-masing k-rank 300, 200, 100, 50, dan 10. Data yang digunakan adalah lirik lagu berbahasa Indonesia dengan julah lirik lagu pada corpus 370 lirik dan pada query terdapat 5 lirik.
Data interpolated average precission dihasilkan dari penghitungan nilai precission dan recall pada masing-masing lirik lagu yang dikembalikan oleh sistem secara terurut. Nilai recall dari masing-masing average precission semakin naik sesuai dengan hasil relevansi lirik lagu yang dikembalikan sistem, jika data lirik musik yang dikembalikan tidak relevan maka nilai recall dan precission adalah 0. Nilai recall berbanding lurus dengan posisi data yang relevan dibagi dengan jumlah keseluruhan data yang relevan. Nilai recall akan semakin baik jika sistem dapat mengenali kerelevanan sebuah lirik lagu dari seluruh hasil kerelevanan yang seharusnya dikenali. Nilai relevan pada proses pengembalian ditentukan berdasarkan adanya label emosi dalam yang sama pada query maupun corpus.
Nilai Mean Average Precission (MAP) pada masing-masing k-rank 300, 200, 100, 50, dan 10. Terlihat bahwa hasil MAP cenderung menurun pada k-rank =100, dengan nilai MAP=0.827 dari nilai MAP=0.831 ketika pada k-rank=200. Sistem menujukkan peningkatan MAP ketika k-rank=50 yaitu dihasilkan MAP=0.870, dan mengalami peningkatan nilai MAP kembali saat nilai k-rank dikecilkan menjadi k-rank=10 dengan MAP=0.899. Dapat disimpulkan bahwa pada k-rank=10 sistem dapat
CI - 78 mengembalikan dengan baik kebutuhan
informasi yang dibutuhkan.
Tabel 2.MAP pada masing-masing k-rank
Query k-rank 300 200 100 50 10 Q1 0.961 0.977 0.943 0.961 0.992 Q2 0.907 0.921 0.938 0.983 0.998 Q3 0.911 0.902 0.904 0.920 0.988 Q4 0.672 0.721 0.730 0.807 0.787 Q5 0.586 0.633 0.621 0.676 0.728 MAP 0.807 0.831 0.827 0.870 0.899
Hasil nilai Average Precission (AP) dari masing-masing pengujian, tergantung dari nilai k-rank. Hasil penelitian ini menunjukkan bahwa rata-rata akurasi sistem akan baik jika input k—rank yang dimasukkan semakin kecil. Gambar 2 menunjukkan hasil MAP pada masing-masing k-rank, yang mengalami peningkatan ketika k-rank semakin kecil.
Gambar 2. Grafik hasil MAP pada tiap k-rank
SIMPULAN
Sistem yang digunakan dalam penentuan lirik lagu berdasarkan emosi pada penelitian ini menunjukkan hasil yang cukup baik, dimana nilai MAP yang dihasilkan mendekati nilai 1. Pada penelitian ini digunakan lirik lagu berbahasa Indonesia, dimana dalam proses stemming, sistem ini mengabaikan penggunaan bahasa yang kurang resmi
(bahasa gaul), yang mengakibatkan banyaknya kata yang dihasilkan proses tokenizing semakin banyak. Jika dimensi antara jumlah kata dan banyaknya lirik lagu semakin besar maka waktu komputasi yang dihasilkan juga cukup lama. Sehingga, digunakan proses reduksi dimensi SVD yang dapat mengurangi jumlah dimensi. Proses LSI menggunakan SVD juga digunakan untuk mencari keterkaitan makna antar kata yang tersembunyi. Proses matematis dalam SVD mampu menunjukkan hubungan semantik antar kata. Pemilihan k-rank yang optimal tidak dapat ditentukan secara pasti karena banyaknya jumlah kata dan dokumen yang berbeda akan memungkinkan untuk menghasilkan k-rank optimal yang berbeda pula.
SARAN
Beberapa saran yang dari hasil penelitian ini diantaranya yaitu banyaknya jumlah kata yang terdapat dalam file lirik lagu berpengaruh dalam proses pembobotan TF-IDF, yang menyebabkan dimensi data tidak dapat diminimalkan, sehingga dibutuhkan pemangkasan frekuensi kata sebelum proses pembobotan dilakukan. Selain itu, penggunaan frasa dalam penentuan makna sangat berpengaruh, misalkan untuk kata “air mata”, sistem ini belum bisa mengenali bahwa “air mata” itu satu buah makna (frasa), akan lebih baik dan menghasilkan presisi yang cukup baik jika penggunaan frasa dilibatkan. Penggunaan frasa dapat diletakkan sebelum menghitung pembobotan dengan menggunakan TF-IDF ternormalisasi. ACKNOWLEDGEMENTS
Ucapan terima kasih kepada Drs.Achmad Ridok, M.Kom dan Drs.Marji M.T yang telah membantu dan membimbing penulis dalam melakukan penelitian ini di Universitas Brawijaya Malang.
CI-79 DAFTAR PUSTAKA
[1] Fuhr, N. 2002. Information Retrieval-Introduction and Survey. Germany. University of Disburg-Essen
[2] Manning, Christoper.D, Raghavan, Prabhakar, dan Schutze, H. 2007. An
Introduction to Information Retrieval.
Cambridge.England.Cambridge University Press
[3] Kleedofer,F,dkk.2008. Oh Oh Oh Whoah!
Towards Automatic Topic Detection in Song Lyrics.Austria. Studio Smart Agent
Tecnologies.
[4] Samat,N.Ab, Murad, M.A.A, Abdullah, M.T, dan Atan, R.2009. Malay Document
Clustering Algorithm Based on Singular Value Decomposition. Malaysia. Fakultas
Ilmu Komputer dan Teknologi Informasi, Universitas Putra Malaysia.
[5] Peter,Rakesh, G, Shivapratap, Dvya G,dan Soman KP. 2009. Evaluation of SVD and
NMF Fungsis for Latent Semantic Analysis. India. Amrita University.
[6] Asian,Jelita, Wiliams, Hugh E, dan Tahaghoghi S.M.M. .2005. Stemming
Indonesian. Australia : School of Computer Science and Information Technology.
[7] Feldman,R dan James S. 2007. The Text
Mining Handbook. England.Cambridge
University Press.
[8] Garcia,E.2006.Vector Models Based on
Normalized Frequencies : Improving Word Weights with Normalized Frequencies.
http://www.miislita.com/word-vector/word-vector-4.html. Diakses tanggal 25 Mei 2011.
[9] Sriyasa,W. 2009. Temu Kembali Informasi
: Rekonstruksi Inverted Index dan Inplementasi Stopwords. Departemen Ilmu
Komputer.IPB
[10] Garcia,E.2006. SVD and LSI Tutorial 3:
Computing the Full SVD of a Matrix.
http://www.miislita.com/information- retrieval-tutorial/svd-lsi-tutorial-3-full-svd.html. Diakses tanggal 7 Mei 2011. [11] Kontostathis, April. 2007. Essential
Dimensions of Latent Semantic Indexing (LSI). Departemen Matematika dan Ilmu
Komputer Universitas Ursinus.USA. [12] Parsons,Kathryn, McCormac, A.,
Butavicius, M, Dennis*,S, dan Ferguson, L. 2009. The Use of Context-Based
Information Retrieval Technique.
Australia. Defence Science and Technology Organization.
[13] Strehl,A,et al.2000.Impact of Similarity
Measures on Web-Page Clustering.
Proceeding of the Workshop of Artificial Intelligent for Web Search, 17th National Conference on Artificial Intelligence,2000. [14] Blanken,H, Vries,Arjen P.de, Blok, Henk Ernst, dan Feng, Ling ,.2007.Multimedia
Retrieval.Springer Berlin Heidelberg New
York
[15] Manning, Christoper.D, Raghavan, Prabhakar, dan Schutze, H. 2009. An
Introduction to Information Retrieval.
Cambridge.England.Cambridge University Press