DAN POLA AKTIFITAS PENGHUNI RUMAH
Skripsi
Oleh
Alfatta Rezqa Winnersyah NIM : 1113091000003
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
DAN POLA AKTIFITAS PENGHUNI RUMAH
Skripsi
Sebagai Salah Satu Syarat Untuk Memperoleh Gelar Sarjana Komputer (S.Kom.)
Fakultas Sains Dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah
Oleh
Alfatta Rezqa Winnersyah NIM : 1113091000003
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
ALGORITMA K-NEAREST NEIGHBOUR DAN POLA AKTIFITAS PENGHUNI RUMAH
Skripsi
Sebagai Salah Satu Syarat untuk
Memperoleh Gelar Sarjana Komputer (S.Kom) Oleh:
Alfatta Rezqa Winnersyah 1113091000003 Menyetujui, Pembimbing I Feri Fahrianto, M.Sc NIP. 198008292011011002 Pembimbing II Nenny Anggraini, M.T NIDN. 0310097601 Mengetahui,
Ketua Program Studi Teknik Informatika,
Arini, M.T
K-Nearest Neighbour dan Pola Aktifitas Penghuni Rumah” telah diuji dan dinyatakan lulus dalam sidang munaqosyah Fakultas Sains Dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah Jakarta pada hari Rabu, 22 November 2017. Skripsi ini telah diterima sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu (S1) Program Studi Teknik Informatika.
Jakarta, 27 November 2017 Menyetujui, Penguji I Dewi Khairani, M.Sc NIP. 198205222011012009 Penguji II
Victor Amrizal, M.Kom NIP. 197406242007101001 Pembimbing I Feri Fahrianto, M.Sc NIP. 198008292011011002 Pembimbing II Nenny Anggraini, M.T NIDN. 0310097601 Mengetahui,
Dekan Fakultas Sains dan Teknologi
Dr. Agus Salim, M.Si. NIP. 197208161999031003
Ketua Program Studi Teknik Informatika
Arini, M.T
1. Skripsi ini merupakan hasil karya asli saya yang diajukan untuk memenuhi salah satu persyaratan memperoleh gelar Strata 1 di UIN Syarif
Hidayatullah Jakarta.
2. Semua sumber yang saya gunakan dalam penulisan ini telah saya cantumkan sesuai dengan ketentuan yang berlaku di UIN Syarif Hidayatullah Jakarta.
3. Apabila di kemudian hari terbukti karya ini bukan hasil karya asli saya atau merupakan hasil jiplakan karya orang lain, maka saya bersedia menerima sanksi yang berlaku di UIN Syarif Hidayatullah Jakarta.
Jakarta, 27 November 2017
bertanda tangan dibawah ini:
Nama : Alfatta Rezqa Winnersyah
NIM : 1113091000003
Program Studi : Teknik Informatika Fakultas : Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti Noneksklusif (Non-exclusive Royalty Free Right) atas karya ilmiah saya yang berjudul:
Metode Identifikasi dan Estimasi Posisi dengan Algoritma K-Nearest Neighbour dan Pola Aktifitas Penghuni Rumah
beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Noneksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalih media/formatkan, mengelola dalam bentuk pangkalan data (database), merawat dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di : Jakarta
Pada tanggal : 27 November 2017
Yang menyatakan
K-Nearest Neighbour dan Pola Aktifitas Penghuni Rumah ABSTRAK
Seiring banyaknya aplikasi rumah berbasis Internet of Things (IoT) seperti home automation dan monitoring perilaku penghuni, informasi lokasi penghuni rumah menjadi suatu kebutuhan. Penelitian sebelumnya telah mampu mengestimasi posisi seseorang dalam ruang menggunakan metode fingerprinting. Pada penelitian ini penulis mengusulkan metode yang mampu mengestimasi posisi penghuni rumah dengan menggabungkan teknik fingerprinting dengan pola aktifitas penghuni rumah menggunakan algoritma K-Nearest Neighbour dengan
Euclidean Distance. Nilai RSS dari tiga buah access point diukur dengan
menggunakan aplikasi training berbasis Android di setiap titik referensi. Estimasi dilakukan dengan membandingkan nilai RSS yang didapat dengan hasil pengukuran sebelumnya lalu dibandingkan dengan pola aktifitas penghuni rumah tersebut. Dari hasil eksperimen, penulis mendapatkan hasil bahwa metode yang penulis usulkan mampu mengestimasi dengan ketepatan hingga 87,8% untuk akurasi dibawah 2 meter dengan rata-rata kesalahan sebesar 0,82 meter.
Kata Kunci : Indoor Positioning System, K-Nearest Neighbour, Pola Aktifitas
memberikan rahmat, pertolongan, dan hidayah-Nya, sehingga penulis dapat menyelesaikan skripsi yang berjudul METODE IDENTIFIKASI DAN ESTIMASI POSISI DENGAN ALGORITMA K-NEAREST NEIGHBOUR DAN POLA AKTIFITAS PENGHUNI RUMAH. Laporan ini penulis susun sebagai salah satu syarat untuk memperoleh gelar sarjana komputer (S.Kom).
Dalam penyusunan laporan ini banyak sekali perlajaran dan peristiwa yang sangat berharga bagi penulis. Suka serta duka yang bahkan tidak pernah penulis bayangkan sebelumnya, namun penulis sangat bersyukur karena selalu dikelilingi oleh orang-orang yang senantiasa mendukung, membimbing dan menginspirasi penulis. Oleh karena itu, penulis ucapkan terima kasih kepada:
1. Bapak Prof. DR. Dede Rosyada, MA selaku Rektor UIN Syarif Hidayatullah Jakarta.
2. Bapak Dr. Agus Salim, M.Si selaku Dekan Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta.
3. Ibu Arini, M.T. selaku Ketua Program Studi Teknik Informatika, Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta.
4. Bapak Feri Fahrianto, M.Sc. selaku Sekretaris Program Studi Teknik Informatika Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta dan Dosen Pembimbing Satu atas arahan, motivasi, dan pengetahuan yang telah diberikan.
5. Ibu Nenny Anggraini, M.T, selaku Dosen Pembimbing Dua atas arahan, motivasi, dan pengetahuan yang telah diberikan.
6. Seluruh dosen Program Studi Teknik Informatika yang tidak mungkin penulis sebutkan satu persatu atas ilmu yang telah diberikan selama menjalani perkuliahan.
8. Dian Karlina, terima kasih atas semangat, dukungan yang tak henti-henti, dan segala bantuannya selama ini hingga selesainya skripsi ini.
9. Keluarga Besar Teknik Informatika 2013 dan semua pihak yang tidak dapat disebutkan satu per satu yang telah membantu hingga laporan ini selesai.
Penulis sangat mengharapkan saran dan kritik yang bersifat membangun demi kesempurnaan skripsi ini. Akhir kata, penulis berharap skripsi ini dapat berguna dan bermanfaat bagi semua pihak yang terkait, untuk itu kritik dan saran sangat diharapkan dengan berkomunikasi melalui email ke arwinnersyah@gmail.com
Jakarta, 27 November 2017
Alfatta Rezqa Winnersyah 1113091000003
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI...iv ABSTRAK...v KATA PENGANTAR...vi DAFTAR ISI...viii DAFTAR TABEL...x DAFTAR GAMBAR...xi BAB I PENDAHULUAN...1
1.1. Latar Belakang Masalah...1
1.2. Rumusan Masalah...4 1.3. Batasan Masalah...4 1.4. Tujuan Penelitian...5 1.5. Manfaat Penelitian...5 1.5.1. Bagi Mahasiswa...5 1.5.2. Bagi Universitas...5
1.5.3. Bagi Penghuni Rumah...5
1.6. Metodologi Penelitian...6
1.6.1. Metode Pengumpulan Data...6
1.6.2. Metode Pengembangan Sistem...6
1.6.3. Metode Pengujian...6
1.7. Sistematika Penulisan...6
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI...8
2.1. Identifikasi...8 2.2. Estimasi Posisi...8 2.3. Android...8 2.4. Pemrograman Android...9 2.5. Pemrograman PHP...11 2.6. Basis Data...12
2.6.1. Basis Data MySQL...12
2.7. Machine Learning...13
2.7.1. Supervised Learning...13
2.7.2. Unsupervised Learning...14
2.7.3. Reinforced Learning...14
2.8. Klasifikasi...15
2.8.1. Klasifikasi Eager Learner...15
2.8.2. Klasifikasi Lazy Learner...15
2.8.3. Pengukuran Kinerja Klasifikasi...16
2.9. Algoritma K-Nearest Neighbour...16
2.9.1. Perhitungan K-Nearest Neighbour...17
2.9.2. Karakteristik Algoritma K-Nearest Neighbour...17
2.13.1. Fase Metode RAD...20
2.14. Metode Uji Coba...22
2.14.1. Uji Coba Black Box...22
2.14.2. Jenis Uji Coba Black Box...23
BAB III METODOLOGI PENELITIAN...27
3.1. Metode Pengumpulan Data...27
3.1.1. Studi Literatur...27
3.1.2. Observasi...27
3.2. Metode Pengembangan...28
3.2.1. Tahap Requirement Planning...28
3.2.2. Tahap Workshop Design...28
3.2.3. Tahap Implementation...29
3.3. Metode Pengujian...31
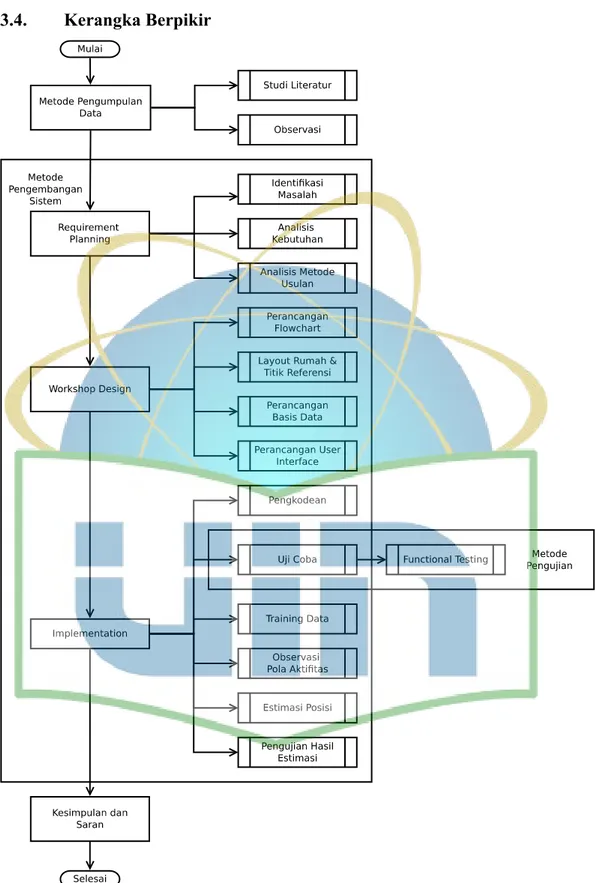
3.4. Kerangka Berpikir...32
BAB IV IMPLEMENTASI EKSPERIMEN...33
4.1. Tahap Requirement Planning...33
4.1.1. Identifikasi Masalah...33
4.1.2. Analisis Metode Usulan...36
4.1.3. Analisis Kebutuhan...38
4.2. Tahap Workshop Design...40
4.2.1. Perancangan Flowchart...40
4.2.2. Layout Rumah dan Titik Referensi...42
4.2.3. Perancangan Basis Data...43
4.2.4. Perancangan User Interface...46
4.3. Tahap Implementation...49
4.3.1. Pengkodean...49
4.3.2. Uji Coba...51
4.3.3. Training Data...52
4.3.4. Observasi Pola Aktifitas Penghuni...55
4.3.5. Estimasi...57
4.3.6. Pengujian Hasil Estimasi...59
BAB V HASIL DAN PEMBAHASAN...60
5.1. Hasil...60
5.2. Pembahasan...62
BAB VI KESIMPULAN DAN SARAN...63
6.1. Kesimpulan...63
6.2. Saran...63
DAFTAR PUSTAKA...64
Tabel 4.2. Kebutuhan Hardware...39
Tabel 4.3. Kebutuhan Software...40
Tabel 4.4. Tabel Database Grid...43
Tabel 4.5. Tabel Database Penghuni...44
Tabel 4.6. Tabel Database Training...44
Tabel 4.7. Tabel Database Estimasi...45
Tabel 4.8. Tabel Database Behaviour...46
Tabel 4.9. Tabel Database Zona...46
Gambar 2.2. Reinforced Learning...14
Gambar 2.3. Pola Aktifitas Penghuni Rumah...19
Gambar 2.4: Fase RAD...21
Gambar 3.1. Kerangka Berpikir...32
Gambar 4.1. Analisis Metode Usulan...38
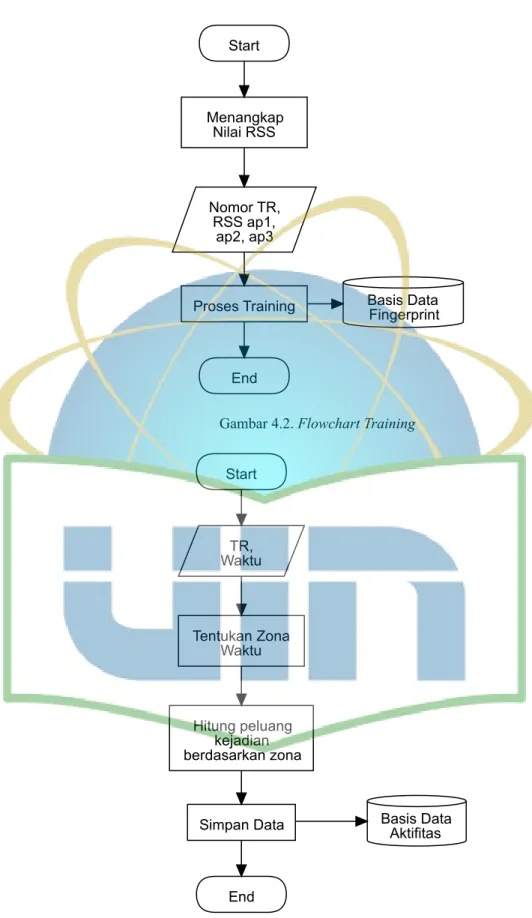
Gambar 4.2. Flowchart Training...41
Gambar 4.3. Flowchart Observasi Aktifitas...41
Gambar 4.4. Flowchart Identifikasi dan Estimasi...42
Gambar 4.5. Layout Rumah dan Titik Referensi...43
Gambar 4.6. Desain Halaman Hasil Estimasi...47
Gambar 4.7. Desain Aplikasi Training...47
Gambar 4.8. Desain Aplikasi Estimasi...48
Gambar 4.9. Aplikasi Training...49
Gambar 4.10. Aplikasi Estimasi...50
Gambar 4.11. Webserver...51
Gambar 4.12. Sample Data Training...52
Gambar 4.13. Data Training Hari Ke-1 Pagi...53
Gambar 4.14. Data Training Hari Ke-1 Sore...53
Gambar 4.15. Data Training Hari Ke-2 Pagi...53
Gambar 4.16. Data Training Hari Ke-2 Sore...54
Gambar 4.17. Data Training Hari Ke-3 Pagi...54
Gambar 4.18. Data Training Hari Ke-3 Sore...54
Gambar 4.19. Data Training Hari Ke-4 Pagi...54
Gambar 4.20. Data Training Hari Ke-4 Sore...55
Gambar 4.21. Data Training Hari Ke-5 Pagi...55
Gambar 4.22. Data Training Hari Ke-5 Sore...55
Gambar 4.23. Sample Data Peluang Aktifitas...56
Gambar 4.24. Basis Data Peluang Aktifitas...56
Gambar 4.25. Basis Data Hasil Estimasi...57
Gambar 4.26. Tampilan Website Hasil Estimasi...58
Gambar 4.27. Hasil Estimasi Pada Smartphone Penghuni...58
1.1. Latar Belakang Masalah
Lokasi merupakan salah satu informasi penting dalam mendapatkan bermacam layanan berbasis context-aware. Dengan banyaknya aplikasi rumah berbasis Internet of Things (IoT) seperti home automation dan monitoring perilaku penghuni, informasi lokasi penghuni rumah menjadi suatu kebutuhan (Du dkk., 2016). Metode penentuan lokasi yang populer saat ini yakni Global
Positioning System (GPS), namun GPS tidak mampu bekerja dengan baik dalam
lingkungan dalam ruang (Toh dan Lau, 2016). Sinyal GPS terhalang oleh konstruksi bangunan dan menjadikan tidak bekerja dengan baik untuk mendapatkan lokasi dalam ruang (Thuong dkk., 2016).
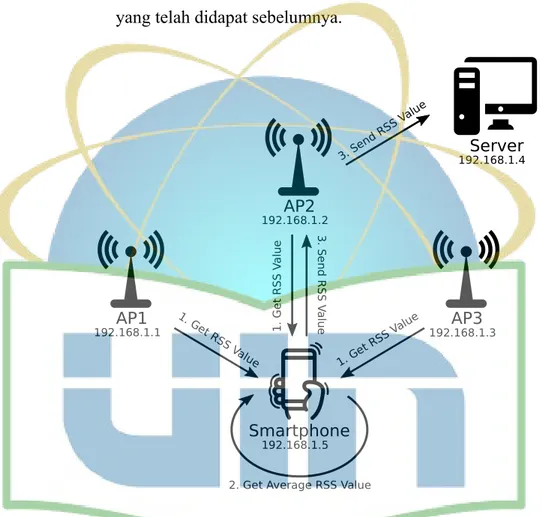
Menurut penelitian Du dkk. (2016), metode estimasi posisi dalam ruang bisa dilakukan dengan menggunakan berbagai cara, seperti menggunakan WiFi, Bluetooth, Ultra-Wide Band (UWB), dan RFID. WiFi merupakan salah satu pendekatan yang cukup baik. Dapat dikatakan cukup baik karena teknologi WiFi sudah banyak diimplementasikan dalam bangunan-bangunan bahkan dalam
smartphone pun telah tertanam teknologi WiFi. Selain itu WiFi memiliki cakupan
sinyal yang lebih luas dibandingkan dengan Bluetooth dan RFID.
Berdasarkan penelitian Pirzada dkk. (2016), WLAN dapat digunakan untuk menentukan posisi seseorang dalam ruang dengan memanfaatkan nilai
Received Signal Strength Indication (RSSI) beberapa access point dan dengan
algoritma tertentu seperti Support Vector Machines, Neural Networks, Weighted K
Nearest Neighbors, atau pendekatan Bayesian. Dilakukan pembelajaran terhadap
sistem pada titik lokasi yang telah ditentukan untuk mendapat data pembelajaran yang akan digunakan pada proses selanjutnya.
Toh dan Lau (2016) dalam penelitiannya yang memanfaatkan infrastruktur WiFi yang sudah ada dalam bangunan universitas berhasil melakukan estimasi posisi dengan akurasi 81,82% hingga 99,85%. Penelitian lainnya mampu menentukan lokasi dengan mengkalkulasi nilai RSS dalam ponsel
pintar yang menggunakan 6 buah access point yang dipasang di ketinggian 1,2 m dari lantai dengan 20 titik referensi (Thuong dkk., 2016). Penelitian ini menemukan bahwa perpindahan benda dalam ruang akan sangat mempengaruhi akurasi dari penentuan lokasi. Selain itu penelitian ini juga mendapatkan hasil yang lebih baik dengan menggunakan hanya 3 access point.
Dalam penelitian Du dkk. (2016), diusulkan metode yang berbeda dengan penelitian Thuong dkk., yakni kalkulasi dan pengambilan nilai RSS tidak sama sekali menggunakan ponsel pengguna. Penelitian ini membuat program
sniffy untuk memonitor probe request dari setiap access point untuk mendapatkan
nilai RSS serta kalkulasi nilai RSS tersebut dilakukan pada server. Hasilnya, penelitian ini mampu menerapkan metode tersebut dengan akurasi jarak kesalahan maksimal sebesar 4,5 m.
Pembelajaran mesin berkaitan dengan bagaimana membangun program komputer yang secara otomatis menjadi lebih baik dengan pengalaman (Mitchel, 1997). Salah satu pendekatan dalam pembelajaran mesin ialah klasifikasi. Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya kedalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu (1) pembangunan model sebagai prototipe untuk disimpan sebagai memori dan (2) penggunaan model tersebut untuk melakukan pengenalan/klasifikasi/prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang sudah disimpannya (Prasetyo, 2012).
Berdasarkan cara pelatihan, algoritma-algoritma klasifikasi dapat dibagi menjadi dua macam yaitu eager learner dan lazy learner. Algoritma-algoritma yang masuk dalam kategori lazy learner hanya sedikit melakukan pelatihan (atau tidak sama sekali), hanya menyimpan sebagian atau seluruh data latih, kemudian menggunakannya dalam proses prediksi. Hal ini mengakibatkan proses prediksi menjadi lama karena model harus membaca kembali semua data latihnya agar dapat memberikan keluaran label kelas dengan benar pada data uji yang diberikan. Kelebihan algoritma seperti ini adalah proses pelatihan yang berjalan dengan cepat. Algoritma-algoritma klasifikasi yang masuk kategori ini, di antaranya,
adalah K-Nearest Neighbor(K-NN), Fuzzy K-Nearest Neighbot (FK-NN), Regresi Linier, dan sebagainya (Prasetyo, 2012).
Dari penelitian Du dkk. (2016), Thuong dkk. (2016), dan Toh dan Lau (2016), metode yang digunakan ialah dengan menghitung jarak terdekat atau kecocokan data yang akan dilakukan estimasi dengan data pembelajaran yang sudah ada. Namun dari jarak terdekat tersebut masih sering didapati data yang dilakukan estimasi akan menghasilkan hasil estimasi yang salah. Pada penentuan posisi penghuni rumah, salah satu indikator yang terkait dengan posisi adalah aktifitas dari penghuni rumah tersebut. Aktifitas penghuni rumah dapat dengan mudah diketahui karena aktifitas rumah tergolong memiliki pola tertentu. Contohnya seperti setiap pagi hari setiap orang pasti terbiasa bangun lalu menggosok gigi atau sarapan (Yan dkk., 2014). Sehingga aktifitas penghuni rumah dapat dijadikan salah satu parameter dalam penentuan posisi penghuni rumah pada waktu tertentu. Pola aktifitas ini akan digunakan sebagai pembanding agar hasil dari metode berbasis WiFi menghasilkan data yang lebih akurat.
Pada proses penentuan posisi berbasis WiFi, penentuan posisi dapat dilakukan dengan mengasumsikan setiap individu membawa perangkat wireless dan dibutuhkan suatu aplikasi pada perangkat tersebut (Akkaya dkk., 2015). Menurut hasil survei Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) tahun 2016, perangkat yang banyak digunakan oleh masyarakat Indonesia ialah
mobile dibanding dengan komputer dengan perbandingan 47,6% menggunakan
mobile, 1,7% menggunakan komputer dan 50,7% menggunakan keduanya bila ditinjau dari perangkat yang digunakan untuk mengakses internet. Bila ditinjau dari perangkat yang digunakan untuk browsing, smartphone paling banyak digunakan dengan persentase 67,8% dibandingkan dengan komputer/pc, laptop, dan tablet. Hal ini juga didukung dengan pemakaian sistem operasi untuk akses internet saat ini yang menunjukkan Android merupakan sistem operasi terbanyak digunakan (sebanyak 37,93%) mengalahkan Windows (sebanyak 37,91%) menurut rilis pers StatCounter April 2017.
Berdasarkan pemaparan diatas penulis tertarik untuk meneliti lebih lanjut mengenai estimasi posisi penghuni rumah. Algoritma K-Nearest Neighbour
penulis pilih karena memiliki kemampuan yang baik dalam memprediksi suatu kelas dari suatu data berdasarkan data pembelajaran yang sudah ada sebelumnya. Dengan demikian penulis melakukan penelitian yang berjudul “METODE IDENTIFIKASI DAN ESTIMASI POSISI DENGAN ALGORITMA K-NEAREST NEIGHBOUR DAN POLA AKTIFITAS PENGHUNI RUMAH” 1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan sebelumnya, rumusan masalah yang akan penulis bahas dalam penelitian ini meliputi:
1. Bagaimana mengestimasi posisi dari penghuni rumah dengan rata-rata kesalahan dibawah 1 meter?
2. Bagaimana meningkatkan akurasi estimasi agar dapat mengurangi tingkat kesalahan dalam estimasi?
1.3. Batasan Masalah
Berikut merupakan batasan masalah dari penelitian ini.
1. Penelitian dilakukan oleh 1 orang dalam lingkup rumah hunian. 2. Proses estimasi menggunakan besarnya kuat sinyal wireless access
point terhadap perangkat pengguna, mac address perangkat
pengguna, serta basis data aktifitas penghuni rumah.
3. Terdapat knowledge base daftar mac address perangkat pengguna yang dibuat penulis dengan lingkup perangkat yg dimiliki penghuni rumah.
4. Perangkat pengguna yang digunakan merupakan ponsel pintar dengan sistem operasi Android.
5. Perancangan Wireless LAN Positioning System menggunakan 3 buah Wireless Access Point yang diletakkan di ketinggian 2,5 meter diatas lantai dan dipasang pada dinding.
6. Diasumsikan pada setiap aktifitas, penghuni rumah selalu membawa smartphone.
1.4. Tujuan Penelitian
Tujuan yang ingin dicapai oleh penulis ialah dapat merancang metode yang dapat mengidentifikasi dan mengestimasi posisi penghuni rumah dengan rata-rata jarak kesalahan dibawah 1 meter.
1.5. Manfaat Penelitian
Berikut merupakan manfaat dari penelitian ini. 1.5.1. Bagi Mahasiswa
1. Dapat menerapkan ilmu yang dimiliki yang didapat dari perkuliahan.
2. Memahami bahasa pemrograman, proses, serta tools yang digunakan dalam penelitian ini.
3. Sebagai salah satu syarat kelulusan Strata Satu (S1) Teknik Informatika UIN Syarif Hidayatullah Jakarta. 1.5.2. Bagi Universitas
1. Mengukur tingkat kemampuan dalam menerapkan ilmu akademis maupun non-akademis.
2. Sebagai penelitian yang dapat dijadikan referensi untuk penelitian lebih lanjut mengenai indoor positioning
system.
1.5.3. Bagi Penghuni Rumah
1. Mendapatkan informasi posisi anggota keluarga dengan tingkat akurasi yang tinggi
2. Mengetahui rekam jejak posisi penghuni rumah dengan jelas
1.6. Metodologi Penelitian
Berikut merupakan metode yang digunakan penulis dalam penelitian ini. 1.6.1. Metode Pengumpulan Data
Untuk menunjang penelitian dan penulisan skripsi ini, penulis menggunakan dua metode pengumpulan data, yaitu :
1. Observasi 2. Studi Literatur
1.6.2. Metode Pengembangan Sistem
Dalam penelitian ini, penulis menggunakan metode Rapid
Application Development (RAD) yang memiliki tahapan sebagai berikut: 1. Requirement Planning
2. Workshop Design 3. Implementation
1.6.3. Metode Pengujian
Untuk memastikan hasil penelitian sesuai dengan keinginan dan kebutuhan pengguna, penulis melakukan pengujian dengan metode uji coba black box.
1.7. Sistematika Penulisan
Dalam penyusunan skripsi ini, penulis membagi skripsi menjadi enam bab pokok bahasan, meliputi :
BAB I PENDAHULUAN
Pada bab ini akan diuraikan mengenai latar belakang masalah, rumusan masalah, batasan masalah, tujuan, manfaat, dan metodologi penelitian serta sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini akan diuraikan mengenai beberapa teori dan literatur sejenis yang mendasari dan terkait pada penelitian ini.
BAB III METODOLOGI PENELITIAN
Pada bab ini akan dijelaskan secara rinci mengenai metode yang digunakan penulis serta kerangka berfikir penulis. BAB IV IMPLEMENTASI EKSPERIMEN
Pada bab ini akan dibahas mengenai hasil dari analisis, perancangan, implementasi, dan pengujian sesuai dengan metode yang digunakan dalam penelitian ini.
BAB V HASIL DAN PEMBAHASAN
Pada bab ini dibahas mengenai hasil dan pembahasan mengenai penelitian yang dilakukan penulis.
BAB VI PENUTUP
Bab ini berisi kesimpulan dari penelitian yang dilakukan penulis serta saran untuk pengembangan lebih lanjut.
2.1. Identifikasi
Identifikasi menurut kamus besar bahasa Indonesia merupakan tanda kenal, bukti diri, atau penentu atau penetapan identitas seseorang. Identifikasi adalah serangkaian pengumpulan data dan pencatatan segala keterangan tentang bukti-bukti dari objek sehingga dapat ditetapkan dan disamakan keterangan tersebut dengan objek lain guna mengenali objek tersebut.
2.2. Estimasi Posisi
Estimasi menurut kamus besar bahasa Indonesia merupakan suatu perkiraan. Sedangkan posisi berarti kedudukan atau letak (orang, barang). Estimasi posisi dapat diartikan sebagai proses memperkirakan atau hasil perkiraan kedudukan seseorang dalam suatu wilayah. Dalam estimasi posisi lingkup besar, teknologi yang sangat berkembang ialah Global Positioning System (GPS). GPS berbasis satelit yang bekerja di cuaca apapun, 24 jam sehari, dan tanpa biaya. Namun GPS memiliki tingkat akurasi yang tidak dapat mencakup posisi di dalam ruang. Berdasarkan penelitian Pirzada dkk. (2016), Wireless LAN (WLAN) dapat digunakan untuk menentukan posisi seseorang dalam ruang dengan memanfaatkan nilai Received Signal Strength Indication (RSSI) beberapa access
point dan dengan algoritma tertentu seperti Support Vector Machines, Neural Networks, Weighted K Nearest Neighbors, atau pendekatan Bayesian.
2.3. Android
Menurut Safaat (2012), Android adalah sebuah sistem operasi untuk perangkat mobile berbasis linux yang mencakup sistem operasi, middleware, dan aplikasi. Android menyediakan platform terbuka bagi para pengembang untuk menciptakan aplikasi mereka. Sejalan dengan pandangan Suprianto dan Agustina (2012), hampir setiap kode program Android diluncurkan berdasarkan lisensi
open-source Apache yang berarti bahwa semua orang yang ingin menggunakan
Android dapat men-download penuh source code-nya.
Android dipuji sebagai “platform mobile pertama yang lengkap, terbuka, dan bebas” (Safaat, 2012).
• Lengkap (Complete Platform): Para desainer dapat melakukan pendekatan yang komprehensif ketika mereka sedang mengembangkan platform Android. Android merupakan sistem operasi yang aman dan banyak menyediakan tools dalam membangun software dan memungkinkan untuk peluang pengembangan aplikasi.
• Terbuka (Open Source Platform): Platform Android disediakan melalui lisensi open source. Pengembang dapat dengan bebas untuk mengembangkan aplikasi.
• Free (Free Platform): Android adalah platform/aplikasi yang bebas untuk dikembangkan. Tidak ada lisensi atau biaya royalti untuk dikembangan pada platform Android. Tidak ada biaya keanggotaan diperlukan. Tidak diperlukan biaya pengujian. Tidak ada kontrak yg diperlukan.
2.4. Pemrograman Android
Keuntungan utama dari Android adalah adanya pendekatan aplikasi secara terpadu. Pengembang hanya berkonsentrasi pada aplikasi saja, aplikasi tersebut bisa berjalan pada beberapa perangkat yang berbeda selama masih ditenagai oleh Android (Supriyanto dan Agustina, 2012).
Secara garis besar sistem operasi Android terbagi menjadi lima tingkatan: • Linux Kernel – Tingkat ini berisi semua driver perangkat tingkat
rendah untuk komponen-komponen hardware perangkat Android.
• Libraries – berisi semua kode program yang menyediakan
layanan-layanan utama sistem operasi Android.
• Android Runtime – kedudukannya setingkat dengan libraries,
diaktifkan oleh pengembang untuk menulis kode aplikasi Android dengan bahasa pemrograman Java.
• Application Framework – adalah kumpulan class built-in yang tertanam dalam sistem operasi Android.
• Applications – Semua aplikasi yang dibuat terletak pada tingkat
Applications.
Menurut Safaat (2012), aplikasi Android ditulis dalam bahasa pemrograman java. Kode java dikompilasi bersama dengan data file resource yang dibutuhkan oleh aplikasi kedalam paket Android sehingga menghasilkan file dengan ekstensi apk.
Ada empat jenis komponen pada aplikasi Android yaitu:
1. Activities
Suatu activity akan menyajikan user interface (UI) kepada pengguna, sehingga pengguna dapat melakukan interaksi.
2. Service
Service tidak memiliki Graphic User Interface (GUI), tetapi service berjalan secara background. Service dijalankan pada thread
utama dari proses aplikasi
3. Broadcast Receiver
Broadcast receiver berfungsi menerima dan bereaksi untuk
menyampaikan notifikasi. Broadcast receiver tidak memiliki user
interface (UI), tetapi memiliki sebuah activity untuk merespon informasi
yang mereka terima, atau mungkin menggunakan Notification Manager.
4. Content Provider
Content provider membuat kumpulan aplikasi data secara spesifik
sehingga bisa digunakan oleh aplikasi lain. Content provider menyediakan cara untuk mengakses data yang dibutuhkan oleh suatu
2.5. Pemrograman PHP
Menurut Raharjo dkk. (2012) PHP adalah salah satu bahasa pemrograman yang dirancang untuk membangun aplikasi web. Ketika dipanggil dari web browser, program yang ditulis dengan PHP akan di-parsing di dalam
web server oleh interpreter PHP dan diterjemahkan ke dalam dokumen HTML,
yang selanjutnya akan ditampilkan kembali ke web browser. Karena pemrosesan program PHP dilakukan di lingkungan web server, PHP dikatakan sebagai bahasa sisi server (server-side). Oleh sebab itu, kode PHP tidak akan terlihat pada saat
user memilih perintah “View Source” pada web browser yang mereka gunakan.
Sedangkan menurut laman resmi PHP, PHP (akronim untuk PHP :
Hypertext Processor) merupakan bahasa pemrograman open source yang sangat
cocok untuk pemrograman web dan dapat disematkan ke dalam HTML. PHP berfokus pada pemrograman server-side. Terdapat tiga area utama dimana PHP digunakan.
1. Server-side scripting
Server-side scripting merupakan bidang utama PHP. Dibutuhkan
tiga hal untuk menjalankannya, yakni PHP parser, web server, dan web
browser.
2. Command line scripting
Script PHP dapat dijalankan tanpa server atau browser. Hanya
dibutuhkan PHP parser untuk menjalankannya. Jenis penggunaan ini ideal untuk script yang dijalankan teratur menggunakan Cron (*nix atau Linux) atau Task Scheduler (Windows).
3. Writing desktop applications
PHP mungkin bukan bahasa terbaik untuk membuat aplikasi
desktop dengan graphical user interface, namun dengan PHP-GTK
2.6. Basis Data
Menurut Nugroho (2011) sistem basis data bisa didefinisikan sebagai koleksi dari data-data yang terorganisir sedemikian rupa sehingga data mudah disimpan dan dimanipulasi (diperbarui, dicari, diolah dengan perhitungan-perhitungan tertentu, serta dihapus). Istilah basis data dapat didefinisikan sebagai suatu kumpulan data terhubung (interrelated data) yang disimpan secara bersama-sama tanpa redudansi yang tidak diperlukan untuk melayani satu atau lebih aplikasi secara optimal (Sutanta, 2011).
Dari definisi tersebut maka basis data mempunyai beberapa kriteria penting yang harus dipenuhi, yakni (Sutanta, 2011):
• Berorientasi pada data (data oriented) dan bukan berorientasi pada program (program oriented) yang akan menggunakannya
• Data dalam basis data dapat berkembang dengan mudah, baik volume maupun strukturnya
• Data yang ada dapat memenuhi kebutuhan sistem-sistem baru secara mudah
• Data dapat digunakan dengan cara yang berbeda-beda • Kerangkapan data (data redundancy) minimal
2.6.1. Basis Data MySQL
Menurut Raharjo (2011), MySQL merupakan software RDBMS (atau server database) yang dapat mengelola database dengan sangat cepat, dapat menampung data dalam jumlah sangat besar, dapat diakses oleh banyak user (multi-user), dan dapat melakukan suatu proses secara sinkron atau berbarengan (multi-threaded). Lisensi MySQL terbagi menjadi dua yaitu sebagai produk open source dibawah GNU General
Public License (gratis) atau lisensi versi komersial yang memiliki
2.7. Machine Learning
Machine learning, menurut Mitchell (1997) merupakan sebuah program
komputer yang belajar dari pengalaman (experience) E dari tugas yang dibebankan (task) T dengan kinerjanya (performance) P yang terukur. Sedangkan menurut Alpaydin (2010), machine learning merupakan pemrograman komputer untuk membuat kesimpulan dari data gabungan antara statistik dan ilmu komputer, dimana statistik menyediakan kerangka matematis membuat kesimpulan dari data dan ilmu komputer bekerja pada implementasi yang efisien metode pengambilan keputusan. Menurut Shekar Bhartiya, terdapat 3 jenis pembelajaran dalam machine learning, yakni supervised learning, reinforced
learning, dan unsupervised learning.
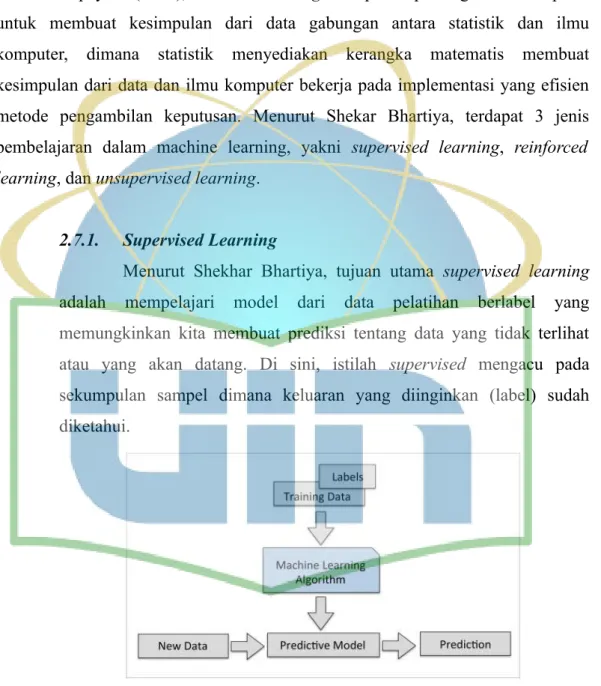
2.7.1. Supervised Learning
Menurut Shekhar Bhartiya, tujuan utama supervised learning adalah mempelajari model dari data pelatihan berlabel yang memungkinkan kita membuat prediksi tentang data yang tidak terlihat atau yang akan datang. Di sini, istilah supervised mengacu pada sekumpulan sampel dimana keluaran yang diinginkan (label) sudah diketahui.
Gambar 2.1. Supervised Learning (Sumber : Shekhar Bhartiya)
2.7.2. Unsupervised Learning
Menurut Shekar Bhartiya, dalam pembelajaran unsupervised
learning, kita berurusan dengan data yang tidak diketahui atau data tanpa
label. Dengan menggunakan teknik unsupervised learning, struktur data dapat dieksplorasi untuk mendapatkan informasi yang bermakna tanpa adanya petunjuk tentang variabel hasil atau fungsi reward yang diketahui.
2.7.3. Reinforced Learning
Dalam reinforced learning, tujuannya adalah untuk mengembangkan suatu sistem (agen) yang meningkatkan kinerjanya berdasarkan interaksi dengan lingkungan. Karena informasi tentang keadaan lingkungan saat ini biasanya juga mencakup yang disebut
reward signal, kita dapat memikirkan pembelajaran penguatan sebagai
bidang yang berkaitan dengan pembelajaran yang diawasi. Melalui interaksi dengan lingkungan, agen kemudian dapat menggunakan pembelajaran penguatan untuk mempelajari serangkaian tindakan yang memaksimalkan penghargaan ini melalui pendekatan trial and error eksploratif atau perencanaan deliberatif.
Gambar 2.2. Reinforced Learning (Sumber : Shekhar Bhartiya)
2.8. Klasifikasi
Menurut Prasetyo (2012), klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukkannya kedalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu (1) pembangunan model sebagai prototipe untuk disimpan sebagai memori dan (2) penggunaan model tersebut untuk melakukan pengenalan/klasifikasi/prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang sudah disimpannya. Klasifikasi menurut Alpaydin (2010) termasuk dalam machine learning dengan jenis supervised learning.
Berdasarkan cara pelatihan, algoritma-algoritma klasifikasi dapat dibagi menjadi dua macam yaitu eager learner dan lazy learner.
2.8.1. Klasifikasi Eager Learner
Algoritma-algoritma yang termasuk dalam kategori eager
learner didesain untuk melakukan pembacaan/pelatihan/pembelajaran
pada data latih agar dapat memetakan dengan benar setiap vektor masukan ke label kelas keluarannya sehingga di akhir proses pelatihan, model sudah dapat memetakan semua vektor data uji ke label kelas keluarannya dengan benar. Selanjutnya, setelah proses pelatihan tersebut selesai, model (biasanya berupa bobot atau sejumlah nilai kuantias tertentu) disimpan sebagai memori, sedangkan semua data latihnya dibuang. Proses prediksi dilakukan dengan model yang tersimpan, tidak melibatkan data latih sama sekali. Cara ini mengakibatkan proses prediksi berjalan cepat, tetapi harus dibayar dengan proses pelatihan yang lama. Algoritma-algoritma klasifikasi yang masuk kategori ini, di antaranya, adalah Artificial Neural Network (ANN), Support Vektor
Machine (SVM), Decision Tree, Bayesian, dan sebagainya.
2.8.2. Klasifikasi Lazy Learner
Sementara algoritma-algoritma yang masuk dalam kategori lazy
hanya menyimpan sebagian atau seluruh data latih, kemudian menggunakannya dalam proses prediksi. Hal ini mengakibatkan proses prediksi menjadi lama karena model harus membaca kembali semua data latihnya agar dapat memberikan keluaran label kelas dengan benar pada data uji yang diberikan. Kelebihan algoritma seperti ini adalah proses pelatihan yang berjalan dengan cepat. Algoritma-algoritma klasifikasi yang masuk kategori ini, di antaranya, adalah K-Nearest
Neighbor(K-NN), Fuzzy K-Nearest Neighbot (FK-Neighbor(K-NN), Regresi Linear, dan
sebagainya.
2.8.3. Pengukuran Kinerja Klasifikasi
Tujuan dari sebuah proses klasifikasi ialah menghasilkan keluaran berupa hasil klasifikasi dimana keseluruhan hasil bernilai benar. Namun tidak dapat dimungkiri suatu sistem tidak selalu berjalan 100% benar sehingga diperlukan pengukuran pengukuran kinerja sistem tersebut. Menurut Prasetyo (2012), umumnya, pengukuran kinerja klasifikasi dilakukan dengan matriks konfusi (confusion matrix). Matriks konfusi merupakan tabel pencatat hasil kerja klasifikasi. Kuantitas matriks konfusi dapat diringkas menjadi dua nilai, yaitu akurasi dan laju eror.
Untuk menghitung akurasi digunakan formula:
Akurasi=Jumlah data yang diprediksisecara benar Jumlah prediksi yang dilakukan
Untuk menghitung laju eror digunakan formula:
Akurasi=Jumlah data yang diprediksisecara salah Jumlah prediksi yang dilakukan
2.9. Algoritma K-Nearest Neighbour
Menurut Prasetyo (2012), algoritma K-Nearest Neighbour (K-NN) merupakan algoritma yang melakukan klasifikasi berdasarkan kedekatan lokasi (jarak) suatu data dengan data yang lain. Pada algoritma K-NN, data berdimansi
digunakan sebagai nilai kedekatan/kemiripan antara data uji dengan data latih. Nilai K pada K-NN berarti jumlah tetangga terdekat yang digunakan sebagai data uji. Pemilihan nilai K yang tepat menjadi salah satu masalah dalam K-NN. Nilai K yang terlalu besar mengakibatkan distorsi data yang besar. Namun jika nilai K terlalu kecil akan mengakibatkan algoritma terlalu sensitif terhadap noise.
2.9.1. Perhitungan K-Nearest Neighbour
Menurut Prasetyo (2012), misal terdapat data uji z = (x`,y`), dimana x` adalah vektor/atribut data uji, sedangkan y` adalah label kelas data uji yang belum diketahui. Hitung jarak (atau kemiripan) data uji ke setiap data latih d(x`,x), kemudian ambil K-tetangga terdekat pertama dalam Dz.Setelah itu, hitung jumlah data yang mengikuti kelas yang ada
dari K-tetangga tersebut. Kelas dengan data terbanyak yang mengikutinya menjadi kelas pemenang yang diberikan sebagai label kelas pada data uji y`.
Berikut langkah algoritma K-Nearest Neighbour:
• z = (x`,y`), adalah data uji dengan vektor x` dan label kelas y` yang belum diketahui
• Hitung jarak d(x`,x), jarak di antara data uji z ke setiap vektor data latih, simpan dalam D
• Pilih Dz⊆D , yaitu K tetangga terdekat dari z
2.9.2. Karakteristik Algoritma K-Nearest Neighbour
Menurut Prasetyo (2012), teknik nearest neighbour merupakan teknik klasifikasi sederhana, tetapi mempunyai hasil kerja yang cukup bagus. Beberapa kelebihan dan kekurangan K-NN sebagai berikut :
1. K-NN merupakan algoritma yang menggunakan seluruh data latih untuk melakukan proses klasifikasi (complete
storage). Hal ini mengakibatkan proses prediksi yang
2. K-NN tidak membedakan setiap fitur dengan suatu bobot. 3. Karena K-NN masuk kategori lazy learning yang
menyimpan sebagian atau semua data dan hampir tidak ada proses pelatihan, K-NN sangat cepat dalam proses pelatihan, tetapi sangat lambat dalam proses prediksi 4. Hal yang rumit adalah menentukan nilai K yang paling
sesuai
5. Perhitungan jarak Euclidean sangat cocok untuk menghitung jarak terdekat antara dua data, tetapi Manhattan sangat teguh untuk mendeteksi outlier dalam data
2.9.3. Euclidean Distance
Salah satu metode perhitungan jarak yang cocok digunakan dalam algoritma K-Nearest Neighbour ialah euclidean distance.
Euclidean distance merupakan jarak lurus antar dua titik yang terdapat di
dalam euclidean space. Untuk jarak antar titik p dan q yang memiliki n dimensi, jarak dihitung dengan rumus :
d ( p , q)=d (q , p)=
√
∑
i =1 n
(qi−pi)2
2.10. Teknik Fingerprinting dalam Estimasi Posisi
Menurut Du (2016), teknik fingerprinting dalam estimasi posisi ialah dengan merekam nilai RSS dari beberapa access point pada suatu titik. Terdapat dua fase utama dalam teknik fingerprinting, yakni fase offline (training) dan fase
online positioning. Posisi titik referensi ditentukan dengan jarak satu atau dua
meter. Pada fase offline nilai RSS diukur dan disimpan kedalam basis data bersama dengan informasi titik referensi. Lalu pada fase online positioning, nilai RSS diukur dan dibandingkan dengan nilai RSS yang ada pada basis data untuk mencari data yang paling cocok.
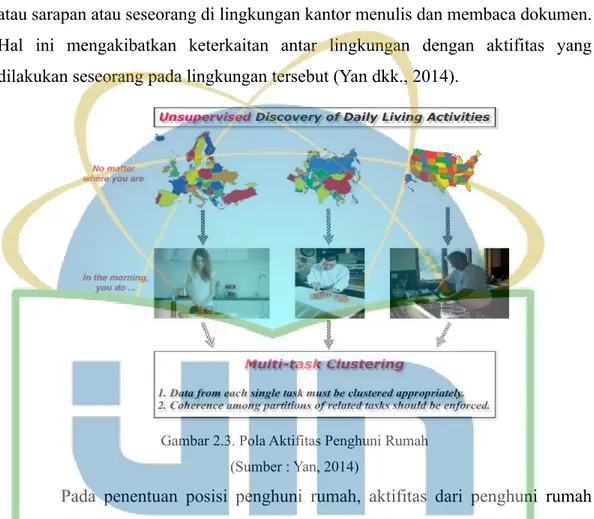
2.11. Pola Aktifitas Penghuni Rumah
Aktifitas penghuni rumah dapat dengan mudah diketahui karena aktifitas rumah tergolong memiliki pola tertentu. Faktanya ialah seseorang cenderung melakukan suatu aktifitas yang sama di lingkungan yang sama. Seperti contohnya seperti setiap pagi hari setiap orang pasti terbiasa bangun lalu menggosok gigi atau sarapan atau seseorang di lingkungan kantor menulis dan membaca dokumen. Hal ini mengakibatkan keterkaitan antar lingkungan dengan aktifitas yang dilakukan seseorang pada lingkungan tersebut (Yan dkk., 2014).
Gambar 2.3. Pola Aktifitas Penghuni Rumah (Sumber : Yan, 2014)
Pada penentuan posisi penghuni rumah, aktifitas dari penghuni rumah tersebut dapat dijadikan salah satu indikator. Dari pola aktifitas yang telah diketahui, pola tersebut akan digunakan sebagai pembanding agar hasil dari metode berbasis WiFi menghasilkan data yang lebih akurat.
2.12. Metode Observasi
Menurut Sangaji & Sopiah (2010), metode observasi merupakan salah satu data primer yang diperoleh secara langsung dari sumber asli. Metode observasi adalah proses pencatatan pola perilaku subyek (orang), obyek (benda), atau kejadian yang sistematis tanpa adanya pertanyaan atau komunikasi dengan individu-individu yang diteliti.
Metode observasi memiliki beberapa tipe yakni: 1. Observasi langsung (direct observation)
2. Observasi terhadap perilaku dan lingkungan sosial
3. Content analysis
4. Observasi mekanik
2.13. Metode Rapid Application Development
Menurut Rosa A.S & M. Shalahuddin (2014), Rapid Application
Development (RAD) adalah model proses pengembangan perangkat lunak yang
bersifat incremental terutama untuk waktu pengerjaan yang pendek. Sedangkan menurut Kendall (2011), RAD adalah suatu pendekatan berorientasi objek terhadap pengembangan sistem yang mencakup suatu metode pengembangan serta perangkat-perangkat lunak. RAD bertujuan mempersingkat waktu yang biasanya diperlukan dalam siklus hidup pengembangan sistem tradisional antara perancangan dan penerapan suatu sistem informasi. Jika kebutuhan perangkat lunak dipahami dengan baik dan lingkup perangkat lunak dibatasi dengan baik maka pembuatan perangkat lunak dapat diselesaikan dengan waktu yang pendek.
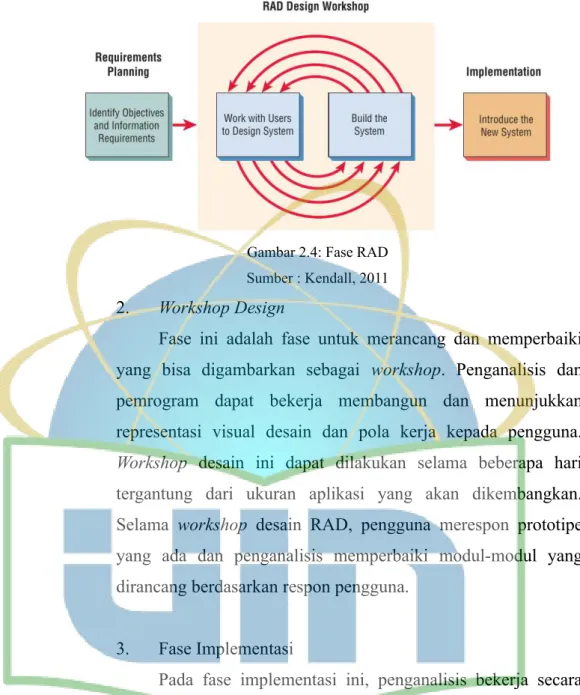
2.13.1. Fase Metode RAD
Menurut Kendall (2011) RAD memiliki tiga fase utama dalam pengembangan sistem, yaitu :
1. Requirement Planning
Dalam fase ini pengguna dan analis bertemu untuk mengidentifikasi tujuan-tujuan aplikasi atau sistem serta mengidentifikasi syarat-syarat informasi yang ditimbulkan dari tujuan tersebut. Fase ini memerlukan peran aktif dari kedua bela pihak. Selain itu juga melibatkan pengguna dari beberapa level yang berbeda dari organisasi. Orientasi pada fase ini adalah menyelesaikan masalah-masalah, meskipun teknologi informasi dan sistem bisa mengarahkan sebagian dari sistem yang diajukan, fokusnya akan tetap pada upaya pencapaian tujuan.
Gambar 2.4: Fase RAD Sumber : Kendall, 2011 2. Workshop Design
Fase ini adalah fase untuk merancang dan memperbaiki yang bisa digambarkan sebagai workshop. Penganalisis dan pemrogram dapat bekerja membangun dan menunjukkan representasi visual desain dan pola kerja kepada pengguna.
Workshop desain ini dapat dilakukan selama beberapa hari
tergantung dari ukuran aplikasi yang akan dikembangkan. Selama workshop desain RAD, pengguna merespon prototipe yang ada dan penganalisis memperbaiki modul-modul yang dirancang berdasarkan respon pengguna.
3. Fase Implementasi
Pada fase implementasi ini, penganalisis bekerja secara intens dengan pengguna selama workshop desain untuk merancang aspek-aspek bisnis dan non-teknis dari proses bisnis yang ada. Setelah aspek-aspek disetujui dan sistem dibangun dan di-sharing, sub-sub sistem diujicoba dan diperkenalkan kepada stakeholder.
2.14. Metode Uji Coba
Uji coba (testing) adalah sebuah proses yang diterapkan sebagai siklus hidup dan merupakan bagian dari proses rekayasa perangkat lunak secara terintegrasi demi memastikan kualitas dari perangkat lunak serta memenuhi kebutuhan teknis yang telah disepakati dari awal (Rizky, 2011). Secara garis besar terdapat dua jenis tipe testing yang paling umum digunakan di dalam lingkup rekayasa perangkat lunak, yakni white box testing dan black box testing. Perbedaan mendasar dari kedua jenis tersebut ialah pada letak konsentrasi pengujian terhadap sistem yang akan diuji. Metode pengujian black-box berkonsentrasi pada fitur-fitur yang akan digunakan oleh user dan penguji tidak memandang struktur kode dari sistem tersebut. Sedangkan metode pengujian
white-box berkonsentrasi pada struktur kode sehingga membutuhkan kemampuan
teknik pemrograman yang baik untuk menjadi penguji. 2.14.1. Uji Coba Black Box
Menurut Rizky (2011), black box testing adalah tipe testing yang memperlakukan perangkat lunak yang tidak diketahui kinerja internalnya. Sehingga para tester memandang perangkat lunak seperti layaknya sebuah “kotak hitam” yang tidak penting dilihat isinya, tapi cukup dikenal proses testing di bagian luar. Jenis testing ini hanya memandang perangkat lunak dari sisi spesifikasi dan kebutuhan yang telah didefinisikan pada saat awal perancangan.
Beberapa keuntungan dari uji coba black box testing antara lain: • Anggota tim tester tidak harus dari seseorang yang
memiliki kemampuan teknis di bidang pemrograman • Kesalahan dari perangkat lunak ataupun bug seringkali
ditemukan oleh komponen tester yang berasal dari pengguna
• Hasil dari black box testing dapat memperjelas kontradiksi ataupun kerancuan yang mungkin timbul dari eksekusi sebuah perangkat lunak.
• Proses testing dapat dilakukan lebih cepat dibandingkan
white box testing.
2.14.2. Jenis Uji Coba Black Box
Menurut Simamarta (2010), uji coba black box memiliki beberapa jenis pengujian, yakni :
1. Functional Testing
Pada jenis pengujian ini, perangkat lunak diuji untuk persyaratan fungsional. Pengujian dilakukan dilakukan dalam bentuk tertulis untuk memeriksa apakah aplikasi berjalan seperti yang diharapkan.
2. Stress Testing
Pengujian ini berkaitan dengan kualitas aplikasi di dalam lingkungan. Idenya adalah untuk menciptakan sebuah lingkungan yang lebih menuntut aplikasi, tidak seperti saat aplikasi dijalankan dalam beban kerja normal.
3. Load Testing
Pada pengujian ini aplikasi akan diuji dengan beban berat atau masukan , untuk mengetahui apakah aplikasi tersebut gagal atau kinerjanya menurun. Beban tinggi akan diberikan ketika sistem dapat menerima dan tetap berfungsi dengan baik. Hal ini tidak bertujuan untuk merusak sistem namun mencoba menjaga agar sistem selalu kuat dan berjalan lancar.
4. Ad-Hoc Testing
Pengujian ini dilakukan tanpa penciptaan rencana pengujian (test plan) atau kasus pengujian (test case), bertujuan untuk menentukan lingkup durasi dari berbagai pengujian lain dan membantu mempelajari aplikasi sebelum pengujian lebih
lanjut. Penggunaan dari metode ini adalah untuk penemuan, pengujian khusus menemukan lubang-lubang dalam pengujian strategi dan dapat mengekspos hubungan diantara subsistem lain yang tidak jelas, dan merupakan alat pemeriksa kelengkapan yang diuji.
5. Exploratory Testing
Mirip dengan pengujian khusus dan dilakukan untuk mempelajari/mencari aplikasi.
6. Usability Testing
Pengujian ini disebut juga ujian untuk keakraban pengguna (testing for User Friendliness). Pengujian ini dilakukan jika antarmuka pengguna dari aplikasinya penting dan harus spesifik untuk jenis pengguna tertentu. Tujuan dari pengujian usability harus membatasi dan menghilangkan kesulitan bagi pengguna dan untuk memengaruhi area yang kuat untuk usability maksimum.
7. Smoke Testing
Jenis pengujian ini disebut juga pengujian kenormalan (sanity testing). Pengujian ini dilakukan untuk memeriksa apakah aplikasi tersebut sudah siap untuk pengujian yang lebih besar dan bekerja dengan baik tanpa celah sampai tingkat yang paling diharapkan.
8. Recovery Testing
Pengujian pemulihan (recovery testing) pada dasarnya dilakukan untuk memeriksa seberapa cepat dan baiknya aplikasi bisa pulih terhadap semua jenis crash atau kegagalan hardware,
masalah bencana, dan lain-lain. Jenis dan taraf pemulihan ditetapkan dalam persyaratan spesifikasi.
9. Volume Testing
Pengujian volume dilakukan terhadap efisiensi dari aplikasi. Jumlah data besar yang diproses melalui aplikasi (yang sedang diuji) untuk memeriksa keterbatasan ekstrem dari sistem.
10. Domain Testing
Pengujian domain adalah penjelasan yang paling sering menjelaskan teknik pengujian. Beberapa penulis hanya menulis tentang pengujian domain ketika mereka menulis desain pengujian. Dugaan dasarnya adalah bahwa penguji mengambil ruang pengujian kemungkinan dari variabel individu dan membaginya kembali kedalam subset (dalam beberapa cara) yang sama. Kemudian, penguji menguji perwakilan dari masing-masing subset.
11. Scenario Testing
Pengujian skenario adalah pengujian yang realistis, kredibel, dan memotivasi stakeholder, tantangan untuk program dan mempermudah penguji untuk melakukan evaluasi. Pengujian ini menyediakan kombinasi variabel-variabel dan fungsi yang sangat berarti daripada kombinasi buatan yang didapatkan dengan pengujian domain atau desain pengujian kombinasi.
12. Regression Testing
Pengujian regresi adalah gaya pengujian yang berfokus kepada pengujian ulang (retesting) setelah ada perubahan. Pada pengujian regresi risiko (risk-oriented regression testing),
daerah yang sama yang sudah diuji, akan kita uji lagi dengan pengujian yang berbeda (semakin kompleks).
13. User Acceptance
Pada jenis pengujian ini, perangkat lunak akan diserahkan kepada pengguna untuk mengetahui apakah perangkat lunak memenuhi harapan pengguna dan bekerja seperti apa yang diharapkan.
14. Alpha Testing
Pada jenis pengujian ini, pengguna akan diundang ke pusat pengembangan. Pengguna akan menggunakan aplikasi dan pengembang mencatat setiap masukan atau tindakan yang dilakukan oleh pengguna
15. Beta Testing
Pada jenis pengujian ini, perangkat lunak didistribusikan sebagai sebuah versi beta dengan pengguna yang menguji aplikasi di situs mereka. Pengecualian/cacat yang terjadi akan dilaporkan kepada pengembang. Pengujian beta dilakukan setelah pengujian alpha. Versi perangkat lunak yang dikenal dengan sebutan versi beta dirilis untuk pengguna terbatas di luar perusahaan.
3.1. Metode Pengumpulan Data
Dalam penelitian ini, penulis menggunakan dua metode dalam pengumpulan data, yakni studi literatur dan observasi.
3.1.1. Studi Literatur
Dalam metode studi pustaka, penulis mencari referensi-referensi yang terkait dengan bidang penelitian yang sedang dilakukan oleh penulis. Referensi tersebut berupa 13 buku, 6 jurnal penelitian, dan 5 literatur online. Referensi yang didapat digunakan sebagai landasan teori serta metode penelitian.
3.1.2. Observasi
Dalam metode observasi, penulis memilih lokasi observasi dengan cara non-probability sampling yaitu di rumah penulis di Jalan Masjid Al-Abror No.18 RT 013/01 Kel. Pondok Karya, Kec. Pondok Aren, Tangerang Selatan. Observasi terdiri atas observasi nilai Received
Signal Strength (RSS) dan observasi pola aktifitas penghuni rumah.
Observasi nilai RSS dilakukan dengan dua fase, yakni fase pembelajaran dan fase estimasi. Fase pembelajaran meliputi perekaman data RSS tiga buah akses poin pada setiap titik yang ditentukan. Fase ini dilakukan pada tanggal 4-8 September 2017. Fase estimasi dilakukan pada tanggal 16-20 Oktober 2017. Sedangkan untuk observasi pola aktifitas penghuni rumah penulis lakukan pada tanggal 3-9 Oktober 2017. Selain itu, penulis juga melakukan pencatatan mac address dari smartphone yang dimiliki penghuni rumah sebagai knowledge base.
3.2. Metode Pengembangan
Dalam proses pengembangan, penulis menggunakan tiga fase utama yang sesuai dengan metode Rapid Application Development (RAD) yakni requirement
planning, workshop design dan implementation.
3.2.1. Tahap Requirement Planning
Dalam pengembangan sistem menggunakan metode RAD, requirement planning merupakan tahap pertama. Dalam tahap ini penulis mengidentifikasi masalah yang ada, menganalisa kebutuhan secara fungsional maupun non-fungsional, menganalisa metode usulan. Dasar dari tahap ini ialah hasil dari studi literatur yang telah dilakukan sebelumnya dan hasil dari requirement planning akan digunakan untuk pedoman dalam proses selanjutnya.
3.2.2. Tahap Workshop Design
Tahap selanjutnya ialah tahap workshop design. Pada tahap ini dilakukan proses perancangan yang meliputi :
1. Perancangan Flowchart
Penulis membuat sebuah flowchart atau alur kerja dari metode yang penulis usulkan untuk mempermudah penulis dalam mengimplementasikan teori, dan algoritma yang dipilih. Perancangan flowchart menggunakan software StarUML.
2. Layout Rumah dan Titik Referensi
Pada tahap ini penulis membuat layout rumah dan menentukan titik referensi yang masing-masing berjarak 1 meter. Selain itu penulis juga menentukan titik peletakan access
point.
3. Perancangan Basis Data
Perancangan basis data penulis mengacu kepada kebutuhan data yang harus ditampung, yakni data training, hasil
estimasi, titik referensi, data penghuni, data aktifitas, dan data zona waktu.
4. Perancangan User Interface
Penulis melakukan perancangan user interface untuk aplikasi training dan estimasi untuk platform android serta user
interface untuk website server. Perancangan menggunakan
teknik mockup dengan bantuan software Pencil. 3.2.3. Tahap Implementation
Setelah selesai tahap sebelumnya, yakni tahap workshop design, desain yang ada lalu diimplementasikan kedalam program. Tahap implementasi terdiri atas:
1. Pengkodean
Dalam mengkodekan sistem penulis membuat 3 jenis program yang masing-masing memiliki fungsi tertentu.
1. Pemrograman Website Server
Website server sebagai pusat penerima data dan
penyedia data. Website server juga menjadi pusat perhitungan estimasi posisi. Website server dibuat dengan bahasa pemrograman PHP berorientasi objek dengan bantuan software PHPStorm.
2. Pemrograman Aplikasi Pembelajaran
Aplikasi pembelajaran digunakan untuk merekam data pembelajaran di setiap titik referensi. Data pembelajaran akan dikirim ke website server untuk diproses lebih lanjut. Aplikasi pembelajaran dibuat untuk
platform Android dengan bahasa pemrograman Java
3. Pemrograman Aplikasi Estimasi
Aplikasi estimasi merupakan aplikasi untuk merekam data RSS penghuni rumah setiap 60 detik. Aplikasi ini mengirimkan nilai RSS ke website server untuk diestimasi dan aplikasi mendapat hasil estimasi dari posisi penghuni tersebut. Sama dengan aplikasi pembelajaran, aplikasi estimasi juga dibuat untuk platform Android dengan bahasa pemrograman Java menggunakan
software AndroidStudio.
2. Pengujian Sistem
Untuk memastikan sistem berjalan dengan baik, penulis melakukan serangkaian uji sistem dengan teknik black box testing dengan jenis functional testing. Uji ini melakukan pengujian pada fitur-fitur dan fungsi sistem apakah sudah berjalan dengan benar atau belum.
3. Training Data
Pembelajaran akan dilakukan dengan merekam nilai RSS dari tiga buah access point di titik referensi yang telah ditentukan menggunakan aplikasi pembelajaran. Data yang diterima akan disimpan ke dalam basis data yang akan digunakan sebagai model untuk proses selanjutnya.
4. Observasi Pola Aktifitas Penghuni
Observasi dilakukan dengan mencatat semua aktifitas penghuni saat berada di dalam rumah. Data yang dicatat ialah waktu dan tempat (berdasarkan titik referensi) aktifitas tersebut dilakukan.
5. Estimasi Posisi
Proses utama dari sistem ini merupakan proses estimasi posisi dari penghuni rumah. Dalam proses ini akan diidentifikasi siapa penghuni rumah dan sedang berada di mana penghuni rumah tersebut. Untuk mengestimasinya dibutuhkan peran aplikasi estimasi yang mengirimkan data nilai RSS ke website
server.
6. Pengujian Hasil Estimasi
Penulis melakukan uji hasil estimasi dengan cara observasi manual kepada 500 data yang penulis pilih secara acak dan dibandingkan dengan posisi sebenarnya yang terjadi.
3.3. Metode Pengujian
Untuk memastikan sistem sudah dapat digunakan dan berjalan dengan benar, penulis melakukan pengujian dengan menggunakan metode pengujian sistem black box testing. Metode black box testing akan menguji setiap fungsi dalam sistem berfungsi dengan baik atau tidak. Dalam hal ini penulis menggunakan salah satu jenis pengujian dalam black box testing, yakni functional
testing yang akan menguji fitur-fitur dan fungsi sistem apakah sudah berjalan
3.4. Kerangka Berpikir
4.1. Tahap Requirement Planning
Tahap pertama yang penulis lakukan ialah requirement planning. Dalam tahap ini penulis melakukan identifikasi masalah, analisis metode usulan, analisis kebutuhan fungsional maupun non-fungsional.
4.1.1. Identifikasi Masalah
Menurut beberapa sumber jurnal yang terkait penelitian ini, hasil dari penelitian-penelitian sebelumnya sebagai berikut:
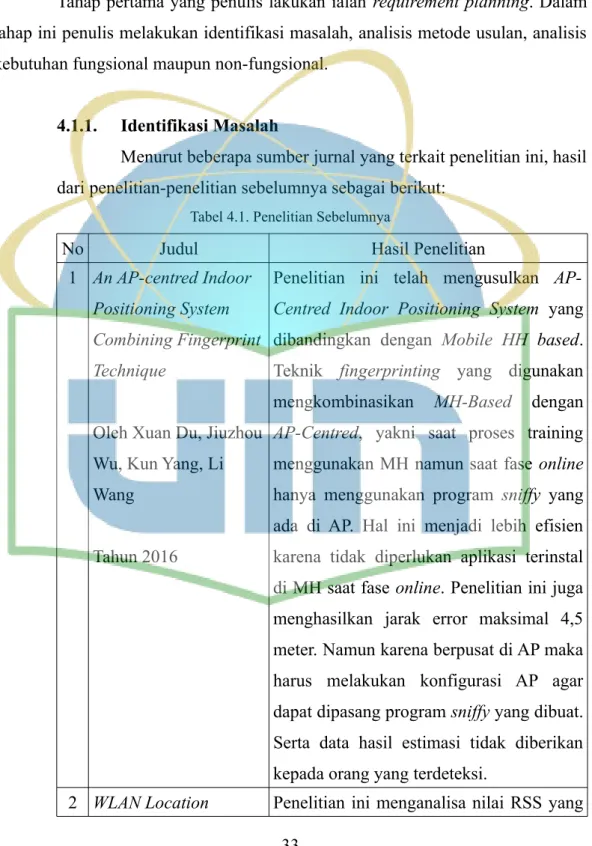
Tabel 4.1. Penelitian Sebelumnya
No Judul Hasil Penelitian
1 An AP-centred Indoor
Positioning System Combining Fingerprint Technique
Oleh Xuan Du, Jiuzhou Wu, Kun Yang, Li Wang
Tahun 2016
Penelitian ini telah mengusulkan
AP-Centred Indoor Positioning System yang
dibandingkan dengan Mobile HH based. Teknik fingerprinting yang digunakan mengkombinasikan MH-Based dengan
AP-Centred, yakni saat proses training
menggunakan MH namun saat fase online hanya menggunakan program sniffy yang ada di AP. Hal ini menjadi lebih efisien karena tidak diperlukan aplikasi terinstal di MH saat fase online. Penelitian ini juga menghasilkan jarak error maksimal 4,5 meter. Namun karena berpusat di AP maka harus melakukan konfigurasi AP agar dapat dipasang program sniffy yang dibuat. Serta data hasil estimasi tidak diberikan kepada orang yang terdeteksi.
No Judul Hasil Penelitian
Fingerprinting Technique for Device-free Indoor
Localization System
Oleh Nasrullah Pirzada, M Yunus Nayan, M Fadzil Hassan, Fazli Subhan, Hamzah Sakidin
Tahun 2016
diukur pada dua ruang kampus yang dibagi menjadi 21 titik. Pengukuran menggunakan laptop dengan software Netsurveyor. Dalam peneitian ini dibandingkan nilai pengukuran dari 4 AP dengan orang didalam, 4 AP tanpa orang didalam, 2 AP dengan orang didalam, dan 2 AP tanpa ada orang didalam. Hasil dari penelitian ini menunjukkan bahwa nilai RSS akan berubah saat kondisi lingkungan berubah. Tantangan dari sistem merupakan konstruksi bangunan, furnitur, dan tubuh manusia.
3 Android Application
for WiFi based Indoor Position: System Design and Perfo-rmance Analysis
Oleh Nguyen Trong Thuong, Hoac Thieu Phong, Dinh-Thuan Do, Phan Van Hieu, Dao Tang Loc Tahun 2016
Penelitian ini mengambil studi kasus pada sebuah ruangan pada universitas. Menggunakan teknik fingerprinting, peneliti melakukan teknik dengan cara mengirim nilai RSS dari android pengguna dan diproses di server. Peneliti menggunakan 6 AP yang telah terpasang di ketinggian 1,2 meter dari lantai. Algoritma K-Nearest Neighbour dengan
Euclidean Distance digunakan dalam
penelitian ini. Area dibagi menjadi 20 titik. Hasil dari penelitian ini menunjukkan implementasi yang mudah dan lebih hemat biaya. Dari data percobaan diketahui perpindahan di area ruangan mempengaruhi nilai RSS dan menurunkan akurasi. Didapat akurasi 42,5%-64,5%
No Judul Hasil Penelitian
dalam jarak 2meter jika terdapat orang dalam ruangan. Sedangkan hasil estimasi dikembalikan pada pengguna dan ditampilkan.
4 Indoor Localisation
using Existing WiFi Infrastructure - A Case Study at a University Building
Oleh Cornelius Toh, Sian Lun Lau
Tahun 2016
Penelitian ini mengukur RSS dengan smarphone untuk 3 dataset. Dataset pertama sebagai data training sedangkan
dataset kedua merupakan data tes dengan
keadaan diletakkan dan dataset ketiga merupakan data tes dengan keadaan
handheld. Area merupakan satu lantai
gedung universitas yang dibagi menjadi 6 titik. Penelitian ini menggunakan teknik
Density-Based Clustering Combined Localisation Algorithm dalam membuat fingerprint. Dihasilkan akurasi yang cukup
tinggi yakni 97,28% hingga 99,85% untuk dataset kedua dan 97,28% hingga 99,85% untuk dataset ketiga. Hal ini menunjukkan posisi smartphone saat pengukuran sangat mempengaruhi hasil akurasi.
Dari beberapa hasil penelitian tersebut, diketahui bahwa teknologi estimasi posisi saat ini sedang sangat berkembang. Metode paling efektif yang digunakan penelitian sebelumnya ialah menggunakan teknik fingerprinting, yakni mengambil beberapa data untuk data
training dan selanjutnya mengumpulkan data dan dicocokkan dengan
data training untuk mendapat hasil perhitungan. Penelitian Toh dan Lau (2016) mampu mendapat akurasi yang tinggi namun dengan jarak antar titik yang cukup besar karena satu lantai gedung universitas hanya dibagi
menjadi enam titik. Sedangkan penelitian Thuong dkk. (2016) menghasilkan aplikasi yang dapat mengetahui posisi dari penggunanya dengan sistem yang bekerja pada server dan menggunakan android sebagai pengirim nilai RSS. Hasilnya, akurasi sudah mencapai 42,75% sampai 64,5%. Hal ini dipengaruhi oleh jumlah orang yang ada dalam ruangan. Sedangkan dalam penelitian Du dkk. (2016), diusulkan metode tanpa aplikasi pada pengguna. Du, dkk. memanfaatkan access point yang sudah terpasang OpenWRT dengan mengembangkan program sniffy guna memantau Probe Request dari perangkat disekitar. Hasilnya, Du dkk. mampu memprediksi posisi dengan jarak error maksimal 4,5 meter namun hasil perhitungan tidak diberikan kepada pengguna secara langsung.
4.1.2. Analisis Metode Usulan
Pada penelitian ini penulis mengusulkan metode identifikasi dan estimasi posisi dengan menggabungkan estimasi posisi menggunakan teknik fingerprinting dengan peluang kebiasaan penghuni rumah. Teknik
fingerprinting yang penulis gunakan menggunakan algoritma K-Nearest Neighbour serta Euclidean Distance sebagai algoritma pencocokan atau
klasifikasi. Terdapat empat fase utama dalam metode yang penulis usulkan yakni :
1. Pengumpulan Data Pendukung
Pada fase ini penulis melakukan pengumpulan data-data yang terkait dengan penelitian, seperti data penghuni rumah beserta smartphone penghuni yang mencakup sistem operasi dan
mac address. Data penghuni rumah akan digunakan dalam
proses identifikasi.
2. Training Data Fingerprint
Pada fase training data fingerprint, penulis membagi area rumah menjadi beberapa titik referensi. Pada titik-titik tersebut
penulis melakukan observasi dengan menggunakan aplikasi training untuk menangkap nilai Received Signal Strength (RSS) pada titik tersebut. Fase ini penulis lakukan selama 5 hari dengan pengambilan data pada pagi dan sore hari sehingga didapatkan 10 set data. Penangkapan nilai dilakukan dengan menangkap nilai tiga buah access point yang telah terpasang di ketinggian 2,5 m dari lantai setiap 5 detik sampai dengan didapat 5 data, lalu dihitung rata-rata dari kelima data tersebut. Data akan disimpan dalam basis data untuk digunakan dalam proses estimasi.
3. Observasi Perilaku Penghuni
Dalam fase observasi, penulis mencatat lokasi setiap aktifitas seluruh penghuni rumah berdasarkan titik referensi yang telah dibuat sebelumnya selama 7x24jam. Data hasil observasi berupa waktu, aktifitas, dan nomor titik referensi dari aktifitas penghuni tersebut. Setelah observasi selesai dilakukan penulis melakukan analisa hasil observasi. Hasil observasi dikelompokkan menjadi 4 zona waktu yakni pagi (04:01-09:00), siang (09:01-15:00), sore (15:01-19:00), dan malam (19:01-04:00). Setelah dikelompokkan, penulis melakukan penghitungan nilai bobot peluang kejadian terjadi pada zona waktu yang ada lalu menyimpannya dalam basis data untuk digunakan dalam proses estimasi.
4. Identifikasi dan Estimasi Posisi
Proses utama dari metode ini ialah mengidentifikasi siapa penghuni dan dimana letak penghuni tersebut. Proses identifikasi menggunakan data mac address dari smartphone penghuni untuk mengetahui siapa penghuni tersebut setiap kali data masuk ke server. Sedangkan untuk proses estimasi, data