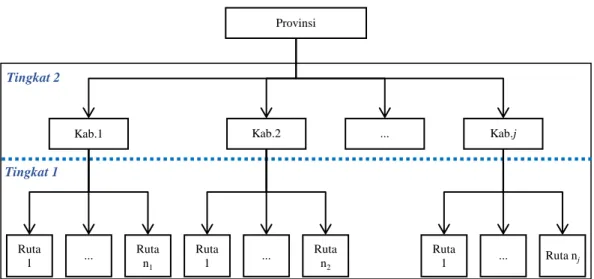
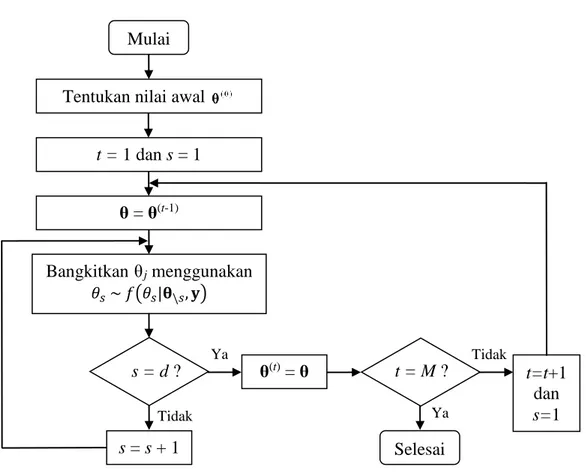
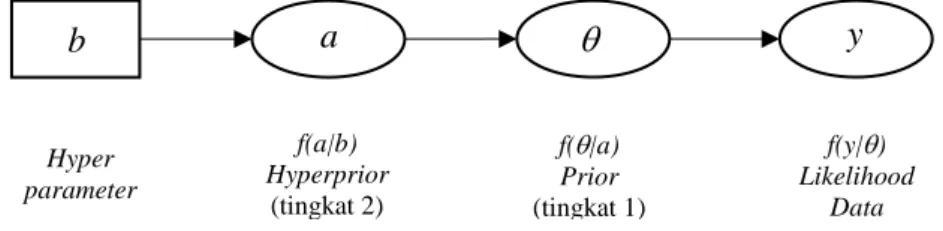
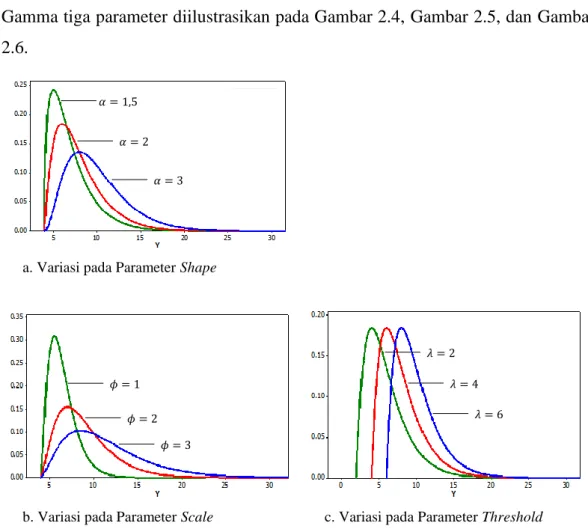
Pemodelan Pengeluaran Per Kapita Rumah Tangga Di Maluku Utara Menggunakan Struktur Hirarki Dua Tingkat Dengan Pendekatan Bayesian
Bebas
131
0
0
Teks penuh
Gambar
+7


Dokumen terkait
